Birdies [LuxAlgo]The Birdies indicator uses a unique technique to provide support/resistance curves based on a circle connecting the last swing high/low.
A specific, customizable part of this circle acts as a curve of interest, which can trigger visual breakout signals.
🔶 USAGE
The script projects a bird-like pattern when a valid Swing point is found. Multiple customization options are included.
🔹 Trend & Support/Resistance Tool
The color fill patterns and the wing boundaries can give insights into the current trend direction as well as serve as potential support/resistance areas.
In the example above, "Birdies" coincide with pullback and support/resistance zones.
🔹 Swing Length & Buffer
Besides the "Swing Length", with higher values returning longer-term Swing Levels, the script's behavior can be fine-tuned with filters ("Settings" - "Validation").
🔹 Validation
To minimize clutter, three filters are included:
Minimum X-Distance: The minimum amount of bars between subsequent Swings
Minimum Y-Distance: The minimum amount of bars between subsequent Swings
Buffer (Multiple of ATR)
The "Minimum X/Y-Distance" creates a zone where a new Swing is considered invalid. Only when the Swing is out of the zone, can it be considered valid.
In other words, in the example above, a Swing High can only be valid when enough bars/time have passed, and the difference between the last Swing and the previous is more than the ATR multiplied by the "Minimum Y-Distance" factor.
The "Buffer" creates a line above/below the "Birdy", derived from the measured ATR at the conception of the "Birdy" multiplied with a factor ("Buffer").
When the closing price crosses the "Birdy", it must also surpass this buffer line to produce a valid signal, lowering the risk of clutter as a result.
🔶 DETAILS
Birdies are derived from a circle that connects two Swing points. The left-wing curve originates from the most recent "Swing point" to the last value on the circle before crossing its midline. The mirror image of the left wing creates the right wing.
Enabling "Origine" will draw a line from the last Swing to the first.
🔹 Style
The publication includes a style setting with four options.
The first, "Birdy," shows a bird-like shape derived from a circle connecting the last Swing High and Swing Low.
The second option holds everything from the first option but connects both wingtips, providing potential horizontal levels of interest.
When setting "Birdy" to "None", the visual breakout signals will not defer from previous settings, but the focus is shifted towards the fill color, which can help detect potential trend shift.
A fourth setting, "Left Wing", will only show the left part of the "Birdy" pattern, removing the right part from the equation. This will change the visual breakout signals, providing alternative signals.
🔶 SETTINGS
Swing Length: The period used for swing detection, with higher values returning longer-term Swing Levels.
🔹 Validation
Minimum X-Distance: The minimum amount of bars between subsequent Swings
Minimum Y-Distance: The minimum amount of bars between subsequent Swings
Buffer (Multiple of ATR)
🔹 Style
Bullish Patterns: Enable / color
Bearish Patterns: Enable / color
Buffer Zone: Show / Color
Color Fill: Show color fill between two Birdies (if available)
Origine: Show the line between both Swing Points
🔹 Calculation
Calculated Bars: Allows the usage of fewer bars for performance/speed improvement
Extrapolation

Extrapolated Previous Trend [LuxAlgo]The Extrapolated Previous Trend indicator extrapolates the estimated linear trend of the prices within a previous interval to the current interval. Intervals can be user-defined.
🔶 USAGE
Returned lines can be used to provide a forecast of trends, assuming trends are persistent in sign and slope.
Using them as support/resistance can also be an effecting usage in case the trend in a new interval does not follow the characteristic of the trend in the previous interval.
The indicator includes a dashboard showing the degree of persistence between segmented trends for uptrends and downtrends. A higher value is indicative of more persistent trend signs.
A lower value could hint at an anti-persistent behavior, with uptrends over an interval often being followed by a down-trend and vice versa. We can invert candle colors to determine future trend direction in this case.
🔶 DETAILS
This indicator can be thought of as a segmented linear model ( a(n)t + b(n) ), where n is the specific interval index. Unlike a regular segmented linear regression model, this indicator is not subject to lookahead bias, coefficients of the model are obtained on previous intervals.
The quality of the fit of the model is dependent on the variability of its coefficients a(n) and b(n) . Coefficients being less subject to change over time are more indicative of trend persistence.
🔶 SETTINGS
Timeframe: Determine the frequency at which new trends are estimated.

Advanced Donchian Channels
Advanced Donchian Channels displays future donchian channel values based on the current information on the chart.
It displays a normal donchian channel at the specified user length with the future values extending from the current bar.
Depending on the direction of price movement, these values do not repaint. It is known when it does and does not repaint, and the actions are normal. See below for more information.
In a down trend, when the price is making new lows, the future "channel low" value will update every time the low is broken. The mean will also update, since the mean is the average of the channel high and channel low.
In a downtrend, the "channel high" value is concrete . It will not update until the high is broken.
Reverse these examples for uptrends.
Q;
How does it know the future values?
A:
Consider This: If we are below the current highest high, going down (aka: not setting new highs), the donchian channel "high" value will create a flat top, the flat top will start to decrease after we go further than our specified length. This is because the highest high within our specified length is no longer what it was previously. This action of time decay is a consistent movement of donchian channels . Because of this I am able to calculate these values before the current bar actually reaches them.
The indicator calculates the current length donchian channel at the current bar and then for every future bar up to your length specified it subtracts 1 from your length, calculates and displays the values accordingly.
The farthest future value is 1 length and the current bar is your specified length.
VALUES WILL ONLY BE UPDATED WHEN THE CHANNEL HIGH OR LOW IS BROKEN.
If price stays within the channel, all the future channel values will become solidified when the time reaches them.
This is not a gimmick, This data is accurate and can be used to help see future price trends
This chart should assist in visualizing what data you are seeing in this indicator.
Enjoy!

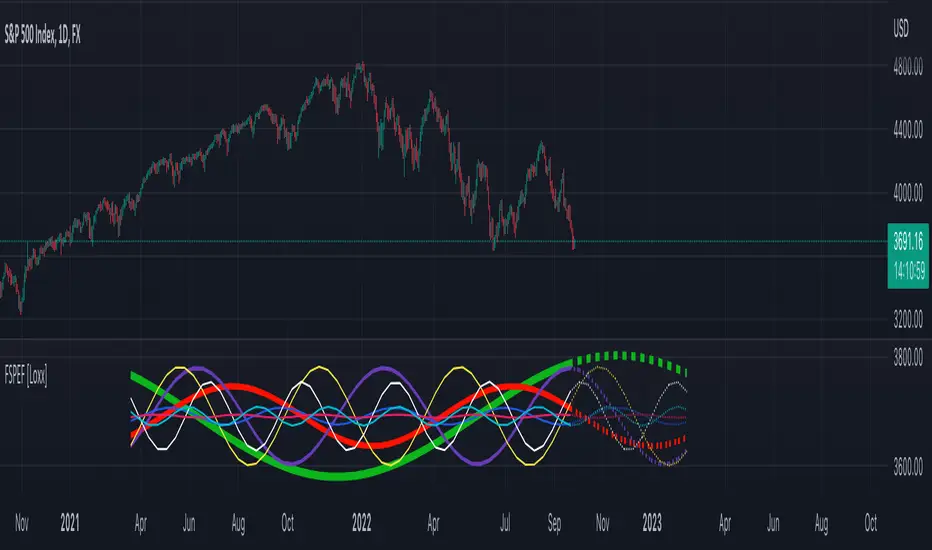
Fourier Spectrometer of Price w/ Extrapolation Forecast [Loxx]Fourier Spectrometer of Price w/ Extrapolation Forecast is a forecasting indicator that forecasts the sinusoidal frequency of input price. This method uses Linear Regression with a Fast Fourier Transform function for the forecast and is different from previous forecasting methods I've posted. Dotted lines are the forecast frequencies. You can change the UI colors and line widths. This comes with 8 frequencies out of the box. Instead of drawing sinusoidal manually on your charts, you can use this instead. This will render better results than eyeballing the Sine Wave that folks use for trading. this is the real math that automates that process.
