DynamicPeriodPublicDynamic Period Calculation Library
This library provides tools for adaptive period determination, useful for creating indicators or strategies that automatically adjust to market conditions.
Overview
The Dynamic Period Library calculates adaptive periods based on pivot points, enabling the creation of responsive indicators and strategies that adjust to market volatility.
Key Features
Dynamic Periods: Computes periods using distances between pivot highs and lows.
Customizable Parameters: Users can adjust detection settings and period constraints.
Robust Handling: Includes fallback mechanisms for cases with insufficient pivot data.
Use Cases
Adaptive Indicators: Build tools that respond to market volatility by adjusting their periods dynamically.
Dynamic Strategies: Enhance trading strategies by integrating pivot-based period adjustments.
Function: `dynamic_period`
Description
Calculates a dynamic period based on the average distances between pivot highs and lows.
Parameters
`left` (default: 5): Number of left-hand bars for pivot detection.
`right` (default: 5): Number of right-hand bars for pivot detection.
`numPivots` (default: 5): Minimum pivots required for calculation.
`minPeriod` (default: 2): Minimum allowed period.
`maxPeriod` (default: 50): Maximum allowed period.
`defaultPeriod` (default: 14): Fallback period if no pivots are found.
Returns
A dynamic period calculated based on pivot distances, constrained by `minPeriod` and `maxPeriod`.
Example
//@version=6
import CrimsonVault/DynamicPeriodPublic/1
left = input.int(5, "Left bars", minval = 1)
right = input.int(5, "Right bars", minval = 1)
numPivots = input.int(5, "Number of Pivots", minval = 2)
period = DynamicPeriodPublic.dynamic_period(left, right, numPivots)
plot(period, title = "Dynamic Period", color = color.blue)
Implementation Notes
Pivot Detection: Requires sufficient historical data to identify pivots accurately.
Edge Cases: Ensures a default period is applied when pivots are insufficient.
Constraints: Limits period values to a user-defined range for stability.
Statistics

lib_kernelLibrary "lib_kernel"
Library "lib_kernel"
This is a tool / library for developers, that contains several common and adapted kernel functions as well as a kernel regression function and enum to easily select and embed a list into the settings dialog.
How to Choose and Modify Kernels in Practice
Compact Support Kernels (e.g., Epanechnikov, Triangular): Use for localized smoothing and emphasizing nearby data.
Oscillatory Kernels (e.g., Wave, Cosine): Ideal for detecting periodic patterns or mean-reverting behavior.
Smooth Tapering Kernels (e.g., Gaussian, Logistic): Use for smoothing long-term trends or identifying global price behavior.
kernel_Epanechnikov(u)
Parameters:
u (float)
kernel_Epanechnikov_alt(u, sensitivity)
Parameters:
u (float)
sensitivity (float)
kernel_Triangular(u)
Parameters:
u (float)
kernel_Triangular_alt(u, sensitivity)
Parameters:
u (float)
sensitivity (float)
kernel_Rectangular(u)
Parameters:
u (float)
kernel_Uniform(u)
Parameters:
u (float)
kernel_Uniform_alt(u, sensitivity)
Parameters:
u (float)
sensitivity (float)
kernel_Logistic(u)
Parameters:
u (float)
kernel_Logistic_alt(u)
Parameters:
u (float)
kernel_Logistic_alt2(u, sigmoid_steepness)
Parameters:
u (float)
sigmoid_steepness (float)
kernel_Gaussian(u)
Parameters:
u (float)
kernel_Gaussian_alt(u, sensitivity)
Parameters:
u (float)
sensitivity (float)
kernel_Silverman(u)
Parameters:
u (float)
kernel_Quartic(u)
Parameters:
u (float)
kernel_Quartic_alt(u, sensitivity)
Parameters:
u (float)
sensitivity (float)
kernel_Biweight(u)
Parameters:
u (float)
kernel_Triweight(u)
Parameters:
u (float)
kernel_Sinc(u)
Parameters:
u (float)
kernel_Wave(u)
Parameters:
u (float)
kernel_Wave_alt(u)
Parameters:
u (float)
kernel_Cosine(u)
Parameters:
u (float)
kernel_Cosine_alt(u, sensitivity)
Parameters:
u (float)
sensitivity (float)
kernel(u, select, alt_modificator)
wrapper for all standard kernel functions, see enum Kernel comments and function descriptions for usage szenarios and parameters
Parameters:
u (float)
select (series Kernel)
alt_modificator (float)
kernel_regression(src, bandwidth, kernel, exponential_distance, alt_modificator)
wrapper for kernel regression with all standard kernel functions, see enum Kernel comments for usage szenarios. performance optimized version using fixed bandwidth and target
Parameters:
src (float) : input data series
bandwidth (simple int) : sample window of nearest neighbours for the kernel to process
kernel (simple Kernel) : type of Kernel to use for processing, see Kernel enum or respective functions for more details
exponential_distance (simple bool) : if true this puts more emphasis on local / more recent values
alt_modificator (float) : see kernel functions for parameter descriptions. Mostly used to pronounce emphasis on local values or introduce a decay/dampening to the kernel output

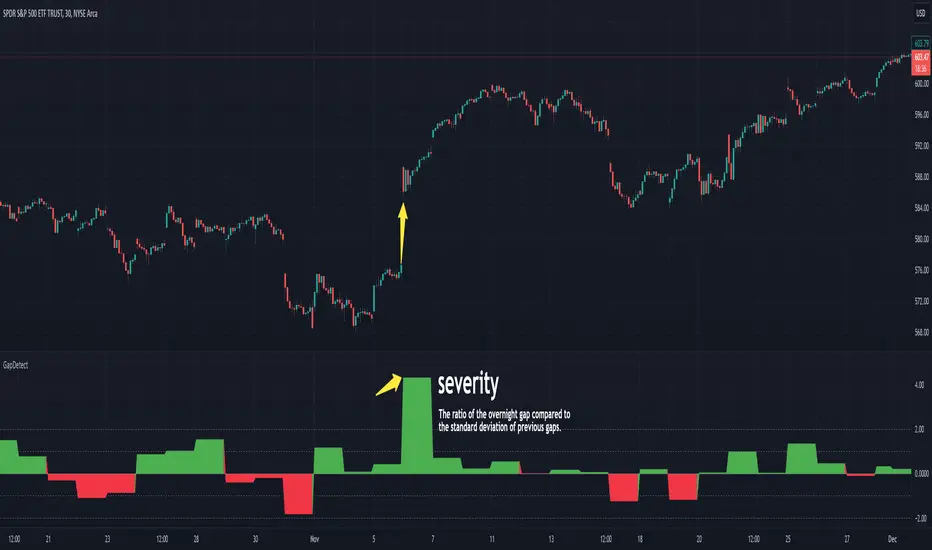
GapDetectGap Severity Analysis Library
This library, GapDetect , simplifies the identification and evaluation of overnight gaps by leveraging statistical metrics such as standard deviation and percentage moves. It is ideal for detecting large abnormal gaps which may be used to modify how strategies may decide to enter or exit.
Key Features:
Overnight Gap Detection
Provides two core functions:
today : Computes the value of today's overnight gap.
todayPercent : Computes the percentage change for today's overnight gap.
Volatility Analysis
Includes functions for statistical gap analysis:
normal : Calculates the normal daily standard deviation of the overnight gap, filtering outliers using customizable thresholds.
normalPercent : Similar to normal , but for percentage-based gap moves.
Gap Severity Metric
severity : a positive or negative value that represents the ratio of the current overnight move compared to the standard deviation of previous ones.
Customizable Parameters
Supports custom session specifications, resolutions, and outlier thresholds.
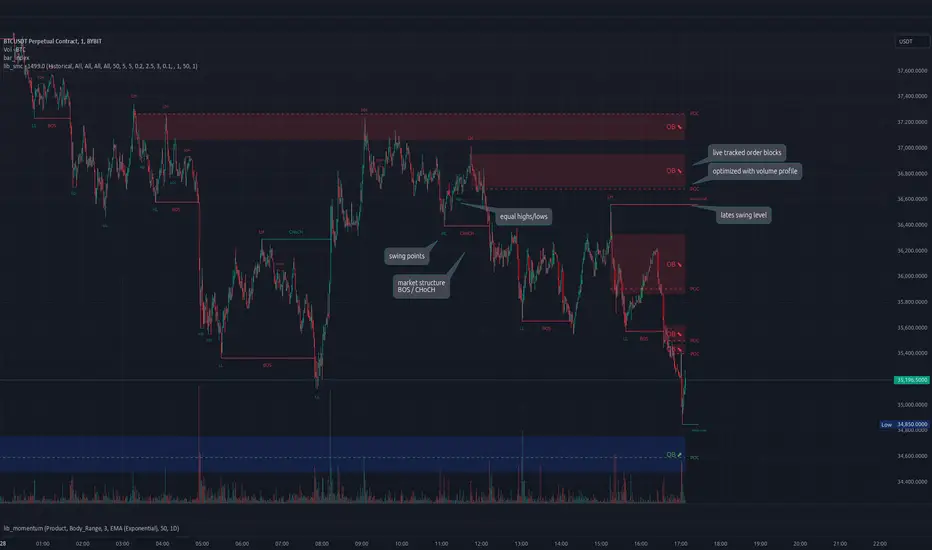
lib_smcLibrary "lib_smc"
This is an adaptation of LuxAlgo's Smart Money Concepts indicator with numerous changes. Main changes include integration of object based plotting, plenty of performance improvements, live tracking of Order Blocks, integration of volume profiles to refine Order Blocks, and many more.
This is a library for developers, if you want this converted into a working strategy, let me know.
buffer(item, len, force_rotate)
Parameters:
item (float)
len (int)
force_rotate (bool)
buffer(item, len, force_rotate)
Parameters:
item (int)
len (int)
force_rotate (bool)
buffer(item, len, force_rotate)
Parameters:
item (Profile type from robbatt/lib_profile/32)
len (int)
force_rotate (bool)
swings(len)
INTERNAL: detect swing points (HH and LL) in given range
Parameters:
len (simple int) : range to check for new swing points
Returns: values are the price level where and if a new HH or LL was detected, else na
method init(this)
Namespace types: OrderBlockConfig
Parameters:
this (OrderBlockConfig)
method delete(this)
Namespace types: OrderBlock
Parameters:
this (OrderBlock)
method clear_broken(this, broken_buffer)
INTERNAL: delete internal order blocks box coordinates if top/bottom is broken
Namespace types: map
Parameters:
this (map)
broken_buffer (map)
Returns: any_bull_ob_broken, any_bear_ob_broken, broken signals are true if an according order block was broken/mitigated, broken contains the broken block(s)
create_ob(id, mode, start_t, start_i, top, end_t, end_i, bottom, break_price, early_confirmation_price, config, init_plot, force_overlay)
INTERNAL: set internal order block coordinates
Parameters:
id (int)
mode (int) : 1: bullish, -1 bearish block
start_t (int)
start_i (int)
top (float)
end_t (int)
end_i (int)
bottom (float)
break_price (float)
early_confirmation_price (float)
config (OrderBlockConfig)
init_plot (bool)
force_overlay (bool)
Returns: signals are true if an according order block was broken/mitigated
method align_to_profile(block, align_edge, align_break_price)
Namespace types: OrderBlock
Parameters:
block (OrderBlock)
align_edge (bool)
align_break_price (bool)
method create_profile(block, opens, tops, bottoms, closes, values, resolution, vah_pc, val_pc, args, init_calculated, init_plot, force_overlay)
Namespace types: OrderBlock
Parameters:
block (OrderBlock)
opens (array)
tops (array)
bottoms (array)
closes (array)
values (array)
resolution (int)
vah_pc (float)
val_pc (float)
args (ProfileArgs type from robbatt/lib_profile/32)
init_calculated (bool)
init_plot (bool)
force_overlay (bool)
method create_profile(block, resolution, vah_pc, val_pc, args, init_calculated, init_plot, force_overlay)
Namespace types: OrderBlock
Parameters:
block (OrderBlock)
resolution (int)
vah_pc (float)
val_pc (float)
args (ProfileArgs type from robbatt/lib_profile/32)
init_calculated (bool)
init_plot (bool)
force_overlay (bool)
track_obs(swing_len, hh, ll, top, btm, bull_bos_alert, bull_choch_alert, bear_bos_alert, bear_choch_alert, min_block_size, max_block_size, config_bull, config_bear, init_plot, force_overlay, enabled, extend_blocks, clear_broken_buffer_before, align_edge_to_value_area, align_break_price_to_poc, profile_args_bull, profile_args_bear, use_soft_confirm, soft_confirm_offset, use_retracements_with_FVG_out)
Parameters:
swing_len (int)
hh (float)
ll (float)
top (float)
btm (float)
bull_bos_alert (bool)
bull_choch_alert (bool)
bear_bos_alert (bool)
bear_choch_alert (bool)
min_block_size (float)
max_block_size (float)
config_bull (OrderBlockConfig)
config_bear (OrderBlockConfig)
init_plot (bool)
force_overlay (bool)
enabled (bool)
extend_blocks (simple bool)
clear_broken_buffer_before (simple bool)
align_edge_to_value_area (simple bool)
align_break_price_to_poc (simple bool)
profile_args_bull (ProfileArgs type from robbatt/lib_profile/32)
profile_args_bear (ProfileArgs type from robbatt/lib_profile/32)
use_soft_confirm (simple bool)
soft_confirm_offset (float)
use_retracements_with_FVG_out (simple bool)
method draw(this, config, extend_only)
Namespace types: OrderBlock
Parameters:
this (OrderBlock)
config (OrderBlockConfig)
extend_only (bool)
method draw(blocks, config)
INTERNAL: plot order blocks
Namespace types: array
Parameters:
blocks (array)
config (OrderBlockConfig)
method draw(blocks, config)
INTERNAL: plot order blocks
Namespace types: map
Parameters:
blocks (map)
config (OrderBlockConfig)
method cleanup(this, ob_bull, ob_bear)
removes all Profiles that are older than the latest OrderBlock from this profile buffer
Namespace types: array
Parameters:
this (array type from robbatt/lib_profile/32)
ob_bull (OrderBlock)
ob_bear (OrderBlock)
_plot_swing_points(mode, x, y, show_swing_points, linecolor_swings, keep_history, show_latest_swings_levels, trail_x, trail_y, trend)
INTERNAL: plot swing points
Parameters:
mode (int) : 1: bullish, -1 bearish block
x (int) : x-coordingate of swing point to plot (bar_index)
y (float) : y-coordingate of swing point to plot (price)
show_swing_points (bool) : switch to enable/disable plotting of swing point labels
linecolor_swings (color) : color for swing point labels and lates level lines
keep_history (bool) : weater to remove older swing point labels and only keep the most recent
show_latest_swings_levels (bool)
trail_x (int) : x-coordinate for latest swing point (bar_index)
trail_y (float) : y-coordinate for latest swing point (price)
trend (int) : the current trend 1: bullish, -1: bearish, to determine Strong/Weak Low/Highs
_pivot_lvl(mode, trend, hhll_x, hhll, super_hhll, filter_insignificant_internal_breaks)
INTERNAL: detect whether a structural level has been broken and if it was in trend direction (BoS) or against trend direction (ChoCh), also track the latest high and low swing points
Parameters:
mode (simple int) : detect 1: bullish, -1 bearish pivot points
trend (int) : current trend direction
hhll_x (int) : x-coordinate of newly detected hh/ll (bar_index)
hhll (float) : y-coordinate of newly detected hh/ll (price)
super_hhll (float) : level/y-coordinate of superior hhll (if this is an internal structure pivot level)
filter_insignificant_internal_breaks (bool) : if true pivot points / internal structure will be ignored where the wick in trend direction is longer than the opposite (likely to push further in direction of main trend)
Returns: coordinates of internal structure that has been broken (x,y): start of structure, (trail_x, trail_y): tracking hh/ll after structure break, (bos_alert, choch_alert): signal whether a structural level has been broken
_plot_structure(x, y, is_bos, is_choch, line_color, line_style, label_style, label_size, keep_history)
INTERNAL: plot structural breaks (BoS/ChoCh)
Parameters:
x (int) : x-coordinate of newly broken structure (bar_index)
y (float) : y-coordinate of newly broken structure (price)
is_bos (bool) : whether this structural break was in trend direction
is_choch (bool) : whether this structural break was against trend direction
line_color (color) : color for the line connecting the structural level and the breaking candle
line_style (string) : style (line.style_dashed/solid) for the line connecting the structural level and the breaking candle
label_style (string) : style (label.style_label_down/up) for the label above/below the line connecting the structural level and the breaking candle
label_size (string) : size (size.small/tiny) for the label above/below the line connecting the structural level and the breaking candle
keep_history (bool) : weater to remove older swing point labels and only keep the most recent
structure_values(length, super_hh, super_ll, filter_insignificant_internal_breaks)
detect (and plot) structural breaks and the resulting new trend
Parameters:
length (simple int) : lookback period for swing point detection
super_hh (float) : level/y-coordinate of superior hh (for internal structure detection)
super_ll (float) : level/y-coordinate of superior ll (for internal structure detection)
filter_insignificant_internal_breaks (bool) : if true pivot points / internal structure will be ignored where the wick in trend direction is longer than the opposite (likely to push further in direction of main trend)
