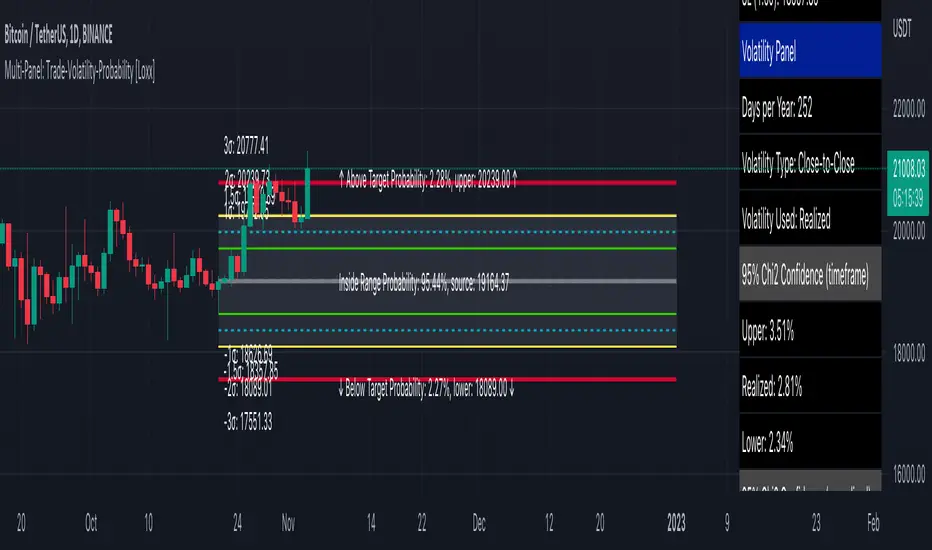
Multi-Panel: Trade-Volatility-Probability [Loxx]Multi-Panel: Trade-Volatility-Probability shows user selected and volatility-based price levels and probabilities on the chart. This is useful for both options and all styles of up/down trading methods that rely on volatility.
Trading Panel: Shows trading information to take profits and stop-loss based on multiples of volatility. Also shows equity inputs by the user to calculate optimal position size
Key things to note about the Trading Panel
-Trade side: Long or short. you change this this to change the take profit and SL levels in displayed on the table to be used w/ up/down trading styles that rely on volatility stops
-Account size: User enters total balance available for trade
-Risk: Total % of account size you're willing to lose should the SL be hit
-Position size: Size of the position given the SL and your preferred Risk
-Take profit/Stop loss levels: Based on multipliers selected by the user in settings. These shouldn't be changed unless you really know what you're doing with volatility stops
-Entry: Source price. can be 1 of 37 different prices. See Loxx's Expanded Source Types:
Volatility Panel: Shows information about the volatility the user selected to be used to take profit/stop-loss/range calculations. Volatility types included are:
Close-to-Close
Close-to-Close volatility is a classic and most commonly used volatility measure, sometimes referred to as historical volatility .
Volatility is an indicator of the speed of a stock price change. A stock with high volatility is one where the price changes rapidly and with a bigger amplitude. The more volatile a stock is, the riskier it is.
Close-to-close historical volatility calculated using only stock's closing prices. It is the simplest volatility estimator. But in many cases, it is not precise enough. Stock prices could jump considerably during a trading session, and return to the open value at the end. That means that a big amount of price information is not taken into account by close-to-close volatility .
Despite its drawbacks, Close-to-Close volatility is still useful in cases where the instrument doesn't have intraday prices. For example, mutual funds calculate their net asset values daily or weekly, and thus their prices are not suitable for more sophisticated volatility estimators.
Parkinson
Parkinson volatility is a volatility measure that uses the stock’s high and low price of the day.
The main difference between regular volatility and Parkinson volatility is that the latter uses high and low prices for a day, rather than only the closing price. That is useful as close to close prices could show little difference while large price movements could have happened during the day. Thus Parkinson's volatility is considered to be more precise and requires less data for calculation than the close-close volatility.
One drawback of this estimator is that it doesn't take into account price movements after market close. Hence it systematically undervalues volatility. That drawback is taken into account in the Garman-Klass's volatility estimator.
Garman-Klass
Garman Klass is a volatility estimator that incorporates open, low, high, and close prices of a security.
Garman-Klass volatility extends Parkinson's volatility by taking into account the opening and closing price. As markets are most active during the opening and closing of a trading session, it makes volatility estimation more accurate.
Garman and Klass also assumed that the process of price change is a process of continuous diffusion (geometric Brownian motion). However, this assumption has several drawbacks. The method is not robust for opening jumps in price and trend movements.
