Dual price forecast with Projection Zone [FXSMARTLAB]The Dual Price Forecast with Projection Zone indicator is built to simulate potential future price paths based on historical price movements over two defined lookback periods. By running multiple trials (or simulations) on these historical price movements, the indicator achieves a more robust forecast, incorporating the inherent variability of price behavior.
Key Components and Calculation Details
1. Lookback Periods and Historical Price Movements
Lookback Period 1 and Lookback Period 2 specify the range of past data used to generate each projection. For each period, the indicator calculates the price variations (differences between the closing and opening prices) and stores these in arrays.
These historical price variations capture the volatility and price patterns within each period, serving as templates for future price behavior.
2. Trials: Purpose and Function
The trials are a critical element in the projection calculation. Each trial represents a single simulation of possible future price movements, derived from a random reordering of the historical price variations in each lookback period.
By running multiple trials , the indicator explores various sequences of historical movements, simulating different possible future paths. Each trial adds to the projection’s robustness by capturing a unique potential price path based on past behavior.
Running these multiple trials allows the indicator to account for randomness in price behavior, making the projections more comprehensive by covering a range of scenarios rather than relying on a single deterministic forecast.
3. Reverse Option
The reverse option allows the indicator to invert the direction of price movements within each lookback period. When enabled, historical uptrends are treated as downtrends, and vice versa.
This feature is particularly valuable in scenarios where traders expect a potential reversal in market direction. By enabling the reverse option, the indicator can simulate what might happen if past trends inverted, providing an alternative forecast path that considers possible market reversals.
This allows traders to assess both continuation and reversal scenarios, giving them a more balanced view of potential future price paths and helping them prepare for either market direction.
4. Generating the Average Projection Path
Once the trials are complete, the indicator calculates an average projected price path for each lookback period by averaging the results of all trials. This average represents the most likely price trend based on historical data and provides a smoothed projection that mitigates extreme outliers.
By averaging across all trial paths, the indicator generates a more reliable and balanced forecast line, smoothing out the fluctuations that might appear if only one trial or a small number of trials were used.
5. Projection Zone Visualization
The indicator plots the two average projection paths (one for each lookback period) as Projection 1 and Projection 2, each in a user-defined color.
The Projection Zone is the area between these two lines, filled with a semi-transparent color. This zone visually represents the potential range of future price movement, highlighting where prices are likely to oscillate if historical trends persist.
The Projection Zone effectively functions as a potential support and resistance boundary, providing traders with a visual reference for possible price fluctuations within a specific range.
6. Display of Lookback Zones
To give context to the projections, the indicator can also display colored lookback zones on the chart. These zones correspond to Lookback Period 1 and Lookback Period 2 and are color-coded to match their respective projection lines.
These zones allow traders to see the sections of historical data used in the calculation, helping them understand which past price behaviors influenced the current projections.
Benefits of the Indicator
The "Dual Price Forecast with Projection Zone" indicator provides a multi-scenario forecast based on past price dynamics. Its use of trials ensures that projections are not based on a single deterministic path but on a range of possible scenarios that better reflect the inherent randomness in financial markets.
By generating a probabilistic forecast within a defined zone, the indicator helps traders to:
Anticipate potential price ranges and areas of support/resistance based on historical trends.
Understand the influence of different timeframes (short-term and long-term lookbacks) on future price behavior.
Make informed decisions by visualizing the likely variability of future prices within a controlled projection zone.
Prepare for both continuation and reversal scenarios, thanks to the reverse option. This feature is especially useful in markets where trends may change direction, as it allows traders to explore what might happen
Simulation

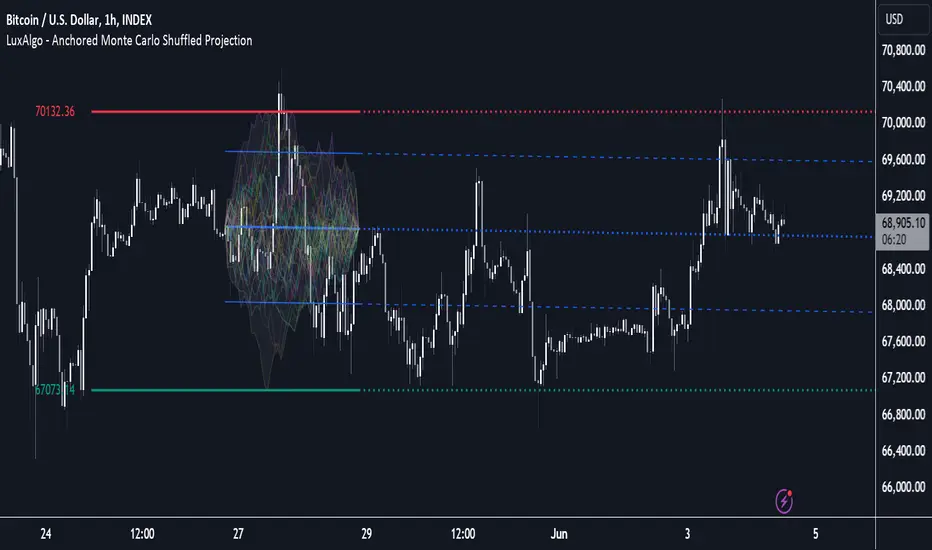
Anchored Monte Carlo Shuffled Projection [LuxAlgo]The Anchored Monte Carlo Shuffled Projection tool randomly simulates future price points based on historical bar movements made before a user-anchored point in time.
