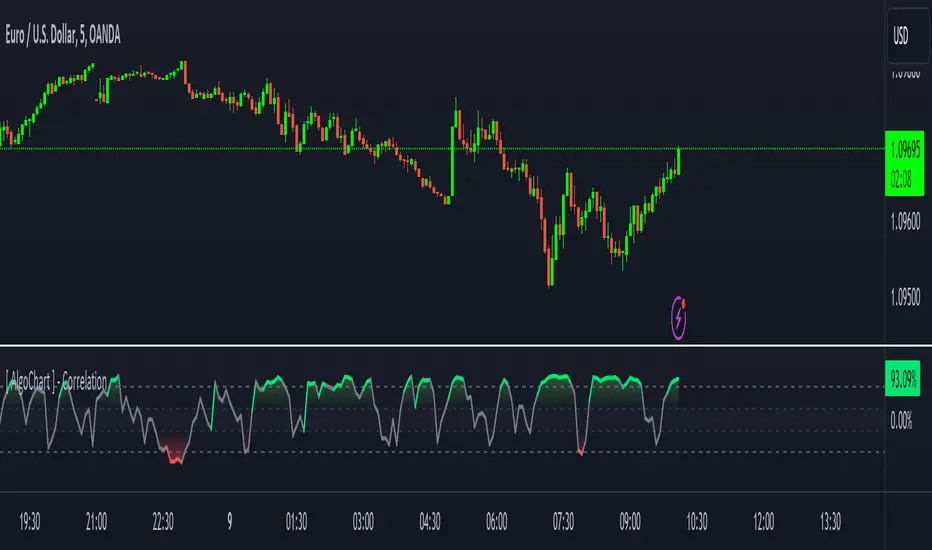
[ AlgoChart ] - Pearson Index CorrelationCorrelation Indicator (Pearson Index)
The correlation indicator measures the strength and direction of the relationship between two financial assets using the Pearson Index.
Correlation values range from +100 to -100, where:
+100 indicates perfect positive correlation, meaning the two assets tend to move in the same direction.
-100 indicates perfect negative correlation, where the two assets move in opposite directions.
The neutral zone ranges from +25% to -25%, suggesting that the asset movements are independent, with no clear correlation between them.
Interpreting Correlation Levels:
Correlation above +75%: The two assets tend to move similarly and in the same direction. This may indicate a risk of overexposure if both assets are traded in the same direction, as their movements will be very similar, increasing the likelihood of double losses or gains.
Correlation below -75%: The two assets tend to move similarly but in opposite directions. This correlation level can be useful for strategies that benefit from opposing movements between assets, such as trading pairs with inverse dynamics.
Practical Use of the Indicator:
Risk management: Use the indicator to monitor asset correlations before opening positions. High correlation may indicate you are duplicating exposure, as two highly correlated assets tend to move similarly. This helps avoid excessive risk and improves portfolio diversification.
Statistical Arbitrage: During moments of temporary decorrelation between two assets, the indicator can be used for statistical arbitrage strategies. In such cases, you can take advantage of the divergence by opening positions and closing them when the correlation returns to higher or positive levels, thus potentially profiting from the reconvergence of movements.
While the correlation indicator provides valuable insights into asset relationships, it is most effective when used in conjunction with other concepts and tools. On its own, it may offer limited relevance in trading decisions.
Statistics
[MAD MBS] L3 Float Operations & ML-NormalizersFirst of all:
This indicator is not a standalone tool ; it relies on other script series for its inputs.
This script is an indicator designed for multi-path float operations with integrated machine learning normalizers.
It supports up to four distinct paths, each customizable with multiple sources, factors, and operations.
Users can perform various mathematical operations on price data, including addition, subtraction, multiplication, division, and percentage changes, as well as more advanced tasks like double and triple moving averages or power operations.
The script also integrates several normalization methods (e.g., Min-Max, Z-Score, Robust) to standardize data—an important step for machine learning models.
Each path supports multiple smoothing techniques (e.g., EMA, SMA, and specialized Ehlers smoothers) to further refine the output.
Designed to handle multiple data inputs simultaneously, this tool is especially useful for traders looking to analyze and normalize data from different price sources.
The combination of advanced mathematical operations, normalization techniques, and smoothing enhances data management, aiding in more effective trading decisions.
Here you can see a single path, out of the four possible:
Details to the screenshot:
First Series
Second Series
Option to override the second series with a custom constant (or when normalizing, use the length instead)
The first selection box sets the mathematical operation or activates the normalizer.
The second selection box sets the normalization method.
The third selection box sets the final smoothing technique, followed by parameters for smoothing length.
These settings are repeated identically for Paths 2–4.
At the bottom of the setup, there's a general offset option (add the 'close' price for overlay purposes).
Additionally, there's an option to display a line at zero for centered results.

Universal Ratio Trend Matrix [InvestorUnknown]The Universal Ratio Trend Matrix is designed for trend analysis on asset/asset ratios, supporting up to 40 different assets. Its primary purpose is to help identify which assets are outperforming others within a selection, providing a broad overview of market trends through a matrix of ratios. The indicator automatically expands the matrix based on the number of assets chosen, simplifying the process of comparing multiple assets in terms of performance.
Key features include the ability to choose from a narrow selection of indicators to perform the ratio trend analysis, allowing users to apply well-defined metrics to their comparison.
Drawback: Due to the computational intensity involved in calculating ratios across many assets, the indicator has a limitation related to loading speed. TradingView has time limits for calculations, and for users on the basic (free) plan, this could result in frequent errors due to exceeded time limits. To use the indicator effectively, users with any paid plans should run it on timeframes higher than 8h (the lowest timeframe on which it managed to load with 40 assets), as lower timeframes may not reliably load.
Indicators:
RSI_raw: Simple function to calculate the Relative Strength Index (RSI) of a source (asset price).
RSI_sma: Calculates RSI followed by a Simple Moving Average (SMA).
RSI_ema: Calculates RSI followed by an Exponential Moving Average (EMA).
CCI: Calculates the Commodity Channel Index (CCI).
Fisher: Implements the Fisher Transform to normalize prices.
Utility Functions:
f_remove_exchange_name: Strips the exchange name from asset tickers (e.g., "INDEX:BTCUSD" to "BTCUSD").
f_remove_exchange_name(simple string name) =>
string parts = str.split(name, ":")
string result = array.size(parts) > 1 ? array.get(parts, 1) : name
result
f_get_price: Retrieves the closing price of a given asset ticker using request.security().
f_constant_src: Checks if the source data is constant by comparing multiple consecutive values.
Inputs:
General settings allow users to select the number of tickers for analysis (used_assets) and choose the trend indicator (RSI, CCI, Fisher, etc.).
Table settings customize how trend scores are displayed in terms of text size, header visibility, highlighting options, and top-performing asset identification.
The script includes inputs for up to 40 assets, allowing the user to select various cryptocurrencies (e.g., BTCUSD, ETHUSD, SOLUSD) or other assets for trend analysis.
Price Arrays:
Price values for each asset are stored in variables (price_a1 to price_a40) initialized as na. These prices are updated only for the number of assets specified by the user (used_assets).
Trend scores for each asset are stored in separate arrays
// declare price variables as "na"
var float price_a1 = na, var float price_a2 = na, var float price_a3 = na, var float price_a4 = na, var float price_a5 = na
var float price_a6 = na, var float price_a7 = na, var float price_a8 = na, var float price_a9 = na, var float price_a10 = na
var float price_a11 = na, var float price_a12 = na, var float price_a13 = na, var float price_a14 = na, var float price_a15 = na
var float price_a16 = na, var float price_a17 = na, var float price_a18 = na, var float price_a19 = na, var float price_a20 = na
var float price_a21 = na, var float price_a22 = na, var float price_a23 = na, var float price_a24 = na, var float price_a25 = na
var float price_a26 = na, var float price_a27 = na, var float price_a28 = na, var float price_a29 = na, var float price_a30 = na
var float price_a31 = na, var float price_a32 = na, var float price_a33 = na, var float price_a34 = na, var float price_a35 = na
var float price_a36 = na, var float price_a37 = na, var float price_a38 = na, var float price_a39 = na, var float price_a40 = na
// create "empty" arrays to store trend scores
var a1_array = array.new_int(40, 0), var a2_array = array.new_int(40, 0), var a3_array = array.new_int(40, 0), var a4_array = array.new_int(40, 0)
var a5_array = array.new_int(40, 0), var a6_array = array.new_int(40, 0), var a7_array = array.new_int(40, 0), var a8_array = array.new_int(40, 0)
var a9_array = array.new_int(40, 0), var a10_array = array.new_int(40, 0), var a11_array = array.new_int(40, 0), var a12_array = array.new_int(40, 0)
var a13_array = array.new_int(40, 0), var a14_array = array.new_int(40, 0), var a15_array = array.new_int(40, 0), var a16_array = array.new_int(40, 0)
var a17_array = array.new_int(40, 0), var a18_array = array.new_int(40, 0), var a19_array = array.new_int(40, 0), var a20_array = array.new_int(40, 0)
var a21_array = array.new_int(40, 0), var a22_array = array.new_int(40, 0), var a23_array = array.new_int(40, 0), var a24_array = array.new_int(40, 0)
var a25_array = array.new_int(40, 0), var a26_array = array.new_int(40, 0), var a27_array = array.new_int(40, 0), var a28_array = array.new_int(40, 0)
var a29_array = array.new_int(40, 0), var a30_array = array.new_int(40, 0), var a31_array = array.new_int(40, 0), var a32_array = array.new_int(40, 0)
var a33_array = array.new_int(40, 0), var a34_array = array.new_int(40, 0), var a35_array = array.new_int(40, 0), var a36_array = array.new_int(40, 0)
var a37_array = array.new_int(40, 0), var a38_array = array.new_int(40, 0), var a39_array = array.new_int(40, 0), var a40_array = array.new_int(40, 0)
f_get_price(simple string ticker) =>
request.security(ticker, "", close)
// Prices for each USED asset
f_get_asset_price(asset_number, ticker) =>
if (used_assets >= asset_number)
f_get_price(ticker)
else
na
// overwrite empty variables with the prices if "used_assets" is greater or equal to the asset number
if barstate.isconfirmed // use barstate.isconfirmed to avoid "na prices" and calculation errors that result in empty cells in the table
price_a1 := f_get_asset_price(1, asset1), price_a2 := f_get_asset_price(2, asset2), price_a3 := f_get_asset_price(3, asset3), price_a4 := f_get_asset_price(4, asset4)
price_a5 := f_get_asset_price(5, asset5), price_a6 := f_get_asset_price(6, asset6), price_a7 := f_get_asset_price(7, asset7), price_a8 := f_get_asset_price(8, asset8)
price_a9 := f_get_asset_price(9, asset9), price_a10 := f_get_asset_price(10, asset10), price_a11 := f_get_asset_price(11, asset11), price_a12 := f_get_asset_price(12, asset12)
price_a13 := f_get_asset_price(13, asset13), price_a14 := f_get_asset_price(14, asset14), price_a15 := f_get_asset_price(15, asset15), price_a16 := f_get_asset_price(16, asset16)
price_a17 := f_get_asset_price(17, asset17), price_a18 := f_get_asset_price(18, asset18), price_a19 := f_get_asset_price(19, asset19), price_a20 := f_get_asset_price(20, asset20)
price_a21 := f_get_asset_price(21, asset21), price_a22 := f_get_asset_price(22, asset22), price_a23 := f_get_asset_price(23, asset23), price_a24 := f_get_asset_price(24, asset24)
price_a25 := f_get_asset_price(25, asset25), price_a26 := f_get_asset_price(26, asset26), price_a27 := f_get_asset_price(27, asset27), price_a28 := f_get_asset_price(28, asset28)
price_a29 := f_get_asset_price(29, asset29), price_a30 := f_get_asset_price(30, asset30), price_a31 := f_get_asset_price(31, asset31), price_a32 := f_get_asset_price(32, asset32)
price_a33 := f_get_asset_price(33, asset33), price_a34 := f_get_asset_price(34, asset34), price_a35 := f_get_asset_price(35, asset35), price_a36 := f_get_asset_price(36, asset36)
price_a37 := f_get_asset_price(37, asset37), price_a38 := f_get_asset_price(38, asset38), price_a39 := f_get_asset_price(39, asset39), price_a40 := f_get_asset_price(40, asset40)
Universal Indicator Calculation (f_calc_score):
This function allows switching between different trend indicators (RSI, CCI, Fisher) for flexibility.
