Half Causal EstimatorOverview
The Half Causal Estimator is a specialized filtering method that provides responsive averages of market variables (volume, true range, or price change) with significantly reduced time delay compared to traditional moving averages. It employs a hybrid approach that leverages both historical data and time-of-day patterns to create a timely representation of market activity while maintaining smooth output.
Core Concept
Traditional moving averages suffer from time lag, which can delay signals and reduce their effectiveness for real-time decision making. The Half Causal Estimator addresses this limitation by using a non-causal filtering method that incorporates recent historical data (the causal component) alongside expected future behavior based on time-of-day patterns (the non-causal component).
This dual approach allows the filter to respond more quickly to changing market conditions while maintaining smoothness. The name "Half Causal" refers to this hybrid methodology—half of the data window comes from actual historical observations, while the other half is derived from time-of-day patterns observed over multiple days. By incorporating these "future" values from past patterns, the estimator can reduce the inherent lag present in traditional moving averages.
How It Works
The indicator operates through several coordinated steps. First, it stores and organizes market data by specific times of day (minutes/hours). Then it builds a profile of typical behavior for each time period. For calculations, it creates a filtering window where half consists of recent actual data and half consists of expected future values based on historical time-of-day patterns. Finally, it applies a kernel-based smoothing function to weight the values in this composite window.
This approach is particularly effective because market variables like volume, true range, and price changes tend to follow recognizable intraday patterns (they are positive values without DC components). By leveraging these patterns, the indicator doesn't try to predict future values in the traditional sense, but rather incorporates the average historical behavior at those future times into the current estimate.
The benefit of using this "average future data" approach is that it counteracts the lag inherent in traditional moving averages. In a standard moving average, recent price action is underweighted because older data points hold equal influence. By incorporating time-of-day averages for future periods, the Half Causal Estimator essentially shifts the center of the filter window closer to the current bar, resulting in more timely outputs while maintaining smoothing benefits.
Understanding Kernel Smoothing
At the heart of the Half Causal Estimator is kernel smoothing, a statistical technique that creates weighted averages where points closer to the center receive higher weights. This approach offers several advantages over simple moving averages. Unlike simple moving averages that weight all points equally, kernel smoothing applies a mathematically defined weight distribution. The weighting function helps minimize the impact of outliers and random fluctuations. Additionally, by adjusting the kernel width parameter, users can fine-tune the balance between responsiveness and smoothness.
The indicator supports three kernel types. The Gaussian kernel uses a bell-shaped distribution that weights central points heavily while still considering distant points. The Epanechnikov kernel employs a parabolic function that provides efficient noise reduction with a finite support range. The Triangular kernel applies a linear weighting that decreases uniformly from center to edges. These kernel functions provide the mathematical foundation for how the filter processes the combined window of past and "future" data points.
Applicable Data Sources
The indicator can be applied to three different data sources: volume (the trading volume of the security), true range (expressed as a percentage, measuring volatility), and change (the absolute percentage change from one closing price to the next).
Each of these variables shares the characteristic of being consistently positive and exhibiting cyclical intraday patterns, making them ideal candidates for this filtering approach.
Practical Applications
The Half Causal Estimator excels in scenarios where timely information is crucial. It helps in identifying volume climaxes or diminishing volume trends earlier than conventional indicators. It can detect changes in volatility patterns with reduced lag. The indicator is also useful for recognizing shifts in price momentum before they become obvious in price action, and providing smoother data for algorithmic trading systems that require reduced noise without sacrificing timeliness.
When volatility or volume spikes occur, conventional moving averages typically lag behind, potentially causing missed opportunities or delayed responses. The Half Causal Estimator produces signals that align more closely with actual market turns.
Technical Implementation
The implementation of the Half Causal Estimator involves several technical components working together. Data collection and organization is the first step—the indicator maintains a data structure that organizes market data by specific times of day. This creates a historical record of how volume, true range, or price change typically behaves at each minute/hour of the trading day.
For each calculation, the indicator constructs a composite window consisting of recent actual data points from the current session (the causal half) and historical averages for upcoming time periods from previous sessions (the non-causal half). The selected kernel function is then applied to this composite window, creating a weighted average where points closer to the center receive higher weights according to the mathematical properties of the chosen kernel. Finally, the kernel weights are normalized to ensure the output maintains proper scaling regardless of the kernel type or width parameter.
This framework enables the indicator to leverage the predictable time-of-day components in market data without trying to predict specific future values. Instead, it uses average historical patterns to reduce lag while maintaining the statistical benefits of smoothing techniques.
Configuration Options
The indicator provides several customization options. The data period setting determines the number of days of observations to store (0 uses all available data). Filter length controls the number of historical data points for the filter (total window size is length × 2 - 1). Filter width adjusts the width of the kernel function. Users can also select between Gaussian, Epanechnikov, and Triangular kernel functions, and customize visual settings such as colors and line width.
