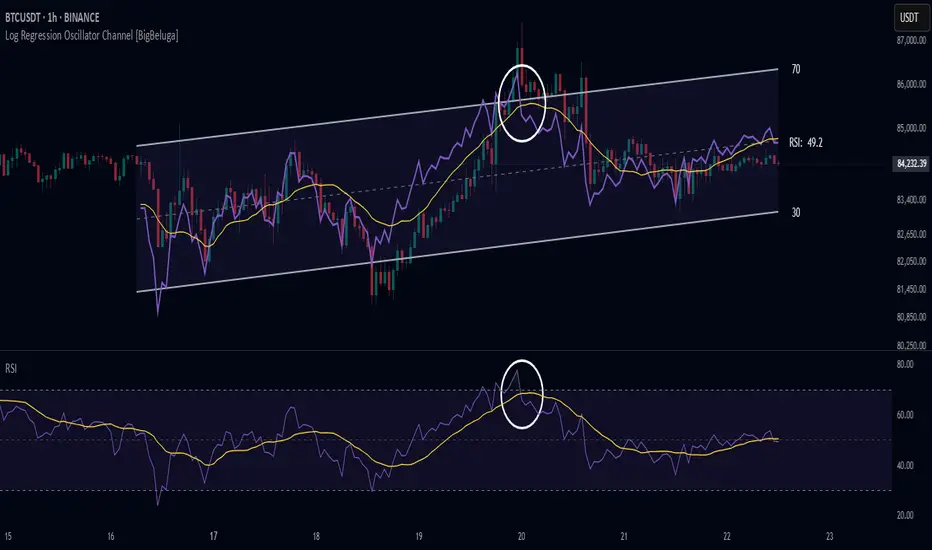
Bloomberg Financial Conditions Index (Proxy)The Bloomberg Financial Conditions Index (BFCI): A Proxy Implementation
Financial conditions indices (FCIs) have become essential tools for economists, policymakers, and market participants seeking to quantify and monitor the overall state of financial markets. Among these measures, the Bloomberg Financial Conditions Index (BFCI) has emerged as a particularly influential metric. Originally developed by Bloomberg L.P., the BFCI provides a comprehensive assessment of stress or ease in financial markets by aggregating various market-based indicators into a single, standardized value (Hatzius et al., 2010).
The original Bloomberg Financial Conditions Index synthesizes approximately 50 different financial market variables, including money market indicators, bond market spreads, equity market valuations, and volatility measures. These variables are normalized using a Z-score methodology, weighted according to their relative importance to overall financial conditions, and then aggregated to produce a composite index (Carlson et al., 2014). The resulting measure is centered around zero, with positive values indicating accommodative financial conditions and negative values representing tighter conditions relative to historical norms.
As Angelopoulou et al. (2014) note, financial conditions indices like the BFCI serve as forward-looking indicators that can signal potential economic developments before they manifest in traditional macroeconomic data. Research by Adrian et al. (2019) demonstrates that deteriorating financial conditions, as measured by indices such as the BFCI, often precede economic downturns by several months, making these indices valuable tools for predicting changes in economic activity.
Proxy Implementation Approach
The implementation presented in this Pine Script indicator represents a proxy of the original Bloomberg Financial Conditions Index, attempting to capture its essential features while acknowledging several significant constraints. Most critically, while the original BFCI incorporates approximately 50 financial variables, this proxy version utilizes only six key market components due to data accessibility limitations within the TradingView platform.
These components include:
Equity market performance (using SPY as a proxy for S&P 500)
Bond market yields (using TLT as a proxy for 20+ year Treasury yields)
Credit spreads (using the ratio between LQD and HYG as a proxy for investment-grade to high-yield spreads)
Market volatility (using VIX directly)
Short-term liquidity conditions (using SHY relative to equity prices as a proxy)
Each component is transformed into a Z-score based on log returns, weighted according to approximated importance (with weights derived from literature on financial conditions indices by Brave and Butters, 2011), and aggregated into a composite measure.
Differences from the Original BFCI
The methodology employed in this proxy differs from the original BFCI in several important ways. First, the variable selection is necessarily limited compared to Bloomberg's comprehensive approach. Second, the proxy relies on ETFs and publicly available indices rather than direct market rates and spreads used in the original. Third, the weighting scheme, while informed by academic literature, is simplified compared to Bloomberg's proprietary methodology, which may employ more sophisticated statistical techniques such as principal component analysis (Kliesen et al., 2012).
These differences mean that while the proxy BFCI captures the general direction and magnitude of financial conditions, it may not perfectly replicate the precision or sensitivity of the original index. As Aramonte et al. (2013) suggest, simplified proxies of financial conditions indices typically capture broad movements in financial conditions but may miss nuanced shifts in specific market segments that more comprehensive indices detect.
Practical Applications and Limitations
Despite these limitations, research by Arregui et al. (2018) indicates that even simplified financial conditions indices constructed from a limited set of variables can provide valuable signals about market stress and future economic activity. The proxy BFCI implemented here still offers significant insight into the relative ease or tightness of financial conditions, particularly during periods of market stress when correlations among financial variables tend to increase (Rey, 2015).
In practical applications, users should interpret this proxy BFCI as a directional indicator rather than an exact replication of Bloomberg's proprietary index. When the index moves substantially into negative territory, it suggests deteriorating financial conditions that may precede economic weakness. Conversely, strongly positive readings indicate unusually accommodative financial conditions that might support economic expansion but potentially also signal excessive risk-taking behavior in markets (López-Salido et al., 2017).
The visual implementation employs a color gradient system that enhances interpretation, with blue representing neutral conditions, green indicating accommodative conditions, and red signaling tightening conditions—a design choice informed by research on optimal data visualization in financial contexts (Few, 2009).
References
Adrian, T., Boyarchenko, N. and Giannone, D. (2019) 'Vulnerable Growth', American Economic Review, 109(4), pp. 1263-1289.
Angelopoulou, E., Balfoussia, H. and Gibson, H. (2014) 'Building a financial conditions index for the euro area and selected euro area countries: what does it tell us about the crisis?', Economic Modelling, 38, pp. 392-403.
Aramonte, S., Rosen, S. and Schindler, J. (2013) 'Assessing and Combining Financial Conditions Indexes', Finance and Economics Discussion Series, Federal Reserve Board, Washington, D.C.
Arregui, N., Elekdag, S., Gelos, G., Lafarguette, R. and Seneviratne, D. (2018) 'Can Countries Manage Their Financial Conditions Amid Globalization?', IMF Working Paper No. 18/15.
Brave, S. and Butters, R. (2011) 'Monitoring financial stability: A financial conditions index approach', Economic Perspectives, Federal Reserve Bank of Chicago, 35(1), pp. 22-43.
Carlson, M., Lewis, K. and Nelson, W. (2014) 'Using policy intervention to identify financial stress', International Journal of Finance & Economics, 19(1), pp. 59-72.
Few, S. (2009) Now You See It: Simple Visualization Techniques for Quantitative Analysis. Analytics Press, Oakland, CA.
Hatzius, J., Hooper, P., Mishkin, F., Schoenholtz, K. and Watson, M. (2010) 'Financial Conditions Indexes: A Fresh Look after the Financial Crisis', NBER Working Paper No. 16150.
Kliesen, K., Owyang, M. and Vermann, E. (2012) 'Disentangling Diverse Measures: A Survey of Financial Stress Indexes', Federal Reserve Bank of St. Louis Review, 94(5), pp. 369-397.
López-Salido, D., Stein, J. and Zakrajšek, E. (2017) 'Credit-Market Sentiment and the Business Cycle', The Quarterly Journal of Economics, 132(3), pp. 1373-1426.
Rey, H. (2015) 'Dilemma not Trilemma: The Global Financial Cycle and Monetary Policy Independence', NBER Working Paper No. 21162.
Indicators and strategies
TASC 2025.06 Cybernetic Oscillator█ OVERVIEW
This script implements the Cybernetic Oscillator introduced by John F. Ehlers in his article "The Cybernetic Oscillator For More Flexibility, Making A Better Oscillator" from the June 2025 edition of the TASC Traders' Tips . It cascades two-pole highpass and lowpass filters, then scales the result by its root mean square (RMS) to create a flexible normalized oscillator that responds to a customizable frequency range for different trading styles.
█ CONCEPTS
Oscillators are indicators widely used by technical traders. These indicators swing above and below a center value, emphasizing cyclic movements within a frequency range. In his article, Ehlers explains that all oscillators share a common characteristic: their calculations involve computing differences . The reliance on differences is what causes these indicators to oscillate about a central point.
The difference between two data points in a series acts as a highpass filter — it allows high frequencies (short wavelengths) to pass through while significantly attenuating low frequencies (long wavelengths). Ehlers demonstrates that a simple difference calculation attenuates lower-frequency cycles at a rate of 6 dB per octave. However, the difference also significantly amplifies cycles near the shortest observable wavelength, making the result appear noisier than the original series. To mitigate the effects of noise in a differenced series, oscillators typically smooth the series with a lowpass filter, such as a moving average.
Ehlers highlights an underlying issue with smoothing differenced data to create oscillators. He postulates that market data statistically follows a pink spectrum , where the amplitudes of cyclic components in the data are approximately directly proportional to the underlying periods. Specifically, he suggests that cyclic amplitude increases by 6 dB per octave of wavelength.
Because some conventional oscillators, such as RSI, use differencing calculations that attenuate cycles by only 6 dB per octave, and market cycles increase in amplitude by 6 dB per octave, such calculations do not have a tangible net effect on larger wavelengths in the analyzed data. The influence of larger wavelengths can be especially problematic when using these oscillators for mean reversion or swing signals. For instance, an expected reversion to the mean might be erroneous because oscillator's mean might significantly deviate from its center over time.
To address the issues with conventional oscillator responses, Ehlers created a new indicator dubbed the Cybernetic Oscillator. It uses a simple combination of highpass and lowpass filters to emphasize a specific range of frequencies in the market data, then normalizes the result based on RMS. The process is as follows:
Apply a two-pole highpass filter to the data. This filter's critical period defines the longest wavelength in the oscillator's passband.
Apply a two-pole SuperSmoother (lowpass filter) to the highpass-filtered data. This filter's critical period defines the shortest wavelength in the passband.
Scale the resulting waveform by its RMS. If the filtered waveform follows a normal distribution, the scaled result represents amplitude in standard deviations.
The oscillator's two-pole filters attenuate cycles outside the desired frequency range by 12 dB per octave. This rate outweighs the apparent rate of amplitude increase for successively longer market cycles (6 dB per octave). Therefore, the Cybernetic Oscillator provides a more robust isolation of cyclic content than conventional oscillators. Best of all, traders can set the periods of the highpass and lowpass filters separately, enabling fine-tuning of the frequency range for different trading styles.
█ USAGE
The "Highpass period" input in the "Settings/Inputs" tab specifies the longest wavelength in the oscillator's passband, and the "Lowpass period" input defines the shortest wavelength. The oscillator becomes more responsive to rapid movements with a smaller lowpass period. Conversely, it becomes more sensitive to trends with a larger highpass period. Ehlers recommends setting the smallest period to a value above 8 to avoid aliasing. The highpass period must not be smaller than the lowpass period. Otherwise, it causes a runtime error.
The "RMS length" input determines the number of bars in the RMS calculation that the indicator uses to normalize the filtered result.
This indicator also features two distinct display styles, which users can toggle with the "Display style" input. With the "Trend" style enabled, the indicator plots the oscillator with one of two colors based on whether its value is above or below zero. With the "Threshold" style enabled, it plots the oscillator as a gray line and highlights overbought and oversold areas based on the user-specified threshold.
Below, we show two instances of the script with different settings on an equities chart. The first uses the "Threshold" style with default settings to pass cycles between 20 and 30 bars for mean reversion signals. The second uses a larger highpass period of 250 bars and the "Trend" style to visualize trends based on cycles spanning less than one year:

Dynamic Volume Clusters with Retest Signals (Zeiierman)█ Overview
The Dynamic Volume Clusters with Retest Signals indicator is designed to detect key Volume Clusters and provide Retest Signals. This tool is specifically engineered for traders looking to capitalize on volume-based trends, reversals, and key price retest points.
The indicator seamlessly combines volume analysis, dynamic cluster calculations, and retest signal logic to present a comprehensive trading framework. It adapts to market conditions, identifying clusters of volume activity and signaling when the price retests critical zones.
█ How It Works
⚪ Volume Cluster Detection
The indicator dynamically calculates volume clusters by analyzing the highest and lowest price points within a specified lookback period.
Cluster Logic:
Bright Lines (Strong Red/Green):
These indicate that the price has frequently revisited these levels, creating a dense cluster.
Such areas serve as support or resistance, where significant historical trading has occurred, often acting as barriers to price movement.
Traders should consider these levels as potential reversal zones or consolidation points.
Faded or Darker Lines:
These lines indicate areas where the price has less historical activity, suggesting weaker clustering.
These zones have less market memory and are more likely to break, supporting trend continuation and rapid price movement.
⚪ Candle Color Logic (Market Memory)
Blue Candles (High Cluster Density):
Candles turn blue when the price has revisited a particular area many times.
This signals a highly clustered zone, likely to act as a barrier, creating consolidation or range phases.
These areas indicate strong market memory, potentially rejecting price attempts to break through.
Green or Red Candles (Low Cluster Density):
Once the price breaks out of these dense clusters, the candles turn green (bullish) or red (bearish).
This suggests the price has moved into a less clustered territory, where the path forward is clearer and trends are likely to extend without immediate resistance.
⚪ Retest Signal Logic
The indicator identifies critical retest points where the price crosses a cluster boundary and then reverses. These points are essential for traders looking to catch continuation or reversal setups.
⚪ Dynamic Price Clustering
The indicator dynamically adapts the clustering logic based on price movement and volume shifts.
Uses a dynamic moving average (VPMA) to maintain adaptive cluster levels.
Integrates a Kalman Filter for smoothing, reducing noise, and improving trend clarity.
Automatically updates as new data is received, keeping the clusters relevant in real-time.
█ How to Use
⚪ Trend Following & Reversal Detection
Use Retest signals to identify potential trend continuation or reversal points.
⚪ Trading Volume Clusters and Market Memory
Identify Key Zones:
Focus on bright, saturated cluster lines (strong red or green) as they indicate high market memory, where price has spent significant time in the past.
These zones are likely to exhibit a more choppy market. Apply range or mean reversion strategies.
Spot Potential Breakouts:
Faded or darker cluster lines indicate areas of low market memory, where the price has moved quickly and spent less time.
Use these areas to identify possible trend setups, as they represent lower resistance to price movement.
⚪ Interpreting Candle Colors for Market Phases
Blue Candles (High Cluster Density):
When candles turn blue, it signals that the price has revisited this area multiple times, creating a dense cluster.
These zones often trap price movement, leading to consolidations or range phases.
Use these areas as caution zones, where price can slow down or reverse.
Green or Red Candles (Low Cluster Density):
Once the price breaks out of these clustered zones, the candles turn green (bullish) or red (bearish), indicating lower market memory.
This signals a trend initiation with less immediate resistance, ideal for momentum and breakout trades.
Use these signals to identify emerging trends and ride the momentum.
█ Settings
Range Lookback Period: Sets the number of bars for calculating the range.
Zone Width (% of Range): Determines how wide the volume clusters are relative to the calculated range.
Volume Line Colors: Customize the appearance of bullish and bearish lines.
Retest Signals: Toggle the appearance of Triangle Up/Down retest markers.
Minimum Bars for Retest: Define the minimum number of bars required before a retest is valid.
Maximum Bars for Retest: Set the maximum number of bars within which a retest can occur.
Price Cluster Period: Adjusts the sensitivity of the dynamic clustering logic.
Cluster Confirmation: Controls how tightly the clusters respond to price action.
Price Cluster Start/Peak: Sets the minimum and maximum touches required to fully form a cluster.
-----------------
Disclaimer
The content provided in my scripts, indicators, ideas, algorithms, and systems is for educational and informational purposes only. It does not constitute financial advice, investment recommendations, or a solicitation to buy or sell any financial instruments. I will not accept liability for any loss or damage, including without limitation any loss of profit, which may arise directly or indirectly from the use of or reliance on such information.
All investments involve risk, and the past performance of a security, industry, sector, market, financial product, trading strategy, backtest, or individual's trading does not guarantee future results or returns. Investors are fully responsible for any investment decisions they make. Such decisions should be based solely on an evaluation of their financial circumstances, investment objectives, risk tolerance, and liquidity needs.

