Ergodic Mean Deviation Indicator [CC]The Ergodic Mean Deviation Indicator was created by William Blau and this is a hidden gem that takes the difference between the current price and it's exponential moving average and then double smooths the result to create this indicator. This double smoothing of course creates a lag that allows it to give off a sustained buy signal during a bullish trend and vice versa. This is a very fun indicator to experiment with and surprised that no one on here gives William Blau much attention so I will go ahead and publish the rest of his scripts eventually. I have included strong buy and sell signals in addition to normal ones so strong signals are darker in color and normal signals are lighter in color. Buy when the line turns green and sell when it turns red.
Let me know if there are any other indicators or scripts you would like to see me publish!
Mean

Ichimoku Kinko Hyo1) Plot up to 8 moving averages or donchian channels.
2) Moving average types include SMA, EMA, Double EMA, Triple EMA, Quadruple EMA, Pentuple EMA, Zero-Lag EMA, Tillson's T3, Hull's MA, Smoothed MA, Weighted MA, Volume-Weighted MA.
3) Donchian channels can be plotted for a user specified period with upper and lower lines based on either A) highest and lowest prices or B) highest candle body (open/close) and lowest candle body (open/close) over a specified period.
4) Plot 2 arithmetic means averaging any 2 to 8 of the previously mentioned moving averages or donchian median lines.
5) Display 2 fills/clouds between any of the previously mentioned plots.
6) Enough flexibility in the script to utilize Ichimoku Kinko Hyo with correctly adjusted offsets.
7) Ichimoku Kinko Hyo is the default settings. Display additional moving averages or donchian channels for comparison.
"One Half" color scheme by Son A. Pham

Deviation BandsThis indicator plots the 1, 2 and 3 standard deviations from the mean as bands of color (hot and cold). Useful in identifying likely points of mean reversion.
Default mean is WMA 200 but can be SMA, EMA, VWMA, and VAWMA.
Calculating the standard deviation is done by first cleaning the data of outliers (configurable).

ETF 3-Day Reversion StrategyIntroduction: This strategy is a modification of the “3-day Mean Reversion Strategy” from the book "High Probability ETF Trading" by Larry Connors and Cesar Alvarez. In the book, the authors discuss a high-probability ETF mean reversion strategy for a 1-day time-frame with these simple rules:
The price must be above the 200 day SMA and below the 5 day SMA.
The low of today must be lower than the low of yesterday (must be true for 3 consecutive days)
The high of today must be lower than the high of yesterday (must be true for 3 consecutive days)
If the 3 rules above are true, then buy on the close of the current day.
Exit when the closing price crosses above the 5 day SMA.
In practice and in backtesting, I’ve found that the strategy consistently works better when using an EMA for the trend-line instead of an SMA. So, this script uses an EMA for the trend-line. I’ve also made the length of the exit EMA adjustable.
How it works:
The Strategy will buy when the buy conditions above are true. The strategy will sell when the closing price crosses over the Exit Moving Average
Plots:
Green line = Exit Moving Average (Default 5 Day EMA)
Blue line = 5 Day EMA (Used as Entry Criteria)
Disclaimer: Open-source scripts I publish in the community are largely meant to spark ideas that can be used as building blocks for part of a more robust trade management strategy. If you would like to implement a version of any script, I would recommend making significant additions/modifications to the strategy & risk management functions. If you don’t know how to program in Pine, then hire a Pine-coder. We can help!

EMA MTF PlusI like trading the 1 minute and 3 minutes time-frames. I'm what is commonly called a "scalper". Long term investments yes, I have some, but for trading, I don't have neither the time,
nor the patience to wait hours or days for my trade to be complete.
This doesn't mean I discount the higher time-frames, no, I actually rely heavily on them. I found that EMAs do a decent job as support/resistance, sometimes to a tick level of precision. And this is important for a 1 minute trader.
As such, I made this script that tracks the higher time-frames EMAs and displays the last value as a line.
I do not need the whole EMA, I'm not interested in crossovers or crossunders, these are anyway late signals for me.