Despite its drawbacks, the Garman-Klass estimator is still more effective than the basic formula since it takes into account not only the price at the beginning and end of the time interval but also intraday price extremums.
Researchers Rogers and Satchel have proposed a more efficient method for assessing historical volatility that takes into account price trends. See Rogers-Satchell Volatility for more detail.
Rogers-Satchell
Rogers-Satchell is an estimator for measuring the volatility of securities with an average return not equal to zero.
Unlike Parkinson and Garman-Klass estimators, Rogers-Satchell incorporates drift term (mean return not equal to zero). As a result, it provides a better volatility estimation when the underlying is trending.
The main disadvantage of this method is that it does not take into account price movements between trading sessions. It means an underestimation of volatility since price jumps periodically occur in the market precisely at the moments between sessions.
A more comprehensive estimator that also considers the gaps between sessions was developed based on the Rogers-Satchel formula in the 2000s by Yang-Zhang. See Yang Zhang Volatility for more detail.
Yang-Zhang
Yang Zhang is a historical volatility estimator that handles both opening jumps and the drift and has a minimum estimation error.
We can think of the Yang-Zhang volatility as the combination of the overnight (close-to-open volatility ) and a weighted average of the Rogers-Satchell volatility and the day’s open-to-close volatility . It considered being 14 times more efficient than the close-to-close estimator.
Garman-Klass-Yang-Zhang
Garman Klass is a volatility estimator that incorporates open, low, high, and close prices of a security.
Garman-Klass volatility extends Parkinson's volatility by taking into account the opening and closing price. As markets are most active during the opening and closing of a trading session, it makes volatility estimation more accurate.
Garman and Klass also assumed that the process of price change is a process of continuous diffusion (geometric Brownian motion). However, this assumption has several drawbacks. The method is not robust for opening jumps in price and trend movements.
Despite its drawbacks, the Garman-Klass estimator is still more effective than the basic formula since it takes into account not only the price at the beginning and end of the time interval but also intraday price extremums.
Researchers Rogers and Satchel have proposed a more efficient method for assessing historical volatility that takes into account price trends. See Rogers-Satchell Volatility for more detail.
Exponential Weighted Moving Average
The Exponentially Weighted Moving Average (EWMA) is a quantitative or statistical measure used to model or describe a time series. The EWMA is widely used in finance, the main applications being technical analysis and volatility modeling.
The moving average is designed as such that older observations are given lower weights. The weights fall exponentially as the data point gets older – hence the name exponentially weighted.
The only decision a user of the EWMA must make is the parameter lambda. The parameter decides how important the current observation is in the calculation of the EWMA. The higher the value of lambda, the more closely the EWMA tracks the original time series.
Standard Deviation of Log Returns
This is the simplest calculation of volatility . It's the standard deviation of ln(close/close(1))
Pseudo GARCH(2,2)
This is calculated using a short- and long-run mean of variance multiplied by θ.
θavg(var ;M) + (1 − θ) avg (var ;N) = 2θvar/(M+1-(M-1)L) + 2(1-θ)var/(M+1-(M-1)L)
Solving for θ can be done by minimizing the mean squared error of estimation; that is, regressing L^-1var - avg (var; N) against avg (var; M) - avg (var; N) and using the resulting beta estimate as θ.
Average True Range
The average true range (ATR) is a technical analysis indicator, introduced by market technician J. Welles Wilder Jr. in his book New Concepts in Technical Trading Systems, that measures market volatility by decomposing the entire range of an asset price for that period.
The true range indicator is taken as the greatest of the following: current high less the current low; the absolute value of the current high less the previous close; and the absolute value of the current low less the previous close. The ATR is then a moving average, generally using 14 days, of the true ranges.
True Range Double
A special case of ATR that attempts to correct for volatility skew.
Chi-squared Confidence Interval:
Confidence interval of volatility is calculated using an inverse CDF of a Chi-Squared Distribution. You can change the volatility input used to either realized, upper confidence interval, or lower confidence interval. This is included in case you'd like to see how far price can extend if volatility hits it's upper or lower confidence levels. Generally, you'd just used realized volatility, so I wouldn't change this setting.
Inverse CDF of a Chi-Squared Distribution
The chi-square distribution is a one-parameter family of curves. The parameter ν is the degrees of freedom.
The icdf of the chi-square distribution is
x=F^−1(p∣ν) = {x:F(x∣ν) = p}
where
p=F(x∣ν)= ∫ (t^(v-2)/2 * e^t/2) / (2^(v/2) / Γ(v/2))
ν is the degrees of freedom, and Γ( · ) is the Gamma function. The result p is the probability that a single observation from the chi-square distribution with ν degrees of freedom falls in the interval .