Returns: trend: direction 1:bullish -1:bearish, (bull_bos_alert, bull_choch_alert, top_x, top_y, trail_up_x, trail_up): whether and which level broke in a bullish direction, trailing high, (bbear_bos_alert, bear_choch_alert, tm_x, btm_y, trail_dn_x, trail_dn): same in bearish direction
structure_plot(trend, bull_bos_alert, bull_choch_alert, top_x, top_y, trail_up_x, trail_up, hh, bear_bos_alert, bear_choch_alert, btm_x, btm_y, trail_dn_x, trail_dn, ll, color_bull, color_bear, show_swing_points, show_latest_swings_levels, show_bos, show_choch, line_style, label_size, keep_history)
detect (and plot) structural breaks and the resulting new trend
Parameters:
trend (int) : crrent trend 1: bullish, -1: bearish
bull_bos_alert (bool) : if there was a bullish bos alert -> plot it
bull_choch_alert (bool) : if there was a bullish choch alert -> plot it
top_x (int) : latest shwing high x
top_y (float) : latest swing high y
trail_up_x (int) : trailing high x
trail_up (float) : trailing high y
hh (float) : if there was a higher high
bear_bos_alert (bool) : if there was a bearish bos alert -> plot it
bear_choch_alert (bool) : if there was a bearish chock alert -> plot it
btm_x (int) : latest swing low x
btm_y (float) : latest swing low y
trail_dn_x (int) : trailing low x
trail_dn (float) : trailing low y
ll (float) : if there was a lower low
color_bull (color) : color for bullish BoS/ChoCh levels
color_bear (color) : color for bearish BoS/ChoCh levels
show_swing_points (bool) : whether to plot swing point labels
show_latest_swings_levels (bool) : whether to track and plot latest swing point levels with lines
show_bos (bool) : whether to plot BoS levels
show_choch (bool) : whether to plot ChoCh levels
line_style (string) : whether to plot BoS levels
label_size (string) : label size of plotted BoS/ChoCh levels
keep_history (bool) : weater to remove older swing point labels and only keep the most recent
structure(length, color_bull, color_bear, super_hh, super_ll, filter_insignificant_internal_breaks, show_swing_points, show_latest_swings_levels, show_bos, show_choch, line_style, label_size, keep_history, enabled)
detect (and plot) structural breaks and the resulting new trend
Parameters:
length (simple int) : lookback period for swing point detection
color_bull (color) : color for bullish BoS/ChoCh levels
color_bear (color) : color for bearish BoS/ChoCh levels
super_hh (float) : level/y-coordinate of superior hh (for internal structure detection)
super_ll (float) : level/y-coordinate of superior ll (for internal structure detection)
filter_insignificant_internal_breaks (bool) : if true pivot points / internal structure will be ignored where the wick in trend direction is longer than the opposite (likely to push further in direction of main trend)
show_swing_points (bool) : whether to plot swing point labels
show_latest_swings_levels (bool) : whether to track and plot latest swing point levels with lines
show_bos (bool) : whether to plot BoS levels
show_choch (bool) : whether to plot ChoCh levels
line_style (string) : whether to plot BoS levels
label_size (string) : label size of plotted BoS/ChoCh levels
keep_history (bool) : weater to remove older swing point labels and only keep the most recent
enabled (bool)
_check_equal_level(mode, len, eq_threshold, enabled)
INTERNAL: detect equal levels (double top/bottom)
Parameters:
mode (int) : detect 1: bullish/high, -1 bearish/low pivot points
len (int) : lookback period for equal level (swing point) detection
eq_threshold (float) : maximum price offset for a level to be considered equal
enabled (bool)
Returns: eq_alert whether an equal level was detected and coordinates of the first and the second level/swing point
_plot_equal_level(show_eq, x1, y1, x2, y2, label_txt, label_style, label_size, line_color, line_style, keep_history)
INTERNAL: plot equal levels (double top/bottom)
Parameters:
show_eq (bool) : whether to plot the level or not
x1 (int) : x-coordinate of the first level / swing point
y1 (float) : y-coordinate of the first level / swing point
x2 (int) : x-coordinate of the second level / swing point
y2 (float) : y-coordinate of the second level / swing point
label_txt (string) : text for the label above/below the line connecting the equal levels
label_style (string) : style (label.style_label_down/up) for the label above/below the line connecting the equal levels
label_size (string) : size (size.tiny) for the label above/below the line connecting the equal levels
line_color (color) : color for the line connecting the equal levels (and it's label)
line_style (string) : style (line.style_dotted) for the line connecting the equal levels
keep_history (bool) : weater to remove older swing point labels and only keep the most recent
equal_levels_values(len, threshold, enabled)
detect (and plot) equal levels (double top/bottom), returns coordinates
Parameters:
len (int) : lookback period for equal level (swing point) detection
threshold (float) : maximum price offset for a level to be considered equal
enabled (bool) : whether detection is enabled
Returns: (eqh_alert, eqh_x1, eqh_y1, eqh_x2, eqh_y2) whether an equal high was detected and coordinates of the first and the second level/swing point, (eql_alert, eql_x1, eql_y1, eql_x2, eql_y2) same for equal lows
equal_levels_plot(eqh_x1, eqh_y1, eqh_x2, eqh_y2, eql_x1, eql_y1, eql_x2, eql_y2, color_eqh, color_eql, show, keep_history)
detect (and plot) equal levels (double top/bottom), returns coordinates
Parameters:
eqh_x1 (int) : coordinates of first point of equal high
eqh_y1 (float) : coordinates of first point of equal high
eqh_x2 (int) : coordinates of second point of equal high
eqh_y2 (float) : coordinates of second point of equal high
eql_x1 (int) : coordinates of first point of equal low
eql_y1 (float) : coordinates of first point of equal low
eql_x2 (int) : coordinates of second point of equal low
eql_y2 (float) : coordinates of second point of equal low
color_eqh (color) : color for the line connecting the equal highs (and it's label)
color_eql (color) : color for the line connecting the equal lows (and it's label)
show (bool) : whether plotting is enabled
keep_history (bool) : weater to remove older swing point labels and only keep the most recent
Returns: (eqh_alert, eqh_x1, eqh_y1, eqh_x2, eqh_y2) whether an equal high was detected and coordinates of the first and the second level/swing point, (eql_alert, eql_x1, eql_y1, eql_x2, eql_y2) same for equal lows
equal_levels(len, threshold, color_eqh, color_eql, enabled, show, keep_history)
detect (and plot) equal levels (double top/bottom)
Parameters:
len (int) : lookback period for equal level (swing point) detection
threshold (float) : maximum price offset for a level to be considered equal
color_eqh (color) : color for the line connecting the equal highs (and it's label)
color_eql (color) : color for the line connecting the equal lows (and it's label)
enabled (bool) : whether detection is enabled
show (bool) : whether plotting is enabled
keep_history (bool) : weater to remove older swing point labels and only keep the most recent
Returns: (eqh_alert) whether an equal high was detected, (eql_alert) same for equal lows
_detect_fvg(mode, enabled, o, h, l, c, filter_insignificant_fvgs, change_tf)
INTERNAL: detect FVG (fair value gap)
Parameters:
mode (int) : detect 1: bullish, -1 bearish gaps
enabled (bool) : whether detection is enabled
o (float) : reference source open
h (float) : reference source high
l (float) : reference source low
c (float) : reference source close
filter_insignificant_fvgs (bool) : whether to calculate and filter small/insignificant gaps
change_tf (bool) : signal when the previous reference timeframe closed, triggers new calculation
Returns: whether a new FVG was detected and its top/mid/bottom levels
_clear_broken_fvg(mode, upper_boxes, lower_boxes)
INTERNAL: clear mitigated FVGs (fair value gaps)
Parameters:
mode (int) : detect 1: bullish, -1 bearish gaps
upper_boxes (array) : array that stores the upper parts of the FVG boxes
lower_boxes (array) : array that stores the lower parts of the FVG boxes
_plot_fvg(mode, show, top, mid, btm, border_color, extend_box)
INTERNAL: plot (and clear broken) FVG (fair value gap)
Parameters:
mode (int) : plot 1: bullish, -1 bearish gap
show (bool) : whether plotting is enabled
top (float) : top level of fvg
mid (float) : center level of fvg
btm (float) : bottom level of fvg
border_color (color) : color for the FVG box
extend_box (int) : how many bars into the future the FVG box should be extended after detection
fvgs_values(o, h, l, c, filter_insignificant_fvgs, change_tf, enabled)
detect (and plot / clear broken) FVGs (fair value gaps), and return alerts and level values
Parameters:
o (float) : reference source open
h (float) : reference source high
l (float) : reference source low
c (float) : reference source close
filter_insignificant_fvgs (bool) : whether to calculate and filter small/insignificant gaps
change_tf (bool) : signal when the previous reference timeframe closed, triggers new calculation
enabled (bool) : whether detection is enabled
Returns: (bullish_fvg_alert, bull_top, bull_mid, bull_btm): whether a new bullish FVG was detected and its top/mid/bottom levels, (bearish_fvg_alert, bear_top, bear_mid, bear_btm): same for bearish FVGs
fvgs_plot(bullish_fvg_alert, bull_top, bull_mid, bull_btm, bearish_fvg_alert, bear_top, bear_mid, bear_btm, color_bull, color_bear, extend_box, show)
Parameters:
bullish_fvg_alert (bool)
bull_top (float)
bull_mid (float)
bull_btm (float)
bearish_fvg_alert (bool)
bear_top (float)
bear_mid (float)
bear_btm (float)
color_bull (color) : color for bullish FVG boxes
color_bear (color) : color for bearish FVG boxes
extend_box (int) : how many bars into the future the FVG box should be extended after detection
show (bool) : whether plotting is enabled
Returns: (bullish_fvg_alert, bull_top, bull_mid, bull_btm): whether a new bullish FVG was detected and its top/mid/bottom levels, (bearish_fvg_alert, bear_top, bear_mid, bear_btm): same for bearish FVGs
fvgs(o, h, l, c, filter_insignificant_fvgs, change_tf, color_bull, color_bear, extend_box, enabled, show)
detect (and plot / clear broken) FVGs (fair value gaps)
Parameters:
o (float) : reference source open
h (float) : reference source high
l (float) : reference source low
c (float) : reference source close
filter_insignificant_fvgs (bool) : whether to calculate and filter small/insignificant gaps
change_tf (bool) : signal when the previous reference timeframe closed, triggers new calculation
color_bull (color) : color for bullish FVG boxes
color_bear (color) : color for bearish FVG boxes
extend_box (int) : how many bars into the future the FVG box should be extended after detection
enabled (bool) : whether detection is enabled
show (bool) : whether plotting is enabled
Returns: (bullish_fvg_alert): whether a new bullish FVG was detected, (bearish_fvg_alert): same for bearish FVGs
OrderBlock
Fields:
id (series int)
dir (series int)
left_top (chart.point)
right_bottom (chart.point)
break_price (series float)
early_confirmation_price (series float)
ltf_high (array)
ltf_low (array)
ltf_volume (array)
plot (Box type from robbatt/lib_plot_objects/49)
profile (Profile type from robbatt/lib_profile/32)
trailing (series bool)
extending (series bool)
awaiting_confirmation (series bool)
touched_break_price_before_confirmation (series bool)
soft_confirmed (series bool)
has_fvg_out (series bool)
hidden (series bool)
broken (series bool)
OrderBlockConfig
Fields:
show (series bool)
show_last (series int)
show_id (series bool)
show_profile (series bool)
args (BoxArgs type from robbatt/lib_plot_objects/49)
txt (series string)
txt_args (BoxTextArgs type from robbatt/lib_plot_objects/49)
delete_when_broken (series bool)
broken_args (BoxArgs type from robbatt/lib_plot_objects/49)
broken_txt (series string)
broken_txt_args (BoxTextArgs type from robbatt/lib_plot_objects/49)
broken_profile_args (ProfileArgs type from robbatt/lib_profile/32)
use_profile (series bool)
profile_args (ProfileArgs type from robbatt/lib_profile/32)
BacktestLibraryLibrary "BacktestLibrary"
A library providing functions for equity calculation and performance metrics.
since(date, active)
: Calculates the number of candles since a specified date.
Parameters:
date (simple float) : (simple float): The starting date in timestamp format (e.g., input.time(timestamp()))
active (simple bool) : (simple bool): If true, counts the number of candles since the date; if false, returns 0.
Returns: (int): The number of candles since the specified date.
buy_and_hold(r, startDate)
: Calculates the Buy and Hold Equity from a specified date.
Parameters:
r (float) : (series float): Daily returns of the asset (e.g., 0.02 for 2% move).
startDate (simple float) : (simple float): Timestamp of the starting date for the equity calculation.
Returns: (float): Buy and Hold Equity of the asset from the specified date.
equity(sig, threshold, r, startDate, signals)
: Calculates the strategy's equity on a candle-by-candle basis.
Parameters:
sig (float) : (series float): Signal values; positive for long, negative for short.
threshold (simple float) : (simple float): Signal threshold for entering trades.
r (float) : (series float): Daily returns of the asset (e.g., 0.02 for 2% move).
startDate (simple float) : (simple float): Timestamp of the starting date for the equity calculation.
signals (simple string) : (simple string): Type of signals to backtest ("Long & Short", "Long Only", "Short Only").
Returns: (float): Strategy equity on a candle-by-candle basis.
PerformanceMetrics(base, Lookback, startDate)
: Calculates performance metrics of a strategy from a specified date.
Parameters:
base (float) : (series float): Equity values of the strategy or Buy and Hold equity.
Lookback (int) : (series int): Number of periods since the start date; recommended to use the 'since' function.
startDate (simple float) : (simple float): Timestamp of the starting date for the equity calculation.
Returns: (float ): Array of performance metrics.
PerfMetricTable(buy_and_hold, strategy)
: Plots a table comparing performance metrics of Buy and Hold and Strategy equity.
Parameters:
buy_and_hold (array) : (float ): Metrics from the PerformanceMetrics() function for Buy and Hold.
strategy (array) : (float ): Metrics from the PerformanceMetrics() function for the strategy.
Returns: : Table displaying the performance metrics comparison.

