Truly Iterative Gaussian ChannelOVERVIEW
The Truly Iterative Gaussian Channel is a robust channeling system that integrates a Gaussian smoothing kernel with a rolling standard deviation to create dynamically adaptive upper and lower boundaries around price. This indicator provides a smooth, yet responsive representation of price movements while minimizing lag and dynamically adjusting channel width to reflect real-time market volatility. Its versatility makes it effective across various timeframes and trading styles, offering significant potential for experimentation and integration into advanced trading systems.
TRADING USES
The Gaussian indicator can be used for multiple trading strategies. Trend following relies on the middle Gaussian line to gauge trend direction: prices above this line indicate bullish momentum, while prices below signal bearish momentum. The upper and lower boundaries act as dynamic support and resistance levels, offering breakout or pullback entry opportunities. Mean reversion focuses on identifying reversal setups when price approaches or breaches the outer boundaries, aiming for a return to the Gaussian centerline. Volatility filtering helps assess market conditions, with narrow channels indicating low volatility or consolidation and suggesting fewer trading opportunities or an impending breakout. Adaptive risk management uses channel width to adjust for market volatility, with wider channels signaling higher risk and tighter channels indicating lower volatility and potentially safer entry points.
THEORY
Gaussian kernel smoothing, derived from the Gaussian normal distribution, is a cornerstone of probability and statistics, valued for its ability to reduce noise while preserving critical signal features. In this indicator, it ensures price movements are smoothed with precision, minimizing distortion while maintaining responsiveness to market dynamics.
The rolling standard deviation complements this by dynamically measuring price dispersion from the mean, enabling the channel to adapt in real time to changing market conditions. This combination leverages the mathematical correctness of both tools to balance smoothness and adaptability.
An iterative framework processes data efficiently, bar by bar, without recalculating historical value to ensure reliability and preventing repainting to create a mathematically grounded channel system suitable for a wide range of market environments.
The Gaussian channel excels at filtering noise while remaining responsive to price action, providing traders with a dependable tool for identifying trends, reversals, and volatility shifts with consistency and precision.
CALIBRATION
Calibration of the Gaussian channel involves adjusting its length to modify sensitivity and adaptability based on trading style. Shorter lengths (e.g., 50-100) are ideal for intraday traders seeking quick responses to price fluctuations. Medium lengths (e.g., 150-200) cater to swing traders aiming to capture broader market trends. Longer lengths (e.g., 250-400+) are better suited for positional traders focusing on long-term price movements and stability.
MARKET USAGE
Stock, Forex, Crypto, Commodities, and Indices.
Channels
Faytterro Bandswhat is Faytterro Bands?
it is a channel indicator like "Bollinger Bands".
what it does?
creates a channel using standard deviations and means. thus giving users an idea about the expensive and cheap zones. It uses a special weighted moving average different from standard bollinger bands, it also averages not only price but also deviations.
how it does it?
it uses this formulas:
how to use it?
its usage is the same as "bollinger band".
length represents the number of candles to be taken into account, source represents the source of those candles and stdev represents the coefficient of the standard deviation.
you can use it with other indicators:
Multi-Optimized Linear Regression ChannelA take on alexgrover 's Optimized Linear Regression Channel script which allows users to apply multiple linear regression channel with unique multiplicative factors.
Multiplicative Factors
Adjust the amount of channels and multiplicative factors of existing or additional channels using the "Mults" input.
An input of "1" creates a single linear regression channel with the multiplicative factor of one.
An input of "4" creates a single linear regression channel with the multiplicative factor of four.
An input of "1,4" creates two linear regression channels with multiplicative factors of one and four.
An input of "1,2,3" creates three linear regression channels with multiplicative factors of one, two, and three.
Linear Regression ChannelsThese channels are generated from the current values of the linear regression channel indicator, the standard deviation is calculated based off of the RSI . This indicator gives an idea of when the linear regression model predicts a change in direction.
You are able to change the length of the linear regression model, as well as the size of the zone. A negative zone size will make the zone stretch away from the center, and a positive zone size will make it stretch towards the centerline.

Channel of linear regression of rate of change from the mean The indicator calculates the difference between the closing price and the average as a percentage and after that it calculates the average linear regression and then draws it in the form of a channel.
Preferably use it on 30 min or 15 min or 1 Hour or 2H time frames .
Exiting outside the upper or lower channel limits represents high price inflation, and returning inside the channel means the possibility of the price rising or falling for the average or the other limit of the channel.
Channel lines may represent places of support and resistance.

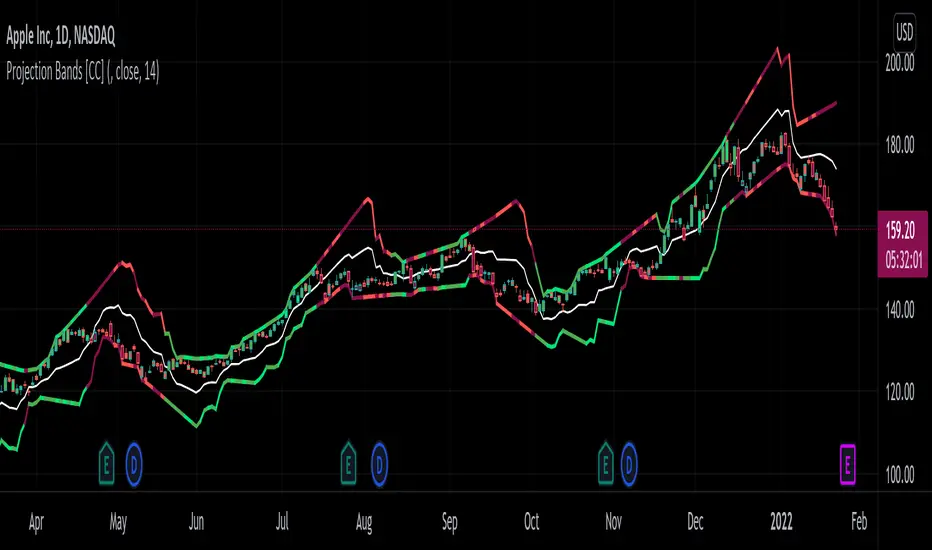
Projection Bands [CC]The Projection Bands were created by Mel Widner (Stocks and Commodities Jul 1995) and this indicator and the other two that rely on this one (I will publish them later) are very underappreciated in my humble opinion. The biggest strength of this indicator is the fact that it is a leading indicator for dramatic price movements. As you can see in my example chart it consistently gives great exit points before a downturn. I have included strong buy and sell signals in addition to normal ones so strong signals are darker in color and normal signals are lighter in color. Buy when the line turns green and sell when it turns red.
