Adaptive Quadratic Kernel EnvelopeThis study draws a fair-value curve from a quadratic-weighted (Nadaraya-Watson) regression. Alpha sets how sharply weights decay inside the look-back window, so you trade lag against smoothness with one slider. Band half-width is ATRslow times a bounded fast/slow ATR ratio, giving an instant response to regime shifts without overshooting on spikes. Work in log space when an instrument grows exponentially, equal percentage moves then map to equal vertical steps. NearBase and FarBase define a progression of adaptive thresholds, useful for sizing exits or calibrating mean-reversion logic. Non-repaint mode keeps one-bar delay for clean back-tests, predictive mode shows the zero-lag curve for live decisions.
Key points
- Quadratic weights cut phase error versus Gaussian or SMA-based envelopes.
- Dual-ATR scaling updates width on the next bar, no residual lag.
- Log option preserves envelope symmetry across multi-decade data.
- Alpha provides direct control of curvature versus noise.
- Built-in alerts trigger on the first adaptive threshold, ready for automation.
Typical uses
Trend bias from the slope of the curve.
Entry timing when price pierces an inner threshold and momentum stalls.
Breakout confirmation when closes hold beyond outer thresholds while volatility expands.
Stops and targets anchored to chosen thresholds, automatically matching current noise.
Nadarayawatson

Kernel Regression Envelope with SMI OscillatorThis script combines the predictive capabilities of the **Nadaraya-Watson estimator**, implemented by the esteemed jdehorty (credit to him for his excellent work on the `KernelFunctions` library and the original Nadaraya-Watson Envelope indicator), with the confirmation strength of the **Stochastic Momentum Index (SMI)** to create a dynamic trend reversal strategy. The core idea is to identify potential overbought and oversold conditions using the Nadaraya-Watson Envelope and then confirm these signals with the SMI before entering a trade.
**Understanding the Nadaraya-Watson Envelope:**
The Nadaraya-Watson estimator is a non-parametric regression technique that essentially calculates a weighted average of past price data to estimate the current underlying trend. Unlike simple moving averages that give equal weight to all past data within a defined period, the Nadaraya-Watson estimator uses a **kernel function** (in this case, the Rational Quadratic Kernel) to assign weights. The key parameters influencing this estimation are:
* **Lookback Window (h):** This determines how many historical bars are considered for the estimation. A larger window results in a smoother estimation, while a smaller window makes it more reactive to recent price changes.
* **Relative Weighting (alpha):** This parameter controls the influence of different time frames in the estimation. Lower values emphasize longer-term price action, while higher values make the estimator more sensitive to shorter-term movements.
* **Start Regression at Bar (x\_0):** This allows you to exclude the potentially volatile initial bars of a chart from the calculation, leading to a more stable estimation.
The script calculates the Nadaraya-Watson estimation for the closing price (`yhat_close`), as well as the highs (`yhat_high`) and lows (`yhat_low`). The `yhat_close` is then used as the central trend line.
**Dynamic Envelope Bands with ATR:**
To identify potential entry and exit points around the Nadaraya-Watson estimation, the script uses **Average True Range (ATR)** to create dynamic envelope bands. ATR measures the volatility of the price. By multiplying the ATR by different factors (`nearFactor` and `farFactor`), we create multiple bands:
* **Near Bands:** These are closer to the Nadaraya-Watson estimation and are intended to identify potential immediate overbought or oversold zones.
* **Far Bands:** These are further away and can act as potential take-profit or stop-loss levels, representing more extreme price extensions.
The script calculates both near and far upper and lower bands, as well as an average between the near and far bands. This provides a nuanced view of potential support and resistance levels around the estimated trend.
**Confirming Reversals with the Stochastic Momentum Index (SMI):**
While the Nadaraya-Watson Envelope identifies potential overextended conditions, the **Stochastic Momentum Index (SMI)** is used to confirm a potential trend reversal. The SMI, unlike a traditional stochastic oscillator, oscillates around a zero line. It measures the location of the current closing price relative to the median of the high/low range over a specified period.
The script calculates the SMI on a **higher timeframe** (defined by the "Timeframe" input) to gain a broader perspective on the market momentum. This helps to filter out potential whipsaws and false signals that might occur on the current chart's timeframe. The SMI calculation involves:
* **%K Length:** The lookback period for calculating the highest high and lowest low.
* **%D Length:** The period for smoothing the relative range.
* **EMA Length:** The period for smoothing the SMI itself.
The script uses a double EMA for smoothing within the SMI calculation for added smoothness.
**How the Indicators Work Together in the Strategy:**
The strategy enters a long position when:
1. The closing price crosses below the **near lower band** of the Nadaraya-Watson Envelope, suggesting a potential oversold condition.
2. The SMI crosses above its EMA, indicating positive momentum.
3. The SMI value is below -50, further supporting the oversold idea on the higher timeframe.
Conversely, the strategy enters a short position when:
1. The closing price crosses above the **near upper band** of the Nadaraya-Watson Envelope, suggesting a potential overbought condition.
2. The SMI crosses below its EMA, indicating negative momentum.
3. The SMI value is above 50, further supporting the overbought idea on the higher timeframe.
Trades are closed when the price crosses the **far band** in the opposite direction of the trade. A stop-loss is also implemented based on a fixed value.
**In essence:** The Nadaraya-Watson Envelope identifies areas where the price might be deviating significantly from its estimated trend. The SMI, calculated on a higher timeframe, then acts as a confirmation signal, suggesting that the momentum is shifting in the direction of a potential reversal. The ATR-based bands provide dynamic entry and exit points based on the current volatility.
**How to Use the Script:**
1. **Apply the script to your chart.**
2. **Adjust the "Kernel Settings":**
* **Lookback Window (h):** Experiment with different values to find the smoothness that best suits the asset and timeframe you are trading. Lower values make the envelope more reactive, while higher values make it smoother.
* **Relative Weighting (alpha):** Adjust to control the influence of different timeframes on the Nadaraya-Watson estimation.
* **Start Regression at Bar (x\_0):** Increase this value if you want to exclude the initial, potentially volatile, bars from the calculation.
* **Stoploss:** Set your desired stop-loss value.
3. **Adjust the "SMI" settings:**
* **%K Length, %D Length, EMA Length:** These parameters control the sensitivity and smoothness of the SMI. Experiment to find settings that work well for your trading style.
