Correlation HeatMap [TradingFinder] Sessions Data Science Stats🔵 Introduction
n financial markets, correlation describes the statistical relationship between the price movements of two assets and how they interact over time. It plays a key role in both trading and investing by helping analyze asset behavior, manage portfolio risk, and understand intermarket dynamics. The Correlation Heatmap is a visual tool that shows how the correlation between multiple assets and a central reference asset (the Main Symbol) changes over time.
It supports four market types forex, stocks, crypto, and a custom mode making it adaptable to different trading environments. The heatmap uses a color-coded grid where warmer tones represent stronger negative correlations and cooler tones indicate stronger positive ones. This intuitive color system allows traders to quickly identify when assets move together or diverge, offering real-time insights that go beyond traditional correlation tables.
🟣 How to Interpret the Heatmap Visually ?
Each cell represents the correlation between the main symbol and one compared asset at a specific time.
Warm colors (e.g. red, orange) suggest strong negative correlation as one asset rises, the other tends to fall.
Cool colors (e.g. blue, green) suggest strong positive correlation both assets tend to move in the same direction.
Lighter shades indicate weaker correlations, while darker shades indicate stronger correlations.
The heatmap updates over time, allowing users to detect changes in correlation during market events or trading sessions.
One of the standout features of this indicator is its ability to overlay global market sessions such as Tokyo, London, New York, or major equity opens directly onto the heatmap timeline. This alignment lets traders observe how correlation structures respond to real-world session changes. For example, they can spot when assets shift from being inversely correlated to moving together as a new session opens, potentially signaling new momentum or macro flow. The customizable symbol setup (including up to 20 compared assets) makes it ideal not only for forex and crypto traders but also for multi-asset and sector-based stock analysis.
🟣 Use Cases and Advantages
Analyze sector rotation in equities by tracking correlation to major indices like SPX or DJI.
Monitor altcoin behavior relative to Bitcoin to find early entry opportunities in crypto markets.
Detect changes in currency alignment with DXY across trading sessions in forex.
Identify correlation breakdowns during market volatility, signaling possible new trends.
Use correlation shifts as confirmation for trade setups or to hedge multi-asset exposure
🔵 How to Use
Correlation is one of the core concepts in financial analysis and allows traders to understand how assets behave in relation to one another. The Correlation Heatmap extends this idea by going beyond a simple number or static matrix. Instead, it presents a dynamic visual map of how correlations shift over time.
In this indicator, a Main Symbol is selected as the reference point for analysis. In standard modes such as forex, stocks, or crypto, the symbol currently shown on the main chart is automatically used as the main symbol. This allows users to begin correlation analysis right away without adjusting any settings.
The horizontal axis of the heatmap shows time, while the vertical axis lists the selected assets. Each cell on the heatmap shows the correlation between that asset and the main symbol at a given moment.
This approach is especially useful for intermarket analysis. In forex, for example, tracking how currency pairs like OANDA:EURUSD EURUSD, FX:GBPUSD GBPUSD, and PEPPERSTONE:AUDUSD AUDUSD correlate with TVC:DXY DXY can give insight into broader capital flow.
If these pairs start showing increasing positive correlation with DXY say, shifting from blue to light green it could signal the start of a new phase or reversal. Conversely, if negative correlation fades gradually, it may suggest weakening relationships and more independent or volatile movement.
In the crypto market, watching how altcoins correlate with Bitcoin can help identify ideal entry points in secondary assets. In the stock market, analyzing how companies within the same sector move in relation to a major index like SP:SPX SPX or DJ:DJI DJI is also a highly effective technique for both technical and fundamental analysts.
This indicator not only visualizes correlation but also displays major market sessions. When enabled, this feature helps traders observe how correlation behavior changes at the start of each session, whether it's Tokyo, London, New York, or the opening of stock exchanges. Many key shifts, breakouts, or reversals tend to happen around these times, and the heatmap makes them easy to spot.
Another important feature is the market selection mode. Users can switch between forex, crypto, stocks, or custom markets and see correlation behavior specific to each one. In custom mode, users can manually select any combination of symbols for more advanced or personalized analysis. This makes the heatmap valuable not only for forex traders but also for stock traders, crypto analysts, and multi-asset strategists.
Finally, the heatmap's color-coded design helps users make sense of the data quickly. Warm colors such as red and orange reflect stronger negative correlations, while cool colors like blue and green represent stronger positive relationships. This simplicity and clarity make the tool accessible to both beginners and experienced traders.
🔵 Settings
Correlation Period: Allows you to set how many historical bars are used for calculating correlation. A higher number means a smoother, slower-moving heatmap, while a lower number makes it more responsive to recent changes.
Select Market: Lets you choose between Forex, Stock, Crypto, or Custom. In the first three options, the chart’s active symbol is automatically used as the Main Symbol. In Custom mode, you can manually define the Main Symbol and up to 20 Compared Symbols.
Show Open Session: Enables the display of major trading sessions such as Tokyo, London, New York, or equity market opening hours directly on the timeline. This helps you connect correlation shifts with real-world market activity.
Market Mode: Lets you select whether the displayed sessions relate to the forex or stock market.
🔵 Conclusion
The Correlation Heatmap is a robust and flexible tool for analyzing the relationship between assets across different markets. By tracking how correlations change in real time, traders can better identify alignment or divergence between symbols and gain valuable insights into market structure.
Support for multiple asset classes, session overlays, and intuitive visual cues make this one of the most effective tools for intermarket analysis.
Whether you’re looking to manage portfolio risk, validate entry points, or simply understand capital flow across markets, this heatmap provides a clear and actionable perspective that you can rely on.
DATA

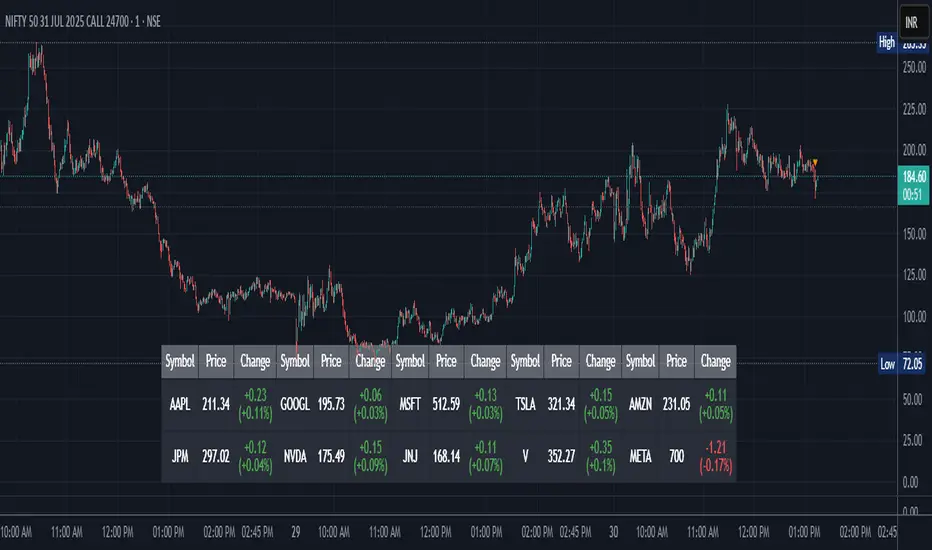
Stock Table aiTrendviewProfessional Stock Market Monitoring Table (Pine Script v5)
This indicator is a real-time multi-asset monitoring table designed for professional traders, analysts, and portfolio managers using TradingView. Built with Pine Script v5, it enables users to track up to 10 instruments (stocks, indices, forex pairs, cryptocurrencies, or commodities) in a unified table embedded directly into the chart. It is intended to streamline portfolio monitoring, cross-market analysis, and rapid visual comparison of asset performance.