Let me know if there are any other indicators or scripts you would like to see me publish!
Dual Mean Reversion Channel (adjusted lower band)This is a public and open-source lighter version compared to the "Overextended Price Channel" which is provided complimentaty to the Trend Insight System.
Introduction :
Channels are very useful tools to assess overextended price, volatility and upcoming retracement or impulsive moves (such as Bollinger Band squeezes). It is an indispensable addition to any trader using Mean Reversion theory for a scalp-trade or swing-trade.
This script contains :
- 2 channels Keltner-style, using the True Range for volatility
- customizable volatility (channel width) and smoothing period
- a standard selection of moving average ; SMA, EMA, VWMA
- an embedded readjustment of the lower bands to avoid the drop on a logarithmic scale (see explanation below)
Why another channel indicator ?
I have found most conventional channels to be either not based on "proper" volatility (e.g. standard deviation of price action for Bollinger Band), or the bottom channel to be ill adapted to the logarithmic scale and plunges to 0 on some high volatility periods, messing with readability on logarithmic auto-scaled chart.
Also, I find the channels to be most useful when superimposed with another one of longer length; especially a pair of channels with a 50 and 200 period moving average respectively. Mean Reversion traders that mostly trade the 50 and 200 SMA/EMA know what I am talking about as having a channel helps to have a better visual for a proper of entry and exit point.
Disclaimer :
This indicator was originally intended to be used along with the Trend Insight System to improve performance, and the default configuration mostly backtested on BTCUSD.
Please use with caution, proper risk management and along with your favorite oscillator, candlestick reading and signals system.
Some explanation :
Based on Mean Reversion paradigm, everything has a tendency to revert back to the mean :
- when the price enters the upper channel, it is supposed to be (or start getting) overbought as the market is getting overheated, thus prone to correction,
- on the other hand, when the price enters the lower channel, it is supposed to be (or getting) oversold and the market looks favorable for a buy-in.
Depending on the trading style used, a trader will usually either wait until the price leaves the channel towards the mean before taking action (conservative style) or you will set limit orders inside the channel as you expect a reversion to the mean (more agressive/risky style).
With two channels, more complex (and maybe precise) rules can be built to optimize one's trading strategy.
Important notes :
In the end, sticking with 50/200 length and a single setting on volatility might be wiser, be wary of overoptimization which is risky at best and counter productive at worst (according to legendary traders such as Mark Douglas). Even if, needless to say, the volatility needs to be adjusted between a nascent and volatile market (such as crypto) compared to standard call markets that are much less volatile.
End notes :
It will always be considered a work in progress to help bring out the best of trading with channels, any comment and suggestion are welcomed.
Fat Side PathI got the idea for a narrow Donchian Channel with a short lookback period which closely follows the price fluctuation in which the sides of the channel have a thickness according to the range of the last touching candle.
Any channel, be it Donchian, Keltner, Bollinger Bands or Parallel, has an upside and a downside, touching the upside is a buy signal as this may initiate an uptrend, the downside a sell signal because a down trend may come.
This gave me the idea to make only the last touched side fat, thus creating visible switching between uptrend and downtrend. However this is ‘too digital’, as in practice also periods of no trend occur in which signaling a trend would give a false signal. In a Donchian channel (and also Bollinger Bands) such periods are marked by narrowing the channel. So I gave a no trend signal to the sides when the channel is narrower than a minimum width to call a trend. I gave the thing nice colours and proper default settings.
Use of the channel in trading.
I think this thing can be useful for swing trading. In channels two typical things may happen that should be noted by the trader, these are LB, Leaving the Border, which signals a trend reversal and FTT, Failure To Traverse, i.e. the price doesn’t manage to cross the channel to the other side. This affirms the trend. FTT’s are not expected in short lookback channels like this path (Sidenote: Fibonacci levels can be regarded as predictions where FTT’s may occur). The fat side indicates direction. Because somehow trends seem to end with a notable range extension, this channel sometimes produces a “Big Blob” where the trend reverses.
I intend to use this thing together with my Keltner Fibzones channel, where the zones serve as a ‘landscape’ in which the Fat Side Path meanders providing ‘comments’ on the short term price movements.
Monte Carlo Range Forecast [DW]This is an experimental study designed to forecast the range of price movement from a specified starting point using a Monte Carlo simulation.
Monte Carlo experiments are a broad class of computational algorithms that utilize random sampling to derive real world numerical results.
These types of algorithms have a number of applications in numerous fields of study including physics, engineering, behavioral sciences, climate forecasting, computer graphics, gaming AI, mathematics, and finance.
Although the applications vary, there is a typical process behind the majority of Monte Carlo methods:
-> First, a distribution of possible inputs is defined.
-> Next, values are generated randomly from the distribution.
-> The values are then fed through some form of deterministic algorithm.
-> And lastly, the results are aggregated over some number of iterations.
In this study, the Monte Carlo process used generates a distribution of aggregate pseudorandom linear price returns summed over a user defined period, then plots standard deviations of the outcomes from the mean outcome generate forecast regions.
The pseudorandom process used in this script relies on a modified Wichmann-Hill pseudorandom number generator (PRNG) algorithm.
Wichmann-Hill is a hybrid generator that uses three linear congruential generators (LCGs) with different prime moduli.
Each LCG within the generator produces an independent, uniformly distributed number between 0 and 1.
The three generated values are then summed and modulo 1 is taken to deliver the final uniformly distributed output.
Because of its long cycle length, Wichmann-Hill is a fantastic generator to use on TV since it's extremely unlikely that you'll ever see a cycle repeat.
