Indicators OverlayHello All,
This script shows the indicators in separate windows on the main chart. Included indicators are RSI, CCI, OBV, Stochastic, Money Flow Index, Average True Range and Chande Momentum Oscillator. indicator windows are located at the top or bottom of the chart according to last moves of the Closing price. Different colors are used for each indicator. Horizontal levels are shown as dashed line and label as well.
Using the options;
You can enable/disable the indicators you want to see or not
You can change source and length for each indicator
You can set window length. using this length indicator windows are located on the chart
After you added this indicator to your chart I recommend: right click on any of the indicator windows => "Visual Order" => "Bring to front" as seen screenshot below:
in this example only 3 indicators enabled and period is set as 80:
indicator windows moves to the top or bottom of the chart according to the close price:
P.S. if you want to see any other indicator in the options then leave a comment under the indicator ;)
Enjoy!
Indicators and strategies

Realtime 5D Profile [LucF]█ OVERVIEW
This indicator displays a realtime profile that can be configured to visualize five dimensions: volume, price, time, activity and age. For each price level in a bar or timeframe, you can display total or delta volume or ticks. The tick count measures activity on a level. The thickness of each level's line indicates its age, which helps you identify the most recent levels.
█ WARNING
The indicator only works in real time. Contrary to TradingView's line of volume profile indicators , it does not show anything on historical bars or closed markets, and it cannot display volume information if none exists for the data feed the chart is using. A realtime indicator such as this one only displays information accumulated while it is running on a chart. The information it calculates cannot be saved on charts, nor can it be recalculated from historical bars. If you refresh the chart, or the script must re-execute for some reason, as when you change inputs, the accumulated information will be lost.
Because "Realtime 5D Profile" requires time to accumulate information on the chart, it will be most useful to traders working on small timeframes who trade only one instrument and do not frequently change their chart's symbol or timeframe. Traders working on higher timeframes or constantly changing charts will be better served by TradingView's volume profiles. Before using this indicator, please see the "Limitations" section further down for other important information.
█ HOW TO USE IT
Load the indicator on an active chart (see here if you don't know how).
The default configuration displays:
• A double-sided volume profile showing at what price levels activity has occurred.
• The left side shows "down" volume, the right side shows "up" volume.
• The value corresponding to each level is displayed.
• The width of lines reflects their relative value.
• The thickness of lines reflects their age. Four thicknesses are used, with the thicker lines being the most recent.
• The total value of down/up values for the profile appears at the top.
To understand how to use profiles in your trading, please research the subject. Searches on "volume profile" or "market profile" will yield many useful results. I provide you with tools — I do not teach trading. To understand more about this indicator, read on. If you choose not to do so, please don't ask me to answer questions that are already answered here, nor to make videos; I don't.
█ CONCEPTS
Delta calculations
Volume is slotted in up or down slots depending on whether the price of each new chart update is higher or lower than the previous update's price. When price does not move between chart updates, the last known direction is used. In a perfect world, Pine scripts would have access to bid and ask levels, as this would allow us to know for sure if market orders are being filled on upticks (at the ask) or downticks (at the bid). Comparing the price of successive chart updates provides the most precise way to calculate volume delta on TradingView, but it is still a compromise. Order books are in constant movement; in some cases, order cancellations can cause sudden movements of both the bid and ask levels such that the next chart update can occur on an uptick at a lower price than the previous one (or vice versa). While this update's volume should be slotted in the up slot because a buy market order was filled, it will erroneously be slotted in the down slot because the price of the chart's update is lower than that of the previous one. Luckily, these conditions are relatively rare, so they should not adversely affect calculations.
Levels
A profile is a tool that displays information organized by price levels. You can select the maximum quantity of levels this indicator displays by using the script's "Levels" input. If the profile's height is small enough for level increments to be less than the symbol's tick size, a smaller quantity of levels is used until the profile's height grows sufficiently to allow your specified quantity of levels to be displayed. The exact position of levels is not tethered to the symbol's tick increments. Activity for one level is that which happens on either side of the level, halfway between its higher or lower levels. The lowest/highest levels in the profile thus appear higher/lower than the profile's low/high limits, which are determined by the lowest/highest points reached by price during the profile's life.
Level Values and Length
The profile's vertical structure is dynamic. As the profile's height changes with the price range, it is rebalanced and the price points of its levels may be recalculated. When this happens, past updates will be redistributed among the new profile's levels, and the level values may thus change. The new levels where updates are slotted will of course always be near past ones, but keep this fluidity in mind when watching level values evolve.
The profile's horizontal structure is also dynamic. The maximum length of level lines is controlled by the "Maximum line length" input value. This maximum length is always used for the largest level value in the profile, and the length of other levels is determined by their value relative to that maximum.
Updates vs Ticks
Strictly speaking, a tick is the record of a transaction between two parties. On TradingView, these are detected on seconds charts. On other charts, ticks are aggregated to form a chart update . I use the broader "update" term when it names both events. Note that, confusingly, tick is also used to name an instrument's minimal price increment.
Volume Quality
If you use volume, it's important to understand its nature and quality, as it varies with sectors and instruments. My Volume X-ray indicator is one way you can appraise the quality of an instrument's intraday volume.
█ FEATURES
Double-Sided Profiles
When you choose one of the first two configuration selections in the "Configuration" field's dropdown menu, you are asking the indicator to display a double-sided profile, i.e., where the down values appear on the left and the up ones on the right. In this mode, the formatting options in the top section of inputs apply to both sides of the profile.
Single-Sided Profiles
The six other selections down the "Configuration" field's dropdown menu select single-sided profiles, where one side aggregates the up/down values for either volume or ticks. In this mode, the formatting options in the top section of inputs apply to the left profile. The ones in the following "Right format" section apply to the right profile.
Calculation Mode
The "Calculation" input field allows the selection of one of two modes which applies to single-sided profiles only. Values can represent the simple total of volume or ticks at each level, or their delta. The mode has no effect when a double-sided profile is used because then, the total is represented by the sum of the left and right sides. Note that when totals are selected, all levels appear in the up color.
Age
The age of each level is always displayed as one of four line thicknesses. Thicker lines are used for the youngest levels. The age of levels is determined by averaging the times of the updates composing that level. When viewing double-sided profiles, the age of each side is calculated independently, which entails you can have a down level on the left side of the profile appear thinner than its corresponding up side level line on the right side because the updates composing the up side are more recent. When calculating the age of single-sided profiles, the age of the up/down values aggregated to calculate the side are averaged. Since they may be different, the averaged level ages will not be as responsive as when using a double-sided profile configuration, where the age of levels on each side is calculated independently and follows price action more closely. Moreover, when displaying two single-sided profiles (volume on one side and ticks on the other), the age of both sides will match because they are calculated from the same realtime updates.
Profile Resets
The profile can reset on timeframes or trend changes. The usual timeframe selections are available, including the chart's, in which case the profile will reset on each new chart bar. One of two trend detection logics can be used: Supertrend or the one used by LazyBear in his Weis Wave indicator . Settings for the trend logics are in the bottommost section of the inputs, where you can also control the display of trend changes and states. Note that the "Timeframe" field's setting also applies to the trend detection mechanism. Whatever the timeframe used for trend detection, its logic will not repaint.
Format
Formatting a profile for charts is often a challenge for traders, and this one is no exception. Varying zoom factors on your chart and the frequency of profile resets will require different profile formats. You can achieve a reasonable variety of effects by playing with the following input fields:
• "Resets on" controls how frequently new profiles are drawn. Spacing out profiles between bars can help make them more usable.
• "Levels" determines the maximum quantity of levels displayed.
• "Offset" allows you to shift the profile horizontally.
• "Profile size" affects the global size of the profile.
• Another "Size" field provides control over the size of the totals displayed above the profile.
• "Maximum line length" controls how far away from the center of the bar the lines will stretch left and right.
Colors
The color and brightness of levels and totals always allows you to determine the winning side between up and down values. On double-sided profiles, each side is always of one color, since the left side is down values and the right side, up values. However, the losing side is colored with half its brightness, so the emphasis is put on the winning side. When there is no winner, the toned-down version of each color is used for both sides. Single-sided profiles use the up and down colors in full brightness on the same side. Which one is used reflects the winning side.
Candles
The indicator can color candle bodies and borders independently. If you choose to do so, you may want to disable the chart's bars by using the eye icon near the symbol's name.
Tooltips
A tooltip showing the value of each level is available. If they do not appear when hovering over levels, select the indicator by clicking on its chart name. This should get the tooltips working.
Data Window
As usual, I provide key values in the Data Window, so you can track them. If you compare total realtime volumes for the profile and the built-in "Volume" indicator, you may see variations at some points. They are due to the different mechanisms running each program. In my experience, the values from the built-in don't always update as often as those of the profile, but they eventually catch up.
█ LIMITATIONS
• The levels do not appear exactly at the position they are calculated. They are positioned slightly lower than their actual price levels.
• Drawing a 20-level double-sided profile with totals requires 42 labels. The script will only display the last 500 labels,
so the number of levels you choose affects how many past profiles will remain visible.
• The script is quite taxing, which will sometimes make the chart's tab less responsive.
• When you first load the indicator on a chart, it will begin calculating from that moment; it will not take into account prior chart activity.
• If you let the script run long enough when using profile reset criteria that make profiles last for a long time, the script will eventually run out of memory,
as it will be tracking unmanageable amounts of chart updates. I don't know the exact quantity of updates that will cause this,
but the script can handle upwards of 60K updates per profile, which should last 1D except on the most active markets. You can follow the number of updates in the Data Window.
• The indicator's nature makes it more useful at very small timeframes, typically in the sub 15min realm.
• The Weis Wave trend detection used here has nothing to do with how David Weis detects trend changes.
LazyBear's version was a port of a port, so we are a few generations removed from the Weis technique, which uses reversals by a price unit.
I believe the version used here is useful nonetheless because it complements Supertrend rather well.
█ NOTES
The aggregated view that volume and tick profiles calculate for traders is a good example of one of the most useful things software can do for traders: look at things from a methodical, mathematical perspective, and present results in a meaningful way. Profiles are powerful because, if the volume data they use is of good enough quality, they tell us what levels are important for traders, regardless of the nature or rationality of the methods traders have used to determine those levels. Profiles don't care whether traders use the news, fundamentals, Fib numbers, pivots, or the phases of the moon to find "their" levels. They don't attempt to forecast or explain markets. They show us real stuff containing zero uncertainty, i.e., what HAS happened. I like this.
The indicator's "VPAA" chart name represents four of the five dimensions the indicator displays: volume, price, activity and age. The time dimension is implied by the fact it's a profile — and I couldn't find a proper place for a "T" in there )
I have not included alerts in the script. I may do so in the future.
For the moment, I have no plans to write a profile indicator that works on historical bars. TradingView's volume profiles already do that, and they run much faster than Pine versions could, so I don't see the point in spending efforts on a poor ersatz.
For Pine Coders
• The script uses labels that draw varying quantities of characters to break the limitation constraining other Pine plots/lines to bar boundaries.
• The code's structure was optimized for performance. When it was feasible, global arrays, "input" and other variables were used from functions,
sacrificing function readability and portability for speed. Code was also repeated in some places, to avoid the overhead of frequent function calls in high-traffic areas.
• I wrote my script using the revised recommendations in the Style Guide from the Pine v5 User Manual.
█ THANKS
• To Duyck for his function that sorts an array while keeping it in synch with another array.
The `sortTwoArrays()` function in my script is derived from the Pine Wizard 's code.
• To the one and only Maestro, RicardoSantos , the creative volcano who worked hard to write a function to produce fixed-width, figure space-padded numeric values.
A change in design made the function unnecessary in this script, but I am grateful to you nonetheless.
• To midtownskr8guy , another Pine Wizard who is also a wizard with colors. I use the colors from his Pine Color Magic and Chart Theme Simulator constantly.
• Finally, thanks to users of my earlier "Delta Volume" scripts. Comments and discussions with them encouraged me to persist in figuring out how to achieve what this indicator does.

