9:30 Opening Price MarkerIndicator Name: 9:30 Opening Price Marker
Description:
The "9:30 Opening Price Marker" is a custom indicator for TradingView that highlights the opening price at 9:30 AM in the UTC-4 time zone (Eastern Daylight Time) on the chart. It helps traders and analysts easily identify and track the price level at which the market opens each day.
Features:
Timezone Conversion: The indicator converts the current time to the UTC-4 timezone (Eastern Daylight Time) to accurately determine the 9:30 AM opening price.
Visual Marker: It visually marks the opening price with a dotted line on the chart, making it prominent for quick reference.
Label: Additionally, it includes a label next to the opening price line, indicating "9:30 Opening Price", enhancing clarity and usability.
Overlay: The indicator is designed to overlay on the price chart, ensuring it doesn't clutter other technical analysis tools or indicators.
Usage:
Day-to-Day Analysis: Traders can use this indicator to quickly gauge market sentiment at the daily opening, which can influence intraday trading strategies.
Reference Point: Acts as a reference point for identifying price movements and potential trading opportunities relative to the day's opening price.
Time-Specific Insights: Provides insights into price action immediately following the market open, aiding in decision-making based on early trading activity.
Installation: Copy the provided Pine Script code into TradingView's Pine Editor, save the script as an indicator, and apply it to your chart.
Disclaimer : This indicator is intended for informational purposes only and should not be solely relied upon for trading decisions. Always consider multiple sources of information and perform thorough analysis before executing trades.
Statistics
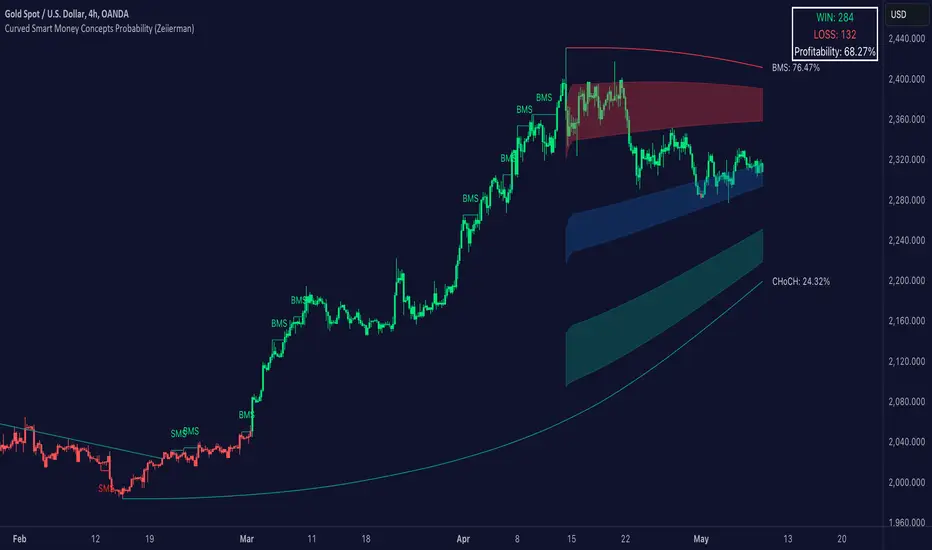
Curved Smart Money Concepts Probability (Zeiierman)█ Overview
The Curved Smart Money Concepts Probability indicator, developed by Zeiierman, is a sophisticated trading tool designed to leverage the principles of Smart Money trading. This indicator identifies key market structure points and adapts to changing market conditions, providing traders with actionable insights into market trends and potential reversals. The trading tool stands out due to its unique curved structure and advanced probability features, which enhance its effectiveness and usability for traders.
█ How It Works
The indicator operates by analyzing market data to identify pivotal moments where institutional investors might be influencing price movements. It employs a combination of adaptive trend lengths, multipliers for sensitivity adjustments, and pivot periods to accurately capture market structure shifts. The indicator calculates upper and lower bands based on adaptive sizes and identifies zones of overbought (premium) and oversold (discount) conditions.
Key Features of Probability Calculations
The Curved Smart Money Concepts Probability indicator integrates sophisticated probability calculations to enhance trading decision-making:
Win/Loss Tracking: The indicator tracks the number of successful (win) and unsuccessful (loss) trades based on the identified market structure points (ChoCH, SMS, BMS). This provides a historical context of the indicator's performance.
Probability Percentages: For each market structure point (ChoCH, SMS, BMS), the indicator calculates the probability of the next move being successful or not. This is presented as a percentage, giving traders a quantifiable measure of confidence in the signals.
Dynamic Adaptation: The probability calculations adapt to market conditions by considering the frequency and success rate of the signals, allowing traders to adjust their strategies based on the indicator’s historical accuracy.
Visual Representation: Probabilities are displayed on the chart, helping traders quickly assess the likelihood of future price movements based on past performance.
Key benefits of the Curved Structure
The Curved Smart Money Concepts Probability indicator features a unique curved structure that offers several advantages over traditional linear structures:
Noise Reduction: The curved structure smooths out short-term market fluctuations, reducing the noise often seen in linear structures. This helps traders focus on the true trend direction rather than getting distracted by minor price movements.
Adaptive Sensitivity: The curved structure adjusts its sensitivity based on market conditions. This means it can effectively capture both short-term and long-term trends by dynamically adapting to changes in market volatility, something linear structures struggle with.
Enhanced Trend Detection: By providing a more gradual transition between market phases, the curved structure helps in identifying trends more accurately. This is particularly useful in volatile markets where linear structures might give false signals due to their rigid nature.
Improved Market Structure Analysis: The curved structure's ability to adapt and smooth out irregularities provides a clearer picture of the overall market structure. This clarity is essential for identifying premium and discount zones, as well as mid-range support and resistance levels, which are crucial for effective ICT Smart Money Trading.
█ Terminology
ChoCH (Change of Character): Indicates a potential reversal in market direction. It is identified when the price breaks a significant high or low, suggesting a shift from a bullish to bearish trend or vice versa.
SMS (Smart Money Shift): Represents the transition phase in market structure where smart money begins accumulating or distributing assets. It typically follows a BMS and indicates the start of a new trend.
BMS (Bullish/Bearish Market Structure): Confirms the trend direction. Bullish Market Structure (BMS) confirms an uptrend, while Bearish Market Structure (BMS) confirms a downtrend. It is characterized by a series of higher highs and higher lows (bullish) or lower highs and lower lows (bearish).
Premium: A zone where the price is considered overbought. It is calculated as the upper range of the current market structure and indicates a potential area for selling or shorting.
Mid Range: The midpoint between the high and low of the market structure. It often acts as a support or resistance level, helping traders identify potential reversal or continuation points.
Discount: A zone where the price is considered oversold. It is calculated as the lower range of the current market structure and indicates a potential area for buying or going long.
█ How to Use
Identifying Trends and Reversals: Traders can use the indicator to identify the overall market trend and potential reversal points. By observing the ChoCH, SMS, and BMS signals, traders can gauge whether the market is transitioning into a new trend or continuing the current trend.
Example Strategies
⚪ Trend Following Strategy:
Identify the current market trend using BMS signals.
Enter a trade in the direction of the trend when the price retraces to the mid-range zone.
Set a stop-loss just below the mid-range (for long trades) or above the mid-range (for short trades).
Take profit in the premium/discount zone or when a ChoCH signal indicates a potential reversal.
