FrizLabz_Time_Utility_MethodsLibrary "FrizLabz_Time_Utility_Methods"
Some time to index and index to time helper methods made them for another library thought I would try to make
them as methods
UTC_helper(utc)
UTC helper function this adds the + to the positive utc times, add "UTC" to the string
and can be used in the timezone arg of for format_time()
Parameters:
utc : (int) | +/- utc offset
Returns: string | string to be added to the timezone paramater for utc timezone usage
bar_time(bar_amount)
from a time to index
Parameters:
bar_amount : (int) | default - 1)
Returns: int bar_time
time_to_index(_time)
from time to bar_index
Parameters:
_time : (int)
Returns: int time_to_index | bar_index that corresponds to time provided
time_to_bars_back(_time)
from a time quanity to bar quanity for use with .
Parameters:
_time : (int)
Returns: int bars_back | yeilds the amount of bars from current bar to reach _time provided
bars_back_to_time(bars_back)
from bars_back to time
Parameters:
bars_back
Returns: int | using same logic as this will return the
time of the bar = to the bar that corresponds to bars_back
index_time(index)
bar_index to UNIX time
Parameters:
index : (int)
Returns: int time | time in unix that corrresponds to the bar_index
to_utc(time_or_index, timezone, format)
method to use with a time or bar_index variable that will detect if it is an index or unix time
and convert it to a printable string
Parameters:
time_or_index : (int) required) | time in unix or bar_index
timezone : (int) required) | utc offset to be appled to output
format : (string) | default - "yyyy-MM-dd'T'HH:mm:ssZ") | the format for the time, provided string is
default one from str.format_time()
Returns: string | time formatted string
GET(line)
Gets the location paramaters of a Line
Parameters:
line : (line)
Returns: tuple
GET(box)
Gets the location paramaters of a Box
Parameters:
box : (box)
Returns: tuple
GET(label)
Gets the location paramaters and text of a Label
Parameters:
label : (label)
Returns: tuple
GET(linefill)
Gets line 1 and 2 from a Linefill
Parameters:
linefill : (linefill)
Returns: tuple
Format(line, timezone)
converts Unix time in time or index params to formatted time
and returns a tuple of the params as string with the time/index params formatted
Parameters:
line : (line) | required
timezone : (int) | default - na
Returns: tuple
Line(x1, y1, x2, y2, extend, color, style, width)
similar to line.new() with the exception
of not needing to include y2 for a flat line, y1 defaults to close,
and it doesnt require xloc.bar_time or xloc.bar_index, if no x1
Parameters:
x1 : (int) default - time
y1 : (float) default - close
x2 : (int) default - last_bar_time/last_bar_index | not required for line that ends on current bar
y2 : (float) default - y1 | not required for flat line
extend : (string) default - extend.none | extend.left, extend.right, extend.both
color : (color) default - chart.fg_color
style : (string) default - line.style_solid | line.style_dotted, line.style_dashed,
line.style_arrow_both, line.style_arrow_left, line.style_arrow_right
width
Returns: line
Box(left, top, right, bottom, extend, border_color, bgcolor, text_color, border_width, border_style, txt, text_halign, text_valign, text_size, text_wrap)
similar to box.new() but only requires top and bottom to create box,
auto detects if it is bar_index or time used in the (left) arg. xloc.bar_time and xloc.bar_index are not used
args are ordered by purpose | position -> colors -> styling -> text options
Parameters:
left : (int) default - time
top : (float) required
right : (int) default - last_bar_time/last_bar_index | will default to current bar index or time
depending on (left) arg
bottom : (float) required
extend : (string) default - extend.none | extend.left, extend.right, extend.both
border_color : (color) default - chart.fg_color
bgcolor : (color) default - color.new(chart.fg_color,75)
text_color : (color) default - chart.bg_color
border_width : (int) default - 1
border_style : (string) default - line.style_solid | line.style_dotted, line.style_dashed,
txt : (string) default - ''
text_halign : (string) default - text.align_center | text.align_left, text.align_right
text_valign : (string) default - text.align_center | text.align_top, text.align_bottom
text_size : (string) default - size.normal | size.tiny, size.small, size.large, size.huge
text_wrap : (string) default - text.wrap_auto | text.wrap_none
Returns: box
Label(x, y, txt, yloc, color, textcolor, style, size, textalign, text_font_family, tooltip)
similar to label.new() but only requires no args to create label,
auto detects if it is bar_index or time used in the (x) arg. xloc.bar_time and xloc.bar_index are not used
args are ordered by purpose | position -> colors -> styling -> text options
Parameters:
x : (int) default - time
y : (float) default - high or low | depending on bar direction
txt : (string) default - ''
yloc : (string) default - yloc.price | yloc.price, yloc.abovebar, yloc.belowbar
color : (color) default - chart.fg_color
textcolor : (color) default - chart.bg_color
style : (string) default - label.style_label_down | label.style_none
label.style_xcross,label.style_cross,label.style_triangleup,label.style_triangledown
label.style_flag, label.style_circle, label.style_arrowup, label.style_arrowdown,
label.style_label_up, label.style_label_down, label.style_label_left, label.style_label_right,
label.style_label_lower_left, label.style_label_lower_right, label.style_label_upper_left,
label.style_label_upper_right, label.style_label_center, label.style_square,
label.style_diamond
size : (string) default - size.normal | size.tiny, size.small, size.large, size.huge
textalign : (string) default - text.align_center | text.align_left, text.align_right
text_font_family : (string) default - font.family_default | font.family_monospace
tooltip : (string) default - na
Returns: label
Pinescript

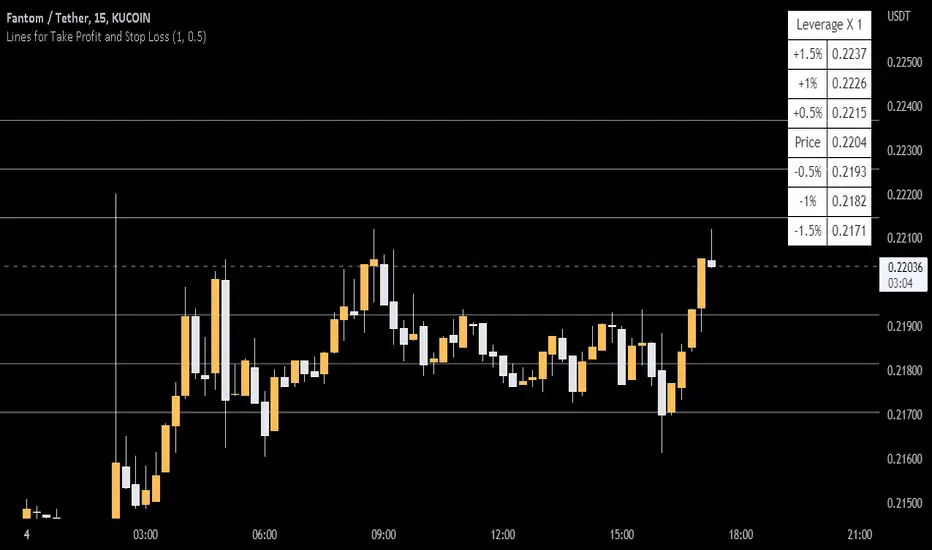
Lines and Table for risk managementABOUT THIS INDICATOR
This is a simple indicator that can help you manage the risk when you are trading, and especially if you are leverage trading. The indicator can also be used to help visualize and to find trades within a suitable or predefined trading range.
This script calculates and draws six “profit and risk lines” (levels) that show the change in percentage from the current price. The values are also shown in a table, to help you get a quick overview of risk before you trade.
ABOUT THE LINES/VALUES
This indicator draws seven percentage-lines, where the dotted line in the middle represents the current price. The other three lines on top of and below the middle line shows the different levels of change in percentage from current price (dotted line). The values are also shown in a table.
DEFAULT VALUES AND SETTINGS
By default the indicator draw lines 0.5%, 1.0%, and 1.5% from current price (step size = 0.5).
The default setting for leverage in this indicator = 1 (i.e. no leverage).
The line closest to dotted line (current price) is calculated by step size (%) * leverage (x) = % from price.
Pay attention to the %-values in the table, they represent the distance from the current price (dotted line) to where the lines are drawn.
* Be aware! If you change the leverage, the distance from the closest lines to the dotted line showing the current price increase.
SETTINGS
1. Leverage: set the leverage for what you are planning to trade on (1 = no leverage, 2 = 2 x leverage, 5 = 5 x leverage...).
2. Stepsize is used to set the distance between the lines and price.
EXAMPLES WITH DIFFERENT SETTINGS
1) Leverage = 1 (no leverage, default setting) and step size 0.5 (%). Lines plotted at (0.5%, 1%, 1.5%, and –0.5%, –1%, –1,5%) from the current price.
