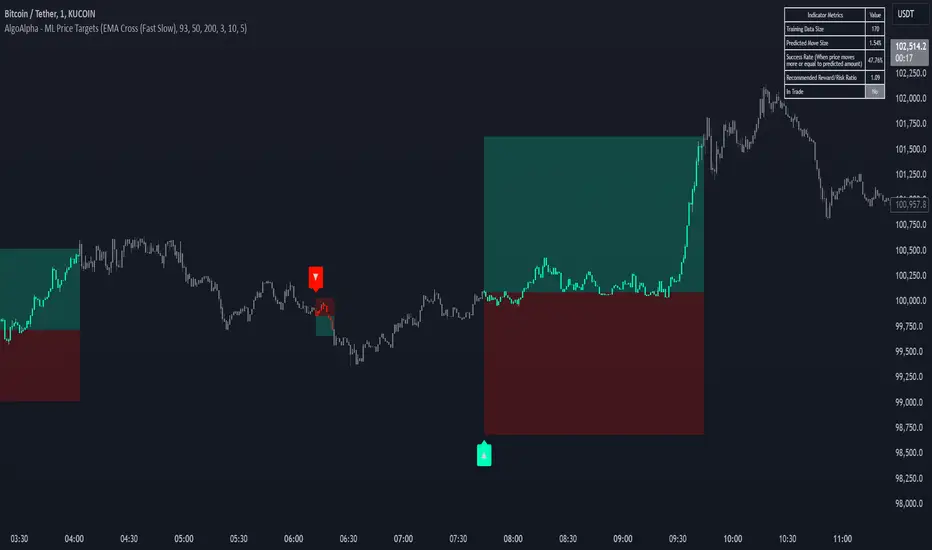
Machine Learning Key Levels [AlgoAlpha]🟠 OVERVIEW
This script plots Machine Learning Key Levels on your chart by detecting historical pivot points and grouping them using agglomerative clustering to highlight price levels with the most past reactions. It combines a pivot detection, hierarchical clustering logic, and an optional silhouette method to automatically select the optimal number of key levels, giving you an adaptive way to visualize price zones where activity concentrated over time.
🟠 CONCEPTS
Agglomerative clustering is a bottom-up method that starts by treating each pivot as its own cluster, then repeatedly merges the two closest clusters based on the average distance between their members until only the desired number of clusters remain. This process creates a hierarchy of groupings that can flexibly describe patterns in how price reacts around certain levels. This offers an advantage over K-means clustering, since the number of clusters does not need to be predefined. In this script, it uses an average linkage approach, where distance between clusters is computed as the average pairwise distance of all contained points.
The script finds pivot highs and lows over a set lookback period and saves them in a buffer controlled by the Pivot Memory setting. When there are at least two pivots, it groups them using agglomerative clustering: it starts with each pivot as its own group and keeps merging the closest pairs based on their average distance until the desired number of clusters is left. This number can be fixed or chosen automatically with the silhouette method, which checks how well each point fits in its cluster compared to others (higher scores mean cleaner separation). Once clustering finishes, the script takes the average price of each cluster to create key levels, sorts them, and draws horizontal lines with labels and colors showing their strength. A metrics table can also display details about the clusters to help you understand how the levels were calculated.
🟠 FEATURES
Agglomerative clustering engine with average linkage to merge pivots into level groups.
Dynamic lines showing each cluster’s price level for clarity.
Labels indicating level strength either as percent of all pivots or raw counts.
A metrics table displaying pivot count, cluster count, silhouette score, and cluster size data.
Optional silhouette-based auto-selection of cluster count to adaptively find the best fit.
🟠 USAGE
Add the indicator to any chart. Choose how far back to detect pivots using Pivot Length and set Pivot Memory to control how many are kept for clustering (more pivots give smoother levels but can slow performance). If you want the script to pick the number of levels automatically, enable Auto No. Levels ; otherwise, set Number of Levels . The colored horizontal lines represent the calculated key levels, and circles show where pivots occurred colored by which cluster they belong to. The labels beside each level indicate its strength, so you can see which levels are supported by more pivots. If Show Metrics Table is enabled, you will see statistics about the clustering in the corner you selected. Use this tool to spot areas where price often reacts and to plan entries or exits around levels that have been significant over time. Adjust settings to better match volatility and history depth of your instrument.
Machinelearning

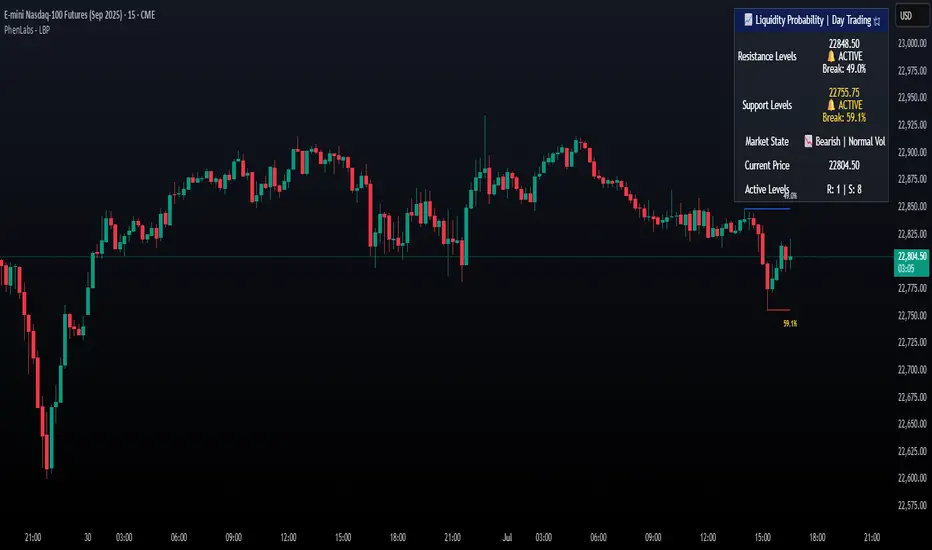
Liquidity Break Probability [PhenLabs]📊 Liquidity Break Probability
Version: PineScript™ v6
The Liquidity Break Probability indicator revolutionizes how traders approach liquidity levels by providing real-time probability calculations for level breaks. This advanced indicator combines sophisticated market analysis with machine learning inspired probability models to predict the likelihood of high/low breaks before they happen.
Unlike traditional liquidity indicators that simply draw lines, LBP analyzes market structure, volume profiles, momentum, volatility, and sentiment to generate dynamic break probabilities ranging from 5% to 95%. This gives traders unprecedented insight into which levels are most likely to hold or break, enabling more confident trading decisions.
🚀 Points of Innovation
Advanced 6-factor probability model weighing market structure, volatility, volume, momentum, patterns, and sentiment
Real-time probability updates that adjust as market conditions change
Intelligent trading style presets (Scalping, Day Trading, Swing Trading) with optimized parameters
Dynamic color-coded probability labels showing break likelihood percentages
Professional tiered input system - from quick setup to expert-level customization
Smart volume filtering that only highlights levels with significant institutional interest
🔧 Core Components
Market Structure Analysis: Evaluates trend alignment, level strength, and momentum buildup using EMA crossovers and price action
Volatility Engine: Incorporates ATR expansion, Bollinger Band positioning, and price distance calculations
Volume Profile System: Analyzes current volume strength, smart money proxies, and level creation volume ratios
Momentum Calculator: Combines RSI positioning, MACD strength, and momentum divergence detection
Pattern Recognition: Identifies reversal patterns (doji, hammer, engulfing) near key levels
Sentiment Analysis: Processes fear/greed indicators and market breadth measurements
🔥 Key Features
Dynamic Probability Labels: Real-time percentage displays showing break probability with color coding (red >70%, orange >50%, white <50%)
Trading Style Optimization: One-click presets automatically configure sensitivity and parameters for your trading timeframe
Professional Dashboard: Live market state monitoring with nearest level tracking and active level counts
Smart Alert System: Customizable proximity alerts and high-probability break notifications
Advanced Level Management: Intelligent line cleanup and historical analysis options
Volume-Validated Levels: Only displays levels backed by significant volume for institutional-grade analysis
🎨 Visualization
Recent Low Lines: Red lines marking validated support levels with probability percentages
Recent High Lines: Blue lines showing resistance zones with break likelihood indicators
Probability Labels: Color-coded percentage labels that update in real-time
Professional Dashboard: Customizable panel showing market state, active levels, and current price
Clean Display Modes: Toggle between active-only view for clean charts or historical view for analysis
📖 Usage Guidelines
Quick Setup
Trading Style Preset
Default: Day Trading
Options: Scalping, Day Trading, Swing Trading, Custom
Description: Automatically optimizes all parameters for your preferred trading timeframe and style
Show Break Probability %
Default: True
Description: Displays percentage labels next to each level showing break probability
Line Display
Default: Active Only
Options: Active Only, All Levels
Description: Choose between clean active-only view or comprehensive historical analysis
Level Detection Settings
Level Sensitivity
Default: 5
Range: 1-20
Description: Lower values show more levels (sensitive), higher values show fewer levels (selective)
Volume Filter Strength
Default: 2.0
Range: 0.5-5.0
Description: Controls minimum volume threshold for level validation
Advanced Probability Model
Market Trend Influence
Default: 25%
Range: 0-50%
Description: Weight given to overall market trend in probability calculations
Volume Influence
Default: 20%
Range: 0-50%
Description: Impact of volume analysis on break probability
✅ Best Use Cases
Identifying high-probability breakout setups before they occur
Determining optimal entry and exit points near key levels
Risk management through probability-based position sizing
Confluence trading when multiple high-probability levels align
Scalping opportunities at levels with low break probability
Swing trading setups using high-probability level breaks
⚠️ Limitations
Probability calculations are estimations based on historical patterns and current market conditions
High-probability setups do not guarantee successful trades - risk management is essential
Performance may vary significantly across different market conditions and asset classes
Requires understanding of support/resistance concepts and probability-based trading
Best used in conjunction with other analysis methods and proper risk management
💡 What Makes This Unique
Probability-Based Approach: First indicator to provide quantitative break probabilities rather than simple S/R lines
Multi-Factor Analysis: Combines 6 different market factors into a comprehensive probability model
Adaptive Intelligence: Probabilities update in real-time as market conditions change
Professional Interface: Tiered input system from beginner-friendly to expert-level customization
Institutional-Grade Filtering: Volume validation ensures only significant levels are displayed
🔬 How It Works
1. Level Detection:
Identifies pivot highs and lows using configurable sensitivity settings
Validates levels with volume analysis to ensure institutional significance
2. Probability Calculation:
Analyzes 6 key market factors: structure, volatility, volume, momentum, patterns, sentiment
Applies weighted scoring system based on user-defined factor importance
Generates probability score from 5% to 95% for each level
3. Real-Time Updates:
Continuously monitors price action and market conditions
Updates probability calculations as new data becomes available
Adjusts for level touches and changing market dynamics
💡 Note: This indicator works best on timeframes from 1-minute to 4-hour charts. For optimal results, combine with proper risk management and consider multiple timeframe analysis. The probability calculations are most accurate in trending markets with normal to high volatility conditions.
Wavelet-Trend ML Integration [Alpha Extract]Alpha-Extract Volatility Quality Indicator
The Alpha-Extract Volatility Quality (AVQ) Indicator provides traders with deep insights into market volatility by measuring the directional strength of price movements. This sophisticated momentum-based tool helps identify overbought and oversold conditions, offering actionable buy and sell signals based on volatility trends and standard deviation bands.
🔶 CALCULATION
The indicator processes volatility quality data through a series of analytical steps:
Bar Range Calculation: Measures true range (TR) to capture price volatility.
Directional Weighting: Applies directional bias (positive for bullish candles, negative for bearish) to the true range.
VQI Computation: Uses an exponential moving average (EMA) of weighted volatility to derive the Volatility Quality Index (VQI).
Smoothing: Applies an additional EMA to smooth the VQI for clearer signals.
Normalization: Optionally normalizes VQI to a -100/+100 scale based on historical highs and lows.
Standard Deviation Bands: Calculates three upper and lower bands using standard deviation multipliers for volatility thresholds.
Signal Generation: Produces overbought/oversold signals when VQI reaches extreme levels (±200 in normalized mode).
Formula:
Bar Range = True Range (TR)
Weighted Volatility = Bar Range × (Close > Open ? 1 : Close < Open ? -1 : 0)
VQI Raw = EMA(Weighted Volatility, VQI Length)
VQI Smoothed = EMA(VQI Raw, Smoothing Length)
VQI Normalized = ((VQI Smoothed - Lowest VQI) / (Highest VQI - Lowest VQI) - 0.5) × 200
Upper Band N = VQI Smoothed + (StdDev(VQI Smoothed, VQI Length) × Multiplier N)
Lower Band N = VQI Smoothed - (StdDev(VQI Smoothed, VQI Length) × Multiplier N)
🔶 DETAILS
Visual Features:
VQI Plot: Displays VQI as a line or histogram (lime for positive, red for negative).
Standard Deviation Bands: Plots three upper and lower bands (teal for upper, grayscale for lower) to indicate volatility thresholds.
Reference Levels: Horizontal lines at 0 (neutral), +100, and -100 (in normalized mode) for context.
Zone Highlighting: Overbought (⋎ above bars) and oversold (⋏ below bars) signals for extreme VQI levels (±200 in normalized mode).
Candle Coloring: Optional candle overlay colored by VQI direction (lime for positive, red for negative).
Interpretation:
VQI ≥ 200 (Normalized): Overbought condition, strong sell signal.
VQI 100–200: High volatility, potential selling opportunity.
VQI 0–100: Neutral bullish momentum.
VQI 0 to -100: Neutral bearish momentum.
VQI -100 to -200: High volatility, strong bearish momentum.
VQI ≤ -200 (Normalized): Oversold condition, strong buy signal.
🔶 EXAMPLES
Overbought Signal Detection: When VQI exceeds 200 (normalized), the indicator flags potential market tops with a red ⋎ symbol.
Example: During strong uptrends, VQI reaching 200 has historically preceded corrections, allowing traders to secure profits.
Oversold Signal Detection: When VQI falls below -200 (normalized), a lime ⋏ symbol highlights potential buying opportunities.
Example: In bearish markets, VQI dropping below -200 has marked reversal points for profitable long entries.
Volatility Trend Tracking: The VQI plot and bands help traders visualize shifts in market momentum.
Example: A rising VQI crossing above zero with widening bands indicates strengthening bullish momentum, guiding traders to hold or enter long positions.
Dynamic Support/Resistance: Standard deviation bands act as dynamic volatility thresholds during price movements.
Example: Price reversals often occur near the third standard deviation bands, providing reliable entry/exit points during volatile periods.