Each signal line can be shown as a linear superposition of periodic (sinusoidal) components with different periods (frequencies) and amplitudes. Roughly, the indicator shows those components. It strongly depends on the probing window and changes (recalculates) after each tick; e.g., you can see the set of frequencies showing whether the signal is fast or slow-changing, etc. Sometimes only a small number of leading / strongest components (e.g., 3) can extrapolate the signal quite well.
Related Indicators
Fourier Extrapolator of 'Caterpillar' SSA of Price
Real-Fast Fourier Transform of Price w/ Linear Regression
Fourier Extrapolator of Price w/ Projection Forecast
Itakura-Saito Autoregressive Extrapolation of Price
Helme-Nikias Weighted Burg AR-SE Extra. of Price
***The period parameter doesn't correspond to how many bars back the drawing begins. Lines re rendered according to skipping mechanism due to TradingView limitations.
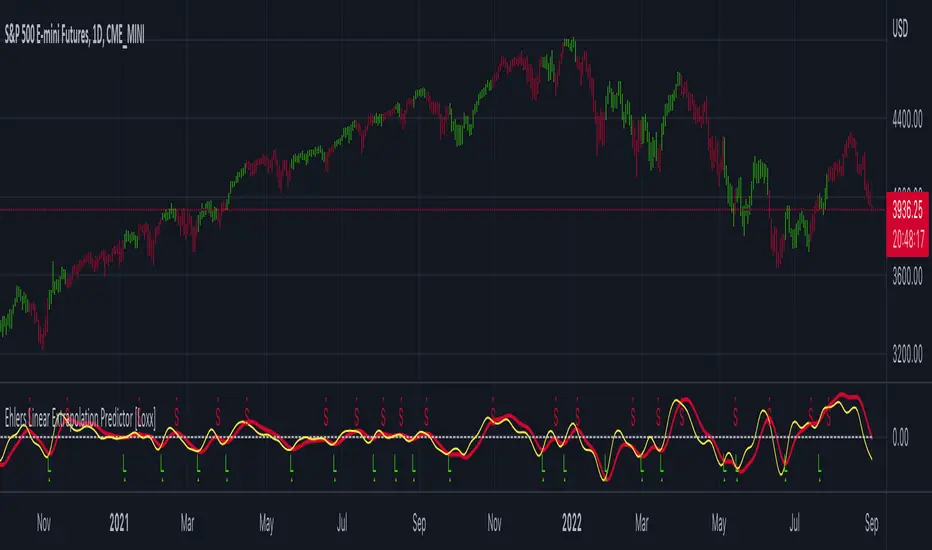
Ehlers Linear Extrapolation Predictor [Loxx]Ehlers Linear Extrapolation Predictor is a new indicator by John Ehlers. The translation of this indicator into PineScript™ is a collaborative effort between @cheatcountry and I.
The following is an excerpt from "PREDICTION" , by John Ehlers
Niels Bohr said “Prediction is very difficult, especially if it’s about the future.”. Actually, prediction is pretty easy in the context of technical analysis. All you have to do is to assume the market will behave in the immediate future just as it has behaved in the immediate past. In this article we will explore several different techniques that put the philosophy into practice.
LINEAR EXTRAPOLATION
Linear extrapolation takes the philosophical approach quite literally. Linear extrapolation simply takes the difference of the last two bars and adds that difference to the value of the last bar to form the prediction for the next bar. The prediction is extended further into the future by taking the last predicted value as real data and repeating the process of adding the most recent difference to it. The process can be repeated over and over to extend the prediction even further.
Linear extrapolation is an FIR filter, meaning it depends only on the data input rather than on a previously computed value. Since the output of an FIR filter depends only on delayed input data, the resulting lag is somewhat like the delay of water coming out the end of a hose after it supplied at the input. Linear extrapolation has a negative group delay at the longer cycle periods of the spectrum, which means water comes out the end of the hose before it is applied at the input. Of course the analogy breaks down, but it is fun to think of it that way. As shown in Figure 1, the actual group delay varies across the spectrum. For frequency components less than .167 (i.e. a period of 6 bars) the group delay is negative, meaning the filter is predictive. However, the filter has a positive group delay for cycle components whose periods are shorter than 6 bars.
Figure 1
Here’s the practical ramification of the group delay: Suppose we are projecting the prediction 5 bars into the future. This is fine as long as the market is continued to trend up in the same direction. But, when we get a reversal, the prediction continues upward for 5 bars after the reversal. That is, the prediction fails just when you need it the most. An interesting phenomenon is that, regardless of how far the extrapolation extends into the future, the prediction will always cross the signal at the same spot along the time axis. The result is that the prediction will have an overshoot. The amplitude of the overshoot is a function of how far the extrapolation has been carried into the future.
But the overshoot gives us an opportunity to make a useful prediction at the cyclic turning point of band limited signals (i.e. oscillators having a zero mean). If we reduce the overshoot by reducing the gain of the prediction, we then also move the crossing of the prediction and the original signal into the future. Since the group delay varies across the spectrum, the effect will be less effective for the shorter cycles in the data. Nonetheless, the technique is effective for both discretionary trading and automated trading in the majority of cases.
EXPLORING THE CODE
Before we predict, we need to create a band limited indicator from which to make the prediction. I have selected a “roofing filter” consisting of a High Pass Filter followed by a Low Pass Filter. The tunable parameter of the High Pass Filter is HPPeriod. Think of it as a “stone wall filter” where cycle period components longer than HPPeriod are completely rejected and cycle period components shorter than HPPeriod are passed without attenuation. If HPPeriod is set to be a large number (e.g. 250) the indicator will tend to look more like a trending indicator. If HPPeriod is set to be a smaller number (e.g. 20) the indicator will look more like a cycling indicator. The Low Pass Filter is a Hann Windowed FIR filter whose tunable parameter is LPPeriod. Think of it as a “stone wall filter” where cycle period components shorter than LPPeriod are completely rejected and cycle period components longer than LPPeriod are passed without attenuation. The purpose of the Low Pass filter is to smooth the signal. Thus, the combination of these two filters forms a “roofing filter”, named Filt, that passes spectrum components between LPPeriod and HPPeriod.
Since working into the future is not allowed in EasyLanguage variables, we need to convert the Filt variable to the data array XX . The data array is first filled with real data out to “Length”. I selected Length = 10 simply to have a convenient starting point for the prediction. The next block of code is the prediction into the future. It is easiest to understand if we consider the case where count = 0. Then, in English, the next value of the data array is equal to the current value of the data array plus the difference between the current value and the previous value. That makes the prediction one bar into the future. The process is repeated for each value of count until predictions up to 10 bars in the future are contained in the data array. Next, the selected prediction is converted from the data array to the variable “Prediction”. Filt is plotted in Red and Prediction is plotted in yellow.