2) Leverage = 3 and stepsize 0.5(%). Lines plotted at (1.5%, 3.0%, 4.5%, and –1.5%, –3.0%, –4.5%) from the current price.
3) Leverage = 3 and stepsize 1(%). Lines plotted at (3%, 6%, 9%, and –3%, –6%, –9%) from the current price.
The distance to the nearest line from the current price is always calculated by the formula: Leverage * step size (%) = % to the nearest line from the current price.
Trendly
╭━━━━╮╱╱╱╱╱╱╱╱╭┳╮
┃╭╮╭╮┃╱╱╱╱╱╱╱╱┃┃┃
╰╯┃┃┣┻┳━━┳━╮╭━╯┃┃╭╮╱╭╮
╱╱┃┃┃╭┫┃━┫╭╮┫╭╮┃┃┃┃╱┃┃
╱╱┃┃┃┃┃┃━┫┃┃┃╰╯┃╰┫╰━╯┃
╱╱╰╯╰╯╰━━┻╯╰┻━━┻━┻━╮╭╯
╱╱╱╱╱╱╱╱╱╱╱╱╱╱╱╱╱╭━╯┃
╱╱╱╱╱╱╱╱╱╱╱╱╱╱╱╱╱╰━━╯
About the script:
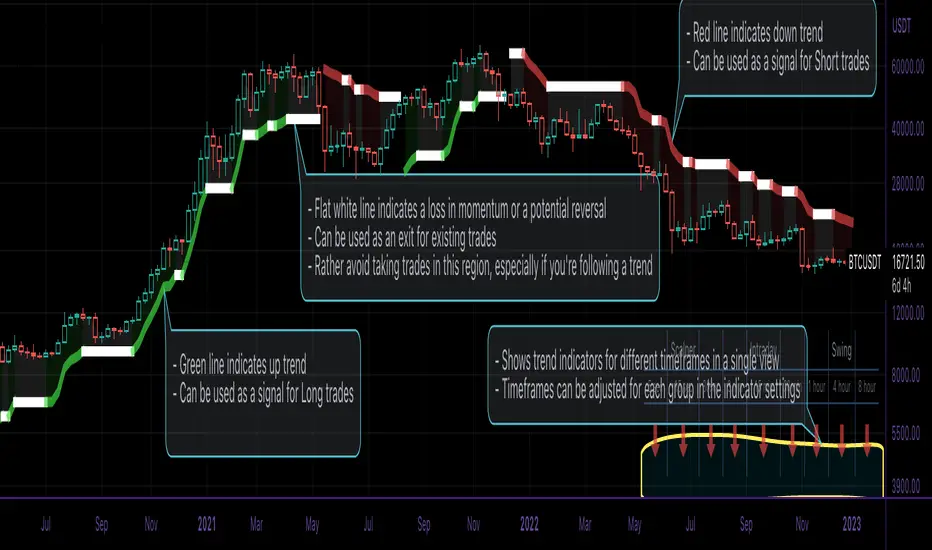
This script is an easy-to-use trend indicator, which is based on another popular indicator called "Supertrend" . The basic idea is very simple, i.e. to compute Average True Range(ATR) and use that as the basis for trend detection. The key difference lies in a custom trend detection method, that computes trends across different timeframes and projects them in a table view. The script also tries to improve the behaviour of the existing indicator by highlighting flat regions on the chart, indicating sideways market or potential trend reversals.
How to use it:
You can use it just like any other indicator, add it to your chart and start analysing market trends. Results can be interpreted as follows.
Indicator output is currently made up of two main components:
>> Trend Table:
Appears at the bottom right of your screen
Contains trend indicator for 9 different timeframes
Timeframes can be adjusted using indicator settings panel
Green Up Arrow --> Up Trend
Red Down Arrow --> Down Trend
>> Enhanced Supertrend:
Shows up as a line plot on the chart
Green line indicates up trend
Red line indicates down trend
White regions indicates slow moving markets or a potential trend reversal
Indicator can be used on any timeframe, it provides a view of current and historical market trend
Can be used as an indicator for entering/exiting trades
Can be used to build custom trading strategies
Selected Dates Filter by @zeusbottradingWe are presenting you feature for strategies in Pine Script.
This function/pine script is about NOT opening trades on selected days. Real usage is for bank holidays or volatile days (PPI, CPI, Interest Rates etc.) in United States and United Kingdom from 2020 to 2030 (10 years of dates of bank holidays in mentioned countries above). Strategy is simple - SMA crossover of two lengts 14 and 28 with close source.
In pine script you can see we picked US and GB bank holidays. If you add this into your strategy, your bot will not open trades on those days. You must make it a rule or a condition. We use it as a rule in opening long/short trades.
You can also add some of your prefered dates, here is just example of our idea. If you want to add your preffered days you can find them on any site like forexfactory, myfxbook and so on. But don’t forget to add function “time_tradingday ! = YourChoosedDate” as it is writen lower in the pine script.
Sometimes the date is substituted for a different day, because the day of the holiday is on Saturday or Sunday.
Made with ❤️ for this community.
If you have any questions or suggestions, let us know.
The script is for informational and educational purposes only. Use of the script does not constitutes professional and/or financial advice. You alone the sole responsibility of evaluating the script output and risks associated with the use of the script. In exchange for using the script, you agree not to hold zeusbottrading TradingView user liable for any possible claim for damages arising from any decision you make based on use of the script.

[-_-] Custom Type ExamplesDescription:
This script shows an example use of new Pinescript's feature called User Defined Types, which can be seen as analogue of from C++ or from Python. It is not an indicator for technical analysis, and serves only as an example of how to use the new feature mentioned above.
In the script I define 4 custom types and a custom initialisation function for each:
- Point (represents a coordinate with x -> bar_index, y -> price)
- Tria (creates a triangle using objects and objects as coordinates of 3 points)
- Path (creates a path-like object from an of )
- Trade (creates a visual representation of a Long/Short trade with set Take Profit and Stop Loss, and displays an info label with realized Profit/Loss)
I'd personally like to see this feature improved by adding methods (so that we could, for example, define functions inside a custom type), which could be an analogue of classes from other programming languages.

FrizBugLibrary "FrizBug"
Debug Tools | Pinescript Debugging Tool Kit
All in one Debugger - the benefit of wrapper functions to simply wrap variables or outputs and have the code still execute the same. Perfect for Debugging on Pine
str(inp)
Overloaded tostring like Function for all type+including Object Variables will also do arrays and matricies of all Types
Parameters:
inp : All types
Returns: string
print_label(str, x_offset, y, barstate, style, color, textcolor, text_align, size)
Label Helper Function - only needs the Str input to work
Parameters:
str :
x_offset : offset from last bar + or -
y : price of label
barstate : barstate built in variable
style : label style settin7
color : color setting
textcolor : textcolor
text_align : text align setting
size : text_sise
Returns: label
init()
initializes the database arrays
Returns: tuple | 2 matrix (1 matrix is varip(live) the other is reagular var (Bar))
update(log, live, live_console, log_console, live_lbl, log_lbl)
Put at the very end of your code / This updates all of the consoles
Parameters:
log : This matrix is the one used for Bar updates
live : This matrix is the one used for Real Time updates
live_console : on_offs for the consoles and lbls - call in the update function
log_console : on_offs for the consoles and lbls - call in the update function
live_lbl : on_offs for the consoles and lbls - call in the update function
log_lbl : on_offs for the consoles and lbls - call in the update function
Returns: void
log(log, inp, str_label, off, rows, index_cols, bars_back)
Function Will push to the Console offset to the right of Current bar, This is the main Console - it has 2 Feeds left and right (changeable)"
Parameters:
log : Matrix - Log or Live
inp : All types
str_label : (optional) This input will label it on the feed
off : Useful for when you don't want to remove the function"
rows : when printing or logging a matrix this will shorten the output will show last # of rows"
index_cols : When printing or logging a array or matrix this will shorten the array or the columns of a matrix by the #"
bars_back : Adjustment for Bars Back - Default is 1 (0 for barstate.islast)"
Returns: inp - all types (The log and print functions can be used as wrapper functions see usage below for examples)
Print(log, str_label, off, bars_back)
Function can be used to send information to a label style Console, Can be used as a wrapper function, Similar to str.format use with str()
Parameters:
log :
str_label : (optional) Can be used to label Data sent to the Console
off : Useful for when you don't want to remove the function
bars_back : Adjustment for Bars Back - Default is 1 (0 for barstate.islast)
Returns: string
print(inp, str_label, off, bars_back)
This Function can be used to send information to a label style Console, Can be used as a wrapper function, Overload print function
Parameters:
inp : All types
str_label : string (optional) Can be used to label Data sent to the Console
off : Useful for when you don't want to remove the function
bars_back : Adjustment for Bars Back - Default is 1 (0 for barstate.islast)
Returns: inp - all types (The log and print functions can be used as wrapper functions see usage below for examples)
Credits:
@kaigouthro - for the font library
@RicardoSantos - for the concept I used to make this
Thanks!