The resulting pseudorandom output from this generator has a minimum repetition cycle length of 6,953,607,871,644.
Fun fact: Wichmann-Hill is a widely used PRNG in various software applications. For example, Excel 2003 and later uses this algorithm in its RAND function, and it was the default generator in Python up to v2.2.
The generation algorithm in this script takes the Wichmann-Hill algorithm, and uses a multi-stage transformation process to generate the results.
First, a parent seed is selected. This can either be a fixed value, or a dynamic value.
The dynamic parent value is produced by taking advantage of Pine's timenow variable behavior. It produces a variable parent seed by using a frozen ratio of timenow/time.
Because timenow always reflects the current real time when frozen and the time variable reflects the chart's beginning time when frozen, the ratio of these values produces a new number every time the cache updates.
After a parent seed is selected, its value is then fed through a uniformly distributed seed array generator, which generates multiple arrays of pseudorandom "children" seeds.
The seeds produced in this step are then fed through the main generators to produce arrays of pseudorandom simulated outcomes, and a pseudorandom series to compare with the real series.
The main generators within this script are designed to (at least somewhat) model the stochastic nature of financial time series data.
The first step in this process is to transform the uniform outputs of the Wichmann-Hill into outputs that are normally distributed.
In this script, the transformation is done using an estimate of the normal distribution quantile function.
Quantile functions, otherwise known as percent-point or inverse cumulative distribution functions, specify the value of a random variable such that the probability of the variable being within the value's boundary equals the input probability.
The quantile equation for a normal probability distribution is μ + σ(√2)erf^-1(2(p - 0.5)) where μ is the mean of the distribution, σ is the standard deviation, erf^-1 is the inverse Gauss error function, and p is the probability.
Because erf^-1() does not have a simple, closed form interpretation, it must be approximated.
To keep things lightweight in this approximation, I used a truncated Maclaurin Series expansion for this function with precomputed coefficients and rolled out operations to avoid nested looping.
This method provides a decent approximation of the error function without completely breaking floating point limits or sucking up runtime memory.
Note that there are plenty of more robust techniques to approximate this function, but their memory needs very. I chose this method specifically because of runtime favorability.
To generate a pseudorandom approximately normally distributed variable, the uniformly distributed variable from the Wichmann-Hill algorithm is used as the input probability for the quantile estimator.
Now from here, we get a pretty decent output that could be used itself in the simulation process. Many Monte Carlo simulations and random price generators utilize a normal variable.
However, if you compare the outputs of this normal variable with the actual returns of the real time series, you'll find that the variability in shocks (random changes) doesn't quite behave like it does in real data.
This is because most real financial time series data is more complex. Its distribution may be approximately normal at times, but the variability of its distribution changes over time due to various underlying factors.
In light of this, I believe that returns behave more like a convoluted product distribution rather than just a raw normal.
So the next step to get our procedurally generated returns to more closely emulate the behavior of real returns is to introduce more complexity into our model.
Through experimentation, I've found that a return series more closely emulating real returns can be generated in a three step process:
-> First, generate multiple independent, normally distributed variables simultaneously.
-> Next, apply pseudorandom weighting to each variable ranging from -1 to 1, or some limits within those bounds. This modulates each series to provide more variability in the shocks by producing product distributions.
-> Lastly, add the results together to generate the final pseudorandom output with a convoluted distribution. This adds variable amounts of constructive and destructive interference to produce a more "natural" looking output.
In this script, I use three independent normally distributed variables multiplied by uniform product distributed variables.
The first variable is generated by multiplying a normal variable by one uniformly distributed variable. This produces a bit more tailedness (kurtosis) than a normal distribution, but nothing too extreme.
The second variable is generated by multiplying a normal variable by two uniformly distributed variables. This produces moderately greater tails in the distribution.
The third variable is generated by multiplying a normal variable by three uniformly distributed variables. This produces a distribution with heavier tails.
For additional control of the output distributions, the uniform product distributions are given optional limits.
These limits control the boundaries for the absolute value of the uniform product variables, which affects the tails. In other words, they limit the weighting applied to the normally distributed variables in this transformation.
All three sets are then multiplied by user defined amplitude factors to adjust presence, then added together to produce our final pseudorandom return series with a convoluted product distribution.
Once we have the final, more "natural" looking pseudorandom series, the values are recursively summed over the forecast period to generate a simulated result.
This process of generation, weighting, addition, and summation is repeated over the user defined number of simulations with different seeds generated from the parent to produce our array of initial simulated outcomes.
After the initial simulation array is generated, the max, min, mean and standard deviation of this array are calculated, and the values are stored in holding arrays on each iteration to be called upon later.
Reference difference series and price values are also stored in holding arrays to be used in our comparison plots.
In this script, I use a linear model with simple returns rather than compounding log returns to generate the output.
The reason for this is that in generating outputs this way, we're able to run our simulations recursively from the beginning of the chart, then apply scaling and anchoring post-process.
This allows a greater conservation of runtime memory than the alternative, making it more suitable for doing longer forecasts with heavier amounts of simulations in TV's runtime environment.
From our starting time, the previous bar's price, volatility, and optional drift (expected return) are factored into our holding arrays to generate the final forecast parameters.
After these parameters are computed, the range forecast is produced.
The basis value for the ranges is the mean outcome of the simulations that were run.
Then, quarter standard deviations of the simulated outcomes are added to and subtracted from the basis up to 3σ to generate the forecast ranges.
All of these values are plotted and colorized based on their theoretical probability density. The most likely areas are the warmest colors, and least likely areas are the coolest colors.
An information panel is also displayed at the starting time which shows the starting time and price, forecast type, parent seed value, simulations run, forecast bars, total drift, mean, standard deviation, max outcome, min outcome, and bars remaining.
The interesting thing about simulated outcomes is that although the probability distribution of each simulation is not normal, the distribution of different outcomes converges to a normal one with enough steps.
In light of this, the probability density of outcomes is highest near the initial value + total drift, and decreases the further away from this point you go.
This makes logical sense since the central path is the easiest one to travel.