The Predict Extrapolation indicator is shown above for the Emini S&P Futures contract using the default input parameters. Filt is plotted in red and Predict is plotted in yellow. The crossings of the Predict and Filt lines provide reliable buy and sell timing signals. There is some overshoot for the shorter cycle periods, for example in February and March 2021, but the only effect is a late timing signal. Further reducing the gain and/or reducing the BarsFwd inputs would provide better timing signals during this period.
ADDITIONS
Loxx's Expanded source types:
Library for expanded source types:
Explanation for expanded source types:
Three different signal types: 1) Prediction/Filter crosses; 2) Prediction middle crosses; and, 3) Filter middle crosses.
Bar coloring to color trend.
Signals, both Long and Short.
Alerts, both Long and Short.
Polynomial Regression Bands w/ Extrapolation of Price [Loxx]Polynomial Regression Bands w/ Extrapolation of Price is a moving average built on Polynomial Regression. This indicator paints both a non-repainting moving average and also a projection forecast based on the Polynomial Regression. I've included 33 source types and 38 moving average types to smooth the price input before it's run through the Polynomial Regression algorithm. This indicator only paints X many bars back so as to increase on screen calculation speed. Make sure to read the tooltips to answer any questions you have.
What is Polynomial Regression?
In statistics, polynomial regression is a form of regression analysis in which the relationship between the independent variable x and the dependent variable y is modeled as an nth degree polynomial in x. Polynomial regression fits a nonlinear relationship between the value of x and the corresponding conditional mean of y, denoted E(y |x). Although polynomial regression fits a nonlinear model to the data, as a statistical estimation problem it is linear, in the sense that the regression function E(y | x) is linear in the unknown parameters that are estimated from the data. For this reason, polynomial regression is considered to be a special case of multiple linear regression .
Related indicators
Polynomial-Regression-Fitted Oscillator
Polynomial-Regression-Fitted RSI
PA-Adaptive Polynomial Regression Fitted Moving Average
Poly Cycle
Fourier Extrapolator of Price w/ Projection Forecast
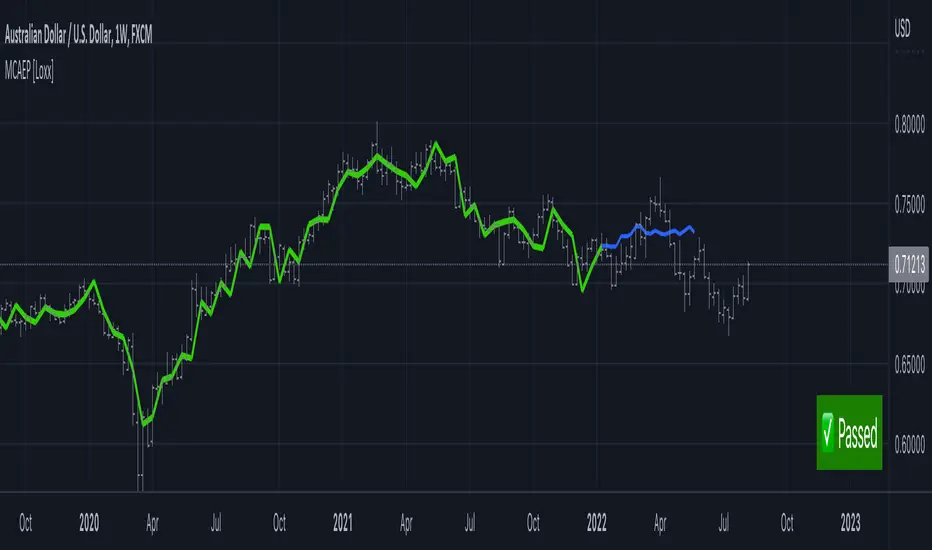
Nearest Neighbor Extrapolation of Price [Loxx]I wasn't going to post this because I don't like how this calculates by puling in the Open price, but I'm posting it anyway. This does work in it's current form but there is a. better way to do this. I'll revisit this in the future.
Anyway...
The k-Nearest Neighbor algorithm (k-NN) searches for k past patterns (neighbors) that are most similar to the current pattern and computes the future prices based on weighted voting of those neighbors. This indicator finds only one nearest neighbor. So, in essence, it is a 1-NN algorithm. It uses the Pearson correlation coefficient between the current pattern and all past patterns as the measure of distance between them. Also, this version of the nearest neighbor indicator gives larger weights to most recent prices while searching for the closest pattern in the past. It uses a weighted correlation coefficient, whose weight decays linearly from newer to older prices within a price pattern.
This indicator also includes an error window that shows whether the calculation is valid. If it's green and says "Passed", then the calculation is valid, otherwise it'll show a red background and and error message.
Inputs
Npast - number of past bars in a pattern;
Nfut -number of future bars in a pattern (must be < Npast).
lastbar - How many bars back to start forecast? Useful to show past prediction accuracy
barsbark - This prevents Pine from trying to calculate on all past bars
Related indicators
Hodrick-Prescott Extrapolation of Price
Itakura-Saito Autoregressive Extrapolation of Price
Helme-Nikias Weighted Burg AR-SE Extra. of Price
Weighted Burg AR Spectral Estimate Extrapolation of Price
Levinson-Durbin Autocorrelation Extrapolation of Price
Fourier Extrapolator of Price w/ Projection Forecast

Hodrick-Prescott Extrapolation of Price [Loxx]Hodrick-Prescott Extrapolation of Price is a Hodrick-Prescott filter used to extrapolate price.
The distinctive feature of the Hodrick-Prescott filter is that it does not delay. It is calculated by minimizing the objective function.
F = Sum((y(i) - x(i))^2,i=0..n-1) + lambda*Sum((y(i+1)+y(i-1)-2*y(i))^2,i=1..n-2)
where x() - prices, y() - filter values.
If the Hodrick-Prescott filter sees the future, then what future values does it suggest? To answer this question, we should find the digital low-frequency filter with the frequency parameter similar to the Hodrick-Prescott filter's one but with the values calculated directly using the past values of the "twin filter" itself, i.e.
y(i) = Sum(a(k)*x(i-k),k=0..nx-1) - FIR filter
or
y(i) = Sum(a(k)*x(i-k),k=0..nx-1) + Sum(b(k)*y(i-k),k=1..ny) - IIR filter
It is better to select the "twin filter" having the frequency-independent delay Тdel (constant group delay). IIR filters are not suitable. For FIR filters, the condition for a frequency-independent delay is as follows:
a(i) = +/-a(nx-1-i), i = 0..nx-1
The simplest FIR filter with constant delay is Simple Moving Average (SMA):
y(i) = Sum(x(i-k),k=0..nx-1)/nx
In case nx is an odd number, Тdel = (nx-1)/2. If we shift the values of SMA filter to the past by the amount of bars equal to Тdel, SMA values coincide with the Hodrick-Prescott filter ones. The exact math cannot be achieved due to the significant differences in the frequency parameters of the two filters.
To achieve the closest match between the filter values, I recommend their channel widths to be similar (for example, -6dB). The Hodrick-Prescott filter's channel width of -6dB is calculated as follows:
wc = 2*arcsin(0.5/lambda^0.25).
