CSVParser█ OVERVIEW
The library contains functions for parsing and importing complex CSV configurations (with a special simple syntax) into a special hierarchical object (of type objProps ) as follows:
Functions:
parseConfig() - reads CSV text into an objProps object.
toT() - displays the contents of an objProps object in a table form, which allows to check the CSV text for syntax errors.
getPropAr() - returns objProps.arS array for child object with `prop` key in mpObj map (or na if not found)
This library is handy in allowing users to store presets for the scripts and switch between them (see, e.g., my HTF moving averages script where users can switch between several preset configuations of 24 MA's across 5 timeframes).
█ HOW THE SCRIPT WORKS.
The script works as follows:
all values read from config text are stored as strings
Nested brackets in config text create a named nested objects of objProps0, ... , objProps9 types.
objProps objects of each level have the following fields:
- array arS for storing values without names (e.g. "12, 23" will be imported into a string array arS as )
- map mpS for storing items with names (e.g. "tf = 60, length = 21" will be imported as <"tf", "60"> and <"length", "21"> pairs into mpS )
- map mpObj for storing nested objects (e.g. "TF1(tf=60, length(21,50,100))" creates a <"TF1, objProps0 object> pair in mpObj map property of the top level object (objProps) , "tf=60" is stored as <"tf", "60"> key-value pair in mpS map property of a next level object (objProps0) and "length (...)" creates a <"length", objProps1> pair in objProps0.mpObj map while length values are stored in objProps1.arS array as strings. Every opening bracket creates a next level objProps object.
If objects or properties with duplicate names are encountered only the latest is imported
(e.g. for "TF1(length(12,22)), TF1(tf=240)" only "TF1(tf=240)" will be imported
Line breaks are not regarded as part of syntax (i.e. values are imported with line breaks, you can supply
symbols "(" , ")" , "," and "=" are special characters and cannot be used within property values (with the exception of a quoted text as a value of a property as explained below)
named properties can have quoted text as their value. In that case special characters within quotation marks are regarded as normal characters. Text between "=" and opening quotation mark as well as text following the closing quotation mark and until next property value is ignored. E.g. "quote = ignored "The quote" also ignored" will be imported as <"quote", "The quote">. Quotation marks within quotes must be excaped with "\" .
if a key names happens to be a multi-line then only first line containing non-space characters (trimmed from spaces) is taken as a key.
")," or ") ," and similar do not create an empty ("") array item while ",," does. (",)" creates an "" array item)
█ CSV CONFIGURATION SYNTAX
Unnamed values: just list them comma separated and they will be imported into arS of the object of the current level.
Named values: use "=" sign as follows: "property1=value1, property2 = value2"
Value of several objects: Use brackets after the name of the object ant list all object properties within the brackets (including its child objects if necessary). E.g. "TF1(tf =60, length(21,200), TF2(tf=240, length(50,200)"
Named and unnamed values as well as objects can go in any order. E.g. "12, tf=60, 21" will be imported as follows: "12", "21" will go to arS array and <"tf", "60"> will go to mpS maP of objProps (the top level object).
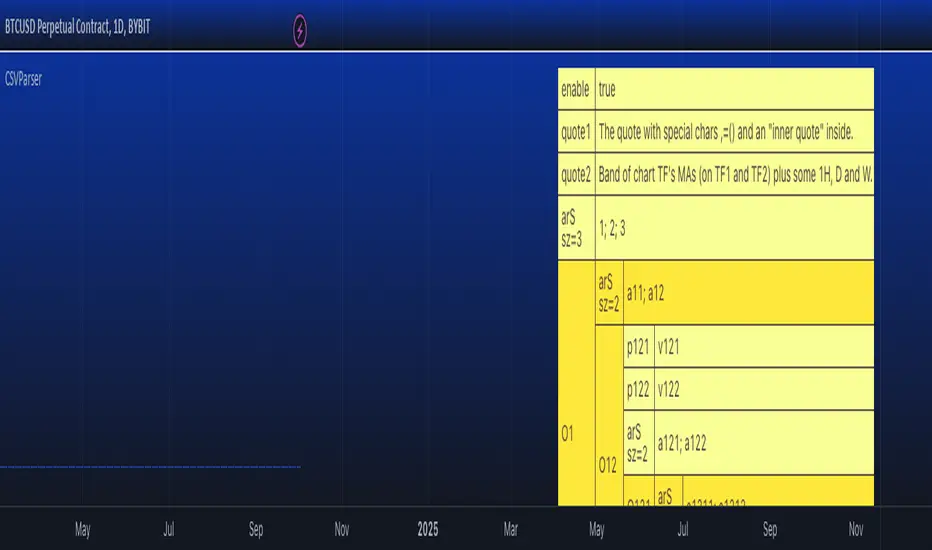
You can play around and test your config text using demo in this library, just edit your text in script settings and see how it is parsed into objProps objects.
