[cache_that_pass] 1m 15m Function - Weighted Standard DeviationTradingview Community,
As I progress through my journey, I have come to the realization that it is time to give back. This script isn't a life changer, but it has the building blocks for a motivated individual to optimize the parameters and have a production script ready to go.
Credit for the indicator is due to @rumpypumpydumpy
I adapted this indicator to a strategy for crypto markets. 15 minute time frame has worked best for me.
It is a standard deviation script that has 3 important user configured parameters. These 3 things are what the end user should tweak for optimum returns. They are....
1) Lookback Length - I have had luck with it set to 20, but any value from 1-1000 it will accept.
2) stopPer - Stop Loss percentage of each trade
3) takePer - Take Profit percentage of each trade
2 and 3 above are where you will see significant changes in returns by altering them and trying different percentages. An experienced pinescript programmer can take this and build on it even more. If you do, I ask that you please share the script with the community in an open-source fashion.
It also already accounts for the commission percentage of 0.075% that Binance.US uses for people who pay fees with BNB.
How it works...
It calculates a weighted standard deviation of the price for the lookback period set (so 20 candles is default). It recalculates each time a new candle is printed. It trades when price lows crossunder the bottom of that deviation channel, and sells when price highs crossover the top of that deviation channel. It works best in mid to long term sideways channels / Wyckoff accumulation periods.
Regression
Ripple (XRP) Model PriceAn article titled Bitcoin Stock-to-Flow Model was published in March 2019 by "PlanB" with mathematical model used to calculate Bitcoin model price during the time. We know that Ripple has a strong correlation with Bitcoin. But does this correlation have a definite rule?
In this study, we examine the relationship between bitcoin's stock-to-flow ratio and the ripple(XRP) price.
The Halving and the stock-to-flow ratio
Stock-to-flow is defined as a relationship between production and current stock that is out there.
SF = stock / flow
The term "halving" as it relates to Bitcoin has to do with how many Bitcoin tokens are found in a newly created block. Back in 2009, when Bitcoin launched, each block contained 50 BTC, but this amount was set to be reduced by 50% every 210,000 blocks (about 4 years). Today, there have been three halving events, and a block now only contains 6.25 BTC. When the next halving occurs, a block will only contain 3.125 BTC. Halving events will continue until the reward for minors reaches 0 BTC.
With each halving, the stock-to-flow ratio increased and Bitcoin experienced a huge bull market that absolutely crushed its previous all-time high. But what exactly does this affect the price of Ripple?
Price Model
I have used Bitcoin's stock-to-flow ratio and Ripple's price data from April 1, 2014 to November 3, 2021 (Daily Close-Price) as the statistical population.
Then I used linear regression to determine the relationship between the natural logarithm of the Ripple price and the natural logarithm of the Bitcoin's stock-to-flow (BSF).
You can see the results in the image below:
Basic Equation : ln(Model Price) = 3.2977 * ln(BSF) - 12.13
The high R-Squared value (R2 = 0.83) indicates a large positive linear association.
Then I "winsorized" the statistical data to limit extreme values to reduce the effect of possibly spurious outliers (This process affected less than 4.5% of the total price data).
ln(Model Price) = 3.3297 * ln(BSF) - 12.214
If we raise the both sides of the equation to the power of e, we will have:
============================================
Final Equation:
■ Model Price = Exp(- 12.214) * BSF ^ 3.3297
Where BSF is Bitcoin's stock-to-flow
============================================
If we put current Bitcoin's stock-to-flow value (54.2) into this equation we get value of 2.95USD. This is the price which is indicated by the model.
There is a power law relationship between the market price and Bitcoin's stock-to-flow (BSF). Power laws are interesting because they reveal an underlying regularity in the properties of seemingly random complex systems.
I plotted XRP model price (black) over time on the chart.
Estimating the range of price movements
I also used several bands to estimate the range of price movements and used the residual standard deviation to determine the equation for those bands.
Residual STDEV = 0.82188
ln(First-Upper-Band) = 3.3297 * ln(BSF) - 12.214 + Residual STDEV =>
ln(First-Upper-Band) = 3.3297 * ln(BSF) – 11.392 =>
■ First-Upper-Band = Exp(-11.392) * BSF ^ 3.3297
In the same way:
■ First-Lower-Band = Exp(-13.036) * BSF ^ 3.3297
I also used twice the residual standard deviation to define two extra bands:
■ Second-Upper-Band = Exp(-10.570) * BSF ^ 3.3297
■ Second-Lower-Band = Exp(-13.858) * BSF ^ 3.3297
These bands can be used to determine overbought and oversold levels.
Estimating of the future price movements
Because we know that every four years the stock-to-flow ratio, or current circulation relative to new supply, doubles, this metric can be plotted into the future.