Use cases at the bottom
iMoku (Ichimoku Complete Tool) - The Quant Science iMoku™ is a professional all-in-one solution for the famous Ichimoku Kinko Hyo indicator.
The algorithm includes:
1. Backtesting spot
2. Visual tool
3. Auto-trading functions
With iMoku you can test four different strategies.
Strategy 1: Cross Tenkan Sen - Kijun Sen
A long position is opened with 100% of the invested capital ($1000) when "Tenkan Sen" crossover "Kijun Sen".
Closing the long position on the opposite condition.
There are 3 different strength signals for this strategy: weak, normal, strong.
Weak : the signal is weak when the condition is true and the price is above the 'Kumo'
Normal : the signal is normal when the condition is true and the price is within the 'Kumo'
Strong : the signal is strong when the condition is true and the price is below the 'Kumo'
Strategy 2: Cross Price - Kijun Sen
A long position is opened with 100% of the invested capital ($1000) when the price crossover the 'Kijun Sen'.
Closing the long position on the opposite condition.
There are 3 different strength signals for this strategy: weak, normal, strong.
Weak : the signal is weak when the condition is true and the price is above the 'Kumo'
Normal : the signal is normal when the condition is true and the price is inside the 'Kumo'
Strong : the signal is strong when the condition is true and the price is below the 'Kumo'
Strategy 3: Kumo Breakout
A long position is opened with 100% of the invested capital ($1000) when the price breakup the 'Kumo'.
Closing the long position with a percentage stop loss and take profit on the invested capital.
Strategy 4: Kumo Twist
A long position is opened with 100% of the invested capital ($1000) when the 'Kumo' goes from negative to positive (called "Twist").
Closing the long position on the opposite condition.
There are 2 different strength signals for this strategy: weak, and strong.
Weak : the signal is weak when the condition is true and the price is above the 'Kumo'
Strong : the signal is strong when the condition is true and the price is below the 'Kumo'
This script is compliant with algorithmic trading.
You can use this script with trading terminals such as 3Commas or CryptoHopper. Connecting this script is very easy.
1. Enter the user interface
2. Select and activate a strategy
3. Copy your bot's links into the dedicated fields
4. Create and activate alert
Disclaimer: algorithmic trading involves risk, the user should consider aspects such as slippage, liquidity and costs when evaluating an asset. The Quant Science is not responsible for any kind of damage resulting from use of this script. By using this script you take all the responsibilities and risks.

FUNCTION: Limited Historical Data WorkaroundFUNCTION: Limited Historical Data Workaround
If you are working with bitcoin weekly charts, or any other ticker with a low amount of price history this function may help you out. For example you want to apply indicators to some shitcoin that just launched? This can help you.
It can be frustrating to use certain built-ins since they will only give an output once the full lookback length is available. This function allows you to avoid that situation and start plotting things with almost no history whatsoever!
In this example code we do it by utilizing a replacement for the built in pine SMA function. This function allows us to pass a series instead of just a simple int to the length variable of the SMA. This can be achieved with all the pine built ins and I believe @pinecoders has a publication already detailing many of them with full coded examples.
Then we replace the length of the SMA with the custom history function. It checks to see if the current bar index is less than the length of the function. Then if it is, it changes the length to the bar index allowing us to get plots and series earlier than otherwise possible.

Symbol InfoFor those who likes clean chart:
Adjustable Symbol ticker and timeframe( AKA watermark) script is here.
1: You can place Symbol ticker and timeframe info anywhere on the chart.
Also you can hide one of them or both.
Position:
Horizontal options: Left Center Right
Vertical options: Top Middle Bottom
Size: Tiny Smal Normal Large Huge Auto
Color is adjustable. Background is optional too.
2: Even more cool part is you can add 2 different custom texts that can switch. (Idea from Pinecoders original script)
You don't have to use text function and reposition it everytime, your message will always stays at one place.
Let the chart deliver your message.
I put my favourite trading slangs there:
1. Do Your Own Research (DYOR)
2. Not a Financial Advice ( NFA)

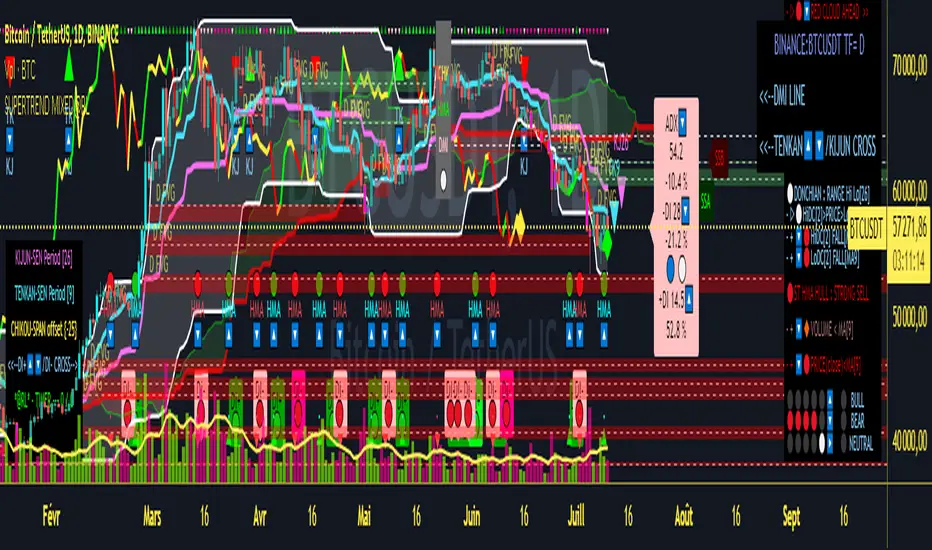
SUPERTREND MIXED ICHI-DMI-DONCHIAN-VOL-GAP-HLBox@RLSUPERTREND MIXED ICHI-DMI-VOL-GAP-HLBox@RL
by RegisL76
This script is based on several trend indicators.
* ICHIMOKU (KINKO HYO)
* DMI (Directional Movement Index)
* SUPERTREND ICHIMOKU + SUPERTREND DMI
* DONCHIAN CANAL Optimized with Colored Bars
* HMA Hull
* Fair Value GAP
* VOLUME/ MA Volume
* PRICE / MA Price
* HHLL BOXES
All these indications are visible simultaneously on a single graph. A data table summarizes all the important information to make a good trade decision.
ICHIMOKU Indicator:
The ICHIMOKU indicator is visualized in the traditional way.
ICHIMOKU standard setting values are respected but modifiable. (Traditional defaults = .
An oriented visual symbol, near the last value, indicates the progression (Ascending, Descending or neutral) of the TENKAN-SEN and the KIJUN-SEN as well as the period used.
The CLOUD (KUMO) and the CHIKOU-SPAN are present and are essential for the complete analysis of the ICHIMOKU.
At the top of the graph are visually represented the crossings of the TENKAN and the KIJUN.
Vertical lines, accompanied by labels, make it possible to quickly visualize the particularities of the ICHIMOKU.
A line displays the current bar.
A line visualizes the end of the CLOUD (KUMO) which is shifted 25 bars into the future.
A line visualizes the end of the chikou-span, which is shifted 25 bars in the past.
DIRECTIONAL MOVEMENT INDEX (DMI) : Treated conventionally : DI+, DI-, ADX and associated with a SUPERTREND DMI.
A visual symbol at the bottom of the graph indicates DI+ and DI- crossings
A line of oriented and colored symbols (DMI Line) at the top of the chart indicates the direction and strength of the trend.
SUPERTREND ICHIMOKU + SUPERTREND DMI :
Trend following by SUPERTREND calculation.
DONCHIAN CHANNEL: Treated conventionally. (And optimized by colored bars when overshooting either up or down.
The lines, high and low of the last values of the channel are represented to quickly visualize the level of the RANGE.
SUPERTREND HMA (HULL) Treated conventionally.
The HMA line visually indicates, according to color and direction, the market trend.
A visual symbol at the bottom of the chart indicates opportunities to sell and buy.
VOLUME:
Calculation of the MOBILE AVERAGE of the volume with comparison of the volume compared to the moving average of the volume.
The indications are colored and commented according to the comparison.
PRICE: Calculation of the MOBILE AVERAGE of the price with comparison of the price compared to the moving average of the price.
The indications are colored and commented according to the comparison.
HHLL BOXES:
Visualizes in the form of a box, for a given period, the max high and min low values of the price.
The configuration allows taking into account the high and low wicks of the price or the opening and closing values.
FAIR VALUE GAP :
This indicator displays 'GAP' levels over the current time period and an optional higher time period.
The script takes into account the high/low values of the current bar and compares with the 2 previous bars.
The "gap" is generated from the lack of overlap between these bars. Bearish or bullish gaps are determined by whether the gap is above or below HmaPrice, as they tend to fill, and can be used as targets.