The channel width of -6dB for the SMA filter is calculated by numerical computing via the following equation:
|H(w)| = sin(nx*wc/2)/sin(wc/2)/nx = 0.5
Prediction algorithms:
The indicator features the two prediction methods:
Metod 1:
1. Set SMA length to 3 and shift it to the past by 1 bar. With such a length, the shifted SMA does not exist only for the last bar (Bar = 0), since it needs the value of the next future price Close(-1).
2. Calculate SMA filer's channel width. Equal it to the Hodrick-Prescott filter's one. Find lambda.
3. Calculate Hodrick-Prescott filter value at the last bar HP(0) and assume that SMA(0) with unknown Close(-1) gives the same value.
4. Find Close(-1) = 3*HP(0) - Close(0) - Close(1)
5. Increase the length of SMA to 5. Repeat all calculations and find Close(-2) = 5*HP(0) - Close(-1) - Close(0) - Close(1) - Close(2). Continue till the specified amount of future FutBars prices is calculated.
Method 2:
1. Set SMA length equal to 2*FutBars+1 and shift SMA to the past by FutBars
2. Calculate SMA filer's channel width. Equal it to the Hodrick-Prescott filter's one. Find lambda.
3. Calculate Hodrick-Prescott filter values at the last FutBars and assume that SMA behaves similarly when new prices appear.
4. Find Close(-1) = (2*FutBars+1)*HP(FutBars-1) - Sum(Close(i),i=0..2*FutBars-1), Close(-2) = (2*FutBars+1)*HP(FutBars-2) - Sum(Close(i),i=-1..2*FutBars-2), etc.
The indicator features the following inputs:
Method - prediction method
Last Bar - number of the last bar to check predictions on the existing prices (LastBar >= 0)
Past Bars - amount of previous bars the Hodrick-Prescott filter is calculated for (the more, the better, or at least PastBars>2*FutBars)
Future Bars - amount of predicted future values
The second method is more accurate but often has large spikes of the first predicted price. For our purposes here, this price has been filtered from being displayed in the chart. This is why method two starts its prediction 2 bars later than method 1. The described prediction method can be improved by searching for the FIR filter with the frequency parameter closer to the Hodrick-Prescott filter. For example, you may try Hanning, Blackman, Kaiser, and other filters with constant delay instead of SMA.
Related indicators
Itakura-Saito Autoregressive Extrapolation of Price
Helme-Nikias Weighted Burg AR-SE Extra. of Price
Weighted Burg AR Spectral Estimate Extrapolation of Price
Levinson-Durbin Autocorrelation Extrapolation of Price
Fourier Extrapolator of Price w/ Projection Forecast

Modified Covariance Autoregressive Estimator of Price [Loxx]What is the Modified Covariance AR Estimator?
The Modified Covariance AR Estimator uses the modified covariance method to fit an autoregressive (AR) model to the input data. This method minimizes the forward and backward prediction errors in the least squares sense. The input is a frame of consecutive time samples, which is assumed to be the output of an AR system driven by white noise. The block computes the normalized estimate of the AR system parameters, A(z), independently for each successive input.
Characteristics of Modified Covariance AR Estimator
Minimizes the forward prediction error in the least squares sense
Minimizes the forward and backward prediction errors in the least squares sense
High resolution for short data records
Able to extract frequencies from data consisting of p or more pure sinusoids
Does not suffer spectral line-splitting
May produce unstable models
Peak locations slightly dependent on initial phase
Minor frequency bias for estimates of sinusoids in noise
Order must be less than or equal to 2/3 the input frame size
Purpose
This indicator calculates a prediction of price. This will NOT work on all tickers. To see whether this works on a ticker for the settings you have chosen, you must check the label message on the lower right of the chart. The label will show either a pass or fail. If it passes, then it's green, if it fails, it's red. The reason for this is because the Modified Covariance method produce unstable models
H(z)= G / A(z) = G / (1+. a(2)z −1 +…+a(p+1)z)
You specify the order, "ip", of the all-pole model in the Estimation order parameter. To guarantee a valid output, you must set the Estimation order parameter to be less than or equal to two thirds the input vector length.
The output port labeled "a" outputs the normalized estimate of the AR model coefficients in descending powers of z.
The implementation of the Modified Covariance AR Estimator in this indicator is the fast algorithm for the solution of the modified covariance least squares normal equations.
Inputs
x - Array of complex data samples X(1) through X(N)
ip - Order of linear prediction model (integer)
Notable local variables
v - Real linear prediction variance at order IP
Outputs
a - Array of complex linear prediction coefficients
stop - value at time of exit, with error message
false - for normal exit (no numerical ill-conditioning)
true - if v is not a positive value
true - if delta and gamma do not lie in the range 0 to 1
true - if v is not a positive value
true - if delta and gamma do not lie in the range 0 to 1
errormessage - an error message based on "stop" parameter; this message will be displayed in the lower righthand corner of the chart. If you see a green "passed" then the analysis is valid, otherwise the test failed.
Indicator inputs
LastBar = bars backward from current bar to test estimate reliability
PastBars = how many bars are we going to analyze
LPOrder = Order of Linear Prediction, and for Modified Covariance AR method, this must be less than or equal to 2/3 the input frame size, so this number has a max value of 0.67
FutBars = how many bars you'd like to show in the future. This algorithm will either accept or reject your value input here and then project forward
Further reading
Spectrum Analysis-A Modern Perspective 1380 PROCEEDINGS OF THE IEEE, VOL. 69, NO. 11, NOVEMBER 1981
Related indicators
Levinson-Durbin Autocorrelation Extrapolation of Price
Weighted Burg AR Spectral Estimate Extrapolation of Price
Helme-Nikias Weighted Burg AR-SE Extra. of Price
Itakura-Saito Autoregressive Extrapolation of Price
Modified Covariance Autoregressive Estimator of Price
Itakura-Saito Autoregressive Extrapolation of Price [Loxx]Itakura-Saito Autoregressive Extrapolation of Price is an indicator that uses an autoregressive analysis to predict future prices. This is a linear technique that was originally derived or speech analysis algorithms.
What is Itakura-Saito Autoregressive Analysis?
The technique of linear prediction has been available for speech analysis since the late 1960s (Itakura & Saito, 1973a, 1970; Atal & Hanauer, 1971), although the basic principles were established long before this by Wiener (1947). Linear predictive coding, which is also known as autoregressive analysis, is a time-series algorithm that has applications in many fields other than speech analysis (see, e.g., Chatfield, 1989).
Itakura and Saito developed a formulation for linear prediction analysis using a lattice form for the inverse filter. The Itakura–Saito distance (or Itakura–Saito divergence) is a measure of the difference between an original spectrum and an approximation of that spectrum. Although it is not a perceptual measure it is intended to reflect perceptual (dis)similarity. It was proposed by Fumitada Itakura and Shuzo Saito in the 1960s while they were with NTT. The distance is defined as: The Itakura–Saito distance is a Bregman divergence, but is not a true metric since it is not symmetric and it does not fulfil triangle inequality.
read more: Selected Methods for Improving Synthesis Speech Quality Using Linear Predictive Coding: System Description, Coefficient Smoothing and Streak
Data inputs
Source Settings: -Loxx's Expanded Source Types. You typically use "open" since open has already closed on the current active bar
LastBar - bar where to start the prediction
PastBars - how many bars back to model
LPOrder - order of linear prediction model; 0 to 1
FutBars - how many bars you want to forward predict
Things to know
Normally, a simple moving average is calculated on source data. I've expanded this to 38 different averaging methods using Loxx's Moving Avreages.
