STD-Filtered, N-Pole Gaussian Filter [Loxx]This is a Gaussian Filter with Standard Deviation Filtering that works for orders (poles) higher than the usual 4 poles that was originally available in Ehlers Gaussian Filter formulas. Because of that, it is a sort of generalized Gaussian filter that can calculate arbitrary (order) pole Gaussian Filter and which makes it a sort of a unique indicator. For this implementation, the practical mathematical maximum is 15 poles after which the precision of calculation is useless--the coefficients for levels above 15 poles are so high that the precision loss actually means very little. Despite this maximal precision utility, I've left the upper bound of poles open-ended so you can try poles of order 15 and above yourself. The default is set to 5 poles which is 1 pole greater than the normal maximum of 4 poles.
The purpose of the standard deviation filter is to filter out noise by and by default it will filter 1 standard deviation. Adjust this number and the filter selections (price, both, GMA, none) to reduce the signal noise.
What is Ehlers Gaussian filter?
This filter can be used for smoothing. It rejects high frequencies (fast movements) better than an EMA and has lower lag. published by John F. Ehlers in "Rocket Science For Traders".
A Gaussian filter is one whose transfer response is described by the familiar Gaussian bell-shaped curve. In the case of low-pass filters, only the upper half of the curve describes the filter. The use of gaussian filters is a move toward achieving the dual goal of reducing lag and reducing the lag of high-frequency components relative to the lag of lower-frequency components.
A gaussian filter with...
One Pole: f = alpha*g + (1-alpha)f
Two Poles: f = alpha*2g + 2(1-alpha)f - (1-alpha)2f
Three Poles: f = alpha*3g + 3(1-alpha)f - 3(1-alpha)2f + (1-alpha)3f
Four Poles: f = alpha*4g + 4(1-alpha)f - 6(1-alpha)2f + 4(1-alpha)3f - (1-alpha)4f
and so on...
For an equivalent number of poles the lag of a Gaussian is about half the lag of a Butterworth filters: Lag = N*P / pi^2, where,
N is the number of poles, and
P is the critical period
Special initialization of filter stages ensures proper working in scans with as few bars as possible.
From Ehlers Book: "The first objective of using smoothers is to eliminate or reduce the undesired high-frequency components in the eprice data. Therefore these smoothers are called low-pass filters, and they all work by some form of averaging. Butterworth low-pass filters can do this job, but nothing comes for free. A higher degree of filtering is necessarily accompanied by a larger amount of lag. We have come to see that is a fact of life."
References John F. Ehlers: "Rocket Science For Traders, Digital Signal Processing Applications", Chapter 15: "Infinite Impulse Response Filters"
Included
Loxx's Expanded Source Types
Signals
Alerts
Bar coloring
Related indicators
STD-Filtered, Gaussian Moving Average (GMA)
STD-Filtered, Gaussian-Kernel-Weighted Moving Average
One-Sided Gaussian Filter w/ Channels
Fisher Transform w/ Dynamic Zones
R-sqrd Adapt. Fisher Transform w/ D. Zones & Divs .
Ehlers

Gaussian Filter MACD [Loxx]Gaussian Filter MACD is a MACD that uses an 1-4 Pole Ehlers Gaussian Filter for its calculations. Compare this with Ehlers Fisher Transform.
What is Ehlers Gaussian filter?
This filter can be used for smoothing. It rejects high frequencies (fast movements) better than an EMA and has lower lag. published by John F. Ehlers in "Rocket Science For Traders". First implemented in Wealth-Lab by Dr René Koch.
A Gaussian filter is one whose transfer response is described by the familiar Gaussian bell-shaped curve. In the case of low-pass filters, only the upper half of the curve describes the filter. The use of gaussian filters is a move toward achieving the dual goal of reducing lag and reducing the lag of high-frequency components relative to the lag of lower-frequency components.
A gaussian filter with...
one pole is equivalent to an EMA filter.
two poles is equivalent to EMA ( EMA ())
three poles is equivalent to EMA ( EMA ( EMA ()))
and so on...
For an equivalent number of poles the lag of a Gaussian is about half the lag of a Butterworth filters: Lag = N * P / (2 * ¶2), where,
N is the number of poles, and
P is the critical period
Special initialization of filter stages ensures proper working in scans with as few bars as possible.
From Ehlers Book: "The first objective of using smoothers is to eliminate or reduce the undesired high-frequency components in the eprice data. Therefore these smoothers are called low-pass filters, and they all work by some form of averaging. Butterworth low-pass filtters can do this job, but nothing comes for free. A higher degree of filtering is necessarily accompanied by a larger amount of lag. We have come to see that is a fact of life."
References John F. Ehlers: "Rocket Science For Traders, Digital Signal Processing Applications", Chapter 15: "Infinite Impulse Response Filters"
Included
Loxx's Expanded Source Types
Signals, zero or signal crossing, signal crossing is very noisy
Alerts
Bar coloring
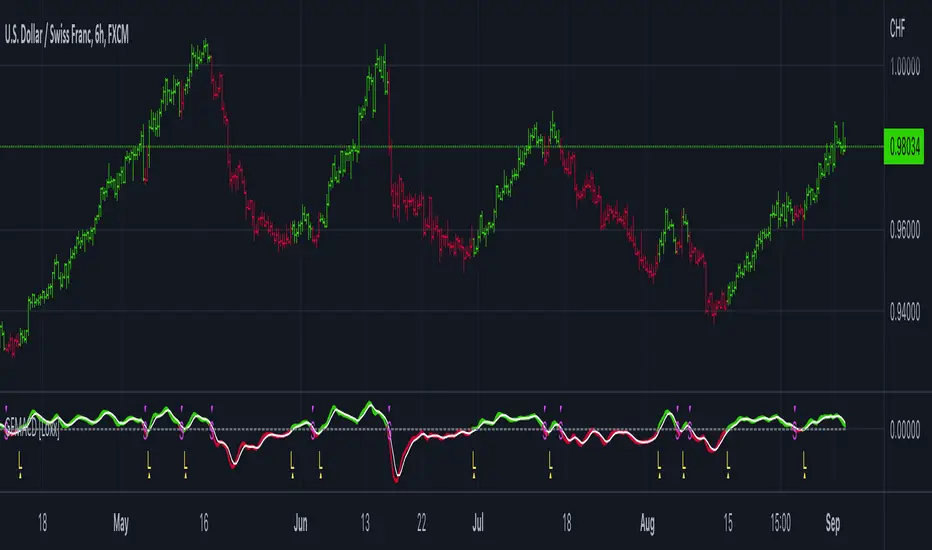
STD-Filtered, Gaussian Moving Average (GMA) [Loxx]STD-Filtered, Gaussian Moving Average (GMA) is a 1-4 pole Ehlers Gaussian Filter with standard deviation filtering. This indicator should perform similar to Ehlers Fisher Transform.
The purpose of the standard deviation filter is to filter out noise by and by default it will filter 1 standard deviation. Adjust this number and the filter selections (price, both, GMA, none) to reduce the signal noise.
What is Ehlers Gaussian filter?
This filter can be used for smoothing. It rejects high frequencies (fast movements) better than an EMA and has lower lag. published by John F. Ehlers in "Rocket Science For Traders". First implemented in Wealth-Lab by Dr René Koch.
A Gaussian filter is one whose transfer response is described by the familiar Gaussian bell-shaped curve. In the case of low-pass filters, only the upper half of the curve describes the filter. The use of gaussian filters is a move toward achieving the dual goal of reducing lag and reducing the lag of high-frequency components relative to the lag of lower-frequency components.
A gaussian filter with...
one pole is equivalent to an EMA filter.
two poles is equivalent to EMA(EMA())
three poles is equivalent to EMA(EMA(EMA()))
and so on...
For an equivalent number of poles the lag of a Gaussian is about half the lag of a Butterworth filters: Lag = N * P / (2 * ¶2), where,
N is the number of poles, and
P is the critical period
Special initialization of filter stages ensures proper working in scans with as few bars as possible.
From Ehlers Book: "The first objective of using smoothers is to eliminate or reduce the undesired high-frequency components in the eprice data. Therefore these smoothers are called low-pass filters, and they all work by some form of averaging. Butterworth low-pass filtters can do this job, but nothing comes for free. A higher degree of filtering is necessarily accompanied by a larger amount of lag. We have come to see that is a fact of life."
References John F. Ehlers: "Rocket Science For Traders, Digital Signal Processing Applications", Chapter 15: "Infinite Impulse Response Filters"
Included
Loxx's Expanded Source Types
Signals
Alerts
Bar coloring
Related indicators
STD-Filtered, Gaussian-Kernel-Weighted Moving Average
One-Sided Gaussian Filter w/ Channels
Fisher Transform w/ Dynamic Zones
R-sqrd Adapt. Fisher Transform w/ D. Zones & Divs.
