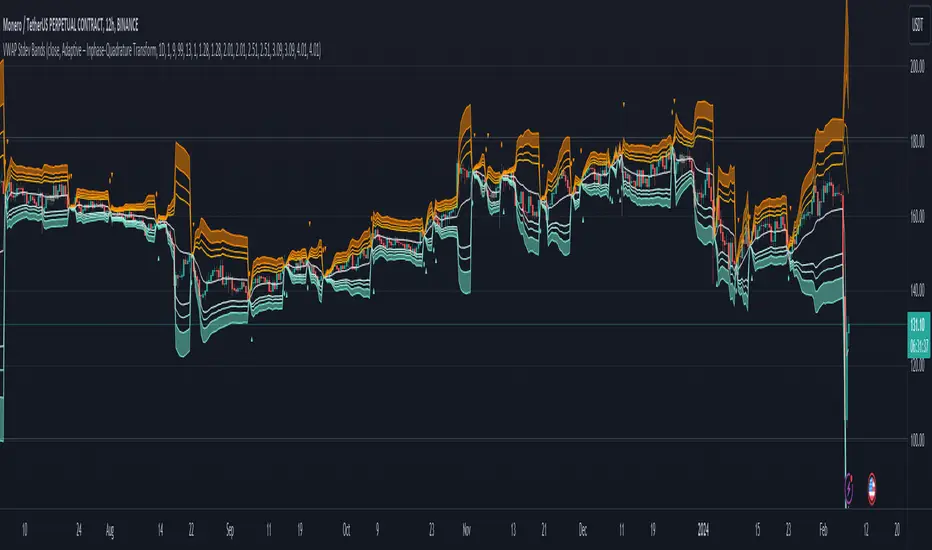
Adaptive VWAP Stdev BandsIntroduction
Heyo, here are some adaptive VWAP Standard Deviation Bands with nice colors.
I used Ehlers dominant cycle theories and ZLSMA smoothing to create this indicator.
You can choose between different algorithms to determine the dominant cycle and this will be used as reset period.
Everytime bar_index can be divided through the dominant cycle length and the result is zero VWAP resets if have chosen an adaptive mode in the settings.
The other reset event you can use is just a simple time-based event, e.g. reset every day.
Usage
I think people buy/sell when it reaches extreme zones.
Enjoy!
---
Credits to:
@SandroTurriate - VWAP Stdev Bands
@blackcat1402 - Dominant Cycle Analysis
@DasanC - Dominant Cycle Analysis
@veryfid - ZLSMA
(Sry, too lazy for linking)
I took parts of their code. Ty guys for your work! Just awesome.
Adaptive
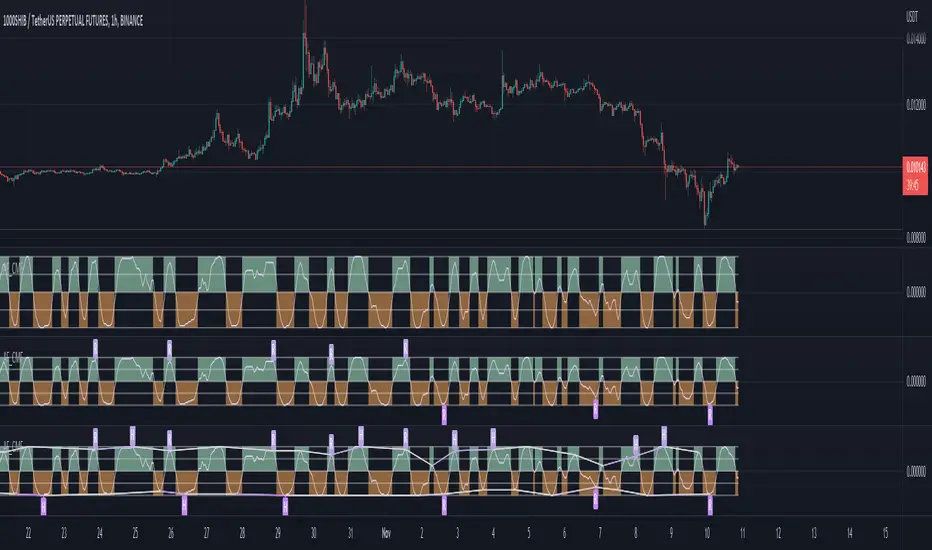
Adaptive Fisherized CMFIntroduction
Heyo, here I made a normalized Chaikin Money Flow (CMF) indicator with Inverse Fisher Transform (IFT) and some smoothing techniques.
I had to normalize the indicator in order to fit it to the IFT range (-1 -> 1).
Moreover, the good old adaptive mode is also included in this indicator. It uses Ehlers superb dominant cycle techniques.
It also has divergence detection, several options for individualisation and doesn't repaint.
Usage
www.investopedia.com
Signals
CMF above 0 => bullish market
CMF below 0 => bearish market
(You can also use the inner bands instead of the zero line, to make these signals more precise)
Bullish regular/hidden divergence => long
Bearish regular/hidden divergence => short
Enjoy guys!
PS: I really would like to hear some feedback of you.
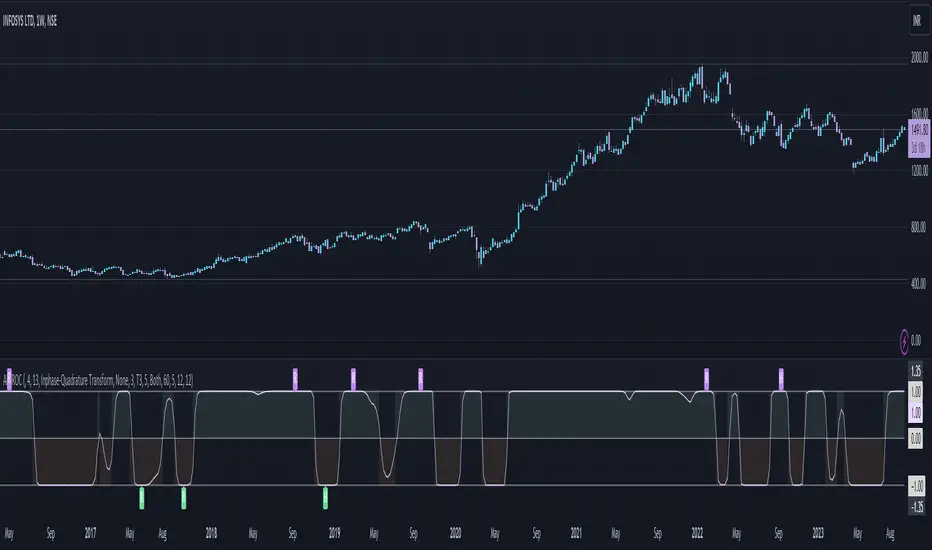
Adaptive Fisherized ROCIntroduction
Hello community, here I applied the Inverse Fisher Transform, Ehlers dominant cycle determination and smoothing methods on a simple Rate of Change (ROC) indicator
You have a lot of options to adjust the indicator.
Usage
The rate of change is most often used to measure the change in a security's price over time.
That's why it is a momentum indicator.
When it is positive, prices are accelerating upward; when negative, downward.
It is useable on every timeframe and could be a potential filter for you your trading system.
IMO it could help you to confirm entries or find exits (e.g. you have a long open, roc goes negative, you exit).