It uses a switch-case structure to calculate the indicator score, where a positive trend is denoted by 1 and a negative trend by 0. Each indicator has its own logic to determine whether the asset is trending up or down.
// use switch to allow "universality" in indicator selection
f_calc_score(source, trend_indicator, int_1, int_2) =>
int score = na
if (not f_constant_src(source)) and source > 0.0 // Skip if you are using the same assets for ratio (for example BTC/BTC)
x = switch trend_indicator
"RSI (Raw)" => RSI_raw(source, int_1)
"RSI (SMA)" => RSI_sma(source, int_1, int_2)
"RSI (EMA)" => RSI_ema(source, int_1, int_2)
"CCI" => CCI(source, int_1)
"Fisher" => Fisher(source, int_1)
y = switch trend_indicator
"RSI (Raw)" => x > 50 ? 1 : 0
"RSI (SMA)" => x > 50 ? 1 : 0
"RSI (EMA)" => x > 50 ? 1 : 0
"CCI" => x > 0 ? 1 : 0
"Fisher" => x > x ? 1 : 0
score := y
else
score := 0
score
Array Setting Function (f_array_set):
This function populates an array with scores calculated for each asset based on a base price (p_base) divided by the prices of the individual assets.
It processes multiple assets (up to 40), calling the f_calc_score function for each.
// function to set values into the arrays
f_array_set(a_array, p_base) =>
array.set(a_array, 0, f_calc_score(p_base / price_a1, trend_indicator, int_1, int_2))
array.set(a_array, 1, f_calc_score(p_base / price_a2, trend_indicator, int_1, int_2))
array.set(a_array, 2, f_calc_score(p_base / price_a3, trend_indicator, int_1, int_2))
array.set(a_array, 3, f_calc_score(p_base / price_a4, trend_indicator, int_1, int_2))
array.set(a_array, 4, f_calc_score(p_base / price_a5, trend_indicator, int_1, int_2))
array.set(a_array, 5, f_calc_score(p_base / price_a6, trend_indicator, int_1, int_2))
array.set(a_array, 6, f_calc_score(p_base / price_a7, trend_indicator, int_1, int_2))
array.set(a_array, 7, f_calc_score(p_base / price_a8, trend_indicator, int_1, int_2))
array.set(a_array, 8, f_calc_score(p_base / price_a9, trend_indicator, int_1, int_2))
array.set(a_array, 9, f_calc_score(p_base / price_a10, trend_indicator, int_1, int_2))
array.set(a_array, 10, f_calc_score(p_base / price_a11, trend_indicator, int_1, int_2))
array.set(a_array, 11, f_calc_score(p_base / price_a12, trend_indicator, int_1, int_2))
array.set(a_array, 12, f_calc_score(p_base / price_a13, trend_indicator, int_1, int_2))
array.set(a_array, 13, f_calc_score(p_base / price_a14, trend_indicator, int_1, int_2))
array.set(a_array, 14, f_calc_score(p_base / price_a15, trend_indicator, int_1, int_2))
array.set(a_array, 15, f_calc_score(p_base / price_a16, trend_indicator, int_1, int_2))
array.set(a_array, 16, f_calc_score(p_base / price_a17, trend_indicator, int_1, int_2))
array.set(a_array, 17, f_calc_score(p_base / price_a18, trend_indicator, int_1, int_2))
array.set(a_array, 18, f_calc_score(p_base / price_a19, trend_indicator, int_1, int_2))
array.set(a_array, 19, f_calc_score(p_base / price_a20, trend_indicator, int_1, int_2))
array.set(a_array, 20, f_calc_score(p_base / price_a21, trend_indicator, int_1, int_2))
array.set(a_array, 21, f_calc_score(p_base / price_a22, trend_indicator, int_1, int_2))
array.set(a_array, 22, f_calc_score(p_base / price_a23, trend_indicator, int_1, int_2))
array.set(a_array, 23, f_calc_score(p_base / price_a24, trend_indicator, int_1, int_2))
array.set(a_array, 24, f_calc_score(p_base / price_a25, trend_indicator, int_1, int_2))
array.set(a_array, 25, f_calc_score(p_base / price_a26, trend_indicator, int_1, int_2))
array.set(a_array, 26, f_calc_score(p_base / price_a27, trend_indicator, int_1, int_2))
array.set(a_array, 27, f_calc_score(p_base / price_a28, trend_indicator, int_1, int_2))
array.set(a_array, 28, f_calc_score(p_base / price_a29, trend_indicator, int_1, int_2))
array.set(a_array, 29, f_calc_score(p_base / price_a30, trend_indicator, int_1, int_2))
array.set(a_array, 30, f_calc_score(p_base / price_a31, trend_indicator, int_1, int_2))
array.set(a_array, 31, f_calc_score(p_base / price_a32, trend_indicator, int_1, int_2))
array.set(a_array, 32, f_calc_score(p_base / price_a33, trend_indicator, int_1, int_2))
array.set(a_array, 33, f_calc_score(p_base / price_a34, trend_indicator, int_1, int_2))
array.set(a_array, 34, f_calc_score(p_base / price_a35, trend_indicator, int_1, int_2))
array.set(a_array, 35, f_calc_score(p_base / price_a36, trend_indicator, int_1, int_2))
array.set(a_array, 36, f_calc_score(p_base / price_a37, trend_indicator, int_1, int_2))
array.set(a_array, 37, f_calc_score(p_base / price_a38, trend_indicator, int_1, int_2))
array.set(a_array, 38, f_calc_score(p_base / price_a39, trend_indicator, int_1, int_2))
array.set(a_array, 39, f_calc_score(p_base / price_a40, trend_indicator, int_1, int_2))
a_array
Conditional Array Setting (f_arrayset):
This function checks if the number of used assets is greater than or equal to a specified number before populating the arrays.
// only set values into arrays for USED assets
f_arrayset(asset_number, a_array, p_base) =>
if (used_assets >= asset_number)
f_array_set(a_array, p_base)
else
na
Main Logic
The main logic initializes arrays to store scores for each asset. Each array corresponds to one asset's performance score.
Setting Trend Values: The code calls f_arrayset for each asset, populating the respective arrays with calculated scores based on the asset prices.
Combining Arrays: A combined_array is created to hold all the scores from individual asset arrays. This array facilitates further analysis, allowing for an overview of the performance scores of all assets at once.
// create a combined array (work-around since pinescript doesn't support having array of arrays)
var combined_array = array.new_int(40 * 40, 0)
if barstate.islast
for i = 0 to 39
array.set(combined_array, i, array.get(a1_array, i))
array.set(combined_array, i + (40 * 1), array.get(a2_array, i))
array.set(combined_array, i + (40 * 2), array.get(a3_array, i))
array.set(combined_array, i + (40 * 3), array.get(a4_array, i))
array.set(combined_array, i + (40 * 4), array.get(a5_array, i))
array.set(combined_array, i + (40 * 5), array.get(a6_array, i))
array.set(combined_array, i + (40 * 6), array.get(a7_array, i))
array.set(combined_array, i + (40 * 7), array.get(a8_array, i))
array.set(combined_array, i + (40 * 8), array.get(a9_array, i))
array.set(combined_array, i + (40 * 9), array.get(a10_array, i))
array.set(combined_array, i + (40 * 10), array.get(a11_array, i))
array.set(combined_array, i + (40 * 11), array.get(a12_array, i))
array.set(combined_array, i + (40 * 12), array.get(a13_array, i))
array.set(combined_array, i + (40 * 13), array.get(a14_array, i))
array.set(combined_array, i + (40 * 14), array.get(a15_array, i))
array.set(combined_array, i + (40 * 15), array.get(a16_array, i))
array.set(combined_array, i + (40 * 16), array.get(a17_array, i))
array.set(combined_array, i + (40 * 17), array.get(a18_array, i))
array.set(combined_array, i + (40 * 18), array.get(a19_array, i))
array.set(combined_array, i + (40 * 19), array.get(a20_array, i))
array.set(combined_array, i + (40 * 20), array.get(a21_array, i))
array.set(combined_array, i + (40 * 21), array.get(a22_array, i))
array.set(combined_array, i + (40 * 22), array.get(a23_array, i))
array.set(combined_array, i + (40 * 23), array.get(a24_array, i))
array.set(combined_array, i + (40 * 24), array.get(a25_array, i))
array.set(combined_array, i + (40 * 25), array.get(a26_array, i))
array.set(combined_array, i + (40 * 26), array.get(a27_array, i))
array.set(combined_array, i + (40 * 27), array.get(a28_array, i))
array.set(combined_array, i + (40 * 28), array.get(a29_array, i))
array.set(combined_array, i + (40 * 29), array.get(a30_array, i))
array.set(combined_array, i + (40 * 30), array.get(a31_array, i))
array.set(combined_array, i + (40 * 31), array.get(a32_array, i))
array.set(combined_array, i + (40 * 32), array.get(a33_array, i))
array.set(combined_array, i + (40 * 33), array.get(a34_array, i))
array.set(combined_array, i + (40 * 34), array.get(a35_array, i))
array.set(combined_array, i + (40 * 35), array.get(a36_array, i))
array.set(combined_array, i + (40 * 36), array.get(a37_array, i))
array.set(combined_array, i + (40 * 37), array.get(a38_array, i))
array.set(combined_array, i + (40 * 38), array.get(a39_array, i))
array.set(combined_array, i + (40 * 39), array.get(a40_array, i))
Calculating Sums: A separate array_sums is created to store the total score for each asset by summing the values of their respective score arrays. This allows for easy comparison of overall performance.