Additional notes on Volatility Panel
-Shows both current timeframe volatility per candle at whatever date backward you select
-Shows annualized volatility basaed on selected days per year and per bar volatility; this is automaitcally caulculated no matter the timeframe used. This means that it'll calculate annualized volatility for the current candle even on the 1 second timeframe. Days per year should be 252 for everything but cryptocurrency; however, for all types of tradable assets, anything over the 3 day timeframe will calculate on 365 days.
Probability Panel
This panel shows the probability levels of a user selected upper and lower price boundary. This includes the inside range of volatility between the lower and upper price levels and the outside probability below the lower price level and above the upper price level. These values are calculated using the CDF (cumulative density function) of a normal distribution. In simpler terms, CDF returns area under a bell curve between two points left and right, or for our purposes, high and low. This yeilds the probabilities you see in the Probability Panel. See the following graphic to visualize how this works:
The red line is the entry bar; the yellow line is the "mean" but in this case just the chosen source price.
Other things to know
You can turn on/off all labels and levels and fills
Cdf
Probability Distribution HistogramProbability Distribution Histogram
During data exploration it is often useful to plot the distribution of the data one is exploring. This indicator plots the distribution of data between different bins.
Essentially, what we do is we look at the min and max of the entire data set to determine its range. When we have the range of the data, we decide how many bins we want to divide this range into, so that the more bins we get, the smaller the range (a.k.a. width) for each bin becomes. We then place each data point in its corresponding bin, to see how many of the data points end up in each bin. For instance, if we have a data set where the smallest number is 5 and the biggest number is 105, we get a range of 100. If we then decide on 20 bins, each bin will have a width of 5. So the left-most bin would therefore correspond to values between 5 and 10, and the bin to the right would correspond to values between 10 and 15, and so on.
Once we have distributed all the data points into their corresponding bins, we compare the count in each bin to the total number of data points, to get a percentage of the total for each bin. So if we have 100 data points, and the left-most bin has 2 data points in it, that would equal 2%. This is also known as probability mass (or well, an approximation of it at least, since we're dealing with a bin, and not an exact number).
Usage
This is not an indicator that will give you any trading signals. This indicator is made to help you examine data. It can take any input you give it and plot how that data is distributed.
The indicator can transform the data in a few ways to help you get the most out of your data exploration. For instance, it is usually more accurate to use logarithmic data than raw data, so there is an option to transform the data using the natural logarithmic function. There is also an option to transform the data into %-Change form or by using data differencing.
Another option that the indicator has is the ability to trim data from the data set before plotting the distribution. This can help if you know there are outliers that are made up of corrupted data or data that is not relevant to your research.
I also included the option to plot the normal distribution as well, for comparison. This can be useful when the data is made up of residuals from a prediction model, to see if the residuals seem to be normally distributed or not.

Cumulative distribution function - Probability Cumulative distribution function (tScore and zScore)
This script provides the calculation of the cumulative distribution function (i.e., probability). The measure allows you to calculate the chances of a value of interest being above or below a hypothesized value over the measurement period—nothing fancy here, just good old statistics and mathematics. The closer you are to 0 or 1, the more significant your measurement. We’ve included a significance level highlighting feature. The ability to turn price and/or volume off.
We have included both the Z and T statistics. Where the ‘Z’ is looking at the difference of the current value, minus the mean, and divided by the standard deviation. This is usually pretty noisy on a single value, so a smoother is included. Nice shoutout to the Pinecoders Github Page with this function also. The t-statistic is measuring the difference between a short measurement, an extended measurement, and divided by the standard error (sigma/sqrt(n)). Both of these are neatly wrapped into a function, so please feel free to use them in your code. Add a bit of science to your guessing game. For the purists out there, we have chosen to use sigma in the t-statistic because we know the population's behavior (as opposed to the s-measure). We’ve also included two levels of the t-statistic cumulative distribution function if you are using a short sample period below 6.
Finally, because everyone loves choices, we’ve included the ability to measure the probability of:
the current value (Price and volume)
change
percent change
momentum (change over a period of time)
Acceleration (change of the change)
contribution (amount of the current bar over the sum)
volatility (natural log ratio of today and the previous bar)
Here is a chart example explaining some of the data for the function.
Here are the various options you have the print the different measurements
A comparison of the t-statistic and z-statistic (t-score and z-score)
And the coloring options

BlockGain Scalping FOREX VER. 1.0THIS INDICATOR WORK WITH TWO SIGNAL YELLOW AND BLUE (FIRST PROFIT 15PIPS) AN STRONG CROSS YELLOW, BLUE, RED CROSS GREEN (MORE 15 PIPS) FOR TIME FRAME 15 MIN , 5 MIN AND 1H