What's with the triangles? These are local tops/bottoms , candles that have a have decent size of the wick. These tops and bottoms are by no means "final", they are merely a rejection at certain levels of price. Due to markets complexities (and human erratic behaviors hehe) these levels could be breached at the very next candle. For a more "final" version (nothing is really final but..) I added Schaff Trend Cycle as filter, so a triangle will pop only when a trend is mature enough ( STC with a value near 0 or near 100).
Colored bars. When the body of the candle is big, it shows strength. Strong bars tend to have follow through, especially when breaking key levels. The script looks at the body of the candle and compares it with ATR (Average True Range), if it's at least 0.8 of ATR it changes the bar color to yellow (bull candles) or fuchsia(bear candles).
Range identifier. This code is copied from Lazy Bear (if there are any issues please let me know), it's very useful in conjunction with colored bars.
I look for breakout candles that go outside of the range as a signal for a trade.
There are many ways in which this script can be useful, like trading mean reversions or momentum trades (breakouts) or simply trend following trades.
I hope you guys find it useful, you can play with default values and change them as you like, these are what I found to be working best for me and my trading universe (mostly crypto).
Special thanks for the original work of:
LazyBear
everget
Jim8080
Pythagorean Means of Moving AveragesDESCRIPTION
Pythagorean Means of Moving Averages
1. Calculates a set of moving averages for high, low, close, open and typical prices, each at multiple periods.
Period values follow the Fibonacci sequence.
The "short" set includes moving average having the following periods: 5, 8, 13, 21, 34, 55, 89, 144, 233, 377.
The "mid" set includes moving average having the following periods: 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597.
The "long" set includes moving average having the following periods: 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597, 2584, 4181.
2. User selects the type of moving average: SMA, EMA, HMA, RMA, WMA, VWMA.
3. Calculates the mean of each set of moving averages.
4. User selects the type of mean to be calculated: 1) arithmetic, 2) geometric, 3) harmonic, 4) quadratic, 5) cubic. Multiple mean calculations may be displayed simultaneously, allowing for comparison.
5. Plots the mean for high, low, close, open, and typical prices.
6. User selects which plots to display: 1) high and low prices, 2) close prices, 3) open prices, and/or 4) typical prices.
7. Calculates and plots a vertical deviation from an origin mean--the mean from which the deviation is measured.
8. Deviation = origin mean x a x b^(x/y)/c.
9. User selects the deviation origin mean: 1) high and low prices plot, 2) close prices plot, or 3) typical prices plot.
10. User defines deviation variables a, b, c, x and y.
Examples of deviation:
a) Percent of the mean = 1.414213562 = 2^(1/2) = Pythagoras's constant (default).
b) Percent of the mean = 0.7071067812 = = = sin 45˚ = cos 45˚.
11. Displaces the plots horizontally +/- by a user defined number of periods.
PURPOSE
1. Identify price trends and potential levels of support and resistance.
CREDITS
1. "Fibonacci Moving Average" by Sofien Kaabar: two plots, each an arithmetic mean of EMAs of 1) high prices and 2) low prices, with periods 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597, 2584, 4181.
2. "Solarized" color scheme by Ethan Schoonover.

Keltner Channels BandsKeltner Channel Bands
Great indicator for mean reversion strategies.
Alerts you can set:
Crossover EMA
Crossunder EMA
Crossover upper band
Crossunder upper band
Crossover lower band
Crossunder lower band
Have fun!