By anchoring our data and projections to a single point in time, users can better understand and reflect on how the price played out while taking into consideration our random simulations.
🔶 USAGE
After selecting the indicator to apply to the chart, you will be prompted to "Set the Anchor Point". Do so by clicking on the desired location on your chart, only time is used as the anchor point.
Note: To select a new anchor point when applied to the chart, click on the 'More' dropdown next to the indicator status bar (○○○), then select "Reset points...".
Alternate Method: You are also able to click and drag the vertical line that displays on the anchor point bar when the indicator is highlighted.
By randomly simulating bar movements, a range is developed of potential price action which could be utilized to locate future price development as well as potential support/resistance levels.
Performing numerous simulations and taking the average at each step will converge toward the result highlighted by the "Average Line", and can point out where the price might develop, assuming the trend and amount of volatility persist.
Current closing price + Sum of changes in the calculation window
This constraint will cause the simulations always to display an endpoint consistent with the current lookback's slope.
While this may be helpful to some traders, this indicator includes an option to produce a less biased range, as seen below:
🔶 DETAILS
The Anchored Monte Carlo Shuffled Projection tool creates simulations based on prices within a user-set lookback window originating at the specified anchor point. Simulations are done as follows:
Collect each bar's price changes in the user-set window.
Randomize the order of each change in the window.
Project the cumulative sum of the shuffled changes from the current closing price.
Collect data on each point along the way.
This is the process for the Default calculation; for the 'Randomize Direction' calculation, when added onto the front for every other change, the value is inverted, creating the randomized endpoints for each simulation.
The script contains each simulation's data for that bar, with a maximum of 1000 simulations.
To get a glimpse behind the scenes, each simulation (up to 99) can be viewed using the 'Visualize Simulations' Options, as seen below.
Because the script holds the full simulation data, the script can also calculate this data, such as standard deviations.
In this script the Standard deviation lines are the average of all standard deviations across the vertical data groups, this provides a singular value that can be displayed a distance away from the simulation center line.
🔶 SETTINGS
Lookback: Sets the number of Bars to include in calculations.
Simulation Count: Sets the number of randomized simulations to calculate. (Max 1000)
Randomize Direction: See Details Above. Creates a more 'Normalized' Distribution
Visualize Simulations: See Details Above. Turns on Visualizations, and colors are randomly generated. Visualized max does not cap the calculated max. If 1000 simulations are used, the data will be from 1000 simulations, however, only the last 99 simulations will be visualized.
🔹 Standard Deviations
Standard Deviation Multiplier: Sets the multiplier to use for the Standard Deviation distance away from the center line.
🔹 Style
Extend Lines: Extends the Simulated Value Lines into the future for further reference and analysis.
Monte Carlo Shuffled Projection [LuxAlgo]The Monte Carlo Shuffled Projection tool randomly simulates future price points based on historical bar movements made within a user-selected window.
The tool shows potential paths price might take in the future, as well as highlighting potential support/resistance levels.
Note that simulations and their resulting elements are subject to slight changes over time.
🔶 USAGE
By randomly simulating bar movements, a range is developed of potential price action which could be utilized to locate future price development as well as potential support/resistance levels.
Performing a large number of simulations and taking the average at each step will converge toward the result highlighted by the "Average Line", and can point out where the price might develop assuming the trend and amount of volatility persist.
Current closing price + Sum of changes in the calculation window)
This constraint will cause the simulations to always display an endpoint consistent with the current lookback's slope.
