Machine Learning Support and Resistance [AlgoAlpha]🚀 Elevate Your Trading with Machine Learning Dynamic Support and Resistance!
The Machine Learning Dynamic Support and Resistance by AlgoAlpha leverages advanced machine learning techniques to identify dynamic support and resistance levels on your chart. This tool is designed to help traders spot key price levels where the market might reverse or stall, enhancing your trading strategy with precise, data-driven insights.
Key Features:
🎯 Dynamic Levels: Continuously adjusts support and resistance levels based on real-time price data using a K-means clustering algorithm.
🧠 Machine Learning: Utilizes clustering methods to optimize the identification of significant price zones.
⏳ Configurable Lookback Periods: Customize the training length and confirmation length for better adaptability to different market conditions.
🎨 Visual Clarity: Clearly distinguish bullish and bearish zones with customizable color schemes.
📉 Trailing and Fixed Levels: Option to display both trailing and fixed support/resistance levels for comprehensive analysis.
🚮 Auto-Cleaning: Automatically removes outdated levels after a specified number of bars to keep your chart clean and relevant.
Quick Guide to Using the Machine Learning Dynamic Support and Resistance Indicator
Maximize your trading with this powerful indicator by following these streamlined steps! 🚀✨
🛠 Add the Indicator: Add the indicator to favorites by pressing the star icon. Customize settings like clustering training length, confirmation length, and whether to show trailing or fixed levels to fit your trading style.
📊 Market Analysis: Monitor the dynamic levels to identify potential reversal points. Use these levels to inform entry and exit points, or to set stop losses.
How It Works
This indicator employs a K-means clustering algorithm to dynamically identify key price levels based on the historical price data within a specified lookback window. It starts by initializing three centroids based on the highest, lowest, and an average between the highest and lowest price over the lookback period. The algorithm then iterates through the price data to cluster the prices around these centroids, dynamically adjusting them until they stabilize, representing potential support and resistance levels. These levels are further confirmed based on a separate confirmation length parameter to identify "fixed" levels, which are then drawn as horizontal lines on the chart. The script continuously updates these levels as new data comes in, while also removing older levels to keep the chart clean and relevant, offering traders a clear and adaptive view of market structure.
Artificial_intelligence

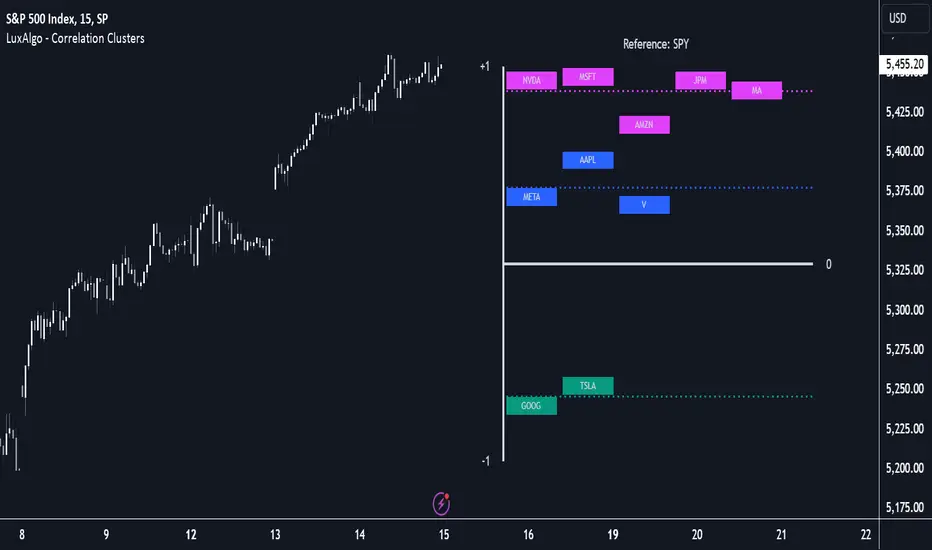
Correlation Clusters [LuxAlgo]The Correlation Clusters is a machine learning tool that allows traders to group sets of tickers with a similar correlation coefficient to a user-set reference ticker.
The tool calculates the correlation coefficients between 10 user-set tickers and a user-set reference ticker, with the possibility of forming up to 10 clusters.
🔶 USAGE
Applying clustering methods to correlation analysis allows traders to quickly identify which set of tickers are correlated with a reference ticker, rather than having to look at them one by one or using a more tedious approach such as correlation matrices.
Tickers belonging to a cluster may also be more likely to have a higher mutual correlation. The image above shows the detailed parts of the Correlation Clusters tool.
The correlation coefficient between two assets allows traders to see how these assets behave in relation to each other. It can take values between +1.0 and -1.0 with the following meaning
Value near +1.0: Both assets behave in a similar way, moving up or down at the same time
Value close to 0.0: No correlation, both assets behave independently
Value near -1.0: Both assets have opposite behavior when one moves up the other moves down, and vice versa
There is a wide range of trading strategies that make use of correlation coefficients between assets, some examples are:
Pair Trading: Traders may wish to take advantage of divergences in the price movements of highly positively correlated assets; even highly positively correlated assets do not always move in the same direction; when assets with a correlation close to +1.0 diverge in their behavior, traders may see this as an opportunity to buy one and sell the other in the expectation that the assets will return to the likely same price behavior.
Sector rotation: Traders may want to favor some sectors that are expected to perform in the next cycle, tracking the correlation between different sectors and between the sector and the overall market.
Diversification: Traders can aim to have a diversified portfolio of uncorrelated assets. From a risk management perspective, it is useful to know the correlation between the assets in your portfolio, if you hold equal positions in positively correlated assets, your risk is tilted in the same direction, so if the assets move against you, your risk is doubled. You can avoid this increased risk by choosing uncorrelated assets so that they move independently.