⚪ Reversal Strategy:
Wait for a ChoCH signal to identify a potential market reversal.
Enter a trade in the direction of the new trend as indicated by the SMS signal.
Set a stop-loss just beyond the recent high (for short trades) or low (for long trades).
Take profit when the price reaches the premium or discount zone opposite to the entry.
█ Settings
Curved Trend Length: Determines the length of the trend used to calculate the adaptive size of the structure. Adjusting this length allows traders to capture either longer-term trends (for smoother curves) or short-term trends (for more reactive curves).
Curved Multiplier: Scales the adjustment factors for the upper and lower bands. Increasing the multiplier widens the bands, reducing sensitivity to price changes. Decreasing it narrows the bands, making the structure more responsive.
Pivot Period: Sets the period for capturing trends. A higher period captures broader trends, while a lower period focuses on short-term trends.
Response Period: Adjusts the structure’s responsiveness. A low value focuses on short-term changes, while a high value smoothens the structure.
Premium/Discount Range: Allows toggling between displaying the active range or previous range to analyze real-time or historical levels.
Structure Candles: Enables the display of curved structure candles on the chart, providing a modified view of price action.
-----------------
Disclaimer
The information contained in my Scripts/Indicators/Ideas/Algos/Systems does not constitute financial advice or a solicitation to buy or sell any securities of any type. I will not accept liability for any loss or damage, including without limitation any loss of profit, which may arise directly or indirectly from the use of or reliance on such information.
All investments involve risk, and the past performance of a security, industry, sector, market, financial product, trading strategy, backtest, or individual's trading does not guarantee future results or returns. Investors are fully responsible for any investment decisions they make. Such decisions should be based solely on an evaluation of their financial circumstances, investment objectives, risk tolerance, and liquidity needs.
My Scripts/Indicators/Ideas/Algos/Systems are only for educational purposes!
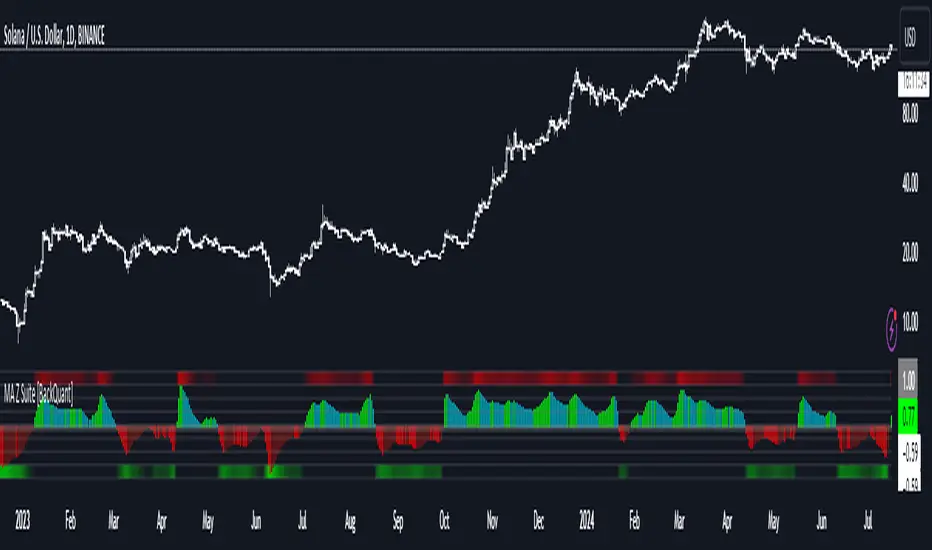
Moving Average Z-Score Suite [BackQuant]Moving Average Z-Score Suite
1. What is this indicator
The Moving Average Z-Score Suite is a versatile indicator designed to help traders identify and capitalize on market trends by utilizing a variety of moving averages. This indicator transforms selected moving averages into a Z-Score oscillator, providing clear signals for potential buy and sell opportunities. The indicator includes options to choose from eleven different moving average types, each offering unique benefits and characteristics. It also provides additional features such as standard deviation levels, extreme levels, and divergence detection, enhancing its utility in various market conditions.
2. What is a Z-Score
A Z-Score is a statistical measurement that describes a value's relationship to the mean of a group of values. It is measured in terms of standard deviations from the mean. For instance, a Z-Score of 1.0 means the value is one standard deviation above the mean, while a Z-Score of -1.0 indicates it is one standard deviation below the mean. In the context of financial markets, Z-Scores can be used to identify overbought or oversold conditions by determining how far a particular value (such as a moving average) deviates from its historical mean.
3. What moving averages can be used
The Moving Average Z-Score Suite allows users to select from the following eleven moving averages:
Simple Moving Average (SMA)
Hull Moving Average (HMA)
Exponential Moving Average (EMA)
Weighted Moving Average (WMA)
Double Exponential Moving Average (DEMA)
Running Moving Average (RMA)
Linear Regression Curve (LINREG) (This script can be found standalone )
Triple Exponential Moving Average (TEMA)
Arnaud Legoux Moving Average (ALMA)
Kalman Hull Moving Average (KHMA)
T3 Moving Average
Each of these moving averages has distinct properties and reacts differently to price changes, allowing traders to select the one that best fits their trading style and market conditions.
4. Why Turning a Moving Average into a Z-Score is Innovative and Its Benefits
Transforming a moving average into a Z-Score is an innovative approach because it normalizes the moving average values, making them more comparable across different periods and instruments. This normalization process helps in identifying extreme price movements and mean-reversion opportunities more effectively. By converting the moving average into a Z-Score, traders can better gauge the relative strength or weakness of a trend and detect potential reversals. This method enhances the traditional moving average analysis by adding a statistical perspective, providing clearer and more objective trading signals.
5. How It Can Be Used in the Context of a Trading System
In a trading system, it can be used to generate buy and sell signals based on the Z-Score values. When the Z-Score crosses above zero, it indicates a potential buying opportunity, suggesting that the price is above its mean and possibly trending upward. Conversely, a Z-Score crossing below zero signals a potential selling opportunity, indicating that the price is below its mean and might be trending downward. Additionally, the indicator's ability to show standard deviation levels and extreme levels helps traders set profit targets and stop-loss levels, improving risk management and trade planning.
6. How It Can Be Used for Trend Following
For trend-following strategies, it can be particularly useful. The Z-Score oscillator helps traders identify the strength and direction of a trend. By monitoring the Z-Score and its rate of change, traders can confirm the persistence of a trend and make informed decisions to enter or exit trades. The indicator's divergence detection feature further enhances trend-following by identifying potential reversals before they occur, allowing traders to capitalize on trend shifts. By providing a clear and quantifiable measure of trend strength, this indicator supports disciplined and systematic trend-following strategies.
