TrigWave Suite [InvestorUnknown]The TrigWave Suite combines Sine-weighted, Cosine-weighted, and Hyperbolic Tangent moving averages (HTMA) with a Directional Movement System (DMS) and a Relative Strength System (RSS).
Hyperbolic Tangent Moving Average (HTMA)
The HTMA smooths the price by applying a hyperbolic tangent transformation to the difference between the price and a simple moving average. It also adjusts this value by multiplying it by a standard deviation to create a more stable signal.
// Function to calculate Hyperbolic Tangent
tanh(x) =>
e_x = math.exp(x)
e_neg_x = math.exp(-x)
(e_x - e_neg_x) / (e_x + e_neg_x)
// Function to calculate Hyperbolic Tangent Moving Average
htma(src, len, mul) =>
tanh_src = tanh((src - ta.sma(src, len)) * mul) * ta.stdev(src, len) + ta.sma(src, len)
htma = ta.sma(tanh_src, len)
Sine-Weighted Moving Average (SWMA)
The SWMA applies sine-based weights to historical prices. This gives more weight to the central data points, making it responsive yet less prone to noise.
// Function to calculate the Sine-Weighted Moving Average
f_Sine_Weighted_MA(series float src, simple int length) =>
var float sine_weights = array.new_float(0)
array.clear(sine_weights) // Clear the array before recalculating weights
for i = 0 to length - 1
weight = math.sin((math.pi * (i + 1)) / length)
array.push(sine_weights, weight)
// Normalize the weights
sum_weights = array.sum(sine_weights)
for i = 0 to length - 1
norm_weight = array.get(sine_weights, i) / sum_weights
array.set(sine_weights, i, norm_weight)
// Calculate Sine-Weighted Moving Average
swma = 0.0
if bar_index >= length
for i = 0 to length - 1
swma := swma + array.get(sine_weights, i) * src
swma
Cosine-Weighted Moving Average (CWMA)
The CWMA uses cosine-based weights for data points, which produces a more stable trend-following behavior, especially in low-volatility markets.
f_Cosine_Weighted_MA(series float src, simple int length) =>
var float cosine_weights = array.new_float(0)
array.clear(cosine_weights) // Clear the array before recalculating weights
for i = 0 to length - 1
weight = math.cos((math.pi * (i + 1)) / length) + 1 // Shift by adding 1
array.push(cosine_weights, weight)
// Normalize the weights
sum_weights = array.sum(cosine_weights)
for i = 0 to length - 1
norm_weight = array.get(cosine_weights, i) / sum_weights
array.set(cosine_weights, i, norm_weight)
// Calculate Cosine-Weighted Moving Average
cwma = 0.0
if bar_index >= length
for i = 0 to length - 1
cwma := cwma + array.get(cosine_weights, i) * src
cwma
Directional Movement System (DMS)
DMS is used to identify trend direction and strength based on directional movement. It uses ADX to gauge trend strength and combines +DI and -DI for directional bias.
// Function to calculate Directional Movement System
f_DMS(simple int dmi_len, simple int adx_len) =>
up = ta.change(high)
down = -ta.change(low)
plusDM = na(up) ? na : (up > down and up > 0 ? up : 0)
minusDM = na(down) ? na : (down > up and down > 0 ? down : 0)
trur = ta.rma(ta.tr, dmi_len)
plus = fixnan(100 * ta.rma(plusDM, dmi_len) / trur)
minus = fixnan(100 * ta.rma(minusDM, dmi_len) / trur)
sum = plus + minus
adx = 100 * ta.rma(math.abs(plus - minus) / (sum == 0 ? 1 : sum), adx_len)
dms_up = plus > minus and adx > minus
dms_down = plus < minus and adx > plus
dms_neutral = not (dms_up or dms_down)
signal = dms_up ? 1 : dms_down ? -1 : 0
Relative Strength System (RSS)
RSS employs RSI and an adjustable moving average type (SMA, EMA, or HMA) to evaluate whether the market is in a bullish or bearish state.
// Function to calculate Relative Strength System
f_RSS(rsi_src, rsi_len, ma_type, ma_len) =>
rsi = ta.rsi(rsi_src, rsi_len)
ma = switch ma_type
"SMA" => ta.sma(rsi, ma_len)
"EMA" => ta.ema(rsi, ma_len)
"HMA" => ta.hma(rsi, ma_len)
signal = (rsi > ma and rsi > 50) ? 1 : (rsi < ma and rsi < 50) ? -1 : 0
ATR Adjustments
To minimize false signals, the HTMA, SWMA, and CWMA signals are adjusted with an Average True Range (ATR) filter:
// Calculate ATR adjusted components for HTMA, CWMA and SWMA
float atr = ta.atr(atr_len)
float htma_up = htma + (atr * atr_mult)
float htma_dn = htma - (atr * atr_mult)
float swma_up = swma + (atr * atr_mult)
float swma_dn = swma - (atr * atr_mult)
float cwma_up = cwma + (atr * atr_mult)
float cwma_dn = cwma - (atr * atr_mult)
This adjustment allows for better adaptation to varying market volatility, making the signal more reliable.
Signals and Trend Calculation
The indicator generates a Trend Signal by aggregating the output from each component. Each component provides a directional signal that is combined to form a unified trend reading. The trend value is then converted into a long (1), short (-1), or neutral (0) state.
Backtesting Mode and Performance Metrics
The Backtesting Mode includes a performance metrics table that compares the Buy and Hold strategy with the TrigWave Suite strategy. Key statistics like Sharpe Ratio, Sortino Ratio, and Omega Ratio are displayed to help users assess performance. Note that due to labels and plotchar use, automatic scaling may not function ideally in backtest mode.
Alerts and Visualization
Trend Direction Alerts: Set up alerts for long and short signals
Color Bars and Gradient Option: Bars are colored based on the trend direction, with an optional gradient for smoother visual feedback.
Important Notes
Customization: Default settings are experimental and not intended for trading/investing purposes. Users are encouraged to adjust and calibrate the settings to optimize results according to their trading style.
Backtest Results Disclaimer: Please note that backtest results are not indicative of future performance, and no strategy guarantees success.
Statistics

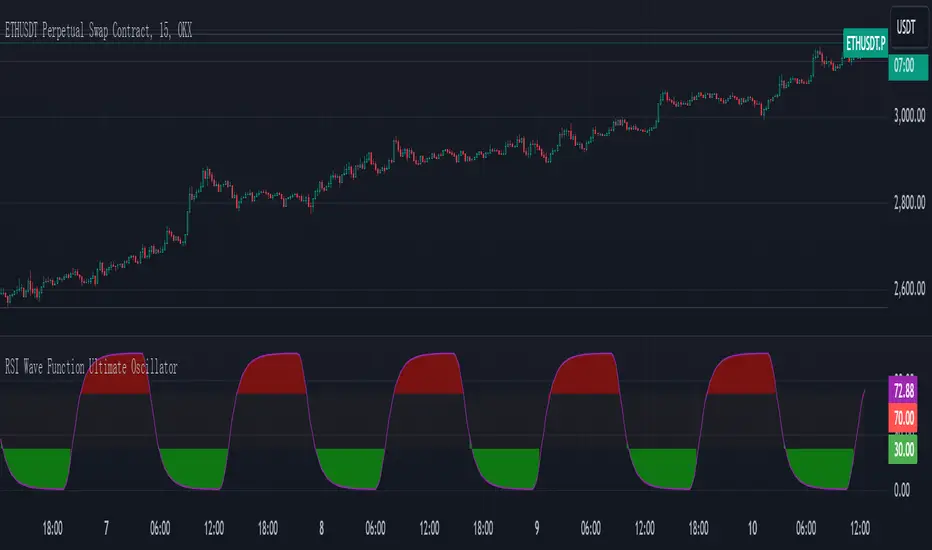
RSI Wave Function Ultimate OscillatorEnglish Explanation of the "RSI Wave Function Ultimate Oscillator" Pine Script Code
Understanding the Code
Purpose:
This Pine Script code creates a custom indicator that combines the Relative Strength Index (RSI) with a wave function to potentially provide more nuanced insights into market dynamics.
Key Components:
* Wave Function: This is a custom calculation that introduces a sinusoidal wave component to the price data. The frequency parameter controls the speed of the oscillation, and the decay factor determines how quickly the influence of past prices diminishes.
* Smoothed Signal: The wave function is applied to the closing price to create a smoothed signal, which is essentially a price series modulated by a sine wave.
* RSI: The traditional RSI is then calculated on this smoothed signal, providing a measure of the speed and change of price movements relative to recent price changes.
Calculation Steps:
* Wave Function Calculation:
* A sinusoidal wave is generated based on the bar index and the frequency parameter.
* The wave is combined with the closing price using a weighted average, where the decay factor determines the weight given to previous values.
* RSI Calculation:
* The RSI is calculated on the smoothed signal using a standard RSI formula.
* Plotting:
* The RSI values are plotted on a chart, along with horizontal lines at 70 and 30 to indicate overbought and oversold conditions.
* The area between the RSI line and the overbought/oversold lines is filled with color to visually represent the market condition.
Interpretation and Usage
* Wave Function: The wave function introduces cyclical patterns into the price data, which can help identify potential turning points or momentum shifts.
