The Bayesian Q OscillatorFirst of all the biggest thanks to @tista and @KivancOzbilgic for publishing their open source public indicators Bayesian BBSMA + nQQE Oscillator. And a mighty round of applause for @MarkBench for once again being my superhero pinescript guy that puts these awesome combination Ideas and ES stradegies in my head together. Now let me go ahead and explain what we have here.
I am gonna call it the Bayesian Q Oscillator I suppose. The goal of the script is to solve an issue both indicators on their own suffer from. QQE signals are not new and often the problem has always been false signals for them. They are good for scalping but the difference between a quality move and a small to nearly nonexistent move following a signal is not so clear. Kivanc made his normalized version to help reduce this problem by adding colors to his histogram type verision that would essentially represent if price was a trending move or in a ranging structure. As you can see I have kept this Idea but instead opted for lines as the oscillator. two yellow line (default color) is a ranging sideways area and when there is red or green it is trending up or down. I wanted to take this to the next level with combining the Bayesian probability oscillator that tista put together.
The Bayesian indicator is the opposite for its issue as it is a probability indicator that shows which candle or price movement is more likely to come next. Red rising means possibly down move soon and green means up soon. I will not go into the complex details of this indicator but will suggest others take a look at his and others to understand the idea behind them. The point I am driving at is that it show probabilities or likelyhood without the most effecient signal device to match it. This original was line form and now it is background filled colors.
The idea. is that you can potentially get some stronger and more accurate reversal signals with these two paired together. when you see a sell signal or cross with the towering or rising red... maybe it is a good jump potentially. The same for green. At the same time it is a double added filter effect from just having yellow represent it is ranging... but now if you get a buy signal (example) and have yellow lines (example) along wi5h a red rising or mountain color background... it not only is an indication of ranging, but also that there is potentially even a counter move coming based on the probabilities. Also if you get into a good trade and see dual yellow qqe crosses with no color represented by the bayesian background... it is possible it might only be noise.
I have found them to work decently in the 1 hour timframe. Let me know your experience.
I hope everyone takes a look at the originals to understand them. Full credit goes to those guys for this to be here. Let me know how it is working out for you.
Here are the original links.
bayesian
Normalized QQE
Probability

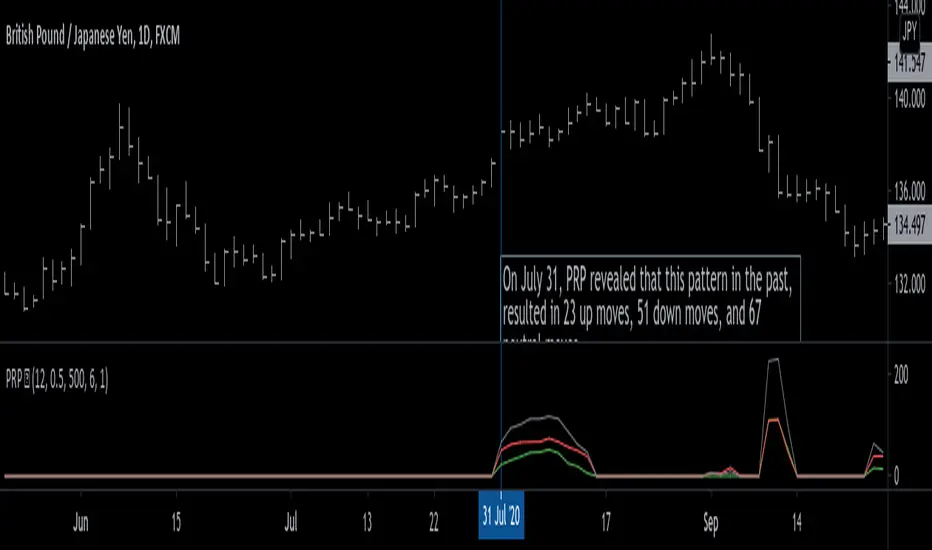
Pattern Recognition Probabilities [racer8]Brief 🌟
Pattern Recognition Probabilities (PRP) is a REALLY smart indicator. It uses the correlation coefficient formula to determine if the current set of bars resembles that of past patterns. It counts the number of times the current pattern has occurred in the past and looks at how it performed historically to determine the probability of an up move, down move, or neutral move.