If you use a trend-following strategy, you could maybe look out for red zones in an in uptrend or green zones in a downtrend to confirm your entry on a pullback.
Signals
ROC above 0 => confirms bullish trend
ROC below 0 => confirms bearish trend
ROC hovers near 0 => price is consolidating
Enjoy! 🚀
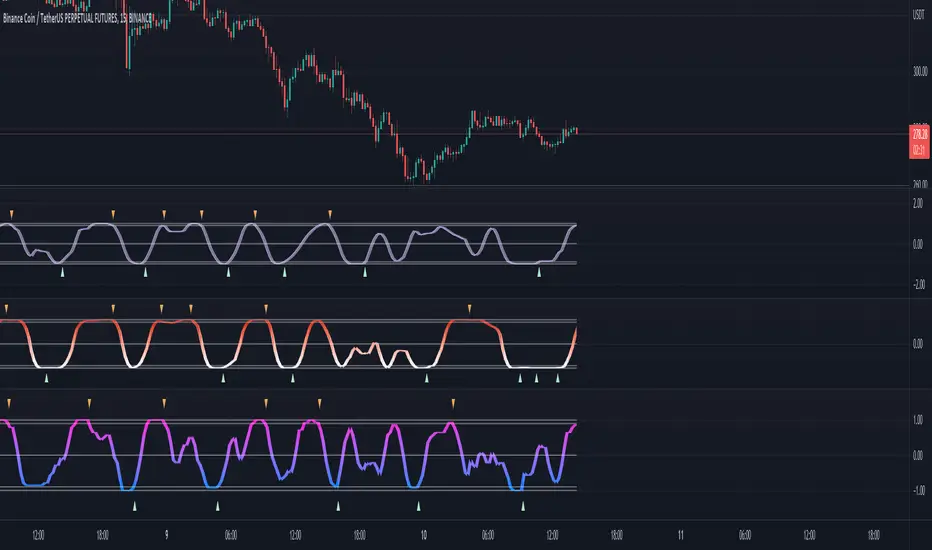
Adaptive Fisherized Stochastic Center of GravityIntroduction
I modified the script "Fisher Stochastic Center of Gravity" of @DasanC for this indicator.
I added inverse Fisher transform, cycle period adaptiveness mode (Ehlers) and smoothing to it.
Moreover, I added buy and sell and beautified some stuff.
Lastly, it is also non-repainting!
Usage
This indicator can be used like a normal stochastic, but I don't recommend divergence analysis on it.
That fisherization stuff seems to make the graphs unuseable for that because it tries.
It works well on every timeframe I would say, but lower timeframes are recommended, because of the fast nature of stochastic.
Usually it does a good job on entry confirmation for reversals and trend continuation trades.
Recommended indicator to combine with this indicator is RSI cyclic smoothed v2 .
This is the best RSI version I know. In trending market it is recommended to look more on the inner bands and in flat market it is recommended to look more on the outer bands.
When RSI shows oversold and this indicator shows a crossover of the Center of Gravity plot through the bottom line -> Long entry is confirmed
When RSI shows overbought and this indicator shows a crossunder of the Center of Gravity plot through the top line -> Short entry is confirmed
Settings
The adaptive mode is enabled by default to give you straight the whole indicator experience.
The default settings are optimized, but should be changed depending on the market.
An example:
Market has a low volatility and a high momentum -> I want a slower/higher length to catch the slower new highs and lows.
Market has higher volatility and a low momentum, -> I want a faster/lower length to catch the faster new highs and lows
Signals
Crossover
Buy -> cog crossover signalLine
Sell -> cog crossunder signalLine
Overbought/Oversold Crossover
Buy -> cog crossover lowerBand
Sell -> cog crossunder lowerBand
I use this indicator a lot, because I don't know a better stochastic on this community here.
@DasanC did an awesome work with his version I used as base for this script.
Enjoy this indicator and let the profit roll! 🔥
Adaptive Parabolic SAR (APSAR) - [MYN]We took the code that we wrote in Myth Busting Strategy #6 to make it more profitable, specifically the timeframe adaptive Parabolic SAR logic and published this as a separate indicator to make it easier for others to use and adopt.
There really is no magic to this. This indicator basically just evaluates the timeframe and derives a multiplier that is applied to the PSAR Max attribute.

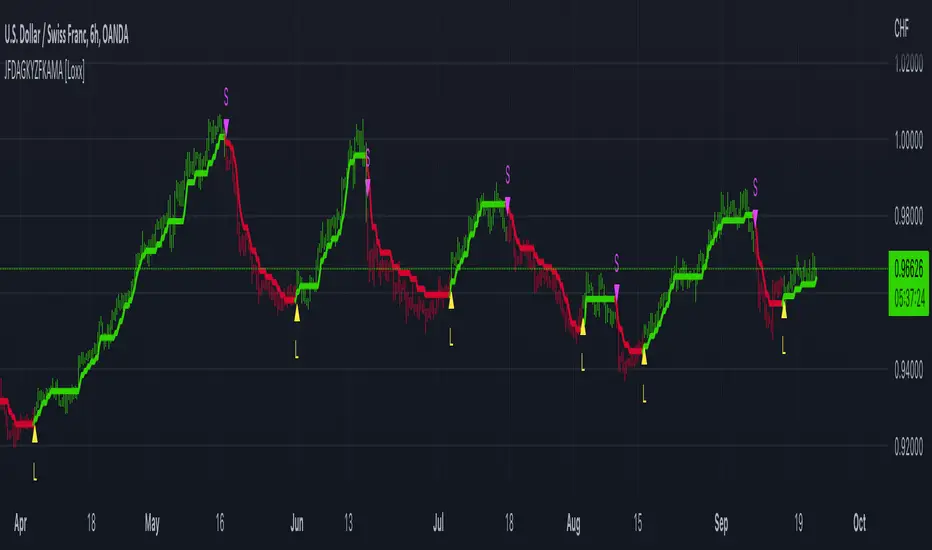
JFD-Adaptive, GKYZ-Filtered KAMA [Loxx]JFD-Adaptive, GKYZ-Filtered KAMA is a Kaufman Adaptive Moving Average with the option to make it Jurik Fractal Dimension Adaptive. This also includes a Garman-Klass-Yang-Zhang Historical Volatility Filter to reduce noise.
What is KAMA?
Developed by Perry Kaufman, Kaufman's Adaptive Moving Average ( KAMA ) is a moving average designed to account for market noise or volatility . KAMA will closely follow prices when the price swings are relatively small and the noise is low. KAMA will adjust when the price swings widen and follow prices from a greater distance. This trend-following indicator can be used to identify the overall trend, time turning points and filter price movements.
What is Jurik Fractal Dimension?
There is a weak and a strong way to measure the random quality of a time series.
The weak way is to use the random walk index ( RWI ). You can download it from the Omega web site. It makes the assumption that the market is moving randomly with an average distance D per move and proposes an amount the market should have changed over N bars of time. If the market has traveled less, then the action is considered random, otherwise it's considered trending.
The problem with this method is that taking the average distance is valid for a Normal (Gaussian) distribution of price activity. However, price action is rarely Normal, with large price jumps occuring much more frequently than a Normal distribution would expect. Consequently, big jumps throw the RWI way off, producing invalid results.