* RSI: The RSI provides a measure of the speed and change of price movements relative to recent price changes. When applied to the smoothed signal, it can help identify overbought and oversold conditions, as well as potential divergences between price and momentum.
* Combined Indicator: The combination of the wave function and RSI aims to provide a more sensitive and potentially earlier indication of market reversals.
* Signals:
* Crossovers: Crossovers of the RSI line above or below the overbought/oversold lines can be used to generate buy or sell signals.
* Divergences: Divergences between the price and the RSI can indicate a weakening trend.
* Oscillations: The amplitude and frequency of the oscillations in the RSI can provide insights into the strength and duration of market trends.
How it Reflects Market Volatility
* Amplified Volatility: The wave function can amplify the volatility of the price data, making it easier to identify potential turning points.
* Smoothing: The decay factor helps to smooth out short-term fluctuations, allowing the indicator to focus on longer-term trends.
* Sensitivity: The combination of the wave function and RSI can make the indicator more sensitive to changes in market momentum.
In essence, this custom indicator attempts to enhance traditional RSI analysis by incorporating a cyclical component that can potentially provide earlier signals of market reversals.
Note: The effectiveness of this indicator will depend on various factors, including the specific market, time frame, and the chosen values for the frequency and decay parameters. It is recommended to conduct thorough backtesting and optimize the parameters to suit your specific trading strategy.
Average Bullish & Bearish Percentage ChangeAverage Bullish & Bearish Percentage Change
Processes two key aspects of directional market movements relative to price levels. Unlike traditional momentum tools, it separately calculates the average of positive and negative percentage changes in price using user-defined independent counts of actual past bullish and bearish candles. This approach delivers comprehensive and precise view of average percentage changes.
FEATURES:
Count-Based Averages: Separate averaging of bullish and bearish %𝜟 based on their respective number of occurrences ensures reliable and precise momentum calculations.
Customizable Averaging: User-defined number of candle count sets number of past bullish and bearish candles used in independent averaging.
Two Methods of Candle Metrics:
1. Net Move: Focuses on the body range of the candle, emphasizing the net directional movement.
2. Full Capacity: Incorporates wicks and gaps to capture full potential of the bar.
The indicator classifies Doji candles contextually, ensuring they are appropriately factored into the bullish or bearish metrics to avoid mistakes in calculation:
1. Standard Doji - open equals close.
2. Flat Close Doji - Candles where the close matches the previous close.
Timeframe Flexibility:
The indicator can be applied across any desired timeframe, allowing for seamless multi-timeframe analysis.
HOW TO USE
Select Method of Bar Metrics:
Net Move: For analyzing markets where price changes are consistent and bars are close to each other.
Full Capacity: Incorporates wicks and gaps, providing relevant figures for markets like stocks
Set the number of past candles to average:
🟩 Average Past Bullish Candles (Default: 10)
🟥 Average Past Bullish Candles (Default: 10)
Why Percentage Change Is Important
Standardized Measurement Across Assets:
Percentage change normalizes price movements, making it easier to compare different assets with varying price levels. For example, a $1 move in a $10 stock is significant, but the same $1 move in a $1,000 stock is negligible.
Highlights Relative Impact:
By measuring the price change as a percentage of the close, traders can better understand the relative impact of a move on the asset’s overall value.
Volatility Insights:
A high percentage change indicates heightened volatility, which can be a signal of potential opportunities or risks, making it more actionable than raw price changes. Percents directly reflect the strength of buying or selling pressure, providing a clearer view of momentum compared to raw price moves, which may not account for the relative size of the move.
By focusing on percentage change, this indicator provides a normalized, actionable, and insightful measure of market momentum, which is critical for comparing, analyzing, and acting on price movements across various assets and conditions.

Sequence Waves [OmegaTools]the sequence waves indicator, developed by omegatools, is a multi-functional tool designed to detect trends, sequences, and potential reversal signals based on price movements and volume. this indicator has two main modes, "trend" and "sequence," which determine how the indicator calculates directional changes. additional enhancements in this version include reversal signals, allowing users to identify potential long and short opportunities with specific entry cues.
input parameters
mode (mode): chooses the calculation basis for directional movement.
- "trend": uses a midline calculated from the highest high and lowest low over the "trend mode length" period to assess if the price is in an upward or downward trend.
- "sequence": compares the current price to the closing price of the previous "sequence mode length" period to detect shifts in direction.
counter mode (modec): sets whether the counter increments by a fixed amount (1 or -1) or the volume of the bar, impacting the indicator’s sensitivity.
- "fixed": increments or decrements the counter by 1.
- "volume": increments or decrements based on the period’s volume, making the indicator more responsive to high-volume periods.
percentile length (lntp): defines the lookback period for calculating overbought and oversold thresholds using a percentile method. shorter lengths make ob/os levels more reactive.
sensitivity (sens): controls the percentile-based ob/os thresholds, ranging from 10 to 100. higher values narrow ob/os zones, while lower values widen them, impacting signal frequency.
trend mode length (lnt1): sets the period length for midline calculation in trend mode, defaulting to 21. longer periods smooth the midline for detecting major trends.
sequence mode length (lnt2): sets the lookback period in sequence mode, with a default of 4. shorter lengths capture more frequent directional changes, while longer lengths smooth signals.
visual colors:
- up color (upc): sets the color for upward movements.
- down color (dnc): sets the color for downward movements.
calculation logic
midline calculation: in trend mode, a midline is derived from the average of the highest high and lowest low over the "trend mode length" period, acting as a reference to detect upward or downward movements.
counter calculation:
- in trend mode, if the close price is above the midline, the counter increases (or volume if volume mode is selected). it decreases when the price is below.
- in sequence mode, the counter increases if the close is above the closing price from "sequence mode length" periods ago and decreases if below.
the counter resets to zero on direction changes, creating clear directional transitions.
overbought/oversold percentiles: separate arrays track the counter’s values each time the direction changes, creating historical up and down values. ob and os thresholds are dynamically determined based on these arrays, with sizes limited by the percentile length and sensitivity inputs.
reversal signals: two new variables, "long" and "short," detect potential reversal points when the counter crosses specific thresholds:
- long: a long signal is generated when the counter switches to positive and exceeds the down percentile.
- short: a short signal is triggered when the counter switches to negative and exceeds the up percentile.
visual and display elements
counter plot: plots the counter value on the chart with color-coded columns, making it easy to spot directional momentum.
up and down percentiles: displays overbought (up percentile) and oversold (down percentile) thresholds to identify potential reversal zones.
regime background: the background color changes based on market regime:
- bullish (up percentile > down percentile): greenish background.
- bearish (down percentile > up percentile): reddish background.
- neutral (both percentiles equal): grayish background.
reversal signals: plotted as small triangles on the chart for visual confirmation of potential long (triangle up) and short (triangle down) reversal signals.
obs background: changes color when the counter exceeds ob or os thresholds, creating a visual cue for extreme market conditions:
- overbought: background changes to a faint down color.
- oversold: background changes to a faint up color.
status table: displayed on the right side of the chart, providing real-time status information:
- status: shows "overbought," "oversold," "long," "short," or "none" based on the current counter position.
- regime: indicates whether the market is in a "bullish," "bearish," or "neutral" state based on the percentile comparison.
- percentile up/down: displays the current up and down percentiles for quick reference.
how to use the indicator
trend following: in trend mode, use the midline-based counter to gauge if the market is in an uptrend (positive counter) or downtrend (negative counter).
reversal detection: the ob/os thresholds assist in identifying potential reversal points. when the counter exceeds the up percentile, it may indicate an overbought state, suggesting a bearish reversal. similarly, dropping below the down percentile may indicate an oversold state, suggesting a bullish reversal.
entry signals: use the long and short reversal signals for potential entry points, particularly in trending or range-bound markets. these signals are indicated by up and down triangles.
sequence trading: in sequence mode, the indicator tracks shorter-term directional shifts, making it suitable for detecting smaller momentum patterns based on recent price comparisons.
volume sensitivity: selecting volume mode enhances sensitivity to high-volume moves, allowing it to detect stronger market activity in both trend and sequence modes.
the sequence waves indicator is suited to both short-term and long-term traders. it allows for detailed trend analysis, reversal detection, and dynamic ob/os signals. the inclusion of visual reversal cues makes it a flexible tool adaptable to a variety of trading strategies.

Low Price VolatilityI highlighted periods of low price volatility in the Nikkei 225 futures trading.
It is Japan Standard Time (JST)
This script is designed to color-code periods in the Nikkei 225 futures market according to times when prices tend to be more volatile and times when they are less volatile. The testing period is from March 11, 2024, to November 1, 2024. It identifies periods and counts where price movement exceeded half of the ATR, and colors are applied based on this data. There are no calculations involved; it simply uses the results of the analysis to apply color.

Volume Bars [jpkxyz]
Multi-Timeframe Volume indicator by @jpkxyz
This script is a Multi-Timeframe Volume Z-Score Indicator. It dynamically calculates /the Z-Score of volume over different timeframes to assess how significantly current
volume deviates from its historical average. The Z-Score is computed for each
timeframe independently and is based on a user-defined lookback period. The
script switches between timeframes automatically, adapting to the chart's current
timeframe using `timeframe.multiplier`.
The Z-Score formula used is: (current volume - mean) / standard deviation, where
mean and standard deviation are calculated over the lookback period.