No backtests for this indicator due to the many options and ways it can be used,
Enjoy
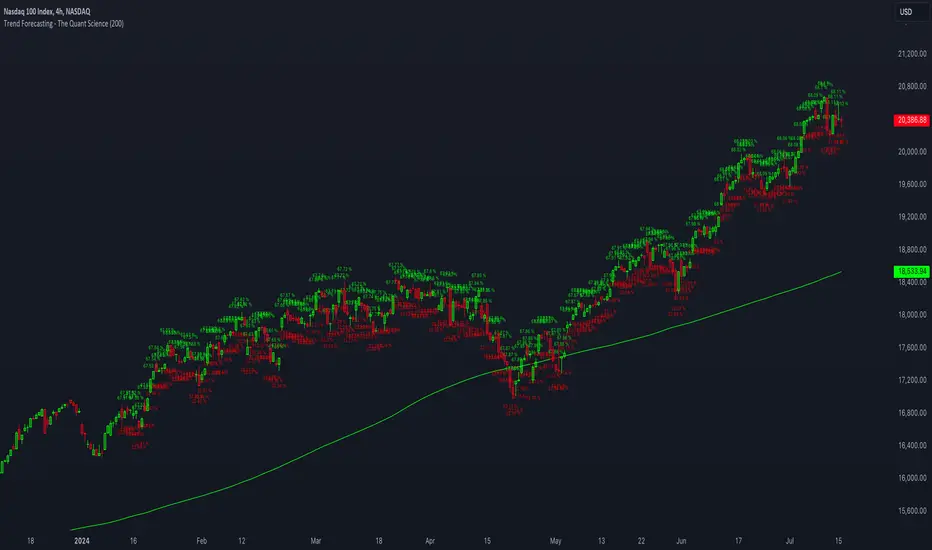
Trend Forecasting - The Quant Science🌏 Trend Forecasting | ENG 🌏
This plug-in acts as a statistical filter, adding new information to your chart that will allow you to quickly verify the direction of a trend and the probability with which the price will be above or below the average in the future, helping you to uncover probable market inefficiencies.
🧠 Model calculation
The model calculates the arithmetic mean in relation to positive and negative events within the available sample for the selected time series. Where a positive event is defined as a closing price greater than the average, and a negative event as a closing price less than the average. Once all events have been calculated, the probabilities are extrapolated by relating each event.
Example
Positive event A: 70
Negative event B: 30
Total events: 100
Probabilities A: (100 / 70) x 100 = 70%
Probabilities B: (100 / 30) x 100 = 30%
Event A has a 70% probability of occurring compared to Event B which has a 30% probability.
🔍 Information Filter
The data on the graph show the future probabilities of prices being above average (default in green) and the probabilities of prices being below average (default in red).
The information that can be quickly retrieved from this indicator is:
1. Trend: Above-average prices together with a constant of data in green greater than 50% + 1 indicate that the observed historical series shows a bullish trend. The probability is correlated proportionally to the value of the data; the higher and increasing the expected value, the greater the observed bullish trend. On the other hand, a below-average price together with a red-coloured data constant show quantitative data regarding the presence of a bearish trend.
2. Future Probability: By analysing the data, it is possible to find the probability with which the price will be above or below the average in the future. In green are classified the probabilities that the price will be higher than the average, in red are classified the probabilities that the price will be lower than the average.
🔫 Operational Filter .
The indicator can be used operationally in the search for investment or trading opportunities given its ability to identify an inefficiency within the observed data sample.
⬆ Bullish forecast
For bullish trades, the inefficiency will appear as a historical series with a bullish trend, with high probability of a bullish trend in the future that is currently below the average.
⬇ Bearish forecast
For short trades, the inefficiency will appear as a historical series with a bearish trend, with a high probability of a bearish trend in the future that is currently above the average.
📚 Settings
Input: via the Input user interface, it is possible to adjust the periods (1 to 500) with which the average is to be calculated. By default the periods are set to 200, which means that the average is calculated by taking the last 200 periods.
Style: via the Style user interface it is possible to adjust the colour and switch a specific output on or off.
🇮🇹Previsione Della Tendenza Futura | ITA 🇮🇹
Questo plug-in funge da filtro statistico, aggiungendo nuove informazioni al tuo grafico che ti permetteranno di verificare rapidamente tendenza di un trend, probabilità con la quale il prezzo si troverà sopra o sotto la media in futuro aiutandoti a scovare probabili inefficienze di mercato.
🧠 Calcolo del modello
Il modello calcola la media aritmetica in relazione con gli eventi positivi e negativi all'intero del campione disponibile per la serie storica selezionata. Dove per evento positivo si intende un prezzo alla chiusura maggiore della media, mentre per evento negativo si intende un prezzo alla chiusura minore della media. Calcolata la totalità degli eventi le probabilità vengono estrapolate rapportando ciascun evento.
Esempio
Evento positivo A: 70
Evento negativo B: 30
Totale eventi : 100
Formula A: (100 / 70) x 100 = 70%
Formula B: (100 / 30) x 100 = 30%
Evento A ha una probabilità del 70% di realizzarsi rispetto all' Evento B che ha una probabilità pari al 30%.
🔍 Filtro informativo
I dati sul grafico mostrano le probabilità future che i prezzi siano sopra la media (di default in verde) e le probabilità che i prezzi siano sotto la media (di default in rosso).
Le informazioni che si possono rapidamente reperire da questo indicatore sono:
1. Trend: I prezzi sopra la media insieme ad una costante di dati in verde maggiori al 50% + 1 indicano che la serie storica osservata presenta un trend rialzista. La probabilità è correlata proporzionalmente al valore del dato; tanto più sarà alto e crescente il valore atteso e maggiore sarà la tendenza rialzista osservata. Viceversa, un prezzo sotto la media insieme ad una costante di dati classificati in colore rosso mostrano dati quantitativi riguardo la presenza di una tendenza ribassista.
2. Probabilità future: analizzando i dati è possibile reperire la probabilità con cui il prezzo si troverà sopra o sotto la media in futuro. In verde vengono classificate le probabilità che il prezzo sarà maggiore alla media, in rosso vengono classificate le probabilità che il prezzo sarà minore della media.
🔫 Filtro operativo
L' indicatore può essere utilizzato a livello operativo nella ricerca di opportunità di investimento o di trading vista la capacità di identificare un inefficienza all'interno del campione di dati osservato.
⬆ Previsione rialzista
Per operatività di tipo rialzista l'inefficienza apparirà come una serie storica a tendenza rialzista, con alte probabilità di tendenza rialzista in futuro che attualmente si trova al di sotto della media.
⬇ Previsione ribassista
Per operatività di tipo short l'inefficienza apparirà come una serie storica a tendenza ribassista, con alte probabilità di tendenza ribassista in futuro che si trova attualmente sopra la media.
📚 Impostazioni
Input: tramite l'interfaccia utente Input è possibile regolare i periodi (da 1 a 500) con cui calcolare la media. Di default i periodi sono impostati sul valore di 200, questo significa che la media viene calcolata prendendo gli ultimi 200 periodi.
Style: tramite l'interfaccia utente Style è possibile regolare il colore e attivare o disattivare un specifico output.