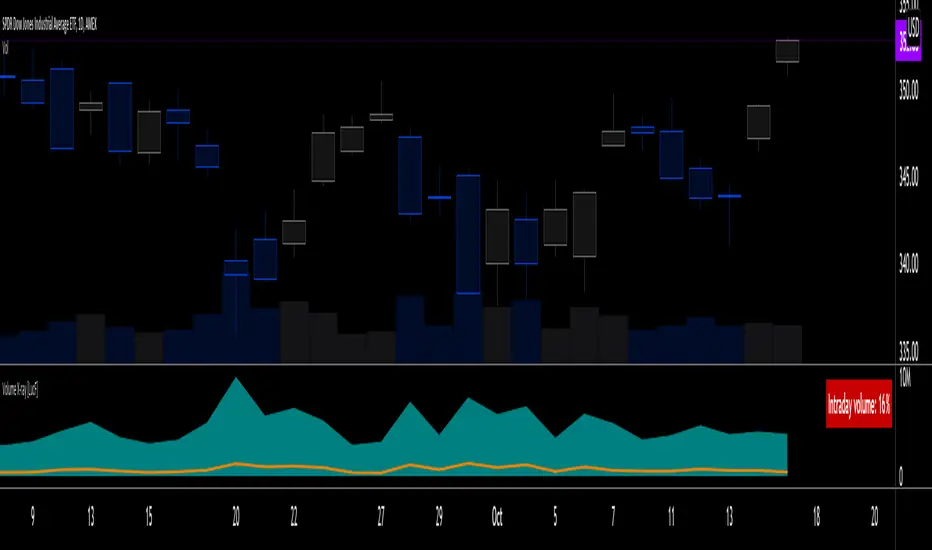
Volume X-ray [LucF]█ OVERVIEW
This tool analyzes the relative size of volume reported on intraday vs EOD (end of day) data feeds on historical bars. If you use volume data to make trading decisions, it can help you improve your understanding of its nature and quality, which is especially important if you trade on intraday timeframes.
I often mention, when discussing volume analysis, how it's important for traders to understand the volume data they are using: where it originates, what it includes and does not include. By helping you spot sizeable differences between volume reported on intraday and EOD data feeds for any given instrument, "Volume X-ray" can point you to instruments where you might want to research the causes of the difference.
█ CONCEPTS
The information used to build a chart's historical bars originates from data providers (exchanges, brokers, etc.) who often maintain distinct historical feeds for intraday and EOD timeframes. How volume data is assembled for intraday and EOD feeds varies with instruments, brokers and exchanges. Variations between the two feeds — or their absence — can be due to how instruments are traded in a particular sector and/or the volume reporting policy for the feeds you are using. Instruments from crypto and forex markets, for example, will often display similar volume on both feeds. Stocks will often display variations because block trades or other types of trades may not be included in their intraday volume data. Futures will also typically display variations. It is even possible that volume from different feeds may not be of the same nature, as you can get trade volume (market volume) on one feed and tick volume (transaction counts) on another. You will sometimes be able to find the details of what different feeds contain from the technical information provided by exchanges/brokers on their feeds. This is an example for the NASDAQ feeds . Once you determine which feeds you are using, you can look for the reporting specs for that feed. This is all research you will need to do on your own; "Volume X-ray" will not help you with that part.
You may elect to forego the deep dive in feed information and simply rely on the figure the indicator will calculate for the instruments you trade. One simple — and unproven — way to interpret "Volume X-ray" values is to infer that instruments with larger percentages of intraday/EOD volume ratios are more "democratic" because at intraday timeframes, you are seeing a greater proportion of the actual traded volume for the instrument. This could conceivably lead one to conclude that such volume data is more reliable than on an instrument where intraday volume accounts for only 3% of EOD volume, let's say.
Note that as intraday vs EOD variations exist for historical bars on some instruments, there will typically also be differences between the realtime feeds used on intraday vs 1D or greater timeframes for those same assets. Realtime reporting rules will often be different from historical feed reporting rules, so variations between realtime feeds will often be different from the variations between historical feeds for the same instrument. A deep dive in reporting rules will quickly reveal what a jungle they are for some instruments, yet it is the only way to really understand the volume information our charts display.
█ HOW TO USE IT
The script is very simple and has no inputs. Just add it to 1D charts and it will calculate the proportion of volume reported on the intraday feed over the EOD volume. The plots show the daily values for both volumes: the teal area is the EOD volume, the orange line is the intraday volume. A value representing the average, cumulative intraday/EOD volume percentage for the chart is displayed in the upper-right corner. Its background color changes with the percentage, with brightness levels proportional to the percentage for both the bull color (% >= 50) or the bear color (% < 50). When abnormal conditions are detected, such as missing volume of one kind or the other, a yellow background is used.
Daily and cumulative values are displayed in indicator values and the Data Window.
The indicator loads in a pane, but you can also use it in overlay mode by moving it on the chart with "Move to" in the script's "More" menu, and disabling the plot display from the "Settings/Style" tab.
█ LIMITATIONS
• The script will not run on timeframes >1D because it cannot produce useful values on them.
• The calculation of the cumulative average will vary on different intraday timeframes because of the varying number of days covered by the dataset.
Variations can also occur because of irregularities in reported volume data. That is the reason I recommend using it on 1D charts.
• The script only calculates on historical bars because in real time there is no distinction between intraday and EOD feeds.
• You will see plenty of special cases if you use the indicator on a variety of instruments:
• Some instruments have no intraday volume, while on others it's the opposite.
• Missing information will sometimes appear here and there on datasets.
• Some instruments have higher intraday than EOD volume.
Please do not ask me the reasons for these anomalies; it's your responsibility to find them. I supply a tool that will spot the anomalies for you — nothing more.
█ FOR PINE CODERS
• This script uses a little-known feature of request.security() , which allows us to specify `"1440"` for the `timeframe` argument.
When you do, data from the 1min intrabars of the historical intraday feed is aggregated over one day, as opposed to the usual EOD feed used with `"D"`.
• I use gaps on my request.security() calls. This is useful because at intraday timeframes I can cumulate non- na values only.
• I use fixnan() on some values. For those who don't know about it yet, it eliminates na values from a series, just like not using gaps will do in a request.security() call.
• I like how the new switch structure makes for more readable code than equivalent if structures.
• I wrote my script using the revised recommendations in the Style Guide from the Pine v5 User Manual.
• I use the new runtime.error() to throw an error when the script user tries to use a timeframe >1D.
Why? Because then, my request.security() calls would be returning values from the last 1D intrabar of the dilation of the, let's say, 1W chart bar.
This of course would be of no use whatsoever — and misleading. I encourage all Pine coders fetching HTF data to protect their script users in the same way.
As tool builders, it is our responsibility to shield unsuspecting users of our scripts from contexts where our calcs produce invalid results.
• While we're on the subject of accessing intrabar timeframes, I will add this to the intention of coders falling victim to what appears to be
a new misconception where the mere fact of using intrabar timeframes with request.security() is believed to provide some sort of edge.
This is a fallacy unless you are sending down functions specifically designed to mine values from request.security() 's intrabar context.
These coders do not seem to realize that:
• They are only retrieving information from the last intrabar of the chart bar.
• The already flawed behavior of their scripts on historical bars will not improve on realtime bars. It will actually worsen because in real time,
intrabars are not yet ordered sequentially as they are on historical bars.
• Alerts or strategy orders using intrabar information acquired through request.security() will be using flawed logic and data most of the time.
The situation reminds me of the mania where using Heikin-Ashi charts to backtest was all the rage because it produced magnificent — and flawed — results.
Trading is difficult enough when doing the right things; I hate to see traders infected by lethal beliefs.
Strive to sharpen your "herd immunity", as Lionel Shriver calls it. She also writes: "Be leery of orthodoxy. Hold back from shared cultural enthusiasms."
Be your own trader.
█ THANKS
This indicator would not exist without the invaluable insights from Tim, a member of the Pine team. Thanks Tim!
TASC 2021.11 MADH Moving Average Difference, Hann█ OVERVIEW
Presented here is code for the "Moving Average Difference, Hann" indicator originally conceived by John Ehlers. The code is also published in the November 2021 issue of Trader's Tips by Technical Analysis of Stocks & Commodities (TASC) magazine.
█ CONCEPTS
By employing a Hann windowed finite impulse response filter (FIR), John Ehlers has enhanced the Moving Average Difference (MAD) to provide an oscillator with exceptional smoothness.
Of notable mention, the wave form of MADH resembles Ehlers' "Reverse EMA" Indicator, formerly revealed in the September 2017 issue of TASC. Many variations of the "Reverse EMA" were published in TradingView's Public Library.
█ FEATURES
Three values in the script's "Settings/Inputs" provide control over the oscillators behavior:
• The price source
• A "Short Length" with a default of 8, to manage the lower band edge of the oscillator
• The "Dominant Cycle", originally set at 27, which appears to be a placeholder for an adaptive control mechanism
Two coloring options are provided for the line's fill:
• "ZeroCross", the default, uses the line's position above/below the zero level. This is the mode used in the top version of MADH on this chart.
• "Momentum" uses the line's up/down state, as shown in the bottom version of the indicator on the chart.
█ NOTES
Calculations
The source price is used in two independent Hann windowed FIR filters having two different periods (lengths) of historical observation for calculation, one being a "Short Length" and the other termed "Dominant Cycle". These are then passed to a "rate of change" calculation and then returned by the reusable function. The secret sauce is that a "windowed Hann FIR filter" is superior tp a generic SMA filter, and that ultimately reveals Ehlers' clever enhancement. We'll have to wait and see what ingenuities Ehlers has next to unleash. Stay tuned...
The `madh()` function code was optimized for computational efficiency in Pine, differing visibly from Ehlers' original formula, but yielding the same results as Ehlers' version.
Background
This indicator has a sibling indicator discussed in the "The MAD Indicator, Enhanced" article by Ehlers. MADH is an evolutionary update from the prior MAD indicator code published in the October 2021 issue of TASC.
Sibling Indicators
• Moving Average Difference (MAD)
• Cycle/Trend Analytics
Related Information
• Cycle/Trend Analytics And The MAD Indicator
• The Reverse EMA Indicator
• Hann Window
• ROC
Join TradingView!