ArrayMovingAveragesLibrary "ArrayMovingAverages"
This library adds several moving average methods to arrays, so you can call, eg.:
myArray.ema(3)
method emaArray(id, length)
Calculate Exponential Moving Average (EMA) for Arrays
Namespace types: array
Parameters:
id (array) : (array) Input array
length (int) : (int) Length of the EMA
Returns: (array) Array of EMA values
method ema(id, length)
Get the last value of the EMA array
Namespace types: array
Parameters:
id (array) : (array) Input array
length (int) : (int) Length of the EMA
Returns: (float) Last EMA value or na if empty
method rmaArray(id, length)
Calculate Rolling Moving Average (RMA) for Arrays
Namespace types: array
Parameters:
id (array) : (array) Input array
length (int) : (int) Length of the RMA
Returns: (array) Array of RMA values
method rma(id, length)
Get the last value of the RMA array
Namespace types: array
Parameters:
id (array) : (array) Input array
length (int) : (int) Length of the RMA
Returns: (float) Last RMA value or na if empty
method smaArray(id, windowSize)
Calculate Simple Moving Average (SMA) for Arrays
Namespace types: array
Parameters:
id (array) : (array) Input array
windowSize (int) : (int) Window size for calculation, defaults to array size
Returns: (array) Array of SMA values
method sma(id, windowSize)
Get the last value of the SMA array
Namespace types: array
Parameters:
id (array) : (array) Input array
windowSize (int) : (int) Window size for calculation, defaults to array size
Returns: (float) Last SMA value or na if empty
method wmaArray(id, windowSize)
Calculate Weighted Moving Average (WMA) for Arrays
Namespace types: array
Parameters:
id (array) : (array) Input array
windowSize (int) : (int) Window size for calculation, defaults to array size
Returns: (array) Array of WMA values
method wma(id, windowSize)
Get the last value of the WMA array
Namespace types: array
Parameters:
id (array) : (array) Input array
windowSize (int) : (int) Window size for calculation, defaults to array size
Returns: (float) Last WMA value or na if empty

QuantifyPS - 1Library "QuantifyPS"
normdist(z)
Parameters:
z (float) : (float): The z-score for which the CDF is to be calculated.
Returns: (float): The cumulative probability corresponding to the input z-score.
Notes:
- Uses an approximation method for the normal distribution CDF, which is computationally efficient.
- The result is accurate for most practical purposes but may have minor deviations for extreme values of `z`.
Formula:
- Based on the approximation formula:
`Φ(z) ≈ 1 - f(z) * P(t)` if `z > 0`, otherwise `Φ(z) ≈ f(z) * P(t)`,
where:
`f(z) = 0.3989423 * exp(-z^2 / 2)` (PDF of standard normal distribution)
`P(t) = Σ [c * t^i]` with constants `c` and `t = 1 / (1 + 0.2316419 * |z|)`.
Implementation details:
- The approximation uses five coefficients for the polynomial part of the CDF.
- Handles both positive and negative values of `z` symmetrically.
Constants:
- The coefficients and scaling factors are chosen to minimize approximation errors.
gamma(x)
Parameters:
x (float) : (float): The input value for which the Gamma function is to be calculated.
Must be greater than 0. For x <= 0, the function returns `na` as it is undefined.
Returns: (float): Approximation of the Gamma function for the input `x`.
Notes:
- The Lanczos approximation provides a numerically stable and efficient method to compute the Gamma function.
- The function is not defined for `x <= 0` and will return `na` in such cases.
- Uses precomputed Lanczos coefficients for accuracy.
- Includes handling for small numerical inaccuracies.
Formula:
- The Gamma function is approximated as:
`Γ(x) ≈ sqrt(2π) * t^(x + 0.5) * e^(-t) * Σ(p / (x + k))`
where `t = x + g + 0.5` and `p` is the array of Lanczos coefficients.
Implementation details:
- Lanczos coefficients (`p`) are precomputed and stored in an array.
- The summation iterates over these coefficients to compute the final result.
- The constant `g` controls the precision of the approximation (commonly `g = 7`).
t_cdf(t, df)
Parameters:
t (float) : (float): The t-statistic for which the CDF value is to be calculated.
df (int) : (int): Degrees of freedom of the t-distribution.
Returns: (float): Approximate CDF value for the given t-statistic.
Notes:
- This function computes a one-tailed p-value.
- Relies on an approximation formula using gamma functions and standard t-distribution properties.
- May not be as accurate as specialized statistical libraries for extreme values or very high degrees of freedom.
Formula:
- Let `x = df / (t^2 + df)`.
- The approximation formula is derived using:
`CDF(t, df) ≈ 1 - * x^((df + 1) / 2) / 2`,
where Γ represents the gamma function.
Implementation details:
- Computes the gamma ratio for normalization.
- Applies the t-distribution formula for one-tailed probabilities.
tStatForPValue(p, df)
Parameters:
p (float) : (float): P-value for which the t-statistic needs to be calculated.
Must be in the interval (0, 1).
df (int) : (int): Degrees of freedom of the t-distribution.
Returns: (float): The t-statistic corresponding to the given p-value.
Notes:
- If `p` is outside the interval (0, 1), the function returns `na` as an error.
- The function uses binary search with a fixed number of iterations and a defined tolerance.
- The result is accurate to within the specified tolerance (default: 0.0001).
- Relies on the cumulative density function (CDF) `t_cdf` for the t-distribution.
Formula:
- Uses the cumulative density function (CDF) of the t-distribution to iteratively find the t-statistic.
Implementation details:
- `low` and `high` define the search interval for the t-statistic.
- The midpoint (`mid`) is iteratively refined until the difference between the cumulative probability
and the target p-value is smaller than the tolerance.
jarqueBera(n, s, k)
Parameters:
n (float) : (series float): Number of observations in the dataset.
s (float) : (series float): Skewness of the dataset.
k (float) : (series float): Kurtosis of the dataset.
Returns: (float): The Jarque-Bera test statistic.
Formula:
JB = n *
Notes:
- A higher JB value suggests that the data deviates more from a normal distribution.
- The test is asymptotically distributed as a chi-squared distribution with 2 degrees of freedom.
- Use this value to calculate a p-value to determine the significance of the result.
skewness(data)
Parameters:
data (float) : (series float): Input data series.
Returns: (float): The skewness value.
Notes:
- Handles missing values (`na`) by ignoring invalid points.
- Includes error handling for zero variance to avoid division-by-zero scenarios.
- Skewness is calculated as the normalized third central moment of the data.
kurtosis(data)
Parameters:
data (float) : (series float): Input data series.
Returns: (float): The kurtosis value.
Notes:
- Handles missing values (`na`) by ignoring invalid points.
- Includes error handling for zero variance to avoid division-by-zero scenarios.
- Kurtosis is calculated as the normalized fourth central moment of the data.
regression(y, x, lag)
Parameters:
y (float) : (series float): Dependent series (observed values).
x (float) : (series float): Independent series (explanatory variable).
lag (int) : (int): Number of lags applied to the independent series (x).
Returns: (tuple): Returns a tuple containing the following values:
- n: Number of valid observations.
- alpha: Intercept of the regression line.
- beta: Slope of the regression line.
- t_stat: T-statistic for the beta coefficient.
- p_value: Two-tailed p-value for the beta coefficient.
- r_squared: Coefficient of determination (R²) indicating goodness of fit.
- skew: Skewness of the residuals.
- kurt: Kurtosis of the residuals.
Notes:
- Handles missing data (`na`) by ignoring invalid points.
- Includes basic error handling for zero variance and division-by-zero scenarios.
- Computes residual-based statistics (skewness and kurtosis) for model diagnostics.
GaussianDistributionLibrary "GaussianDistribution"
This library defines a custom type `distr` representing a Gaussian (or other statistical) distribution.
It provides methods to calculate key statistical moments and scores, including mean, median, mode, standard deviation, variance, skewness, kurtosis, and Z-scores.
This library is useful for analyzing probability distributions in financial data.
Disclaimer:
I am not a mathematician, but I have implemented this library to the best of my understanding and capacity. Please be indulgent as I tried to translate statistical concepts into code as accurately as possible. Feedback, suggestions, and corrections are welcome to improve the reliability and robustness of this library.
mean(source, length)
Calculate the mean (average) of the distribution
Parameters:
source (float) : Distribution source (typically a price or indicator series)
length (int) : Window length for the distribution (must be >= 30 for meaningful statistics)
Returns: Mean (μ)
stdev(source, length)
Calculate the standard deviation (σ) of the distribution
Parameters:
source (float) : Distribution source (typically a price or indicator series)
length (int) : Window length for the distribution (must be >= 30 for meaningful statistics)
Returns: Standard deviation (σ)
skewness(source, length, mean, stdev)
Calculate the skewness (γ₁) of the distribution
Parameters:
source (float) : Distribution source (typically a price or indicator series)
length (int) : Window length for the distribution (must be >= 30 for meaningful statistics)
mean (float) : the mean (average) of the distribution
stdev (float) : the standard deviation (σ) of the distribution
@return Skewness (γ₁)
skewness(source, length)
Overloaded skewness to calculate from source and length
Parameters:
source (float) : Distribution source (typically a price or indicator series)
length (int) : Window length for the distribution (must be >= 30 for meaningful statistics)
@return Skewness (γ₁)
mode(mean, stdev, skewness)
Estimate mode - Most frequent value in the distribution (approximation based on skewness)
Parameters:
mean (float) : the mean (average) of the distribution
stdev (float) : the standard deviation (σ) of the distribution
skewness (float) : the skewness (γ₁) of the distribution
@return Mode
mode(source, length)
Overloaded mode to calculate from source and length
Parameters:
source (float) : Distribution source (typically a price or indicator series)
length (int) : Window length for the distribution (must be >= 30 for meaningful statistics)
@return Mode
median(mean, stdev, skewness)
Estimate median - Middle value of the distribution (approximation)
Parameters:
mean (float) : the mean (average) of the distribution
stdev (float) : the standard deviation (σ) of the distribution
skewness (float) : the skewness (γ₁) of the distribution
@return Median
median(source, length)
Overloaded median to calculate from source and length
Parameters:
source (float) : Distribution source (typically a price or indicator series)
length (int) : Window length for the distribution (must be >= 30 for meaningful statistics)
@return Median
variance(stdev)
Calculate variance (σ²) - Square of the standard deviation
Parameters:
stdev (float) : the standard deviation (σ) of the distribution
@return Variance (σ²)
variance(source, length)
Overloaded variance to calculate from source and length
Parameters:
source (float) : Distribution source (typically a price or indicator series)
length (int) : Window length for the distribution (must be >= 30 for meaningful statistics)
@return Variance (σ²)
kurtosis(source, length, mean, stdev)
Calculate kurtosis (γ₂) - Degree of "tailedness" in the distribution
Parameters:
source (float) : Distribution source (typically a price or indicator series)
length (int) : Window length for the distribution (must be >= 30 for meaningful statistics)
mean (float) : the mean (average) of the distribution
stdev (float) : the standard deviation (σ) of the distribution
@return Kurtosis (γ₂)
kurtosis(source, length)
Overloaded kurtosis to calculate from source and length
Parameters:
source (float) : Distribution source (typically a price or indicator series)
length (int) : Window length for the distribution (must be >= 30 for meaningful statistics)
@return Kurtosis (γ₂)
normal_score(source, mean, stdev)
Calculate Z-score (standard score) assuming a normal distribution
Parameters:
source (float) : Distribution source (typically a price or indicator series)
mean (float) : the mean (average) of the distribution
stdev (float) : the standard deviation (σ) of the distribution
@return Z-Score
normal_score(source, length)
Overloaded normal_score to calculate from source and length
Parameters:
source (float) : Distribution source (typically a price or indicator series)
length (int) : Window length for the distribution (must be >= 30 for meaningful statistics)
@return Z-Score
non_normal_score(source, mean, stdev, skewness, kurtosis)
Calculate adjusted Z-score considering skewness and kurtosis
Parameters:
source (float) : Distribution source (typically a price or indicator series)
mean (float) : the mean (average) of the distribution
stdev (float) : the standard deviation (σ) of the distribution
skewness (float) : the skewness (γ₁) of the distribution
kurtosis (float) : the "tailedness" in the distribution
@return Z-Score
non_normal_score(source, length)
Overloaded non_normal_score to calculate from source and length
Parameters:
source (float) : Distribution source (typically a price or indicator series)
length (int) : Window length for the distribution (must be >= 30 for meaningful statistics)
@return Z-Score
method init(this)
Initialize all statistical fields of the `distr` type
Namespace types: distr
Parameters:
this (distr)
method init(this, source, length)
Overloaded initializer to set source and length
Namespace types: distr
Parameters:
this (distr)
source (float)
length (int)
distr
Custom type to represent a Gaussian distribution
Fields:
source (series float) : Distribution source (typically a price or indicator series)
length (series int) : Window length for the distribution (must be >= 30 for meaningful statistics)
mode (series float) : Most frequent value in the distribution
median (series float) : Middle value separating the greater and lesser halves of the distribution
mean (series float) : μ (1st central moment) - Average of the distribution
stdev (series float) : σ or standard deviation (square root of the variance) - Measure of dispersion
variance (series float) : σ² (2nd central moment) - Squared standard deviation
skewness (series float) : γ₁ (3rd central moment) - Asymmetry of the distribution
kurtosis (series float) : γ₂ (4th central moment) - Degree of "tailedness" relative to a normal distribution
normal_score (series float) : Z-score assuming normal distribution
non_normal_score (series float) : Adjusted Z-score considering skewness and kurtosis
MathHelpersLibrary "MathHelpers"
Overview
A collection of helper functions for designing indicators and strategies.
calculateATR(length, log)
Calculates the Average True Range (ATR) or Log ATR based on the 'log' parameter. Sans Wilder's Smoothing
Parameters:
length (simple int)
log (simple bool)
Returns: float The calculated ATR value. Returns Log ATR if `log` is true, otherwise returns standard ATR.
CDF(z)
Computes the Cumulative Distribution Function (CDF) for a given value 'z', mimicking the CDF function in "Statistically Sound Indicators" by Timothy Masters.
Parameters:
z (simple float)
Returns: float The CDF value corresponding to the input `z`, ranging between 0 and 1.
logReturns(lookback)
Calculates the logarithmic returns over a specified lookback period.
Parameters:
lookback (simple int)
Returns: float The calculated logarithmic return. Returns `na` if insufficient data is available.
RHR_CANDLELibrary "RHR_CANDLE"
Library for Expansion Contraction Indicator, a zero-lag dual perspective indicator based on Jake Bernstein’s principles of Moving Average Channel system.
calc(shortLookback, longLookback)
Calculates Expansion Contraction values.
Parameters:
shortLookback (int) : Integer for the short lookback calculation, defaults to 8
longLookback (int) : Integer for the long lookback calculation, defaults to 32
@return Returns array of Expansion Contraction values
stdevCalc(positiveShort, negativeShort, positiveLong, negativeLong, stdevLookback)
Calculates standard deviation lines based on Expansion Contraction Long and Short values.
Parameters:
positiveShort (float) : Float for the positive short XC value from calculation
negativeShort (float) : Float for the negative short XC value from calculation
positiveLong (float) : Float for the positive long XC value from calculation
negativeLong (float) : Float for the negative long XC value from calculation
stdevLookback (int) : Integer for the standard deviation lookback, defaults to 500
@return Returns array of standard deviation values
trend(positiveShort, negativeShort, positiveLong, negativeLong)
Determines if trend is strong or weak based on Expansion Contraction values.