The indicator highlights periods of "significant" and "massive" volume by comparing
the Z-Score to user-specified thresholds (`zScoreThreshold` for significant volume
and `massiveZScoreThreshold` for massive volume). The script flags buy or sell
conditions based on whether the current close is higher or lower than the open.
Visual cues:
- Dark Green for massive buy volume.
- Red for massive sell volume.
- Green for significant buy volume.
- Orange for significant sell volume.
- Gray for normal volume.
The script also provides customizable alert conditions for detecting significant or massive buy/sell volume events, allowing users to set real-time alerts.
FTMO Rules MonitorFTMO Rules Monitor: Stay on Track with Your FTMO Challenge Goals
TLDR; You can test with this template whether your strategy for one asset would pass the FTMO challenges step 1 then step 2, then with real money conditions.
Passing a prop firm challenge is ... challenging.
I believe a toolkit allowing to test in minutes whether a strategy would have passed a prop firm challenge in the past could be very powerful.
The FTMO Rules Monitor is designed to help you stay within FTMO’s strict risk management guidelines directly on your chart. Whether you’re aiming for the $10,000 or the $200,000 account challenge, this tool provides real-time tracking of your performance against FTMO’s rules to ensure you don’t accidentally breach any limits.
NOTES
The connected indicator for this post doesn't matter.
It's just a dummy double supertrends (see below)
The strategy results for this script post does not matter as I'm posting a FTMO rules template on which you can connect any indicator/strategy.
//@version=5
indicator("Supertrends", overlay=true)
// Supertrend 1 Parameters
var string ST1 = "Supertrend 1 Settings"
st1_atrPeriod = input.int(10, "ATR Period", minval=1, maxval=50, group=ST1)
st1_factor = input.float(2, "Factor", minval=0.5, maxval=10, step=0.5, group=ST1)
// Supertrend 2 Parameters
var string ST2 = "Supertrend 2 Settings"
st2_atrPeriod = input.int(14, "ATR Period", minval=1, maxval=50, group=ST2)
st2_factor = input.float(3, "Factor", minval=0.5, maxval=10, step=0.5, group=ST2)
// Calculate Supertrends
= ta.supertrend(st1_factor, st1_atrPeriod)
= ta.supertrend(st2_factor, st2_atrPeriod)
// Entry conditions
longCondition = direction1 == -1 and direction2 == -1 and direction1 == 1
shortCondition = direction1 == 1 and direction2 == 1 and direction1 == -1
// Optional: Plot Supertrends
plot(supertrend1, "Supertrend 1", color = direction1 == -1 ? color.green : color.red, linewidth=3)
plot(supertrend2, "Supertrend 2", color = direction2 == -1 ? color.lime : color.maroon, linewidth=3)
plotshape(series=longCondition, location=location.belowbar, color=color.green, style=shape.triangleup, title="Long")
plotshape(series=shortCondition, location=location.abovebar, color=color.red, style=shape.triangledown, title="Short")
signal = longCondition ? 1 : shortCondition ? -1 : na
plot(signal, "Signal", display = display.data_window)
To connect your indicator to this FTMO rules monitor template, please update it as follow
Create a signal variable to store 1 for the long/buy signal or -1 for the short/sell signal
Plot it in the display.data_window panel so that it doesn't clutter your chart
signal = longCondition ? 1 : shortCondition ? -1 : na
plot(signal, "Signal", display = display.data_window)
In the FTMO Rules Monitor template, I'm capturing this external signal with this input.source variable
entry_connector = input.source(close, "Entry Connector", group="Entry Connector")
longCondition = entry_connector == 1
shortCondition = entry_connector == -1
🔶 USAGE
This indicator displays essential FTMO Challenge rules and tracks your progress toward meeting each one. Here’s what’s monitored:
Max Daily Loss
• 10k Account: $500
• 25k Account: $1,250
• 50k Account: $2,500
• 100k Account: $5,000
• 200k Account: $10,000
Max Total Loss
• 10k Account: $1,000
• 25k Account: $2,500
• 50k Account: $5,000
• 100k Account: $10,000
• 200k Account: $20,000
Profit Target
• 10k Account: $1,000
• 25k Account: $2,500
• 50k Account: $5,000
• 100k Account: $10,000
• 200k Account: $20,000
Minimum Trading Days: 4 consecutive days for all account sizes
🔹 Key Features
1. Real-Time Compliance Check
The FTMO Rules Monitor keeps track of your daily and total losses, profit targets, and trading days. Each metric updates in real-time, giving you peace of mind that you’re within FTMO’s rules.
2. Color-Coded Visual Feedback
Each rule’s status is shown clearly with a ✓ for compliance or ✗ if the limit is breached. When a rule is broken, the indicator highlights it in red, so there’s no confusion.
3. Completion Notification
Once all FTMO requirements are met, the indicator closes all open positions and displays a celebratory message on your chart, letting you know you’ve successfully completed the challenge.
4. Easy-to-Read Table
A table on your chart provides an overview of each rule, your target, current performance, and whether you’re meeting each goal. The table adjusts its color scheme based on your chart settings for optimal visibility.
5. Dynamic Position Sizing
Integrated ATR-based position sizing helps you manage risk and avoid large drawdowns, ensuring each trade aligns with FTMO’s risk management principles.
Daveatt

Dynamic Market Correlation Analyzer (DMCA) v1.0Description
The Dynamic Market Correlation Analyzer (DMCA) is an advanced TradingView indicator designed to provide real-time correlation analysis between multiple assets. It offers a comprehensive view of market relationships through correlation coefficients, technical indicators, and visual representations.
Key Features
- Multi-asset correlation tracking (up to 5 symbols)
- Dynamic correlation strength categorization
- Integrated technical indicators (RSI, MACD, DX)
- Customizable visualization options
- Real-time price change monitoring
- Flexible timeframe selection
## Use Cases
1. **Portfolio Diversification**
- Identify highly correlated assets to avoid concentration risk
- Find negatively correlated assets for hedging strategies
- Monitor correlation changes during market events
2. Pairs Trading
- Detect correlation breakdowns for potential trading opportunities
- Track correlation strength for pair selection
- Monitor technical indicators for trade timing
3. Risk Management
- Assess portfolio correlation risk in real-time
- Monitor correlation shifts during market stress
- Identify potential portfolio vulnerabilities
4. **Market Analysis**
- Study sector relationships and rotations
- Analyze cross-asset correlations (e.g., stocks vs. commodities)
- Track market regime changes through correlation patterns
Components
Input Parameters
- **Timeframe**: Custom timeframe selection for analysis
- **Length**: Correlation calculation period (default: 20)
- **Source**: Price data source selection
- **Symbol Selection**: Up to 5 customizable symbols
- **Display Options**: Table position, text color, and size settings
Technical Indicators
1. **Correlation Coefficient**
- Range: -1 to +1
- Strength categories: Strong/Moderate/Weak (Positive/Negative)
2. **RSI (Relative Strength Index)**
- 14-period default setting
- Momentum comparison across assets
3. **MACD (Moving Average Convergence Divergence)**
- Standard settings (12, 26, 9)
- Trend direction indicator
4. **DX (Directional Index)**
- Trend strength measurement
- Based on DMI calculations
Visual Components
1. **Correlation Table**
- Symbol identifiers
- Correlation coefficients
- Correlation strength descriptions
- Price change percentages
- Technical indicator values
2. **Correlation Plot**
- Real-time correlation visualization
- Multiple correlation lines
- Reference levels at -1, 0, and +1
- Color-coded for easy identification
Installation and Setup
1. Load the indicator on TradingView
2. Configure desired symbols (up to 5)
3. Adjust timeframe and calculation length
4. Customize display settings
5. Enable/disable desired components (table, plot, RSI)
Best Practices
1. **Symbol Selection**
- Choose related but distinct assets
- Include a mix of asset classes
- Consider market cap and liquidity
2. **Timeframe Selection**
- Match timeframe to trading strategy
- Consider longer timeframes for strategic analysis
- Use shorter timeframes for tactical decisions
3. **Interpretation**
- Monitor correlation changes over time
- Consider multiple timeframes
- Combine with other technical analysis tools
- Account for market conditions and volatility
Performance Notes
- Calculations update in real-time
- Resource usage scales with number of active symbols
- Historical data availability may affect initial calculations
Version History
- v1.0: Initial release with core functionality
- Multi-symbol correlation analysis
- Technical indicator integration
- Customizable display options
Future Enhancements (Planned)
- Additional technical indicators
- Advanced correlation algorithms
- Enhanced visualization options
- Custom alert conditions
- Statistical significance testing

[Volatility] [Gain & Loss] - OverviewFX:EURUSD
Indicator Overview: Volatility & Gain/Loss - Forex Pair Analysis
This indicator, " —Overview" , is designed for users interested in analyzing the volatility and gain/loss metrics of multiple forex pairs. The tool is especially useful for traders aiming to assess currency pair volatility alongside gain and loss percentages over selected periods. It enables a clearer understanding of pair behavior and aids in decision-making.
Key Features
Customizable Volatility and Gain/Loss Periods : Define your preferred calculation periods and timeframes for both volatility and gain/loss to tailor the indicator to specific trading strategies. Multi-Pair Analysis : This indicator supports up to six forex pairs (default pairs include EURUSD, GBPUSD, USDJPY, USDCHF, AUDUSD, and USDCAD) and allows you to adjust these pairs as needed. Visual Ranking : Forex pairs are sorted by volatility, displaying the highest pairs at the top for quick reference. Top Gain/Loss Highlighting : The pair with the maximum gain and the pair with the maximum loss are highlighted in the table, making it easy to identify the best and worst performers at a glance.
