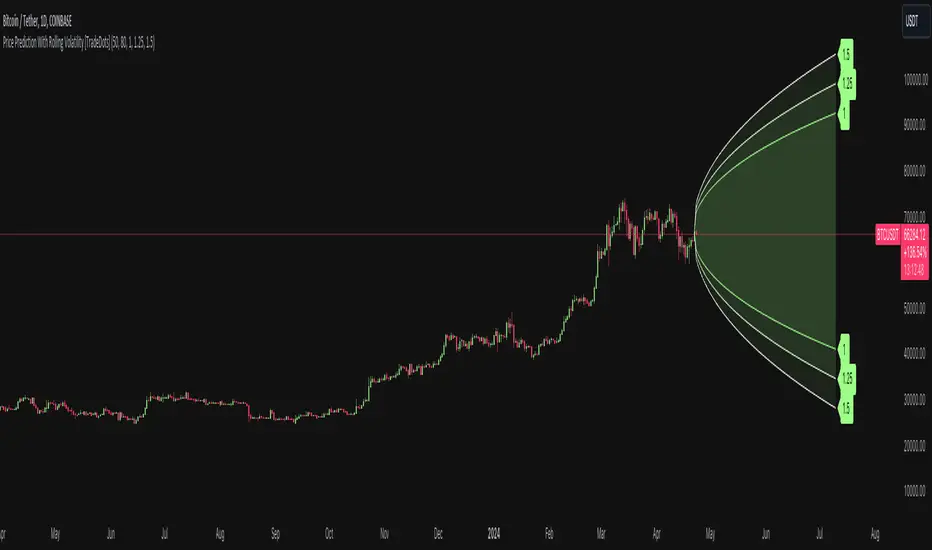
Price Prediction With Rolling Volatility [TradeDots]The "Price Prediction With Rolling Volatility" is a trading indicator that estimates future price ranges based on the volatility of price movements within a user-defined rolling window.
HOW DOES IT WORK
This indicator utilizes 3 types of user-provided data to conduct its calculations: the length of the rolling window, the number of bars projecting into the future, and a maximum of three sets of standard deviations.
Firstly, the rolling window. The algorithm amasses close prices from the number of bars determined by the value in the rolling window, aggregating them into an array. It then calculates their standard deviations in order to forecast the prospective minimum and maximum price values.
Subsequently, a loop is initiated running into the number of bars into the future, as dictated by the second parameter, to calculate the maximum price change in both the positive and negative direction.
The third parameter introduces a series of standard deviation values into the forecasting model, enabling users to dictate the volatility or confidence level of the results. A larger standard deviation correlates with a wider predicted range, thereby enhancing the probability factor.
APPLICATION
The purpose of the indicator is to provide traders with an understanding of the potential future movement of the price, demarcating maximum and minimum expected outcomes. For instance, if an asset demonstrates a substantial spike beyond the forecasted range, there's a significantly high probability of that price being rejected and reversed.
However, this indicator should not be the sole basis for your trading decisions. The range merely reflects the volatility within the rolling window and may overlook significant historical price movements. As with any trading strategies, synergize this with other indicators for a more comprehensive and reliable analysis.
Note: In instances where the number of predicted bars is exceedingly high, the lines may become scattered, presumably due to inherent limitations on the TradingView platform. Consequently, when applying three SD in your indicator, it is advised to limit the predicted bars to fewer than 80.
RISK DISCLAIMER
Trading entails substantial risk, and most day traders incur losses. All content, tools, scripts, articles, and education provided by TradeDots serve purely informational and educational purposes. Past performances are not definitive predictors of future results.
Standard Deviation
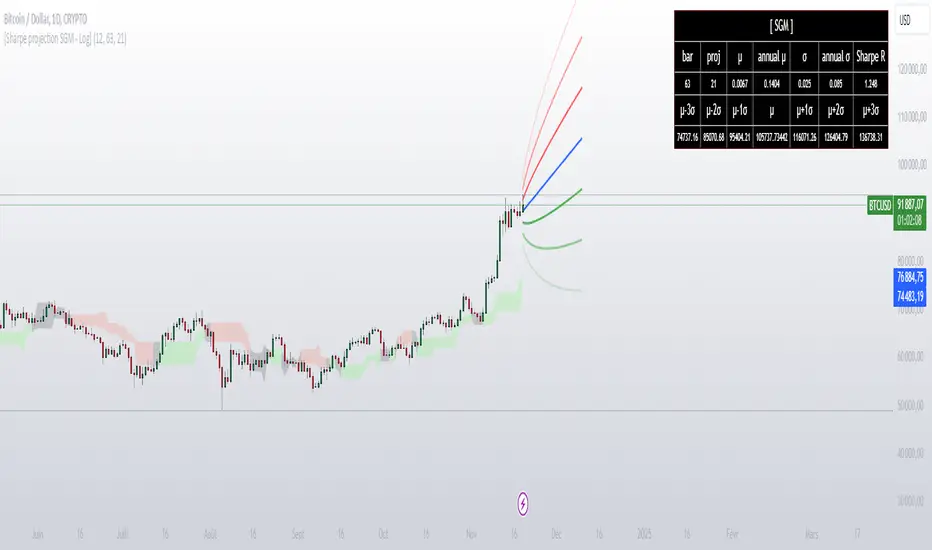
[Sharpe projection SGM]Dynamic Support and Resistance: Traces adjustable support and resistance lines based on historical prices, signaling new market barriers.
Price Projections and Volatility: Calculates future price projections using moving averages and plots annualized standard deviation-based volatility bands to anticipate price dispersion.
Intuitive Coloring: Colors between support and resistance lines show up or down trends, making it easy to analyze quickly.
Analytics Dashboard: Displays key metrics such as the Sharpe Ratio, which measures average ROI adjusted for asset volatility
Volatility Management for Options Trading: The script helps evaluate strike prices and strategies for options, based on support and resistance levels and projected volatility.
Importance of Diversification: It is necessary to diversify investments to reduce risks and stabilize returns.
Disclaimer on Past Performance: Past performance does not guarantee future results, projections should be supplemented with other analyses.
The script settings can be adjusted according to the specific needs of each user.
The mean and standard deviation are two fundamental statistical concepts often represented in a Gaussian curve, or normal distribution. Here's a quick little lesson on these concepts:
Average
The mean (or arithmetic mean) is the result of the sum of all values in a data set divided by the total number of values. In a data distribution, it represents the center of gravity of the data points.
Standard Deviation
The standard deviation measures the dispersion of the data relative to its mean. A low standard deviation indicates that the data is clustered near the mean, while a high standard deviation shows that it is more spread out.
Gaussian curve
The Gaussian curve or normal distribution is a graphical representation showing the probability of distribution of data. It has the shape of a symmetrical bell centered on the middle. The width of the curve is determined by the standard deviation.
68-95-99.7 rule (rule of thumb): Approximately 68% of the data is within one standard deviation of the mean, 95% is within two standard deviations, and 99.7% is within three standard deviations.
In statistics, understanding the mean and standard deviation allows you to infer a lot about the nature of the data and its trends, and the Gaussian curve provides an intuitive visualization of this information.
In finance, it is crucial to remember that data dispersion can be more random and unpredictable than traditional statistical models like the normal distribution suggest. Financial markets are often affected by unforeseen events or changes in investor behavior, which can result in return distributions with wider standard deviations or non-symmetrical distributions.