█ USAGE RECOMMENDATIONS AND SAMPLE USE
I suggest the following approach:
- create functions for your UDT which can set properties by name.
- create enumerator functions which iterates through all the property names (supplied as a const string array) and imports their values into the object
█ SAMPLE USE
A sample use of this library can be seen in my Multi-timeframe 24 moving averages + BB+SAR+Supertrend+VWAP script where settings for the MAs across many timeframes are imported from CSV configurations (presets).
█ FULL LIST OF FUNCTIONS AND PROPERTIES
nzs(_s, nz)
Like nz() but for strings. Returns `nz` arg (default = "") if _s is na.
Parameters:
_s (string)
nz (string)
method init(this)
Initializes objProps obj (creates child maps and arrays)
Namespace types: objProps
Parameters:
this (objProps)
method toT(this, nz)
Outputs objProps to string matrices for further display using autotable().
Namespace types: objProps, objProps1, ..., objProps9
Parameters:
this (objProps/objProps1/..../objProps9)
nz (string)
Returns: A tuple - value, merge and color matrix (autotable() parameters)
method parseConfig(this, s)
Reads config text into objProps (unnamed values into arS, named into mpS, sub-levels into mpObj)
Namespace types: objProps
Parameters:
this (objProps)
s (string)
method getPropArS(this, prop)
Returns a string array of values for a given property name `prop`. Looks for a key `prop` in objProps.mpObj
if finds pair returns obj.arS, otherwise returns na. Returns a reference to the original, not a copy.
Namespace types: objProps, objProps1, ..., objProps8
Parameters:
this (objProps/objProps1/..../objProps8)
prop (string)
method getPropVal(this, prop, id)
Checks if there is an array of values for property `prop` and returns its `id`'s element or na if not found
Namespace types: objProps, objProps1, ..., objProps8
Parameters:
this (objProps/objProps1/..../objProps8) : objProps object containing array of property values in a child objProp object corresponding to propertty name.
prop (string) : (string) Name of the property
id (int) : (int) Id of the element to be returned from the array pf property values
objProps9 type
Object for storing values read from CSV relating to a particular object or property name.
Fields:
mpS (map) : (map() Stores property values as pairs
arS (array) : (string ) Array of values
objProps, objProps0, ... objProps8 types
Object for storing values read from CSV relating to a particular object or property name.
Fields:
mpS (map) : (map() Stores property values as pairs
arS (array) : (string ) Array of values
mpObj (map) : (map() Stores objProps objects containing properties's data as pairs
CSV
RegexLib█ OVERVIEW
This library contains regular expression (regex) search functions which are helpful, in particular, in reading configuration inputs.
feedRgx(): Searches for the first occurrence of `regex` pattern in the `src` and returns `src` split into parts as a tuple: ` `. If no match returns ` `
countRgx(): Counts `regex` occurrences in the `src`.
matchRgx(): Finds given `occurence` of `regex` pattern in `src` string.
NB! countRgx() and matchRgx() do not support `^` (beginning of the string placeholder), lookbehind some other complex patterns, because they works by cutting off the part of the string up to the first found occurence (inclusive) and then continuing the search on the remainder of the string. E.g. in a four line source `(?<= ).+ ` should match the second and the third lines but matchRgx only matches the second line since after matching it continues to search in the remainder AFTER the match only.