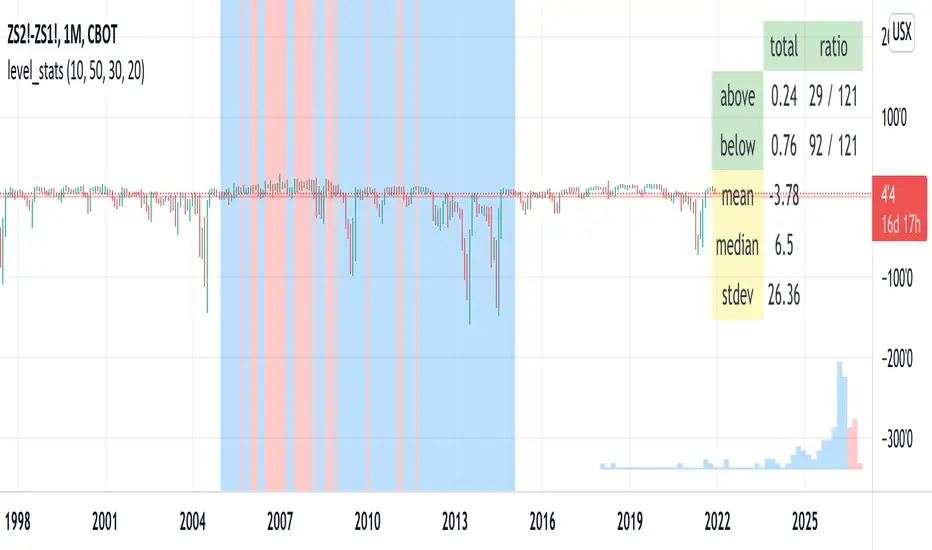
level_statsThis script tells you the percentage of time an instrument's closing value is above and below a level of your choosing. The background color visually indicates periods where the instrument closed at or above the level (red) and below it (blue). For "stationary-ish" processes, you can get a loose feel for the mean, high, and low values. The historical information conveyed through the background coloring can help you plan derivatives trades. Try with your favorite pairs, commodities, or volatility indices.
Usage: pick a level of interest using the input.
[cache_that_pass] 1m 15m Function - Weighted Standard DeviationTradingview Community,
As I progress through my journey, I have come to the realization that it is time to give back. This script isn't a life changer, but it has the building blocks for a motivated individual to optimize the parameters and have a production script ready to go.
Credit for the indicator is due to @rumpypumpydumpy
I adapted this indicator to a strategy for crypto markets. 15 minute time frame has worked best for me.
It is a standard deviation script that has 3 important user configured parameters. These 3 things are what the end user should tweak for optimum returns. They are....
1) Lookback Length - I have had luck with it set to 20, but any value from 1-1000 it will accept.
2) stopPer - Stop Loss percentage of each trade
3) takePer - Take Profit percentage of each trade
2 and 3 above are where you will see significant changes in returns by altering them and trying different percentages. An experienced pinescript programmer can take this and build on it even more. If you do, I ask that you please share the script with the community in an open-source fashion.
It also already accounts for the commission percentage of 0.075% that Binance.US uses for people who pay fees with BNB.
How it works...
It calculates a weighted standard deviation of the price for the lookback period set (so 20 candles is default). It recalculates each time a new candle is printed. It trades when price lows crossunder the bottom of that deviation channel, and sells when price highs crossover the top of that deviation channel. It works best in mid to long term sideways channels / Wyckoff accumulation periods.
MomentsLibrary "Moments"
Based on Moments (Mean,Variance,Skewness,Kurtosis) . Rewritten for Pinescript v5.
logReturns(src) Calculates log returns of a series (e.g log percentage change)
Parameters:
src : Source to use for the returns calculation (e.g. close).
Returns: Log percentage returns of a series
mean(src, length) Calculates the mean of a series using ta.sma
Parameters:
src : Source to use for the mean calculation (e.g. close).
length : Length to use mean calculation (e.g. 14).
Returns: The sma of the source over the length provided.
variance(src, length) Calculates the variance of a series
Parameters:
src : Source to use for the variance calculation (e.g. close).
length : Length to use for the variance calculation (e.g. 14).
Returns: The variance of the source over the length provided.
standardDeviation(src, length) Calculates the standard deviation of a series
Parameters:
src : Source to use for the standard deviation calculation (e.g. close).
length : Length to use for the standard deviation calculation (e.g. 14).
Returns: The standard deviation of the source over the length provided.
skewness(src, length) Calculates the skewness of a series
Parameters:
src : Source to use for the skewness calculation (e.g. close).
length : Length to use for the skewness calculation (e.g. 14).