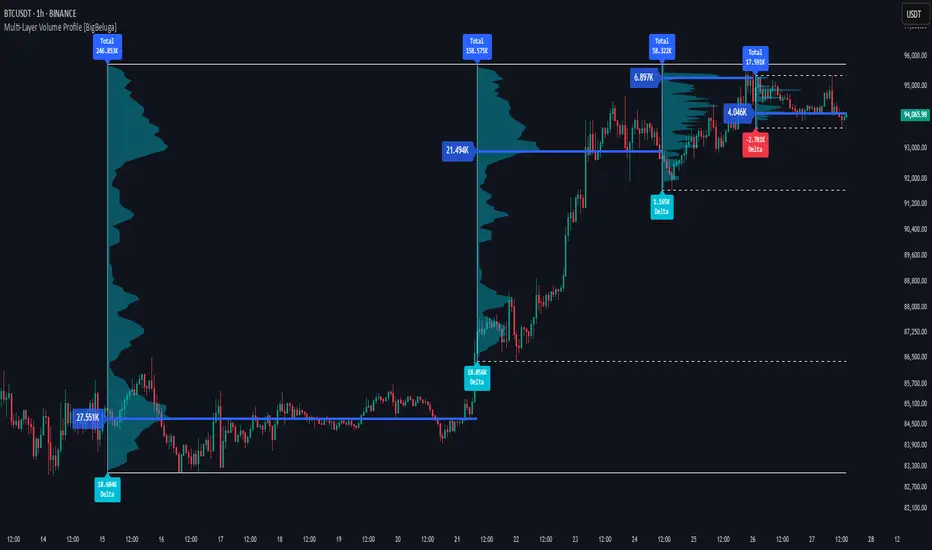
Multi-Layer Volume Profile [BigBeluga]A powerful multi-resolution volume analysis tool that stacks multiple profiles of historical trading activity to reveal true market structure.
This indicator breaks down total and delta volume distribution across time at four adjustable depths — enabling traders to spot major POCs, volume shelves, and zones of price acceptance or rejection with unmatched clarity.
🔵 KEY FEATURES
Multi-Layer Volume Profiles:
Up to 4 separate volume profiles are stacked on the chart:
- Profile 1: Full period
- Profile 2: Half-length
- Profile 3: Quarter-length
- Profile 4: One-eighth-length
This layering helps traders assess confluence across different time horizons.
Custom Bin Resolution:
Each profile uses a customizable number of bins to control visual precision.
More bins = higher granularity, fewer bins = smoother profile.
Precise POC Highlighting:
The price level with the maximum traded volume in each profile is highlighted with a thick blue POC line.
This key level shows the most accepted price for each period.
Total and Delta Volume Labels:
- Total Volume: Displays cumulative volume over the profile period at the top of the profile box.
- Delta Volume: The difference between bullish and bearish volume is labeled at the base, showing directional pressure.
Positive delta = buyer dominance, negative delta = seller dominance.
Range Levels:
Each profile includes horizontal reference lines showing its high, low, bounds.
These edges often align with price reaction zones and become future resistance/support.
🔵 HOW IT WORKS
For each active profile, the indicator:
- Collects price range (highs/lows) across the selected `length`
- Divides this range into equal bins
- Assigns volume into bins based on candle close location
- Aggregates volume per bin to form the profile (polylines)
Separately tracks:
- Total volume (sum of all candles in range)
- Delta volume (sum of candle volumes: positive for bullish, negative for bearish closes)
Highlights the bin with maximum volume (POC)
and marks it with a thick blue line.
Adds auxiliary lines for high/low of each profile box
and total/delta volume tags with tooltips.
🔵 USAGE
Spot Acceptance Zones:
Thick, flat areas on the profile show where price stayed longest — ideal for building positions.
Identify Rejection Zones:
Thin volume areas signal price rejection and are often used for stop placement or entries.
Delta Confirmation:
Use strong positive/negative delta readings as directional bias confirmation for breakout trades.
Confluence Detection:
Watch for overlapping POCs between layers to identify extremely strong support/resistance zones.
🔵 CONCLUSION
Multi-Layer Volume Profile equips traders with a deeply layered market structure view.
Whether you're scalping intraday levels or analyzing macro support zones, the ability to stack volume perspectives, visualize directional delta, and anchor POCs provides an edge in anticipating market moves.
Use this tool to validate entries, confirm structure, and make more informed, volume-aware trading decisions.
pymath█ OVERVIEW
This library ➕ enhances Pine Script's built-in types (`float`, `int`, `array`, `array`) with mathematical methods, mirroring 🪞 many functions from Python's `math` module. Import this library to overload or add to built-in capabilities, enabling calls like `myFloat.sin()` or `myIntArray.gcd()`.
█ CONCEPTS
This library wraps Pine's built-in `math.*` functions and implements others where necessary, expanding the mathematical toolkit available within Pine Script. It provides a more object-oriented approach to mathematical operations on core data types.
█ HOW TO USE
• Import the library: i mport kaigouthro/pymath/1
• Call methods directly on variables: myFloat.sin() , myIntArray.gcd()
• For raw integer literals, you MUST use parentheses: `(1234).factorial()`.
█ FEATURES
• **Infinity Handling:** Includes `isinf()` and `isfinite()` for robust checks. Uses `POS_INF_PROXY` to represent infinity.
• **Comprehensive Math Functions:** Implements a wide range of methods, including trigonometric, logarithmic, hyperbolic, and array operations.
• **Object-Oriented Approach:** Allows direct method calls on `int`, `float`, and arrays for cleaner code.
• **Improved Accuracy:** Some functions (e.g., `remainder()`) offer improved accuracy compared to default Pine behavior.
• **Helper Functions:** Internal helper functions optimize calculations and handle edge cases.
█ NOTES
This library improves upon Pine Script's built-in `math` functions by adding new ones and refining existing implementations. It handles edge cases such as infinity, NaN, and zero values, enhancing the reliability of your Pine scripts. For Speed, it wraps and uses built-ins, as thy are fastest.
█ EXAMPLES
//@version=6
indicator("My Indicator")
// Import the library
import kaigouthro/pymath/1
// Create some Vars
float myFloat = 3.14159
int myInt = 10
array myIntArray = array.from(1, 2, 3, 4, 5)
// Now you can...
plot( myFloat.sin() ) // Use sin() method on a float, using built in wrapper
plot( (myInt).factorial() ) // Factorial of an integer (note parentheses)
plot( myIntArray.gcd() ) // GCD of an integer array
method isinf(self)
isinf: Checks if this float is positive or negative infinity using a proxy value.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) value to check.
Returns: (bool) `true` if the absolute value of `self` is greater than or equal to the infinity proxy, `false` otherwise.
method isfinite(self)
isfinite: Checks if this float is finite (not NaN and not infinity).
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The value to check.
Returns: (bool) `true` if `self` is not `na` and not infinity (as defined by `isinf()`), `false` otherwise.
method fmod(self, divisor)
fmod: Returns the C-library style floating-point remainder of `self / divisor` (result has the sign of `self`).
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) Dividend `x`.
divisor (float) : (float) Divisor `y`. Cannot be zero or `na`.
Returns: (float) The remainder `x - n*y` where n is `trunc(x/y)`, or `na` if divisor is 0, `na`, or inputs are infinite in a way that prevents calculation.
method factorial(self)
factorial: Calculates the factorial of this non-negative integer.
Namespace types: series int, simple int, input int, const int
Parameters:
self (int) : (int) The integer `n`. Must be non-negative.
Returns: (float) `n!` as a float, or `na` if `n` is negative or overflow occurs (based on `isinf`).
method isqrt(self)
isqrt: Calculates the integer square root of this non-negative integer (floor of the exact square root).
Namespace types: series int, simple int, input int, const int
Parameters:
self (int) : (int) The non-negative integer `n`.
Returns: (int) The greatest integer `a` such that a² <= n, or `na` if `n` is negative.
method comb(self, k)
comb: Calculates the number of ways to choose `k` items from `self` items without repetition and without order (Binomial Coefficient).
Namespace types: series int, simple int, input int, const int
Parameters:
self (int) : (int) Total number of items `n`. Must be non-negative.
k (int) : (int) Number of items to choose. Must be non-negative.
Returns: (float) The binomial coefficient nCk, or `na` if inputs are invalid (n<0 or k<0), `k > n`, or overflow occurs.
method perm(self, k)
perm: Calculates the number of ways to choose `k` items from `self` items without repetition and with order (Permutations).
Namespace types: series int, simple int, input int, const int
Parameters:
self (int) : (int) Total number of items `n`. Must be non-negative.
k (simple int) : (simple int = na) Number of items to choose. Must be non-negative. Defaults to `n` if `na`.
Returns: (float) The number of permutations nPk, or `na` if inputs are invalid (n<0 or k<0), `k > n`, or overflow occurs.
method log2(self)
log2: Returns the base-2 logarithm of this float. Input must be positive. Wraps `math.log(self) / math.log(2.0)`.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The input number. Must be positive.
Returns: (float) The base-2 logarithm, or `na` if input <= 0.
method trunc(self)
trunc: Returns this float with the fractional part removed (truncates towards zero).
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The input number.
Returns: (int) The integer part, or `na` if input is `na` or infinite.
method abs(self)
abs: Returns the absolute value of this float. Wraps `math.abs()`.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The input number.
Returns: (float) The absolute value, or `na` if input is `na`.
method acos(self)
acos: Returns the arccosine of this float, in radians. Wraps `math.acos()`. Input must be between -1 and 1.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The input number. Must be between -1 and 1.
Returns: (float) Angle in radians , or `na` if input is outside or `na`.
method asin(self)
asin: Returns the arcsine of this float, in radians. Wraps `math.asin()`. Input must be between -1 and 1.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The input number. Must be between -1 and 1.
Returns: (float) Angle in radians , or `na` if input is outside or `na`.
method atan(self)
atan: Returns the arctangent of this float, in radians. Wraps `math.atan()`.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The input number.
Returns: (float) Angle in radians , or `na` if input is `na`.
method ceil(self)
ceil: Returns the ceiling of this float (smallest integer >= self). Wraps `math.ceil()`.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The input number.
Returns: (int) The ceiling value, or `na` if input is `na` or infinite.
method cos(self)
cos: Returns the cosine of this float (angle in radians). Wraps `math.cos()`.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The angle in radians.
Returns: (float) The cosine, or `na` if input is `na`.
method degrees(self)
degrees: Converts this float from radians to degrees. Wraps `math.todegrees()`.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The angle in radians.
Returns: (float) The angle in degrees, or `na` if input is `na`.
method exp(self)
exp: Returns e raised to the power of this float. Wraps `math.exp()`.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The exponent.
Returns: (float) `e**self`, or `na` if input is `na`.
method floor(self)
floor: Returns the floor of this float (largest integer <= self). Wraps `math.floor()`.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The input number.
Returns: (int) The floor value, or `na` if input is `na` or infinite.
method log(self)
log: Returns the natural logarithm (base e) of this float. Wraps `math.log()`. Input must be positive.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The input number. Must be positive.
Returns: (float) The natural logarithm, or `na` if input <= 0 or `na`.
method log10(self)
log10: Returns the base-10 logarithm of this float. Wraps `math.log10()`. Input must be positive.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The input number. Must be positive.
Returns: (float) The base-10 logarithm, or `na` if input <= 0 or `na`.
method pow(self, exponent)
pow: Returns this float raised to the power of `exponent`. Wraps `math.pow()`.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The base.
exponent (float) : (float) The exponent.
Returns: (float) `self**exponent`, or `na` if inputs are `na` or lead to undefined results.
method radians(self)
radians: Converts this float from degrees to radians. Wraps `math.toradians()`.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The angle in degrees.
Returns: (float) The angle in radians, or `na` if input is `na`.
method round(self)
round: Returns the nearest integer to this float. Wraps `math.round()`. Ties are rounded away from zero.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The input number.
Returns: (int) The rounded integer, or `na` if input is `na` or infinite.
method sign(self)
sign: Returns the sign of this float (-1, 0, or 1). Wraps `math.sign()`.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The input number.
Returns: (int) -1 if negative, 0 if zero, 1 if positive, `na` if input is `na`.
method sin(self)
sin: Returns the sine of this float (angle in radians). Wraps `math.sin()`.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The angle in radians.
Returns: (float) The sine, or `na` if input is `na`.
method sqrt(self)
sqrt: Returns the square root of this float. Wraps `math.sqrt()`. Input must be non-negative.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The input number. Must be non-negative.
Returns: (float) The square root, or `na` if input < 0 or `na`.
method tan(self)
tan: Returns the tangent of this float (angle in radians). Wraps `math.tan()`.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The angle in radians.
Returns: (float) The tangent, or `na` if input is `na`.
method acosh(self)
acosh: Returns the inverse hyperbolic cosine of this float. Input must be >= 1.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The input number. Must be >= 1.
Returns: (float) The inverse hyperbolic cosine, or `na` if input < 1 or `na`.
method asinh(self)
asinh: Returns the inverse hyperbolic sine of this float.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The input number.
Returns: (float) The inverse hyperbolic sine, or `na` if input is `na`.
method atanh(self)
atanh: Returns the inverse hyperbolic tangent of this float. Input must be between -1 and 1 (exclusive).
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The input number. Must be between -1 and 1 (exclusive).
Returns: (float) The inverse hyperbolic tangent, or `na` if input is outside (-1, 1) or `na`.
method cosh(self)
cosh: Returns the hyperbolic cosine of this float.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The input number.
Returns: (float) The hyperbolic cosine, or `na` if input is `na`.
method sinh(self)
sinh: Returns the hyperbolic sine of this float.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The input number.
Returns: (float) The hyperbolic sine, or `na` if input is `na`.
method tanh(self)
tanh: Returns the hyperbolic tangent of this float.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The input number.
Returns: (float) The hyperbolic tangent, or `na` if input is `na`.
method atan2(self, dx)
atan2: Returns the angle in radians between the positive x-axis and the point (dx, self). Wraps `math.atan2()`.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The y-coordinate `y`.
dx (float) : (float) The x-coordinate `x`.
Returns: (float) The angle in radians , result of `math.atan2(self, dx)`. Returns `na` if inputs are `na`. Note: `math.atan2(0, 0)` returns 0 in Pine.
Optimization: Use built-in math.atan2()
method cbrt(self)
cbrt: Returns the cube root of this float.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The value to find the cube root of.
Returns: (float) The real cube root. Handles negative inputs correctly, or `na` if input is `na`.
method exp2(self)
exp2: Returns 2 raised to the power of this float. Calculated as `2.0.pow(self)`.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The exponent.
Returns: (float) `2**self`, or `na` if input is `na` or results in non-finite value.
method expm1(self)
expm1: Returns `e**self - 1`. Calculated as `self.exp() - 1.0`. May offer better precision for small `self` in some environments, but Pine provides no guarantee over `self.exp() - 1.0`.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The exponent.
Returns: (float) `e**self - 1`, or `na` if input is `na` or `self.exp()` is `na`.
method log1p(self)
log1p: Returns the natural logarithm of (1 + self). Calculated as `(1.0 + self).log()`. Pine provides no specific precision guarantee for self near zero.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) Value to add to 1. `1 + self` must be positive.
Returns: (float) Natural log of `1 + self`, or `na` if input is `na` or `1 + self <= 0`.
method modf(self)
modf: Returns the fractional and integer parts of this float as a tuple ` `. Both parts have the sign of `self`.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The number `x` to split.
Returns: ( ) A tuple containing ` `, or ` ` if `x` is `na` or non-finite.
method remainder(self, divisor)
remainder: Returns the IEEE 754 style remainder of `self` with respect to `divisor`. Result `r` satisfies `abs(r) <= 0.5 * abs(divisor)`. Uses round-half-to-even.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) Dividend `x`.
divisor (float) : (float) Divisor `y`. Cannot be zero or `na`.
Returns: (float) The IEEE 754 remainder, or `na` if divisor is 0, `na`, or inputs are non-finite in a way that prevents calculation.
method copysign(self, signSource)
copysign: Returns a float with the magnitude (absolute value) of `self` but the sign of `signSource`.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) Value providing the magnitude `x`.
signSource (float) : (float) Value providing the sign `y`.
Returns: (float) `abs(x)` with the sign of `y`, or `na` if either input is `na`.
method frexp(self)
frexp: Returns the mantissa (m) and exponent (e) of this float `x` as ` `, such that `x = m * 2^e` and `0.5 <= abs(m) < 1` (unless `x` is 0).
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The number `x` to decompose.
Returns: ( ) A tuple ` `, or ` ` if `x` is 0, or ` ` if `x` is non-finite or `na`.
method isclose(self, other, rel_tol, abs_tol)
isclose: Checks if this float `a` and `other` float `b` are close within relative and absolute tolerances.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) First value `a`.
other (float) : (float) Second value `b`.
rel_tol (simple float) : (simple float = 1e-9) Relative tolerance. Must be non-negative and less than 1.0.
abs_tol (simple float) : (simple float = 0.0) Absolute tolerance. Must be non-negative.
Returns: (bool) `true` if `abs(a - b) <= max(rel_tol * max(abs(a), abs(b)), abs_tol)`. Handles `na`/`inf` appropriately. Returns `na` if tolerances are invalid.
method ldexp(self, exponent)
ldexp: Returns `self * (2**exponent)`. Inverse of `frexp`.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) Mantissa part `x`.
exponent (int) : (int) Exponent part `i`.
Returns: (float) The result of `x * pow(2, i)`, or `na` if inputs are `na` or result is non-finite.
method gcd(self)
gcd: Calculates the Greatest Common Divisor (GCD) of all integers in this array.
Namespace types: array
Parameters:
self (array) : (array) An array of integers.
Returns: (int) The largest positive integer that divides all non-zero elements, 0 if all elements are 0 or array is empty. Returns `na` if any element is `na`.
method lcm(self)
lcm: Calculates the Least Common Multiple (LCM) of all integers in this array.
Namespace types: array
Parameters:
self (array) : (array) An array of integers.
Returns: (int) The smallest positive integer that is a multiple of all non-zero elements, 0 if any element is 0, 1 if array is empty. Returns `na` on potential overflow or if any element is `na`.
method dist(self, other)
dist: Returns the Euclidean distance between this point `p` and another point `q` (given as arrays of coordinates).
Namespace types: array
Parameters:
self (array) : (array) Coordinates of the first point `p`.
other (array) : (array) Coordinates of the second point `q`. Must have the same size as `p`.
Returns: (float) The Euclidean distance, or `na` if arrays have different sizes, are empty, or contain `na`/non-finite values.
method fsum(self)
fsum: Returns an accurate floating-point sum of values in this array. Uses built-in `array.sum()`. Note: Pine Script does not guarantee the same level of precision tracking as Python's `math.fsum`.
Namespace types: array
Parameters:
self (array) : (array) The array of floats to sum.
Returns: (float) The sum of the array elements. Returns 0.0 for an empty array. Returns `na` if any element is `na`.
method hypot(self)
hypot: Returns the Euclidean norm (distance from origin) for this point given by coordinates in the array. `sqrt(sum(x*x for x in coordinates))`.
Namespace types: array
Parameters:
self (array) : (array) Array of coordinates defining the point.
Returns: (float) The Euclidean norm, or 0.0 if the array is empty. Returns `na` if any element is `na` or non-finite.
method prod(self, start)
prod: Calculates the product of all elements in this array.
Namespace types: array
Parameters:
self (array) : (array) The array of values to multiply.
start (simple float) : (simple float = 1.0) The starting value for the product (returned if the array is empty).
Returns: (float) The product of array elements * start. Returns `na` if any element is `na`.
method sumprod(self, other)
sumprod: Returns the sum of products of values from this array `p` and another array `q` (dot product).
Namespace types: array
Parameters:
self (array) : (array) First array of values `p`.
other (array) : (array) Second array of values `q`. Must have the same size as `p`.
Returns: (float) The sum of `p * q ` for all i, or `na` if arrays have different sizes or contain `na`/non-finite values. Returns 0.0 for empty arrays.