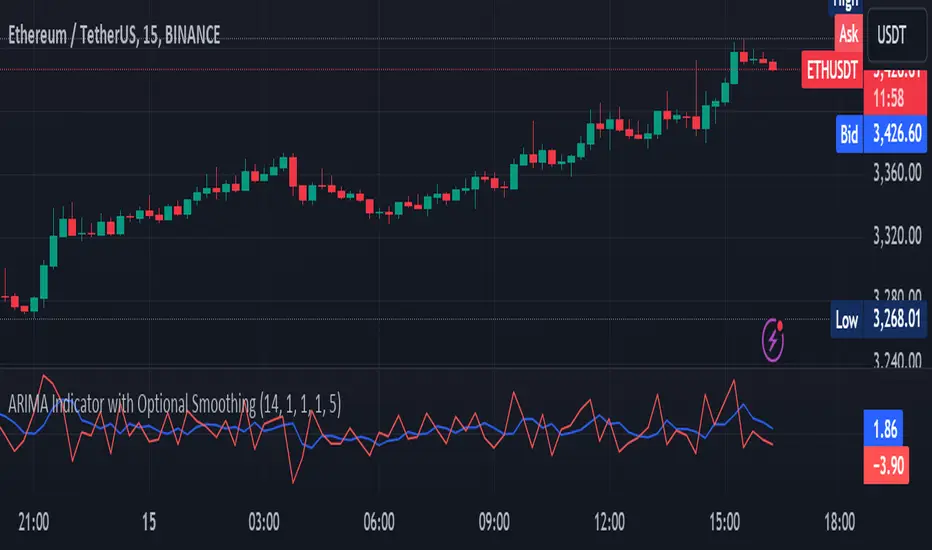
ARIMA Indicator with Optional SmoothingOverview
The ARIMA (AutoRegressive Integrated Moving Average) Indicator is a powerful tool used to forecast future price movements by combining differencing, autoregressive, and moving average components. This indicator is designed to help traders identify trends and potential reversal points by analyzing the historical price data.
Key Features
AutoRegressive Component (AR): Utilizes past values to predict future prices.
Moving Average Component (MA): Averages past price differences to smooth out noise.
Differencing: Reduces non-stationarity in the time series data.
Optional Smoothing: Applies EMA to the ARIMA output for a smoother signal.
Customizable Parameters: Allows users to adjust AR and MA orders, differencing periods, and smoothing lengths.
Concepts Underlying the Calculations
Differencing: Subtracts previous prices from current prices to remove trends and seasonality, making the data stationary.
AutoRegressive Component (AR): Predicts future prices based on a linear combination of past values.
Moving Average Component (MA): Uses past forecast errors to refine future predictions.
Exponential Moving Average (EMA): Applies more weight to recent prices, providing a smoother and more responsive signal.
How It Works
The ARIMA Indicator first calculates the differenced series to achieve stationarity. Then, it computes the simple moving average (SMA) of this differenced series. The indicator uses the AR and MA components to adjust the SMA, creating an approximation of the ARIMA model. Finally, an optional smoothing step using EMA can be applied to the ARIMA approximation to produce a smoother signal.
How Traders Can Use It
Traders can use the ARIMA Indicator to:
Identify Trends: Detect emerging trends by observing the direction of the ARIMA line.
Spot Reversals: Look for divergences between the ARIMA line and the price to identify potential reversal points.
Generate Trading Signals: Use crossovers between the ARIMA line and the price to generate buy or sell signals.
Filter Noise: Enable the optional smoothing to filter out market noise and focus on significant price movements.
Example Usage Instructions
Add the ARIMA Indicator to your chart.
Adjust the input parameters to suit your trading strategy:
Set the SMA Length (e.g., 14).
Choose the Differencing Period (e.g., 1).
Define the AR Order (p) and MA Order (q) (e.g., 1).
Configure the Smoothing Length if smoothing is desired (e.g., 5).
Enable or disable smoothing as needed.
Observe the ARIMA line (blue) and compare it to the price chart.
Use the ARIMA line to identify trends and potential reversals.
Implement trading decisions based on the ARIMA line’s behavior relative to the price.
MarketAnalysisLibrary "MarketAnalysis"
A collection of frequently used market analysis functions in my scripts.
bullFibRet(priceLow, priceHigh, fibLevel)
Calculates a bullish fibonacci retracement value.
Parameters:
priceLow (float) : (float) The lowest price point.
priceHigh (float) : (float) The highest price point.
fibLevel (float) : (float) The fibonacci level to calculate.
Returns: The fibonacci value of the given retracement level.
bearFibRet(priceLow, priceHigh, fibLevel)
Calculates a bearish fibonacci retracement value.
Parameters:
priceLow (float) : (float) The lowest price point.
priceHigh (float) : (float) The highest price point.
fibLevel (float) : (float) The fibonacci level to calculate.
Returns: The fibonacci value of the given retracement level.
bullFibExt(priceLow, priceHigh, thirdPivot, fibLevel)
Calculates a bullish fibonacci extension value.
Parameters:
priceLow (float) : (float) The lowest price point.
priceHigh (float) : (float) The highest price point.
thirdPivot (float) : (float) The third price point.
fibLevel (float) : (float) The fibonacci level to calculate.
Returns: The fibonacci value of the given extension level.
bearFibExt(priceLow, priceHigh, thirdPivot, fibLevel)
Calculates a bearish fibonacci extension value.
Parameters:
priceLow (float) : (float) The lowest price point.
priceHigh (float) : (float) The highest price point.
thirdPivot (float) : (float) The third price point.
fibLevel (float) : (float) The fibonacci level to calculate.
Returns: The fibonacci value of the given extension level.
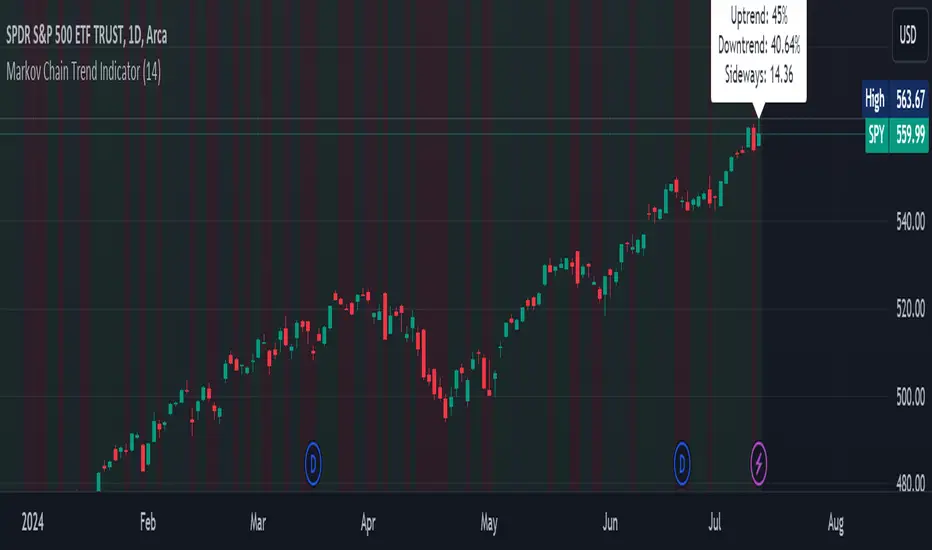
Markov Chain Trend IndicatorOverview
The Markov Chain Trend Indicator utilizes the principles of Markov Chain processes to analyze stock price movements and predict future trends. By calculating the probabilities of transitioning between different market states (Uptrend, Downtrend, and Sideways), this indicator provides traders with valuable insights into market dynamics.
Key Features
State Identification: Differentiates between Uptrend, Downtrend, and Sideways states based on price movements.
Transition Probability Calculation: Calculates the probability of transitioning from one state to another using historical data.
Real-time Dashboard: Displays the probabilities of each state on the chart, helping traders make informed decisions.
Background Color Coding: Visually represents the current market state with background colors for easy interpretation.
Concepts Underlying the Calculations
Markov Chains: A stochastic process where the probability of moving to the next state depends only on the current state, not on the sequence of events that preceded it.