Trend Analysis with Standard Deviation by zdmre This script analyzes trends in financial markets using standard deviation.
The script works by first calculating the standard deviation of a security's price over a specified period of time. The script then uses this standard deviation to identify potential trend reversals.
For example, if the standard deviation of a security's price is high, this could indicate that the security is overvalued and due for a correction. Conversely, if the standard deviation of a security's price is low, this could indicate that the security is undervalued and due for a rally.
The script can be used to analyze any security, including stocks, bonds, and currencies. It can also be used to analyze different time frames, such as daily, weekly, and monthly.
How to Use the Script
To use the script, you will need to specify the following parameters:
Time frame: The time frame you want to analyze.
Standard deviation: The standard deviation you want to use.
Once you have specified these parameters, the script will calculate the standard deviation of the security's price over the specified time frame. The script will then use this standard deviation to identify potential trend reversals.
#DYOR

VWAP SpiderThe VWAP Spider indicator enhances the conventional Volume Weighted Average Price (VWAP) analysis by anchoring it to the first candle and incorporating an extensive series of standard deviation (SD) lines, extending up to +8 SDs with additional half-step increments. This configuration provides a more suitable set of lines for identifying support and resistance, distinguishing it from existing VWAP and SD indicators. Its design, featuring color gradients for fills and distinct labels for each line, aims to improve the utility and user experience.
Optimal Timeframes:
It is recommended for use on weekly or monthly resolutions to ensure all price and volume history is included.
Distinctive Features:
The indicator includes a more extensive array of SD lines than typically found in VWAP indicators, enhancing the depth of market analysis.
The visual presentation is optimized with color gradients and clear labeling, facilitating ease of use and integration into trading strategies.
Practical Use of the VWAP Spider:
SD Lines as Support and Resistance : Observe the interactions between the price and the SD lines closely. These can serve as dynamic support and resistance indicators, influencing trading decisions.
Analyzing Historical Price Action : Investigate how the price has historically interacted with the SD lines. Identify which lines have frequently acted as support and resistance in the past, as they will often continue to be revisited.
Strategic Application : Leverage insights from the interactions between price and SD lines to fine-tune entry and exit points. For example, a rebound from an SD line may suggest a strong entry point, while breaching an SD line could indicate a potential exit.
This indicator is freely available and open-source on TradingView for all. It is designed to help traders enhance their market analysis and strategic decision-making.

BTC Spread Indicator"Hot potato, Bitcoin style!
In the dynamic world of cryptocurrency, keeping an eye on price movements across different exchanges can be as exhilarating as a game of hot potato. By calculating the average Bitcoin price across major exchanges, we can then dive deeper to identify the spreads between this global average and the prices on individual exchanges. This analysis reveals who's currently 'holding the potato'—or dealing with higher prices—and predicts who might be next. It's a fun, yet insightful way to visualize market volatility and trading opportunities. Let's see where the potato lands next!"

Bitcoin Leverage Sentiment - Strategy [presentTrading]█ Introduction and How it is Different
The "Bitcoin Leverage Sentiment - Strategy " represents a novel approach in the realm of cryptocurrency trading by focusing on sentiment analysis through leveraged positions in Bitcoin. Unlike traditional strategies that primarily rely on price action or technical indicators, this strategy leverages the power of Z-Score analysis to gauge market sentiment by examining the ratio of leveraged long to short positions. By assessing how far the current sentiment deviates from the historical norm, it provides a unique lens to spot potential reversals or continuation in market trends, making it an innovative tool for traders who wish to incorporate market psychology into their trading arsenal.
BTC 4h L/S Performance
local
█ Strategy, How It Works: Detailed Explanation
🔶 Data Collection and Ratio Calculation
Firstly, the strategy acquires data on leveraged long (**`priceLongs`**) and short positions (**`priceShorts`**) for Bitcoin. The primary metric of interest is the ratio of long positions relative to the total of both long and short positions:
BTC Ratio=priceLongs / (priceLongs+priceShorts)
This ratio reflects the prevailing market sentiment, where values closer to 1 indicate a bullish sentiment (dominance of long positions), and values closer to 0 suggest bearish sentiment (prevalence of short positions).
🔶 Z-Score Calculation
The Z-Score is then calculated to standardize the BTC Ratio, allowing for comparison across different time periods. The Z-Score formula is:
Z = (X - μ) / σ
Where:
- X is the current BTC Ratio.
- μ is the mean of the BTC Ratio over a specified period (**`zScoreCalculationPeriod`**).
- σ is the standard deviation of the BTC Ratio over the same period.
The Z-Score helps quantify how far the current sentiment deviates from the historical norm, with high positive values indicating extreme bullish sentiment and high negative values signaling extreme bearish sentiment.
🔶 Signal Generation: Trading signals are derived from the Z-Score as follows:
Long Entry Signal: Occurs when the BTC Ratio Z-Score crosses above the thresholdLongEntry, suggesting bullish sentiment.
- Condition for Long Entry = BTC Ratio Z-Score > thresholdLongEntry
Long Exit/Short Entry Signal: Triggered when the BTC Ratio Z-Score drops below thresholdLongExit for exiting longs or below thresholdShortEntry for entering shorts, indicating a shift to bearish sentiment.
- Condition for Long Exit/Short Entry = BTC Ratio Z-Score < thresholdLongExit or BTC Ratio Z-Score < thresholdShortEntry
Short Exit Signal: Happens when the BTC Ratio Z-Score exceeds the thresholdShortExit, hinting at reducing bearish sentiment and a potential switch to bullish conditions.
- Condition for Short Exit = BTC Ratio Z-Score > thresholdShortExit
🔶Implementation and Visualization: The strategy applies these conditions for trade management, aligning with the selected trade direction. It visualizes the BTC Ratio Z-Score with horizontal lines at entry and exit thresholds, illustrating the current sentiment against historical norms.
█ Trade Direction
The strategy offers flexibility in trade direction, allowing users to choose between long, short, or both, depending on their market outlook and risk tolerance. This adaptability ensures that traders can align the strategy with their individual trading style and market conditions.
█ Usage
To employ this strategy effectively:
1. Customization: Begin by setting the trade direction and adjusting the Z-Score calculation period and entry/exit thresholds to match your trading preferences.
2. Observation: Monitor the Z-Score and its moving average for potential trading signals. Look for crossover events relative to the predefined thresholds to identify entry and exit points.
3. Confirmation: Consider using additional analysis or indicators for signal confirmation, ensuring a comprehensive approach to decision-making.
█ Default Settings
- Trade Direction: Determines if the strategy engages in long, short, or both types of trades, impacting its adaptability to market conditions.
- Timeframe Input: Influences signal frequency and sensitivity, affecting the strategy's responsiveness to market dynamics.
- Z-Score Calculation Period: Affects the strategy’s sensitivity to market changes, with longer periods smoothing data and shorter periods increasing responsiveness.
- Entry and Exit Thresholds: Set the Z-Score levels for initiating or exiting trades, balancing between capturing opportunities and minimizing false signals.
- Impact of Default Settings: Provides a balanced approach to leverage sentiment trading, with adjustments needed to optimize performance across various market conditions.