The core logic of this script involves retrieving live price data through TradingView’s request.security() function for each of the selected symbols. It calculates both absolute price change and percentage price change relative to the previous bar close. This ensures users can see real-time movements in each asset’s price. These calculations are updated at the close of every bar to optimize performance and reduce processing load using the barstate.islast condition.
The display structure is dynamically generated using table.new() and related functions. Internally, the script stores symbol and price data in arrays for efficient processing. Symbols are cleaned to remove exchange prefixes (e.g., "NASDAQ:", "BINANCE:") so only the ticker name is displayed. Based on the selected layout (1 to 5 columns), the table auto-adjusts its row structure to maintain clarity and symmetry. Each cell reflects the ticker symbol, current price, and changes, with conditional formatting applied to indicate price movement direction using green (positive), red (negative), or neutral colors.
Users can customize many visual elements including text size, color themes, transparency, table position, and whether headers are shown. The script includes built-in fallbacks for invalid symbols or empty data, ensuring robustness and uninterrupted performance during live market hours.
Use cases include:
Intraday traders monitoring multiple instruments simultaneously.
Swing traders assessing relative strength and correlation.
Portfolio managers scanning asset performance without switching charts.
Analysts preparing multi-asset presentations or watchlists.
To use the tool:
Paste the Pine Script into the Pine Editor.
Add the script to the chart.
Enter your desired symbols via the input fields.
Customize table position, layout, size, and color to suit your workspace.
This script does not provide trade signals or financial advice. It is purely a market visualization and data presentation tool. All calculations are based on live chart data and are synchronized with the chart’s timeframe.
Disclaimer from aiTrendview:
This script is a visual tool developed for market awareness and comparative observation. It does not constitute financial advice or guarantee trading results. aiTrendview and its affiliates are not responsible for any losses arising from decisions made based on this tool. All trading involves risk, and past performance is not indicative of future results. Always consult with a qualified financial advisor before making trading decisions.
Ticker DataThis script mostly for Pine coders but may be useful for regular users too.
I often find myself needing quick access to certain information about a ticker — like its full ticker name, mintick, last bar index and so on. Usually, I write a few lines of code just to display this info and check it.
Today I got tired of doing that manually, so I created a small script that shows the most essential data in one place. I also added a few extra fields that might be useful or interesting to regular users.
Description for regular users (from Pine Script Reference Manual)
tickerid - full ticker name
description - description for the current symbol
industry - the industry of the symbol. Example: "Internet Software/Services", "Packaged software", "Integrated Oil", "Motor Vehicles", etc.
country - the two-letter code of the country where the symbol is traded
sector - the sector of the symbol. Example: "Electronic Technology", "Technology services", "Energy Minerals", "Consumer Durables", etc.
session - session type (regular or extended)
timezone - timezone of the exchange of the chart
type - the type of market the symbol belongs to. Example: "stock", "fund", "index", "forex", "futures", "spread", "economic", "fundamental", "crypto".
volumetype - volume type of the current symbol.
mincontract - the smallest amount of the current symbol that can be traded
mintick - min tick value for the current symbol (the smallest increment between a symbol's price movements)
pointvalue - point value for the current symbol
pricescale - a whole number used to calculate mintick (usually (when minmove is 1), it shows the resolution — how many decimal places the price has. For example, a pricescale 100 means the price will have two decimal places - 1 / 100 = 0.01)
bar index - last bar index (if add 1 (because indexes starts from 0) it will shows how many bars available to you on the chart)
If you need some more information at table feel free to leave a comment.

Correlation Coefficient Master TableThe Correlation Coefficient Master Table is a comprehensive tool designed to calculate and visualize the correlation coefficient between a selected base asset and multiple other assets over various time periods. It provides traders and analysts with a clear understanding of the relationships between assets, enabling them to analyze trends, diversification opportunities, and market dynamics. You can define key parameters such as the base asset’s data source (e.g., close price), the assets to compare against (up to six symbols), and multiple lookback periods for granular analysis.
The indicator calculates the covariance and normalizes it by the product of the standard deviations. The correlation coefficient ranges from -1 to +1, with +1 indicating a perfect positive relationship, -1 a perfect negative relationship, and 0 no relationship.
You can specify the lookback periods (e.g., 15, 30, 90, or 120 bars) to tailor the calculation to their analysis needs. The results are visualized as both a line plot and a table. The line plot shows the correlation over the primary lookback period (the Chart Length), which can be used to inspect a certain length close up, or could be used in conjunction with the table to provide you with five lookback periods at once for the same base asset. The dynamically created table provides a detailed breakdown of correlation values for up to six target assets across the four user-defined lengths. The table’s cells are formatted with rounded values and color-coded for easy interpretation.
This indicator is ideal for traders, portfolio managers, and market researchers who need an in-depth understanding of asset interdependencies. By providing both the numerical correlation coefficients and their visual representation, users can easily identify patterns, assess diversification strategies, and monitor correlations across multiple timeframes, making it a valuable tool for decision-making.

Dynamic Risk-Adjusted Performance Ratios with TableWith this indicator, you have everything you need to monitor and compare the Sharpe ratio, Sortino ratio, and Omega ratio across multiple assets—all in one place. This tool is designed to help save time and improve efficiency by letting you track up to 15 assets simultaneously in a fully customizable table. You can adjust the lookback period to fit your trading strategy and get a clearer picture of how your assets perform over time. Instead of switching between charts, this indicator puts all the critical information you need at your fingertips.
Sharpe Ratio -
Helps evaluate the overall efficiency of investments by comparing the average return to the total risk (measured by the standard deviation of all returns). Essentially, it tells you how much excess return you’re getting for each unit of risk you’re taking. A higher Sharpe ratio means you’re getting better risk-adjusted performance—something you’ll want to aim for in your portfolio.
Sortino Ratio -
Goes a step further by focusing only on downside risk—because let’s face it, no one worries about positive volatility. This ratio is calculated by dividing the average return by the standard deviation of only the negative returns. Perfect for those concerned about avoiding losses rather than chasing extreme gains. It gives you a sharper view of how well your assets are performing relative to the risks you’re trying to avoid.
Omega Ratio -
Offers a unique perspective by comparing the sum of positive returns to the absolute sum of negative returns. It’s a straightforward way to see if your wins outweigh your losses. A higher Omega ratio means your positive returns significantly exceed the downside, which is exactly what you want when building a strong, reliable portfolio.
This indicator is perfect for traders who want to streamline their decision-making process and gain an edge. Bringing together these three critical ratios into a single user-defined table makes it easy to compare and rank assets at a glance. Whether optimizing a portfolio or looking for the best opportunities, this tool helps you stay ahead by focusing on risk-adjusted returns. The customizable lookback period lets you tailor the analysis to fit your unique trading approach, giving you insights that align with your goals. If you’re serious about making data-driven decisions and improving your trading outcomes, this indicator is a game-changer for your toolkit.