This indicator repaints
Related Indicators (linear extrapolation of price)
Levinson-Durbin Autocorrelation Extrapolation of Price
Weighted Burg AR Spectral Estimate Extrapolation of Price
Helme-Nikias Weighted Burg AR-SE Extra. of Price
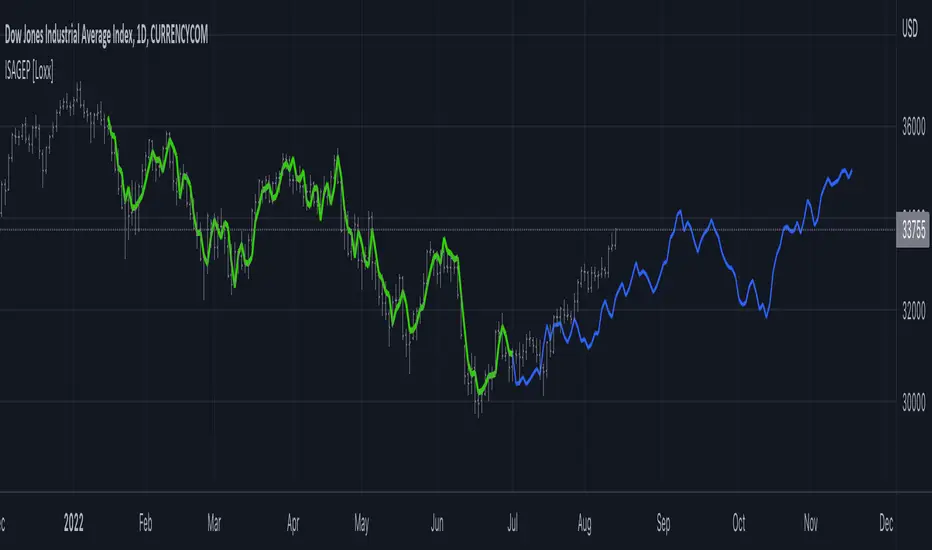
Fourier Extrapolator of Variety RSI w/ Bollinger Bands [Loxx]Fourier Extrapolator of Variety RSI w/ Bollinger Bands is an RSI indicator that shows the original RSI, the Fourier Extrapolation of RSI in the past, and then the projection of the Fourier Extrapolated RSI for the future. This indicator has 8 different types of RSI including a new type of RSI called T3 RSI. The purpose of this indicator is to demonstrate the Fourier Extrapolation method used to model past data and to predict future price movements. This indicator will repaint. If you wish to use this for trading, then make sure to take a screenshot of the indicator when you enter the trade to save your analysis. This is the first of a series of forecasting indicators that can be used in trading. Due to how this indicator draws on the screen, you must choose values of npast and nfut that are equal to or less than 200. this is due to restrictions by TradingView and Pine Script in only allowing 500 lines on the screen at a time. Enjoy!
What is Fourier Extrapolation?
This indicator uses a multi-harmonic (or multi-tone) trigonometric model of a price series xi, i=1..n, is given by:
xi = m + Sum( a*Cos(w*i) + b*Sin(w*i), h=1..H )
Where:
xi - past price at i-th bar, total n past prices;
m - bias;
a and b - scaling coefficients of harmonics;
w - frequency of a harmonic ;
h - harmonic number;
H - total number of fitted harmonics.
Fitting this model means finding m, a, b, and w that make the modeled values to be close to real values. Finding the harmonic frequencies w is the most difficult part of fitting a trigonometric model. In the case of a Fourier series, these frequencies are set at 2*pi*h/n. But, the Fourier series extrapolation means simply repeating the n past prices into the future.
This indicator uses the Quinn-Fernandes algorithm to find the harmonic frequencies. It fits harmonics of the trigonometric series one by one until the specified total number of harmonics H is reached. After fitting a new harmonic , the coded algorithm computes the residue between the updated model and the real values and fits a new harmonic to the residue.
see here: A Fast Efficient Technique for the Estimation of Frequency , B. G. Quinn and J. M. Fernandes, Biometrika, Vol. 78, No. 3 (Sep., 1991), pp . 489-497 (9 pages) Published By: Oxford University Press
The indicator has the following input parameters:
src - input source
npast - number of past bars, to which trigonometric series is fitted;
Nfut - number of predicted future bars;
nharm - total number of harmonics in model;
frqtol - tolerance of frequency calculations.
Included:
Loxx's Expanded Source Types
Loxx's Variety RSI
Other indicators using this same method
Fourier Extrapolator of Price w/ Projection Forecast
Fourier Extrapolator of Price
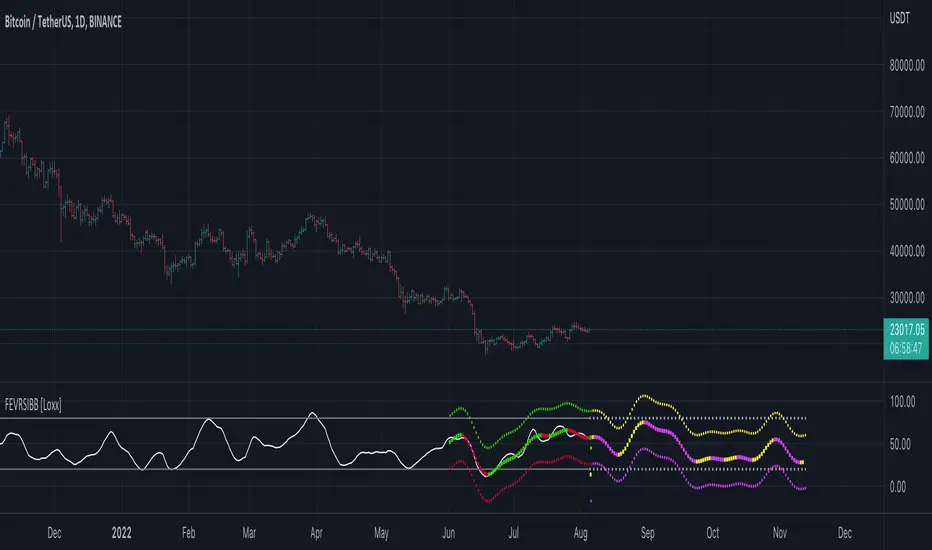
Quadratic RegressionFit a quadratic polynomial (parabola) to the last length data points by minimizing the sum of squares between the data and the fitted results. The script can extrapolate the results in the future and can also display the R-squared of the model. Note that this script is subject to some limitations (more in the "Notes" section).
Settings
Length : Number of data points to use as input.
Offset : Determine the number of past fitted values to be displayed, if 0 only the extrapolated values are displayed, if 55 only the past fitted values are displayed.
Src : Input data of the indicator
Show R2 : Determine if the value of the R-squared must be displayed, by default true.
Usage
When the underlying trend in the price is not linear, we might use more advanced models to estimate it, this is where using a higher-degree regression model might be required, as such a quadratic model (second-degree) is appropriate when the underlying trend is parabolic.
Here we can see that the quadratic regression (in blue) offer a better fit than a linear one.
Another advantage of the quadratic regression is that a linear one will always have the same direction, that's not the case with the quadratic regression and as such, it is possible to forecast reversals.
Above a linear regression (in red) and two quadratic regression (in blue) with both length = 54. Note that for the sake of clarity, the above image uses a quadratic regression to show all the past fitted values and another one to show all the forecasted values.