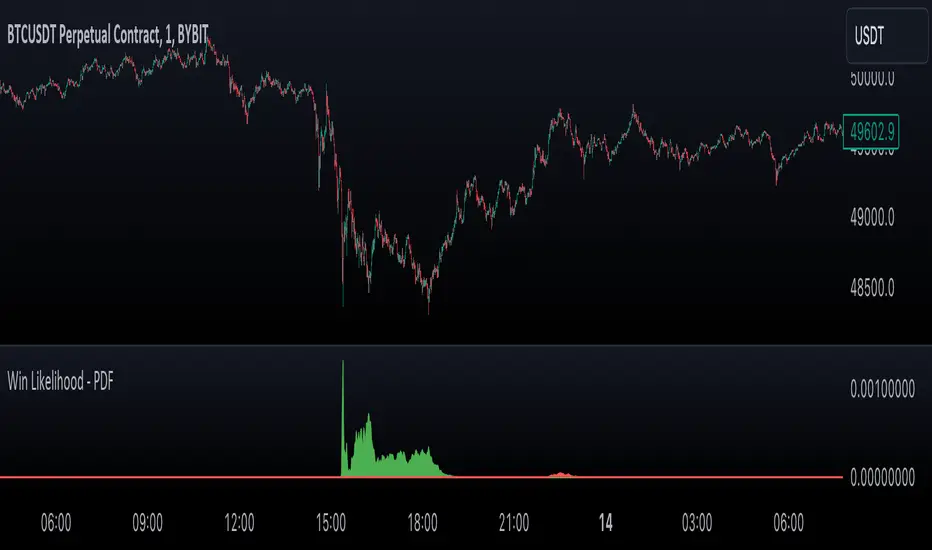
Likelihood of Winning - Probability Density FunctionIn developing the "Likelihood of Winning - Probability Density Function (PDF)" indicator, my aim was to offer traders a statistical tool to quantify the probability of reaching target prices. This indicator, grounded in risk assessment principles, enables users to analyze potential outcomes based on the normal distribution, providing insights into market dynamics.
The tool's flexibility allows for customization of the data series, lookback periods, and target settings for both long and short scenarios. It features a color-coded visualization to easily distinguish between probabilities of hitting specified targets, enhancing decision-making in trading strategies.
I'm excited to share this indicator with the trading community, hoping it will enhance data-driven decision-making and offer a deeper understanding of market risks and opportunities. My goal is to continuously improve this tool based on user feedback and market evolution, contributing to more informed trading practices.
This indicator leverages the "NormalDistributionFunctions" library, enabling easy integration into other indicators or strategies. Users can readily embed advanced statistical analysis into their trading tools, fostering innovation within the Pine Script community.
VWAP Bands @shrilssVWAP Bands Integrates VWAP with standard deviation bands to provide traders with insights into potential support and resistance levels based on volume dynamics. VWAP is a key metric used by institutional traders to gauge the average price a security has traded at throughout the trading day, taking into account both price and volume.
This script calculates the VWAP for each trading session and overlays it on the price chart as a solid line. Additionally, it plots multiple standard deviation bands around the VWAP to indicate potential areas of price extension or contraction. These bands are derived from multiplying the standard deviation of price by predetermined factors, offering traders a visual representation of potential price ranges.
Implied Volatility and Historical VolatilityThis indicator provides a visualization of two different volatility measures, aiding in understanding market perceptions and actual price movements. Remember to combine it with other technical analysis tools and risk management strategies for informed trading decisions. The two measures of volatility:
Implied Volatility: Based on the standard deviation of recent price changes, it represents the market's expectation of future volatility.
Historical Volatility: Measured by the daily high-low range as a percentage of the closing price, it reflects the actual volatility experienced recently. It is intended to be used along side the Mean and Standard Deviation Lines indicator.
Inputs:
Period (Days): Defines the number of past bars used to calculate both types of volatility.
Calculations:
Interpretation:
Comparing the lines: Divergence between the lines can indicate potential mispricing:
If the Implied Volatility is higher than the Historical Volatility, the market might be overestimating future volatility.
Conversely, if the Implied Volatility is lower, the market might be underestimating future volatility.
Monitoring trends: Track changes in both lines over time to identify potential shifts in volatility expectations or actual market behavior.
Limitations:
Assumes normality in price distribution, which may not always hold true.
Historical Volatility only reflects past behavior, not future expectations.
Consider other factors like market sentiment and news events for comprehensive volatility analysis.

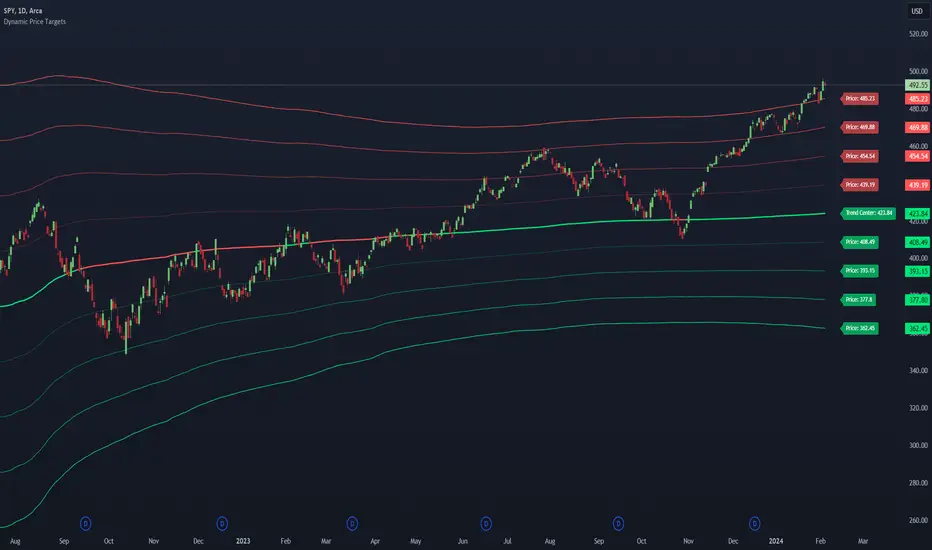
Dynamic Price Targets @shrilssDynamic Price Targets is a designed to provide traders with a comprehensive view of dynamic price levels based on Volume Weighted Moving Average (VWMA) and standard deviation. This script allows users to identify potential support and resistance zones, aiding in strategic decision-making during market analysis.
The script calculates the VWMA of a chosen price source over a specified length, establishing a dynamic baseline for market trends. The standard deviation is then used to derive multiple upper and lower targets, each representing a certain deviation from the VWMA. These levels are color-coded for clarity, with upper targets displayed in shades of red and lower targets in shades of green.
Modern Portfolio TheoryModern Portfolio Theory
The indicator is designed to apply the principles of Modern Portfolio Theory, a financial theory developed by Harry Markowitz. MPT aims to maximize portfolio returns for a given level of risk by diversifying investments.
User Inputs:
Users can customize various parameters, including the bar scale, risk-free rate, and the start year for the portfolio. Additionally, users can assign weights to different assets (symbols) in the portfolio.
Asset Selection:
Users can choose up to 10 different symbols (assets) for the portfolio. The script supports a variety of symbols, including cryptocurrencies such as BTCUSD and ETHUSD.
Weights and Allocation:
Users can assign weights to each selected asset, determining its percentage allocation in the portfolio. The script calculates the total portfolio weight to ensure it equals 100%. If total portfolio weight is lower then 100% you will see orange color with additional cash % bellow
If total portfolio weight is bigger then 100% you will see red big % warning.
Warning: (Total Weight must be 100%)
Cash Mode:
Risk and Return Calculation:
The script calculates the daily returns and standard deviation for each selected asset. These metrics are essential for assessing the risk and return of each asset, as well as the overall portfolio.