While this may be helpful to some traders, this indicator includes an option to produce a less biased range as seen below:
🔶 DETAILS
The Monte Carlo Shuffled Projection tool creates simulations based on the most recent prices within a user-set window. Simulations are done as follows:
Collect each bar's price changes in the user-set window.
Randomize the order of each change in the window.
Project the cumulative sum of the shuffled changes from the current closing price.
Collect data on each point along the way.
This is the process for the Default calculation, for the 'Randomize Direction' calculation, when added onto the front for every other change, the value is inverted, creating the randomized endpoints for each simulation.
The script contains each simulation's data for that bar with a maximum of 1000 simulations.
To get a glimpse behind the scenes each simulation (up to 99) can be viewed using the 'Visualize Simulations' Options as seen below.
Because the script holds the full simulation data, the script can also do calculations on this data, such as calculating standard deviations.
In this script the Standard deviation lines are the average of all standard deviations across the vertical data groups, this provides a singular value that can be displayed a distance away from the simulation center line.
🔶 SETTINGS
Color and Toggle Options are Provided throughout.
Lookback: Sets the number of Bars to include in calculations.
Simulation Count: Sets the number of randomized simulations to calculate. (Max 1000)
Randomize Direction: See Details Above. Creates a more 'Normalized' Distribution
Visualize Simulations: See Details Above. Turns on Visualizations, and colors are randomly generated. Visualized max does not cap the calculated max. If 1000 simulations are used, the data will be from 1000 simulations, however only the last 99 simulations will be visualized.
Standard Deviation Multiplier: Sets the multiplier to use for the Standard Deviation distance away from the center line.

Easy Backtester PROWHAT IS EasyBacktester ?
EasyBacktester is a tool that helps you backtest trading strategies built by yourself with an included strategy builder and a multitude of options.
From within the parameters of the tool, you can specifically pick your entry settings across 12 most common indicators, such as "RSI", "MACD", "Moving Averages" etc... Then you can immediately visualise your setup's Stop-loss & Take Profit, your expected Profits & Loss and a lot of other statistics for your entry strategy. Once you are satisfied with your entry strategy, you are given a set of tools to optimize your setup using stop-loss rules, take profits rules, partial profits, trailing-stops, entry timing...
WHY IS THIS TOOL DIFFERENT ?
EasyBacktester is a backtesting engine with no coding skills required. TradingView allows for "Strategy Scripting" using PineScript, which is not an option for non-coder audience. EasyBacktester fills this gap and allow non-coders to get an idea of how their trading strategies may perform using mouse clicks only.
Some similar attempts have been made on TradingView, allowing some limited options, but none have the same capabilities EasyBacktester offers, for instance, as of April 2022 these features have not been seen in any other TradingView tools:
- partial take profits
- leverage simulation
- a multitude of trailing stop-loss possibilities including trail triggers and trail parameters
- visualisation of entries including stop-loss, take profits, partial take profits, and trailing stops. One can now visualize such complex setups.
- visualisation of Profits & Loss
- time in trade
- wait strategy after a signal: for example, when RSI is oversold, "WAIT until price retraces 100% of the original signal" amongst other possibilities
QUICK START GUIDE:
STEP 1: DEFINE YOUR SIGNAL STRATEGY
From the settings of the tool, find the "SIGNALS STRATEGY" section.
Select a type of entry you wish to simulate, for example "LONGs", and activate the checkbox right before "Simulate".
Right below, you will find 4 signal builder for you to play with and pick your strategy accordingly.
For example, to simulate a signal when RSI is oversold, follow these steps:
- On the 1st multiple choice box, select "RSI"
- On the 2nd multiple choice box, select "is below..."
- On the 3rd multiple choice box, select "OverSold level"
Don't forget to activate this rule by checking the checkbox in front of it.
After this first step, one should immediately see the chart affected with some plots. The dots represents the signal entry defined by the rule we just created, and the red/green boxes visually represent trades that could have been taken with this signal which, in this example, occurs "when RSI is below oversold level". Note that all specific parameters for RSI including its specific "oversold level" is customisable at the end of the tools settings along with all other indicators settings.
STEP 2: STATISTICS
By default, the "APPEARANCE" section only plots potential entry signals (materialized by dots) and actual entry boxes (materialized by red/green boxes).
But the user can easily add other precious statistics to the chart, and obviously the most important one for backtesting: Profits & Loss (P&L).
In the "STATISTICS" section please check the "P&L" box to see appear a chart of the simulated P&L for our example. You should immediately see a new graph below the chart representing the evolution of the P&L after each entry.