The strong way is to not make any assumption regarding the distribution of price changes and, instead, measure the fractal dimension of the time series. Fractal Dimension requires a lot of data to be accurate. If you are trading 30 minute bars, use a multi-chart where this indicator is running on 5 minute bars and you are trading on 30 minute bars.
What is Garman-Klass-Yang-Zhang Historical Volatility?
Yang and Zhang derived an extension to the Garman Klass historical volatility estimator that allows for opening jumps. It assumes Brownian motion with zero drift. This is currently the preferred version of open-high-low-close volatility estimator for zero drift and has an efficiency of 8 times the classic close-to-close estimator. Note that when the drift is nonzero, but instead relative large to the volatility , this estimator will tend to overestimate the volatility . The Garman-Klass-Yang-Zhang Historical Volatility calculation is as follows:
GKYZHV = sqrt((Z/n) * sum((log(open(k)/close( k-1 )))^2 + (0.5*(log(high(k)/low(k)))^2) - (2*log(2) - 1)*(log(close(k)/open(2:end)))^2))
Included
Alerts
Signals
Loxx's Expanded Source Types
Bar coloring
STD-Adaptive T3 [Loxx]STD-Adaptive T3 is a standard deviation adaptive T3 moving average filter. This indicator acts more like a trend overlay indicator with gradient coloring.
What is the T3 moving average?
Better Moving Averages Tim Tillson
November 1, 1998
Tim Tillson is a software project manager at Hewlett-Packard, with degrees in Mathematics and Computer Science. He has privately traded options and equities for 15 years.
Introduction
"Digital filtering includes the process of smoothing, predicting, differentiating, integrating, separation of signals, and removal of noise from a signal. Thus many people who do such things are actually using digital filters without realizing that they are; being unacquainted with the theory, they neither understand what they have done nor the possibilities of what they might have done."
This quote from R. W. Hamming applies to the vast majority of indicators in technical analysis . Moving averages, be they simple, weighted, or exponential, are lowpass filters; low frequency components in the signal pass through with little attenuation, while high frequencies are severely reduced.
"Oscillator" type indicators (such as MACD , Momentum, Relative Strength Index ) are another type of digital filter called a differentiator.
Tushar Chande has observed that many popular oscillators are highly correlated, which is sensible because they are trying to measure the rate of change of the underlying time series, i.e., are trying to be the first and second derivatives we all learned about in Calculus.
We use moving averages (lowpass filters) in technical analysis to remove the random noise from a time series, to discern the underlying trend or to determine prices at which we will take action. A perfect moving average would have two attributes:
It would be smooth, not sensitive to random noise in the underlying time series. Another way of saying this is that its derivative would not spuriously alternate between positive and negative values.
It would not lag behind the time series it is computed from. Lag, of course, produces late buy or sell signals that kill profits.
The only way one can compute a perfect moving average is to have knowledge of the future, and if we had that, we would buy one lottery ticket a week rather than trade!
Having said this, we can still improve on the conventional simple, weighted, or exponential moving averages. Here's how:
Two Interesting Moving Averages
We will examine two benchmark moving averages based on Linear Regression analysis.
In both cases, a Linear Regression line of length n is fitted to price data.
I call the first moving average ILRS, which stands for Integral of Linear Regression Slope. One simply integrates the slope of a linear regression line as it is successively fitted in a moving window of length n across the data, with the constant of integration being a simple moving average of the first n points. Put another way, the derivative of ILRS is the linear regression slope. Note that ILRS is not the same as a SMA ( simple moving average ) of length n, which is actually the midpoint of the linear regression line as it moves across the data.
We can measure the lag of moving averages with respect to a linear trend by computing how they behave when the input is a line with unit slope. Both SMA (n) and ILRS(n) have lag of n/2, but ILRS is much smoother than SMA .
Our second benchmark moving average is well known, called EPMA or End Point Moving Average. It is the endpoint of the linear regression line of length n as it is fitted across the data. EPMA hugs the data more closely than a simple or exponential moving average of the same length. The price we pay for this is that it is much noisier (less smooth) than ILRS, and it also has the annoying property that it overshoots the data when linear trends are present.
However, EPMA has a lag of 0 with respect to linear input! This makes sense because a linear regression line will fit linear input perfectly, and the endpoint of the LR line will be on the input line.
These two moving averages frame the tradeoffs that we are facing. On one extreme we have ILRS, which is very smooth and has considerable phase lag. EPMA has 0 phase lag, but is too noisy and overshoots. We would like to construct a better moving average which is as smooth as ILRS, but runs closer to where EPMA lies, without the overshoot.
A easy way to attempt this is to split the difference, i.e. use (ILRS(n)+EPMA(n))/2. This will give us a moving average (call it IE /2) which runs in between the two, has phase lag of n/4 but still inherits considerable noise from EPMA. IE /2 is inspirational, however. Can we build something that is comparable, but smoother? Figure 1 shows ILRS, EPMA, and IE /2.
Filter Techniques
Any thoughtful student of filter theory (or resolute experimenter) will have noticed that you can improve the smoothness of a filter by running it through itself multiple times, at the cost of increasing phase lag.
There is a complementary technique (called twicing by J.W. Tukey) which can be used to improve phase lag. If L stands for the operation of running data through a low pass filter, then twicing can be described by:
L' = L(time series) + L(time series - L(time series))
That is, we add a moving average of the difference between the input and the moving average to the moving average. This is algebraically equivalent to:
2L-L(L)
This is the Double Exponential Moving Average or DEMA , popularized by Patrick Mulloy in TASAC (January/February 1994).
In our taxonomy, DEMA has some phase lag (although it exponentially approaches 0) and is somewhat noisy, comparable to IE /2 indicator.
We will use these two techniques to construct our better moving average, after we explore the first one a little more closely.
Fixing Overshoot
An n-day EMA has smoothing constant alpha=2/(n+1) and a lag of (n-1)/2.
Thus EMA (3) has lag 1, and EMA (11) has lag 5. Figure 2 shows that, if I am willing to incur 5 days of lag, I get a smoother moving average if I run EMA (3) through itself 5 times than if I just take EMA (11) once.
This suggests that if EPMA and DEMA have 0 or low lag, why not run fast versions (eg DEMA (3)) through themselves many times to achieve a smooth result? The problem is that multiple runs though these filters increase their tendency to overshoot the data, giving an unusable result. This is because the amplitude response of DEMA and EPMA is greater than 1 at certain frequencies, giving a gain of much greater than 1 at these frequencies when run though themselves multiple times. Figure 3 shows DEMA (7) and EPMA(7) run through themselves 3 times. DEMA^3 has serious overshoot, and EPMA^3 is terrible.
The solution to the overshoot problem is to recall what we are doing with twicing:
DEMA (n) = EMA (n) + EMA (time series - EMA (n))
The second term is adding, in effect, a smooth version of the derivative to the EMA to achieve DEMA . The derivative term determines how hot the moving average's response to linear trends will be. We need to simply turn down the volume to achieve our basic building block:
EMA (n) + EMA (time series - EMA (n))*.7;
This is algebraically the same as:
EMA (n)*1.7-EMA( EMA (n))*.7;
I have chosen .7 as my volume factor, but the general formula (which I call "Generalized Dema") is:
GD (n,v) = EMA (n)*(1+v)-EMA( EMA (n))*v,
Where v ranges between 0 and 1. When v=0, GD is just an EMA , and when v=1, GD is DEMA . In between, GD is a cooler DEMA . By using a value for v less than 1 (I like .7), we cure the multiple DEMA overshoot problem, at the cost of accepting some additional phase delay. Now we can run GD through itself multiple times to define a new, smoother moving average T3 that does not overshoot the data:
T3(n) = GD ( GD ( GD (n)))
In filter theory parlance, T3 is a six-pole non-linear Kalman filter. Kalman filters are ones which use the error (in this case (time series - EMA (n)) to correct themselves. In Technical Analysis , these are called Adaptive Moving Averages; they track the time series more aggressively when it is making large moves.
