Auto Trend Channel + Buy/Sell AlertsThis indicator automatically detects trend channels using a linear regression line, and dynamically plots upper and lower channel boundaries based on standard deviation. It helps traders identify potential Buy and Sell zones with clear visual signals and customizable alerts.
💡 How It Works:
🧠 Regression-Based Channel: Calculates the central trend line using ta.linreg() over a user-defined length.
📏 Dynamic Boundaries: Upper and lower channel lines are offset by a multiplier of the standard deviation for precision volatility tracking.
✅ Buy Signals: Triggered when price crosses above the lower boundary — potential bounce entry.
❌ Sell Signals: Triggered when price crosses below the upper boundary — potential reversal exit.
🔔 Alerts Enabled: Get real-time alerts when price touches the channel lines.
Regressions

TASC 2025.05 Trading The Channel█ OVERVIEW
This script implements channel-based trading strategies based on the concepts explained by Perry J. Kaufman in the article "A Test Of Three Approaches: Trading The Channel" from the May 2025 edition of TASC's Traders' Tips . The script explores three distinct trading methods for equities and futures using information from a linear regression channel. Each rule set corresponds to different market behaviors, offering flexibility for trend-following, breakout, and mean-reversion trading styles.
█ CONCEPTS
Linear regression
Linear regression is a model that estimates the relationship between a dependent variable and one or more independent variables by fitting a straight line to the observed data. In the context of financial time series, traders often use linear regression to estimate trends in price movements over time.
The slope of the linear regression line indicates the strength and direction of the price trend. For example, a larger positive slope indicates a stronger upward trend, and a larger negative slope indicates the opposite. Traders can look for shifts in the direction of a linear regression slope to identify potential trend trading signals, and they can analyze the magnitude of the slope to support trading decisions.
One caveat to linear regression is that most financial time series data does not follow a straight line, meaning a regression line cannot perfectly describe the relationships between values. Prices typically fluctuate around a regression line to some degree. As such, analysts often project ranges above and below regression lines, creating channels to model the expected extent of the data's variability. This strategy constructs a channel based on the method used in Kaufman's article. It measures the maximum distances from points on the linear regression line to historical price values, then adds those distances and the current slope to the regression points.
Depending on the trading style, traders might look for prices to move outside an established channel for breakout signals, or they might look for price action to reach extremes within the channel for potential mean reversion opportunities.
█ STRATEGY CALCULATIONS
Primary trade rules
This strategy implements three distinct sets of rules for trend, breakout, and mean-reversion trades based on the methods Kaufman describes in his article:
Trade the trend (Rule 1) : Open new positions when the sign of the slope changes, indicating a potential trend reversal. Close short trades and enter a long trade when the slope changes from negative to positive, and do the opposite when the slope changes from positive to negative.
Trade channel breakouts (Rule 2) : Open new positions when prices cross outside the linear regression channel for the current sample. Close short trades and enter a long trade when the price moves above the channel, and do the opposite when the price moves below the channel.
Trade within the channel (Rule 3) : Open new positions based on price values within the channel's range. Close short trades and enter a long trade when the price is near the channel's low, within a specified percentage of the channel's range, and do the opposite when the price is near the channel's high. With this rule, users can also filter the trades based on the channel's slope. When the filter is active, long positions are allowed only when the slope is positive, and short positions are allowed only when it is negative.
Position sizing
Kaufman's strategy uses specific trade sizes for equities and futures markets:
For an equities symbol, the number of shares traded is $10,000 divided by the current price.
For a futures symbol, the number of contracts traded is based on a volatility-adjusted formula that divides $25,000 by the product of the 20-bar average true range and the instrument's point value.
By default, this script automatically uses these sizes for its trade simulation on equities and futures symbols and does not simulate trading on other symbols. However, users can control position sizes from the "Settings/Properties" tab and enable trade simulation on other symbol types by selecting the "Manual" option in the script's "Position sizing" input.
Stop-loss
This strategy includes the option to place an accompanying stop-loss order for each trade, which users can enable from the "SL %" input in the "Settings/Inputs" tab. When enabled, the strategy places a stop-loss order at a specified percentage distance from the closing price where the entry order occurs, allowing users to compare how the strategy performs with added loss protection.
█ USAGE
This strategy adapts its display logic for the three trading approaches based on the rule selected in the "Trade rule" input:
For all rules, the script plots the linear regression slope in a separate pane. The plot is color-coded to indicate whether the current slope is positive or negative.
When the selected rule is "Trade the trend", the script plots triangles in the separate pane to indicate when the slope's direction changes from positive to negative or vice versa. Additionally, it plots a color-coded SMA on the main chart pane, allowing visual comparison of the slope to directional changes in a moving average.
When the rule is "Trade channel breakouts" or "Trade within the channel", the script draws the current period's linear regression channel on the main chart pane, and it plots bands representing the history of the channel values from the specified start time onward.
When the rule is "Trade within the channel", the script plots overbought and oversold zones between the bands based on a user-specified percentage of the channel range to indicate the value ranges where new trades are allowed.
Users can customize the strategy's calculations with the following additional inputs in the "Settings/Inputs" tab:
Start date : Sets the date and time when the strategy begins simulating trades. The script marks the specified point on the chart with a gray vertical line. The plots for rules 2 and 3 display the bands and trading zones from this point onward.
Period : Specifies the number of bars in the linear regression channel calculation. The default is 40.
Linreg source : Specifies the source series from which to calculate the linear regression values. The default is "close".
Range source : Specifies whether the script uses the distances from the linear regression line to closing prices or high and low prices to determine the channel's upper and lower ranges for rules 2 and 3. The default is "close".
Zone % : The percentage of the channel's overall range to use for trading zones with rule 3. The default is 20, meaning the width of the upper and lower zones is 20% of the range.
SL% : If the checkbox is selected, the strategy adds a stop-loss to each trade at the specified percentage distance away from the closing price where the entry order occurs. The checkbox is deselected by default, and the default percentage value is 5.
Position sizing : Determines whether the strategy uses Kaufman's predefined trade sizes ("Auto") or allows user-defined sizes from the "Settings/Properties" tab ("Manual"). The default is "Auto".
Long trades only : If selected, the strategy does not allow short positions. It is deselected by default.
Trend filter : If selected, the strategy filters positions for rule 3 based on the linear regression slope, allowing long positions only when the slope is positive and short positions only when the slope is negative. It is deselected by default.
NOTE: Because of this strategy's trading rules, the simulated results for a specific symbol or channel configuration might have significantly fewer than 100 trades. For meaningful results, we recommend adjusting the start date and other parameters to achieve a reasonable number of closed trades for analysis.
Additionally, this strategy does not specify commission and slippage amounts by default, because these values can vary across market types. Therefore, we recommend setting realistic values for these properties in the "Cost simulation" section of the "Settings/Properties" tab.