The R-Squared is also extremely useful when it comes to measuring the accuracy of the model, with values closer to 1 indicating that the model is appropriate, and thus suggesting that the underlying trend in the price is parabolic. The R-squared can also measure the strength of the trend.
Notes
The script uses the function line.new , as such only a maximum of 54 observations are displayed, getting more observations can be done by using an additional quadratic regression like we did in the previous section. Another thing is that line.new use xloc.bar_time , as such it is possible to observe some errors with the displayed results of the indicator, such as:
This will happen when applying the indicator to symbols with session breaks, I apologize for this inconvenience and I'll try to find solutions. Note however that the indicator will work perfectly on cryptos.
Summary
That's an indicator I really wanted to make, even if it is important to note that such models are rarely useful in stock markets, however it is more than possible to create a quadratic regression (with severe limitations) with pinescript.
Today I turn 21, while I should be celebrating I still wanted to share something with the community, it's also some kind of present to myself that tells me that I am a bit better at using pinescript than last year, and I am glad I could progress (instead of regress, regression , got it?). Thx a lot for reading!
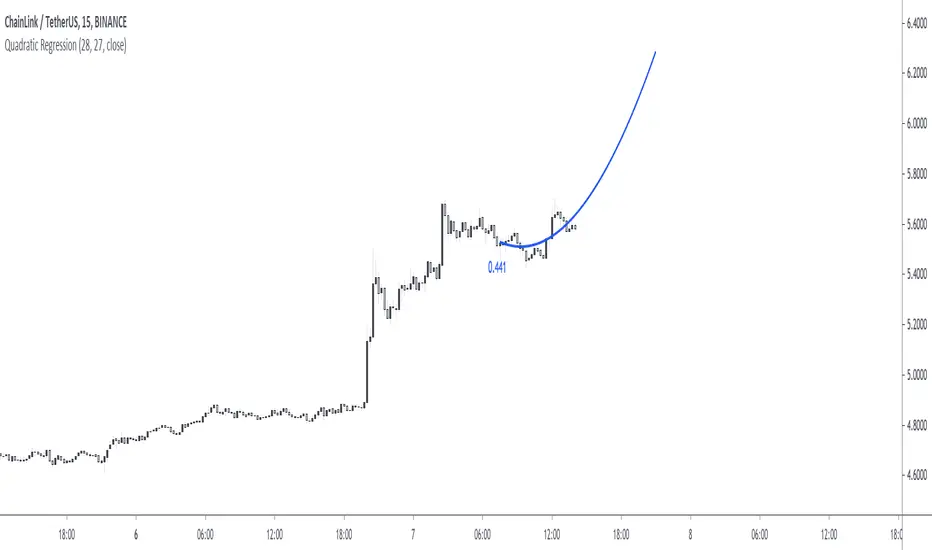
Forecasting - Drift MethodIntroduction
Nothing fancy in terms of code, take this post as an educational post where i provide information rather than an useful tool.
Time-Series Forecasting And The Drift Method
In time-series analysis one can use many many forecasting methods, some share similarities but they can all by classified in groups and sub-groups, the drift method is a forecasting method that unlike averages/naive methods does not have a constant (flat) forecast, instead the drift method can increase or decrease over time, this is why its a great method when it comes to forecasting linear trends.
Basically a drift forecast is like a linear extrapolation, first you take the first and last point of your data and draw a line between those points, extend this line into the future and you have a forecast, thats pretty much it.
One of the advantage of this method is first its simplicity, everyone could do it by hand without any mathematical calculations, then its ability to be non-conservative, conservative methods involve methods that fit the data very well such as linear/non-linear regression that best fit a curve to the data using the method of least-squares, those methods take into consideration all the data points, however the drift method only care about the first and last point.
Understanding Bias And Variance
In order to follow with the ability of methods to be non-conservative i want to introduce the concept of bias and variance, which are essentials in time-series analysis and machine learning.
First lets talk about training a model, when forecasting a time-series we can divide our data set in two, the first part being the training set and the second one the testing set. In the training set we fit a model to the training data, for example :
We use 200 data points, we split this set in two sets, the first one is for training which is in blue, and the other one for testing which is in green.
Basically the Bias is related to how well a forecasting model fit the training set, while the variance is related to how well the model fit the testing set. In our case we can see that the drift line does not fit the training set very well, it is then said to have high bias. If we check the testing set :
We can see that it does not fit the testing set very well, so the model is said to have high variance. It can be better to talk of bias and variance when using regression, but i think you get it. This is an important concept in machine learning, you'll often see the term "overfitting" which relate to a model fitting the training set really well, those models have a low to no bias, however when it comes to testing they don't fit well at all, they have high variance.
Conclusion On The Drift Method
The drift method is good at forecasting linear trends, and thats all...you see, when forecasting financial data you need models that are able to capture the complexity of the price structure as well as being robust to noise and outliers, the drift method isn't able to capture such complexity, its not a super smart method, same goes for linear regression. This is why more peoples are switching to more advanced models such a neural networks that can sometimes capture such complexity and return decent results.
So this method might not be the best but if you like lines then here you go.
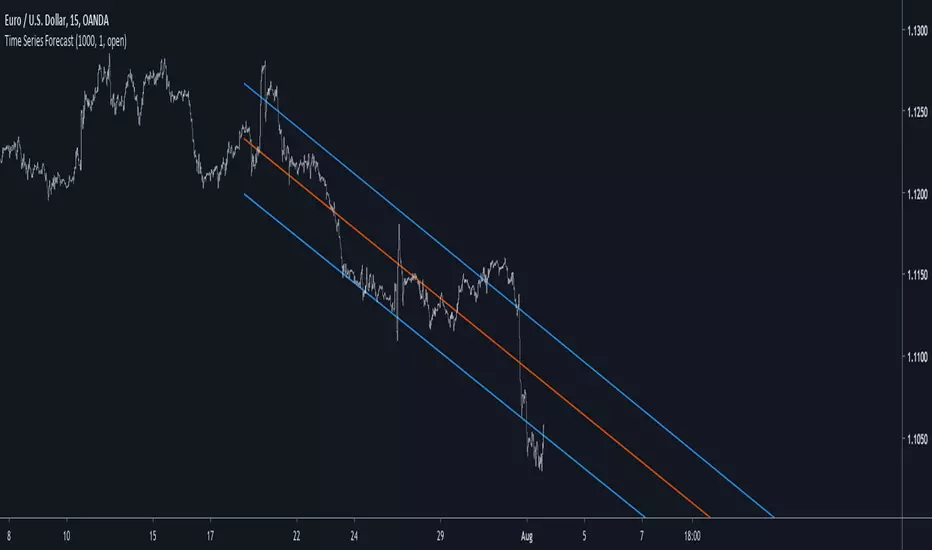
Time Series ForecastIntroduction
Forecasting is a blurry science that deal with lot of uncertainty. Most of the time forecasting is made with the assumption that past values can be used to forecast a time series, the accuracy of the forecast depend on the type of time series, the pre-processing applied to it, the forecast model and the parameters of the model.
In tradingview we don't have much forecasting models appart from the linear regression which is definitely not adapted to forecast financial markets, instead we mainly use it as support/resistance indicator. So i wanted to try making a forecasting tool based on the lsma that might provide something at least interesting, i hope you find an use to it.