Logarithmic Returns: Used to normalize price changes and identify states based on significant movements.
Transition Matrices: Utilized to store and calculate the probabilities of moving from one state to another.
How It Works
The indicator first calculates the logarithmic returns of the stock price to identify significant movements. Based on these returns, it determines the current state (Uptrend, Downtrend, or Sideways). It then updates the transition matrices to keep track of how often the price moves from one state to another. Using these matrices, the indicator calculates the probabilities of transitioning to each state and displays this information on the chart.
How Traders Can Use It
Traders can use the Markov Chain Trend Indicator to:
Identify Market Trends: Quickly determine if the market is in an uptrend, downtrend, or sideways state.
Predict Future Movements: Use the transition probabilities to forecast potential market movements and make informed trading decisions.
Enhance Trading Strategies: Combine with other technical indicators to refine entry and exit points based on predicted trends.
Example Usage Instructions
Add the Markov Chain Trend Indicator to your TradingView chart.
Observe the background color to quickly identify the current market state:
Green for Uptrend, Red for Downtrend, Gray for Sideways
Check the dashboard label to see the probabilities of transitioning to each state.
Use these probabilities to anticipate market movements and adjust your trading strategy accordingly.
Combine the indicator with other technical analysis tools for more robust decision-making.
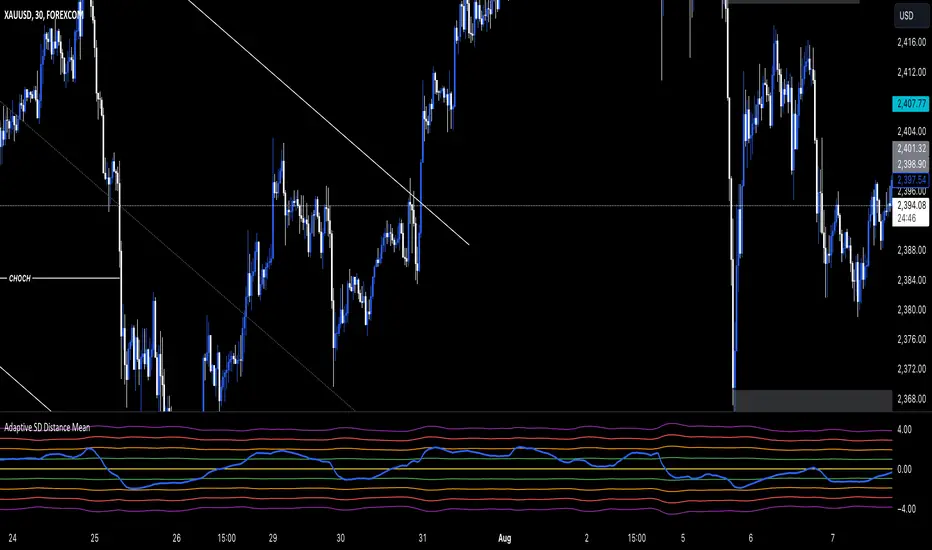
SD Distance Mean BetaThe "SD Distance Mean Indicator" is a currently a developing tool designed to enhance trading precision by dynamically adjusting to market conditions. This indicator provides insights into price deviations from the mean, helping traders make inf OANDA:XAUUSD ormed decisions based on significant price movements.
Key Features:
Adaptive Length Adjustment:
The indicator dynamically adjusts the calculation period based on the Average True Range (ATR). This allows it to respond to different market conditions, using a shorter length during consolidations and a longer length during trends.
Standardized Distance Calculation:
The indicator calculates the distance of the current price from the mean and standardizes it using the standard deviation. This standardized distance is then smoothed to reduce noise and provide clearer signals.
Dynamic Standard Deviation (SD) Levels:
SD levels are adjusted dynamically based on ATR, providing a more accurate representation of price volatility. These levels are further smoothed to minimize wiggling on shorter timeframes like the 30-minute chart.
Visual Cues for Trading Signals:
The indicator plots multiple SD levels (+1, +2, +3, +4 and their negatives) and highlights significant price movements. When the standardized distance line hits or exceeds these levels, it signals potential overbought or oversold conditions.
Customizable Smoothing: The smoothing length for both the standardized distance and SD levels can be customized to suit different trading strategies and timeframes. Default values are set to provide a balance between responsiveness and stability.
Usage:
Identifying Reversals : The indicator helps in spotting potential reversal points. When the smoothed standardized distance line hits +2 SD or -2 SD and rebounds, it signals a possible price reversal back towards the mean.
Confirming Trends: Dynamic SD levels provide a clear visual representation of price volatility, helping traders confirm trend strength and potential breakout points.
Enhancing Precision: By dynamically adjusting to market conditions, the indicator enhances trading precision, making it suitable for various market environments.
This script is an essential addition to any trader's toolkit, offering a blend of adaptability, precision, and visual clarity to support more informed trading decisions.
Settings:
Short Length: Period length used during consolidations.
Long Length: Period length used during trends.
ATR Length: Length for ATR calculation.
ATR Threshold: Threshold value to switch between short and long lengths.
Smoothing Length: Length for smoothing the standardized distance.
SD Smoothing Length: Length for smoothing the dynamic SD levels.
By using this indicator, traders can leverage its adaptive capabilities to navigate various market conditions effectively and enhance their trading performance on XAUUSD and other assets.
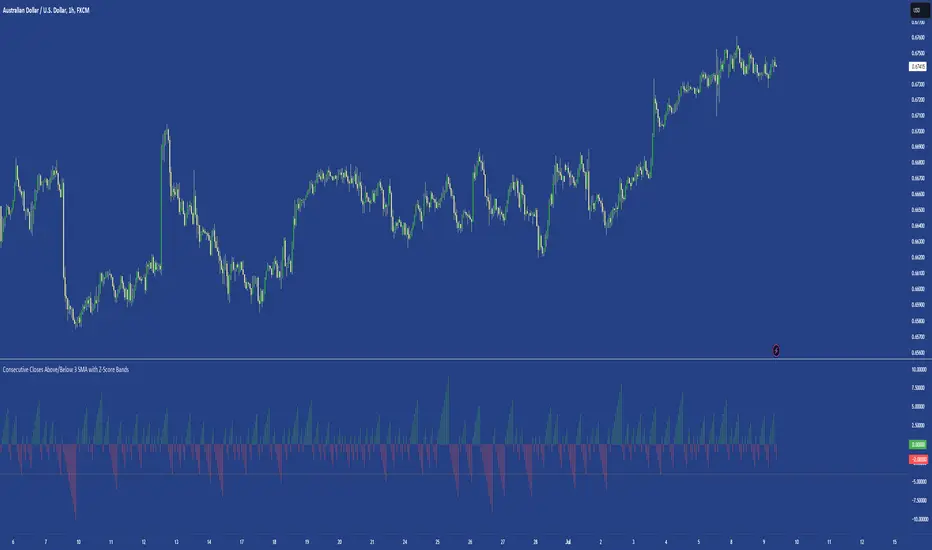
Consecutive Closes Above/Below 3 SMA with Z-Score BandsA simple indicator that measures consecutive closes above & below the 3-period simple moving average. An upper and lower Z-score has been calculated to indicate where the 4 standard deviations of the last 60 bars sits.
Useful for identifying directional runs in price.