Parameters:
positiveShort (float) : Float for the positive short XC value from calculation
negativeShort (float) : Float for the negative short XC value from calculation
positiveLong (float) : Float for the positive long XC value from calculation
negativeLong (float) : Float for the negative long XC value from calculation
@return Returns array of boolean values indicating strength or weakness of trend

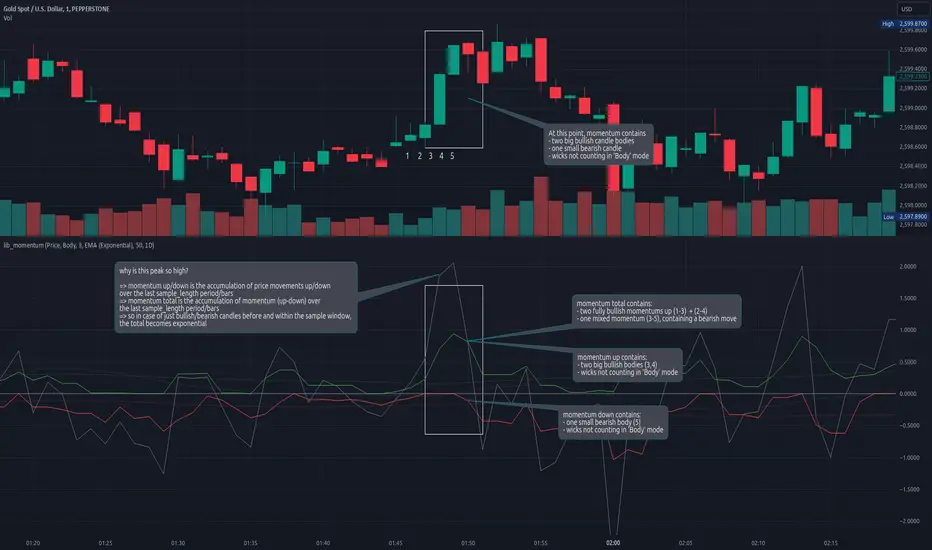
lib_momentumLibrary "lib_momentum"
This library calculates the momentum, derived from a sample range of prior candles. Depending on set MomentumType it either deduces the momentum from the price, volume, or a product of both. If price/product are selected, you can choose from SampleType if only candle body, full range from high to low or a combination of both (body counts full, wicks half for each direction) should be used. Optional: You can choose to normalize the results, dividing each value by its average (normalization_ma_length, normalization_ma). This will allow comparison between different instruments. For the normalization Moving Average you can choose any currently supported in my lib_no_delay.
get_momentum(momentum_type, sample_type, sample_length, normalization_ma_length, normalization_ma)
Parameters:
momentum_type (series MomentumType) : select one of MomentumType. to sample the price, volume or a product of both
sample_type (series SampleType) : select one of SampleType. to sample the body, total range from high to low or a combination of both (body count full, wicks half for each direction)
sample_length (simple int) : how many candles should be sampled (including the current)
normalization_ma_length (simple int) : if you want to normalize results (momentum / momentum average) this sets the period for the average. (default = 0 => no normalization)
normalization_ma (simple MovingAverage enum from robbatt/lib_no_delay/9) : is the type of moving average to normalize / compare with
Returns: returns the current momentum where the total line is not just (up - down) but also sampled over the sample_length and can therefore be used as trend indicator. If up/down fail to reach total's level it's a sign of decreasing momentum, if up/down exceed total the trend it's a sign of increasing momentum.
PRINT_DROVINGLibrary "PRINT_DROVING"
method print_droving(foot_bar, sup)
printing all footprint objects
Namespace types: footprint_type.Footprint_bar
Parameters:
foot_bar (Footprint_bar type from Alesetup/PRINT_TYPE/1) : instance of Footprint_bar type
sup (Support_objects type from Alesetup/PRINT_TYPE/1) : instance of Support_objects type
Returns: Void.

PRINT_LOGICLibrary "PRINT_LOGIC"
method fill_imba_line(imba_line, foot_bar, sup)
fill imbalance line
Namespace types: footprint_type.Imbalance_line
Parameters:
imba_line (Imbalance_line type from Alesetup/PRINT_TYPE/1) : instance of Imbalance_line type
foot_bar (Footprint_bar type from Alesetup/PRINT_TYPE/1) : instance of Footprint_bar type
sup (Support_objects type from Alesetup/PRINT_TYPE/1) : instance of Support_objects type
Returns: Void
method fill_footprint_type(foot_bar, sup)
Namespace types: footprint_type.Footprint_bar
Parameters:
foot_bar (Footprint_bar type from Alesetup/PRINT_TYPE/1) : instance of Footprint_bar type
sup (Support_objects type from Alesetup/PRINT_TYPE/1) : instance of Support_objects type
Returns: Void
method fill_footprint_object(foot_bar, sup)
fill all footprint objects
Namespace types: footprint_type.Footprint_bar
Parameters:
foot_bar (Footprint_bar type from Alesetup/PRINT_TYPE/1) : instance of Footprint_bar type
sup (Support_objects type from Alesetup/PRINT_TYPE/1) : instance of Support_objects type
Returns: Void
PRINT_TYPELibrary "PRINT_TYPE"
Inputs
Inputs objects
Fields:
inbalance_percent (series int) : percentage coefficient to determine the Imbalance of price levels
stacked_input (series int) : minimum number of consecutive Imbalance levels required to draw extended lines
show_summary_footprint (series bool)
procent_volume_area (series int) : definition size Value area
new_imbalance_cond (series bool) : bool input for setup alert on new imbalance buy and sell
new_imbalance_line_cond (series bool) : bool input for setup alert on new imbalance line buy and sell
stop_past_imbalance_line_cond (series bool) : bool input for setup alert on stop past imbalance line buy and sell
Constants
Constants all Constants objects
Fields:
imbalance_high_char (series string) : char for printing buy imbalance
imbalance_low_char (series string) : char for printing sell imbalance
color_title_sell (series color) : color for footprint sell
color_title_buy (series color) : color for footprint buy
color_line_sell (series color) : color for sell line
color_line_buy (series color) : color for buy line
color_title_none (series color) : color None
Calculation_data
Calculation_data data for calculating
Fields:
detail_open (array) : array open from calculation timeframe
detail_high (array) : array high from calculation timeframe
detail_low (array) : array low from calculation timeframe
detail_close (array) : array close from calculation timeframe
detail_vol (array) : array volume from calculation timeframe
previos_detail_close (array) : array close from calculation timeframe
isBuyVolume (series bool) : attribute previosly bar buy or sell
Footprint_row
Footprint_row objects one footprint row
Fields:
price (series float) : row price
buy_vol (series float) : buy volume
sell_vol (series float) : sell volume
imbalance_buy (series bool) : attribute buy inbalance
imbalance_sell (series bool) : attribute sell imbalance
buy_vol_box (series box) : for ptinting buy volume
sell_vol_box (series box) : for printing sell volume
buy_vp_box (series box) : for ptinting volume profile buy
sell_vp_box (series box) : for ptinting volume profile sell
row_line (series label) : for ptinting row price
empty (series bool) : = true attribute row with zero volume buy and zero volume sell
Imbalance_line_var_object
Imbalance_line_var_object var objects printing and calculation imbalance line
Fields:
cum_buy_line (array) : line array for saving all history buy imbalance line
cum_sell_line (array) : line array for saving all history sell imbalance line
Imbalance_line
Imbalance_line objects printing and calculation imbalance line
Fields:
buy_price_line (array) : float array for saving buy imbalance price level
sell_price_line (array) : float array for saving sell imbalance price level
var_imba_line (Imbalance_line_var_object) : var objects this type
Footprint_bar
Footprint_bar all objects one bar with footprint
Fields:
foot_rows (array) : objects one row footprint
imba_line (Imbalance_line) : objects imbalance line
row_size (series float) : size rows
total_vol (series float) : total volume one footprint bar
foot_buy_vol (series float) : buy volume one footprint bar
foot_sell_vol (series float) : sell volume one footprint bar
foot_max_price_vol (map) : map with one value - price row with max volume buy + sell
calc_data (Calculation_data) : objects with detail data from calculation resolution
Support_objects
Support_objects support object for footprint calculation
Fields:
consts (Constants) : all consts objects
inp (Inputs) : all input objects
bar_index_show_condition (series bool) : calculation bool value for show all objects footprint
row_line_color (series color) : calculation value - color for row price
dop_info (series string)
show_table_cond (series bool)
analytics_tablesLibrary "analytics_tables"
📝 Description
This library provides the implementation of several performance-related statistics and metrics, presented in the form of tables.
The metrics shown in the afforementioned tables where developed during the past years of my in-depth analalysis of various strategies in an atempt to reason about the performance of each strategy.
The visualization and some statistics where inspired by the existing implementations of the "Seasonality" script, and the performance matrix implementations of @QuantNomad and @ZenAndTheArtOfTrading scripts.
While this library is meant to be used by my strategy framework "Template Trailing Strategy (Backtester)" script, I wrapped it in a library hoping this can be usefull for other community strategy scripts that will be released in the future.
🤔 How to Guide
To use the functionality this library provides in your script you have to import it first!
Copy the import statement of the latest release by pressing the copy button below and then paste it into your script. Give a short name to this library so you can refer to it later on. The import statement should look like this:
import jason5480/analytics_tables/1 as ant
There are three types of tables provided by this library in the initial release. The stats table the metrics table and the seasonality table.
Each one shows different kinds of performance statistics.
The table UDT shall be initialized once using the `init()` method.
They can be updated using the `update()` method where the updated data UDT object shall be passed.
The data UDT can also initialized and get updated on demend depending on the use case
A code example for the StatsTable is the following:
var ant.StatsData statsData = ant.StatsData.new()
statsData.update(SideStats.new(), SideStats.new(), 0)
if (barstate.islastconfirmedhistory or (barstate.isrealtime and barstate.isconfirmed))
var statsTable = ant.StatsTable.new().init(ant.getTablePos('TOP', 'RIGHT'))
statsTable.update(statsData)
A code example for the MetricsTable is the following:
var ant.StatsData statsData = ant.StatsData.new()
statsData.update(ant.SideStats.new(), ant.SideStats.new(), 0)
if (barstate.islastconfirmedhistory or (barstate.isrealtime and barstate.isconfirmed))
var metricsTable = ant.MetricsTable.new().init(ant.getTablePos('BOTTOM', 'RIGHT'))
metricsTable.update(statsData, 10)
A code example for the SeasonalityTable is the following:
var ant.SeasonalData seasonalData = ant.SeasonalData.new().init(Seasonality.monthOfYear)
seasonalData.update()
if (barstate.islastconfirmedhistory or (barstate.isrealtime and barstate.isconfirmed))
var seasonalTable = ant.SeasonalTable.new().init(seasonalData, ant.getTablePos('BOTTOM', 'LEFT'))
seasonalTable.update(seasonalData)
🏋️♂️ Please refer to the "EXAMPLE" regions of the script for more advanced and up to date code examples!
Special thanks to @Mrcrbw for the proposal to develop this library and @DCNeu for the constructive feedback 🏆.
getTablePos(ypos, xpos)
Get table position compatible string
Parameters:
ypos (simple string) : The position on y axise
xpos (simple string) : The position on x axise
Returns: The position to be passed to the table
method init(this, pos, height, width, positiveTxtColor, negativeTxtColor, neutralTxtColor, positiveBgColor, negativeBgColor, neutralBgColor)
Initialize the stats table object with the given colors in the given position
Namespace types: StatsTable
Parameters:
this (StatsTable) : The stats table object
pos (simple string) : The table position string
height (simple float) : The height of the table as a percentage of the charts height. By default, 0 auto-adjusts the height based on the text inside the cells
width (simple float) : The width of the table as a percentage of the charts height. By default, 0 auto-adjusts the width based on the text inside the cells
positiveTxtColor (simple color) : The text color when positive
negativeTxtColor (simple color) : The text color when negative
neutralTxtColor (simple color) : The text color when neutral
positiveBgColor (simple color) : The background color with transparency when positive
negativeBgColor (simple color) : The background color with transparency when negative
neutralBgColor (simple color) : The background color with transparency when neutral
method init(this, pos, height, width, neutralBgColor)
Initialize the metrics table object with the given colors in the given position
Namespace types: MetricsTable
Parameters:
this (MetricsTable) : The metrics table object
pos (simple string) : The table position string
height (simple float) : The height of the table as a percentage of the charts height. By default, 0 auto-adjusts the height based on the text inside the cells
width (simple float) : The width of the table as a percentage of the charts width. By default, 0 auto-adjusts the width based on the text inside the cells
neutralBgColor (simple color) : The background color with transparency when neutral
method init(this, seas)
Initialize the seasonal data
Namespace types: SeasonalData
Parameters:
this (SeasonalData) : The seasonal data object
seas (simple Seasonality) : The seasonality of the matrix data
method init(this, data, pos, maxNumOfYears, height, width, extended, neutralTxtColor, neutralBgColor)
Initialize the seasonal table object with the given colors in the given position
Namespace types: SeasonalTable
Parameters:
this (SeasonalTable) : The seasonal table object
data (SeasonalData) : The seasonality data of the table
pos (simple string) : The table position string
maxNumOfYears (simple int) : The maximum number of years that fit into the table
height (simple float) : The height of the table as a percentage of the charts height. By default, 0 auto-adjusts the height based on the text inside the cells
width (simple float) : The width of the table as a percentage of the charts width. By default, 0 auto-adjusts the width based on the text inside the cells
extended (simple bool) : The seasonal table with extended columns for performance
neutralTxtColor (simple color) : The text color when neutral
neutralBgColor (simple color) : The background color with transparency when neutral
method update(this, wins, losses, numOfInconclusiveExits)
Update the strategy info data of the strategy
Namespace types: StatsData
Parameters:
this (StatsData) : The strategy statistics object
wins (SideStats)
losses (SideStats)
numOfInconclusiveExits (int) : The number of inconclusive trades
method update(this, stats, positiveTxtColor, negativeTxtColor, negativeBgColor, neutralBgColor)
Update the stats table object with the given data
Namespace types: StatsTable
Parameters:
this (StatsTable) : The stats table object
stats (StatsData) : The stats data to update the table
positiveTxtColor (simple color) : The text color when positive
negativeTxtColor (simple color) : The text color when negative
negativeBgColor (simple color) : The background color with transparency when negative
neutralBgColor (simple color) : The background color with transparency when neutral
method update(this, stats, buyAndHoldPerc, positiveTxtColor, negativeTxtColor, positiveBgColor, negativeBgColor)
Update the metrics table object with the given data
Namespace types: MetricsTable
Parameters:
this (MetricsTable) : The metrics table object
stats (StatsData) : The stats data to update the table
buyAndHoldPerc (float) : The buy and hold percetage
positiveTxtColor (simple color) : The text color when positive
negativeTxtColor (simple color) : The text color when negative
positiveBgColor (simple color) : The background color with transparency when positive
negativeBgColor (simple color) : The background color with transparency when negative
method update(this)
Update the seasonal data based on the season and eon timeframe
Namespace types: SeasonalData
Parameters:
this (SeasonalData) : The seasonal data object
method update(this, data, positiveTxtColor, negativeTxtColor, neutralTxtColor, positiveBgColor, negativeBgColor, neutralBgColor, timeBgColor)
Update the seasonal table object with the given data
Namespace types: SeasonalTable
Parameters:
this (SeasonalTable) : The seasonal table object
data (SeasonalData) : The seasonal cell data to update the table
positiveTxtColor (simple color) : The text color when positive
negativeTxtColor (simple color) : The text color when negative
neutralTxtColor (simple color) : The text color when neutral
positiveBgColor (simple color) : The background color with transparency when positive
negativeBgColor (simple color) : The background color with transparency when negative
neutralBgColor (simple color) : The background color with transparency when neutral
timeBgColor (simple color) : The background color of the time gradient
SideStats
Object that represents the strategy statistics data of one side win or lose
Fields:
numOf (series int)
sumFreeProfit (series float)
freeProfitStDev (series float)
sumProfit (series float)
profitStDev (series float)
sumGain (series float)
gainStDev (series float)
avgQuantityPerc (series float)
avgCapitalRiskPerc (series float)
avgTPExecutedCount (series float)
avgRiskRewardRatio (series float)
maxStreak (series int)
StatsTable
Object that represents the stats table
Fields:
table (series table) : The actual table
rows (series int) : The number of rows of the table
columns (series int) : The number of columns of the table
StatsData
Object that represents the statistics data of the strategy
Fields:
wins (SideStats)
losses (SideStats)
numOfInconclusiveExits (series int)
avgFreeProfitStr (series string)
freeProfitStDevStr (series string)
lossFreeProfitStDevStr (series string)
avgProfitStr (series string)
profitStDevStr (series string)
lossProfitStDevStr (series string)
avgQuantityStr (series string)
MetricsTable
Object that represents the metrics table
Fields:
table (series table) : The actual table
rows (series int) : The number of rows of the table
columns (series int) : The number of columns of the table
SeasonalData
Object that represents the seasonal table dynamic data
Fields:
seasonality (series Seasonality)
eonToMatrixRow (map)
numOfEons (series int)
mostRecentMatrixRow (series int)
balances (matrix)
returnPercs (matrix)
maxDDs (matrix)
eonReturnPercs (array)
eonCAGRs (array)
eonMaxDDs (array)
SeasonalTable
Object that represents the seasonal table
Fields:
table (series table) : The actual table
headRows (series int) : The number of head rows of the table
headColumns (series int) : The number of head columns of the table
eonRows (series int) : The number of eon rows of the table
seasonColumns (series int) : The number of season columns of the table
statsRows (series int)
statsColumns (series int) : The number of stats columns of the table
rows (series int) : The number of rows of the table
columns (series int) : The number of columns of the table
extended (series bool) : Whether the table has additional performance statistics

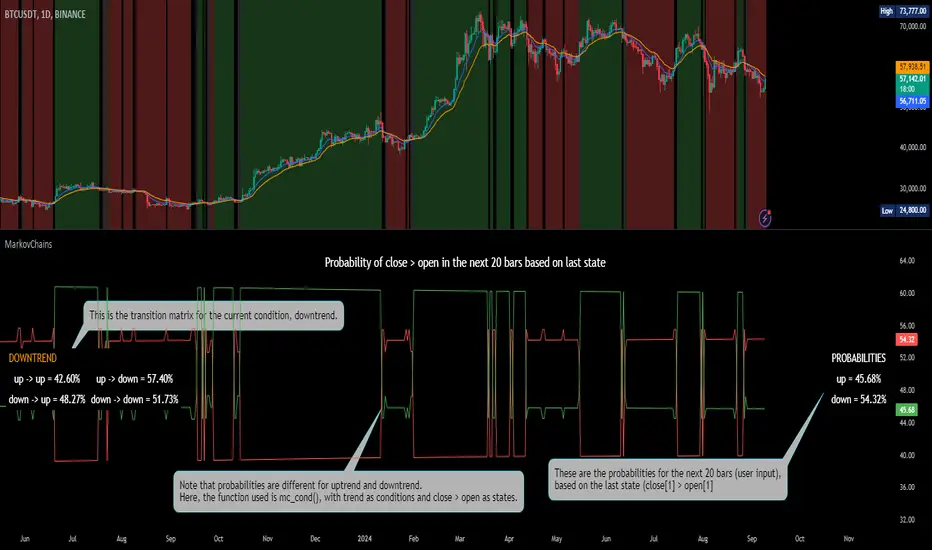
[ALGOA+] Markov Chains Library by @metacamaleoLibrary "MarkovChains"
Markov Chains library by @metacamaleo. Created in 09/08/2024.