* **Timeframe:** Select the higher timeframe you want to use for SMI confirmation.
4. **Adjust the "ATR Length" and "Near/Far ATR Factor":** These settings control the width and sensitivity of the envelope bands. Smaller ATR lengths make the bands more reactive to recent volatility.
5. **Customize the "Color Settings"** to your preference.
6. **Observe the plots:**
* The **Nadaraya-Watson Estimation (yhat)** line represents the estimated underlying trend.
* The **near and far upper and lower bands** visualize potential overbought and oversold zones based on the ATR.
* The **fill areas** highlight the regions between the near and far bands.
7. **Look for entry signals:** A long entry is considered when the price touches or crosses below the lower near band and the SMI confirms upward momentum. A short entry is considered when the price touches or crosses above the upper near band and the SMI confirms downward momentum.
8. **Manage your trades:** The script provides exit signals when the price crosses the far band. The fixed stop-loss will also close trades if the price moves against your position.
**Justification for Combining Nadaraya-Watson Envelope and SMI:**
The combination of the Nadaraya-Watson Envelope and the SMI provides a more robust approach to identifying potential trend reversals compared to using either indicator in isolation. The Nadaraya-Watson Envelope excels at identifying potential areas where the price is overextended relative to its recent history. However, relying solely on the envelope can lead to false signals, especially in choppy or volatile markets. By incorporating the SMI as a confirmation tool, we add a momentum filter that helps to validate the potential reversals signaled by the envelope. The higher timeframe SMI further helps to filter out noise and focus on more significant shifts in momentum. The ATR-based bands add a dynamic element to the entry and exit points, adapting to the current market volatility. This mashup aims to leverage the strengths of each indicator to create a more reliable trading strategy.

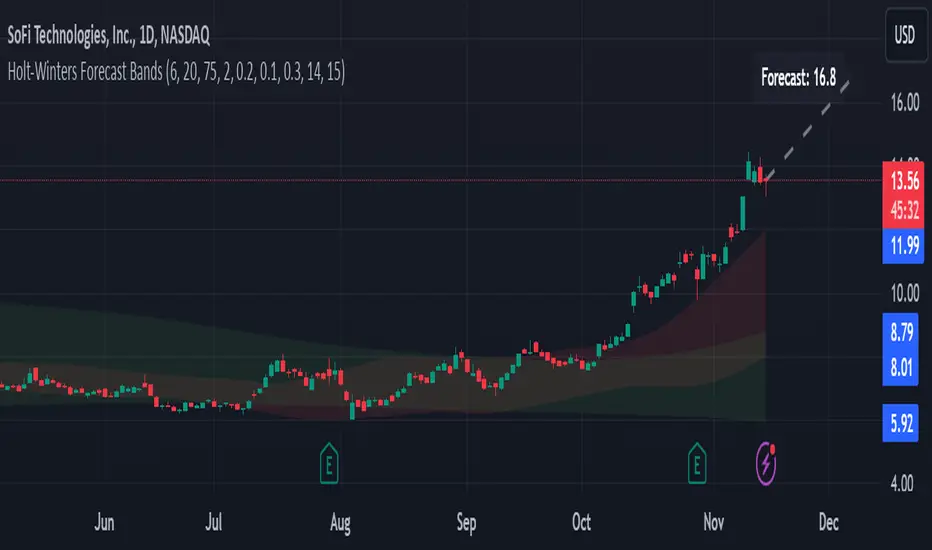
Holt-Winters Forecast BandsDescription:
The Holt-Winters Adaptive Bands indicator combines seasonal trend forecasting with adaptive volatility bands. It uses the Holt-Winters triple exponential smoothing model to project future price trends, while Nadaraya-Watson smoothed bands highlight dynamic support and resistance zones.
This indicator is ideal for traders seeking to predict future price movements and visualize potential market turning points. By focusing on broader seasonal and trend data, it provides insight into both short- and long-term market directions. It’s particularly effective for swing trading and medium-to-long-term trend analysis on timeframes like daily and 4-hour charts, although it can be adjusted for other timeframes.
Key Features:
Holt-Winters Forecast Line: The core of this indicator is the Holt-Winters model, which uses three components — level, trend, and seasonality — to project future prices. This model is widely used for time-series forecasting, and in this script, it provides a dynamic forecast line that predicts where price might move based on historical patterns.
Adaptive Volatility Bands: The shaded areas around the forecast line are based on Nadaraya-Watson smoothing of historical price data. These bands provide a visual representation of potential support and resistance levels, adapting to recent volatility in the market. The bands' fill colors (red for upper and green for lower) allow traders to identify potential reversal zones without cluttering the chart.
Dynamic Confidence Levels: The indicator adapts its forecast based on market volatility, using inputs such as average true range (ATR) and price deviations. This means that in high-volatility conditions, the bands may widen to account for increased price movements, helping traders gauge the current market environment.
How to Use:
Forecasting: Use the forecast line to gain insight into potential future price direction. This line provides a directional bias, helping traders anticipate whether the price may continue along a trend or reverse.
Support and Resistance Zones: The shaded bands act as dynamic support and resistance zones. When price enters the upper (red) band, it may be in an overbought area, while the lower (green) band may indicate oversold conditions. These bands adjust with volatility, so they reflect the current market conditions rather than fixed levels.
Timeframe Recommendations:
This indicator performs best on daily and 4-hour charts due to its reliance on trend and seasonality. It can be used on lower timeframes, but accuracy may vary due to increased price noise.
For traders looking to capture swing trades, the daily and 4-hour timeframes provide a balance of trend stability and signal reliability.
Adjustable Settings:
Alpha, Beta, and Gamma: These settings control the level, trend, and seasonality components of the forecast. Alpha is generally the most sensitive setting for adjusting responsiveness to recent price movements, while Beta and Gamma help fine-tune the trend and seasonal adjustments.
Band Smoothing and Deviation: These settings control the lookback period and width of the volatility bands, allowing users to customize how closely the bands follow price action.
Parameters:
Prediction Length: Sets the length of the forecast, determining how far into the future the prediction line extends.
Season Length: Defines the seasonality cycle. A setting of 14 is typical for bi-weekly cycles, but this can be adjusted based on observed market cycles.