Pullback SARPullback SAR - Parabolic SAR with Pullback Detection
Description: The "Pullback SAR" is an advanced indicator built on the classic Parabolic SAR but with additional functionality for detecting pullbacks. It helps identify moments when the price pulls back from the main trend, offering potential entry signals. Perfect for traders looking to enter the market after a correction.
Key Features:
SAR (Parabolic SAR): The Parabolic SAR indicator is used to determine potential trend reversal points. It marks levels where the price could reverse its direction.
Pullback Detection: The indicator catches periods when the price moves away from the main trend and then returns, which may suggest a re-entry opportunity.
Long and Short Signals: Once a pullback in the direction of the main trend is identified, the indicator generates signals that could be used to open positions.
Simple and Clear Construction: The indicator is based on the classic SAR, with added pullback detection logic to enhance the accuracy of the signals.
Parameters:
Start (SAR Step): Determines the initial step for the SAR calculation, which controls the rate of change in the indicator at the beginning.
Increment (SAR Increment): Defines the maximum step size for SAR, allowing traders to adjust the indicator’s sensitivity to market volatility.
Max Value (SAR Max): Sets the upper limit for the SAR value, controlling its volatility.
Usage:
Swing Trading: Ideal for swing strategies, aiming to capture larger price moves while maintaining a safe margin.
Scalping: Due to its precise pullback detection, it can also be used in scalping, especially when the price quickly returns to the main trend.
Risk Management: The combination of SAR and pullback detection allows traders to adjust their positions according to changing market conditions.
Special Notes:
Adjusting Parameters: Depending on the market and trading style, users can adjust the SAR parameters (Start, Increment, Max Value) to fit their needs.
Combination with Other Indicators: It's recommended to use the indicator alongside other technical analysis tools (e.g., EMA, RSI) to enhance the accuracy of the signals.
Link to the script: This open-source version of the indicator is available on TradingView, enabling full customization and adjustments to meet your personal trading strategy. Share your experiences and suggestions!

ML Deep Regression Pro (TechnoBlooms)ML Deep Regression Pro is a machine-learning-inspired trading indicator that integrates Polynomial Regression, Linear Regression and Statistical Deviation models to provide a powerful, data-driven approach to market trend analysis.
Designed for traders, quantitative analysts and developers, this tool transforms raw market data into predictive trend insights, allowing for better decision-making and trend validation.
By leveraging statistical regression techniques, ML Deep Regression Pro eliminates market noise and identifies key trend shifts, making it a valuable addition to both manual and algorithmic trading strategies.
REGRESSION ANALYSIS
Regression is a statistical modeling technique used in machine learning and data science to identify patterns and relationships between variables. In trading, it helps detect price trends, reversals and volatility changes by fitting price data into a predictive model.
1. Linear Regression -
The most widely used regression model in trading, providing a best-fit plotted line to track price trends.
2. Polynomial Regression -
A more advanced form of regression that fits curved price structures, capturing complex market cycles and improving trend forecasting accuracy.
3. Standard Deviation Bands -
Based on regression calculations, these bands measure price dispersion and identify overbought/ oversold conditions, similar to Bollinger Bands. By default, these lines are hidden and user can make it visible through Settings.
KEY FEATURES :-
✅ Hybrid Regression Engine – Combines Linear and Polynomial Regression to detect market trends with greater accuracy.
✅ Dynamic Trend Bias Analysis – Identifies bullish & bearish market conditions using real-time regression models.
✅ Standard Deviation Bands – Measures price volatility and potential reversals with an advanced deviation model.
✅ Adaptive EMA Crossover Signals – Generates buy/sell signals when price momentum shifts relative to the regression trend.

Adaptive Trend FinderAdaptive Trend Finder - The Ultimate Trend Detection Tool
Introducing Adaptive Trend Finder, the next evolution of trend analysis on TradingView. This powerful indicator is an enhanced and refined version of Adaptive Trend Finder (Log), designed to offer even greater flexibility, accuracy, and ease of use.
What’s New?
Unlike the previous version, Adaptive Trend Finder allows users to fully configure and adjust settings directly within the indicator menu, eliminating the need to modify chart settings manually. A major improvement is that users no longer need to adjust the chart's logarithmic scale manually in the chart settings; this can now be done directly within the indicator options, ensuring a smoother and more efficient experience. This makes it easier to switch between linear and logarithmic scaling without disrupting the analysis. This provides a seamless user experience where traders can instantly adapt the indicator to their needs without extra steps.
One of the most significant improvements is the complete code overhaul, which now enables simultaneous visualization of both long-term and short-term trend channels without needing to add the indicator twice. This not only improves workflow efficiency but also enhances chart readability by allowing traders to monitor multiple trend perspectives at once.
The interface has been entirely redesigned for a more intuitive user experience. Menus are now clearer, better structured, and offer more customization options, making it easier than ever to fine-tune the indicator to fit any trading strategy.
Key Features & Benefits
Automatic Trend Period Selection: The indicator dynamically identifies and applies the strongest trend period, ensuring optimal trend detection with no manual adjustments required. By analyzing historical price correlations, it selects the most statistically relevant trend duration automatically.
Dual Channel Display: Traders can view both long-term and short-term trend channels simultaneously, offering a broader perspective of market movements. This feature eliminates the need to apply the indicator twice, reducing screen clutter and improving efficiency.
Fully Adjustable Settings: Users can customize trend detection parameters directly within the indicator settings. No more switching chart settings – everything is accessible in one place.
Trend Strength & Confidence Metrics: The indicator calculates and displays a confidence score for each detected trend using Pearson correlation values. This helps traders gauge the reliability of a given trend before making decisions.
Midline & Channel Transparency Options: Users can fine-tune the visibility of trend channels, adjusting transparency levels to fit their personal charting style without overwhelming the price chart.
Annualized Return Calculation: For daily and weekly timeframes, the indicator provides an estimate of the trend’s performance over a year, helping traders evaluate potential long-term profitability.
Logarithmic Adjustment Support: Adaptive Trend Finder is compatible with both logarithmic and linear charts. Traders who analyze assets like cryptocurrencies, where log scaling is common, can enable this feature to refine trend calculations.
Intuitive & User-Friendly Interface: The updated menu structure is designed for ease of use, allowing quick and efficient modifications to settings, reducing the learning curve for new users.
Why is this the Best Trend Indicator?
Adaptive Trend Finder stands out as one of the most advanced trend analysis tools available on TradingView. Unlike conventional trend indicators, which rely on fixed parameters or lagging signals, Adaptive Trend Finder dynamically adjusts its settings based on real-time market conditions. By combining automatic trend detection, dual-channel visualization, real-time performance metrics, and an intuitive user interface, this indicator offers an unparalleled edge in trend identification and trading decision-making.
Traders no longer have to rely on guesswork or manually tweak settings to identify trends. Adaptive Trend Finder does the heavy lifting, ensuring that users are always working with the strongest and most reliable trends. The ability to simultaneously display both short-term and long-term trends allows for a more comprehensive market overview, making it ideal for scalpers, swing traders, and long-term investors alike.
With its state-of-the-art algorithms, fully customizable interface, and professional-grade accuracy, Adaptive Trend Finder is undoubtedly one of the most powerful trend indicators available.
Try it today and experience the future of trend analysis.
This indicator is a technical analysis tool designed to assist traders in identifying trends. It does not guarantee future performance or profitability. Users should conduct their own research and apply proper risk management before making trading decisions.
// Created by Julien Eche - @Julien_Eche