Hedging: Traders may want to hedge positions with correlated assets, from a hedging perspective, if you are long an asset, you can hedge going long a negatively correlated asset or going short a positively correlated asset.
Grouping different assets with similar behavior can be very helpful to traders to avoid over-exposure to those assets, traders may have multiple long positions on different assets as a way of minimizing overall risk when in reality if those assets are part of the same cluster traders are maximizing their risk by taking positions on assets with the same behavior.
As a rule of thumb, a trader can minimize risk via diversification by taking positions on assets with no correlations, the proposed tool can effectively show a set of uncorrelated candidates from the reference ticker if one or more clusters centroids are located near 0.
🔶 DETAILS
K-means clustering is a popular machine-learning algorithm that finds observations in a data set that are similar to each other and places them in a group.
The process starts by randomly assigning each data point to an initial group and calculating the centroid for each. A centroid is the center of the group. K-means clustering forms the groups in such a way that the variances between the data points and the centroid of the cluster are minimized.
It's an unsupervised method because it starts without labels and then forms and labels groups itself.
🔹 Execution Window
In the image above we can see how different execution windows provide different correlation coefficients, informing traders of the different behavior of the same assets over different time periods.
Users can filter the data used to calculate correlations by number of bars, by time, or not at all, using all available data. For example, if the chart timeframe is 15m, traders may want to know how different assets behave over the last 7 days (one week), or for an hourly chart set an execution window of one month, or one year for a daily chart. The default setting is to use data from the last 50 bars.
🔹 Clusters
On this graph, we can see different clusters for the same data. The clusters are identified by different colors and the dotted lines show the centroids of each cluster.
Traders can select up to 10 clusters, however, do note that selecting 10 clusters can lead to only 4 or 5 returned clusters, this is caused by the machine learning algorithm not detecting any more data points deviating from already detected clusters.
Traders can fine-tune the algorithm by changing the 'Cluster Threshold' and 'Max Iterations' settings, but if you are not familiar with them we advise you not to change these settings, the defaults can work fine for the application of this tool.
🔹 Correlations
Different correlations mean different behaviors respecting the same asset, as we can see in the chart above.
All correlations are found against the same asset, traders can use the chart ticker or manually set one of their choices from the settings panel. Then they can select the 10 tickers to be used to find the correlation coefficients, which can be useful to analyze how different types of assets behave against the same asset.
🔶 SETTINGS
Execution Window Mode: Choose how the tool collects data, filter data by number of bars, time, or no filtering at all, using all available data.
Execute on Last X Bars: Number of bars for data collection when the 'Bars' execution window mode is active.
Execute on Last: Time window for data collection when the `Time` execution window mode is active. These are full periods, so `Day` means the last 24 hours, `Week` means the last 7 days, and so on.
🔹 Clusters
Number of Clusters: Number of clusters to detect up to 10. Only clusters with data points are displayed.
Cluster Threshold: Number used to compare a new centroid within the same cluster. The lower the number, the more accurate the centroid will be.
Max Iterations: Maximum number of calculations to detect a cluster. A high value may lead to a timeout runtime error (loop takes too long).
🔹 Ticker of Reference
Use Chart Ticker as Reference: Enable/disable the use of the current chart ticker to get the correlation against all other tickers selected by the user.
Custom Ticker: Custom ticker to get the correlation against all the other tickers selected by the user.
🔹 Correlation Tickers
Select the 10 tickers for which you wish to obtain the correlation against the reference ticker.
🔹 Style
Text Size: Select the size of the text to be displayed.
Display Size: Select the size of the correlation chart to be displayed, up to 500 bars.
Box Height: Select the height of the boxes to be displayed. A high height will cause overlapping if the boxes are close together.
Clusters Colors: Choose a custom colour for each cluster.
Machine Learning Adaptive SuperTrend [AlgoAlpha]📈🤖 Machine Learning Adaptive SuperTrend - Take Your Trading to the Next Level! 🚀✨
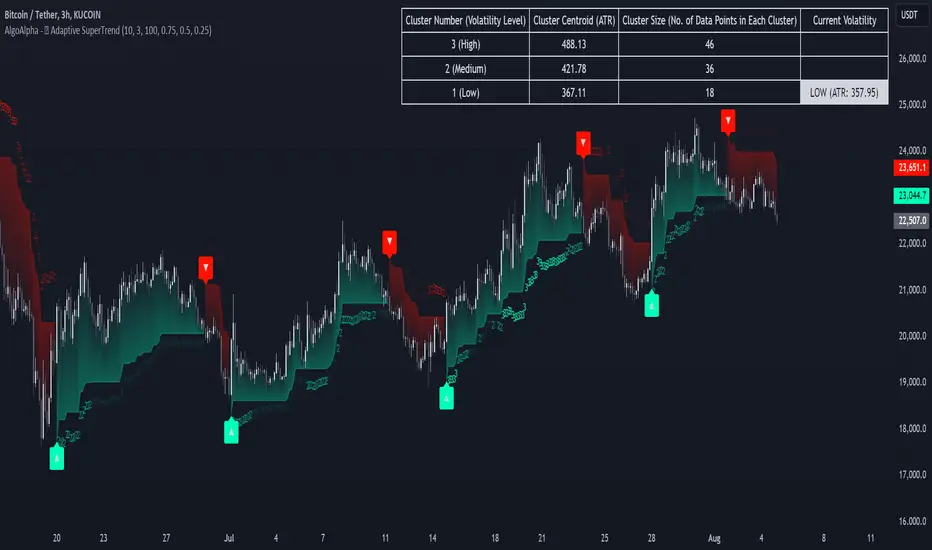
Introducing the Machine Learning Adaptive SuperTrend , an advanced trading indicator designed to adapt to market volatility dynamically using machine learning techniques. This indicator employs k-means clustering to categorize market volatility into high, medium, and low levels, enhancing the traditional SuperTrend strategy. Perfect for traders who want an edge in identifying trend shifts and market conditions.