Returns: The skewness of the source over the length provided.
kurtosis(src, length) Calculates the kurtosis of a series
Parameters:
src : Source to use for the kurtosis calculation (e.g. close).
length : Length to use for the kurtosis calculation (e.g. 14).
Returns: The kurtosis of the source over the length provided.
skewnessStandardError(sampleSize) Estimates the standard error of skewness based on sample size
Parameters:
sampleSize : The number of samples used for calculating standard error.
Returns: The standard error estimate for skewness based on the sample size provided.
kurtosisStandardError(sampleSize) Estimates the standard error of kurtosis based on sample size
Parameters:
sampleSize : The number of samples used for calculating standard error.
Returns: The standard error estimate for kurtosis based on the sample size provided.
skewnessCriticalValue(sampleSize) Estimates the critical value of skewness based on sample size
Parameters:
sampleSize : The number of samples used for calculating critical value.
Returns: The critical value estimate for skewness based on the sample size provided.
kurtosisCriticalValue(sampleSize) Estimates the critical value of kurtosis based on sample size
Parameters:
sampleSize : The number of samples used for calculating critical value.
Returns: The critical value estimate for kurtosis based on the sample size provided.

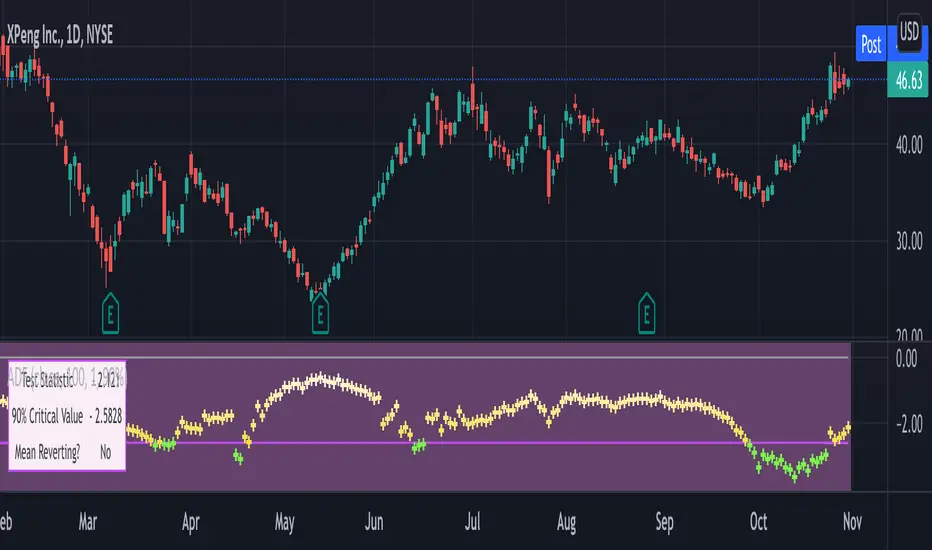
Augmented Dickey–Fuller (ADF) mean reversion testThe augmented Dickey-Fuller test (ADF) is a statistical test for the tendency of a price series sample to mean revert .
The current price of a mean-reverting series may tell us something about the next move (as opposed, for example, to a geometric Brownian motion). Thus, the ADF test allows us to spot market inefficiencies and potentially exploit this information in a trading strategy.
Mathematically, the mean reversion property means that the price change in the next time period is proportional to the difference between the average price and the current price. The purpose of the ADF test is to check if this proportionality constant is zero. Accordingly, the ADF test statistic is defined as the estimated proportionality constant divided by the corresponding standard error.
In this script, the ADF test is applied in a rolling window with a user-defined lookback length. The calculated values of the ADF test statistic are plotted as a time series. The more negative the test statistic, the stronger the rejection of the hypothesis that there is no mean reversion. If the calculated test statistic is less than the critical value calculated at a certain confidence level (90%, 95%, or 99%), then the hypothesis of a mean reversion is accepted (strictly speaking, the opposite hypothesis is rejected).
Input parameters:
Source - The source of the time series being tested.