CAPM Alpha & BetaThe CAPM Alpha & Beta indicator is a crucial tool in finance and investment analysis derived from the Capital Asset Pricing Model (CAPM) . It provides insights into an asset's risk-adjusted performance (Alpha) and its relationship to broader market movements (Beta). Here’s a breakdown:
1. How Does It Work?
Alpha:
Definition: Alpha measures the portion of an investment's return that is not explained by market movements, i.e., the excess return over and above what the market is expected to deliver.
Purpose: It represents the value a fund manager or strategy adds (or subtracts) from an investment’s performance, adjusting for market risk.
Calculation:
Alpha is derived from comparing actual returns to expected returns predicted by CAPM:
Alpha = Actual Return − (Risk-Free Rate + β × (Market Return − Risk-Free Rate))
Alpha = Actual Return − (Risk-Free Rate + β × (Market Return − Risk-Free Rate))
Interpretation:
Positive Alpha: The investment outperformed its CAPM prediction (good performance for additional value/risk).
Negative Alpha: The investment underperformed its CAPM prediction.
Beta:
Definition: Beta measures the sensitivity of an asset's returns relative to the overall market's returns. It quantifies systematic risk.
Purpose: Indicates how volatile or correlated an investment is relative to the market benchmark (e.g., S&P 500).
Calculation:
Beta is computed as the ratio of the covariance of the asset and market returns to the variance of the market returns:
β = Covariance (Asset Return, Market Return) / Variance (Market Return)
β = Variance (Market Return) Covariance (Asset Return, Market Return)
Interpretation:
Beta = 1: The asset’s price moves in line with the market.
Beta > 1: The asset is more volatile than the market (higher risk/higher potential reward).
Beta < 1: The asset is less volatile than the market (lower risk/lower reward).
Beta < 0: The asset moves inversely to the market.
2. How to Use It?
Using Alpha:
Portfolio Evaluation: Investors use Alpha to gauge whether a portfolio manager or a strategy has successfully outperformed the market on a risk-adjusted basis.
If Alpha is consistently positive, the portfolio may deliver higher-than-expected returns for the given level of risk.
Stock/Asset Selection: Compare Alpha across multiple securities. Positive Alpha signals that the asset may be a good addition to your portfolio for excess returns.
Adjusting Investment Strategy: If Alpha is negative, reassess the asset's role in the portfolio and refine strategies.
Using Beta:
Risk Management:
A high Beta (e.g., 1.5) indicates higher sensitivity to market movements. Use such assets if you want to take on more risk during bullish market phases or expect higher returns.
A low Beta (e.g., 0.7) indicates stability and is useful in diversifying risk in volatile or bearish markets.
Portfolio Diversification: Combine assets with varying Betas to achieve the desired level of market responsiveness and smooth out portfolio volatility.
Monitoring Systematic Risk: Beta helps identify whether an investment aligns with your risk tolerance. For example, high-Beta stocks may not be suitable for conservative investors.
Practical Application:
Use both Alpha and Beta together:
Assess performance with Alpha (excess returns).
Assess risk exposure with Beta (market sensitivity).
Example: A stock with a Beta of 1.2 and a highly positive Alpha might suggest a solid performer that is slightly more volatile than the market, making it a suitable pick for risk-tolerant, return-maximizing investors.
In conclusion, the CAPM Alpha & Beta indicator gives a comprehensive view of an asset's performance and risk. Alpha enables performance evaluation on a risk-adjusted basis, while Beta reveals the level of market risk. Together, they help investors make informed decisions, build optimal portfolios, and align investments with their risk-return preferences.

Simple APF Strategy Backtesting [The Quant Science]Simple backtesting strategy for the quantitative indicator Autocorrelation Price Forecasting. This is a Buy & Sell strategy that operates exclusively with long orders. It opens long positions and generates profit based on the future price forecast provided by the indicator. It's particularly suitable for trend-following trading strategies or directional markets with an established trend.
Main functions
1. Cycle Detection: Utilize autocorrelation to identify repetitive market behaviors and cycles.
2. Forecasting for Backtesting: Simulate trades and assess the profitability of various strategies based on future price predictions.
Logic
The strategy works as follow:
Entry Condition: Go long if the hypothetical gain exceeds the threshold gain (configurable by user interface).
Position Management: Sets a take-profit level based on the future price.
Position Sizing: Automatically calculates the order size as a percentage of the equity.
No Stop-Loss: this strategy doesn't includes any stop loss.
Example Use Case
A trader analyzes a dayli period using 7 historical bars for autocorrelation.
Sets a threshold gain of 20 points using a 5% of the equity for each trade.
Evaluates the effectiveness of a long-only strategy in this period to assess its profitability and risk-adjusted performance.
User Interface
Length: Set the length of the data used in the autocorrelation price forecasting model.
Thresold Gain: Minimum value to be considered for opening trades based on future price forecast.
Order Size: percentage size of the equity used for each single trade.
Strategy Limit
This strategy does not use a stop loss. If the price continues to drop and the future price forecast is incorrect, the trader may incur a loss or have their capital locked in the losing trade.
Disclaimer!
This is a simple template. Use the code as a starting point rather than a finished solution. The script does not include important parameters, so use it solely for educational purposes or as a boilerplate.