Divergence-Support/ResistenceAnother script based on zigzag, divergence, and to yield support and resistence levels.
This idea started with below two concepts:
▶ Support and resistence are simply levels where price has rejected to go further down or up. Usually, we can derive this based on pivots. But, if we start looking at every pivot, there will be many of them and may be confusing to understand which one to consider.
▶ Lot of people asked about one of my previous script on divergence detector on how to use it. I believe divergence should be considered as area of support and resistence because, they only amount to temporary weakness in momentum and nothing more. As per my understanding
Trend > Hidden Divergence > Divergence > Oscillator Levels of Overbought and Oversold
⬜ Process
▶ Now combining the above two concepts - what we are trying to do here is draw support resistence lines only on pivots which has observed either divergence or hidden divergence. Continuation and indecision pivots are ignored.
▶ Input requires only few parameters.
Zigzag lengths and oscillator to be used. Oscillator periods are automatically calculated based on zigzag length. Hence no other information required. You can also chose custom oscillator via external source.
▶ Display include horizontal lines of support/resistence which are drawn from the candle from where divergence or hidden divergence is detected.
▶ Support resistence lines are colored based on divergence. Green shades for bullish divergence and bullish hidden divergence whereas red shades for bearish divervence and bearish hidden divergence. Please note, red and green lines does not mean they only provide resistence or support. Any lines which are below the price should be treated as support and any line which are above the price should be treated as resistence.
▶ Divergence symbols are also printed on the bar from where divergence/hidden divergence is detected.
↗ - Bullish Hidden Divergence
↘ - Bearish Hidden Divergence
⤴ - Bullish Divergence
⤵ - Bearish Divergence
▶ Script also demonstrates usage of libraries effectively. I have used following libraries in this code.
import HeWhoMustNotBeNamed/ zigzag /2 as zg
import HeWhoMustNotBeNamed/enhanced_ta/8 as eta
import HeWhoMustNotBeNamed/ supertrend /4 as st
Can be good combination to use it with harmonic patterns.