Other statistics are available to the user, including: Equity, Number of Trades, Time in Position, Number of trades Won, Number of trades Lost, Number of trades Stopped.
Play around with those to see them plotted on your chart.
STEP 3: OPTIMIZE YOUR ENTRY
Under the "ENTRY STRATEGY" section, one can pick how to enter AFTER the signal, which provides the user with an extensive flexibility to pick its timing.
Here there are a various set of choices offered, ranging from the default "Market Order at Next Candle Open", to "Limit Order: at signal's candle open" or even "Stop-Buy: at break of last candle high". As its name suggests, this option allows you to actually wait before randomly enter in trade.
It is important to also note that the user can totally prevent entry if the conditions are not filled after a customizable number of candles represented in "Max bars to wait for entry" (default being 1, meaning the engine will wait the condition to be filled during only 1 candle)
STEP 4: MANAGE YOUR RISK
Under the "RISK MANAGEMENT" section, the user is given a series of options to set the amount (s)he would like to risk.
This is extremely important to set, and is the result of a combination of customizable options including:
- the Initial Capital of the account
- the amount to risk per trade, and HOW to risk it: some fixed % the initial equity or adjust the stop-loss to the desired risk ?
- use of leverage or not
- initial stop-loss, as well as minimum and maximum
- trailing stop-loss: what should trigger the trailing ? and by how much should the engine trail ?
STEP 5: HAVE AN EXIT PLAN
Under the "EXIT STRATEGY", the user can define how to exit the trade.
For instance, here again a lot of options are given:
- Take Profit: exit at some level of profits defined by a multiple of the stop-loss, or a multiple of the ATR, or some % or points
- Partial Profit taking before exit
- Panic close position after some time spent on the trade
STEP 6: FURTHER OPTIMIZATIONS
Under the sections "Commissions" & "Calendar & Sessions", one can simulate real trading conditions by including commissions fees as well as filtering actual dates and trading sessions. These sections are straightforward for any user to use.
SETP 7: INDICATORS SETTINGS
Since EasyBacktester uses a predefined set of indicators to get started, those indicators are also customizable in the last section of the settings. Here, one can easily customize RSI periodicity, MACD lengths, Moving averages types & lengths, ATR, etc...
STEP 8: GOING FURTHER
This is only a start to give users an overview of how various options affect their trading performance. But of course, each trader has its special recipe and specific detailed setup that is not possible to embed in a single tool. For advanced simulation, EasyBacktester provides plug & play connectors for advanced users. Namely, there are 3 connectors:
- signal connector
- trail trigger connector
- exit connector
Each of these connectors are an opportunity to customize the engine signals, trail trigger and exit choices with the user's own options. This case does require a little bit of coding, but it can easily be implemented by copy-pasting existing resources or with a slight help of a professional. In fact, the only conditions to build a proper connector is to export a plot with the numbers 1 (for signals), 2 (for trigger trails) and 3 (for exits). Here is an example of custom SIGNAL connector compatible with EasyBacktester, to produce a signal when last RSI was below 30 and current RSI reads above 30:
============================================================
//@version=5
indicator("My custom RSI signal")
// when previous RSI 14 was below 30 and current RSI 14 is above 30, set "custom_signal" to 1, otherwise set "custom_signal" to 0
custom_signal = ta.rsi(close, 14) < 30 and ta.rsi(close, 14) > 30 ? 1 : 0
// Export a plot of "custom_signal", but do not display it
plot(custom_signal, title="my signal", display=display.none)
============================================================
Once this indicator has been built, the user only needs to connect it with EasyBacktester as follow:
1. Open a desired chart, and add both EasyBacktester indicator as well as the custom "My custom signal" we just created above.
2. Open EasyBacktester's settings, and in the first option, there is "Connect signals source" which by default is set to "close". In the multiple choices, find your custom signal which should be named something like "My custom RSI signal: my signal", generally speaking the name is built like this " : ".
3. Now the custom code is connected to EasyBacktester, but we need to indicate the engine we actually want to use it as custom signal.
4. Under the "SIGNALS STRATEGY" section, where we generally build signals rules, there is special rule for this specific connection named "Use external source as entry signal". Just check the checkbox to activate it and see how the chart took our custom signal into consideration.
That's it for the overview of EasyBacktester. Thank you for reading and happy trading :)

QuantMEX Walk Forward Simulation - RSIQuantMEX Walk Forward Simulation - RSI
Simulation is one of the most powerful analytical techniques ever created. It is a crucial step in finding effective strategies. The purpose of this indicador is the walf-forward simulation method for the classic Relative Strength Index , adopting a systematic and orderly procedure designed to realistically test a hypothesis based on its functionalities without the need to use the Tradingview backtest. The indicator allows to check the net profit, percentage of winning traders, total trades, profit factor and payoff of several parameters simultaneously.