Ranking Assets: The final part of the code ranks the assets based on their total scores stored in array_sums. It assigns a rank to each asset, where the asset with the highest score receives the highest rank.
// create array for asset RANK based on array.sum
var ranks = array.new_int(used_assets, 0)
// for loop that calculates the rank of each asset
if barstate.islast
for i = 0 to (used_assets - 1)
int rank = 1
for x = 0 to (used_assets - 1)
if i != x
if array.get(array_sums, i) < array.get(array_sums, x)
rank := rank + 1
array.set(ranks, i, rank)
Dynamic Table Creation
Initialization: The table is initialized with a base structure that includes headers for asset names, scores, and ranks. The headers are set to remain constant, ensuring clarity for users as they interpret the displayed data.
Data Population: As scores are calculated for each asset, the corresponding values are dynamically inserted into the table. This is achieved through a loop that iterates over the scores and ranks stored in the combined_array and array_sums, respectively.
Automatic Extending Mechanism
Variable Asset Count: The code checks the number of assets defined by the user. Instead of hardcoding the number of rows in the table, it uses a variable to determine the extent of the data that needs to be displayed. This allows the table to expand or contract based on the number of assets being analyzed.
Dynamic Row Generation: Within the loop that populates the table, the code appends new rows for each asset based on the current asset count. The structure of each row includes the asset name, its score, and its rank, ensuring that the table remains consistent regardless of how many assets are involved.
// Automatically extending table based on the number of used assets
var table table = table.new(position.bottom_center, 50, 50, color.new(color.black, 100), color.white, 3, color.white, 1)
if barstate.islast
if not hide_head
table.cell(table, 0, 0, "Universal Ratio Trend Matrix", text_color = color.white, bgcolor = #010c3b, text_size = fontSize)
table.merge_cells(table, 0, 0, used_assets + 3, 0)
if not hide_inps
table.cell(table, 0, 1,
text = "Inputs: You are using " + str.tostring(trend_indicator) + ", which takes: " + str.tostring(f_get_input(trend_indicator)),
text_color = color.white, text_size = fontSize), table.merge_cells(table, 0, 1, used_assets + 3, 1)
table.cell(table, 0, 2, "Assets", text_color = color.white, text_size = fontSize, bgcolor = #010c3b)
for x = 0 to (used_assets - 1)
table.cell(table, x + 1, 2, text = str.tostring(array.get(assets, x)), text_color = color.white, bgcolor = #010c3b, text_size = fontSize)
table.cell(table, 0, x + 3, text = str.tostring(array.get(assets, x)), text_color = color.white, bgcolor = f_asset_col(array.get(ranks, x)), text_size = fontSize)
for r = 0 to (used_assets - 1)
for c = 0 to (used_assets - 1)
table.cell(table, c + 1, r + 3, text = str.tostring(array.get(combined_array, c + (r * 40))),
text_color = hl_type == "Text" ? f_get_col(array.get(combined_array, c + (r * 40))) : color.white, text_size = fontSize,
bgcolor = hl_type == "Background" ? f_get_col(array.get(combined_array, c + (r * 40))) : na)
for x = 0 to (used_assets - 1)
table.cell(table, x + 1, x + 3, "", bgcolor = #010c3b)
table.cell(table, used_assets + 1, 2, "", bgcolor = #010c3b)
for x = 0 to (used_assets - 1)
table.cell(table, used_assets + 1, x + 3, "==>", text_color = color.white)
table.cell(table, used_assets + 2, 2, "SUM", text_color = color.white, text_size = fontSize, bgcolor = #010c3b)
table.cell(table, used_assets + 3, 2, "RANK", text_color = color.white, text_size = fontSize, bgcolor = #010c3b)
for x = 0 to (used_assets - 1)
table.cell(table, used_assets + 2, x + 3,
text = str.tostring(array.get(array_sums, x)),
text_color = color.white, text_size = fontSize,
bgcolor = f_highlight_sum(array.get(array_sums, x), array.get(ranks, x)))
table.cell(table, used_assets + 3, x + 3,
text = str.tostring(array.get(ranks, x)),
text_color = color.white, text_size = fontSize,
bgcolor = f_highlight_rank(array.get(ranks, x)))

Third-order moment by TonymontanovThe "Third-order moment" indicator is designed to help traders identify asymmetries and potential turning points in a financial instrument's price distribution over a specified period. By calculating the skewness of the price distribution, this indicator provides insights into the potential future movement direction of the market.
User Parameters:
- Length: This parameter defines the number of bars (or periods) used to compute the mean and third-order moment. A longer length provides a broader historical context, which may smooth out short-term volatility.
- Source: The data input for calculations, defaulting to the closing price of each bar, although users can select alternatives like open, high, low, or any custom value to suit their analysis preferences.
Operational Algorithm:
1. Mean Calculation:
- The indicator begins by calculating the arithmetic mean of the selected data source over the specified period.
2. Third-order Moment Calculation:
- A deviation from the mean is calculated for each data point. These deviations are then cubed to capture any asymmetry in the price distribution.
- The third-order moment is determined by summing these cubed deviations over the specified length and dividing by the number of periods, providing a measure of skewness.
3. Graphical Representation:
- The indicator plots the third-order moment as a column plot. The color of the columns changes based on the sign of the moment: green for positive and red for negative, suggesting bullish and bearish skewness, respectively.
- A zero line is included to help visualize transitions between positive and negative skewness clearly.
- Additionally, the background color shifts depending on whether the third-order moment is above or below zero, further highlighting the prevailing market sentiment.
The "Third-order moment" indicator is a valuable tool for traders looking to gauge the market's skewness, helping identify potential trend continuations or reversals. By understanding the dominance of positive or negative skewness, traders can make more informed decisions.
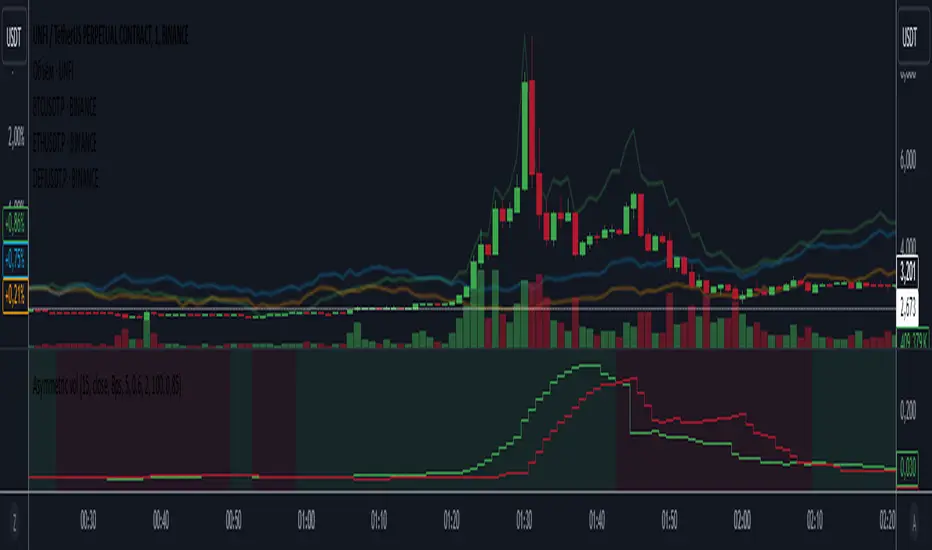
Asymmetric volatilityThe "Asymmetric Volatility" indicator is designed to visualize the differences in volatility between upward and downward price movements of a selected instrument. It operates on the principle of analyzing price movements over a specified time period, with particular focus on the symmetrical evaluation of both price rises and falls.
User Parameters:
- Length: This parameter specifies the number of bars (candles) used to calculate the average volatility. The larger the value, the longer the time period, and the smoother the volatility data will be.
- Source: This represents the input data for the indicator calculations. By default, the close value of each bar is used, but the user can choose another data source (such as open, high, low, or any custom value).
Operational Algorithm:
1. Movement Calculation:
- UpMoves: Computed as the positive difference between the current bar value and the previous bar value, if it is greater than zero.
- DownMoves: Computed as the positive difference between the previous bar value and the current bar value, if it is greater than zero.
2. Volatility Calculation:
- UpVolatility: This is the arithmetic mean of the UpMoves values over the specified period.
- DownVolatility: This is the arithmetic mean of the DownMoves values over the specified period.
3. Graphical Representation:
- The indicator displays two plots: upward and downward volatility, represented by green and red lines, respectively.
- The background color changes based on which volatility is dominant: a green background indicates that upward volatility prevails, while a red background indicates downward volatility.
The indicator allows traders to quickly assess in which direction the market is more volatile at the moment, which can be useful for making trading decisions and evaluating the current market situation.
Statistics plot1. setting the price range
At the beginning of the script, set the price range (interval). Price ranges are used to divide prices into several groups (buckets) and record how many prices have been reached within each group. For example, setting the price range to “10” will divide the price into intervals 0-10, 10-20, 20-30, and so on.
The price range can also be set manually by the user or automatically calculated based on the initial price. This allows for flexibility in adjusting price ranges for different assets and different time frames.
2. aggregate the number of times a price is reached
Record how many times the price reached each price range (e.g., 100-110, 110-120, etc.). This aggregate data is stored in a data structure called an array.
Each element of the array corresponds to a price range, and when a price reaches that range, the corresponding array value is incremented by one. This process is performed in real time, tracking price movements.
3. initializing and extending price ranges
The first bar of the script (when the chart is first loaded) divides the price ranges into several groups and initializes a count of 0 for each range.
When a price reaches a new range, the array is expanded as needed to add the new price range. This allows the script to work with any price movement, even if the price range continues to grow.
4. visualize the number of price arrivals with a histogram
The aggregated number of arrivals per price range is visually displayed in the form of a histogram. This histogram is designed to allow the user to see at a glance which price range is being reached most frequently.
For example, if prices frequently reach the 100-110 range, the histogram bar corresponding to that range will appear higher than the other ranges. This allows you to visually identify price “dwell points” or support and resistance levels.
5. display of moving averages
A moving average (MA) of the number of times a price has been reached is drawn above the histogram. Moving averages are indicators that show a smooth trend for the number of price arrivals and are useful for understanding the overall direction of price movements.
The duration of the moving average (how many data points it is calculated based on) can be set by the user. This allows for flexible analysis of short or long term price trends. 6.
6. price range tracking and labeling
The script keeps track of which price range the current price is located in. Based on this, information related to the current price range is displayed on the chart as labels.
In particular, labels indicate the beginning and end points of the price range, including which range the price was in at the beginning and which range the price reached at the end. These labels are a useful feature to visually identify price ranges on the chart.
7. labeling of current price range
To confirm which price range the current price is in, when a price reaches a specific price range, a label corresponding to that price range is displayed. This label indicates the position of the price in real-time, allowing traders to visually track where the current price is in the area.
8. calculating the start and end points of the range
The script calculates the start and end points of a range with a non-zero number of price arrivals to find the minimum and maximum of the range. This calculation allows you to see where prices are concentrated within a range.