At the time of the next halving event, Bitcoins will be produced at a rate of 450 BTC / day. There will be around 19,900,000 coins in circulation by August 2025
It is estimated that during first year of Bitcoin (2009) Satoshi Nakamoto (Bitcoin creator) mined around 1 million Bitcoins and did not move them until today. It can be debated if those coins might be lost or Satoshi is just waiting still to sell them but the fact is that they are not moving at all ever since. We simply decrease stock amount for 1 million BTC so stock to flow value would be:
BSF = (19,900,000 – 1.000.000) / (450 * 365) =115.07
Thus, Bitcoin's stock-to-flow will increase to around 115 until AUG 2025. If we put this number in the equation:
Model Price = Exp(- 12.214) * 114 ^ 3.3297 = 36.06$
Ripple has a fixed supply rate. In AUG 2025, the total number of coins in circulation will be about 56,000,000,000. According to the equation, Ripple's market cap will reach $2 trillion.
Note that these studies have been conducted only to better understand price movements and are not a financial advice.

Polynomial Regression Style Examplejust a example on how to edit line style on the output of the polynomial regression library..

Nadaraya-Watson Envelope [LuxAlgo]This indicator builds upon the previously posted Nadaraya-Watson smoothers. Here we have created an envelope indicator based on Kernel Smoothing with integrated alerts from crosses between the price and envelope extremities. Unlike the Nadaraya-Watson estimator, this indicator follows a contrarian methodology.
Please note that by default this indicator can be subject to repainting. Users can use a non-repainting smoothing method available from the settings. The triangle labels are designed so that the indicator remains useful in real-time applications.
🔶 USAGE
🔹 Non Repainting
This tool can outline extremes made by the prices. This is achieved by estimating the underlying trend in the price, then calculating the mean absolute deviations from it, the obtained result is added/subtracted to the estimated underlying trend.
The non-repainting method estimates the underlying trend in price using an "endpoint Nadaraya-Watson estimator", and would return similar results to more classical band indicators.
🔹 Repainting
The repainting method makes use of the Nadaraya-Watson estimator to estimate the underlying trend in the price. The construction of the band extremities is the same as in the non-repainting method.
We can expect the price to reverse when crossing one of the envelope extremities. Crosses between the price and the envelopes extremities are indicated with triangles on the chart.
For real-time applications, triangles are always displayed when a cross occurs and remain displayed at the location it first appeared even if the cross is no longer visible after a recalculation of the envelope.
By popular demand, we have integrated alerts for this indicator from the crosses between the price and the envelope extremities. However, we do not recommend this precise method to be used alone or for solely real-time applications. We do not have data supporting the performance of this tool over more classical bands/envelope/channels indicators.
🔶 SETTINGS
Bandwidth: Controls the degree of smoothness of the envelopes, with higher values returning smoother results.
Mult: Controls the envelope width.
Source: Input source of the indicator.
Repainting Smoothing: Determine if a repainting or non-repainting method should be used for the calculation of the indicator.
🔶 RELATED SCRIPTS
For more information on the Nadaraya-Watson estimator see:
FunctionPolynomialRegressionLibrary "FunctionPolynomialRegression"
TODO:
polyreg(sample_x, sample_y) Method to return a polynomial regression channel using (X,Y) sample points.
Parameters:
sample_x : float array, sample data X points.
sample_y : float array, sample data Y points.
Returns: tuple with:
_predictions: Array with adjusted Y values.
_max_dev: Max deviation from the mean.
_min_dev: Min deviation from the mean.
_stdev/_sizeX: Average deviation from the mean.
draw(sample_x, sample_y, extend, mid_color, mid_style, mid_width, std_color, std_style, std_width, max_color, max_style, max_width) Method for drawing the Polynomial Regression into chart.
Parameters:
sample_x : float array, sample point X value.
sample_y : float array, sample point Y value.
extend : string, default=extend.none, extend lines.
mid_color : color, default=color.blue, middle line color.
mid_style : string, default=line.style_solid, middle line style.
mid_width : int, default=2, middle line width.
std_color : color, default=color.aqua, standard deviation line color.
std_style : string, default=line.style_dashed, standard deviation line style.
std_width : int, default=1, standard deviation line width.
max_color : color, default=color.purple, max range line color.
max_style : string, default=line.style_dotted, max line style.
max_width : int, default=1, max line width.
Returns: line array.
log-log Regression From ArraysCalculates a log-log regression from arrays. Due to line limits, for sets greater than the limit, only every nth value is plotted in order to cover the entire set.