Included
Bar coloring
Loxx's Expanded Source Types

Adaptive Two-Pole Super Smoother Entropy MACD [Loxx]Adaptive Two-Pole Super Smoother Entropy (Math) MACD is an Ehlers Two-Pole Super Smoother that is transformed into an MACD oscillator using entropy mathematics. Signals are generated using Discontinued Signal Lines.
What is Ehlers; Two-Pole Super Smoother?
From "Cycle Analytics for Traders Advanced Technical Trading Concepts" by John F. Ehlers
A SuperSmoother filter is used anytime a moving average of any type would otherwise be used, with the result that the SuperSmoother filter output would have substantially less lag for an equivalent amount of smoothing produced by the moving average. For example, a five-bar SMA has a cutoff period of approximately 10 bars and has two bars of lag. A SuperSmoother filter with a cutoff period of 10 bars has a lag a half bar larger than the two-pole modified Butterworth filter.Therefore, such a SuperSmoother filter has a maximum lag of approximately 1.5 bars and even less lag into the attenuation band of the filter. The differential in lag between moving average and SuperSmoother filter outputs becomes even larger when the cutoff periods are larger.
Market data contain noise, and removal of noise is the reason for using smoothing filters. In fact, market data contain several kinds of noise. I’ll group one kind of noise as systemic, caused by the random events of trades being exercised. A second kind of noise is aliasing noise, caused by the use of sampled data. Aliasing noise is the dominant term in the data for shorter cycle periods.
It is easy to think of market data as being a continuous waveform, but it is not. Using the closing price as representative for that bar constitutes one sample point. It doesn’t matter if you are using an average of the high and low instead of the close, you are still getting one sample per bar. Since sampled data is being used, there are some dSP aspects that must be considered. For example, the shortest analysis period that is possible (without aliasing)2 is a two-bar cycle.This is called the Nyquist frequency, 0.5 cycles per sample.A perfect two-bar sine wave cycle sampled at the peaks becomes a square wave due to sampling. However, sampling at the cycle peaks can- not be guaranteed, and the interference between the sampling frequency and the data frequency creates the aliasing noise.The noise is reduced as the data period is longer. For example, a four-bar cycle means there are four samples per cycle. Because there are more samples, the sampled data are a better replica of the sine wave component. The replica is better yet for an eight-bar data component.The improved fidelity of the sampled data means the aliasing noise is reduced at longer and longer cycle periods.The rate of reduction is 6 dB per octave. My experience is that the systemic noise rarely is more than 10 dB below the level of cyclic information, so that we create two conditions for effective smoothing of aliasing noise:
1. It is difficult to use cycle periods shorter that two octaves below the Nyquist frequency.That is, an eight-bar cycle component has a quantization noise level 12 dB below the noise level at the Nyquist frequency. longer cycle components therefore have a systemic noise level that exceeds the aliasing noise level.
2. A smoothing filter should have sufficient selectivity to reduce aliasing noise below the systemic noise level. Since aliasing noise increases at the rate of 6 dB per octave above a selected filter cutoff frequency and since the SuperSmoother attenuation rate is 12 dB per octave, the Super- Smoother filter is an effective tool to virtually eliminate aliasing noise in the output signal.
What are DSL Discontinued Signal Line?
A lot of indicators are using signal lines in order to determine the trend (or some desired state of the indicator) easier. The idea of the signal line is easy : comparing the value to it's smoothed (slightly lagging) state, the idea of current momentum/state is made.
Discontinued signal line is inheriting that simple signal line idea and it is extending it : instead of having one signal line, more lines depending on the current value of the indicator.
"Signal" line is calculated the following way :
When a certain level is crossed into the desired direction, the EMA of that value is calculated for the desired signal line
When that level is crossed into the opposite direction, the previous "signal" line value is simply "inherited" and it becomes a kind of a level
This way it becomes a combination of signal lines and levels that are trying to combine both the good from both methods.
In simple terms, DSL uses the concept of a signal line and betters it by inheriting the previous signal line's value & makes it a level.
Included:
Bar coloring
Alerts
Signals
Loxx's Expanded Source Types

Softmax Normalized Jurik Filter Histogram [Loxx]Softmax Normalized Jurik Filter Histogram is a Jurik Filter that is morphed into a normalized oscillator from -1 to 1.
What is the Softmax function?
The softmax function, also known as softargmax: or normalized exponential function, converts a vector of K real numbers into a probability distribution of K possible outcomes. It is a generalization of the logistic function to multiple dimensions, and used in multinomial logistic regression. The softmax function is often used as the last activation function of a neural network to normalize the output of a network to a probability distribution over predicted output classes, based on Luce's choice axiom.
What is Jurik Volty used in the Juirk Filter?
One of the lesser known qualities of Juirk smoothing is that the Jurik smoothing process is adaptive. "Jurik Volty" (a sort of market volatility ) is what makes Jurik smoothing adaptive. The Jurik Volty calculation can be used as both a standalone indicator and to smooth other indicators that you wish to make adaptive.
What is the Jurik Moving Average?
Have you noticed how moving averages add some lag (delay) to your signals? ... especially when price gaps up or down in a big move, and you are waiting for your moving average to catch up? Wait no more! JMA eliminates this problem forever and gives you the best of both worlds: low lag and smooth lines.
Included:
Bar coloring
Signals
Alerts
Loxx's Expanded Source Types

Fractal-Dimension-Index-Adaptive Trend Cipher Candles [Loxx]Fractal-Dimension-Index-Adaptive Trend Cipher Candles is a candle coloring indicator that shows both trend and trend exhaustion using Fractal Dimension Index Adaptivity. To do this, we first calculate the dynamic period outputs from the FDI algorithm and then we injection those period inputs into a correlation function that correlates price input price to the candle index. The closer the correlation is to 1, the lighter the green color until the color turns yellow, sometimes, indicating upward price exhaustion. The closer the correlation is to -1, the lighter the red color until it reaches Fuchsia color indicating downward price exhaustion. Green means uptrend, red means downtrend, yellow means reversal from uptrend to downtrend, fuchsia means reversal from downtrend to uptrend.
What is the Fractal Dimension Index?
The goal of the fractal dimension index is to determine whether the market is trending or in a trading range. It does not measure the direction of the trend. A value less than 1.5 indicates that the price series is persistent or that the market is trending. Lower values of the FDI indicate a stronger trend. A value greater than 1.5 indicates that the market is in a trading range and is acting in a more random fashion.