Scatter Plot Visualization:
The indicator includes a scatter plot that visualizes the risk-return profile of each asset. Each point on the plot represents an asset, and its position is determined by its risk (X-axis) and return (Y-axis).
Portfolio Optimization:
The script calculates the risk and return of the overall portfolio based on the selected assets and their weights. Based on the selected assets and their weights user can create optimal portfolio with preferable risk and return.
It then plots the portfolio point on the scatter plot, indicating its risk-return profile.
Additional Information:
The indicator provides a table displaying information about each selected asset, including its symbol, weight, and total portfolio weight. The table also shows the total portfolio weight and, if applicable, the percentage allocated to cash.
Visualization and Legend:
The script includes visual elements such as a legend, capital allocation line (CAL), and labels for risk-free rate and key information. This enhances the overall understanding of the portfolio's risk and return characteristics.
User Guidance:
The script provides informative labels and comments to guide users through the interpretation of the scatter plot, risk-return axes, and other key elements.
Interactivity:
Users can interact with the indicator on the TradingView platform, exploring different asset combinations and weightings to observe the resulting changes in the portfolio's risk and return.
In summary, this Pine Script serves as a comprehensive tool for traders and investors interested in applying Modern Portfolio Theory principles to optimize their portfolio allocations based on individual asset characteristics, risk preferences, and return

Z-score changeAs a wise man once said that:
1. beginners think in $ change
2. intermediates think in % change
3. pros think in Z change
Here is the "Z-score change" indicator that calculates up/down moves normalized by standard deviation (volatility) displayed as bar chart with 1,2 and 3 stdev levels.

CARNAC Elasticity IndicatorThe CARNAC Elasticity Indicator (EI) is a technical analysis tool designed for traders and investors using TradingView. It calculates the percentage deviation of the current price from an Exponential Moving Average (EMA) and helps traders identify potential overbought and oversold conditions in a financial instrument.
Key Features:
EMA Length: Users can customize the length of the Exponential Moving Average (EMA) used in the calculations by adjusting the "EMA Length" parameter in the indicator settings.
Percentage Deviation: The indicator calculates the percentage deviation of the current price from the EMA. Positive values indicate prices above the EMA, while negative values indicate prices below the EMA.
Maximum Deviations: The indicator tracks the maximum positive (above EMA) and negative (below EMA) percentage deviations over time, allowing traders to monitor extreme price movements.
Bands: Upper and lower bands are displayed on the indicator chart at 100 and -100, respectively. Additionally, dashed middle bands at 50 and -50 provide reference points for moderate deviations.
Dynamic Color Coding: The indicator uses dynamic color coding to highlight the current percentage deviation. It turns red for values above 50 (indicating potential overbought conditions), green for values below -50 (indicating potential oversold conditions), and purple for values in between.
How to Use:
Overbought Conditions: Watch for the percentage deviation to cross above 50, indicating potential overbought conditions. This might be a signal to consider selling or taking profits.
Oversold Conditions: Look for the percentage deviation to cross below -50, signaling potential oversold conditions. This could be an opportunity to consider buying or entering a long position.
Historical Extremes: Keep an eye on the upper and lower bands (100 and -100) to identify historical extremes in percentage deviation.
The CARNAC Elasticity Indicator can be a valuable tool for traders seeking to identify potential trend reversals and assess the strength of price movements. However, it should be used in conjunction with other technical analysis tools and risk management strategies for comprehensive trading decisions.

Rolling VWAP [QuantraSystems]Rolling VWAP
Introduction
The Rolling VWAP (R͜͡oll-VWAP) indicator modernizes the traditional VWAP by recalculating continuously on a rolling window, making it adept at pinpointing market trends and breakout points.
Its dual functionality includes both the dynamic rolling VWAP and a customizable anchored VWAP, enhanced by color-coded visual cues, thereby offering traders valuable flexibility and insight for their market analysis.
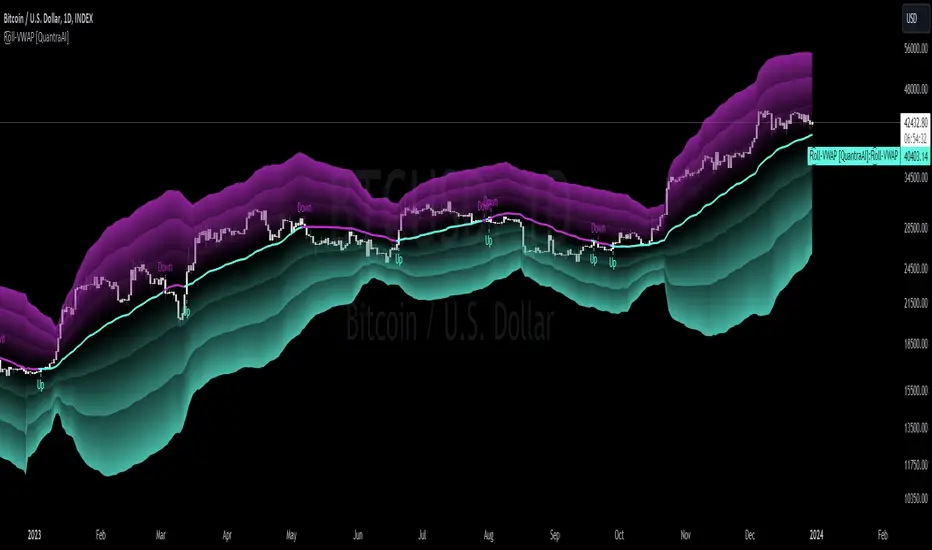
Legend
In the Image you can see the BTCUSD 1D Chart with the R͜͡oll-VWAP overlay.
You can see the individually activatable Standard Deviation (SD) Bands and the main VWAP Line.
It also features a Trend Signal which is deactivated by default and can be enabled if required.
Furthermore you can find the coloring of the VWAP line to represent the Trend.
In this case the trend itself is defined as:
Close being greater than the VWAP line -> Uptrend
Close below the VWAP line -> Downtrend
Notes
The R͜͡oll-VWAP can be used in a variety of ways.
Volatility adjusted expected range
This aims to identify in which range the asset is likely to move - according to the historical values the SD Bands are calculated and thus their according probabilities displayed.
Trend analysis
Trending above or below the VWAP shows up or down trends accordingly.
S/R Levels
Based on the probability distribution the 2. SD often works as a Resistance level and either mid line or 1. SD lines can act as S/R levels
Unsustainable levels
Based on the probability distributions a SD level of beyond 2.5, especially 3 and higher is hit very seldom and highly unsustainable.
This can either mean a mean reversion state or a momentum slowdown is necessary to get back to a sustainable level.
Please note that we always advise to find more confluence by additional indicators.
Traders are encouraged to test and determine the most suitable settings for their specific trading strategies and timeframes.
Methodology
The R͜͡oll-VWAP is based on the inbuilt TV VWAP.
It expands upon the limitations of having an anchored timeframe and thus a limited data set that is being reset constantly.
Instead we have integrated a rolling nature that continuously calculates the VWAP over a customizable lookback.
To also keep the base utility it is possible to use the anchored timeframes as well.
Furthermore the visualization has been improved and we added the coloring of the main VWAP line according to the Trend as stated above.
The applicable Trend signals are also part of that.
The parameter settings and also the visualizations allow for ample customizations by the trader.