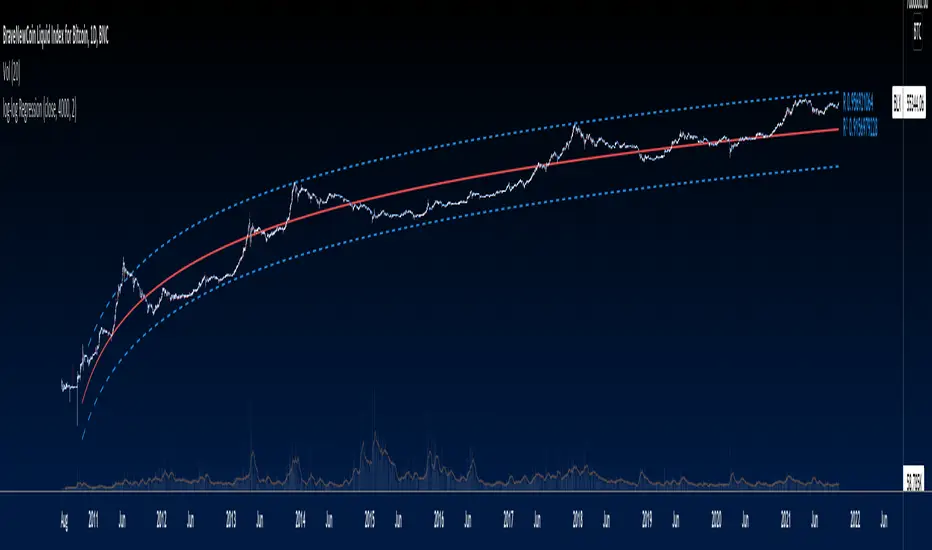
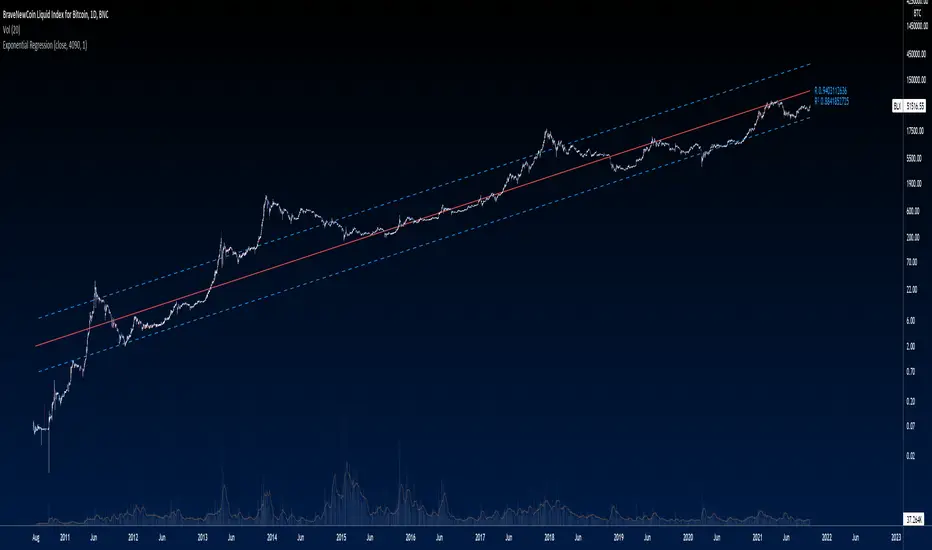
Exponential Regression From ArraysCalculates an exponential regression from arrays. Due to line limits, for sets greater than the limit, only every nth value is plotted in order to cover the entire set.
Nadaraya-Watson Smoothers [LuxAlgo]The following tool smoothes the price data using various methods derived from the Nadaraya-Watson estimator, a simple Kernel regression method. This method makes use of the Gaussian kernel as a weighting function.
Users have the option to use a non-repainting as well as a repainting method, see the USAGE section for more information.
🔶 USAGE
🔹 Non Repainting
When Repainting Smoothing is disabled the returned indicator acts similarly to a regular causal moving average. This result could be described as an "endpoint Nadaraya-Watson estimator".
Unlike a regular moving average whose degree of smoothness is commonly determined by the length of its calculation window, the degree of smoothness of the proposed indicator is determined by the bandwidth setting, with a higher value returning smoother results.
In the above chart, a bandwidth value of 50 is used. An increasing value of the smoother is indicative of an uptrend, while a decreasing value is indicative of a downtrend.
🔹 Repainting
Non-causal smoothing methods have found low support from technical analysts because they tend to repaint. Yet, they can provide powerful insights such as estimating underlying trends in the price as well as seeing how far prices deviate from them. They can also make drawing certain patterns easier and can help see underlying structures in the price more clearly.
Using higher bandwidth values allows for estimating longer-term trends in the price.
Triangular labels highlight points where the direction of the estimator change. This allows for the identification of tops and bottoms in the underlying trend which can be compared to the actual price tops and bottoms.
Note that multiple labels can appear in real time, highlighting real-time changes in the estimator's direction. The most recent label on a series of labels is the first to appear. This can eventually be useful for the real-time predictive application of the estimator. However, it is not a usage we particularly recommend.
🔶 DETAILS
The Nadaraya-Watson estimator can be described as a series of weighted averages using a specific normalized kernel as a weighting function. For each point of the estimator at time t , the peak of the kernel is located at time t , as such the highest weights are attributed to values neighboring the price located at time t .
A lower bandwidth value would contribute toward a more important weighting of the price at a precise point and would as such less smooth results. In the case where our bandwidth is so small that the resulting kernel is just an impulse, we would get the raw price back.