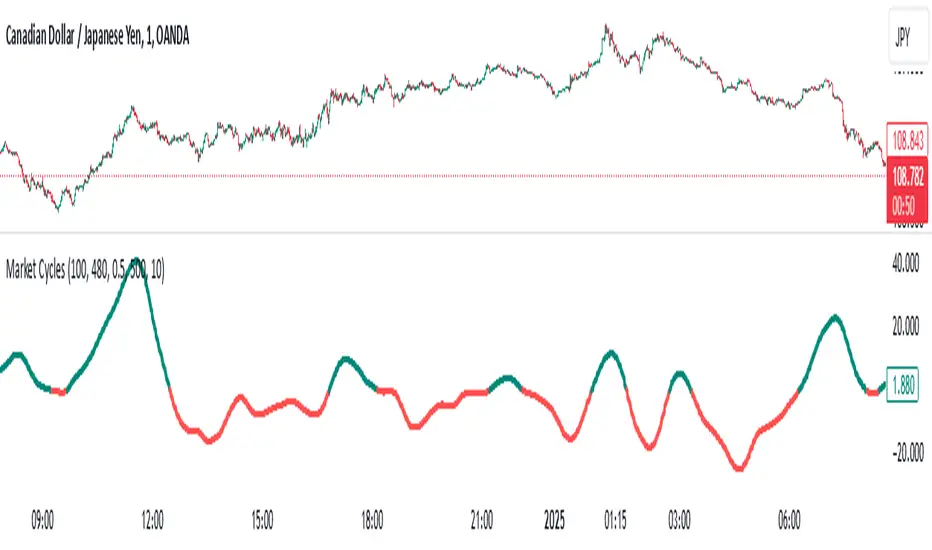
Market Cycles
The Market Cycles indicator transforms market price data into a stochastic wave, offering a unique perspective on market cycles. The wave is bounded between positive and negative values, providing clear visual cues for potential bullish and bearish trends. When the wave turns green, it signals a bullish cycle, while red indicates a bearish cycle.
Designed to show clarity and precision, this tool helps identify market momentum and cyclical behavior in an intuitive way. Ideal for fine-tuning entries or analyzing broader trends, this indicator aims to enhance the decision-making process with simplicity and elegance.
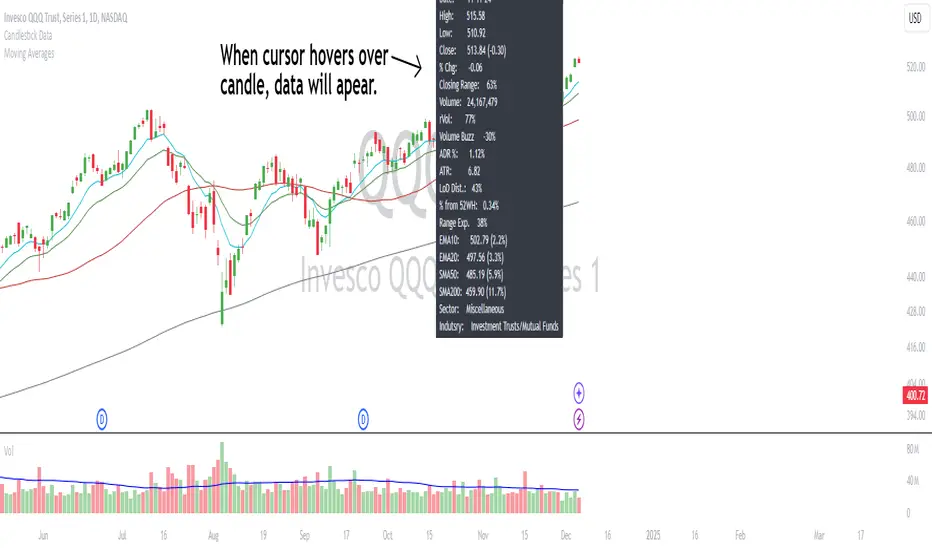
Candlestick DataCandlestick Data Indicator
The Candlestick Data indicator provides a comprehensive overview of key metrics for analyzing price action and volume in real-time. This overlay indicator displays essential candlestick data and calculations directly on your chart, offering an all-in-one toolkit for traders seeking in-depth insights.
Key Features:
Price Metrics: View the daily high, low, close, and percentage change.
Volume Insights: Analyze volume, relative volume, and volume buzz for breakout or consolidation signals.
Range Analysis: Includes closing range, distance from low of day (LoD), and percentage change in daily range expansion.
Advanced Metrics: Calculate ADR% (Average Daily Range %), ATR (Average True Range), and % from 52-week high.
Moving Averages: Supports up to four customizable moving averages (EMA or SMA) with distance from price.
Market Context: Displays the sector and industry group for the asset.
This indicator is fully customizable, allowing you to toggle on or off specific metrics to suit your trading style. Designed for active traders, it brings critical data to your fingertips, streamlining decision-making and enhancing analysis.
Perfect for momentum, swing, and day traders looking to gain a data-driven edge!
Volume CalendarDescription:
The indicator displays a calendar with Volume data for up to 6 last months. It is designed to work on any timeframe, but works best on Daily and below. It is also consistent in that it displays the same data even if you go to lower timeframes like 5 minutes (even though the data is used is Daily).
Features:
- displays volume data for last N months (volume, volume change, % of weekly, monthly and yearly volume)
- display total volume for each month
- display monthly sentiment
- find dates with volume spikes
Inputs:
- Number of months -> how many last months of data to display (from 1 to 6)
- Volume Type -> display only Bullish, only Bearish or all volume
- Cell color is based on -> Volume - the brighter the cell the higher volume was on that day; Volume Change - the brighter the cell the higher was the volume change that day; Volume Spike - the brighter the cell the higher was volume spike that day (volume spike is based on volume being above its average over last N candles)
- Cell color timeframe -> Weekly - the cell color is calculated comparing volume of that cell with weekly volume; Monthly - comparing volume with monthly volume
- Use volume for sentiment -> take the volume into account when calculating monthly sentiment (otherwise calculate it based on number of Bullish and Bearish days in the month)
- Spike Average Period -> period of the moving average used for spike calculation
- Spike Threshold -> current volume must be this many times greater than the average for it to be considered a spike
- Table Size -> size of the table
- Theme -> colouring of the table

csv_series_libraryThe CSV Series Library is an innovative tool designed for Pine Script developers to efficiently parse and handle CSV data for series generation. This library seamlessly integrates with TradingView, enabling the storage and manipulation of large CSV datasets across multiple Pine Script libraries. It's optimized for performance and scalability, ensuring smooth operation even with extensive data.
Features:
Multi-library Support: Allows for distribution of large CSV datasets across several libraries, ensuring efficient data management and retrieval.
Dynamic CSV Parsing: Provides robust Python scripts for reading, formatting, and partitioning CSV data, tailored specifically for Pine Script requirements.
Extensive Data Handling: Supports parsing CSV strings into Pine Script-readable series, facilitating complex financial data analysis.
Automated Function Generation: Automatically wraps CSV blocks into distinct Pine Script functions, streamlining the process of integrating CSV data into Pine Script logic.