1) Data segmentation: We divided the historical database with an interval of 8 months. The initial data segments correspond to 75% of the sample and the final data segments correspond to 25% of the sample.
2) Parameters for optimization: Through the oldest data and we found the specific parameters that would have maximized the performance of the risk / return ratio for the RSI. We systematically vary the RSI parameters in order to identify which specific variables would have produced the greatest returns in relation to the risk of loss. Older data segments are known as in-sample data, while newer data segments, not yet used, are known as out-of-sample data.
3) Walk-Forward SIMULATION: The discovered parameters are projected over time for the next and most recent unseen and out-of-sample data segments, which were not included in the research on brute force optimizations carried out in the previous steps.
As a reference, we used the concepts of the classic book "The Evaluation and Optimization of Trading Strategies" by Robert Pardo.


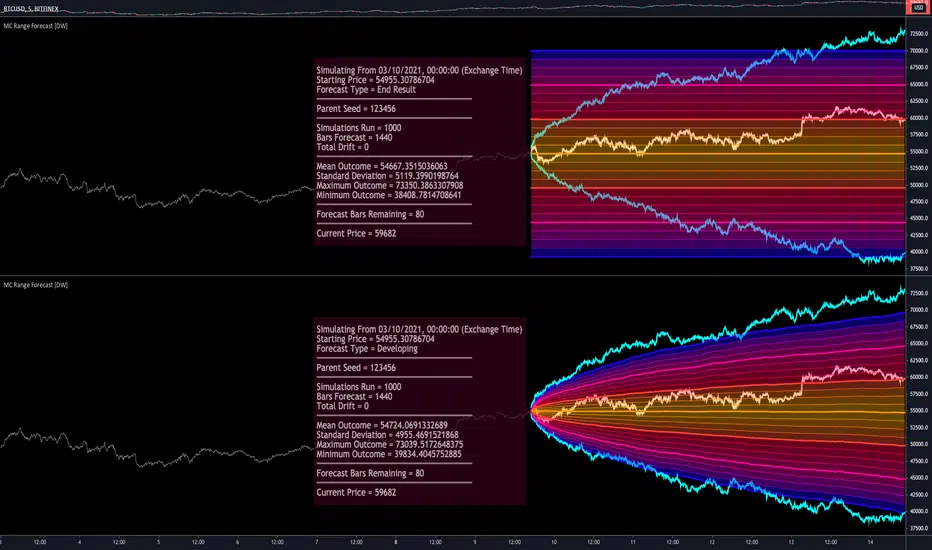
Monte Carlo Range Forecast [DW]This is an experimental study designed to forecast the range of price movement from a specified starting point using a Monte Carlo simulation.
Monte Carlo experiments are a broad class of computational algorithms that utilize random sampling to derive real world numerical results.
These types of algorithms have a number of applications in numerous fields of study including physics, engineering, behavioral sciences, climate forecasting, computer graphics, gaming AI, mathematics, and finance.
Although the applications vary, there is a typical process behind the majority of Monte Carlo methods:
-> First, a distribution of possible inputs is defined.
-> Next, values are generated randomly from the distribution.
-> The values are then fed through some form of deterministic algorithm.
-> And lastly, the results are aggregated over some number of iterations.
In this study, the Monte Carlo process used generates a distribution of aggregate pseudorandom linear price returns summed over a user defined period, then plots standard deviations of the outcomes from the mean outcome generate forecast regions.
The pseudorandom process used in this script relies on a modified Wichmann-Hill pseudorandom number generator (PRNG) algorithm.
Wichmann-Hill is a hybrid generator that uses three linear congruential generators (LCGs) with different prime moduli.
Each LCG within the generator produces an independent, uniformly distributed number between 0 and 1.
The three generated values are then summed and modulo 1 is taken to deliver the final uniformly distributed output.
Because of its long cycle length, Wichmann-Hill is a fantastic generator to use on TV since it's extremely unlikely that you'll ever see a cycle repeat.
The resulting pseudorandom output from this generator has a minimum repetition cycle length of 6,953,607,871,644.
Fun fact: Wichmann-Hill is a widely used PRNG in various software applications. For example, Excel 2003 and later uses this algorithm in its RAND function, and it was the default generator in Python up to v2.2.