Ethereum Logarithmic Regression Bands (Fine-Tuned)This indicator, "Ethereum Logarithmic Regression Bands (Fine-Tuned)," is my attempt to create a tool for estimating long-term trends in Ethereum (ETH/USD) price action using logarithmic regression bands. Please note that I am not an expert in financial modeling or coding—I developed this as a personal project to serve as a rough estimation rather than a precise or professional trading tool. The data was fitted to non-bubble periods of Ethereum's history to provide a general trendline, but it’s far from perfect.
I’m sharing this because I couldn’t find a similar indicator available, and I thought it might be useful for others who are also exploring ETH’s long-term behavior. The bands start from Ethereum’s launch price and are adjustable via input parameters, but they are based on my best effort to align with historical data. With some decent coding experience, I’m sure someone could refine this further—perhaps by optimizing the coefficients or incorporating more advanced fitting techniques. Feel free to tweak the code, suggest improvements, or use it as a starting point for your own projects!
How to Use:
** THIS CHART IS SPECIFICALLY CODED FOR ETH/USD (KRAKEN) ON THE WEEKLY TIMEFRAME IN LOG VIEW**
The main band (blue) represents the logarithmic regression line.
The upper (red) and lower (green) bands provide a range around the main trend, adjustable with multipliers.
Adjust the "Launch Price," "Base Coefficient," "Growth Coefficient," and other inputs to experiment with different fits.
Disclaimer:
This is not financial advice. Use at your own risk, and always conduct your own research before making trading decisions.

ICT Session by LasinsName: ICT Session by Lasins
Purpose: To visually identify and differentiate between the Asian, London, and New York trading sessions on the chart.
Features:
Highlights the background of the chart during each session.
Includes a mini dashboard in the top-right corner to show the active session.
Allows customization of time zones (exchange timezone or UTC).
Displays copyright and author information.
Key Components
Inputs:
useExchangeTimezone: A boolean input to toggle between using the exchange timezone or UTC for session times.
showDashboard: A boolean input to toggle the visibility of the mini dashboard.
Session Times:
The script defines three trading sessions:
Asian Session: 2000-0000 UTC (or adjusted for exchange timezone).
London Session: 0200-0500 UTC (or adjusted for exchange timezone).
New York Session: 0700-1000 UTC (or adjusted for exchange timezone).
Session Detection:
The is_session function checks if the current time falls within a specified session using the time function.
Background Coloring:
The bgcolor function is used to highlight the chart background during each session:
Asian Session: Red background.
London Session: Green background.
New York Session: Blue background.
Mini Dashboard:
A table is created in the top-right corner of the chart to display the active session and its corresponding color.
The dashboard includes:
A header row with "Session" and "Color".
Rows for each session (Asian, London, New York) with their respective colors.
Copyright and Author Information:
A label is added to the chart to display the copyright and author information ("© ICT Session by Lasins Raj").
How It Works
The script checks the current time and compares it to the predefined session times.
If the current time falls within a session, the chart background is highlighted with the corresponding color.
The mini dashboard updates to reflect the active session.
The copyright and author information is displayed at the bottom of the chart.
Customization
You can adjust the session times in the script to match your preferred timezone or trading hours.
The useExchangeTimezone input allows you to switch between UTC and the exchange timezone.
The showDashboard input lets you toggle the visibility of the mini dashboard.
Example Use Case
Traders who follow the ICT (Inner Circle Trader) methodology can use this indicator to identify key trading sessions and plan their trades accordingly.
The visual representation of sessions helps traders quickly recognize when major markets are open and active.

TASC 2025.03 A New Solution, Removing Moving Average Lag█ OVERVIEW
This script implements a novel technique for removing lag from a moving average, as introduced by John Ehlers in the "A New Solution, Removing Moving Average Lag" article featured in the March 2025 edition of TASC's Traders' Tips .
█ CONCEPTS
In his article, Ehlers explains that the average price in a time series represents a statistical estimate for a block of price values, where the estimate is positioned at the block's center on the time axis. In the case of a simple moving average (SMA), the calculation moves the analyzed block along the time axis and computes an average after each new sample. Because the average's position is at the center of each block, the SMA inherently lags behind price changes by half the data length.
As a solution to removing moving average lag, Ehlers proposes a new projected moving average (PMA) . The PMA smooths price data while maintaining responsiveness by calculating a projection of the average using the data's linear regression slope.
The slope of linear regression on a block of financial time series data can be expressed as the covariance between prices and sample points divided by the variance of the sample points. Ehlers derives the PMA by adding this slope across half the data length to the SMA, creating a first-order prediction that substantially reduces lag:
PMA = SMA + Slope * Length / 2
In addition, the article includes methods for calculating predictions of the PMA and the slope based on second-order and fourth-order differences. The formulas for these predictions are as follows:
PredictPMA = PMA + 0.5 * (Slope - Slope ) * Length
PredictSlope = 1.5 * Slope - 0.5 * Slope
Ehlers suggests that crossings between the predictions and the original values can help traders identify timely buy and sell signals.
█ USAGE
This indicator displays the SMA, PMA, and PMA prediction for a specified series in the main chart pane, and it shows the linear regression slope and prediction in a separate pane. Analyzing the difference between the PMA and SMA can help to identify trends. The differences between PMA or slope and its corresponding prediction can indicate turning points and potential trade opportunities.
The SMA plot uses the chart's foreground color, and the PMA and slope plots are blue by default. The plots of the predictions have a green or red hue to signify direction. Additionally, the indicator fills the space between the SMA and PMA with a green or red color gradient based on their differences:
Users can customize the source series, data length, and plot colors via the inputs in the "Settings/Inputs" tab.
█ NOTES FOR Pine Script® CODERS
The article's code implementation uses a loop to calculate all necessary sums for the slope and SMA calculations. Ported into Pine, the implementation is as follows:
pma(float src, int length) =>
float PMA = 0., float SMA = 0., float Slope = 0.
float Sx = 0.0 , float Sy = 0.0
float Sxx = 0.0 , float Syy = 0.0 , float Sxy = 0.0
for count = 1 to length
float src1 = src
Sx += count
Sy += src
Sxx += count * count
Syy += src1 * src1
Sxy += count * src1
Slope := -(length * Sxy - Sx * Sy) / (length * Sxx - Sx * Sx)
SMA := Sy / length
PMA := SMA + Slope * length / 2
However, loops in Pine can be computationally expensive, and the above loop's runtime scales directly with the specified length. Fortunately, Pine's built-in functions often eliminate the need for loops. This indicator implements the following function, which simplifies the process by using the ta.linreg() and ta.sma() functions to calculate equivalent slope and SMA values efficiently:
pma(float src, int length) =>
float Slope = ta.linreg(src, length, 0) - ta.linreg(src, length, 1)
float SMA = ta.sma(src, length)
float PMA = SMA + Slope * length * 0.5
To learn more about loop elimination in Pine, refer to this section of the User Manual's Profiling and optimization page.
UM-Optimized Linear Regression ChannelDESCRIPTION
This indicator was inspired by Dr. Stoxx at drstoxx.com. Shout out to him and his services for introducing me to this idea. This indicator is a slightly different take on the standard linear regression indicator.
It uses two standard deviations to draw bands and dynamically attempts to best-fit the data lookback period using an R-squared statistical measure. The R-squared value ranges between zero and one with zero being no fit to the data at all and 1 being a 100% match of the data to linear regression line. The R-squared calculation is weighted exponentially to give more weight to the most recent data.
The label provides the number of periods identified as the optimal best-fit period, the type of loopback period determination (Manual or Auto) and the R-squared value (0-100, 100% being a perfect fit). >=90% is a great fit of the data to the regression line. <50% is a difficult fit and more or less considered random data.
The lookback mode can also be set manually and defaults to a value of 100 periods.
DEFAULTS
The defaults are 1.5 and 2.0 for standard deviation. This creates 2 bands above and below the regression line. The default mode for best-fit determination with "Auto" selected in the dropdown. When manual mode is selected, the default is 100. The modes, manual lookback periods, colors, and standard deviations are user-configurable.
HOW TO USE
Overlay this indicator on any chart of any timeframe. Look for turning points at extremes in the upper and lower bands. Look for crossovers of the centerline. Look at the Auto-determination for best fit. Compare this to your favorite Manual mode setting (Manual Mode is set to 100 by default lookback periods.)
When price is at an extreme, look for turnarounds or reversals. Use your favorite indicators, in addition to this indicator, to determine reversals. Try this indicator against your favorite securities and timeframes.
CHART EXAMPLE
The chart I used for an example is the daily chart of IWM. I illustrated the extremes with white text. This is where I consider proactively exiting an existing position and/or begin looking for a reversal.