Usage:
Ideal for traders and developers who require extensive data analysis capabilities within Pine Script, especially when dealing with large datasets that need to be partitioned into manageable blocks. The library includes a set of predefined functions for parsing CSV data into usable series, making it indispensable for advanced trading strategy development.
Example Implementation:
CSV data is transformed into Pine Script series using generated functions.
Multiple CSV blocks can be managed and parsed, allowing for flexible data series creation.
The library includes comprehensive examples demonstrating the conversion of standard CSV files into functional Pine Script code.
To effectively utilize the CSV Series Library in Pine Script, it is imperative to initially generate the correct data format using the accompanying Python program. Here is a detailed explanation of the necessary steps:
1. Preparing the CSV Data:
The Python script provided with the CSV Series Library is designed to handle CSV files that strictly contain no-space, comma-separated single values. It is crucial that your CSV file adheres to this format to ensure compatibility and correctness of the data processing.
2. Using the Python Program to Generate Data:
Once your CSV file is prepared, you need to use the Python program to convert this file into a format that Pine Script can interpret. The Python script performs several key functions:
Reads the CSV file, ensuring that it matches the required format of no-space, comma-separated values.
Formats the data into blocks, where each block is a string of data that does not exceed a specified character limit (default is 4,000 characters). This helps manage large datasets by breaking them down into manageable chunks.
Wraps these blocks into Pine Script functions, each block being encapsulated in its own function to maintain organization and ease of access.
3. Generating and Managing Multiple Libraries:
If the data from your CSV file exceeds the Pine Script or platform limits (e.g., too many characters for a single script), the Python script can split this data into multiple blocks across several files.
4. Creating a Pine Script Library:
After generating the formatted data blocks, you must create a Pine Script library where these blocks are integrated. Each block of data is contained within its function, like my_csv_0(), my_csv_1(), etc. The full_csv() function in Pine Script then dynamically loads and concatenates these blocks to reconstruct the full data series.
5. Exporting the full_csv() Function:
Once your Pine Script library is set up with all the CSV data blocks and the full_csv() function, you export this function from the library. This exported function can then be used in your actual trading projects. It allows Pine Script to access and utilize the entire dataset as if it were a single, continuous series, despite potentially being segmented across multiple library files.
6. Reconstructing the Full Series Using vec :
When your dataset is particularly large, necessitating division into multiple parts, the vec type is instrumental in managing this complexity. Here’s how you can effectively reconstruct and utilize your segmented data:
Definition of vec Type: The vec type in Pine Script is specifically designed to hold a dataset as an array of floats, allowing you to manage chunks of CSV data efficiently.
Creating an Array of vec Instances: Once you have your data split into multiple blocks and each block is wrapped into its own function within Pine Script libraries, you will need to construct an array of vec instances. Each instance corresponds to a segment of your complete dataset.
Using array.from(): To create this array, you utilize the array.from() function in Pine Script. This function takes multiple arguments, each being a vec instance that encapsulates a data block. Here’s a generic example:
vec series_vector = array.from(vec.new(data_block_1), vec.new(data_block_2), ..., vec.new(data_block_n))
In this example, data_block_1, data_block_2, ..., data_block_n represent the different segments of your dataset, each returned from their respective functions like my_csv_0(), my_csv_1(), etc.
Accessing and Utilizing the Data: Once you have your vec array set up, you can access and manipulate the full series through Pine Script functions designed to handle such structures. You can traverse through each vec instance, processing or analyzing the data as required by your trading strategy.
This approach allows Pine Script users to handle very large datasets that exceed single-script limits by segmenting them and then methodically reconstructing the dataset for comprehensive analysis. The vec structure ensures that even with segmentation, the data can be accessed and utilized as if it were contiguous, thus enabling powerful and flexible data manipulation within Pine Script.
Library "csv_series_library"
A library for parsing and handling CSV data to generate series in Pine Script. Generally you will store the csv strings generated from the python code in libraries. It is set up so you can have multiple libraries to store large chunks of data. Just export the full_csv() function for use with this library.
method csv_parse(data)
Namespace types: array
Parameters:
data (array)
method make_series(series_container, start_index)
Namespace types: array
Parameters:
series_container (array)
start_index (int)
Returns: A tuple containing the current value of the series and a boolean indicating if the data is valid.
method make_series(series_vector, start_index)
Namespace types: array
Parameters:
series_vector (array)
start_index (int)
Returns: A tuple containing the current value of the series and a boolean indicating if the data is valid.
vec
A type that holds a dataset as an array of float arrays.
Fields:
data_set (array) : A chunk of csv data. (A float array)
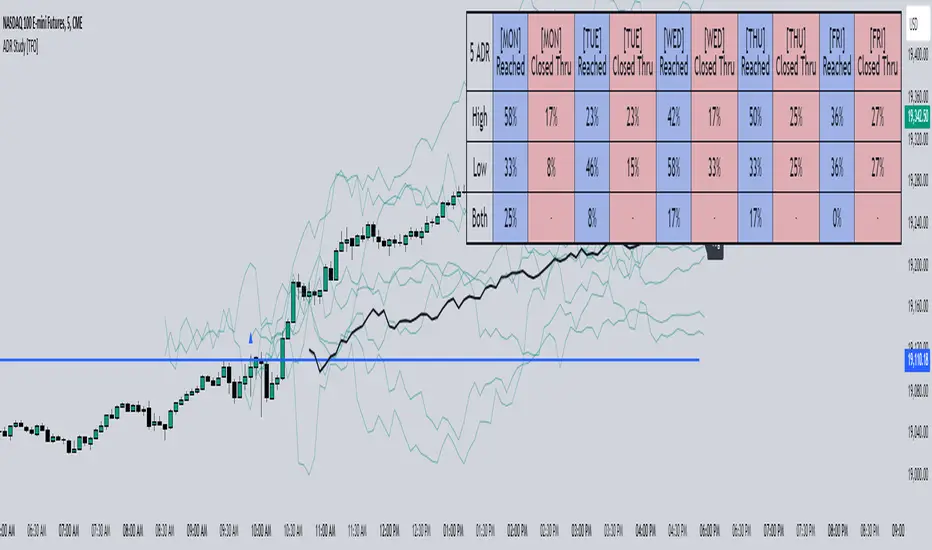
ADR Study [TFO]This indicator is focused on the Average Daily Range (ADR), with the goal of collecting data to show how often price reaches/closes through these levels, as well as a look at historical moves that reached ADR and at similar times of day to study how price moved for the remainder of the session.
The ADR here (blue line) is calculated using the difference between a day's highest and lowest points. If our ADR length is 5, then we are taking this difference from the last 5 days and averaging them together. At the following day's open, we take half of this average and plot it above and below the daily opening price to place theoretical limits on how far price may move according to the lookback period. The triangles indicate when price has reached ADR (either +ADR or -ADR), and alerts can be created for these events.
The Scale Factor is an optional parameter to scale the ADR by a certain amount. If set to 2 for example, then the ADR would be 2x the average daily range. This value will be reflected in the statistics options so that users can see how different values affect the outcomes.