NOTE: FAIR VALUE GAP has no values displayed in the table and/or label.
Important information (DATA) relating to each indicator is displayed in real time in a table and/or a label.
Each information is commented and colored according to direction, value, comparison etc.
Each piece of information indicates the values of the current bar and the previous value (in "FULL" mode).
The other possible modes for viewing the table and/or the label allow a more synthetic view of the information ("CONDENSED" and "MINIMAL" modes).
In order not to overload the vision of the chart too much, the visualization box of the RANGE DONCHIAN, the vertical lines of the shifted marks of the ICHIMOKU, as well as the boxes of the HHLL Boxes indicator are only visualized intermittently (managed by an adjustable time delay ).
The "HISTORICAL INFO READING" configuration parameter set to zero (by default) makes it possible to read all the information of the current bar in progress (Bar #0). All other values allow to read the information of a historical bar. The value 1 reads the information of the bar preceding the current bar (-1). The value 10 makes it possible to read the information of the tenth bar behind (-10) compared to the current bar, etc.
At the bottom of the DATAS table and label, lights, red, green or white indicate quickly summarize the trend from the various indicators.
Each light represents the number of indicators with the same trend at a given time.
Green for a bullish trend, red for a bearish trend and white for a neutral trend.
The conditions for determining a trend are for each indicator:
SUPERTREND ICHIMOHU + DMI: the 2 Super trends together are either bullish or bearish.
Otherwise the signal is neutral.
DMI: 2 main conditions:
BULLISH if DI+ >= DI- and ADX >25.
BEARISH if DI+ < DI- and ADX >25.
NEUTRAL if the 2 conditions are not met.
ICHIMOKU: 3 main conditions:
BULLISH if PRICE above the cloud and TENKAN > KIJUN and GREEN CLOUD AHEAD.
BEARISH if PRICE below the cloud and TENKAN < KIJUN and RED CLOUD AHEAD.
The other additional conditions (Data) complete the analysis and are present for informational purposes of the trend and depend on the context.
DONCHIAN CHANNEL: 1 main condition:
BULLISH: the price has crossed above the HIGH DC line.
BEARISH: the price has gone below the LOW DC line.
NEUTRAL if the price is between the HIGH DC and LOW DC lines
The 2 other complementary conditions (Datas) complete the analysis:
HIGH DC and LOW DC are increasing, falling or stable.
SUPERTREND HMA HULL: The script determines several trend levels:
STRONG BUY, BUY, STRONG SELL, SELL AND NEUTRAL.
VOLUME: 3 trend levels:
VOLUME > MOVING AVERAGE,
VOLUME < MOVING AVERAGE,
VOLUME = MOVING AVERAGE.
PRICE: 3 trend levels:
PRICE > MOVING AVERAGE,
PRICE < MOVING AVERAGE,
PRICE = MOVING AVERAGE.
If you are using this indicator/strategy and you are satisfied with the results, you can possibly make a donation (a coffee, a pizza or more...) via paypal to: lebourg.regis@free.fr.
Thanks in advance !!!
Have good winning Trades.
**************************************************************************************************************************
SUPERTREND MIXED ICHI-DMI-VOL-GAP-HLBox@RL
by RegisL76
Ce script est basé sur plusieurs indicateurs de tendance.
* ICHIMOKU (KINKO HYO)
* DMI (Directional Movement Index)
* SUPERTREND ICHIMOKU + SUPERTREND DMI
* DONCHIAN CANAL Optimized with Colored Bars
* HMA Hull
* Fair Value GAP
* VOLUME/ MA Volume
* PRIX / MA Prix
* HHLL BOXES
Toutes ces indications sont visibles simultanément sur un seul et même graphique.
Un tableau de données récapitule toutes les informations importantes pour prendre une bonne décision de Trade.
I- Indicateur ICHIMOKU :
L’indicateur ICHIMOKU est visualisé de manière traditionnelle
Les valeurs de réglage standard ICHIMOKU sont respectées mais modifiables. (Valeurs traditionnelles par défaut =
Un symbole visuel orienté, à proximité de la dernière valeur, indique la progression (Montant, Descendant ou neutre) de la TENKAN-SEN et de la KIJUN-SEN ainsi que la période utilisée.
Le NUAGE (KUMO) et la CHIKOU-SPAN sont bien présents et sont primordiaux pour l'analyse complète de l'ICHIMOKU.
En haut du graphique sont représentés visuellement les croisements de la TENKAN et de la KIJUN.
Des lignes verticales, accompagnées d'étiquettes, permettent de visualiser rapidement les particularités de l'ICHIMOKU.
Une ligne visualise la barre en cours.
Une ligne visualise l'extrémité du NUAGE (KUMO) qui est décalé de 25 barres dans le futur.
Une ligne visualise l'extrémité de la chikou-span, qui est décalée de 25 barres dans le passé.
II-DIRECTIONAL MOVEMENT INDEX (DMI)
Traité de manière conventionnelle : DI+, DI-, ADX et associé à un SUPERTREND DMI
Un symbole visuel en bas du graphique indique les croisements DI+ et DI-
Une ligne de symboles orientés et colorés (DMI Line) en haut du graphique, indique la direction et la puissance de la tendance.
III SUPERTREND ICHIMOKU + SUPERTREND DMI
Suivi de tendance par calcul SUPERTREND
IV- DONCHIAN CANAL :
Traité de manière conventionnelle.
(Et optimisé par des barres colorées en cas de dépassement soit vers le haut, soit vers le bas.
Les lignes, haute et basse des dernières valeurs du canal sont représentées pour visualiser rapidement la fourchette du RANGE.
V- SUPERTREND HMA (HULL)
Traité de manière conventionnelle.
La ligne HMA indique visuellement, selon la couleur et l'orientation, la tendance du marché.
Un symbole visuel en bas du graphique indique les opportunités de vente et d'achat.
*VI VOLUME :
Calcul de la MOYENNE MOBILE du volume avec comparaison du volume par rapport à la moyenne mobile du volume.
Les indications sont colorées et commentées en fonction de la comparaison.
*VII PRIX :
Calcul de la MOYENNE MOBILE du prix avec comparaison du prix par rapport à la moyenne mobile du prix.
Les indications sont colorées et commentées en fonction de la comparaison.
*VIII HHLL BOXES :
Visualise sous forme de boite, pour une période donnée, les valeurs max hautes et min basses du prix.
La configuration permet de prendre en compte les mèches hautes et basses du prix ou bien les valeurs d'ouverture et de fermeture.
IX - FAIR VALUE GAP
Cet indicateur affiche les niveaux de 'GAP' sur la période temporelle actuelle ET une période temporelle facultative supérieure.
Le script prend en compte les valeurs haut/bas de la barre actuelle et compare avec les 2 barres précédentes.
Le "gap" est généré à partir du manque de recouvrement entre ces barres.
Les écarts baissiers ou haussiers sont déterminés selon que l'écart est supérieurs ou inférieur à HmaPrice, car ils ont tendance à être comblés, et peuvent être utilisés comme cibles.
NOTA : FAIR VALUE GAP n'a pas de valeurs affichées dans la table et/ou l'étiquette.
Les informations importantes (DATAS) relatives à chaque indicateur sont visualisées en temps réel dans une table et/ou une étiquette.
Chaque information est commentée et colorée en fonction de la direction, de la valeur, de la comparaison etc.
Chaque information indique la valeurs de la barre en cours et la valeur précédente ( en mode "COMPLET").
Les autres modes possibles pour visualiser la table et/ou l'étiquette, permettent une vue plus synthétique des informations (modes "CONDENSÉ" et "MINIMAL").
Afin de ne pas trop surcharger la vision du graphique, la boite de visualisation du RANGE DONCHIAN, les lignes verticales des marques décalées de l'ICHIMOKU, ainsi que les boites de l'indicateur HHLL Boxes ne sont visualisées que de manière intermittente (géré par une temporisation réglable ).
Le paramètre de configuration "HISTORICAL INFO READING" réglé sur zéro (par défaut) permet de lire toutes les informations de la barre actuelle en cours (Barre #0).
Toutes autres valeurs permet de lire les informations d'une barre historique. La valeur 1 permet de lire les informations de la barre précédant la barre en cours (-1).
La valeur 10 permet de lire les information de la dixième barre en arrière (-10) par rapport à la barre en cours, etc.
Dans le bas de la table et de l'étiquette de DATAS, des voyants, rouge, vert ou blanc indique de manière rapide la synthèse de la tendance issue des différents indicateurs.
Chaque voyant représente le nombre d'indicateur ayant la même tendance à un instant donné. Vert pour une tendance Bullish, rouge pour une tendance Bearish et blanc pour une tendance neutre.
Les conditions pour déterminer une tendance sont pour chaque indicateur :
SUPERTREND ICHIMOHU + DMI : les 2 Super trends sont ensemble soit bullish soit Bearish. Sinon le signal est neutre.