I'd like to say, I'm proud of this indicator 😆🤙 This is the SMARTEST indicator I have ever made 🧠🧠🧠
Note: PRP doesn't give you actual probabilities, but gives you instead the historical occurrences of up, down, and neutral moves that resulted after the pattern. So you can calculate probabilities based on these valuable statistics. So for example, PRP can tell you this pattern has historically resulted in 55 up moves, 20 down moves, and 60 neutral moves.
Parameters 🌟
You can adjust the Pattern length, Minimum correlation, Statistics lookback, Exit after time, and Atr multiplier parameters.
Pattern length - determines how long the pattern is
Minimum correlation - determines the minimum correlation coefficient needed to pass as a similiar enough pattern.
Statistics lookback - lookback period for gathering all the patterns in the past.
Exit after time - determines when exit occurred (number of periods after pattern) ; is the point that represents the pattern's result.
Atr multiplier - determines minimum atr move needed to qualify whether result was an up/down move or a neutral move. If a particular historical pattern resulted in a move that was less than the min atr, then it is recorded as a neutral move in the statistics.
Thanks for reading! 🙏
Good luck 🍀 Stay safe 😷 Drink lots of water💧
Enjoy! 🥳 and Hit the like button! 👍
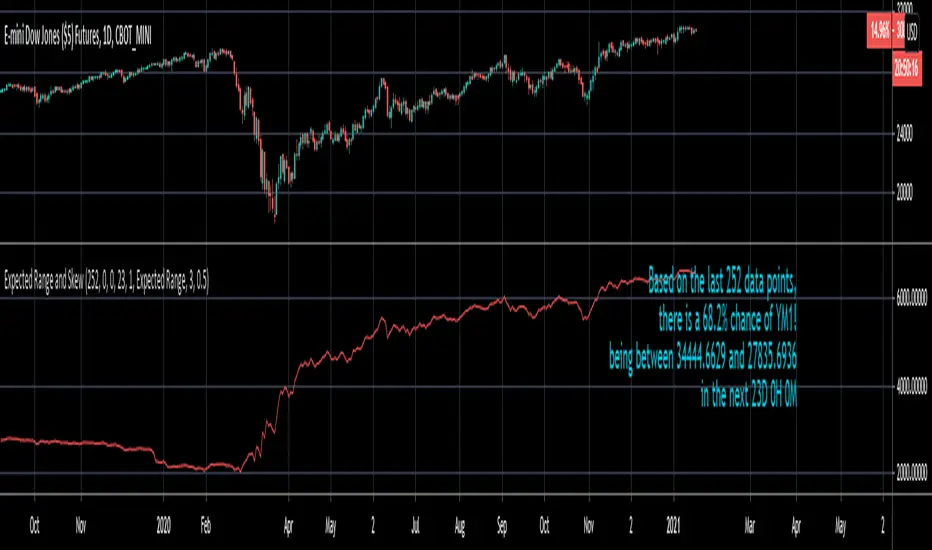
Expected Range and SkewThis is an open source and updated version of my previous "Confidence Interval" script. This script provides you with the expected range over a given time period in the future and the skew of that range. For example, if you wanted to know the expected 1 standard deviation range of MSFT over the next 20 days, this will tell you that. Additionally, this script will also tell you the skew of the expected range.
How to use this script:
1) Enter the length, this will determine the number of data points used in the calculation of the expected range.
2) Enter the amount of time you want projected forward in minutes, hours, and days.
3) Input standard deviation of the expected range.
4) Pick the type of data you want shown from the dropdown menu. Your choices are either the expected range or the skew of the expected range.
5) Enter the x and y coordinates of the label (optional). This is useful so it doesn't impede your view of the plot.
Here are a few notes about this script:
First, the expected range line gives you the width of said range (upper bound - lower bound), and the label will tell you specifically what the upper and lower bounds of the expected range are.
