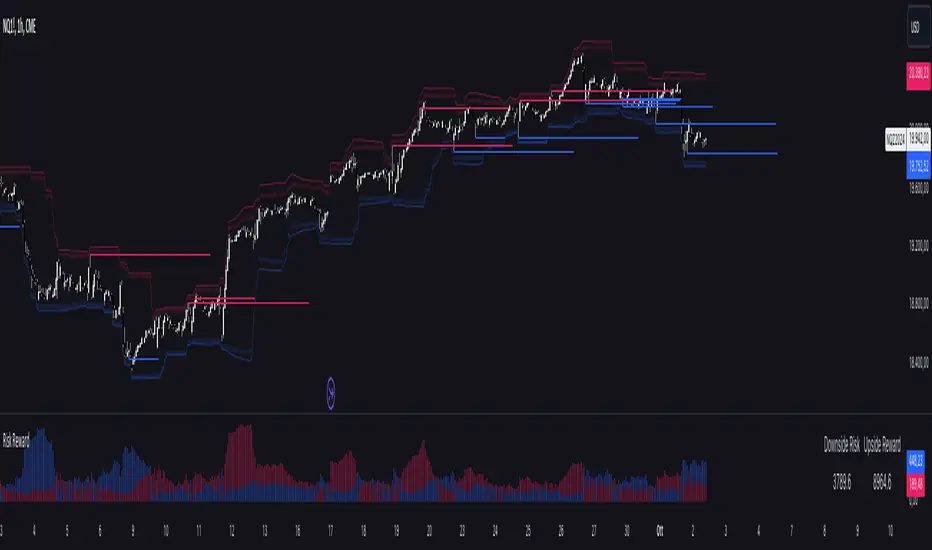
Risk RewardThe Risk Reward indicator, developed by OmegaTools, is a versatile technical tool designed to help traders visualize and evaluate potential reward and risk levels in their trades. By comparing recent price action against moving averages and volatility deviations, it calculates a range-weighted assessment of upside reward and downside risk. It provides a clear, color-coded visual representation of these potential ranges, along with critical support and resistance levels to aid in trade decision-making. This indicator is ideal for traders seeking to optimize their risk-reward ratio and make informed trade management decisions.
Features
Reward and Risk Visualization: Provides a histogram showing the relative potential of upside reward versus downside risk based on current price action.
Dynamic Support and Resistance Levels: Calculates and plots key price levels based on extreme of historical volatility, helping traders to identify important price zones.
Trade Size Customization: Users can adjust the trade size, and the indicator will calculate and display the estimated risk and reward in monetary terms based on the contract value.
Adaptive Volatility Extensions: Automatically adjusts extension lines based on volume, helping traders anticipate future price ranges and potential breakouts or breakdowns.
Customizable Visuals: Allows users to personalize the color scheme for bullish and bearish scenarios, making the chart more intuitive and user-friendly.
User Guide
Trade Size (size): Adjust the trade size in units (default is 1). This parameter impacts the risk and reward calculation shown in the summary table.
Length (lnt): Set the length for the exponential moving average (EMA) and the highest/lowest price calculations. This length determines the sensitivity of the indicator.
Different Visual (down): A boolean input to adjust the method for calculating downside risk. When set to true, it uses a different visual scheme.
Bullish Color (upc): Customize the color of the bullish (upside) histogram and support levels.
Bearish Color (dnc): Customize the color of the bearish (downside) histogram and resistance levels.
Plots
First Probability: Displays a histogram representing the higher value between reward and risk. It is colored according to whether the upside or downside is greater, providing a clear signal for potential trade direction.
Second Probability: A secondary histogram plot that visualizes the lower value between reward and risk, offering an additional perspective on the trade’s risk-reward balance.
Low Level/High Level: Displays dynamic support and resistance levels based on historical price data and volatility deviations.
Extension Lines: Visualize potential future price levels using volatility-adjusted projections. These lines help traders anticipate where price could move based on current conditions.
On-Chart Labels and Risk-Reward Table:
Risk and Reward Calculations: The indicator calculates the monetary value of downside risk and upside reward based on the provided trade size, volatility measures, and price movements.
Risk/Reward Table: Displayed directly on the chart, showing the downside risk and upside reward in easy-to-understand numerical values. This helps traders quickly assess the feasibility of a trade.
How It Works:
Moving Average Comparison: The indicator first calculates the 21-period (default) exponential moving average (EMA). It then compares the current price against this moving average to determine whether the market is in a bullish or bearish phase.
Deviation Calculation: It calculates the average deviation between the price and the EMA for both bullish and bearish movements, which is used to establish dynamic support and resistance levels.
Risk-Reward Calculation: Based on the highest and lowest price levels over the set period and the calculated deviations, it determines the potential upside reward and downside risk. The reward is calculated as the distance between the current price and the upper resistance levels, while the risk is determined as the distance to the lower support levels.
Visual Representation
The indicator plots histograms representing the relative magnitude of potential reward and risk.
Support and resistance levels are dynamically plotted on the chart using circles and lines, helping traders easily spot key areas of interest.
Extension lines are drawn to visualize potential future price levels based on current volatility.
Risk/Reward Table: This feature displays the calculated monetary risk and reward based on the trade size. It updates dynamically with price changes, offering a constant reference point for traders to evaluate their trade setup.
Practical Application
Identify Entry Points: Use the dynamic support and resistance levels to identify ideal trade entry points. The histogram helps determine whether the potential reward justifies the risk.
Risk Management: The calculated downside risk provides traders with an objective view of where to place stop-loss levels, while the upside reward aids in setting profit targets.
Trade Execution: By visually assessing whether reward outweighs risk, traders can make more informed decisions on trade execution, with the risk-reward ratio clearly displayed on the chart.
Best Practices:
Use Alongside Other Indicators: While this indicator offers a powerful standalone tool for assessing risk and reward, it works best when combined with other trend or momentum indicators for confirmation.
Adjust Inputs Based on Market Conditions: Adjust the length and trade size inputs depending on the asset being traded and the time horizon, as different assets may require different sensitivity settings.
Bands and Channels
Donchian Channels Osciliator with MA validationWhat's it all about?
This nifty little tool, the Donchian Channels Oscillator, helps you spot when a stock might be overbought or oversold. It's like a price detective, looking for clues in the historical data to figure out if it's time to buy or sell.
How does it work?
Think of it as a seesaw. When the price is way above the Donchian Channels, it's like the seesaw is tilted too far to one side. That might mean it's time to sell before it falls. On the other hand, if the price is way below the channels, it's like the seesaw is tilted too far to the other side. This could be a good sign to buy, as the price might be ready to bounce back.
Key Points:
Donchian Channels: These are like safety nets. They're calculated based on the highest and lowest prices over a certain period.
Oscillator: This is just a fancy word for a tool that swings back and forth. In this case, it swings between overbought and oversold zones.
EMA-Line: This is a smoothed-out version of the oscillator. It helps you see the overall trend more clearly.
How to Use It:
Add it to your chart: Find it in the indicator search bar.
Adjust settings: You can tweak the length of the Donchian Channels and the offset to fit your trading style.
Watch the swings: When the oscillator goes way up, it might be time to sell. When it goes way down, it might be time to buy. But always use this with other indicators for confirmation.
Remember: This is just a tool, not a magic crystal ball. Don't rely solely on it for trading decisions. Always do your own research and consider other factors.
Happy trading!

KAMA Cloud STIndicator:
Description:
The KAMA Cloud indicator is a sophisticated trading tool designed to provide traders with insights into market trends and their intensity. This indicator is built on the Kaufman Adaptive Moving Average (KAMA), which dynamically adjusts its sensitivity to filter out market noise and respond to significant price movements. The KAMA Cloud leverages multiple KAMAs to gauge trend direction and strength, offering a visual representation that is easy to interpret.
How It Works:
The KAMA Cloud uses twenty different KAMA calculations, each set to a distinct lookback period ranging from 5 to 100. These KAMAs are calculated using the average of the open, high, low, and close prices (OHLC4), ensuring a balanced view of price action. The relative positioning of these KAMAs helps determine the direction of the market trend and its momentum.
By measuring the cumulative relative distance between these KAMAs, the indicator effectively assesses the overall trend strength, akin to how the Average True Range (ATR) measures market volatility. This cumulative measure helps in identifying the trend’s robustness and potential sustainability.
The visualization component of the KAMA Cloud is particularly insightful. It plots a 'cloud' formed between the base KAMA (set at a 100-period lookback) and an adjusted KAMA that incorporates the cumulative relative distance scaled up. This cloud changes color based on the trend direction — green for upward trends and red for downward trends, providing a clear, visual representation of market conditions.
How the Strategy Works:
The KAMA Cloud ST strategy employs multiple KAMA calculations with varying lengths to capture the nuances of market trends. It measures the relative distances between these KAMAs to determine the trend's direction and strength, much like the original indicator. The strategy enhances decision-making by plotting a 'cloud' formed between the base KAMA (set to a 100-period lookback) and an adjusted KAMA that scales according to the cumulative relative distance of all KAMAs.
Key Components of the Strategy:
Multiple KAMA Layers: The strategy calculates KAMAs for periods ranging from 5 to 100 to analyze short to long-term market trends.
Dynamic Cloud: The cloud visually represents the trend’s strength and direction, updating in real-time as the market evolves.
Signal Generation: Trade signals are generated based on the orientation of the cloud relative to a smoothed version of the upper KAMA boundary. Long positions are initiated when the market trend is upward, and the current cloud value is above its smoothed average. Conversely, positions are closed when the trend reverses, indicated by the cloud falling below the smoothed average.
Suggested Usage:
Market: Stocks, not cryptocurrency
Timeframe: 1 Hour
Indicator:

Prior Day High/Low and Highest High/Lowest LowFeatures:
Prior Day High and Low:
The script tracks and displays the previous trading day's high and low prices. These levels can serve as important areas of support or resistance, helping traders to make informed decisions about potential price reversals or breakouts.
Highest High and Lowest Low Over N Days:
This indicator also tracks and displays the highest high and lowest low over the last N days, where N is user-configurable. This allows traders to see broader trends in price action and identify key levels for potential trend changes.
User-Configurable Inputs:
Show Prior Day High/Low: Toggle whether to display the prior day’s high and low levels.
Days to Consider for Highest High/Lowest Low: Define the number of days over which the highest high and lowest low are calculated.
Show Highest High/Lowest Low: Toggle whether to display the highest high and lowest low levels over the specified period.
Low Source and High Source: Customize the data sources for the high and low values.