PEV Price BandThe PEV Price Band shows prices calculated using the high and low P/FQ EV of the previous period. (price to enterprise value per share for the last quarter) multiplied by FQ's current EVPS (similar to comparing marketcap to enterprise value but edit equations that are close to the theory of P/E)
If the current price is lower than the minimum P/EVPS, it is considered cheap. In other words, a current price is above the maximum is considered expensive.
PEV Price Band consists of 2 parts.
- First of all, the current P/EVPS value is "green" (if the markecap is less than the enterprise value) or "red" (if the marketcap is more than the enterprise value) or "gold" (if the market value is less than the enterprise value and less than equity)
- Second, the blue line is the closing price.
Easy Scalping Lot Calculator for ForexThe calculator was created to make it easier to calculate the lot size on Forex. I planned to use it for the following pairs: AUDCAD, AUDCHF, AUDJPY, AUDUSD, EURAUD, EURCAD, EURCHF, EURGBP, EURJPY, EURNZD, EURUSD, GBPCHF, GBPJPY, GBPUSD, NZDUSD, USDCAD, USDCHF, USDJPY, XAUUSD.
The indicator is a table that shows the calculation of the lot for a predetermined stop loss.
For example, you are planning a trade, have calculated a stop loss of 15 points, and by checking the table you understand approximately what lot you need to use to limit your risk.
In the settings you can change the risk and also determine the stop loss value in points.
The calculator does not take into account the spread in the calculations.
There are websites where you can accurately calculate the lot, but if you trade on small time frames this is not suitable for you.
The calculator uses the formula:
Lot size = maximum risk / stop loss (in pips) / minimum pip value x minimum trading lot.

Holding ValueTrading view requires me to add a larger description:
Short done by me: Show your holding value at each candlestick
Chatgpt:
This Pine Script plugin is designed to help traders and investors visualize the current value of their holdings in USD directly on TradingView charts. The plugin calculates the total value of the specified holdings based on the closing price of each candle and displays this value dynamically, formatted to show in thousands (k) or millions (m) with a maximum of two decimal places.
Features
Holdings Input: Allows the user to input the amount of the asset they hold.
Dynamic Calculation: Calculates the current value of holdings based on the closing price of each candle.
Formatted Display: Formats the value in thousands or millions with up to two decimal places.
Chart Label: Displays the formatted value as a label on the chart.
Data Window Display: Uses plotchar to display the current value in the data window without plotting it directly on the chart.

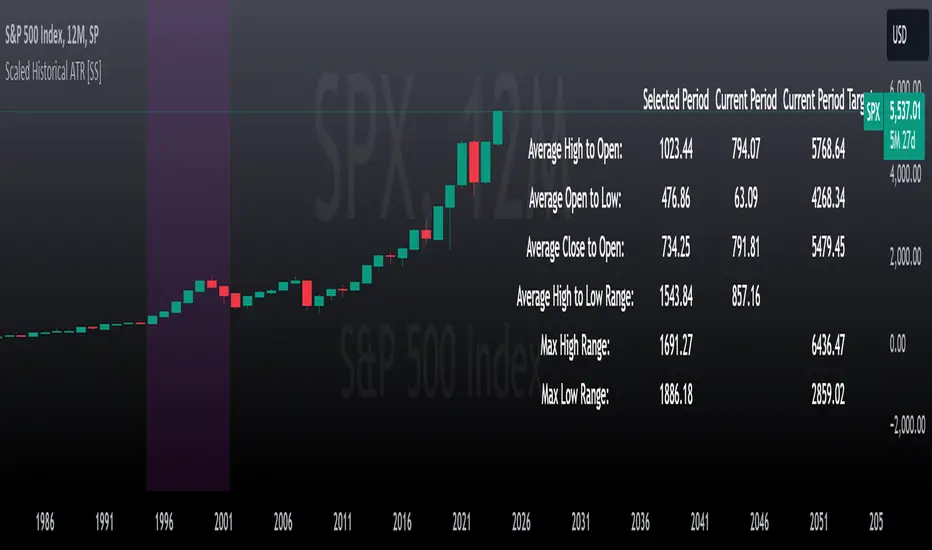
Scaled Historical ATR [SS]Hello again everyone,
This is the Scaled ATR Range indicator. This was done in response to an article/analysis I posted regarding the expected high and range on SPX. I would encourage you to read it here:
Essentially, I took SPX data, scaled it to correct for inflation, then calculated the ATR for Bullish years to get our average range to expect and our close range to expected.
I accomplished this analysis using Excel; however, I figured Pinescript would handle this type of task more elegantly, and I was correct!
This indicator is the result.
What it does:
This indicator permits the analyst to select a historic period in time. The indicator will then scale the period into returns and convert the range to a corrected range based on the current position of the ticker. How it does this is by converting the returns of the historic period selected, then multiplying the returns by the current period open, to ensure that the range amounts are corrected for inflation and natural growth of a ticker.
I say analyst because this indicator is intended to be used by both professional and recreational analysts, to give them an easy way to:
a) Scale historic data and correct it based on the current rate; and
b) Offer insight into a ticker’s ATR and behaviour during bullish and bearish periods.
Prior to this indicator, the only way to do this would be manually or the use of statistical software.
How to use?
The indicator’s use is quite simple. Once launched, the indicator will ask the user to input a timeframe period that the user is interested in assessing. In the main chart above, I chose SPX between 1995 and 2001.
The user can further filter down the data using the settings menu. In the settings menu, there is an option to filter by “All”, “Bullish Periods” or “Bearish Periods”.
Filtering by “All”
Filtering by “All” will include all candles selected within the timeframe. This includes both bearish and bullish candles. It will give you the averaged out range for the entire period of time, including both bearish and bullish instances.
Filtering by “Bullish”
Filtering by “Bullish” will omit any red candles from the analysis. It will only return the ATR ranges for green, bullish candles.
Filtering by “Bearish”
Inverse to filtering by Bullish, if you filter by Bearish, it will only include the red, bearish candles in the analysis.
My suggestion? If you are trying to determine t he likely outcome of a bullish year, filter by Bullish instances. If you want the likely outcome of a bearish year, filter by Bearish.
Other features of the Indicator:
The indicator will display the current period statistics. In the main chart above, you can see that the current ranges for this year are displayed. This allows you to do a side by side comparison of the current period vs. the historic period you are looking at. This can alert you to further upside, further downside and the anticipated close range. It can also alert you to whether or not we are following a similar trajectory as the historical periods you are looking at.
As well, the indicator will list target prices for the current period based on the historical periods you are looking at. This helps to put things into perspective.
Concluding Remarks
And that is the indicator in a nutshell! I encourage you to read the article I linked above to see how you may use it in an analysis. This would be the best example of a real world application of this indicator!
Otherwise, I hope you enjoy and, as always, safe trades!
MVRV-Z adjusted EN version (by ilyaevp95)Descriptions:
The MVRV Z-Score indicator is a powerful tool designed by original authors Murad Mahmudov and David Puell for BTC to help traders make informed decisions about their cryptocurrency investments. It is based on the MVRV (Market Value to Realized Value) metric, which measures the relationship between the market capitalization and the realized capitalization of a cryptocurrency. The indicator provides signals for accumulating or selling an asset based on deviations in market capitalization from realized capitalization.
How it works:
Market Capitalization : This is the total value of coins that have been issued at a given point in time. Market capitalization is calculated by multiplying the current price of the asset by the number of coins that have been issued.