Best SMA FinderThis script, Best SMA Finder, is a tool designed to identify the most robust simple moving average (SMA) length for a given chart, based on historical backtest performance. It evaluates hundreds of SMA values (from 10 to 1000) and selects the one that provides the best balance between profitability, consistency, and trade frequency.
What it does:
The script performs individual backtests for each SMA length using either "Long Only" or "Buy & Sell" logic, as selected by the user. For each tested SMA, it computes:
- Total number of trades
- Profit Factor (total profits / total losses)
- Win Rate
- A composite Robustness Score, which integrates Profit Factor, number of trades (log-scaled), and win rate.
Only SMA configurations that meet the user-defined minimum trade count are considered valid. Among all valid candidates, the script selects the SMA length with the highest robustness score and plots it on the chart.
How to use it:
- Choose the strategy type: "Long Only" or "Buy & Sell"
- Set the minimum trade count to filter out statistically irrelevant results
- Enable or disable the summary stats table (default: enabled)
The selected optimal SMA is plotted on the chart in blue. The optional table in the top-right corner shows the corresponding SMA length, trade count, Profit Factor, Win Rate, and Robustness Score for transparency.
Key Features:
- Exhaustive SMA optimization across 991 values
- Customizable trade direction and minimum trade filters
- In-chart visualization of results via table and plotted optimal SMA
- Uses a custom robustness formula to rank SMA lengths
Use cases:
Ideal for traders who want to backtest and auto-select a historically effective SMA without manual trial-and-error. Useful for swing and trend-following strategies across different timeframes.
📌 Limitations:
- Not a full trading strategy with position sizing or stop-loss logic
- Only one entry per direction at a time is allowed
- Designed for exploration and optimization, not as a ready-to-trade system
This script is open-source and built entirely from original code and logic. It does not replicate any closed-source script or reuse significant external open-source components.

Bitcoin Monthly Seasonality [Alpha Extract]The Bitcoin Monthly Seasonality indicator analyzes historical Bitcoin price performance across different months of the year, enabling traders to identify seasonal patterns and potential trading opportunities. This tool helps traders:
Visualize which months historically perform best and worst for Bitcoin.
Track average returns and win rates for each month of the year.
Identify seasonal patterns to enhance trading strategies.
Compare cumulative or individual monthly performance.
🔶 CALCULATION
The indicator processes historical Bitcoin price data to calculate monthly performance metrics
Monthly Return Calculation
Inputs:
Monthly open and close prices.
User-defined lookback period (1-15 years).
Return Types:
Percentage: (monthEndPrice / monthStartPrice - 1) × 100
Price: monthEndPrice - monthStartPrice
Statistical Measures
Monthly Averages: ◦ Average return for each month calculated from historical data.
Win Rate: ◦ Percentage of positive returns for each month.
Best/Worst Detection: ◦ Identifies months with highest and lowest average returns.
Cumulative Option
Standard View: Shows discrete monthly performance.
Cumulative View: Shows compounding effect of consecutive months.
Example Calculation (Pine Script):
monthReturn = returnType == "Percentage" ?
(monthEndPrice / monthStartPrice - 1) * 100 :
monthEndPrice - monthStartPrice
calcWinRate(arr) =>
winCount = 0
totalCount = array.size(arr)
if totalCount > 0
for i = 0 to totalCount - 1
if array.get(arr, i) > 0
winCount += 1
(winCount / totalCount) * 100
else
0.0
🔶 DETAILS
Visual Features
Monthly Performance Bars: ◦ Color-coded bars (teal for positive, red for negative returns). ◦ Special highlighting for best (yellow) and worst (fuchsia) months.
Optional Trend Line: ◦ Shows continuous performance across months.
Monthly Axis Labels: ◦ Clear month names for easy reference.
Statistics Table: ◦ Comprehensive view of monthly performance metrics. ◦ Color-coded rows based on performance.
Interpretation
Strong Positive Months: Historically bullish periods for Bitcoin.
Strong Negative Months: Historically bearish periods for Bitcoin.
Win Rate Analysis: Higher win rates indicate more consistently positive months.
Pattern Recognition: Identify recurring seasonal patterns across years.
Best/Worst Identification: Quickly spot the historically strongest and weakest months.
🔶 EXAMPLES
The indicator helps identify key seasonal patterns
Bullish Seasons: Visualize historically strong months where Bitcoin tends to perform well, allowing traders to align long positions with favorable seasonality.
Bearish Seasons: Identify historically weak months where Bitcoin tends to underperform, helping traders avoid unfavorable periods or consider short positions.
Seasonal Strategy Development: Create trading strategies that capitalize on recurring monthly patterns, such as entering positions in historically strong months and reducing exposure during weak months.
Year-to-Year Comparison: Assess how current year performance compares to historical seasonal patterns to identify anomalies or confirmation of trends.
🔶 SETTINGS
Customization Options
Lookback Period: Adjust the number of years (1-15) used for historical analysis.
Return Type: Choose between percentage returns or absolute price changes.
Cumulative Option: Toggle between discrete monthly performance or cumulative effect.
Visual Style Options: Bar Display: Enable/disable and customize colors for positive/negative bars, Line Display: Enable/disable and customize colors for trend line, Axes Display: Show/hide reference axes.
Visual Enhancement: Best/Worst Month Highlighting: Toggle special highlighting of extreme months, Custom highlight colors for best and worst performing months.
The Bitcoin Monthly Seasonality indicator provides traders with valuable insights into Bitcoin's historical performance patterns throughout the year, helping to identify potentially favorable and unfavorable trading periods based on seasonal tendencies.

Market Manipulation Index (MMI)The Composite Manipulation Index (CMI) is a structural integrity tool that quantifies how chaotic or orderly current market conditions are, with the aim of detecting potentially manipulated or unstable environments. It blends two distinct mathematical models that assess price behavior in terms of both structural rhythm and predictability.
1. Sine-Fit Deviation Model:
This component assumes that ideal, low-manipulation price behavior resembles a smooth oscillation, such as a sine wave. It generates a synthetic sine wave using a user-defined period and compares it to actual price movement over an adaptive window. The error between the real price and this synthetic wave—normalized by price variance—forms the Sine-Based Manipulation Index. A high error indicates deviation from natural rhythm, suggesting structural disorder.
2. Predictability-Based Model:
The second component estimates how well current price can be predicted using recent price lags. A two-variable rolling linear regression is computed between the current price and two lagged inputs (close and close ). If the predicted price diverges from the actual price, this error—also normalized by price variance—reflects unpredictability. High prediction error implies a more manipulated or erratic environment.
3. Adaptive Mechanism:
Both components are calculated using an adaptive smoothing window based on the Average True Range (ATR). This allows the indicator to respond proportionally to market volatility. During high volatility, the analysis window expands to avoid over-sensitivity; during calm periods, it contracts for better responsiveness.
4. Composite Output:
The two normalized metrics are averaged to form the final CMI value, which is then optionally smoothed further. The output is scaled between 0 and 1:
0 indicates a highly structured, orderly market.
1 indicates complete structural breakdown or randomness.
Suggested Interpretation:
CMI < 0.3: Market is clean and structured. Trend-following or breakout strategies may perform better.
CMI > 0.7: Market is structurally unstable. Choppy price action, fakeouts, or manipulative behavior may dominate.
CMI 0.3–0.7: Transitional zone. Caution or reduced risk may be warranted.
This indicator is designed to serve as a contextual filter, helping traders assess whether current market conditions are conducive to structured strategies, or if discretion and defense are more appropriate.
Dual-Phase Trend Regime Oscillator (Zeiierman)█ Overview
Trend Regime: Dual-Phase Oscillator (Zeiierman) is a volatility-sensitive trend classification tool that dynamically switches between two oscillators, one optimized for low volatility, the other for high volatility.
By analyzing standard deviation-based volatility states and applying correlation-derived oscillators, this indicator reveals not only whether the market is trending but also what kind of trend regime it is in —Bullish or Bearish —and how that regime reacts to market volatility.
█ Its Uniqueness
Most trend indicators assume a static market environment; they don't adjust their logic when the underlying volatility shifts. That often leads to false signals in choppy conditions or late entries in trending phases.
Trend Regime: Dual-Phase Oscillator solves this by introducing volatility-aware adaptability. It switches between a slow, stable oscillator in calm markets and a fast, reactive oscillator in volatile ones, ensuring the right sensitivity at the right time.
█ How It Works
⚪ Volatility State Engine
Calculates returns-based volatility using standard deviation of price change
Smooths the current volatility with a moving average
Builds a volatility history window and performs median clustering to determine typical "Low" and "High" volatility zones
Dynamically assigns the chart to one of two internal volatility regimes: Low or High
⚪ Dual Oscillators
In Low Volatility, it uses a Slow Trend Oscillator (longer lookback, smoother)
In High Volatility, it switches to a Fast Trend Oscillator (shorter lookback, responsive)
Both oscillators use price-time correlation as a measure of directional strength
The output is normalized between 0 and 1, allowing for consistent interpretation
⚪ Trend Regime Classification
The active oscillator is compared to a neutral threshold (0.5)
If above: Bullish Regime, if below: Bearish Regime, else: Neutral
The background and markers update to reflect regime changes visually
Triangle markers highlight bullish/bearish regime shifts
█ How to Use
⚪ Identify Current Trend Regime
Use the background color and chart table to immediately recognize whether the market is trending up or down.
⚪ Trade Regime Shifts
Use triangle markers (▲ / ▼) to spot fresh regime entries, which are ideal for confirming breakouts within trends.
⚪ Pullback Trading
Look for pullbacks when the trend is in a stable condition and the slow oscillator remains consistently near the upper or lower threshold. Watch for moments when the fast oscillator retraces back toward the midline, or slightly above/below it — this often signals a potential pullback entry in the direction of the prevailing trend.
█ Settings Explained
Length (Slow Trend Oscillator) – Used in calm conditions. Longer = smoother signals
Length (Fast Trend Oscillator) – Used in volatile conditions. Shorter = more responsive
Volatility Refit Interval – Controls how often the system recalculates Low/High volatility levels
Current Volatility Period – Lookback used for immediate volatility measurement
Volatility Smoothing Length – Applies an SMA to the raw volatility to reduce noise
-----------------
Disclaimer
The content provided in my scripts, indicators, ideas, algorithms, and systems is for educational and informational purposes only. It does not constitute financial advice, investment recommendations, or a solicitation to buy or sell any financial instruments. I will not accept liability for any loss or damage, including without limitation any loss of profit, which may arise directly or indirectly from the use of or reliance on such information.
All investments involve risk, and the past performance of a security, industry, sector, market, financial product, trading strategy, backtest, or individual's trading does not guarantee future results or returns. Investors are fully responsible for any investment decisions they make. Such decisions should be based solely on an evaluation of their financial circumstances, investment objectives, risk tolerance, and liquidity needs.