DMI : 2 conditions principales :
BULLISH si DI+ >= DI- et ADX >25.
BEARISH si DI+ < DI- et ADX >25.
NEUTRE si les 2 conditions ne sont pas remplies.
ICHIMOKU : 3 conditions principales :
BULLISH si PRIX au dessus du nuage et TENKAN > KIJUN et NUAGE VERT DEVANT.
BEARISH si PRIX en dessous du nuage et TENKAN < KIJUN et NUAGE ROUGE DEVANT.
Les autres conditions complémentaires (Datas) complètent l'analyse et sont présents à titre informatif de la tendance et dépendent du contexte.
CANAL DONCHIAN : 1 condition principale :
BULLISH : le prix est passé au dessus de la ligne HIGH DC.
BEARISH : le prix est passé au dessous de la ligne LOW DC.
NEUTRE si le prix se situe entre les lignes HIGH DC et LOW DC
Les 2 autres conditions complémentaires (Datas) complètent l'analyse : HIGH DC et LOW DC sont croissants, descendants ou stables.
SUPERTREND HMA HULL :
Le script détermine plusieurs niveaux de tendance :
STRONG BUY, BUY, STRONG SELL, SELL ET NEUTRE.
VOLUME : 3 niveaux de tendance :
VOLUME > MOYENNE MOBILE, VOLUME < MOYENNE MOBILE, VOLUME = MOYENNE MOBILE.
PRIX : 3 niveaux de tendance :
PRIX > MOYENNE MOBILE, PRIX < MOYENNE MOBILE, PRIX = MOYENNE MOBILE.
Si vous utilisez cet indicateur/ stratégie et que vous êtes satisfait des résultats,
vous pouvez éventuellement me faire un don (un café, une pizza ou plus ...) via paypal à : lebourg.regis@free.fr.
Merci d'avance !!!
Ayez de bons Trades gagnants.
No Active BarThis is probably the only script on TradingView that's clinically proven to lower your blood pressure!***
This script in conjunction with some chart settings changes can completely hide the active candle, only showing historic candles, thus, reducing risk of cardiac arrest and or panic attack.
What to do:
0. Make sure you are using a candlestick chart or this script won't work properly
1. Right click the chart and select "Settings..."
2. Select "Symbol" under the "Chart Settings" menu
3. Disable every item EXCEPT for the "Body"
4. Click on the boxes next to "Body" to access the color picker then change both box's transparency settings down to 0
(the script only colors closed bars, so the active bar will be present just transparent)
5. Right click on the price scale on the far left or far right side of the screen and hover the mouse over "Labels". If any selections have a check mark next to them click them to disable them (especially the "Ask & Bid" price setting since it tracks current price)
That's it! Instead of wicks the High & Low prices are plotted above and below the candles using a step line. It looks a bit strange at first but you'll get used to it. Check out the indicator settings to change the color and style of the High & Low lines.
***The statement could prove true for some but is mostly complete bullshit

Level 1 - Learn to code simply - PineScriptThe goal of this script is honestly to help everyone learn about trading with bots and algos.
At least, to get started.
Level 1:
10 lines of code.
learn to plot 2 moving averages on your chart.
learn to create a signal from a crossover.
learn the very basics of Pine Script algo.

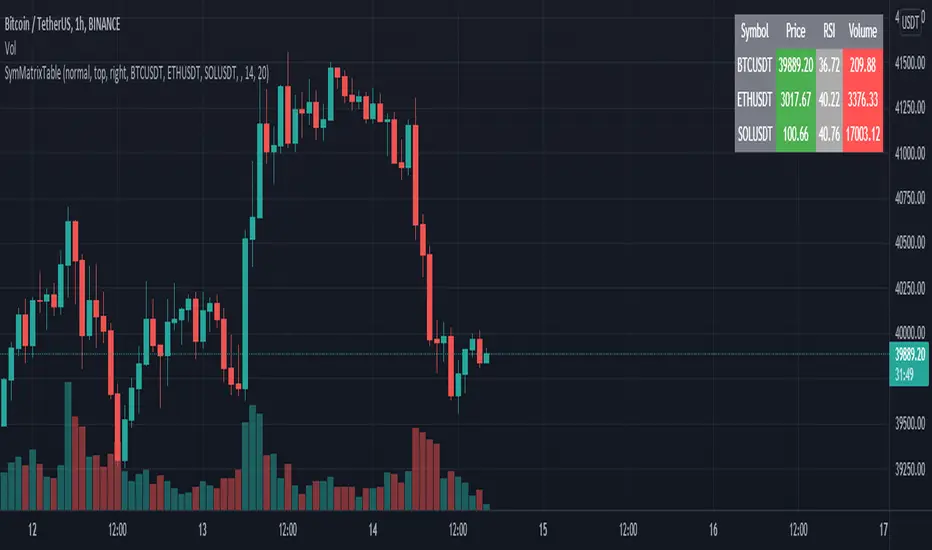
SymMatrixTableSimple Example Table for Displaying Price, RSI, Volume of multiple Tickers on selected Timeframe
Displays Price, RSI and Volume of 3 Tickers and Timeframe selected by user input
Conditional Table Cell coloring
Price color green if > than previous candle close and red if < previous candle close
RSI color green if < 30 and red if > 70 (RSI14 by default)
Volume color green if above average volume and red if less than that (SMA20 volume by default)
Can turn on/off whole table, header columns, row indices, or select individual columns or rows to show/hide
// Example Mixed Type Matrix To Table //
access the simple example script by uncommenting the code at the end
Basically I wanted to have the headers and indices as strings and the rest of the matrix for the table body as floats, then conditional coloring on the table cells
And also the functionality to turn rows and columns on/off from table through checkboxes of user input
Before I was storing each of the values separately in arrays that didn't have a centralized way of controlling table structure
so now the structure is :
- string header array, string index array
- float matrix for table body
- color matrix with bool conditions for coloring table cells
- bool checkboxes for controlling table display
Study forloop Star Triangle'Study forloop' pinescript Program to print star Triangle
The Program Logic
For example, the following Pinescript programme will need two nested for loops. The outer forloop is for rows and the inner forloop is for columns or stars. to create a triangle shape.

Invisible FriendLooking into a question from user Alex100, i realized many people do want some kind of values displayed on chart when they hover the mouse over different bars.
As pinescript does not have any feature like pop up box, the only way is to plot a line and than see indicator values at top left. So when mouse is moved around the value displayed changes. As we just need the value, we do not want to clutter the chart with another line.
Using display.none will hide the value from indicator value also
Using color.white will also color the indicator value to white, making it invisible
So the solution is very simple, and requires a bit of creativity. We create an invisible line, in any color we like :)
This indicator is a tutorial on how to display indicator values without the line showing up and also this can be implemented as displaying data for each bar on mouse hover.
-----
Check My Public Creations In The Meantime:
Buy Monday Exit Tuesday with StopLoss and TakeProfit
Close Combination Lock Style Visual Appeal Indicator
High-Low Box between Earnings with ability to Add Custom Boxes

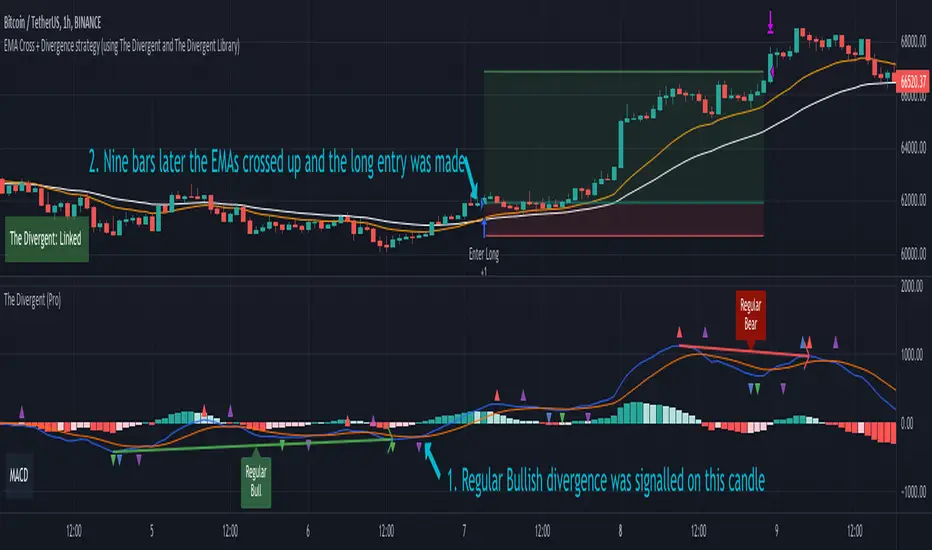
EMA Cross + Divergence strategy (Div. signals by The Divergent)A sample strategy demonstrating the usage of The Divergent divergence indicator and The Divergent Library .