The Method
Remember that the regression model and the lsma are closely related, both share the same equation ax + b but the lsma will use running parameters while a and b are constants in a linear regression, the last point of the lsma of period p is the last point of the linear regression that fit a line to the price at time p to 1, try to add a linear regression with count = 100 and an lsma of length = 100 and you will see, this is why the lsma is also called "end point moving average".
The forecast of the linear regression is the linear extrapolation of the fitted line, however the proposed indicator forecast is the linear extrapolation between the value of the lsma at time length and the last value of the lsma when short term extrapolation is false, when short term extrapolation is checked the forecast is the linear extrapolation between the lsma value prior to the last point and the last lsma value.
long term extrapolation, length = 1000
short term extrapolation, length = 1000
How To Use
Intervals are create from the running mean absolute error between the price and the lsma. Those intervals can be interpreted as possible support and resistance levels when using long term extrapolation, make sure that the intervals have been priorly tested, this mean the intervals are more significants.
The short term extrapolation is made with the assumption that the price will follow the last two lsma points direction, the forecast tend to become inaccurate during a trend change or when noise affect heavily the lsma.
You can test both method accuracy with the replay mode.
Comparison With The Linear Regression
Both methods share similitudes, but they have different results, lets compare them.
In blue the indicator and in red a linear regression of both period 200, the linear regression is always extremely conservative since she fit a line using the least squares method, at the contrary the indicator is less conservative which can be an advantage as well as a problem.
Conclusion
Linear models are good when what we want to forecast is approximately linear, thats not the case with market price and this is why other methods are used. But the use of the lsma to provide a forecast is still an interesting method that might require further studies.
Thanks for reading !
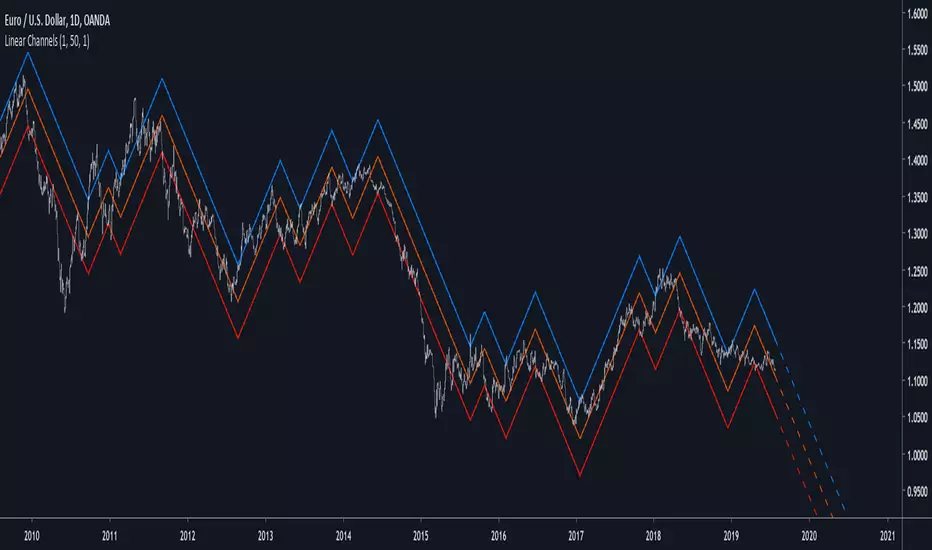
Linear ChannelsIntroduction
I already made an indicator (simple line) that tried to make lines on price such that the results would not repaint and give a good fit to the price, today i publish a channels indicator based on the simple line indicator. The indicator aim to show possible support and resistance levels when the central line posses a low sum of squares with the price, a linear extrapolation was also provided in order to show possible future price positions respective to the channels.
The Indicator
The emphasis parameter of the simple line indicator has been removed, instead we keep length and mult as numerical input parameters. In general length control how persistent the lines are, larger values will create longer lines on average, mult help make the line fit to the price better but might as well affect how spread the channels are as well as the lines average length. When mult > length the lines will fit better the price while when length >= mult the fit might not be the best.
The point parameter allow you to fix the indicator when using it on high market price values or when the indicator exhibit a weird behaviour.
point = false on btcusd
point = true
If the lines still does not fit well enough try to lower length.
I know this might result inconvenient in so many ways but i'am working on simplifying things. Therefore some larger price values might use lower length and use mult instead. For market not using the point parameters a settings of : length > 1 and mult = length*2 might provide a good to go setup.
The channel spreading parameter allow to make spread the channels by a certain factor.
Issues
I'am still not good with line extensions, if it bother you deactivate the extrapolation parameter. Sorry for the inconvenience.
Conclusion
It is possible to make non repainting linear indicators, and i'am working on some of them. While some might argue that price is not linear thus not requiring the use of linear indicators it can still be interesting to use those if they, unlike the linear regression, don't repaints and provide a way to change their directions according to the price trend.
Thanks for reading !
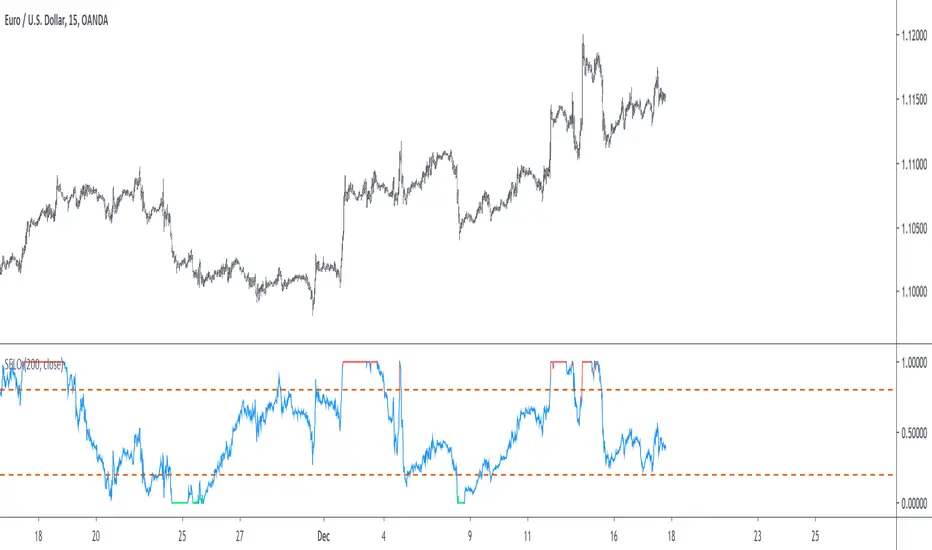
Stationary Extrapolated Levels OscillatorIntroduction
The oscillator version of the stationary extrapolated levels indicator. The methodology behind the extrapolated levels where to minimize the risk of making a decision based only on a forecast, therefore the indicator plotted levels in order to determine possible reversal points, signals where generated when the detrended series crossed over/under those levels.
The Indicator
First we detrend the price, this is because forecasting the trend is often harder than a series without trend (stationarity > non-stationarity) , then we forecast the detrended price with a linear extrapolation over a period of length and apply a max/min filter twice to the forecast, the max/min filters are just the highest and lowest function in pine. So the max/min filter have lag length/2 , by applying it two times we have a lag of length which is the period of the forecast. Because we use highest and lowest we can apply min-max normalization in the form of :
x' = (x - min(x, min'))/(max(x,max') - min(x, min'))
where x is the detrended price, max' the highest of the forecast of x and min' the lowest of the forecast of x . This result in a scaled oscillator in a range of (1,0),
When the indicator is equal to 1 or 0 there are high chances of reversals, more in depth this mean that the detrended price have crossed the highest/lowest of the forecast, when the indicator is equal to 0 or 1 for a long time this mean that the forecast was quite inaccurate, you can minimize risk by focusing on the cross between the detrended price and the 0.8/0.2 levels.