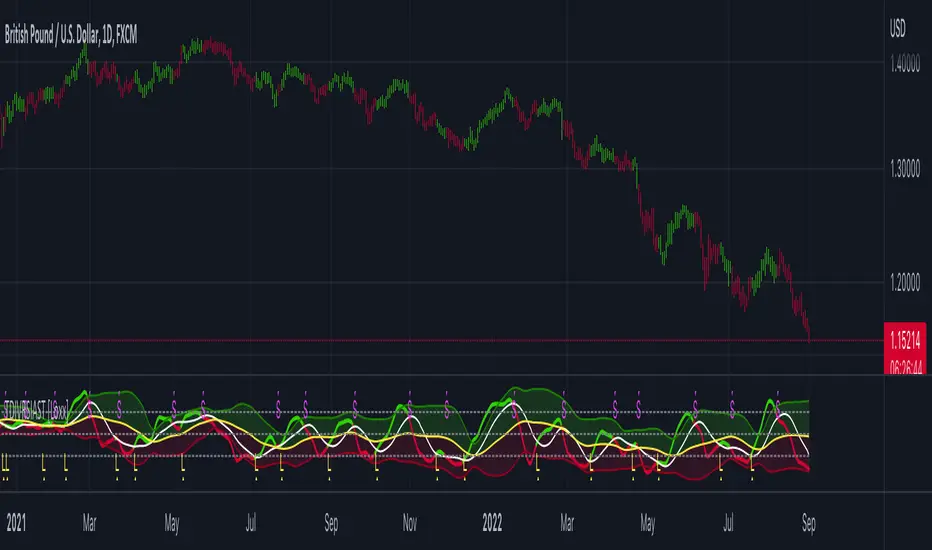
TDI w/ Variety RSI, Averages, & Source Types [Loxx]This hybrid indicator is developed to assist traders in their ability to decipher and monitor market conditions related to trend direction, market strength, and market volatility. Even though comprehensive, the Traders Dynamic Index (TDI) is easy to read and use. This version of TDI has 7 different types of RSI, 38 different types of Moving Averages, 33 source types, and 5 types of signals as well as alerts and coloring. Default RSI type is set to Jurik's RSX. This indicator can be used on any timeframe.
Green/Red line = RSI Price line
White line = Trade Signal line
Dark Green/Red lines = Volatility Band
Yellow line = Market Base Line
Gray dashed lines = Horizontal boundary lines, oversold/overbought
5 Signal Types w/ Alerts
Signal Crosses = Green/Red line crosses over or under White line
Floating Boundary Crosses = Green/Red line crosses over or under upper Dark Green/ lower Red lines
Horizontal Boundary Crosses = Green/Red line crosses over or under Gray dashed upper/lower lines
Floating Middle Crosses = Green/Red line crosses over or under Yellow line
Horizontal Middle Crosses = Green/Red line crosses over or under Gray dashed middle line
Manual Signal Types (no alerts included, this requires manual analysis)
Volatility Band Signals (Dark Green/Red lines) = When the Dark Green/Red lines are expanding, the market is strong and trending. When Dark Green/Red lines are constricting, the market is weak and in a range. When the Dark Green/Red lines are extremely tight in a narrow range, expect an economic announcement or other market condition to spike the market
Beyond these simple signal rules, there are various other signals or methods that can be used to derive long/short/exit signals from TDI included slope of the Green/Red line and bounces off the Yellow line.
Included
Loxx's Expanded Source Types
Loxx's Variety RSI
Loxx's Moving Averages
Signals
Alerts
Bar coloring
Ehlers Two-Pole Predictor [Loxx]Ehlers Two-Pole Predictor is a new indicator by John Ehlers . The translation of this indicator into PineScript™ is a collaborative effort between @cheatcountry and I.
The following is an excerpt from "PREDICTION" , by John Ehlers
Niels Bohr said “Prediction is very difficult, especially if it’s about the future.”. Actually, prediction is pretty easy in the context of technical analysis . All you have to do is to assume the market will behave in the immediate future just as it has behaved in the immediate past. In this article we will explore several different techniques that put the philosophy into practice.
LINEAR EXTRAPOLATION
Linear extrapolation takes the philosophical approach quite literally. Linear extrapolation simply takes the difference of the last two bars and adds that difference to the value of the last bar to form the prediction for the next bar. The prediction is extended further into the future by taking the last predicted value as real data and repeating the process of adding the most recent difference to it. The process can be repeated over and over to extend the prediction even further.
Linear extrapolation is an FIR filter, meaning it depends only on the data input rather than on a previously computed value. Since the output of an FIR filter depends only on delayed input data, the resulting lag is somewhat like the delay of water coming out the end of a hose after it supplied at the input. Linear extrapolation has a negative group delay at the longer cycle periods of the spectrum, which means water comes out the end of the hose before it is applied at the input. Of course the analogy breaks down, but it is fun to think of it that way. As shown in Figure 1, the actual group delay varies across the spectrum. For frequency components less than .167 (i.e. a period of 6 bars) the group delay is negative, meaning the filter is predictive. However, the filter has a positive group delay for cycle components whose periods are shorter than 6 bars.
Figure 1
Here’s the practical ramification of the group delay: Suppose we are projecting the prediction 5 bars into the future. This is fine as long as the market is continued to trend up in the same direction. But, when we get a reversal, the prediction continues upward for 5 bars after the reversal. That is, the prediction fails just when you need it the most. An interesting phenomenon is that, regardless of how far the extrapolation extends into the future, the prediction will always cross the signal at the same spot along the time axis. The result is that the prediction will have an overshoot. The amplitude of the overshoot is a function of how far the extrapolation has been carried into the future.
But the overshoot gives us an opportunity to make a useful prediction at the cyclic turning point of band limited signals (i.e. oscillators having a zero mean). If we reduce the overshoot by reducing the gain of the prediction, we then also move the crossing of the prediction and the original signal into the future. Since the group delay varies across the spectrum, the effect will be less effective for the shorter cycles in the data. Nonetheless, the technique is effective for both discretionary trading and automated trading in the majority of cases.
EXPLORING THE CODE
Before we predict, we need to create a band limited indicator from which to make the prediction. I have selected a “roofing filter” consisting of a High Pass Filter followed by a Low Pass Filter. The tunable parameter of the High Pass Filter is HPPeriod. Think of it as a “stone wall filter” where cycle period components longer than HPPeriod are completely rejected and cycle period components shorter than HPPeriod are passed without attenuation. If HPPeriod is set to be a large number (e.g. 250) the indicator will tend to look more like a trending indicator. If HPPeriod is set to be a smaller number (e.g. 20) the indicator will look more like a cycling indicator. The Low Pass Filter is a Hann Windowed FIR filter whose tunable parameter is LPPeriod. Think of it as a “stone wall filter” where cycle period components shorter than LPPeriod are completely rejected and cycle period components longer than LPPeriod are passed without attenuation. The purpose of the Low Pass filter is to smooth the signal. Thus, the combination of these two filters forms a “roofing filter”, named Filt, that passes spectrum components between LPPeriod and HPPeriod.
Since working into the future is not allowed in EasyLanguage variables, we need to convert the Filt variable to the data array XX. The data array is first filled with real data out to “Length”. I selected Length = 10 simply to have a convenient starting point for the prediction. The next block of code is the prediction into the future. It is easiest to understand if we consider the case where count = 0. Then, in English, the next value of the data array is equal to the current value of the data array plus the difference between the current value and the previous value. That makes the prediction one bar into the future. The process is repeated for each value of count until predictions up to 10 bars in the future are contained in the data array. Next, the selected prediction is converted from the data array to the variable “Prediction”. Filt is plotted in Red and Prediction is plotted in yellow.
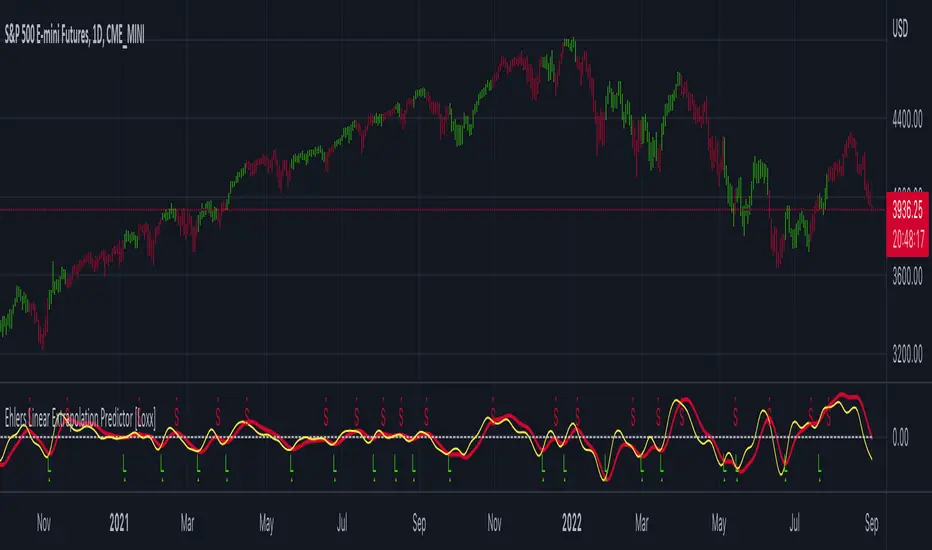
The Predict Extrapolation indicator is shown below for the Emini S&P Futures contract using the default input parameters. Filt is plotted in red and Predict is plotted in yellow. The crossings of the Predict and Filt lines provide reliable buy and sell timing signals. There is some overshoot for the shorter cycle periods, for example in February and March 2021, but the only effect is a late timing signal. Further reducing the gain and/or reducing the BarsFwd inputs would provide better timing signals during this period.