CandelaCharts - Fib Retracement (OTE) 📝 Overview
The CandelaCharts Fib Retracement (OTE) indicator is a precision tool designed to help traders identify Optimal Trade Entry (OTE) levels based on Fibonacci retracement principles, as taught in ICT (Inner Circle Trader) methodology.
This indicator automatically plots Fibonacci retracement levels between a selected swing high and swing low, highlighting the key OTE zone between the 61.8% and 78.6% retracement levels—a prime area for potential reversals in trending markets.
📦 Features
Automatic & Custom lookback modes
Customizable fib levels
Dynamic coloring
Reverse & extend
⚙️ Settings
Lookback: Controls the number of bars to look back. You can choose between **Automatic** or **Custom** mode.
Line Style: Sets the line style for the Fibonacci levels.
Levels: 0, 0.236, 0.0.382, 0.500, 0.620, 0.705, 0.790, 0.886, 1.000. Allows you to toggle the visibility of Fibonacci levels.
Dynamic Coloring: Colors Fibonacci levels according to trend direction.
Show Labels: Shows the price value at each Fibonacci level.
Reverse: Flips the Fibonacci levels in the opposite direction.
Extend Left: Extends the Fibonacci levels to the left.
⚡️ Showcase
Dynamic Coloring
Manual Coloring
Fib Retracement
Extended
Custom Length
📒 Usage
Using the CandelaCharts Fib Retracement (OTE) is pretty straightforward—just follow these steps to spot high-probability trade setups and refine your entries.
Identify the Trend – Determine whether the market is in an uptrend or downtrend.
Select Swing Points – The indicator automatically plots from the most recent swing high to swing low (or vice versa).
Wait for Price to Enter OTE Zone – Look for price action confirmation within the optimal entry zone (61.8%-78.6%).
Enter the Trade – Consider longs in an uptrend at the OTE zone, and shorts in a downtrend.
Set Stop & Target – Place stops below/above the swing low/high and target extension levels (127.2%, 161.8%).
🎯 Key takeways
The CandelaCharts Fib Retracement (OTE) is a must-have tool for traders looking to refine their entries and maximize risk-reward potential with precision-based ICT trading strategies. 🚀
🚨 Alerts
The indicator does not provide any alerts!
⚠️ Disclaimer
Trading involves significant risk, and many participants may incur losses. The content on this site is not intended as financial advice and should not be interpreted as such. Decisions to buy, sell, hold, or trade securities, commodities, or other financial instruments carry inherent risks and are best made with guidance from qualified financial professionals. Past performance is not indicative of future results.