For questions or recommendations, please feel free to seek contact in the comments.
Volatility ZigZagIt calculates and plots zigzag lines based on volatility and price movements. It has various inputs for customization, allowing you to adjust parameters like source data, length, deviation, line styling, and labeling options.
The indicator identifies pivot points in the price movement, drawing lines between these pivots based on the deviation from certain price levels or volatility measures.
The script labels various data points at the ZigZag pivot points on the chart. These labels provide information about different aspects of the price movement and volume around these pivot points. Here's a breakdown of what gets labeled:
Price Change: Indicates the absolute and average percentage change between the two pivot points. It displays the absolute or relative change in price as a percentage. Additionally, the average absolute price increase or the average rate of increase can also be labeled.
Volume: Shows the total volume and average volume between the two pivot points.
Number of Bars: Indicates the number of bars between the current and the last pivot point.
Reversal Price: Displays the price of the reversal point (the previous pivot).
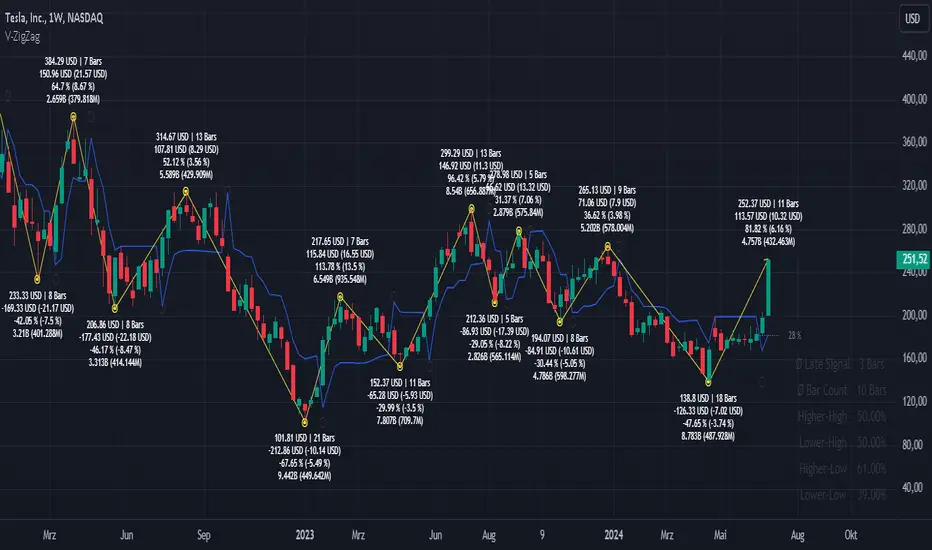
Machine Learning: STDEV Oscillator [YinYangAlgorithms]This Indicator aims to fill a gap within traditional Standard Deviation Analysis. Rather than its usual applications, this Indicator focuses on applying Standard Deviation within an Oscillator and likewise applying a Machine Learning approach to it. By doing so, we may hope to achieve an Adaptive Oscillator which can help display when the price is deviating from its standard movement. This Indicator may help display both when the price is Overbought or Underbought, and likewise, where the price may face Support and Resistance. The reason for this is that rather than simply plotting a Machine Learning Standard Deviation (STDEV), we instead create a High and a Low variant of STDEV, and then use its Highest and Lowest values calculated within another Deviation to create Deviation Zones. These zones may help to display these Support and Resistance locations; and likewise may help to show if the price is Overbought or Oversold based on its placement within these zones. This Oscillator may also help display Momentum when the High and/or Low STDEV crosses the midline (0). Lastly, this Oscillator may also be useful for seeing the spacing between the High and Low of the STDEV; large spacing may represent volatility within the STDEV which may be helpful for seeing when there is Momentum in the form of volatility.
Tutorial:
Above is an example of how this Indicator looks on BTC/USDT 1 Day. As you may see, when the price has parabolic movement, so does the STDEV. This is due to this price movement deviating from the mean of the data. Therefore when these parabolic movements occur, we create the Deviation Zones accordingly, in hopes that it may help to project future Support and Resistance locations as well as helping to display when the price is Overbought and Oversold.
If we zoom in a little bit, you may notice that the Support Zone (Blue) is smaller than the Resistance Zone (Orange). This is simply because during the last Bull Market there was more parabolic price deviation than there was during the Bear Market. You may see this if you refer to their values; the Resistance Zone goes to ~18k whereas the Support Zone is ~10.5k. This is completely normal and the way it is supposed to work. Due to the nature of how STDEV works, this Oscillator doesn’t use a 1:1 ratio and instead can develop and expand as exponential price action occurs.
The Neutral (0) line may also act as a Support and Resistance location. In the example above we can see how when the STDEV is below it, it acts as Resistance; and when it’s above it, it acts as Support.
This Neutral line may also provide us with insight as towards the momentum within the market and when it has shifted. When the STDEV is below the Neutral line, the market may be considered Bearish. When the STDEV is above the Neutral line, the market may be considered Bullish.
The Red Line represents the STDEV’s High and the Green Line represents the STDEV’s Low. When the STDEV’s High and Low get tight and close together, this may represent there is currently Low Volatility in the market. Low Volatility may cause consolidation to occur, however it also leaves room for expansion.
However, when the STDEV’s High and Low are quite spaced apart, this may represent High levels of Volatility in the market. This may mean the market is more prone to parabolic movements and expansion.
We will conclude our Tutorial here. Hopefully this has given you some insight into how applying Machine Learning to a High and Low STDEV then creating Deviation Zones based on it may help project when the Momentum of the Market is Bullish or Bearish; likewise when the price is Overbought or Oversold; and lastly where the price may face Support and Resistance in the form of STDEV.
If you have any questions, comments, ideas or concerns please don't hesitate to contact us.
HAPPY TRADING!
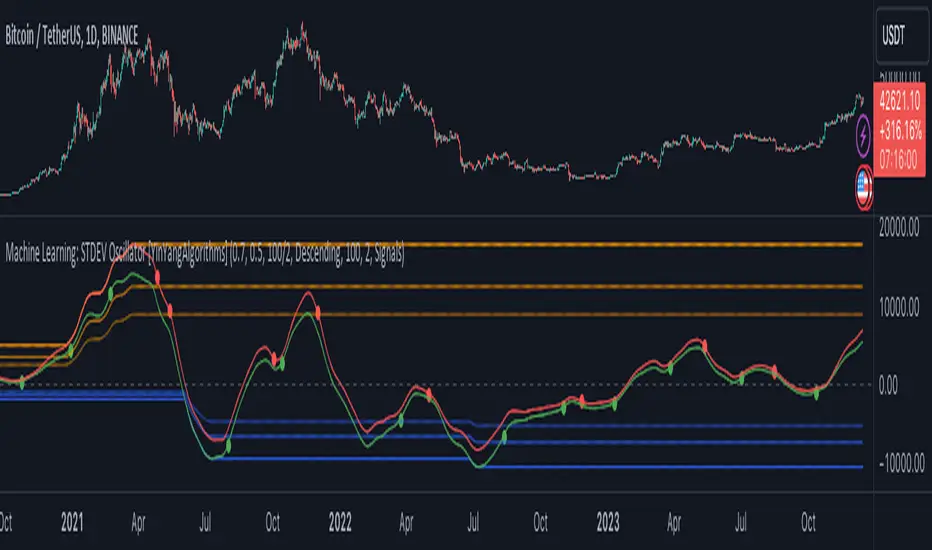
Linear Regression MTF + Bands
Multiple Time Frames (MTFs): The indicator allows you to view linear regression trends over three different time frames (TF1, TF2, TF3) simultaneously. This means a trader can observe short, medium, and long-term trends on a single chart, which is valuable for understanding overall market direction and making cross-timeframe comparisons.