Second, this script will work on any of the default timeframes, but you need to be careful with how far out you try to project the expected range depending on the timeframe you're using. For example, if you're using the 1min timeframe, it probably won't do you any good trying to project the expected range over the next 20 days; or if you're using the daily timeframe it doesn't make sense to try to project the expected range for the next 5 hours. You can tell if the time horizon you're trying to project doesn't work well with the chart timeframe you're using if the current price is outside of either the upper or lower bounds provided in the label. If the current price is within the upper and lower bounds provided in the label, then the time horizon that you're projecting over is reasonable for the chart timeframe you're using.
Third, this script does not countdown automatically, so the time provided in the label will stay the same. For example, in the picture above, the expected range of Dow Futures over the next 23 days from January 12th, 2021 is calculated. But when tomorrow comes it won't count down to 22 days, instead it will show the range over the next 23 days from January 13th, 2021. So if you want the time horizon to change as time goes on you will have to update this yourself manually.
Lastly, if you try to set an alert on this script, you will get a warning about it possibly repainting. This is because of the label, not the plot itself. The label constantly updates itself, which triggers the warning. I tested setting alerts on this script both with and without the inclusion of the label, and without the label the repainting warning did not occur. So remember, if you set an alert on this script you will get a warning about it possibly repainting, but this is because of the label constantly updating, not the plot itself.
Probability Function [racer8]It's my birthday today! Just turned 20, so I decided to make another indicator. There's not very many indicators on TV that calculate pure probability. Many indicators on TV have the word "Probability" in their titles but they don't actually calculate probability...I call them "false titles". This indicator aims to change that. This is the indicator that every option trader dreams of having. Even if you're not an options trader, it's still very interesting to know the probability of a price movement.
Probability Function calculates the probability of a data point (price) falling within a certain number of standard deviations away from the mean.
So for example, setting the parameter to 2 standard deviations will calculate the probability of price staying within a 2-standard-deviations-channel away from the mean (or moving average). This description is exactly what Bollinger Bands are...which makes it a direct application of this indicator, and Bollinger Bands are used by many traders.
The indicator's formula is an approximation of the integral of the standard normal distribution function. It uses one parameter called "Standard deviation multiple" (SDM). An input of 1 stdev yields 68%, 2 stdevs yields 95%, 3 stdevs yields approx 99.7%, and so on eventually converging to 100%...and it makes sense the bigger the stdev channel, the more likely price will stay within it.
Enjoy and hit the like button!

Probability of ATR Index [racer8]Deriving the indicator:
PAI is an indicator I created that tells you the probability of current price moving a specified ATR distance over a specified number of periods into the future. It takes into account 4 variables: the ATR & the standard deviation of price, and the 2 parameters: ATR distance and # bars (time).
The formula is very complex so I will not be able to explain it without confusion arising.
What I can say is that I used integral calculus & the Taylor series to derive a formula that calculates the area under half of the normal distribution function. Thus, the formula was repeated twice in the code to derive the full probability (half + half = whole). If you can read the code, you might be wondering why the formula is so long...
The reason for this is because in Pine Script, the erf function doesn't exist. You see, the formula for normal distribution is: f(x) = (1/sqrt(2pi))*e^(-xx/2), assuming of course that the standard deviation = 1 and mu (mean) = 1. The next step is to take the integral of this formula in order to find the area under f(x). The problem is that I found the integral, F(x), of the normal distribution formula to be equal to F(x) = erf(x/sqrt(2))/2...and the erf function cannot be directly computed into Pinescript.
So I developed a solution...why not estimate the integral function? So that's exactly what I did using a technique involving the Taylor series. The Taylor series is an algebraic function that allows you to create a new function that can estimate the existing function. On a graph, the new function has the same values as the existing one, the only difference is that it uses a differnt formula, in this case, a formula that makes it possible to compute the integral. The disadvantage of using this new formula is that it is super long and if you want it to better represent the original integral over a wider range of x-values, you have to make it longer.