9. out-of-range price processing
When a price reaches outside the range, the script automatically adds the array element corresponding to that price range and inserts the data in the appropriate location for the count. This allows the script to follow the price as it moves unexpectedly.

Volume CalendarDescription:
The indicator displays a calendar with Volume data for up to 6 last months. It is designed to work on any timeframe, but works best on Daily and below. It is also consistent in that it displays the same data even if you go to lower timeframes like 5 minutes (even though the data is used is Daily).
Features:
- displays volume data for last N months (volume, volume change, % of weekly, monthly and yearly volume)
- display total volume for each month
- display monthly sentiment
- find dates with volume spikes
Inputs:
- Number of months -> how many last months of data to display (from 1 to 6)
- Volume Type -> display only Bullish, only Bearish or all volume
- Cell color is based on -> Volume - the brighter the cell the higher volume was on that day; Volume Change - the brighter the cell the higher was the volume change that day; Volume Spike - the brighter the cell the higher was volume spike that day (volume spike is based on volume being above its average over last N candles)
- Cell color timeframe -> Weekly - the cell color is calculated comparing volume of that cell with weekly volume; Monthly - comparing volume with monthly volume
- Use volume for sentiment -> take the volume into account when calculating monthly sentiment (otherwise calculate it based on number of Bullish and Bearish days in the month)
- Spike Average Period -> period of the moving average used for spike calculation
- Spike Threshold -> current volume must be this many times greater than the average for it to be considered a spike
- Table Size -> size of the table
- Theme -> colouring of the table

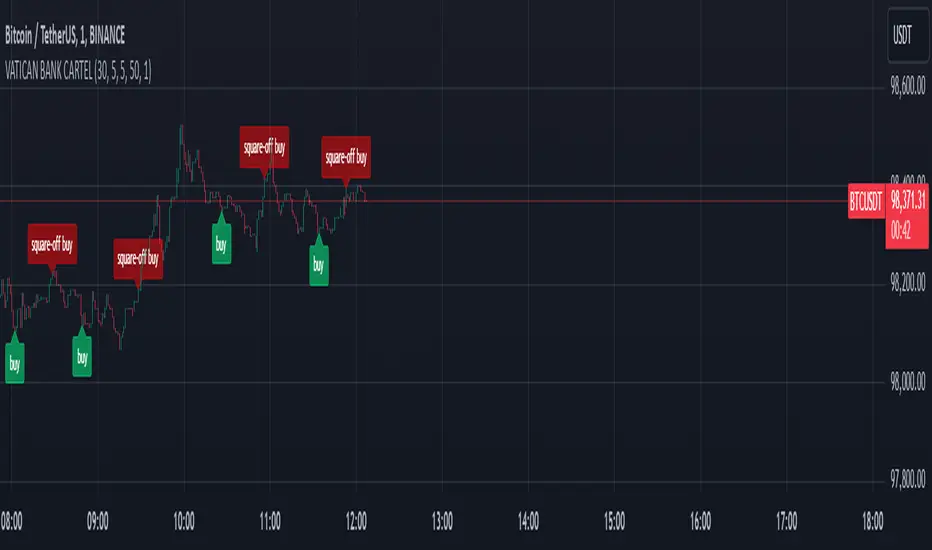
VATICAN BANK CARTELVATICAN BANK CARTEL - Precision Signal Detection for Buyers.
The VATICAN BANK CARTEL indicator is a highly sophisticated tool designed specifically for buyers, helping them identify key market trends and generate actionable buy signals. Utilizing advanced algorithms, this indicator employs a multi-variable detection mechanism that dynamically adapts to price movements, offering real-time insights to assist in executing profitable buy trades. This indicator is optimized solely for identifying buying opportunities, ensuring that traders are equipped to make well-timed entries and exits, without signals for shorting or selling.
The recommended settings for VATICAN BANK CARTEL indicator is as follows:-
Depth Engine = 20,30,40,50,100.
Deviation Engine = 3,5,7,15,20.
Backstep Engine = 15,17,20,25.
NOTE:- But you can also use this indicator as per your setting, whichever setting gives you best results use that setting.
Key Features:
1.Adaptive Depth, Deviation, and Backstep Inputs:
The core of this indicator is its customizable Depth Engine, Deviation Engine, and Backstep Engine parameters. These inputs allow traders to adjust the sensitivity of the trend detection algorithm based on specific market conditions:
Depth: Defines how deep the indicator scans historical price data for potential trend reversals.
Deviation: Determines the minimum required price fluctuation to confirm a market movement.
Backstep: Sets the retracement level to filter false signals and maintain the accuracy of trend detection.
2. Visual Signal Representation:
The VATICAN BANK CARTEL plots highly visible labels on the chart to mark trend reversals. These labels are customizable in terms of size and transparency, ensuring clarity in various chart environments. Traders can quickly spot buying opportunities with green labels and potential square-off points with red labels, focusing exclusively on buy-side signals.
3.Real-Time Alerts:
The indicator is equipped with real-time alert conditions to notify traders of significant buy or square-off buy signals. These alerts, which are triggered based on the indicator’s internal signal logic, ensure that traders never miss a critical market movement on the buy side.
4.Custom Label Size and Transparency:
To enhance visual flexibility, the indicator allows the user to adjust label size (from small to large) and transparency levels. This feature provides a clean, adaptable view suited for different charting styles and timeframes.
How It Works:
The VATICAN BANK CARTEL analyzes the price action using a sophisticated algorithm that considers historical low and high points, dynamically detecting directional changes. When a change in market direction is detected, the indicator plots a label at the key reversal points, helping traders confirm potential entry points:
- Buy Signal (Green): Indicates potential buying opportunities based on a trend reversal.
- Square-Off Buy Signal (Red): Marks the exit point for open buy positions, allowing traders to take profits or protect capital from potential market reversals.
Note: This indicator is exclusively designed to provide signals for buyers. It does not generate sell or short signals, making it ideal for traders focused solely on identifying optimal buying opportunities in the market.
Customizable Parameters:
- Depth Engine: Fine-tunes the historical data analysis for signal generation.
- Deviation Engine: Adjusts the minimum price change required for detecting trends.
- Backstep Engine: Controls the indicator's sensitivity to retracements, minimizing false signals.
- Labels Transparency: Adjusts the opacity of the labels, ensuring they integrate seamlessly into any chart layout.
- Buy and Sell Colors: Customizable color options for buy and square-off buy labels to match your preferred color scheme.
- Label Size: Select between five different label sizes for optimal chart visibility.
Ideal For:
This indicator is ideal for both beginner and experienced traders looking to enhance their buying strategy with a highly reliable, visual, and alert-driven tool. The VATICAN BANK CARTEL adapts to various timeframes, making it suitable for day traders, swing traders, and long-term investors alike—focused exclusively on buying opportunities.
Benefits and Applications:
1.Intraday Trading: The VATICAN BANK CARTEL indicator is particularly well-suited for intraday trading, as it provides accurate and timely "buy" and "square-off buy" signals based on the current market dynamics.
2.Trend-following Strategies: Traders who employ trend-following strategies can leverage the indicator's ability to identify the overall market direction, allowing them to align their trades with the dominant trend.
3.Swing Trading: The dynamic price tracking and signal generation capabilities of the indicator can be beneficial for swing traders, who aim to capture medium-term price movements.
Security Measures:
1. The code includes a security notice at the beginning, indicating that it is subject to the Mozilla Public License 2.0, which is a reputable open-source license.
2. The code does not appear to contain any obvious security vulnerabilities or malicious content that could compromise user data or accounts.
NOTE:- This indicator is provided under the Mozilla Public License 2.0 and is subject to its terms and conditions.
Disclaimer: The usage of VATICAN BANK CARTEL indicator might or might not contribute to your trading capital(money) profits and losses and the author is not responsible for the same.
IMPORTANT NOTICE:
While the indicator aims to provide reliable "buy" and "square-off buy" signals, it is crucial to understand that the market can be influenced by unpredictable events, such as natural disasters, political unrest, changes in monetary policies, or economic crises. These unforeseen situations may occasionally lead to false signals generated by the VATICAN BANK CARTEL indicator.
Users should exercise caution and diligence when relying on the indicator's signals, as the market's behavior can be unpredictable, and external factors may impact the accuracy of the signals. It is recommended to thoroughly backtest the indicator's performance in various market conditions and to use it as one of the many tools in a comprehensive trading strategy, rather than solely relying on its output.
Ultimately, the success of the VATICAN BANK CARTEL indicator will depend on the user's ability to adapt it to their specific trading style, market conditions, and risk management approach. Continuous monitoring, analysis, and adjustment of the indicator's settings may be necessary to maintain its effectiveness in the ever-evolving financial markets.
DEVELOPER:- yashgode9
PineScript:- version:- 5
This indicator aims to enhance trading decision-making by combining DEPTH, DEVIATION, BACKSTEP with custom signal generation, offering a comprehensive tool for traders seeking clear "buy" and "square-off buy" signals on the TradingView platform.
Adaptive Gaussian MA For Loop [BackQuant]Adaptive Gaussian MA For Loop
PLEASE Read the following carefully before applying this indicator to your trading system. Knowing the core logic behind the tools you're using allows you to integrate them into your strategy with confidence and precision.
Introducing BackQuant's Adaptive Gaussian Moving Average For Loop (AGMA FL) — a sophisticated trading indicator that merges the Gaussian Moving Average (GMA) with adaptive volatility to provide dynamic trend analysis. This unique indicator further enhances its effectiveness by utilizing a for-loop scoring mechanism to detect potential shifts in market direction. Let's dive into the components, the rationale behind them, and how this indicator can be practically applied to your trading strategies.
Understanding the Gaussian Moving Average (GMA)
The Gaussian Moving Average (GMA) is a smoothed moving average that applies Gaussian weighting to price data. Gaussian weighting gives more significance to data points near the center of the lookback window, making the GMA particularly effective at reducing noise while maintaining sensitivity to changes in price direction. In contrast to simpler moving averages like the SMA or EMA, GMA provides a more refined smoothing function, which can help traders follow the true trend in volatile markets.
In this script, the GMA is calculated over a defined Calculation Period (default 14), applying a Gaussian filter to smooth out market fluctuations and provide a clearer view of underlying trends.
Adaptive Volatility: A Dynamic Edge
The Adaptive feature in this indicator gives it the ability to adjust its sensitivity based on current market volatility. If the Adaptive option is enabled, the GMA uses a standard deviation-based volatility measure (with a default period of 20) to dynamically adjust the width of the Gaussian filter, allowing the GMA to react faster in volatile markets and more slowly in calm conditions. This dynamic nature ensures that the GMA stays relevant across different market environments.
When the Adaptive setting is disabled, the script defaults to a constant standard deviation value (default 1.0), providing a more stable but less responsive smoothing function.
Why Use Adaptive Gaussian Moving Average?
The Gaussian Moving Average already provides smoother results than standard moving averages, but by adding an adaptive component, the indicator becomes even more responsive to real-time price changes. In fast-moving or highly volatile markets, this adaptation allows traders to react quicker to emerging trends. Conversely, in quieter markets, it reduces over-sensitivity to minor fluctuations, thus lowering the risk of false signals.