Nasan Risk Score & Postion Size Estimator** THE RISK SCORE AND POSITION SIZE WILL ONLY BE CALCUTAED ON DIALY TIMEFRAME NOT IN OTHER TIMEFRAMES.
The typically accepted generic rule for risk management is not to risk more than 1% - 2 % of the capital in any given trade. It has its own basis however it does not take into account the stocks historic & current performance and does not consider the traders performance metrics (like win rate, profit ratio).
The Nasan Risk Score & Position size calculator takes into account all the listed parameters into account and estimates a Risk %. The position size is calculated using the estimated risk % , current ATR and a dynamically adjusted ATR multiple (ATR multiple is adjusted based on true range's volatility and stocks relative performance).
It follows a series of calculations:
Unadjusted Nasan Risk Score = (Min Risk)^a + b*
Min Risk = ( 5 year weighted avg Annual Stock Return - 5 year weighted avg Annual Bench Return) / 5 year weighted avg Annual Max ATR%
Max Risk = ( 5 year weighted avg Annual Stock Return - 5 year weighted avg Annual Bench Return) / 5 year weighted avg Annual Min ATR%
The min and max return is calculated based on stocks excess return in comparison to the Benchmark return and adjusted for volatility of the stock.
When a stock underperforms the benchmark, the default is, it does not calculate a position size , however if we opt it to calculate it will use 1% for Min Risk% and 2% for Max Risk% but all the other calculations and scaling remain the same.
Rationale:
Stocks outperforming their benchmark with lower volatility (ATR%) score higher.
A stock with high returns but excessive volatility gets penalized.
This ensures volatility-adjusted performance is emphasized rather than absolute returns.
Depending on the risk preference aggressive or conservative
Aggressive Risk Scaling: a = max (m, n) and b = min (m, n)
Conservative Scaling: a = min (m, n) and b = max (m, n)
where n = traders win % /100 and m = 1 - (1/ (1+ profit ratio))
A default of 50% is used for win factor and 1.5 for profit ratio.
Aggressive risk scaling increases exposure when the strategy's strongest factor is favorable.
Conservative risk scaling ensures more stable risk levels by focusing on the weaker factor.
The Unadjusted Nasan risk is score is further refined based on a tolerance factor which is based on the stocks maximum annual drawdown and the trader's maximum draw down tolerance.
Tolerance = /100
The correction factor (Tolerance) adjusts the risk score based on downside risk. Here's how it works conceptually:
The formula calculates how much the stock's actual drawdown exceeds your acceptable limit.
If stocks maximum Annual drawdown is smaller than Trader's maximum acceptable drawdown % , this results in a positive correction factor (indicating the drawdown is within your acceptable range and increases the unadjusted score.
If stocks maximum Annual drawdown exceeds Trader's maximum acceptable drawdown %, the correction factor will decrease (indicating that the downside risk is greater than what you are comfortable with, so it will adjust the risk exposure).
Once the Risk Score (numerically equal to Risk %) The position size is calculated based on the current market conditions.
Nasan Risk Score (Risk%) = Unadjusted Nasan Risk Score * Tolerance.
Position Size = (Capital * Risk% )/ ATR-Multiplier * ATR
The ATR Multiplier is dynamically adjusted based on the stocks recent relative performance and the variability of the true range itself. It would range between 1 - 3.5.
The multiplier widens when conditions are not favorable decreasing the position size and increases position size when conditions are favorable.
This Calculation /Estimate Does not give you a very different result than the arbitrary 1% - 2%. However it does fine tune the % based on sock performance, traders performance and tolerance level.

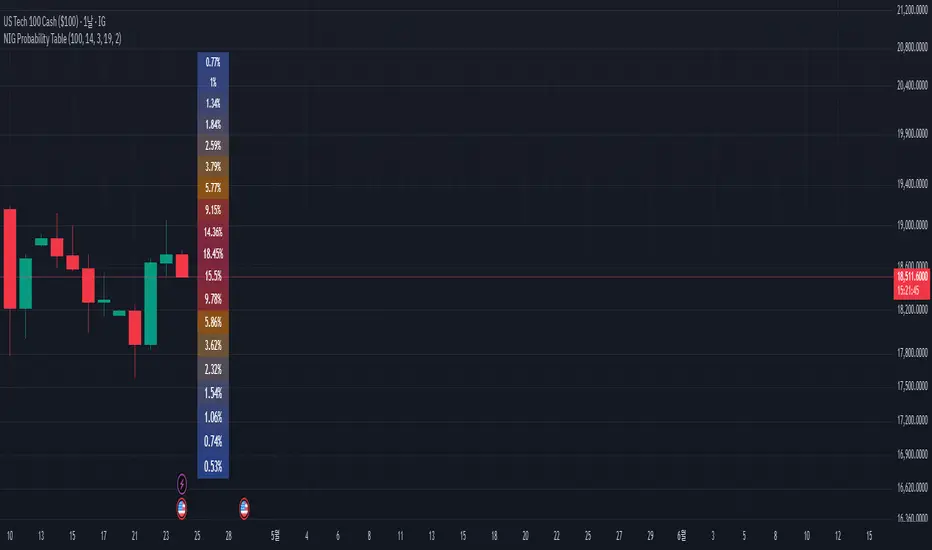
NIG Probability TableNormal-Inverse Gaussian Probability Table
This indicator implements the Normal-Inverse Gaussian (NIG) distribution to estimate the likelihood of future price based on recent market behavior.
📊 Key Features:
- Estimates the parameters (α: tail heaviness, β: skewness, δ: scale, μ: location)
of the NIG distribution using a sliding window over log returns.
- Uses a numerically approximated version of the modified Bessel function (K₁)
to calculate the NIG probability density function (PDF).
- Normalizes the total probability across all bins to ensure the values are interpretable.
- Displays a dynamic probability table showing the chance of future returns falling into each bin.
⚠️ Notes:
- This is a real-time approximation. The Bessel function and posterior inference are simplified.
- Tail probabilities and shape parameters are sensitive to the window size and input settings.
- Useful for risk analysis, option overlays, and strategy filters.
Log-Normal Price ForecastLog-Normal Price Forecast
This Pine Script creates a log-normal forecast model of future price movements on a TradingView chart, based on historical log returns. It plots expected price trajectories and bands representing different levels of statistical deviation.
Parameters
Model Length – Number of bars used to calculate average and standard deviation of log returns (default: 100).
Forecast Length – Number of bars into the future for which the forecast is projected (default: 100, max: 500).
Volatility SMA Length – The smoothing length for the standard deviation (default: 20).
Confidence Intervals – Confidence intervals for price bands (default: 95%, 99%, 99.9%).

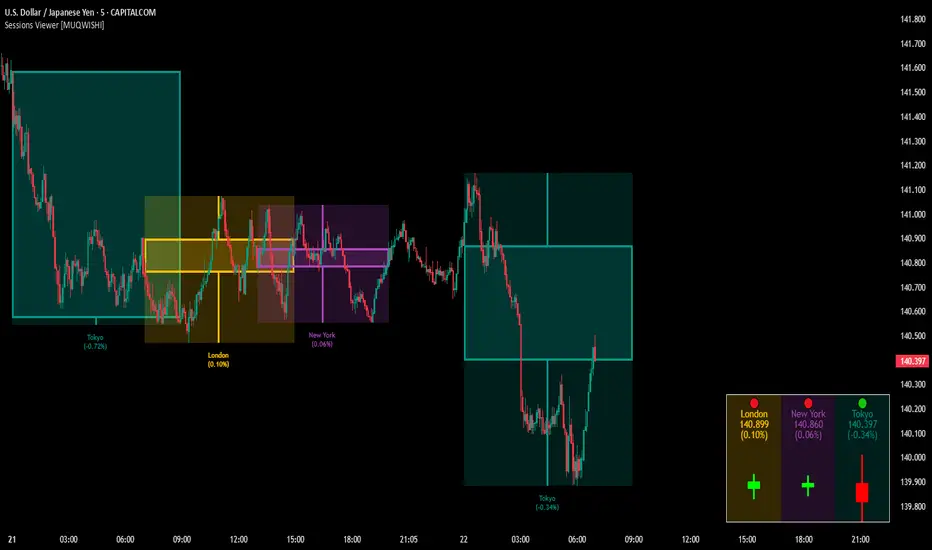
Market Sessions & Viewer Panel [By MUQWISHI]▋ INTRODUCTION :
The “Market Sessions & Viewer Panel” is a clean and intuitive visual indicator tool that highlights up to four trading sessions directly on the chart. Each session is fully customizable with its name, session time, and color. It also generates a panel that provides a quick-glance summary of each session’s candle/bar shape, helping traders gain insight into the volatility across all trading sessions.
_______________________
▋ OVERVIEW:
_______________________
▋ CREDIT:
This indicator utilizes the “ Timezone — Library ”. A huge thanks to @n00btraders for effort and well-organized work.
_______________________
▋ SESSION PANEL:
The Session Panel allows traders to visually compare session volatility using a candlestick/bar pattern.
Each bar represents the price action during a session and includes the session status, session name, closing price, change(%) from open, and a tooltip that reveals detailed OHLC and volume when hovered over.
Chart Type:
It offers two styles Bar or Candle to display based on traders’ preference
Sorting:
Allowing to arrange session candles/bars based on…
—Left to Right: The most recently opened on the left, moving backward in time to the right.
—Right to Left: The most recently opened on the right, moving backward in time to the left.
—Default: Arrange sessions in the user-defined input order.
_______________________
▋ CHART VISUALIZATION:
The chart visualization highlights each trading session using color-coded backgrounds in two selectable drawing styles that span their respective active timeframes. Each session block provides session’s name, close price, and change from open.
Chart Type: Candle
Chart Type: Box
Extra Drawing Feature:
This feature may not exist in other indicators within the same category, it extends the session block drawing to the projected end of the session. This's done through estimation based on historical data; however, it doesn’t function fully on seconds-based timeframes due to drawing limitations.
_______________________
▋ INDICATOR SETTINGS:
Section(1): Sessions
(1) Universal Timezone.
(2) Each Session: Enable/Disable, Name, Color, and Time.
Section(2): Session Panel
(1) Show/Hide Session Panel.
(2) Chart Type: Candle/Bar.
(3) Bar’s Up/Down color.
(4) Width and Height of the bar.
(5) Location of Session Panel on chat.
(6) Sort: Left to Right (most recent session is placed on the left), Right to Left (most recent session is placed on the right), and Default (as input arrangement).
Section(3): Chart Visualization
(1) Show/Hide Chart Block Visualization.
(2) Draw Shape: Box/Candle.
(3) Border Style and Size.
(4) Label Styling includes location, size, and some essential selectable infos.
Please let me know if you have any questions
Elastic Volume-Weighted Student-T TensionOverview
The Elastic Volume-Weighted Student-T Tension Bands indicator dynamically adapts to market conditions using an advanced statistical model based on the Student-T distribution. Unlike traditional Bollinger Bands or Keltner Channels, this indicator leverages elastic volume-weighted averaging to compute real-time dispersion and location parameters, making it highly responsive to volatility changes while maintaining robustness against price fluctuations.
This methodology is inspired by incremental calculation techniques for weighted mean and variance, as outlined in the paper by Tony Finch:
📄 "Incremental Calculation of Weighted Mean and Variance" .
Key Features
✅ Adaptive Volatility Estimation – Uses an exponentially weighted Student-T model to dynamically adjust band width.
✅ Volume-Weighted Mean & Dispersion – Incorporates real-time volume weighting, ensuring a more accurate representation of market sentiment.
✅ High-Timeframe Volume Normalization – Provides an option to smooth volume impact by referencing a higher timeframe’s cumulative volume, reducing noise from high-variability bars.
✅ Customizable Tension Parameters – Configurable standard deviation multipliers (σ) allow for fine-tuned volatility sensitivity.
✅ %B-Like Oscillator for Relative Price Positioning – The main indicator is in form of a dedicated oscillator pane that normalizes price position within the sigma ranges, helping identify overbought/oversold conditions and potential momentum shifts.
✅ Robust Statistical Foundation – Utilizes kurtosis-based degree-of-freedom estimation, enhancing responsiveness across different market conditions.
How It Works
Volume-Weighted Elastic Mean (eμ) – Computes a dynamic mean price using an elastic weighted moving average approach, influenced by trade volume, if not volume detected in series, study takes true range as replacement.
Dispersion (eσ) via Student-T Distribution – Instead of assuming a fixed normal distribution, the bands adapt to heavy-tailed distributions using kurtosis-driven degrees of freedom.
Incremental Calculation of Variance – The indicator applies Tony Finch’s incremental method for computing weighted variance instead of arithmetic sum's of fixed bar window or arrays, improving efficiency and numerical stability.
Tension Calculation – There are 2 dispersion custom "zones" that are computed based on the weighted mean and dynamically adjusted standard student-t deviation.
%B-Like Oscillator Calculation – The oscillator normalizes the price within the band structure, with values between 0 and 1:
* 0.00 → Price is at the lower band (-2σ).
* 0.50 → Price is at the volume-weighted mean (eμ).
* 1.00 → Price is at the upper band (+2σ).
* Readings above 1.00 or below 0.00 suggest extreme movements or possible breakouts.
Recommended Usage
For scalping in lower timeframes, it is recommended to use the fixed α Decay Factor, it is in raw format for better control, but you can easily make a like of transformation to N-bar size window like in EMA-1 bar dividing 2 / decayFactor or like an RMA dividing 1 / decayFactor.
The HTF selector catch quite well Higher Time Frame analysis, for example using a Daily chart and using as HTF the 200-day timeframe, weekly or monthly.
Suitable for trend confirmation, breakout detection, and mean reversion plays.
The %B-like oscillator helps gauge momentum strength and detect divergences in price action if user prefer a clean chart without bands, this thanks to pineScript v6 force overlay feature.
Ideal for markets with volume-driven momentum shifts (e.g., futures, forex, crypto).
Customization Parameters
Fixed α Decay Factor – Controls the rate of volume weighting influence for an approximation EWMA approach instead of using sum of series or arrays, making the code lightweight & computing fast O(1).
HTF Volume Smoothing – Instead of a fixed denominator for computing α , a volume sum of the last 2 higher timeframe closed candles are used as denominator for our α weight factor. This is useful to review mayor trends like in daily, weekly, monthly.
Tension Multipliers (±σ) – Adjusts sensitivity to dispersion sigma parameter (volatility).
Oscillator Zone Fills – Visual cues for price positioning within the cloud range.
Posible Interpretations
As market within indicators relay on each individual edge, this are just some key ideas to glimpse how the indicator could be interpreted by the user:
📌 Price inside bands – Market is considered somehow "stable"; price is like resting from tension or "charging batteries" for volume spike moves.
📌 Price breaking outer bands – Potential breakout or extreme movement; watch for reversals or continuation from strong moves. Market is already in tension or generating it.
📌 Narrowing Bands – Decreasing volatility; expect contraction before expansion.
📌 Widening Bands – Increased volatility; prepare for high probability pull-back moves, specially to the center location of the bands (the mean) or the other side of them.
📌 Oscillator is just the interpretation of the price normalized across the Student-T distribution fitting "curve" using the location parameter, our Elastic Volume weighted mean (eμ) fixed at 0.5 value.
Final Thoughts
The Elastic Volume-Weighted Student-T Tension indicator provides a powerful, volume-sensitive alternative to traditional volatility bands. By integrating real-time volume analysis with an adaptive statistical model, incremental variance computation, in a relative price oscillator that can be overlayed in the chart as bands, it offers traders an edge in identifying momentum shifts, trend strength, and breakout potential. Think of the distribution as a relative "tension" rubber band in which price never leave so far alone.
DISCLAIMER:
The Following indicator/code IS NOT intended to be a formal investment advice or recommendation by the author, nor should be construed as such. Users will be fully responsible by their use regarding their own trading vehicles/assets.
The following indicator was made for NON LUCRATIVE ACTIVITIES and must remain as is, following TradingView's regulations. Use of indicator and their code are published for work and knowledge sharing. All access granted over it, their use, copy or re-use should mention authorship(s) and origin(s).
WARNING NOTICE!
THE INCLUDED FUNCTION MUST BE CONSIDERED FOR TESTING. The models included in the indicator have been taken from open sources on the web and some of them has been modified by the author, problems could occur at diverse data sceneries, compiler version, or any other externality.