🔶 SETTINGS
Customization Options:
VQI Length: Adjust the EMA period for VQI calculation (default: 14, range: 1–50).
Smoothing Length: Set the EMA period for smoothing (default: 5, range: 1–50).
Standard Deviation Multipliers: Customize multipliers for bands (defaults: 1.0, 2.0, 3.0).
Normalization: Toggle normalization to -100/+100 scale and adjust lookback period (default: 200, min: 50).
Display Style: Switch between line or histogram plot for VQI.
Candle Overlay: Enable/disable VQI-colored candles (lime for positive, red for negative).
The Alpha-Extract Volatility Quality Indicator empowers traders with a robust tool to navigate market volatility. By combining directional price range analysis with smoothed volatility metrics, it identifies overbought and oversold conditions, offering clear buy and sell signals. The customizable standard deviation bands and optional normalization provide precise context for market conditions, enabling traders to make informed decisions across various market cycles.

CNN Statistical Trading System [PhenLabs]📌 DESCRIPTION
An advanced pattern recognition system utilizing Convolutional Neural Network (CNN) principles to identify statistically significant market patterns and generate high-probability trading signals.
CNN Statistical Trading System transforms traditional technical analysis by applying machine learning concepts directly to price action. Through six specialized convolution kernels, it detects momentum shifts, reversal patterns, consolidation phases, and breakout setups simultaneously. The system combines these pattern detections using adaptive weighting based on market volatility and trend strength, creating a sophisticated composite score that provides both directional bias and signal confidence on a normalized -1 to +1 scale.
🚀 CONCEPTS
• Built on Convolutional Neural Network pattern recognition methodology adapted for financial markets
• Six specialized kernels detect distinct price patterns: upward/downward momentum, peak/trough formations, consolidation, and breakout setups
• Activation functions create non-linear responses with tanh-like behavior, mimicking neural network layers
• Adaptive weighting system adjusts pattern importance based on current market regime (volatility < 2% and trend strength)
• Multi-confirmation signals require CNN threshold breach (±0.65), RSI boundaries, and volume confirmation above 120% of 20-period average
🔧 FEATURES
Six-Kernel Pattern Detection:
Simultaneous analysis of upward momentum, downward momentum, peak/resistance, trough/support, consolidation, and breakout patterns using mathematically optimized convolution kernels.
Adaptive Neural Architecture:
Dynamic weight adjustment based on market volatility (ATR/Price) and trend strength (EMA differential), ensuring optimal performance across different market conditions.
Professional Visual Themes:
Four sophisticated color palettes (Professional, Ocean, Sunset, Monochrome) with cohesive design language. Default Monochrome theme provides clean, distraction-free analysis.
Confidence Band System:
Upper and lower confidence zones at 150% of threshold values (±0.975) help identify high-probability signal areas and potential exhaustion zones.
Real-Time Information Panel:
Live display of CNN score, market state with emoji indicators, net momentum, confidence percentage, and RSI confirmation with dynamic color coding based on signal strength.
Individual Feature Analysis:
Optional display of all six kernel outputs with distinct visual styles (step lines, circles, crosses, area fills) for advanced pattern component analysis.
User Guide
• Monitor CNN Score crossing above +0.65 for long signals or below -0.65 for short signals with volume confirmation
• Use confidence bands to identify optimal entry zones - signals within confidence bands carry higher probability
• Background intensity reflects signal strength - darker backgrounds indicate stronger conviction
• Enter long positions when blue circles appear above oscillator with RSI < 75 and volume > 120% average
• Enter short positions when dark circles appear below oscillator with RSI > 25 and volume confirmation
• Information panel provides real-time confidence percentage and momentum direction for position sizing decisions
• Individual feature plots allow granular analysis of specific pattern components for strategy refinement
💡Conclusion
CNN Statistical Trading System represents the evolution of technical analysis, combining institutional-grade pattern recognition with retail accessibility. The six-kernel architecture provides comprehensive market pattern coverage while adaptive weighting ensures relevance across all market conditions. Whether you’re seeking systematic entry signals or advanced pattern confirmation, this indicator delivers mathematically rigorous analysis with intuitive visual presentation.

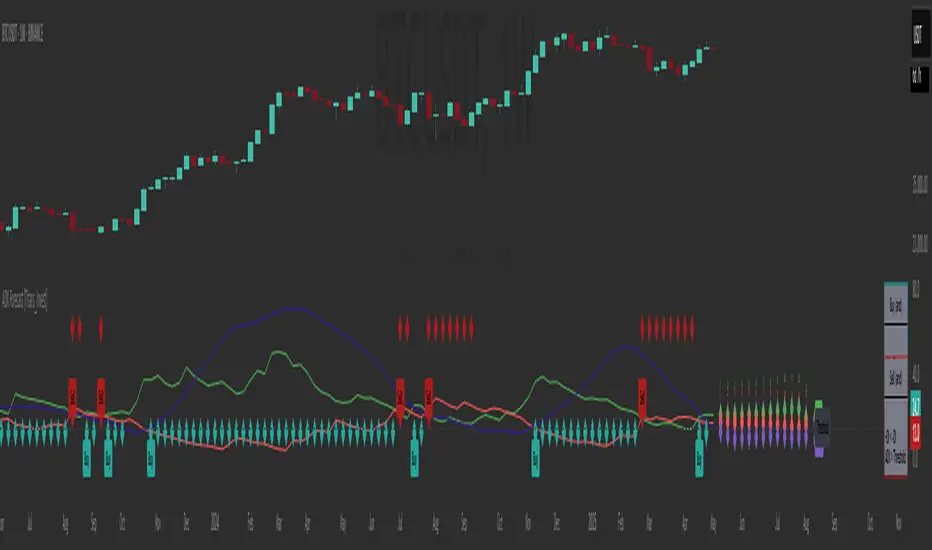
ADX Forecast [Titans_Invest]ADX Forecast
This isn’t just another ADX indicator — it’s the most powerful and complete ADX tool ever created, and without question the best ADX indicator on TradingView, possibly even the best in the world.
ADX Forecast represents a revolutionary leap in trend strength analysis, blending the timeless principles of the classic ADX with cutting-edge predictive modeling. For the first time on TradingView, you can anticipate future ADX movements using scientifically validated linear regression — a true game-changer for traders looking to stay ahead of trend shifts.
1. Real-Time ADX Forecasting
By applying least squares linear regression, ADX Forecast projects the future trajectory of the ADX with exceptional accuracy. This forecasting power enables traders to anticipate changes in trend strength before they fully unfold — a vital edge in fast-moving markets.
2. Unmatched Customization & Precision
With 26 long entry conditions and 26 short entry conditions, this indicator accounts for every possible ADX scenario. Every parameter is fully customizable, making it adaptable to any trading strategy — from scalping to swing trading to long-term investing.
3. Transparency & Advanced Visualization
Visualize internal ADX dynamics in real time with interactive tags, smart flags, and fully adjustable threshold levels. Every signal is transparent, logic-based, and engineered to fit seamlessly into professional-grade trading systems.
4. Scientific Foundation, Elite Execution
Grounded in statistical precision and machine learning principles, ADX Forecast upgrades the classic ADX from a reactive lagging tool into a forward-looking trend prediction engine. This isn’t just an indicator — it’s a scientific evolution in trend analysis.
⯁ SCIENTIFIC BASIS LINEAR REGRESSION
Linear Regression is a fundamental method of statistics and machine learning, used to model the relationship between a dependent variable y and one or more independent variables 𝑥.
The general formula for a simple linear regression is given by:
y = β₀ + β₁x + ε
β₁ = Σ((xᵢ - x̄)(yᵢ - ȳ)) / Σ((xᵢ - x̄)²)
β₀ = ȳ - β₁x̄
Where:
y = is the predicted variable (e.g. future value of RSI)
x = is the explanatory variable (e.g. time or bar index)
β0 = is the intercept (value of 𝑦 when 𝑥 = 0)
𝛽1 = is the slope of the line (rate of change)
ε = is the random error term
The goal is to estimate the coefficients 𝛽0 and 𝛽1 so as to minimize the sum of the squared errors — the so-called Random Error Method Least Squares.
⯁ LEAST SQUARES ESTIMATION
To minimize the error between predicted and observed values, we use the following formulas:
β₁ = /
β₀ = ȳ - β₁x̄
Where:
∑ = sum
x̄ = mean of x
ȳ = mean of y
x_i, y_i = individual values of the variables.
Where:
x_i and y_i are the means of the independent and dependent variables, respectively.
i ranges from 1 to n, the number of observations.
These equations guarantee the best linear unbiased estimator, according to the Gauss-Markov theorem, assuming homoscedasticity and linearity.
⯁ LINEAR REGRESSION IN MACHINE LEARNING
Linear regression is one of the cornerstones of supervised learning. Its simplicity and ability to generate accurate quantitative predictions make it essential in AI systems, predictive algorithms, time series analysis, and automated trading strategies.
By applying this model to the ADX, you are literally putting artificial intelligence at the heart of a classic indicator, bringing a new dimension to technical analysis.
⯁ VISUAL INTERPRETATION
Imagine an ADX time series like this:
Time →
ADX →
The regression line will smooth these values and extend them n periods into the future, creating a predicted trajectory based on the historical moment. This line becomes the predicted ADX, which can be crossed with the actual ADX to generate more intelligent signals.
⯁ SUMMARY OF SCIENTIFIC CONCEPTS USED
Linear Regression Models the relationship between variables using a straight line.
Least Squares Minimizes the sum of squared errors between prediction and reality.
Time Series Forecasting Estimates future values based on historical data.
Supervised Learning Trains models to predict outputs from known inputs.
Statistical Smoothing Reduces noise and reveals underlying trends.
⯁ WHY THIS INDICATOR IS REVOLUTIONARY
Scientifically-based: Based on statistical theory and mathematical inference.
Unprecedented: First public ADX with least squares predictive modeling.
Intelligent: Built with machine learning logic.
Practical: Generates forward-thinking signals.
Customizable: Flexible for any trading strategy.
⯁ CONCLUSION
By combining ADX with linear regression, this indicator allows a trader to predict market momentum, not just follow it.
ADX Forecast is not just an indicator — it is a scientific breakthrough in technical analysis technology.
⯁ Example of simple linear regression, which has one independent variable:
⯁ In linear regression, observations ( red ) are considered to be the result of random deviations ( green ) from an underlying relationship ( blue ) between a dependent variable ( y ) and an independent variable ( x ).
⯁ Visualizing heteroscedasticity in a scatterplot against 100 random fitted values using Matlab:
⯁ The data sets in the Anscombe's quartet are designed to have approximately the same linear regression line (as well as nearly identical means, standard deviations, and correlations) but are graphically very different. This illustrates the pitfalls of relying solely on a fitted model to understand the relationship between variables.
⯁ The result of fitting a set of data points with a quadratic function:
_______________________________________________________________________
🥇 This is the world’s first ADX indicator with: Linear Regression for Forecasting 🥇_______________________________________________________________________
_________________________________________________
🔮 Linear Regression: PineScript Technical Parameters 🔮
_________________________________________________
Forecast Types:
• Flat: Assumes prices will remain the same.
• Linreg: Makes a 'Linear Regression' forecast for n periods.
Technical Information:
ta.linreg (built-in function)
Linear regression curve. A line that best fits the specified prices over a user-defined time period. It is calculated using the least squares method. The result of this function is calculated using the formula: linreg = intercept + slope * (length - 1 - offset), where intercept and slope are the values calculated using the least squares method on the source series.
Syntax:
• Function: ta.linreg()
Parameters:
• source: Source price series.
• length: Number of bars (period).
• offset: Offset.
• return: Linear regression curve.
This function has been cleverly applied to the RSI, making it capable of projecting future values based on past statistical trends.
______________________________________________________
______________________________________________________
⯁ WHAT IS THE ADX❓
The Average Directional Index (ADX) is a technical analysis indicator developed by J. Welles Wilder. It measures the strength of a trend in a market, regardless of whether the trend is up or down.
The ADX is an integral part of the Directional Movement System, which also includes the Plus Directional Indicator (+DI) and the Minus Directional Indicator (-DI). By combining these components, the ADX provides a comprehensive view of market trend strength.
⯁ HOW TO USE THE ADX❓
The ADX is calculated based on the moving average of the price range expansion over a specified period (usually 14 periods). It is plotted on a scale from 0 to 100 and has three main zones:
• Strong Trend: When the ADX is above 25, indicating a strong trend.
• Weak Trend: When the ADX is below 20, indicating a weak or non-existent trend.
• Neutral Zone: Between 20 and 25, where the trend strength is unclear.
______________________________________________________
______________________________________________________
⯁ ENTRY CONDITIONS
The conditions below are fully flexible and allow for complete customization of the signal.
______________________________________________________
______________________________________________________
🔹 CONDITIONS TO BUY 📈
______________________________________________________
• Signal Validity: The signal will remain valid for X bars .
• Signal Sequence: Configurable as AND or OR .
🔹 +DI > -DI
🔹 +DI < -DI
🔹 +DI > ADX
🔹 +DI < ADX
🔹 -DI > ADX
🔹 -DI < ADX
🔹 ADX > Threshold
🔹 ADX < Threshold
🔹 +DI > Threshold
🔹 +DI < Threshold
🔹 -DI > Threshold
🔹 -DI < Threshold
🔹 +DI (Crossover) -DI
🔹 +DI (Crossunder) -DI
🔹 +DI (Crossover) ADX
🔹 +DI (Crossunder) ADX
🔹 +DI (Crossover) Threshold
🔹 +DI (Crossunder) Threshold
🔹 -DI (Crossover) ADX
🔹 -DI (Crossunder) ADX
🔹 -DI (Crossover) Threshold
🔹 -DI (Crossunder) Threshold
🔮 +DI (Crossover) -DI Forecast
🔮 +DI (Crossunder) -DI Forecast
🔮 ADX (Crossover) +DI Forecast
🔮 ADX (Crossunder) +DI Forecast
______________________________________________________
______________________________________________________
🔸 CONDITIONS TO SELL 📉
______________________________________________________
• Signal Validity: The signal will remain valid for X bars .
• Signal Sequence: Configurable as AND or OR .
🔸 +DI > -DI
🔸 +DI < -DI
🔸 +DI > ADX
🔸 +DI < ADX
🔸 -DI > ADX
🔸 -DI < ADX
🔸 ADX > Threshold
🔸 ADX < Threshold
🔸 +DI > Threshold
🔸 +DI < Threshold
🔸 -DI > Threshold
🔸 -DI < Threshold
🔸 +DI (Crossover) -DI
🔸 +DI (Crossunder) -DI
🔸 +DI (Crossover) ADX
🔸 +DI (Crossunder) ADX
🔸 +DI (Crossover) Threshold
🔸 +DI (Crossunder) Threshold
🔸 -DI (Crossover) ADX
🔸 -DI (Crossunder) ADX
🔸 -DI (Crossover) Threshold
🔸 -DI (Crossunder) Threshold
🔮 +DI (Crossover) -DI Forecast
🔮 +DI (Crossunder) -DI Forecast
🔮 ADX (Crossover) +DI Forecast
🔮 ADX (Crossunder) +DI Forecast
______________________________________________________
______________________________________________________
🤖 AUTOMATION 🤖
• You can automate the BUY and SELL signals of this indicator.