What is K-Means Clustering and How It Works
K-means clustering is a machine learning algorithm that partitions data into distinct groups based on similarity. In this indicator, the algorithm analyzes ATR (Average True Range) values to classify volatility into three clusters: high, medium, and low. The algorithm iterates to optimize the centroids of these clusters, ensuring accurate volatility classification.
Key Features
🎨 Customizable Appearance: Adjust colors for bullish and bearish trends.
🔧 Flexible Settings: Configure ATR length, SuperTrend factor, and initial volatility guesses.
📊 Volatility Classification: Uses k-means clustering to adapt to market conditions.
📈 Dynamic SuperTrend Calculation: Applies the classified volatility level to the SuperTrend calculation.
🔔 Alerts: Set alerts for trend shifts and volatility changes.
📋 Data Table Display: View cluster details and current volatility on the chart.
Quick Guide to Using the Machine Learning Adaptive SuperTrend Indicator
🛠 Add the Indicator: Add the indicator to favorites by pressing the star icon. Customize settings like ATR length, SuperTrend factor, and volatility percentiles to fit your trading style.
📊 Market Analysis: Observe the color changes and SuperTrend line for trend reversals. Use the data table to monitor volatility clusters.
🔔 Alerts: Enable notifications for trend shifts and volatility changes to seize trading opportunities without constant chart monitoring.
How It Works
The indicator begins by calculating the ATR values over a specified training period to assess market volatility. Initial guesses for high, medium, and low volatility percentiles are inputted. The k-means clustering algorithm then iterates to classify the ATR values into three clusters. This classification helps in determining the appropriate volatility level to apply to the SuperTrend calculation. As the market evolves, the indicator dynamically adjusts, providing real-time trend and volatility insights. The indicator also incorporates a data table displaying cluster centroids, sizes, and the current volatility level, aiding traders in making informed decisions.
Add the Machine Learning Adaptive SuperTrend to your TradingView charts today and experience a smarter way to trade! 🌟📊
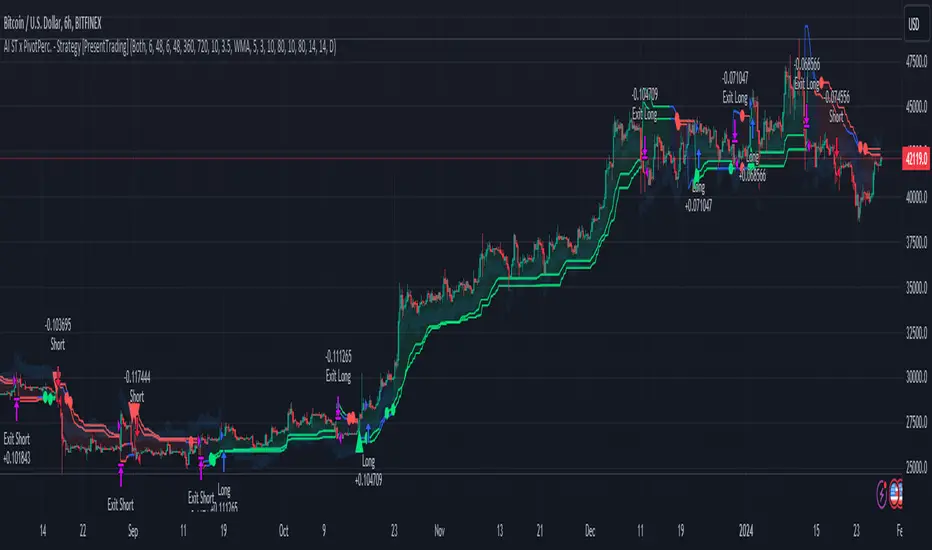
AI SuperTrend x Pivot Percentile - Strategy [PresentTrading]█ Introduction and How it is Different
The AI SuperTrend x Pivot Percentile strategy is a sophisticated trading approach that integrates AI-driven analysis with traditional technical indicators. Combining the AI SuperTrend with the Pivot Percentile strategy highlights several key advantages:
1. Enhanced Accuracy in Trend Prediction: The AI SuperTrend utilizes K-Nearest Neighbors (KNN) algorithm for trend prediction, improving accuracy by considering historical data patterns. This is complemented by the Pivot Percentile analysis which provides additional context on trend strength.
2. Comprehensive Market Analysis: The integration offers a multi-faceted approach to market analysis, combining AI insights with traditional technical indicators. This dual approach captures a broader range of market dynamics.
BTC 6H L/S Performance
Local
█ Strategy: How it Works - Detailed Explanation
🔶 AI-Enhanced SuperTrend Indicators
1. SuperTrend Calculation:
- The SuperTrend indicator is calculated using a moving average and the Average True Range (ATR). The basic formula is:
- Upper Band = Moving Average + (Multiplier × ATR)
- Lower Band = Moving Average - (Multiplier × ATR)
- The moving average type (SMA, EMA, WMA, RMA, VWMA) and the length of the moving average and ATR are adjustable parameters.
- The direction of the trend is determined based on the position of the closing price in relation to these bands.
2. AI Integration with K-Nearest Neighbors (KNN):
- The KNN algorithm is applied to predict trend direction. It uses historical price data and SuperTrend values to classify the current trend as bullish or bearish.
- The algorithm calculates the 'distance' between the current data point and historical points. The 'k' nearest data points (neighbors) are identified based on this distance.
- A weighted average of these neighbors' trends (bullish or bearish) is calculated to predict the current trend.
For more please check: Multi-TF AI SuperTrend with ADX - Strategy
🔶 Pivot Percentile Analysis
1. Percentile Calculation:
- This involves calculating the percentile ranks for high and low prices over a set of predefined lengths.
- The percentile function is typically defined as:
- Percentile = Value at (P/100) × (N + 1)th position
- Where P is the desired percentile, and N is the number of data points.