Dynamic RSI Regression Bands (Zeiierman)█ Overview
The Dynamic RSI Regression Bands (Zeiierman) is a regression channel tool that dynamically resets based on RSI overbought and oversold conditions. It adapts to trend shifts in real time, creating a highly responsive regression framework that visualizes market sentiment and directional momentum with every RSI-triggered event.
Unlike static regression models, this indicator recalibrates its slope and deviation bands only after the RSI crosses predefined thresholds, helping traders pinpoint new phases of momentum, exhaustion, or reversal.
You’re not just measuring the trend — you’re tracking when and where the trend deserves to be re-evaluated.
█ The Assumption:
"A major momentum shift (RSI crossing OB/OS) signals a potential regime change, and thus, the trend model should be recalibrated from that point."
Instead of using a fixed-length regression (which assumes trend relevance over a static window), this script resets the regression calculation every time RSI crosses into extreme territory. The underlying idea is that extreme RSI levels often represent emotional peaks in market behavior and are statistically likely to be followed by a new price structure.
█ How It Works
⚪ RSI-Based Channel Reset
RSI is monitored continuously
If RSI crosses above the Overbought level, the indicator resets and starts a new regression channel
If RSI crosses below the Oversold level, the same reset logic applies
These events act as “anchor points” for dynamic trend analysis
⚪ Regression Channel Logic
A custom linear regression is calculated from the RSI reset point forward
The lookback grows with each bar after the reset, up to a user-defined max
Regression lines are drawn from the reset point to the current bar
⚪ Standard Deviation Bands
Upper and lower bands are plotted around the regression line using the standard deviation
These serve as dynamic volatility envelopes, great for spotting breakouts or reversals
⚪ Rejection Markers
If price hits the upper/lower band and then closes back inside it, a rejection marker is plotted
Helps visualize failed breakouts and areas of absorption or reversal pressure
█ How to Use
⚪ Detect Trend Shifts
Use the RSI resets to identify when the trend might be starting fresh.
⚪ Watch the Bands for Volatility Extremes
Use the outer bands as soft areas of potential reversal or momentum breakout.
⚪ Spot Rejections for Potential Entry Signals
If price moves outside a band but then quickly returns inside, it often means the breakout failed, and price may reverse.
█ Settings Explained
RSI Length – How many bars RSI uses. Shorter = faster.
OB / OS Levels – Crossing these triggers a regression reset.
Base Regression Length – Max number of bars regression can use post-reset.
StdDev Multiplier – Controls band width from the regression line.
Min Bars After Reset – Ensures channel doesn’t form immediately; waits for structure.
Show Reset Markers – Triangles mark where RSI crossed OB/OS.
Show Rejection Markers – Circles mark where the price rejected the channel edge.
-----------------
Disclaimer
The content provided in my scripts, indicators, ideas, algorithms, and systems is for educational and informational purposes only. It does not constitute financial advice, investment recommendations, or a solicitation to buy or sell any financial instruments. I will not accept liability for any loss or damage, including without limitation any loss of profit, which may arise directly or indirectly from the use of or reliance on such information.
All investments involve risk, and the past performance of a security, industry, sector, market, financial product, trading strategy, backtest, or individual's trading does not guarantee future results or returns. Investors are fully responsible for any investment decisions they make. Such decisions should be based solely on an evaluation of their financial circumstances, investment objectives, risk tolerance, and liquidity needs.

The Mayan CalendarThis indicator displays the current date in the Mayan Calendar, based on real-time UTC time. It calculates and presents:
🌀 Long Count (Baktun.Katun.Tun.Uinal.Kin) – A linear count of days since the Mayan epoch (August 11, 3114 BCE).
🔮 Tzolk'in Date – A 260-day sacred cycle combining a number (1–13) and one of 20 day names (e.g., 4 Ajaw).
🌾 Haab' Date – A 365-day civil cycle divided into 18 months of 20 days + 5 "nameless" days (Wayeb').
The calculations follow Smithsonian standards and align with the Maya Calendar Converter from the National Museum of the American Indian:
👉 maya.nmai.si.edu
The results are shown in a table overlay on your chart's top-right corner. This indicator is great for symbolic traders, astro enthusiasts, or anyone interested in ancient timekeeping systems woven into financial timeframes. Enjoy, time travelers! ⌛

Machine Learning RSI ║ BullVisionOverview:
Introducing the Machine Learning RSI with KNN Adaptation – a cutting-edge momentum indicator that blends the classic Relative Strength Index (RSI) with machine learning principles. By leveraging K-Nearest Neighbors (KNN), this indicator aims at identifying historical patterns that resemble current market behavior and uses this context to refine RSI readings with enhanced sensitivity and responsiveness.
Unlike traditional RSI models, which treat every market environment the same, this version adapts in real-time based on how similar past conditions evolved, offering an analytical edge without relying on predictive assumptions.
Key Features:
🔁 KNN-Based RSI Refinement
This indicator uses a machine learning algorithm (K-Nearest Neighbors) to compare current RSI and price action characteristics to similar historical conditions. The resulting RSI is weighted accordingly, producing a dynamically adjusted value that reflects historical context.
📈 Multi-Feature Similarity Analysis
Pattern similarity is calculated using up to five customizable features:
RSI level
RSI momentum
Volatility
Linear regression slope
Price momentum
Users can adjust how many features are used to tailor the behavior of the KNN logic.
🧠 Machine Learning Weight Control
The influence of the machine learning model on the final RSI output can be fine-tuned using a simple slider. This lets you blend traditional RSI and machine learning-enhanced RSI to suit your preferred level of adaptation.
🎛️ Adaptive Filtering
Additional smoothing options (Kalman Filter, ALMA, Double EMA) can be applied to the RSI, offering better visual clarity and helping to reduce noise in high-frequency environments.
🎨 Visual & Accessibility Settings
Custom color palettes, including support for color vision deficiencies, ensure that trend coloring remains readable for all users. A built-in neon mode adds high-contrast visuals to improve RSI visibility across dark or light themes.
How It Works:
Similarity Matching with KNN:
At each candle, the current RSI and optional market characteristics are compared to historical bars using a KNN search. The algorithm selects the closest matches and averages their RSI values, weighted by similarity. The more similar the pattern, the greater its influence.
Feature-Based Weighting:
Similarity is determined using normalized values of the selected features, which gives a more refined result than RSI alone. You can choose to use only 1 (RSI) or up to all 5 features for deeper analysis.
Filtering & Blending:
After the machine learning-enhanced RSI is calculated, it can be optionally smoothed using advanced filters to suppress short-term noise or sharp spikes. This makes it easier to evaluate RSI signals in different volatility regimes.
Parameters Explained:
📊 RSI Settings:
Set the base RSI length and select your preferred smoothing method from 10+ moving average types (e.g., EMA, ALMA, TEMA).
🧠 Machine Learning Controls:
Enable or disable the KNN engine
Select how many nearest neighbors to compare (K)
Choose the number of features used in similarity detection
Control how much the machine learning engine affects the RSI calculation
🔍 Filtering Options:
Enable one of several advanced smoothing techniques (Kalman Filter, ALMA, Double EMA) to adjust the indicator’s reactivity and stability.
📏 Threshold Levels:
Define static overbought/oversold boundaries or reference dynamically adjusted thresholds based on historical context identified by the KNN algorithm.
🎨 Visual Enhancements:
Select between trend-following or impulse coloring styles. Customize color palettes to accommodate different types of color blindness. Enable neon-style effects for visual clarity.
Use Cases:
Swing & Trend Traders
Can use the indicator to explore how current RSI readings compare to similar market phases, helping to assess trend strength or potential turning points.
Intraday Traders
Benefit from adjustable filters and fast-reacting smoothing to reduce noise in shorter timeframes while retaining contextual relevance.
Discretionary Analysts
Use the adaptive OB/OS thresholds and visual cues to supplement broader confluence zones or market structure analysis.
Customization Tips:
Higher Volatility Periods: Use more neighbors and enable filtering to reduce noise.
Lower Volatility Markets: Use fewer features and disable filtering for quicker RSI adaptation.
Deeper Contextual Analysis: Increase KNN lookback and raise the feature count to refine pattern recognition.
Accessibility Needs: Switch to Deuteranopia or Monochrome mode for clearer visuals in specific color vision conditions.
Final Thoughts:
The Machine Learning RSI combines familiar momentum logic with statistical context derived from historical similarity analysis. It does not attempt to predict price action but rather contextualizes RSI behavior with added nuance. This makes it a valuable tool for those looking to elevate traditional RSI workflows with adaptive, research-driven enhancements.