However, when the bandwidth is sufficiently large, prices would be weighted similarly, thus resulting in a result closer to the price mean.
It can be interesting to note that due to the nature of the estimator and its weighting procedure, real-time results would not deviate drastically for points in the estimator near the center of the calculation window.
🔶 SETTINGS
Bandwidth : controls the bandwidth of the Gaussian kernel, with higher values returning smoother results.
Src : Input source of the kernel regression.
Repainting Smoothing : Determine if the smoothing method should repaint or not. If disabled the "endpoint Nadaraya-Watson estimator" is returned.

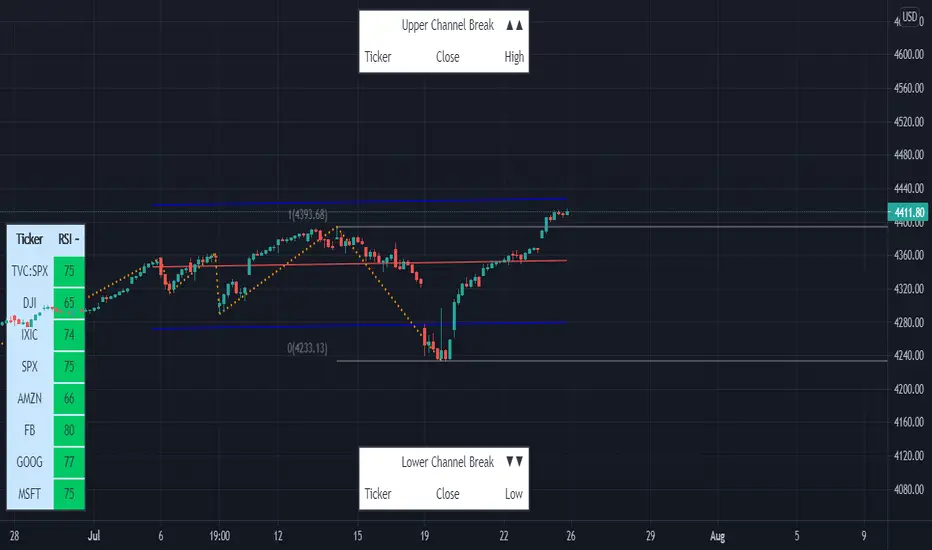
Linear Regression & RSI Multi-Function Screener with Table-LabelHi fellow traders..
Happy to share a Linear Regression & RSI Multi-Function Custom Screener with Table-Labels...
The Screener scans for Linear Regression 2-SD Breakouts and RSI OB/OS levels for the coded tickers and gives Summary alerts
Uses Tables (dynamica resizing) for the scanner output instead of standard labels!
This Screener cum indicator collection has two distinct objectives..
1. Attempt re-entry into trending trades.
2. Attempt Counter trend trades using linear regression , RSI and Zigzag.
Briefly about the Screener functions..
a. It uses TABLES as Labels a FIRST for any Screener on TV.
b. Tables dynamically resize based on criteria..
c. Alerts for breakouts of the UPPER and the LOWER regression channels.(2 SD)
d. In addition to LinReg it also Screens RSI for OB/OS levels so a multifunction Screener.
e. Of course has the standard summary Alerts and programmable format for Custom functions.
f. Uses only the inbuilt Auto Fib and Lin Reg code for the screener.(No proprietary stuff)
g. The auto Zigzag code is derived(Auto fib).
Question what are all these doing in a single screener ??
ZigZag is very useful in determining Trend Up or Down from one Pivot to another.
So Once you have a firm view of the Current Trend for your chosen timeframe and ticker…
We can consider few possible trading scenarios..
a. Re-entry in an Up Trend - Combination of OS Rsi And a Lower Channel breach followed by a re-entry back into the regression channel CAN be used as an effective re-entry.
b. Similarily one can join a Down Trend on OB Rsi and Upper Channel line breach followed by re-entry into the regression channel.
If ZigZag signals a range-bound market, bound within channel lines then the Upper breakout can be used to Sell and vice-versa!
In short many possibilities for using these functions together with Scanner and Alerts.
This facilitates timely PROFITABLE Trending and Counter trend opportunities across multiple tickers.
You must give a thorough READ to the various available tutorials on ZigZag / Regression and Fib retracements before attempting counter trend trades using these tools!!
A small TIP – Markets are sideways or consolidating 70% of the time!!
Acknowledgements: - Thanks a lot DGTRD for the Auto ZigZag code and also for the eagerness to help wherever possible..Respect!!
Disclaimer: The Alerts and Screener are just few tools among many and not any kind of Buy/Sell recommendations. Unless you have sufficient trading experience please consult a Financial advisor before investing real money.
*The alerts are set for crossovers however for viewing tickers trading above or below the channel use code in line 343 and 344 after setting up the Alerts!
** RSI alerts are disabled by default to avoid clutter, but if needed one can activate code lines 441,442,444 and 445
Wish you all, Happy Profitable Trading!
Log Scale Linear RegressionThis indicator is basically the standard linear regression but adjusted to be suitable for log scale.