2. Trend Strength Evaluation:
- The calculated percentiles for highs and lows are used to determine the strength of bullish and bearish trends.
- For instance, a high percentile rank in the high prices may indicate a strong bullish trend, and vice versa for bearish trends.
For more please check: Pivot Percentile Trend - Strategy
🔶 Strategy Integration
1. Combining SuperTrend and Pivot Percentile:
- The strategy synthesizes the insights from both AI-enhanced SuperTrend and Pivot Percentile analysis.
- It compares the trend direction indicated by the SuperTrend with the strength of the trend as suggested by the Pivot Percentile analysis.
2. Signal Generation:
- A trading signal is generated when both the AI-enhanced SuperTrend and the Pivot Percentile analysis agree on the trend direction.
- For instance, a bullish signal is generated when both the SuperTrend is bullish, and the Pivot Percentile analysis shows strength in bullish trends.
🔶 Risk Management and Filters
- ADX and DMI Filter: The strategy uses the Average Directional Index (ADX) and the Directional Movement Index (DMI) as filters to assess the trend's strength and direction.
- Dynamic Trailing Stop Loss: Based on the SuperTrend indicator, the strategy dynamically adjusts stop-loss levels to manage risk effectively.
This strategy stands out for its ability to combine real-time AI analysis with established technical indicators, offering traders a nuanced and responsive tool for navigating complex market conditions. The equations and algorithms involved are pivotal in accurately identifying market trends and potential trade opportunities.
█ Usage
To effectively use this strategy, traders should:
1. Understand the AI and Pivot Percentile Indicators: A clear grasp of how these indicators work will enable traders to make informed decisions.
2. Interpret the Signals Accurately: The strategy provides bullish, bearish, and neutral signals. Traders should align these signals with their market analysis and trading goals.
3. Monitor Market Conditions: Given that this strategy is sensitive to market dynamics, continuous monitoring is crucial for timely decision-making.
4. Adjust Settings as Needed: Traders should feel free to tweak the input parameters to suit their trading preferences and to respond to changing market conditions.
█Default Settings and Their Impact on Performance
1. Trading Direction (Default: "Both")
Effect: Determines whether the strategy will take long positions, short positions, or both. Adjusting this setting can align the strategy with the trader's market outlook or risk preference.
2. AI Settings (Neighbors: 3, Data Points: 24)
Neighbors: The number of nearest neighbors in the KNN algorithm. A higher number might smooth out noise but could miss subtle, recent changes. A lower number makes the model more sensitive to recent data but may increase noise.
Data Points: Defines the amount of historical data considered. More data points provide a broader context but may dilute recent trends' impact.
3. SuperTrend Settings (Length: 10, Factor: 3.0, MA Source: "WMA")
Length: Affects the sensitivity of the SuperTrend indicator. A longer length results in a smoother, less sensitive indicator, ideal for long-term trends.
Factor: Determines the bandwidth of the SuperTrend. A higher factor creates wider bands, capturing larger price movements but potentially missing short-term signals.
MA Source: The type of moving average used (e.g., WMA - Weighted Moving Average). Different MA types can affect the trend indicator's responsiveness and smoothness.
4. AI Trend Prediction Settings (Price Trend: 10, Prediction Trend: 80)
Price Trend and Prediction Trend Lengths: These settings define the lengths of weighted moving averages for price and SuperTrend, impacting the responsiveness and smoothness of the AI's trend predictions.
5. Pivot Percentile Settings (Length: 10)
Length: Influences the calculation of pivot percentiles. A shorter length makes the percentile more responsive to recent price changes, while a longer length offers a broader view of price trends.
6. ADX and DMI Settings (ADX Length: 14, Time Frame: 'D')
ADX Length: Defines the period for the Average Directional Index calculation. A longer period results in a smoother ADX line.
Time Frame: Sets the time frame for the ADX and DMI calculations, affecting the sensitivity to market changes.
7. Commission, Slippage, and Initial Capital
These settings relate to transaction costs and initial investment, directly impacting net profitability and strategy feasibility.
Multi-TF AI SuperTrend with ADX - Strategy [PresentTrading]
## █ Introduction and How it is Different
The trading strategy in question is an enhanced version of the SuperTrend indicator, combined with AI elements and an ADX filter. It's a multi-timeframe strategy that incorporates two SuperTrends from different timeframes and utilizes a k-nearest neighbors (KNN) algorithm for trend prediction. It's different from traditional SuperTrend indicators because of its AI-based predictive capabilities and the addition of the ADX filter for trend strength.
BTC 8hr Performance
ETH 8hr Performance
## █ Strategy, How it Works: Detailed Explanation (Revised)
### Multi-Timeframe Approach
The strategy leverages the power of multiple timeframes by incorporating two SuperTrend indicators, each calculated on a different timeframe. This multi-timeframe approach provides a holistic view of the market's trend. For example, a 8-hour timeframe might capture the medium-term trend, while a daily timeframe could capture the longer-term trend. When both SuperTrends align, the strategy confirms a more robust trend.
### K-Nearest Neighbors (KNN)
The KNN algorithm is used to classify the direction of the trend based on historical SuperTrend values. It uses weighted voting of the 'k' nearest data points. For each point, it looks at its 'k' closest neighbors and takes a weighted average of their labels to predict the current label. The KNN algorithm is applied separately to each timeframe's SuperTrend data.
### SuperTrend Indicators
Two SuperTrend indicators are used, each from a different timeframe. They are calculated using different moving averages and ATR lengths as per user settings. The SuperTrend values are then smoothed to make them suitable for KNN-based prediction.
### ADX and DMI Filters
The ADX filter is used to eliminate weak trends. Only when the ADX is above 20 and the directional movement index (DMI) confirms the trend direction, does the strategy signal a buy or sell.