These parameters allow for fine-tuning the balance between responsiveness and smoothness based on individual trading preferences and the specific characteristics of the traded instrument.
Limitations
The indicator requires minute-based intraday timeframes, securities with volume data (when using volume as the source), and sufficient historical data to establish time-of-day patterns.
Conclusion
The Half Causal Estimator represents an innovative approach to technical analysis that addresses one of the fundamental limitations of traditional indicators: time lag. By incorporating time-of-day patterns into its calculations, it provides a more timely representation of market variables while maintaining the noise-reduction benefits of smoothing. This makes it a valuable tool for traders who need to make decisions based on real-time information about volume, volatility, or price changes.
Kernelestimation

Kernels©2024, GoemonYae; copied from @jdehorty's "KernelFunctions" on 2024-03-09 to ensure future dependency compatibility. Will also add more functions to this script.
Library "KernelFunctions"
This library provides non-repainting kernel functions for Nadaraya-Watson estimator implementations. This allows for easy substition/comparison of different kernel functions for one another in indicators. Furthermore, kernels can easily be combined with other kernels to create newer, more customized kernels.
rationalQuadratic(_src, _lookback, _relativeWeight, startAtBar)
Rational Quadratic Kernel - An infinite sum of Gaussian Kernels of different length scales.
Parameters:
_src (float) : The source series.
_lookback (simple int) : The number of bars used for the estimation. This is a sliding value that represents the most recent historical bars.
_relativeWeight (simple float) : Relative weighting of time frames. Smaller values resut in a more stretched out curve and larger values will result in a more wiggly curve. As this value approaches zero, the longer time frames will exert more influence on the estimation. As this value approaches infinity, the behavior of the Rational Quadratic Kernel will become identical to the Gaussian kernel.
startAtBar (simple int)
Returns: yhat The estimated values according to the Rational Quadratic Kernel.
gaussian(_src, _lookback, startAtBar)
Gaussian Kernel - A weighted average of the source series. The weights are determined by the Radial Basis Function (RBF).
Parameters:
_src (float) : The source series.
_lookback (simple int) : The number of bars used for the estimation. This is a sliding value that represents the most recent historical bars.
startAtBar (simple int)
Returns: yhat The estimated values according to the Gaussian Kernel.
periodic(_src, _lookback, _period, startAtBar)
Periodic Kernel - The periodic kernel (derived by David Mackay) allows one to model functions which repeat themselves exactly.
Parameters:
_src (float) : The source series.
_lookback (simple int) : The number of bars used for the estimation. This is a sliding value that represents the most recent historical bars.
_period (simple int) : The distance between repititions of the function.
startAtBar (simple int)
Returns: yhat The estimated values according to the Periodic Kernel.
locallyPeriodic(_src, _lookback, _period, startAtBar)
Locally Periodic Kernel - The locally periodic kernel is a periodic function that slowly varies with time. It is the product of the Periodic Kernel and the Gaussian Kernel.
Parameters:
_src (float) : The source series.
_lookback (simple int) : The number of bars used for the estimation. This is a sliding value that represents the most recent historical bars.
_period (simple int) : The distance between repititions of the function.
startAtBar (simple int)
Returns: yhat The estimated values according to the Locally Periodic Kernel.

Bandwidth Volatility - Silverman Rule of thumb EstimatorOverview
This indicator calculates volatility using the Rule of Thumb bandwidth estimator and incorporating the standard deviations of returns to get historical volatility. There are two options: one for the original rule of thumb bandwidth estimator, and another for the modified rule of thumb estimator. This indicator comes with the bandwidth , which is shown with the color gradient columns, which are colored by a percentile of the bandwidth, and the moving average of the bandwidth, which is the dark shaded area.
The rule of thumb bandwidth estimator is a simple and quick method for estimating the bandwidth parameter in kernel density estimation (KSE) or kernel regression. It provides a rough approximation of the bandwidth without requiring extensive computation resources or fine-tuning. One common rule of thumb estimator is Silverman rule, which is given by
h = 1.06*σ*n^(-1/5)
where
h is the bandwidth
σ is the standard deviation of the data
n is the number of data points
This rule of thumb is based on assuming a Gaussian kernel and aims to strike a balance between over-smoothing and under-smoothing the data. It is simple to implement and usually provides reasonable bandwidth estimates for a wide range of datasets. However , it is important to note that this rule of thumb may not always have optimal results, especially for non-Gaussian or multimodal distributions. In such cases, a modified bandwidth selection, such as cross-validation or even applying a log transformation (if the data is right-skewed), may be preferable.