The generation algorithm in this script takes the Wichmann-Hill algorithm, and uses a multi-stage transformation process to generate the results.
First, a parent seed is selected. This can either be a fixed value, or a dynamic value.
The dynamic parent value is produced by taking advantage of Pine's timenow variable behavior. It produces a variable parent seed by using a frozen ratio of timenow/time.
Because timenow always reflects the current real time when frozen and the time variable reflects the chart's beginning time when frozen, the ratio of these values produces a new number every time the cache updates.
After a parent seed is selected, its value is then fed through a uniformly distributed seed array generator, which generates multiple arrays of pseudorandom "children" seeds.
The seeds produced in this step are then fed through the main generators to produce arrays of pseudorandom simulated outcomes, and a pseudorandom series to compare with the real series.
The main generators within this script are designed to (at least somewhat) model the stochastic nature of financial time series data.
The first step in this process is to transform the uniform outputs of the Wichmann-Hill into outputs that are normally distributed.
In this script, the transformation is done using an estimate of the normal distribution quantile function.
Quantile functions, otherwise known as percent-point or inverse cumulative distribution functions, specify the value of a random variable such that the probability of the variable being within the value's boundary equals the input probability.
The quantile equation for a normal probability distribution is μ + σ(√2)erf^-1(2(p - 0.5)) where μ is the mean of the distribution, σ is the standard deviation, erf^-1 is the inverse Gauss error function, and p is the probability.
Because erf^-1() does not have a simple, closed form interpretation, it must be approximated.
To keep things lightweight in this approximation, I used a truncated Maclaurin Series expansion for this function with precomputed coefficients and rolled out operations to avoid nested looping.
This method provides a decent approximation of the error function without completely breaking floating point limits or sucking up runtime memory.
Note that there are plenty of more robust techniques to approximate this function, but their memory needs very. I chose this method specifically because of runtime favorability.
To generate a pseudorandom approximately normally distributed variable, the uniformly distributed variable from the Wichmann-Hill algorithm is used as the input probability for the quantile estimator.
Now from here, we get a pretty decent output that could be used itself in the simulation process. Many Monte Carlo simulations and random price generators utilize a normal variable.
However, if you compare the outputs of this normal variable with the actual returns of the real time series, you'll find that the variability in shocks (random changes) doesn't quite behave like it does in real data.
This is because most real financial time series data is more complex. Its distribution may be approximately normal at times, but the variability of its distribution changes over time due to various underlying factors.
In light of this, I believe that returns behave more like a convoluted product distribution rather than just a raw normal.
So the next step to get our procedurally generated returns to more closely emulate the behavior of real returns is to introduce more complexity into our model.
Through experimentation, I've found that a return series more closely emulating real returns can be generated in a three step process:
-> First, generate multiple independent, normally distributed variables simultaneously.
-> Next, apply pseudorandom weighting to each variable ranging from -1 to 1, or some limits within those bounds. This modulates each series to provide more variability in the shocks by producing product distributions.
-> Lastly, add the results together to generate the final pseudorandom output with a convoluted distribution. This adds variable amounts of constructive and destructive interference to produce a more "natural" looking output.
In this script, I use three independent normally distributed variables multiplied by uniform product distributed variables.
The first variable is generated by multiplying a normal variable by one uniformly distributed variable. This produces a bit more tailedness (kurtosis) than a normal distribution, but nothing too extreme.
The second variable is generated by multiplying a normal variable by two uniformly distributed variables. This produces moderately greater tails in the distribution.
The third variable is generated by multiplying a normal variable by three uniformly distributed variables. This produces a distribution with heavier tails.
For additional control of the output distributions, the uniform product distributions are given optional limits.
These limits control the boundaries for the absolute value of the uniform product variables, which affects the tails. In other words, they limit the weighting applied to the normally distributed variables in this transformation.
All three sets are then multiplied by user defined amplitude factors to adjust presence, then added together to produce our final pseudorandom return series with a convoluted product distribution.
Once we have the final, more "natural" looking pseudorandom series, the values are recursively summed over the forecast period to generate a simulated result.
This process of generation, weighting, addition, and summation is repeated over the user defined number of simulations with different seeds generated from the parent to produce our array of initial simulated outcomes.
After the initial simulation array is generated, the max, min, mean and standard deviation of this array are calculated, and the values are stored in holding arrays on each iteration to be called upon later.
Reference difference series and price values are also stored in holding arrays to be used in our comparison plots.
In this script, I use a linear model with simple returns rather than compounding log returns to generate the output.