Automatic Data Handling:
The script automatically tracks the daily high and low prices, storing them in arrays, and calculates the highest and lowest prices over the user-specified number of days. When a new day begins, the prior day's data is saved, and the calculations are updated accordingly.
Visual Display:
The indicator uses distinct colors and plotting styles:
Prior day’s high and low are plotted as blue circles.
The highest high over N days is plotted as a red circle.
The lowest low over N days is plotted as a green circle.
This indicator helps traders stay informed about significant price levels, which are often used in trading strategies for breakouts, trend following, or reversals.

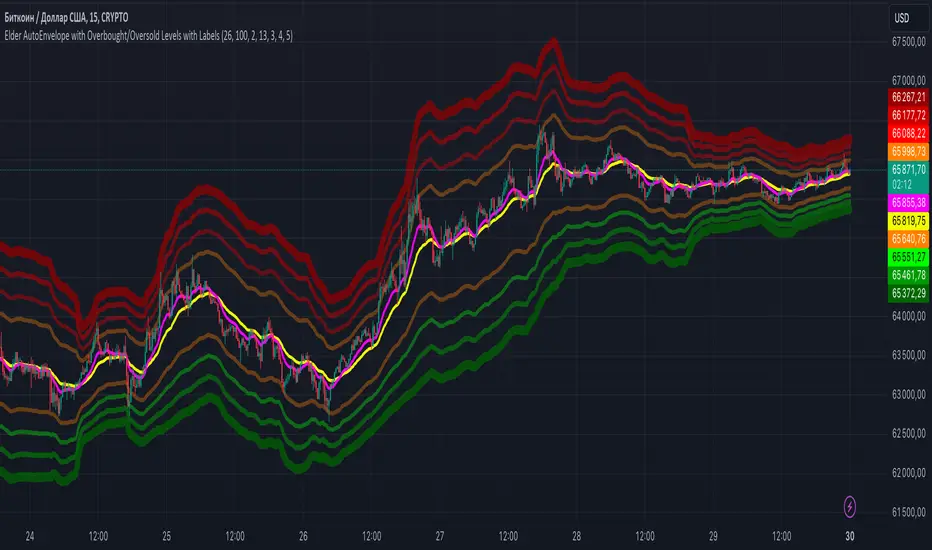
Elder AutoEnvelope with Overbought/Oversold Levels with LabelsThe **"Elder AutoEnvelope with Overbought/Oversold Levels with Labels"** is a technical analysis tool designed to help identify overbought and oversold levels in the market, as well as potential reversal points. It uses moving averages and price volatility to detect possible price extremes.
### Indicator Description:
- **Center EMA (26)**: Acts as the main trend line.
- **Envelope Channels**: These are constructed around the central EMA using the current price volatility. The main channel lines are determined by multiplying the standard deviation of the price by the chosen multiplier.
- **Additional Overbought/Oversold Levels**: Displayed on the chart with different colors and thicknesses to highlight small, moderate, strong, and very strong levels.
- **Labels**: Show specific levels when the price reaches areas of overbought or oversold conditions.
### How to Apply in Practice:
1. **Identifying Extremes**: The indicator shows areas where the price is considered overbought or oversold relative to the current trend. When the price touches or exceeds these levels, it can indicate a potential reversal or correction.
2. **Entry/Exit Signals**:
- **Entry on Oversold**: If the price reaches the lower Envelope lines (especially at strong or very strong oversold levels), it may be a good buying signal.
- **Exit on Overbought**: If the price touches the upper lines (especially at strong or very strong overbought levels), it signals a potential selling opportunity.
3. **Combining with Other Indicators**: It’s recommended to use this indicator alongside oscillators like RSI or MACD for signal confirmation.
4. **Trend Analysis**: The central EMA (26) helps identify the trend direction. If the price is above it, the trend is considered bullish; if below, bearish.
This indicator is particularly useful in volatile markets and helps detect price movements near highs or lows.
Advanced Position Management [Mr_Rakun]Advanced Position Management
This Pine Script code is for a strategy titled "Advanced Position Management," aimed at effective trade execution and management using multiple take profit levels, trailing stop loss, and dynamic position sizing.
Take Profit Levels: It defines up to three take profit (TP) levels, allowing partial position exits at different price thresholds. The take profit levels and their respective quantities are adjustable using inputs.
Stop Loss and Trailing Stop: The script implements an initial stop loss based on a percentage from the entry price. Additionally, it features a trailing stop that moves based on either a percentage or previous TP levels, dynamically adjusting to maximize gains while protecting profits.
Position Size: The position size is customizable and based on USD value, allowing the trader to manage risk more effectively.
Advantages:
Flexibility: Multiple take profit levels and a dynamic stop loss system allow traders to lock in profits while keeping the position open for further gains.
Risk Management: The initial stop loss and trailing stop help to limit losses and protect profits as the trade moves in the desired direction.
Automation: Once the strategy is deployed, it automatically handles entry, exit, and stop management, reducing the need for constant monitoring.
------ TR ------
Gelişmiş Pozisyon Yönetimi
Bu Pine Script kodu, Gelişmiş Pozisyon Yönetimi için kendi stratejilerinize kolayca entegre edeceğiniz bir risk yönetimidir. Çoklu kâr al seviyeleri, takip eden stop-loss ve dinamik pozisyon büyüklüğü kullanarak işlem yürütme ve yönetiminde etkilidir.
Gelişmiş Pozisyon Yönetimi
Kâr Alma Seviyeleri;
Kod, pozisyonların farklı fiyat seviyelerinde kısmi kapatılmasını sağlayan üç farklı kâr alma (TP) seviyesini tanımlar. Bu kâr alma seviyeleri ve ilgili miktarları, girişlerle ayarlanabilir.
Stop Loss ve Takip Eden Stop;
Koda, giriş fiyatından bir yüzdeye dayalı olarak başlangıçta stop-loss uygulanır. Ayrıca, fiyat hareketine göre kendini ayarlayan takip eden bir stop-loss sistemi bulunur. Ayrıca TP seviyelerini takip eden stop loss özelliğide vardır.
Avantajları:
Esneklik;
Çoklu kâr alma seviyeleri ve dinamik stop-loss sistemi, trader'ların kazançlarını kilitleyip aynı zamanda pozisyonu açık tutmalarına olanak tanır.
Risk Yönetimi;
Başlangıç stop-loss ve takip eden stop, zararı sınırlamaya ve kazançları korumaya yardımcı olur.
Otomasyon;
Strateji bir kez devreye alındığında, giriş, çıkış ve stop yönetimi otomatik olarak gerçekleştirilir, bu da sürekli takip ihtiyacını azaltır.

Pivot-based Swing Highs and LowsRelease Notes for Pivot-based Swing Highs and Lows Indicator with HH, HL, LH, LL and Labels
Version 1.0.0
Release Date: 29th Sept 2024
Overview:
This Pine Script version 5 indicator is designed to identify and display Swing Highs and Swing Lows based on pivot points. The indicator visually marks Higher Highs (HH), Lower Highs (LH), Higher Lows (HL), and Lower Lows (LL) on the chart. The release introduces an improved visual representation with dotted lines and colored labels for easy identification of market structure, using plotshape() and line.new().
Key Features:
1. Pivot-Based Swing Identification:
The indicator uses ta.pivothigh() and ta.pivotlow() to detect significant pivot points on the chart.
The length of the pivot can be adjusted through the pivot_length parameter, allowing users to customize the sensitivity of swing identification.
2. Swing Highs and Lows with Labels:
Higher High (HH) and Lower High (LH) points are marked with green downward triangles.
Higher Low (HL) and Lower Low (LL) points are marked with red upward triangles.
The plotshape() function is used to provide clear visual markers, making it easy to spot the changes in market structure.
3. Dotted Line Visuals:
Green Dotted Lines: Connect Higher Highs (HH) and Higher Lows (HL) to their corresponding previous swings.
Red Dotted Lines: Connect Lower Highs (LH) and Lower Lows (LL) to their corresponding previous swings.
The use of color-coded dotted lines ensures better visual understanding of the trend continuation or reversal patterns.
4. Customizable Input:
The user can adjust the pivot_length parameter to fine-tune the detection of pivot highs and lows according to different timeframes or trading strategies.
Usage:
Higher High (HH): Green downward triangle, indicating a new high compared to the previous pivot high.
Lower High (LH): Green downward triangle, indicating a lower high compared to the previous pivot high.
Higher Low (HL): Red upward triangle, indicating a higher low compared to the previous pivot low.
Lower Low (LL): Red upward triangle, indicating a new lower low compared to the previous pivot low.
Dotted Lines: Connect previous swing points, helping users visualize the trend and potential market structure changes.
Improvements:
Label Substitution: In place of label.new() (which might cause issues in some environments), the indicator now uses plotshape() to provide a reliable and visually effective solution for marking swings.
Streamlined Performance: The logic for determining higher highs, lower highs, higher lows, and lower lows has been optimized for smooth performance across multiple timeframes.
Known Limitations:
No Direct Text Labels: Due to the constraints of plotshape(), text labels like "HH", "LH", "HL", and "LL" are not directly displayed. Instead, color-coded shapes are used for easy identification.
How to Use:
Apply the script to your chart via the TradingView Pine Editor.
Customize the pivot_length to suit your trading style or the timeframe you are analyzing.
Monitor the chart for marked Higher Highs, Lower Highs, Higher Lows, and Lower Lows for potential trend continuation or reversal opportunities.
Use the dotted lines to trace the evolution of market structure.
Please share your comments, thoughts. Also please follow me for more scripts in future. Mean time Happy Trading :)

Mean Reversion Indictor, Based on Standard Deviations Description:
The Reversal Candle Mean Reversion Indicator is designed for traders seeking to identify potential reversal points in the market based on key price action and volatility. This indicator combines price action analysis (sweeping prior highs or lows) with mean reversion theory, highlighting opportunities where the price tests or touches a moving average's standard deviation bands.
By focusing on these moments of price extremes, the indicator helps traders spot bullish and bearish reversal signals when the price retraces from volatile movements. These conditions often signal a return to the mean—an ideal setup for reversal traders who thrive on fading exaggerated price moves.
How It Works:
1. Price Action Reversal Signal:
* Bullish Reversal: The indicator flags a bullish signal when the current candle's low sweeps the prior candle's low, and the candle closes higher than the prior candle's close.
* Bearish Reversal: The indicator flags a bearish signal when the current candle's high sweeps the prior candle's high, and the candle closes lower than the prior candle's close.