This library provides tools to calculate and visualize Markov Chain-based transition matrices and probabilities. This library supports two primary algorithms: a rolling window Markov Chain and a conditional Markov Chain (which operates based on specified conditions). The key concepts used include Markov Chain states, transition matrices, and future state probabilities based on past market conditions or indicators.
Key functions:
- `mc_rw()`: Builds a transition matrix using a rolling window Markov Chain, calculating probabilities based on a fixed length of historical data.
- `mc_cond()`: Builds a conditional Markov Chain transition matrix, calculating probabilities based on the current market condition or indicator state.
Basically, you will just need to use the above functions on your script to default outputs and displays.
Exported UDTs include:
- s_map: An UDT variable used to store a map with dummy states, i.e., if possible states are bullish, bearish, and neutral, and current is bullish, it will be stored
in a map with following keys and values: "bullish", 1; "bearish", 0; and "neutral", 0. You will only use it to customize your own script, otherwise, it´s only for internal use.
- mc_states: This UDT variable stores user inputs, calculations and MC outputs. As the above, you don´t need to use it, but you may get features to customize your own script.
For example, you may use mc.tm to get the transition matrix, or the prob map to customize the display. As you see, functions are all based on mc_states UDT. The s_map UDT is used within mc_states´s s array.
Optional exported functions include:
- `mc_table()`: Displays the transition matrix in a table format on the chart for easy visualization of the probabilities.
- `display_list()`: Displays a map (or array) of string and float/int values in a table format, used for showing transition counts or probabilities.
- `mc_prob()`: Calculates and displays probabilities for a given number of future bars based on the current state in the Markov Chain.
- `mc_all_states_prob()`: Calculates probabilities for all states for future bars, considering all possible transitions.
The above functions may be used to customize your outputs. Use the returned variable mc_states from mc_rw() and mc_cond() to display each of its matrix, maps or arrays using mc_table() (for matrices) and display_list() (for maps and arrays) if you desire to debug or track the calculation process.
See the examples in the end of this script.
Have good trading days!
Best regards,
@metacamaleo
-----------------------------
KEY FUNCTIONS
mc_rw(state, length, states, pred_length, show_table, show_prob, table_position, prob_position, font_size)
Builds the transition matrix for a rolling window Markov Chain.
Parameters:
state (string) : The current state of the market or system.
length (int) : The rolling window size.
states (array) : Array of strings representing the possible states in the Markov Chain.
pred_length (int) : The number of bars to predict into the future.
show_table (bool) : Boolean to show or hide the transition matrix table.
show_prob (bool) : Boolean to show or hide the probability table.
table_position (string) : Position of the transition matrix table on the chart.
prob_position (string) : Position of the probability list on the chart.
font_size (string) : Size of the table font.
Returns: The transition matrix and probabilities for future states.
mc_cond(state, condition, states, pred_length, show_table, show_prob, table_position, prob_position, font_size)
Builds the transition matrix for conditional Markov Chains.
Parameters:
state (string) : The current state of the market or system.
condition (string) : A string representing the condition.
states (array) : Array of strings representing the possible states in the Markov Chain.
pred_length (int) : The number of bars to predict into the future.
show_table (bool) : Boolean to show or hide the transition matrix table.
show_prob (bool) : Boolean to show or hide the probability table.
table_position (string) : Position of the transition matrix table on the chart.
prob_position (string) : Position of the probability list on the chart.
font_size (string) : Size of the table font.
Returns: The transition matrix and probabilities for future states based on the HMM.
lib_no_delayLibrary "lib_no_delay"
This library contains modifications to standard functions that return na before reaching the bar of their 'length' parameter.
That is because they do not compromise speed at current time for correct results in the past. This is good for live trading in short timeframes but killing applications on Monthly / Weekly timeframes if instruments, like in crypto, do not have extensive history (why would you even trade the monthly on a meme coin ... not my decision).
Also, some functions rely on source (value at previous bar), which is not available on bar 1 and therefore cascading to a na value up to the last bar ... which in turn leads to a non displaying indicator and waste of time debugging this)
Anyway ... there you go, let me know if I should add more functions.
sma(source, length)
Parameters:
source (float) : Series of values to process.
length (simple int) : Number of bars (length).
Returns: Simple moving average of source for length bars back.
ema(source, length)
Parameters:
source (float) : Series of values to process.
length (simple int) : Number of bars (length).
Returns: (float) The exponentially weighted moving average of the source.
rma(source, length)
Parameters:
source (float) : Series of values to process.
length (simple int) : Number of bars (length).
Returns: Exponential moving average of source with alpha = 1 / length.
atr(length)
Function atr (average true range) returns the RMA of true range. True range is max(high - low, abs(high - close ), abs(low - close )). This adapted version extends ta.atr to start without delay at first bar and deliver usable data instead of na by averaging ta.tr(true) via manual SMA.
Parameters:
length (simple int) : Number of bars back (length).
Returns: Average true range.
rsi(source, length)
Relative strength index. It is calculated using the ta.rma() of upward and downward changes of source over the last length bars. This adapted version extends ta.rsi to start without delay at first bar and deliver usable data instead of na.
Parameters:
source (float) : Series of values to process.
length (simple int) : Number of bars back (length).
Returns: Relative Strength Index.

GraphLibrary "Graph"
Library to collect data and draw scatterplot and heatmap as graph
method init(this)
Initialise Quadrant Data
Namespace types: Quadrant
Parameters:
this (Quadrant) : Quadrant object that needs to be initialised
Returns: current Quadrant object
method init(this)
Initialise Graph Data
Namespace types: Graph
Parameters:
this (Graph) : Graph object that needs to be initialised with 4 Quadrants
Returns: current Graph object
method add(this, data)
Add coordinates to graph
Namespace types: Graph
Parameters:
this (Graph) : Graph object
data (Coordinate) : Coordinates containing x, y data
Returns: current Graph object
method calculate(this)
Calculation required for plotting the graph
Namespace types: Graph
Parameters:
this (Graph) : Graph object
Returns: current Graph object
method paint(this)
Draw graph
Namespace types: Graph
Parameters:
this (Graph) : Graph object
Returns: current Graph object
Coordinate
Coordinates of sample data
Fields:
xValue (series float) : x value of the sample data
yValue (series float) : y value of the sample data
Quadrant
Data belonging to particular quadrant
Fields:
coordinates (array) : Coordinates present in given quadrant
GraphProperties
Properties of Graph that needs to be drawn
Fields:
rows (series int) : Number of rows (y values) in each quadrant
columns (series int) : number of columns (x values) in each quadrant
graphtype (series GraphType) : Type of graph - scatterplot or heatmap
plotColor (series color) : color of plots or heatmap
plotSize (series string) : size of cells in the table
plotchar (series string) : Character to be printed for display of scatterplot
outliers (series int) : Excude the outlier percent of data from calculating the min and max
position (series string) : Table position
bgColor (series color) : graph background color
PlotRange
Range of a plot in terms of x and y values and the number of data points that fall within the Range
Fields:
minX (series float) : min range of X value
maxX (series float) : max range of X value
minY (series float) : min range of Y value
maxY (series float) : max range of Y value
count (series int) : number of samples in the range
Graph
Graph data and properties
Fields:
properties (GraphProperties) : Graph Properties object associated
quadrants (array) : Array containing 4 quadrant data
plotRanges (matrix) : range and count for each cell
xArray (array) : array of x values
yArray (array) : arrray of y values

PubLibPatternLibrary "PubLibPattern"
pattern conditions for indicator and strategy development
bear_5_0(ab_low_tol, ab_up_tol, bc_low_tol, bc_up_tol, cd_low_tol, cd_up_tol)
bearish 5-0 harmonic pattern condition
Parameters:
ab_low_tol (float)
ab_up_tol (float)
bc_low_tol (float)
bc_up_tol (float)
cd_low_tol (float)
cd_up_tol (float)
Returns: bool
bull_5_0(ab_low_tol, ab_up_tol, bc_low_tol, bc_up_tol, cd_low_tol, cd_up_tol)
bullish 5-0 harmonic pattern condition
Parameters:
ab_low_tol (float)
ab_up_tol (float)
bc_low_tol (float)
bc_up_tol (float)
cd_low_tol (float)
cd_up_tol (float)
Returns: bool
bear_abcd(bc_low_tol, bc_up_tol, cd_low_tol, cd_up_tol)
bearish abcd harmonic pattern condition
Parameters:
bc_low_tol (float)
bc_up_tol (float)
cd_low_tol (float)
cd_up_tol (float)
Returns: bool
bull_abcd(bc_low_tol, bc_up_tol, cd_low_tol, cd_up_tol)
bullish abcd harmonic pattern condition
Parameters:
bc_low_tol (float)
bc_up_tol (float)
cd_low_tol (float)
cd_up_tol (float)
Returns: bool
bear_alt_bat(ab_low_tol, ab_up_tol, bc_low_tol, bc_up_tol, cd_low_tol, cd_up_tol, ad_low_tol, ad_up_tol)
bearish alternate bat harmonic pattern condition
Parameters:
ab_low_tol (float)
ab_up_tol (float)
bc_low_tol (float)
bc_up_tol (float)
cd_low_tol (float)
cd_up_tol (float)
ad_low_tol (float)
ad_up_tol (float)
Returns: bool
bull_alt_bat(ab_low_tol, ab_up_tol, bc_low_tol, bc_up_tol, cd_low_tol, cd_up_tol, ad_low_tol, ad_up_tol)
bullish alternate bat harmonic pattern condition
Parameters:
ab_low_tol (float)
ab_up_tol (float)
bc_low_tol (float)
bc_up_tol (float)
cd_low_tol (float)
cd_up_tol (float)
ad_low_tol (float)
ad_up_tol (float)
Returns: bool
bear_bat(ab_low_tol, ab_up_tol, bc_low_tol, bc_up_tol, cd_low_tol, cd_up_tol, ad_low_tol, ad_up_tol)
bearish bat harmonic pattern condition
Parameters:
ab_low_tol (float)
ab_up_tol (float)
bc_low_tol (float)
bc_up_tol (float)
cd_low_tol (float)
cd_up_tol (float)
ad_low_tol (float)
ad_up_tol (float)
Returns: bool
bull_bat(ab_low_tol, ab_up_tol, bc_low_tol, bc_up_tol, cd_low_tol, cd_up_tol, ad_low_tol, ad_up_tol)
bullish bat harmonic pattern condition
Parameters:
ab_low_tol (float)
ab_up_tol (float)
bc_low_tol (float)
bc_up_tol (float)
cd_low_tol (float)
cd_up_tol (float)
ad_low_tol (float)
ad_up_tol (float)
Returns: bool
bear_butterfly(ab_low_tol, ab_up_tol, bc_low_tol, bc_up_tol, cd_low_tol, cd_up_tol, ad_low_tol, ad_up_tol)
bearish butterfly harmonic pattern condition
Parameters:
ab_low_tol (float)
ab_up_tol (float)
bc_low_tol (float)
bc_up_tol (float)
cd_low_tol (float)
cd_up_tol (float)
ad_low_tol (float)
ad_up_tol (float)
Returns: bool
bull_butterfly(ab_low_tol, ab_up_tol, bc_low_tol, bc_up_tol, cd_low_tol, cd_up_tol, ad_low_tol, ad_up_tol)
bullish butterfly harmonic pattern condition
Parameters:
ab_low_tol (float)
ab_up_tol (float)
bc_low_tol (float)
bc_up_tol (float)
cd_low_tol (float)
cd_up_tol (float)
ad_low_tol (float)
ad_up_tol (float)
Returns: bool
bear_cassiopeia_a(ab_low_tol, ab_up_tol, bc_low_tol, bc_up_tol, cd_low_tol, cd_up_tol)
bearish cassiopeia a harmonic pattern condition
Parameters:
ab_low_tol (float)
ab_up_tol (float)
bc_low_tol (float)
bc_up_tol (float)
cd_low_tol (float)
cd_up_tol (float)
Returns: bool
bull_cassiopeia_a(ab_low_tol, ab_up_tol, bc_low_tol, bc_up_tol, cd_low_tol, cd_up_tol)
bullish cassiopeia a harmonic pattern condition
Parameters:
ab_low_tol (float)
ab_up_tol (float)
bc_low_tol (float)
bc_up_tol (float)
cd_low_tol (float)
cd_up_tol (float)
Returns: bool
bear_cassiopeia_b(ab_low_tol, ab_up_tol, bc_low_tol, bc_up_tol, cd_low_tol, cd_up_tol)
bearish cassiopeia b harmonic pattern condition
Parameters:
ab_low_tol (float)
ab_up_tol (float)
bc_low_tol (float)
bc_up_tol (float)
cd_low_tol (float)
cd_up_tol (float)
Returns: bool
bull_cassiopeia_b(ab_low_tol, ab_up_tol, bc_low_tol, bc_up_tol, cd_low_tol, cd_up_tol)
bullish cassiopeia b harmonic pattern condition
Parameters:
ab_low_tol (float)
ab_up_tol (float)
bc_low_tol (float)
bc_up_tol (float)
cd_low_tol (float)
cd_up_tol (float)
Returns: bool
bear_cassiopeia_c(ab_low_tol, ab_up_tol, bc_low_tol, bc_up_tol, cd_low_tol, cd_up_tol)
bearish cassiopeia c harmonic pattern condition
Parameters:
ab_low_tol (float)
ab_up_tol (float)
bc_low_tol (float)
bc_up_tol (float)
cd_low_tol (float)
cd_up_tol (float)
Returns: bool
bull_cassiopeia_c(ab_low_tol, ab_up_tol, bc_low_tol, bc_up_tol, cd_low_tol, cd_up_tol)
bullish cassiopeia c harmonic pattern condition
Parameters:
ab_low_tol (float)
ab_up_tol (float)
bc_low_tol (float)
bc_up_tol (float)
cd_low_tol (float)
cd_up_tol (float)
Returns: bool
bear_crab(ab_low_tol, ab_up_tol, bc_low_tol, bc_up_tol, cd_low_tol, cd_up_tol, ad_low_tol, ad_up_tol)
bearish crab harmonic pattern condition
Parameters:
ab_low_tol (float)
ab_up_tol (float)
bc_low_tol (float)
bc_up_tol (float)
cd_low_tol (float)
cd_up_tol (float)
ad_low_tol (float)
ad_up_tol (float)
Returns: bool
bull_crab(ab_low_tol, ab_up_tol, bc_low_tol, bc_up_tol, cd_low_tol, cd_up_tol, ad_low_tol, ad_up_tol)
bullish crab harmonic pattern condition
Parameters:
ab_low_tol (float)
ab_up_tol (float)
bc_low_tol (float)
bc_up_tol (float)
cd_low_tol (float)
cd_up_tol (float)
ad_low_tol (float)
ad_up_tol (float)
Returns: bool