Included
Loxx's Expanded Source Types
Related indicators:
Adaptive Trend Cipher loxx]
CFB-Adaptive Trend Cipher Candles
Dynamic Zones Polychromatic Momentum Candles
RSI Precision Trend Candles
FDI-Adaptive, Jurik-Filtered, TMA w/ Price Zones [Loxx]FDI-Adaptive, Jurik-Filtered, TMA w/ Price Zones is a Triangular Moving Average that is Fractal Dimension Index Adaptive with Jurik Smoothing. You'll notice that this combination not only smooths out the signal but also catches bottoms better than other FIR digital filters. This is a multi-layered adaptive moving average. Price zones are calculated using a weighted range function. Future updates will included signals associated with these range bands. For now, however, these range bands serve as support and resistance, stop-loss or take profit, or indicators of market reversal.
What is the Triangular Moving Average
The Triangular Moving Average is basically a double-smoothed Simple Moving Average that gives more weight to the middle section of the data interval. The TMA has a significant lag to current prices and is not well-suited to fast moving markets. TMA = SUM ( SMA values)/ N Where N = the number of periods.
What is the Fractal Dimension Index?
The goal of the fractal dimension index is to determine whether the market is trending or in a trading range. It does not measure the direction of the trend. A value less than 1.5 indicates that the price series is persistent or that the market is trending. Lower values of the FDI indicate a stronger trend. A value greater than 1.5 indicates that the market is in a trading range and is acting in a more random fashion.
What is Jurik Volty used in the Juirk Filter?
One of the lesser known qualities of Juirk smoothing is that the Jurik smoothing process is adaptive. "Jurik Volty" (a sort of market volatility ) is what makes Jurik smoothing adaptive. The Jurik Volty calculation can be used as both a standalone indicator and to smooth other indicators that you wish to make adaptive.
What is the Jurik Moving Average?
Have you noticed how moving averages add some lag (delay) to your signals? ... especially when price gaps up or down in a big move, and you are waiting for your moving average to catch up? Wait no more! JMA eliminates this problem forever and gives you the best of both worlds: low lag and smooth lines.
Included:
Bar coloring
Signals
Alerts
FDI-Adaptive Supertrend w/ Floating Levels [Loxx]FDI-Adaptive Supertrend w/ Floating Levels is a Fractal Dimension Index adaptive Supertrend indicator. This allows Supertrend to better adaptive to volatility of the market. This also includes floating levels that act as support and resistance, stop loss or take profit, or indication of market reversal. Additional signal types will be added in the future based on these floating levels.
What is the Fractal Dimension Index?
The goal of the fractal dimension index is to determine whether the market is trending or in a trading range. It does not measure the direction of the trend. A value less than 1.5 indicates that the price series is persistent or that the market is trending. Lower values of the FDI indicate a stronger trend. A value greater than 1.5 indicates that the market is in a trading range and is acting in a more random fashion.
What is the Supertrend?
Supertrend indicator was created by Olivier Seban to work on different time frames. It works for futures , forex, and equities. It is used in 15 minutes, hourly, weekly, and daily charts . Based on the parameters of multiplier and period, the indicator normally uses 3 for multiplier and 7 for the ATR period as default values. Average True Range is represented by the number of days while the multiplier is the value by which the range is multiplied.
Included:
Bar coloring
Alerts
Signals

FDI-Adaptive Fisher Transform [Loxx]FDI-Adaptive Fisher Transform is a Fractal Dimension Adaptive Fisher Transform indicator.
What is the Fractal Dimension Index?
The goal of the fractal dimension index is to determine whether the market is trending or in a trading range. It does not measure the direction of the trend. A value less than 1.5 indicates that the price series is persistent or that the market is trending. Lower values of the FDI indicate a stronger trend. A value greater than 1.5 indicates that the market is in a trading range and is acting in a more random fashion.
What is Fisher Transform?
The Fisher Transform is a technical indicator created by John F. Ehlers that converts prices into a Gaussian normal distribution.
The indicator highlights when prices have moved to an extreme, based on recent prices. This may help in spotting turning points in the price of an asset. It also helps show the trend and isolate the price waves within a trend.
Included:
Zero-line and signal cross options for bar coloring
Customizable overbought/oversold thresh-holds
Alerts
Signals
End-pointed SSA of FDASMA [Loxx]End-pointed SSA of FDASMA is a modification of Fractal-Dimension-Adaptive SMA (FDASMA) using End-Pointed Singular Spectrum Analysis. This is a multilayer adaptive indicator.
What is the Fractal Dimension Index?
The goal of the fractal dimension index is to determine whether the market is trending or in a trading range. It does not measure the direction of the trend. A value less than 1.5 indicates that the price series is persistent or that the market is trending. Lower values of the FDI indicate a stronger trend. A value greater than 1.5 indicates that the market is in a trading range and is acting in a more random fashion.
See here for more info:
Fractal-Dimension-Adaptive SMA (FDASMA) w/ DSL
What is Singular Spectrum Analysis ( SSA )?
Singular spectrum analysis ( SSA ) is a technique of time series analysis and forecasting. It combines elements of classical time series analysis, multivariate statistics, multivariate geometry, dynamical systems and signal processing. SSA aims at decomposing the original series into a sum of a small number of interpretable components such as a slowly varying trend, oscillatory components and a ‘structureless’ noise. It is based on the singular value decomposition ( SVD ) of a specific matrix constructed upon the time series. Neither a parametric model nor stationarity-type conditions have to be assumed for the time series. This makes SSA a model-free method and hence enables SSA to have a very wide range of applicability.
For our purposes here, we are only concerned with the "Caterpillar" SSA . This methodology was developed in the former Soviet Union independently (the ‘iron curtain effect’) of the mainstream SSA . The main difference between the main-stream SSA and the "Caterpillar" SSA is not in the algorithmic details but rather in the assumptions and in the emphasis in the study of SSA properties. To apply the mainstream SSA , one often needs to assume some kind of stationarity of the time series and think in terms of the "signal plus noise" model (where the noise is often assumed to be ‘red’). In the "Caterpillar" SSA , the main methodological stress is on separability (of one component of the series from another one) and neither the assumption of stationarity nor the model in the form "signal plus noise" are required.
"Caterpillar" SSA
The basic "Caterpillar" SSA algorithm for analyzing one-dimensional time series consists of:
Transformation of the one-dimensional time series to the trajectory matrix by means of a delay procedure (this gives the name to the whole technique);
Singular Value Decomposition of the trajectory matrix;
Reconstruction of the original time series based on a number of selected eigenvectors.
This decomposition initializes forecasting procedures for both the original time series and its components. The method can be naturally extended to multidimensional time series and to image processing.
The method is a powerful and useful tool of time series analysis in meteorology, hydrology, geophysics, climatology and, according to our experience, in economics, biology, physics, medicine and other sciences; that is, where short and long, one-dimensional and multidimensional, stationary and non-stationary, almost deterministic and noisy time series are to be analyzed.