Given the ever changing state of markets, I find this tool to be best suited for shorter term forecasts.
However, if the movements of price are expected to remain relatively stable, longer term forecasts may be equally as valid.
There are many possible ways for users to apply this tool to their analysis setups. For example, the forecast ranges may be used as a guide to help users set risk targets.
Or, the generated levels could be used in conjunction with other indicators for meaningful confluence signals.
More advanced users could even extrapolate the functions used within this script for various purposes, such as generating pseudorandom data to test systems on, perform integration and approximations, etc.
These are just a few examples of potential uses of this script. How you choose to use it to benefit your trading, analysis, and coding is entirely up to you.
If nothing else, I think this is a pretty neat script simply for the novelty of it.
----------
How To Use:
When you first add the script to your chart, you will be prompted to confirm the starting date and time, number of bars to forecast, number of simulations to run, and whether to include drift assumption.
You will also be prompted to confirm the forecast type. There are two types to choose from:
-> End Result - This uses the values from the end of the simulation throughout the forecast interval.
-> Developing - This uses the values that develop from bar to bar, providing a real-time outlook.
You can always update these settings after confirmation as well.
Once these inputs are confirmed, the script will boot up and automatically generate the forecast in a separate pane.
Note that if there is no bar of data at the time you wish to start the forecast, the script will automatically detect use the next available bar after the specified start time.
From here, you can now control the rest of the settings.
The "Seeding Settings" section controls the initial seed value used to generate the children that produce the simulations.
In this section, you can control whether the seed is a fixed value, or a dynamic one.
Since selecting the dynamic parent option will change the seed value every time you change the settings or refresh your chart, there is a "Regenerate" input built into the script.
This input is a dummy input that isn't connected to any of the calculations. The purpose of this input is to force an update of the dynamic parent without affecting the generator or forecast settings.
Note that because we're running a limited number of simulations, different parent seeds will typically yield slightly different forecast ranges.
When using a small number of simulations, you will likely see a higher amount of variance between differently seeded results because smaller numbers of sampled simulations yield a heavier bias.
The more simulations you run, the smaller this variance will become since the outcomes become more convergent toward the same distribution, so the differences between differently seeded forecasts will become more marginal.
When using a dynamic parent, pay attention to the dispersion of ranges.
When you find a set of ranges that is dispersed how you like with your configuration, set your fixed parent value to the parent seed that shows in the info panel.
This will allow you to replicate that dispersion behavior again in the future.
An important thing to note when settings alerts on the plotted levels, or using them as components for signals in other scripts, is to decide on a fixed value for your parent seed to avoid minor repainting due to seed changes.
When the parent seed is fixed, no repainting occurs.
The "Amplitude Settings" section controls the amplitude coefficients for the three differently tailed generators.
These amplitude factors will change the difference series output for each simulation by controlling how aggressively each series moves.
When "Adjust Amplitude Coefficients" is disabled, all three coefficients are set to 1.
Note that if you expect volatility to significantly diverge from its historical values over the forecast interval, try experimenting with these factors to match your anticipation.
The "Weighting Settings" section controls the weighting boundaries for the three generators.
These weighting limits affect how tailed the distributions in each generator are, which in turn affects the final series outputs.
The maximum absolute value range for the weights is . When "Limit Generator Weights" is disabled, this is the range that is automatically used.
The last set of inputs is the "Display Settings", where you can control the visual outputs.
From here, you can select to display either "Forecast" or "Difference Comparison" via the "Output Display Type" dropdown tab.
"Forecast" is the type displayed by default. This plots the end result or developing forecast ranges.
There is an option with this display type to show the developing extremes of the simulations. This option is enabled by default.
There's also an option with this display type to show one of the simulated price series from the set alongside actual prices.
This allows you to visually compare simulated prices alongside the real prices.
"Difference Comparison" allows you to visually compare a synthetic difference series from the set alongside the actual difference series.
This display method is primarily useful for visually tuning the amplitude and weighting settings of the generators.
There are also info panel settings on the bottom, which allow you to control size, colors, and date format for the panel.
It's all pretty simple to use once you get the hang of it. So play around with the settings and see what kinds of forecasts you can generate!
----------
ADDITIONAL NOTES & DISCLAIMERS
Although I've done a number of things within this script to keep runtime demands as low as possible, the fact remains that this script is fairly computationally heavy.
Because of this, you may get random timeouts when using this script.
This could be due to either random drops in available runtime on the server, using too many simulations, or running the simulations over too many bars.
If it's just a random drop in runtime on the server, hide and unhide the script, re-add it to the chart, or simply refresh the page.
If the timeout persists after trying this, then you'll need to adjust your settings to a less demanding configuration.
Please note that no specific claims are being made in regards to this script's predictive accuracy.
It must be understood that this model is based on randomized price generation with assumed constant drift and dispersion from historical data before the starting point.
Models like these not consider the real world factors that may influence price movement (economic changes, seasonality, macro-trends, instrument hype, etc.), nor the changes in sample distribution that may occur.
In light of this, it's perfectly possible for price data to exceed even the most extreme simulated outcomes.
The future is uncertain, and becomes increasingly uncertain with each passing point in time.
Predictive models of any type can vary significantly in performance at any point in time, and nobody can guarantee any specific type of future performance.
When using forecasts in making decisions, DO NOT treat them as any form of guarantee that values will fall within the predicted range.
When basing your trading decisions on any trading methodology or utility, predictive or not, you do so at your own risk.
No guarantee is being issued regarding the accuracy of this forecast model.
Forecasting is very far from an exact science, and the results from any forecast are designed to be interpreted as potential outcomes rather than anything concrete.
With that being said, when applied prudently and treated as "general case scenarios", forecast models like these may very well be potentially beneficial tools to have in the arsenal.

Polynomial Regression Bands + Channel [DW]This is an experimental study designed to calculate polynomial regression for any order polynomial that TV is able to support.
This study aims to educate users on polynomial curve fitting, and the derivation process of Least Squares Moving Averages (LSMAs).
I also designed this study with the intent of showcasing some of the capabilities and potential applications of TV's fantastic new array functions.