Length - The number of points in the rolling lookback window. The larger sample length makes the ADF test results more reliable.
Maximum lag - The maximum lag included in the test, that defines the order of an autoregressive process being implied in the model. Generally, a non-zero lag allows taking into account the serial correlation of price changes. When dealing with price data, a good starting point is lag 0 or lag 1.
Confidence level - The probability level at which the critical value of the ADF test statistic is calculated. If the test statistic is below the critical value, it is concluded that the sample of the price series is mean-reverting. Confidence level is calculated based on MacKinnon (2010) .
Show Infobox - If True, the results calculated for the last price bar are displayed in a table on the left.
More formal background:
Formally, the ADF test is a test for a unit root in an autoregressive process. The model implemented in this script involves a non-zero constant and zero time trend. The zero lag corresponds to the simple case of the AR(1) process, while higher order autoregressive processes AR(p) can be approached by setting the maximum lag of p. The null hypothesis is that there is a unit root, with the alternative that there is no unit root. The presence of unit roots in an autoregressive time series is characteristic for a non-stationary process. Thus, if there is no unit root, the time series sample can be concluded to be stationary, i.e., manifesting the mean-reverting property.
A few more comments:
It should be noted that the ADF test tells us only about the properties of the price series now and in the past. It does not directly say whether the mean-reverting behavior will retain in the future.
The ADF test results don't directly reveal the direction of the next price move. It only tells wether or not a mean-reverting trading strategy can be potentially applicable at the given moment of time.
The ADF test is related to another statistical test, the Hurst exponent. The latter is available on TradingView as implemented by balipour , QuantNomad and DonovanWall .
The ADF test statistics is a negative number. However, it can take positive values, which usually corresponds to trending markets (even though there is no statistical test for this case).
Rigorously, the hypothesis about the mean reversion is accepted at a given confidence level when the value of the test statistic is below the critical value. However, for practical trading applications, the values which are low enough - but still a bit higher than the critical one - can be still used in making decisions.
Examples:
The VIX volatility index is known to exhibit mean reversion properties (volatility spikes tend to fade out quickly). Accordingly, the statistics of the ADF test tend to stay below the critical value of 90% for long time periods.
The opposite case is presented by BTCUSD. During the same time range, the bitcoin price showed strong momentum - the moves away from the mean did not follow by the counter-move immediately, even vice versa. This is reflected by the ADF test statistic that consistently stayed above the critical value (and even above 0). Thus, using a mean reversion strategy would likely lead to losses.
Pythagorean Moving Averages (and more)When you think of the question "take the mean of this dataset", you'd normally think of using the arithmetic mean because usually the norm is equal to 1; however, there are an infinite number of other types of means depending on the function norm (p).
Pythagoras' is credited for the main types of means: his harmonic mean, his geometric mean, and his arithmetic mean:
Harmonic Average (p = -1):
- Take the reciprocal of all the numbers in the dataset, add them all together, divide by the amount of numbers added together, then take the reciprocal of the final answer.
Geometric Average (p = 0):
- Multiply all the numbers in the dataset, then take the nth root where n is equal to the amount of number you multiplied together.
Arithmetic Mean (p = 1):
- Add all the numbers in the dataset, then divide by the amount of numbers you added by.
A couple other means included in this script were the quadratic mean (p = 2) and the cubic mean (p = 3).
Quadratic Mean (p = 2):
- Square every number in the dataset, then divide by the amount of numbers your added by, then take the square root.
Cubic Mean (p = 3):
- Cube every number in the dataset, then divide by the amount of numbers you added by, then take the cube root.
There are an infinite number of means for every scenario of p, but they begin to follow a pattern after p = 3.
Read more:
www.cs.uni.edu
en.wikipedia.org
en.wikipedia.org
Note : I added the functions for the quadratic mean and cubic mean, but since market charts don't have those types of graphs, the functions don't usually work. It's the same reason why sometimes you'll see the harmonic average not working.
Disclaimer : This is not financial or mathematical advice, please look for someone certified before making any decisions.