### Combining Elements
A trade signal is generated only when both SuperTrends and the ADX filter confirm the trend direction. This multi-timeframe, multi-indicator approach reduces false positives and increases the robustness of the strategy.
By considering multiple timeframes and using machine learning for trend classification, the strategy aims to provide more accurate and reliable trade signals.
BTC 8hr Performance (Zoom-in)
## █ Trade Direction
The strategy allows users to specify the trade direction as 'Long', 'Short', or 'Both'. This is useful for traders who have a specific market bias. For instance, in a bullish market, one might choose to only take 'Long' trades.
## █ Usage
Parameters: Adjust the number of neighbors, data points, and moving averages according to the asset and market conditions.
Trade Direction: Choose your preferred trading direction based on your market outlook.
ADX Filter: Optionally, enable the ADX filter to avoid trading in a sideways market.
Risk Management: Use the trailing stop-loss feature to manage risks.
## █ Default Settings
Neighbors (K): 3
Data points for KNN: 12
SuperTrend Length: 10 and 5 for the two different SuperTrends
ATR Multiplier: 3.0 for both
ADX Length: 21
ADX Time Frame: 240
Default trading direction: Both
By customizing these settings, traders can tailor the strategy to fit various trading styles and assets.

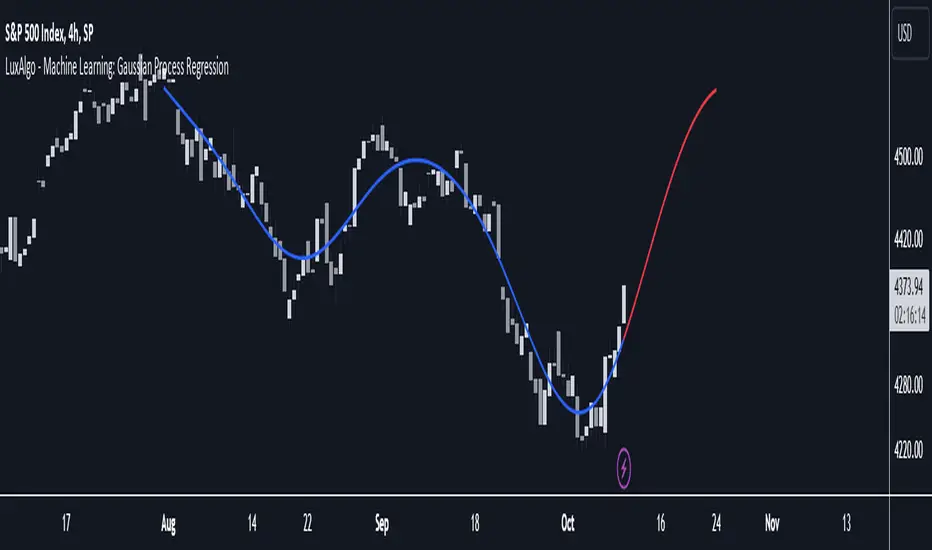
Machine Learning: Gaussian Process Regression [LuxAlgo]We provide an implementation of the Gaussian Process Regression (GPR), a popular machine-learning method capable of estimating underlying trends in prices as well as forecasting them.
While this implementation is adapted to real-time usage, do remember that forecasting trends in the market is challenging, do not use this tool as a standalone for your trading decisions.
🔶 USAGE
The main goal of our implementation of GPR is to forecast trends. The method is applied to a subset of the most recent prices, with the Training Window determining the size of this subset.
Two user settings controlling the trend estimate are available, Smooth and Sigma . Smooth determines the smoothness of our estimate, with higher values returning smoother results suitable for longer-term trend estimates.
Sigma controls the amplitude of the forecast, with values closer to 0 returning results with a higher amplitude. Do note that due to the calculation of the method, lower values of sigma can return errors with higher values of the training window.
🔹 Updating Mechanisms
The script includes three methods to update a forecast. By default a forecast will not update for new bars (Lock Forecast).
The forecast can be re-estimated once the price reaches the end of the forecasting window when using the "Update Once Reached" method.
Finally "Continuously Update" will update the whole forecast on any new bar.
🔹 Estimating Trends
Gaussian Process Regression can be used to estimate past underlying local trends in the price, allowing for a noise-free interpretation of trends.
This can be useful for performing descriptive analysis, such as highlighting patterns more easily.
🔶 SETTINGS
Training Window: Number of most recent price observations used to fit the model
Forecasting Length: Forecasting horizon, determines how many bars in the future are forecasted.
Smooth: Controls the degree of smoothness of the model fit.
Sigma: Noise variance. Controls the amplitude of the forecast, lower values will make it more sensitive to outliers.
Update: Determines when the forecast is updated, by default the forecast is not updated for new bars.
Double AI Super Trend Trading - Strategy [PresentTrading]█ Introduction and How It is Different
The Double AI Super Trend Trading Strategy is a cutting-edge approach that leverages the power of not one, but two AI algorithms, in tandem with the SuperTrend technical indicator. The strategy aims to provide traders with enhanced precision in market entry and exit points. It is designed to adapt to market conditions dynamically, offering the flexibility to trade in both bullish and bearish markets.
*The KNN part is mainly referred from @Zeiierman.
BTCUSD 8hr performance
ETHUSD 8hr performance
█ Strategy, How It Works: Detailed Explanation
1. SuperTrend Calculation
The SuperTrend is a popular indicator that captures market trends through a combination of the Volume-Weighted Moving Average (VWMA) and the Average True Range (ATR). This strategy utilizes two sets of SuperTrend calculations with varying lengths and factors to capture both short-term and long-term market trends.
2. KNN Algorithm
The strategy employs k-Nearest Neighbors (KNN) algorithms, which are supervised machine learning models. Two sets of KNN algorithms are used, each focused on different lengths of historical data and number of neighbors. The KNN algorithms classify the current SuperTrend data point as bullish or bearish based on the weighted sum of the labels of the k closest historical data points.