Signal Interpretion:
The hotter the colour, the more likely price will reach your specified distance.
The 2 values of PAI in the bottom window represent probability & average probability of your specifed distance geting hit.
Applications:
Stop loss placement---
This indicator is useful because it gives you an idea of the likelihood that a stop loss at a particular distance away from price (in ATRs) will be hit over a period of time specified. This is helpful in placing stop losses.
Options trading---
PAI can also be used in options trading. For example, you are using a strangle options strategy, and you want to make sure that price stays within the Strangle's profit range. So you only trade when PAI presents a low probability value of moving at a particular distance in ATRs over n periods.
Anyhow, I hope you guys like it. Enjoy! and hit that like button for me :)

Momentum Adjusted EMA TrendThe script draws a moving average which responds to trend changes extraordinary fast!
It's calculated using Momentum, Acceleration and Probability (Psychological Effect) by interfering the Golden Ratio!
I got the idea thanks to Tradingview user DGT (dgtrd) and his/her excellent descriptions.
The indicator is simplified for users and the default settings work great, so use it as you like specially as a trend indicator.


Cumulative distribution function - Probability Cumulative distribution function (tScore and zScore)
This script provides the calculation of the cumulative distribution function (i.e., probability). The measure allows you to calculate the chances of a value of interest being above or below a hypothesized value over the measurement period—nothing fancy here, just good old statistics and mathematics. The closer you are to 0 or 1, the more significant your measurement. We’ve included a significance level highlighting feature. The ability to turn price and/or volume off.
We have included both the Z and T statistics. Where the ‘Z’ is looking at the difference of the current value, minus the mean, and divided by the standard deviation. This is usually pretty noisy on a single value, so a smoother is included. Nice shoutout to the Pinecoders Github Page with this function also. The t-statistic is measuring the difference between a short measurement, an extended measurement, and divided by the standard error (sigma/sqrt(n)). Both of these are neatly wrapped into a function, so please feel free to use them in your code. Add a bit of science to your guessing game. For the purists out there, we have chosen to use sigma in the t-statistic because we know the population's behavior (as opposed to the s-measure). We’ve also included two levels of the t-statistic cumulative distribution function if you are using a short sample period below 6.
Finally, because everyone loves choices, we’ve included the ability to measure the probability of:
the current value (Price and volume)
change
percent change
momentum (change over a period of time)
Acceleration (change of the change)
contribution (amount of the current bar over the sum)
volatility (natural log ratio of today and the previous bar)
Here is a chart example explaining some of the data for the function.
Here are the various options you have the print the different measurements
A comparison of the t-statistic and z-statistic (t-score and z-score)
And the coloring options

Momentum adjusted Moving Average by DGTA brand new Moving Average , calculated using Momentum, Acceleration and Probability (Psychological Effect).
Momentum adjusted Moving Average(MaMA) is an indicator that measures Price Action by taking into consideration not only Price movements but also its Momentum, Acceleration and Probability. MaMA, provides faster responses comparing to the regular Moving Average
Here is the math of the MaMA idea
Momentum measures change in price over a specified time period
momentum = source – source(length)
where,
source, indicates current bar’s price value
source(length), indicates historical price value of length bars earlier
Lets play with this formula and rewrite it by moving source(length) to other side of the equation
source = source(length) + momentum
to avoid confusion let’s call the source that we aim to predict as adjustedSource
adjustedSource = source(length) + momentum
looks nice the next value of source simply can be calculated by summing of historical value of the source value and value of the momentum. I wish it was so easy, the formula holds true only when the momentum is conserved/constant/steady but momentum move up or down with the price fluctuations (accelerating or decelerating)
Let’s add acceleration effects on our formula, where acceleration is change in momentum for a given length. Then the formula will become as (skipped proof part of acceleration effects, you may google for further details)
adjustedSource = source(length) + momentum + 1/2 * acceleration
here again the formula holds true when the acceleration is constant and once again it is not the case for trading, acceleration also changes with the price fluctuations
Then, how we can benefit from all of this, it has value yet requires additional approaches for better outcome
Let’s simulate behaviour with some predictive approach such as using probability (also known as psychological effect ), where probability is a measure for calculating the chances or the possibilities of the occurrence of a random event. As stated earlier above momentum and acceleration are changing with the price fluctuations, by using the probability approach we can add a predictive skill to determine the likelihood of momentum and acceleration changes (remember it is a predictive approach). With this approach, our equations can be expresses as follows
adjustedSource = source(length) + momentum * probability
adjustedSource = source(length) + ( momentum + 1/2 * acceleration ) * probability , with acceleration effect
Finally, we plot MaMA with the new predicted source adjustedSource, applying acceleration effect is made settable by the used from the dialog box, default value is true.