For-Loop Scoring Mechanism
The heart of this indicator lies in its for-loop scoring system, which evaluates the smoothed price data (the GMA) over a specified range, comparing it to previous values. This scoring system assigns a numerical value based on whether the current GMA is higher or lower than previous values, creating a trend score.
Long Signals: These are generated when the for-loop score surpasses the Long Threshold (default set at 40), signaling that the GMA is gaining upward momentum, potentially identifying a favorable buying opportunity.
Short Signals: These are triggered when the score crosses below the Short Threshold (default set at -10), indicating that the market may be losing strength and that a selling or shorting opportunity could be emerging.
Thresholds & Customization Options
This indicator offers a high degree of flexibility, allowing you to fine-tune the settings according to your trading style and risk preferences:
Calculation Period: Adjust the lookback period for the Gaussian filter, affecting how smooth or responsive the indicator is to price changes.
Adaptive Mode: Toggle the adaptive feature on or off, allowing the GMA to dynamically adjust based on market volatility or remain consistent with a fixed standard deviation.
Volatility Settings: Control the standard deviation period for adaptive mode, fine-tuning how quickly the GMA responds to shifts in volatility.
For-Loop Settings: Modify the start and end points for the for-loop score calculation, adjusting the depth of analysis for trend signals.
Thresholds for Signals: Set custom long and short thresholds to determine when buy or sell signals should be generated.
Visualization Options: Choose to color bars based on trend direction, plot signal lines, or adjust the background color to reflect current market sentiment visually.
Trading Applications
The Adaptive Gaussian MA For Loop can be applied to a variety of trading styles and markets. Here are some key ways you can use this indicator in practice:
Trend Following: The combination of Gaussian smoothing and adaptive volatility helps traders stay on top of market trends, identifying significant momentum shifts while filtering out noise. The for-loop scoring system enhances this by providing a numerical representation of trend strength, making it easier to spot when a new trend is emerging or when an existing one is gaining strength.
Mean Reversion: For traders looking to capitalize on short-term market corrections, the adaptive nature of this indicator makes it easier to identify when price action is deviating too far from its smoothed trend, allowing for strategic entries and exits based on overbought or oversold conditions.
Swing Trading: With its ability to capture medium-term price movements while avoiding the noise of short-term fluctuations, this indicator is well-suited for swing traders who aim to profit from market reversals or short-to-mid-term trends.
Volatility Management: The adaptive feature allows the indicator to adjust dynamically in volatile markets, ensuring that it remains responsive in times of increased uncertainty while avoiding unnecessary noise in calmer periods. This makes it an effective tool for traders who want to manage risk by staying in tune with changing market conditions.
Final Thoughts
The Adaptive Gaussian MA For Loop is a powerful and flexible indicator that merges the elegance of Gaussian smoothing with the adaptability of volatility-based adjustments. By incorporating a for-loop scoring mechanism, this indicator provides traders with a comprehensive view of market trends and potential trade opportunities.
It’s important to test the settings on historical data and adapt them to your specific trading style, timeframe, and market conditions. As with any technical tool, the AGMA For Loop should be used in conjunction with other indicators and solid risk management practices for the best results.
Thus following all of the key points here are some sample backtests on the 1D Chart
Disclaimer: Backtests are based off past results, and are not indicative of the future.
INDEX:BTCUSD
INDEX:ETHUSD
BINANCE:SOLUSD

Two Pole Butterworth For Loop [BackQuant]Two Pole Butterworth For Loop
PLEASE read the following carefully, as understanding the underlying concepts and logic behind the indicator is key to incorporating it into your trading system in a sound and methodical manner.
Introducing BackQuant's Two Pole Butterworth For Loop (2P BW FL) — an advanced indicator that fuses the power of the Two Pole Butterworth filter with a dynamic for-loop scoring mechanism. This unique approach is designed to extract actionable trading signals by smoothing out price data and then analyzing it using a comparative scoring method. Let's delve into how this indicator works, why it was created, and how it can be used in various trading scenarios.
Understanding the Two Pole Butterworth Filter
The Butterworth filter is a signal processing tool known for its smooth response and minimal distortion. It's often used in electronic and communication systems to filter out unwanted noise. In trading, the Butterworth filter can be applied to price data to smooth out the volatility, providing traders with a clearer view of underlying trends without the whipsaws often associated with market noise.
The Two Pole Butterworth variant further enhances this effect by applying the filter with two poles, effectively creating a sharper transition between the passband and stopband. In simple terms, this allows the filter to follow the price action more closely, reacting to changes while maintaining smoothness.
In this script, the Two Pole Butterworth filter is applied to the Calculation Source (default is set to the closing price), creating a smoothed price series that serves as the foundation for further analysis.
Why Use a Two Pole Butterworth Filter?
The Two Pole Butterworth filter is chosen for its ability to reduce lag while maintaining a smooth output. This makes it an ideal choice for traders who want to capture trends without being misled by short-term volatility or market noise. By filtering the price data, the Two Pole Butterworth enables traders to focus on the broader market movements and avoid false signals.
The For-Loop Scoring Mechanism
In addition to the Butterworth filter, this script uses a for-loop scoring system to evaluate the smoothed price data. The for-loop compares the current value of the filtered price (referred to as "subject") to previous values over a defined range (set by the start and end input). The score is calculated based on whether the subject is higher or lower than the previous points, and the cumulative score is used to determine the strength of the trend.
Long and Short Signal Logic
Long Signals: A long signal is triggered when the score surpasses the Long Threshold (default set at 40). This suggests that the price has built sufficient upward momentum, indicating a potential buying opportunity.
Short Signals: A short signal is triggered when the score crosses under the Short Threshold (default set at -10). This indicates weakening price action or a potential downtrend, signaling a possible selling or shorting opportunity.
By utilizing this scoring system, the indicator identifies moments when the price momentum is shifting, helping traders enter positions at opportune times.
Customization and Visualization Options
One of the strengths of this indicator is its flexibility. Traders can customize various settings to fit their personal trading style or adapt it to different markets and timeframes:
Calculation Periods: Adjust the lookback period for the Butterworth filter, allowing for shorter or longer smoothing depending on the desired sensitivity.
Threshold Levels: Set the long and short thresholds to define when signals should be triggered, giving you control over the balance between sensitivity and specificity.
Signal Line Width and Colors: Customize the visual presentation of the indicator on the chart, including the width of the signal line and the colors used for long and short conditions.
Candlestick and Background Colors: If desired, the indicator can color the candlesticks or the background according to the detected trend, offering additional clarity at a glance.
Trading Applications
This Two Pole Butterworth For Loop indicator is versatile and can be adapted to various market conditions and trading strategies. Here are a few use cases where this indicator shines:
Trend Following: The Butterworth filter smooths the price data, making it easier to follow trends and identify when they are gaining or losing strength. The for-loop scoring system enhances this by providing a clear indication of how strong the current trend is compared to recent history.
Mean Reversion: For traders looking to identify potential reversals, the indicator’s ability to compare the filtered price to previous values over a range of periods allows it to spot moments when the trend may be losing steam, potentially signaling a reversal.
Swing Trading: The combination of smoothing and scoring allows swing traders to capture short to medium-term price movements by filtering out the noise and focusing on significant shifts in momentum.
Risk Management: By providing clear long and short signals, this indicator helps traders manage their risk by offering well-defined entry and exit points. The smooth nature of the Butterworth filter also reduces the risk of getting caught in false signals due to market noise.
Final Thoughts
The Two Pole Butterworth For Loop indicator offers traders a powerful combination of smoothing and scoring to detect meaningful trends and shifts in price momentum. Whether you are a trend follower, swing trader, or someone looking to refine your entry and exit points, this indicator provides the tools to make more informed trading decisions.
As always, it's essential to backtest the indicator on historical data and tailor the settings to your specific trading style and market. While the Butterworth filter helps reduce noise and smooth trends, no indicator can predict the future with absolute certainty, so it should be used in conjunction with other tools and sound risk management practices.
Thus following all of the key points here are some sample backtests on the 1D Chart
Disclaimer: Backtests are based off past results, and are not indicative of the future.
INDEX:BTCUSD
INDEX:ETHUSD
BINANCE:SOLUSD

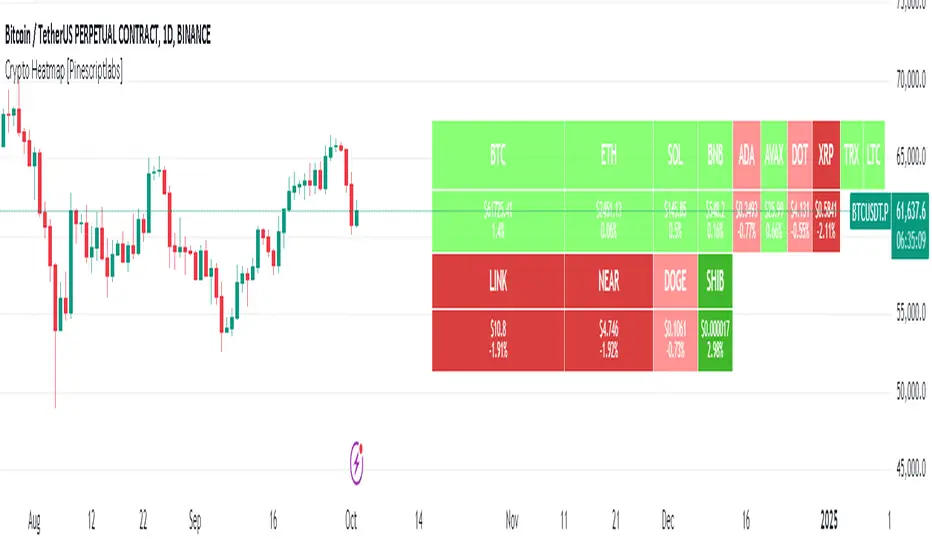
Crypto Heatmap [Pinescriptlabs]🌟 Crypto Heatmap is a visual tool that enables quick and efficient visualization of price behavior and percentage changes of various cryptocurrencies.
📊 It generates a heatmap to show variations in daily closing prices, helping traders quickly identify assets with the most movement.
📈 Percentage Change Calculation: It calculates the difference between the current price and the previous day's price, updating with each ticker.
✨ It uses a dynamic approach that adjusts colors based on market movements, making it easier to detect trading opportunities.
👀 You will notice for a moment that some cells disappear; this is because the table updates with each ticker to show real-time changes.
Español:
🌟 Crypto Heatmap es una herramienta visual que permite una rápida y eficiente visualización del comportamiento de precios y cambios porcentuales de varias criptomonedas.
📊 Genera un mapa de calor para mostrar las variaciones en los precios de cierre diario, ayudando a los traders a identificar rápidamente los activos con mayor movimiento.
📈 Cálculo del cambio porcentual: Calcula la diferencia entre el precio actual y el del día anterior, actualizándose en cada ticker.