3. Signal Generation
Based on the KNN classifications and the SuperTrend indicator, the strategy generates signals for the start of a new trend and the continuation of an existing trend.
4. Trading Logic
The strategy uses these signals to enter long or short positions. It also incorporates dynamic trailing stops for exit conditions.
Local picture
█ Trade Direction
The strategy allows traders to specify their trading direction: long, short, or both. This enables the strategy to be versatile and adapt to various market conditions.
█ Usage
ToolTips: Comprehensive tooltips are provided for each parameter to guide the user through the customization process.
Inputs: Traders can customize numerous parameters including the number of neighbors in KNN, ATR multiplier, and types of moving averages.
Plotting: The strategy also provides visual cues on the chart to indicate bullish or bearish trends.
Order Execution: Based on the generated signals, the strategy will execute buy or sell orders automatically.
█ Default Settings
The default settings are configured to offer a balanced approach suitable for most scenarios:
Initial Capital: $10,000
Default Quantity Type: 10% of equity
Commission: 0.1%
Slippage: 1
Currency: USD
These settings can be modified to suit various trading styles and asset classes.

AI SuperTrend - Strategy [presentTrading]
█ Introduction and How it is Different
The AI Supertrend Strategy is a unique hybrid approach that employs both traditional technical indicators and machine learning techniques. Unlike standard strategies that rely solely on traditional indicators or mathematical models, this strategy integrates the power of k-Nearest Neighbors (KNN), a machine learning algorithm, with the tried-and-true SuperTrend indicator. This blend aims to provide traders with more accurate, responsive, and context-aware trading signals.
*The KNN part is mainly referred from @Zeiierman.
BTCUSD 8hr performance
ETHUSD 8hr performance
█ Strategy, How it Works: Detailed Explanation
SuperTrend Calculation
Volume-Weighted Moving Average (VWMA): A VWMA of the close price is calculated based on the user-defined length (len). This serves as the central line around which the upper and lower bands are calculated.
Average True Range (ATR): ATR is calculated over a period defined by len. It measures the market's volatility.
Upper and Lower Bands: The upper band is calculated as VWMA + (factor * ATR) and the lower band as VWMA - (factor * ATR). The factor is a user-defined multiplier that decides how wide the bands should be.
KNN Algorithm
Data Collection: An array (data) is populated with recent n SuperTrend values. Corresponding labels (labels) are determined by whether the weighted moving average price (price) is greater than the weighted moving average of the SuperTrend (sT).
Distance Calculation: The absolute distance between each data point and the current SuperTrend value is calculated.
Sorting & Weighting: The distances are sorted in ascending order, and the closest k points are selected. Each point is weighted by the inverse of its distance to the current point.
Classification: A weighted sum of the labels of the k closest points is calculated. If the sum is closer to 1, the trend is predicted as bullish; if closer to 0, bearish.
Signal Generation
Start of Trend: A new bullish trend (Start_TrendUp) is considered to have started if the current trend color is bullish and the previous was not bullish. Similarly for bearish trends (Start_TrendDn).
Trend Continuation: A bullish trend (TrendUp) is considered to be continuing if the direction is negative and the KNN prediction is 1. Similarly for bearish trends (TrendDn).
Trading Logic
Long Condition: If Start_TrendUp or TrendUp is true, a long position is entered.
Short Condition: If Start_TrendDn or TrendDn is true, a short position is entered.
Exit Condition: Dynamic trailing stops are used for exits. If the trend does not continue as indicated by the KNN prediction and SuperTrend direction, an exit signal is generated.
The synergy between SuperTrend and KNN aims to filter out noise and produce more reliable trading signals. While SuperTrend provides a broad sense of the market direction, KNN refines this by predicting short-term price movements, leading to a more nuanced trading strategy.
Local picture
█ Trade Direction
The strategy allows traders to choose between taking only long positions, only short positions, or both. This is particularly useful for adapting to different market conditions.
█ Usage
ToolTips: Explains what each parameter does and how to adjust them.
Inputs: Customize values like the number of neighbors in KNN, ATR multiplier, and moving average type.
Plotting: Visual cues on the chart to indicate bullish or bearish trends.
Order Execution: Based on the generated signals, the strategy will execute buy/sell orders.
█ Default Settings
The default settings are selected to provide a balanced approach, but they can be modified for different trading styles and asset classes.
Initial Capital: $10,000
Default Quantity Type: 10% of equity
Commission: 0.1%
Slippage: 1
Currency: USD
By combining both machine learning and traditional technical analysis, this strategy offers a sophisticated and adaptive trading solution.

FunctionNNLayerLibrary "FunctionNNLayer"
Generalized Neural Network Layer method.
function(inputs, weights, n_nodes, activation_function, bias, alpha, scale) Generalized Layer.
Parameters:
inputs : float array, input values.
weights : float array, weight values.
n_nodes : int, number of nodes in layer.
activation_function : string, default='sigmoid', name of the activation function used.
bias : float, default=1.0, bias to pass into activation function.
alpha : float, default=na, if required to pass into activation function.
scale : float, default=na, if required to pass into activation function.
Returns: float

FunctionNNPerceptronLibrary "FunctionNNPerceptron"
Perceptron Function for Neural networks.
function(inputs, weights, bias, activation_function, alpha, scale) generalized perceptron node for Neural Networks.
Parameters:
inputs : float array, the inputs of the perceptron.
weights : float array, the weights for inputs.
bias : float, default=1.0, the default bias of the perceptron.
activation_function : string, default='sigmoid', activation function applied to the output.
alpha : float, default=na, if required for activation.
scale : float, default=na, if required for activation.
@outputs float

MLActivationFunctionsLibrary "MLActivationFunctions"
Activation functions for Neural networks.
binary_step(value) Basic threshold output classifier to activate/deactivate neuron.
Parameters:
value : float, value to process.