2. Mean Reversion Confirmation:
* Mean Reversion Signal is triggered when the price touches or tests the upper or lower bands, calculated using a user-selected moving average (SMA, EMA, WMA, VWMA, or Hull MA) and standard deviation.
* The indicator combines price action and volatility, providing stronger reversal signals when the price reaches an extreme distance from the moving average.
3. Customization Options:
* Moving Average Type: Choose from SMA, EMA, WMA, VWMA, or Hull MA.
* Moving Average Length: Adjust the length of the moving average (default: 20).
* Standard Deviation Multiplier: Set the number of standard deviations for the volatility bands (default: 2.0).
* Custom Candle Colors: Choose custom colors for bullish and bearish reversal candles to easily spot signals.
How to Use for Trading Reversals:
1. Identify Extremes:
* Watch for candles where the price tests or touches the standard deviation bands. These are key moments when the price has moved significantly from the moving average, indicating a potential overbought or oversold condition.
2. Look for Reversals:
* When the price tests a band and simultaneously forms a bullish reversal pattern (sweeping the prior low and closing higher), it signals a potential mean reversion to the upside.
* When the price tests a band and forms a bearish reversal pattern (sweeping the prior high and closing lower), it signals a potential mean reversion to the downside.
3. Entry Points:
* Long Trades: Enter a long trade after a bullish signal appears (green candle) near the lower band, indicating a likely price reversal back towards the mean.
* Short Trades: Enter a short trade after a bearish signal appears (red candle) near the upper band, indicating a likely price pullback.
4. Exit Strategy:
* Set a profit target at the moving average (the mean) or a specific price level based on your strategy.
* Consider using a trailing stop to capture additional profit in case of a stronger reversal beyond the mean.
5. Risk Management:
* Place stops just below the low of the bullish reversal candle or just above the high of the bearish reversal candle to manage risk efficiently.

EMA GridThe EMA Grid indicator is a powerful tool that calculates the overall market sentiment by comparing the order of 20 different Exponential Moving Averages (EMAs) over various lengths. The indicator assigns a rating based on how well-ordered the EMAs are relative to each other, representing the strength and direction of the market trend. It also smooths out the macro movements using cumulative calculations and visually represents the market sentiment through color-coded bands.
EMA Calculation:
The indicator uses a series of EMAs with different lengths, starting from 5 and going up to 100. Each EMA is calculated either using the exponential moving averages.
The EMAs form the grid that the indicator uses to measure the order and distance between them.
Rating Calculation:
The indicator computes the relative distance between consecutive EMAs and sums these differences.
The cumulative sum is further smoothed using multiple EMAs with different lengths (from 3 to 21). This smooths out short-term fluctuations and helps identify broader trends.
Market Sentiment Rating:
The overall sentiment is calculated by comparing the values of these smoothing EMAs. If the shorter-term EMA is above the longer-term EMA, it contributes positively to the sentiment; otherwise, it contributes negatively.
The final rating is a normalized value based on the relationship between these EMAs, producing a sentiment score between 1 (bullish) and -1 (bearish).
Color Coding and Bands:
The indicator uses the sentiment rating to color the space between the 100 EMA and 200 EMA, representing the strength of the trend.
If the sentiment is bullish (rating > 0), the band is shaded green. If the sentiment is bearish (rating < 0), the band is shaded red.
The intensity of the color is based on the strength of the sentiment, with stronger trends resulting in more saturated colors.
Utility for Traders:
The EMA Grid is ideal for traders looking to gauge the broader market trend by analyzing the structure and alignment of multiple EMAs. The color-coded band between the 100 and 200 EMAs provides an at-a-glance view of market momentum, helping traders make informed decisions based on the trend's strength and direction.
This indicator can be used to identify bullish or bearish conditions and offers a smoothed perspective on market trends, reducing noise and highlighting significant trend shifts.

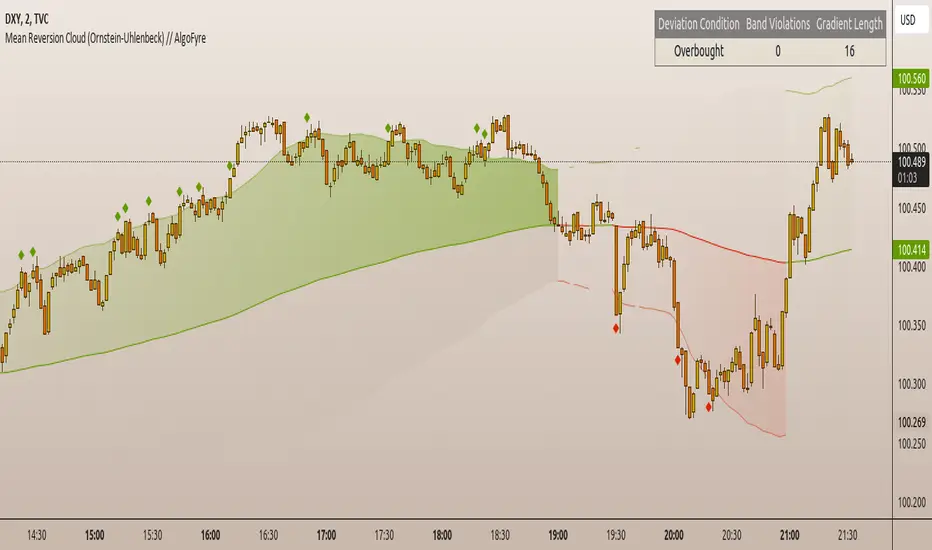
Mean Reversion Cloud (Ornstein-Uhlenbeck) // AlgoFyreThe Mean Reversion Cloud (Ornstein-Uhlenbeck) indicator detects mean-reversion opportunities by applying the Ornstein-Uhlenbeck process. It calculates a dynamic mean using an Exponential Weighted Moving Average, surrounded by volatility bands, signaling potential buy/sell points when prices deviate.
TABLE OF CONTENTS
🔶 ORIGINALITY
🔸Adaptive Mean Calculation
🔸Volatility-Based Cloud
🔸Speed of Reversion (θ)
🔶 FUNCTIONALITY
🔸Dynamic Mean and Volatility Bands
🞘 How it works
🞘 How to calculate
🞘 Code extract
🔸Visualization via Table and Plotshapes
🞘 Table Overview
🞘 Plotshapes Explanation
🞘 Code extract
🔶 INSTRUCTIONS
🔸Step-by-Step Guidelines
🞘 Setting Up the Indicator
🞘 Understanding What to Look For on the Chart
🞘 Possible Entry Signals
🞘 Possible Take Profit Strategies
🞘 Possible Stop-Loss Levels
🞘 Additional Tips
🔸Customize settings
🔶 CONCLUSION
▅▅▅▅▅▅▅▅▅▅▅▅▅▅▅▅▅▅▅▅▅▅▅▅▅▅▅▅▅▅▅▅▅▅▅▅▅▅▅▅▅▅▅▅▅▅
🔶 ORIGINALITY The Mean Reversion Cloud (Ornstein-Uhlenbeck) is a unique indicator that applies the Ornstein-Uhlenbeck stochastic process to identify mean-reverting behavior in asset prices. Unlike traditional moving average-based indicators, this model uses an Exponentially Weighted Moving Average (EWMA) to calculate the long-term mean, dynamically adjusting to recent price movements while still considering all historical data. It also incorporates volatility bands, providing a "cloud" that visually highlights overbought or oversold conditions. By calculating the speed of mean reversion (θ) through the autocorrelation of log returns, this indicator offers traders a more nuanced and mathematically robust tool for identifying mean-reversion opportunities. These innovations make it especially useful for markets that exhibit range-bound characteristics, offering timely buy and sell signals based on statistical deviations from the mean.
🔸Adaptive Mean Calculation Traditional MA indicators use fixed lengths, which can lead to lagging signals or over-sensitivity in volatile markets. The Mean Reversion Cloud uses an Exponentially Weighted Moving Average (EWMA), which adapts to price movements by dynamically adjusting its calculation, offering a more responsive mean.
🔸Volatility-Based Cloud Unlike simple moving averages that only plot a single line, the Mean Reversion Cloud surrounds the dynamic mean with volatility bands. These bands, based on standard deviations, provide traders with a visual cue of when prices are statistically likely to revert, highlighting potential reversal zones.
🔸Speed of Reversion (θ) The indicator goes beyond price averages by calculating the speed at which the price reverts to the mean (θ), using the autocorrelation of log returns. This gives traders an additional tool for estimating the likelihood and timing of mean reversion, making the signals more reliable in practice.
🔶 FUNCTIONALITY The Mean Reversion Cloud (Ornstein-Uhlenbeck) indicator is designed to detect potential mean-reversion opportunities in asset prices by applying the Ornstein-Uhlenbeck stochastic process. It calculates a dynamic mean through the Exponentially Weighted Moving Average (EWMA) and plots volatility bands based on the standard deviation of the asset's price over a specified period. These bands create a "cloud" that represents expected price fluctuations, helping traders to identify overbought or oversold conditions. By calculating the speed of reversion (θ) from the autocorrelation of log returns, the indicator offers a more refined way of assessing how quickly prices may revert to the mean. Additionally, the inclusion of volatility provides a comprehensive view of market conditions, allowing for more accurate buy and sell signals.
Let's dive into the details:
🔸Dynamic Mean and Volatility Bands The dynamic mean (μ) is calculated using the EWMA, giving more weight to recent prices but considering all historical data. This process closely resembles the Ornstein-Uhlenbeck (OU) process, which models the tendency of a stochastic variable (such as price) to revert to its mean over time. Volatility bands are plotted around the mean using standard deviation, forming the "cloud" that signals overbought or oversold conditions. The cloud adapts dynamically to price fluctuations and market volatility, making it a versatile tool for mean-reversion strategies. 🞘 How it works Step one: Calculate the dynamic mean (μ) The Ornstein-Uhlenbeck process describes how a variable, such as an asset's price, tends to revert to a long-term mean while subject to random fluctuations. In this indicator, the EWMA is used to compute the dynamic mean (μ), mimicking the mean-reverting behavior of the OU process. Use the EWMA formula to compute a weighted mean that adjusts to recent price movements. Assign exponentially decreasing weights to older data while giving more emphasis to current prices. Step two: Plot volatility bands Calculate the standard deviation of the price over a user-defined period to determine market volatility. Position the upper and lower bands around the mean by adding and subtracting a multiple of the standard deviation. 🞘 How to calculate Exponential Weighted Moving Average (EWMA)
The EWMA dynamically adjusts to recent price movements:
mu_t = lambda * mu_{t-1} + (1 - lambda) * P_t
Where mu_t is the mean at time t, lambda is the decay factor, and P_t is the price at time t. The higher the decay factor, the more weight is given to recent data.