Indicator Settings
Volatility Settings : Period : Adjust the number of periods used in the ATR (Average True Range) calculation. A default period of 14 is set. Timeframe : Select a timeframe (e.g., Daily, Weekly) for volatility calculation to match your analysis preference.
Gain/Loss Settings : Period : Choose the number of periods for gain/loss calculation. The default is set to 1. Timeframe : Select the timeframe for gain/loss calculation, independent of the volatility timeframe.
Symbol Selection : Configure up to six forex pairs. By default, popular forex pairs are pre-loaded but can be customized to include other currency pairs.
Output and Visualization
Table Display : This indicator displays data in a neatly structured table positioned in the top-right corner of your chart. Columns : Includes columns for the Forex Pair, Volatility Percentage, Gain Percentage, and Loss Percentage. Color Coding : Volatility is displayed in a standard color for clear readability. Gain values are highlighted in green, and Loss values are highlighted in red, allowing for quick visual differentiation. Highlighting : Rows representing the pair with the highest gain and the pair with the most significant loss are especially highlighted for emphasis.
How to Use
Volatility Analysis : This metric gives insight into the average price range movements for each pair over the specified period and timeframe, helping you evaluate the potential for rapid price changes. Gain/Loss Tracking : Gain or loss percentages show the pair's recent performance, allowing you to observe whether a currency pair is trending positively or negatively over the chosen period. Comparative Pair Ranking : Use the table to identify pairs with the highest volatility and extremes in gain or loss to guide trading decisions based on market conditions.
Ideal For
Swing Traders and Day Traders looking to understand short-term market fluctuations in currency pairs. Risk Management : Helps traders gauge pairs with higher risk (volatility) and recent performance (gain/loss) for informed position sizing and risk control.
This indicator is a comprehensive tool for visualizing and analyzing key forex pairs, making it an essential addition for traders looking to stay updated on volatility trends and recent price changes.
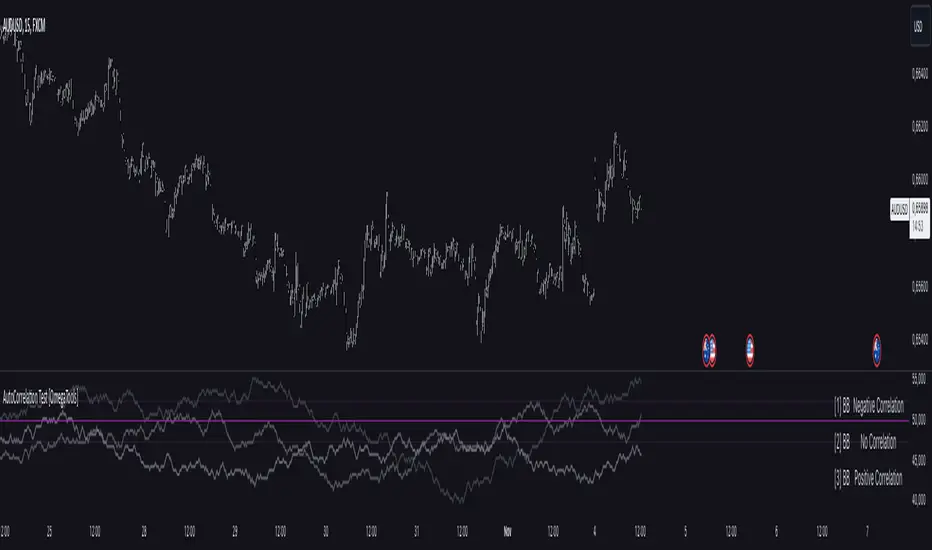
AutoCorrelation Test [OmegaTools]Overview
The AutoCorrelation Test indicator is designed to analyze the correlation patterns of a financial asset over a specified period. This tool can help traders identify potential predictive patterns by measuring the relationship between sequential returns, effectively assessing the autocorrelation of price movements.
Autocorrelation analysis is useful in identifying the consistency of directional trends (upward or downward) and potential cyclical behavior. This indicator provides an insight into whether recent price movements are likely to continue in a similar direction (positive correlation) or reverse (negative correlation).
Key Features
Multi-Period Autocorrelation: The indicator calculates autocorrelation across three periods, offering a granular view of price movement consistency over time.
Customizable Length & Sensitivity: Adjustable parameters allow users to tailor the length of analysis and sensitivity for detecting correlation.
Visual Aids: Three separate autocorrelation plots are displayed, along with an average correlation line. Dotted horizontal lines mark the thresholds for positive and negative correlation, helping users quickly assess potential trend continuation or reversal.
Interpretive Table: A table summarizing correlation status for each period helps traders make quick, informed decisions without needing to interpret the plot details directly.
Parameters
Source: Defines the price source (default: close) for calculating autocorrelation.
Length: Sets the analysis period, ranging from 10 to 2000 (default: 200).
Sensitivity: Adjusts the threshold sensitivity for defining correlation as positive or negative (default: 2.5).
Interpretation
Above 50 + Sensitivity: Indicates Positive Correlation. The price movements over the selected period are likely to continue in the same direction, potentially signaling a trend continuation.
Below 50 - Sensitivity: Indicates Negative Correlation. The price movements show a likelihood of reversing, which could signal an upcoming trend reversal.
Between 50 ± Sensitivity: Indicates No Correlation. Price movements are less predictable in direction, with no clear trend continuation or reversal tendency.
How It Works
The indicator calculates the logarithmic returns of the selected source price over each length period.
It then compares returns over consecutive periods, categorizing them as either "winning" (consistent direction) or "losing" (inconsistent direction) movements.
The result for each period is displayed as a percentage, with values above 50% indicating a higher degree of directional consistency (positive or negative).
A table updates with descriptive labels (Positive Correlation, Negative Correlation, No Correlation) for each tested period, providing a quick overview.
Visual Elements
Plots:
AutoCorrelation Test : Displays autocorrelation for the closest period (lag 1).
AutoCorrelation Test : Displays autocorrelation for the second period (lag 2).
AutoCorrelation Test : Displays autocorrelation for the third period (lag 3).
Average: Displays the simple moving average of the three test periods for a smoothed view of overall correlation trends.
Horizontal Lines:
No Correlation (50%): A baseline indicating neutral correlation.
Positive/Negative Correlation Thresholds: Dotted lines set at 50 ± Sensitivity, marking the thresholds for significant correlation.
Usage Guide
Adjust Parameters:
Select the Source to define which price metric (e.g., close, open) will be analyzed.
Set the Length based on your preferred analysis window (e.g., shorter for intraday trends, longer for swing trading).
Modify Sensitivity to fine-tune the thresholds based on market volatility and personal trading preference.
Interpret Table and Plots:
Use the table to quickly check the correlation status of each lag period.
Analyze the plots for changes in correlation. If multiple lags show positive correlation above the sensitivity threshold, a trend continuation may be expected. Conversely, negative values suggest a potential reversal.
Integrate with Other Indicators:
For enhanced insights, consider using the AutoCorrelation Test indicator in conjunction with other trend or momentum indicators.
This indicator offers a powerful method to assess market conditions, identify potential trend continuations or reversals, and better inform trading decisions. Its customization options provide flexibility for various trading styles and timeframes.
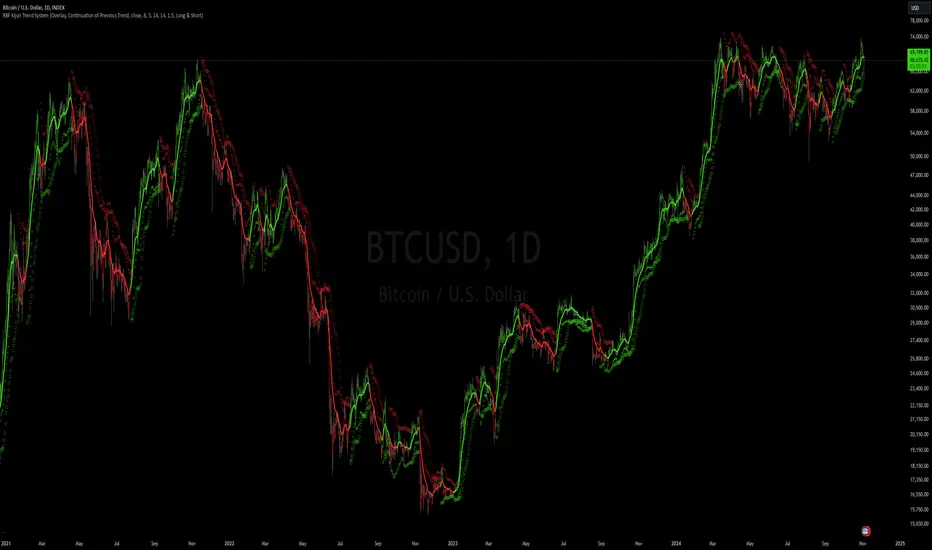
RBF Kijun Trend System [InvestorUnknown]The RBF Kijun Trend System utilizes advanced mathematical techniques, including the Radial Basis Function (RBF) kernel and Kijun-Sen calculations, to provide traders with a smoother trend-following experience and reduce the impact of noise in price data. This indicator also incorporates ATR to dynamically adjust smoothing and further minimize false signals.