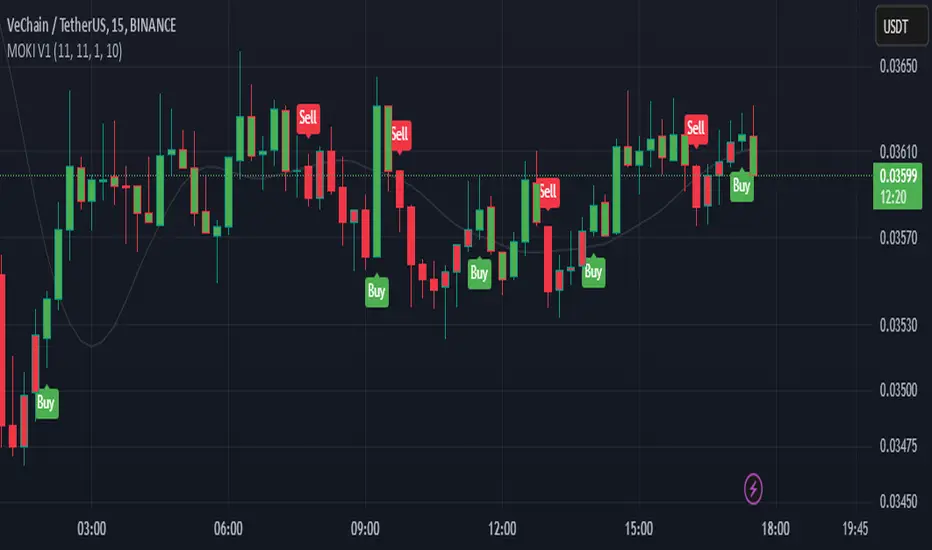
MOKI V1The "MOKI V1" script is a trading strategy on the TradingView platform that uses a combination of two key indicators to identify buy and sell signals:
EMA200 (Exponential Moving Average 200): Used to determine the overall market trend. This line helps ensure that trades are made in the direction of the primary market trend.
RSI (Relative Strength Index): Used to measure the strength or weakness of a trend. In this strategy, a reading above 50 for the RSI indicates stronger buy signals.
Engulfing Pattern: This candlestick pattern occurs when a green (bullish) candle completely engulfs the previous red (bearish) candle. It is used as a buy signal when combined with the other indicators.
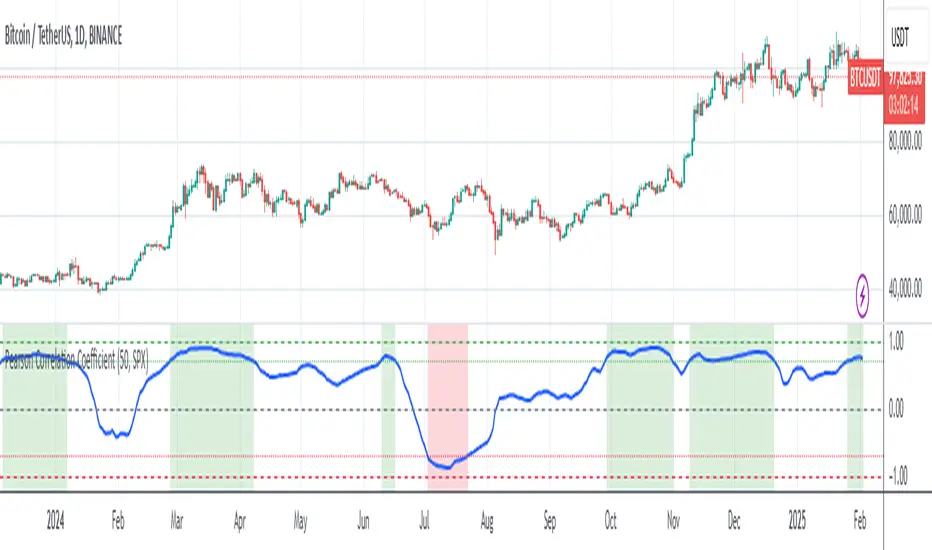
Pearson Correlation CoefficientDescription: The Pearson Correlation Coefficient measures the strength and direction of the linear relationship between two data series. Its value ranges from -1 to +1, where:
+1 indicates a perfect positive linear correlation: as one asset increases, the other asset increases proportionally.
0 indicates no linear correlation: variations in one asset have no relation to variations in the other asset.
-1 indicates a perfect negative linear correlation: as one asset increases, the other asset decreases proportionally.
This measure is widely used in technical analysis to assess the degree of correlation between two financial assets. The "Pearson Correlation (Manual Compare)" indicator allows users to manually select two assets and visually display their correlation relationship on a chart.
Features:
Correlation Period: The time period used for calculating the correlation can be adjusted (default: 50).
Comparison Asset: Users can select a secondary asset for comparison.
Visual Plots: The chart includes reference lines for perfect correlations (+1 and -1) and strong correlations (+0.7 and -0.7).
Alerts: Set alerts for when the correlation exceeds certain threshold values (e.g., +0.7 for strong positive correlation).
How to Select the Second Asset:
Primary Asset Selection: The primary asset is the one you select for viewing on the chart. This can be done by simply opening the chart for the desired asset.
Secondary Asset Selection: To select the secondary asset for comparison, use the input field labeled "Comparison Asset" in the script settings. You can manually enter the ticker symbol of the secondary asset you want to compare with the primary asset.
This indicator is ideal for traders looking to identify relationships and correlations between different financial assets to make informed trading decisions.
Statistical Arbitrage Pairs Trading - Long-Side OnlyThis strategy implements a simplified statistical arbitrage (" stat arb ") approach focused on mean reversion between two correlated instruments. It identifies opportunities where the spread between their normalized price series (Z-scores) deviates significantly from historical norms, then executes long-only trades anticipating reversion to the mean.
Key Mechanics:
1. Spread Calculation: The strategy computes Z-scores for both instruments to normalize price movements, then tracks the spread between these Z-scores.
2. Modified Z-Score: Uses a robust measure combining the median and Median Absolute Deviation (MAD) to reduce outlier sensitivity.
3. Entry Signal: A long position is triggered when the spread’s modified Z-score falls below a user-defined threshold (e.g., -1.0), indicating extreme undervaluation of the main instrument relative to its pair.
4. Exit Signal: The position closes automatically when the spread reverts to its historical mean (Z-score ≥ 0).
Risk management:
Trades are sized as a percentage of equity (default: 10%).
Includes commissions and slippage for realistic backtesting.
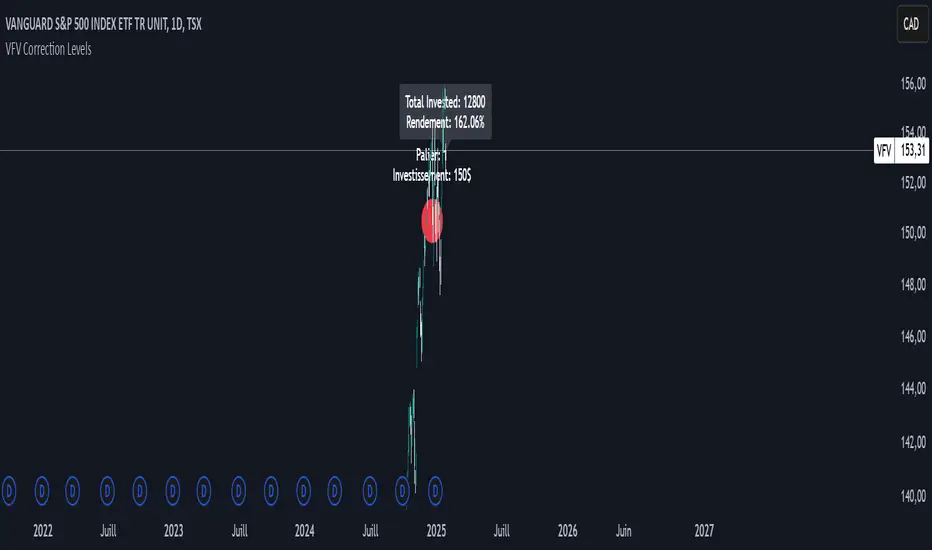
VFV Correction Levels
This Pine Script, "VFV Correction Levels," identifies significant daily price corrections and calculates corresponding investments based on fixed thresholds (paliers). Key features include:
Six predefined correction levels trigger investments between $150 and $600 based on the percentage drop.
Larger corrections correspond to higher investment amounts.
Graphical Indicators:
Visual labels mark correction levels and display investment amounts directly on the chart.
Investment Tracking:
Calculates total invested and tracks performance (yield percentage) relative to the initial correction price.
Smoothed Gaussian Trend Filter [AlgoAlpha]Experience seamless trend detection and market analysis with the Smoothed Gaussian Trend Filter by AlgoAlpha! This cutting-edge indicator combines advanced Gaussian filtering with linear regression smoothing to identify and enhance market trends, making it an essential tool for traders seeking precise and actionable signals.
Key Features :
🔍 Gaussian Trend Filtering: Utilizes a customizable Gaussian filter with adjustable length and pole settings for tailored smoothing and trend identification.
📊 Linear Regression Smoothing: Reduces noise and further refines the Gaussian output with user-defined smoothing length and offset, ensuring clarity in trend representation.
✨ Dynamic Visual Highlights: Highlights trends and signals based on volume intensity, allowing for real-time insights into market behavior.
📉 Choppy Market Detection: Identifies ranging or choppy markets, helping traders avoid false signals.
🔔 Custom Alerts: Set alerts for bullish and bearish signals, trend reversals, or choppy market conditions to stay on top of trading opportunities.
🎨 Color-Coded Visuals: Fully customizable colors for bullish and bearish signals, ensuring clear and intuitive chart analysis.
How to Use :
Add the Indicator: Add it to your favorites and apply it to your TradingView chart.
Interpret the Chart: Observe the trend line for directional changes and use the accompanying buy/sell signals for entry and exit opportunities. Choppy market conditions are flagged for additional caution.
Set Alerts: Enable alerts for trend signals or choppy market detections to act promptly without constant chart monitoring.
How It Works :
The Smoothed Gaussian Trend Filter uses a combination of advanced smoothing techniques to identify trends and enhance market clarity. First, a Gaussian filter is applied to price data, using a user-defined length (Gaussian length) and poles (smoothness level) to calculate an alpha value that determines the degree of smoothing. This creates a refined trend line that minimizes noise while preserving key market movements. The output is then further processed using linear regression smoothing, allowing traders to adjust the length and offset to flatten minor oscillations and emphasize the dominant trend. To incorporate market activity, volume intensity is analyzed through a normalized Hull Moving Average (HMA), dynamically adjusting the trend line's color transparency based on trading activity. The indicator also identifies trend direction by comparing the smoothed trend line with a calculated SuperTrend-style level, generating clear trend regimes and highlighting ranging or choppy conditions where trends are less reliable and avoiding false signals. This seamless integration of Gaussian smoothing, regression analysis, and volume dynamics provides traders with a powerful and intuitive tool for market analysis.