Show Table will display data collected on how often price reaches these levels, and how often price closes through them, for each day of the week. By default, these are colored as blue and red, respectively. From the following chart of NQ1!, we can see for example that on Mondays, price reached +ADR 38% of the time and closed through it 23% of the time. Note that the statistics for closing through the ADR levels are derived from all instances, not just those that reached ADR.
Show Sample Sizes will display how many instances were collected for all given sets of data. Referring to the same example of NQ1!, we can see that this particular chart has collected data from 109 Mondays. From those Mondays, 41 reached +ADR (38%, verifying our initial claim) and 25 closed through it (23%). This is important to understand the scope of the data that we're working with, as percentages can be misleading for smaller sample sizes.
Show Histogram will plot the same exact data as the table, just in a histogram form to visually emphasize the differences on a day-by-day basis. On this chart of RTY1!, we can see for example from the top histogram that on Wednesdays, 40% reached +ADR and only 22% closed through it. Similarly if we look at the bottom histogram, we can see that Wednesdays reached -ADR 46% of the time and closed through it only 28% of the time.
We can also use Show Sample Sizes to display the same information that would be in the table, showing how many instances were collected for each event. In this case we can see that we observed 175 Fridays, where 76 reached +ADR (43%) and 44 closed above it (25%).
Show Historical Moves is an interesting feature of this script. When enabled, if price has reached +/- ADR in the current session, the indicator will plot the evolution of the close prices from all past sessions that reached +/- ADR to see how they traded for the remainder of the session. These calculations are made with respect to the ADR range at the time that price traded through these levels.
Historical Proximity (Bars) allows the user to observe historical moves where price reached ADR within this many bars of the current session (assuming price has reached an ADR level in the current session). In the above chart, this is set to 1000 so that we can observe each and every instance where price reached an ADR level. However, we can refine this a bit more.
By limiting the Historical Proximity to something like 20, we are only considering historical moves that reached ADR within 20 bars of todays +ADR reach (9:50 am EST, noted by the blue triangle up). We can enable Show Average Move to display the average move by the filtered dataset, and Match +/-ADR to only observe moves inline with the current day's price action (in this case, only moves that reached +ADR, since price has not reached -ADR).
We can add one more filter to this data with the setting Only Show Days That: closed through ADR; closed within ADR; or either. The option either is what you see above, as we are considering both days that closed through ADR and days that closed within it (note that in this case, closing within ADR simply means that price reached +ADR and closed the day below it, and vice versa for -ADR; this does not mean that price must have closed in between +ADR and -ADR). If we set this to only show instances that closed within ADR, we see the following data.
Alternatively, we can choose to Only Show Days That closed through ADR, where we would see the following data. In this case, the average move very much resembles the price action that occurred on this particular day. This is in no way guaranteed, but it makes an interesting case for how we could use this data in our analysis by observing similar, historical price action.
Please note that this data will change over time on a rolling basis due to TradingView's bar lookback, and that for this same reason, lower timeframes will yield less data than larger timeframes.
Day/Week/Month Metrics (Zeiierman)█ Overview
The Day/Week/Month Metrics (Zeiierman) indicator is a powerful tool for traders looking to incorporate historical performance into their trading strategy. It computes statistical metrics related to the performance of a trading instrument on different time scales: daily, weekly, and monthly. Breaking down the performance into daily, weekly, and monthly metrics provides a granular view of the instrument's behavior.
The indicator requires the chart to be set on a daily timeframe.
█ Key Statistics
⚪ Day in month
The performance of financial markets can show variability across different days within a month. This phenomenon, often referred to as the "monthly effect" or "turn-of-the-month effect," suggests that certain days of the month, especially the first and last days, tend to exhibit higher than average returns in many stock markets around the world. This effect is attributed to various factors including payroll contributions, investment of monthly dividends, and psychological factors among traders and investors.
⚪ Edge
The Edge calculation identifies days within a month that consistently outperform the average monthly trading performance. It provides a statistical advantage by quantifying how often trading on these specific days yields better returns than the overall monthly average. This insight helps traders understand not just when returns might be higher, but also how reliable these patterns are over time. By focusing on days with a higher "Edge," traders can potentially increase their chances of success by aligning their strategies with historically more profitable days.
⚪ Month
Historically, the stock market has exhibited seasonal trends, with certain months showing distinct patterns of performance. One of the most well-documented patterns is the "Sell in May and go away" phenomenon, suggesting that the period from November to April has historically brought significantly stronger gains in many major stock indices compared to the period from May to October. This pattern highlights the potential impact of seasonal investor sentiment and activities on market performance.
⚪ Day in week
Various studies have identified the "day-of-the-week effect," where certain days of the week, particularly Monday and Friday, show different average returns compared to other weekdays. Historically, Mondays have been associated with lower or negative average returns in many markets, a phenomenon often linked to the settlement of trades from the previous week and negative news accumulation over the weekend. Fridays, on the other hand, might exhibit positive bias as investors adjust positions ahead of the weekend.
⚪ Week in month
The performance of markets can also vary within different weeks of the month, with some studies suggesting a "week of the month effect." Typically, the first and the last week of the month may show stronger performance compared to the middle weeks. This pattern can be influenced by factors such as the timing of economic reports, monthly investment flows, and options and futures expiration dates which tend to cluster around these periods, affecting investor behavior and market liquidity.
█ How It Works
⚪ Day in Month
For each day of the month (1-31), the script calculates the average percentage change between the opening and closing prices of a trading instrument. This metric helps identify which days have historically been more volatile or profitable.
It uses arrays to store the sum of percentage changes for each day and the total occurrences of each day to calculate the average percentage change.
⚪ Month
The script calculates the overall gain for each month (January-December) by comparing the closing price at the start of a month to the closing price at the end, expressed as a percentage. This metric offers insights into which months might offer better trading opportunities based on historical performance.
Monthly gains are tracked using arrays that store the sum of these gains for each month and the count of occurrences to calculate the average monthly gain.
⚪ Day in Week
Similar to the day in the month analysis, the script evaluates the average percentage change between the opening and closing prices for each day of the week (Monday-Sunday). This information can be used to assess which days of the week are typically more favorable for trading.
The script uses arrays to accumulate percentage changes and occurrences for each weekday, allowing for the calculation of average changes per day of the week.
⚪ Week in Month
The script assesses the performance of each week within a month, identifying the gain from the start to the end of each week, expressed as a percentage. This can help traders understand which weeks within a month may have historically presented better trading conditions.
It employs arrays to track the weekly gains and the number of weeks, using a counter to identify which week of the month it is (1-4), allowing for the calculation of average weekly gains.
█ How to Use
Traders can use this indicator to identify patterns or trends in the instrument's performance. For example, if a particular day of the week consistently shows a higher percentage of bullish closes, a trader might consider this in their strategy. Similarly, if certain months show stronger performance historically, this information could influence trading decisions.
Identifying High-Performance Days and Periods
Day in Month & Day in Week Analysis: By examining the average percentage change for each day of the month and week, traders can identify specific days that historically have shown higher volatility or profitability. This allows for targeted trading strategies, focusing on these high-performance days to maximize potential gains.
Month Analysis: Understanding which months have historically provided better returns enables traders to adjust their trading intensity or capital allocation in anticipation of seasonally stronger or weaker periods.
Week in Month Analysis: Identifying which weeks within a month have historically been more profitable can help traders plan their trades around these periods, potentially increasing their chances of success.