Radial Basis Function (RBF) Kernel Smoothing
The RBF kernel is a mathematical method used to smooth the price series. By calculating weights based on the distance between data points, the RBF kernel ensures smoother transitions and a more refined representation of the price trend.
The RBF Kernel Weighted Moving Average is computed using the formula:
f_rbf_kernel(x, xi, sigma) =>
math.exp(-(math.pow(x - xi, 2)) / (2 * math.pow(sigma, 2)))
The smoothed price is then calculated as a weighted sum of past prices, using the RBF kernel weights:
f_rbf_weighted_average(src, kernel_len, sigma) =>
float total_weight = 0.0
float weighted_sum = 0.0
// Compute weights and sum for the weighted average
for i = 0 to kernel_len - 1
weight = f_rbf_kernel(kernel_len - 1, i, sigma)
total_weight := total_weight + weight
weighted_sum := weighted_sum + (src * weight)
// Check to avoid division by zero
total_weight != 0 ? weighted_sum / total_weight : na
Kijun-Sen Calculation
The Kijun-Sen, a component of Ichimoku analysis, is used here to further establish trends. The Kijun-Sen is computed as the average of the highest high and the lowest low over a specified period (default: 14 periods).
This Kijun-Sen calculation is based on the RBF-smoothed price to ensure smoother and more accurate trend detection.
f_kijun_sen(len, source) =>
math.avg(ta.lowest(source, len), ta.highest(source, len))
ATR-Adjusted RBF and Kijun-Sen
To mitigate false signals caused by price volatility, the indicator features ATR-adjusted versions of both the RBF smoothed price and Kijun-Sen.
The ATR multiplier is used to create upper and lower bounds around these lines, providing dynamic thresholds that account for market volatility.
Neutral State and Trend Continuation
This indicator can interpret a neutral state, where the signal is neither bullish nor bearish. By default, the indicator is set to interpret a neutral state as a continuation of the previous trend, though this can be adjusted to treat it as a truly neutral state.
Users can configure this setting using the signal_str input:
simple string signal_str = input.string("Continuation of Previous Trend", "Treat 0 State As", options = , group = G1)
Visual difference between "Neutral" (Bottom) and "Continuation of Previous Trend" (Top). Click on the picture to see it in full size.
Customizable Inputs and Settings:
Source Selection: Choose the input source for calculations (open, high, low, close, etc.).
Kernel Length and Sigma: Adjust the RBF kernel parameters to change the smoothing effect.
Kijun Length: Customize the lookback period for Kijun-Sen.
ATR Length and Multiplier: Modify these settings to adapt to market volatility.
Backtesting and Performance Metrics
The indicator includes a Backtest Mode, allowing users to evaluate the performance of the strategy using historical data. In Backtest Mode, a performance metrics table is generated, comparing the strategy's results to a simple buy-and-hold approach. Key metrics include mean returns, standard deviation, Sharpe ratio, and more.
Equity Calculation: The indicator calculates equity performance based on signals, comparing it against the buy-and-hold strategy.
Performance Metrics Table: Detailed performance analysis, including probabilities of positive, neutral, and negative returns.
Alerts
To keep traders informed, the indicator supports alerts for significant trend shifts:
// - - - - - ALERTS - - - - - //{
alert_source = sig
bool long_alert = ta.crossover (intrabar ? alert_source : alert_source , 0)
bool short_alert = ta.crossunder(intrabar ? alert_source : alert_source , 0)
alertcondition(long_alert, "LONG (RBF Kijun Trend System)", "RBF Kijun Trend System flipped ⬆LONG⬆")
alertcondition(short_alert, "SHORT (RBF Kijun Trend System)", "RBF Kijun Trend System flipped ⬇Short⬇")
//}
Important Notes
Calibration Needed: The default settings provided are not optimized and are intended for demonstration purposes only. Traders should adjust parameters to fit their trading style and market conditions.
Neutral State Interpretation: Users should carefully choose whether to treat the neutral state as a continuation or a separate signal.
Backtest Results: Historical performance is not indicative of future results. Market conditions change, and past trends may not recur.
Dual Momentum StrategyThis Pine Script™ strategy implements the "Dual Momentum" approach developed by Gary Antonacci, as presented in his book Dual Momentum Investing: An Innovative Strategy for Higher Returns with Lower Risk (McGraw Hill Professional, 2014). Dual momentum investing combines relative momentum and absolute momentum to maximize returns while minimizing risk. Relative momentum involves selecting the asset with the highest recent performance between two options (a risky asset and a safe asset), while absolute momentum considers whether the chosen asset has a positive return over a specified lookback period.
In this strategy:
Risky Asset (SPY): Represents a stock index fund, typically more volatile but with higher potential returns.
Safe Asset (TLT): Represents a bond index fund, which generally has lower volatility and acts as a hedge during market downturns.
Monthly Momentum Calculation: The momentum for each asset is calculated based on its price change over the last 12 months. Only assets with a positive momentum (absolute momentum) are considered for investment.
Decision Rules:
Invest in the risky asset if its momentum is positive and greater than that of the safe asset.
If the risky asset’s momentum is negative or lower than the safe asset's, the strategy shifts the allocation to the safe asset.
Scientific Reference
Antonacci's work on dual momentum investing has shown the strategy's ability to outperform traditional buy-and-hold methods while reducing downside risk. This approach has been reviewed and discussed in both academic and investment publications, highlighting its strong risk-adjusted returns (Antonacci, 2014).
Reference: Antonacci, G. (2014). Dual Momentum Investing: An Innovative Strategy for Higher Returns with Lower Risk. McGraw Hill Professional.

XRP Comparative Price Action Indicator - Final VersionXRP Comparative Price Action Indicator - Final Version
The XRP Comparative Price Action Indicator provides a comprehensive visual analysis of XRP’s price movements relative to key cryptocurrencies and market indices. This indicator normalises price data across various assets, allowing traders and investors to assess XRP’s performance against its peers and major market influences at a glance.
Key Features:
• Normalised Price Data: Prices are scaled between 0.00 and 1.00,
enabling straightforward comparisons between different assets.
• Key Comparisons: Includes normalised prices for:
• XRP/USD (Bitstamp)
• XRP Dominance (CryptoCap)
• XRP/BTC (Bitstamp)
• BTC/USD (Bitstamp)
• BTC Dominance (CryptoCap)
• USDT Dominance (CryptoCap)
• S&P 500 (SPY)
• DXY (Dollar Index)
• ETH/USD (Bitstamp)
• ETH Dominance (CryptoCap)
• XRP/ETH (Binance)
• Visual Clarity: Each asset is plotted with distinct colors for easy identification,
with thicker lines enhancing visibility on the chart.
• Reference Lines: Optional horizontal lines indicate the minimum (0) and maximum (1) normalised values, providing clear reference points for analysis.
This indicator is ideal for traders looking to understand XRP’s relative performance, gauge market sentiment, and make informed trading decisions based on comparative price action.

Autocorrelogram (YavuzAkbay)The Autocorrelogram (ACF) is a statistical tool designed for traders and analysts to evaluate the autocorrelation of price movements over time. Autocorrelation measures the correlation of a signal with a delayed version of itself, providing insights into the degree to which past price movements influence future price movements. This indicator is particularly useful for identifying trends and patterns in time series data, helping traders make informed decisions based on historical price behavior.
Key Components and Functionality
1. Input Parameters:
Sample Size: This parameter defines the number of data points used in the calculation of the autocorrelation function. A minimum value of 9 ensures statistical relevance. The default value is set to 100, which provides a broad view of the price behavior.
Data Source: Users can select the price data they wish to analyze (e.g., closing prices). This flexibility allows traders to apply the ACF to various price types, depending on their trading strategy.
Significance Level: This parameter determines the threshold for statistical significance in the autocorrelation values. The default value is set at 1.96, corresponding to a 95% confidence level, but users can adjust it to their preferences.
Calculate Change: This boolean option allows users to choose whether to calculate the change in the selected data source (e.g., daily price changes) rather than using the raw data. Analyzing changes can highlight momentum shifts that may be obscured in absolute price levels.
2. Core Calculations:
Simple Moving Average (SMA): The indicator computes the SMA of the selected data source over the defined sample size. This average serves as a baseline for assessing deviations in price behavior.
Variance Calculation: The variance of the price changes is calculated to understand the spread of the data. The variance is scaled by the sample size to ensure that the autocorrelation values are appropriately normalized.
Lag Value: The indicator calculates a lag value based on the sample size to determine how many periods back the autocorrelation will be calculated. This helps in assessing correlations at different time intervals.
3. Autocorrelation Calculation:
The script calculates the autocorrelation for lags ranging from 0 to 53. For each lag, it computes the autocovariance (the correlation of the signal with itself at different time intervals) and normalizes this by the variance. The result is a set of autocorrelation values that indicate the strength and direction of the relationship between current and past price movements.
4. Visualization:
The autocorrelation values are plotted as lines on the chart, with different colors indicating positive and negative correlations. Lines are dynamically drawn for each lag, providing a visual representation of how past prices influence current prices. A maximum of 54 lines (for lags 0 to 53) is maintained, with the oldest line being removed when the limit is exceeded.