Half Causal EstimatorOverview
The Half Causal Estimator is a specialized filtering method that provides responsive averages of market variables (volume, true range, or price change) with significantly reduced time delay compared to traditional moving averages. It employs a hybrid approach that leverages both historical data and time-of-day patterns to create a timely representation of market activity while maintaining smooth output.
Core Concept
Traditional moving averages suffer from time lag, which can delay signals and reduce their effectiveness for real-time decision making. The Half Causal Estimator addresses this limitation by using a non-causal filtering method that incorporates recent historical data (the causal component) alongside expected future behavior based on time-of-day patterns (the non-causal component).
This dual approach allows the filter to respond more quickly to changing market conditions while maintaining smoothness. The name "Half Causal" refers to this hybrid methodology—half of the data window comes from actual historical observations, while the other half is derived from time-of-day patterns observed over multiple days. By incorporating these "future" values from past patterns, the estimator can reduce the inherent lag present in traditional moving averages.
How It Works
The indicator operates through several coordinated steps. First, it stores and organizes market data by specific times of day (minutes/hours). Then it builds a profile of typical behavior for each time period. For calculations, it creates a filtering window where half consists of recent actual data and half consists of expected future values based on historical time-of-day patterns. Finally, it applies a kernel-based smoothing function to weight the values in this composite window.
This approach is particularly effective because market variables like volume, true range, and price changes tend to follow recognizable intraday patterns (they are positive values without DC components). By leveraging these patterns, the indicator doesn't try to predict future values in the traditional sense, but rather incorporates the average historical behavior at those future times into the current estimate.
The benefit of using this "average future data" approach is that it counteracts the lag inherent in traditional moving averages. In a standard moving average, recent price action is underweighted because older data points hold equal influence. By incorporating time-of-day averages for future periods, the Half Causal Estimator essentially shifts the center of the filter window closer to the current bar, resulting in more timely outputs while maintaining smoothing benefits.
Understanding Kernel Smoothing
At the heart of the Half Causal Estimator is kernel smoothing, a statistical technique that creates weighted averages where points closer to the center receive higher weights. This approach offers several advantages over simple moving averages. Unlike simple moving averages that weight all points equally, kernel smoothing applies a mathematically defined weight distribution. The weighting function helps minimize the impact of outliers and random fluctuations. Additionally, by adjusting the kernel width parameter, users can fine-tune the balance between responsiveness and smoothness.
The indicator supports three kernel types. The Gaussian kernel uses a bell-shaped distribution that weights central points heavily while still considering distant points. The Epanechnikov kernel employs a parabolic function that provides efficient noise reduction with a finite support range. The Triangular kernel applies a linear weighting that decreases uniformly from center to edges. These kernel functions provide the mathematical foundation for how the filter processes the combined window of past and "future" data points.
Applicable Data Sources
The indicator can be applied to three different data sources: volume (the trading volume of the security), true range (expressed as a percentage, measuring volatility), and change (the absolute percentage change from one closing price to the next).
Each of these variables shares the characteristic of being consistently positive and exhibiting cyclical intraday patterns, making them ideal candidates for this filtering approach.
Practical Applications
The Half Causal Estimator excels in scenarios where timely information is crucial. It helps in identifying volume climaxes or diminishing volume trends earlier than conventional indicators. It can detect changes in volatility patterns with reduced lag. The indicator is also useful for recognizing shifts in price momentum before they become obvious in price action, and providing smoother data for algorithmic trading systems that require reduced noise without sacrificing timeliness.
When volatility or volume spikes occur, conventional moving averages typically lag behind, potentially causing missed opportunities or delayed responses. The Half Causal Estimator produces signals that align more closely with actual market turns.
Technical Implementation
The implementation of the Half Causal Estimator involves several technical components working together. Data collection and organization is the first step—the indicator maintains a data structure that organizes market data by specific times of day. This creates a historical record of how volume, true range, or price change typically behaves at each minute/hour of the trading day.
For each calculation, the indicator constructs a composite window consisting of recent actual data points from the current session (the causal half) and historical averages for upcoming time periods from previous sessions (the non-causal half). The selected kernel function is then applied to this composite window, creating a weighted average where points closer to the center receive higher weights according to the mathematical properties of the chosen kernel. Finally, the kernel weights are normalized to ensure the output maintains proper scaling regardless of the kernel type or width parameter.
This framework enables the indicator to leverage the predictable time-of-day components in market data without trying to predict specific future values. Instead, it uses average historical patterns to reduce lag while maintaining the statistical benefits of smoothing techniques.
Configuration Options
The indicator provides several customization options. The data period setting determines the number of days of observations to store (0 uses all available data). Filter length controls the number of historical data points for the filter (total window size is length × 2 - 1). Filter width adjusts the width of the kernel function. Users can also select between Gaussian, Epanechnikov, and Triangular kernel functions, and customize visual settings such as colors and line width.
These parameters allow for fine-tuning the balance between responsiveness and smoothness based on individual trading preferences and the specific characteristics of the traded instrument.
Limitations
The indicator requires minute-based intraday timeframes, securities with volume data (when using volume as the source), and sufficient historical data to establish time-of-day patterns.
Conclusion
The Half Causal Estimator represents an innovative approach to technical analysis that addresses one of the fundamental limitations of traditional indicators: time lag. By incorporating time-of-day patterns into its calculations, it provides a more timely representation of market variables while maintaining the noise-reduction benefits of smoothing. This makes it a valuable tool for traders who need to make decisions based on real-time information about volume, volatility, or price changes.

BIN Based Support and Resistance [SS]This indicator presents a version of an alternative way to determine support and resistance, using a method called "Bins".
Bins provide for a flexible and interesting way to determine support and resistance levels.
First off, let's discuss BINS:
Bins are ranges or containers into which your data points can be sorted. For example, if you're grouping ages, you might have bins like 0–18, 19–35, 36–50, and 51+. Any data point within these intervals gets placed in the corresponding bin.
Binning simplifies complex data sets by grouping values into categories. This is useful for such things as
Visualizing data in histograms or bar charts.
Reducing noise and highlighting trends.
This indicator groups the price action into 10 separate bins. It determines the Support / Resistance level by averaging the values in the Bins to find an iteration of the "central tendency" or average reoccurring value.
Pros and Cons
Since this is a different approach to support and resistance, I think its important to highlight some of the pros and advantages, but also be open about the cons.
First off the PROS
Bin Based Support and Resistance Levels dynamically adjust to ranges as opposed to hard / fast peaks and valleys. This makes them better at analyzing price action vs simply drawing lines at random peaks and valleys.
Because Bins are analyzing ALL PA within a period's max and min range, Bin Support and Resistance can actually be used similar to Volume profile, where you are able to identify a pseudo-POC, or areas where price tends to consolidate. Take a look at this example on SPY:
You can see these 2 SR lines are close together. This represents that this general price range is an area where price likes to accumulate/consolidate. You can see the SPY ended up coming back to this range and consolidating there for a bit.
This is a strength of using a BIN based approach to calculating support and resistance, because as indicated before, it looks at price action vs peaks and valleys.
As a tip, these areas are areas you want to wait for a break in one direction or the other.
The indicator provides for backtest results of the support and resistance lines, to see how many times certain areas acted as resistance or support. Because this is analyzing and distributing PA evenly throughout the period's max and min, the indicator can tell you which areas tend to have higher rejection zones and which have higher support zones.
Now the CONS
Because bin based SR take an average approach, the SR lines can sometimes be slightly broken before the ticker finds rejection:
To combat this, make sure there is confirmed support. How the indicator actually backtests these lines is by waiting to see if the ticker has 3 consecutive closes above the support line or below the resistance line. So these are things to be mindful of.
It doesn't consider pivots. Most support and resistance indicators either identify max and min peaks and valleys or use pivot points. Pivot points are a great way to identify peaks and valleys and thus by extension support and resistance. However, this is also somewhat of a strength, as using BINS forces the indicator to consider ALL price action and not just the extremes (highs and lows).
Can be slightly skewed in highly volatile environments. Any time there is a massive drop or rally, it can skew the indicator to give extreme ranges to both ends. For example, the Tariff news collapse on ES1!:
Owning to limitations in lookback length, sometimes the min and max range can be exceeded and other traditional areas of support / resistance is where a ticker will find support.
Using the indicator
Here are some basic use/functionalities of the indicator:
Selecting display of backtest results: You can select to have the backtest results shown in a table:
Or directly on the lines:
Inversely, you can toggle them off completely:
You can modify the lookback length. The suggested lookback length is between 250 to 500 candles on smaller timeframes. I also suggest 252 on daily timeframes (which represents 1 trading year).
And that's the indicator!
It is very easy to use, so you should pick it up in no time!
Enjoy and as always, 🚀🚀 safe trades! 🚀🚀

Probability Grid [LuxAlgo]The Probability Grid tool allows traders to see the probability of where and when the next reversal would occur, it displays a 10x10 grid and/or dashboard with the probability of the next reversal occurring beyond each cell or within each cell.
🔶 USAGE
By default, the tool displays deciles (percentiles from 0 to 90), users can enable, disable and modify each percentile, but two of them must always be enabled or the tool will display an error message alerting of it.
The use of the tool is quite simple, as shown in the chart above, the further the price moves on the grid, the higher the probability of a reversal.
In this case, the reversal took place on the cell with a probability of 9%, which means that there is a probability of 91% within the square defined by the last reversal and this cell.
🔹 Grid vs Dashboard
The tool can display a grid starting from the last reversal and/or a dashboard at three predefined locations, as shown in the chart above.
🔶 DETAILS
🔹 Raw Data vs Normalized Data
By default the tool displays the normalized data, this means that instead of using the raw data (price delta between reversals) it uses the returns between each reversal, this is useful to make an apples to apples comparison of all the data in the dataset.
This can be seen in the left side of the chart above (BTCUSD Daily chart) where normalize data is disabled, the percentiles from 0 to 40 overlap and are indistinguishable from each other because the tool uses the raw price delta over the entire bitcoin history, with normalize data enabled as we can see in the right side of the chart we can have a fair comparison of the data over the entire history.
🔹 Probability Beyond or Within Each Cell
Two different probability modes are available, the default mode is Probability Beyond Each Cell, the number displayed in each cell is the probability of the next reversal to be located in the area beyond the cell, for example, if the cell displays 20%, it means that in the area formed by the square starting from the last reversal and ending at the cell, there is an 80% probability and outside that square there is a 20% probability for the location of the next reversal.
The second probability mode is the probability within each cell, this outlines the chance that the next reversal will be within the cell, as we can see on the right chart above, when using deciles as percentiles (default settings), each cell has the same 1% probability for the 10x10 grid.
🔶 SETTINGS
Swing Length: The maximum length in bars used to identify a swing
Maximum Reversals: Maximum number of reversals included in calculations
Normalize Data: Use returns between swings instead of raw price
Probability: Choose between two different probability modes: beyond and inside each cell
Percentiles: Enable/disable each of the ten percentiles and select the percentile number and line style
🔹 Dashboard
Show Dashboard: Enable or disable the dashboard
Position: Choose dashboard location
Size: Choose dashboard size
🔹 Style
Show Grid: Enable or disable the grid
Size: Choose grid text size
Colors: Choose grid background colors
Show Marks: Enable/disable reversal markers