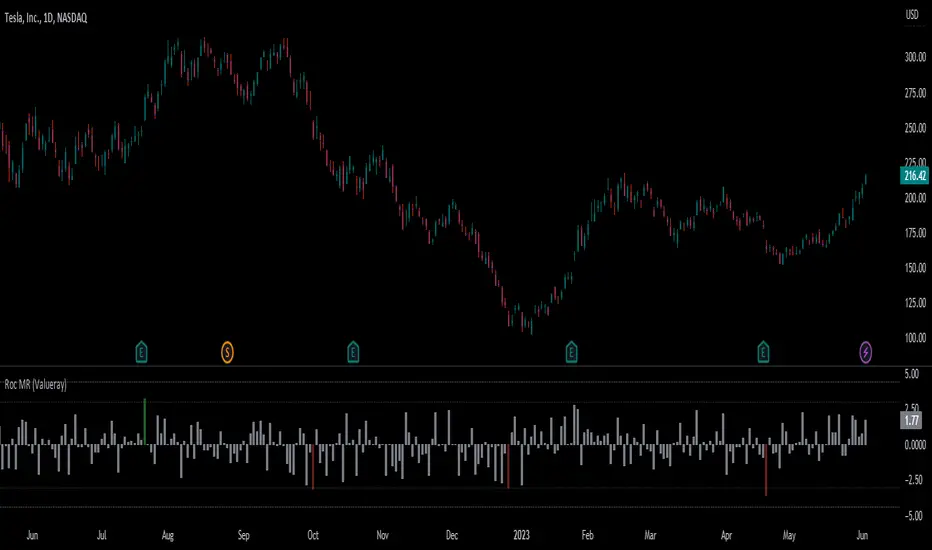
Roc Mean Reversion (ValueRay)This Indicator shows the Absolute Rate of Change in correlation to its Moving Average.
Values over 3 (gray dotted line) can savely be considered as a breakout; values over 4.5 got a high mean-reverting chance (red dotted line).
This Indicator can be used in all timeframes, however, i recommend to use it <30m, when you want search for meaningful Mean-Reverting Signals.
Please like, share and subscribe. With your love, im encouraged to write and publish more Indicators.
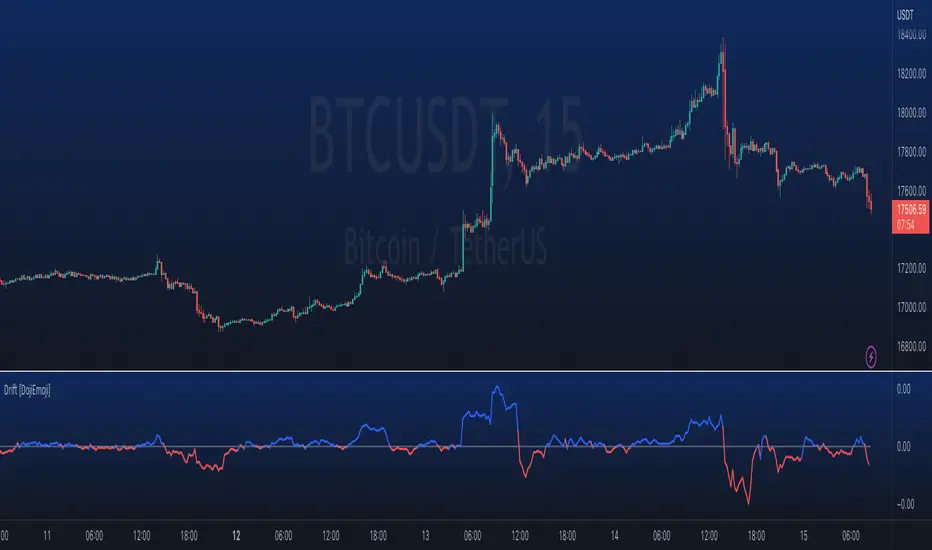
Drift Study (Inspired by Monte Carlo Simulations with BM) [KL]Inspired by the Brownian Motion ("BM") model that could be applied to conducting Monte Carlo Simulations, this indicator plots out the Drift factor contributing to BM.