The Divergent is an advanced divergence indicator which you can easily incorporate into your own strategies.
In order to use this strategy (and to use the signals in your own strategy), you need to have the Pro version of The Divergent applied to your chart.
For more information, please see the comments inlined in the code.
The Divergent LibraryLibrary "TheDivergentLibrary"
The Divergent Library is only useful when combined with the Pro version of The Divergent - Advanced divergence indicator . This is because the Basic (free) version of The Divergent does not expose the "Divergence Signal" value.
Usage instructions:
1. Create a new chart
2. Add The Divergent (Pro) indicator to your chart
3. Create a new strategy, import this library, add a "source" input, link it to "The Divergent: Divergence Signal", and use the library to decode the divergence signals from The Divergent (You can find example strategy code published in our profile)
4. Act on the divergences signalled by The Divergent
---
isRegularBullishEnabled(context) Returns a boolean value indicating whether Regular Bullish divergence detection is enabled in The Divergent.
Parameters:
context : The context of The Divergent Library.
Returns: A boolean value indicating whether Regular Bullish divergence detection is enabled in The Divergent.
isHiddenBullishEnabled(context) Returns a boolean value indicating whether Hidden Bullish divergence detection is enabled in The Divergent.
Parameters:
context : The context of The Divergent Library.
Returns: A boolean value indicating whether Hidden Bullish divergence detection is enabled in The Divergent.
isRegularBearishEnabled(context) Returns a boolean value indicating whether Regular Bearish divergence detection is enabled in The Divergent.
Parameters:
context : The context of The Divergent Library.
Returns: A boolean value indicating whether Regular Bearish divergence detection is enabled in The Divergent.
isHiddenBearishEnabled(context) Returns a boolean value indicating whether Hidden Bearish divergence detection is enabled in The Divergent.
Parameters:
context : The context of The Divergent Library.
Returns: A boolean value indicating whether Hidden Bearish divergence detection is enabled in The Divergent.
getPivotDetectionSource(context) Returns the 'Pivot Detection Source' setting of The Divergent. The returned value can be either "Oscillator" or "Price".
Parameters:
context : The context of The Divergent Library.
Returns: One of the following string values: "Oscillator" or "Price".
getPivotDetectionMode(context) Returns the 'Pivot Detection Mode' setting of The Divergent. The returned value can be either "Bodies" or "Wicks".
Parameters:
context : The context of The Divergent Library.
Returns: One of the following string values: "Bodies" or "Wicks".
isLinked(context) Returns a boolean value indicating the link status to The Divergent indicator.
Parameters:
context : The context of The Divergent Library.
Returns: A boolean value indicating the link status to The Divergent indicator.
init(firstBarSignal, displayLinkStatus, debug) Initialises The Divergent Library's context with the signal produced by The Divergent on the first bar. The value returned from this function is called the "context of The Divergent Library". Some of the other functions of this library requires you to pass in this context.
Parameters:
firstBarSignal : The signal from The Divergent indicator on the first bar.
displayLinkStatus : A boolean value indicating whether the Link Status window should be displayed in the bottom left corner of the chart. Defaults to true.
debug : A boolean value indicating whether the Link Status window should display debug information. Defaults to false.
Returns: A bool array containing the context of The Divergent Library.
processSignal(signal) Processes a signal from The Divergent and returns a 5-tuple with the decoded signal: [ int divergenceType, int priceBarIndexStart, int priceBarIndexEnd, int oscillatorBarIndexStart, int oscillatorBarIndexEnd]. `divergenceType` can be one of the following values: na → No divergence was detected, 1 → Regular Bullish, 2 → Regular Bullish early, 3 → Hidden Bullish, 4 → Hidden Bullish early, 5 → Regular Bearish, 6 → Regular Bearish early, 7 → Hidden Bearish, 8 → Hidden Bearish early.
Parameters:
signal : The signal from The Divergent indicator.
Returns: A 5-tuple with the following values: [ int divergenceType, int priceBarIndexStart, int priceBarIndexEnd, int oscillatorBarIndexStart, int oscillatorBarIndexEnd].

Sentiment Estimator [AstrideUnicorn]Sentiment Estimator is an indicator that estimates market sentiment using only its pricing data. It counts bullish and bearish candles in a rolling window and calculates their relative values as percentages of the total amount of candles in the window. Market sentiment shows the direction in which the market is biased to move or the current trend direction. Extreme values of the market sentiment are contrarian signals. When the market sentiment is too bullish, it is time to sell and vice versa.
HOW TO USE
Sentiment Estimator plots a pair of green and red circles for each candle. They represent bullish and bearish sentiments, respectively.
The vertical positions of the circles show corresponding sentiment values in percentage units. For example, if a green circle's height is 60, the market is 60% bullish. In this case, the red circle's height will be 40, as bullish and bearish parts of the market sentiment sum to 100%.
The blue line plotted at the 50% level shows the neutral sentiment level. If a green circle is above the blue line, the prevailing market sentiment at that time is bullish, and the market is biased to move up. If a red one is above, the market has predominantly bearish sentiment and is prone to move down.
The red level shows extreme sentiment level. If a green or red circle is above this line, it means that the market is extremely bullish or bearish, respectively. It is a contrarian signal, and one can expect a reversal soon. In this case, a blue label with the text "reversal expected" is shown.
SETTINGS
Timeframe - allows choosing a timeframe other than the chart's one for the indicator calculation.
Look-Back Window - sets the historical window length used to perform the calculations. You can adjust the window to get the best results for a particular market or timeframe.

RKs Notepad++ Pine Script V5█ OVERVIEW
After reading all the new names and renames that Pine Script V5 brought to us, I knew that my old Notepad++ User Defined Language (UDL) would need a big update, so I decided to do a complete remake using the same Dark color scheme theme of the Pine Editor.
Then, I create a Notepad++ Theme and the Auto-Completion file with the Parameter hints for every built-in function to make everything look nicer
█ IMPORTANT
This is not an indicator!!
These are 3 XML files to copy and paste inside the Notepad++ folder.
You can use any Notepad Software to create the XML files.
The main Notepad++ folder is normally on %AppData%\Notepad++\
To avoid mistakes, always make a Backup of your files before anything.
█ INSTALLATION
Just follow these steps:
1. open a New Document File;
2. Copy everything between ↓↓↓ and ↑↑↑ symbols to this new document;
3. Remove the "//" of every single line;
4. Save each document with the correct name in the right folder;
5. Restart the Notepad++
█ NOTES:
If you have some problem installing, ask me, and I will try to help you.
But, in any case, here is the link to these files on my GitHub:

2 Dimensional Array using one floating point entry This is an attempt to create a two dimensional floating point array from the pine single dimension array.
It enables some useful array functions like sorting, when you are trying to keep track of price and location in time or bars and you would like to sort the array.
Other array functions on this array will not work, like average and other statistical functions - they will provide bad results. I would suggest continuing to use a single dimensional array for each element where that kind of array function is required.
I wrote this simply as a mean of using the sort functions when I had to sort price and try to keep the bar location or time in synch.
Other array functions could be written to manipulate this kind of array, leave that to others. The goal here was to avoid using for loops which would be a performance impact on large arrays.
The basic concept is to create one floating point number from two, put that into an array, and then be able to pull the compound value out and parse out the individual components.
I imagine it could also accommodate a 3 or 4 dimensional array with some work, as long as you had some idea of how many digits are consumed by each element. For example you may be interested in storing price, RSI, x_loc values and then be able to sort and parse them out.
Indicator PanelHello All,
This script shows Indicator panel in a Table. Table.new() is a new feature and released today! Thanks a lot to Pine Team to add this new great feature! This new feature is a game changer!
The script shows indicator values for each symbol and changes background color of each cell by using current and last values of the indicators for each symbol. if current value is greater than last value then backgroung color is green, if lower than last value then red, if they are equals then gray.
You can choose the indicators to display. Number of columns in the table is dynamic and is changed by number of the indicators.
You can choose 5 different Symbols, 6 Indicators and 2 Simple or Exponential Moving averages, you can set type of moving averages and the lengths. You can also set the lengths for each Indicators.
Indicators:
- RSI
- MACD ( MACD and Signal and Histogram )
- DMI ( +DI and -DI + and ADX )
- CCI
- MFI
- Momentum
- MA with Length 50 (length can be set)
- MA with Length 200 (length can be set)
In this example RSI, MACD and MA 200 were chosen, you can see how table size changes dynamically:
Enjoy!