Price Projection by Linear RegressionPurpose:
This is a TradingView Pine Script indicator that performs a linear regression on historical price data to project potential future price levels. It's designed to help traders visualize long-term price trends and potential future price targets.
Key Components:
User Inputs:
Historical Data Points (default 1000 bars) - The amount of historical data used to calculate the trend
Years to Project (default 10 years) - How far into the future to project the price
Technical Implementation:
Uses linear regression (ta.linreg) to calculate the trend slope
Converts years to trading days using 252 trading days per year
Limits visible projection to 500 bars due to TradingView's drawing limitations
Projects prices using the formula: current_price + (slope × number_of_bars)
Visual Elements:
Blue line showing actual historical prices
Red projection line showing the expected price path
Label showing the projected price at the visible end of the line
Information table in the top-right corner showing:
Current price
Final projected price after the full time period
Limitations:
Can only display projections up to 500 bars into the future (about 2 years) due to TradingView limitations
The full projection value is still calculated and shown in the table
Past performance doesn't guarantee future results - this is a mathematical projection based on historical trends
Usage:
Traders can use this to:
Visualize potential long-term price trends
Set long-term price targets
Understand the historical trend's trajectory
Compare current prices with projected future values

Previous Candle Sweep IndicatorThis script identifies candlesticks where the current candle's high is higher than the previous candle's high, and the current candle's low is lower than the previous candle's low. If both conditions are met, the candle's body is highlighted in blue on the chart, allowing traders to quickly spot these patterns.
Features:
Highlights candles with both higher highs and lower lows.
Uses clear visual cues (blue body) for easy identification.
Ideal for traders looking to identify specific volatility patterns or reversals.

Adjust Asset for Future Interest (Brazil)Este script foi criado para ajustar o preço de um ativo com base na taxa de juros DI11!, que reflete a expectativa do mercado para os juros futuros. O objetivo é mostrar como o valor do ativo seria influenciado se fosse diretamente ajustado pela variação dessa taxa de juros.
Como funciona?
Preço do Ativo
O script começa capturando o preço de fechamento do ativo que está sendo visualizado no gráfico. Esse é o ponto de partida para o cálculo.
Taxa de Juros DI11!
Em seguida, ele busca os valores diários da taxa DI11! no mercado. Esta taxa é uma referência de juros de curto prazo, usada para ajustes financeiros e projeções econômicas.
Fator de Ajuste
Com a taxa de juros DI11!, o script calcula um fator de ajuste simples:
Fator de Ajuste
=
1
+
DI11
100
Fator de Ajuste=1+
100
DI11
Esse fator traduz a taxa percentual em um multiplicador aplicado ao preço do ativo.
Cálculo do Ativo Ajustado
Multiplica o preço do ativo pelo fator de ajuste para obter o valor ajustado do ativo. Este cálculo mostra como o preço seria se fosse diretamente influenciado pela variação da taxa DI11!.
Exibição no Gráfico
O script plota o preço ajustado do ativo como uma linha azul no gráfico, com maior espessura para facilitar a visualização. O resultado é uma curva que reflete o impacto teórico da taxa de juros DI11! sobre o ativo.
Utilidade
Este indicador é útil para entender como as taxas de juros podem influenciar ativos financeiros de forma hipotética. Ele é especialmente interessante para analistas que desejam avaliar a relação entre o mercado de renda variável e as condições de juros no curto prazo.
This script was created to adjust the price of an asset based on the DI11! interest rate, which reflects the market's expectation for future interest rates. The goal is to show how the asset's value would be influenced if it were directly adjusted by the variation of this interest rate.
How does it work?
Asset Price
The script starts by capturing the closing price of the asset that is being viewed on the chart. This is the starting point for the calculation.
DI11! Interest Rate
The script then searches for the daily values of the DI11! rate in the market. This rate is a short-term interest reference, used for financial adjustments and economic projections.
Adjustment Factor
With the DI11! interest rate, the script calculates a simple adjustment factor:
Adjustment Factor
=
1
+
DI11
100
Adjustment Factor=1+
100
DI11
This factor translates the percentage rate into a multiplier applied to the asset's price.
Adjusted Asset Calculation
Multiplies the asset price by the adjustment factor to obtain the adjusted asset value. This calculation shows how the price would be if it were directly influenced by the variation of the DI11! rate.
Display on the Chart
The script plots the adjusted asset price as a blue line on the chart, with greater thickness for easier visualization. The result is a curve that reflects the theoretical impact of the DI11! interest rate on the asset.
Usefulness
This indicator is useful for understanding how interest rates can hypothetically influence financial assets. It is especially interesting for analysts who want to assess the relationship between the equity market and short-term interest rate conditions.