Linear Regression Bands: For each time frame, the indicator calculates linear regression bands. These bands represent the expected price range based on past prices. The middle line is the linear regression line, and the upper and lower lines are set at a specified deviation from this line. Traders can use these bands to spot potential overbought or oversold conditions, or to anticipate future price movements.
History Bands: Looking at linear regression channels can be deceiving if the user does not understand the calculation. In order to see where the channel was at in history the user can display the history bands to see where price actual was in a non-repainting fashion.
Customization Options: Traders can customize various aspects of the indicator, such as whether to display each time frame, the length of the linear regression (how many past data points it considers), and the deviation for the bands. This flexibility allows traders to adapt the indicator to their specific trading style and the asset they are analyzing.
Alerts: The script includes functionality to set alerts based on the price crossing the upper or lower bands of any time frame. This feature helps traders to be notified of potential trading opportunities or risks without constantly monitoring the chart.
Examples
The 15minute linear regression is overlayed onto a 5 minute chart. We are able to see higher timeframe average and extremes. The average is the middle of the channel and the extremes are the outer edges of the bands. The bands are non-repainting meaning that is the actual value of the channel at that place in time.
Here multiple channels are shown at once. We have a linear regression for the 5, 15, and 60 minute charts. If your strategy uses those timeframes you can see the average and overbought/oversold areas without having to flip through charts.
In this example we show just the history bands. The bands could be thought of as a "don't diddle in the middle" area if your strategy is looking for reversals
You can extend the channel into the future via the various input settings.
Bollinger Bands StrategyBollinger Bands Strategy :
INTRODUCTION :
This strategy is based on the famous Bollinger Bands. These are constructed using a standard moving average (SMA) and the standard deviation of past prices. The theory goes that 90% of the time, the price is contained between these two bands. If it were to break out, this would mean either a reversal or a continuation. However, when a reversal occurs, the movement is weak, whereas when a continuation occurs, the movement is substantial and profits can be interesting. We're going to use BB to take advantage of this strong upcoming movement, while managing our risks reasonably. There's also a money management method for reinvesting part of the profits or reducing the size of orders in the event of substantial losses.
BOLLINGER BANDS :
The construction of Bollinger bands is straightforward. First, plot the SMA of the price, with a length specified by the user. Then calculate the standard deviation to measure price dispersion in relation to the mean, using this formula :
stdv = (((P1 - avg)^2 + (P2 - avg)^2 + ... + (Pn - avg)^2) / n)^1/2
To plot the two Bollinger bands, we then add a user-defined number of standard deviations to the initial SMA. The default is to add 2. The result is :
Upper_band = SMA + 2*stdv
Lower_band = SMA - 2*stdv
When the price leaves this channel defined by the bands, we obtain buy and sell signals.
PARAMETERS :
BB Length : This is the length of the Bollinger Bands, i.e. the length of the SMA used to plot the bands, and the length of the price series used to calculate the standard deviation. The default is 120.
Standard Deviation Multipler : adds or subtracts this number of times the standard deviation from the initial SMA. Default is 2.
SMA Exit Signal Length : Exit signals for winning and losing trades are triggered by another SMA. This parameter defines the length of this SMA. The default is 110.
Max Risk per trade (in %) : It's the maximum percentage the user can lose in one trade. The default is 6%.
Fixed Ratio : This is the amount of gain or loss at which the order quantity is changed. The default is 400, meaning that for each $400 gain or loss, the order size is increased or decreased by a user-selected amount.
Increasing Order Amount : This is the amount to be added to or subtracted from orders when the fixed ratio is reached. The default is $200, which means that for every $400 gain, $200 is reinvested in the strategy. On the other hand, for every $400 loss, the order size is reduced by $200.
Initial capital : $1000
Fees : Interactive Broker fees apply to this strategy. They are set at 0.18% of the trade value.
Slippage : 3 ticks or $0.03 per trade. Corresponds to the latency time between the moment the signal is received and the moment the order is executed by the broker.
Important : A bot has been used to test the different parameters and determine which ones maximize return while limiting drawdown. This strategy is the most optimal on BITSTAMP:BTCUSD in 8h timeframe with the following parameters :
BB Length = 120
Standard Deviation Multipler = 2
SMA Exit Signal Length = 110
Max Risk per trade (in %) = 6%
ENTER RULES :
The entry rules are simple:
If close > Upper_band it's a LONG signal
If close < Lower_band it's a SHORT signal
EXIT RULES :
If we are LONG and close < SMA_EXIT, position is closed
If we are SHORT and close > SMA_EXIT, the position is closed
Positions close automatically if they lose more than 6% to limit risk
RISK MANAGEMENT :
This strategy is subject to losses. We manage our risk using the exit SMA or using a SL sets to 6%. This SMA gives us exit signals when the price closes below or above, thus limiting losses. If the signal arrives too late, the position is closed after a loss of 6%.
MONEY MANAGEMENT :
The fixed ratio method was used to manage our gains and losses. For each gain of an amount equal to the fixed ratio value, we increase the order size by a value defined by the user in the "Increasing order amount" parameter. Similarly, each time we lose an amount equal to the value of the fixed ratio, we decrease the order size by the same user-defined value. This strategy increases both performance and drawdown.
NOTE :
Please note that the strategy is backtested from 2017-01-01. As the timeframe is 8h, this strategy is a medium/long-term strategy. That's why only 51 trades were closed. Be careful, as the test sample is small and performance may not necessarily reflect what may happen in the future.
Enjoy the strategy and don't forget to take the trade :)

Z-Score - AsymmetrikZ-Score-Asymmetrik User Manual
Introduction
The Z-Score Indicator is a powerful tool used in technical analysis to measure how far a data point is from the mean value of a dataset, measured in terms of standard deviations. This indicator helps traders identify potential overbought or oversold conditions in the market.
This user manual provides a comprehensive guide on how to use the Z-Score Indicator in TradingView.
0. Quickstart
- Set the thresholds based on your asset (number of standard deviations that you consider being extreme for this asset / timeframe).
- Red background indicates a possible overbought situation, green background an oversold one.
- The color and direction of the Z-Score Line acts as a confirmation of the trend reversal.
1. Indicator Overview
The Z-Score Indicator, also known as the Z-Score Oscillator, is designed to display the Z-Score of a selected financial instrument on your TradingView chart. The Z-Score measures how many standard deviations an asset's price is from its mean (average) price over a specified period.
The indicator consists of the following components:
- Z-Score Line: This line represents the Z-Score value and is displayed on the indicator panel.
- Background Color: The background color of the indicator panel changes based on user-defined thresholds.
2. Inputs
The indicator provides several customizable inputs to tailor it to your specific trading preferences:
- Number of Periods: This input allows you to define the number of periods over which the Z-Score will be calculated. A longer period will provide a smoother Z-Score line but may be less responsive to recent price changes.
- Z-Score Low Threshold: Sets the lower threshold value for the Z-Score. When the Z-Score crosses below this threshold, the background color of the indicator panel changes accordingly.
- Z-Score High Threshold: Sets the upper threshold value for the Z-Score. When the Z-Score crosses above this threshold, the background color of the indicator panel changes accordingly.