How it works:
This indicator computes the bandwidth volatility using returns, which are used in the standard deviation calculation. It then estimates the bandwidth based on either the Silverman rule of thumb or a modified version considering the interquartile range. The percentile ranks of the bandwidth estimate are then used to visualize the volatility levels, identify high and low volatility periods, and show them with colors.
Modified Rule of thumb Bandwidth:
The modified rule of thumb bandwidth formula combines elements of standard deviations and interquartile ranges, scaled by a multiplier of 0.9 and inversely with a number of periods. This modification aims to provide a more robust and adaptable bandwidth estimation method, particularly suitable for financial time series data with potentially skewed or heavy-tailed data.
Formula for Modified Rule of Thumb Bandwidth:
h = 0.9 * min(σ, (IQR/1.34))*n^(-1/5)
This modification introduces the use of the IQR divided by 1.34 as an alternative to the standard deviation. It aims to improve the estimation, mainly when the underlying distribution deviates from a perfect Gaussian distribution.
Analysis
Rule of thumb Bandwidth: Provides a broader perspective on volatility trends, smoothing out short-term fluctuations and focusing more on the overall shape of the density function.
Historical Volatility: Offers a more granular view of volatility, capturing day-to-day or intra-period fluctuations in asset prices and returns.
Modelling Requirements
Rule of thumb Bandwidth: Provides a broader perspective on volatility trends, smoothing out short-term fluctuations and focusing more on the overall shape of the density function.
Historical Volatility: Offers a more granular view of volatility, capturing day-to-day or intra-period fluctuations in asset prices and returns.
Pros of Bandwidth as a volatility measure
Robust to Data Distribution: Bandwidth volatility, especially when estimated using robust methods like Silverman's rule of thumb or its modifications, can be less sensitive to outliers and non-normal distributions compared to some other measures of volatility
Flexibility: It can be applied to a wide range of data types and can adapt to different underlying data distributions, making it versatile for various analytical tasks.
How can traders use this indicator?
In finance, volatility is thought to be a mean-reverting process. So when volatility is at an extreme low, it is expected that a volatility expansion happens, which comes with bigger movements in price, and when volatility is at an extreme high, it is expected for volatility to eventually decrease, leading to smaller price moves, and many traders view this as an area to take profit in.
In the context of this indicator, low volatility is thought of as having the green color, which indicates a low percentile value, and also being below the moving average. High volatility is thought of as having the yellow color and possibly being above the moving average, showing that you can eventually expect volatility to decrease.

Bandwidth Bands - Silverman's rule of thumbWhat are Bandwidth Bands?
This indicator uses Silverman Rule of Thumb Bandwidth to estimate the width of bands around the rolling moving average which takes in the log transformation of price to remove most of price skewness for the rest of the volatility calculations and then a exp() function is performed to convert it back to a right skewed distribution. These bandwidths bands could offer insights into price volatility and trading extremes.
Silverman rule of thumb bandwidth:
The Silverman Rule of Thumb Bandwidth is a heuristic method used to estimate the optimal bandwidth for kernel density estimation, a statistical technique for estimating the probability density function of a random variable. In the context of financial analysis, such as in this indicator, it helps determine the width of bands around a moving average, providing insights into the level of volatility in the market. This method is particularly useful because it offers a quick and straightforward way to estimate bandwidth without requiring extensive computational resources or complex mathematical calculation
The bandwidth estimator automatically adjust to the characteristics of the data, providing a flexible and dynamic measure of dispersion that can capture variations in volatility over time. Standard deviations alone may not be as adaptive to changes in data distributions. The Bandwidth considers the overall shape and structure of the data distribution rather than just focusing on the spread of data points.