█ FULL LIST OF FUNCTIONS AND PARAMETERS
method feedRgx(src, regex)
Searches for the first occurrence of ` regex ` pattern in the ` src ` and returns ` src ` split into parts as a tuple: ` `. If no match returns ` `
Namespace types: series string, simple string, input string, const string
Parameters:
src (string) : (string) String to search for the regex pattern
regex (string) : (string) RegEx pattern
Returns: A tuple ` ` where `begS` is the part of the `src` string from the beginning up to the
first occurence of the `regex` pattern (or up to the end if not found), `matchS` - the first occurrence of the
regex pattern and `endS` the part of the strinf following the first occurrence of the `regex` pattern.
method countRgx(src, regex)
Counts `regex` occurrences in the `src`. ___NB!___ _Does not support `^` (beginning of the string
placeholder), lookbehind some other complex patterns, because it works by cutting off the part of the string up to
the first found occurence (inclusive) and then continuing the search on the remainder of the string. E.g. in a four line source `(?<= ).+ ` should match the second and the third lines but matchRgx only
matches the second line since after matching it continues to search in the remainder AFTER the match only. _
Namespace types: series string, simple string, input string, const string
Parameters:
src (string) : (string) String in which the regex pattern occurences are to be counted
regex (string) : (string) RegEx pattern
Returns: The number of occurrences of the `regex` pattern in the `src` string.
method matchRgx(src, regex, occurrence)
Finds given `occurence` of `regex` pattern in `src` string. ___NB!___ _Does not support `^` (beginning of the string placeholder), lookbehind and some other complex patterns, because it works by cutting off the part of the string up to the first found occurence (inclusive) and then continuing the search on the remainder of the string. E.g. in a four line source `(?<= ).+ ` should match the second and the third lines but matchRgx only matches the second line since after matching it continues to search in the remainder AFTER the match only. _
Namespace types: series string, simple string, input string, const string
Parameters:
src (string) : (string) String to search for the regex pattern
regex (string) : (string) RegEx pattern
occurrence (int) : (int) (Default is 1) The number of the occurrence to search for. If this params exceeds the actual
number of occurrences of the pattern in the `src` string the following tuple is returned
Returns: A tuple, matchS - matched substring, matchPos - position of the match, matchL - match length
█ HOW TO USE
See DEMO section in the script.
You can test regex patterns by playing around with script input settings.
Another usage example can be found in my CSVParser and HTFMAs libraries.

csv_series_libraryThe CSV Series Library is an innovative tool designed for Pine Script developers to efficiently parse and handle CSV data for series generation. This library seamlessly integrates with TradingView, enabling the storage and manipulation of large CSV datasets across multiple Pine Script libraries. It's optimized for performance and scalability, ensuring smooth operation even with extensive data.
Features:
Multi-library Support: Allows for distribution of large CSV datasets across several libraries, ensuring efficient data management and retrieval.
Dynamic CSV Parsing: Provides robust Python scripts for reading, formatting, and partitioning CSV data, tailored specifically for Pine Script requirements.
Extensive Data Handling: Supports parsing CSV strings into Pine Script-readable series, facilitating complex financial data analysis.
Automated Function Generation: Automatically wraps CSV blocks into distinct Pine Script functions, streamlining the process of integrating CSV data into Pine Script logic.
Usage:
Ideal for traders and developers who require extensive data analysis capabilities within Pine Script, especially when dealing with large datasets that need to be partitioned into manageable blocks. The library includes a set of predefined functions for parsing CSV data into usable series, making it indispensable for advanced trading strategy development.
Example Implementation:
CSV data is transformed into Pine Script series using generated functions.
Multiple CSV blocks can be managed and parsed, allowing for flexible data series creation.
The library includes comprehensive examples demonstrating the conversion of standard CSV files into functional Pine Script code.