CAGR Custom Range█ OVERVIEW
This script calculates an annualized Compound Annual Growth Rate from two points in time which you can select on the chart. It previews an upcoming feature where Pine scripts will be able to provide users with interactive inputs for time and price values.
👉🏼 We are looking for feedback on our first take of this feature.
Please comment in this publication's "Comments" section if you have suggestions for improvement.
█ HOW TO USE IT
When you first load this script on a chart, you will enter the new interactive selection mode. At that point, the script is waiting for you to pick two points in time on your chart by clicking on the chart. Once you select the two points, the script will find the close value for each of the two selected bars, and calculate the CAGR value from them. It will then display a line between the two points, and the CAGR value above or below the last point in time.
If the CAGR value is positive, the line and label will display in their "up" color (see the "🠅" color in the script's "Settings/Inputs" tab), otherwise they appear in their "down" color (the "🠇" color in the inputs). You can also control the line's width from the inputs.
You have the option of comparing the chart's CAGR value with that of another symbol, which you specify in the "Compare to" input. When a comparison is made, the label's background color will be dependent on the result of the comparison. The line's color will still be determined by the chart's value.
Once time points have been selected on the chart and the script is displaying the line, you can change the time points by clicking on the script's name on the chart. A small, blue rectangular handle will then appear for each point, which you can then grab and move. If you reset the inputs using the "Defaults/Reset Settings" button in the script's inputs, the two time points will reset to the beginning of September and October 2021, respectively.
█ CONCEPTS
The CAGR is a notional, annualized growth rate that assumes all profits are reinvested. It calculates from the close value of the two end points. It does not account for drawdowns, so it does not calculate risk. It can be used as a yardstick to compare the performance of two instruments. Because it annualizes values, the function requires a minimum of one day between the two end points (annualizing returns over smaller periods of times doesn't produce very meaningful figures).
█ LIMITATIONS
• The two selected points must be distant from a minimum of one day. A runtime error will occur otherwise.
• There is currently no way to restart the interactive mode from scratch without re-adding the script to the chart.
• The points in time you select on one chart may map quite differently on other charts,
depending on their constituent bars (e.g., intraday charts for 24x7 and conventional markets).
█ FOR PINE CODERS
• Our script uses the most recent version of Pine, as the `//@version=5` compiler directive indicates.
• Interactive inputs were a long-standing and highly-requested feature by our beloved community of Pine coders.
We hope you find this first step promising, as it opens up entirely new possibilities for both Pine coders and script users.
You can, for example, use interactive inputs to draw shapes with your scripts, or support and resistance levels, etc.
We're sure you'll come up with more creative uses of the feature than we could ever dream up )
• Interactive inputs are implemented for input.time() and input.price() , the specialized input functions now available in v5.
See the User Manual's new page on inputs for more information about them.
You can also create one interactive input for both time and price values
by using the same `inline` argument in a pair of input.time() and input.price() function calls.
• Our min/max filtering when initializing `entryTime` and `exitTime` will handle cases where
the script user inverts the two points on the chart.
• The script uses the new runtime.error() function to throw an error in the `if days < 1` conditional structure.
• We use the `cagr()` function from our recently-published ta Pine library .
Pine libraries — not to be confused with the Public Library showcasing scripts published by our community of Pine coders —
are one of the new features available with the recent Pine v5.
• Note that our `strRightOf()` function cannot be used to generate ticker identifier strings for use in `request.*()` functions.
This is because it produces results of "series" form while the functions require
arguments of "simple" form for their `symbol` or `ticker` parameters.
Have a look at our new User Manual page on Pine's Type system if you need to brush up on Pine forms and types.
• We use a simple, repainting request.security() call because our calculations are not used to generate orders or alerts.
• We document our user-defined functions using the same compiler directives used in exported functions in libraries.
It will make conversion of those functions to library format easier if we ever choose to do so.
• We use two Unicode hair spaces (U+200A) to push the "%" sign slightly away from values in our str.format() calls.
While the impact is minimal, it increases readability.
• Note the `priceIsHigh` logic used to determine if we place the label above or below bars.
When price is higher than recent prices, we place the label above the bar, otherwise we place it below.
It's not foolproof but it provides optimal positioning most of the time.
• The point of the complicated "bool" expression initializing `displayCAGR` is to ensure that we only draw the line and labels once.
When no comparison with another symbol is made, this occurs the first time we encounter a non- na value from the `cagr()` function.
When a comparison is required, it occurs the first time both values are not na .
• Before all mentions of "CAGR" in our description, we use a Unicode zero-width space (U+200B)
to prevent the auto-linking feature to kick in for the term.
This prevents the dashed underscore and a link like this (CAGR) from appearing every time "CAGR" is mentioned.
• With Pine v5, the `study()` declaration statement was renamed to indicator() .
Accordingly, we will be eliminating the use of the "study" term from documentation and the UI.
The generic "script" term will continue to designate Pine code that can be an indicator, a strategy or a library, when applicable.
• We followed our new Style guide recommendations to write our script.
• We used the techniques explained in the How We Write and Format Script Descriptions publication by PineCoders.
• That's it! We've covered all the new features and tricks we used. We sincerely hope you enjoy the new interactive inputs,
and please remember to comment here if you have suggestions for improvement. 💙
Look first. Then leap.