You can use 2 different standard deviation values, choose the data source and lookback length.
The colors are chosen directly on the main menu.
Enjoy!

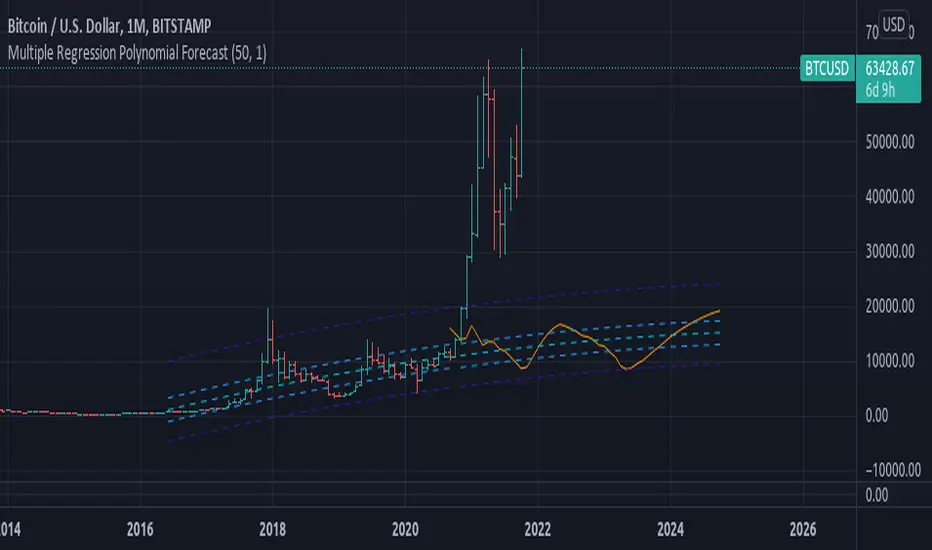
Multiple Regression Polynomial ForecastEXPERIMENTAL:
Forecasting using a polynomial regression over the estimates of multiple linear regression forecasts.
note: on low data the estimates are skewd away of initial value, i added the i_min_estimate option in to try curve this issue with limited success "o_o.
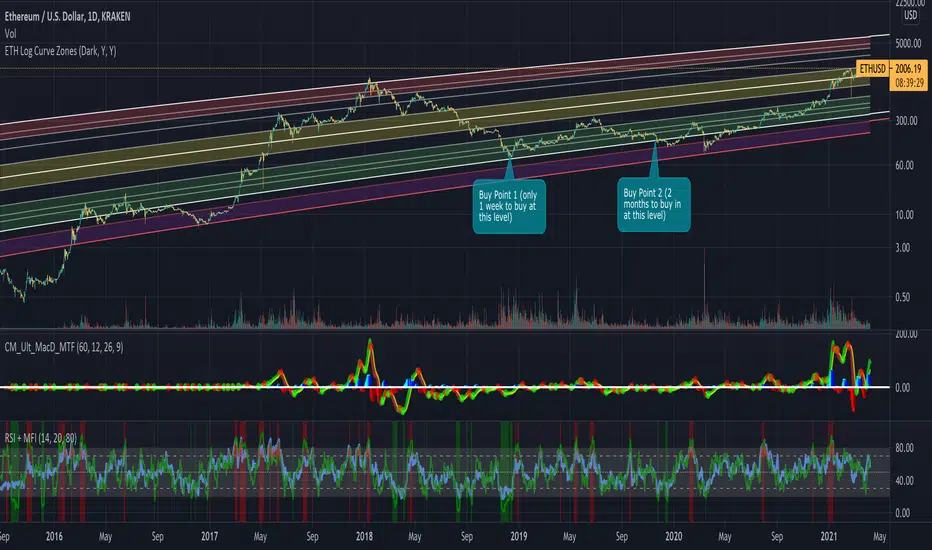
Ethereum Logarithmic Growth Curves & ZonesThis script was modified to fit ethereum logarithmic pricing action.
Robust Channel [tbiktag]Introducing the Robust Channel indicator.
This indicator is based on a remarkable property of robust statistics , namely, the resistance to the presence of data points that deviate significantly from the established trend (generally speaking, outliers ). Being outlier-resistant, the Robust Channel indicator “remembers” a pre-existing trend and thus exhibits a very peculiar "lag" in case of a sharp price change. This allows high-confidence identification of such price actions as a trend reversal, range break, pullback, etc.
In the case of trending and range-bound market conditions, the price remains within the channel most of the time, fluctuating around the central line.
Technical details
The central line is calculated using the repeated median slope algorithm. For each data point in a lookback window of a user-specified Length , this method calculates the median slope of the lines that connect that point to all other points inside the window. The overall median of these median slopes is then calculated and used as an estimate of the trend slope. The algorithm is very efficient as it uses an on-the-fly procedure to update the array containing the slopes (new data pushed - old data removed).
The outer line is then calculated as the central line plus the Length -period standard deviation of the price data multiplied by a user-defined Channel Width Factor . The inner line is defined analogously below the central line.