______________________________________________________
______________________________________________________
⯁ UNIQUE FEATURES
______________________________________________________
Linear Regression: (Forecast)
Signal Validity: The signal will remain valid for X bars
Signal Sequence: Configurable as AND/OR
Condition Table: BUY/SELL
Condition Labels: BUY/SELL
Plot Labels in the Graph Above: BUY/SELL
Automate and Monitor Signals/Alerts: BUY/SELL
Linear Regression (Forecast)
Signal Validity: The signal will remain valid for X bars
Signal Sequence: Configurable as AND/OR
Table of Conditions: BUY/SELL
Conditions Label: BUY/SELL
Plot Labels in the graph above: BUY/SELL
Automate & Monitor Signals/Alerts: BUY/SELL
______________________________________________________
📜 SCRIPT : ADX Forecast
🎴 Art by : @Titans_Invest & @DiFlip
👨💻 Dev by : @Titans_Invest & @DiFlip
🎑 Titans Invest — The Wizards Without Gloves 🧤
✨ Enjoy!
______________________________________________________
o Mission 🗺
• Inspire Traders to manifest Magic in the Market.
o Vision 𐓏
• To elevate collective Energy 𐓷𐓏
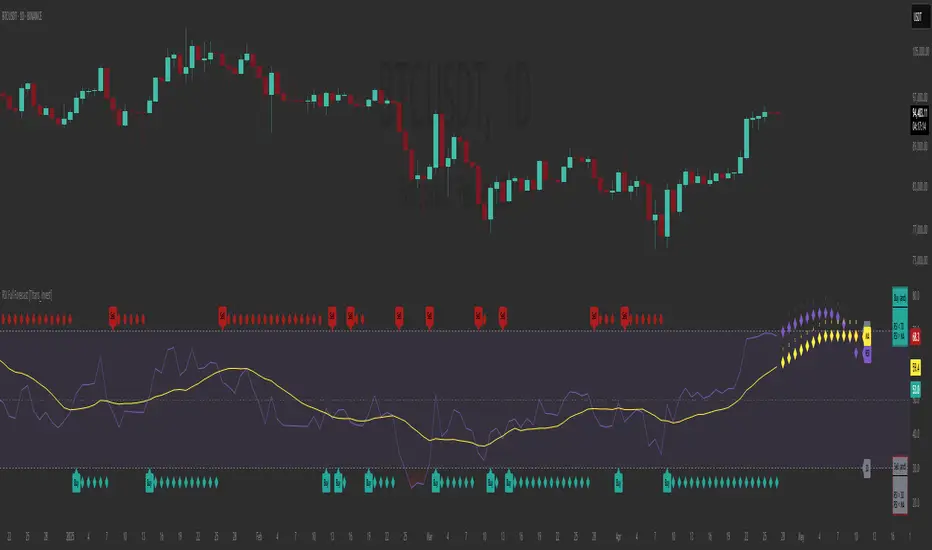
RSI Full Forecast [Titans_Invest]RSI Full Forecast
Get ready to experience the ultimate evolution of RSI-based indicators – the RSI Full Forecast, a boosted and even smarter version of the already powerful: RSI Forecast
Now featuring over 40 additional entry conditions (forecasts), this indicator redefines the way you view the market.
AI-Powered RSI Forecasting:
Using advanced linear regression with the least squares method – a solid foundation for machine learning - the RSI Full Forecast enables you to predict future RSI behavior with impressive accuracy.
But that’s not all: this new version also lets you monitor future crossovers between the RSI and the MA RSI, delivering early and strategic signals that go far beyond traditional analysis.
You’ll be able to monitor future crossovers up to 20 bars ahead, giving you an even broader and more precise view of market movements.
See the Future, Now:
• Track upcoming RSI & RSI MA crossovers in advance.
• Identify potential reversal zones before price reacts.
• Uncover statistical behavior patterns that would normally go unnoticed.
40+ Intelligent Conditions:
The new layer of conditions is designed to detect multiple high-probability scenarios based on historical patterns and predictive modeling. Each additional forecast is a window into the price's future, powered by robust mathematics and advanced algorithmic logic.
Full Customization:
All parameters can be tailored to fit your strategy – from smoothing periods to prediction sensitivity. You have complete control to turn raw data into smart decisions.
Innovative, Accurate, Unique:
This isn’t just an upgrade. It’s a quantum leap in technical analysis.
RSI Full Forecast is the first of its kind: an indicator that blends statistical analysis, machine learning, and visual design to create a true real-time predictive system.
⯁ SCIENTIFIC BASIS LINEAR REGRESSION
Linear Regression is a fundamental method of statistics and machine learning, used to model the relationship between a dependent variable y and one or more independent variables 𝑥.
The general formula for a simple linear regression is given by:
y = β₀ + β₁x + ε
β₁ = Σ((xᵢ - x̄)(yᵢ - ȳ)) / Σ((xᵢ - x̄)²)
β₀ = ȳ - β₁x̄
Where:
y = is the predicted variable (e.g. future value of RSI)
x = is the explanatory variable (e.g. time or bar index)
β0 = is the intercept (value of 𝑦 when 𝑥 = 0)
𝛽1 = is the slope of the line (rate of change)
ε = is the random error term
The goal is to estimate the coefficients 𝛽0 and 𝛽1 so as to minimize the sum of the squared errors — the so-called Random Error Method Least Squares.
⯁ LEAST SQUARES ESTIMATION
To minimize the error between predicted and observed values, we use the following formulas:
β₁ = /
β₀ = ȳ - β₁x̄
Where:
∑ = sum
x̄ = mean of x
ȳ = mean of y
x_i, y_i = individual values of the variables.
Where:
x_i and y_i are the means of the independent and dependent variables, respectively.
i ranges from 1 to n, the number of observations.
These equations guarantee the best linear unbiased estimator, according to the Gauss-Markov theorem, assuming homoscedasticity and linearity.
⯁ LINEAR REGRESSION IN MACHINE LEARNING
Linear regression is one of the cornerstones of supervised learning. Its simplicity and ability to generate accurate quantitative predictions make it essential in AI systems, predictive algorithms, time series analysis, and automated trading strategies.
By applying this model to the RSI, you are literally putting artificial intelligence at the heart of a classic indicator, bringing a new dimension to technical analysis.
⯁ VISUAL INTERPRETATION
Imagine an RSI time series like this:
Time →
RSI →
The regression line will smooth these values and extend them n periods into the future, creating a predicted trajectory based on the historical moment. This line becomes the predicted RSI, which can be crossed with the actual RSI to generate more intelligent signals.
⯁ SUMMARY OF SCIENTIFIC CONCEPTS USED
Linear Regression Models the relationship between variables using a straight line.
Least Squares Minimizes the sum of squared errors between prediction and reality.
Time Series Forecasting Estimates future values based on historical data.
Supervised Learning Trains models to predict outputs from known inputs.
Statistical Smoothing Reduces noise and reveals underlying trends.
⯁ WHY THIS INDICATOR IS REVOLUTIONARY
Scientifically-based: Based on statistical theory and mathematical inference.
Unprecedented: First public RSI with least squares predictive modeling.
Intelligent: Built with machine learning logic.
Practical: Generates forward-thinking signals.
Customizable: Flexible for any trading strategy.
⯁ CONCLUSION
By combining RSI with linear regression, this indicator allows a trader to predict market momentum, not just follow it.
RSI Full Forecast is not just an indicator — it is a scientific breakthrough in technical analysis technology.
⯁ Example of simple linear regression, which has one independent variable:
⯁ In linear regression, observations ( red ) are considered to be the result of random deviations ( green ) from an underlying relationship ( blue ) between a dependent variable ( y ) and an independent variable ( x ).
⯁ Visualizing heteroscedasticity in a scatterplot against 100 random fitted values using Matlab:
⯁ The data sets in the Anscombe's quartet are designed to have approximately the same linear regression line (as well as nearly identical means, standard deviations, and correlations) but are graphically very different. This illustrates the pitfalls of relying solely on a fitted model to understand the relationship between variables.
⯁ The result of fitting a set of data points with a quadratic function:
_________________________________________________
🔮 Linear Regression: PineScript Technical Parameters 🔮
_________________________________________________
Forecast Types:
• Flat: Assumes prices will remain the same.
• Linreg: Makes a 'Linear Regression' forecast for n periods.
Technical Information:
ta.linreg (built-in function)
Linear regression curve. A line that best fits the specified prices over a user-defined time period. It is calculated using the least squares method. The result of this function is calculated using the formula: linreg = intercept + slope * (length - 1 - offset), where intercept and slope are the values calculated using the least squares method on the source series.
Syntax:
• Function: ta.linreg()
Parameters:
• source: Source price series.
• length: Number of bars (period).
• offset: Offset.
• return: Linear regression curve.
This function has been cleverly applied to the RSI, making it capable of projecting future values based on past statistical trends.
______________________________________________________
______________________________________________________
⯁ WHAT IS THE RSI❓
The Relative Strength Index (RSI) is a technical analysis indicator developed by J. Welles Wilder. It measures the magnitude of recent price movements to evaluate overbought or oversold conditions in a market. The RSI is an oscillator that ranges from 0 to 100 and is commonly used to identify potential reversal points, as well as the strength of a trend.
⯁ HOW TO USE THE RSI❓
The RSI is calculated based on average gains and losses over a specified period (usually 14 periods). It is plotted on a scale from 0 to 100 and includes three main zones:
• Overbought: When the RSI is above 70, indicating that the asset may be overbought.
• Oversold: When the RSI is below 30, indicating that the asset may be oversold.
• Neutral Zone: Between 30 and 70, where there is no clear signal of overbought or oversold conditions.
______________________________________________________
______________________________________________________
⯁ ENTRY CONDITIONS
The conditions below are fully flexible and allow for complete customization of the signal.
______________________________________________________
______________________________________________________
🔹 CONDITIONS TO BUY 📈
______________________________________________________
• Signal Validity: The signal will remain valid for X bars .
• Signal Sequence: Configurable as AND or OR .
📈 RSI Conditions:
🔹 RSI > Upper
🔹 RSI < Upper
🔹 RSI > Lower
🔹 RSI < Lower
🔹 RSI > Middle
🔹 RSI < Middle
🔹 RSI > MA
🔹 RSI < MA
📈 MA Conditions:
🔹 MA > Upper
🔹 MA < Upper
🔹 MA > Lower
🔹 MA < Lower
📈 Crossovers:
🔹 RSI (Crossover) Upper
🔹 RSI (Crossunder) Upper
🔹 RSI (Crossover) Lower
🔹 RSI (Crossunder) Lower
🔹 RSI (Crossover) Middle
🔹 RSI (Crossunder) Middle
🔹 RSI (Crossover) MA
🔹 RSI (Crossunder) MA
🔹 MA (Crossover) Upper
🔹 MA (Crossunder) Upper
🔹 MA (Crossover) Lower
🔹 MA (Crossunder) Lower
📈 RSI Divergences:
🔹 RSI Divergence Bull
🔹 RSI Divergence Bear
📈 RSI Forecast:
🔹 RSI (Crossover) MA Forecast
🔹 RSI (Crossunder) MA Forecast
🔹 RSI Forecast 1 > MA Forecast 1
🔹 RSI Forecast 1 < MA Forecast 1
🔹 RSI Forecast 2 > MA Forecast 2
🔹 RSI Forecast 2 < MA Forecast 2
🔹 RSI Forecast 3 > MA Forecast 3
🔹 RSI Forecast 3 < MA Forecast 3
🔹 RSI Forecast 4 > MA Forecast 4
🔹 RSI Forecast 4 < MA Forecast 4
🔹 RSI Forecast 5 > MA Forecast 5
🔹 RSI Forecast 5 < MA Forecast 5
🔹 RSI Forecast 6 > MA Forecast 6
🔹 RSI Forecast 6 < MA Forecast 6
🔹 RSI Forecast 7 > MA Forecast 7
🔹 RSI Forecast 7 < MA Forecast 7
🔹 RSI Forecast 8 > MA Forecast 8
🔹 RSI Forecast 8 < MA Forecast 8
🔹 RSI Forecast 9 > MA Forecast 9
🔹 RSI Forecast 9 < MA Forecast 9
🔹 RSI Forecast 10 > MA Forecast 10
🔹 RSI Forecast 10 < MA Forecast 10
🔹 RSI Forecast 11 > MA Forecast 11
🔹 RSI Forecast 11 < MA Forecast 11
🔹 RSI Forecast 12 > MA Forecast 12
🔹 RSI Forecast 12 < MA Forecast 12
🔹 RSI Forecast 13 > MA Forecast 13
🔹 RSI Forecast 13 < MA Forecast 13
🔹 RSI Forecast 14 > MA Forecast 14
🔹 RSI Forecast 14 < MA Forecast 14
🔹 RSI Forecast 15 > MA Forecast 15
🔹 RSI Forecast 15 < MA Forecast 15
🔹 RSI Forecast 16 > MA Forecast 16
🔹 RSI Forecast 16 < MA Forecast 16
🔹 RSI Forecast 17 > MA Forecast 17
🔹 RSI Forecast 17 < MA Forecast 17
🔹 RSI Forecast 18 > MA Forecast 18
🔹 RSI Forecast 18 < MA Forecast 18
🔹 RSI Forecast 19 > MA Forecast 19
🔹 RSI Forecast 19 < MA Forecast 19
🔹 RSI Forecast 20 > MA Forecast 20
🔹 RSI Forecast 20 < MA Forecast 20
______________________________________________________
______________________________________________________
🔸 CONDITIONS TO SELL 📉
______________________________________________________
• Signal Validity: The signal will remain valid for X bars .
• Signal Sequence: Configurable as AND or OR .