Included:
Bar coloring
Alerts
Signals
Loxx's Expanded Source Types
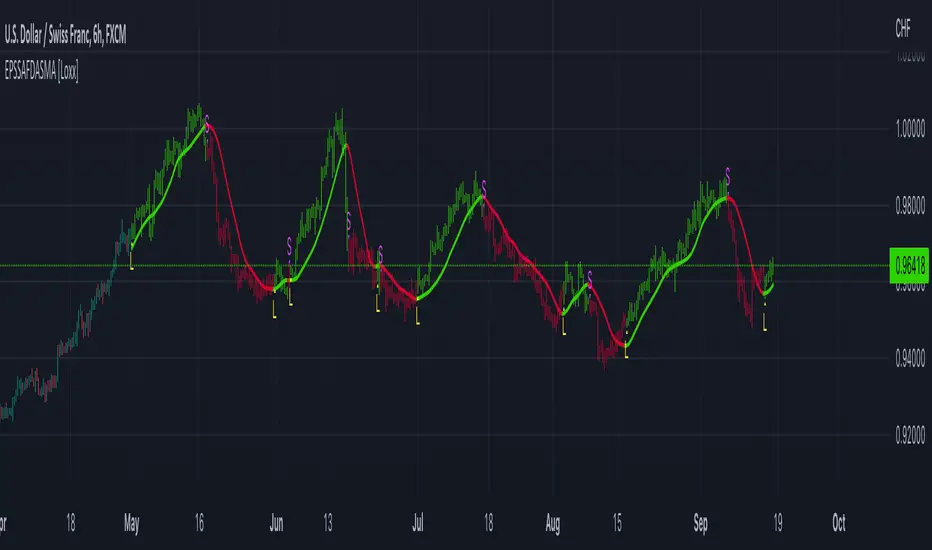
Fractal Dimension Index Adaptive Period [Loxx]Fractal Dimension Index Adaptive Period is the adaptive period out of Fractal Dimension Index Adaptivity. This isn't an indicator that shows a signal, instead, it's to be used as auxiliary support and an educational tool to create other indicators. This value can be injected into other indicators to make those indicators Fractal Dimension Index Adaptive.
What is the Fractal Dimension Index?
The goal of the fractal dimension index is to determine whether the market is trending or in a trading range. It does not measure the direction of the trend. A value less than 1.5 indicates that the price series is persistent or that the market is trending. Lower values of the FDI indicate a stronger trend. A value greater than 1.5 indicates that the market is in a trading range and is acting in a more random fashion.
Included
Loxx's Expanded Source Types

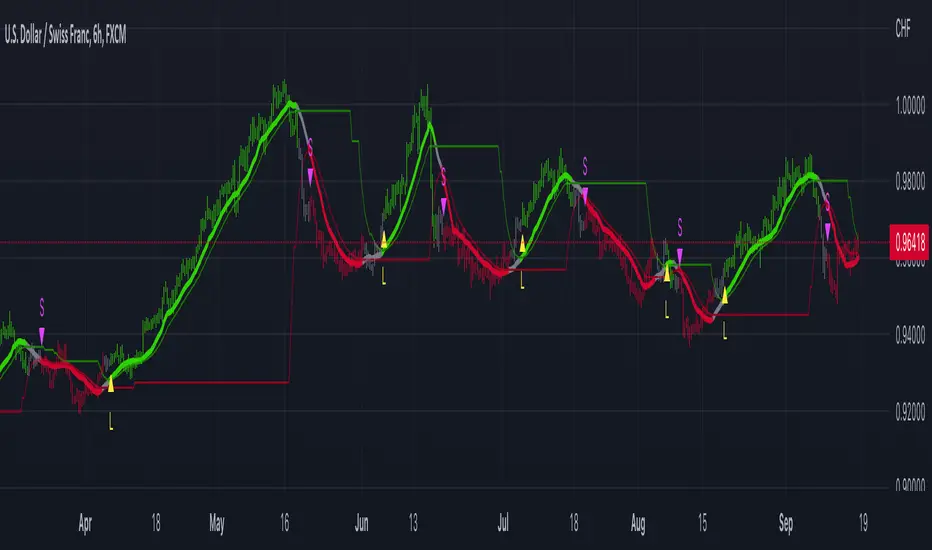
Fractal-Dimension-Adaptive SMA (FDASMA) w/ DSL [Loxx]Fractal-Dimension-Adaptive SMA (FDASMA) w/ DSL is a fractal-dimension-index-adaptive SMA. The SMA is accelerated during a trend and slowed down during a sideways market, so as to avoid false signals. This indicator uses the fractal dimension to compute an ingest period length into the SMA to output the FDASMA.
What is the Fractal Dimension Index?
The goal of the fractal dimension index is to determine whether the market is trending or in a trading range. It does not measure the direction of the trend. A value less than 1.5 indicates that the price series is persistent or that the market is trending. Lower values of the FDI indicate a stronger trend. A value greater than 1.5 indicates that the market is in a trading range and is acting in a more random fashion.
What are DSL Discontinued Signal Line?
A lot of indicators are using signal lines in order to determine the trend (or some desired state of the indicator) easier. The idea of the signal line is easy : comparing the value to it's smoothed (slightly lagging) state, the idea of current momentum/state is made.
Discontinued signal line is inheriting that simple signal line idea and it is extending it : instead of having one signal line, more lines depending on the current value of the indicator.
"Signal" line is calculated the following way :
When a certain level is crossed into the desired direction, the EMA of that value is calculated for the desired signal line
When that level is crossed into the opposite direction, the previous "signal" line value is simply "inherited" and it becomes a kind of a level
This way it becomes a combination of signal lines and levels that are trying to combine both the good from both methods.
In simple terms, DSL uses the concept of a signal line and betters it by inheriting the previous signal line's value & makes it a level.
Included
2 Signal types
Alerts
Loxx's Expanded Source Types
Bar coloring
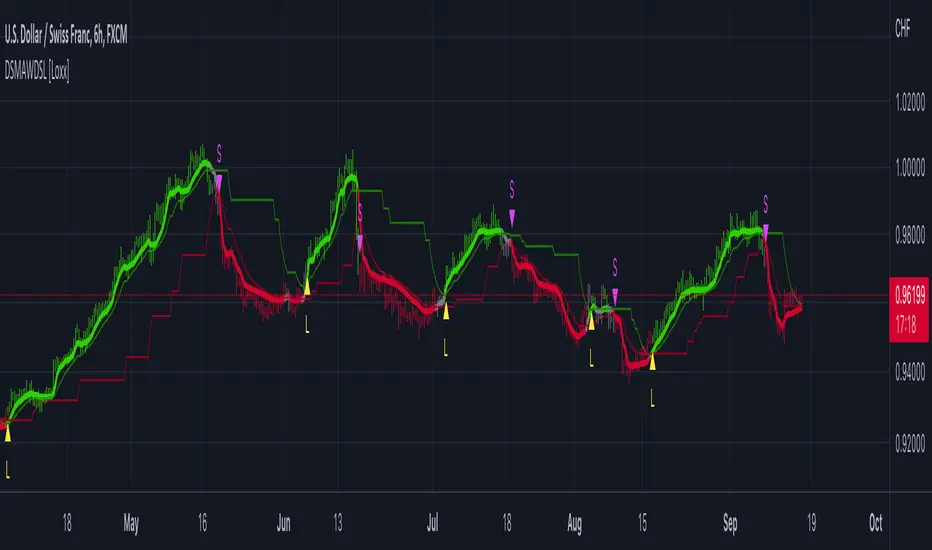
Deviation Scaled Moving Average w/ DSL [Loxx]Deviation Scaled Moving Average w/ DSL as described in the “The Deviation-Scaled Moving Average.” article of July 2018 TASC . This is an adaptive moving average average that has the ability to rapidly adapt to volatility in price movement. This version adds Discontinued Signal Lines create the buy/sell signals.