Usage
As a stand-alone indicator, the Robust Channel can be applied similarly to the Bollinger Bands and the Keltner Channel:
A close above the outer line can be interpreted as a bullish signal and a close below the inner line as a bearish signal.
Likewise, a return to the channel from below after a break may serve as a bullish signal, while a return from above may indicate bearish sentiment.
Robust Channel can be also used to confirm chart patterns such as double tops and double bottoms.
If you like this indicator, feel free to leave your feedback in the comments below!

Matrix Library (Linear Algebra, incl Multiple Linear Regression)What's this all about?
Ever since 1D arrays were added to Pine Script, many wonderful new opportunities have opened up. There has been a few implementations of matrices and matrix math (most notably by TradingView-user tbiktag in his recent Moving Regression script: ). However, so far, no comprehensive libraries for matrix math and linear algebra has been developed. This script aims to change that.
I'm not math expert, but I like learning new things, so I took it upon myself to relearn linear algebra these past few months, and create a matrix math library for Pine Script. The goal with the library was to make a comprehensive collection of functions that can be used to perform as many of the standard operations on matrices as possible, and to implement functions to solve systems of linear equations. The library implements matrices using arrays, and many standard functions to manipulate these matrices have been added as well.
The main purpose of the library is to give users the ability to solve systems of linear equations (useful for Multiple Linear Regression with K number of independent variables for example), but it can also be used to simulate 2D arrays for any purpose.
So how do I use this thing?
Personally, what I do with my private Pine Script libraries is I keep them stored as text-files in a Libraries folder, and I copy and paste them into my code when I need them. This library is quite large, so I have made sure to use brackets in comments to easily hide any part of the code. This helps with big libraries like this one.
The parts of this script that you need to copy are labeled "MathLib", "ArrayLib", and "MatrixLib". The matrix library is dependent on the functions from these other two libraries, but they are stripped down to only include the functions used by the MatrixLib library.
When you have the code in your script (pasted somewhere below the "study()" call), you can create a matrix by calling one of the constructor functions. All functions in this library start with "matrix_", and all constructors start with either "create" or "copy". I suggest you read through the code though. The functions have very descriptive names, and a short description of what each function does is included in a header comment directly above it. The functions generally come in the following order:
Constructors: These are used to create matrices (empy with no rows or columns, set shape filled with 0s, from a time series or an array, and so on).
Getters and setters: These are used to get data from a matrix (like the value of an element or a full row or column).
Matrix manipulations: These functions manipulate the matrix in some way (for example, functions to append columns or rows to a matrix).
Matrix operations: These are the matrix operations. They include things like basic math operations for two indices, to transposing a matrix.
Decompositions and solvers: Next up are functions to solve systems of linear equations. These include LU and QR decomposition and solvers, and functions for calculating the pseudo-inverse or inverse of a matrix.
Multiple Linear Regression: Lastly, we find an implementation of a multiple linear regression, including all the standard statistics one can expect to find in most statistical software packages.
Are there any working examples of how to use the library?
Yes, at the very end of the script, there is an example that plots the predictions from a multiple linear regression with two independent (explanatory) X variables, regressing the chart data (the Y variable) on these X variables. You can look at this code to see a real-world example of how to use the code in this library.
Are there any limitations?
There are no hard limiations, but the matrices uses arrays, so the number of elements can never exceed the number of elements supported by Pine Script (minus 2, since two elements are used internally by the library to store row and column count). Some of the operations do use a lot of resources though, and as a result, some things can not be done without timing out. This can vary from time to time as well, as this is primarily dependent on the available resources from the Pine Script servers. For instance, the multiple linear regression cannot be used with a lookback window above 10 or 12 most of the time, if the statistics are reported. If no statistics are reported (and therefore not calculated), the lookback window can usually be extended to around 60-80 bars before the servers time out the execution.
Hopefully the dev-team at TradingView sees this script and find ways to implement this functionality diretly into Pine Script, as that would speed up many of the operations and make things like MLR (multiple linear regression) possible on a bigger lookback window.
Some parting words
This library has taken a few months to write, and I have taken all the steps I can think of to test it for bugs. Some may have slipped through anyway, so please let me know if you find any, and I'll try my best to fix them when I have time to do so. This library is intended to help the community. Therefore, I am releasing the library as open source, in the hopes that people may improving on it, or using it in their own work. If you do make something cool with this, or if you find ways to improve the code, please let me know in the comments.

Linear Regression CandlesThere are many linear regression indicators out there, most of them draw lines or channels, but this one actually draws a chart.
Moving Regression Band Breakout strategyFollowing the introduction of the Moving Regression Prediction Bands indicator (see link below), I'd like to propose how to utilize it in a simple band breakout strategy :
Go long after the candle closes above the upper band . The lower band (alternatively, the lower band minus the 14-period ATR or the central line ) will serve as a support line .
Exit as soon as the candle closes below the support line .