bear_deep_crab(ab_low_tol, ab_up_tol, bc_low_tol, bc_up_tol, cd_low_tol, cd_up_tol, ad_low_tol, ad_up_tol)
bearish deep crab harmonic pattern condition
Parameters:
ab_low_tol (float)
ab_up_tol (float)
bc_low_tol (float)
bc_up_tol (float)
cd_low_tol (float)
cd_up_tol (float)
ad_low_tol (float)
ad_up_tol (float)
Returns: bool
bull_deep_crab(ab_low_tol, ab_up_tol, bc_low_tol, bc_up_tol, cd_low_tol, cd_up_tol, ad_low_tol, ad_up_tol)
bullish deep crab harmonic pattern condition
Parameters:
ab_low_tol (float)
ab_up_tol (float)
bc_low_tol (float)
bc_up_tol (float)
cd_low_tol (float)
cd_up_tol (float)
ad_low_tol (float)
ad_up_tol (float)
Returns: bool
bear_cypher(ab_low_tol, ab_up_tol, bc_low_tol, bc_up_tol, cd_low_tol, cd_up_tol, xc_low_tol, xc_up_tol)
bearish cypher harmonic pattern condition
Parameters:
ab_low_tol (float)
ab_up_tol (float)
bc_low_tol (float)
bc_up_tol (float)
cd_low_tol (float)
cd_up_tol (float)
xc_low_tol (float)
xc_up_tol (float)
Returns: bool
bull_cypher(ab_low_tol, ab_up_tol, bc_low_tol, bc_up_tol, cd_low_tol, cd_up_tol, xc_low_tol, xc_up_tol)
bullish cypher harmonic pattern condition
Parameters:
ab_low_tol (float)
ab_up_tol (float)
bc_low_tol (float)
bc_up_tol (float)
cd_low_tol (float)
cd_up_tol (float)
xc_low_tol (float)
xc_up_tol (float)
Returns: bool
bear_gartley(ab_low_tol, ab_up_tol, bc_low_tol, bc_up_tol, cd_low_tol, cd_up_tol, ad_low_tol, ad_up_tol)
bearish gartley harmonic pattern condition
Parameters:
ab_low_tol (float)
ab_up_tol (float)
bc_low_tol (float)
bc_up_tol (float)
cd_low_tol (float)
cd_up_tol (float)
ad_low_tol (float)
ad_up_tol (float)
Returns: bool
bull_gartley(ab_low_tol, ab_up_tol, bc_low_tol, bc_up_tol, cd_low_tol, cd_up_tol, ad_low_tol, ad_up_tol)
bullish gartley harmonic pattern condition
Parameters:
ab_low_tol (float)
ab_up_tol (float)
bc_low_tol (float)
bc_up_tol (float)
cd_low_tol (float)
cd_up_tol (float)
ad_low_tol (float)
ad_up_tol (float)
Returns: bool
bear_shark(ab_low_tol, ab_up_tol, bc_low_tol, bc_up_tol, xc_low_tol, xc_up_tol)
bearish shark harmonic pattern condition
Parameters:
ab_low_tol (float)
ab_up_tol (float)
bc_low_tol (float)
bc_up_tol (float)
xc_low_tol (float)
xc_up_tol (float)
Returns: bool
bull_shark(ab_low_tol, ab_up_tol, bc_low_tol, bc_up_tol, xc_low_tol, xc_up_tol)
bullish shark harmonic pattern condition
Parameters:
ab_low_tol (float)
ab_up_tol (float)
bc_low_tol (float)
bc_up_tol (float)
xc_low_tol (float)
xc_up_tol (float)
Returns: bool
bear_three_drive(x1_low_tol, a1_low_tol, a1_up_tol, a2_low_tol, a2_up_tol, b2_low_tol, b2_up_tol, b3_low_tol, b3_upt_tol)
bearish three drive harmonic pattern condition
Parameters:
x1_low_tol (float)
a1_low_tol (float)
a1_up_tol (float)
a2_low_tol (float)
a2_up_tol (float)
b2_low_tol (float)
b2_up_tol (float)
b3_low_tol (float)
b3_upt_tol (float)
Returns: bool
bull_three_drive(x1_low_tol, a1_low_tol, a1_up_tol, a2_low_tol, a2_up_tol, b2_low_tol, b2_up_tol, b3_low_tol, b3_upt_tol)
bullish three drive harmonic pattern condition
Parameters:
x1_low_tol (float)
a1_low_tol (float)
a1_up_tol (float)
a2_low_tol (float)
a2_up_tol (float)
b2_low_tol (float)
b2_up_tol (float)
b3_low_tol (float)
b3_upt_tol (float)
Returns: bool
asc_broadening()
ascending broadening pattern condition
Returns: bool
broadening()
broadening pattern condition
Returns: bool
desc_broadening()
descending broadening pattern condition
Returns: bool
double_bot(low_tol, up_tol)
double bottom pattern condition
Parameters:
low_tol (float)
up_tol (float)
Returns: bool
double_top(low_tol, up_tol)
double top pattern condition
Parameters:
low_tol (float)
up_tol (float)
Returns: bool
triple_bot(low_tol, up_tol)
triple bottom pattern condition
Parameters:
low_tol (float)
up_tol (float)
Returns: bool
triple_top(low_tol, up_tol)
triple top pattern condition
Parameters:
low_tol (float)
up_tol (float)
Returns: bool
bear_elliot()
bearish elliot wave pattern condition
Returns: bool
bull_elliot()
bullish elliot wave pattern condition
Returns: bool
bear_alt_flag(ab_ratio, bc_ratio)
bearish alternate flag pattern condition
Parameters:
ab_ratio (float)
bc_ratio (float)
Returns: bool
bull_alt_flag(ab_ratio, bc_ratio)
bullish alternate flag pattern condition
Parameters:
ab_ratio (float)
bc_ratio (float)
Returns: bool
bear_flag(ab_ratio, bc_ratio, be_ratio)
bearish flag pattern condition
Parameters:
ab_ratio (float)
bc_ratio (float)
be_ratio (float)
Returns: bool
bull_flag(ab_ratio, bc_ratio, be_ratio)
bullish flag pattern condition
Parameters:
ab_ratio (float)
bc_ratio (float)
be_ratio (float)
Returns: bool
bear_asc_head_shoulders()
bearish ascending head and shoulders pattern condition
Returns: bool
bull_asc_head_shoulders()
bullish ascending head and shoulders pattern condition
Returns: bool
bear_desc_head_shoulders()
bearish descending head and shoulders pattern condition
Returns: bool
bull_desc_head_shoulders()
bullish descending head and shoulders pattern condition
Returns: bool
bear_head_shoulders()
bearish head and shoulders pattern condition
Returns: bool
bull_head_shoulders()
bullish head and shoulders pattern condition
Returns: bool
bear_pennant(ab_ratio, bc_ratio)
bearish pennant pattern condition
Parameters:
ab_ratio (float)
bc_ratio (float)
Returns: bool
bull_pennant(ab_ratio, bc_ratio)
bullish pennant pattern condition
Parameters:
ab_ratio (float)
bc_ratio (float)
Returns: bool
asc_wedge()
ascending wedge pattern condition
Returns: bool
desc_wedge()
descending wedge pattern condition
Returns: bool
wedge()
wedge pattern condition
Returns: bool

PubLibTrendLibrary "PubLibTrend"
trend, multi-part trend, double trend and multi-part double trend conditions for indicator and strategy development
rlut()
return line uptrend condition
Returns: bool
dt()
downtrend condition
Returns: bool
ut()
uptrend condition
Returns: bool
rldt()
return line downtrend condition
Returns: bool
dtop()
double top condition
Returns: bool
dbot()
double bottom condition
Returns: bool
rlut_1p()
1-part return line uptrend condition
Returns: bool
rlut_2p()
2-part return line uptrend condition
Returns: bool
rlut_3p()
3-part return line uptrend condition
Returns: bool
rlut_4p()
4-part return line uptrend condition
Returns: bool
rlut_5p()
5-part return line uptrend condition
Returns: bool
rlut_6p()
6-part return line uptrend condition
Returns: bool
rlut_7p()
7-part return line uptrend condition
Returns: bool
rlut_8p()
8-part return line uptrend condition
Returns: bool
rlut_9p()
9-part return line uptrend condition
Returns: bool
rlut_10p()
10-part return line uptrend condition
Returns: bool
rlut_11p()
11-part return line uptrend condition
Returns: bool
rlut_12p()
12-part return line uptrend condition
Returns: bool
rlut_13p()
13-part return line uptrend condition
Returns: bool
rlut_14p()
14-part return line uptrend condition
Returns: bool
rlut_15p()
15-part return line uptrend condition
Returns: bool
rlut_16p()
16-part return line uptrend condition
Returns: bool
rlut_17p()
17-part return line uptrend condition
Returns: bool
rlut_18p()
18-part return line uptrend condition
Returns: bool
rlut_19p()
19-part return line uptrend condition
Returns: bool
rlut_20p()
20-part return line uptrend condition
Returns: bool
rlut_21p()
21-part return line uptrend condition
Returns: bool
rlut_22p()
22-part return line uptrend condition
Returns: bool
rlut_23p()
23-part return line uptrend condition
Returns: bool
rlut_24p()
24-part return line uptrend condition
Returns: bool
rlut_25p()
25-part return line uptrend condition
Returns: bool
rlut_26p()
26-part return line uptrend condition
Returns: bool
rlut_27p()
27-part return line uptrend condition
Returns: bool
rlut_28p()
28-part return line uptrend condition
Returns: bool
rlut_29p()
29-part return line uptrend condition
Returns: bool
rlut_30p()
30-part return line uptrend condition
Returns: bool
dt_1p()
1-part downtrend condition
Returns: bool
dt_2p()
2-part downtrend condition
Returns: bool
dt_3p()
3-part downtrend condition
Returns: bool
dt_4p()
4-part downtrend condition
Returns: bool
dt_5p()
5-part downtrend condition
Returns: bool
dt_6p()
6-part downtrend condition
Returns: bool
dt_7p()
7-part downtrend condition
Returns: bool
dt_8p()
8-part downtrend condition
Returns: bool
dt_9p()
9-part downtrend condition
Returns: bool
dt_10p()
10-part downtrend condition
Returns: bool
dt_11p()
11-part downtrend condition
Returns: bool
dt_12p()
12-part downtrend condition
Returns: bool
dt_13p()
13-part downtrend condition
Returns: bool
dt_14p()
14-part downtrend condition
Returns: bool
dt_15p()
15-part downtrend condition
Returns: bool
dt_16p()
16-part downtrend condition
Returns: bool
dt_17p()
17-part downtrend condition
Returns: bool
dt_18p()
18-part downtrend condition
Returns: bool
dt_19p()
19-part downtrend condition
Returns: bool
dt_20p()
20-part downtrend condition
Returns: bool
dt_21p()
21-part downtrend condition
Returns: bool
dt_22p()
22-part downtrend condition
Returns: bool
dt_23p()
23-part downtrend condition
Returns: bool
dt_24p()
24-part downtrend condition
Returns: bool
dt_25p()
25-part downtrend condition
Returns: bool
dt_26p()
26-part downtrend condition
Returns: bool
dt_27p()
27-part downtrend condition
Returns: bool
dt_28p()
28-part downtrend condition
Returns: bool
dt_29p()
29-part downtrend condition
Returns: bool
dt_30p()
30-part downtrend condition
Returns: bool
ut_1p()
1-part uptrend condition
Returns: bool
ut_2p()
2-part uptrend condition
Returns: bool
ut_3p()
3-part uptrend condition
Returns: bool
ut_4p()
4-part uptrend condition
Returns: bool
ut_5p()
5-part uptrend condition
Returns: bool
ut_6p()
6-part uptrend condition
Returns: bool
ut_7p()
7-part uptrend condition
Returns: bool
ut_8p()
8-part uptrend condition
Returns: bool
ut_9p()
9-part uptrend condition
Returns: bool
ut_10p()
10-part uptrend condition
Returns: bool
ut_11p()
11-part uptrend condition
Returns: bool
ut_12p()
12-part uptrend condition
Returns: bool
ut_13p()
13-part uptrend condition
Returns: bool
ut_14p()
14-part uptrend condition
Returns: bool
ut_15p()
15-part uptrend condition
Returns: bool
ut_16p()
16-part uptrend condition
Returns: bool
ut_17p()
17-part uptrend condition
Returns: bool
ut_18p()
18-part uptrend condition
Returns: bool
ut_19p()
19-part uptrend condition
Returns: bool
ut_20p()
20-part uptrend condition
Returns: bool
ut_21p()
21-part uptrend condition
Returns: bool
ut_22p()
22-part uptrend condition
Returns: bool
ut_23p()
23-part uptrend condition
Returns: bool
ut_24p()
24-part uptrend condition
Returns: bool
ut_25p()
25-part uptrend condition
Returns: bool
ut_26p()
26-part uptrend condition
Returns: bool
ut_27p()
27-part uptrend condition
Returns: bool
ut_28p()
28-part uptrend condition
Returns: bool
ut_29p()
29-part uptrend condition
Returns: bool
ut_30p()
30-part uptrend condition
Returns: bool
rldt_1p()
1-part return line downtrend condition
Returns: bool
rldt_2p()
2-part return line downtrend condition
Returns: bool
rldt_3p()
3-part return line downtrend condition
Returns: bool
rldt_4p()
4-part return line downtrend condition
Returns: bool
rldt_5p()
5-part return line downtrend condition
Returns: bool
rldt_6p()
6-part return line downtrend condition
Returns: bool
rldt_7p()
7-part return line downtrend condition
Returns: bool
rldt_8p()
8-part return line downtrend condition
Returns: bool
rldt_9p()
9-part return line downtrend condition
Returns: bool
rldt_10p()
10-part return line downtrend condition
Returns: bool
rldt_11p()
11-part return line downtrend condition
Returns: bool
rldt_12p()
12-part return line downtrend condition
Returns: bool
rldt_13p()
13-part return line downtrend condition
Returns: bool
rldt_14p()
14-part return line downtrend condition
Returns: bool
rldt_15p()
15-part return line downtrend condition
Returns: bool
rldt_16p()
16-part return line downtrend condition
Returns: bool
rldt_17p()
17-part return line downtrend condition
Returns: bool
rldt_18p()
18-part return line downtrend condition
Returns: bool
rldt_19p()
19-part return line downtrend condition
Returns: bool
rldt_20p()
20-part return line downtrend condition
Returns: bool
rldt_21p()
21-part return line downtrend condition
Returns: bool
rldt_22p()
22-part return line downtrend condition
Returns: bool
rldt_23p()
23-part return line downtrend condition
Returns: bool
rldt_24p()
24-part return line downtrend condition
Returns: bool
rldt_25p()
25-part return line downtrend condition
Returns: bool
rldt_26p()
26-part return line downtrend condition
Returns: bool
rldt_27p()
27-part return line downtrend condition
Returns: bool
rldt_28p()
28-part return line downtrend condition
Returns: bool
rldt_29p()
29-part return line downtrend condition
Returns: bool
rldt_30p()
30-part return line downtrend condition
Returns: bool
dut()
double uptrend condition
Returns: bool
ddt()
double downtrend condition
Returns: bool
dut_1p()
1-part double uptrend condition
Returns: bool
dut_2p()
2-part double uptrend condition
Returns: bool
dut_3p()
3-part double uptrend condition
Returns: bool
dut_4p()
4-part double uptrend condition
Returns: bool
dut_5p()
5-part double uptrend condition
Returns: bool
dut_6p()
6-part double uptrend condition
Returns: bool
dut_7p()
7-part double uptrend condition
Returns: bool
dut_8p()
8-part double uptrend condition
Returns: bool
dut_9p()
9-part double uptrend condition
Returns: bool
dut_10p()
10-part double uptrend condition
Returns: bool
dut_11p()
11-part double uptrend condition
Returns: bool
dut_12p()
12-part double uptrend condition
Returns: bool
dut_13p()
13-part double uptrend condition
Returns: bool
dut_14p()
14-part double uptrend condition
Returns: bool
dut_15p()
15-part double uptrend condition
Returns: bool
dut_16p()
16-part double uptrend condition
Returns: bool
dut_17p()
17-part double uptrend condition
Returns: bool
dut_18p()
18-part double uptrend condition
Returns: bool
dut_19p()
19-part double uptrend condition
Returns: bool
dut_20p()
20-part double uptrend condition
Returns: bool
dut_21p()
21-part double uptrend condition
Returns: bool
dut_22p()
22-part double uptrend condition
Returns: bool
dut_23p()
23-part double uptrend condition
Returns: bool
dut_24p()
24-part double uptrend condition
Returns: bool
dut_25p()
25-part double uptrend condition
Returns: bool
dut_26p()