What are DSL Discontinued Signal Line?
A lot of indicators are using signal lines in order to determine the trend (or some desired state of the indicator) easier. The idea of the signal line is easy : comparing the value to it's smoothed (slightly lagging) state, the idea of current momentum/state is made.
Discontinued signal line is inheriting that simple signal line idea and it is extending it : instead of having one signal line, more lines depending on the current value of the indicator.
"Signal" line is calculated the following way :
When a certain level is crossed into the desired direction, the EMA of that value is calculated for the desired signal line
When that level is crossed into the opposite direction, the previous "signal" line value is simply "inherited" and it becomes a kind of a level
This way it becomes a combination of signal lines and levels that are trying to combine both the good from both methods.
In simple terms, DSL uses the concept of a signal line and betters it by inheriting the previous signal line's value & makes it a level.
Included
2 Signal types
Alerts
Loxx's Expanded Source Types
Bar coloring
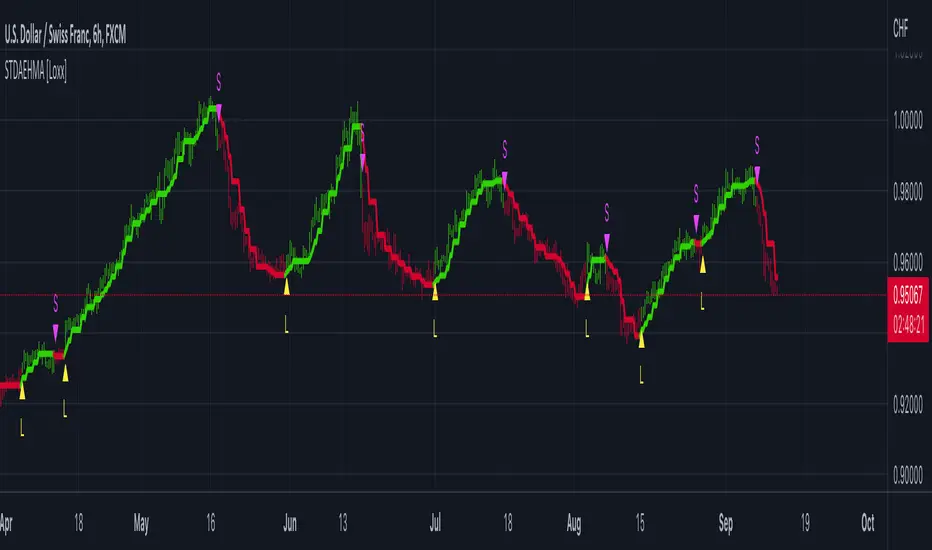
STD-Filtered, Adaptive Exponential Hull Moving Average [Loxx]STD-Filtered, Adaptive Exponential Hull Moving Average is a Kaufman Efficiency Ratio Adaptive Hull Moving Average that uses EMA instead of WMA for its computation. I've also added standard deviation stepping to further smooth the signal. Using EMA instead of WMA turns the Hull into what's called the AEHMA. You can read more about the EHMA here: eceweb1.rutgers.edu
What is the traditional Hull Moving Average?
The Hull Moving Average (HMA) attempts to minimize the lag of a traditional moving average while retaining the smoothness of the moving average line. Developed by Alan Hull in 2005, this indicator makes use of weighted moving averages to prioritize more recent values and greatly reduce lag. The resulting average is more responsive and well-suited for identifying entry points.
What is Kaufman's Efficiency Ratio?
The Efficiency Ratio (ER) was first presented by Perry Kaufman in his 1995 book ‘Smarter Trading‘. It is calculated by dividing the price change over a period by the absolute sum of the price movements that occurred to achieve that change. The resulting ratio ranges between 0 and 1 with higher values representing a more efficient or trending market.
The value of the ER ranges between 0 and 1. It has the value of 1 when prices move in the same direction for the full time over which the indicator is calculated, e.g. n bars period. It has a value of 0 when prices are unchanged over the n periods. When prices move in wide swings within the interval, the sum of the denominator becomes very large compared to the numerator and ER approaches zero.
Some uses for ER:
A qualifier for a trend following trade; a trend is considered “persistent” only when RE is above a certain value, e.g. 0.3 or 0.4 .
A filter to screen out choppy stocks/markets, where breakouts are frequently “fakeouts”.
In an adaptive trading system, helping to determine whether to apply a trend following algorithm or a mean reversion algorithm.
It is used in the calculation of Kaufman’s Adaptive Moving Average (KAMA).
How to calculate the Hull Adaptive Moving Average (HAMA)
Find Signal to Noise ratio (SNR)
Normalize SNR from 0 to 1
Calculate adaptive alphas
Apply EMAs
Included
Bar coloring
Signals
Alerts
Loxx's Expanded Source Types
Variety N-Tuple Moving Averages w/ Variety Stepping [Loxx]Variety N-Tuple Moving Averages w/ Variety Stepping is a moving average indicator that allows you to create 1- 30 tuple moving average types; i.e., Double-MA, Triple-MA, Quadruple-MA, Quintuple-MA, ... N-tuple-MA. This version contains 2 different moving average types. For example, using "50" as the depth will give you Quinquagintuple Moving Average. If you'd like to find the name of the moving average type you create with the depth input with this indicator, you can find a list of tuples here: Tuples extrapolated
Due to the coding required to adapt a moving average to fit into this indicator, additional moving average types will be added as they are created to fit into this unique use case. Since this is a work in process, there will be many future updates of this indicator. For now, you can choose from either EMA or RMA.
This indicator is also considered one of the top 10 forex indicators. See details here: forex-station.com
Additionally, this indicator is a computationally faster, more streamlined version of the following indicators with the addition of 6 stepping functions and 6 different bands/channels types.
STD-Stepped, Variety N-Tuple Moving Averages
STD-Stepped, Variety N-Tuple Moving Averages is the standard deviation stepped/filtered indicator of the following indicator
Last but not least, a big shoutout to @lejmer for his help in formulating a looping solution for this streamlined version. this indicator is speedy even at 50 orders deep. You can find his scripts here: www.tradingview.com
How this works
Step 1: Run factorial calculation on the depth value,
Step 2: Calculate weights of nested moving averages
factorial(depth) / (factorial(depth - k) * factorial(k); where depth is the depth and k is the weight position
Examples of coefficient outputs:
6 Depth: 6 15 20 15 6
7 Depth: 7 21 35 35 21 7
8 Depth: 8 28 56 70 56 28 8
9 Depth: 9 36 34 84 126 126 84 36 9
10 Depth: 10 45 120 210 252 210 120 45 10
11 Depth: 11 55 165 330 462 462 330 165 55 11
12 Depth: 12 66 220 495 792 924 792 495 220 66 12
13 Depth: 13 78 286 715 1287 1716 1716 1287 715 286 78 13
Step 3: Apply coefficient to each moving average
For QEMA, which is 5 depth EMA , the calculation is as follows
ema1 = ta. ema ( src , length)
ema2 = ta. ema (ema1, length)
ema3 = ta. ema (ema2, length)
ema4 = ta. ema (ema3, length)
ema5 = ta. ema (ema4, length)
In this new streamlined version, these MA calculations are packed into an array inside loop so Pine doesn't have to keep all possible series information in memory. This is handled with the following code:
temp = array.get(workarr, k + 1) + alpha * (array.get(workarr, k) - array.get(workarr, k + 1))
array.set(workarr, k + 1, temp)
After we pack the array, we apply the coefficients to derive the NTMA:
qema = 5 * ema1 - 10 * ema2 + 10 * ema3 - 5 * ema4 + ema5
Stepping calculations
First off, you can filter by both price and/or MA output. Both price and MA output can be filtered/stepped in their own way. You'll see two selectors in the input settings. Default is ATR ATR. Here's how stepping works in simple terms: if the price/MA output doesn't move by X deviations, then revert to the price/MA output one bar back.