📉 RSI Conditions:
🔸 RSI > Upper
🔸 RSI < Upper
🔸 RSI > Lower
🔸 RSI < Lower
🔸 RSI > Middle
🔸 RSI < Middle
🔸 RSI > MA
🔸 RSI < MA
📉 MA Conditions:
🔸 MA > Upper
🔸 MA < Upper
🔸 MA > Lower
🔸 MA < Lower
📉 Crossovers:
🔸 RSI (Crossover) Upper
🔸 RSI (Crossunder) Upper
🔸 RSI (Crossover) Lower
🔸 RSI (Crossunder) Lower
🔸 RSI (Crossover) Middle
🔸 RSI (Crossunder) Middle
🔸 RSI (Crossover) MA
🔸 RSI (Crossunder) MA
🔸 MA (Crossover) Upper
🔸 MA (Crossunder) Upper
🔸 MA (Crossover) Lower
🔸 MA (Crossunder) Lower
📉 RSI Divergences:
🔸 RSI Divergence Bull
🔸 RSI Divergence Bear
📉 RSI Forecast:
🔸 RSI (Crossover) MA Forecast
🔸 RSI (Crossunder) MA Forecast
🔸 RSI Forecast 1 > MA Forecast 1
🔸 RSI Forecast 1 < MA Forecast 1
🔸 RSI Forecast 2 > MA Forecast 2
🔸 RSI Forecast 2 < MA Forecast 2
🔸 RSI Forecast 3 > MA Forecast 3
🔸 RSI Forecast 3 < MA Forecast 3
🔸 RSI Forecast 4 > MA Forecast 4
🔸 RSI Forecast 4 < MA Forecast 4
🔸 RSI Forecast 5 > MA Forecast 5
🔸 RSI Forecast 5 < MA Forecast 5
🔸 RSI Forecast 6 > MA Forecast 6
🔸 RSI Forecast 6 < MA Forecast 6
🔸 RSI Forecast 7 > MA Forecast 7
🔸 RSI Forecast 7 < MA Forecast 7
🔸 RSI Forecast 8 > MA Forecast 8
🔸 RSI Forecast 8 < MA Forecast 8
🔸 RSI Forecast 9 > MA Forecast 9
🔸 RSI Forecast 9 < MA Forecast 9
🔸 RSI Forecast 10 > MA Forecast 10
🔸 RSI Forecast 10 < MA Forecast 10
🔸 RSI Forecast 11 > MA Forecast 11
🔸 RSI Forecast 11 < MA Forecast 11
🔸 RSI Forecast 12 > MA Forecast 12
🔸 RSI Forecast 12 < MA Forecast 12
🔸 RSI Forecast 13 > MA Forecast 13
🔸 RSI Forecast 13 < MA Forecast 13
🔸 RSI Forecast 14 > MA Forecast 14
🔸 RSI Forecast 14 < MA Forecast 14
🔸 RSI Forecast 15 > MA Forecast 15
🔸 RSI Forecast 15 < MA Forecast 15
🔸 RSI Forecast 16 > MA Forecast 16
🔸 RSI Forecast 16 < MA Forecast 16
🔸 RSI Forecast 17 > MA Forecast 17
🔸 RSI Forecast 17 < MA Forecast 17
🔸 RSI Forecast 18 > MA Forecast 18
🔸 RSI Forecast 18 < MA Forecast 18
🔸 RSI Forecast 19 > MA Forecast 19
🔸 RSI Forecast 19 < MA Forecast 19
🔸 RSI Forecast 20 > MA Forecast 20
🔸 RSI Forecast 20 < MA Forecast 20
______________________________________________________
______________________________________________________
🤖 AUTOMATION 🤖
• You can automate the BUY and SELL signals of this indicator.
______________________________________________________
______________________________________________________
⯁ UNIQUE FEATURES
______________________________________________________
Linear Regression: (Forecast)
Signal Validity: The signal will remain valid for X bars
Signal Sequence: Configurable as AND/OR
Condition Table: BUY/SELL
Condition Labels: BUY/SELL
Plot Labels in the Graph Above: BUY/SELL
Automate and Monitor Signals/Alerts: BUY/SELL
Linear Regression (Forecast)
Signal Validity: The signal will remain valid for X bars
Signal Sequence: Configurable as AND/OR
Condition Table: BUY/SELL
Condition Labels: BUY/SELL
Plot Labels in the Graph Above: BUY/SELL
Automate and Monitor Signals/Alerts: BUY/SELL
______________________________________________________
📜 SCRIPT : RSI Full Forecast
🎴 Art by : @Titans_Invest & @DiFlip
👨💻 Dev by : @Titans_Invest & @DiFlip
🎑 Titans Invest — The Wizards Without Gloves 🧤
✨ Enjoy!
______________________________________________________
o Mission 🗺
• Inspire Traders to manifest Magic in the Market.
o Vision 𐓏
• To elevate collective Energy 𐓷𐓏
Machine Learning | Adaptive Trend Signals [Bitwardex]⚙️🧠Machine Learning | Adaptive Trend Signals
🔷Overview
Machine Learning | Adaptive Trend Signals is a Pine Script™ v6 indicator designed to visualize market trends and generate signals through a combination of volatility clustering, Gaussian smoothing, and adaptive trend calculations. Built as an overlay indicator, it integrates advanced techniques inspired by machine learning concepts, such as K-Means clustering, to adapt to changing market conditions. The script is highly customizable, includes a backtesting module, and supports alert conditions, making it suitable for traders exploring trend-based strategies and developers studying volatility-driven indicator design.
🔷Functionality
The indicator performs the following core functions:
• Volatility Clustering: Uses K-Means clustering to categorize market volatility into high, medium, and low states, adjusting trend sensitivity accordingly.
• Trend Calculation: Computes adaptive trend lines (SmartTrend) based on volatility-adjusted standard deviation, smoothed RSI, and ADX filters.
• Signal Generation: Identifies potential buy and sell points through trend line crossovers and directional confirmation.
• Backtesting Module: Tracks trade outcomes based on the SmartTrend3 value, displaying win rate and total trades.
• Visualization: Plots trend lines with gradient colors and optional signal markers (bullish 🐮 and bearish 🐻).
• Alerts: Provides configurable alerts for trend shifts and volatility state changes.
🔷Technical Methodology
Volatility Clustering with K-Means
The indicator employs a K-Means clustering algorithm to classify market volatility, measured via the Average True Range (ATR), into three distinct clusters:
• Data Collection: Gathers ATR values over a user-defined training period (default: 100 bars).
• Centroid Initialization: Sets initial centroids at the highest, lowest, and midpoint ATR values within the training period.
• Iterative Clustering: Assigns ATR data points to the nearest centroid, recalculates centroid means, and repeats until convergence.
• Dynamic Adjustment: Assigns a volatility state (high, medium, or low) based on the closest centroid, adjusting the trend factor (e.g., tighter for high volatility, wider for low volatility).
This approach allows the indicator to adapt its sensitivity to varying market conditions, providing a data-driven foundation for trend calculations.
🔷Gaussian Smoothing
To enhance signal clarity and reduce noise, the indicator applies Gaussian kernel smoothing to:
• RSI: Smooths the Relative Strength Index (calculated from OHLC4) to filter short-term fluctuations.
• SmartTrend: Smooths the primary trend line for a more stable output.
The Gaussian kernel uses a sigma value derived from the user-defined smoothing length, ensuring mathematically consistent noise reduction.
🔷SmartTrend Calculation
The pineSmartTrend function is the core of the indicator, producing three trend lines:
• SmartTrend: The primary trend line, calculated using a volatility-adjusted standard deviation, smoothed RSI, and ADX conditions.
• SmartTrend2: A secondary trend line with a wider factor (base factor * 1.382) for signal confirmation.
SmartTrend3: The average of SmartTrend and SmartTrend2, used for plotting and backtesting.
Key components of the calculation include:
• Dynamic Standard Deviation: Scales based on ATR relative to its 50-period smoothed average, with multipliers (1.0 to 1.4) applied according to volatility thresholds.
• RSI and ADX Filters: Requires RSI > 50 for bullish trends or < 50 for bearish trends, alongside ADX > 15 and rising to confirm trend strength.
Volatility-Adjusted Bands: Constructs upper and lower bands around price action, adjusted by the volatility cluster’s dynamic factor.
🔷Signal Generation
The generate_signals function generates signals as follows:
• Buy Signal: Triggered when SmartTrend crosses above SmartTrend2 and the price is above SmartTrend, with directional confirmation.
• Sell Signal: Triggered when SmartTrend crosses below SmartTrend2 and the price is below SmartTrend, with directional confirmation.
Directional Logic: Tracks trend direction to filter out conflicting signals, ensuring alignment with the broader market context.
Signals are visualized as small circles with bullish (🐮) or bearish (🐻) emojis, with an option to toggle visibility.
🔷Backtesting
The get_backtest function evaluates signal outcomes using the SmartTrend3 value (rather than closing prices) to align with the trend-based methodology.
It tracks:
• Total Trades: Counts completed long and short trades.
• Win Rate: Calculates the percentage of trades where SmartTrend3 moves favorably (higher for longs, lower for shorts).
Position Management: Closes opposite positions before opening new ones, simulating a single-position trading system.
Results are displayed in a table at the top-right of the chart, showing win rate and total trades. Note that backtest results reflect the indicator’s internal logic and should not be interpreted as predictive of real-world performance.
🔷Visualization and Alerts
• Trend Lines: SmartTrend3 is plotted with gradient colors reflecting trend direction and volatility cluster, accompanied by a secondary line for visual clarity.
• Signal Markers: Optional buy/sell signals are plotted as small circles with customizable colors.
• Alerts: Supports alerts for:
• Bullish and bearish trend shifts (confirmed on bar close).
Transitions to high, medium, or low volatility states.
🔷Input Parameters
• ATR Length (default: 14): Period for ATR calculation, used in volatility clustering.
• Period (default: 21): Common period for RSI, ADX, and standard deviation calculations.
• Base SmartTrend Factor (default: 2.0): Base multiplier for volatility-adjusted bands.
• SmartTrend Smoothing Length (default: 10): Length for Gaussian smoothing of the trend line.
• Show Buy/Sell Signals? (default: true): Enables/disables signal markers.
• Bullish/Bearish Color: Customizable colors for trend lines and signals.
🔷Usage Instructions
• Apply to Chart: Add the indicator to any TradingView chart.
• Configure Inputs: Adjust parameters to align with your trading style or market conditions (e.g., shorter ATR length for faster markets).
• Interpret Output:
• Trend Lines: Use SmartTrend3’s direction and color to gauge market bias.
• Signals: Monitor bullish (🐮) and bearish (🐻) markers for potential entry/exit points.
• Backtest Table: Review win rate and total trades to understand the indicator’s behavior in historical data.
• Set Alerts: Configure alerts for trend shifts or volatility changes to support manual or automated trading workflows.
• Combine with Analysis: Use the indicator alongside other tools or market context, as it is designed to complement, not replace, comprehensive analysis.
🔷Technical Notes
• Data Requirements: Requires at least 100 bars for accurate volatility clustering. Ensure sufficient historical data is loaded.
• Market Suitability: The indicator is designed for trend detection and may perform differently in ranging or volatile markets due to its reliance on RSI and ADX filters.
• Backtesting Scope: The backtest module uses SmartTrend3 values, which may differ from price-based outcomes. Results are for informational purposes only.
• Computational Intensity: The K-Means clustering and Gaussian smoothing may increase processing time on lower timeframes or with large datasets.
🔷For Developers
The script is modular, well-commented, encouraging reuse and modification with proper attribution.
Key functions include:
• gaussianSmooth: Applies Gaussian kernel smoothing to any data series.
• pineSmartTrend: Computes adaptive trend lines with volatility and momentum filters.
• getDynamicFactor: Adjusts trend sensitivity based on volatility clusters.
• get_backtest: Evaluates signal performance using SmartTrend3.
Developers can extend these functions for custom indicators or strategies, leveraging the volatility clustering and smoothing methodologies. The K-Means implementation is particularly useful for adaptive volatility analysis.
🔷Limitations
• The indicator is not predictive and should be used as part of a broader trading strategy.
• Performance varies by market, timeframe, and parameter settings, requiring user experimentation.
• Backtest results are based on historical data and internal logic, not real-world trading conditions.
• Volatility clustering assumes sufficient historical data; incomplete data may affect accuracy.
🔷Acknowledgments
Developed by Bitwardex, inspired by machine learning concepts and adaptive trading methodologies. Community feedback is welcome via TradingView’s platform.
🔷 Risk Disclaimer
Trading involves significant risks, and most traders may incur losses. Bitwardex AI Algo is provided for informational and educational purposes only and does not constitute financial advice or a recommendation to buy or sell any financial instrument . The signals, metrics, and features are tools for analysis and do not guarantee profits or specific outcomes. Past performance is not indicative of future results. Always conduct your own due diligence and consult a financial advisor before making trading decisions.

RSI Forecast [Titans_Invest]RSI Forecast
Introducing one of the most impressive RSI indicators ever created – arguably the best on TradingView, and potentially the best in the world.
RSI Forecast is a visionary evolution of the classic RSI, merging powerful customization with groundbreaking predictive capabilities. While preserving the core principles of traditional RSI, it takes analysis to the next level by allowing users to anticipate potential future RSI movements.
Real-Time RSI Forecasting:
For the first time ever, an RSI indicator integrates linear regression using the least squares method to accurately forecast the future behavior of the RSI. This innovation empowers traders to stay one step ahead of the market with forward-looking insight.
Highly Customizable:
Easily adapt the indicator to your personal trading style. Fine-tune a variety of parameters to generate signals perfectly aligned with your strategy.
Innovative, Unique, and Powerful:
This is the world’s first RSI Forecast to apply this predictive approach using least squares linear regression. A truly elite-level tool designed for traders who want a real edge in the market.
⯁ SCIENTIFIC BASIS LINEAR REGRESSION
Linear Regression is a fundamental method of statistics and machine learning, used to model the relationship between a dependent variable y and one or more independent variables 𝑥.
The general formula for a simple linear regression is given by:
y = β₀ + β₁x + ε
Where:
y = is the predicted variable (e.g. future value of RSI)
x = is the explanatory variable (e.g. time or bar index)
β0 = is the intercept (value of 𝑦 when 𝑥 = 0)
𝛽1 = is the slope of the line (rate of change)
ε = is the random error term
The goal is to estimate the coefficients 𝛽0 and 𝛽1 so as to minimize the sum of the squared errors — the so-called Random Error Method Least Squares.
⯁ LEAST SQUARES ESTIMATION
To minimize the error between predicted and observed values, we use the following formulas:
β₁ = /
β₀ = ȳ - β₁x̄
Where:
∑ = sum
x̄ = mean of x
ȳ = mean of y
x_i, y_i = individual values of the variables.
Where:
x_i and y_i are the means of the independent and dependent variables, respectively.
i ranges from 1 to n, the number of observations.
These equations guarantee the best linear unbiased estimator, according to the Gauss-Markov theorem, assuming homoscedasticity and linearity.
⯁ LINEAR REGRESSION IN MACHINE LEARNING
Linear regression is one of the cornerstones of supervised learning. Its simplicity and ability to generate accurate quantitative predictions make it essential in AI systems, predictive algorithms, time series analysis, and automated trading strategies.