Interpretation : If the Drift value is positive, then prices are possibly moving in an uptrend. Vice versa for negative drifts.

Res/Sup With Concavity & Increasing / Decreasing Trend AnalysisPurple means the concavity is down blue means concavity is up which is good.
Yellow means increasing, Red means decreasing.
Sup = Green
Res = Red

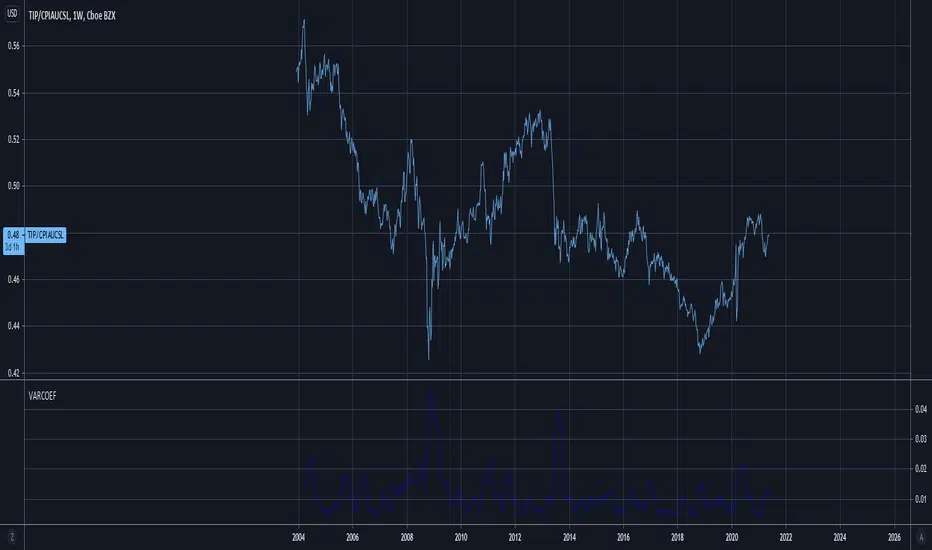
Coefficient of variation (standard deviation over mean)Shows the coefficient of variation defined as standard deviation over mean (for the specified window).
Jaws Mean Reversion [Strategy]This very simple strategy is an implementation of PJ Sutherlands' Jaws Mean reversion algorithm. It simply buys when a small moving average period (e.g. 2) is below
a longer moving average period (e.g. 5) by a certain percentage and closes when the small period average crosses over the longer moving average.
If you are going to use this, you may wish to apply this to a range of investment assets using a screener for setups, as the amount signals are low. Alternatively, you may wish to tweak the settings to provide more signals.
Context can be found here:
LINK
Hurst ExponentMy first try to implement Full Hurst Exponent.
The Hurst exponent is used as a measure of long-term memory of time series. It relates to the autocorrelations of the time series and the rate at which these decrease as the lag between pairs of values increases
The Hurst exponent is referred to as the "index of dependence" or "index of long-range dependence". It quantifies the relative tendency of a time series either to regress strongly to the mean or to cluster in a direction.
In short, depending on the value you can spot the trending / reversing market.
Values 0.5 to 1 - market trending
Values 0 to 0.5 - market tend to mean revert
Hurst Exponent is computed using Rescaled range (R/S) analysis.
I split the lookback period (N) in the number of shorter samples (for ex. N/2, N/4, N/8, etc.). Then I calculate rescaled range for each sample size.
The Hurst exponent is estimated by fitting the power law. Basically finding the slope of log(samples_size) to log(RS).
You can choose lookback and sample sizes yourself. Max 8 possible at the moment, if you want to use less use 0 in inputs.
It's pretty computational intensive, so I added an input so you can limit from what date you want it to be calculated. If you hit the time limit in PineScript - limit the history you're using for calculations.
####################
Disclaimer
Please remember that past performance may not be indicative of future results.
Due to various factors, including changing market conditions, the strategy may no longer perform as good as in historical backtesting.