What to look for:
• Trend Identification
• Support and Resistance
• Price Crossovers
Recommended settings are applied as default settings, if you wish to change the length of the MaMA then you should also adjust length of Momentum (and/or Probability). For example for faster moving average such as 21 period it would be suggested to set momentum length to 13
Alternative usage , set moving average length to 1 and keep rest lengths with default values, it will produce a predictive price line based on momentum and probability. Experience acceleration factor by enabling and disabling it
Conclusion
MaMA provide an added level of confidence to a trading strategy and yet it is important to always be aware that it implements a predictive approach in a chaotic market use with caution just like with any indicator
Trading success is all about following your trading strategy and the indicators should fit within your trading strategy, and not to be traded upon solely
Disclaimer : The script is for informational and educational purposes only. Use of the script does not constitutes professional and/or financial advice. You alone the sole responsibility of evaluating the script output and risks associated with the use of the script. In exchange for using the script, you agree not to hold dgtrd TradingView user liable for any possible claim for damages arising from any decision you make based on use of the script
multi pack fisher's and EMACross and Probabilty densityFisher dönüşümün farklı türlerini en çok kullanılan indikartörlerle yeniden sentezlenmesi sonucu ve farklı ema kesimlerine olasılık dağılım yoğunluğu eklenerek içinde bulunan piyasanın trend gücünü görseleştirme amaçlanmıştır.Çalışma tamamen eğitim amaçlı olup, farklı indikatörlerin bir arada kullanımını göstermek için hazırlanmıştır.Kesinlikle yatırım tavsiyesi değildir.
Saygılarımla...
LazEngineer ,Elecrical Engineer
// English explanation
It is aimed to visualize the trend of the market containing the result of re-synthesis with the most used indicator in different types of fisher trasform and by adding the density of the distribution Z transform, required for cutting different ema.
Yours truly ...
LazEngineer, Electrical Engineer

Minkovski Distance Period DVOGThis script was created by building my Dependent Variable Odd Generator script on the Minkovski Distance Adaptive Period.
I have tried this on MACD before.
Script related to MACD :
I used an older version that does not use Dow Factor to suit multi timeframe analysis.
In this way, market situations provide the opportunity to see histograms in an adaptive period as a Multi Timeframe.
Minkowski Distance Function Original Script by RicardoSantos :
Regards.
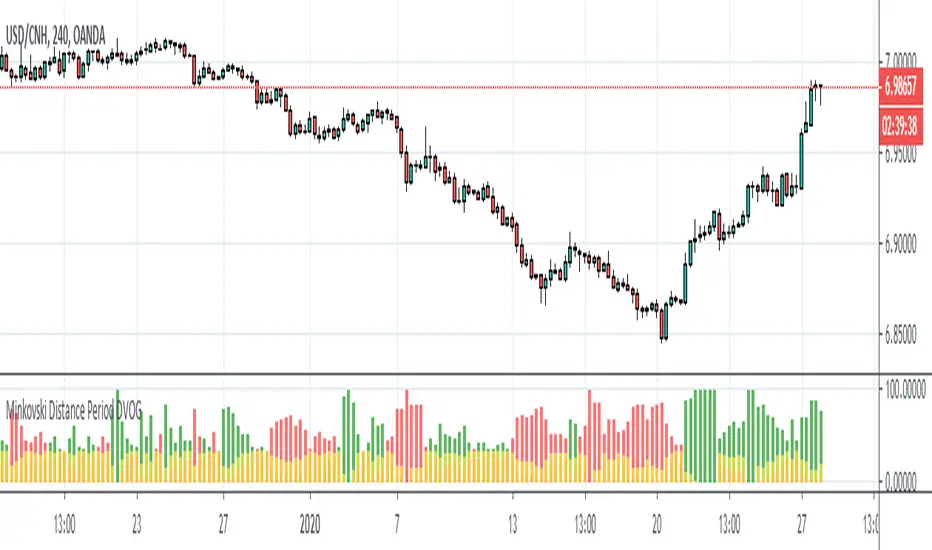
Dependent Variable Odd Generator Risk Detector
In fact, I wrote this script for detect Bollinger and Linear Regression Bands squeeze.