By applying this model to the RSI, you are literally putting artificial intelligence at the heart of a classic indicator, bringing a new dimension to technical analysis.
⯁ VISUAL INTERPRETATION
Imagine an RSI time series like this:
Time →
RSI →
The regression line will smooth these values and extend them n periods into the future, creating a predicted trajectory based on the historical moment. This line becomes the predicted RSI, which can be crossed with the actual RSI to generate more intelligent signals.
⯁ SUMMARY OF SCIENTIFIC CONCEPTS USED
Linear Regression Models the relationship between variables using a straight line.
Least Squares Minimizes the sum of squared errors between prediction and reality.
Time Series Forecasting Estimates future values based on historical data.
Supervised Learning Trains models to predict outputs from known inputs.
Statistical Smoothing Reduces noise and reveals underlying trends.
⯁ WHY THIS INDICATOR IS REVOLUTIONARY
Scientifically-based: Based on statistical theory and mathematical inference.
Unprecedented: First public RSI with least squares predictive modeling.
Intelligent: Built with machine learning logic.
Practical: Generates forward-thinking signals.
Customizable: Flexible for any trading strategy.
⯁ CONCLUSION
By combining RSI with linear regression, this indicator allows a trader to predict market momentum, not just follow it.
RSI Forecast is not just an indicator — it is a scientific breakthrough in technical analysis technology.
⯁ Example of simple linear regression, which has one independent variable:
⯁ In linear regression, observations ( red ) are considered to be the result of random deviations ( green ) from an underlying relationship ( blue ) between a dependent variable ( y ) and an independent variable ( x ).
⯁ Visualizing heteroscedasticity in a scatterplot against 100 random fitted values using Matlab:
⯁ The data sets in the Anscombe's quartet are designed to have approximately the same linear regression line (as well as nearly identical means, standard deviations, and correlations) but are graphically very different. This illustrates the pitfalls of relying solely on a fitted model to understand the relationship between variables.
⯁ The result of fitting a set of data points with a quadratic function:
_______________________________________________________________________
🥇 This is the world’s first RSI indicator with: Linear Regression for Forecasting 🥇_______________________________________________________________________
_________________________________________________
🔮 Linear Regression: PineScript Technical Parameters 🔮
_________________________________________________
Forecast Types:
• Flat: Assumes prices will remain the same.
• Linreg: Makes a 'Linear Regression' forecast for n periods.
Technical Information:
ta.linreg (built-in function)
Linear regression curve. A line that best fits the specified prices over a user-defined time period. It is calculated using the least squares method. The result of this function is calculated using the formula: linreg = intercept + slope * (length - 1 - offset), where intercept and slope are the values calculated using the least squares method on the source series.
Syntax:
• Function: ta.linreg()
Parameters:
• source: Source price series.
• length: Number of bars (period).
• offset: Offset.
• return: Linear regression curve.
This function has been cleverly applied to the RSI, making it capable of projecting future values based on past statistical trends.
______________________________________________________
______________________________________________________
⯁ WHAT IS THE RSI❓
The Relative Strength Index (RSI) is a technical analysis indicator developed by J. Welles Wilder. It measures the magnitude of recent price movements to evaluate overbought or oversold conditions in a market. The RSI is an oscillator that ranges from 0 to 100 and is commonly used to identify potential reversal points, as well as the strength of a trend.
⯁ HOW TO USE THE RSI❓
The RSI is calculated based on average gains and losses over a specified period (usually 14 periods). It is plotted on a scale from 0 to 100 and includes three main zones:
• Overbought: When the RSI is above 70, indicating that the asset may be overbought.
• Oversold: When the RSI is below 30, indicating that the asset may be oversold.
• Neutral Zone: Between 30 and 70, where there is no clear signal of overbought or oversold conditions.
______________________________________________________
______________________________________________________
⯁ ENTRY CONDITIONS
The conditions below are fully flexible and allow for complete customization of the signal.
______________________________________________________
______________________________________________________
🔹 CONDITIONS TO BUY 📈
______________________________________________________
• Signal Validity: The signal will remain valid for X bars .
• Signal Sequence: Configurable as AND or OR .
📈 RSI Conditions:
🔹 RSI > Upper
🔹 RSI < Upper
🔹 RSI > Lower
🔹 RSI < Lower
🔹 RSI > Middle
🔹 RSI < Middle
🔹 RSI > MA
🔹 RSI < MA
📈 MA Conditions:
🔹 MA > Upper
🔹 MA < Upper
🔹 MA > Lower
🔹 MA < Lower
📈 Crossovers:
🔹 RSI (Crossover) Upper
🔹 RSI (Crossunder) Upper
🔹 RSI (Crossover) Lower
🔹 RSI (Crossunder) Lower
🔹 RSI (Crossover) Middle
🔹 RSI (Crossunder) Middle
🔹 RSI (Crossover) MA
🔹 RSI (Crossunder) MA
🔹 MA (Crossover) Upper
🔹 MA (Crossunder) Upper
🔹 MA (Crossover) Lower
🔹 MA (Crossunder) Lower
📈 RSI Divergences:
🔹 RSI Divergence Bull
🔹 RSI Divergence Bear
📈 RSI Forecast:
🔮 RSI (Crossover) MA Forecast
🔮 RSI (Crossunder) MA Forecast
______________________________________________________
______________________________________________________
🔸 CONDITIONS TO SELL 📉
______________________________________________________
• Signal Validity: The signal will remain valid for X bars .
• Signal Sequence: Configurable as AND or OR .
📉 RSI Conditions:
🔸 RSI > Upper
🔸 RSI < Upper
🔸 RSI > Lower
🔸 RSI < Lower
🔸 RSI > Middle
🔸 RSI < Middle
🔸 RSI > MA
🔸 RSI < MA
📉 MA Conditions:
🔸 MA > Upper
🔸 MA < Upper
🔸 MA > Lower
🔸 MA < Lower
📉 Crossovers:
🔸 RSI (Crossover) Upper
🔸 RSI (Crossunder) Upper
🔸 RSI (Crossover) Lower
🔸 RSI (Crossunder) Lower
🔸 RSI (Crossover) Middle
🔸 RSI (Crossunder) Middle
🔸 RSI (Crossover) MA
🔸 RSI (Crossunder) MA
🔸 MA (Crossover) Upper
🔸 MA (Crossunder) Upper
🔸 MA (Crossover) Lower
🔸 MA (Crossunder) Lower
📉 RSI Divergences:
🔸 RSI Divergence Bull
🔸 RSI Divergence Bear
📉 RSI Forecast:
🔮 RSI (Crossover) MA Forecast
🔮 RSI (Crossunder) MA Forecast
______________________________________________________
______________________________________________________
🤖 AUTOMATION 🤖
• You can automate the BUY and SELL signals of this indicator.
______________________________________________________
______________________________________________________
⯁ UNIQUE FEATURES
______________________________________________________
Linear Regression: (Forecast)
Signal Validity: The signal will remain valid for X bars
Signal Sequence: Configurable as AND/OR
Condition Table: BUY/SELL
Condition Labels: BUY/SELL
Plot Labels in the Graph Above: BUY/SELL
Automate and Monitor Signals/Alerts: BUY/SELL
Linear Regression (Forecast)
Signal Validity: The signal will remain valid for X bars
Signal Sequence: Configurable as AND/OR
Condition Table: BUY/SELL
Condition Labels: BUY/SELL
Plot Labels in the Graph Above: BUY/SELL
Automate and Monitor Signals/Alerts: BUY/SELL
______________________________________________________
📜 SCRIPT : RSI Forecast
🎴 Art by : @Titans_Invest & @DiFlip
👨💻 Dev by : @Titans_Invest & @DiFlip
🎑 Titans Invest — The Wizards Without Gloves 🧤
✨ Enjoy!
______________________________________________________
o Mission 🗺
• Inspire Traders to manifest Magic in the Market.
o Vision 𐓏
• To elevate collective Energy 𐓷𐓏

Machine Learning RSI ║ BullVisionOverview:
Introducing the Machine Learning RSI with KNN Adaptation – a cutting-edge momentum indicator that blends the classic Relative Strength Index (RSI) with machine learning principles. By leveraging K-Nearest Neighbors (KNN), this indicator aims at identifying historical patterns that resemble current market behavior and uses this context to refine RSI readings with enhanced sensitivity and responsiveness.
Unlike traditional RSI models, which treat every market environment the same, this version adapts in real-time based on how similar past conditions evolved, offering an analytical edge without relying on predictive assumptions.
Key Features:
🔁 KNN-Based RSI Refinement
This indicator uses a machine learning algorithm (K-Nearest Neighbors) to compare current RSI and price action characteristics to similar historical conditions. The resulting RSI is weighted accordingly, producing a dynamically adjusted value that reflects historical context.
📈 Multi-Feature Similarity Analysis
Pattern similarity is calculated using up to five customizable features:
RSI level
RSI momentum
Volatility
Linear regression slope
Price momentum
Users can adjust how many features are used to tailor the behavior of the KNN logic.
🧠 Machine Learning Weight Control
The influence of the machine learning model on the final RSI output can be fine-tuned using a simple slider. This lets you blend traditional RSI and machine learning-enhanced RSI to suit your preferred level of adaptation.
🎛️ Adaptive Filtering
Additional smoothing options (Kalman Filter, ALMA, Double EMA) can be applied to the RSI, offering better visual clarity and helping to reduce noise in high-frequency environments.
🎨 Visual & Accessibility Settings
Custom color palettes, including support for color vision deficiencies, ensure that trend coloring remains readable for all users. A built-in neon mode adds high-contrast visuals to improve RSI visibility across dark or light themes.
How It Works:
Similarity Matching with KNN:
At each candle, the current RSI and optional market characteristics are compared to historical bars using a KNN search. The algorithm selects the closest matches and averages their RSI values, weighted by similarity. The more similar the pattern, the greater its influence.
Feature-Based Weighting:
Similarity is determined using normalized values of the selected features, which gives a more refined result than RSI alone. You can choose to use only 1 (RSI) or up to all 5 features for deeper analysis.
Filtering & Blending:
After the machine learning-enhanced RSI is calculated, it can be optionally smoothed using advanced filters to suppress short-term noise or sharp spikes. This makes it easier to evaluate RSI signals in different volatility regimes.
Parameters Explained:
📊 RSI Settings:
Set the base RSI length and select your preferred smoothing method from 10+ moving average types (e.g., EMA, ALMA, TEMA).
🧠 Machine Learning Controls:
Enable or disable the KNN engine
Select how many nearest neighbors to compare (K)
Choose the number of features used in similarity detection
Control how much the machine learning engine affects the RSI calculation
🔍 Filtering Options:
Enable one of several advanced smoothing techniques (Kalman Filter, ALMA, Double EMA) to adjust the indicator’s reactivity and stability.
📏 Threshold Levels:
Define static overbought/oversold boundaries or reference dynamically adjusted thresholds based on historical context identified by the KNN algorithm.
🎨 Visual Enhancements:
Select between trend-following or impulse coloring styles. Customize color palettes to accommodate different types of color blindness. Enable neon-style effects for visual clarity.
Use Cases:
Swing & Trend Traders
Can use the indicator to explore how current RSI readings compare to similar market phases, helping to assess trend strength or potential turning points.
Intraday Traders
Benefit from adjustable filters and fast-reacting smoothing to reduce noise in shorter timeframes while retaining contextual relevance.
Discretionary Analysts
Use the adaptive OB/OS thresholds and visual cues to supplement broader confluence zones or market structure analysis.
Customization Tips:
Higher Volatility Periods: Use more neighbors and enable filtering to reduce noise.
Lower Volatility Markets: Use fewer features and disable filtering for quicker RSI adaptation.
Deeper Contextual Analysis: Increase KNN lookback and raise the feature count to refine pattern recognition.
Accessibility Needs: Switch to Deuteranopia or Monochrome mode for clearer visuals in specific color vision conditions.
Final Thoughts:
The Machine Learning RSI combines familiar momentum logic with statistical context derived from historical similarity analysis. It does not attempt to predict price action but rather contextualizes RSI behavior with added nuance. This makes it a valuable tool for those looking to elevate traditional RSI workflows with adaptive, research-driven enhancements.

Professional MSTI+ Trading Indicator"Professional MSTI+ Trading Indicator" is a comprehensive technical analysis tool that combines over 20 indicators to generate high-quality trading signals and assess market sentiment. The script integrates standard indicators (MACD, RSI, Bollinger Bands, Stochastic, Simple Moving Averages, and Volume Analysis) with advanced components (Squeeze Momentum, Fisher Transform, True Strength Index, Heikin-Ashi, Laguerre RSI, Hull MA) and further includes metrics such as ADX, Chaikin Money Flow, Williams %R, VWAP, and EMA for in-depth market analysis.
Key Features:
Multiple Presets for Different Trading Styles:
Choose from optimal configurations like Professional, Swing Trading, Day Trading, Scalping, or Reversal Hunter. Note that the presets may not work perfectly on all pairs, and manual calibration might be required. This flexibility allows you to fine-tune the settings to align with your unique strategies and signals.
Multi-Layered Signal Filtering:
Filters based on trend, volume, and volatility help eliminate false signals, enhancing the accuracy of market entries.
Comprehensive Fear & Greed Index:
The indicator aggregates data from RSI, volatility, momentum, trend, and volume to gauge overall market sentiment, providing an additional layer of market context.
Dynamic Information Panel:
Displays detailed status updates for each component (e.g., MACD, RSI, Laguerre RSI, TSI, Fisher Transform, Squeeze, Hull MA, etc.) along with a visual strength bar that represents the intensity of the trading signal.
Signal Generation:
Buy and sell signals are generated when a predefined number of conditions are met and confirmed over multiple bars. These signals are clearly displayed on the chart with arrows, making it easier to spot potential entry and exit points.
Alert Setup:
Built-in alert conditions allow you to receive real-time notifications when trading signals are generated, helping you stay on top of market movements.
"Professional MSTI+ Trading Indicator" is designed to enhance your trading strategy by providing a multi-faceted market analysis and an intuitive visual interface. While the presets offer a robust starting point, they may require manual calibration on certain pairs, giving you the flexibility to configure your own unique strategies and signals.

Machine Learning Trendlines Cluster [LuxAlgo]The ML Trendlines Cluster indicator allows traders to automatically identify trendlines using a machine learning algorithm based on k-means clustering and linear regression, highlighting trendlines from clustered prices.
For trader's convenience, trendlines can be filtered based on their slope, allowing them to filter out trendlines that are too horizontal, or instead keep them depending on the user-selected settings.
🔶 USAGE
Traders only need to set the number of trendlines (clusters) they want the tool to detect and the algorithm will do the rest.