Polynomial regression is a form of regression analysis in which the relationship between the independent variable x and the dependent variable y is modeled as a polynomial of nth degree (order).
For clarification, linear regression can also be described as a first order polynomial regression. The process of deriving linear, quadratic, cubic, and higher order polynomial relationships is all the same.
In addition, although deriving a polynomial regression equation results in a nonlinear output, the process of solving for polynomials by least squares is actually a special case of multiple linear regression.
So, just like in multiple linear regression, polynomial regression can be solved in essentially the same way through a system of linear equations.
In this study, you are first given the option to smooth the input data using the 2 pole Super Smoother Filter from John Ehlers.
I chose this specific filter because I find it provides superior smoothing with low lag and fairly clean cutoff. You can, of course, implement your own filter functions to see how they compare if you feel like experimenting.
Filtering noise prior to regression calculation can be useful for providing a more stable estimation since least squares regression can be rather sensitive to noise.
This is especially true on lower sampling lengths and higher degree polynomials since the regression output becomes more "overfit" to the sample data.
Next, data arrays are populated for the x-axis and y-axis values. These are the main datasets utilized in the rest of the calculations.
To keep the calculations more numerically stable for higher periods and orders, the x array is filled with integers 1 through the sampling period rather than using current bar numbers.
This process can be thought of as shifting the origin of the x-axis as new data emerges.
This keeps the axis values significantly lower than the 10k+ bar values, thus maintaining more numerical stability at higher orders and sample lengths.
The data arrays are then used to create a pseudo 2D matrix of x power sums, and a vector of x power*y sums.
These matrices are a representation the system of equations that need to be solved in order to find the regression coefficients.
Below, you'll see some examples of the pattern of equations used to solve for our coefficients represented in augmented matrix form.
For example, the augmented matrix for the system equations required to solve a second order (quadratic) polynomial regression by least squares is formed like this:
(∑x^0 ∑x^1 ∑x^2 | ∑(x^0)y)
(∑x^1 ∑x^2 ∑x^3 | ∑(x^1)y)
(∑x^2 ∑x^3 ∑x^4 | ∑(x^2)y)
The augmented matrix for the third order (cubic) system is formed like this:
(∑x^0 ∑x^1 ∑x^2 ∑x^3 | ∑(x^0)y)
(∑x^1 ∑x^2 ∑x^3 ∑x^4 | ∑(x^1)y)
(∑x^2 ∑x^3 ∑x^4 ∑x^5 | ∑(x^2)y)
(∑x^3 ∑x^4 ∑x^5 ∑x^6 | ∑(x^3)y)
This pattern continues for any n ordered polynomial regression, in which the coefficient matrix is a n + 1 wide square matrix with the last term being ∑x^2n, and the last term of the result vector being ∑(x^n)y.
Thanks to this pattern, it's rather convenient to solve the for our regression coefficients of any nth degree polynomial by a number of different methods.
In this script, I utilize a process known as LU Decomposition to solve for the regression coefficients.
Lower-upper (LU) Decomposition is a neat form of matrix manipulation that expresses a 2D matrix as the product of lower and upper triangular matrices.
This decomposition method is incredibly handy for solving systems of equations, calculating determinants, and inverting matrices.
For a linear system Ax=b, where A is our coefficient matrix, x is our vector of unknowns, and b is our vector of results, LU Decomposition turns our system into LUx=b.
We can then factor this into two separate matrix equations and solve the system using these two simple steps:
1. Solve Ly=b for y, where y is a new vector of unknowns that satisfies the equation, using forward substitution.
2. Solve Ux=y for x using backward substitution. This gives us the values of our original unknowns - in this case, the coefficients for our regression equation.
After solving for the regression coefficients, the values are then plugged into our regression equation:
Y = a0 + a1*x + a1*x^2 + ... + an*x^n, where a() is the ()th coefficient in ascending order and n is the polynomial degree.
From here, an array of curve values for the period based on the current equation is populated, and standard deviation is added to and subtracted from the equation to calculate the channel high and low levels.
The calculated curve values can also be shifted to the left or right using the "Regression Offset" input
Changing the offset parameter will move the curve left for negative values, and right for positive values.
This offset parameter shifts the curve points within our window while using the same equation, allowing you to use offset datapoints on the regression curve to calculate the LSMA and bands.
The curve and channel's appearance is optionally approximated using Pine's v4 line tools to draw segments.
Since there is a limitation on how many lines can be displayed per script, each curve consists of 10 segments with lengths determined by a user defined step size. In total, there are 30 lines displayed at once when active.
By default, the step size is 10, meaning each segment is 10 bars long. This is because the default sampling period is 100, so this step size will show the approximate curve for the entire period.
When adjusting your sampling period, be sure to adjust your step size accordingly when curve drawing is active if you want to see the full approximate curve for the period.
Note that when you have a larger step size, you will see more seemingly "sharp" turning points on the polynomial curve, especially on higher degree polynomials.
The polynomial functions that are calculated are continuous and differentiable across all points. The perceived sharpness is simply due to our limitation on available lines to draw them.
The approximate channel drawings also come equipped with style inputs, so you can control the type, color, and width of the regression, channel high, and channel low curves.
I also included an input to determine if the curves are updated continuously, or only upon the closing of a bar for reduced runtime demands. More about why this is important in the notes below.
For additional reference, I also included the option to display the current regression equation.
This allows you to easily track the polynomial function you're using, and to confirm that the polynomial is properly supported within Pine.
There are some cases that aren't supported properly due to Pine's limitations. More about this in the notes on the bottom.
In addition, I included a line of text beneath the equation to indicate how many bars left or right the calculated curve data is currently shifted.
The display label comes equipped with style editing inputs, so you can control the size, background color, and text color of the equation display.
The Polynomial LSMA, high band, and low band in this script are generated by tracking the current endpoints of the regression, channel high, and channel low curves respectively.
The output of these bands is similar in nature to Bollinger Bands, but with an obviously different derivation process.
By displaying the LSMA and bands in tandem with the polynomial channel, it's easy to visualize how LSMAs are derived, and how the process that goes into them is drastically different from a typical moving average.