Settings
Source
Sample length
1-4 SD options to disable or enable each band
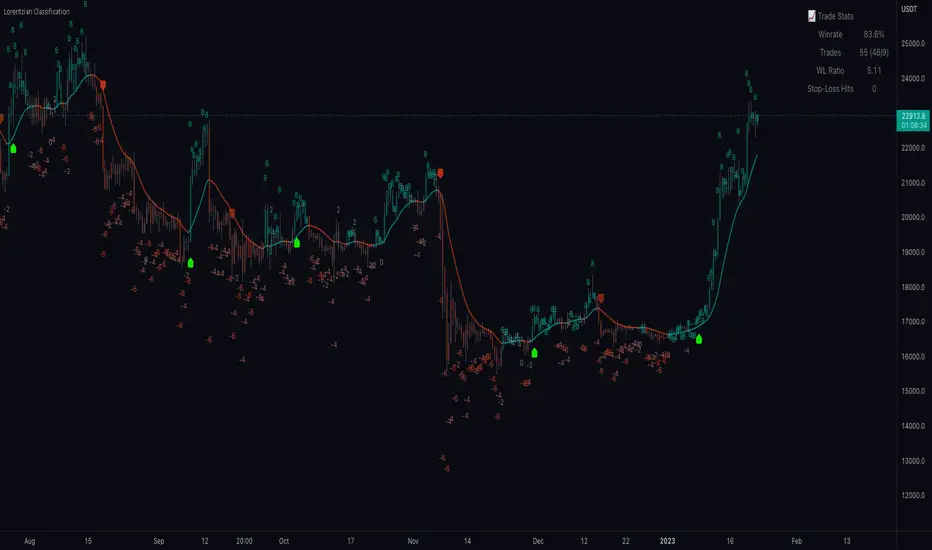
Machine Learning: Lorentzian Classification█ OVERVIEW
A Lorentzian Distance Classifier (LDC) is a Machine Learning classification algorithm capable of categorizing historical data from a multi-dimensional feature space. This indicator demonstrates how Lorentzian Classification can also be used to predict the direction of future price movements when used as the distance metric for a novel implementation of an Approximate Nearest Neighbors (ANN) algorithm.
█ BACKGROUND
In physics, Lorentzian space is perhaps best known for its role in describing the curvature of space-time in Einstein's theory of General Relativity (2). Interestingly, however, this abstract concept from theoretical physics also has tangible real-world applications in trading.
Recently, it was hypothesized that Lorentzian space was also well-suited for analyzing time-series data (4), (5). This hypothesis has been supported by several empirical studies that demonstrate that Lorentzian distance is more robust to outliers and noise than the more commonly used Euclidean distance (1), (3), (6). Furthermore, Lorentzian distance was also shown to outperform dozens of other highly regarded distance metrics, including Manhattan distance, Bhattacharyya similarity, and Cosine similarity (1), (3). Outside of Dynamic Time Warping based approaches, which are unfortunately too computationally intensive for PineScript at this time, the Lorentzian Distance metric consistently scores the highest mean accuracy over a wide variety of time series data sets (1).
Euclidean distance is commonly used as the default distance metric for NN-based search algorithms, but it may not always be the best choice when dealing with financial market data. This is because financial market data can be significantly impacted by proximity to major world events such as FOMC Meetings and Black Swan events. This event-based distortion of market data can be framed as similar to the gravitational warping caused by a massive object on the space-time continuum. For financial markets, the analogous continuum that experiences warping can be referred to as "price-time".
Below is a side-by-side comparison of how neighborhoods of similar historical points appear in three-dimensional Euclidean Space and Lorentzian Space:
This figure demonstrates how Lorentzian space can better accommodate the warping of price-time since the Lorentzian distance function compresses the Euclidean neighborhood in such a way that the new neighborhood distribution in Lorentzian space tends to cluster around each of the major feature axes in addition to the origin itself. This means that, even though some nearest neighbors will be the same regardless of the distance metric used, Lorentzian space will also allow for the consideration of historical points that would otherwise never be considered with a Euclidean distance metric.
Intuitively, the advantage inherent in the Lorentzian distance metric makes sense. For example, it is logical that the price action that occurs in the hours after Chairman Powell finishes delivering a speech would resemble at least some of the previous times when he finished delivering a speech. This may be true regardless of other factors, such as whether or not the market was overbought or oversold at the time or if the macro conditions were more bullish or bearish overall. These historical reference points are extremely valuable for predictive models, yet the Euclidean distance metric would miss these neighbors entirely, often in favor of irrelevant data points from the day before the event. By using Lorentzian distance as a metric, the ML model is instead able to consider the warping of price-time caused by the event and, ultimately, transcend the temporal bias imposed on it by the time series.
For more information on the implementation details of the Approximate Nearest Neighbors (ANN) algorithm used in this indicator, please refer to the detailed comments in the source code.
█ HOW TO USE
Below is an explanatory breakdown of the different parts of this indicator as it appears in the interface:
Below is an explanation of the different settings for this indicator:
General Settings:
Source - This has a default value of "hlc3" and is used to control the input data source.
Neighbors Count - This has a default value of 8, a minimum value of 1, a maximum value of 100, and a step of 1. It is used to control the number of neighbors to consider.
Max Bars Back - This has a default value of 2000.
Feature Count - This has a default value of 5, a minimum value of 2, and a maximum value of 5. It controls the number of features to use for ML predictions.
Color Compression - This has a default value of 1, a minimum value of 1, and a maximum value of 10. It is used to control the compression factor for adjusting the intensity of the color scale.
Show Exits - This has a default value of false. It controls whether to show the exit threshold on the chart.
Use Dynamic Exits - This has a default value of false. It is used to control whether to attempt to let profits ride by dynamically adjusting the exit threshold based on kernel regression.