By default the tool is set to detect 4 clusters over the last 500 bars, in the image above it is set to detect 10 clusters over the same period.
This approach only focuses on drawing trendlines from prices that share a common trading range, offering a unique perspective to traditional trendlines. Trendlines with a significant slope can highlight higher dispersion within its cluster.
🔹 Trendline Slope Filtering
Traders can filter trendlines by their slope to display only steep or flat trendlines relative to a user-defined threshold.
The image above shows the three different configurations of this feature:
Filtering disabled
Filter slopes above threshold
Filter slopes below threshold
🔶 DETAILS
K-means clustering is a popular machine-learning algorithm that finds observations in a data set that are similar to each other and places them in a group.
The process starts by randomly assigning each data point to an initial group and calculating the centroid for each. A centroid is the center of the group. K-means clustering forms the groups in such a way that the variances between the data points and the centroid of the cluster are minimized.
The trendlines are displayed according to the linear regression function calculated for each cluster.
🔶 SETTINGS
Window Size: Maximum number of bars to get data from
Clusters: Maximum number of clusters (trendlines) to detect
🔹 Optimization
Maximum Iteration Steps: Maximum loop iterations for cluster computation
🔹 Slope Filter
Threshold Multiplier: Multiplier applied to a volatility measure, higher multiplier equals higher threshold
Filter Slopes: Enable/Disable Trendline Slope Filtering, select to filter trendlines with slopes ABOVE or BELOW the threshold
🔹 Style
Upper Zone: Color to display in the top zone
Lower Zone: Color to display in the bottom zone
Lines: Style for the lines
Size: Line size

Volume Predictor [PhenLabs]📊 Volume Predictor
Version: PineScript™ v6
📌 Description
The Volume Predictor is an advanced technical indicator that leverages machine learning and statistical modeling techniques to forecast future trading volume. This innovative tool analyzes historical volume patterns to predict volume levels for upcoming bars, providing traders with valuable insights into potential market activity. By combining multiple prediction algorithms with pattern recognition techniques, the indicator delivers forward-looking volume projections that can enhance trading strategies and market analysis.
🚀 Points of Innovation:
Machine learning pattern recognition using Lorentzian distance metrics
Multi-algorithm prediction framework with algorithm selection
Ensemble learning approach combining multiple prediction methods
Real-time accuracy metrics with visual performance dashboard
Dynamic volume normalization for consistent scale representation
Forward-looking visualization with configurable prediction horizon
🔧 Core Components
Pattern Recognition Engine : Identifies similar historical volume patterns using Lorentzian distance metrics
Multi-Algorithm Framework : Offers five distinct prediction methods with configurable parameters
Volume Normalization : Converts raw volume to percentage scale for consistent analysis
Accuracy Tracking : Continuously evaluates prediction performance against actual outcomes
Advanced Visualization : Displays actual vs. predicted volume with configurable future bar projections
Interactive Dashboard : Shows real-time performance metrics and prediction accuracy
🔥 Key Features
The indicator provides comprehensive volume analysis through:
Multiple Prediction Methods : Choose from Lorentzian, KNN Pattern, Ensemble, EMA, or Linear Regression algorithms
Pattern Matching : Identifies similar historical volume patterns to project future volume
Adaptive Predictions : Generates volume forecasts for multiple bars into the future
Performance Tracking : Calculates and displays real-time prediction accuracy metrics
Normalized Scale : Presents volume as a percentage of historical maximums for consistent analysis
Customizable Visualization : Configure how predictions and actual volumes are displayed
Interactive Dashboard : View algorithm performance metrics in a customizable information panel
🎨 Visualization
Actual Volume Columns : Color-coded green/red bars showing current normalized volume
Prediction Columns : Semi-transparent blue columns representing predicted volume levels
Future Bar Projections : Forward-looking volume predictions with configurable transparency
Prediction Dots : Optional white dots highlighting future prediction points
Reference Lines : Visual guides showing the normalized volume scale
Performance Dashboard : Customizable panel displaying prediction method and accuracy metrics
📖 Usage Guidelines
History Lookback Period
Default: 20
Range: 5-100
This setting determines how many historical bars are analyzed for pattern matching. A longer period provides more historical data for pattern recognition but may reduce responsiveness to recent changes. A shorter period emphasizes recent market behavior but might miss longer-term patterns.
🧠 Prediction Method
Algorithm
Default: Lorentzian
Options: Lorentzian, KNN Pattern, Ensemble, EMA, Linear Regression
Selects the algorithm used for volume prediction:
Lorentzian: Uses Lorentzian distance metrics for pattern recognition, offering excellent noise resistance
KNN Pattern: Traditional K-Nearest Neighbors approach for historical pattern matching
Ensemble: Combines multiple methods with weighted averaging for robust predictions
EMA: Simple exponential moving average projection for trend-following predictions
Linear Regression: Projects future values based on linear trend analysis
Pattern Length
Default: 5
Range: 3-10
Defines the number of bars in each pattern for machine learning methods. Shorter patterns increase sensitivity to recent changes, while longer patterns may identify more complex structures but require more historical data.
Neighbors Count
Default: 3
Range: 1-5
Sets the K value (number of nearest neighbors) used in KNN and Lorentzian methods. Higher values produce smoother predictions by averaging more historical patterns, while lower values may capture more specific patterns but could be more susceptible to noise.
Prediction Horizon
Default: 5
Range: 1-10
Determines how many future bars to predict. Longer horizons provide more forward-looking information but typically decrease accuracy as the prediction window extends.
📊 Display Settings
Display Mode
Default: Overlay
Options: Overlay, Prediction Only
Controls how volume information is displayed:
Overlay: Shows both actual volume and predictions on the same chart
Prediction Only: Displays only the predictions without actual volume
Show Prediction Dots
Default: false
When enabled, adds white dots to future predictions for improved visibility and clarity.
Future Bar Transparency (%)
Default: 70
Range: 0-90
Controls the transparency of future prediction bars. Higher values make future bars more transparent, while lower values make them more visible.
📱 Dashboard Settings
Show Dashboard
Default: true
Toggles display of the prediction accuracy dashboard. When enabled, shows real-time accuracy metrics.
Dashboard Location
Default: Bottom Right
Options: Top Left, Top Right, Bottom Left, Bottom Right
Determines where the dashboard appears on the chart.
Dashboard Text Size
Default: Normal
Options: Small, Normal, Large
Controls the size of text in the dashboard for various display sizes.
Dashboard Style
Default: Solid
Options: Solid, Transparent
Sets the visual style of the dashboard background.
Understanding Accuracy Metrics
The dashboard provides key performance metrics to evaluate prediction quality:
Average Error
Shows the average difference between predicted and actual values
Positive values indicate the prediction tends to be higher than actual volume
Negative values indicate the prediction tends to be lower than actual volume
Values closer to zero indicate better prediction accuracy
Accuracy Percentage
A measure of how close predictions are to actual outcomes
Higher percentages (>70%) indicate excellent prediction quality
Moderate percentages (50-70%) indicate acceptable predictions
Lower percentages (<50%) suggest weaker prediction reliability
The accuracy metrics are color-coded for quick assessment:
Green: Strong prediction performance
Orange: Moderate prediction performance
Red: Weaker prediction performance
✅ Best Use Cases
Anticipate upcoming volume spikes or drops
Identify potential volume divergences from price action
Plan entries and exits around expected volume changes
Filter trading signals based on predicted volume support
Optimize position sizing by forecasting market participation
Prepare for potential volatility changes signaled by volume predictions
Enhance technical pattern analysis with volume projection context
⚠️ Limitations
Volume predictions become less accurate over longer time horizons
Performance varies based on market conditions and asset characteristics
Works best on liquid assets with consistent volume patterns
Requires sufficient historical data for pattern recognition
Sudden market events can disrupt prediction accuracy
Volume spikes may be muted in predictions due to normalization
💡 What Makes This Unique
Machine Learning Approach : Applies Lorentzian distance metrics for robust pattern matching
Algorithm Selection : Offers multiple prediction methods to suit different market conditions
Real-time Accuracy Tracking : Provides continuous feedback on prediction performance
Forward Projection : Visualizes multiple future bars with configurable display options
Normalized Scale : Presents volume as a percentage of maximum volume for consistent analysis
Interactive Dashboard : Displays key metrics with customizable appearance and placement
🔬 How It Works
The Volume Predictor processes market data through five main steps:
1. Volume Normalization:
Converts raw volume to percentage of maximum volume in lookback period
Creates consistent scale representation across different timeframes and assets
Stores historical normalized volumes for pattern analysis
2. Pattern Detection:
Identifies similar volume patterns in historical data
Uses Lorentzian distance metrics for robust similarity measurement
Determines strength of pattern match for prediction weighting
3. Algorithm Processing:
Applies selected prediction algorithm to historical patterns
For KNN/Lorentzian: Finds K nearest neighbors and calculates weighted prediction
For Ensemble: Combines multiple methods with optimized weighting
For EMA/Linear Regression: Projects trends based on statistical models
4. Accuracy Calculation:
Compares previous predictions to actual outcomes
Calculates average error and prediction accuracy
Updates performance metrics in real-time
5. Visualization:
Displays normalized actual volume with color-coding
Shows current and future volume predictions
Presents performance metrics through interactive dashboard
💡 Note:
The Volume Predictor performs optimally on liquid assets with established volume patterns. It’s most effective when used in conjunction with price action analysis and other technical indicators. The multi-algorithm approach allows adaptation to different market conditions by switching prediction methods. Pay special attention to the accuracy metrics when evaluating prediction reliability, as sudden market changes can temporarily reduce prediction quality. The normalized percentage scale makes the indicator consistent across different assets and timeframes, providing a standardized approach to volume analysis.

AI Adaptive Oscillator [PhenLabs]📊 Algorithmic Adaptive Oscillator
Version: PineScript™ v6
📌 Description
The AI Adaptive Oscillator is a sophisticated technical indicator that employs ensemble learning and adaptive weighting techniques to analyze market conditions. This innovative oscillator combines multiple traditional technical indicators through an AI-driven approach that continuously evaluates and adjusts component weights based on historical performance. By integrating statistical modeling with machine learning principles, the indicator adapts to changing market dynamics, providing traders with a responsive and reliable tool for market analysis.
🚀 Points of Innovation:
Ensemble learning framework with adaptive component weighting
Performance-based scoring system using directional accuracy
Dynamic volatility-adjusted smoothing mechanism
Intelligent signal filtering with cooldown and magnitude requirements
Signal confidence levels based on multi-factor analysis
🔧 Core Components
Ensemble Framework : Combines up to five technical indicators with performance-weighted integration
Adaptive Weighting : Continuous performance evaluation with automated weight adjustment
Volatility-Based Smoothing : Adapts sensitivity based on current market volatility
Pattern Recognition : Identifies potential reversal patterns with signal qualification criteria
Dynamic Visualization : Professional color schemes with gradient intensity representation
Signal Confidence : Three-tiered confidence assessment for trading signals
🔥 Key Features
The indicator provides comprehensive market analysis through:
Multi-Component Ensemble : Integrates RSI, CCI, Stochastic, MACD, and Volume-weighted momentum
Performance Scoring : Evaluates each component based on directional prediction accuracy
Adaptive Smoothing : Automatically adjusts based on market volatility
Pattern Detection : Identifies potential reversal patterns in overbought/oversold conditions
Signal Filtering : Prevents excessive signals through cooldown periods and minimum change requirements
Confidence Assessment : Displays signal strength through intuitive confidence indicators (average, above average, excellent)
🎨 Visualization
Gradient-Filled Oscillator : Color intensity reflects strength of market movement
Clear Signal Markers : Distinct bullish and bearish pattern signals with confidence indicators
Range Visualization : Clean representation of oscillator values from -6 to 6
Zero Line : Clear demarcation between bullish and bearish territory
Customizable Colors : Color schemes that can be adjusted to match your chart style
Confidence Symbols : Intuitive display of signal confidence (no symbol, +, or ++) alongside direction markers
📖 Usage Guidelines
⚙️ Settings Guide
Color Settings
Bullish Color
Default: #2b62fa (Blue)
This setting controls the color representation for bullish movements in the oscillator. The color appears when the oscillator value is positive (above zero), with intensity indicating the strength of the bullish momentum. A brighter shade indicates stronger bullish pressure.
Bearish Color
Default: #ce9851 (Amber)
This setting determines the color representation for bearish movements in the oscillator. The color appears when the oscillator value is negative (below zero), with intensity reflecting the strength of the bearish momentum. A more saturated shade indicates stronger bearish pressure.
Signal Settings
Signal Cooldown (bars)
Default: 10
Range: 1-50
This parameter sets the minimum number of bars that must pass before a new signal of the same type can be generated. Higher values reduce signal frequency and help prevent overtrading during choppy market conditions. Lower values increase signal sensitivity but may generate more false positives.
Min Change For New Signal
Default: 1.5
Range: 0.5-3.0
This setting defines the minimum required change in oscillator value between consecutive signals of the same type. It ensures that new signals represent meaningful changes in market conditions rather than minor fluctuations. Higher values produce fewer but potentially higher-quality signals, while lower values increase signal frequency.
AI Core Settings
Base Length
Default: 14
Minimum: 2
This fundamental setting determines the primary calculation period for all technical components in the ensemble (RSI, CCI, Stochastic, etc.). It represents the lookback window for each component’s base calculation. Shorter periods create a more responsive but potentially noisier oscillator, while longer periods produce smoother signals with potential lag.
Adaptive Speed
Default: 0.1
Range: 0.01-0.3
Controls how quickly the oscillator adapts to new market conditions through its volatility-adjusted smoothing mechanism. Higher values make the oscillator more responsive to recent price action but potentially more erratic. Lower values create smoother transitions but may lag during rapid market changes. This parameter directly influences the indicator’s adaptiveness to market volatility.
Learning Lookback Period
Default: 150
Minimum: 10
Determines the historical data range used to evaluate each ensemble component’s performance and calculate adaptive weights. This setting controls how far back the AI “learns” from past performance to optimize current signals. Longer periods provide more stable weight distribution but may be slower to adapt to regime changes. Shorter periods adapt more quickly but may overreact to recent anomalies.
Ensemble Size
Default: 5
Range: 2-5
Specifies how many technical components to include in the ensemble calculation.
Understanding The Interaction Between Settings
Base Length and Learning Lookback : The base length determines the reactivity of individual components, while the lookback period determines how their weights are adjusted. These should be balanced according to your timeframe - shorter timeframes benefit from shorter base lengths, while the lookback should generally be 10-15 times the base length for optimal learning.
Adaptive Speed and Signal Cooldown : These settings control sensitivity from different angles. Increasing adaptive speed makes the oscillator more responsive, while reducing signal cooldown increases signal frequency. For conservative trading, keep adaptive speed low and cooldown high; for aggressive trading, do the opposite.