The main difference between LSMA and other MAs is that LSMA is showing the value of the regression curve on the current bar, which is the result of a modelled relationship between x and the expected value of y.
With other MA / filter types, they are typically just averaging or frequency filtering the samples. This is an important distinction in interpretation. However, both can be applied similarly when trading.
An important distinction with the LSMA in this script is that since we can model higher degree polynomial relationships, the LSMA here is not limited to only linear as it is in TV's built in LSMA.
Bar colors are also included in this script. The color scheme is based on disparity between source and the LSMA.
This script is a great study for educating yourself on the process that goes into polynomial regression, as well as one of the many processes computers utilize to solve systems of equations.
Also, the Polynomial LSMA and bands are great components to try implementing into your own analysis setup.
I hope you all enjoy it!
--------------------------------------------------------
NOTES:
- Even though the algorithm used in this script can be implemented to find any order polynomial relationship, TV has a limit on the significant figures for its floating point outputs.
This means that as you increase your sampling period and / or polynomial order, some higher order coefficients will be output as 0 due to floating point round-off.
There is currently no viable workaround for this issue since there isn't a way to calculate more significant figures than the limit.
However, in my humble opinion, fitting a polynomial higher than cubic to most time series data is "overkill" due to bias-variance tradeoff.
Although, this tradeoff is also dependent on the sampling period. Keep that in mind. A good rule of thumb is to aim for a nice "middle ground" between bias and variance.
If TV ever chooses to expand its significant figure limits, then it will be possible to accurately calculate even higher order polynomials and periods if you feel the desire to do so.
To test if your polynomial is properly supported within Pine's constraints, check the equation label.
If you see a coefficient value of 0 in front of any of the x values, reduce your period and / or polynomial order.
- Although this algorithm has less computational complexity than most other linear system solving methods, this script itself can still be rather demanding on runtime resources - especially when drawing the curves.
In the event you find your current configuration is throwing back an error saying that the calculation takes too long, there are a few things you can try:
-> Refresh your chart or hide and unhide the indicator.
The runtime environment on TV is very dynamic and the allocation of available memory varies with collective server usage.
By refreshing, you can often get it to process since you're basically just waiting for your allotment to increase. This method works well in a lot of cases.
-> Change the curve update frequency to "Close Only".
If you've tried refreshing multiple times and still have the error, your configuration may simply be too demanding of resources.
v4 drawing objects, most notably lines, can be highly taxing on the servers. That's why Pine has a limit on how many can be displayed in the first place.
By limiting the curve updates to only bar closes, this will significantly reduce the runtime needs of the lines since they will only be calculated once per bar.
Note that doing this will only limit the visual output of the curve segments. It has no impact on regression calculation, equation display, or LSMA and band displays.
-> Uncheck the display boxes for the drawing objects.
If you still have troubles after trying the above options, then simply stop displaying the curve - unless it's important to you.
As I mentioned, v4 drawing objects can be rather resource intensive. So a simple fix that often works when other things fail is to just stop them from being displayed.
-> Reduce sampling period, polynomial order, or curve drawing step size.
If you're having runtime errors and don't want to sacrifice the curve drawings, then you'll need to reduce the calculation complexity.
If you're using a large sampling period, or high order polynomial, the operational complexity becomes significantly higher than lower periods and orders.
When you have larger step sizes, more historical referencing is used for x-axis locations, which does have an impact as well.
By reducing these parameters, the runtime issue will often be solved.
Another important detail to note with this is that you may have configurations that work just fine in real time, but struggle to load properly in replay mode.
This is because the replay framework also requires its own allotment of runtime, so that must be taken into consideration as well.
- Please note that the line and label objects are reprinted as new data emerges. That's simply the nature of drawing objects vs standard plots.
I do not recommend or endorse basing your trading decisions based on the drawn curve. That component is merely to serve as a visual reference of the current polynomial relationship.
No repainting occurs with the Polynomial LSMA and bands though. Once the bar is closed, that bar's calculated values are set.
So when using the LSMA and bands for trading purposes, you can rest easy knowing that history won't change on you when you come back to view them.
- For those who intend on utilizing or modifying the functions and calculations in this script for their own scripts, I included debug dialogues in the script for all of the arrays to make the process easier.
To use the debugs, see the "Debugs" section at the bottom. All dialogues are commented out by default.
The debugs are displayed using label objects. By default, I have them all located to the right of current price.
If you wish to display multiple debugs at once, it will be up to you to decide on display locations at your leisure.
When using the debugs, I recommend commenting out the other drawing objects (or even all plots) in the script to prevent runtime issues and overlapping displays.
Donchian Channel Strategy [for free bot]
I present to you a script for testing the Donchian channel breakout strategy for the Binance_exchange.
This strategy is trending, and is especially effective for trading cryptocurrency futures.
This strategy is very flexible, and you can configure virtually all possible parameters, moreover, separately for longs and separately for shorts.
In the script, you can configure the parameters of the channel for entry and exit, the exit method, enable or disable purchases / sales, specify take profit and stop loss, and more.
On the example of optimization, only 20% of the deposit is used. This is done for diversification, since there are 37 contracts on binance_futures (at the time of writing the script description). That is, by optimizing the parameters for different currencies, you can very well reduce risks.
Представляю Вам скрипт для тестирования стратегии пробоя канала Дончиана для биржи Бинанс.
Данная стратегия относится к трендовым, и особенно эффективная на торговли криптовалютных фьючерсов.
Данная стратегия очень гибкая, и можно настроить фактически все возможные параметры, при чем, отдельно для покупок и отдельно для продаж.
В скрипте можно настроить параметры канала на вход и на выход, метод выхода, разрешить или запретить покупки/проаджи, указать тейк-профит и стоп-лосс и другое.
На примере оптимизации используется всего 20% от депозита. Это сделано для диверсификации, так как на фьючерсах бинансе присутсвует 37 контрактов (на момент написания описания скрипта). Т.е., оптимизировав параметры под разные валюты, можно очень хорошо снизить риски.