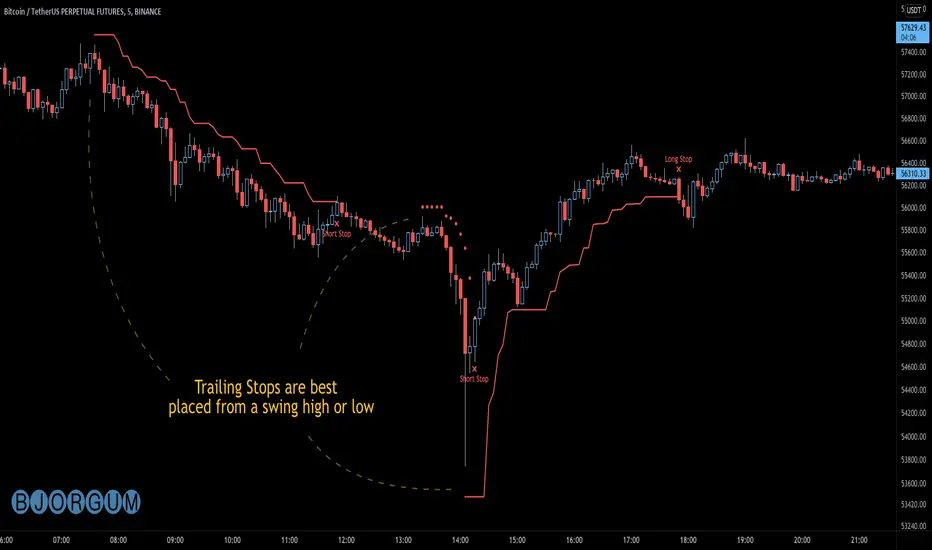
Bjorgum AutoTrailOne Time Trade Risk Management
Incorporating the new interactive feature, this script is meant as a one time trailing stop for the active trader to manage positional risk of an ongoing trade. As a crypto trader or Fx trader, many may find themselves in a position late into the evening, or perhaps daily life is calling while a trade progresses in their favor. Adding a trailing stop to a position thats trending can help to keep you in the trade and lock in gains if things turn around when you are unable to react.
To use the trail, the user would add the script to the chart. Once added, a set of crosshairs will appear allowing the user to choose a point to begin. Often choosing to start a trail from a swing high/ low can be an ideal option. This tends to provide some protection for a stop by placing it under support for a long trade or above resistance for a short trade.
Price based trail
The trail will automatically plot and the offset is a factor of the distance from price action selected by the crosshairs. If placed above price action the script will plot a short trail, if placed below it will trail for a long position.
Additionally, there are several other trail types other than price based. There is also percent based, which offsets the trail as a percent from close. A hard stop is placed at the cross hair value, then once the distance is exceeded by the percentage specified, the trail begins.
There are 2 more volatility based trails. There is a PSAR trail which can provide quicker and tighter stops that accelerate with the trend locking in gains faster, and an ATR trail that keeps a distance from price action as a function of volatility. Volatility levels can be adjusted from the menu.
Volatility based trail (ATR)
Volatility based trail (PSAR)
Lastly, within the code for more the more technical savvy, is some starting setups for string alerts to be sent to exchanges via 3rd party or custom API applications. Some string manipulation is required for specific providers to meet their requirements, but there is some building block alerts that will take the ticker symbol, recognize the asset your trading (Fx, Crypto, etc) and take input quantity or exchange names from the settings via inputs.
Complex strings can be built to perform almost any trade related task when to comes to alerts via web hook. A little setup this way with some technology to back your system can mean a semi-automated half man, half machine setup that actually manages your trail stop while you cannot. For those that don’t go this far, there is some basic alert functionality that well trigger when a trail is hit so you can react and make a decision.
Please note that for now, interactive mode is engaged only when the script is added to the chart. Additional stops, or for adjustments to be made it is best to add a new version. Also as real trades could be at play managing an actual position, alerts are designed to go off only once to ensure no duplicate orders are sent meaning alerts are not reoccurring. Once an alert is triggered, a new trail is to be set up.
A modified version of the TradingView built in SAR equation was used in this script. To provide the value of the SAR on the stop candle, it was necessary to alter the equation to extract this value as the regular SAR “flips” at this point. Thank you to TradingView for supplying access to the built in formula so that this SAR could behave the same as the built-in function outside of these alterations
Example of SAR value maintained in trigger candle
Cheers and happy trading.
Liquidity Levels [LuxAlgo]The Peak Activity Levels indicator displays support and resistance levels from prices accompanied by significant volume. The indicator includes a histogram returning the frequency of closing prices falling between two parallel levels, each bin shows the number of bullish candles within the levels.
1. Settings
Length: Lookback for the detection of volume peaks.
Number Of Levels: Determines the number of levels to display.
Levels Color Mode: Determines how the levels should be colored. "Relative" will color the levels based on their location relative to the current price. "Random" will apply a random color to each level. "Fixed" will use a single color for each level.
Levels Style: Style of the displayed levels. Styles include solid, dashed, and dotted.
1.1 Histogram
Show Histogram: Determines whether to display the histogram or not.
Histogram Window: Lookback period of the histogram calculation.
Bins Colors: Control the color of the histogram bins.
2. Usage
The indicator can be used to display ready-to-use support and resistance. These are constructed from peaks in volume. When a peak occurs, we take the price where this peak occurred and use it as the value for our level.
If one of the levels was previously tested, we can hypothesize that the level might be used as support/resistance in the future. Additional analysis using volume can be done in order to confirm a potential bounce.
The histogram can return various information to the user. It can show if the price stayed within two levels for a long time and if the price within two levels was mostly made of bullish or bearish candles.
In the chart above, we can see that over the most recent 200 bars (determined by Histogram Window) 68 closing prices fall between levels A and B, with 27 bars being bullish.
Additionally, the width of a bin and its length can sometimes give information about the volatility of a specific price variation. If a bin is very wide but short (a low number of closing prices fallen within the levels) then we can conclude a most of the movement was done on a short amount of time.

Auto Fibonacci and Gann Fan/Retracements ComboIntroduction
This is a combination of Fibonacci and Gann fan/retracements.
The script can automatically draw as many:
Fibonacci Retracements
Fibonacci Fan
Gann Retracements
Gann Fan
as the user requires on the chart. Each level set or fan consists of 7 lines based on the most important ratios of Fibonacci/Gann.
Basics
What are Fibonacci retracements?
Fibonacci retracement levels are horizontal lines that indicate where support and resistance are likely to occur. They stem from Fibonacci’s sequence. Each level is associated with a percentage which is how much of a prior move the price has retraced. The Fibonacci retracement levels are 23.6%, 38.2%, 61.8%, and 78.6%. While not officially a Fibonacci ratio, 50% is also used. The indicator is useful because it can be drawn between any two significant price points, such as a high and a low. The indicator will then create the levels between those two points.
What are Gann retracements?
A developer of technical analysis and trading was W.D. Gann. Gann theory expects a normal retracement of 50 percent. This means that under normal selling pressure, the stock price will decline half the amount of its most recent rise, and vice versa. It also suggests that retracements occur at the halfway point of a move, such as 25 percent (half of 50 percent), 12.5 percent (half of 25 percent), and so on.
What is Fibonacci fan?
Fibonacci fan is a set of sequential trend lines drawn from a trough or peak through a set of points dictated by Fibonacci retracements. The first step to create it is to draw a trend line covering the local lowest and highest prices of a security. To reach retracement levels, the trader divides the difference in price at the low and high end by ratios determined by the Fibonacci series. The lines formed by connecting the starting point for the base trend line and each retracement level create the Fibonacci fan.
What is Gann fan?
A Gann fan consists of a series of lines called Gann angles. These angles are superimposed over a price chart to show potential support and resistance levels. The resulting image is supposed to help technical analysts predict price changes. Gann believed the 45-degree angle to be most important, but the Gann fan also draws angles at degrees like 75, 63.75, 26.25 and 15. The Gann fan originates at a low or high point. The resulting lines show areas of potential future support and resistance. The 45-degree line is known as the 1:1 line because the price will rise or fall at a 45-degree angle when the price moves up/down one unit for each unit of time. All other lines in the Gann fan are drawn above and below the 1:1 line. The other angles are associated with 2:1, 3:1, 4:1, 8:1 and 1:8, 1:4, 1:3, and 1:2 time-to-price moves.
Challenges
The most of the time I dedicated to writing this script has been spent on handling these problems:
1. Finding Local Highest/Lowest Prices
In order to draw Fibonacci and Gann fan/retracements, it's necessary to find local highest and lowest price points (Extrema) on the chart. As this could be so challenging, most traders and coders draw the lines covering the low and high prices over a given period of time or a limited number of bars back instead. I already wrote an indicator using this approach ( Auto Fibonacci Combo ).
In this new script I tried to find the exact highest and lowest prices based on this idea that: if a high point is formed lower than previous high which was after a lowest point, then that previous one was the local highest point, and vice versa if a low point is formed higher than previous low which was after a highest point, then that previous one was the local lowest point. So logically an extremum price on the chart won't be found until the next high/low point is formed.
2. Finding Proper Chart Scale for Gann Fan
Based on the theory, Gann angles are sensitive to the chart price scale and in order to have the right angles, the chart must be made with the proper scale. J.A. Hyerczyk in his book "Pattern, Price & Time - Using Gann Theory in Technical Analysis" suggests that the easiest way to determine the scale of a market is by taking the difference between top-to-top and bottom-to-bottom and dividing it by the time it took the market to move from top to top and bottom to bottom.
Thus on a properly constructed chart, the basic equation for calculating Gann angles is: Price * Time.
3. Drawing Fans and Relocating Fan Labels at Each New Bar in Pine (A Programming-Related Subject)
To do this, I used linear equations and line slopes. Of course it was so complicated and exhausting, but finally I overcame that thanks to my genius cousin.
Settings and Usage
By default, the script shows detected extremum points plus 1 Fibonacci fan, 1 Gann fan, 1 set of Fibonacci retracements and no Gann retracements on the chart. All of these could be changed in the indicator settings beside the color and transparency of each line.
Feel free to use this and send me your thoughts!