Ensemble Size and Min Change : Larger ensembles provide more stable signals, allowing for a lower minimum change threshold. Smaller ensembles might benefit from a higher threshold to filter out noise.
Understanding Signal Confidence Levels
The indicator provides three distinct confidence levels for both bullish and bearish signals:
Average Confidence (▲ or ▼) : Basic signal that meets the minimum pattern and filtering criteria. These signals indicate potential reversals but with moderate confidence in the prediction. Consider using these as initial alerts that may require additional confirmation.
Above Average Confidence (▲+ or ▼+) : Higher reliability signal with stronger underlying metrics. These signals demonstrate greater consensus among the ensemble components and/or stronger historical performance. They offer increased probability of successful reversals and can be traded with less additional confirmation.
Excellent Confidence (▲++ or ▼++) : Highest quality signals with exceptional underlying metrics. These signals show strong agreement across oscillator components, excellent historical performance, and optimal signal strength. These represent the indicator’s highest conviction trade opportunities and can be prioritized in your trading decisions.
Confidence assessment is calculated through a multi-factor analysis including:
Historical performance of ensemble components
Degree of agreement between different oscillator components
Relative strength of the signal compared to historical thresholds
✅ Best Use Cases:
Identify potential market reversals through oscillator extremes
Filter trade signals based on AI-evaluated component weights
Monitor changing market conditions through oscillator direction and intensity
Confirm trade signals from other indicators with adaptive ensemble validation
Detect early momentum shifts through pattern recognition
Prioritize trading opportunities based on signal confidence levels
Adjust position sizing according to signal confidence (larger for ++ signals, smaller for standard signals)
⚠️ Limitations
Requires sufficient historical data for accurate performance scoring
Ensemble weights may lag during dramatic market condition changes
Higher ensemble sizes require more computational resources
Performance evaluation quality depends on the learning lookback period length
Even high confidence signals should be considered within broader market context
💡 What Makes This Unique
Adaptive Intelligence : Continuously adjusts component weights based on actual performance
Ensemble Methodology : Combines strength of multiple indicators while minimizing individual weaknesses
Volatility-Adjusted Smoothing : Provides appropriate sensitivity across different market conditions
Performance-Based Learning : Utilizes historical accuracy to improve future predictions
Intelligent Signal Filtering : Reduces noise and false signals through sophisticated filtering criteria
Multi-Level Confidence Assessment : Delivers nuanced signal quality information for optimized trading decisions
🔬 How It Works
The indicator processes market data through five main components:
Ensemble Component Calculation :
Normalizes traditional indicators to consistent scale
Includes RSI, CCI, Stochastic, MACD, and volume components
Adapts based on the selected ensemble size
Performance Evaluation :
Analyzes directional accuracy of each component
Calculates continuous performance scores
Determines adaptive component weights
Oscillator Integration :
Combines weighted components into unified oscillator
Applies volatility-based adaptive smoothing
Scales final values to -6 to 6 range
Signal Generation :
Detects potential reversal patterns
Applies cooldown and magnitude filters
Generates clear visual markers for qualified signals
Confidence Assessment :
Evaluates component agreement, historical accuracy, and signal strength
Classifies signals into three confidence tiers (average, above average, excellent)
Displays intuitive confidence indicators (no symbol, +, ++) alongside direction markers
💡 Note:
The AI Adaptive Oscillator performs optimally when used with appropriate timeframe selection and complementary indicators. Its adaptive nature makes it particularly valuable during changing market conditions, where traditional fixed-weight indicators often lose effectiveness. The ensemble approach provides a more robust analysis by leveraging the collective intelligence of multiple technical methodologies. Pay special attention to the signal confidence indicators to optimize your trading decisions - excellent (++) signals often represent the most reliable trade opportunities.
Bayesian TrendEnglish Description (primary)
1. Overview
This script implements a Naive Bayesian classifier to estimate the probability of an upcoming bullish, bearish, or neutral move. It combines multiple indicators—RSI, MACD histogram, EMA price difference in ATR units, ATR level vs. its average, and Volume vs. its average—to calculate likelihoods for each market direction. Each indicator is “binned” (categorized into discrete zones) and assigned conditional probabilities for bullish/bearish/neutral scenarios. The script then normalizes these probabilities and paints bars in green if bullish is most likely, red if bearish is most likely, or blue if neutral is most likely. A small table is also displayed in the top-right corner of the chart, showing real-time probabilities.
2. How it works
Indicator Calculations: The script calculates RSI, MACD (line and histogram), EMA, ATR, and Volume metrics.
Binning: Each metric is converted into a discrete category (e.g., low, medium, high). For example, RSI < 30 is binned as “low,” while RSI > 70 is binned as “high.”
Conditional Probabilities: User-defined tables specify the conditional probabilities of each bin under three hypotheses (Up, Down, Neutral).
Naive Bayesian Formula: The script multiplies the relevant conditional probabilities, normalizes them, and derives the final probabilities (Up, Down, or Neutral).
Visualization:
Bar Colors: Bars are green when the Up probability exceeds 50%, red for Down, and blue otherwise.
Table: Displays numeric probabilities of Up, Down, and Neutral in percentage terms.
3. How to use it
Add the script to your chart.
Observe the colored bars:
Green suggests a higher probability for bullish movement.
Red suggests a higher probability for bearish movement.
Blue indicates a higher probability of sideways or uncertain conditions.
Check the table in the top-right corner to see exact probabilities (Up/Down/Neutral).
Use the input settings to adjust thresholds (RSI, MACD, Volume, etc.), define alert conditions (e.g., when Up probability crosses 50%), and decide whether to trigger alerts on bar close or in real-time.
4. Originality and usefulness
Originality: This script uniquely applies a Naive Bayesian approach to a blend of classic and volume-based indicators. It demonstrates how different indicator “zones” can be combined to produce probabilistic insights.
Usefulness: Traders can interpret the probability breakdown to gauge the script’s bias. Unlike single indicators, this approach synthesizes several signals, potentially offering a more holistic perspective on market conditions.
5. Limitations
The conditional probabilities are manually assigned and may not reflect actual market behavior across all instruments or timeframes.
Results depend on the user’s choice of thresholds and indicator settings.
Like any indicator, past performance does not guarantee future results. Always confirm signals with additional analysis.
6. Disclaimer
This script is intended for educational and informational purposes only. It does not constitute financial advice. Trading involves significant risk, and you should make decisions based on your own analysis. Neither the script’s author nor TradingView is liable for any financial losses.
Русское описание (Russian translation, optional)
Этот индикатор реализует наивный Байесовский классификатор для оценки вероятности предстоящего роста (Up), падения (Down) или бокового движения (Neutral). Он комбинирует несколько индикаторов—RSI, гистограмму MACD, разницу цены и EMA в единицах ATR, уровень ATR относительно своего среднего значения и объём относительно своего среднего—чтобы вычислить вероятности для каждого направления рынка. Каждый индикатор делится на «зоны» (low, mid, high), которым приписаны условные вероятности для бычьего/медвежьего/нейтрального исхода. Скрипт нормирует эти вероятности и раскрашивает бары в зелёный, красный или синий цвет в зависимости от того, какая вероятность выше. Также в правом верхнем углу отображается таблица с текущими значениями вероятностей.

SuperTrend + Relative Volume (Kernel Optimized)Introducing our new KDE Optimized Supertrend + Relative Volume Indicator!
This innovative indicator combines the power of the Supertrend indicator along with Relative Volume. It utilizes the Kernel Density Estimation (KDE) to estimate the probability of a candlestick marking a significant trend break or reversal.
❓How to Interpret the KDE %:
The KDE % is a crucial metric that reflects the likelihood that the current candlestick represents a true break in the SuperTrend line, supported by an increase in relative volume. It estimates the probability of a trend shift or continuation based on historical SuperTrend breaks and volume patterns:
Low KDE %: A lower probability that the current break is significant. Price action is less likely to reverse, and the trend may continue.
Moderate KDE - High KDE %: An increased possibility that a trend reversal or consolidation could occur. Traders should start watching for confirmation signals.
📌How Does It Work?
The SuperTrend indicator uses the Average True Range (ATR) to determine the direction of the trend and identifies when the price crosses the SuperTrend line, signaling a potential trend reversal. Here's how the KDE Optimized SuperTrend Indicator works:
SuperTrend Calculation: The SuperTrend indicator is calculated, and when the price breaks above (bullish) or below (bearish) the SuperTrend line, it is logged as a significant event.
Relative Volume: For each break in the SuperTrend line, we calculate the relative volume (current volume vs. the average volume over a defined period). High relative volume can suggest stronger confirmation of the trend break.
KDE Array Calculation: KDE is applied to the break points and relative volume data:
Define the KDE options: Bandwidth, Number of Steps, and Array Range (Array Max - Array Min).
Create a density range array using the defined number of steps, corresponding to potential break points.
Apply a Gaussian kernel function to the break points and volume data to estimate the likelihood of the trend break being significant.
KDE Value and Signal Generation: The KDE array is updated as each break occurs. The KDE % is calculated for the breakout candlestick, representing the likelihood of the trend break being significant. If the KDE value exceeds the defined activation threshold, a darker bullish or bearish arrow is plotted after bar confirmation. If the KDE value falls below the threshold, a more transparent arrow is drawn, indicating a possible but lower probability break.
⚙️Settings:
SuperTrend Settings:
ATR Length: The period over which the Average True Range (ATR) is calculated.
Multiplier: The multiplier applied to the ATR to determine the SuperTrend threshold.
KDE Settings:
Bandwidth: Determines the smoothness of the KDE function and the width of the influence of each break point.
Number of Bins (Steps): Defines the precision of the KDE algorithm, with higher values offering more detailed calculations.
KDE Threshold %: The level at which relative volume is considered significant for confirming a break.
Relative Volume Length: The number of historic candles used in calculating KDE %
Bars pattern MLThis script implements a K-Nearest Neighbors (KNN)-based machine learning model to predict future price movements in financial markets. It analyzes past price action using Euclidean distance and selects the most similar historical patterns to estimate future price changes. Unlike traditional KNN implementations, this approach optimizes distance calculations by maintaining a dynamically updated list of the closest neighbors, ensuring efficient selection without the need for sorting. The model generates a forecasted price trajectory based on incremental predictions, which are visualized on the chart using polylines for better interpretability.
Machine Learning: kNN Trend PredictorThe kNN Trend Predictor is a machine learning-based indicator that uses the k-Nearest Neighbors (kNN) algorithm for price prediction in trading. By analyzing historical price movements and computing Euclidean distances, the script identifies the closest past price patterns and forecasts potential trends. It provides color-coded trend signals, optional trade entry labels, and alerts for long and short signals.
Naive Bayes Candlestick Pattern Classifier v1.1 BETAAn intermezzo on why i made this script publication..
A : Candlestick Pattern took hours to backtest, why not using Machine Learning techniques?
B : Machine Learning, no that's gonna be really heavy bro!
A : Not really, because we use Naive Bayes.
B : The simplest, yet powerful machine learning algorithm to separate (a.k.a classify) multivariate data.
----------------------------------------------------------------------------------------------------------------------
Hello, everyone!
After deep research in extracting meaningful information from the market, I ended up building this powerful machine learning indicator based on the evolution of Bayesian Statistics. This indicator not only leverages the simplicity of Naive Bayes but also extends its application to candlestick pattern analysis, making it an invaluable tool for traders who are looking to enhance their technical analysis without spending countless hours manually backtesting each pattern on each market!.
What most interesting part is actually after learning all of likely useless methods like fibonacci, supply and demand, volume profile, etc. We always ended up back to basic like support and resistance and candlestick patterns, but with a slight twist on strategy algorithm design and statistical approach. Thus, the only reason why i made this, because i exactly know that you guys will ended up in this position as time goes by.
The essence of this indicator lies in its ability to automate the recognition and statistical evaluation of various candlestick patterns. Traditionally, traders have relied on visual inspection and manual backtesting to determine the effectiveness of patterns like Bullish Engulfing, Bearish Engulfing, Harami variations, Hammer formations, and even more complex multi-candle patterns such as Three White Soldiers, Three Black Crows, Dark Cloud Cover, and Piercing Pattern. However, these conventional methods are both time-consuming and prone to subjective bias.
To address these challenges, I employed Naive Bayes—a probabilistic classifier that, despite its simplicity, offers robust performance in various domains. Naive Bayes assumes that each feature is independent of the others given the class label, which, although a strong assumption, works remarkably well in practice, especially when the dataset is large like market data and the feature space is high-dimensional. In our case, each candlestick pattern acts as a feature that can be statistically evaluated based on its historical performance. The indicator calculates a probability that a given pattern will lead to a price reversal, by comparing the pattern’s close price to the highest or lowest price achieved in a lookahead window.
One of the standout features of this script is its flexibility. Each candlestick pattern is not only coded into the system but also comes with individual toggles to enable or disable them based on your trading strategy. This means you can choose to focus on single-candle patterns like Bullish Engulfing or more complex multi-candle formations such as Three White Soldiers, without modifying the core code. The built-in customization options allow you to adjust colors and labels for each pattern, giving you the freedom to tailor the visual output to your preference. This level of customization ensures that the indicator integrates seamlessly into your existing TradingView setup.
Moreover, the indicator isn’t just about pattern recognition—it also incorporates outcome-based learning. Every time a pattern is detected, it looks ahead a predefined number of bars to evaluate if the expected reversal actually materialized. This outcome is then stored in arrays, and over time, the script dynamically calculates the probability of success for each pattern. These probabilities are presented in a real-time updating table on your chart, which shows not only the percentage probability but also the count of historical occurrences. With this information at your fingertips, you can quickly gauge the reliability of each pattern in your chosen market and timeframe.
Another significant advantage of this approach is its speed and efficiency. While more complex machine learning models like neural networks might require heavy computational resources and longer training times, the Naive Bayes classifier in this script is lightweight, instantaneous and can be updated on the fly with each new bar. This real-time capability is essential for modern traders who need to make quick decisions in fast-paced markets.
Furthermore, by automating the process of backtesting, the indicator frees up your time to focus on other aspects of trading strategy development. Instead of manually analyzing hundreds or even thousands of candles, you can rely on the statistical power of Naive Bayes to provide you with insights on which patterns are most likely to result in profitable moves. This not only enhances your efficiency but also helps to eliminate the cognitive biases that often plague manual analysis.
In summary, this indicator represents a fusion of traditional candlestick analysis with modern machine learning techniques. It harnesses the simplicity and effectiveness of Naive Bayes to deliver a dynamic, real-time evaluation of various candlestick patterns. Whether you are a seasoned trader looking to refine your technical analysis or a beginner eager to understand market dynamics, this tool offers a powerful, customizable, and efficient solution. Welcome to a new era where advanced statistical methods meet practical trading insights—happy trading and may your patterns always be in your favor!