It's a side script.
Logic works like this:
Only the stagnant market probability is drawn from the Bollinger bandwidth by Dependent Variable Odd Generator and MFI index is calculated taking into account the volume.
This value ranges from 0 to 100.
To be sure, this value is averaged over a small period.
If you break the average and exceed 50, the bollinger band is too narrow and the risk is too high.
This means more commissions, more transactions, and vain work.
Or, when in position, the warning is not ignored due to unnecessary signals.
This code is open source under the MIT license. If you have any improvements or corrections to suggest, please send me a pull request via the github repository github.com
Stay tuned , best regards.

Dependent Variable Odd Generator For Machine Learning TechniquesCAUTION : Not suitable for strategy, open to development.
If can we separate the stagnant market from other markets, can we be so much more accurate?
This project was written to research it. It is just the tiny part of the begining.
And this is a very necessary but very small side function in the main function. Lets start :
Hi users, I had this idea in my mind for a long time but I had a hard time finding the parameters that would make the market stagnant. This idea is my first original command system. Although it is very difficult to make sense of the stagnant market, I think that this command system can achieve realistic proportions. With 's money flow index, I opened the track to determine the level. On the other hand, the prices were also using a money flow index, and it forced me to make the limitations between the levels in a logical way. But the good thing is that since the bollinger bandwidth uses a larger period, we are able to print normal values at extreme buy and sell values.
In terms of price, we can define excessive purchase and sale values as the period is smaller. I have repeatedly looked at the limit values that determine the bull, bear, and bollinger bandwidth (mfi), and I think this is the right one. Then I have included these values in the probability set.
The bull and bear market did not form the intersection of the cluster, and because there are connected events, the stagnant market, which is the intersection, will be added to the other markets with the same venn diagram logic and the sum of the probability set will be 1. is equal to. I hope that we can renew the number generators in the very important parameters of machine learning such as Markov Process with generators dependent on dependent variables, which bring us closer to reality. This function is open to development and can be made of various ideas on machine learning. Best wishes.
This code is open source under the MIT license. If you have any improvements or corrections to suggest, please send me a pull request via the github repository github.com

Function Markov ProcessEXPERIMENTAL:
this is very experimental and INCOMPLETE, use at your own discretion.