Figure 2. Predict Extrapolation Provides Reliable Timing Signals
I have experimented with other FIR filters for predictions, but found none that had a significant advantage over linear extrapolation.
MESA
MESA is an acronym for Maximum Entropy Spectral Analysis. Conceptually, it removes spectral components until the residual is left with maximum entropy. It does this by forming an all-pole filter whose order is determined by the selected number of coefficients. It maximally addresses the data within the selected window and ignores all other data. Its resolution is determined only by the number of filter coefficients selected. Since the resulting filter is an IIR filter, a prediction can be formed simply by convolving the filter coefficients with the data. MESA is one of the few, if not the only way to practically determine the coefficients of a higher order IIR filter. Discussion of MESA is beyond the scope of this article.
TWO POLE IIR FILTER
While the coefficients of a higher order IIR filter are difficult to compute without MESA, it is a relatively simple matter to compute the coefficients of a two pole IIR filter.
(Skip this paragraph if you don’t care about DSP) We can locate the conjugate pole positions parametrically in the Z plane in polar coordinates. Let the radius be QQ and the principal angle be 360 / P2Period. The first order component is 2*QQ*Cosine(360 / P2Period) and the second order component is just QQ2. Therefore, the transfer response becomes:
H(z) = 1 / (1 - 2*QQ*Cosine(360 / P2Period)*Z-1 + QQ2*Z-2)
By mixing notation we can easily convert the transfer response to code.
Output / Input = 1 / (1 - 2*QQ*Cosine(360 / P2Period)* + QQ2* )
Output - 2*QQ*Cosine(360 / P2Period)*Output + QQ2*Output = Input
Output = Input + 2*QQ*Cosine(360 / P2Period)*Output - QQ2*Output
The Two Pole Predictor starts by computing the same “roofing filter” design as described for the Linear Extrapolation Predictor. The HPPeriod and LPPeriod inputs adjust the roofing filter to obtain the desired appearance of an indicator. Since EasyLanguage variables cannot be extended into the future, the prediction process starts by loading the XX data array with indicator data up to the value of Length. I selected Length = 10 simply to have a convenient place from which to start the prediction. The coefficients are computed parametrically from the conjugate pole positions and are normalized to their sum so the IIR filter will have unity gain at zero frequency.
The prediction is formed by convolving the IIR filter coefficients with the historical data. It is easiest to see for the case where count = 0. This is the initial prediction. In this case the new value of the XX array is formed by successively summing the product of each filter coefficient with its respective historical data sample. This process is significantly different from linear extrapolation because second order curvature is introduced into the prediction rather than being strictly linear. Further, the prediction is adaptive to market conditions because the degree of curvature depends on recent historical data. The prediction in the data array is converted to a variable by selecting the BarsFwd value. The prediction is then plotted in yellow, and is compared to the indicator plotted in red.
The Predict 2 Pole indicator is shown above being applied to the Emini S&P Futures contract for most of 2021. The default parameters for the roofing filter and predictor were used. By comparison to the Linear Extrapolation prediction of Figure 2, the Predict 2 Pole indicator has a more consistent prediction. For example, there is little or no overshoot in February or March while still giving good predictions in April and May.
Input parameters can be varied to adjust the appearance of the prediction. You will find that the indicator is relatively insensitive to the BarsFwd input. The P2Period parameter primarily controls the gain of the prediction and the QQ parameter primarily controls the amount of prediction lead during trending sections of the indicator.
TAKEAWAYS
1. A more or less universal band limited “roofing filter” indicator was used to demonstrate the predictors. The HPPeriod input parameter is used to control whether the indicator looks more like a trend indicator or more like a cycle indicator. The LPPeriod input parameter is used to control the smoothness of the indicator.
2. A linear extrapolation predictor is formed by adding the difference of the two most recent data bars to the value of the last data bar. The result is considered to be a real data point and the process is repeated to extend the prediction into the future. This is an FIR filter having a one bar negative group delay at zero frequency, but the group delay is not constant across the spectrum. This variable group delay causes the linear extrapolation prediction to be inconsistent across a range of market conditions.
3. The degree of prediction by linear extrapolation can be controlled by varying the gain of the prediction to reduce the overshoot to be about the same amplitude as the peak swing of the indicator.
4. I was unable to experimentally derive a higher order FIR filter predictor that had advantages over the simple linear extrapolation predictor.
5. A Two Pole IIR predictor can be created by parametrically locating the conjugate pole positions.
6. The Two Pole predictor is a second order filter, which allows curvature into the prediction, thus mitigating overshoot. Further, the curvature is adaptive because the prediction depends on previously computed prediction values.
7. The Two Pole predictor is more consistent over a range of market conditions.
ADDITIONS
Loxx's Expanded source types:
Library for expanded source types:
Explanation for expanded source types:
Three different signal types: 1) Prediction/Filter crosses; 2) Prediction middle crosses; and, 3) Filter middle crosses.
Bar coloring to color trend.
Signals, both Long and Short.
Alerts, both Long and Short.

Ehlers Linear Extrapolation Predictor [Loxx]Ehlers Linear Extrapolation Predictor is a new indicator by John Ehlers. The translation of this indicator into PineScript™ is a collaborative effort between @cheatcountry and I.
The following is an excerpt from "PREDICTION" , by John Ehlers
Niels Bohr said “Prediction is very difficult, especially if it’s about the future.”. Actually, prediction is pretty easy in the context of technical analysis. All you have to do is to assume the market will behave in the immediate future just as it has behaved in the immediate past. In this article we will explore several different techniques that put the philosophy into practice.
LINEAR EXTRAPOLATION
Linear extrapolation takes the philosophical approach quite literally. Linear extrapolation simply takes the difference of the last two bars and adds that difference to the value of the last bar to form the prediction for the next bar. The prediction is extended further into the future by taking the last predicted value as real data and repeating the process of adding the most recent difference to it. The process can be repeated over and over to extend the prediction even further.
Linear extrapolation is an FIR filter, meaning it depends only on the data input rather than on a previously computed value. Since the output of an FIR filter depends only on delayed input data, the resulting lag is somewhat like the delay of water coming out the end of a hose after it supplied at the input. Linear extrapolation has a negative group delay at the longer cycle periods of the spectrum, which means water comes out the end of the hose before it is applied at the input. Of course the analogy breaks down, but it is fun to think of it that way. As shown in Figure 1, the actual group delay varies across the spectrum. For frequency components less than .167 (i.e. a period of 6 bars) the group delay is negative, meaning the filter is predictive. However, the filter has a positive group delay for cycle components whose periods are shorter than 6 bars.
Figure 1
Here’s the practical ramification of the group delay: Suppose we are projecting the prediction 5 bars into the future. This is fine as long as the market is continued to trend up in the same direction. But, when we get a reversal, the prediction continues upward for 5 bars after the reversal. That is, the prediction fails just when you need it the most. An interesting phenomenon is that, regardless of how far the extrapolation extends into the future, the prediction will always cross the signal at the same spot along the time axis. The result is that the prediction will have an overshoot. The amplitude of the overshoot is a function of how far the extrapolation has been carried into the future.
But the overshoot gives us an opportunity to make a useful prediction at the cyclic turning point of band limited signals (i.e. oscillators having a zero mean). If we reduce the overshoot by reducing the gain of the prediction, we then also move the crossing of the prediction and the original signal into the future. Since the group delay varies across the spectrum, the effect will be less effective for the shorter cycles in the data. Nonetheless, the technique is effective for both discretionary trading and automated trading in the majority of cases.
EXPLORING THE CODE
Before we predict, we need to create a band limited indicator from which to make the prediction. I have selected a “roofing filter” consisting of a High Pass Filter followed by a Low Pass Filter. The tunable parameter of the High Pass Filter is HPPeriod. Think of it as a “stone wall filter” where cycle period components longer than HPPeriod are completely rejected and cycle period components shorter than HPPeriod are passed without attenuation. If HPPeriod is set to be a large number (e.g. 250) the indicator will tend to look more like a trending indicator. If HPPeriod is set to be a smaller number (e.g. 20) the indicator will look more like a cycling indicator. The Low Pass Filter is a Hann Windowed FIR filter whose tunable parameter is LPPeriod. Think of it as a “stone wall filter” where cycle period components shorter than LPPeriod are completely rejected and cycle period components longer than LPPeriod are passed without attenuation. The purpose of the Low Pass filter is to smooth the signal. Thus, the combination of these two filters forms a “roofing filter”, named Filt, that passes spectrum components between LPPeriod and HPPeriod.
Since working into the future is not allowed in EasyLanguage variables, we need to convert the Filt variable to the data array XX . The data array is first filled with real data out to “Length”. I selected Length = 10 simply to have a convenient starting point for the prediction. The next block of code is the prediction into the future. It is easiest to understand if we consider the case where count = 0. Then, in English, the next value of the data array is equal to the current value of the data array plus the difference between the current value and the previous value. That makes the prediction one bar into the future. The process is repeated for each value of count until predictions up to 10 bars in the future are contained in the data array. Next, the selected prediction is converted from the data array to the variable “Prediction”. Filt is plotted in Red and Prediction is plotted in yellow.