To manage the risk of false breakouts, a fixed stop loss is set to the value of the support line at the time of opening a position. When the support line moves above the position opening price, shift the stop loss to breakeven.
The same logic but in reverse applies to short positions.
As an option, it is possible to allow long entries only when the slope of the Moving Regression curve is positive (and short entries when the slope is negative).
Model parameters:
Length and Polynomial Order define the lag and smoothness of the model.
Multiplier specifies the width of the channel.
As the default model parameter values, I set those that I found to provide optimal risk / reward ratio on the daily timeframe (for both trending and range-bound market). However, the settings are very flexible and can be well-adjusted to particular market conditions. Feel free to play around and leave feedback in the comments!
Here's the original Moving Regression Prediction Bands script:

Moving Regression Prediction BandsIntroducing the Moving Regression Prediction Bands indicator.
Here I aimed to combine the principles of traditional band indicators (such as Bollinger Bands), regression channel and outlier detection methods. Its upper and lower bands define an interval in which the current price was expected to fall with a prescribed probability, as predicted by the previous-step result of the local polynomial regression (for the original Moving Regression script, see link below).
Algorithm
1. At every time step, the script performs local polynomial regression of the sample data within the lookback window specified by the Length input parameter.
2. The fitted polynomial is used to construct the Moving Regression time series as well as to extrapolate data, that is, to predict the next data point ( MRPrediction ).
3. The accuracy of local interpolation is estimated by means of the root-mean-square error ( RMSE ), that is, the deviation between the fitted polynomial and the observed values.
4. The MRPrediction and RMSE values calculated for the previous bar are then used to build the upper and lower bands , which I define as follows:
Upper Band = MRPrediction_prev + Multiplier *( RMSE_prev )
Lower Band = MRPrediction_prev - Multiplier *( RMSE_prev )
Here the Multiplier is a user-defined parameter that should be interpreted as a quantile in the standard normal distribution (the default value of 2.0 roughly corresponds to the 95% prediction interval).
To visualize the central line , the script offers the following options:
Previous-Period MR Prediction: MRPrediction_prev time series from the above equation.
MR: Conventional Moving Regression time series.
Ribbon: “Previous-Period MR Prediction” and “MR” curves plotted together and colored according to their relative value (green if MR > Previous MR Prediction; red otherwise).
Usage
My original idea was to use the band breakouts as potential trading signals. For example, the price crossing above the upper band is a bullish signal , being a potential sign that price is gaining momentum and is out of a previously predicted trend. The exit signal could be the crossing under the lower band or under the central line.
However, be aware that it is an experimental indicator, so you might fin some better strategies.
Feel free to play around!

Combo Backtest 123 Reversal & Line Regression Intercept This is combo strategies for get a cumulative signal.
First strategy
This System was created from the Book "How I Tripled My Money In The
Futures Market" by Ulf Jensen, Page 183. This is reverse type of strategies.
The strategy buys at market, if close price is higher than the previous close
during 2 days and the meaning of 9-days Stochastic Slow Oscillator is lower than 50.
The strategy sells at market, if close price is lower than the previous close price
during 2 days and the meaning of 9-days Stochastic Fast Oscillator is higher than 50.
Second strategy
Linear Regression Intercept is one of the indicators calculated by using the
Linear Regression technique. Linear regression indicates the value of the Y
(generally the price) when the value of X (the time series) is 0. Linear
Regression Intercept is used along with the Linear Regression Slope to create
the Linear Regression Line. The Linear Regression Intercept along with the Slope
creates the Regression line.
WARNING:
- For purpose educate only
- This script to change bars colors.

[JRL] Pivot Regression OscillatorIntroducing the Pivot Regression Oscillator. This oscillator uses a similar formula to the Stochastic Oscillator. However, instead of comparing the closing price to the lowest price of a period, it compares the distance between current price and the current pivot point. By basing our oscillator on pivot levels, we incorporate a much more relevant and consequential price point around which to base our comparisons.
The indicator can give reliable overbought and oversold signals, and it plots two exponential moving averages as output, which provides crossover signals that can be used to help time trades.
The Pivot Regression Oscillator can be effective for timing re-entries into a trend and seems to be able to avoid some of the false signals of other indicators.
Let me know if you find this useful. Cheers!

Machine Learning: Logistic RegressionMulti-timeframe Strategy based on Logistic Regression algorithm
Description:
This strategy uses a classic machine learning algorithm that came from statistics - Logistic Regression (LR).
The first and most important thing about logistic regression is that it is not a 'Regression' but a 'Classification' algorithm. The name itself is somewhat misleading. Regression gives a continuous numeric output but most of the time we need the output in classes (i.e. categorical, discrete). For example, we want to classify emails into “spam” or 'not spam', classify treatment into “success” or 'failure', classify statement into “right” or 'wrong', classify election data into 'fraudulent vote' or 'non-fraudulent vote', classify market move into 'long' or 'short' and so on. These are the examples of logistic regression having a binary output (also called dichotomous).