Moving Average Cross; Linear RegressionThis Pine Script is designed to display smoothed linear regression lines on a chart, with an option to adjust the regression period lengths and smoothing factor. The script calculates short-term and long-term linear regression lines based on the selected timeframe. These regression lines act as a regressed moving average cross , visually representing the interaction between the two smoothed linear regressions.
Short Regression Line: A linear regression line based on a short lookback period, colored blue for an uptrend and orange for a downtrend .
Long Regression Line: A linear regression line based on a longer lookback period, similarly colored blue for an uptrend and orange for a downtrend .
The script provides input options to adjust:
The length of short and long regression periods.
The smoothing length for the regression lines.
The timeframe for the linear regression calculations.
This tool can help traders observe the crossovers between the two smoothed linear regression lines, which are similar to moving average crossovers, but with the added benefit of regression-based smoothing to reduce noise. The color-coding allows for easy trend identification, with blue indicating an uptrend and orange indicating a downtrend.

Log Regression OscillatorThe Log Regression Oscillator transforms the logarithmic regression curves into an easy-to-interpret oscillator that displays potential cycle tops/bottoms.
🔶 USAGE
Calculating the logarithmic regression of long-term swings can help show future tops/bottoms. The relationship between previous swing points is calculated and projected further. The calculated levels are directly associated with swing points, which means every swing point will change the calculation. Importantly, all levels will be updated through all bars when a new swing is detected.
The "Log Regression Oscillator" transforms the calculated levels, where the top level is regarded as 100 and the bottom level as 0. The price values are displayed in between and calculated as a ratio between the top and bottom, resulting in a clear view of where the price is situated.
The main picture contains the Logarithmic Regression Alternative on the chart to compare with this published script.
Included are the levels 30 and 70. In the example of Bitcoin, previous cycles showed a similar pattern: the bullish parabolic was halfway when the oscillator passed the 30-level, and the top was very near when passing the 70-level.
🔹 Proactive
A "Proactive" option is included, which ensures immediate calculations of tentative unconfirmed swings.
Instead of waiting 300 bars for confirmation, the "Proactive" mode will display a gray-white dot (not confirmed swing) and add the unconfirmed Swing value to the calculation.
The above example shows that the "Calculated Values" of the potential future top and bottom are adjusted, including the provisional swing.
When the swing is confirmed, the calculations are again adjusted, showing a red dot (confirmed top swing) or a green dot (confirmed bottom swing).
🔹 Dashboard
When less than two swings are available (top/bottom), this will be shown in the dashboard.
The user can lower the "Threshold" value or switch to a lower timeframe.
🔹 Notes
Logarithmic regression is typically used to model situations where growth or decay accelerates rapidly at first and then slows over time, meaning some symbols/tickers will fit better than others.
Since the logarithmic regression depends on swing values, each new value will change the calculation. A well-fitted model could not fit anymore in the future.
Users have to check the validity of swings; for example, if the direction of swings is downwards, then the dataset is not fitted for logarithmic regression.
In the example above, the "Threshold" is lowered. However, the calculated levels are unreliable due to the swings, which do not fit the model well.
Here, the combination of downward bottom swings and price accelerates slower at first and faster recently, resulting in a non-fit for the logarithmic regression model.
Note the price value (white line) is bound to a limit of 150 (upwards) and -150 (down)
In short, logarithmic regression is best used when there are enough tops/bottoms, and all tops are around 100, and all bottoms around 0.
Also, note that this indicator has been developed for a daily (or higher) timeframe chart.
🔶 DETAILS
In mathematics, the dot product or scalar product is an algebraic operation that takes two equal-length sequences of numbers (arrays) and returns a single number, the sum of the products of the corresponding entries of the two sequences of numbers.
The usual way is to loop through both arrays and sum the products.
In this case, the two arrays are transformed into a matrix, wherein in one matrix, a single column is filled with the first array values, and in the second matrix, a single row is filled with the second array values.
After this, the function matrix.mult() returns a new matrix resulting from the product between the matrices m1 and m2.
Then, the matrix.eigenvalues() function transforms this matrix into an array, where the array.sum() function finally returns the sum of the array's elements, which is the dot product.
dot(x, y)=>
if x.size() > 1 and y.size() > 1
m1 = matrix.new()
m2 = matrix.new()
m1.add_col(m1.columns(), y)
m2.add_row(m2.rows (), x)
m1.mult (m2)
.eigenvalues()
.sum()
🔶 SETTINGS
Threshold: Period used for the swing detection, with higher values returning longer-term Swing Levels.
Proactive: Tentative Swings are included with this setting enabled.
Style: Color Settings
Dashboard: Toggle, "Location" and "Text Size"

Custom Strategy: ETH Martingale 2.0Strategic characteristics
ETH Little Martin 2.0 is a self-developed trading strategy based on the Martingale strategy, mainly used for trading ETH (Ethereum). The core idea of this strategy is to place orders in the same direction at a fixed price interval, and then use Martin's multiple investment principle to reduce losses, but this is also the main source of losses.
Parameter description:
1 Interval: The minimum spacing for taking profit, stop loss, and opening/closing of orders. Different targets have different spacing. Taking ETH as an example, it is generally recommended to have a spacing of 2% for fluctuations in the target.
2 Base Price: This is the price at which you triggered the first order. Similarly, I am using ETH as an example. If you have other targets, I suggest using the initial value of a price that can be backtesting. The Base Price is only an initial order price and has no impact on subsequent orders.
3 Initial Order Amount: Users can set an initial order amount to control the risk of each transaction. If the stop loss is reached, we will double the amount based on this value. This refers to the value of the position held, not the number of positions held.
4 Loss Multiplier: The strategy will increase the next order amount based on the set multiple after the stop loss, in order to make up for the previous losses through a larger position. Note that after taking profit, it will be reset to 1 times the Initial Order Amount.
5. Long Short Operation: The first order of the strategy is a multiple entry, and in subsequent orders, if the stop loss is reached, a reverse order will be opened. The position value of a one-way order is based on the Loss Multiplier multiple investment, so it is generally recommended that the Loss Multiplier default to 2.
Improvement direction
Although this strategy already has a certain trading logic, there are still some improvement directions that can be considered:
1. Dynamic adjustment of spacing: Currently, the spacing is fixed, and it can be considered to dynamically adjust the spacing based on market volatility to improve the adaptability of the strategy. Try using dynamic spacing, which may be more suitable for the actual market situation.
2. Filtering criteria: Orders and no orders can be optimized separately. The biggest problem with this strategy is that it will result in continuous losses during fluctuations, and eventually increase the investment amount. You can consider filtering out some fluctuations or only focusing on trend trends.
3. Risk management: Add more risk management measures, such as setting a maximum loss limit to avoid huge losses caused by continuous stop loss.
4. Optimize the stop loss multiple: Currently, the stop loss multiple is fixed, and it can be considered to dynamically adjust the multiple according to market conditions to reduce risk.