Dead Simple - 3 greens or 3 reds each bigger than the last High probability reversal pattern best used for scalping on lower time frame charts like the 15 second chart. very basic script for those just starting to learn pine
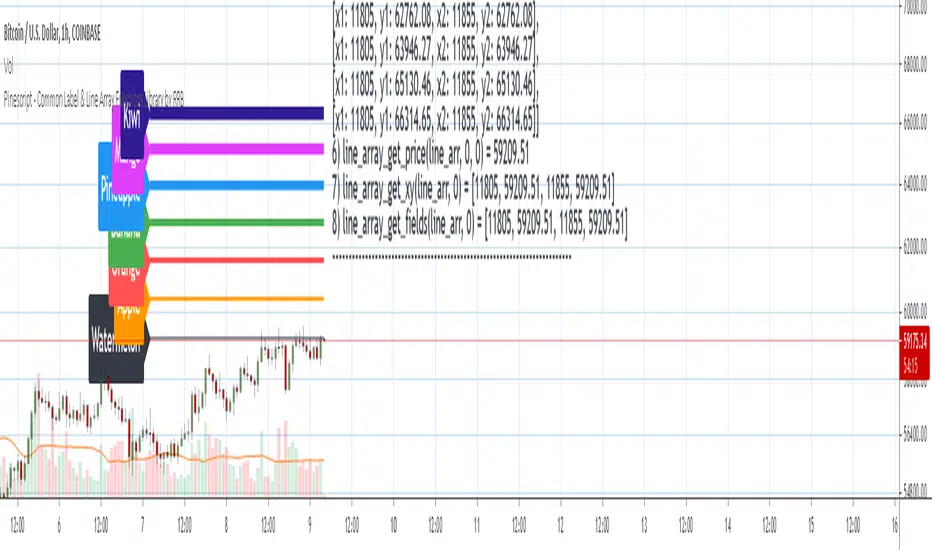
Pinescript - Common Label & Line Array Functions Library by RRBPinescript - Common Label & Line Array Functions Library by RagingRocketBull 2021
Version 1.0
This script provides a library of common array functions for arrays of label and line objects with live testing of all functions.
Using this library you can easily create, update, delete, join label/line object arrays, and get/set properties of individual label/line object array items.
You can find the full list of supported label/line array functions below.
There are several libraries:
- Common String Functions Library
- Standard Array Functions Library
- Common Fixed Type Array Functions Library
- Common Label & Line Array Functions Library
- Common Variable Type Array Functions Library
Features:
- 30 array functions in categories create/update/delete/join/get/set with support for both label/line objects (45+ including all implementations)
- Create, Update label/line object arrays from list/array params
- GET/SET properties of individual label/line array items by index
- Join label/line objects/arrays into a single string for output
- Supports User Input of x,y coords of 5 different types: abs/rel/rel%/inc/inc% list/array, auto transforms x,y input into list/array based on type, base and xloc, translates rel into abs bar indexes
- Supports User Input of lists with shortened names of string properties, auto expands all standard string properties to their full names for use in functions
- Live Output for all/selected functions based on User Input. Test any function for possible errors you may encounter before using in script.
- Output filters: hide all excluded and show only allowed functions using a list of function names
- Output Panel customization options: set custom style, color, text size, and line spacing
Usage:
- select create function - create label/line arrays from lists or arrays (optional). Doesn't affect the update functions. The only change in output should be function name regardless of the selected implementation.
- specify num_objects for both label/line arrays (default is 7)
- specify common anchor point settings x,y base/type for both label/line arrays and GET/SET items in Common Settings
- fill lists with items to use as inputs for create label/line array functions in Create Label/Line Arrays section
- specify label/line array item index and properties to SET in corresponding sections
- select label/line SET function to see the changes applied live
Code Structure:
- translate x,y depending on x,y type, base and xloc as specified in UI (required for all functions)
- expand all shortened standard property names to full names (required for create/update* from arrays and set* functions, not needed for create/update* from lists) to prevent errors in label.new and line.new
- create param arrays from string lists (required for create/update* from arrays and set* functions, not needed for create/update* from lists)
- create label/line array from string lists (property names are auto expanded) or param arrays (requires already expanded properties)
- update entire label/line array or
- get/set label/line array item properties by index
Transforming/Expanding Input values:
- for this script to work on any chart regardless of price/scale, all x*,y* are specified as % increase relative to x0,y0 base levels by default, but user can enter abs x,price values specific for that chart if necessary.
- all lists can be empty, contain 1 or several items, have the same/different lengths. Array Length = min(min(len(list*)), mum_objects) is used to create label/line objects. Missing list items are replaced with default property values.
- when a list contains only 1 item it is duplicated (label name/tooltip is also auto incremented) to match the calculated Array Length
- since this script processes user input, all x,y values must be translated to abs bar indexes before passing them to functions. Your script may provide all data internally and doesn't require this step.
- at first int x, float y arrays are created from user string lists, transformed as described below and returned as x,y arrays.
- translated x,y arrays can then be passed to create from arrays function or can be converted back to x,y string lists for the create from lists function if necessary.
- all translation logic is separated from create/update/set functions for the following reasons:
- to avoid redundant code/dependency on ext functions/reduce local scopes and to be able to translate everything only once in one place - should be faster
- to simplify internal logic of all functions
- because your script may provide all data internally without user input and won't need the translation step
- there are 5 types available for both x,y: abs, rel, rel%, inc, inc%. In addition to that, x can be: bar index or time, y is always price.
- abs - absolute bar index/time from start bar0 (x) or price (y) from 0, is >= 0
- rel - relative bar index/time from cur bar n (x) or price from y0 base level, is >= 0
- rel% - relative % increase of bar index/time (x) or price (y) from corresponding base level (x0 or y0), can be <=> 0
- inc - relative increment (step) for each new level of bar index/time (x) or price (y) from corresponding base level (x0 or y0), can be <=> 0
- inc% - relative % increment (% step) for each new level of bar index/time (x) or price (y) from corresponding base level (x0 or y0), can be <=> 0
- x base level >= 0
- y base level can be 0 (empty) or open, close, high, low of cur bar
- single item x1_list = "50" translates into:
- for x type abs: "50, 50, 50 ..." num_objects times regardless of xloc => x = 50
- for x type rel: "50, 50, 50 ... " num_objects times => x = x_base + 50
- for x type rel%: "50%, 50%, 50% ... " num_objects times => x_base * (1 + 0.5)
- for x type inc: "0, 50, 100 ... " num_objects times => x_base + 50 * i
- for x type inc%: "0%, 50%, 100% ... " num_objects times => x_base * (1 + 0.5 * i)
- when xloc = xloc.bar_index each rel*/inc* value in the above list is then subtracted from n: n - x to convert rel to abs bar index, values of abs type are not affected
- x1_list = "0, 50, 100, ..." of type rel is the same as "50" of type inc
- x1_list = "50, 50, 50, ..." of type abs/rel/rel% produces a sequence of the same values and can be shortened to just "50"
- single item y1_list = "2" translates into (ragardless of yloc):
- for y type abs: "2, 2, 2 ..." num_objects times => y = 2
- for y type rel: "2, 2, 2 ... " num_objects times => y = y_base + 2
- for y type rel%: "2%, 2%, 2% ... " num_objects times => y = y_base * (1 + 0.02)
- for y type inc: "0, 2, 4 ... " num_objects times => y = y_base + 2 * i
- for y type inc%: "0%, 2%, 4% ... " num_objects times => y = y_base * (1 + 0.02 * i)
- when yloc != yloc.price all calculated values above are simply ignored
- y1_list = "0, 2, 4" of type rel% is the same as "2" with type inc%
- y1_list = "2, 2, 2" of type abs/rel/rel% produces a sequence of the same values and can be shortened to just "2"
- you can enter shortened property names in lists. To lookup supported shortened names use corresponding dropdowns in Set Label/Line Array Item Properties sections
- all shortened standard property names must be expanded to full names (required for create/update* from arrays and set* functions, not needed for create/update* from lists) to prevent errors in label.new and line.new
- examples of shortened property names that can be used in lists: bar_index, large, solid, label_right, white, left, left, price
- expanded to their corresponding full names: xloc.bar_index, size.large, line.style_solid, label.style_label_right, color.white, text.align_left, extend.left, yloc.price
- all expanding logic is separated from create/update* from arrays and set* functions for the same reasons as above, and because param arrays already have different types, implying the use of final values.
- all expanding logic is included in the create/update* from lists functions because it seemed more natural to process string lists from user input directly inside the function, since they are already strings.
Creating Label/Line Objects:
- use study max_lines_count and max_labels_count params to increase the max number of label/line objects to 500 (+3) if necessary. Default number of label/line objects is 50 (+3)
- all functions use standard param sequence from methods in reference, except style always comes before colors.
- standard label/line.get* functions only return a few properties, you can't read style, color, width etc.
- label.new(na, na, "") will still create a label with x = n-301, y = NaN, text = "" because max default scope for a var is 300 bars back.
- there are 2 types of color na, label color requires color(na) instead of color_na to prevent error. text_color and line_color can be color_na
- for line to be visible both x1, x2 ends must be visible on screen, also when y1 == y2 => abs(x1 - x2) >= 2 bars => line is visible
- xloc.bar_index line uses abs x1, x2 indexes and can only be within 0 and n ends, where n <= 5000 bars (free accounts) or 10000 bars (paid accounts) limit, can't be plotted into the future
- xloc.bar_time line uses abs x1, x2 times, can't go past bar0 time but can continue past cur bar time into the future, doesn't have a length limit in bars.