3. How to Use the Indicator
Here are the steps to use the Z-Score Indicator:
- Adjust Parameters: Modify the indicator's inputs as needed. You can change the number of periods for the Z-Score calculation and set your desired low and high thresholds.
- Interpret the Indicator: Observe the Z-Score line on the indicator panel. It fluctuates above and below zero. Pay attention to the background color changes when the Z-Score crosses your specified thresholds.
4. Interpreting the Indicator
- Z-Score Line: The Z-Score line represents the current Z-Score value. When it is above zero, it suggests that the asset's price is above the mean, indicating potential overvaluation. When below zero, it suggests undervaluation.
- Background Color: The background color of the indicator panel changes based on the Z-Score's position relative to the specified thresholds. Green indicates the Z-Score is below the low threshold (potential undervaluation), while red indicates it is above the high threshold (potential overvaluation).
- Z-Score Line Color: The color of the Z-Score line shows that the Z-Score is trending up compared to its moving average. This can be used as a validation of the background color.
5. Customization Options
You can customize the Z-Score Indicator in the following ways:
- Adjust Inputs: Modify the number of periods and the Z-Score thresholds.
- Change Line and Background Colors: You can customize the colors of the Z-Score line and background by editing the indicator's script.
6. Troubleshooting
If you encounter any issues while using the Z-Score Indicator, make sure to check the following:
- Ensure that the indicator is applied correctly to your chart.
- Verify that the indicator's inputs match your intended settings.
- Contact me for more support if needed
7. Conclusion
The Z-Score Indicator is a valuable tool for traders and investors to identify potential overbought and oversold conditions in the market. By understanding how the Z-Score works and customizing it to your preferences, you can integrate it into your trading strategy to make informed decisions.
Remember that trading involves risk, and it's essential to combine technical indicators like the Z-Score with other analysis methods and risk management strategies for successful trading.

Bias of Volume Share inside Std Deviation ChannelThe "Bias of Volume Share inside STD Deviation Channel" indicator is a powerful tool for traders aiming to assess market sentiment within a standard deviation (STD) price channel. This indicator calculates the bullish or bearish bias by analysing the share of volume within the standard deviation channel and provides valuable insights for decision-making.
Usage:
This indicator is a valuable tool for traders seeking to gain in-depth insights into market sentiment within a specified price channel. By focusing on price movements that fall within the standard distribution range and filtering out noise and market manipulations, it provides a clear view of prevailing bullish or bearish biases. Traders can leverage this information to make well-informed trading decisions that align with current market conditions, enhancing their trading strategies and potential for success.
Please ensure you review and adhere to the terms of the Mozilla Public License 2.0, as outlined in the indicator's source code.

Advanced Weighted Residual Arbitrage AnalyzerThe Advanced Weighted Residual Arbitrage Analyzer is a sophisticated tool designed for traders aiming to exploit price deviations between various asset pairs. By examining the differences in normalized price relations and their weighted residuals, this indicator provides insights into potential arbitrage opportunities in the market.
Key Features:
Multiple Relation Analysis: Analyze up to five different asset relations simultaneously, offering a comprehensive view of potential arbitrage setups.
Normalization Functions: Choose from a variety of normalization techniques like SMA, EMA, WMA, and HMA to ensure accurate comparisons between different price series.
Dynamic Weighting: Residuals are weighted based on their correlation, ensuring that stronger correlations have a more pronounced impact on the analysis. Weighting can be adjusted using several functions including square, sigmoid, and logistic.
Regression Flexibility: Incorporate linear, polynomial, or robust regression to calculate residuals, tailoring the analysis to different market conditions.
Customizable Display: Decide which plots to display for clarity and focus, including normalized relations, weighted residuals, and the difference between the screen relation and the average weighted residual.
Usage Guidelines:
Configure the asset pairs you wish to analyze using the Symbol Relations group in the settings.
Adjust the normalization, volatility, regression, and weighting functions based on your preference and the specific characteristics of the asset pairs.
Monitor the weighted residuals for deviations from the mean. Larger deviations suggest stronger arbitrage opportunities.
Use the difference plot (between the screen relation and average weighted residual) as a quick visual cue for potential trade setups. When this plot deviates significantly from zero, it indicates a possible arbitrage opportunity.
Regularly update and adjust the parameters to account for changing market conditions and ensure the most accurate analysis.
In the Advanced Weighted Residual Arbitrage Analyzer , the value set in Alert Threshold plays a crucial role in delineating a normalized band. This band serves as a guide to identify significant deviations and potential trading opportunities.
When we observe the plots of the green line and the purple line, the Alert Threshold provides a boundary for these plots. The following points explain the significance:
Breach of the Band: When either the green or purple line crosses above or below the Alert Threshold , it indicates a significant deviation from the mean. This breach can be interpreted as a potential trading signal, suggesting a possible arbitrage opportunity.
Convergence to the Mean: If the green line converges with the purple line , it denotes that the price relation has reverted to its mean. This convergence typically suggests that the arbitrage opportunity has been exhausted, and the market dynamics are returning to equilibrium.
Trade Execution: A trader can consider entering a trade when the lines breach the Alert Threshold . The return of the green line to align closely with the purple line can be seen as a signal to exit the trade, capitalizing on the reversion to the mean.
By monitoring these plots in conjunction with the Alert Threshold , traders can gain insights into market imbalances and exploit potential arbitrage opportunities. The convergence and divergence of these lines, relative to the normalized band, serve as valuable visual cues for trade initiation and termination.
When you're analyzing relations between two symbols (for instance, BINANCE:SANDUSDT/BINANCE:NEARUSDT ), you're essentially looking at the price relationship between the two underlying assets. This relationship provides insights into potential imbalances between the assets, which arbitrage traders can exploit.
Breach of the Lower Band: If the purple line touches or crosses below the lower Alert Threshold , it indicates that the first symbol (in our example, SANDUSDT ) is undervalued relative to the second symbol ( NEARUSDT ). In practical terms:
Action: You would consider buying the first symbol ( SANDUSDT ) and selling the second symbol ( NEARUSDT ).
Rationale: The expectation is that the price of the first symbol will rise, or the price of the second symbol will fall, or both, thereby converging back to their historical mean relationship.
Breach of the Upper Band: Conversely, if the difference plot touches or crosses above the upper Alert Threshold , it suggests that the first symbol is overvalued compared to the second. This implies:
Action: You'd consider selling the first symbol ( SANDUSDT ) and buying the second symbol ( NEARUSDT ).
Rationale: The anticipation here is that the price of the first symbol will decrease, or the price of the second will increase, or both, bringing the relationship back to its historical average.
Convergence to the Mean: As mentioned earlier, when the green line aligns closely with the purple line, it's an indication that the assets have returned to their typical price relationship. This serves as a signal for traders to consider closing out their positions, locking in the gains from the arbitrage opportunity.
It's important to note that when you're trading based on symbol relations, you're essentially betting on the relative performance of the two assets. This strategy, often referred to as "pairs trading," seeks to capitalize on price imbalances between related financial instruments. By taking opposing positions in the two symbols, traders aim to profit from the eventual reversion of the price difference to the mean.

Opening Range Gap + Std Dev [starclique]The ICT Opening Range Gap is a concept taught by Inner Circle Trader and is discussed in the videos: 'One Trading Setup For Life' and 2023 ICT Mentorship - Opening Range Gap Repricing Macro
ORGs, or Opening Range Gaps, are gaps that form only on the Regular Trading Hours chart.