The Predict Extrapolation indicator is shown above for the Emini S&P Futures contract using the default input parameters. Filt is plotted in red and Predict is plotted in yellow. The crossings of the Predict and Filt lines provide reliable buy and sell timing signals. There is some overshoot for the shorter cycle periods, for example in February and March 2021, but the only effect is a late timing signal. Further reducing the gain and/or reducing the BarsFwd inputs would provide better timing signals during this period.
ADDITIONS
Loxx's Expanded source types:
Library for expanded source types:
Explanation for expanded source types:
Three different signal types: 1) Prediction/Filter crosses; 2) Prediction middle crosses; and, 3) Filter middle crosses.
Bar coloring to color trend.
Signals, both Long and Short.
Alerts, both Long and Short.
TheATR: Fisher Oscillator.Fisher Oscillator(FO).
The Fisher Oscillator is inspired by John Ehlers "Fisher Transform".
The oscillator highlights when prices have moved to an extreme, based on recent prices.
The FO may help in spotting turning points, in the short-medium trends of an asset, also, it helps in recognizing the asset's trends themselves, giving a picture of mkt conditions affected by less noise.
Fisher Oscillator Components.
Fisher V1 -> Main FO.
Fisher V2 -> Past Candle FO.
0-line threshold -> Directional Component.
How to read the Fisher Oscillator.
The FO is super easy to read by itself.. also, I coded some features which make it even easier to read.
It's suggestions, which we can call "Signals", come from 2 different sources, accessible thanks to the variable "Signals Type".
- 0-Line Crosses:
When the "Fisher V1" upcrosses the oscillator 0-line, the oscillator suggests a Long scenario.
When the "Fisher V1" downcrosses the oscillator 0-line, the oscillator suggests a Short scenario.
- Classic Lines Crosses:
When the "Fisher V1" upcrosses the "Fisher V2", the oscillator suggests a Long scenario.
When the "Fisher V1" downcrosses the "Fisher V2", the oscillator suggests a Short scenario.
Users will be able to recognise these Signals visually, thanks to some color customisation to the "Fisher V1" line, and thanks to the ability of the oscillator of plotting Signals.
TheATR Documentation regarding TheATR: Fisher Oscillator.
Researching and backtesting the FO, I noticed it's skill of being able to dynamically identify trend reversals with a nice degree of reliability.
Also, the FO's able to keep up with trends up to their tops/bottoms, as it's very responsive.
This makes the FO a trend-following oscillator in my personal view, because its nature of being very fast in detecting reversals will lead to many false reversals as well.
On the other face of this coin, if we look at the FO as a source for confirmations for a trend-following strategy, may be very useful.
To conclude, I would use the FO as a confirmation oscillator, in a trend-following strategy that needs to have other components.
Thanks for reading,
TheATR.

Reverse Ehler Instantaneous Trendline - TraderHalaiThis script uses a reverse function of the famous Ehler Instantaneous Trendline to calculate the source price required in order to change from Bullish to bearish
From my analysis, the reverse price does appear to be rather choppy, though it is 100% accurate. This is because Ehler's Instantaneous Trendline tends to remain trending for longer periods of time with above average hold periods.
The main suitability for this would be higher level timeframes, such as Weekly, 5 daily, 3 daily. From my findings Smoothed Heikin Ashi Trend, tends to provide better risk-adjusted returns across most timeframes (Higher return to drawdown ratio)
As I have spent a bit of time getting the reverse function mathematics to work, I decided to publish this as open source for the benefit, scrutiny and for further development by the TradingView community anyways.
Enjoy!

STD-Filtered Variety RSI of Double Averages w/ DSL [Loxx]STD-Filtered Variety RSI of Double Averages w/ DSL is a standard deviation step filtered RSI indicator that is calculated using double smoothing. The user can choose from 8 different RSI types and 38 different double smoothing types. This indicator uses Discontinued Signal Lines instead of regular signals and levels. This allows the signals to be more precise in catching early trend breakouts and breakdowns.
Things to note
Double smoothing of the source does not function like DEMA, for example. This double smoothing is just smoothing of smoothing of source
There are two types of smoothing for Discontinued Signals Lines: Regular EMA and Fast EMA
T3 RSI has been added on top of Loxx's Variety RSI library
Contained inside this indicator
Loxx's Moving Averages
Loxx's Variety RSI
Related indicators
Corrected RSI w/ Floating Levels
Adaptive, Jurik-Filtered, Floating RSI
Variety RSI w/ Dynamic Zones
Included
Bar coloring
Alerts
2 types of signals with precision adjustment
Loxx's Variety RSI
Loxx's Moving Averages

Cycle-Period Adaptive, Linear Regression Slope Oscillator [Loxx]Cycle-Period Adaptive, Linear Regression Slope Oscillator is an osciallator that solves for the Linear Regression slope and turns it into an oscillator. This is a very simple calculation and uses one of Ehler's first implementations of his cycle period calculations. The output slope value is smoothed after calculation and before being drawn. This is a sort of momentum indicator and has a rich history with Forex traders around the world.
What is the Cycle Period?
The spectral content of the data are measured in a bank of contiguous filters as described in "Measuring Cycle Periods" in the March 2008 issue of Stocks & Commodities Magazine. The filter having the strongest output is selected as the current dominant cycle period. The cycle period is measured as the number of bars contained in one full cycle period.
What is Linear Regression?
In statistics, linear regression is a linear approach for modeling the relationship between a scalar response and one or more explanatory variables. The case of one explanatory variable is called simple linear regression; for more than one, the process is called multiple linear regression.
Included:
Bar coloring
2 signal types
Alerts
Loxx's Expanded Source Types
Loxx's Moving Averages

Non-Lag Inverse Fisher Transform of RSX [Loxx]Non-Lag Inverse Fisher Transform of RSX is an Inverse Fisher Transform on the Non-Lagged Smoothing Filter of Jurik RSX.
What is the Inverse Fisher Transform?
The Inverse Fisher Transform was authored by John Ehlers. The IFT applies some math functions and constants to a moving average of the relative strength index (rsi) of the closing price to calculate its oscillator position. T
read more here: www.mesasoftware.com
What is RSX?
RSI is a very popular technical indicator, because it takes into consideration market speed, direction and trend uniformity. However, the its widely criticized drawback is its noisy (jittery) appearance. The Jurk RSX retains all the useful features of RSI , but with one important exception: the noise is gone with no added lag.
What is the Non-lag moving average?
The Non Lag Moving average follows price closely and gives very quick signals as well as early signals of price change. As a standalone Moving Average, it should not be used on its own, but as an additional confluence tool for early signals.
Included:
Alerts
Signals
Bar coloring
EMA-Deviation-Corrected Super Smoother [Loxx]This indicator is using the modified "correcting" method. Instead of using standard deviation for calculation, it is using EMA deviation and is applied to Ehlers' Super Smoother.
What is EMA-Deviation?
By definition, the Standard Deviation (SD, also represented by the Greek letter sigma σ or the Latin letter s) is a measure that is used to quantify the amount of variation or dispersion of a set of data values. In technical analysis we usually use it to measure the level of current volatility.
Standard Deviation is based on Simple Moving Average calculation for mean value. This version is not doing that. It is, instead, using the properties of EMA to calculate what can be called a new type of deviation, and since it is based on EMA. It is similar to Standard Deviation, but on a first glance you shall notice that it is "faster" than the Standard Deviation and that makes it useful when the speed of reaction to volatility is expected from any code or trading system.
What is Ehlers Super Smoother?
The Super Smoother filter uses John Ehlers’s “Super Smoother” which consists of a a Two-pole Butterworth filter combined with a 2-bar SMA (Simple Moving Average) that suppresses the 22050 Hz Nyquist frequency: A characteristic of a sampler, which converts a continuous function or signal into a discrete sequence.
Things to know
The yellow and fuchsia thin line is the original Super Smoother
The green and red line is the Corrected Super Smoother
When the original Super Smoother crosses above the Corrected Super Smoother line, its a long, when it crosses below, its a short
Included
Alerts
Signals
Bar coloring
PA-Adaptive Polynomial Regression Fitted Moving Average [Loxx]PA-Adaptive Polynomial Regression Fitted Moving Average is a moving average that is calculated using Polynomial Regression Analysis. The purpose of this indicator is to introduce polynomial fitting that is to be used in future indicators. This indicator also has Phase Accumulation adaptive period inputs. Even though this first indicator is for demonstration purposes only, its still one of the only viable implementations of Polynomial Regression Analysis on TradingView is suitable for trading, and while this same method can be used to project prices forward, I won't be doing that since forecasting is generally worthless and causes unavoidable repainting. This indicator only repaints on the current bar. Once the bar closes, any signal on that bar won't change.
For other similar Polynomial Regression Fitted methodologies, see here
Poly Cycle
What is the Phase Accumulation Cycle?