- xloc.bar_time line with length = exact number of bars can be plotted only within bar0 and cur bar, can't be plotted into the future reliably because of future gaps due to sessions on some charts
- xloc.bar_index line can't be created on bar 0 with fixed length value because there's only 1 bar of horiz length
- it can be created on cur bar using fixed length x < n <= 5000 or
- created on bar0 using na and then assigned final x* values on cur bar using set_x*
- created on bar0 using n - fixed_length x and then updated on cur bar using set_x*, where n <= 5000
- default orientation of lines (for style_arrow* and extend) is from left to right (from bar 50 to bar 0), it reverses when x1 and x2 are swapped
- price is a function, not a line object property
Variable Type Arrays:
- you can't create an if/function that returns var type value/array - compiler uses strict types and doesn't allow that
- however you can assign array of any type to another array of any type creating an arr pointer of invalid type that must be reassigned to a matching array type before used in any expression to prevent error
- create_any_array2 uses this loophole to return an int_arr pointer of a var type array
- this works for all array types defined with/without var keyword and doesn't work for string arrays defined with var keyword for some reason
- you can't do this with var type vars, only var type arrays because arrays are pointers passed by reference, while vars are actual values passed by value.
- you can only pass a var type value/array param to a function if all functions inside support every type - otherwise error
- alternatively values of every type must be passed simultaneously and processed separately by corresponding if branches/functions supporting these particular types returning a common single type result
- get_var_types solves this problem by generating a list of dummy values of every possible type including the source type, tricking the compiler into allowing a single valid branch to execute without error, while ignoring all dummy results
Notes:
- uses Pinescript v3 Compatibility Framework
- uses Common String Functions Library, Common Fixed Type Array Functions Library, Common Variable Type Array Functions Library
- has to be a separate script to reduce the number of local scopes/compiled file size, can't be merged with another library.
- lets you live test all label/line array functions for errors. If you see an error - change params in UI
- if you see "Loop too long" error - hide/unhide or reattach the script
- if you see "Chart references too many candles" error - change x type or value between abs/rel*. This can happen on charts with 5000+ bars when a rel bar index x is passed to label.new or line.new instead of abs bar index n - x
- create/update_label/line_array* use string lists, while create/update_label/line_array_from_arrays* use array params to create label/line arrays. "from_lists" is dropped to shorten the names of the most commonly used functions.
- create_label/line_array2,4 are preferable, 5,6 are listed for pure demonstration purposes only - don't use them, they don't improve anything but dramatically increase local scopes/compiled file size
- for this reason you would mainly be using create/update_label/line_array2,4 for list params or create/update_label/line_array_from_arrays2 for array params
- all update functions are executed after each create as proof of work and can be disabled. Only create functions are required. Use update functions when necessary - when list/array params are changed by your script.
- both lists and array item properties use the same x,y_type, x,y_base from common settings
- doesn't use pagination, a single str contains all output
- why is this so complicated? What are all these functions for?
- this script merges standard label/line object methods with standard array functions to create a powerful set of label/line object array functions to simplify manipulation of these arrays.
- this library also extends the functionality of Common Variable Type Array Functions Library providing support for label/line types in var type array functions (any_to_str6, join_any_array5)
- creating arrays from either lists or arrays adds a level of flexibility that comes with complexity. It's very likely that in your script you'd have to deal with both string lists as input, and arrays internally, once everything is converted.
- processing user input, allowing customization and targeting for any chart adds a whole new layer of complexity, all inputs must be translated and expanded before used in functions.
- different function implementations can increase/reduce local scopes and compiled file size. Select a version that best suits your needs. Creating complex scripts often requires rewriting your code multiple times to fit the limits, every line matters.
P.S. Don't rely too much on labels, for too often they are fables.
List of functions*:
* - functions from other libraries are not listed
1. Join Functions
Labels
- join_label_object(label_, d1, d2)
- join_label_array(arr, d1, d2)
- join_label_array2(arr, d1, d2, d3)
Lines
- join_line_object(line_, d1, d2)
- join_line_array(arr, d1, d2)
- join_line_array2(arr, d1, d2, d3)
Any Type
- any_to_str6(arr, index, type)
- join_any_array4(arr, d1, d2, type)
- join_any_array5(arr, d, type)
2. GET/SET Functions
Labels
- label_array_get_text(arr, index)
- label_array_get_xy(arr, index)
- label_array_get_fields(arr, index)
- label_array_set_text(arr, index, str)
- label_array_set_xy(arr, index, x, y)
- label_array_set_fields(arr, index, x, y, str)
- label_array_set_all_fields(arr, index, x, y, str, xloc, yloc, label_style, label_color, text_color, text_size, text_align, tooltip)
- label_array_set_all_fields2(arr, index, x, y, str, xloc, yloc, label_style, label_color, text_color, text_size, text_align, tooltip)
Lines
- line_array_get_price(arr, index, bar)
- line_array_get_xy(arr, index)
- line_array_get_fields(arr, index)
- line_array_set_text(arr, index, width)
- line_array_set_xy(arr, index, x1, y1, x2, y2)
- line_array_set_fields(arr, index, x1, y1, x2, y2, width)
- line_array_set_all_fields(arr, index, x1, y1, x2, y2, xloc, extend, line_style, line_color, width)
- line_array_set_all_fields2(arr, index, x1, y1, x2, y2, xloc, extend, line_style, line_color, width)
3. Create/Update/Delete Functions
Labels
- delete_label_array(label_arr)
- create_label_array(list1, list2, list3, list4, list5, d)
- create_label_array2(x_list, y_list, str_list, xloc_list, yloc_list, style_list, color1_list, color2_list, size_list, align_list, tooltip_list, d)
- create_label_array3(x_list, y_list, str_list, xloc_list, yloc_list, style_list, color1_list, color2_list, size_list, align_list, tooltip_list, d)
- create_label_array4(x_list, y_list, str_list, xloc_list, yloc_list, style_list, color1_list, color2_list, size_list, align_list, tooltip_list, d)
- create_label_array5(x_list, y_list, str_list, xloc_list, yloc_list, style_list, color1_list, color2_list, size_list, align_list, tooltip_list, d)
- create_label_array6(x_list, y_list, str_list, xloc_list, yloc_list, style_list, color1_list, color2_list, size_list, align_list, tooltip_list, d)
- update_label_array2(label_arr, x_list, y_list, str_list, xloc_list, yloc_list, style_list, color1_list, color2_list, size_list, align_list, tooltip_list, d)
- update_label_array4(label_arr, x_list, y_list, str_list, xloc_list, yloc_list, style_list, color1_list, color2_list, size_list, align_list, tooltip_list, d)
- create_label_array_from_arrays2(x_arr, y_arr, str_arr, xloc_arr, yloc_arr, style_arr, color1_arr, color2_arr, size_arr, align_arr, tooltip_arr, d)
- create_label_array_from_arrays4(x_arr, y_arr, str_arr, xloc_arr, yloc_arr, style_arr, color1_arr, color2_arr, size_arr, align_arr, tooltip_arr, d)
- update_label_array_from_arrays2(label_arr, x_arr, y_arr, str_arr, xloc_arr, yloc_arr, style_arr, color1_arr, color2_arr, size_arr, align_arr, tooltip_arr, d)
Lines
- delete_line_array(line_arr)
- create_line_array(list1, list2, list3, list4, list5, list6, d)
- create_line_array2(x1_list, y1_list, x2_list, y2_list, xloc_list, extend_list, style_list, color_list, width_list, d)
- create_line_array3(x1_list, y1_list, x2_list, y2_list, xloc_list, extend_list, style_list, color_list, width_list, d)
- create_line_array4(x1_list, y1_list, x2_list, y2_list, xloc_list, extend_list, style_list, color_list, width_list, d)
- create_line_array5(x1_list, y1_list, x2_list, y2_list, xloc_list, extend_list, style_list, color_list, width_list, d)
- create_line_array6(x1_list, y1_list, x2_list, y2_list, xloc_list, extend_list, style_list, color_list, width_list, d)
- update_line_array2(line_arr, x1_list, y1_list, x2_list, y2_list, xloc_list, extend_list, style_list, color_list, width_list, d)
- update_line_array4(line_arr, x1_list, y1_list, x2_list, y2_list, xloc_list, extend_list, style_list, color_list, width_list, d)
- create_line_array_from_arrays2(x1_arr, y1_arr, x2_arr, y2_arr, xloc_arr, extend_arr, style_arr, color_arr, width_arr, d)
- update_line_array_from_arrays2(line_arr, x1_arr, y1_arr, x2_arr, y2_arr, xloc_arr, extend_arr, style_arr, color_arr, width_arr, d)