✨ Utiliza un enfoque dinámico que ajusta los colores según los movimientos del mercado, facilitando la detección de oportunidades de trading.
Aquí tienes la traducción al español:
👀 **Observarás por un momento que algunas celdas desaparecen; esto es porque la tabla se actualiza en cada ticker para mostrar el cambio en tiempo real.**
2024 - Seasonality - Open to CloseScript Description:
This Pine Script is designed to visualise **seasonality** in the financial markets by calculating the **open-to-close percentage change** for each month of a selected asset. It creates a **heatmap** table to display the monthly performance over multiple years. The script provides detailed statistical summaries, including:
- **Average monthly percentage changes**
- **Standard deviation** of the changes
- **Percentage of months with positive returns**
The script also allows users to adjust colour intensities for positive and negative values, specify which year to start from, and skip specific months. Key metrics such as averages, standard deviations, and percentages of positive months can be toggled on or off based on user preferences. The result is a clear, visual representation of how an asset typically performs month by month, aiding in seasonality analysis.
Every $5 (3 Up, 3 Down) GOLD onlyDescription :
This indicator plots customizable horizontal lines spaced every $5 on the XAUUSD chart, with exactly 3 lines above and 3 lines below the nearest $5 level from the current price.
Key Features :
Line Spacing: The lines are plotted at $5 intervals starting from the nearest whole $5 price below the current price (e.g., $1900, $1905, etc.).
Customizable Line Color : Users can select the color of the lines via the indicator settings, making it adaptable to different chart themes and styles.
Customizable Line Style : The indicator allows you to choose from the following line styles:
Solid : Continuous line.
Dashed: Dashed line for a more discrete visual.
Dotted: Dotted line for minimalistic visibility.
Visibility Control : The indicator limits the number of lines to 3 above and 3 below the current price, keeping the chart clean and uncluttered while providing key levels of interest.
Use Cases :
Support and Resistance Identification: Easily spot key psychological levels in $5 increments, useful for identifying potential support or resistance zones in XAUUSD trading.
Price Action Monitoring : Traders can visually track how XAUUSD interacts with specific price levels spaced by $5 increments.
Customization Options :
Color Selection: Modify the line color to match your chart theme or highlight important levels.
Line Style: Select between solid, dashed, or dotted lines to customize the look of your chart.
This indicator is ideal for XAUUSD traders looking for clear, customizable visual levels on their charts to aid in decision-making, whether you're tracking price action or setting targets for entry and exit.

Forex - Lot size calculatorThis indicator is specifically designed for Forex traders who need a convenient lot size calculator directly on their charts. It allows users to input their account balance, risk percentage, and stop-loss distance in pips to easily determine the appropriate lot size for a given trade, ensuring effective risk management.
Key Features:
Lot Size Calculation: Automatically calculates the lot size based on user-defined inputs: account balance, risk percentage, and stop-loss distance.
Error Handling: The indicator only works with Forex pairs. If applied to non-Forex assets, a clear and prominent red error message will appear in the bottom-right corner of the chart, reminding the user that this script is intended exclusively for Forex trading.
Simple Visualization: The calculated lot size is displayed in an easy-to-read table directly on the chart.
How to Use:
Add the indicator to a Forex chart.
Enter your account balance, risk percentage, and stop-loss pips in the input fields.
The indicator will display the calculated lot size for the chosen Forex pair.
Important Notes:
This script is intended only for Forex assets. If used on other instruments (e.g., stocks, crypto, indices), an error message will be shown.
Always validate lot sizes with your broker, as there can be slight variations depending on broker specifications and leverage settings.

Indicator Test with Conditions TableOverview: The "Indicator Test with Conditions Table" is a customizable trading strategy developed using Pine Script™ for the TradingView platform. It allows users to define complex entry conditions for both long and short positions based on various technical indicators and price levels.
Key Features:
Customizable Input Conditions:
Users can configure up to three input conditions for both long and short entries, each with its own logical operator (AND/OR) for combining conditions.
Input conditions can be based on:
Price Sources: Users can select any price data (e.g., close, open, high, low) for each condition.
Comparison Operators: Users can choose from a variety of operators, including:
Greater than (>)
Greater than or equal to (>=)
Less than (<)
Less than or equal to (<=)
Equal to (=)
Not equal to (!=)
Crossover (crossover)
Crossunder (crossunder)
Logical Operators:
The strategy provides options for combining conditions using logical operators (AND/OR) for greater flexibility in defining entry criteria.
Dynamic Condition Evaluation:
The strategy evaluates the defined conditions dynamically, checking whether they are enabled before proceeding with the comparison.
Users can toggle conditions on and off using boolean inputs, allowing for quick adjustments without modifying the code.
Visual Feedback:
A table is displayed on the chart, providing real-time status updates on the conditions and whether they are enabled. This enhances user experience by allowing easy monitoring of the strategy's logic.
Order Execution:
The strategy enters long or short positions based on the combined conditions' evaluations, automatically executing trades when the criteria are met.
How to Use:
Set Up Input Conditions:
Navigate to the strategy’s input settings to configure your desired price sources, operators, and logical combinations for long and short conditions.
Monitor Conditions:
Observe the condition table displayed at the bottom right of the chart to see which conditions are enabled and their current evaluations.
Adjust Strategy Parameters:
Modify the conditions, logical operators, and input sources as needed to optimize the strategy for different market scenarios or trading styles.
Execution:
Once the conditions are met, the strategy will automatically enter trades based on the defined logic.
Conclusion: The "Indicator Test with Conditions Table" strategy is a robust tool for traders looking to implement customized trading logic based on various market conditions. Its flexibility and real-time monitoring capabilities make it suitable for both novice and experienced traders.

GBP Index vs CAD Index Currency OscillatorGBP vs CAD Currency Oscillator
This custom oscillator compares the relative strength of GBP (British Pound) and CAD (Canadian Dollar) against a basket of other currencies to determine potential overbought and oversold conditions. The indicator is designed to help traders evaluate momentum shifts and identify possible trend reversals between these two currencies, not just the GBPCAD pair.
How it Works:
Currency Index Calculation:
The oscillator calculates the average percentage change in 7 key GBP pairs (GBPUSD, EURGBP, GBPJPY, GBPAUD, GBPNZD, GBPCAD, and GBPCHF).
Similarly, it calculates the average percentage change for 7 key CAD pairs (USDCAD, EURCAD, CADJPY, AUDCAD, NZDCAD, GBPCAD, and CADCHF).
Stochastic Oscillator:
The indicator calculates a 0-100 oscillator for both the GBP and CAD currency indices based on the highest high and lowest low over a user-defined lookback period (default is 14 anlthough 60 works great on 1m chart).
The oscillator is smoothed using a simple moving average (default smoothing period is 3) to reduce noise and improve visual clarity.
Overbought/Oversold Conditions:
Overbought: When both the GBP and CAD oscillators exceed 80, the background turns red, indicating potential overbought conditions.
Oversold: When both oscillators fall below 20, the background turns green, signaling possible oversold conditions.
Crossovers:
When the GBP oscillator crosses above the CAD oscillator, a green dot appears at the bottom of the chart, signaling potential GBP strength.
When the GBP oscillator crosses below the CAD oscillator, a red dot appears, signaling potential CAD strength.
How to Use:
Overbought/Oversold Conditions: Use the red and green background highlights to spot potential overbought or oversold market conditions, helping you identify possible turning points.
Customization Options:
Lookback Period: You can adjust the lookback period for the stochastic calculation, allowing for sensitivity tuning (default: 14).
Smoothing Period: Control the degree of smoothing applied to the oscillators (default: 3).
This oscillator is ideal for traders focused on trading GBP and CAD pairs, offering a comparative analysis that can assist in better decision-making based on relative currency strength.
analytics_tablesLibrary "analytics_tables"
📝 Description
This library provides the implementation of several performance-related statistics and metrics, presented in the form of tables.
The metrics shown in the afforementioned tables where developed during the past years of my in-depth analalysis of various strategies in an atempt to reason about the performance of each strategy.
The visualization and some statistics where inspired by the existing implementations of the "Seasonality" script, and the performance matrix implementations of @QuantNomad and @ZenAndTheArtOfTrading scripts.
While this library is meant to be used by my strategy framework "Template Trailing Strategy (Backtester)" script, I wrapped it in a library hoping this can be usefull for other community strategy scripts that will be released in the future.
🤔 How to Guide
To use the functionality this library provides in your script you have to import it first!
Copy the import statement of the latest release by pressing the copy button below and then paste it into your script. Give a short name to this library so you can refer to it later on. The import statement should look like this:
import jason5480/analytics_tables/1 as ant
There are three types of tables provided by this library in the initial release. The stats table the metrics table and the seasonality table.
Each one shows different kinds of performance statistics.
The table UDT shall be initialized once using the `init()` method.
They can be updated using the `update()` method where the updated data UDT object shall be passed.
The data UDT can also initialized and get updated on demend depending on the use case
A code example for the StatsTable is the following:
var ant.StatsData statsData = ant.StatsData.new()
statsData.update(SideStats.new(), SideStats.new(), 0)
if (barstate.islastconfirmedhistory or (barstate.isrealtime and barstate.isconfirmed))
var statsTable = ant.StatsTable.new().init(ant.getTablePos('TOP', 'RIGHT'))
statsTable.update(statsData)
A code example for the MetricsTable is the following:
var ant.StatsData statsData = ant.StatsData.new()
statsData.update(ant.SideStats.new(), ant.SideStats.new(), 0)
if (barstate.islastconfirmedhistory or (barstate.isrealtime and barstate.isconfirmed))
var metricsTable = ant.MetricsTable.new().init(ant.getTablePos('BOTTOM', 'RIGHT'))
metricsTable.update(statsData, 10)
A code example for the SeasonalityTable is the following:
var ant.SeasonalData seasonalData = ant.SeasonalData.new().init(Seasonality.monthOfYear)
seasonalData.update()
if (barstate.islastconfirmedhistory or (barstate.isrealtime and barstate.isconfirmed))
var seasonalTable = ant.SeasonalTable.new().init(seasonalData, ant.getTablePos('BOTTOM', 'LEFT'))
seasonalTable.update(seasonalData)
🏋️♂️ Please refer to the "EXAMPLE" regions of the script for more advanced and up to date code examples!