The phase accumulation method of computing the dominant cycle is perhaps the easiest to comprehend. In this technique, we measure the phase at each sample by taking the arctangent of the ratio of the quadrature component to the in-phase component. A delta phase is generated by taking the difference of the phase between successive samples. At each sample we can then look backwards, adding up the delta phases.When the sum of the delta phases reaches 360 degrees, we must have passed through one full cycle, on average.The process is repeated for each new sample.
The phase accumulation method of cycle measurement always uses one full cycle’s worth of historical data.This is both an advantage and a disadvantage.The advantage is the lag in obtaining the answer scales directly with the cycle period.That is, the measurement of a short cycle period has less lag than the measurement of a longer cycle period. However, the number of samples used in making the measurement means the averaging period is variable with cycle period. longer averaging reduces the noise level compared to the signal.Therefore, shorter cycle periods necessarily have a higher out- put signal-to-noise ratio.
What is Polynomial Regression?
In statistics, polynomial regression is a form of regression analysis in which the relationship between the independent variable x and the dependent variable y is modelled as an nth degree polynomial in x. Polynomial regression fits a nonlinear relationship between the value of x and the corresponding conditional mean of y, denoted E(y |x). Although polynomial regression fits a nonlinear model to the data, as a statistical estimation problem it is linear, in the sense that the regression function E(y | x) is linear in the unknown parameters that are estimated from the data. For this reason, polynomial regression is considered to be a special case of multiple linear regression.
Things to know
You can select from 33 source types
The source is smoothed before being injected into the Polynomial fitting algorithm, there are 35+ moving averages to choose from for smoothing
The output of the Polynomial fitting algorithm is then smoothed to create the signal, there are 35+ moving averages to choose from for smoothing
Included
Alerts
Signals
Bar coloring
VHF-Adaptive, Digital Kahler Variety RSI w/ Dynamic Zones [Loxx]VHF-Adaptive, Digital Kahler Variety RSI w/ Dynamic Zones is an RSI indicator with adaptive inputs, Digital Kahler filtering, and Dynamic Zones. This indicator uses a Vertical Horizontal Filter for calculating the adaptive period inputs and allows the user to select from 7 different types of RSI.
What is VHF Adaptive Cycle?
Vertical Horizontal Filter (VHF) was created by Adam White to identify trending and ranging markets. VHF measures the level of trend activity, similar to ADX DI. Vertical Horizontal Filter does not, itself, generate trading signals, but determines whether signals are taken from trend or momentum indicators. Using this trend information, one is then able to derive an average cycle length.
What is Digital Kahler?
From Philipp Kahler's article for www.traders-mag.com, August 2008. "A Classic Indicator in a New Suit: Digital Stochastic"
Digital Indicators
Whenever you study the development of trading systems in particular, you will be struck in an extremely unpleasant way by the seemingly unmotivated indentations and changes in direction of each indicator. An experienced trader can recognise many false signals of the indicator on the basis of his solid background; a stupid trading system usually falls into any trap offered by the unclear indicator course. This is what motivated me to improve even further this and other indicators with the help of a relatively simple procedure. The goal of this development is to be able to use this indicator in a trading system with as few additional conditions as possible. Discretionary traders will likewise be happy about this clear course, which is not nerve-racking and makes concentrating on the essential elements of trading possible.
How Is It Done?
The digital stochastic is a child of the original indicator. We owe a debt of gratitude to George Lane for his idea to design an indicator which describes the position of the current price within the high-low range of the historical price movement. My contribution to this indicator is the changed pattern which improves the quality of the signal without generating too long delays in giving signals. The trick used to generate this “digital” behavior of the indicator. It can be used with most oscillators like RSI or CCI .
First of all, the original is looked at. The indicator always moves between 0 and 100. The precise position of the indicator or its course relative to the trigger line are of no interest to me, I would just like to know whether the indicator is quoted below or above the value 50. This is tantamount to the question of whether the market is just trading above or below the middle of the high-low range of the past few days. If the market trades in the upper half of its high-low range, then the digital stochastic is given the value 1; if the original stochastic is below 50, then the value –1 is given. This leads to a sequence of 1/-1 values – the digital core of the new indicator. These values are subsequently smoothed by means of a short exponential moving average . This way minor false signals are eliminated and the indicator is given its typical form.
What are Dynamic Zones?
As explained in "Stocks & Commodities V15:7 (306-310): Dynamic Zones by Leo Zamansky, Ph .D., and David Stendahl"
Most indicators use a fixed zone for buy and sell signals. Here’ s a concept based on zones that are responsive to past levels of the indicator.
One approach to active investing employs the use of oscillators to exploit tradable market trends. This investing style follows a very simple form of logic: Enter the market only when an oscillator has moved far above or below traditional trading lev- els. However, these oscillator- driven systems lack the ability to evolve with the market because they use fixed buy and sell zones. Traders typically use one set of buy and sell zones for a bull market and substantially different zones for a bear market. And therein lies the problem.
Once traders begin introducing their market opinions into trading equations, by changing the zones, they negate the system’s mechanical nature. The objective is to have a system automatically define its own buy and sell zones and thereby profitably trade in any market — bull or bear. Dynamic zones offer a solution to the problem of fixed buy and sell zones for any oscillator-driven system.
An indicator’s extreme levels can be quantified using statistical methods. These extreme levels are calculated for a certain period and serve as the buy and sell zones for a trading system. The repetition of this statistical process for every value of the indicator creates values that become the dynamic zones. The zones are calculated in such a way that the probability of the indicator value rising above, or falling below, the dynamic zones is equal to a given probability input set by the trader.
To better understand dynamic zones, let's first describe them mathematically and then explain their use. The dynamic zones definition:
Find V such that:
For dynamic zone buy: P{X <= V}=P1
For dynamic zone sell: P{X >= V}=P2
where P1 and P2 are the probabilities set by the trader, X is the value of the indicator for the selected period and V represents the value of the dynamic zone.
The probability input P1 and P2 can be adjusted by the trader to encompass as much or as little data as the trader would like. The smaller the probability, the fewer data values above and below the dynamic zones. This translates into a wider range between the buy and sell zones. If a 10% probability is used for P1 and P2, only those data values that make up the top 10% and bottom 10% for an indicator are used in the construction of the zones. Of the values, 80% will fall between the two extreme levels. Because dynamic zone levels are penetrated so infrequently, when this happens, traders know that the market has truly moved into overbought or oversold territory.
Calculating the Dynamic Zones
The algorithm for the dynamic zones is a series of steps. First, decide the value of the lookback period t. Next, decide the value of the probability Pbuy for buy zone and value of the probability Psell for the sell zone.
For i=1, to the last lookback period, build the distribution f(x) of the price during the lookback period i. Then find the value Vi1 such that the probability of the price less than or equal to Vi1 during the lookback period i is equal to Pbuy. Find the value Vi2 such that the probability of the price greater or equal to Vi2 during the lookback period i is equal to Psell. The sequence of Vi1 for all periods gives the buy zone. The sequence of Vi2 for all periods gives the sell zone.
In the algorithm description, we have: Build the distribution f(x) of the price during the lookback period i. The distribution here is empirical namely, how many times a given value of x appeared during the lookback period. The problem is to find such x that the probability of a price being greater or equal to x will be equal to a probability selected by the user. Probability is the area under the distribution curve. The task is to find such value of x that the area under the distribution curve to the right of x will be equal to the probability selected by the user. That x is the dynamic zone.
Included:
Bar coloring
4 signal types
Alerts
Loxx's Expanded Source Types
Loxx's Moving Averages
Loxx's Variety RSI
Loxx's Dynamic Zones

PA-Adaptive TRIX Log [Loxx]PA-Adaptive TRIX Log is a Phase Accumulation Adaptive TRIX Log indicator. This adaptation smooths the signal to catch larger trends.
What is TRIX?
TRIX is a momentum oscillator that displays the percent rate of change of a TEMA . It was developed in the early 1980's by Jack Hutson, an editor for "Technical Analysis of Stocks and Commodities" magazine. With its triple smoothing, TRIX is designed to filter insignificant price movements. In his article he uses a logarithm of a price (which is in many versions, left out).
What is the Phase Accumulation Cycle?
The phase accumulation method of computing the dominant cycle is perhaps the easiest to comprehend. In this technique, we measure the phase at each sample by taking the arctangent of the ratio of the quadrature component to the in-phase component. A delta phase is generated by taking the difference of the phase between successive samples. At each sample we can then look backwards, adding up the delta phases.When the sum of the delta phases reaches 360 degrees, we must have passed through one full cycle, on average.The process is repeated for each new sample.
The phase accumulation method of cycle measurement always uses one full cycle’s worth of historical data.This is both an advantage and a disadvantage.The advantage is the lag in obtaining the answer scales directly with the cycle period.That is, the measurement of a short cycle period has less lag than the measurement of a longer cycle period. However, the number of samples used in making the measurement means the averaging period is variable with cycle period. longer averaging reduces the noise level compared to the signal.Therefore, shorter cycle periods necessarily have a higher out- put signal-to-noise ratio.