Feature Engineering Settings:
Note: The Feature Engineering section is for fine-tuning the features used for ML predictions. The default values are optimized for the 4H to 12H timeframes for most charts, but they should also work reasonably well for other timeframes. By default, the model can support features that accept two parameters (Parameter A and Parameter B, respectively). Even though there are only 4 features provided by default, the same feature with different settings counts as two separate features. If the feature only accepts one parameter, then the second parameter will default to EMA-based smoothing with a default value of 1. These features represent the most effective combination I have encountered in my testing, but additional features may be added as additional options in the future.
Feature 1 - This has a default value of "RSI" and options are: "RSI", "WT", "CCI", "ADX".
Feature 2 - This has a default value of "WT" and options are: "RSI", "WT", "CCI", "ADX".
Feature 3 - This has a default value of "CCI" and options are: "RSI", "WT", "CCI", "ADX".
Feature 4 - This has a default value of "ADX" and options are: "RSI", "WT", "CCI", "ADX".
Feature 5 - This has a default value of "RSI" and options are: "RSI", "WT", "CCI", "ADX".
Filters Settings:
Use Volatility Filter - This has a default value of true. It is used to control whether to use the volatility filter.
Use Regime Filter - This has a default value of true. It is used to control whether to use the trend detection filter.
Use ADX Filter - This has a default value of false. It is used to control whether to use the ADX filter.
Regime Threshold - This has a default value of -0.1, a minimum value of -10, a maximum value of 10, and a step of 0.1. It is used to control the Regime Detection filter for detecting Trending/Ranging markets.
ADX Threshold - This has a default value of 20, a minimum value of 0, a maximum value of 100, and a step of 1. It is used to control the threshold for detecting Trending/Ranging markets.
Kernel Regression Settings:
Trade with Kernel - This has a default value of true. It is used to control whether to trade with the kernel.
Show Kernel Estimate - This has a default value of true. It is used to control whether to show the kernel estimate.
Lookback Window - This has a default value of 8 and a minimum value of 3. It is used to control the number of bars used for the estimation. Recommended range: 3-50
Relative Weighting - This has a default value of 8 and a step size of 0.25. It is used to control the relative weighting of time frames. Recommended range: 0.25-25
Start Regression at Bar - This has a default value of 25. It is used to control the bar index on which to start regression. Recommended range: 0-25
Display Settings:
Show Bar Colors - This has a default value of true. It is used to control whether to show the bar colors.
Show Bar Prediction Values - This has a default value of true. It controls whether to show the ML model's evaluation of each bar as an integer.
Use ATR Offset - This has a default value of false. It controls whether to use the ATR offset instead of the bar prediction offset.
Bar Prediction Offset - This has a default value of 0 and a minimum value of 0. It is used to control the offset of the bar predictions as a percentage from the bar high or close.
Backtesting Settings:
Show Backtest Results - This has a default value of true. It is used to control whether to display the win rate of the given configuration.
█ WORKS CITED
(1) R. Giusti and G. E. A. P. A. Batista, "An Empirical Comparison of Dissimilarity Measures for Time Series Classification," 2013 Brazilian Conference on Intelligent Systems, Oct. 2013, DOI: 10.1109/bracis.2013.22.
(2) Y. Kerimbekov, H. Ş. Bilge, and H. H. Uğurlu, "The use of Lorentzian distance metric in classification problems," Pattern Recognition Letters, vol. 84, 170–176, Dec. 2016, DOI: 10.1016/j.patrec.2016.09.006.
(3) A. Bagnall, A. Bostrom, J. Large, and J. Lines, "The Great Time Series Classification Bake Off: An Experimental Evaluation of Recently Proposed Algorithms." ResearchGate, Feb. 04, 2016.
(4) H. Ş. Bilge, Yerzhan Kerimbekov, and Hasan Hüseyin Uğurlu, "A new classification method by using Lorentzian distance metric," ResearchGate, Sep. 02, 2015.
(5) Y. Kerimbekov and H. Şakir Bilge, "Lorentzian Distance Classifier for Multiple Features," Proceedings of the 6th International Conference on Pattern Recognition Applications and Methods, 2017, DOI: 10.5220/0006197004930501.
(6) V. Surya Prasath et al., "Effects of Distance Measure Choice on KNN Classifier Performance - A Review." .
█ ACKNOWLEDGEMENTS
@veryfid - For many invaluable insights, discussions, and advice that helped to shape this project.
@capissimo - For open sourcing his interesting ideas regarding various KNN implementations in PineScript, several of which helped inspire my original undertaking of this project.
@RikkiTavi - For many invaluable physics-related conversations and for his helping me develop a mechanism for visualizing various distance algorithms in 3D using JavaScript
@jlaurel - For invaluable literature recommendations that helped me to understand the underlying subject matter of this project.