Realized Capitalization (Realized Price) : This is the amount of money that has been spent on purchasing a particular asset. In the context of cryptocurrencies, it represents the sum of all transaction values for a specific blockchain. Realized capitalization can be calculated using historical data on transaction prices.
MVRV Metric : The MVRV metric compares market capitalization with realized capitalization, providing a measure of how overvalued or undervalued a cryptocurrency is relative to its historical transaction data. A high MVRV value indicates that the market is overvaluing the asset, while a low MVRV suggests undervaluation.
Z-Score Calculation : The Z-score is a statistical measure that normalizes the deviation of market capitalization from its mean value (realized capitalization) to a standard deviation. This makes it possible to compare assets that have different values and time periods, as it takes into account the volatility of the market.
Note: For accurate Z-score calculation, you need to use the indicator on a chart with a mostly complete historical data set for a specific cryptocurrency.
Signals : Based on the Z-score, the indicator generates signals for accumulation or sale. If the Z-score falls below a certain threshold (negative), it may indicate an opportunity to accumulate the asset. Conversely, if the Z-score rises above a positive threshold, it could suggest a potential sell signal.
The indicator uses a color-coded system to provide traders with visual cues:
Green background indicates a signal to accumulate.
Orange (Red) background indicates a signal to sell.
Deviations exceeding the specified thresholds by 1 and 2 Z (positive direction), 0.5 and 1 Z (negative direction) are highlighted in a brighter color, indicating more extreme deviations.
Note: The signals provided by this indicator should not be considered financial advice. Traders should conduct their own research (DYOR) before making any investment decisions.
Parameters: The indicator provides several parameters for customization:
Blockchain : The blockchain for which the analysis is performed. This allows the user to select the specific blockchain they are interested in analyzing. The default value is BTC.
Z threshold for positive deviations : This parameter sets the threshold above which the deviation will be considered positive. A higher value will result in fewer signals, while a lower value may generate more false signals. The default value is 3.0.
Z threshold for negative deviations : Similar to the previous parameter, this sets the threshold below which the deviation will be considered negative. The default value is 0.
Market Capitalization : There are two types of market capitalization available: Standard and Free float coin capitalization. Free float is calculated by multiplying its current price by the total number of units in free circulation - the number that are not locked in any contracts or other forms of restriction. For DASH, ZEC, BAT and ALGO available only Free float capitalization. The default value is "Standard"
Negative Deviation Filter Mode : When enabled, if the deviation has been positive for a certain number of previous weeks (the default value is 40 weeks), the indicator will not generate a signal to accumulate. This helps to avoid false signals during the start of a bearish market. This may be helpful for volatile coins, whose price can drastically fall below the realized price after the end of a bull market. The default setting is "disabled".
Display Options:
MVRV plot : Displays the MVRV metric for the selected blockchain.
Z-Score plot : Shows the Z-score calculated by the indicator.
Realized Price plot : Provides a visual representation of the realized price of the cryptocurrency on main chart.
S ignal Display : Choose whether to display signals on the main chart or in a separate panel.
Historical mode : Choose whether to show signals for all historical data on the chart or for a certain number of periods. The default setting is "disabled".

Thuvien_publishLibrary "Thuvien_publish"
Thư viện build Strategy
entry_volume_func(risk, entry, sl)
Hàm tính khối lượng vào lệnh
Parameters:
risk (float)
entry (float)
sl (float)
Returns: entry_volume: trả về khối lượng cần vào
tp_sl_func(sl, entry, rr)
Tính TP/SL theo RR cho trước
Parameters:
sl (float)
entry (float)
rr (float)
Returns: Trả về giá trị Take profit

Groupings [SS]Hey everyone,
Releasing this indicator called groupings.
If you watch/read my analyses on Tradingview, you will have heard me talk about groups. Groups is something I invented. What it is, is just taking the Euclidean Distance (ED) of the previous 5 candles in a specified period (i.e. daily timeframe, weekly, 1 minute, 5 minute, etc.) and rounding the ED up to a whole number.
I have had great success in this approach because the information provided is broad enough to give leniency in interpretation but narrow enough to hone in on potential moves and target prices.
This indicator is a simplified version of how I do groupings in other software, however it is no less powerful!
What do groups tell us?
A "group" takes into account the previous 5 candles, using the ED. This gives Pinescript a general idea of what the short term trend looks like mathematically. From there, Pinescript can look for other groups that looked similar to how this current trend looks. From there, it can offer us insights into what tends to happen in candles subsequent to this group. For example, the ATR range, the close range and whether it is bearish or bullish.
And that is precisely how this indicator operates, Pinescript will calculate the group of the previous 5 canndles in the timeframe period you are looking at. It will then lookback over the designated "train" length and identify previous groups, and what happened in those groups. It looks specifically at:
- What is that average High ATR associated with that group,
- What is the average Low ATR associated with that group,
- What is the average close range associated with that group,
- What is the sentiment associated with that group.
How to use the indicator?
In terms of use, the indicator is relatively simple to use. It will plot three lines, a red for the anticipated low range, a green for the anticipated high range and purple for the opening range (where the current candle opened at).
In addition, it will plot a dot for the anticipated close area. When the dot is green, it expects a bullish close. When the dot is red, it expects a bearish close.
The indicator is going to give you a heads up as to whether we are in a bullish group, what you can anticipate the high and low range to be and where you can anticipate the close.
Of course, its not always exact, as in the image above you can see it underestimated the high range and over-estimated the low range; however, we did close within the anticipate range.
The indicator is meant to help you with your bias. I will reference this indicator on the daily timeframe at open to see what the expectations are for the day.
However, you can use it on any timeframe you wish.
Other functions:
The indicator can plot the EMA 9, 21 and 5. These are the 3 indicators I like and I find them helpful for both intraday and swing trading. However, they can be toggled off if you do not wish to view them.
In addition, the EMAs will be green if the ticker is trending above the EMA 21 (which is a critical EMA for me to determine the immediate sentiment). If the ticker is below, they will turn red.
There is also the ability to adjust the train time. The default is 1,000 candles back, but I usually have it on 1500. If you have a lot of indicators and a lot going on, on your chart, you may find that 1500 is too much and it will lag/error. That’s okay, 500 candles is sufficient and will not put a lot of stress on Pinescript.
Concluding remarks
Its overall a fairly simple concept and indicator, but it has been a neat and helpful / insightful invention. I originally developed this using R and happy to have now brought it into Pinescript.
I hope you enjoy!
Safe trades everyone!