You can also think of logistic regression as a special case of linear regression when the outcome variable is categorical, where we are using log of odds as dependent variable. In simple words, it predicts the probability of occurrence of an event by fitting data to a logit function.
Basically, the theory behind Logistic Regression is very similar to the one from Linear Regression, where we seek to draw a best-fitting line over data points, but in Logistic Regression, we don’t directly fit a straight line to our data like in linear regression. Instead, we fit a S shaped curve, called Sigmoid, to our observations, that best SEPARATES data points. Technically speaking, the main goal of building the model is to find the parameters (weights) using gradient descent.
In this script the LR algorithm is retrained on each new bar trying to classify it into one of the two categories. This is done via the logistic_regression function by updating the weights w in the loop that continues for iterations number of times. In the end the weights are passed through the sigmoid function, yielding a prediction.
Mind that some assets require to modify the script's input parameters. For instance, when used with BTCUSD and USDJPY, the 'Normalization Lookback' parameter should be set down to 4 (2,...,5..), and optionally the 'Use Price Data for Signal Generation?' parameter should be checked. The defaults were tested with EURUSD.
Note: TradingViews's playback feature helps to see this strategy in action.
Warning: Signals ARE repainting.
Style tags: Trend Following, Trend Analysis
Asset class: Equities, Futures, ETFs, Currencies and Commodities
Dataset: FX Minutes/Hours/Days

Delta-RSI OscillatorIntroducing the Delta-RSI Oscillator.
This oscillator is a time derivative of the RSI, plotted as a histogram and serving as a momentum indicator. The derivative is calculated explicitly by means of local polynomial regression. It is designed to provide minimum false and premature buy/sell signals compared to many traditional momentum indicators such as Momentum, RSI, Rate of Change.
Application:
Potential trading signals provided by the Delta-RSI Oscillator include:
- zero crossing (negative-to-positive as a bullish sign and positive-to-negative sign as a bearish signal),
- change of direction (consider going long if the oscillator starts to advance, and short otherwise).
In addition, the strength of a particular trend can be estimated by looking at the Delta-RSI value (positive D-RSI in case of the uptrend, and negative in case of the downtrend).
Choosing the model Parameters:
-RSI Length: The timeframe of the RSI that is being differentiated.
- Frame Length: The length of the lookback frame used for local regression.
- Polynomial Order: The order of the local polynomial function.
Longer frames and lower order of polynomials will result in a " smoother " D-RSI, but at the expense of greater lag. Increasing the polynomial order while maintaining the frame length will reduce lag while producing more variance. The values set as default (Length=18, Order=2) were found to provide optimum the variance/lag tradeoff. However, other options (e.g., Length=35, Order=3) can also work well.
Relationship with other methods:
When developing this indicator, I was inspired by Connie Brown’s Derivative Oscillator. The latter pursues the same goal but evaluates the RSI derivative by means of triple smoothing. This paves the way for more clear interpretation and easier tuning of model parameters.

Moving RegressionMoving Regression is a generalization of moving average and polynomial regression.
The procedure approximates a specified number of prior data points with a polynomial function of a user-defined degree. Then, polynomial interpolation of the last data point is used to construct a Moving Regression time series.
Application:
Moving Regression allows one to smooth noise on the analyzed chart, assess momentum, confirm trends, and establish areas of support and resistance.
In addition, it can be used as a simple stand-alone forecasting method to identify trend direction and trend reversal points. When the local polynomial is predicted to move up in the next time step, the color of the Moving Regression curve will be green. Otherwise, the color of the curve is red. This function is (de)activated using the Predict Trend Direction flag.
Selecting the model parameters:
The effects of the moving window Length and the Local Polynomial Degree are confounded. This allows for finding the optimal trade-off between noise (variance) and lag (bias). Higher Length and lower Polynomial Degree (such as 1, i.e. linear), will result in "smoother" time series but at the cost of greater lag. Increasing the Polynomial Degree to, for example, 2 (squared) while maintaining the Length will diminish the lag and thus compromise the noise-lag tradeoff.
Relation to other methods:
When the degree of the local polynomial is set to 0 (i.e., fitting data to a constant level), the Moving Regression time series exactly matches the Simple Moving Average of the same length.

Linear Regression ChannelHello Traders,
There are several nice Linear Regression Channel scripts in the Public Library. and I tried to make one with some extra features too. This one can check if the Price breaks the channel and it shows where is was broken. Also it checks the momentum of the channel and shows it's increasing/decreasing/equal in a label, shape of the label also changes. The line colors change according to direction.
using the options, you can;
- Set the Source (Close, HL2 etc)
- Set the Channel length
- Set Deviation
- Change Up/Down Line colors
- Show/hide broken channels
- Change line width
meaning of arrows:
⇑ : Uptrend and moment incresing
⇗ : Uptrend and moment decreasing
⇓ : Downtrend and moment incresing
⇘ : Downtrend and moment decreasing
⇒ : No trend
An example for how color of lines, arrow direction and shape of label change.
Enjoy!