Donchian Channel CloudsFor this indicator, I got inspired by this paragraph in an article on Investopedia:
"Donchian channels also make natural partners with another moving average indicator for a crossover strategy. The Donchian moving average middle line is likely to form the short-term average in these situations, although some have used a 20-day Donchian channel in conjunction with a five- or 10-day channel to exit a position before a consolidation eats into short-term profits."
The default is a 20-period Donchian channel with the middle line from a 10-period channel superimposed on it. Red for 20, green for 10. When 10 is over 20, the cloud between them is green; the cloud is red when 20 is over 10.

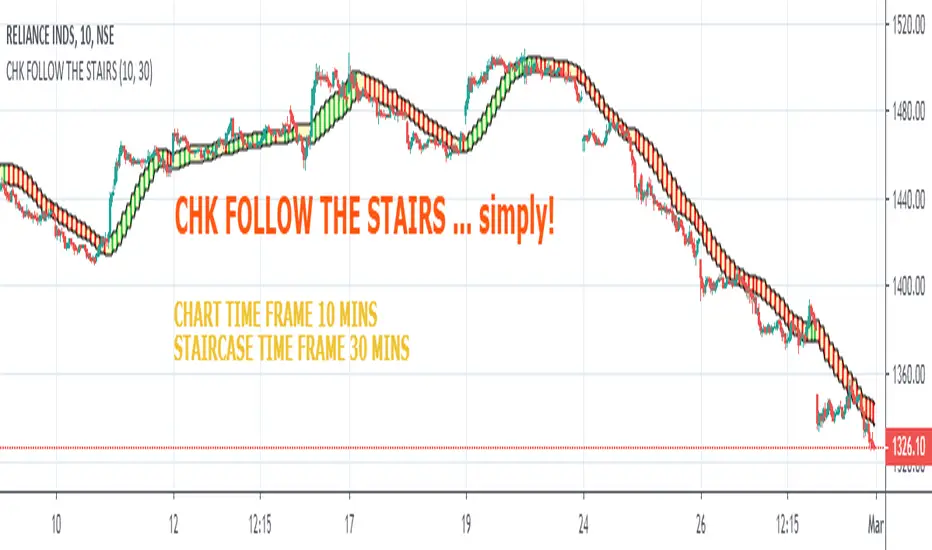
CHK FOLLOW THE STAIRSCHK FOLLOW THE STAIRS....
The stairs are nothing but HIGH LOW CHANNEL at HTF or LTF
I observed 10 Period Moving Average an optimum length for the Staircase
you can change it to 8 or 13, one will generate noise, other will generate lag
Tinker with the Staircase Time Frame to get an optimum fit
The script also shows Strength of the Trend.
If there is a gap between the price and the stairs, that is relection of the strength
The script can also be used for scalping.
[LunaOwl] 樂活投資:價格通道 (LOHAS Investor - PriceChannel)- Introduction -
Price channel is an ancient strategy, which is very convenient for office workers. since most people no time do it.
so they are suitable for simple strategies. There are several conditions to become a "LOHAS Investor" -
價格通道是很老的投資策略,對於肯做功課的上班族來說非常方便,而且多數人沒時間操作。
如果要當「樂活投資人」有幾點條件:
1) set moderate ROI expectations.
- 設定溫和的投資報酬率期望。
2) use appropriate stock selection methods to build portfolios and reduce single error rates.
- 使用適當的選股方式建立投資組合,減少單一股票失誤率。
3) simple trade strategy, executed regularly.
- 使用簡單的策略規律執行。
4) wealth accumulates over time and learns every day.
- 財富依靠時間積累,每天勤學新知。
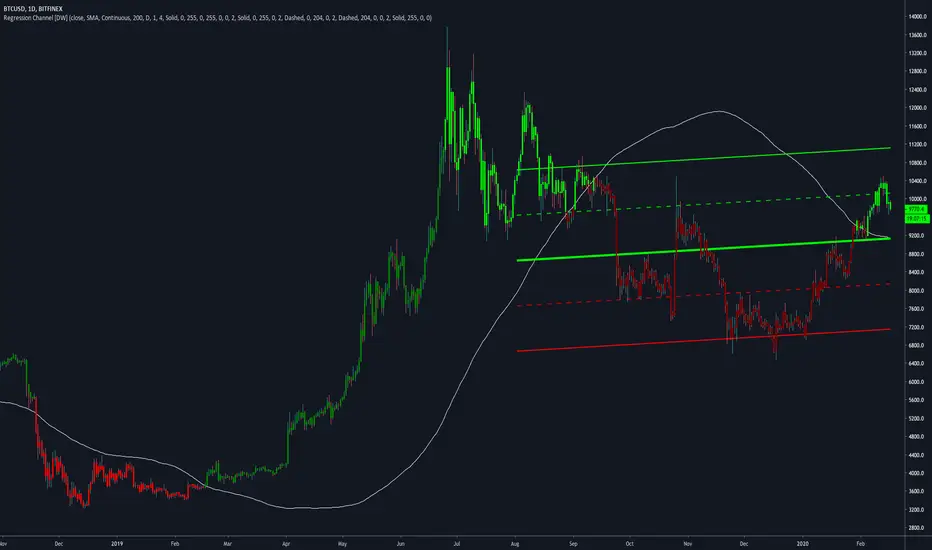
Regression Channel [DW]This is an experimental study which calculates a linear regression channel over a specified period or interval using custom moving average types for its calculations.
Linear regression is a linear approach to modeling the relationship between a dependent variable and one or more independent variables.
In linear regression, the relationships are modeled using linear predictor functions whose unknown model parameters are estimated from the data.
The regression channel in this study is modeled using the least squares approach with four base average types to choose from:
-> Arnaud Legoux Moving Average (ALMA)
-> Exponential Moving Average (EMA)
-> Simple Moving Average (SMA)
-> Volume Weighted Moving Average (VWMA)
When using VWMA, if no volume is present, the calculation will automatically switch to tick volume, making it compatible with any cryptocurrency, stock, currency pair, or index you want to analyze.
There are two window types for calculation in this script as well:
-> Continuous, which generates a regression model over a fixed number of bars continuously.
-> Interval, which generates a regression model that only moves its starting point when a new interval starts. The number of bars for calculation cumulatively increases until the end of the interval.