Special thanks to @Mrcrbw for the proposal to develop this library and @DCNeu for the constructive feedback 🏆.
getTablePos(ypos, xpos)
Get table position compatible string
Parameters:
ypos (simple string) : The position on y axise
xpos (simple string) : The position on x axise
Returns: The position to be passed to the table
method init(this, pos, height, width, positiveTxtColor, negativeTxtColor, neutralTxtColor, positiveBgColor, negativeBgColor, neutralBgColor)
Initialize the stats table object with the given colors in the given position
Namespace types: StatsTable
Parameters:
this (StatsTable) : The stats table object
pos (simple string) : The table position string
height (simple float) : The height of the table as a percentage of the charts height. By default, 0 auto-adjusts the height based on the text inside the cells
width (simple float) : The width of the table as a percentage of the charts height. By default, 0 auto-adjusts the width based on the text inside the cells
positiveTxtColor (simple color) : The text color when positive
negativeTxtColor (simple color) : The text color when negative
neutralTxtColor (simple color) : The text color when neutral
positiveBgColor (simple color) : The background color with transparency when positive
negativeBgColor (simple color) : The background color with transparency when negative
neutralBgColor (simple color) : The background color with transparency when neutral
method init(this, pos, height, width, neutralBgColor)
Initialize the metrics table object with the given colors in the given position
Namespace types: MetricsTable
Parameters:
this (MetricsTable) : The metrics table object
pos (simple string) : The table position string
height (simple float) : The height of the table as a percentage of the charts height. By default, 0 auto-adjusts the height based on the text inside the cells
width (simple float) : The width of the table as a percentage of the charts width. By default, 0 auto-adjusts the width based on the text inside the cells
neutralBgColor (simple color) : The background color with transparency when neutral
method init(this, seas)
Initialize the seasonal data
Namespace types: SeasonalData
Parameters:
this (SeasonalData) : The seasonal data object
seas (simple Seasonality) : The seasonality of the matrix data
method init(this, data, pos, maxNumOfYears, height, width, extended, neutralTxtColor, neutralBgColor)
Initialize the seasonal table object with the given colors in the given position
Namespace types: SeasonalTable
Parameters:
this (SeasonalTable) : The seasonal table object
data (SeasonalData) : The seasonality data of the table
pos (simple string) : The table position string
maxNumOfYears (simple int) : The maximum number of years that fit into the table
height (simple float) : The height of the table as a percentage of the charts height. By default, 0 auto-adjusts the height based on the text inside the cells
width (simple float) : The width of the table as a percentage of the charts width. By default, 0 auto-adjusts the width based on the text inside the cells
extended (simple bool) : The seasonal table with extended columns for performance
neutralTxtColor (simple color) : The text color when neutral
neutralBgColor (simple color) : The background color with transparency when neutral
method update(this, wins, losses, numOfInconclusiveExits)
Update the strategy info data of the strategy
Namespace types: StatsData
Parameters:
this (StatsData) : The strategy statistics object
wins (SideStats)
losses (SideStats)
numOfInconclusiveExits (int) : The number of inconclusive trades
method update(this, stats, positiveTxtColor, negativeTxtColor, negativeBgColor, neutralBgColor)
Update the stats table object with the given data
Namespace types: StatsTable
Parameters:
this (StatsTable) : The stats table object
stats (StatsData) : The stats data to update the table
positiveTxtColor (simple color) : The text color when positive
negativeTxtColor (simple color) : The text color when negative
negativeBgColor (simple color) : The background color with transparency when negative
neutralBgColor (simple color) : The background color with transparency when neutral
method update(this, stats, buyAndHoldPerc, positiveTxtColor, negativeTxtColor, positiveBgColor, negativeBgColor)
Update the metrics table object with the given data
Namespace types: MetricsTable
Parameters:
this (MetricsTable) : The metrics table object
stats (StatsData) : The stats data to update the table
buyAndHoldPerc (float) : The buy and hold percetage
positiveTxtColor (simple color) : The text color when positive
negativeTxtColor (simple color) : The text color when negative
positiveBgColor (simple color) : The background color with transparency when positive
negativeBgColor (simple color) : The background color with transparency when negative
method update(this)
Update the seasonal data based on the season and eon timeframe
Namespace types: SeasonalData
Parameters:
this (SeasonalData) : The seasonal data object
method update(this, data, positiveTxtColor, negativeTxtColor, neutralTxtColor, positiveBgColor, negativeBgColor, neutralBgColor, timeBgColor)
Update the seasonal table object with the given data
Namespace types: SeasonalTable
Parameters:
this (SeasonalTable) : The seasonal table object
data (SeasonalData) : The seasonal cell data to update the table
positiveTxtColor (simple color) : The text color when positive
negativeTxtColor (simple color) : The text color when negative
neutralTxtColor (simple color) : The text color when neutral
positiveBgColor (simple color) : The background color with transparency when positive
negativeBgColor (simple color) : The background color with transparency when negative
neutralBgColor (simple color) : The background color with transparency when neutral
timeBgColor (simple color) : The background color of the time gradient
SideStats
Object that represents the strategy statistics data of one side win or lose
Fields:
numOf (series int)
sumFreeProfit (series float)
freeProfitStDev (series float)
sumProfit (series float)
profitStDev (series float)
sumGain (series float)
gainStDev (series float)
avgQuantityPerc (series float)
avgCapitalRiskPerc (series float)
avgTPExecutedCount (series float)
avgRiskRewardRatio (series float)
maxStreak (series int)
StatsTable
Object that represents the stats table
Fields:
table (series table) : The actual table
rows (series int) : The number of rows of the table
columns (series int) : The number of columns of the table
StatsData
Object that represents the statistics data of the strategy
Fields:
wins (SideStats)
losses (SideStats)
numOfInconclusiveExits (series int)
avgFreeProfitStr (series string)
freeProfitStDevStr (series string)
lossFreeProfitStDevStr (series string)
avgProfitStr (series string)
profitStDevStr (series string)
lossProfitStDevStr (series string)
avgQuantityStr (series string)
MetricsTable
Object that represents the metrics table
Fields:
table (series table) : The actual table
rows (series int) : The number of rows of the table
columns (series int) : The number of columns of the table
SeasonalData
Object that represents the seasonal table dynamic data
Fields:
seasonality (series Seasonality)
eonToMatrixRow (map)
numOfEons (series int)
mostRecentMatrixRow (series int)
balances (matrix)
returnPercs (matrix)
maxDDs (matrix)
eonReturnPercs (array)
eonCAGRs (array)
eonMaxDDs (array)
SeasonalTable
Object that represents the seasonal table
Fields:
table (series table) : The actual table
headRows (series int) : The number of head rows of the table
headColumns (series int) : The number of head columns of the table
eonRows (series int) : The number of eon rows of the table
seasonColumns (series int) : The number of season columns of the table
statsRows (series int)
statsColumns (series int) : The number of stats columns of the table
rows (series int) : The number of rows of the table
columns (series int) : The number of columns of the table
extended (series bool) : Whether the table has additional performance statistics

Double BBW OverlayDouble BBW Overlay Indicator
Overview
The Double BBW (Bollinger Band Width) Overlay indicator is a custom script for TradingView that combines two BBW indicators with adjustable settings. It allows traders to compare the volatility of two different periods of Bollinger Bands on the same chart. By default, the first BBW is calculated with a 10-period center line, and the second BBW with a 20-period center line, but these values can be customized.
How It Works
Bollinger Bands consist of an upper band, a lower band, and a middle band (typically a moving average). The Bollinger Band Width (BBW) measures the distance between the upper and lower bands relative to the center line. The width of these bands indicates market volatility:
Narrow Bands: Low volatility, usually preceding a breakout.
Wide Bands: High volatility, often following a strong price movement.
This indicator plots two BBW values on a non-overlay chart, making it easy to visualize and compare different market conditions over different periods.
Indicator Components
BBW 1 (default period: 10)
Calculates the BBW using a center line based on a 10-period moving average.
The width is plotted in blue by default.
BBW 2 (default period: 20)
Calculates the BBW using a center line based on a 20-period moving average.
The width is plotted in red by default.
Zero Line
A gray horizontal line at the value of 0 for reference, helping to understand the scale of BBW values.
Input Parameters
Center Line Period for BBW 1 (length1)
Default: 10
This controls the length of the moving average for the first BBW calculation. It defines how many periods are used to calculate the middle Bollinger Band for BBW 1.
Center Line Period for BBW 2 (length2)
Default: 20
This controls the length of the moving average for the second BBW calculation. It defines how many periods are used to calculate the middle Bollinger Band for BBW 2.
Standard Deviation Multiplier (mult)
Default: 2.0
This controls how far the upper and lower Bollinger Bands are from the center line. The multiplier affects how sensitive the Bollinger Bands are to price changes, with higher values producing wider bands.
How to Use
Adding the Indicator: Once the script is added to your TradingView account, simply apply the indicator to any chart. It will be displayed as a separate pane below the price chart, showing two BBW lines corresponding to the two different periods.
Customizing Periods: Use the settings panel to adjust the center line periods for BBW 1 and BBW 2 to match your desired trading strategy. For instance, you can analyze short-term versus long-term volatility by adjusting the periods.
Volatility Analysis:
When both BBW lines are narrow, it indicates low volatility across both short-term and long-term periods, which could suggest that a breakout is imminent.
If both BBW lines widen simultaneously, it shows that volatility is increasing in both timeframes, possibly indicating a strong trend.
Use Cases
Breakout Strategy: When the BBW lines contract significantly, it may signal that a low-volatility period is about to end, which is often followed by a price breakout in either direction.
Trend Strength: Comparing short-term and long-term BBW values can help determine if recent price movements are supported by broader market volatility or if they are isolated to the short term.
Chart Display
BBW 1: Blue line, representing the Bollinger Band Width calculated with a center line period of 10 (or your customized value).
BBW 2: Red line, representing the Bollinger Band Width calculated with a center line period of 20 (or your customized value).
Zero Line: A gray line at 0 is provided for reference, although BBW values are always positive.
Advantages of Using Double BBW
Comprehensive View of Volatility: By overlaying two BBW indicators with different timeframes, you can gain insights into both short-term and long-term market volatility trends.
Customizable: You can easily adjust the moving average periods and the standard deviation multiplier to match your preferred trading strategy or the characteristics of the asset you are trading.
Easy Visualization: The separate plots of BBW values make it easier to see shifts in market volatility, allowing you to spot potential trading opportunities.
Entry Weight Indicator(Dual Labels)이 지표는 트레이더가 동적으로 진입 비중을 결정할 수 있도록 도와주는 도구입니다. 이전 캔들의 종가를 기준으로 두 가지 다른 진입 비중을 계산하여 표시합니다.
주요 특징:
1. 두 가지 진입 비중 계산:
- 저점 기준 (EW Long): 이전 캔들 종가와 룩백 기간 내 최저가 사이의 거리를 기준으로 계산
- 고점 기준 (EW Short): 이전 캔들 종가와 룩백 기간 내 최고가 사이의 거리를 기준으로 계산
2. 시각적 표시:
- 초록색 라벨 (EW Long): 캔들 위에 표시
- 빨간색 라벨 (EW Short): 캔들 아래에 표시
- 룩백 기간 내 최고가와 최저가를 녹색과 빨간색 선으로 표시
3. 사용자 정의 파라미터:
- 원하는 손실 비율 (Desired Loss Percentage)
- 레버리지 (Leverage)
- 룩백 기간 (Lookback Period)
4. 추가 정보 표시:
- 차트 우측 상단에 이전 종가, 최고가, 최저가, 손실 비율 등의 정보를 표시
사용 방법:
1. 원하는 손실 비율, 레버리지, 룩백 기간을 설정합니다.
2. 차트에 표시되는 라벨을 통해 각 캔들에 대한 두 가지 진입 비중을 확인합니다.