Autocorrelation (ρ) and Standard Deviation (σ)
To measure mean reversion speed and volatility: rho = correlation(log(close), log(close ), length) Where rho is the autocorrelation of log returns over a specified period.
To calculate volatility:
sigma = stdev(close, length)
Where sigma is the standard deviation of the asset's closing price over a specified length.
Upper and Lower Bands
The upper and lower bands are calculated as follows:
upper_band = mu + (threshold * sigma)
lower_band = mu - (threshold * sigma)
Where threshold is a multiplier for the standard deviation, usually set to 2. These bands represent the range within which the price is expected to fluctuate, based on current volatility and the mean.
🞘 Code extract // Calculate Returns
returns = math.log(close / close )
// Calculate Long-Term Mean (μ) using EWMA over the entire dataset
var float ewma_mu = na // Initialize ewma_mu as 'na'
ewma_mu := na(ewma_mu ) ? close : decay_factor * ewma_mu + (1 - decay_factor) * close
mu = ewma_mu
// Calculate Autocorrelation at Lag 1
rho1 = ta.correlation(returns, returns , corr_length)
// Ensure rho1 is within valid range to avoid errors
rho1 := na(rho1) or rho1 <= 0 ? 0.0001 : rho1
// Calculate Speed of Mean Reversion (θ)
theta = -math.log(rho1)
// Calculate Volatility (σ)
sigma = ta.stdev(close, corr_length)
// Calculate Upper and Lower Bands
upper_band = mu + threshold * sigma
lower_band = mu - threshold * sigma
🔸Visualization via Table and Plotshapes
The table shows key statistics such as the current value of the dynamic mean (μ), the number of times the price has crossed the upper or lower bands, and the consecutive number of bars that the price has remained in an overbought or oversold state.
Plotshapes (diamonds) are used to signal buy and sell opportunities. A green diamond below the price suggests a buy signal when the price crosses below the lower band, and a red diamond above the price indicates a sell signal when the price crosses above the upper band.
The table and plotshapes provide a comprehensive visualization, combining both statistical and actionable information to aid decision-making.
🞘 Code extract // Reset consecutive_bars when price crosses the mean
var consecutive_bars = 0
if (close < mu and close >= mu) or (close > mu and close <= mu)
consecutive_bars := 0
else if math.abs(deviation) > 0
consecutive_bars := math.min(consecutive_bars + 1, dev_length)
transparency = math.max(0, math.min(100, 100 - (consecutive_bars * 100 / dev_length)))
🔶 INSTRUCTIONS
The Mean Reversion Cloud (Ornstein-Uhlenbeck) indicator can be set up by adding it to your TradingView chart and configuring parameters such as the decay factor, autocorrelation length, and volatility threshold to suit current market conditions. Look for price crossovers and deviations from the calculated mean for potential entry signals. Use the upper and lower bands as dynamic support/resistance levels for setting take profit and stop-loss orders. Combining this indicator with additional trend-following or momentum-based indicators can improve signal accuracy. Adjust settings for better mean-reversion detection and risk management.
🔸Step-by-Step Guidelines
🞘 Setting Up the Indicator
Adding the Indicator to the Chart:
Go to your TradingView chart.
Click on the "Indicators" button at the top.
Search for "Mean Reversion Cloud (Ornstein-Uhlenbeck)" in the indicators list.
Click on the indicator to add it to your chart.
Configuring the Indicator:
Open the indicator settings by clicking on the gear icon next to its name on the chart.
Decay Factor: Adjust the decay factor (λ) to control the responsiveness of the mean calculation. A higher value prioritizes recent data.
Autocorrelation Length: Set the autocorrelation length (θ) for calculating the speed of mean reversion. Longer lengths consider more historical data.
Threshold: Define the number of standard deviations for the upper and lower bands to determine how far price must deviate to trigger a signal.
Chart Setup:
Select the appropriate timeframe (e.g., 1-hour, daily) based on your trading strategy.
Consider using other indicators such as RSI or MACD to confirm buy and sell signals.
🞘 Understanding What to Look For on the Chart
Indicator Behavior:
Observe how the price interacts with the dynamic mean and volatility bands. The price staying within the bands suggests mean-reverting behavior, while crossing the bands signals potential entry points.
The indicator calculates overbought/oversold conditions based on deviation from the mean, highlighted by color-coded cloud areas on the chart.
Crossovers and Deviation:
Look for crossovers between the price and the mean (μ) or the bands. A bullish crossover occurs when the price crosses below the lower band, signaling a potential buying opportunity.
A bearish crossover occurs when the price crosses above the upper band, suggesting a potential sell signal.
Deviations from the mean indicate market extremes. A large deviation indicates that the price is far from the mean, suggesting a potential reversal.
Slope and Direction:
Pay attention to the slope of the mean (μ). A rising slope suggests bullish market conditions, while a declining slope signals a bearish market.
The steepness of the slope can indicate the strength of the mean-reversion trend.
🞘 Possible Entry Signals
Bullish Entry:
Crossover Entry: Enter a long position when the price crosses below the lower band with a positive deviation from the mean.
Confirmation Entry: Use additional indicators like RSI (above 50) or increasing volume to confirm the bullish signal.
Bearish Entry:
Crossover Entry: Enter a short position when the price crosses above the upper band with a negative deviation from the mean.
Confirmation Entry: Look for RSI (below 50) or decreasing volume to confirm the bearish signal.
Deviation Confirmation:
Enter trades when the deviation from the mean is significant, indicating that the price has strayed far from its expected value and is likely to revert.
🞘 Possible Take Profit Strategies
Static Take Profit Levels:
Set predefined take profit levels based on historical volatility, using the upper and lower bands as guides.
Place take profit orders near recent support/resistance levels, ensuring you're capitalizing on the mean-reversion behavior.
Trailing Stop Loss:
Use a trailing stop based on a percentage of the price deviation from the mean to lock in profits as the trend progresses.
Adjust the trailing stop dynamically along the calculated bands to protect profits as the price returns to the mean.
Deviation-Based Exits:
Exit when the deviation from the mean starts to decrease, signaling that the price is returning to its equilibrium.
🞘 Possible Stop-Loss Levels
Initial Stop Loss:
Place an initial stop loss outside the lower band (for long positions) or above the upper band (for short positions) to protect against excessive deviations.
Use a volatility-based buffer to avoid getting stopped out during normal price fluctuations.
Dynamic Stop Loss:
Move the stop loss closer to the mean as the price converges back towards equilibrium, reducing risk.
Adjust the stop loss dynamically along the bands to account for sudden market movements.
🞘 Additional Tips
Combine with Other Indicators:
Enhance your strategy by combining the Mean Reversion Cloud with momentum indicators like MACD, RSI, or Bollinger Bands to confirm market conditions.
Backtesting and Practice:
Backtest the indicator on historical data to understand how it performs in various market environments.
Practice using the indicator on a demo account before implementing it in live trading.
Market Awareness:
Keep an eye on market news and events that might cause extreme price movements. The indicator reacts to price data and might not account for news-driven events that can cause large deviations.
🔸Customize settings 🞘 Decay Factor (λ): Defines the weight assigned to recent price data in the calculation of the mean. A value closer to 1 places more emphasis on recent prices, while lower values create a smoother, more lagging mean.
🞘 Autocorrelation Length (θ): Sets the period for calculating the speed of mean reversion and volatility. Longer lengths capture more historical data, providing smoother calculations, while shorter lengths make the indicator more responsive.
🞘 Threshold (σ): Specifies the number of standard deviations used to create the upper and lower bands. Higher thresholds widen the bands, producing fewer signals, while lower thresholds tighten the bands for more frequent signals.
🞘 Max Gradient Length (γ): Determines the maximum number of consecutive bars for calculating the deviation gradient. This setting impacts the transparency of the plotted bands based on the length of deviation from the mean.
🔶 CONCLUSION
The Mean Reversion Cloud (Ornstein-Uhlenbeck) indicator offers a sophisticated approach to identifying mean-reversion opportunities by applying the Ornstein-Uhlenbeck stochastic process. This dynamic indicator calculates a responsive mean using an Exponentially Weighted Moving Average (EWMA) and plots volatility-based bands to highlight overbought and oversold conditions. By incorporating advanced statistical measures like autocorrelation and standard deviation, traders can better assess market extremes and potential reversals. The indicator’s ability to adapt to price behavior makes it a versatile tool for traders focused on both short-term price deviations and longer-term mean-reversion strategies. With its unique blend of statistical rigor and visual clarity, the Mean Reversion Cloud provides an invaluable tool for understanding and capitalizing on market inefficiencies.
MTF SqzMom [tradeviZion]Credits:
John Carter for creating the TTM Squeeze and TTM Squeeze Pro.
Lazybear for the original interpretation of the TTM Squeeze: Squeeze Momentum Indicator.
Makit0 for evolving Lazybear's script by incorporating TTM Squeeze Pro upgrades – Squeeze PRO Arrows.
MTF SqzMom - Multi-Timeframe Squeeze & Momentum Tool
MTF SqzMom is a tool designed to help traders easily monitor squeeze and momentum signals across multiple timeframes in a simple, organized format. Built using Pine Script 5, it ensures that data remains consistent, even when switching between different time intervals on the chart.
Key Features:
Multi-Timeframe Monitoring: Track squeeze and momentum signals across various timeframes, all in one view. This includes key timeframes like 1-minute, 5-minute, hourly, and daily.
Dynamic Table Display: A color-coded table that automatically adjusts based on the selected timeframes, offering a clear view of market conditions.
Alerts for Key Market Events: Get notifications when a squeeze starts or fires across your chosen timeframes, so you can stay informed without needing to monitor the chart continuously.
Customizable Appearance: Tailor the look of the table by selecting colors for squeeze levels and momentum shifts, and choose the best position on your chart for easy access.
How It Works:
MTF SqzMom is based on the concept of the squeeze, which signals periods of lower volatility where price breakouts may occur. The tool tracks this by monitoring the contraction of Bollinger Bands within Keltner Channels. Along with this, it provides momentum analysis to help you gauge the potential direction of the market after a squeeze.
Squeeze Conditions: The script tracks four levels of squeeze conditions (no squeeze, low, mid, and high), each represented by a different color in the table.