Included
Bar coloring
2 signal options
Alerts

One-Sided Gaussian Support & Resistance Rate [Loxx]One-Sided Gaussian Support & Resistance Rate is a mean reversion oscillator much like Fisher Transform. This indicator is built using a one-sided Gaussian filter. If you pair this with Fisher Transform and line up the settings, you'll notice similar outcomes. You'll notice that as the oscillator levels out at around zero or one that this signifies a zone of resistance or support. See here for more details on calculating the OS Gaussian Filter:
Included:
Bar coloring
Signals
Alerts
Ehlers 2-Pole Super Smoothing for smoothing source inputs

One-Sided Gaussian Filter w/ Channels [Loxx]One-Sided Gaussian Filter w/ Channels is a Gaussian Moving Average that is calculated using a Fibonacci weighting function. Keltner channels have been added to show zones of exhaustion. A better name would be "Half Gaussian bell weighted" or "Half normal distribution weighted" indicator, since the weights for calculation of the average (similar to linear weighted average) are taken from a normal distribution curve like function--but only the half of the curve is used for calculation.
Information of the Gaussian distribution can be found here : en.wikipedia.org and once you take a look at the standard normal distribution curve, it will be much clearer what is exactly done in this indicator.
After the Gaussian Filter is applied to the source input, an Ehlers' 2-Pole Super Smoother is applied to reduce noise without significant lag.
Included:
Bar coloring
Signals
Alerts
Loxx's Expanded Source Types

STD-Adaptive T3 Channel w/ Ehlers Swiss Army Knife Mod. [Loxx]STD-Adaptive T3 Channel w/ Ehlers Swiss Army Knife Mod. is an adaptive T3 indicator using standard deviation adaptivity and Ehlers Swiss Army Knife indicator to adjust the alpha value of the T3 calculation. This helps identify trends and reduce noise. In addition. I've included a Keltner Channel to show reversal/exhaustion zones.
What is the Swiss Army Knife Indicator?
John Ehlers explains the calculation here: www.mesasoftware.com
What is the T3 moving average?
Better Moving Averages Tim Tillson
November 1, 1998
Tim Tillson is a software project manager at Hewlett-Packard, with degrees in Mathematics and Computer Science. He has privately traded options and equities for 15 years.
Introduction
"Digital filtering includes the process of smoothing, predicting, differentiating, integrating, separation of signals, and removal of noise from a signal. Thus many people who do such things are actually using digital filters without realizing that they are; being unacquainted with the theory, they neither understand what they have done nor the possibilities of what they might have done."
This quote from R. W. Hamming applies to the vast majority of indicators in technical analysis . Moving averages, be they simple, weighted, or exponential, are lowpass filters; low frequency components in the signal pass through with little attenuation, while high frequencies are severely reduced.
"Oscillator" type indicators (such as MACD , Momentum, Relative Strength Index ) are another type of digital filter called a differentiator.
Tushar Chande has observed that many popular oscillators are highly correlated, which is sensible because they are trying to measure the rate of change of the underlying time series, i.e., are trying to be the first and second derivatives we all learned about in Calculus.
We use moving averages (lowpass filters) in technical analysis to remove the random noise from a time series, to discern the underlying trend or to determine prices at which we will take action. A perfect moving average would have two attributes:
It would be smooth, not sensitive to random noise in the underlying time series. Another way of saying this is that its derivative would not spuriously alternate between positive and negative values.
It would not lag behind the time series it is computed from. Lag, of course, produces late buy or sell signals that kill profits.
The only way one can compute a perfect moving average is to have knowledge of the future, and if we had that, we would buy one lottery ticket a week rather than trade!
Having said this, we can still improve on the conventional simple, weighted, or exponential moving averages. Here's how:
Two Interesting Moving Averages
We will examine two benchmark moving averages based on Linear Regression analysis.
In both cases, a Linear Regression line of length n is fitted to price data.
I call the first moving average ILRS, which stands for Integral of Linear Regression Slope. One simply integrates the slope of a linear regression line as it is successively fitted in a moving window of length n across the data, with the constant of integration being a simple moving average of the first n points. Put another way, the derivative of ILRS is the linear regression slope. Note that ILRS is not the same as a SMA ( simple moving average ) of length n, which is actually the midpoint of the linear regression line as it moves across the data.
We can measure the lag of moving averages with respect to a linear trend by computing how they behave when the input is a line with unit slope. Both SMA (n) and ILRS(n) have lag of n/2, but ILRS is much smoother than SMA .
Our second benchmark moving average is well known, called EPMA or End Point Moving Average. It is the endpoint of the linear regression line of length n as it is fitted across the data. EPMA hugs the data more closely than a simple or exponential moving average of the same length. The price we pay for this is that it is much noisier (less smooth) than ILRS, and it also has the annoying property that it overshoots the data when linear trends are present.
However, EPMA has a lag of 0 with respect to linear input! This makes sense because a linear regression line will fit linear input perfectly, and the endpoint of the LR line will be on the input line.
These two moving averages frame the tradeoffs that we are facing. On one extreme we have ILRS, which is very smooth and has considerable phase lag. EPMA has 0 phase lag, but is too noisy and overshoots. We would like to construct a better moving average which is as smooth as ILRS, but runs closer to where EPMA lies, without the overshoot.
A easy way to attempt this is to split the difference, i.e. use (ILRS(n)+EPMA(n))/2. This will give us a moving average (call it IE /2) which runs in between the two, has phase lag of n/4 but still inherits considerable noise from EPMA. IE /2 is inspirational, however. Can we build something that is comparable, but smoother? Figure 1 shows ILRS, EPMA, and IE /2.
Filter Techniques
Any thoughtful student of filter theory (or resolute experimenter) will have noticed that you can improve the smoothness of a filter by running it through itself multiple times, at the cost of increasing phase lag.
There is a complementary technique (called twicing by J.W. Tukey) which can be used to improve phase lag. If L stands for the operation of running data through a low pass filter, then twicing can be described by:
L' = L(time series) + L(time series - L(time series))
That is, we add a moving average of the difference between the input and the moving average to the moving average. This is algebraically equivalent to:
2L-L(L)
This is the Double Exponential Moving Average or DEMA , popularized by Patrick Mulloy in TASAC (January/February 1994).
In our taxonomy, DEMA has some phase lag (although it exponentially approaches 0) and is somewhat noisy, comparable to IE /2 indicator.
We will use these two techniques to construct our better moving average, after we explore the first one a little more closely.
Fixing Overshoot
An n-day EMA has smoothing constant alpha=2/(n+1) and a lag of (n-1)/2.
Thus EMA (3) has lag 1, and EMA (11) has lag 5. Figure 2 shows that, if I am willing to incur 5 days of lag, I get a smoother moving average if I run EMA (3) through itself 5 times than if I just take EMA (11) once.
This suggests that if EPMA and DEMA have 0 or low lag, why not run fast versions (eg DEMA (3)) through themselves many times to achieve a smooth result? The problem is that multiple runs though these filters increase their tendency to overshoot the data, giving an unusable result. This is because the amplitude response of DEMA and EPMA is greater than 1 at certain frequencies, giving a gain of much greater than 1 at these frequencies when run though themselves multiple times. Figure 3 shows DEMA (7) and EPMA(7) run through themselves 3 times. DEMA^3 has serious overshoot, and EPMA^3 is terrible.
The solution to the overshoot problem is to recall what we are doing with twicing:
DEMA (n) = EMA (n) + EMA (time series - EMA (n))
The second term is adding, in effect, a smooth version of the derivative to the EMA to achieve DEMA . The derivative term determines how hot the moving average's response to linear trends will be. We need to simply turn down the volume to achieve our basic building block:
EMA (n) + EMA (time series - EMA (n))*.7;
This is algebraically the same as:
EMA (n)*1.7-EMA( EMA (n))*.7;
I have chosen .7 as my volume factor, but the general formula (which I call "Generalized Dema") is:
GD (n,v) = EMA (n)*(1+v)-EMA( EMA (n))*v,
Where v ranges between 0 and 1. When v=0, GD is just an EMA , and when v=1, GD is DEMA . In between, GD is a cooler DEMA . By using a value for v less than 1 (I like .7), we cure the multiple DEMA overshoot problem, at the cost of accepting some additional phase delay. Now we can run GD through itself multiple times to define a new, smoother moving average T3 that does not overshoot the data:
T3(n) = GD ( GD ( GD (n)))
In filter theory parlance, T3 is a six-pole non-linear Kalman filter. Kalman filters are ones which use the error (in this case (time series - EMA (n)) to correct themselves. In Technical Analysis , these are called Adaptive Moving Averages; they track the time series more aggressively when it is making large moves.
Included:
Bar coloring
Signals
Alerts
Loxx's Expanded Source Types
PA-Adaptive, Stepped-MA of Composite RSI [Loxx]PA-Adaptive, Stepped-MA of Composite RSI is an RSI indicator using a different kind of RSI called Composite RSI. This indicator is Phase Accumulation Cycle Adaptive and uses a stepped moving average.
What is Composite RSI?
The name of the composite RSI might mislead a bit.
Composite RSI is not "compositing" RSIs but is a rather new way of calculating the RSI. Unlike the RSI that is a sort of a momentum indicators, composite RSI is more a trending indicator. It tends to filter out insignificant price changes and seems to be good in identifying the underlying trends.