Correlation Heatmap█ OVERVIEW
This indicator creates a correlation matrix for a user-specified list of symbols based on their time-aligned weekly or monthly price returns. It calculates the Pearson correlation coefficient for each possible symbol pair, and it displays the results in a symmetric table with heatmap-colored cells. This format provides an intuitive view of the linear relationships between various symbols' price movements over a specific time range.
█ CONCEPTS
Correlation
Correlation typically refers to an observable statistical relationship between two datasets. In a financial time series context, it usually represents the extent to which sampled values from a pair of datasets, such as two series of price returns, vary jointly over time. More specifically, in this context, correlation describes the strength and direction of the relationship between the samples from both series.
If two separate time series tend to rise and fall together proportionally, they might be highly correlated. Likewise, if the series often vary in opposite directions, they might have a strong anticorrelation . If the two series do not exhibit a clear relationship, they might be uncorrelated .
Traders frequently analyze asset correlations to help optimize portfolios, assess market behaviors, identify potential risks, and support trading decisions. For instance, correlation often plays a key role in diversification . When two instruments exhibit a strong correlation in their returns, it might indicate that buying or selling both carries elevated unsystematic risk . Therefore, traders often aim to create balanced portfolios of relatively uncorrelated or anticorrelated assets to help promote investment diversity and potentially offset some of the risks.
When using correlation analysis to support investment decisions, it is crucial to understand the following caveats:
• Correlation does not imply causation . Two assets might vary jointly over an analyzed range, resulting in high correlation or anticorrelation in their returns, but that does not indicate that either instrument directly influences the other. Joint variability between assets might occur because of shared sensitivities to external factors, such as interest rates or global sentiment, or it might be entirely coincidental. In other words, correlation does not provide sufficient information to identify cause-and-effect relationships.
• Correlation does not predict the future relationship between two assets. It only reflects the estimated strength and direction of the relationship between the current analyzed samples. Financial time series are ever-changing. A strong trend between two assets can weaken or reverse in the future.
Correlation coefficient
A correlation coefficient is a numeric measure of correlation. Several coefficients exist, each quantifying different types of relationships between two datasets. The most common and widely known measure is the Pearson product-moment correlation coefficient , also known as the Pearson correlation coefficient or Pearson's r . Usually, when the term "correlation coefficient" is used without context, it refers to this correlation measure.
The Pearson correlation coefficient quantifies the strength and direction of the linear relationship between two variables. In other words, it indicates how consistently variables' values move together or in opposite directions in a proportional, linear manner. Its formula is as follows:
𝑟(𝑥, 𝑦) = cov(𝑥, 𝑦) / (𝜎𝑥 * 𝜎𝑦)
Where:
• 𝑥 is the first variable, and 𝑦 is the second variable.
• cov(𝑥, 𝑦) is the covariance between 𝑥 and 𝑦.
• 𝜎𝑥 is the standard deviation of 𝑥.
• 𝜎𝑦 is the standard deviation of 𝑦.
In essence, the correlation coefficient measures the covariance between two variables, normalized by the product of their standard deviations. The coefficient's value ranges from -1 to 1, allowing a more straightforward interpretation of the relationship between two datasets than what covariance alone provides:
• A value of 1 indicates a perfect positive correlation over the analyzed sample. As one variable's value changes, the other variable's value changes proportionally in the same direction .
• A value of -1 indicates a perfect negative correlation (anticorrelation). As one variable's value increases, the other variable's value decreases proportionally.
• A value of 0 indicates no linear relationship between the variables over the analyzed sample.
Aligning returns across instruments
In a financial time series, each data point (i.e., bar) in a sample represents information collected in periodic intervals. For instance, on a "1D" chart, bars form at specific times as successive days elapse.
However, the times of the data points for a symbol's standard dataset depend on its active sessions , and sessions vary across instrument types. For example, the daily session for NYSE stocks is 09:30 - 16:00 UTC-4/-5 on weekdays, Forex instruments have 24-hour sessions that span from 17:00 UTC-4/-5 on one weekday to 17:00 on the next, and new daily sessions for cryptocurrencies start at 00:00 UTC every day because crypto markets are consistently open.
Therefore, comparing the standard datasets for different asset types to identify correlations presents a challenge. If two symbols' datasets have bars that form at unaligned times, their correlation coefficient does not accurately describe their relationship. When calculating correlations between the returns for two assets, both datasets must maintain consistent time alignment in their values and cover identical ranges for meaningful results.
To address the issue of time alignment across instruments, this indicator requests confirmed weekly or monthly data from spread tickers constructed from the chart's ticker and another specified ticker. The datasets for spreads are derived from lower-timeframe data to ensure the values from all symbols come from aligned points in time, allowing a fair comparison between different instrument types. Additionally, each spread ticker ID includes necessary modifiers, such as extended hours and adjustments.
In this indicator, we use the following process to retrieve time-aligned returns for correlation calculations:
1. Request the current and previous prices from a spread representing the sum of the chart symbol and another symbol ( "chartSymbol + anotherSymbol" ).
2. Request the prices from another spread representing the difference between the two symbols ( "chartSymbol - anotherSymbol" ).
3. Calculate half of the difference between the values from both spreads ( 0.5 * (requestedSum - requestedDifference) ). The results represent the symbol's prices at times aligned with the sample points on the current chart.
4. Calculate the arithmetic return of the retrieved prices: (currentPrice - previousPrice) / previousPrice
5. Repeat steps 1-4 for each symbol requiring analysis.
It's crucial to note that because this process retrieves prices for a symbol at times consistent with periodic points on the current chart, the values can represent prices from before or after the closing time of the symbol's usual session.
Additionally, note that the maximum number of weeks or months in the correlation calculations depends on the chart's range and the largest time range common to all the requested symbols. To maximize the amount of data available for the calculations, we recommend setting the chart to use a daily or higher timeframe and specifying a chart symbol that covers a sufficient time range for your needs.
█ FEATURES
This indicator analyzes the correlations between several pairs of user-specified symbols to provide a structured, intuitive view of the relationships in their returns. Below are the indicator's key features:
Requesting a list of securities
The "Symbol list" text box in the indicator's "Settings/Inputs" tab accepts a comma-separated list of symbols or ticker identifiers with optional spaces (e.g., "XOM, MSFT, BITSTAMP:BTCUSD"). The indicator dynamically requests returns for each symbol in the list, then calculates the correlation between each pair of return series for its heatmap display.
Each item in the list must represent a valid symbol or ticker ID. If the list includes an invalid symbol, the script raises a runtime error.
To specify a broker/exchange for a symbol, include its name as a prefix with a colon in the "EXCHANGE:SYMBOL" format. If a symbol in the list does not specify an exchange prefix, the indicator selects the most commonly used exchange when requesting the data.
Note that the number of symbols allowed in the list depends on the user's plan. Users with non-professional plans can compare up to 20 symbols with this indicator, and users with professional plans can compare up to 32 symbols.
Timeframe and data length selection
The "Returns timeframe" input specifies whether the indicator uses weekly or monthly returns in its calculations. By default, its value is "1M", meaning the indicator analyzes monthly returns. Note that this script requires a chart timeframe lower than or equal to "1M". If the chart uses a higher timeframe, it causes a runtime error.
To customize the length of the data used in the correlation calculations, use the "Max periods" input. When enabled, the indicator limits the calculation window to the number of periods specified in the input field. Otherwise, it uses the chart's time range as the limit. The top-left corner of the table shows the number of confirmed weeks or months used in the calculations.
It's important to note that the number of confirmed periods in the correlation calculations is limited to the largest time range common to all the requested datasets, because a meaningful correlation matrix requires analyzing each symbol's returns under the same market conditions. Therefore, the correlation matrix can show different results for the same symbol pair if another listed symbol restricts the aligned data to a shorter time range.
Heatmap display
This indicator displays the correlations for each symbol pair in a heatmap-styled table representing a symmetric correlation matrix. Each row and column corresponds to a specific symbol, and the cells at their intersections correspond to symbol pairs . For example, the cell at the "AAPL" row and "MSFT" column shows the weekly or monthly correlation between those two symbols' returns. Likewise, the cell at the "MSFT" row and "AAPL" column shows the same value.
Note that the main diagonal cells in the display, where the row and column refer to the same symbol, all show a value of 1 because any series of non-na data is always perfectly correlated with itself.
The background of each correlation cell uses a gradient color based on the correlation value. By default, the gradient uses blue hues for positive correlation, orange hues for negative correlation, and white for no correlation. The intensity of each blue or orange hue corresponds to the strength of the measured correlation or anticorrelation. Users can customize the gradient's base colors using the inputs in the "Color gradient" section of the "Settings/Inputs" tab.
█ FOR Pine Script® CODERS
• This script uses the `getArrayFromString()` function from our ValueAtTime library to process the input list of symbols. The function splits the "string" value by its commas, then constructs an array of non-empty strings without leading or trailing whitespaces. Additionally, it uses the str.upper() function to convert each symbol's characters to uppercase.
• The script's `getAlignedReturns()` function requests time-aligned prices with two request.security() calls that use spread tickers based on the chart's symbol and another symbol. Then, it calculates the arithmetic return using the `changePercent()` function from the ta library. The `collectReturns()` function uses `getAlignedReturns()` within a loop and stores the data from each call within a matrix . The script calls the `arrayCorrelation()` function on pairs of rows from the returned matrix to calculate the correlation values.
• For consistency, the `getAlignedReturns()` function includes extended hours and dividend adjustment modifiers in its data requests. Additionally, it includes other settings inherited from the chart's context, such as "settlement-as-close" preferences.
• A Pine script can execute up to 40 or 64 unique `request.*()` function calls, depending on the user's plan. The maximum number of symbols this script compares is half the plan's limit, because `getAlignedReturns()` uses two request.security() calls.
• This script can use the request.security() function within a loop because all scripts in Pine v6 enable dynamic requests by default. Refer to the Dynamic requests section of the Other timeframes and data page to learn more about this feature, and see our v6 migration guide to learn what's new in Pine v6.
• The script's table uses two distinct color.from_gradient() calls in a switch structure to determine the cell colors for positive and negative correlation values. One call calculates the color for values from -1 to 0 based on the first and second input colors, and the other calculates the colors for values from 0 to 1 based on the second and third input colors.
Look first. Then leap.
Tetris with Auto-PlayThis indicator is implemented in Pine Script™ v6 and serves as a demonstration of TradingView's capabilities. The core concept is to simulate a classic Tetris game by creating a grid-based environment and managing game state entirely within Pine Script.
Key Technical Aspects:
Grid Representation:
The script defines a custom grid structure using a user-defined type that holds the grid’s dimensions and a one-dimensional array to simulate a two-dimensional board. This structure is used to track occupied cells, clear full rows, and determine stack height.
Piece Management:
A second custom type is used to represent the state of a tetromino piece, including its type, rotation, and position. The code includes functions to calculate the block offsets for each tetromino based on its rotation state.
Collision Detection and Piece Locking:
Dedicated functions check for collisions against the grid borders and existing blocks. When a collision is detected during a downward move, the piece is locked into the grid, and any complete lines are cleared.
AIgo-Driven Placement:
The script incorporates a simple heuristic to determine the best placement for the next tetromino. It simulates different rotations and horizontal positions, evaluating each based on aggregated column height, cleared lines, holes, and bumpiness. This decision-making process is encapsulated in an AI-like function that returns the optimal rotation and placement.
Rendering Using Tables:
The visual representation is managed via TradingView’s table objects. The game board is rendered with a bordered layout, while a separate preview table displays the next piece and the current score. Each cell is updated with text and background colors that correspond to the state of the game.
Execution Flow and Timing:
The main execution loop handles real-time updates by dropping pieces at set intervals and checking for game-over conditions. The code leverages persistent variables and time comparisons to control game speed and manage transitions between piece drops.
Executing:
Add the indicator to the chart
It starts playing itself till game over
There are no parameters to change in this version but the grid in the code directly
p.s. Sadly we have no interactive buttons in the current pinescript versions to play ourself, but its about the possibilitys what we could do ;-)
Maybe in a future version there is more possible, if i find time to enhance and expand the idea
Have fun :-)
Log Regression Oscillator Channel [BigBeluga]
This unique overlay tool blends logarithmic trend analysis with dynamic oscillator behavior. It projects RSI, MFI, or Stochastic lines directly into a log regression channel on the price chart — offering an intuitive way to detect overbought/oversold momentum within the broader price structure.
🔵Key Features:
Logarithmic Regression Channel:
➣ Draws a trend-based channel using logarithmic regression, adapting to price growth curvature over time.
➣ Features upper, lower, and optional midline boundaries to visualize trend flow and range extremes.
Oscillator Overlay (RSI / MFI / Stochastic):
➣ Projects your chosen oscillator inside the channel using dynamic polylines.
➣ Allows switching between RSI, Money Flow Index, or Stochastic for versatile momentum insight.
Threshold-Based Scaling:
➣ The top and bottom of the channel represent traditional oscillator thresholds (e.g., RSI 70/30).
➣ Users can modify the scale in settings to customize what "overbought" or "oversold" means visually.
Signal Line Integration:
➣ Adds a yellow moving average (signal line) for smoother confirmation of oscillator turns.
➣ Helps identify divergence, momentum shifts, and fakeouts with better clarity.
Live Oscillator Readout:
➣ Displays the real-time oscillator value at the right edge of the chart.
➣ Ensures traders stay aware of current momentum levels without switching panels.
🔵Usage:
Momentum Context:
➣ When the oscillator touches the upper regression band, it may signal local overbought pressure.
➣ Touching the lower band may indicate oversold conditions within the current log trend.
Divergence Detection:
➣ Use the oscillator’s behavior relative to the channel slope to spot divergence from price.
➣ For example, RSI rising inside a falling channel can flag early trend shifts.
Trend-Sensitive Entries:
➣ Combine oscillator signals with log channel direction to filter trades in trend alignment.
➣ Signal line crossovers inside the channel act as early warning for momentum turns.
The Log Regression Oscillator Channel transforms how traders view classic momentum tools. By embedding oscillators into a logarithmic trend structure, it offers unmatched clarity on momentum positioning relative to price expansion. Ideal for swing traders, mean-reverters, or trend followers looking to sharpen entries and exits with style.