26-part double uptrend condition
Returns: bool
dut_27p()
27-part double uptrend condition
Returns: bool
dut_28p()
28-part double uptrend condition
Returns: bool
dut_29p()
29-part double uptrend condition
Returns: bool
dut_30p()
30-part double uptrend condition
Returns: bool
ddt_1p()
1-part double downtrend condition
Returns: bool
ddt_2p()
2-part double downtrend condition
Returns: bool
ddt_3p()
3-part double downtrend condition
Returns: bool
ddt_4p()
4-part double downtrend condition
Returns: bool
ddt_5p()
5-part double downtrend condition
Returns: bool
ddt_6p()
6-part double downtrend condition
Returns: bool
ddt_7p()
7-part double downtrend condition
Returns: bool
ddt_8p()
8-part double downtrend condition
Returns: bool
ddt_9p()
9-part double downtrend condition
Returns: bool
ddt_10p()
10-part double downtrend condition
Returns: bool
ddt_11p()
11-part double downtrend condition
Returns: bool
ddt_12p()
12-part double downtrend condition
Returns: bool
ddt_13p()
13-part double downtrend condition
Returns: bool
ddt_14p()
14-part double downtrend condition
Returns: bool
ddt_15p()
15-part double downtrend condition
Returns: bool
ddt_16p()
16-part double downtrend condition
Returns: bool
ddt_17p()
17-part double downtrend condition
Returns: bool
ddt_18p()
18-part double downtrend condition
Returns: bool
ddt_19p()
19-part double downtrend condition
Returns: bool
ddt_20p()
20-part double downtrend condition
Returns: bool
ddt_21p()
21-part double downtrend condition
Returns: bool
ddt_22p()
22-part double downtrend condition
Returns: bool
ddt_23p()
23-part double downtrend condition
Returns: bool
ddt_24p()
24-part double downtrend condition
Returns: bool
ddt_25p()
25-part double downtrend condition
Returns: bool
ddt_26p()
26-part double downtrend condition
Returns: bool
ddt_27p()
27-part double downtrend condition
Returns: bool
ddt_28p()
28-part double downtrend condition
Returns: bool
ddt_29p()
29-part double downtrend condition
Returns: bool
ddt_30p()
30-part double downtrend condition
Returns: bool

PubLibSwingLibrary "PubLibSwing"
swing high and swing low conditions, prices, bar indices and range ratios for indicator and strategy development
sh()
swing high condition
Returns: bool
sl()
swing low condition
Returns: bool
shbi(occ)
swing high bar index, condition occurrence n
Parameters:
occ (simple int)
Returns: int
slbi(occ)
swing low bar index, condition occurrence n
Parameters:
occ (simple int)
Returns: int
shcp(occ)
swing high close price, condition occurrence n
Parameters:
occ (simple int)
Returns: float
slcp(occ)
swing low close price, condition occurrence n
Parameters:
occ (simple int)
Returns: float
shp(occ)
swing high price, condition occurrence n
Parameters:
occ (simple int)
Returns: float
slp(occ)
swing low price, condition occurrence n
Parameters:
occ (simple int)
Returns: float
shpbi(occ)
swing high price bar index, condition occurrence n
Parameters:
occ (simple int)
Returns: int
slpbi(occ)
swing low price bar index, condition occurrence n
Parameters:
occ (simple int)
Returns: int
shrr(occ)
swing high range ratio, condition occurrence n
Parameters:
occ (simple int)
Returns: float
slrr(occ)
swing low range ratio, condition occurrence n
Parameters:
occ (simple int)
Returns: float
PubLibCandleTrendLibrary "PubLibCandleTrend"
candle trend, multi-part candle trend, multi-part green/red candle trend, double candle trend and multi-part double candle trend conditions for indicator and strategy development
chh()
candle higher high condition
Returns: bool
chl()
candle higher low condition
Returns: bool
clh()
candle lower high condition
Returns: bool
cll()
candle lower low condition
Returns: bool
cdt()
candle double top condition
Returns: bool
cdb()
candle double bottom condition
Returns: bool
gc()
green candle condition
Returns: bool
gchh()
green candle higher high condition
Returns: bool
gchl()
green candle higher low condition
Returns: bool
gclh()
green candle lower high condition
Returns: bool
gcll()
green candle lower low condition
Returns: bool
gcdt()
green candle double top condition
Returns: bool
gcdb()
green candle double bottom condition
Returns: bool
rc()
red candle condition
Returns: bool
rchh()
red candle higher high condition
Returns: bool
rchl()
red candle higher low condition
Returns: bool
rclh()
red candle lower high condition
Returns: bool
rcll()
red candle lower low condition
Returns: bool
rcdt()
red candle double top condition
Returns: bool
rcdb()
red candle double bottom condition
Returns: bool
chh_1p()
1-part candle higher high condition
Returns: bool
chh_2p()
2-part candle higher high condition
Returns: bool
chh_3p()
3-part candle higher high condition
Returns: bool
chh_4p()
4-part candle higher high condition
Returns: bool
chh_5p()
5-part candle higher high condition
Returns: bool
chh_6p()
6-part candle higher high condition
Returns: bool
chh_7p()
7-part candle higher high condition
Returns: bool
chh_8p()
8-part candle higher high condition
Returns: bool
chh_9p()
9-part candle higher high condition
Returns: bool
chh_10p()
10-part candle higher high condition
Returns: bool
chh_11p()
11-part candle higher high condition
Returns: bool
chh_12p()
12-part candle higher high condition
Returns: bool
chh_13p()
13-part candle higher high condition
Returns: bool
chh_14p()
14-part candle higher high condition
Returns: bool
chh_15p()
15-part candle higher high condition
Returns: bool
chh_16p()
16-part candle higher high condition
Returns: bool
chh_17p()
17-part candle higher high condition
Returns: bool
chh_18p()
18-part candle higher high condition
Returns: bool
chh_19p()
19-part candle higher high condition
Returns: bool
chh_20p()
20-part candle higher high condition
Returns: bool
chh_21p()
21-part candle higher high condition
Returns: bool
chh_22p()
22-part candle higher high condition
Returns: bool
chh_23p()
23-part candle higher high condition
Returns: bool
chh_24p()
24-part candle higher high condition
Returns: bool
chh_25p()
25-part candle higher high condition
Returns: bool
chh_26p()
26-part candle higher high condition
Returns: bool
chh_27p()
27-part candle higher high condition
Returns: bool
chh_28p()
28-part candle higher high condition
Returns: bool
chh_29p()
29-part candle higher high condition
Returns: bool
chh_30p()
30-part candle higher high condition
Returns: bool
chl_1p()
1-part candle higher low condition
Returns: bool
chl_2p()
2-part candle higher low condition
Returns: bool
chl_3p()
3-part candle higher low condition
Returns: bool
chl_4p()
4-part candle higher low condition
Returns: bool
chl_5p()
5-part candle higher low condition
Returns: bool
chl_6p()
6-part candle higher low condition
Returns: bool
chl_7p()
7-part candle higher low condition
Returns: bool
chl_8p()
8-part candle higher low condition
Returns: bool
chl_9p()
9-part candle higher low condition
Returns: bool
chl_10p()
10-part candle higher low condition
Returns: bool
chl_11p()
11-part candle higher low condition
Returns: bool
chl_12p()
12-part candle higher low condition
Returns: bool
chl_13p()
13-part candle higher low condition
Returns: bool
chl_14p()
14-part candle higher low condition
Returns: bool
chl_15p()
15-part candle higher low condition
Returns: bool
chl_16p()
16-part candle higher low condition
Returns: bool
chl_17p()
17-part candle higher low condition
Returns: bool
chl_18p()
18-part candle higher low condition
Returns: bool
chl_19p()
19-part candle higher low condition
Returns: bool
chl_20p()
20-part candle higher low condition
Returns: bool
chl_21p()
21-part candle higher low condition
Returns: bool
chl_22p()
22-part candle higher low condition
Returns: bool
chl_23p()
23-part candle higher low condition
Returns: bool
chl_24p()
24-part candle higher low condition
Returns: bool
chl_25p()
25-part candle higher low condition
Returns: bool
chl_26p()
26-part candle higher low condition
Returns: bool
chl_27p()
27-part candle higher low condition
Returns: bool
chl_28p()
28-part candle higher low condition
Returns: bool
chl_29p()
29-part candle higher low condition
Returns: bool
chl_30p()
30-part candle higher low condition
Returns: bool
clh_1p()
1-part candle lower high condition
Returns: bool
clh_2p()
2-part candle lower high condition
Returns: bool
clh_3p()
3-part candle lower high condition
Returns: bool
clh_4p()
4-part candle lower high condition
Returns: bool
clh_5p()
5-part candle lower high condition
Returns: bool
clh_6p()
6-part candle lower high condition
Returns: bool
clh_7p()
7-part candle lower high condition
Returns: bool
clh_8p()
8-part candle lower high condition
Returns: bool
clh_9p()
9-part candle lower high condition
Returns: bool
clh_10p()
10-part candle lower high condition
Returns: bool
clh_11p()
11-part candle lower high condition
Returns: bool
clh_12p()
12-part candle lower high condition
Returns: bool
clh_13p()
13-part candle lower high condition
Returns: bool
clh_14p()
14-part candle lower high condition
Returns: bool
clh_15p()
15-part candle lower high condition
Returns: bool
clh_16p()
16-part candle lower high condition
Returns: bool
clh_17p()
17-part candle lower high condition
Returns: bool
clh_18p()
18-part candle lower high condition
Returns: bool
clh_19p()
19-part candle lower high condition
Returns: bool
clh_20p()
20-part candle lower high condition
Returns: bool
clh_21p()
21-part candle lower high condition
Returns: bool
clh_22p()
22-part candle lower high condition
Returns: bool
clh_23p()
23-part candle lower high condition
Returns: bool
clh_24p()
24-part candle lower high condition
Returns: bool
clh_25p()
25-part candle lower high condition
Returns: bool
clh_26p()
26-part candle lower high condition
Returns: bool
clh_27p()
27-part candle lower high condition
Returns: bool
clh_28p()
28-part candle lower high condition
Returns: bool
clh_29p()
29-part candle lower high condition
Returns: bool
clh_30p()
30-part candle lower high condition
Returns: bool
cll_1p()
1-part candle lower low condition
Returns: bool
cll_2p()
2-part candle lower low condition
Returns: bool
cll_3p()
3-part candle lower low condition
Returns: bool
cll_4p()
4-part candle lower low condition
Returns: bool
cll_5p()
5-part candle lower low condition
Returns: bool
cll_6p()
6-part candle lower low condition
Returns: bool
cll_7p()
7-part candle lower low condition
Returns: bool
cll_8p()
8-part candle lower low condition
Returns: bool
cll_9p()
9-part candle lower low condition
Returns: bool
cll_10p()
10-part candle lower low condition
Returns: bool
cll_11p()
11-part candle lower low condition
Returns: bool
cll_12p()
12-part candle lower low condition
Returns: bool
cll_13p()
13-part candle lower low condition
Returns: bool
cll_14p()
14-part candle lower low condition
Returns: bool
cll_15p()
15-part candle lower low condition
Returns: bool
cll_16p()
16-part candle lower low condition
Returns: bool
cll_17p()
17-part candle lower low condition
Returns: bool
cll_18p()
18-part candle lower low condition
Returns: bool
cll_19p()
19-part candle lower low condition
Returns: bool
cll_20p()
20-part candle lower low condition
Returns: bool
cll_21p()
21-part candle lower low condition
Returns: bool
cll_22p()
22-part candle lower low condition
Returns: bool
cll_23p()
23-part candle lower low condition
Returns: bool
cll_24p()
24-part candle lower low condition
Returns: bool
cll_25p()
25-part candle lower low condition
Returns: bool
cll_26p()
26-part candle lower low condition
Returns: bool
cll_27p()
27-part candle lower low condition
Returns: bool
cll_28p()
28-part candle lower low condition
Returns: bool
cll_29p()
29-part candle lower low condition
Returns: bool
cll_30p()
30-part candle lower low condition
Returns: bool
gc_1p()
1-part green candle condition
Returns: bool
gc_2p()
2-part green candle condition
Returns: bool
gc_3p()
3-part green candle condition
Returns: bool
gc_4p()
4-part green candle condition
Returns: bool
gc_5p()
5-part green candle condition
Returns: bool
gc_6p()
6-part green candle condition
Returns: bool
gc_7p()
7-part green candle condition
Returns: bool
gc_8p()
8-part green candle condition
Returns: bool
gc_9p()
9-part green candle condition
Returns: bool
gc_10p()
10-part green candle condition
Returns: bool
gc_11p()
11-part green candle condition
Returns: bool
gc_12p()
12-part green candle condition
Returns: bool
gc_13p()
13-part green candle condition
Returns: bool
gc_14p()
14-part green candle condition
Returns: bool
gc_15p()
15-part green candle condition
Returns: bool
gc_16p()
16-part green candle condition
Returns: bool
gc_17p()
17-part green candle condition
Returns: bool
gc_18p()
18-part green candle condition
Returns: bool
gc_19p()
19-part green candle condition
Returns: bool
gc_20p()
20-part green candle condition
Returns: bool
gc_21p()
21-part green candle condition
Returns: bool
gc_22p()
22-part green candle condition
Returns: bool
gc_23p()
23-part green candle condition
Returns: bool
gc_24p()
24-part green candle condition
Returns: bool
gc_25p()
25-part green candle condition
Returns: bool
gc_26p()
26-part green candle condition
Returns: bool
gc_27p()
27-part green candle condition
Returns: bool
gc_28p()
28-part green candle condition
Returns: bool
gc_29p()
29-part green candle condition
Returns: bool
gc_30p()
30-part green candle condition
Returns: bool
rc_1p()
1-part red candle condition
Returns: bool
rc_2p()
2-part red candle condition
Returns: bool
rc_3p()
3-part red candle condition
Returns: bool
rc_4p()
4-part red candle condition
Returns: bool
rc_5p()
5-part red candle condition
Returns: bool
rc_6p()
6-part red candle condition
Returns: bool
rc_7p()
7-part red candle condition
Returns: bool
rc_8p()
8-part red candle condition
Returns: bool
rc_9p()
9-part red candle condition
Returns: bool
rc_10p()
10-part red candle condition
Returns: bool
rc_11p()
11-part red candle condition
Returns: bool
rc_12p()
12-part red candle condition
Returns: bool
rc_13p()
13-part red candle condition
Returns: bool
rc_14p()
14-part red candle condition
Returns: bool
rc_15p()
15-part red candle condition
Returns: bool
rc_16p()
16-part red candle condition
Returns: bool
rc_17p()
17-part red candle condition
Returns: bool
rc_18p()
18-part red candle condition
Returns: bool
rc_19p()
19-part red candle condition