Returns: float
linear(value) Input is the same as output.
Parameters:
value : float, value to process.
Returns: float
sigmoid(value) Sigmoid or logistic function.
Parameters:
value : float, value to process.
Returns: float
sigmoid_derivative(value) Derivative of sigmoid function.
Parameters:
value : float, value to process.
Returns: float
tanh(value) Hyperbolic tangent function.
Parameters:
value : float, value to process.
Returns: float
tanh_derivative(value) Hyperbolic tangent function derivative.
Parameters:
value : float, value to process.
Returns: float
relu(value) Rectified linear unit (RELU) function.
Parameters:
value : float, value to process.
Returns: float
relu_derivative(value) RELU function derivative.
Parameters:
value : float, value to process.
Returns: float
leaky_relu(value) Leaky RELU function.
Parameters:
value : float, value to process.
Returns: float
leaky_relu_derivative(value) Leaky RELU function derivative.
Parameters:
value : float, value to process.
Returns: float
relu6(value) RELU-6 function.
Parameters:
value : float, value to process.
Returns: float
softmax(value) Softmax function.
Parameters:
value : float array, values to process.
Returns: float
softplus(value) Softplus function.
Parameters:
value : float, value to process.
Returns: float
softsign(value) Softsign function.
Parameters:
value : float, value to process.
Returns: float
elu(value, alpha) Exponential Linear Unit (ELU) function.
Parameters:
value : float, value to process.
alpha : float, default=1.0, predefined constant, controls the value to which an ELU saturates for negative net inputs. .
Returns: float
selu(value, alpha, scale) Scaled Exponential Linear Unit (SELU) function.
Parameters:
value : float, value to process.
alpha : float, default=1.67326324, predefined constant, controls the value to which an SELU saturates for negative net inputs. .
scale : float, default=1.05070098, predefined constant.
Returns: float
exponential(value) Pointer to math.exp() function.
Parameters:
value : float, value to process.
Returns: float
function(name, value, alpha, scale) Activation function.
Parameters:
name : string, name of activation function.
value : float, value to process.
alpha : float, default=na, if required.
scale : float, default=na, if required.
Returns: float
derivative(name, value, alpha, scale) Derivative Activation function.
Parameters:
name : string, name of activation function.
value : float, value to process.
alpha : float, default=na, if required.
scale : float, default=na, if required.
Returns: float

MLLossFunctionsLibrary "MLLossFunctions"
Methods for Loss functions.
mse(expects, predicts) Mean Squared Error (MSE) " MSE = 1/N * sum ((y - y')^2) ".
Parameters:
expects : float array, expected values.
predicts : float array, prediction values.
Returns: float
binary_cross_entropy(expects, predicts) Binary Cross-Entropy Loss (log).
Parameters:
expects : float array, expected values.
predicts : float array, prediction values.
Returns: float

Artificial Intelligence Indicator (BTCUSD) [revolutionai.ca]OFFICIAL LAUNCH DATE: February 15th, 2021 (our website will be updated on this date and the values of this indicator will be updated aswell)
One of the only (if not the only) artificial intelligence indicator for BTC/USD
Which markets it's meant for: BTC/USD
Under which conditions: Any conditions, preferably 1H / 4H / 12H charts
How to gain access: Visit www.trader.revolutionai.ca on February 15th or later, in order to gain access
How it works behind (and how this indicator is different from the other indicators):
We have a trading bot running and everytime the trading bot thinks the price is going up or down, it will manually update this indicator.
In normal circonstances, TradingView doesn't allow the usage of external programs. However we have made that our trading robot manually update itself through TradingView, meaning that everytime it thinks that the price will go up or down, it will manually move the mouse like a human, and edit the indicator's script, and manually type using the keyboard the pine script to specifically say which candle to highlight that the price is going up or down.
We're pretty confident we're one of the only real artificial intelligence indicator out there, but feel free to let us know if someone else is doing something similar.
Any questions? Leave a comment below and we will do our best to answer you as quickly as possible.
- Revolution AI team

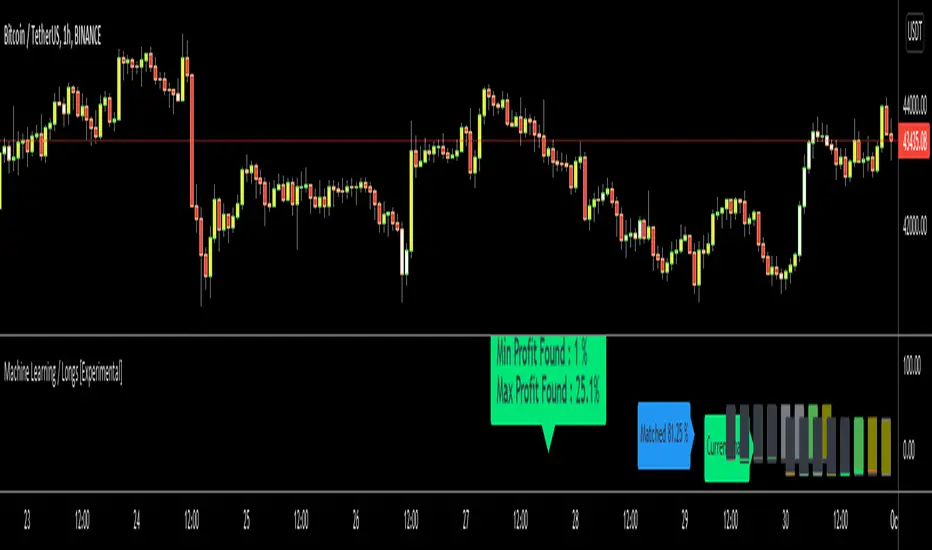
Machine Learning / Longs [Experimental]Hello Traders/Programmers,
For long time I thought that if it's possible to make a script that has own memory and criterias in Pine. it would learn and find patterns as images according to given criterias. after we have arrays of strings, lines, labels I tried and made this experimental script. The script works only for Long positions.