█ Settings
Enable or disable the types of statistics you want to display in the table.
Table Size: Users can select the size of the table displayed on the chart, ranging from "Tiny" to "Auto," which adjusts based on screen size.
Table Position: Users can choose the location of the table on the chart
-----------------
Disclaimer
The information contained in my Scripts/Indicators/Ideas/Algos/Systems does not constitute financial advice or a solicitation to buy or sell any securities of any type. I will not accept liability for any loss or damage, including without limitation any loss of profit, which may arise directly or indirectly from the use of or reliance on such information.
All investments involve risk, and the past performance of a security, industry, sector, market, financial product, trading strategy, backtest, or individual's trading does not guarantee future results or returns. Investors are fully responsible for any investment decisions they make. Such decisions should be based solely on an evaluation of their financial circumstances, investment objectives, risk tolerance, and liquidity needs.
My Scripts/Indicators/Ideas/Algos/Systems are only for educational purposes!

multidataLibrary "multidata"
A library for multi-dimensional data arrays.
Full documentation: faiyaz7283.github.io
This library is designed to enhance data storage capabilities in Pine Script, enabling users to work with two separate data structures: data2d (key -> main-value | alternate-value) and data3d (primary key -> data key-> main-value | alternate-value). These structures facilitate storing key-value pairs in a flexible and efficient manner, offering various methods for manipulation and retrieval of data. Please check out the full documentation at faiyaz7283.github.io .

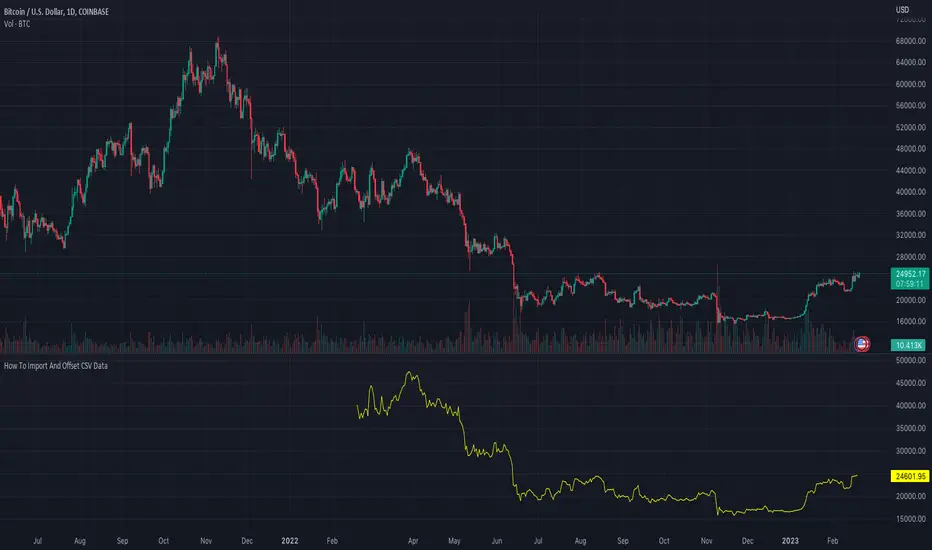
How To Input And Offset CSV DataExample method of how to use an input text area to import, offset, and plot CSV data using an array. Note that when using this method there is a limit of 4096 total characters per input.
For working with data sets larger than 4096 total characters an alternative method of pasting CSV data directly within the script can be seen below :
NOTICE: This is an example script and not meant to be used as an actual strategy. By using this script or any portion thereof, you acknowledge that you have read and understood that this is for research purposes only and I am not responsible for any financial losses you may incur by using this script!
SmartVPSGTitle: Identifying Volume Spikes, Price Movements and Gap Ups: A TradingView Script
Introduction:
In the world of trading, identifying volume spikes and price movements can provide valuable insights into market trends and potential trading opportunities. In this article, we'll explore a TradingView script that helps traders visualize volume spikes, price up moves with volume spikes, and gap-up days on their charts.
Detecting Price Up Moves:
The script starts by calculating price up moves. It compares the current day's closing price with the previous day's closing price and checks if it has increased by 3% or more. This helps traders spot significant upward price movements.
Detecting Volume Spurts:
Next, the script focuses on detecting volume spikes, which are often associated with increased market activity and potential trading opportunities. It compares the current day's volume with the highest volume of the previous nine sessions. If the current volume exceeds all the volumes of the previous nine sessions, it is considered a volume spurt.
Example:
Let's consider a hypothetical scenario where we have the following volume data for a stock:
Day 1: 100,000
Day 2: 80,000
Day 3: 120,000
Day 4: 150,000
Day 5: 200,000
Day 6: 90,000
Day 7: 110,000
Day 8: 130,000
Day 9: 140,000
Day 10: 250,000 (current day)
To determine if there is a volume spurt on Day 10, the script compares the current day's volume (250,000) with the highest volume of the previous nine sessions. In this case, the highest volume among the previous nine sessions is 200,000 (on Day 5). Since the current day's volume (250,000) exceeds the highest volume of the previous nine sessions (200,000), it is considered a volume spurt.
Identifying Gap-Up Days:
Gap-up days occur when the market opens significantly higher than the previous day's close. To identify these days, the script compares the current day's low price with the previous day's high price. If the low price is greater than the previous day's high, it is marked as a gap-up day.
Visualizing the Findings:
To provide a clear visual representation of the identified patterns, the script uses different shapes and colors. First, it plots small red dots above the candles whenever a volume spurt is detected. These dots help traders quickly identify periods of increased volume activity.
For price up moves with volume spikes, the script utilizes blue triangular shapes below the candles. This allows traders to pinpoint instances where both price and volume are showing positive signs, indicating potential bullish movements.
Additionally, the script incorporates green candles to represent gap-up days. These candles help traders recognize days when the market opens with a significant upward gap, suggesting a potential shift in market sentiment.
Conclusion:
The TradingView script discussed in this article provides traders with a visual representation of volume spikes , price up moves with volume spikes , and gap-up days . By incorporating these visual cues into their analysis, traders can gain valuable insights into market trends and potential trading opportunities.
Remember, this script should be used for educational and informational purposes only and does not serve as financial advice or recommendations. Traders are encouraged to customize and modify the script according to their specific trading strategies and risk tolerance.
Share this script with other traders on TradingView to enhance their chart analysis and trading decisions.
PS: This TradingView script is designed to work specifically on the daily timeframe (daily candles). It calculates and identifies volume spurts based on the volume data of the daily timeframe. Since it is designed for the daily timeframe, it may not produce accurate results or work as intended on other timeframes.

TooltipLibrary "Tooltip"
This library helps creating and managing nice looking data (key/value) tooltips that you can use for
labels. The tooltips data key/value will align automatically. It is optional to convert the data to a values only string too.
method addSpacesToKey(this)
Calculates the amount of spaces needed after the key to make it the key least 4 characters wide.
Namespace types: Data
Parameters:
this (Data) : (Data) The Data.
method addTabs(this, longestKeyLength)
Calculates the amount of tabs to be used.
Namespace types: Data
Parameters:
this (Data) : (Data) The Data.
longestKeyLength (int)
method longestKeyLength(this)
Returns the length of the longest key string in the array.
Namespace types: Data
Parameters:
this (Data ) : (Tooltip) The object to work with.
@return (int) The length of the key.
method toString(tooltips, withKey)
Helper function for the tooltip.
Namespace types: Data
Parameters:
tooltips (Data )
withKey (bool) : (bool) Wether to create a string with keys in it.
@return (string) The string
new()
Creates a new array to store tooltip data in
@return (Data) The data array.
Data
Key/Value pair for tooltips
Fields:
key (series string)
value (series string)
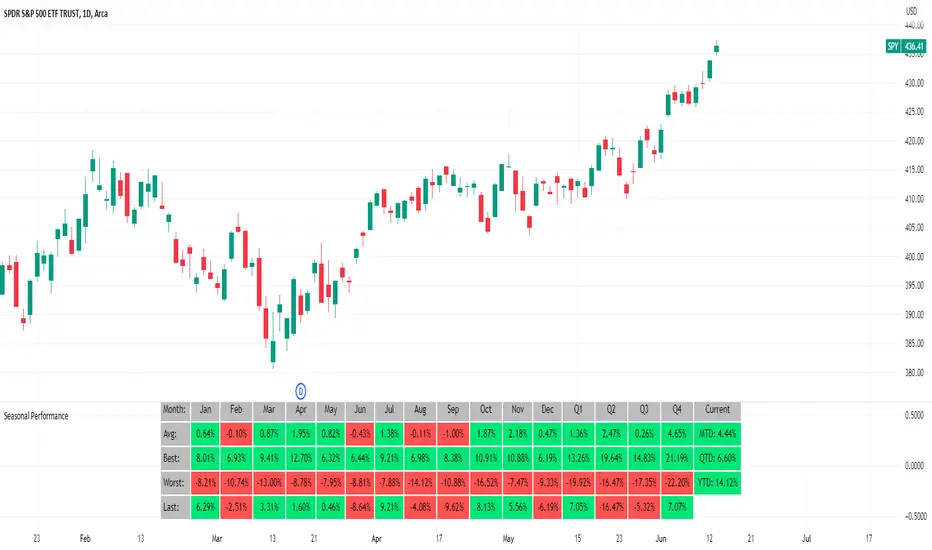
Seasonal Performance for Stocks & CryptoThe Seasonal Performance indicator quickly allows you to see if you are in a bullish or bearish time of year for an underlying security and where the current performance stacks up compared to the same time of year historically. Table is fully customizable from colors to what data to see.
Table Displays
Average Performance
Best Performance
Worst Performance
Last Performance
Current Performance
Note this indicator will only work with Stocks, ETF's, Index's or Crypto.
XAUXXXThis simple script is meant to get around the limitations some data providers have, in terms of the length of historical data they choose to provide traders. Inspired by OANDA's XAUCAD pair only having data as far back as 2005, whereas XAUUSD has data back to to the 19th century.
By taking the OHLC data from XAUUSD and multiplying it by the price of USD in a desired currency you are able to see further back in time, the limitation now being the length of FX data available instead of the price of Precious metal / currency pair. As shown in the chart you can now see the price of Gold in CAD as far back as the late 1960s, a nearly half century of data uncovered for all to see!

How To Import And Offset CSV DataExample method of how to import, offset, and plot CSV data using an array.
NOTICE: This is an example script and not meant to be used as an actual strategy. By using this script or any portion thereof, you acknowledge that you have read and understood that this is for research purposes only and I am not responsible for any financial losses you may incur by using this script!
Probabilities Module - The Quant Science This module can be integrate in your code strategy or indicator and will help you to calculate the percentage probability on specific event inside your strategy. The main goal is improve and simplify the workflow if you are trying to build a quantitative strategy or indicator based on statistics or reinforcement model.
Logic
The script made a simulation inside your code based on a single event. For single event mean a trading logic composed by three different objects: entry, take profit, stop loss.
The script scrape in the past through a look back function and return the positive percentage probability about the positive event inside the data sample. In this way you are able to understand and calculate how many time (in percentage term) the conditions inside the single event are positive, helping to create your statistical edge.
You can adjust the look back period in you user interface.
How can set up the module for your use case
At the top of the script you can find:
1. entry_condition : replace the default condition with your specific entry condition.
2. TPcondition_exit : replace the default condition with your specific take profit condition.
3. SLcondition_exit : replace the default condition with your specific stop loss condition.

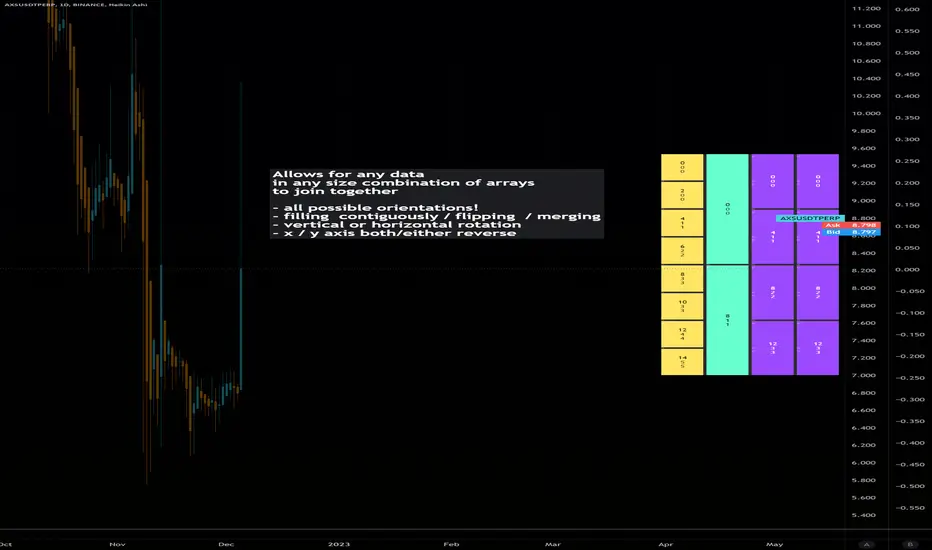
Dynamic Array Table (versatile display methods)Library "datTable"
Dynamic Array Table.... Configurable Shape/Size Table from Arrays
Allows for any data in any size combination of arrays to join together
with:
all possible orientations!
filling all cells contiguously and/or flipping at boundaries
vertical or horizontal rotation
x/y axis direction swapping
all types array inputs for data.
please notify of any bugs. thanks
init(_posit)
Get Table (otional gapping cells)
Parameters:
_posit : String or Int (1-9 3x3 grid L to R)
Returns: Table
coords()
Req'd coords Seperate for VARIP table, non-varip coords
add
Add arrays to display table. coords reset each calc
uses displaytable object, string titles, and color optional array, and second line optional data array.