Significance Levels: Horizontal lines are drawn at the defined significance levels, helping traders quickly identify when the autocorrelation values exceed the statistically significant threshold. These lines serve as benchmarks for interpreting the relevance of the autocorrelation values.
How to Use the ACF Indicator
Identifying Trends: Traders can use the ACF indicator to spot trends in the data. Strong positive autocorrelation at a given lag indicates that past price movements have a lasting influence on future movements, suggesting a potential continuation of the current trend. Conversely, significant negative autocorrelation may indicate reversals or mean reversion.
Decision Making: By comparing the autocorrelation values against the significance levels, traders can make informed decisions. For example, if the autocorrelation at lag 1 is significantly positive, it may suggest that a trend is likely to persist in the immediate future, prompting traders to consider long positions.
Setting Parameters: Adjusting the sample size and significance level allows traders to tailor the indicator to their specific market conditions and trading style. A larger sample size may provide more stable estimates but could obscure short-term fluctuations, while a smaller size may capture quick changes but with higher variability.
Combining with Other Indicators: The ACF can be used in conjunction with other technical indicators (like Moving Averages or RSI) to enhance trading strategies. Confirming signals from multiple indicators can provide stronger trade confirmations.
Vertical Line on Custom DateThis Pine Script code creates a custom indicator for TradingView that draws a vertical line on the chart at a specific date and time defined by the user.
User Input: Allows the user to specify the day, hour, and minute when the vertical line should appear.
Vertical Line Drawing: When the current date and time match the user’s inputs, a vertical line is drawn on the chart at the corresponding bar, offset by one bar to align properly.
Customizable Color and Width: The vertical line is displayed in purple with a customizable width.
Overall, this indicator helps traders visually mark important dates and times on their price charts.
Power Root SuperTrend [AlgoAlpha]📈🚀 Power Root SuperTrend by AlgoAlpha - Elevate Your Trading Strategy! 🌟
Introducing the Power Root SuperTrend by AlgoAlpha, an advanced trading indicator that enhances the traditional SuperTrend by incorporating Root-Mean-Square (RMS) calculations for a more responsive and adaptive trend detection. This innovative tool is designed to help traders identify trend directions, potential take-profit levels, and optimize entry and exit points with greater accuracy, making it an excellent addition to your trading arsenal.
Key Features:
🔹 Root-Mean-Square SuperTrend Calculation : Utilizes the RMS of closing prices to create a smoother and more sensitive SuperTrend line that adapts quickly to market changes.
🔸 Multiple Take-Profit Levels : Automatically calculates and plots up to seven take-profit levels (TP1 to TP7) based on market volatility and the change in SuperTrend values.
🟢 Dynamic Trend Coloring : Visually distinguish between bullish and bearish trends with customizable colors for clearer market visualization.
📊 RSI-Based Take-Profit Signals : Incorporates the Relative Strength Index (RSI) of the distance between the price and the SuperTrend line to generate additional take-profit signals.
🔔 Customizable Alerts : Set alerts for trend direction changes, achievement of take-profit levels, and RSI-based take-profit conditions to stay informed without constant chart monitoring.
How to Use:
Add the Indicator : Add the indicator to favorites by pressing the ⭐ icon or search for "Power Root SuperTrend " in the TradingView indicators library and add it to your chart. Adjust parameters such as the ATR multiplier, ATR length, RMS length, and RSI take-profit length to suit your trading style and the specific asset you are analyzing.
Analyze the Chart : Observe the SuperTrend line and the plotted take-profit levels. The color changes indicate trend directions—green for bullish and red for bearish trends.
Set Alerts : Utilize the built-in alert conditions to receive notifications when the trend direction changes, when each TP level is drawn, or when RSI-based take-profit conditions are met.
How It Works:
The Power Root SuperTrend indicator enhances traditional SuperTrend calculations by applying a Root-Mean-Square (RMS) function to the closing prices, resulting in a more responsive trend line that better reflects recent price movements. It calculates the Average True Range (ATR) to determine the volatility and sets the upper and lower SuperTrend bands accordingly. When a trend direction change is detected—signified by the SuperTrend line switching from above to below the price or vice versa—the indicator calculates the change in the SuperTrend value. This change is then used to establish multiple take-profit levels (TP1 to TP7), each representing incremental targets based on market volatility. Additionally, the indicator computes the RSI of the distance between the current price and the SuperTrend line to generate extra take-profit signals when the RSI crosses under a specific threshold. The combination of RMS calculations, multiple TP levels, dynamic coloring, and RSI signals provides traders with a comprehensive tool for identifying trends and optimizing trade exits. Customizable alerts ensure that traders can stay updated on important market developments without needing to constantly watch the charts.
Elevate your trading strategy with the Power Root SuperTrend indicator and gain a smarter edge in the markets! 🚀✨

S&P 100 Option Expiration Week StrategyThe Option Expiration Week Strategy aims to capitalize on increased volatility and trading volume that often occur during the week leading up to the expiration of options on stocks in the S&P 100 index. This period, known as the option expiration week, culminates on the third Friday of each month when stock options typically expire in the U.S. During this week, investors in this strategy take a long position in S&P 100 stocks or an equivalent ETF from the Monday preceding the third Friday, holding until Friday. The strategy capitalizes on potential upward price pressures caused by increased option-related trading activity, rebalancing, and hedging practices.
The phenomenon leveraged by this strategy is well-documented in finance literature. Studies demonstrate that options expiration dates have a significant impact on stock returns, trading volume, and volatility. This effect is driven by various market dynamics, including portfolio rebalancing, delta hedging by option market makers, and the unwinding of positions by institutional investors (Stoll & Whaley, 1987; Ni, Pearson, & Poteshman, 2005). These market activities intensify near option expiration, causing price adjustments that may create short-term profitable opportunities for those aware of these patterns (Roll, Schwartz, & Subrahmanyam, 2009).
The paper by Johnson and So (2013), Returns and Option Activity over the Option-Expiration Week for S&P 100 Stocks, provides empirical evidence supporting this strategy. The study analyzes the impact of option expiration on S&P 100 stocks, showing that these stocks tend to exhibit abnormal returns and increased volume during the expiration week. The authors attribute these patterns to intensified option trading activity, where demand for hedging and arbitrage around options expiration causes temporary price adjustments.
Scientific Explanation
Research has found that option expiration weeks are marked by predictable increases in stock returns and volatility, largely due to the role of options market makers and institutional investors. Option market makers often use delta hedging to manage exposure, which requires frequent buying or selling of the underlying stock to maintain a hedged position. As expiration approaches, their activity can amplify price fluctuations. Additionally, institutional investors often roll over or unwind positions during expiration weeks, creating further demand for underlying stocks (Stoll & Whaley, 1987). This increased demand around expiration week typically leads to temporary stock price increases, offering profitable opportunities for short-term strategies.
Key Research and Bibliography
Johnson, T. C., & So, E. C. (2013). Returns and Option Activity over the Option-Expiration Week for S&P 100 Stocks. Journal of Banking and Finance, 37(11), 4226-4240.
This study specifically examines the S&P 100 stocks and demonstrates that option expiration weeks are associated with abnormal returns and trading volume due to increased activity in the options market.
Stoll, H. R., & Whaley, R. E. (1987). Program Trading and Expiration-Day Effects. Financial Analysts Journal, 43(2), 16-28.
Stoll and Whaley analyze how program trading and portfolio insurance strategies around expiration days impact stock prices, leading to temporary volatility and increased trading volume.
Ni, S. X., Pearson, N. D., & Poteshman, A. M. (2005). Stock Price Clustering on Option Expiration Dates. Journal of Financial Economics, 78(1), 49-87.
This paper investigates how option expiration dates affect stock price clustering and volume, driven by delta hedging and other option-related trading activities.
Roll, R., Schwartz, E., & Subrahmanyam, A. (2009). Options Trading Activity and Firm Valuation. Journal of Financial Markets, 12(3), 519-534.
The authors explore how options trading activity influences firm valuation, finding that higher options volume around expiration dates can lead to temporary price movements in underlying stocks.
Cao, C., & Wei, J. (2010). Option Market Liquidity and Stock Return Volatility. Journal of Financial and Quantitative Analysis, 45(2), 481-507.
This study examines the relationship between options market liquidity and stock return volatility, finding that increased liquidity needs during expiration weeks can heighten volatility, impacting stock returns.
Summary
The Option Expiration Week Strategy utilizes well-researched financial market phenomena related to option expiration. By positioning long in S&P 100 stocks or ETFs during this period, traders can potentially capture abnormal returns driven by option market dynamics. The literature suggests that options-related activities—such as delta hedging, position rollovers, and portfolio adjustments—intensify demand for underlying assets, creating short-term profit opportunities around these key dates.

Payday Anomaly StrategyThe "Payday Effect" refers to a predictable anomaly in financial markets where stock returns exhibit significant fluctuations around specific pay periods. Typically, these are associated with the beginning, middle, or end of the month when many investors receive wages and salaries. This influx of funds, often directed automatically into retirement accounts or investment portfolios (such as 401(k) plans in the United States), temporarily increases the demand for equities. This phenomenon has been linked to a cycle where stock prices rise disproportionately on and around payday periods due to increased buy-side liquidity.