ATR
The average true range (ATR) is a technical analysis indicator, introduced by market technician J. Welles Wilder Jr. in his book New Concepts in Technical Trading Systems, that measures market volatility by decomposing the entire range of an asset price for that period.
Standard Deviation
Standard deviation is a statistic that measures the dispersion of a dataset relative to its mean and is calculated as the square root of the variance. The standard deviation is calculated as the square root of variance by determining each data point's deviation relative to the mean. If the data points are further from the mean, there is a higher deviation within the data set; thus, the more spread out the data, the higher the standard deviation.
Adaptive Deviation
By definition, the Standard Deviation (STD, also represented by the Greek letter sigma σ or the Latin letter s) is a measure that is used to quantify the amount of variation or dispersion of a set of data values. In technical analysis we usually use it to measure the level of current volatility .
Standard Deviation is based on Simple Moving Average calculation for mean value. This version of standard deviation uses the properties of EMA to calculate what can be called a new type of deviation, and since it is based on EMA , we can call it EMA deviation. And added to that, Perry Kaufman's efficiency ratio is used to make it adaptive (since all EMA type calculations are nearly perfect for adapting).
The difference when compared to standard is significant--not just because of EMA usage, but the efficiency ratio makes it a "bit more logical" in very volatile market conditions.
See how this compares to Standard Devaition here:
Adaptive Deviation
Median Absolute Deviation
The median absolute deviation is a measure of statistical dispersion. Moreover, the MAD is a robust statistic, being more resilient to outliers in a data set than the standard deviation. In the standard deviation, the distances from the mean are squared, so large deviations are weighted more heavily, and thus outliers can heavily influence it. In the MAD, the deviations of a small number of outliers are irrelevant.
Because the MAD is a more robust estimator of scale than the sample variance or standard deviation, it works better with distributions without a mean or variance, such as the Cauchy distribution.
For this indicator, I used a manual recreation of the quantile function in Pine Script. This is so users have a full inside view into how this is calculated.
Efficiency-Ratio Adaptive ATR
Average True Range (ATR) is widely used indicator in many occasions for technical analysis . It is calculated as the RMA of true range. This version adds a "twist": it uses Perry Kaufman's Efficiency Ratio to calculate adaptive true range
See how this compares to ATR here:
ER-Adaptive ATR
Mean Absolute Deviation
The mean absolute deviation (MAD) is a measure of variability that indicates the average distance between observations and their mean. MAD uses the original units of the data, which simplifies interpretation. Larger values signify that the data points spread out further from the average. Conversely, lower values correspond to data points bunching closer to it. The mean absolute deviation is also known as the mean deviation and average absolute deviation.
This definition of the mean absolute deviation sounds similar to the standard deviation (SD). While both measure variability, they have different calculations. In recent years, some proponents of MAD have suggested that it replace the SD as the primary measure because it is a simpler concept that better fits real life.
For Pine Coders, this is equivalent of using ta.dev()
Bands/Channels
See the information above for how bands/channels are calculated. After the one of the above deviations is calculated, the channels are calculated as output +/- deviation * multiplier
Signals
Green is uptrend, red is downtrend, yellow "L" signal is Long, fuchsia "S" signal is short.
Included:
Alerts
Loxx's Expanded Source Types
Bar coloring
Signals
6 bands/channels types
6 stepping types
Related indicators
3-Pole Super Smoother w/ EMA-Deviation-Corrected Stepping
STD-Stepped Fast Cosine Transform Moving Average
ATR-Stepped PDF MA

Adaptive Deviation [Loxx]Adaptive Deviation is an educational/conceptual indicator that is a new spin on the regular old standard deviation. By definition, the Standard Deviation (STD, also represented by the Greek letter sigma σ or the Latin letter s) is a measure that is used to quantify the amount of variation or dispersion of a set of data values. In technical analysis we usually use it to measure the level of current volatility.
Standard Deviation is based on Simple Moving Average calculation for mean value. This version of standard deviation uses the properties of EMA to calculate what can be called a new type of deviation, and since it is based on EMA, we can call it EMA deviation. And added to that, Perry Kaufman's efficiency ratio is used to make it adaptive (since all EMA type calculations are nearly perfect for adapting).
The difference when compared to standard is significant--not just because of EMA usage, but the efficiency ratio makes it a "bit more logical" in very volatile market conditions.
The green line is the Adaptive Deviation, the white line is regular Standard Deviation. This concept will be used in future indicators to further reduce noise and adapt to price volatility.
Included
Loxx's Expanded Source Types
Adaptive-Lookback Stochastic [Loxx]Adaptive-Lookback Stochastic is an adaptive stochastic indicator.
The Adaptive lookback is truly a market-driven period input used to determine the variable lookback period for many different indicators, instead of a traditional, fixed figure.
It is based on the frequency of market swings - the time between swing highs or swing lows. A swing high is defined as two consecutive higher highs followed by two consecutive lower highs; a swing low is defined by two consecutive lower lows followed by two consecutive higher lows. As swing points typically accompany reversals, they occur more frequently in choppier and volatile markets than in trends.
Adaptive lookback period is determined as :
Determine the initial number of swing points (swing count parameter) to use in the calculation.
Count the number of price bars it takes for the n swing points to form.
Divide step 2 by step 1 and round the result.
As an addition, adjust the "speed" of the produced period using the speed parameter - the smaller the speed parameter, the "slower" the average, and vice versa
Included
Bar coloring
Loxx Expanded Source Types
3 types of signals: levels crosses, slope, and middle crosses
Alerts
STD-Filtered, ATR-Adaptive Laguerre Filter [Loxx]STD-Filtered, ATR-Adaptive Laguerre Filter is a standard Laguerre Filter that is first made ATR-adaptive and the passed through a standard deviation filter. This helps reduce noise and refine the output signal. Can apply the standard deviation filter to the price, signal, both or neither.
What is the Laguerre Filter?
The Laguerre RSI indicator created by John F. Ehlers is described in his book "Cybernetic Analysis for Stocks and Futures". The Laguerre Filter is a smoothing filter which is based on Laguerre polynomials. The filter requires the current price, three prior prices, a user defined factor called Alpha to fill its calculation. Adjusting the Alpha coefficient is used to increase or decrease its lag and it's smoothness.
Included:
Bar coloring
Signals
Alerts
Loxx's Expanded Source Types
Adaptive Rebound Line (ARL)The Adaptive Rebound Line (ARL) focuses on the rebound of price action according to the trend.
While it does not focus on showing the trend, it does help in anticipating price rebounds.
It achieves this by adapting quickly and by reducing lag.
It is recommended to use this with a trend-identifying indicator.
It was inspired by the Hull Moving Average and the KAMA.
Additional indicator show in the chart is Tide Finder Plus .