@annutara - For help in beta-testing this indicator and for sharing many helpful ideas and insights early on in its development.
@jasontaylor7 - For helping to beta-test this indicator and for many helpful conversations that helped to shape my backtesting workflow
@meddymarkusvanhala - For helping to beta-test this indicator
@dlbnext - For incredibly detailed backtesting testing of this indicator and for sharing numerous ideas on how the user experience could be improved.
WaveTrend 3D█ OVERVIEW
WaveTrend 3D (WT3D) is a novel implementation of the famous WaveTrend (WT) indicator and has been completely redesigned from the ground up to address some of the inherent shortcomings associated with the traditional WT algorithm.
█ BACKGROUND
The WaveTrend (WT) indicator has become a widely popular tool for traders in recent years. WT was first ported to PineScript in 2014 by the user @LazyBear, and since then, it has ascended to become one of the Top 5 most popular scripts on TradingView.
The WT algorithm appears to have origins in a lesser-known proprietary algorithm called Trading Channel Index (TCI), created by AIQ Systems in 1986 as an integral part of their commercial software suite, TradingExpert Pro. The software’s reference manual states that “TCI identifies changes in price direction” and is “an adaptation of Donald R. Lambert’s Commodity Channel Index (CCI)”, which was introduced to the world six years earlier in 1980. Interestingly, a vestige of this early beginning can still be seen in the source code of LazyBear’s script, where the final EMA calculation is stored in an intermediate variable called “tci” in the code.
█ IMPLEMENTATION DETAILS
WaveTrend 3D is an alternative implementation of WaveTrend that directly addresses some of the known shortcomings of the indicator, including its unbounded extremes, susceptibility to whipsaw, and lack of insight into other timeframes.
In the canonical WT approach, an exponential moving average (EMA) for a given lookback window is used to assess the variability between price and two other EMAs relative to a second lookback window. Since the difference between the average price and its associated EMA is essentially unbounded, an arbitrary scaling factor of 0.015 is typically applied as a crude form of rescaling but still fails to capture 20-30% of values between the range of -100 to 100. Additionally, the trigger signal for the final EMA (i.e., TCI) crossover-based oscillator is a four-bar simple moving average (SMA), which further contributes to the net lag accumulated by the consecutive EMA calculations in the previous steps.
The core idea behind WT3D is to replace the EMA-based crossover system with modern Digital Signal Processing techniques. By assuming that price action adheres approximately to a Gaussian distribution, it is possible to sidestep the scaling nightmare associated with unbounded price differentials of the original WaveTrend method by focusing instead on the alteration of the underlying Probability Distribution Function (PDF) of the input series. Furthermore, using a signal processing filter such as a Butterworth Filter, we can eliminate the need for consecutive exponential moving averages along with the associated lag they bring.
Ideally, it is convenient to have the resulting probability distribution oscillate between the values of -1 and 1, with the zero line serving as a median. With this objective in mind, it is possible to borrow a common technique from the field of Machine Learning that uses a sigmoid-like activation function to transform our data set of interest. One such function is the hyperbolic tangent function (tanh), which is often used as an activation function in the hidden layers of neural networks due to its unique property of ensuring the values stay between -1 and 1. By taking the first-order derivative of our input series and normalizing it using the quadratic mean, the tanh function performs a high-quality redistribution of the input signal into the desired range of -1 to 1. Finally, using a dual-pole filter such as the Butterworth Filter popularized by John Ehlers, excessive market noise can be filtered out, leaving behind a crisp moving average with minimal lag.
Furthermore, WT3D expands upon the original functionality of WT by providing:
First-class support for multi-timeframe (MTF) analysis
Kernel-based regression for trend reversal confirmation
Various options for signal smoothing and transformation
A unique mode for visualizing an input series as a symmetrical, three-dimensional waveform useful for pattern identification and cycle-related analysis
█ SETTINGS
This is a summary of the settings used in the script listed in roughly the order in which they appear. By default, all default colors are from Google's TensorFlow framework and are considered to be colorblind safe.
Source: The input series. Usually, it is the close or average price, but it can be any series.
Use Mirror: Whether to display a mirror image of the source series; for visualizing the series as a 3D waveform similar to a soundwave.
Use EMA: Whether to use an exponential moving average of the input series.
EMA Length: The length of the exponential moving average.
Use COG: Whether to use the center of gravity of the input series.
COG Length: The length of the center of gravity.
Speed to Emphasize: The target speed to emphasize.
Width: The width of the emphasized line.
Display Kernel Moving Average: Whether to display the kernel moving average of the signal. Like PCA, an unsupervised Machine Learning technique whereby neighboring vectors are projected onto the Principal Component.