Zigzag Trend/Divergence DetectorPullbacks are always hardest part of the trade and when it happen, we struggle to make decision on whether to continue the trade and wait for recovery or cut losses. Similarly, when an instrument is trending well, it is often difficult decision to make if we want to take some profit off the table. This indicator is aimed to make these decisions easier by providing a combined opinion of sentiment based on trend and possible divergence.
⬜ Process
▶ Use any indicator to find trend bias. Here we are using simple supertrend
▶ Use any oscillator. I have added few inbuilt oscillators as option. Default used is RSI.
▶ Find divergence by using zigzag to detect pivot high/low of price and observing indicator movement difference between subsequent pivots in the same direction.
▶ Combine divregence type, divergence bias and trend bias to derive overall sentiment.
Complete details of all the possible combinations are present here along with table legend
⬜Chart Legend
C - Continuation
D - Divergence
H - Hidden Divergence
I - Indeterminate
⬜ Settings
▶ Zigzag parameters : These let you chose zigzag properties. If you check "Use confirmed pivots", then unconfirmed pivot will be ignored in the table and in the chart
▶ Oscillator parameters : Lets you select different oscillators and settings. Available oscillators involve
CCI - Commodity Channel Index
CMO - Chande Momentum Oscillator
COG - Center Of Gravity
DMI - Directional Movement Index (Only ADX is used here)
MACD - Moving average convergence divergence (Can chose either histogram or MACD line)
MFI - Money Flow Index
MOM - Momentum oscillator
ROC - Rate Of Change
RSI - Relative Strength Index
TSI - Total Strength Index
WPR - William Percent R
BB - Bollinger Percent B
KC - Keltner Channel Percent K
DC - Donchian Channel Percent D
ADC - Adoptive Donchian Channel Percent D ( Adoptive-Donchian-Channel )
▶ Trend bias : Supertrend is used for trend bias. Coloring option color candles in the direction of supertrend. More option for trend bias can be added in future.
▶ Stats : Enables you to display history in tabular format.
Overview of settings present here:
⬜ Notes
Trend detection is done only with respect to previous pivot in the same direction. Hence, if chart has too many zigzags in short period, try increasing the zigzag length or chart timeframe. Similarly, if there is a steep trend, use lower timeframe charts to dig further.
Oscillators does not always make pivots at same bar as price. Due to this some the divergence calculation may not be correct. Hence visual inspection is always recommended.
⬜ Possible future enhancements
More options for trend bias
Enhance divergence calculation. Possible options include using oscillator based zigzag as primary or using close prices based zigzag instead of high/low.
Multi level zigzag option - Can be messy to include more than one zigzag. Option can be added to chose either Level1 or Level2 zigzags.
Alerts - Alerts can only be added for confirmed pivots - otherwise it will generate too many unwanted alerts. Will think about it :)
If I get time, I will try to make a video.

Momentum-based ZigZag (incl. QQE) NON-REPAINTINGI spent a lot of time searching for the best ZigZag indicator. Difficulty with all of them is that they are always betting on some pre-defined rules which identify or confirm pivot points. Usually it is time factor - pivot point gets confirmed after a particular number of candles. This methodology is probably the best when market is moving relatively slow, but when price starts chopping up and down, there is no way the ZigZag follows accurately. On the other hand if you set it too tight (for example pivot confirmation after only 2 or even 1 candle), you will get hundreds of zigzag lines and they will tell you nothing.
My point of view is to follow the market. If it has reversed, then it has reversed, and there is no need to wait pre-defined number of candles for the confirmation. Such reversals will always be visible on momentum indicators, such as the most popular MACD. But a single-line moving average can be also good enough to notice reversals. Or my favourite one - QQE, which I borrowed (and improved) from JustUncleL, who borrowed it from Glaz, who borrowed it from... I don't even know where Quantitative Qualitative Estimation originates from. Thanks to all these guys for their input and code.
So whichever momentum indicator you choose - yes, there is a pick-your-poison-type selector as in in-famous Moving Average indicators - once it reverses, a highest (or lowest) point from the impulse is caught and ZigZag gets printed.
One thing I need to emphasize. This indicator DOES NOT REPAINT. It might look like the lines are a bit delayed, especially when compared to all the other ZigZag indicators on TradingView, but they are actually TRUE. There is a value in this - my indicator prints pivot points and Zigzag exactly on the moment they have been noticed, not earlier faking to be faster than they could be.
As a bonus, the indicator marks which impulse had strength in it. It is very nice to see a progressing impulse, but without force - a very likely that reversal on a bigger move is happening.
I'm about to publish some more scripts based on this ZigZag algo, so follow me on TradingView to get notified.
Enjoy!

Trading ABCHello Traders,
For a few months I have been getting requests from my followers about ABC pattern and finally I decided to make this indicator.
How it works?
- It creates Trend Cloud using Simple and Exponential moving averages with the lenghts 50, 100, 150, 200, 20, 40 by default and checks the trend. you can change the lengths as you wish
- It also creates ZigZag using the ZigZag Period in the options.
- Using last 2 zigzag waves it checks if there is suitable ABC pattern according the Trend, the Min/Max Fibonacci levels and Error Rate
- Then it check if the price bounces after this ABC pattern
- And if all these conditions met then it plot triangle
- If there are multiple bouncing then you can see multiple triangles
You can change/set;
- Zigzag Period
- Fibonacci Max level
- Fibonacci Min Level
- Error Rate
- The Lengths that are used for Moving Averages
- Keeping old ABC lines/labels
- Show Zigzag and min/max Fibonacci levels
- Show Trend Cloud
- and colors
if you don't want to see old ABC lines/labels you can disable it:
if you don't want to see Trend Cloud you can disable it:
Zigzag and Fibonacci levels:
P.S. if you have new ideas to improve this indicator then let me know please. We together can do this life easier!
Enjoy!