To effectively utilize the CSV Series Library in Pine Script, it is imperative to initially generate the correct data format using the accompanying Python program. Here is a detailed explanation of the necessary steps:
1. Preparing the CSV Data:
The Python script provided with the CSV Series Library is designed to handle CSV files that strictly contain no-space, comma-separated single values. It is crucial that your CSV file adheres to this format to ensure compatibility and correctness of the data processing.
2. Using the Python Program to Generate Data:
Once your CSV file is prepared, you need to use the Python program to convert this file into a format that Pine Script can interpret. The Python script performs several key functions:
Reads the CSV file, ensuring that it matches the required format of no-space, comma-separated values.
Formats the data into blocks, where each block is a string of data that does not exceed a specified character limit (default is 4,000 characters). This helps manage large datasets by breaking them down into manageable chunks.
Wraps these blocks into Pine Script functions, each block being encapsulated in its own function to maintain organization and ease of access.
3. Generating and Managing Multiple Libraries:
If the data from your CSV file exceeds the Pine Script or platform limits (e.g., too many characters for a single script), the Python script can split this data into multiple blocks across several files.
4. Creating a Pine Script Library:
After generating the formatted data blocks, you must create a Pine Script library where these blocks are integrated. Each block of data is contained within its function, like my_csv_0(), my_csv_1(), etc. The full_csv() function in Pine Script then dynamically loads and concatenates these blocks to reconstruct the full data series.
5. Exporting the full_csv() Function:
Once your Pine Script library is set up with all the CSV data blocks and the full_csv() function, you export this function from the library. This exported function can then be used in your actual trading projects. It allows Pine Script to access and utilize the entire dataset as if it were a single, continuous series, despite potentially being segmented across multiple library files.
6. Reconstructing the Full Series Using vec :
When your dataset is particularly large, necessitating division into multiple parts, the vec type is instrumental in managing this complexity. Here’s how you can effectively reconstruct and utilize your segmented data:
Definition of vec Type: The vec type in Pine Script is specifically designed to hold a dataset as an array of floats, allowing you to manage chunks of CSV data efficiently.
Creating an Array of vec Instances: Once you have your data split into multiple blocks and each block is wrapped into its own function within Pine Script libraries, you will need to construct an array of vec instances. Each instance corresponds to a segment of your complete dataset.
Using array.from(): To create this array, you utilize the array.from() function in Pine Script. This function takes multiple arguments, each being a vec instance that encapsulates a data block. Here’s a generic example:
vec series_vector = array.from(vec.new(data_block_1), vec.new(data_block_2), ..., vec.new(data_block_n))
In this example, data_block_1, data_block_2, ..., data_block_n represent the different segments of your dataset, each returned from their respective functions like my_csv_0(), my_csv_1(), etc.
Accessing and Utilizing the Data: Once you have your vec array set up, you can access and manipulate the full series through Pine Script functions designed to handle such structures. You can traverse through each vec instance, processing or analyzing the data as required by your trading strategy.
This approach allows Pine Script users to handle very large datasets that exceed single-script limits by segmenting them and then methodically reconstructing the dataset for comprehensive analysis. The vec structure ensures that even with segmentation, the data can be accessed and utilized as if it were contiguous, thus enabling powerful and flexible data manipulation within Pine Script.
Library "csv_series_library"
A library for parsing and handling CSV data to generate series in Pine Script. Generally you will store the csv strings generated from the python code in libraries. It is set up so you can have multiple libraries to store large chunks of data. Just export the full_csv() function for use with this library.
method csv_parse(data)
Namespace types: array
Parameters:
data (array)
method make_series(series_container, start_index)
Namespace types: array
Parameters:
series_container (array)
start_index (int)
Returns: A tuple containing the current value of the series and a boolean indicating if the data is valid.
method make_series(series_vector, start_index)
Namespace types: array
Parameters:
series_vector (array)
start_index (int)
Returns: A tuple containing the current value of the series and a boolean indicating if the data is valid.
vec
A type that holds a dataset as an array of float arrays.
Fields:
data_set (array) : A chunk of csv data. (A float array)