Momentum Analysis: Momentum is visually represented by colors indicating four stages: up increasing, up decreasing, down increasing, and down decreasing. This color coding helps you quickly assess whether the market is gaining or losing momentum.
Using Alerts:
You can enable two types of alerts: when a squeeze starts (indicating consolidation) and when a squeeze fires (indicating a breakout). These alerts cover all timeframes you’ve selected, so you never miss important signals.
How to Set It Up:
1. Enable Alerts in Settings: Turn on "Alert for Squeeze Start" and "Alert for Squeeze Fire" in the settings.
2. Add Alerts to Your Chart:
Click the three dots next to the indicator name.
Select "Add alert on tradeviZion - MTF SqzMom."
3. Customize and Save: Adjust alert options, choose your notification type, and click "Create."
Why Use MTF SqzMom ?
Consistent Data: The tool ensures that squeeze and momentum data remain consistent, even when you switch between chart intervals.
Real-Time Alerts: Stay updated with alerts for squeeze conditions without needing to constantly watch the chart.
Simple to Use, Customizable to Fit: You can easily adjust the table’s look and choose the timeframes and colors that best suit your trading style.
Acknowledgment:
While this tool builds on the TTM Squeeze concept developed by John Carter of Simpler Trading, it offers added flexibility through multi-timeframe analysis, alerts, and customizability to make monitoring market conditions more accessible.

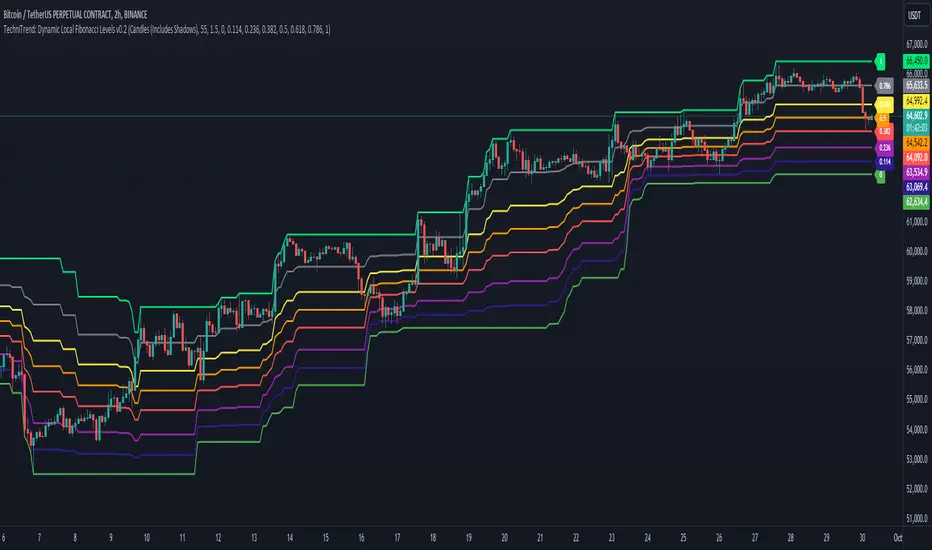
TechniTrend: Dynamic Local Fibonacci LevelsTechniTrend: Dynamic Local Fibonacci Levels
Description: The "Dynamic Local Fibonacci Levels" indicator dynamically displays Fibonacci levels only when the market is experiencing significant volatility. By detecting volatile price movements, this tool helps traders focus on Fibonacci retracement levels that are most relevant during high market activity, reducing noise from calm market periods.
Key Features:
Adaptive Fibonacci Levels: The indicator calculates and plots Fibonacci levels (from 0 to 1) only during periods of high volatility. This helps traders focus on actionable levels during significant price swings.
Customizable Chart Type: Users can choose between Candlestick charts (including shadows) or Line charts (excluding shadows) to determine the high and low price points for Fibonacci level calculations.
Volatility-Based Detection: The Average True Range (ATR) is used to detect significant volatility. Traders can adjust the ATR multiplier to fine-tune the sensitivity of the indicator to price movements.
Fully Customizable Fibonacci Levels: Traders can modify the default Fibonacci levels according to their preferences or trading strategies.
Real-Time Volatility Confirmation: Fibonacci levels are displayed only if the price range between the local high and low exceeds a user-defined volatility threshold, ensuring that these levels are only plotted when the market is truly volatile.
Customization Options:
Chart Type: Select between "Candles (Includes Shadows)" and "Line (Excludes Shadows)" for detecting price highs and lows.
Length for High/Low Detection: Choose the period for detecting the highest and lowest price in the given time frame.
ATR Multiplier for Volatility Detection: Adjust the sensitivity of the volatility threshold by setting the ATR multiplier.
Fibonacci Levels: Customize the specific Fibonacci levels to be displayed, from 0 to 1.
Usage Tips:
Focus on Key Levels During Volatility: This indicator is best suited for periods of high volatility. It can help traders identify potential support and resistance levels that may be more significant in turbulent markets.
Adjust ATR Multiplier: Depending on the asset you're trading, you might want to fine-tune the ATR multiplier to better suit the market conditions and volatility.
Recommended Settings:
ATR Multiplier: 1.5
Fibonacci Levels: Default levels set to 0.00, 0.114, 0.236, 0.382, 0.5, 0.618, 0.786, and 1.0
Length for High/Low Detection: 55
Use this indicator to detect key Fibonacci retracement levels in volatile market conditions and make more informed trading decisions based on price dynamics and volatility.
Breakout LevelsBreakout Levels Indicator
The Breakout Levels indicator is a tool designed to help traders identify potential breakout points based on a specified time range and market volatility. By combining user-defined time frames with Average True Range (ATR) calculations, it provides actionable entry and stop-loss levels for both upward and downward breakouts. Additionally, it includes risk management features to calculate appropriate position sizes based on your account capital and risk tolerance.
Key Features
Custom Time Range Selection: Define a specific period during which the indicator calculates the highest high and lowest low to establish breakout levels.
ATR-Based Calculations: Use the ATR to adjust entry and stop-loss levels according to market volatility.
Risk Management: Automatically calculate position sizes based on your account capital and desired risk per trade.
Indicator Inputs
Start Time : The beginning of the time range for calculating the highest high and lowest low.
End Time : The end of the time range.
Entry Multiplier: A factor that determines how far the entry level is from the breakout level, scaled by the ATR.
Stop-Loss Multiplier: A factor that determines the distance of the stop-loss from the entry level, scaled by the ATR.
Risk per Trade (%) : The percentage of your account capital you're willing to risk on each trade.
Account Capital : Your total trading capital used for position size calculations.
ATR Length : The number of periods over which the ATR is calculated.
Position Size Up / Down : Shows you Lot size to maintain no loss more than allowed percentage at that entry

Bitcoin Logarithmic Growth Curve 2024The Bitcoin logarithmic growth curve is a concept used to analyze Bitcoin's price movements over time. The idea is based on the observation that Bitcoin's price tends to grow exponentially, particularly during bull markets. It attempts to give a long-term perspective on the Bitcoin price movements.
The curve includes an upper and lower band. These bands often represent zones where Bitcoin's price is overextended (upper band) or undervalued (lower band) relative to its historical growth trajectory. When the price touches or exceeds the upper band, it may indicate a speculative bubble, while prices near the lower band may suggest a buying opportunity.
Unlike most Bitcoin growth curve indicators, this one includes a logarithmic growth curve optimized using the latest 2024 price data, making it, in our view, superior to previous models. Additionally, it features statistical confidence intervals derived from linear regression, compatible across all timeframes, and extrapolates the data far into the future. Finally, this model allows users the flexibility to manually adjust the function parameters to suit their preferences.
The Bitcoin logarithmic growth curve has the following function:
y = 10^(a * log10(x) - b)
In the context of this formula, the y value represents the Bitcoin price, while the x value corresponds to the time, specifically indicated by the weekly bar number on the chart.
How is it made (You can skip this section if you’re not a fan of math):
To optimize the fit of this function and determine the optimal values of a and b, the previous weekly cycle peak values were analyzed. The corresponding x and y values were recorded as follows:
113, 18.55
240, 1004.42
451, 19128.27
655, 65502.47
The same process was applied to the bear market low values:
103, 2.48
267, 211.03
471, 3192.87
676, 16255.15
Next, these values were converted to their linear form by applying the base-10 logarithm. This transformation allows the function to be expressed in a linear state: y = a * x − b. This step is essential for enabling linear regression on these values.
For the cycle peak (x,y) values:
2.053, 1.268
2.380, 3.002
2.654, 4.282
2.816, 4.816
And for the bear market low (x,y) values:
2.013, 0.394
2.427, 2.324
2.673, 3.504
2.830, 4.211
Next, linear regression was performed on both these datasets. (Numerous tools are available online for linear regression calculations, making manual computations unnecessary).
Linear regression is a method used to find a straight line that best represents the relationship between two variables. It looks at how changes in one variable affect another and tries to predict values based on that relationship.
The goal is to minimize the differences between the actual data points and the points predicted by the line. Essentially, it aims to optimize for the highest R-Square value.
Below are the results:
It is important to note that both the slope (a-value) and the y-intercept (b-value) have associated standard errors. These standard errors can be used to calculate confidence intervals by multiplying them by the t-values (two degrees of freedom) from the linear regression.
These t-values can be found in a t-distribution table. For the top cycle confidence intervals, we used t10% (0.133), t25% (0.323), and t33% (0.414). For the bottom cycle confidence intervals, the t-values used were t10% (0.133), t25% (0.323), t33% (0.414), t50% (0.765), and t67% (1.063).
The final bull cycle function is:
y = 10^(4.058 ± 0.133 * log10(x) – 6.44 ± 0.324)
The final bear cycle function is:
y = 10^(4.684 ± 0.025 * log10(x) – -9.034 ± 0.063)
The main Criticisms of growth curve models:
The Bitcoin logarithmic growth curve model faces several general criticisms that we’d like to highlight briefly. The most significant, in our view, is its heavy reliance on past price data, which may not accurately forecast future trends. For instance, previous growth curve models from 2020 on TradingView were overly optimistic in predicting the last cycle’s peak.
This is why we aimed to present our process for deriving the final functions in a transparent, step-by-step scientific manner, including statistical confidence intervals. It's important to note that the bull cycle function is less reliable than the bear cycle function, as the top band is significantly wider than the bottom band.
Even so, we still believe that the Bitcoin logarithmic growth curve presented in this script is overly optimistic since it goes parly against the concept of diminishing returns which we discussed in this post:
This is why we also propose alternative parameter settings that align more closely with the theory of diminishing returns.