3. EW Long (초록색)은 Long 진입 시 비중을, EW Short (빨간색)는 Short 진입 시 비중을 나타냅니다.
주의: 이 지표는 투자 시 직접적인 성과를 가져다주는 지표가 아니며, 실제 거래 결정 시에는 다른 분석 도구와 함께 사용하는 것이 좋습니다.
This indicator is a tool that helps traders dynamically determine their entry weight. It calculates and displays two different entry weights based on the closing price of the previous candle.
Key features:
1. Calculation of two entry weights:
- Low-based (EW Long): Calculated based on the distance between the previous candle's close and the lowest price within the lookback period
- High-based (EW Short): Calculated based on the distance between the previous candle's close and the highest price within the lookback period
2. Visual display:
- Green label (EW Long): Displayed above the candle
- Red label (EW Short): Displayed below the candle
- Highest and lowest prices within the lookback period are shown as green and red lines
3. User-defined parameters:
- Desired Loss Percentage
- Leverage
- Lookback Period
4. Additional information display:
- Information such as previous close, highest price, lowest price, and loss percentage is displayed in the upper right corner of the chart
How to use:
1. Set the desired loss percentage, leverage, and lookback period.
2. Check the two entry weights for each candle through the labels displayed on the chart.
3. EW Long (green) represents the entry weight for long positions, while EW Short (red) represents the entry weight for short positions.
Caution: This indicator does not directly lead to investment performance. When making actual trading decisions, it is advisable to use it in conjunction with other analytical tools.

Monthly Breakout StrategyThis Monthly High/Low Breakout Strategy is designed to take long or short positions based on breakouts from the high or low of the previous month. Users can select whether they want to go long at a breakout above the previous month’s high, short at a breakdown below the previous month’s low, or use the reverse logic. Additionally, it includes a month filter, allowing trades to be executed only during user-specified months.
Breakout strategies, particularly those based on monthly highs and lows, aim to capitalize on price momentum. These systems rely on the assumption that once a significant price level is breached (such as the previous month's high or low), the market is likely to continue moving in the same direction due to increased volatility and trend-following behaviors by traders. Studies have demonstrated the potential effectiveness of breakout strategies in financial markets.
Scientific Evidence Supporting Breakout Strategies:
Momentum in Financial Markets:
Research on momentum-based strategies, which include breakout trading, shows that securities breaking key levels of support or resistance tend to continue their price movement in the direction of the breakout. Jegadeesh and Titman (1993) found that stocks with strong performance over a given period tend to continue performing well in subsequent periods, a principle also applied to breakout strategies.
Behavioral Finance:
The psychological factor of herd behavior is one of the driving forces behind breakout strategies. When prices break out of a key level (such as a monthly high), it triggers increased buying or selling pressure as traders join the trend. Barberis, Shleifer, and Vishny (1998) explained how cognitive biases, such as overconfidence and sentiment, can amplify price trends, which breakout strategies attempt to exploit.
Market Efficiency:
While markets are generally efficient, periods of inefficiency can occur, particularly around the breakouts of significant price levels. These inefficiencies often result in temporary price trends, which breakout strategies can exploit before the market corrects itself (Fama, 1970).
Risk Considerations:
Despite the potential for profit, the Monthly Breakout Strategy comes with several risks:
False Breakouts:
One of the most common risks in breakout strategies is the occurrence of false breakouts. These happen when the price temporarily moves above (or below) a key level but quickly reverses direction, causing losses for traders who entered positions too early. This is particularly risky in low-volatility environments.
Market Volatility:
Monthly breakout strategies rely on momentum, which may not be consistent across different market conditions. During periods of low volatility, price breakouts might lack the follow-through required for the strategy to succeed, leading to poor performance.
Whipsaw Risk:
The strategy is vulnerable to whipsaw markets, where prices oscillate around key levels without establishing a clear direction. This can result in frequent entry and exit signals that lead to losses, especially if trading costs are not managed properly.
Overfitting to Past Data:
If the month-selection filter is overly optimized based on historical data, the strategy may suffer from overfitting—performing well in backtests but poorly in real-time trading. This happens when strategies are tailored to past market conditions that may not repeat.
Conclusion:
While monthly breakout strategies can be effective in markets with strong momentum, they are subject to several risks, including false breakouts, volatility dependency, and whipsaw behavior. It is crucial to backtest this strategy thoroughly and ensure it aligns with your risk tolerance before implementing it in live trading.
References:
Jegadeesh, N., & Titman, S. (1993). Returns to Buying Winners and Selling Losers: Implications for Stock Market Efficiency. Journal of Finance, 48(1), 65-91.
Barberis, N., Shleifer, A., & Vishny, R. (1998). A Model of Investor Sentiment. Journal of Financial Economics, 49(3), 307-343.
Fama, E. F. (1970). Efficient Capital Markets: A Review of Theory and Empirical Work. Journal of Finance, 25(2), 383-417.
EV Calculator [CHE]EV Calculator with Adjustable Boxes and Custom Colors for TradingView
Introduction:
As a trader, one of the key metrics you need to evaluate is the Expected Value (EV) of your trading strategy. Understanding EV helps you gauge whether your trades will be profitable in the long run. This TradingView script allows you to visualize your EV alongside customizable win rates and risk-to-reward ratios. With adjustable visual components, you can quickly determine whether your trading strategy has a positive or negative EV, and make informed decisions.
Features of the Script:
1. Customizable Inputs:
- Win Rate: Set your win probability (0.0 to 1.0), which represents how often your strategy is successful.
- Risk and Reward: Define how much you're risking and the potential reward for each trade.
2. Visual Representation:
- The script creates colored boxes representing different EV scenarios:
- Green Box: Indicates a good EV (>2), suggesting a highly profitable strategy.
- Yellow Box: Represents a neutral EV (between 0 and 2), where the strategy could work but is not optimal.
- Red Box: Shows a negative EV (<0), signaling that the strategy may lead to losses.
3. Adjustable Box Size:
- You can modify the width and height of the boxes to fit your chart display preferences, giving you better visual clarity based on your screen or chart style.
4. Dynamic Labels:
- Each bar in the chart includes dynamic labels showing:
- Win Rate: Displays the percentage chance of success.
- EV Value: Shows the calculated expected value based on the win rate and risk-reward ratio.
- Guide: Explains what each colored box means so that you can easily interpret the chart.
5. Scalability and Flexibility:
- The script only keeps a maximum of 20 recent entries, ensuring that your chart stays clean and organized.
- Both the number of labels and boxes adjust automatically to match your preferred settings, enhancing usability.
How the EV Calculation Works:
The formula for EV is based on a standard risk-to-reward model:
EV = (Win\ Rate \times Reward) - (Loss\ Probability \times Risk)
For example:
- If your win rate is 60% and your risk-to-reward ratio is 1:3, the script will calculate whether this strategy is expected to yield positive returns or result in long-term losses.
Example Use Case:
Let's say you are trading with a 60% win rate, risking 1 unit to gain 3 units. The script calculates that your EV is positive and represents this with a Green Box, showing you that your strategy has a high likelihood of being profitable. If your strategy slips and the win rate drops, the EV calculation will adjust, and you may see Yellow or Red Boxes, signaling a need for adjustment.
Final Thoughts:
This script is designed for traders who want to take their analysis beyond the basics. By providing real-time visualization of your EV, you can better assess whether your strategy is sound and make adjustments as needed.
How to Use:
- Adjust the input parameters for Win Rate, Risk, and Reward to match your trading strategy.
- Observe the colored boxes and labels to quickly understand if your current strategy is in a healthy EV zone.
- Use this visual feedback to refine your approach and stay on track towards profitability.
This tool simplifies the complex calculations behind EV and turns it into an intuitive and powerful decision-making aid for traders.
Now you're ready to integrate the EV Calculator with Adjustable Boxes and Custom Colors into your trading routine and start optimizing your strategies for long-term success!
Happy Trading and best regards Chervolino
High/Low Breakout Statistical Analysis StrategyThis Pine Script strategy is designed to assist in the statistical analysis of breakout systems on a monthly, weekly, or daily timeframe. It allows the user to select whether to open a long or short position when the price breaks above or below the respective high or low for the chosen timeframe. The user can also define the holding period for each position in terms of bars.
Core Functionality:
Breakout Logic:
The strategy triggers trades based on price crossing over (for long positions) or crossing under (for short positions) the high or low of the selected period (daily, weekly, or monthly).
Timeframe Selection:
A dropdown menu enables the user to switch between the desired timeframe (monthly, weekly, or daily).
Trade Direction:
Another dropdown allows the user to select the type of trade (long or short) depending on whether the breakout occurs at the high or low of the timeframe.
Holding Period:
Once a trade is opened, it is automatically closed after a user-defined number of bars, making it useful for analyzing how breakout signals perform over short-term periods.
This strategy is intended exclusively for research and statistical purposes rather than real-time trading, helping users to assess the behavior of breakouts over different timeframes.
Relevance of Breakout Systems:
Breakout trading systems, where trades are executed when the price moves beyond a significant price level such as the high or low of a given period, have been extensively studied in financial literature for their potential predictive power.
Momentum and Trend Following:
Breakout strategies are a form of momentum-based trading, exploiting the tendency of prices to continue moving in the direction of a strong initial movement after breaching a critical support or resistance level. According to academic research, momentum strategies, including breakouts, can produce returns above average market returns when applied consistently. For example, Jegadeesh and Titman (1993) demonstrated that stocks that performed well in the past 3-12 months continued to outperform in the subsequent months, suggesting that price continuation patterns, like breakouts, hold value .
Market Efficiency Hypothesis:
While the Efficient Market Hypothesis (EMH) posits that markets are generally efficient, and it is difficult to outperform the market through technical strategies, some studies show that in less liquid markets or during specific times of market stress, breakout systems can capitalize on temporary inefficiencies. Taylor (2005) and other researchers have found instances where breakout systems can outperform the market under certain conditions.
Volatility and Breakouts:
Breakouts are often linked to periods of increased volatility, which can generate trading opportunities. Coval and Shumway (2001) found that periods of heightened volatility can make breakouts more significant, increasing the likelihood that price trends will follow the breakout direction. This correlation between volatility and breakout reliability makes it essential to study breakouts across different timeframes to assess their potential profitability .
In summary, this breakout strategy offers an empirical way to study price behavior around key support and resistance levels. It is useful for researchers and traders aiming to statistically evaluate the effectiveness and consistency of breakout signals across different timeframes, contributing to broader research on momentum and market behavior.
References:
Jegadeesh, N., & Titman, S. (1993). Returns to Buying Winners and Selling Losers: Implications for Stock Market Efficiency. Journal of Finance, 48(1), 65-91.
Fama, E. F., & French, K. R. (1996). Multifactor Explanations of Asset Pricing Anomalies. Journal of Finance, 51(1), 55-84.
Taylor, S. J. (2005). Asset Price Dynamics, Volatility, and Prediction. Princeton University Press.
Coval, J. D., & Shumway, T. (2001). Expected Option Returns. Journal of Finance, 56(3), 983-1009.