What is the Phase Accumulation Cycle?
The phase accumulation method of computing the dominant cycle is perhaps the easiest to comprehend. In this technique, we measure the phase at each sample by taking the arctangent of the ratio of the quadrature component to the in-phase component. A delta phase is generated by taking the difference of the phase between successive samples. At each sample we can then look backwards, adding up the delta phases.When the sum of the delta phases reaches 360 degrees, we must have passed through one full cycle, on average.The process is repeated for each new sample.
The phase accumulation method of cycle measurement always uses one full cycle’s worth of historical data.This is both an advantage and a disadvantage.The advantage is the lag in obtaining the answer scales directly with the cycle period.That is, the measurement of a short cycle period has less lag than the measurement of a longer cycle period. However, the number of samples used in making the measurement means the averaging period is variable with cycle period. longer averaging reduces the noise level compared to the signal.Therefore, shorter cycle periods necessarily have a higher out- put signal-to-noise ratio.
Included
Bar coloring
Signals
Alerts
Loxx's Expanded Source Types
Loxx's Special Phase Accumulation Cycle
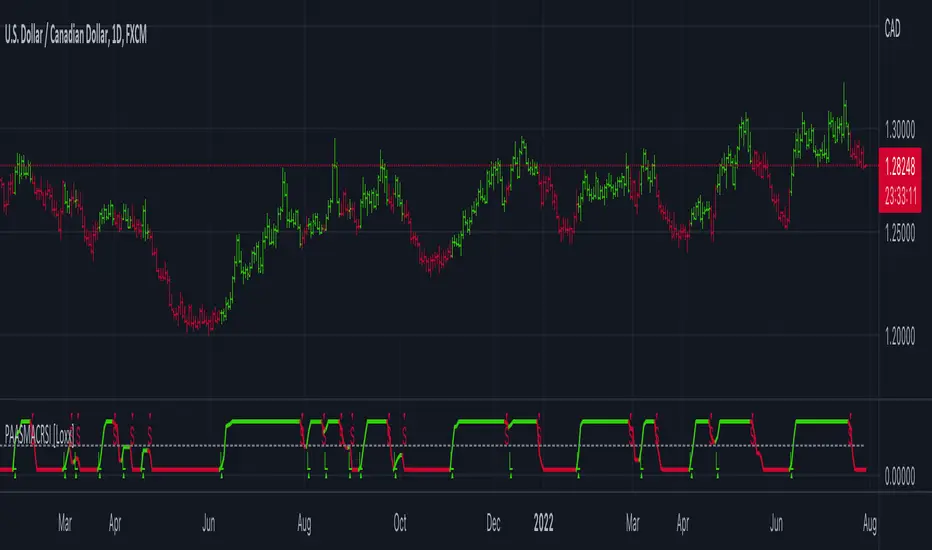
R-sqrd Adapt. Fisher Transform w/ D. Zones & Divs. [Loxx]The full name of this indicator is R-Squared Adaptive Fisher Transform w/ Dynamic Zones and Divergences. This is an R-squared adaptive Fisher transform with adjustable dynamic zones, signals, alerts, and divergences.
What is Fisher Transform?
The Fisher Transform is a technical indicator created by John F. Ehlers that converts prices into a Gaussian normal distribution.
The indicator highlights when prices have moved to an extreme, based on recent prices. This may help in spotting turning points in the price of an asset. It also helps show the trend and isolate the price waves within a trend.
What is R-squared Adaptive?
One tool available in forecasting the trendiness of the breakout is the coefficient of determination ( R-squared ), a statistical measurement.
The R-squared indicates linear strength between the security's price (the Y - axis) and time (the X - axis). The R-squared is the percentage of squared error that the linear regression can eliminate if it were used as the predictor instead of the mean value. If the R-squared were 0.99, then the linear regression would eliminate 99% of the error for prediction versus predicting closing prices using a simple moving average .
R-squared is used here to derive an r-squared value that is then modified by a user input "factor"
What are Dynamic Zones?
As explained in "Stocks & Commodities V15:7 (306-310): Dynamic Zones by Leo Zamansky, Ph .D., and David Stendahl"
Most indicators use a fixed zone for buy and sell signals. Here’ s a concept based on zones that are responsive to past levels of the indicator.
One approach to active investing employs the use of oscillators to exploit tradable market trends. This investing style follows a very simple form of logic: Enter the market only when an oscillator has moved far above or below traditional trading lev- els. However, these oscillator- driven systems lack the ability to evolve with the market because they use fixed buy and sell zones. Traders typically use one set of buy and sell zones for a bull market and substantially different zones for a bear market. And therein lies the problem.
Once traders begin introducing their market opinions into trading equations, by changing the zones, they negate the system’s mechanical nature. The objective is to have a system automatically define its own buy and sell zones and thereby profitably trade in any market — bull or bear. Dynamic zones offer a solution to the problem of fixed buy and sell zones for any oscillator-driven system.
An indicator’s extreme levels can be quantified using statistical methods. These extreme levels are calculated for a certain period and serve as the buy and sell zones for a trading system. The repetition of this statistical process for every value of the indicator creates values that become the dynamic zones. The zones are calculated in such a way that the probability of the indicator value rising above, or falling below, the dynamic zones is equal to a given probability input set by the trader.
To better understand dynamic zones, let's first describe them mathematically and then explain their use. The dynamic zones definition:
Find V such that:
For dynamic zone buy: P{X <= V}=P1
For dynamic zone sell: P{X >= V}=P2
where P1 and P2 are the probabilities set by the trader, X is the value of the indicator for the selected period and V represents the value of the dynamic zone.
The probability input P1 and P2 can be adjusted by the trader to encompass as much or as little data as the trader would like. The smaller the probability, the fewer data values above and below the dynamic zones. This translates into a wider range between the buy and sell zones. If a 10% probability is used for P1 and P2, only those data values that make up the top 10% and bottom 10% for an indicator are used in the construction of the zones. Of the values, 80% will fall between the two extreme levels. Because dynamic zone levels are penetrated so infrequently, when this happens, traders know that the market has truly moved into overbought or oversold territory.
Calculating the Dynamic Zones
The algorithm for the dynamic zones is a series of steps. First, decide the value of the lookback period t. Next, decide the value of the probability Pbuy for buy zone and value of the probability Psell for the sell zone.
For i=1, to the last lookback period, build the distribution f(x) of the price during the lookback period i. Then find the value Vi1 such that the probability of the price less than or equal to Vi1 during the lookback period i is equal to Pbuy. Find the value Vi2 such that the probability of the price greater or equal to Vi2 during the lookback period i is equal to Psell. The sequence of Vi1 for all periods gives the buy zone. The sequence of Vi2 for all periods gives the sell zone.
In the algorithm description, we have: Build the distribution f(x) of the price during the lookback period i. The distribution here is empirical namely, how many times a given value of x appeared during the lookback period. The problem is to find such x that the probability of a price being greater or equal to x will be equal to a probability selected by the user. Probability is the area under the distribution curve. The task is to find such value of x that the area under the distribution curve to the right of x will be equal to the probability selected by the user. That x is the dynamic zone.
Included:
Bar coloring
4 signal variations w/ alerts
Divergences w/ alerts
Loxx's Expanded Source Types
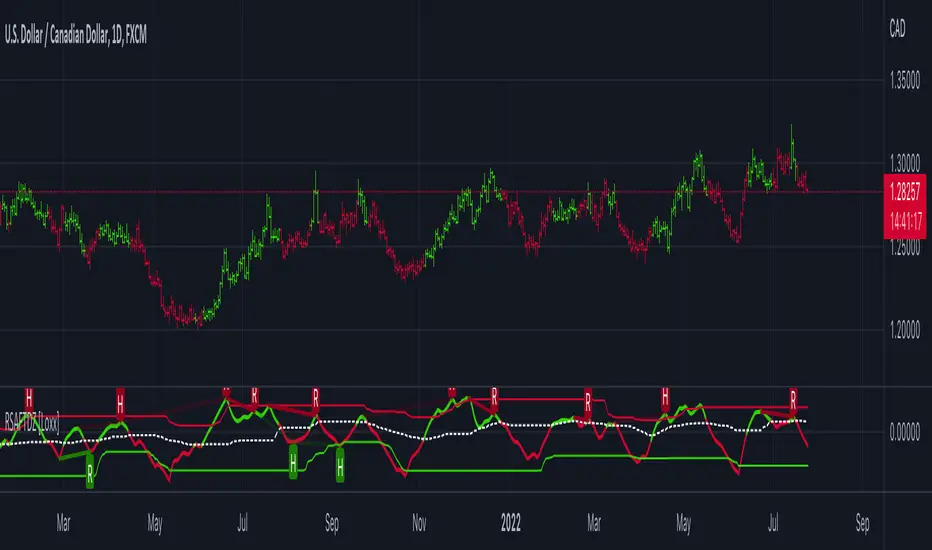
Variety RSI w/ Dynamic Zones [Loxx]Variety RSI w/ Dynamic Zones is an indicator with 7 different RSI types with Dynamic Zones. This indicator has signal crossing options for signal, middle, and all Dynamic Zone levels.
What is RSI?