Our recommendations:
Drawing on the concept of diminishing returns, we propose alternative settings for this model that we believe provide a more realistic forecast aligned with this theory. The adjusted parameters apply only to the top band: a-value: 3.637 ± 0.2343 and b-parameter: -5.369 ± 0.6264. However, please note that these values are highly subjective, and you should be aware of the model's limitations.
Conservative bull cycle model:
y = 10^(3.637 ± 0.2343 * log10(x) - 5.369 ± 0.6264)

ATR+StdTR Band and Trailing StopThis Pine Script code plots the "ATR+StdTR Band and Trailing Stop," serving as a tool for volatility-based risk management and trend detection. While bands are typically set using a multiple of ATR, this script uses StdTR (the True Range standard deviation) and sets the band width based on ±(ATR + n times StdTR). StdTR is a great tool for detecting price volatility and anomalies, allowing traders to adapt to rapid changes in extreme market conditions. This helps traders proactively manage risk during sudden market fluctuations.
The following features are provided:
Table Display
A table is shown on the chart, allowing traders to visually track the current ATR value, StdTR (σ), and the long/short stop-loss levels (±ATR ± nσ). This enables real-time monitoring of risk management data.
Band Plots
The script plots bands that combine ATR with StdTR (nσ).
The upper and lower bands are calculated using the previous candle’s closing price (the source is customizable) and are plotted as ±(ATR + nσ), providing a clear visual of the price range.
ATR ± nσ Trailing Stop
The trailing stop dynamically adjusts the stop-loss levels based on price movements. In an uptrend, the stop-loss rises, while in a downtrend, it lowers, helping traders lock in profits while minimizing losses during significant reversals.
Breakout Detection
Breakouts are detected when the price exceeds the upper band or drops below the lower band. A visual marker (X) is displayed on the chart, allowing traders to quickly recognize when the price has moved beyond normal volatility ranges, making it easier to respond to trend formations or reversals.
Customization Points:
The ATR period and StdTR (n) are fully customizable.
The source for ATR band calculation can be adjusted, allowing traders to choose from close, open, high, low, etc.
The table’s display position and design (text color, size, etc.) can be customized to present the information clearly and effectively.

Price Iterations with Pips*Script Name:* Price Iterations with Pips
*Description:* This script plots horizontal lines above and below a user-defined initial price, representing price iterations based on a specified number of pips.
*Functionality:*
1. Asks for user input:
- Initial Price
- Pips per Iteration
- Number of Iterations
2. Calculates the price change per pip.
3. Plots horizontal lines:
- Above the initial price (green)
- Below the initial price (red)
4. Extends lines dynamically to both sides.
*Use Cases:*
1. *Support and Resistance Levels:* Use the script to visualize potential support and resistance levels based on price iterations.
2. *Price Targets:* Set the initial price as a target and use the iterations to estimate potential profit/loss levels.
3. *Risk Management:* Utilize the script to visualize risk levels based on pip iterations.
4. *Technical Analysis:* Combine the script with other technical indicators to identify potential trading opportunities.
*Trading Platforms:* This script is designed for TradingView.
*How to Use:*
1. Add the script to your TradingView chart.
2. Set the initial price, pips per iteration, and number of iterations.
3. Adjust the colors and line styles as needed.
4. Zoom in/out and pan to see the lines adjust.
*Benefits:*
1. Visualize price iterations and potential support/resistance levels.
2. Simplify risk management and price target estimation.
3. Enhance technical analysis with customizable price levels.
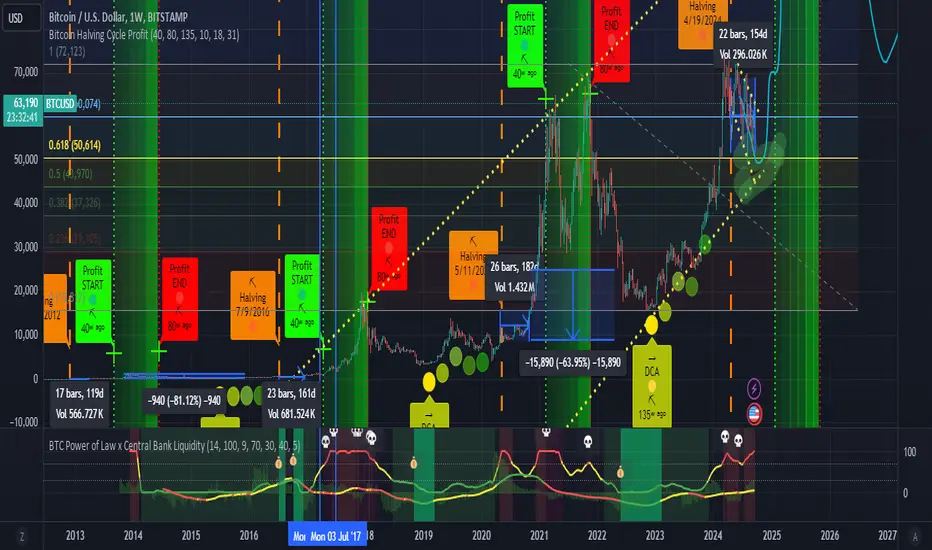
BTC Power of Law x Central Bank LiquidityThis indicator combines Bitcoin's long-term growth model (Power Law) with global central bank liquidity to help identify potential buy and sell signals.
How it works:
Power Law Oscillator: This part of the indicator tracks how far Bitcoin's current price is from its expected long-term growth, based on an exponential model. It helps you see when Bitcoin may be overbought (too expensive) or oversold (cheap) compared to its historical trend.
Central Bank Liquidity: This measures the amount of money injected into the financial system by major central banks (like the Fed or ECB). When more money is printed, asset prices, including Bitcoin, tend to rise. When liquidity dries up, prices often fall.
By combining these two factors, the indicator gives you a more accurate view of Bitcoin's price trends.
How to interpret:
Green Line : Bitcoin is undervalued compared to its long-term growth, and the liquidity environment is supportive. This is typically a buy signal.
Yellow Line: Bitcoin is trading near its expected value, or there's uncertainty due to mixed liquidity conditions. This is a hold signal.
Red Line: Bitcoin is overvalued, or liquidity is tightening. This is a potential sell signal.
Zones:
The background will turn green when Bitcoin is in a buy zone and red when it's in a sell zone, giving you easy-to-read visual cues.
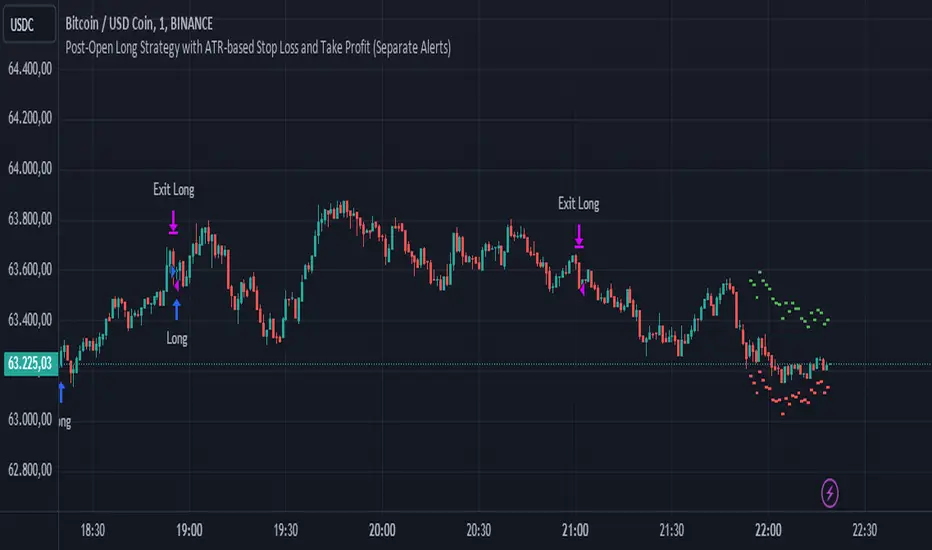
Post-Open Long Strategy with ATR-based Stop Loss and Take ProfitThe "Post-Open Long Strategy with ATR-Based Stop Loss and Take Profit" is designed to identify buying opportunities after the German and US markets open. It combines various technical indicators to filter entry signals, focusing on breakout moments following price lateralization periods.
Key Components and Their Interaction:
Bollinger Bands (BB):
Description: Uses BB with a 14-period length and standard deviation multiplier of 1.5, creating narrower bands for lower timeframes.
Role in the Strategy: Identifies low volatility phases (lateralization). The lateralization condition is met when the price is near the simple moving average of the BB, suggesting an imminent increase in volatility.
Exponential Moving Averages (EMA):
10-period EMA: Quickly detects short-term trend direction.
200-period EMA: Filters long-term trends, ensuring entries occur in a bullish market.
Interaction: Positions are entered only if the price is above both EMAs, indicating a consolidated positive trend.
Relative Strength Index (RSI):
Description: 7-period RSI with a threshold above 30.
Role in the Strategy: Confirms the market is not oversold, supporting the validity of the buy signal.
Average Directional Index (ADX):
Description: 7-period ADX with 7-period smoothing and a threshold above 10.
Role in the Strategy: Assesses trend strength. An ADX above 10 indicates sufficient momentum to justify entry.
Average True Range (ATR) for Dynamic Stop Loss and Take Profit:
Description: 14-period ATR with multipliers of 2.0 for Stop Loss and 4.0 for Take Profit.
Role in the Strategy: Adjusts exit levels based on current volatility, enhancing risk management.
Resistance Identification and Breakout:
Description: Analyzes the highs of the last 20 candles to identify resistance levels with at least two touches.
Role in the Strategy: A breakout above this level signals a potential continuation of the bullish trend.
Time Filters and Market Conditions:
Trading Hours: Operates only during the opening of the German market (8:00 - 12:00) and US market (15:30 - 19:00).
Panic Candle: The current candle must close negative, leveraging potential emotional reactions in the market.
Avoiding Entry During Pullbacks:
Description: Checks that the two previous candles are not both bearish.
Role in the Strategy: Avoids entering during a potential pullback, improving trade success probability.
Post-Open Long Strategy with ATR-Based Stop Loss and Take Profit
The "Post-Open Long Strategy with ATR-Based Stop Loss and Take Profit" is designed to identify buying opportunities after the German and US markets open. It combines various technical indicators to filter entry signals, focusing on breakout moments following price lateralization periods.