Now lets look at how it works:
On each candle it creates an image of last 8 candles. before the image is created it finds highest/lowest levels of 8 candles, and creates a string with the lengths 64 (8 * 8). and for each square, it checks if it contains wick, green or red body, green or red body with wicks. see the following picture:
Each square gets the value:
0: nothing in it
1: only wick in it
2: only red body in it
3. only green body in it
4: red body and wick in it
5: green body and wick in it
And then it checks if price went up equal or higher than user-defined profit. if yes then it adds the image to the memory/array. and I call this part as Learning Part.
what I mean by image is:
if there is 1 or more element in the memory, it creates image for current 8 candles and checks the memory if there is a similar images. If the image has similarity higher than user-defined similarty level then if show the label "Matched" and similarity rate and the image in the memory. if it find any with the similarity rate is equal/greater than user-defined level then it stop searching more.
As an example matched image:
and then price increased and you got the profit :)
Options:
Period: if there is possible profit higher than user-defined minimum profit in that period, it checks the images from 2. to X. bars.
Min Profit: you need to set the minimum expected profit accordingly. for example in 1m chart don't enter %10 as min profit :)
Similarity Rate: as told above, you can set minimum similarity rate, higher similarity rate means better results but if you set higher rates, number of images will decrease. set it wisely :)
Max Memory Size: you can set number of images (that gives the profit equal/higher than you set) to be saved that in memory
Change Bar Color: optionally it can change bar colors if current image is found in the memory
Current version of the script doesn't check if the price reach the minimum profit target, so no statistics.
This is completely experimental work and I made it for fun. No one or no script can predict the future. and you should not try to predict the future.
P.S. it starts searching on last bar, it doesn't check historical bars. if you want you should check it in replay mode :)
if you get calculation time out error then hide/unhide the script. ;)
Enjoy!
ANN MACD WTI (West Texas Intermediate) This script created by training WTI 4 hour data , 7 indicators and 12 Guppy Exponential Moving Averages.
Details :
Learning cycles: 1
AutoSave cycles: 100
Training error: 0.007593 ( Smaller than average target ! )
Input columns: 19
Output columns: 1
Excluded columns: 0
Training example rows: 300
Validating example rows: 0
Querying example rows: 0
Excluded example rows: 0
Duplicated example rows: 0
Input nodes connected: 19
Hidden layer 1 nodes: 2
Hidden layer 2 nodes: 6
Hidden layer 3 nodes: 0
Output nodes: 1
Learning rate: 0.7000
Momentum: 0.8000
Target error: 0.0100
Special thanks to wroclai for his great effort.
Deep learning series will continue. But I need to rest my eyes a little :)
Stay tuned ! Regards.

ANN MACD S&P 500 This script is formed by training the S & P 500 Index with various indicators. Details :
Learning cycles: 78089
AutoSave cycles: 100
Training error: 0.011650 (Far less than the target, but acceptable.)
Input columns: 19
Output columns: 1
Excluded columns: 0
Training example rows: 300
Validating example rows: 0
Querying example rows: 0
Excluded example rows: 0
Duplicated example rows: 0
Input nodes connected: 19
Hidden layer 1 nodes: 2
Hidden layer 2 nodes: 1
Hidden layer 3 nodes: 0
Output nodes: 1
Learning rate: 0.7000
Momentum: 0.8000
Target error: 0.0100
Note : Thanks for dear wroclai for his great effort .
Deep learning series will continue . Stay tuned! Regards.

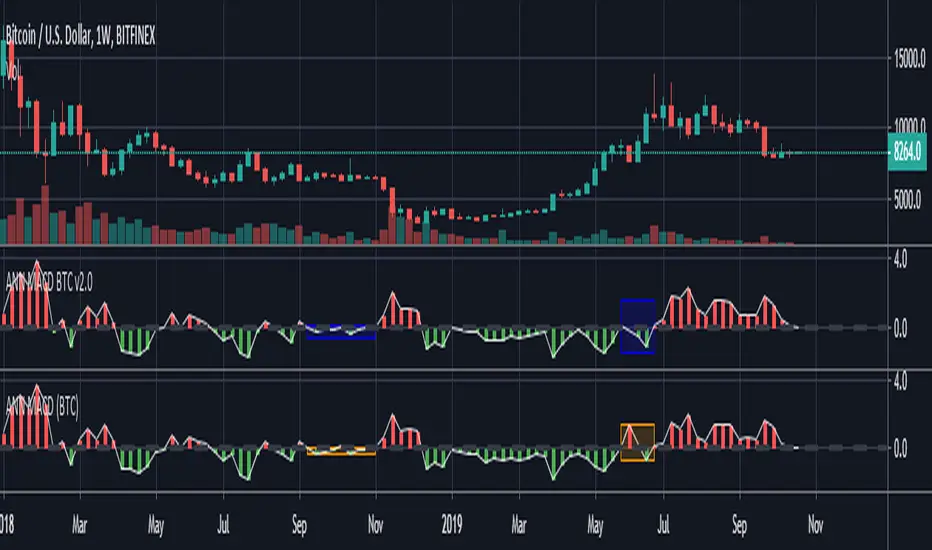
ANN MACD BTC v2.0 This script is the 2nd version of the BTC Deep Learning (ANN) system.
Created with the following indicators and tools:
RSI
MACD
MOM
Bollinger Bands
Guppy Exponential Moving Averages:
(3,5,8,10,12,15,30,35,40,45,50,60)
Note: I was inspired by the CM Guppy Ema script.
Thank you very much to dear wroclai for his great help.
He has been a big help in the deep learning series.
That's why the licenses in this series are for both of us.
I'm sharing these series and thats the first. Stay tuned and regards!
Note : Alerts added.