Academic research on the payday effect suggests that this pattern is tied to systematic cash flows into financial markets, primarily driven by employee retirement and savings plans. The regularity of these cash infusions creates a calendar-based pattern that can be exploited in trading strategies. Studies show that returns on days around typical payroll dates tend to be above average, and this pattern remains observable across various time periods and regions.
The rationale behind the payday effect is rooted in the behavioral tendencies of investors, specifically the automatic reinvestment mechanisms used in retirement funds, which align with monthly or semi-monthly salary payments. This regular injection of funds can cause market microstructure effects where stock prices temporarily increase, only to stabilize or reverse after the funds have been invested. Consequently, the payday effect provides traders with a potentially profitable opportunity by predicting these inflows.
Scientific Bibliography on the Payday Effect
Ma, A., & Pratt, W. R. (2017). Payday Anomaly: The Market Impact of Semi-Monthly Pay Periods. Social Science Research Network (SSRN).
This study provides a comprehensive analysis of the payday effect, exploring how returns tend to peak around payroll periods due to semi-monthly cash flows. The paper discusses how systematic inflows impact returns, leading to predictable stock performance patterns on specific days of the month.
Lakonishok, J., & Smidt, S. (1988). Are Seasonal Anomalies Real? A Ninety-Year Perspective. The Review of Financial Studies, 1(4), 403-425.
This foundational study explores calendar anomalies, including the payday effect. By examining data over nearly a century, the authors establish a framework for understanding seasonal and monthly patterns in stock returns, which provides historical support for the payday effect.
Owen, S., & Rabinovitch, R. (1983). On the Predictability of Common Stock Returns: A Step Beyond the Random Walk Hypothesis. Journal of Business Finance & Accounting, 10(3), 379-396.
This paper investigates predictability in stock returns beyond random fluctuations. It considers payday effects among various calendar anomalies, arguing that certain dates yield predictable returns due to regular cash inflows.
Loughran, T., & Schultz, P. (2005). Liquidity: Urban versus Rural Firms. Journal of Financial Economics, 78(2), 341-374.
While primarily focused on liquidity, this study provides insight into how cash flows, such as those from semi-monthly paychecks, influence liquidity levels and consequently impact stock prices around predictable pay dates.
Ariel, R. A. (1990). High Stock Returns Before Holidays: Existence and Evidence on Possible Causes. The Journal of Finance, 45(5), 1611-1626.
Ariel’s work highlights stock return patterns tied to certain dates, including paydays. Although the study focuses on pre-holiday returns, it suggests broader implications of predictable investment timing, reinforcing the calendar-based effects seen with payday anomalies.
Summary
Research on the payday effect highlights a repeating pattern in stock market returns driven by scheduled payroll investments. This cyclical increase in stock demand aligns with behavioral finance insights and market microstructure theories, offering a valuable basis for trading strategies focused on the beginning, middle, and end of each month.

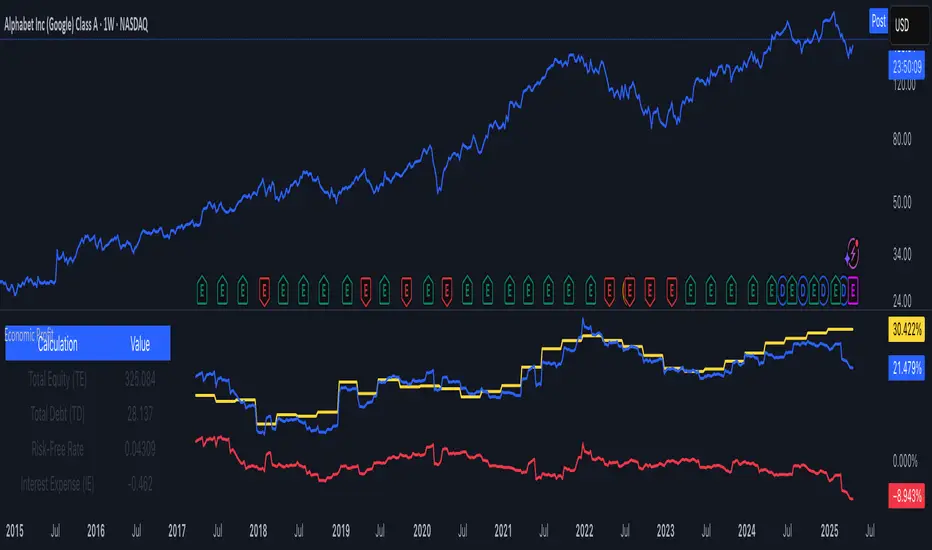
Economic Profit (YavuzAkbay)The Economic Profit Indicator is a Pine Script™ tool for assessing a company’s economic profit based on key financial metrics like Return on Invested Capital (ROIC) and Weighted Average Cost of Capital (WACC). This indicator is designed to give traders a more accurate understanding of risk-adjusted returns.
Features
Customizable inputs for Risk-Free Rate and Corporate Tax Rate assets for people who are trading in other countries.
Calculates Economic Profit based on ROIC and WACC, with values shown as both plots and in an on-screen table.
Provides detailed breakdowns of all key calculations, enabling deeper insights into financial performance.
How to Use
Open the stock to be analyzed. In the settings, enter the risk-free asset (usually a 10-year bond) of the country where the company to be analyzed is located. Then enter the corporate tax of the country (USCTR for the USA, DECTR for Germany). Then enter the average return of the index the stock is in. I prefer 10% (0.10) for the SP500, different rates can be entered for different indices. Finally, the beta of the stock is entered. In future versions I will automatically pull beta and index returns, but in order to publish the indicator a bit earlier, I have left it entirely up to the investor.
How to Interpret
We see 3 pieces of data on the indicator. The dark blue one is ROIC, the dark orange one is WACC and the light blue line represents the difference between WACC and ROIC.
In a scenario where both ROIC and WACC are negative, if ROIC is lower than WACC, the share is at a complete economic loss.
In a scenario where both ROIC and WACC are negative, if ROIC has started to rise above WACC and is moving towards positive, the share is still in an economic loss but tending towards profit.
A scenario where ROIC is positive and WACC is negative is the most natural scenario for a company. In this scenario, we know that the company is doing well by a gradually increasing ROIC and a stable WACC.
In addition, if the ROIC and WACC difference line goes above 0, the company is now economically in net profit. This is the best scenario for a company.
My own investment strategy as a developer of the code is to look for the moment when ROIC is greater than WACC when ROIC and WACC are negative. At that point the stock is the best time to invest.
Trading is risky, and most traders lose money. The indicators Yavuz Akbay offers are for informational and educational purposes only. All content should be considered hypothetical, selected after the facts to demonstrate my product, and not constructed as financial advice. Decisions to buy, sell, hold, or trade in securities, commodities, and other investments involve risk and are best made based on the advice of qualified financial professionals. Past performance does not guarantee future results.
This indicator is experimental and will always remain experimental. The indicator will be updated by Yavuz Akbay according to market conditions.
Customizable BTC Seasonality StrategyThis strategy leverages intraday seasonality effects in Bitcoin, specifically targeting hours of statistically significant returns during periods when traditional financial markets are closed. Padysak and Vojtko (2022) demonstrate that Bitcoin exhibits higher-than-average returns from 21:00 UTC to 23:00 UTC, a period in which all major global exchanges, such as the New York Stock Exchange (NYSE), Tokyo Stock Exchange, and London Stock Exchange, are closed. The absence of competing trading activity from traditional markets during these hours appears to contribute to these statistically significant returns.
The strategy proceeds as follows:
Entry Time: A long position in Bitcoin is opened at a user-specified time, which defaults to 21:00 UTC, aligning with the beginning of the identified high-return window.
Holding Period: The position is held for two hours, capturing the positive returns typically observed during this period.
Exit Time: The position is closed at a user-defined time, defaulting to 23:00 UTC, allowing the strategy to exit as the favorable period concludes.
This simple seasonality strategy aims to achieve a 33% annualized return with a notably reduced volatility of 20.93% and maximum drawdown of -22.45%. The results suggest that investing only during these high-return hours is more stable and less risky than a passive holding strategy (Padysak & Vojtko, 2022).
References
Padysak, M., & Vojtko, R. (2022). Seasonality, Trend-following, and Mean reversion in Bitcoin.

Mean Trend OscillatorMean Trend Oscillator
The Mean Trend Oscillator offers an original approach to trend analysis by integrating multiple technical indicators, using statistic to get a probable signal, and dynamically adapting to market volatility.
This tool aggregates signals from four popular indicators—Relative Strength Index (RSI), Simple Moving Average (SMA), Exponential Moving Average (EMA), and Relative Moving Average (RMA)—and adjusts thresholds using the Average True Range (ATR). By using this, we can use Statistics to aggregate or take the average of each indicators signal. Mathematically, Taking an average of these indicators gives us a better probability on entering a trending state.
By consolidating these distinct perspectives, the Mean Trend Oscillator provides a comprehensive view of market direction, helping traders make informed decisions based on a broad, data-driven trend assessment. Traders can use this indicator to enter long spot or leveraged positions. The Mean Trend Oscillator is intended to be use in long term trending markets. Scalping MUST NOT be used with this indicator. (This indicator will give false signals when the Timeframe is too low. The best intended use for high-quality signals are longer timeframes).