The Regular Trading Hours gap occurs between 16:15 PM - 9:29 AM EST (UTC-4)
These times are considered overnight trading, so it is useful to filter the PA (price action) formed there.
The RTH option is only available for futures contracts and continuous futures from CME Group.
To change your chart to RTH, first things first, make sure you’re looking at a futures contract for an asset class, then on the bottom right of your chart, you’ll see ETH (by default) - Click on that, and change it to RTH.
Now your charts are filtering the price action that happened overnight.
To draw out your gap, use the Close of the 4:14 PM candle and the open of the 9:30 AM candle.
How is this concept useful?
Well, It can be used in many ways.
---
How To Use The ORG
One of the ways you can use the opening range gap is simply as support and resistance
If we extend out the ORG from the example above, we can see that there is a clean retest of the opening range gap high after breaking structure to the upside and showing acceptance outside of the gap after consolidating within it.
The ORG High (4:14 Candle Close in this case) was used as support.
We then see an expansion to the upside.
Another way to implement the ORG is by using it as a draw on liquidity (magnet for price)
In this example, if we looked to the left, there was a huge ORG to the downside, leaving a massive gap.
The market will want to rebalance that gap during the regular trading hours.
The market rallies higher, rejects, comes down to clear the current days ORG low, then closes.
That is one example of how you can combine liquidity & ICT market structure concepts with Opening Range Gaps to create a story in the charts.
Now let’s discuss standard deviations.
---
Standard Deviations
Standard Deviations are essentially projection levels for ranges / POIs (Point of Interests)
By this I mean, if you have a range, and you would like to see where it could potentially expand to, you’d place your fibonacci retracement tool on and high and low of the range, then use extension levels to find specific price points where price might reject from.
Since 0 and 1 are your Range High and Low respectively, your projection levels would be something like 1.5, 2, 2.5, and 3, for the extension from your 1 Fib Level, and -0.5, -1, -1.5, and -2 for your 0 Fib level.
The -1 and 2 level produce a 1:1 projection of your range low and high, meaning, if you expect price to expand as much as it did from the range low to range high, then you can project a -1 and 2 on your Fib, and it would show you what ICT calls “symmetrical price”
Now, how are standard deviations relevant here?
Well, if you’ve been paying attention to ICT’s recent videos, you would’ve caught that he’s recently started using Standard Deviation levels on breakers.
So my brain got going while watching his video on ORGs, and I decided to place the fib on the ORG high and low and see what it’d produce.
The results were very interesting.
Using this same example, if we place our fib on the ORG High and Low, and add some projection levels, we can see that we rejected right at the -2 Standard Deviation Level.
---
You can see that I also marked out the EQ (Equilibrium, 50%, 0.5 of Fib) of the ORG. This is because we can use this level as a take profit level if we’re using an old ORG as our draw.
In days like these, where the gap formed was within a consolidation, and it continued to consolidate within the ORG zone that we extended, we can use the EQ in the same way we’d use an EQ for a range.
If it’s showing acceptance above the EQ, we are bullish, and expect the high of the ORG to be tapped, and vice versa.
---
Using The Indicator
Here’s where our indicator comes in play.
To avoid having to do all this work of zooming in and marking out the close and open of the respective ORG candles, we created the Opening Range Gap + Standard Deviations Indicator, with the help of our dedicated Star Clique coder, a1tmaniac.
With the ORG + STD DEV indicator, you will be able to view ORG’s and their projections on the ETH (Electronic Trading Hours) chart.
---
Features
Range Box
- Change the color of your Opening Range Gap to your liking
- Enable or disable the box from appearing using the checkbox
Range Midline
- Change the color of your Opening Range Gap Equilibrium
- Enable or disable the midline from appearing using the checkbox
Std. Dev
- Add whichever standard deviation levels you’d like.
- By default, the indicator comes with 0.5, 1, 1.5, and 2 standard deviation levels.
- Ensure that you add a comma ( , ) in between each standard deviation level
- Enable or disable the standard deviations from appearing using the opacity of the color (change to 0%)
Labels / Offset
- Adjust the offset of the label for the Standard Deviations
- Enable or disable the Labels from appearing using the checkbox
Time
- Adjust the time used for the indicators range
- If you’d like to use this for a Session or ICT Killzone instead, adjust the time
- Adjust the timezone used for the time referenced
- Options are UTC, US (UTC-4, New York Local Time) or UK (UTC+1, London Time)
- By default, the indicator is set to US

Z-Score Heikin-Ashi TransformedThe Z-Score Heikin-Ashi Transformed (𝘡 𝘏-𝘈) indicator is a powerful technical tool that combines the principles of Z-Score and Heikin Ashi to provide traders with a smoothed representation of price movements and a standardized measure of market volatility.
The 𝘡 𝘏-𝘈 indicator applies the Z-Score calculation to price data and then transforms the resulting Z-Scores using the Heikin Ashi technique. Understanding the individual components of Z-Score and Heikin Ashi will provide a foundation for comprehending the methodology and unique features of this indicator.
Z-Score:
Z-Score is a statistical measure that quantifies the distance between a data point and the mean, relative to the standard deviation. It provides a standardized value that allows traders to compare different data points on a common scale. In the context of the 𝘡 𝘏-𝘈 indicator, Z-Score is calculated based on price data, enabling the identification of extreme price movements and the assessment of their significance.
Heikin Ashi:
Heikin Ashi is a popular charting technique that aims to filter out market noise and provide a smoother representation of price trends. It involves calculating each candlestick based on the average of the previous candle's open, close, high, and low prices. This approach results in a chart that reduces the impact of short-term price fluctuations and reveals the underlying trend more clearly.
Methodology:
The 𝘡 𝘏-𝘈 indicator starts by calculating the Z-Score of the price data, which provides a standardized measure of how far each price point deviates from the mean. Next, the resulting Z-Scores are transformed using the Heikin Ashi technique. Each Z-Score value is modified according to the Heikin Ashi formula, which incorporates the average of the previous Heikin Ashi candle's open and close prices. This transformation smooths out the Z-Score values and reduces the impact of short-term price fluctuations, providing a clearer view of market trends.
This tool enables traders to identify significant price movements and assess their relative strength compared to historical data. Positive transformed Z-Scores indicate that prices are above the average, suggesting potential overbought conditions, while negative transformed Z-Scores indicate prices below the average, suggesting potential oversold conditions. Traders can utilize this information to identify potential reversals, confirm trend strength, and generate trading signals.
Utility:
The indicator offers valuable insights into price volatility and trend analysis. By combining the standardized measure of Z-Score with the smoothing effect of Heikin Ashi, traders can make more informed trading decisions and improve their understanding of market dynamics. 𝘡 𝘏-𝘈 can be used in various trading strategies, including identifying overbought or oversold conditions, confirming trend reversals, and establishing entry and exit points.
Note that the 𝘡 𝘏-𝘈 should be used in conjunction with other technical indicators and analysis tools to validate signals and avoid false positives. Additionally, traders are encouraged to conduct thorough backtesting and experimentation with different parameter settings to optimize the effectiveness of the indicator for their specific trading approach.
Key Features:
Optional Reversion Doritos
Adjustable Reversion Threshold
2 Adjustable EMAs
Example Charts:
See Also:
On Balance Volume Heikin-Ashi Transformed