The reason for this is that in generating outputs this way, we're able to run our simulations recursively from the beginning of the chart, then apply scaling and anchoring post-process.
This allows a greater conservation of runtime memory than the alternative, making it more suitable for doing longer forecasts with heavier amounts of simulations in TV's runtime environment.
From our starting time, the previous bar's price, volatility, and optional drift (expected return) are factored into our holding arrays to generate the final forecast parameters.
After these parameters are computed, the range forecast is produced.
The basis value for the ranges is the mean outcome of the simulations that were run.
Then, quarter standard deviations of the simulated outcomes are added to and subtracted from the basis up to 3σ to generate the forecast ranges.
All of these values are plotted and colorized based on their theoretical probability density. The most likely areas are the warmest colors, and least likely areas are the coolest colors.
An information panel is also displayed at the starting time which shows the starting time and price, forecast type, parent seed value, simulations run, forecast bars, total drift, mean, standard deviation, max outcome, min outcome, and bars remaining.
The interesting thing about simulated outcomes is that although the probability distribution of each simulation is not normal, the distribution of different outcomes converges to a normal one with enough steps.
In light of this, the probability density of outcomes is highest near the initial value + total drift, and decreases the further away from this point you go.
This makes logical sense since the central path is the easiest one to travel.
Given the ever changing state of markets, I find this tool to be best suited for shorter term forecasts.
However, if the movements of price are expected to remain relatively stable, longer term forecasts may be equally as valid.
There are many possible ways for users to apply this tool to their analysis setups. For example, the forecast ranges may be used as a guide to help users set risk targets.
Or, the generated levels could be used in conjunction with other indicators for meaningful confluence signals.
More advanced users could even extrapolate the functions used within this script for various purposes, such as generating pseudorandom data to test systems on, perform integration and approximations, etc.
These are just a few examples of potential uses of this script. How you choose to use it to benefit your trading, analysis, and coding is entirely up to you.
If nothing else, I think this is a pretty neat script simply for the novelty of it.
----------
How To Use:
When you first add the script to your chart, you will be prompted to confirm the starting date and time, number of bars to forecast, number of simulations to run, and whether to include drift assumption.
You will also be prompted to confirm the forecast type. There are two types to choose from:
-> End Result - This uses the values from the end of the simulation throughout the forecast interval.
-> Developing - This uses the values that develop from bar to bar, providing a real-time outlook.
You can always update these settings after confirmation as well.
Once these inputs are confirmed, the script will boot up and automatically generate the forecast in a separate pane.
Note that if there is no bar of data at the time you wish to start the forecast, the script will automatically detect use the next available bar after the specified start time.
From here, you can now control the rest of the settings.
The "Seeding Settings" section controls the initial seed value used to generate the children that produce the simulations.
In this section, you can control whether the seed is a fixed value, or a dynamic one.
Since selecting the dynamic parent option will change the seed value every time you change the settings or refresh your chart, there is a "Regenerate" input built into the script.
This input is a dummy input that isn't connected to any of the calculations. The purpose of this input is to force an update of the dynamic parent without affecting the generator or forecast settings.
Note that because we're running a limited number of simulations, different parent seeds will typically yield slightly different forecast ranges.
When using a small number of simulations, you will likely see a higher amount of variance between differently seeded results because smaller numbers of sampled simulations yield a heavier bias.
The more simulations you run, the smaller this variance will become since the outcomes become more convergent toward the same distribution, so the differences between differently seeded forecasts will become more marginal.
When using a dynamic parent, pay attention to the dispersion of ranges.
When you find a set of ranges that is dispersed how you like with your configuration, set your fixed parent value to the parent seed that shows in the info panel.
This will allow you to replicate that dispersion behavior again in the future.
An important thing to note when settings alerts on the plotted levels, or using them as components for signals in other scripts, is to decide on a fixed value for your parent seed to avoid minor repainting due to seed changes.
When the parent seed is fixed, no repainting occurs.
The "Amplitude Settings" section controls the amplitude coefficients for the three differently tailed generators.
These amplitude factors will change the difference series output for each simulation by controlling how aggressively each series moves.
When "Adjust Amplitude Coefficients" is disabled, all three coefficients are set to 1.
Note that if you expect volatility to significantly diverge from its historical values over the forecast interval, try experimenting with these factors to match your anticipation.
The "Weighting Settings" section controls the weighting boundaries for the three generators.
These weighting limits affect how tailed the distributions in each generator are, which in turn affects the final series outputs.
The maximum absolute value range for the weights is . When "Limit Generator Weights" is disabled, this is the range that is automatically used.