Note : On this current released beta version, you must manually adjust reversal percentage move based on each market. Further updates may include automated best range detection and probability.
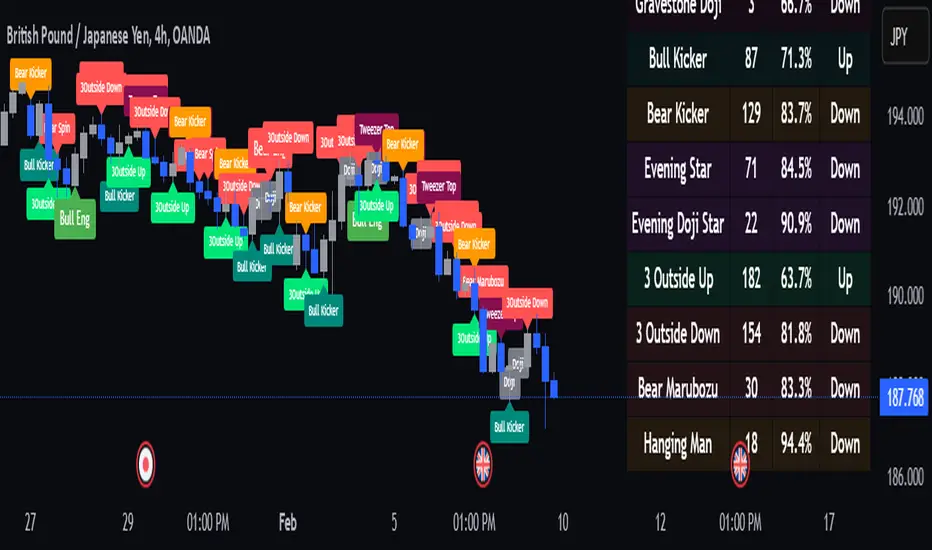
Machine Learning SupertrendThe Machine Learning Supertrend is an advanced trend-following indicator that enhances the traditional Supertrend with Gaussian Process Regression (GPR) and kernel-based learning. Unlike conventional methods that rely purely on historical ATR values, this indicator integrates machine learning techniques to dynamically estimate volatility and forecast future price movements, resulting in a more adaptive and robust trend detection system.
At the core of this indicator lies Gaussian Process Regression (GPR), which utilizes a Radial Basis Function (RBF) kernel to model price distributions and anticipate future trends. Instead of simply looking at past price action, it constructs a kernel matrix, enabling a probabilistic approach to price forecasting. This allows the indicator to not only detect current trends but also project potential trend reversals with greater accuracy.
By applying machine learning to ATR estimation, the ML Supertrend dynamically adjusts its thresholds based on predicted values rather than a fixed multiplier. This makes the trend signals more responsive to market conditions, reducing false signals and minimizing whipsaws often seen with traditional Supertrend indicators. The upper and lower bands are no longer static but evolve based on the underlying price structure, improving the reliability of trend shifts.
When the price crosses these adaptive levels, the indicator detects a trend change and plots it accordingly. Green signifies a bullish trend, while red indicates a bearish one. Alerts can also be triggered when the trend shifts, allowing traders to react quickly to potential reversals.
What makes this approach powerful is its ability to adapt to different market conditions. Traditional ATR-based methods use fixed parameters that might not always be optimal, whereas this ML-driven Supertrend continuously refines its estimations based on real-time data. The result is a more intelligent, less lagging, and highly adaptive trend-following tool.
This indicator is particularly useful for traders looking to enhance trend-following strategies with AI-driven insights. It reduces noise, improves signal reliability, and even offers a degree of trend forecasting, making it ideal for those who want a more advanced and dynamic alternative to standard Supertrend indicators.
This indicator is provided for educational and informational purposes only. It does not constitute financial advice, and past performance is not indicative of future results. Trading involves risk, and users should conduct their own research and use proper risk management before making investment decisions.
Johnny's Machine Learning Moving Average (MLMA) w/ Trend Alerts📖 Overview
Johnny's Machine Learning Moving Average (MLMA) w/ Trend Alerts is a powerful adaptive moving average indicator designed to capture market trends dynamically. Unlike traditional moving averages (e.g., SMA, EMA, WMA), this indicator incorporates volatility-based trend detection, Bollinger Bands, ADX, and RSI, offering a comprehensive view of market conditions.
The MLMA is "machine learning-inspired" because it adapts dynamically to market conditions using ATR-based windowing and integrates multiple trend strength indicators (ADX, RSI, and volatility bands) to provide an intelligent moving average calculation that learns from recent price action rather than being static.
🛠 How It Works
1️⃣ Adaptive Moving Average Selection
The MLMA automatically selects one of four different moving averages:
📊 EMA (Exponential Moving Average) – Reacts quickly to price changes.
🔵 HMA (Hull Moving Average) – Smooth and fast, reducing lag.
🟡 WMA (Weighted Moving Average) – Gives recent prices more importance.
🔴 VWAP (Volume Weighted Average Price) – Accounts for volume impact.
The user can select which moving average type to use, making the indicator customizable based on their strategy.
2️⃣ Dynamic Trend Detection
ATR-Based Adaptive Window 📏
The Average True Range (ATR) determines the window size dynamically.
When volatility is high, the moving average window expands, making the MLMA more stable.
When volatility is low, the window shrinks, making the MLMA more responsive.
Trend Strength Filters 📊
ADX (Average Directional Index) > 25 → Indicates a strong trend.
RSI (Relative Strength Index) > 70 or < 30 → Identifies overbought/oversold conditions.
Price Position Relative to Upper/Lower Bands → Determines bullish vs. bearish momentum.
3️⃣ Volatility Bands & Dynamic Support/Resistance
Bollinger Bands (BB) 📉
Uses standard deviation-based bands around the MLMA to detect overbought and oversold zones.
Upper Band = Resistance, Lower Band = Support.
Helps traders identify breakout potential.
Adaptive Trend Bands 🔵🔴
The MLMA has built-in trend envelopes.
When price breaks the upper band, bullish momentum is confirmed.
When price breaks the lower band, bearish momentum is confirmed.
4️⃣ Visual Enhancements
Dynamic Gradient Fills 🌈
The trend strength (ADX-based) determines the gradient intensity.
Stronger trends = More vivid colors.
Weaker trends = Lighter colors.
Trend Reversal Arrows 🔄
🔼 Green Up Arrow: Bullish reversal signal.
🔽 Red Down Arrow: Bearish reversal signal.
Trend Table Overlay 🖥
Displays ADX, RSI, and Trend State dynamically on the chart.
📢 Trading Signals & How to Use It
1️⃣ Bullish Signals 📈
✅ Conditions for a Long (Buy) Trade:
The MLMA crosses above the lower band.
The ADX is above 25 (confirming trend strength).
RSI is above 55, indicating positive momentum.
Green trend reversal arrow appears (confirmation of a bullish reversal).
🔹 How to Trade It:
Enter a long trade when the MLMA turns bullish.
Set stop-loss below the lower Bollinger Band.
Target previous resistance levels or use the upper band as take-profit.
2️⃣ Bearish Signals 📉
✅ Conditions for a Short (Sell) Trade:
The MLMA crosses below the upper band.
The ADX is above 25 (confirming trend strength).
RSI is below 45, indicating bearish pressure.
Red trend reversal arrow appears (confirmation of a bearish reversal).
🔹 How to Trade It:
Enter a short trade when the MLMA turns bearish.
Set stop-loss above the upper Bollinger Band.
Target the lower band as take-profit.
💡 What Makes This a Machine Learning Moving Average?
📍 1️⃣ Adaptive & Self-Tuning
Unlike static moving averages that rely on fixed parameters, this MLMA automatically adjusts its sensitivity to market conditions using:
ATR-based dynamic windowing 📏 (Expands/contracts based on volatility).
Adaptive smoothing using EMA, HMA, WMA, or VWAP 📊.
Multi-indicator confirmation (ADX, RSI, Volatility Bands) 🏆.
📍 2️⃣ Intelligent Trend Confirmation
The MLMA "learns" from recent price movements instead of blindly following a fixed-length average.
It incorporates ADX & RSI trend filtering to reduce noise & false signals.
📍 3️⃣ Dynamic Color-Coding for Trend Strength
Strong trends trigger more vivid colors, mimicking confidence levels in machine learning models.
Weaker trends appear faded, suggesting uncertainty.
🎯 Why Use the MLMA?
✅ Pros
✔ Combines multiple trend indicators (MA, ADX, RSI, BB).
✔ Automatically adjusts to market conditions.
✔ Filters out weak trends, making it more reliable.
✔ Visually intuitive (gradient colors & reversal arrows).
✔ Works across all timeframes and assets.
⚠️ Cons
❌ Not a standalone strategy → Best used with volume confirmation or candlestick analysis.
❌ Can lag slightly in fast-moving markets (due to smoothing).

QT RSI [ W.ARITAS ]The QT RSI is an innovative technical analysis indicator designed to enhance precision in market trend identification and decision-making. Developed using advanced concepts in quantum mechanics, machine learning (LSTM), and signal processing, this indicator provides actionable insights for traders across multiple asset classes, including stocks, crypto, and forex.
Key Features:
Dynamic Color Gradient: Visualizes market conditions for intuitive interpretation:
Green: Strong buy signal indicating bullish momentum.
Blue: Neutral or observation zone, suggesting caution or lack of a clear trend.
Red: Strong sell signal indicating bearish momentum.
Quantum-Enhanced RSI: Integrates adaptive energy levels, dynamic smoothing, and quantum oscillators for precise trend detection.
Hybrid Machine Learning Model: Combines LSTM neural networks and wavelet transforms for accurate prediction and signal refinement.
Customizable Settings: Includes advanced parameters for dynamic thresholds, sensitivity adjustment, and noise reduction using Kalman and Jurik filters.
How to Use:
Interpret the Color Gradient:
Green Zone: Indicates bullish conditions and potential buy opportunities. Look for upward momentum in the RSI plot.
Blue Zone: Represents a neutral or consolidation phase. Monitor the market for trend confirmation.
Red Zone: Indicates bearish conditions and potential sell opportunities. Look for downward momentum in the RSI plot.
Follow Overbought/Oversold Boundaries:
Use the upper and lower RSI boundaries to identify overbought and oversold conditions.
Leverage Advanced Filtering:
The smoothed signals and quantum oscillator provide a robust framework for filtering false signals, making it suitable for volatile markets.
Application: Ideal for traders and analysts seeking high-precision tools for:
Identifying entry and exit points.
Detecting market reversals and momentum shifts.
Enhancing algorithmic trading strategies with cutting-edge analytics.
Machine Learning Moving Average [LuxAlgo]The Machine Learning Moving Average (MLMA) is a responsive moving average making use of the weighting function obtained Gaussian Process Regression method. Characteristic such as responsiveness and smoothness can be adjusted by the user from the settings.
The moving average also includes bands, used to highlight possible reversals.
🔶 USAGE
The Machine Learning Moving Average smooths out noisy variations from the price, directly estimating the underlying trend in the price.
A higher "Window" setting will return a longer-term moving average while increasing the "Forecast" setting will affect the responsiveness and smoothness of the moving average, with higher positive values returning a more responsive moving average and negative values returning a smoother but less responsive moving average.
Do note that an excessively high "Forecast" setting will result in overshoots, with the moving average having a poor fit with the price.
The moving average color is determined according to the estimated trend direction based on the bands described below, shifting to blue (default) in an uptrend and fushia (default) in downtrends.
The upper and lower extremities represent the range within which price movements likely fluctuate.
Signals are generated when the price crosses above or below the band extremities, with turning points being highlighted by colored circles on the chart.
🔶 SETTINGS
Window: Calculation period of the moving average. Higher values yield a smoother average, emphasizing long-term trends and filtering out short-term fluctuations.
Forecast: Sets the projection horizon for Gaussian Process Regression. Higher values create a more responsive moving average but will result in more overshoots, potentially worsening the fit with the price. Negative values will result in a smoother moving average.
Sigma: Controls the standard deviation of the Gaussian kernel, influencing weight distribution. Higher Sigma values return a longer-term moving average.
Multiplicative Factor: Adjusts the upper and lower extremity bounds, with higher values widening the bands and lowering the amount of returned turning points.
🔶 RELATED SCRIPTS
Machine-Learning-Gaussian-Process-Regression
SuperTrend-AI-Clustering
Machine Learning Price Target Prediction Signals [AlgoAlpha]Introducing the Machine Learning Price Target Predictions, a cutting-edge trading tool that leverages kernel regression to provide accurate price targets and enhance your trading strategy. This indicator combines trend-based signals with advanced machine learning techniques, offering predictive insights into potential price movements. Perfect for traders looking to make data-driven decisions with confidence.
What is Kernel Regression and How It Works
Kernel regression is a non-parametric machine learning technique that estimates the relationship between variables by weighting data points based on their similarity to a given input. The similarity is determined using a kernel function, such as the Gaussian (RBF) kernel, which assigns higher weights to closer data points and progressively lower weights to farther ones. This allows the model to make smooth and adaptive predictions, balancing recent data and historical trends.
Key Features
🎯 Predictive Price Targets : Uses kernel regression to estimate the magnitude of price movements.
📈 Dynamic Trend Analysis : Multiple trend detection methods, including EMA crossovers, Hull Moving Average, and SuperTrend.
🔧 Customizable Settings : Adjust bandwidth for kernel regression and tweak trend indicator parameters to suit your strategy.
📊 Visual Trade Levels : Displays take-profit and stop-loss levels directly on the chart with customizable colors.
📋 Performance Metrics : Real-time win rate, recommended risk-reward ratio, and training data size displayed in an on-chart table.
🔔 Alerts : Get notified for new trends, take-profit hits, and stop-loss triggers.
How to Use
🛠 Add the Indicator : Add it to your favorites and apply it to your chart. Configure the trend detection method (SuperTrend, HMA, or EMA crossover) and other parameters based on your preferences.
📊 Analyze Predictions : Observe the predicted move size, recommended risk-reward ratio, and trend direction. Use the displayed levels for trade planning.
🔔 Set Alerts : Enable alerts for trend signals, take-profit hits, or stop-loss triggers to stay informed without constant monitoring.
How It Works
The indicator calculates features such as price volatility, relative strength, and trend signals, which are stored during training periods. When a trend change is detected, the kernel regression model predicts the likely price move based on these features. Predictions are smoothed using the specified bandwidth to avoid overfitting while ensuring timely responses to feature changes. Visualized take-profit and stop-loss levels help traders optimize risk management. Real-time metrics like win rate and recommended risk-reward ratios provide actionable insights for decision-making.