example: Event StatisticsEXPERIMENTAL:
A example on how to retrieve statistics from a recurring event.
Can be used to optimized strategy's, trade parameters, etc..
Optimized

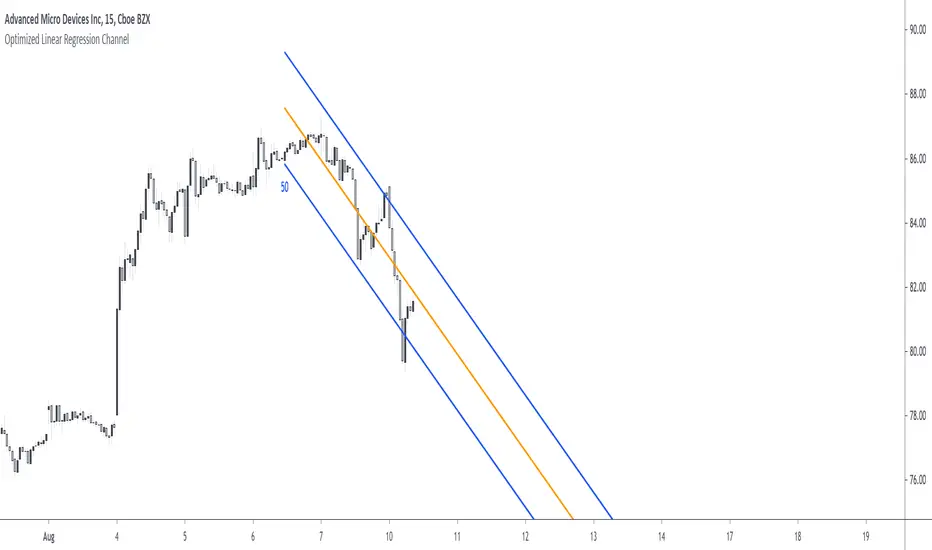
Optimized Linear Regression ChannelReturn a linear regression channel with a window size within the range (min, max) such that the R-squared is maximized, this allows a better estimate of an underlying linear trend, a better detection of significant historical supports and resistance points, and avoid finding a good window size manually.
Settings
Min : Minimum window size value
Max : Maximum window size value
Mult : Multiplicative factor for the rmse, control the channel width.
Src : Source input of the indicator
Details
The indicator displays the specific window size that maximizes the R-squared at the bottom of the lower channel.
When optimizing we want to find parameters such that they maximize or minimize a certain function, here the r-squared. The R-squared is given by 1 minus the ratio between the sum of squares (SSE) of the linear regression and the sum of squares of the mean. We know that the mean will always produce an SSE greater or equal to the one of the linear regression, so the R-squared will always be in a (0,1) range. In the case our data has a linear trend, the linear regression will have a better fit, thus having a lower SSE than the SSE of the mean, has such the ratio between the linear regression SSE and the mean SSE will be low, 1 minus this ratio will return a greater result. A lower R-squared will tell you that your linear regression produces a fit similar to the one produced by the mean. The R-squared is also given by the square of the correlation coefficient between the dependent and independent variables.
In pinescript optimization can be done by running a function inside a loop, we run the function for each setting and keep the one that produces the maximum or minimum result, however, it is not possible to do that with most built-in functions, including the function of interest, correlation , as such we must recreate a rolling correlation function that can be used inside loops, such functions are generally loops-free, this means that they are not computed using a loop in the first place, fortunately, the rolling correlation function is simply based on moving averages and standard deviations, both can be computed without using a loop by using cumulative sums, this is what is done in the code.
Note that because the R-squared is based on the SSE of the linear regression, maximizing the R-squared also minimizes the linear regression SSE, another thing that is minimized is the horizontality of the fit.
In the example above we have a total window size of 27, the script will try to find the setting that maximizes the R-squared, we must avoid every data points before the volatile bearish candle, using any of these data points will produce a poor fit, we see that the script avoid it, thus running as expected. Another interesting thing is that the best R-squared is not always associated to the lowest window size.
Note that optimization does not fix core problems in a model, with the linear regression we assume that our data set posses a linear trend, if it's not the case, then no matter how many settings you use you will still have a model that is not adapted to your data.
Minimum Variance SMAReturn the value of a simple moving average with a period within the range min to max such that the variance of the same period is the smallest available.
Since the smallest variance is often the one with the smallest period, a penalty setting is introduced, and allows the indicator to return moving averages values with higher periods more often, with higher penalty values returning moving averages values with higher periods.
Because variances with smaller periods are more reactive than ones with higher periods, it is common for the indicator to return the value of an SMA of a higher period during more volatile market, this can be seen on the image below:
here variances from period 10 to 15 are plotted, a blueish color represents a higher period, note how they are the smallest ones when fluctuations are more volatile.
Indicator with min = 50, max = 200 and penalty = 0.5
In blue the indicator with penalty = 0, in red with penalty = 1, with both min = 50 and max = 200.
On The Script
The script minimize Var(i)/p with i ∈ (min,max) and p = i^penalty , this is done by computing the variance for each period i and keeping the smallest one currently in the loop, if we get a variance value smaller than the previously one found we calculate the value of an SMA with period i , as such the script deal with brute force optimization.
For our use case it is not possible to use the built-in sma and variance functions within a loop, as such we use cumulative forms for both functions.

UCS_Squeeze_OptimizationSqueeze Momentum Indicator - Optimized
All Updates from Version 3 + Squeeze Optimized further.