[UTILS] Unit Testing FrameworkTL;DR
This script doesn't provide any buy/sell signals.
This script won't make you profitable implicitly.
This script is intended for utility function testing, library testing, custom assertions.
It is free and open-source.
Introduction
About the idea: is not exclusive, programmers tend to use this method a lot and for a long time.
The point is to ensure that parts of a software, "units" (i.e modules, functions, procedures, class methods etc), work as they should, meet they design and behave as intended. That's why we use the term "Unit testing".
In PineScript we don't have a lot of entities mentioned above yet. What we have are functions. For example, a function that sums numbers should return a number, a particular sum. Or a professor wrote a function that calculates something or whatever. He and you want to be sure that the function works as expected and further code changes (refactoring) won't break its behaviour. What the professor needs to do is to write unit tests for his function/library of functions. And what you need to do is to check if the professor wrote tests or not.
No tests = No code
- Total test-driven development
Ok, it is not so serious, but very important in software development. And I created a tool for that.
I tried to follow the APIs of testing tools/libs/frameworks I worked or work with: Jasmine (Javascript), Mocha/Chai (Javascript), Jest (Javascript), RSpec (Ruby), unittest (Python), pytest (Python) and others. Got something workable but it would be much easier to implement (and it would look much better) if PineScript had a higher-order functions feature.
API
_describe(suiteName: string)
A function to declare a test suite. Each suite with tests may have 2 statuses:
✔️ Passed
❌ Failed
A suite is considered to be failed if at least one of the specs in it has failed.
_it(specName: string, actual: any, expected: any)
A function to run a test. Each test may have 3 statuses:
✔️ Passed
❌ Failed
⛔ Skipped
Some examples:
_it("is a falsey value", 1 != 2, true)
_it("is not a number", na(something), true)
_it("should sum two integers", _sum(1, 2), 1)
_it("arrays are equal", _isEqual(array.from(1, 2), array.from(1, 2)), true)
Remember that both the 'actual' and 'expected' arguments must be of the same type.
And a group of _it() functions must be preceded by a _describe() declaration (see in the code).
_test(specName: string, actual: any, expected: any)
An alias for _it . Does the same thing.
_xit(specName: string, actual: any, expected: any)
A function to skip a particular test for a while. Doesn't make any comparisons, but the test will appear in the results as skipped.
This feature is unstable and may be removed in the future releases.
_xtest(specName: string, actual: any, expected: any)
An alias for _xit . Does the same thing.
_isEqual(id_1: array, id_2: array)
A function to compare two arrays for equality. Both arrays must be of the same type.
This function doesn't take into account the order of elements in each array. So arrays like (1, 2, 3) and (3, 2, 1) will be equal.
_isStrictEqual(id_1: array, id_2: array)
A function to compare two arrays for equality. Both arrays must be of the same type.
This function is a stricter version of _isEqual because it takes into account the order of elements in each array. So arrays like (1, 2, 3) and (3, 2, 1) won't be equal.
Usage
To use this script to test your library you need to do the following steps:
1) Copy all the code you see between line #5 and #282 (Unit Testing Framework Core)
2) Place the copied code at the very beginning of your script (but below study())
3) Start to write suites and tests where your code ends. That's it.
NOTE
The current version is 0.0.1 which means that a lot of things may be changed on the way to 1.0.0 - the first stable version.
Volume Profile Auto [line]This project is about:
- VPSV
- array.new_line()
- array.new_box()
VPSV (pine) is one of the rare features that draws lines/figures BETWEEN bars
It doesn't run on Pine script, which makes it possible to do such things.
I wanted to have something similar while a restriction of Pine script is the impossibility to draw between bars, the only way I could think of is by using line width
In this script the higher timeframe is started with several lines (left) and a box, this box goes further until the higher timeframe ends.
During the creation of the box, each candle (lower timeframe) in this box (higher timeframe - period) is checked for position and volume, the volume is added to the left line, so when you see a thicker line, this means at that level there is more volume traded.
One of the big differences with other volume profiles is that many look back to a previous period, here when a period starts, the lines collect data - volume until the period ends, it is especially very visible in very low TF's (seconds)
This is my first script with array.new_line() - array.new_box(), which is a very nice Pine feature!
I hope this script can be helpful to see the possibilities
Settings:
'Parts' -> amount of lines (left of box)
5 Parts:
15 Parts:
25 Parts:
50 Parts:
'Max Width' -> Sets the max width of the lines
'Automatic Settings' -> Sets the higher time frame automatically, see the tooltip ⓘ for more info
The yellow line is the max volume line of that period, last period has a red line (POC), also referring the max.
Cheers!
MY:Aggregated Volume BTC:SPOT█ MY Aggregated Volume BTC SPOT
This indicator shows a panel to display the Bitcoin Trading Volume of different exchanges. A lot of traders follow the default volume indicator provided by tradingview. This default indicator shows the volume for the current ticker (example BTCUSD:BITSTAMP), but each exchange has its own volume.
In a matter of visibility and accessibility, I've decided to aggregate the volume of almost all the Bitcoin exchanges (tickers) in tradingview. Some have been commented out (Kucoin, FTX) due to high volume data which was hiding the other ones.
This indicator helps identifying decreasing volume, where the volume comes from (spot or derivatives). A decreasing SPOT volume isn't a good sign as it shows a decrease in the buying pressure.
The panel has 1 main configuration : Display mode, showing Aggregated (all exchanges in one bar) or Difference (Stacked bar)
The other configuration Legend Item Gap and Legend X Gap is for when the difference mode is selected. It affects the position of the legend. Some might have smaller screens, bigger screens, viewport zoomed in etc.
Due to the number of exchanges, and pinescript limitations, I had to split the volume in 2 indicators, the SPOT volume, and the DERIVATIVES volume. The script in this page is specific to the SPOT volume. For the DERIVATIVES, please refer to my other available script.
Exchange list :
// BINANCE:BTCUSD
// BINANCE:BTCUSDT
// BINANCE:BTCEUR
// COINBASE:BTCUSD
// COINBASE:BTCUSDT
// COINBASE:BTCEUR
// KRAKEN:XBTUSD
// KRAKEN:XBTUSDT
// KRAKEN:XBTEUR
// BITFINEX:BTCUSD
// BITFINEX:BTCEUR
// HUOBI:BTCUSDT
// HUOBI:BTCUSDC
// OKEX:BTCUSDT
// FTX:BTCUSD DISABLED FOR NOW, TO MUCH VOLUME
// FTX:BTCUSDT DISABLED FOR NOW, TO MUCH VOLUME
// KUCOIN:BTCUSDT DISABLED FOR NOW, TO MUCH VOLUME
// KUCOIN:BTCUSDC DISABLED FOR NOW, TO MUCH VOLUME
// GEMINI:BTCUSD
// GEMINI:BTCEUR
// PHEMEX:BTCUSDT
// BITTREX:BTCUSD
// BITTREX:BTCUSDT
// BITTREX:BTCEUR

3Commas BotBjorgum 3Commas Bot
A strategy in a box to get you started today
With 3rd party API providers growing in popularity, many are turning to automating their strategies on their favorite assets. With so many options and layers of customization possible, TradingView offers a place no better for young or even experienced coders to build a platform from to meet these needs. 3Commas has offered easy access with straight forward TradingView compatibility. Before long many have their brokers hooked up and are ready to send their alerts (or perhaps they have been trying with mixed success for some time now) only they realize there might just be a little bit more to building a strategy that they are comfortable letting out of their sight to trade their money while they eat, sleep, etc. Many may have ideas for entry criteria they are excited to try, but further questions arise... "What about risk mitigation?" "How can I set stop or limit orders?" "Is there not some basic shell of a strategy that has laid some of this out for me to get me going?"
Well now there is just that. This strategy is meant for those that have begun to delve into the world of algorithmic trading providing a template that offers risk defined positions complete with stops, limit orders, and even trailing stops should one so choose to employ any of these criteria. It provides a framework that is easily manipulated (with some basic working knowledge of pine coding) to encompass ones own ideas and entry criteria, while also providing an already functioning strategy.
The default settings have a basic 1:1 risk to reward ratio, which sets a limit and a stop equal distance from the entry. The entry is a simple MA cross (up for long, down for short). There a variety of MA's to choose from and the user can define the lengths of the averages. The ratio can be adjusted from the menu along with a volatility based adder (ATR) that helps to distance a stop from support or resistance. These values are calculated off the swing low/high of the user defined lookback period. Risk is calculated from position entry to stop, and projected upwards to the limit as a function of the desired risk to reward ratio. Of note: the default settings include 0.05% commissions. Competitive commissions of the leading cryptocurrency exchanges are .1% round trip (one buy and one sell) for market orders. There is also some slippage to allow time for alerts to be sent and orders to fill giving the back test results a more accurate representation of real time conditions. Its recommended to research the going rates for your exchange and set them to default for the strategy you use or build.
To get started a user would:
1) Make a copy of the code and paste in their bot keys in the area provided under the "3Comma Keys" section
- eg. Long bot "start deal" copied from 3commas in to define "Long" etc. (code is commented)
2) Place alert on desired asset with desired settings ensuring to select "Order fills and alert() function calls"
3) Paste webhook into the webhook box and select webhook URL alerts (3rd party provided webhook)
3) Delete contents of alert message box and replace with {{strategy.order.alert_message}} and nothing else
- the codes will be sent to the webhook appropriately as the strategy enters and exits positions. Only 1 alert is needed
settings used for the display image:
1hr chart on BTCUSD
-ATR stop
-Risk adjustment 1.2
-ATR multiplier 1.3
-RnR 0.6
-MAs HEMA/SMA
-MA Length 50/100
-Order size percent of equity
-Trail trigger 60% of target
Experiment with your own settings on your crypto of choice or implement your own code!
Implementing your trailing stop (optional)
Among the options for possible settings is a trailing stop. This stop will ratchet higher once triggered as a function of the Average True Range (ATR). There is a variable level to choose where the user would like to begin trailing the stop during the trade. The level can be assigned with a decimal between 0 and 1 (eg. 0.5 = 50% of the distance between entry and the target which must be exceeded before the trail triggers to begin). This can allow for some dips to occur during the trade possibly keeping you in the trade for longer, while potentially reducing risk of drawdown over time. The default for this setting is 0 meaning unless adjusted, the trail will trigger on entry if the trailing stop exit method is selected. An example can be seen below:
Again, optional as well is the choice to implement a limit order. If one were to select a trailing stop they could choose not to set a limit, which could allow a trail to run further until hit. Drawdowns of this strategy would be foregoing locking gains at highs on target on other trades. This is a trade-off the user can decide on and test. An example of this working in favor can be observed below:
Conclusion
Although a simple strategy is implemented here, the benefits of this script allow a user a starting platform to build their strategies from with built in risk mitigation. This allows the user to sidestep some of the potential difficulties' that can arise while learning Pine and taking on the endeavor of automating their trading strategies. It is meant as an aid, a structure, and an educational piece that can be seen as a "pick-up-and-go" strategy with easy 3Commas compatibility. Additionally, this can help users become more comfortable with strategy alert messages and sending strings in the form of alerts from Pine. As well, FAQs are often littered with questions regarding "strategy.exit" calls, how to implement stops. how to properly set a trailing stop based on ATR, and more. The time this can save an individual to get started is likely of the best "take-aways" here.
Happy trading