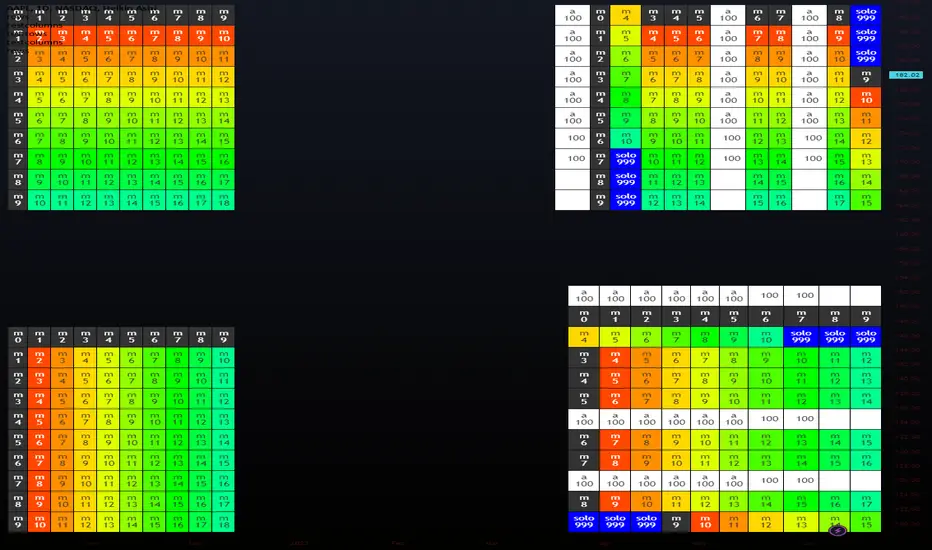
columnsLibrary "columns"
Error Tolerant Matrix Setter/Getter Operations. Easy ways to add/remove items into start and end of Columns as well as arrays to grow and shrink matrix.
if mismatched sizes occur the typified NA value will be there to prevent catastrophic crashing.
Rows and Columns are split into 2 libraries due to limitations on number of exports as well as ease of style (columns.shift(), rows.pop() )
pop(_matrix)
do pop last Column off of matrix
Parameters:
_matrix : Matrix To Edit
Returns: Array of Last Column, removing it from matrix
shift(_matrix)
do shift the first Column off of matrix
Parameters:
_matrix : Matrix To Edit
Returns: Array of First Column, removing it from matrix
get(_matrix, _clmnNum)
retrieve specific Column of matrix
Parameters:
_matrix : Matrix To Edit
_clmnNum : Column being Targeted
Returns: Array of selected Column number, leaving in place
push(_matrix, _clmnNum, _item)
add single item onto end of Column
Parameters:
_matrix : Matrix To Edit
_clmnNum : Column being Targeted
_item : Item to Push on Column
Returns: shifted item from Column start
push(_matrix, _array)
add single item onto end of matrix
Parameters:
_matrix : Matrix To Edit
_array : Array to Push on Matrix
Returns: Void
unshift(_matrix, _clmnNum, _item)
slide single item into start of Column remove last
Parameters:
_matrix : Matrix To Edit
_clmnNum : Column being Targeted
_item : Item to Unshift on Column
Returns: popped item from Column end
unshift(_matrix, _array)
add single item into first Column of matrix
Parameters:
_matrix : Matrix To Edit
_array : Array to unshift into Matrix
Returns: Void
set(_matrix, _clmnNum, _array)
replace an array to an existing Column
Parameters:
_matrix : Matrix To Edit
_clmnNum : Column being Targeted
_array : Array to place in Matrix
Returns: Column that was replaced
insert(_matrix, _clmnNum, _array)
insert an array to a new Column
Parameters:
_matrix : Matrix To Edit
_clmnNum : Column being Targeted
_array : Array to place in Matrix
Returns: void
slideDown(_matrix, _array)
add single item onto end of Column
Parameters:
_matrix : Matrix To Edit
_array : Array to push to Matrix
Returns: shifted first Column
slideUp(_matrix, _array)
add single item onto end of Column
Parameters:
_matrix : Matrix To Edit
_array : Array to unshift to Matrix
Returns: poppeed last Column
pullOut(_matrix, _clmnNum)
add single item onto end of Column
Parameters:
_matrix : Matrix To Edit
_clmnNum : Column being Targeted
Returns: removed selected Column

rowsLibrary "rows"
Error Tolerant Matrix Setter/Getter Operations. Easy ways to add/remove items into start and end of rows as well as arrays to grow and shrink matrix.
if mismatched sizes occur the typified NA value will be there to prevent catastrophic crashing.
columns and rows are split into 2 libraries due to limitations on number of exports as well as ease of style (columns.shift(), rows.pop() )
pop(_matrix)
do pop last row off of matrix
Parameters:
_matrix : Matrix To Edit
Returns: Array of Last row, removing it from matrix
shift(_matrix)
do shift the first row off of matrix
Parameters:
_matrix : Matrix To Edit
Returns: Array of First row, removing it from matrix
get(_matrix, _rowNum)
retrieve specific row of matrix
Parameters:
_matrix : Matrix To Edit
_rowNum : Row being Targeted
Returns: Array of selected row number, leaving in place
push(_matrix, _rowNum, _item)
add single item onto end of row
Parameters:
_matrix : Matrix To Edit
_rowNum : Row being Targeted
_item : Item to Push on Row
Returns: shifted item from row start
push(_matrix, _array)
add single item onto end of matrix
Parameters:
_matrix : Matrix To Edit
_array : Array to Push on Matrix
Returns: Void
unshift(_matrix, _rowNum, _item)
slide single item into start of row remove last
Parameters:
_matrix : Matrix To Edit
_rowNum : Row being Targeted
_item : Item to Unshift on Row
Returns: popped item from row end
unshift(_matrix, _array)
add single item into first row of matrix
Parameters:
_matrix : Matrix To Edit
_array : Array to unshift into Matrix
Returns: Void
set(_matrix, _rowNum, _array)
replace an array to an existing row
Parameters:
_matrix : Matrix To Edit
_rowNum : Row being Targeted
_array : Array to place in Matrix
Returns: row that was replaced
insert(_matrix, _rowNum, _array)
insert an array to a new row
Parameters:
_matrix : Matrix To Edit
_rowNum : Row being Targeted
_array : Array to place in Matrix
Returns: void
slideDown(_matrix, _array)
add single item onto end of row
Parameters:
_matrix : Matrix To Edit
_array : Array to push to Matrix
Returns: shifted first row
slideUp(_matrix, _array)
add single item onto end of row
Parameters:
_matrix : Matrix To Edit
_array : Array to unshift to Matrix
Returns: popped last row
pullOut(_matrix, _rowNum)
add single item onto end of row
Parameters:
_matrix : Matrix To Edit
_rowNum : Row being Targeted
Returns: removed selected row
FUNCTION: Limited Historical Data WorkaroundFUNCTION: Limited Historical Data Workaround
If you are working with bitcoin weekly charts, or any other ticker with a low amount of price history this function may help you out. For example you want to apply indicators to some shitcoin that just launched? This can help you.
It can be frustrating to use certain built-ins since they will only give an output once the full lookback length is available. This function allows you to avoid that situation and start plotting things with almost no history whatsoever!
In this example code we do it by utilizing a replacement for the built in pine SMA function. This function allows us to pass a series instead of just a simple int to the length variable of the SMA. This can be achieved with all the pine built ins and I believe @pinecoders has a publication already detailing many of them with full coded examples.
Then we replace the length of the SMA with the custom history function. It checks to see if the current bar index is less than the length of the function. Then if it is, it changes the length to the bar index allowing us to get plots and series earlier than otherwise possible.