Returns: bool
rc_20p()
20-part red candle condition
Returns: bool
rc_21p()
21-part red candle condition
Returns: bool
rc_22p()
22-part red candle condition
Returns: bool
rc_23p()
23-part red candle condition
Returns: bool
rc_24p()
24-part red candle condition
Returns: bool
rc_25p()
25-part red candle condition
Returns: bool
rc_26p()
26-part red candle condition
Returns: bool
rc_27p()
27-part red candle condition
Returns: bool
rc_28p()
28-part red candle condition
Returns: bool
rc_29p()
29-part red candle condition
Returns: bool
rc_30p()
30-part red candle condition
Returns: bool
cdut()
candle double uptrend condition
Returns: bool
cddt()
candle double downtrend condition
Returns: bool
cdut_1p()
1-part candle double uptrend condition
Returns: bool
cdut_2p()
2-part candle double uptrend condition
Returns: bool
cdut_3p()
3-part candle double uptrend condition
Returns: bool
cdut_4p()
4-part candle double uptrend condition
Returns: bool
cdut_5p()
5-part candle double uptrend condition
Returns: bool
cdut_6p()
6-part candle double uptrend condition
Returns: bool
cdut_7p()
7-part candle double uptrend condition
Returns: bool
cdut_8p()
8-part candle double uptrend condition
Returns: bool
cdut_9p()
9-part candle double uptrend condition
Returns: bool
cdut_10p()
10-part candle double uptrend condition
Returns: bool
cdut_11p()
11-part candle double uptrend condition
Returns: bool
cdut_12p()
12-part candle double uptrend condition
Returns: bool
cdut_13p()
13-part candle double uptrend condition
Returns: bool
cdut_14p()
14-part candle double uptrend condition
Returns: bool
cdut_15p()
15-part candle double uptrend condition
Returns: bool
cdut_16p()
16-part candle double uptrend condition
Returns: bool
cdut_17p()
17-part candle double uptrend condition
Returns: bool
cdut_18p()
18-part candle double uptrend condition
Returns: bool
cdut_19p()
19-part candle double uptrend condition
Returns: bool
cdut_20p()
20-part candle double uptrend condition
Returns: bool
cdut_21p()
21-part candle double uptrend condition
Returns: bool
cdut_22p()
22-part candle double uptrend condition
Returns: bool
cdut_23p()
23-part candle double uptrend condition
Returns: bool
cdut_24p()
24-part candle double uptrend condition
Returns: bool
cdut_25p()
25-part candle double uptrend condition
Returns: bool
cdut_26p()
26-part candle double uptrend condition
Returns: bool
cdut_27p()
27-part candle double uptrend condition
Returns: bool
cdut_28p()
28-part candle double uptrend condition
Returns: bool
cdut_29p()
29-part candle double uptrend condition
Returns: bool
cdut_30p()
30-part candle double uptrend condition
Returns: bool
cddt_1p()
1-part candle double downtrend condition
Returns: bool
cddt_2p()
2-part candle double downtrend condition
Returns: bool
cddt_3p()
3-part candle double downtrend condition
Returns: bool
cddt_4p()
4-part candle double downtrend condition
Returns: bool
cddt_5p()
5-part candle double downtrend condition
Returns: bool
cddt_6p()
6-part candle double downtrend condition
Returns: bool
cddt_7p()
7-part candle double downtrend condition
Returns: bool
cddt_8p()
8-part candle double downtrend condition
Returns: bool
cddt_9p()
9-part candle double downtrend condition
Returns: bool
cddt_10p()
10-part candle double downtrend condition
Returns: bool
cddt_11p()
11-part candle double downtrend condition
Returns: bool
cddt_12p()
12-part candle double downtrend condition
Returns: bool
cddt_13p()
13-part candle double downtrend condition
Returns: bool
cddt_14p()
14-part candle double downtrend condition
Returns: bool
cddt_15p()
15-part candle double downtrend condition
Returns: bool
cddt_16p()
16-part candle double downtrend condition
Returns: bool
cddt_17p()
17-part candle double downtrend condition
Returns: bool
cddt_18p()
18-part candle double downtrend condition
Returns: bool
cddt_19p()
19-part candle double downtrend condition
Returns: bool
cddt_20p()
20-part candle double downtrend condition
Returns: bool
cddt_21p()
21-part candle double downtrend condition
Returns: bool
cddt_22p()
22-part candle double downtrend condition
Returns: bool
cddt_23p()
23-part candle double downtrend condition
Returns: bool
cddt_24p()
24-part candle double downtrend condition
Returns: bool
cddt_25p()
25-part candle double downtrend condition
Returns: bool
cddt_26p()
26-part candle double downtrend condition
Returns: bool
cddt_27p()
27-part candle double downtrend condition
Returns: bool
cddt_28p()
28-part candle double downtrend condition
Returns: bool
cddt_29p()
29-part candle double downtrend condition
Returns: bool
cddt_30p()
30-part candle double downtrend condition
Returns: bool
Harmonic Patterns Library [TradingFinder]🔵 Introduction
Harmonic patterns blend geometric shapes with Fibonacci numbers, making these numbers fundamental to understanding the patterns.
One person who has done a lot of research on harmonic patterns is Scott Carney.Scott Carney's research on harmonic patterns in technical analysis focuses on precise price structures based on Fibonacci ratios to identify market reversals.
Key patterns include the Gartley, Bat, Butterfly, and Crab, each with specific alignment criteria. These patterns help traders anticipate potential market turning points and make informed trading decisions, enhancing the predictability of technical analysis.
🟣 Understanding 5-Point Harmonic Patterns
In the current library version, you can easily draw and customize most XABCD patterns. These patterns often form M or W shapes, or a combination of both. By calculating the Fibonacci ratios between key points, you can estimate potential price movements.
All five-point patterns share a similar structure, differing only in line lengths and Fibonacci ratios. Learning one pattern simplifies understanding others.
🟣 Exploring the Gartley Pattern
The Gartley pattern appears in both bullish (M shape) and bearish (W shape) forms. In the bullish Gartley, point X is below point D, and point A surpasses point C. Point D marks the start of a strong upward trend, making it an optimal point to place a buy order.
The bearish Gartley mirrors the bullish pattern with inverted Fibonacci ratios. In this scenario, point D indicates the start of a significant price drop. Traders can place sell orders at this point and buy at lower prices for profit in two-way markets.
🟣 Analyzing the Butterfly Pattern
The Butterfly pattern also manifests in bullish (M shape) and bearish (W shape) forms. It resembles the Gartley pattern but with point D lower than point X in the bullish version.
The Butterfly pattern involves deeper price corrections than the Gartley, leading to more significant price fluctuations. Point D in the bullish Butterfly indicates the beginning of a sharp price rise, making it an entry point for buy orders.
The bearish Butterfly has inverted Fibonacci ratios, with point D marking the start of a sharp price decline, ideal for sell orders followed by buying at lower prices in two-way markets.
🟣 Insights into the Bat Pattern
The Bat pattern, appearing in bullish (M shape) and bearish (W shape) forms, is one of the most precise harmonic patterns. It closely resembles the Butterfly and Gartley patterns, differing mainly in Fibonacci levels.
The bearish Bat pattern shares the Fibonacci ratios with the bullish Bat, with an inverted structure. Point D in the bearish Bat marks the start of a significant price drop, suitable for sell orders followed by buying at lower prices for profit.
🟣 The Crab Pattern Explained
The Crab pattern, found in both bullish (M shape) and bearish (W shape) forms, is highly favored by analysts. Discovered in 2000, the Crab pattern features a larger final wave correction compared to other harmonic patterns.
The bearish Crab shares Fibonacci ratios with the bullish version but in an inverted form. Point D in the bearish Crab signifies the start of a sharp price decline, making it an ideal point for sell orders followed by buying at lower prices for profitable trades.
🟣 Understanding the Shark Pattern
The Shark pattern appears in bullish (M shape) and bearish (W shape) forms. It differs from previous patterns as point C in the bullish Shark surpasses point A, with unique level measurements.
The bearish Shark pattern mirrors the Fibonacci ratios of the bullish Shark but is inverted. Point D in the bearish Shark indicates the start of a sharp price drop, ideal for placing sell orders and buying at lower prices to capitalize on the pattern.
🟣 The Cypher Pattern Overview
The Cypher pattern is another that appears in both bullish (M shape) and bearish (W shape) forms. It resembles the Shark pattern, with point C in the bullish Cypher extending beyond point A, and point D forming within the XA line.
The bearish Cypher shares the Fibonacci ratios with the bullish Cypher but in an inverted structure. Point D in the bearish Cypher marks the start of a significant price drop, perfect for sell orders followed by buying at lower prices.
🟣 Introducing the Nen-Star Pattern
The Nen-Star pattern appears in both bullish (M shape) and bearish (W shape) forms. In the bullish Nen-Star, point C extends beyond point A, and point D, the final point, forms outside the XA line, making CD the longest wave.
The bearish Nen-Star has inverted Fibonacci ratios, with point D indicating the start of a significant price drop. Traders can place sell orders at point D and buy at lower prices to profit from this pattern in two-way markets.
The 5-point harmonic patterns, commonly referred to as XABCD patterns, are specific geometric price structures identified in financial markets. These patterns are used by traders to predict potential price movements based on historical price data and Fibonacci retracement levels.
Here are the main 5-point harmonic patterns :
Gartley Pattern
Anti-Gartley Pattern
Bat Pattern
Anti-Bat Pattern
Alternate Bat Pattern
Butterfly Pattern
Anti-Butterfly Pattern
Crab Pattern
Anti-Crab Pattern
Deep Crab Pattern
Shark Pattern
Anti- Shark Pattern
Anti Alternate Shark Pattern
Cypher Pattern
Anti-Cypher Pattern
🔵 How to Use
To add "Order Block Refiner Library", you must first add the following code to your script.
import TFlab/Harmonic_Chart_Pattern_Library_TradingFinder/1 as HP
🟣 Parameters
XABCD(Name, Type, Show, Color, LineWidth, LabelSize, ShVF, FLPC, FLPCPeriod, Pivot, ABXAmin, ABXAmax, BCABmin, BCABmax, CDBCmin, CDBCmax, CDXAmin, CDXAmax) =>
Parameters:
Name (string)
Type (string)
Show (bool)
Color (color)
LineWidth (int)
LabelSize (string)
ShVF (bool)
FLPC (bool)
FLPCPeriod (int)
Pivot (int)
ABXAmin (float)
ABXAmax (float)
BCABmin (float)
BCABmax (float)
CDBCmin (float)
CDBCmax (float)
CDXAmin (float)
CDXAmax (float)
🟣 Genaral Parameters
Name : The name of the pattern.
Type: Enter "Bullish" to draw a Bullish pattern and "Bearish" to draw an Bearish pattern.
Show : Enter "true" to display the template and "false" to not display the template.
Color : Enter the desired color to draw the pattern in this parameter.
LineWidth : You can enter the number 1 or numbers higher than one to adjust the thickness of the drawing lines. This number must be an integer and increases with increasing thickness.
LabelSize : You can adjust the size of the labels by using the "size.auto", "size.tiny", "size.smal", "size.normal", "size.large" or "size.huge" entries.
🟣 Logical Parameters
ShVF : If this parameter is on "true" mode, only patterns will be displayed that they have exact format and no noise can be seen in them. If "false" is, the patterns displayed that maybe are noisy and do not exactly correspond to the original pattern.
FLPC : if Turned on, you can see this ability of patterns when their last pivot is formed. If this feature is off, it will see the patterns as soon as they are formed. The advantage of this option being clear is less formation of fielded patterns, and it is accompanied by the lateest pattern seeing and a sharp reduction in reward to risk.
FLPCPeriod : Using this parameter you can determine that the last pivot is based on Pivot period.
Pivot : You need to determine the period of the zigzag indicator. This factor is the most important parameter in pattern recognition.
ABXAmin : Minimum retracement of "AB" line compared to "XA" line.
ABXAmax : Maximum retracement of "AB" line compared to "XA" line.
BCABmin : Minimum retracement of "BC" line compared to "AB" line.
BCABmax : Maximum retracement of "BC" line compared to "AB" line.
CDBCmin : Minimum retracement of "CD" line compared to "BC" line.
CDBCmax : Maximum retracement of "CD" line compared to "BC" line.
CDXAmin : Minimum retracement of "CD" line compared to "XA" line.
CDXAmax : Maximum retracement of "CD" line compared to "XA" line.
🟣 Function Outputs
This library has two outputs. The first output is related to the alert of the formation of a new pattern. And the second output is related to the formation of the candlestick pattern and you can draw it using the "plotshape" tool.
Candle Confirmation Logic :
Example :
import TFlab/Harmonic_Chart_Pattern_Library_TradingFinder/1 as HP
PP = input.int(3, 'ZigZag Pivot Period')
ShowBull = input.bool(true, 'Show Bullish Pattern')
ShowBear = input.bool(true, 'Show Bearish Pattern')
ColorBull = input.color(#0609bb, 'Color Bullish Pattern')
ColorBear = input.color(#0609bb, 'Color Bearish Pattern')
LineWidth = input.int(1 , 'Width Line')
LabelSize = input.string(size.small , 'Label size' , options = )
ShVF = input.bool(false , 'Show Valid Format')
FLPC = input.bool(false , 'Show Formation Last Pivot Confirm')
FLPCPeriod =input.int(2, 'Period of Formation Last Pivot')
//Call function
= HP.XABCD('Bullish Bat', 'Bullish', ShowBull, ColorBull , LineWidth, LabelSize ,ShVF, FLPC, FLPCPeriod, PP, 0.382, 0.50, 0.382, 0.886, 1.618, 2.618, 0.85, 0.9)
= HP.XABCD('Bearish Bat', 'Bearish', ShowBear, ColorBear , LineWidth, LabelSize ,ShVF, FLPC, FLPCPeriod, PP, 0.382, 0.50, 0.382, 0.886, 1.618, 2.618, 0.85, 0.9)
//Alert
if BearAlert
alert('Bearish Harmonic')
if BullAlert
alert('Bulish Harmonic')
//CandleStick Confirm
plotshape(BearCandleConfirm, style = shape.arrowdown, color = color.red)
plotshape(BullCandleConfirm, style = shape.arrowup, color = color.green, location = location.belowbar )