Key Components and Their Interaction:
Bollinger Bands (BB):
Description: Uses BB with a 14-period length and standard deviation multiplier of 1.5, creating narrower bands for lower timeframes.
Role in the Strategy: Identifies low volatility phases (lateralization). The lateralization condition is met when the price is near the simple moving average of the BB, suggesting an imminent increase in volatility.
Exponential Moving Averages (EMA):
10-period EMA: Quickly detects short-term trend direction.
200-period EMA: Filters long-term trends, ensuring entries occur in a bullish market.
Interaction: Positions are entered only if the price is above both EMAs, indicating a consolidated positive trend.
Relative Strength Index (RSI):
Description: 7-period RSI with a threshold above 30.
Role in the Strategy: Confirms the market is not oversold, supporting the validity of the buy signal.
Average Directional Index (ADX):
Description: 7-period ADX with 7-period smoothing and a threshold above 10.
Role in the Strategy: Assesses trend strength. An ADX above 10 indicates sufficient momentum to justify entry.
Average True Range (ATR) for Dynamic Stop Loss and Take Profit:
Description: 14-period ATR with multipliers of 2.0 for Stop Loss and 4.0 for Take Profit.
Role in the Strategy: Adjusts exit levels based on current volatility, enhancing risk management.
Resistance Identification and Breakout:
Description: Analyzes the highs of the last 20 candles to identify resistance levels with at least two touches.
Role in the Strategy: A breakout above this level signals a potential continuation of the bullish trend.
Time Filters and Market Conditions:
Trading Hours: Operates only during the opening of the German market (8:00 - 12:00) and US market (15:30 - 19:00).
Panic Candle: The current candle must close negative, leveraging potential emotional reactions in the market.
Avoiding Entry During Pullbacks:
Description: Checks that the two previous candles are not both bearish.
Role in the Strategy: Avoids entering during a potential pullback, improving trade success probability.
Entry and Exit Conditions:
Long Entry:
The price breaks above the identified resistance.
The market is in a lateralization phase with low volatility.
The price is above the 10 and 200-period EMAs.
RSI is above 30, and ADX is above 10.
No short-term downtrend is detected.
The last two candles are not both bearish.
The current candle is a "panic candle" (negative close).
Order Execution: The order is executed at the close of the candle that meets all conditions.
Exit from Position:
Dynamic Stop Loss: Set at 2 times the ATR below the entry price.
Dynamic Take Profit: Set at 4 times the ATR above the entry price.
The position is automatically closed upon reaching the Stop Loss or Take Profit.
How to Use the Strategy:
Application on Volatile Instruments:
Ideal for financial instruments that show significant volatility during the target market opening hours, such as indices or major forex pairs.
Recommended Timeframes:
Intraday timeframes, such as 5 or 15 minutes, to capture significant post-open moves.
Parameter Customization:
The default parameters are optimized but can be adjusted based on individual preferences and the instrument analyzed.
Backtesting and Optimization:
Backtesting is recommended to evaluate performance and make adjustments if necessary.
Risk Management:
Ensure position sizing respects risk management rules, avoiding risking more than 1-2% of capital per trade.
Originality and Benefits of the Strategy:
Unique Combination of Indicators: Integrates various technical metrics to filter signals, reducing false positives.
Volatility Adaptability: The use of ATR for Stop Loss and Take Profit allows the strategy to adapt to real-time market conditions.
Focus on Post-Lateralization Breakout: Aims to capitalize on significant moves following consolidation periods, often associated with strong directional trends.
Important Notes:
Commissions and Slippage: Include commissions and slippage in settings for more realistic simulations.
Capital Size: Use a realistic trading capital for the average user.
Number of Trades: Ensure backtesting covers a sufficient number of trades to validate the strategy (ideally more than 100 trades).
Warning: Past results do not guarantee future performance. The strategy should be used as part of a comprehensive trading approach.
With this strategy, traders can identify and exploit specific market opportunities supported by a robust set of technical indicators and filters, potentially enhancing their trading decisions during key times of the day.
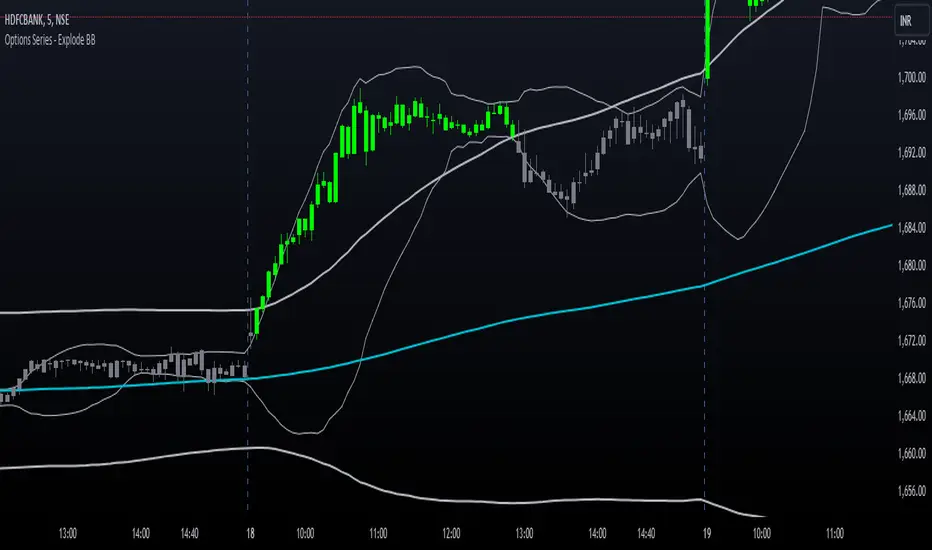
Options Series - Explode BB⭐ Bullish Zone:
⭐ Bearish Zone:
⭐ Neutral Zone:
The provided script integrates Bollinger Bands with different lengths (20 and 200 periods) and applies customized candle coloring based on certain conditions. Here's a breakdown of its importance and insights:
⭐ 1. Dual Bollinger Bands (BBs):
Bollinger Bands (BB) with 20-period length:
This is the standard setting for Bollinger Bands, with a 20-period simple moving average (SMA) as the central line and upper/lower bands derived from the standard deviation.
These bands are used to identify volatility. Wider bands indicate higher volatility, while narrower bands indicate low volatility.
200-period BB:
This is a longer-term indicator providing insight into the overall trend and long-term volatility.
The 200-period bands filter out noise and offer a "macro" view of price movements compared to the 20-period bands, which focus on short-term price actions.
⭐ 2. Overlay of Bollinger Bands and SMA:
The script plots the Bollinger Bands along with the SMA (Simple Moving Average) of the 200-period BB. This gives traders both a short-term (20-period) and long-term (200-period) perspective, which is valuable for detecting major trend shifts or key support and resistance zones.
Using multiple time frames (20-period for short-term and 200-period for long-term) can help traders spot both immediate opportunities and overarching trends.
⭐ 3. Candle Coloring Based on Key Conditions:
Bullish Signal (GreenFluroscent): When the price closes above the upper 200-period Bollinger Band, the candle turns green, indicating a potential bullish breakout.
Bearish Signal (RedFluroscent): If the price closes below the lower 200-period Bollinger Band, the candle turns red, suggesting a bearish breakout.
Neutral or Uncertain Market: Candles are gray when the price remains between the upper and lower bands, indicating a lack of a strong directional bias.
This color-coded visualization allows traders to quickly assess market sentiment based on the Bollinger Bands' extremes.
⭐ 4. Strategic Importance of the Setup:
Multi-timeframe Analysis: Combining short-term (20-period) and long-term (200-period) Bollinger Bands enables traders to assess the market's overall volatility and trend strength. The longer-term bands act as a reference for broader trend direction, while the shorter-term bands can signal shorter-term pullbacks or entry/exit points.
Breakout Identification: By color-coding the candles when prices cross either the upper or lower 200-period bands, the script makes it easier to spot potential breakouts. This can be particularly helpful in trading strategies that rely on volatility expansions or trend-following tactics.
⭐ 5. Customization and Flexibility:
Custom Colors: The script uses distinct fluorescent green and red colors to highlight key bullish and bearish conditions, providing clear visual cues.
Simplicity with Flexibility: Despite its simplicity, the script leaves room for customization, allowing traders to adjust the Bollinger Band multipliers or apply different conditions to candle coloring for more nuanced setups.
This script enhances standard Bollinger Band usage by introducing multi-timeframe analysis, breakout signals, and visual cues for trend strength, making it a powerful tool for both trend-following and mean-reversion strategies.
🚀 Conclusion:
This script effectively simplifies volatility analysis by visually marking bullish, bearish, and neutral zones, making it a robust tool for identifying trade opportunities across multiple timeframes. Its dual-band approach ensures both trend-following and mean-reversion strategies are supported.
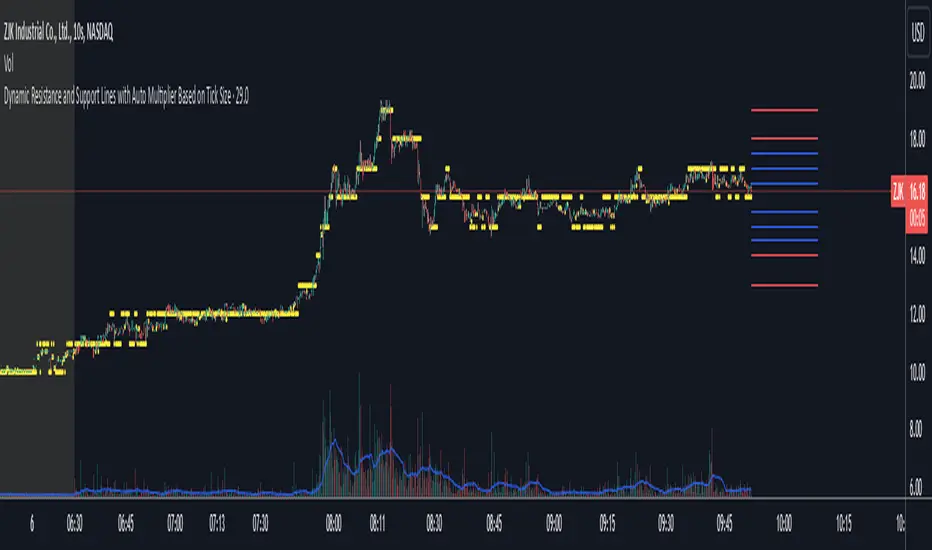
Dynamic Resistance and Support LinesThis script is designed to dynamically plot support and resistance lines based on full-dollar and half-dollar price levels relative to the close price on a chart. The script is particularly useful for day traders and scalpers, as it helps visualize key psychological price levels that often act as support and resistance zones in volatile and fast-moving markets in real time.