Display Kernel Signal: Whether to display the kernel estimator for the emphasized line. Like the Kernel MA, it can show underlying shifts in bias within a more significant trend by the colors reflected on the ribbon itself.
Show Oscillator Lines: Whether to show the oscillator lines.
Offset: The offset of the emphasized oscillator plots.
Fast Length: The length scale factor for the fast oscillator.
Fast Smoothing: The smoothing scale factor for the fast oscillator.
Normal Length: The length scale factor for the normal oscillator.
Normal Smoothing: The smoothing scale factor for the normal frequency.
Slow Length: The length scale factor for the slow oscillator.
Slow Smoothing: The smoothing scale factor for the slow frequency.
Divergence Threshold: The number of bars for the divergence to be considered significant.
Trigger Wave Percent Size: How big the current wave should be relative to the previous wave.
Background Area Transparency Factor: Transparency factor for the background area.
Foreground Area Transparency Factor: Transparency factor for the foreground area.
Background Line Transparency Factor: Transparency factor for the background line.
Foreground Line Transparency Factor: Transparency factor for the foreground line.
Custom Transparency: Transparency of the custom colors.
Total Gradient Steps: The maximum amount of steps supported for a gradient calculation is 256.
Fast Bullish Color: The color of the fast bullish line.
Normal Bullish Color: The color of the normal bullish line.
Slow Bullish Color: The color of the slow bullish line.
Fast Bearish Color: The color of the fast bearish line.
Normal Bearish Color: The color of the normal bearish line.
Slow Bearish Color: The color of the slow bearish line.
Bullish Divergence Signals: The color of the bullish divergence signals.
Bearish Divergence Signals: The color of the bearish divergence signals.
█ ACKNOWLEDGEMENTS
@LazyBear - For authoring the original WaveTrend port on TradingView
@PineCoders - For the beautiful color gradient framework used in this indicator
@veryfid - For the inspiration of using mirrored signals for cycle analysis and using multiple lookback windows as proxies for other timeframes

KernelFunctionsLibrary "KernelFunctions"
This library provides non-repainting kernel functions for Nadaraya-Watson estimator implementations. This allows for easy substitution/comparison of different kernel functions for one another in indicators. Furthermore, kernels can easily be combined with other kernels to create newer, more customized kernels. Compared to Moving Averages (which are really just simple kernels themselves), these kernel functions are more adaptive and afford the user an unprecedented degree of customization and flexibility.
rationalQuadratic(_src, _lookback, _relativeWeight, _startAtBar)
Rational Quadratic Kernel - An infinite sum of Gaussian Kernels of different length scales.
Parameters:
_src : The source series.
_lookback : The number of bars used for the estimation. This is a sliding value that represents the most recent historical bars.
_relativeWeight : Relative weighting of time frames. Smaller values result in a more stretched-out curve, and larger values will result in a more wiggly curve. As this value approaches zero, the longer time frames will exert more influence on the estimation. As this value approaches infinity, the behavior of the Rational Quadratic Kernel will become identical to the Gaussian kernel.
_startAtBar : Bar index on which to start regression. The first bars of a chart are often highly volatile, and omitting these initial bars often leads to a better overall fit.
Returns: yhat The estimated values according to the Rational Quadratic Kernel.
gaussian(_src, _lookback, _startAtBar)
Gaussian Kernel - A weighted average of the source series. The weights are determined by the Radial Basis Function (RBF).
Parameters:
_src : The source series.
_lookback : The number of bars used for the estimation. This is a sliding value that represents the most recent historical bars.
_startAtBar : Bar index on which to start regression. The first bars of a chart are often highly volatile, and omitting these initial bars often leads to a better overall fit.
Returns: yhat The estimated values according to the Gaussian Kernel.
periodic(_src, _lookback, _period, _startAtBar)
Periodic Kernel - The periodic kernel (derived by David Mackay) allows one to model functions that repeat themselves exactly.
Parameters:
_src : The source series.
_lookback : The number of bars used for the estimation. This is a sliding value that represents the most recent historical bars.
_period : The distance between repititions of the function.
_startAtBar : Bar index on which to start regression. The first bars of a chart are often highly volatile, and omitting these initial bars often leads to a better overall fit.
Returns: yhat The estimated values according to the Periodic Kernel.
locallyPeriodic(_src, _lookback, _period, _startAtBar)
Locally Periodic Kernel - The locally periodic kernel is a periodic function that slowly varies with time. It is the product of the Periodic Kernel and the Gaussian Kernel.
Parameters:
_src : The source series.
_lookback : The number of bars used for the estimation. This is a sliding value that represents the most recent historical bars.
_period : The distance between repititions of the function.