The current price of a beginning trend series may tell us something about the next move. Thus, the Mean Trend Oscillator allows us to spot a high probability trending market and potentially exploit this information enter long or shorts strategy. (again, this indicator will give false signals when the Timeframe is too low. The best intended use for high-quality signals are longer timeframes).
Concept and Calculation and Inputs
The Mean Trend Oscillator calculates a “net trend” score as follows:
RSI evaluates market momentum, identifying overbought and oversold conditions, essential for confirming trend direction.
SMA, EMA, and RMA introduce varied smoothing methods to capture short- to medium-term trends, balancing quick price changes with smoothed averages.
ATR-Enhanced Thresholds: ATR is used as a dynamic multiplier, adjusting each indicator’s thresholds to current volatility levels, which helps reduce noise in low-volatility conditions and emphasizes significant signals when volatility spikes.
Length could be used to adjust how quickly each indicator can more or how slower each indicator can be.
Time Coherency for Inputs: Each indicator must be calculated where each signal is relatively around the same area.
For example:
Simply:
SMA, RMA, EMA, and RSI enters long around each intended trend period. Doesn't have to be perfect, but the indicators all enter long around there.
Each indicator contributes a score (+1 for bullish and -1 for bearish), and these scores are averaged to generate the final trend score:
A positive score, shown as a green line, suggests bullish conditions.
A negative score, indicated by a red line, signifies bearish conditions.
Thus, giving us a signal to long or short.
How to Use the Mean Trend Oscillator
This indicator’s output is straightforward and can fit into various trading strategies:
Bullish Signal: A green line shows that the trend is bullish, based on a positive average score across the indicators, signaling a consideration of longing an asset.
Bearish Signal: A red line indicates bearish conditions, with an overall negative trend score, signaling a consideration to shorting an asset.
By aggregating these indicators, the Mean Trend Oscillator helps traders identify strong trends while filtering out minor fluctuations, making it a versatile tool for both short- and long-term analysis. This multi-layered, adaptive approach to trend detection sets it apart from traditional single-indicator trend tools.

Performance Summary and Shading (Offset Version)Modified "Recession and Crisis Shading" Indicator by @haribotagada (Original Link: )
The updated indicator accepts a days offset (positive or negative) to calculate performance between the offset date and the input date.
Potential uses include identifying performance one week after company earnings or an FOMC meeting.
This feature simplifies input by enabling standardized offset dates, while still allowing flexibility to adjust ranges by overriding inputs as needed.
Summary of added features and indicator notes:
Inputs both positive and negative offset.
By default, the script calculates performance from the close of the input date to the close of the date at (input date + offset) for positive offsets, and from the close of (input date - offset) to the close of the input date for negative offsets. For example, with an input date of November 1, 2024, an offset of 7 calculates performance from the close on November 1 to the close on November 8, while an offset of -7 calculates from the close on October 25 to the close on November 1.
Allows user to perform the calculation using the open price on the input date instead of close price
The input format has been modified to allow overrides for the default duration, while retaining the original capabilities of the indicator.
The calculation shows both the average change and the average annualized change. For bar-wise calculations, annualization assumes 252 trading days per year. For date-wise calculations, it assumes 365 days for annualization.
Carries over all previous inputs to retain functionality of the previous script. Changes a few small settings:
Calculates start to end date performance by default instead of peak to trough performance.
Updates visuals of label text to make it easier to read and less transparent.
Changed stat box color scheme to make the text easier to read
Updated default input data to new format of input with offsets
Changed default duration statistic to number of days instead of number of bars with an option to select number of bars.
Potential Features to Add:
Import dataset from CSV files or by plugging into TradingView calendar
Example Input Datasets:
Recessions:
2020-02-01,COVID-19,59
2007-12-01,Subprime mortgages,547
2001-03-01,Dot-com,243
1990-07-01,Oil shock,243
1981-07-01,US unemployment,788
1980-01-01,Volker,182
1973-11-01,OPEC,485
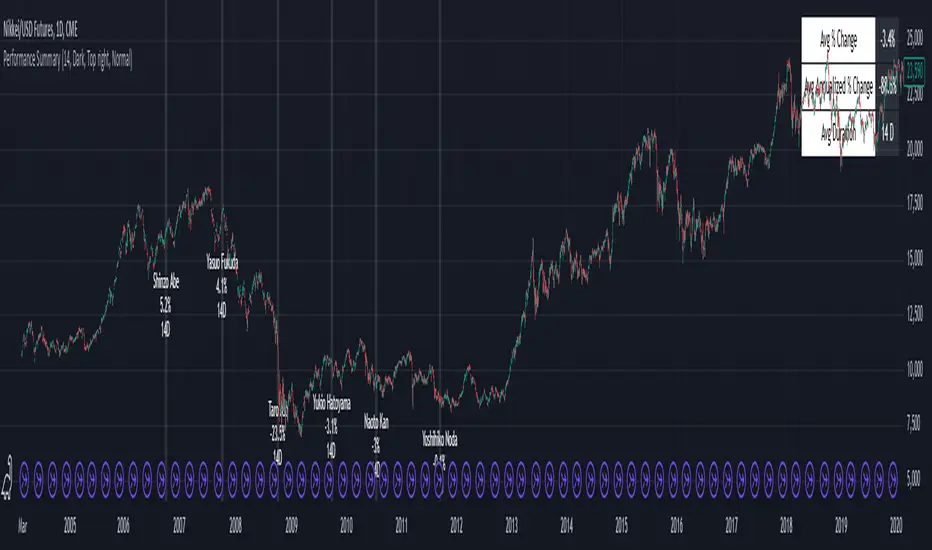
Japan Revolving Door Elections
2006-09-26, Shinzo Abe
2007-09-26, Yasuo Fukuda
2008-09-24, Taro Aso
2009-09-16, Yukio Hatoyama
2010-07-08, Naoto Kan
2011-09-02, Yoshihiko Noda
Hope you find the modified indicator useful and let me know if you would like any features to be added!
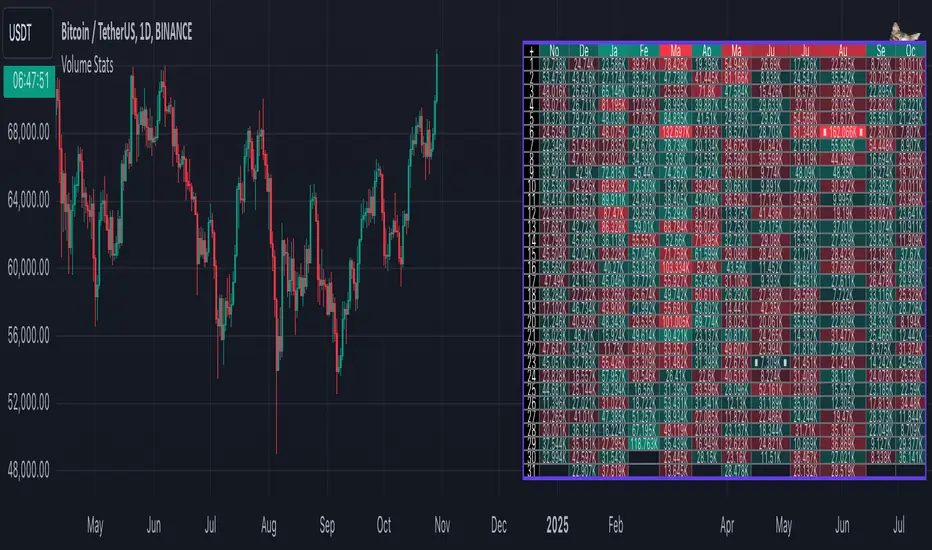
Volume StatsDescription:
Volume Stats displays volume data and statistics for every day of the year, and is designed to work on "1D" timeframe. The data is displayed in a table with columns being months of the year, and rows being days of each month. By default, latest data is displayed, but you have an option to switch to data of the previous year as well.
The statistics displayed for each day is:
- volume
- % of total yearly volume
- % of total monthly volume
The statistics displayed for each column (month) is:
- monthly volume
- % of total yearly volume
- sentiment (was there more bullish or bearish volume?)
- min volume (on which day of the month was the min volume)
- max volume (on which day of the month was the max volume)
The cells change their colors depending on whether the volume is bullish or bearish, and what % of total volume the current cell has (either yearly or monthly). The header cells also change their color (based either on sentiment or what % of yearly volume the current month has).
This is the first (and free) version of the indicator, and I'm planning to create a "PRO" version of this indicator in future.
Parameters:
- Timezone
- Cell data -> which data to display in the cells (no data, volume or percentage)
- Highlight min and max volume -> if checked, cells with min and max volume (either monthly or yearly) will be highlighted with a dot or letter (depending on the "Cell data" input)
- Cell stats mode -> which data to use for color and % calculation (All data = yearly, Column = monthly)
- Display data from previous year -> if checked, the data from previous year will be used
- Header color is calculated from -> either sentiment or % of the yearly volume
- Reverse theme -> the table colors are automatically changed based on the "Dark mode" of Tradingview, this checkbox reverses the logic (so that darker colors will be used when "Dark mode" is off, and lighter colors when it's on)
- Hide logo -> hides the cat logo (PLEASE DO NOT HIDE THE CAT)
Conclusion:
Let me know what you think of the indicator. As I said, I'm planning to make a PRO version with more features, for which I already have some ideas, but if you have any suggestions, please let me know.