This post and the script don’t provide any financial advice.

Simple Hurst Exponent [QuantNomad]This is a simplified version of the Hurst Exponent indicator.
In the meantime, I'm working on the full version. It's computationally intensive, so it's a challenge to squeeze it to PineScript limits. It will require some time to optimize it, so I decided to publish a simplified version for now.
The Hurst exponent is used as a measure of long-term memory of time series. It relates to the autocorrelations of the time series, and the rate at which these decrease as the lag between pairs of values increases
The Hurst exponent is referred to as the "index of dependence" or "index of long-range dependence". It quantifies the relative tendency of a time series either to regress strongly to the mean or to cluster in a direction.
In short depend on value you can spot trending / reversing market.
Values 0.5 to 1 - market trending
Values 0 to 0.5 - market tend to mean revert
####################
Disclaimer
Please remember that past performance may not be indicative of future results.
Due to various factors, including changing market conditions, the strategy may no longer perform as good as in historical backtesting.
This post and the script don’t provide any financial advice.

Examples of Rolling Average Using Automated AnchoringIn this study, I present a method to expose NaN values to development environment.
This exposure allows NaN values to be used by methods in scripts.
I also show how to use values, even NaN values, as anchors from which statistics can be computed from.
I demonstrate how to do this with constants and variables in methods for computing the cumulative/rolling average of a series.
I also show how to calculate the cumulative/rolling average from the start of a ticker series using the aforementioned methods.
Each method has a description on how some of their parts work as well as their constraints.
Method #1 - Can only be used for computing the rolling average on the ticker series.
Method #2 - The simple moving average from the Pine Script reference.
- Can be used to calculate the rolling average of the ticker series and number values of a series.
- This method seems to cause an error when there are many bars in the series.
Method #3 - The most versatile method due to the use of computing the rolling average using an array.
- Timeout will occur when computing the rolling average of an entire ticker series which is long.
- Timeout has not occurred when computing a rolling average of a series from NaN or non-NaN anchor points even when the series is long.
This is an attempt to get around the constraints of the built-in sma(source, length) function in which length cannot be dynamically adjusted.
Other Pine Script functions have that constraint which we can get around by defining our own functions.

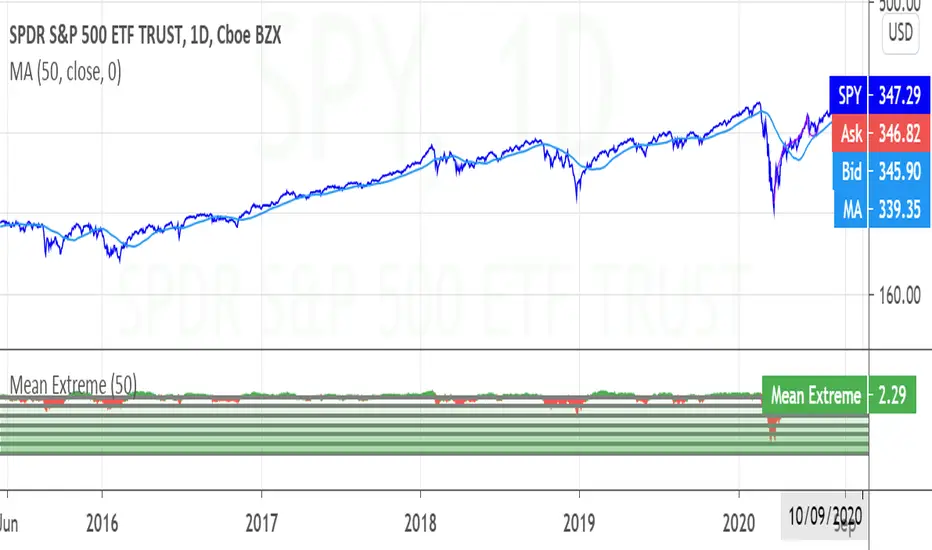
Mean ExtremeA simple script that shows the distance from a the mean, expressed as a percentage.
Simple Moving Average, in this case.
Informational only.