The relative strength index ( RSI ) is a momentum indicator used in technical analysis . RSI measures the speed and magnitude of a security's recent price changes to evaluate overvalued or undervalued conditions in the price of that security.
The RSI is displayed as an oscillator (a line graph) on a scale of zero to 100. The indicator was developed by J. Welles Wilder Jr. and introduced in his seminal 1978 book, New Concepts in Technical Trading Systems.
The RSI can do more than point to overbought and oversold securities. It can also indicate securities that may be primed for a trend reversal or corrective pullback in price. It can signal when to buy and sell. Traditionally, an RSI reading of 70 or above indicates an overbought situation. A reading of 30 or below indicates an oversold condition.
What are Dynamic Zones?
As explained in "Stocks & Commodities V15:7 (306-310): Dynamic Zones by Leo Zamansky, Ph .D., and David Stendahl"
Most indicators use a fixed zone for buy and sell signals. Here’ s a concept based on zones that are responsive to past levels of the indicator.
One approach to active investing employs the use of oscillators to exploit tradable market trends. This investing style follows a very simple form of logic: Enter the market only when an oscillator has moved far above or below traditional trading lev- els. However, these oscillator- driven systems lack the ability to evolve with the market because they use fixed buy and sell zones. Traders typically use one set of buy and sell zones for a bull market and substantially different zones for a bear market. And therein lies the problem.
Once traders begin introducing their market opinions into trading equations, by changing the zones, they negate the system’s mechanical nature. The objective is to have a system automatically define its own buy and sell zones and thereby profitably trade in any market — bull or bear. Dynamic zones offer a solution to the problem of fixed buy and sell zones for any oscillator-driven system.
An indicator’s extreme levels can be quantified using statistical methods. These extreme levels are calculated for a certain period and serve as the buy and sell zones for a trading system. The repetition of this statistical process for every value of the indicator creates values that become the dynamic zones. The zones are calculated in such a way that the probability of the indicator value rising above, or falling below, the dynamic zones is equal to a given probability input set by the trader.
To better understand dynamic zones, let's first describe them mathematically and then explain their use. The dynamic zones definition:
Find V such that:
For dynamic zone buy: P{X <= V}=P1
For dynamic zone sell: P{X >= V}=P2
where P1 and P2 are the probabilities set by the trader, X is the value of the indicator for the selected period and V represents the value of the dynamic zone.
The probability input P1 and P2 can be adjusted by the trader to encompass as much or as little data as the trader would like. The smaller the probability, the fewer data values above and below the dynamic zones. This translates into a wider range between the buy and sell zones. If a 10% probability is used for P1 and P2, only those data values that make up the top 10% and bottom 10% for an indicator are used in the construction of the zones. Of the values, 80% will fall between the two extreme levels. Because dynamic zone levels are penetrated so infrequently, when this happens, traders know that the market has truly moved into overbought or oversold territory.
Calculating the Dynamic Zones
The algorithm for the dynamic zones is a series of steps. First, decide the value of the lookback period t. Next, decide the value of the probability Pbuy for buy zone and value of the probability Psell for the sell zone.
For i=1, to the last lookback period, build the distribution f(x) of the price during the lookback period i. Then find the value Vi1 such that the probability of the price less than or equal to Vi1 during the lookback period i is equal to Pbuy. Find the value Vi2 such that the probability of the price greater or equal to Vi2 during the lookback period i is equal to Psell. The sequence of Vi1 for all periods gives the buy zone. The sequence of Vi2 for all periods gives the sell zone.
In the algorithm description, we have: Build the distribution f(x) of the price during the lookback period i. The distribution here is empirical namely, how many times a given value of x appeared during the lookback period. The problem is to find such x that the probability of a price being greater or equal to x will be equal to a probability selected by the user. Probability is the area under the distribution curve. The task is to find such value of x that the area under the distribution curve to the right of x will be equal to the probability selected by the user. That x is the dynamic zone.
Included
RSI source pre-smoothing options
Bar coloring
4 types of signal crossing options
Alerts
Loxx's Expanded Source Types
Loxx's RSI Variety RSI types
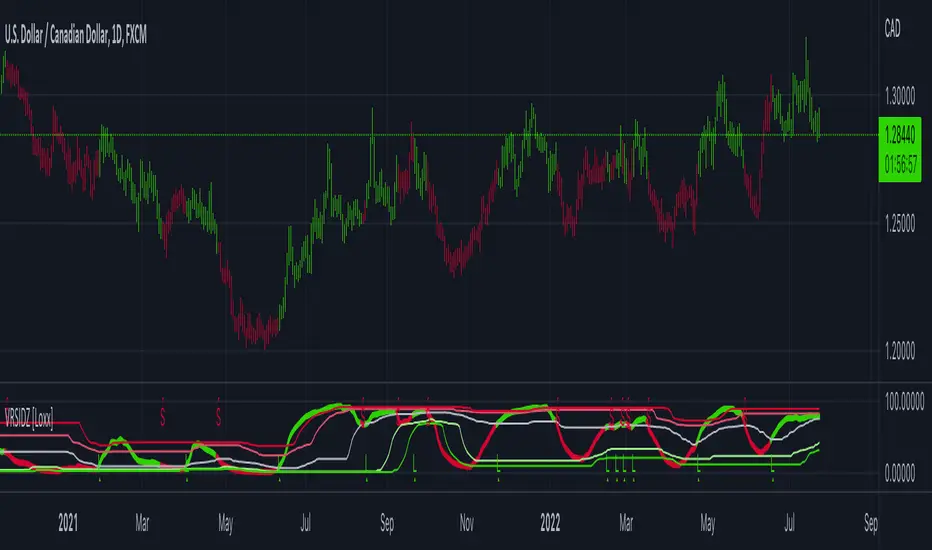
Variety RSI w/ Fibonacci Auto Channel [Loxx]Variety RSI w/ Fibonacci Auto Channel is an RSI indicator with 7 different RSI types and 4 Fibonacci Channels. This indicator has signal crossing options for signal, middle, and all Fibonacci levels. Bar and fill coloring is using a signal-determinant gradient coloring system to show signal strength or weakness.
What is RSI?
The relative strength index (RSI) is a momentum indicator used in technical analysis. RSI measures the speed and magnitude of a security's recent price changes to evaluate overvalued or undervalued conditions in the price of that security.
The RSI is displayed as an oscillator (a line graph) on a scale of zero to 100. The indicator was developed by J. Welles Wilder Jr. and introduced in his seminal 1978 book, New Concepts in Technical Trading Systems.
The RSI can do more than point to overbought and oversold securities. It can also indicate securities that may be primed for a trend reversal or corrective pullback in price. It can signal when to buy and sell. Traditionally, an RSI reading of 70 or above indicates an overbought situation. A reading of 30 or below indicates an oversold condition.
Included
Bar coloring
6 types of signal crossing options
Alerts
Loxx's Expanded Source Types
Loxx's RSI Variety RSI types
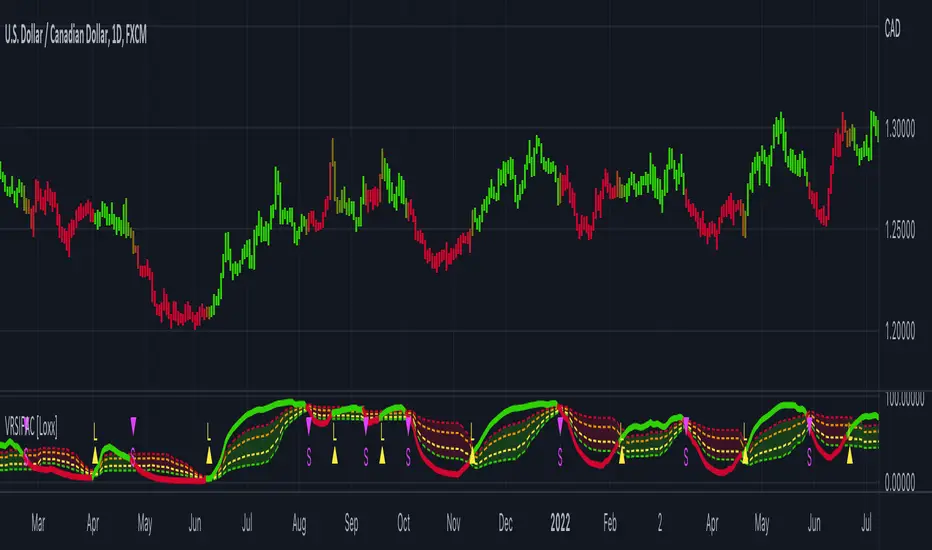
Pips-Stepped MA of RSI Adaptive EMA [Loxx]Pips-Stepped MA of RSI Adaptive EMA is a pips-stepping, adaptive moving average that first, filers source input price using an EMA calculated using an RSI-modified alpha value and second, and last, its plugged into a pips-stepping algorithm to output the final chart signals. This is mainly a forex indicator although it can be used for any asset, but you must adjust the step size to pips relative to the asset, For Bitcoin this may be 5000 or more.
Included
Bar coloring
Signals
Alerts
Loxx's Expanded Source Types
Loxx's RSI Variety RSI types