Conclusion
I've shown an oscillator version of my previous "Stationary extrapolated levels" indicator, the method involving taking the highest and lowest of the forecast is a great way to minimize the risk involved by time-series forecasting driven decisions. So i hope you find an use to it.
Thanks for reading !
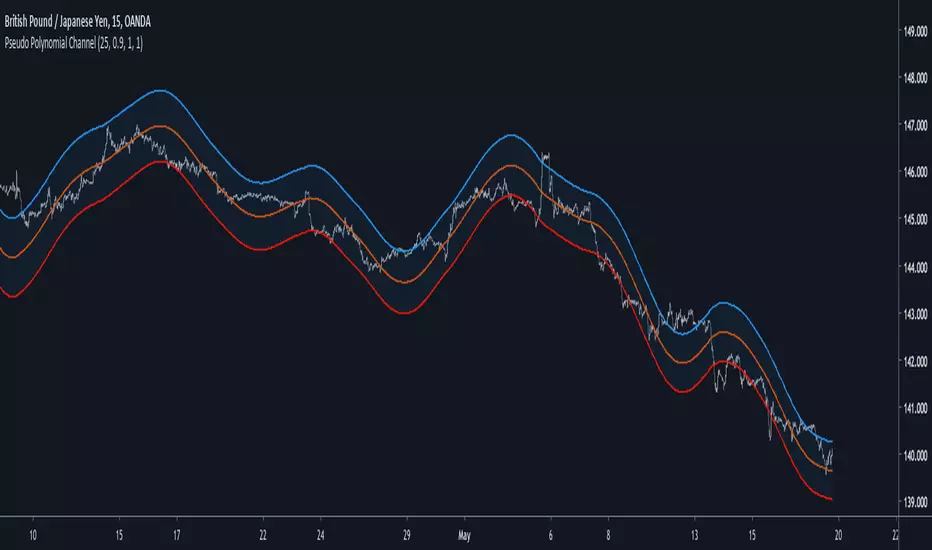
Pseudo Polynomial ChannelIntroduction
Back when i started using pine i made a script called periodic channel who aimed to rescale an average correlated sine wave to the price...don't worked very well. So i tried to fix problems induced by the indicator without much success, i had to redo it from scratch while abandoning the idea of rescaling correlated smooth functions to the price, at that time i also received requests regarding polynomial channel, some plateformes included this indicator, this led me to the idea to estimate it in order to both respond to the periodic channel problems and the requests i received, i have tried many many things and recently i tweaked a linear extrapolation to have an approximation.
Linear Extrapolation To Pseudo Polynomial Regression
I could be wrong but a polynomial regression must use constant parameters in order to provide a really smooth output, at least constant for a set of time. The moving averages forms (Savitzky-Golay moving average) who smooth polynomials across a window to the data don't have such smoothness, so how to estimate a polynomial regression while having a parameter providing control over the smoothness, a response to this is by using a recursive linear extrapolation. I posted a linear extrapolation indicator long ago, i used the same formula while adding a function to morph the output and the input in the form of :
morph * output + (1-morph) * input
How can this provide an estimate of a polynomial regression ? Well i'm not even sure myself but if you use the output as input (morph = 1) for the linear extrapolation function you should get a rough estimate of a line, this is what i thought at first and it proved to be right
Based on this observation i thought that it would be possible to get polynomial results by lowering morph, and as expected it worked well but showed a periodic pattern, this is why i smooth k in line 10.
0.9 for morph work well, higher values create sometimes smoother results but damage heavily the estimation.
Parameters
Morph have been introduced earlier, it control the amount of output and input the linear extrapolation should process, lower values create rougher but more stables results, if you see that the estimation is going nuts lower morph or change length, also lower length if you increase morph .
High overshoot, morph to 0.8 can help have a better estimation at the cost of less smoothness.
Length control the indicator smoothing, this parameter differ heavily from other filters, therefore low values can create mid/long term smoothing, it can also depend on which market instrument you are applying it, so there are no fixed optimal length.
Mult control how spread the bands are, to do so mult multiply the cumulative mean error, you can change this error measurement by anything you want like standard deviation/atr/range but take into account that you may create a separate parameter to control the error instead of length . Mult can be a float and like length can have different optimal values depending on the market the indicator is applied to.
Flatten do exactly what is name imply, it flatten the overall output to have a better estimation, can be a float. The result is less smooth.
Flatten = 2
More Exemples
BTCUSD length = 25 and mult = 4
XPDUSD length = 25 and mult = 1
ALPHABET length = 6 and morph = 0.99
Conclusion
I tried to estimate a polynomial channel by using recursion in the linear extrapolation function. This build is way more stable than the periodic channel but its still a bit inaccurate in my opinion. I hope this code can still help someone build something really nice, if so share your results :)
I apologize for those expecting a legit polynomial channel build but i really don't know how to do that, as i said parameters for the regression must be constants, i hope it still fine :)
Thanks for reading !
Spiky Iguana Multi RSI Bands (Reverse RSI for the Price) by RRBSpiky Iguana Multi RSI Bands by RagingRocketBull 2018
Version 1.0
This indicator shows multiple RSI Bands with prices corresponding to specified overbought/oversold RSI levels.
It is used to extrapolate the exact price levels currently matching a given set of RSI levels based on prior price/RSI levels action.
You can think of it as a reverse RSI where RSI levels are moving dynamically around the price instead of price bouncing between straight lines.
Features:
- 6+6 = 12 customizable Overbought(R)/Oversold(S) RSI Levels + 6 Mean(M) lines
- Multicolor levels/fill ranges
- Show/Hide specific S/R/M levels and fill ranges
1. uses plot*, fill and is based on RSIBANDS_LB
Good Luck! Feel free to explore and learn from the code

Stationary Extrapolated LevelsBeta Peek/Valey based forecast
The idea behind this indicator is to extrapolate a stationary time series and find the peeks of the extrapolated result. The highest and lowest of the extrapolated data represent really precise support and resistance if the data and its extrapolation are barelly equal with an error lower than the average.
When the detrended price ( in blue ) crossover the lower level then the indicator detect a valey and the possibility of an up movement, if the higher is crossed down then the indicator detect a peek and the possibility a down movement.
When "Show extrapolated values" is checked the indicator will show the forecast of the detrended price with a forecast of length periods ahead.
Feel free to contact me for any questions regarding my indicators :)

Linear ExtrapolationBasic extrapolator for forecast a time-series, all forecasts are mades length periods ahead.
This is not a estimation of the exact price
This should only be used for forecasting direction, dont expect the price to be at the same value of its forecast.
Bias, Mean absolute error, Mean percentage error...etc look useless here, its better to use correlation as a accuracy measurement.
Correlation(Forecast ,close,period)
Rescaling for a better forecast ?
Transforming a non-stationary signal to a stationary signal can increase the forecasting accuracy, this can be done by detrending. Here is a list of somes detrending methods:
Auto-Bias : price - price
Mean-Bias : price - price moving average
Log transform : log(price/price moving average)
Correlation : correlation(price,n,period)