The last set of inputs is the "Display Settings", where you can control the visual outputs.
From here, you can select to display either "Forecast" or "Difference Comparison" via the "Output Display Type" dropdown tab.
"Forecast" is the type displayed by default. This plots the end result or developing forecast ranges.
There is an option with this display type to show the developing extremes of the simulations. This option is enabled by default.
There's also an option with this display type to show one of the simulated price series from the set alongside actual prices.
This allows you to visually compare simulated prices alongside the real prices.
"Difference Comparison" allows you to visually compare a synthetic difference series from the set alongside the actual difference series.
This display method is primarily useful for visually tuning the amplitude and weighting settings of the generators.
There are also info panel settings on the bottom, which allow you to control size, colors, and date format for the panel.
It's all pretty simple to use once you get the hang of it. So play around with the settings and see what kinds of forecasts you can generate!
----------
ADDITIONAL NOTES & DISCLAIMERS
Although I've done a number of things within this script to keep runtime demands as low as possible, the fact remains that this script is fairly computationally heavy.
Because of this, you may get random timeouts when using this script.
This could be due to either random drops in available runtime on the server, using too many simulations, or running the simulations over too many bars.
If it's just a random drop in runtime on the server, hide and unhide the script, re-add it to the chart, or simply refresh the page.
If the timeout persists after trying this, then you'll need to adjust your settings to a less demanding configuration.
Please note that no specific claims are being made in regards to this script's predictive accuracy.
It must be understood that this model is based on randomized price generation with assumed constant drift and dispersion from historical data before the starting point.
Models like these not consider the real world factors that may influence price movement (economic changes, seasonality, macro-trends, instrument hype, etc.), nor the changes in sample distribution that may occur.
In light of this, it's perfectly possible for price data to exceed even the most extreme simulated outcomes.
The future is uncertain, and becomes increasingly uncertain with each passing point in time.
Predictive models of any type can vary significantly in performance at any point in time, and nobody can guarantee any specific type of future performance.
When using forecasts in making decisions, DO NOT treat them as any form of guarantee that values will fall within the predicted range.
When basing your trading decisions on any trading methodology or utility, predictive or not, you do so at your own risk.
No guarantee is being issued regarding the accuracy of this forecast model.
Forecasting is very far from an exact science, and the results from any forecast are designed to be interpreted as potential outcomes rather than anything concrete.
With that being said, when applied prudently and treated as "general case scenarios", forecast models like these may very well be potentially beneficial tools to have in the arsenal.
Particle Physics Moving AverageThis indicator simulates the physics of a particle attracted by a distance-dependent force towards the evolving value of the series it's applied to.
Its parameters include:
The mass of the particle
The exponent of the force function f=d^x
A "medium damping factor" (viscosity of the universe)
Compression/extension damping factors (for simulating spring-damping functions)
This implementation also adds a second set of all of these parameters, and tracks 16 particles evenly interpolated between the two sets.
It's a kind of Swiss Army Knife of Moving Average-type functions; For instance, because the position and velocity of the particle include a "historical knowlege" of the series, it turns out that the Exponential Moving Average function simply "falls out" of the algorithm in certain configurations; instead of being configured by defining a period of samples over which to calculate an Exponential Moving Average, in this derivation, it is tuned by changing the mass and/or medium damping parameters.
But the algorithm can do much more than simply replicate an EMA... A particle acted on by a force that is a linear function of distance (force exponent=1) simulates the physics of a sprung-mass system, with a mass-dependent resonant frequency. By altering the particle mass and damping parameters, you can simulate something like an automobile suspension, letting your particle track a stock's price like a Cadillac or a Corvette (or both, including intermediates) depending on your setup. Particles will have a natural resonance with a frequency that depends on its mass... A higher mass particle (i.e. higher inertia) will resonate at a lower frequency than one with a lower mass (and of course, in this indicator, you can display particles that interpolate through a range of masses.)
The real beauty of this general-purpose algorithm is that the force function can be extended with other components, affecting the trajectory of the particle; For instance "volume" could be factored into the current distance-based force function, strengthening or weakening the impulse accordingly. (I'll probably provide updates to the script that incoroprate different ideas I come up with.)
As currently pictured above, the indicator is interpolating between a medium-damped EMA-like configuration (red) and a more extension-damped suspension-like configuration (blue).
This indicator is merely a tool that provides a space to explore such a simulation, to let you see how tweaking parameters affects the simulations. It doesn't provide buy or sell signals, although you might find that it could be adapted into an MACD-like signal generator... But you're on your own for that.