thanks glaz for the help :)

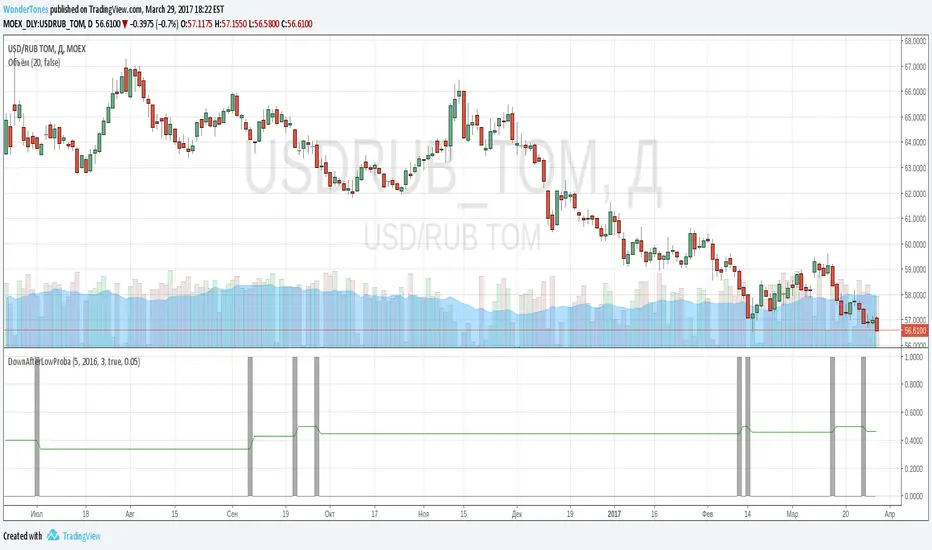
DownAfterLowProba// The script is useful to inspect probability:
// If previous day closed at lowest price for several days
// how often next day would be red bar
// As one can see gray lines indicate bars with lowest close. If next bar is green, increment diff_hi, overwise increment diff_lo
// Probability is counted as diff_lo / (diff_hi+diff_lo)
// One can copy script and change conditions to count other interesting probabilities
[RS]Study into sequential probabilitys V0EXPERIMENTAL:
just some experimentation to check results, putting it out there. :P
odds of the next bar being up or down bar.

Moving CO-covariance (covariance on covariance)This is Covariance on Covariance. It shows you how much a given covariance period has deviated from it mean over another defined period. Because it is a time series, It can allow you to spot changes in how covariance changes. You can apply trend lines, Fibonacci retracements, etc. This is also volume weighting covariance.
This is not a directional indicator nor is moving covariance. This is used for forecasting volatility. This must be used in conjunction with moving covariance.
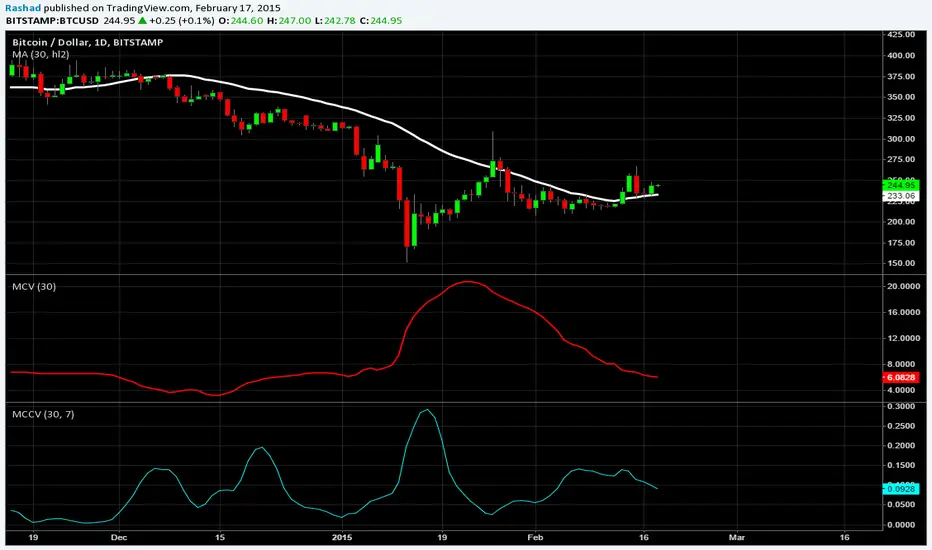
Moving CovarianceCo-variance is a representation of the average percent data points deviate from there mean. A standard calculation of Co-variance uses One standard Deviation. Using the empirical rule, we can assume that about 68.26% of Data points lie in this range.
The advantage to plotting co variance as a time series is that it will show you how volatility of a trailing period changes. Therefore trend lines and other methods of analysis such as Fibonacci retracements could be applied in order to generate volatility targets.
For the purpose of this indicator I have the mean using a vwma derived from vwap. This makes this measurement of co-variance more sensitive to changes in volume, likewise are more representative a change in volatility, thus giving this indicator a "leading aspect".