Candle Body ShapesExperimental:
displays the frequency of candle types.
reference: its a exploration of this topic: www.elitetrader.com
Monthly Returns in PineScript StrategiesI'm not 100% satisfied with the strategy performance output I receive from TradingView. Quite often I want to see something that is not available by default. I usually export raw trades/metrics from TradingView and then do additional analysis manually.
But with tables, you can build additional metrics and tools for your strategies quite easily.
This script will just show a table with monthly/yearly performance of your script. Quite a lot of traders/investors used to look at returns like that. Also, it might help you to identify periods of time when your strategy performed good/bad than expected and try to analyze that better.
The script is very simple and I believe you can easily apply it to your own strategies.
Disclaimer
Please remember that past performance may not be indicative of future results.
Due to various factors, including changing market conditions, the strategy may no longer perform as well as in historical backtesting.
This post and the script don’t provide any financial advice.
Nunchucks✖ Nunchucks
A new way to display market data
Does not flip color during current candle
Displays Higher and Lower than the previous nunchuck's range
Use it with current price line

Zigzag CloudThis is Bollinger Band built on top of Zigzags instead of regular price + something more.
Indicator presents 7 lines and cloud around it. This can be used to visualize how low or high price is with respect to its past movement.
Middle line is moving average of last N zigzag pivots
Lines adjacent to moving average are also moving averages. But, they are made of only pivot highs and pivot lows. Means, line above moving average is pivot high moving average and line below moving average is pivot low moving average.
Lines after pivot high/low moving averages are upper and lower bolllinger bands based on Moving Average Line with 2 standard deviation difference.
Outermost lines are bollinger band top of Moving average pivot high and bollinger band bottom of moving average pivot low.

MESA Stochastic Multi LengthJohn Ehler's MESA Stochastic uses super smoothing to give solid signals. This indicator uses the same rules as every other Stochastic indicator so it would be worth looking into if you are not already familiar with reading a Stochastic. There are 4 different lengths displayed to give traders an edge on reading the market. This is a great tool to analyze waves and find tops and bottoms. It gives great pump and dump signals and even helps filter out bad trades when used with other indicators such as Boom Hunter.
Below are some examples of signals to look out for:
oo

Fast Fourier Transform (FFT) FilterDear friends!
I'm happy to present an implementation of the Fast Fourier Transform (FFT) algorithm. The script uses the FFT procedure to decompose the input time series into its cyclical constituents, in other words, its frequency components , and convert it back to the time domain with modified frequency content, that is, to filter it.
Input Description and Usage
Source and Length :
Indicates where the data comes from and the size of the lookback window used to build the dataset.
Standardize Input Dataset :
If enabled, the dataset is preprocessed by subtracting its mean and normalizing the result by the standard deviation, which is sometimes useful when analyzing seasonalities. This procedure is not recommended when using the FFT filter for smoothing (see below), as it will not preserve the average of the dataset.
Show Frequency-Domain Power Spectrum :
When enabled, the results of Fourier analysis (for the last price bar!) are plotted as a frequency-domain power spectrum , where “power” is a measure of the significance of the component in the dataset. In the spectrum, lower frequencies (longer cycles) are on the right, higher frequencies are on the left. The graph does not display the 0th component, which contains only information about the mean value. Frequency components that are allowed to pass through the filter (see below) are highlighted in magenta .
Dominant Cycles, Rows :
If this option is activated, the periods and relative powers of several dominant cyclical components that is, those that have a higher power, are listed in the table. The number of the component in the power spectrum (N) is shown in the first column. The number of rows in the table is defined by the user.
Show Inverse Fourier Transform (Filtered) :
When enabled, the reconstructed and filtered time-domain dataset (for the last price bar!) is displayed.
Apply FFT Filter in a Moving Window :
When enabled, the FFT filter with the same parameters is applied to each bar. The last data point of the reconstructed and filtered dataset is used to build a new time series. For example, by getting rid of high-frequency noise, the FFT filter can make the data smoother. By removing slowly evolving low-frequency components (including non-periodic constituents), one can reveal and analyze shorter cycles. Since filtering is done in real-time in a moving window (similar to the moving average), the modified data can potentially be used as part of a strategy and be subjected to other technical indicators.
Lowest Allowed N :
Indicates the number of the lowest frequency component used in the reconstructed time series.
Highest Allowed N :
Indicates the number of the highest frequency component used in the reconstructed time series.
Filtering Time Range block:
Specifies the time range over which real-time FFT filtering is applied. The reason for the presence of this block is that the FFT procedure is relatively computationally intensive. Therefore, the script execution may encounter the time limit imposed by TradingView when all historical bars are processed.
As always, I look forward to your feedback!
Also, leave a comment if you'd be interested in the tutorial on how to use this tool and/or in seeing the FFT filter in a strategy.

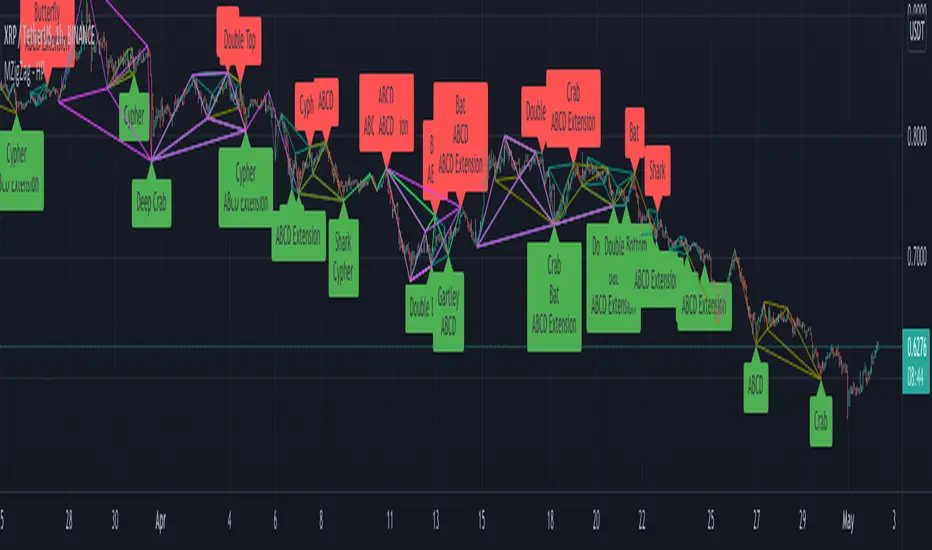
Multi ZigZag Harmonic PatternsCombining Multizigzag with harmonic patterns - this script generates harmonic patterns based on multiple deapth zigzags.
Input parameter allows to chose which Zigzag to be included in pattern identification and set different length, line color, width and style for each Zigzag combinations.
Pattern rules are as below:
Gartley
xab = 0.618
0.382 <= abc <= 0.886
1.272 <= bcd <= 1.618 OR xad = 0.786
Crab
0.382 <= xab <= 0.618
0.382 <= abc <= 0.886
2.24 <= bcd <= 3.618 OR xad = 1.618
Deep Crab
xab = 0.886
0.382 <= abc <= 0.886
2.0 <= bcd <= 3.618 OR xad = 1.618
Bat
0.382 <= xab <= 0.50
0.382 <= abc <= 0.886
1.618 <= bcd <= 2.618 OR xad = 0.886
Butterfly
xab = 0.786
0.382 <= abc <= 0.886
1.618 <= bcd <= 2.618 OR 1.272 <= xad <= 2.618
Shark
xab = 0.786
1.13 <= abc <= 1.618
1.618 <= bcd <= 2.24 OR 0.886 <= xad <= 1.13
Cypher
0.382 <= xab <= 0.618
1.13 <= abc <= 1.414
1.272 <= bcd <= 2.0 OR xad = 0.786
Three Drives
oxa = 0.618
1.27 <= xab <= 1.618
abc = 0.618
1.27 <= bcd <= 1.618
5-0
1.13 <= xab <= 1.618
1.618 <= abc <= 2.24
bcd = 0.5
Related scripts are present here: