Crypto Correlation MatrixA crypto correlation matrix or table is a tool that displays the correlation between different cryptocurrencies and other financial assets. The matrix provides an overview of the degree to which various cryptocurrencies move in tandem or independently of each other. Each cell represents the correlation between the row and column assets respectively.
The correlation matrix can be useful for traders and investors in several ways:
First, it allows them to identify trends and patterns in the behavior of different cryptocurrencies. By looking at the correlations between different assets, traders can gain insight into the intra-relationships of the crypto market and make more informed trading decisions. For example, if two cryptocurrencies have a high positive correlation, meaning that they tend to move in the same direction, a trader may want to diversify their portfolio by choosing to invest in only one of the two assets.
Additionally, the correlation matrix can help traders and investors to manage risk. By analyzing the correlations between different assets, traders can identify opportunities to hedge their positions or limit their exposure to particular risks. For example, if a trader holds a portfolio of cryptocurrencies that are highly correlated with each other, they may be at greater risk of losses if the market moves against them. By diversifying their portfolio with assets that are less correlated with each other, they can reduce their overall risk.
Some of the unique properties for this specific script are the correlation strength levels in conjunction with the color gradient of cells, intended for clearer readability.
Features:
Supports up to 64 different crypto assets.
Dark/Light mode.
Correlation strength levels and cell coloring.
Adjustable positioning on the chart.
Alerts at the close of a bar. (Daily timeframe or higher recommended)
Pearson

Advanced Trend Detection StrategyThe Advanced Trend Detection Strategy is a sophisticated trading algorithm based on the indicator "Percent Levels From Previous Close".
This strategy is based on calculating the Pearson's correlation coefficient of logarithmic-scale linear regression channels across a range of lengths from 50 to 1000. It then selects the highest value to determine the length for the channel used in the strategy, as well as for the computation of the Simple Moving Average (SMA) that is incorporated into the strategy.
In this methodology, a script is applied to an equity in which multiple length inputs are taken into consideration. For each of these lengths, the slope, average, and intercept are calculated using logarithmic values. Deviation, the Pearson's correlation coefficient, and upper and lower deviations are also computed for each length.
The strategy then selects the length with the highest Pearson's correlation coefficient. This selected length is used in the channel of the strategy and also for the calculation of the SMA. The chosen length is ultimately the one that best fits the logarithmic regression line, as indicated by the highest Pearson's correlation coefficient.
In short, this strategy leverages the power of Pearson's correlation coefficient in a logarithmic scale linear regression framework to identify optimal trend channels across a broad range of lengths, assisting traders in making more informed decisions.

DominantCycleCollection of Dominant Cycle estimators. Length adaptation used in the Adaptive Moving Averages and the Adaptive Oscillators try to follow price movements and accelerate/decelerate accordingly (usually quite rapidly with a huge range). Cycle estimators, on the other hand, try to measure the cycle period of the current market, which does not reflect price movement or the rate of change (the rate of change may also differ depending on the cycle phase, but the cycle period itself usually changes slowly). This collection may become encyclopaedic, so if you have any working cycle estimator, drop me a line in the comments below. Suggestions are welcome. Currently included estimators are based on the work of John F. Ehlers
mamaPeriod(src, dynLow, dynHigh) MESA Adaptation - MAMA Cycle
Parameters:
src : Series to use
dynLow : Lower bound for the dynamic length
dynHigh : Upper bound for the dynamic length
Returns: Calculated period
Based on MESA Adaptive Moving Average by John F. Ehlers
Performs Hilbert Transform Homodyne Discriminator cycle measurement
Unlike MAMA Alpha function (in LengthAdaptation library), this does not compute phase rate of change
Introduced in the September 2001 issue of Stocks and Commodities
Inspired by the @everget implementation:
Inspired by the @anoojpatel implementation:
paPeriod(src, dynLow, dynHigh, preHP, preSS, preHP) Pearson Autocorrelation
Parameters:
src : Series to use
dynLow : Lower bound for the dynamic length
dynHigh : Upper bound for the dynamic length
preHP : Use High Pass prefilter (default)
preSS : Use Super Smoother prefilter (default)
preHP : Use Hann Windowing prefilter
Returns: Calculated period
Based on Pearson Autocorrelation Periodogram by John F. Ehlers
Introduced in the September 2016 issue of Stocks and Commodities
Inspired by the @blackcat1402 implementation:
Inspired by the @rumpypumpydumpy implementation:
Corrected many errors, and made small speed optimizations, so this could be the best implementation to date (still slow, though, so may revisit in future)
High Pass and Super Smoother prefilters are used in the original implementation
dftPeriod(src, dynLow, dynHigh, preHP, preSS, preHP) Discrete Fourier Transform
Parameters:
src : Series to use
dynLow : Lower bound for the dynamic length
dynHigh : Upper bound for the dynamic length
preHP : Use High Pass prefilter (default)
preSS : Use Super Smoother prefilter (default)
preHP : Use Hann Windowing prefilter
Returns: Calculated period
Based on Spectrum from Discrete Fourier Transform by John F. Ehlers
Inspired by the @blackcat1402 implementation:
High Pass, Super Smoother and Hann Windowing prefilters are used in the original implementation
phasePeriod(src, dynLow, dynHigh, preHP, preSS, preHP) Phase Accumulation
Parameters:
src : Series to use
dynLow : Lower bound for the dynamic length
dynHigh : Upper bound for the dynamic length
preHP : Use High Pass prefilter (default)
preSS : Use Super Smoother prefilter (default)
preHP : Use Hamm Windowing prefilter
Returns: Calculated period
Based on Dominant Cycle from Phase Accumulation by John F. Ehlers
High Pass and Super Smoother prefilters are used in the original implementation
doAdapt(type, src, len, dynLow, dynHigh, chandeSDLen, chandeSmooth, chandePower, preHP, preSS, preHP) Execute a particular Length Adaptation or Dominant Cycle Estimator from the list
Parameters:
type : Length Adaptation or Dominant Cycle Estimator type to use
src : Series to use
len : Reference lookback length
dynLow : Lower bound for the dynamic length
dynHigh : Upper bound for the dynamic length
chandeSDLen : Lookback length of Standard deviation for Chande's Dynamic Length
chandeSmooth : Smoothing length of Standard deviation for Chande's Dynamic Length
chandePower : Exponent of the length adaptation for Chande's Dynamic Length (lower is smaller variation)
preHP : Use High Pass prefilter for the Estimators that support it (default)
preSS : Use Super Smoother prefilter for the Estimators that support it (default)
preHP : Use Hann Windowing prefilter for the Estimators that support it
Returns: Calculated period (float, not limited)
doEstimate(type, src, dynLow, dynHigh, preHP, preSS, preHP) Execute a particular Dominant Cycle Estimator from the list
Parameters:
type : Dominant Cycle Estimator type to use
src : Series to use
dynLow : Lower bound for the dynamic length
dynHigh : Upper bound for the dynamic length
preHP : Use High Pass prefilter for the Estimators that support it (default)
preSS : Use Super Smoother prefilter for the Estimators that support it (default)
preHP : Use Hann Windowing prefilter for the Estimators that support it
Returns: Calculated period (float, not limited)

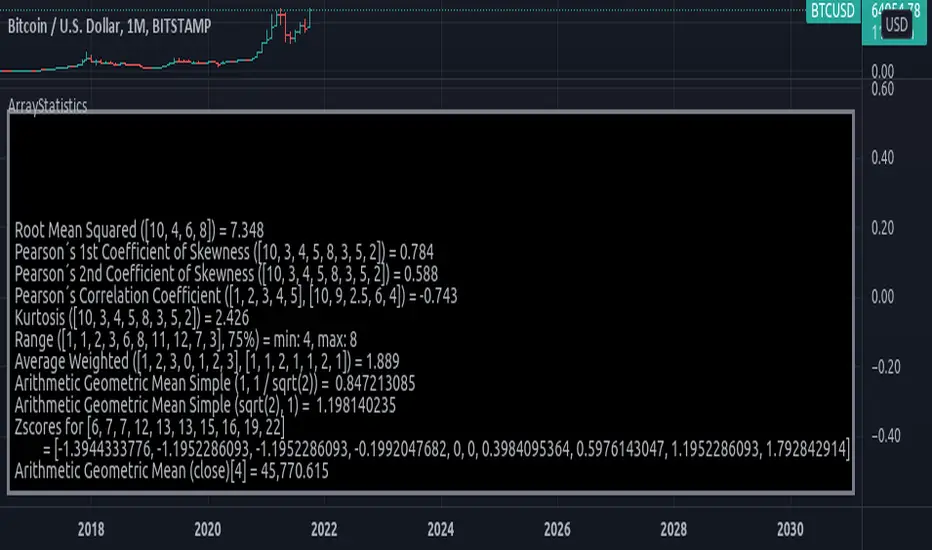
ArrayStatisticsLibrary "ArrayStatistics"
Statistic Functions using arrays.
rms(sample) Root Mean Squared
Parameters:
sample : float array, data sample points.
Returns: float
skewness_pearson1(sample) Pearson's 1st Coefficient of Skewness.
Parameters:
sample : float array, data sample.
Returns: float
skewness_pearson2(sample) Pearson's 2nd Coefficient of Skewness.
Parameters:
sample : float array, data sample.
Returns: float
pearsonr(sample_a, sample_b) Pearson correlation coefficient measures the linear relationship between two datasets.
Parameters:
sample_a : float array, sample with data.
sample_b : float array, sample with data.
Returns: float p
kurtosis(sample) Kurtosis of distribution.
Parameters:
sample : float array, data sample.
Returns: float
range_int(sample, percent) Get range around median containing specified percentage of values.
Parameters:
sample : int array, Histogram array.
percent : float, Values percentage around median.
Returns: tuple with , Returns the range which containes specifies percentage of values.
Auto_Corr_DailyThis indicator shows the Pearson correlation coefficient between different periods of one financial instrument. Two dates are set, which are the starting points of two series, between which the correlation coefficient is calculated. The correlation period is taken from the difference of the current date from the second reference point. The indicator is designed to analyze the correlation only on the 1D timeframe.

Dual Purpose Pine Based CorrelationThis is my "Pine-based" correlation() function written in raw Pine Script. Other names applied to it are "Pearson Correlation", "Pearson's r", and one I can never remember being "Pearson Product-Moment Correlation Coefficient(PPMCC)". There is two basic ways to utilize this script. One is checking correlation with another asset such as the S&P 500 (provided as a default). The second is using it as a handy independent indicator correlated to time using Pine's bar_index variable. Also, this is in fact two separate correlation indicators with independent period adjustments, so I guess you could say this indicator has a dual purpose split personality. My intention was to take standard old correlation and apply a novel approach to it, and see what happens. Either way you use it, I hope you may find it most helpful enough to add to your daily TV tool belt.
You will notice I used the Pine built-in correlation() in combination with my custom function, so it shows they are precisely equal, even when the first two correlation() parameters are reversed on purpose or by accident. Additionally, there's an interesting technique to provide a visually appealing line with two overlapping plot()s combined together. I'm sure many members may find that plotting tactic useful when a bird's nest of plotting is occurring on the overlay pane in some scenarios. One more thing about correlation is it's always confined to +/-1.0 irregardless of time intervals or the asset(s) it is applied to, making it a unique oscillator.
As always, I have included advanced Pine programming techniques that conform to proper "Pine Etiquette". For those of you who are newcomers to Pine Script, this code release may also help you comprehend the "Power of Pine" by employing advanced programming techniques in Pine exhibiting code utilization in a most effective manner. One of the many tricks I applied here was providing floating point number safeties for _correlation(). While it cannot effectively use a floating point number, it won't error out in the event this should occur especially when applying "dominant cycle periods" to it, IF you might attempt this.
NOTICE: You may have observed there is a sqrt() custom function and you may be thinking... "Did he just sick and twistedly overwrite the Pine built-in sqrt() function?" The answer is... YES, I am and yes I did! One thing I noticed, is that it does provide slightly higher accuracy precision decimal places compared to the Pine built-in sqrt(). Be forewarned, "MY" sqrt() is technically speaking slower than snail snot compared to the native Pine sqrt(), so I wouldn't advise actually using it religiously in other scripts as a daily habit. It is seemingly doing quite well in combination with these simple calculations without being "sluggish". Lastly, of course you may always just delete the custom sqrt() function, via Pine Editor, and then the script will still operate flawlessly, yet more efficiently.
Features List Includes:
Dark Background - Easily disabled in indicator Settings->Style for "Light" charts or with Pine commenting
AND much, much more... You have the source!
The comments section below is solely just for commenting and other remarks, ideas, compliments, etc... regarding only this indicator, not others. When available time provides itself, I will consider your inquiries, thoughts, and concepts presented below in the comments section, should you have any questions or comments regarding this indicator. When my indicators achieve more prevalent use by TV members, I may implement more ideas when they present themselves as worthy additions. As always, "Like" it if you simply just like it with a proper thumbs up, and also return to my scripts list occasionally for additional postings. Have a profitable future everyone!