Alpha, Beta, Gamma: These parameters adjust the Holt-Winters model's sensitivity to recent prices, trends, and seasonal patterns.
Band Smoothing: Determines the smoothing applied to the bands, making them either more reactive or smoother.
Ideal Use Cases:
Swing Trading and Trend Following: The Holt-Winters model is particularly suited for capturing larger market trends. Use the forecast line to determine trend direction and the bands to gauge support/resistance levels for potential entries or exits.
Identifying Reversal Zones: The adaptive bands act as dynamic overbought and oversold zones, giving traders potential reversal areas when price reaches these levels.
Important Notes:
No Buy/Sell Signals: This indicator does not produce direct buy or sell signals. It’s intended for visual trend analysis and support/resistance identification, leaving trade decisions to the user.
Not for High-Frequency Trading: Due to the nature of the Holt-Winters model, this indicator is optimized for higher timeframes like the daily and 4-hour charts. It may not be suitable for high-frequency or scalping strategies on very short timeframes.
Adjust for Volatility: If using the indicator on lower timeframes or more volatile assets, consider adjusting the band smoothing and prediction length settings for better responsiveness.
Kernel Regression RibbonKernel Regression Ribbon is a flexible, visually pleasing trend identification tool. Plotting 8 different kernel regressions of different types and parameters allows the user to see where levels of support and resistance are being tested, retested and broken.
What’s Kernel Regression?
A statistical method for estimating the best fitting curve for a dataset, in this case, a time/price chart.
How’s Kernel Regression different from a Moving Average?
A Moving Average is basically a simple form of Kernel Regression, in that it uses a fixed (Retangular) Kernel function. In an MA, all data points are weighted equally over its length. However, a Kernel function reacts more to data points that are closer to the current point. This means it will adapt more quickly to changes in data than an MA. Due to this adaptability, Kernel functions often form part of Machine Learning.
Using this indicator:
Explore the default Regular mode first to get a feel for the inputs, which are more numerous than for MAs. Try out different settings, filters and intervals to get the best out of each kernel. Not all parameters are available for each KR. There are info tips to explain this in the menu, but I’ve also included handy, optional labels on the chart for each KR as a more accessible guide.
Once you know your way round the Regular mode, check out the Presets and start changing the parameters of each kernel to your liking in the “User KR1, KR2, … “ mode. Each kernel type has its strong and weak points. Blending different kernels is where this indicator comes into its own. Give your charts a funky shine!
This indicator does NOT repaint.
This script acknowledges, and hopefully showcases, the great work of @veryfid Kernel Regression Toolkit.

Bollinger Bands (Nadaraya Smoothed) | Flux ChartsTicker: AMEX:SPY , Timeframe: 1m, Indicator settings: default
General Purpose
This script is an upgrade to the classic Bollinger Bands. The idea behind Bollinger bands is the detection of price movements outside of a stock's typical fluctuations. Bollinger Bands use a moving average over period n plus/minus the standard deviation over period n times a multiplier. When price closes above or below either band this can be considered an abnormal movement. This script allows for the classic Bollinger Band interpretation while de-noising or "smoothing" the bands.
Efficacy
Ticker: AMEX:SPY , Timeframe: 1m, Indicator settings: Standard Dev: 2; Level 1 : off; Level 2: off; labels: off
Upper Band Key:
Blue: Bollinger No smoothing
Orange: Bollinger SMA smoothing period of 10
Purple: Bollinger EMA smoothing period of 10
Red: Nadaraya Smoothed Bollinger bandwidth of 6
Here we chose periods so that each would have a similar offset from the original Bollinger's. Notice that the Red Band has a much smoother result while on average having a similar fit to the other smoothing techniques. Increasing the EMA's or SMA's period would result in them being smoother however the offset would increase making them less accurate to the original data.
Ticker: AMEX:SPY , Timeframe: 1m, Indicator settings: Standard Dev: 2; Level 1: off; Level 2: off; labels: off
Upper Band Key:
Blue: Bollinger No smoothing
Orange: Bollinger SMA smoothing period of 20
Purple: Bollinger EMA smoothing period of 20
Red: Nadaraya Smoothed Bollinger bandwidth of 6
This makes the Nadaraya estimator a particularly efficacious technique in this use case as it achieves a superior smoothness to fit ratio.
How to Use
This indicator is not intended to be used on its own. Its use case is to identify outlier movements and periods of consolidation. The Smoothing Factor when lowered results in a more reactive but noisy graph. This setting is also known as the "bandwidth" ; it essentially raises the amplitude of the kernel function causing a greater weighting to recent data similar to lowering the period of a SMA or EMA. The repaint smoothing simply draws on the Bollinger's each chart update. Typically repaint would be used for processing and displaying discrete data however currently it's simply another way to display the Bollinger Bands.
What makes this script unique.
Since Bollinger bands use standard deviation they have excess noise. By noise we mean minute fluctuations which most traders will not find useful in their strategies. The Nadaraya-Watson estimator, as used, is essentially a weighted average akin to an ema. A gaussian kernel is placed at the candlestick of interest. That candlestick's value will have the highest weight. From that point the other candlesticks' values effect on the average will decrease with the slope of the kernel function. This creates a localized mean of the Bollinger Bands allowing for reduced noise with minimal distortion of the original Bollinger data.

Nadaraya-Watson Envelope Strategy (Non-Repainting) Log ScaleIn the diverse world of trading strategies, the Nadaraya-Watson Envelope Strategy offers a different approach. Grounded in mathematical analysis, this strategy utilizes the Nadaraya-Watson kernel regression, a method traditionally employed for interpreting complex data patterns.
At the core of this strategy lies the concept of 'envelopes', which are essentially dynamic volatility bands formed around the price based on a custom Average True Range (ATR). These envelopes help provide guidance on potential market entry and exit points. The strategy suggests considering a buy when the price crosses the lower envelope and a sell when it crosses the upper envelope.
One distinctive characteristic of the Nadaraya-Watson Envelope Strategy is its use of a logarithmic scale, as opposed to a linear scale. The logarithmic scale can be advantageous when dealing with larger timeframes and assets with wide-ranging price movements.
The strategy is implemented using Pine Script v5, and includes several adjustable parameters such as the lookback window, relative weighting, and the regression start point, providing a level of flexibility.
However, it's important to maintain a balanced view. While the use of mathematical models like the Nadaraya-Watson kernel regression may provide insightful data analysis, no strategy can guarantee success. Thorough backtesting, understanding the mathematical principles involved, and sound risk management are always essential when applying any trading strategy.
The Nadaraya-Watson Envelope Strategy thus offers another tool for traders to consider. As with all strategies, its effectiveness will largely depend on the trader's understanding, application, and the specific market conditions.
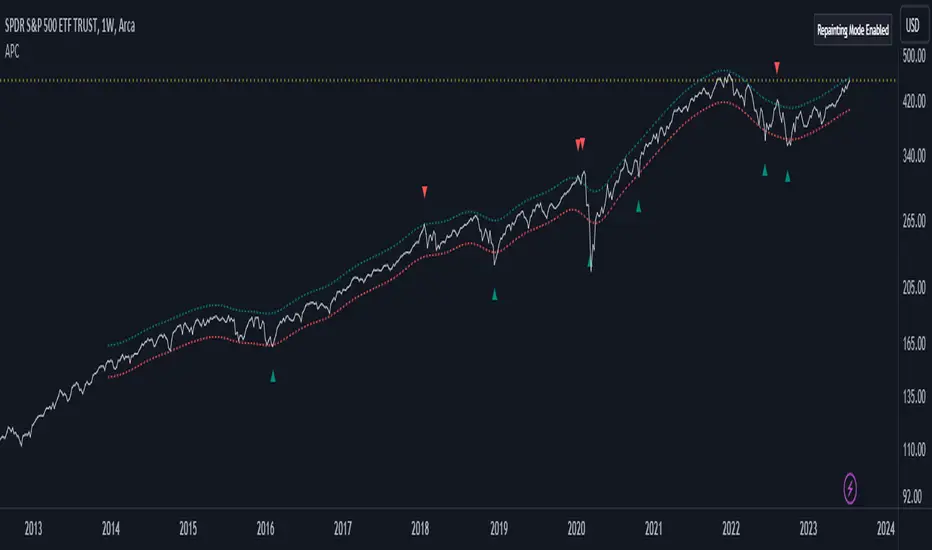
Adaptive Price Channel (log scale)The field of technical analysis is consistently expanding, with numerous indicators used for market forecasting. Amongst them, a novel indicator dubbed the Adaptive Price Channel (log scale), inspired by the renowned Nadaraya-Watson Envelope (LuxAlgo) from LuxAlgo, is gaining traction for its distinctive features and versatility. Unlike its predecessor, the Adaptive Price Channel (log scale) is applicable on a logarithmic scale, thereby allowing it to be utilized on both smaller and larger timeframes.
1. Key Features
The Adaptive Price Channel (log scale) is founded on the trading view Pinescript language, version 5, with its primary aim to maximize the versatility and scalability of trading indicators. It allows traders to adapt it according to their preferred timeframe, thereby making it applicable for a wide range of trading strategies.
Its bandwidth can be adjusted through the input parameters, offering traders the flexibility to manipulate the indicator according to their strategic requirements. Furthermore, it provides an option for repainting smoothing. This option enables users to control the repainting effect in which the historical output of the indicator may change over time. When disabled, the indicator provides the endpoints of the calculations, ensuring consistency in historical values.
Moreover, the Adaptive Price Channel (log scale) allows for color customization, thereby improving visibility and user-friendliness. The colors of the indicator's upward and downward directions can be changed according to the user's preference.
2. Working Mechanism
The Adaptive Price Channel (log scale) uses the logarithm of the source, which is typically the closing price of a trading instrument. It leverages a Gaussian function that exponentially decreases the further the price moves away from the mean, accounting for both positive and negative values. The bandwidth of the Gaussian function can be adjusted to adapt to different market conditions.
Additionally, the Adaptive Price Channel (log scale) features an array of 500 lines for each bar, which helps in defining the boundaries or envelope for price movements. The calculations are executed using the Nadaraya-Watson estimator, which uses kernel regression for non-parametric analysis.
The calculated values for the upper and lower bounds of the envelope are then converted back from the logarithmic scale using the exponential function. This calculation process continues for each bar until the last bar in the data set.
To ensure optimal performance, the Adaptive Price Channel (log scale) uses dynamic repainting. If the repainting mode is enabled, it adjusts the smoothing of the indicator for the entire historical data, making the results more accurate.
3. Visualization and Alerts
The Adaptive Price Channel (log scale) offers an array of visual aids, including labels and plots. The upper and lower bounds of the envelope are plotted, and the indicator triggers labels at points where the closing price crosses these boundaries. These labels serve as alerts for potential trading opportunities.
4. Conclusion
The Adaptive Price Channel (log scale) is an innovative and adaptable trading indicator, drawing inspiration from its predecessor but introducing unique features to increase its versatility. By providing a repainting option, it ensures consistent historical values, thereby enhancing the reliability of the indicator. Furthermore, the capability to operate on a logarithmic scale broadens its usability for different timeframes. The Adaptive Price Channel (log scale) is a powerful tool for any trader, facilitating a better understanding of market dynamics, and enabling more informed decision-making.
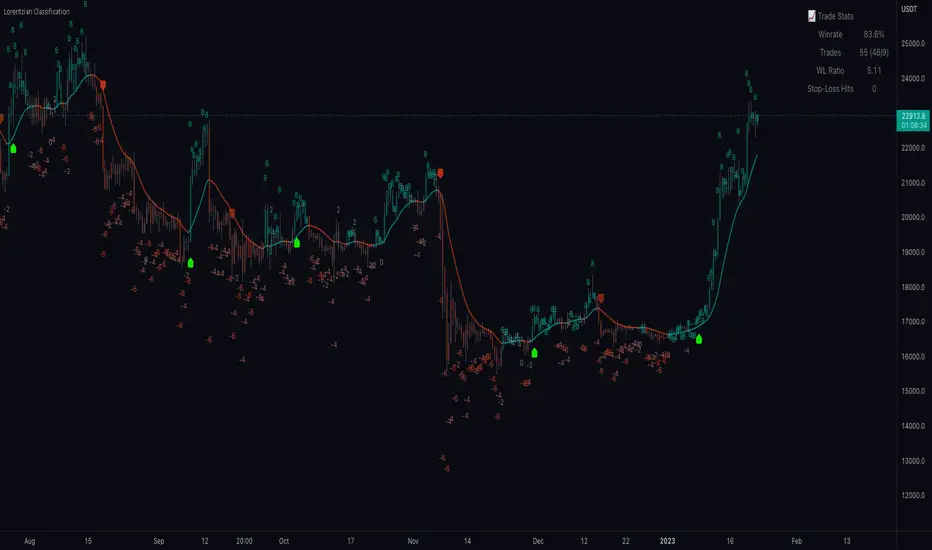
Machine Learning: Lorentzian Classification█ OVERVIEW
A Lorentzian Distance Classifier (LDC) is a Machine Learning classification algorithm capable of categorizing historical data from a multi-dimensional feature space. This indicator demonstrates how Lorentzian Classification can also be used to predict the direction of future price movements when used as the distance metric for a novel implementation of an Approximate Nearest Neighbors (ANN) algorithm.
█ BACKGROUND
In physics, Lorentzian space is perhaps best known for its role in describing the curvature of space-time in Einstein's theory of General Relativity (2). Interestingly, however, this abstract concept from theoretical physics also has tangible real-world applications in trading.
Recently, it was hypothesized that Lorentzian space was also well-suited for analyzing time-series data (4), (5). This hypothesis has been supported by several empirical studies that demonstrate that Lorentzian distance is more robust to outliers and noise than the more commonly used Euclidean distance (1), (3), (6). Furthermore, Lorentzian distance was also shown to outperform dozens of other highly regarded distance metrics, including Manhattan distance, Bhattacharyya similarity, and Cosine similarity (1), (3). Outside of Dynamic Time Warping based approaches, which are unfortunately too computationally intensive for PineScript at this time, the Lorentzian Distance metric consistently scores the highest mean accuracy over a wide variety of time series data sets (1).
Euclidean distance is commonly used as the default distance metric for NN-based search algorithms, but it may not always be the best choice when dealing with financial market data. This is because financial market data can be significantly impacted by proximity to major world events such as FOMC Meetings and Black Swan events. This event-based distortion of market data can be framed as similar to the gravitational warping caused by a massive object on the space-time continuum. For financial markets, the analogous continuum that experiences warping can be referred to as "price-time".
Below is a side-by-side comparison of how neighborhoods of similar historical points appear in three-dimensional Euclidean Space and Lorentzian Space:
This figure demonstrates how Lorentzian space can better accommodate the warping of price-time since the Lorentzian distance function compresses the Euclidean neighborhood in such a way that the new neighborhood distribution in Lorentzian space tends to cluster around each of the major feature axes in addition to the origin itself. This means that, even though some nearest neighbors will be the same regardless of the distance metric used, Lorentzian space will also allow for the consideration of historical points that would otherwise never be considered with a Euclidean distance metric.
Intuitively, the advantage inherent in the Lorentzian distance metric makes sense. For example, it is logical that the price action that occurs in the hours after Chairman Powell finishes delivering a speech would resemble at least some of the previous times when he finished delivering a speech. This may be true regardless of other factors, such as whether or not the market was overbought or oversold at the time or if the macro conditions were more bullish or bearish overall. These historical reference points are extremely valuable for predictive models, yet the Euclidean distance metric would miss these neighbors entirely, often in favor of irrelevant data points from the day before the event. By using Lorentzian distance as a metric, the ML model is instead able to consider the warping of price-time caused by the event and, ultimately, transcend the temporal bias imposed on it by the time series.
For more information on the implementation details of the Approximate Nearest Neighbors (ANN) algorithm used in this indicator, please refer to the detailed comments in the source code.
█ HOW TO USE
Below is an explanatory breakdown of the different parts of this indicator as it appears in the interface:
Below is an explanation of the different settings for this indicator:
General Settings:
Source - This has a default value of "hlc3" and is used to control the input data source.
Neighbors Count - This has a default value of 8, a minimum value of 1, a maximum value of 100, and a step of 1. It is used to control the number of neighbors to consider.
Max Bars Back - This has a default value of 2000.
Feature Count - This has a default value of 5, a minimum value of 2, and a maximum value of 5. It controls the number of features to use for ML predictions.
Color Compression - This has a default value of 1, a minimum value of 1, and a maximum value of 10. It is used to control the compression factor for adjusting the intensity of the color scale.
Show Exits - This has a default value of false. It controls whether to show the exit threshold on the chart.
Use Dynamic Exits - This has a default value of false. It is used to control whether to attempt to let profits ride by dynamically adjusting the exit threshold based on kernel regression.
Feature Engineering Settings:
Note: The Feature Engineering section is for fine-tuning the features used for ML predictions. The default values are optimized for the 4H to 12H timeframes for most charts, but they should also work reasonably well for other timeframes. By default, the model can support features that accept two parameters (Parameter A and Parameter B, respectively). Even though there are only 4 features provided by default, the same feature with different settings counts as two separate features. If the feature only accepts one parameter, then the second parameter will default to EMA-based smoothing with a default value of 1. These features represent the most effective combination I have encountered in my testing, but additional features may be added as additional options in the future.
Feature 1 - This has a default value of "RSI" and options are: "RSI", "WT", "CCI", "ADX".
Feature 2 - This has a default value of "WT" and options are: "RSI", "WT", "CCI", "ADX".
Feature 3 - This has a default value of "CCI" and options are: "RSI", "WT", "CCI", "ADX".
Feature 4 - This has a default value of "ADX" and options are: "RSI", "WT", "CCI", "ADX".
Feature 5 - This has a default value of "RSI" and options are: "RSI", "WT", "CCI", "ADX".
Filters Settings:
Use Volatility Filter - This has a default value of true. It is used to control whether to use the volatility filter.
Use Regime Filter - This has a default value of true. It is used to control whether to use the trend detection filter.
Use ADX Filter - This has a default value of false. It is used to control whether to use the ADX filter.
Regime Threshold - This has a default value of -0.1, a minimum value of -10, a maximum value of 10, and a step of 0.1. It is used to control the Regime Detection filter for detecting Trending/Ranging markets.
ADX Threshold - This has a default value of 20, a minimum value of 0, a maximum value of 100, and a step of 1. It is used to control the threshold for detecting Trending/Ranging markets.
Kernel Regression Settings:
Trade with Kernel - This has a default value of true. It is used to control whether to trade with the kernel.
Show Kernel Estimate - This has a default value of true. It is used to control whether to show the kernel estimate.
Lookback Window - This has a default value of 8 and a minimum value of 3. It is used to control the number of bars used for the estimation. Recommended range: 3-50
Relative Weighting - This has a default value of 8 and a step size of 0.25. It is used to control the relative weighting of time frames. Recommended range: 0.25-25
Start Regression at Bar - This has a default value of 25. It is used to control the bar index on which to start regression. Recommended range: 0-25
Display Settings:
Show Bar Colors - This has a default value of true. It is used to control whether to show the bar colors.
Show Bar Prediction Values - This has a default value of true. It controls whether to show the ML model's evaluation of each bar as an integer.
Use ATR Offset - This has a default value of false. It controls whether to use the ATR offset instead of the bar prediction offset.
Bar Prediction Offset - This has a default value of 0 and a minimum value of 0. It is used to control the offset of the bar predictions as a percentage from the bar high or close.
Backtesting Settings:
Show Backtest Results - This has a default value of true. It is used to control whether to display the win rate of the given configuration.
█ WORKS CITED
(1) R. Giusti and G. E. A. P. A. Batista, "An Empirical Comparison of Dissimilarity Measures for Time Series Classification," 2013 Brazilian Conference on Intelligent Systems, Oct. 2013, DOI: 10.1109/bracis.2013.22.
(2) Y. Kerimbekov, H. Ş. Bilge, and H. H. Uğurlu, "The use of Lorentzian distance metric in classification problems," Pattern Recognition Letters, vol. 84, 170–176, Dec. 2016, DOI: 10.1016/j.patrec.2016.09.006.
(3) A. Bagnall, A. Bostrom, J. Large, and J. Lines, "The Great Time Series Classification Bake Off: An Experimental Evaluation of Recently Proposed Algorithms." ResearchGate, Feb. 04, 2016.
(4) H. Ş. Bilge, Yerzhan Kerimbekov, and Hasan Hüseyin Uğurlu, "A new classification method by using Lorentzian distance metric," ResearchGate, Sep. 02, 2015.
(5) Y. Kerimbekov and H. Şakir Bilge, "Lorentzian Distance Classifier for Multiple Features," Proceedings of the 6th International Conference on Pattern Recognition Applications and Methods, 2017, DOI: 10.5220/0006197004930501.
(6) V. Surya Prasath et al., "Effects of Distance Measure Choice on KNN Classifier Performance - A Review." .
█ ACKNOWLEDGEMENTS
@veryfid - For many invaluable insights, discussions, and advice that helped to shape this project.
@capissimo - For open sourcing his interesting ideas regarding various KNN implementations in PineScript, several of which helped inspire my original undertaking of this project.
@RikkiTavi - For many invaluable physics-related conversations and for his helping me develop a mechanism for visualizing various distance algorithms in 3D using JavaScript
@jlaurel - For invaluable literature recommendations that helped me to understand the underlying subject matter of this project.
@annutara - For help in beta-testing this indicator and for sharing many helpful ideas and insights early on in its development.
@jasontaylor7 - For helping to beta-test this indicator and for many helpful conversations that helped to shape my backtesting workflow
@meddymarkusvanhala - For helping to beta-test this indicator
@dlbnext - For incredibly detailed backtesting testing of this indicator and for sharing numerous ideas on how the user experience could be improved.
Nadaraya-Watson: Envelope (Non-Repainting)Due to popular request, this is an envelope implementation of my non-repainting Nadaraya-Watson indicator using the Rational Quadratic Kernel. For more information on this implementation, please refer to the original indicator located here:
What is an Envelope?
In technical analysis, an "envelope" typically refers to a pair of upper and lower bounds that surrounds price action to help characterize extreme overbought and oversold conditions. Envelopes are often derived from a simple moving average (SMA) and are placed at a predefined distance above and below the SMA from which they were generated. However, envelopes do not necessarily need to be derived from a moving average; they can be derived from any estimator, including a kernel estimator such as Nadaraya-Watson.
How to use this indicator?
Overall, this indicator offers a high degree of flexibility, and the location of the envelope's bands can be adjusted by (1) tweaking the parameters for the Rational Quadratic Kernel and (2) adjusting the lookback window for the custom ATR calculation. In a trending market, it is often helpful to use the Nadaraya-Watson estimate line as a floating SR and/or reversal zone. In a ranging market, it is often more convenient to use the two Upper Bands and two Lower Bands as reversal zones.
How are the Upper and Lower bounds calculated?
In this indicator, the Rational Quadratic (RQ) Kernel estimates the price value at each bar in a user-defined lookback window. From this estimation, the upper and lower bounds of the envelope are calculated based on a custom ATR calculated from the kernel estimations for the high, low, and close series, respectively. These calculations are then scaled against a user-defined multiplier, which can be used to further customize the Upper and Lower bounds for a given chart.
How to use Kernel Estimations like this for other indicators?
Kernel Functions are highly underrated, and when calibrated correctly, they have the potential to provide more value than any mundane moving average. For those interested in using non-repainting Kernel Estimations for technical analysis, I have written a Kernel Functions library that makes it easy to access various well-known kernel functions quickly. The Rational Quadratic Kernel is used in this implementation, but one can conveniently swap out other kernels from the library by modifying only a single line of code. For more details and usage examples, please refer to the Kernel Functions library located here:

Nadaraya-Watson non repainting [LPWN]// ENGLISH
The problem of the wonderfuls Nadaraya-Watson indicators is that they repainting, @jdehorty made an aproximation of the Nadaraya-Watson Estimator using raational Quadratic Kernel so i used this indicator as inspiration i just added the Upper and lower band using ATR with this we get an aproximation of Nadaraya-Watson Envelope without repainting
Settings:
Bandwidth. This is the number of bars that the indicator will use as a lookback window.
Relative Weighting Parameter. The alpha parameter for the Rational Quadratic Kernel function. This is a hyperparameter that controls the smoothness of the curve. A lower value of alpha will result in a smoother, more stretched-out curve, while a lower value will result in a more wiggly curve with a tighter fit to the data. As this parameter approaches 0, the longer time frames will exert more influence on the estimation, and as it approaches infinity, the curve will become identical to the one produced by the Gaussian Kernel.
Color Smoothing. Toggles the mechanism for coloring the estimation plot between rate of change and cross over modes.
ATR Period. Period to calculate the ATR (upper and lower bands)
Multiplier. Separation of the bands
// SPANISH
El problema de los maravillosos indicadores de Nadaraya-Watson es que repintan, @jdehorty hizo una aproximación delNadaraya-Watson Estimator usando un Kernel cuadrático racional, así que usé este indicador como inspiración y solo agregamos la banda superior e inferior usando ATR con esto obtenemos una aproximación de Nadaraya-Watson Envelope sin volver a pintar
Configuración:
Banda ancha. Este es el número de barras que el indicador utilizará como ventana retrospectiva.
Parámetro de ponderación relativa. El parámetro alfa para la función Rational Quadratic Kernel. Este es un hiperparámetro que controla la suavidad de la curva. Un valor más bajo de alfa dará como resultado una curva más suave y estirada, mientras que un valor más bajo dará como resultado una curva más ondulada con un ajuste más ajustado a los datos. A medida que este parámetro se acerque a 0, los marcos de tiempo más largos ejercerán más influencia en la estimación y, a medida que se acerque al infinito, la curva será idéntica a la que produce el Gaussian Kernel.
Suavizado de color. Alterna el mecanismo para colorear el gráfico de estimación entre la tasa de cambio y los modos cruzados.
Período ATR. Periodo para calcular el ATR (bandas superior e inferior)
Multiplicador. Separación de las bandas

KernelFunctionsLibrary "KernelFunctions"
This library provides non-repainting kernel functions for Nadaraya-Watson estimator implementations. This allows for easy substitution/comparison of different kernel functions for one another in indicators. Furthermore, kernels can easily be combined with other kernels to create newer, more customized kernels. Compared to Moving Averages (which are really just simple kernels themselves), these kernel functions are more adaptive and afford the user an unprecedented degree of customization and flexibility.
rationalQuadratic(_src, _lookback, _relativeWeight, _startAtBar)
Rational Quadratic Kernel - An infinite sum of Gaussian Kernels of different length scales.
Parameters:
_src : The source series.
_lookback : The number of bars used for the estimation. This is a sliding value that represents the most recent historical bars.
_relativeWeight : Relative weighting of time frames. Smaller values result in a more stretched-out curve, and larger values will result in a more wiggly curve. As this value approaches zero, the longer time frames will exert more influence on the estimation. As this value approaches infinity, the behavior of the Rational Quadratic Kernel will become identical to the Gaussian kernel.
_startAtBar : Bar index on which to start regression. The first bars of a chart are often highly volatile, and omitting these initial bars often leads to a better overall fit.
Returns: yhat The estimated values according to the Rational Quadratic Kernel.
gaussian(_src, _lookback, _startAtBar)
Gaussian Kernel - A weighted average of the source series. The weights are determined by the Radial Basis Function (RBF).
Parameters:
_src : The source series.
_lookback : The number of bars used for the estimation. This is a sliding value that represents the most recent historical bars.
_startAtBar : Bar index on which to start regression. The first bars of a chart are often highly volatile, and omitting these initial bars often leads to a better overall fit.
Returns: yhat The estimated values according to the Gaussian Kernel.
periodic(_src, _lookback, _period, _startAtBar)
Periodic Kernel - The periodic kernel (derived by David Mackay) allows one to model functions that repeat themselves exactly.
Parameters:
_src : The source series.
_lookback : The number of bars used for the estimation. This is a sliding value that represents the most recent historical bars.
_period : The distance between repititions of the function.
_startAtBar : Bar index on which to start regression. The first bars of a chart are often highly volatile, and omitting these initial bars often leads to a better overall fit.
Returns: yhat The estimated values according to the Periodic Kernel.
locallyPeriodic(_src, _lookback, _period, _startAtBar)
Locally Periodic Kernel - The locally periodic kernel is a periodic function that slowly varies with time. It is the product of the Periodic Kernel and the Gaussian Kernel.
Parameters:
_src : The source series.
_lookback : The number of bars used for the estimation. This is a sliding value that represents the most recent historical bars.
_period : The distance between repititions of the function.
_startAtBar : Bar index on which to start regression. The first bars of a chart are often highly volatile, and omitting these initial bars often leads to a better overall fit.
Returns: yhat The estimated values according to the Locally Periodic Kernel.
Nadaraya-Watson CombineThis is a combination of the Lux Algo Nadaraya-Watson Estimator and Envelope. Please note the repainting issue.
In addition, I've added a plot of the actual values of the current barstate of
the Nadaraya-Watson windows as they are computed (lines 92-95). It only plots values for the current data at
each time update. It is interesting to compare the trajectory of the end points of the Estimator and
Envelope to the smoothing function at each time update. Due to the kernel smoothing at each update the
history is lost at each update (repaint).
I've added a feature to allow adjustment to the kernel smoothing algorithm as suggested by thomsonraja (line 59).
The settings and usage are repeated from Lux Algo below.
Settings
Window Size: Determines the number of recent price observations to be used to fit the Nadaraya-Watson Estimator.
Bandwidth: Controls the degree of smoothness of the envelopes , with higher values returning smoother results.
Mult: Controls the envelope width.
Src: Input source of the indicator.
Kernel power: See line 59, adjusts the exponential power (powh) as suggested by thomsonraja
Kernel denominator: See line 59, adjusts the denominator (den) as suggested by thomsonraja
Usage
This tool outlines extremes made by the prices within the selected window size.
This is achieved by estimating the underlying trend in the price using kernel smoothing,
calculating the mean absolute deviations from it, and adding/subtracting it
from the estimated underlying trend.
I repeat Lux Algo's caution: 'we do not recommend this tool to be used alone
or solely for real time applications.'
STD-Filtered, Gaussian-Kernel-Weighted Moving Average [Loxx]STD-Filtered, Gaussian-Kernel-Weighted Moving Average is a moving average that weights price by using a Gaussian kernel function to calculate data points. This indicator also allows for filtering both source input price and output signal using a standard deviation filter.
Purpose
This purpose of this indicator is to take the concept of Kernel estimation and apply it in a way where instead of predicting past values, the weighted function predicts the current bar value at each bar to create a moving average that is suitable for trading. Normally this method is used to create an array of past estimators to model past data but this method is not useful for trading as the past values will repaint. This moving average does NOT repaint, however you much allow signals to close on the current bar before taking the signal. You can compare this to Nadaraya-Watson Estimator wherein they use Nadaraya-Watson estimator method with normalized kernel weighted function to model price.
What are Kernel Functions?
A kernel function is used as a weighing function to develop non-parametric regression model is discussed. In the beginning of the article, a brief discussion about properties of kernel functions and steps to build kernels around data points are presented.
Kernel Function
In non-parametric statistics, a kernel is a weighting function which satisfies the following properties.
A kernel function must be symmetrical. Mathematically this property can be expressed as K (-u) = K (+u). The symmetric property of kernel function enables its maximum value (max(K(u)) to lie in the middle of the curve.
The area under the curve of the function must be equal to one. Mathematically, this property is expressed as: integral −∞ + ∞ ∫ K(u)d(u) = 1
Value of kernel function can not be negative i.e. K(u) ≥ 0 for all −∞ < u < ∞.
Kernel Estimation
In this article, Gaussian kernel function is used to calculate kernels for the data points. The equation for Gaussian kernel is:
K(u) = (1 / sqrt(2pi)) * e^(-0.5 *(j / bw)^2)
Where xi is the observed data point. j is the value where kernel function is computed and bw is called the bandwidth. Bandwidth in kernel regression is called the smoothing parameter because it controls variance and bias in the output. The effect of bandwidth value on model prediction is discussed later in this article.
Included
Loxx's Expanded Source types
Signals
Alerts
Bar coloring
Nadaraya-Watson Envelope [LuxAlgo]This indicator builds upon the previously posted Nadaraya-Watson smoothers. Here we have created an envelope indicator based on Kernel Smoothing with integrated alerts from crosses between the price and envelope extremities. Unlike the Nadaraya-Watson estimator, this indicator follows a contrarian methodology.
Please note that by default this indicator can be subject to repainting. Users can use a non-repainting smoothing method available from the settings. The triangle labels are designed so that the indicator remains useful in real-time applications.
🔶 USAGE
🔹 Non Repainting
This tool can outline extremes made by the prices. This is achieved by estimating the underlying trend in the price, then calculating the mean absolute deviations from it, the obtained result is added/subtracted to the estimated underlying trend.
The non-repainting method estimates the underlying trend in price using an "endpoint Nadaraya-Watson estimator", and would return similar results to more classical band indicators.
🔹 Repainting
The repainting method makes use of the Nadaraya-Watson estimator to estimate the underlying trend in the price. The construction of the band extremities is the same as in the non-repainting method.
We can expect the price to reverse when crossing one of the envelope extremities. Crosses between the price and the envelopes extremities are indicated with triangles on the chart.
For real-time applications, triangles are always displayed when a cross occurs and remain displayed at the location it first appeared even if the cross is no longer visible after a recalculation of the envelope.
By popular demand, we have integrated alerts for this indicator from the crosses between the price and the envelope extremities. However, we do not recommend this precise method to be used alone or for solely real-time applications. We do not have data supporting the performance of this tool over more classical bands/envelope/channels indicators.
🔶 SETTINGS
Bandwidth: Controls the degree of smoothness of the envelopes, with higher values returning smoother results.
Mult: Controls the envelope width.
Source: Input source of the indicator.
Repainting Smoothing: Determine if a repainting or non-repainting method should be used for the calculation of the indicator.
🔶 RELATED SCRIPTS
For more information on the Nadaraya-Watson estimator see:
Nadaraya-Watson Smoothers [LuxAlgo]The following tool smoothes the price data using various methods derived from the Nadaraya-Watson estimator, a simple Kernel regression method. This method makes use of the Gaussian kernel as a weighting function.
Users have the option to use a non-repainting as well as a repainting method, see the USAGE section for more information.
🔶 USAGE
🔹 Non Repainting
When Repainting Smoothing is disabled the returned indicator acts similarly to a regular causal moving average. This result could be described as an "endpoint Nadaraya-Watson estimator".
Unlike a regular moving average whose degree of smoothness is commonly determined by the length of its calculation window, the degree of smoothness of the proposed indicator is determined by the bandwidth setting, with a higher value returning smoother results.
In the above chart, a bandwidth value of 50 is used. An increasing value of the smoother is indicative of an uptrend, while a decreasing value is indicative of a downtrend.
🔹 Repainting
Non-causal smoothing methods have found low support from technical analysts because they tend to repaint. Yet, they can provide powerful insights such as estimating underlying trends in the price as well as seeing how far prices deviate from them. They can also make drawing certain patterns easier and can help see underlying structures in the price more clearly.
Using higher bandwidth values allows for estimating longer-term trends in the price.
Triangular labels highlight points where the direction of the estimator change. This allows for the identification of tops and bottoms in the underlying trend which can be compared to the actual price tops and bottoms.
Note that multiple labels can appear in real time, highlighting real-time changes in the estimator's direction. The most recent label on a series of labels is the first to appear. This can eventually be useful for the real-time predictive application of the estimator. However, it is not a usage we particularly recommend.
🔶 DETAILS
The Nadaraya-Watson estimator can be described as a series of weighted averages using a specific normalized kernel as a weighting function. For each point of the estimator at time t , the peak of the kernel is located at time t , as such the highest weights are attributed to values neighboring the price located at time t .
A lower bandwidth value would contribute toward a more important weighting of the price at a precise point and would as such less smooth results. In the case where our bandwidth is so small that the resulting kernel is just an impulse, we would get the raw price back.
However, when the bandwidth is sufficiently large, prices would be weighted similarly, thus resulting in a result closer to the price mean.
It can be interesting to note that due to the nature of the estimator and its weighting procedure, real-time results would not deviate drastically for points in the estimator near the center of the calculation window.
🔶 SETTINGS
Bandwidth : controls the bandwidth of the Gaussian kernel, with higher values returning smoother results.
Src : Input source of the kernel regression.
Repainting Smoothing : Determine if the smoothing method should repaint or not. If disabled the "endpoint Nadaraya-Watson estimator" is returned.