_startAtBar : Bar index on which to start regression. The first bars of a chart are often highly volatile, and omitting these initial bars often leads to a better overall fit.
Returns: yhat The estimated values according to the Locally Periodic Kernel.
Nadaraya-Watson: Rational Quadratic Kernel (Non-Repainting)What is Nadaraya–Watson Regression?
Nadaraya–Watson Regression is a type of Kernel Regression, which is a non-parametric method for estimating the curve of best fit for a dataset. Unlike Linear Regression or Polynomial Regression, Kernel Regression does not assume any underlying distribution of the data. For estimation, it uses a kernel function, which is a weighting function that assigns a weight to each data point based on how close it is to the current point. The computed weights are then used to calculate the weighted average of the data points.
How is this different from using a Moving Average?
A Simple Moving Average is actually a special type of Kernel Regression that uses a Uniform (Retangular) Kernel function. This means that all data points in the specified lookback window are weighted equally. In contrast, the Rational Quadratic Kernel function used in this indicator assigns a higher weight to data points that are closer to the current point. This means that the indicator will react more quickly to changes in the data.
Why use the Rational Quadratic Kernel over the Gaussian Kernel?
The Gaussian Kernel is one of the most commonly used Kernel functions and is used extensively in many Machine Learning algorithms due to its general applicability across a wide variety of datasets. The Rational Quadratic Kernel can be thought of as a Gaussian Kernel on steroids; it is equivalent to adding together many Gaussian Kernels of differing length scales. This allows the user even more freedom to tune the indicator to their specific needs.
The formula for the Rational Quadratic function is:
K(x, x') = (1 + ||x - x'||^2 / (2 * alpha * h^2))^(-alpha)
where x and x' data are points, alpha is a hyperparameter that controls the smoothness (i.e. overall "wiggle") of the curve, and h is the band length of the kernel.
Does this Indicator Repaint?
No, this indicator has been intentionally designed to NOT repaint. This means that once a bar has closed, the indicator will never change the values in its plot. This is useful for backtesting and for trading strategies that require a non-repainting indicator.
Settings:
Bandwidth. This is the number of bars that the indicator will use as a lookback window.
Relative Weighting Parameter. The alpha parameter for the Rational Quadratic Kernel function. This is a hyperparameter that controls the smoothness of the curve. A lower value of alpha will result in a smoother, more stretched-out curve, while a lower value will result in a more wiggly curve with a tighter fit to the data. As this parameter approaches 0, the longer time frames will exert more influence on the estimation, and as it approaches infinity, the curve will become identical to the one produced by the Gaussian Kernel.
Color Smoothing. Toggles the mechanism for coloring the estimation plot between rate of change and cross over modes.

STD-Filtered, Gaussian-Kernel-Weighted Moving Average [Loxx]STD-Filtered, Gaussian-Kernel-Weighted Moving Average is a moving average that weights price by using a Gaussian kernel function to calculate data points. This indicator also allows for filtering both source input price and output signal using a standard deviation filter.
Purpose
This purpose of this indicator is to take the concept of Kernel estimation and apply it in a way where instead of predicting past values, the weighted function predicts the current bar value at each bar to create a moving average that is suitable for trading. Normally this method is used to create an array of past estimators to model past data but this method is not useful for trading as the past values will repaint. This moving average does NOT repaint, however you much allow signals to close on the current bar before taking the signal. You can compare this to Nadaraya-Watson Estimator wherein they use Nadaraya-Watson estimator method with normalized kernel weighted function to model price.
What are Kernel Functions?
A kernel function is used as a weighing function to develop non-parametric regression model is discussed. In the beginning of the article, a brief discussion about properties of kernel functions and steps to build kernels around data points are presented.
Kernel Function
In non-parametric statistics, a kernel is a weighting function which satisfies the following properties.
A kernel function must be symmetrical. Mathematically this property can be expressed as K (-u) = K (+u). The symmetric property of kernel function enables its maximum value (max(K(u)) to lie in the middle of the curve.
The area under the curve of the function must be equal to one. Mathematically, this property is expressed as: integral −∞ + ∞ ∫ K(u)d(u) = 1
Value of kernel function can not be negative i.e. K(u) ≥ 0 for all −∞ < u < ∞.
Kernel Estimation
In this article, Gaussian kernel function is used to calculate kernels for the data points. The equation for Gaussian kernel is:
K(u) = (1 / sqrt(2pi)) * e^(-0.5 *(j / bw)^2)
Where xi is the observed data point. j is the value where kernel function is computed and bw is called the bandwidth. Bandwidth in kernel regression is called the smoothing parameter because it controls variance and bias in the output. The effect of bandwidth value on model prediction is discussed later in this article.
Included
Loxx's Expanded Source types
Signals
Alerts
Bar coloring