The channel is generated by calculating standard deviation multiplied by the channel width coefficient, adding it to and subtracting it from the regression line, then dividing it into quartiles.
To observe the path of the regression, I've included a tracer line, which follows the current point of the regression line. This is also referred to as a Least Squares Moving Average (LSMA).
For added predictive capability, there is an option to extend the channel lines into the future.
A custom bar color scheme based on channel direction and price proximity to the current regression value is included.
I don't necessarily recommend using this tool as a standalone, but rather as a supplement to your analysis systems.
Regression analysis is far from an exact science. However, with the right combination of tools and strategies in place, it can greatly enhance your analysis and trading.
Dynamic Price ChannelsThis indicator plots dynamic price channels based on the security highest close and lowest open.
The default is to display 8 core channels (with the option to plot the sub channel lines, off by default).
It’s simple really—this just divides the price action into equal channels. I’ve found this pattern helpful across all markets.
It’s dynamic because if a new high close or a new low close is created the all channels will adjust.
The key levels are 75% (blue), 50% (aqua), 25% (blue).
In between those key levels is a level separator.
The high close and the low open are both red.
These can all be customized in the settings.
What you’ll typically see at these channel boundaries are price slow downs, reversals, support and resistance.
Turning on sub-channels will provide further channel plots. On these sub-channels you’ll also see the same type of price action activity as mentioned above.
I’ve developed a trading system where this indicator helps identify key pivot areas. Combined with a few other indicators and key EMAs this trade system provides high probability trades around these key channel areas.

Iron Trader of BiznesFilosofThis indicator is intended for those who have nerves of steel and trades for a long time. You can change the settings for other tasks, but the goal was different.
If the "Turn Line" is above the baseline, then the market mood is long. This is also indicated by an arrow and signed. If the "Turn Line" is below the baseline, then the market mood is short. This is also signed and indicated by the arrow.
If the private trend changes, then the "Turn Line" color to another (red to green and green to red). This is a signal to close a position.
In more detail about the indicator on my channel in YouTube.
===
Этот индикатор предназначен для тех, кто имеет стальные нервы и торгует долго. Можно изменить параметры и для других задач, но цель была другая.
Если "Линия Переворота" выше базовой, то настроение рынка - лонг. Также это показано стрелкой и подписано. Если "Линия Переворота" ниже базовой, то настроение рынка - шорт. Это тоже подписано и показано стрелкой.
Если меняется частный тренд, то цвет "Линия Переворота" на другой (красный на зеленый, а зелёный на красный). Это сигнал для закрытия позиции.
Более подробно про индикатор на моём канале в Ютуб.

LR ChannelScript draws actual positions of linear regression channel boundaries and doesn't repaint.
Green lines color - for a positive slope of standard linear regression channel, red - for a negative slope.

Index Adaptive Keltner Channels [DW]This study is an experiment in adaptive filtering. The process in this study was inspired by KAMA and ZLEMA filtering techniques.
First, data is given an optional modification for lag reduction.
Then, an adaptive filter of your choice is calculated. There are 6 different adaptive filters to choose from in this study:
-Commodity Channel Index Adaptive Moving Average (CCIAMA)
-Relative Strength Index Adaptive Moving Average (RSIAMA)
-%R Adaptive Moving Average (%RAMA)
-Klinger Volume Oscillator Adaptive Moving Average (KVOAMA)
-Money Flow Index Adaptive Moving Average (MFIAMA)
-Correlation Coefficient Adaptive Moving Average (CCAMA)
Next, ATR is calculated using the specified adaptive filter.
A set of ranges is calculated by multiplying ATR by the square root of the sampling period, then dividing it by 2 and 4.
And Finally, the ranges are added to and subtracted from the adaptive filter to generate the channels.
Custom bar colors are included. The formula for the color scheme is based on filter direction and price.

Fractal Regression Bands [DW]This study is an experimental regression curve built around fractal and ATR calculations.
First, Williams Fractals are calculated, and used as anchoring points.
Next, high anchor points are connected to negative sloping lines, and low anchor points to positive sloping lines. The slope is a specified percentage of the current ATR over the sampling period.
The median between the positive and negative sloping lines is then calculated, then the best fit line (linear regression) of the median is calculated to generate the basis line.
Lastly, a Golden Mean ATR is taken of price over the sampling period and multiplied by 1/2, 1, 2, and 3. The results are added and subtracted from the basis line to generate the bands.
Williams Fractals are included in the plots. The color scheme indicated whether each fractal is engulfing or non-engulfing.
Custom bar color scheme is included.
Moving Average Range Channels [DW]This study is an experiment based off the concept used in my Dynamic Range Channel indicator.
Rather than using a McGinley Dynamic, a moving average of your choice is used in this calculation.
There are eight different moving average types to choose from in this script:
- Kaufman's Adaptive Moving Average
- Geometric Moving Average
- Hull Moving Average
- Volume Weighted Moving Average
- Least Squares Moving Average
- Arnaud Legoux Moving Average
- Exponential Moving Average
- Simple Moving Average
For a more refined picture of volatility, I've added upper and lower extension channels. They are calculated by adding the upper half range to the channel high, and subtracting the lower half range from the channel low.
The new custom bar color scheme indicates trends, midline crosses, MA crosses, and overbought and oversold conditions.

Dynamic Range Channel [DW]This is an experimental study that utilizes Kaufman's Adaptive Moving Average and the McGinley Dynamic.
First, a fast and slow KAMA based McGinley Dynamic are calculated. The divergence between them is used to indicate wave direction.
The channel's bounds are calculated by taking the highest high and lowest low of the slow McGinley Dynamic over a specified channel period.
The dynamic midline is calculated by taking the mean of the highest and lowest values over the specified channel period.
Custom bar colors are included.
Also includes Williams Fractals for additional confirmation signals.

Periodic Volatility Channels [DW]This is an experimental study in which a geometric moving average is taken of price, then the range is multiplied by average annualized volatility based on the current trading timeframe and specified lookback, and by Fibonacci numbers 1 through 21.