Key Features:
Dynamic Resistance and Support Levels:
Full-dollar levels: These are calculated by rounding the close price to the nearest full dollar and then extending the levels by adding and subtracting increments of 1 (e.g., $1, $2, $3).
Half-dollar levels: These are calculated by adding and subtracting 0.5 increments to the nearest full-dollar price, providing additional reference points. The historical full-dollar levels remain where support and resistance may have occurred in the past.
Extend Lines:
You can toggle whether the support and resistance lines are extended to the right, left, or both directions. This allows flexibility in projecting potential future areas of support or resistance.
Custom Line Extension:
The user can set the number of bars (or time periods) that the support and resistance lines will extend, giving control over how long the levels remain on the chart.
Color-Coded Lines:
Red lines represent full-dollar resistance and support levels.
Blue lines represent half-dollar levels, making it easy to differentiate between key psychological price zones.
Line Flexibility:
The script allows the lines to extend both left and right on the chart, making it useful for analyzing historical price action or projecting future price movements. The number of bars for extension is customizable, allowing for tailored setups.
Nearest Full Dollar Plot:
The nearest full-dollar price level is plotted as a yellow circle on the chart. This serves as a quick visual cue for traders to monitor price proximity to critical levels.
Benefits in Day Trading, Scalping, and Volatile Markets:
Visualizing Key Psychological Levels:
Full-dollar and half-dollar price levels often act as psychological barriers for traders. This script helps traders easily identify these levels, which are important in both fast-moving markets and during sideways consolidation.
Improved Decision-Making:
By automatically drawing these support and resistance levels, the script helps day traders and scalpers make quicker and more informed decisions, especially in volatile markets where every second counts.
Adaptability to Market Conditions:
The flexibility of extending lines based on trader preferences allows the user to adapt the script to various market conditions, such as high volatility or trend-based trading, providing a clear view of potential breakout or reversal areas.
Better Risk Management:
Having predefined support and resistance levels helps traders better manage risk, as these levels can act as logical areas for setting stop losses or taking profits.
This script is especially valuable for traders looking to capitalize on quick market movements or identify key entry and exit points during market volatility.
Indicator 10**Indicator 10** is a sophisticated technical analysis tool designed for use on trading platforms that support Pine Script (version 5). This indicator is primarily focused on analyzing price movements over different timeframes, incorporating elements of ZigZag analysis, Fibonacci levels, and historical price range calculations. Below is a detailed description of its features and functionalities:
#### Key Features:
1. **Input Variables:**
- **Year_calc:** Specifies the number of years to consider for historical price range calculations.
- **Size_fibo:** Defines the size of the Fibonacci levels in points.
- **Dig:** Represents the minimum tick size for the instrument being analyzed.
- **ZigZag Parameters:**
- **Period (zigzag_len):** The length of the ZigZag indicator.
- **Depth (zigzag_depth):** The depth percentage for the ZigZag indicator.
- **Display Count (zigzag_hist):** The number of ZigZag points to display.
- **Font Size (font_size):** The size of the font used for labels.
2. **Historical Price Range Calculation:**
- The indicator calculates the average weekly and monthly price ranges over the specified number of years (`Year_calc`).
- These ranges are used to adjust the Fibonacci levels dynamically based on historical volatility.
3. **ZigZag Analysis:**
- The indicator employs a custom ZigZag function to identify significant price swings on different timeframes (H4, D1, W1).
- The ZigZag points are stored in arrays, allowing for the visualization of recent price swings.
4. **Fibonacci Adjustment:**
- The Fibonacci levels are adjusted based on the historical price ranges (`W1_Val`, `MN1_Val`, `D1_Val`).
- These adjusted levels are used to draw support and resistance lines on the chart.
5. **Visualization:**
- The indicator draws lines and labels on the chart to represent the ZigZag points and adjusted Fibonacci levels.
- Different colors are used to distinguish between upward and downward trends.
6. **Dynamic Updates:**
- The indicator continuously updates the ZigZag points and Fibonacci levels as new price data becomes available.
- It ensures that only the most recent ZigZag points are displayed, maintaining a clean and relevant chart.
#### How It Works:
1. **Initialization:**
- The indicator initializes variables for storing historical price ranges and ZigZag points.
- It sets the start date for historical calculations based on the current year minus the specified number of years (`Year_calc`).
2. **Historical Data Retrieval:**
- The indicator retrieves weekly and monthly high and low prices for the specified period.
- It calculates the total price range and the average range for each timeframe.
3. **ZigZag Calculation:**
- The custom ZigZag function identifies local highs and lows based on the specified period and depth.
- These points are stored in arrays for later visualization.
4. **Fibonacci Adjustment:**
- The Fibonacci levels are adjusted based on the historical price ranges and the specified Fibonacci size.
- These adjusted levels are used to draw lines on the chart.
5. **Visualization:**
- The indicator draws lines connecting ZigZag points and labels indicating the direction of the trend.
- It ensures that only the most recent ZigZag points are displayed, maintaining a clean and relevant chart.
6. **Continuous Updates:**
- The indicator continuously updates the ZigZag points and Fibonacci levels as new price data becomes available.
- It ensures that only the most recent ZigZag points are displayed, maintaining a clean and relevant chart.
#### Conclusion:
**Indicator 10** is a powerful tool for traders who rely on historical price analysis, ZigZag patterns, and Fibonacci levels to make trading decisions. Its dynamic and adaptive nature ensures that the chart remains relevant and useful, providing traders with a clear view of recent price movements and potential support/resistance levels.

Wedge BreakoutThe Wedge Breakout indicator is designed to identify and signal potential breakouts from a wedge pattern, a common technical analysis formation. A wedge pattern typically forms when the price moves within converging trendlines, indicating a potential upcoming breakout either upwards (bullish) or downwards (bearish).
Identifying Pivot Points:
The indicator first calculates pivot points, which are significant highs and lows that define the wedge's upper and lower boundaries.
Pivot Lows: It identifies the lowest price points over a specified length (input_len), which serves as the lower boundary of the wedge.
Pivot Highs: Similarly, it identifies the highest price points over the same length, forming the upper boundary of the wedge.
Drawing Trendlines:
The pivot points are connected to form dashed trendlines that represent the upper and lower boundaries of the wedge.
The indicator uses the SimpleTrendlines library to manage and draw these trendlines dynamically:
Green Trendline: Indicates an upward slope (bullish).
Red Trendline: Indicates a downward slope (bearish).
Calculating the Breakout Conditions:
A breakout is confirmed when the price action fulfills two conditions:
The candle's high exceeds the upper trendline's highest point.
The candle's low drops below the lower trendline's lowest point.
This condition suggests that the price is squeezing within the wedge pattern and is about to break out.
Determining Breakout Direction:
The direction of the breakout is determined by the candle's closing position relative to its opening:
Bullish Breakout (Upward): When the candle closes above its opening price (close > open) after breaching both trendlines, it suggests a bullish breakout. This condition is marked with a green upward triangle .
Bearish Breakout (Downward): When the candle closes below its opening price (close < open) after breaching both trendlines, it suggests a bearish breakout. This condition is marked with a red downward triangle.
Visual Representation:
Green Triangle Up: Plotted below the bar to indicate a potential bullish breakout.
Red Triangle Down: Plotted above the bar to indicate a potential bearish breakout.
Used library:
www.tradingview.com

Adaptive VWAP [QuantAlgo]Introducing the Adaptive VWAP by QuantAlgo 📈🧬
Enhance your trading and investing strategies with the Adaptive VWAP , a versatile tool designed to provide dynamic insights into market trends and price behavior. This indicator offers a flexible approach to VWAP calculations by allowing users to adapt it based on lookback periods or fixed timeframes, making it suitable for a wide range of market conditions.
🌟 Key Features:
🛠 Customizable VWAP Settings: Choose between an adaptive VWAP that adjusts based on a rolling lookback period, or switch to a fixed timeframe (e.g., daily, weekly, monthly) for a more structured approach. Adjust the VWAP to suit your trading or investing style.
💫 Dynamic Bands and ATR Filter: Configurable deviation bands with multipliers allow you to visualize price movement around VWAP, while an ATR-based noise filter helps reduce false signals during periods of market fluctuation.
🎨 Trend Visualization: Color-coded trend identification helps you easily spot uptrends and downtrends based on VWAP positioning. The indicator fills the areas between the bands for clearer visual representation of price volatility and trend strength.
🔔 Custom Alerts: Set up alerts for when price crosses above or below the VWAP, signaling potential uptrend or downtrend opportunities. Stay informed without needing to monitor the charts constantly.
✍️ How to Use:
✅ Add the Indicator: Add the Adaptive VWAP to your favourites and apply to your chart. Choose between adaptive or timeframe-based VWAP calculation, adjust the lookback period, and configure the deviation bands to your preferred settings.
👀 Monitor Bands and Trends: Watch for price interaction with the VWAP and its deviation bands. The color-coded signals and band fills help identify potential trend shifts or price extremes.
🔔 Set Alerts: Configure alerts for uptrend and downtrend signals based on price crossing the VWAP, so you’re always informed of significant market movements.
⚙️ How It Works:
The Adaptive VWAP adjusts its calculation based on the user’s chosen configuration, allowing for a flexible approach to market analysis. The adaptive setting uses a rolling lookback period to continuously adjust the VWAP, while the fixed timeframe option anchors VWAP to key timeframes like daily, weekly, or monthly periods. This flexibility enables traders and investors to use the tool in various market environments.
Deviation bands, calculated with customizable multipliers, provide a clear visual of how far the price has moved from the VWAP, helping you gauge potential overbought or oversold conditions. To reduce false signals, an ATR-based filter can be applied, ensuring that only significant price movements trigger trend confirmations.
The tool also includes a fast exponential smoothing function for the VWAP, helping smooth out price fluctuations without sacrificing responsiveness. Trend confirmation is reinforced by the number of bars that price stays above or below the VWAP, ensuring a more consistent trend identification process.
Disclaimer:
The Adaptive VWAP is designed to enhance your market analysis but should not be relied upon as the sole basis for trading or investing decisions. Always combine it with other analytical tools and practices. No statements or signals from this indicator constitute financial advice. Past performance is not indicative of future results.