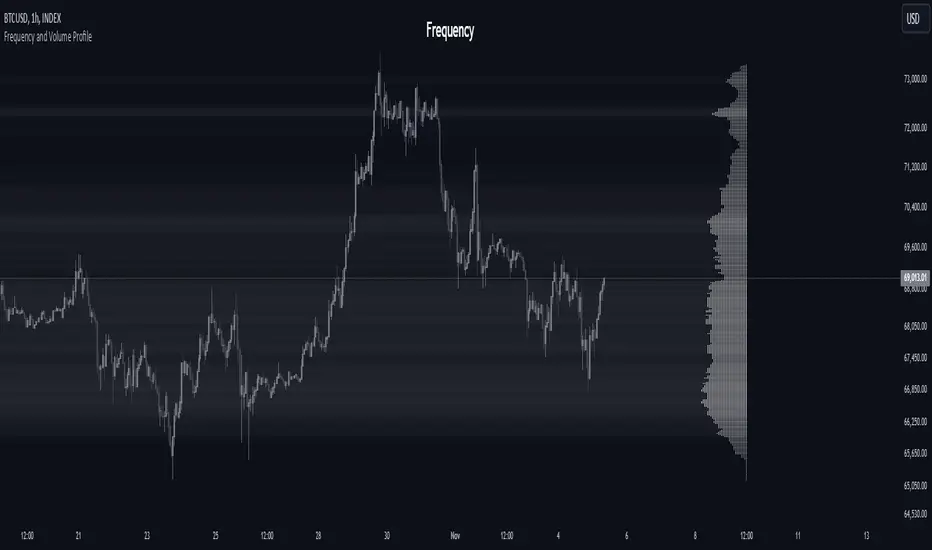
Frequency and Volume ProfileFREQUENCY & VOLUME PROFILE
⚪ OVERVIEW
The Frequency and Volume Profile indicator plots a frequency or volume profile based on the visible bars on the chart, providing insights into price levels with significant trading activity.
⚪ USAGE
● Market Structure Analysis:
Identify key price levels where significant trading activity occurred, which can act as support and resistance zones.
● Volume Analysis:
Use the volume mode to understand where the highest trading volumes have occurred, helping to confirm strong price levels.
● Trend Confirmation:
Analyze the distribution of trading activity to confirm or refute trends, mark important levels as support and resistance, aiding in making more informed trading decisions.
● Frequency Distribution:
In statistics, a frequency distribution is a list of the values that a variable takes in a sample. It is usually a list. Displayed as a histogram.
⚪ SETTINGS
Source: Select the price data to use for the profile calculation (default: hl2).
Move Profile: Set the number of bars to offset the profile from the current bar (default: 100).
Mode: Choose between "Frequency" and "Volume" for the profile calculation.
Profile Color: Customize the color of the profile lines.
Lookback Period: Uses 5000 bars for daily and higher timeframes, otherwise 10000 bars.
The Frequency Profile indicator is a powerful tool for visualizing price levels with significant trading activity, whether in terms of frequency or volume. Its dynamic calculation and customizable settings make it a versatile addition to any trading strategy.
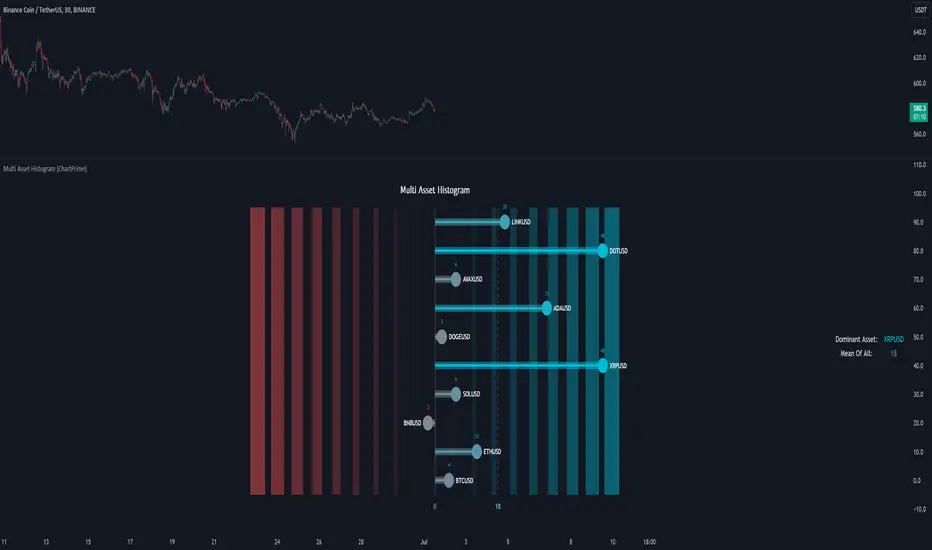
Multi Asset Histogram [ChartPrime]Multi Asset Histogram Indicator
Overview:
The "Multi Asset Histogram" indicator provides a comprehensive visualization of the performance of multiple assets relative to each other. By calculating a score for each asset and displaying it in a histogram format, this indicator helps traders quickly identify the trends, dominant asset and the average performance of the assets in the selected group.
Key Features:
◆ Multi-Asset Score Calculation:
The indicator calculates a trend score for each selected asset based on the price source (e.g., hl2).
The trend score is determined by comparing the current price to the prices over the past bars back defined by user, adding or subtracting points based on whether the current price is higher or lower than previous prices.
// Score Function
trscore(src) =>
total = 0.0
for i = 1 to 50
total += (src >= nz(src ) ? 1 : -1)
total
◆ Flexible Symbol Input:
Traders can input up to 10 different symbols (e.g., BTCUSD, ETHUSD, etc.) to be included in the histogram analysis.
◆ Dynamic Visualization:
A histogram is plotted for each asset, with bars colored based on the score, providing a clear visual representation of the relative performance.
Color gradients from red to aqua indicate the performance, with red representing negative scores and aqua representing positive scores.
◆ Adaptive Histogram Lines:
The width and placement of histogram lines adapt based on the calculated scores, ensuring clear visualization regardless of the values.
Dashed lines represent the mean score of all assets, helping traders identify the overall market trend.
◆Detailed Labels and Values:
Labels are placed on the histogram to display the exact score for each asset.
Mean value and zero line labels provide additional context for the overall performance.
◆ Visual Scaling Lines:
Zero line and mean line are clearly marked, helping traders understand the distribution and scale of scores.
Scales on the left and right of the histogram indicate the performance range.
◆ Informative Table:
A table is displayed on the chart, showing the dominant asset (the one with the highest score) and the mean score of all assets.
The table updates dynamically to reflect real-time changes in asset performance.
◆ Settings:
Length: The value of number bars back is greater or less than the current value of the source
Source: The price source to be used for score calculation (e.g., hl2).
Symbols: Up to 10 different asset symbols can be input for analysis.
Usage Notes:
This indicator is useful for traders who monitor multiple assets simultaneously and need a quick visual reference to identify the strongest and weakest performers.
The color coding and dynamic labels make it easy to interpret the relative performance and make informed trading decisions.
This indicator is designed to enhance multi-asset analysis by providing a clear, visual representation of each asset's performance relative to the others, making it easier to identify trends and dominant assets in the market.
Asset Drawdown & Drawdown HeatMap [InvestorUnknown]Overview
The "Asset Drawdown & Drawdown HeatMap" indicator is designed for educational purposes to help users visualize and analyze the drawdowns of various assets. It highlights both recent and historical drawdowns, offering valuable insights into the performance and risk of different investments. Additionally, it can serve as a complementary analysis tool for trading and investing decisions.
Features
Drawdown Calculation:
Computes the drawdown from the highest value (ATH) to the current value, showing the percentage decline.
Displays both the current drawdown and the maximum historical drawdown for the selected assets.
HeatMap Visualization:
Uses a gradient color scheme to represent the magnitude of drawdowns over a specified lookback period.
Helps identify periods of significant decline and recovery visually.
Multiple Assets:
Supports up to 10 different assets (adding more would make it harder to see the drawdowns of different assets), allowing users to compare drawdowns across various symbols.
Each asset can be individually plotted and color-coded for clarity.
Customizable Settings:
User inputs for high and low value calculations, color preferences, and lookback periods.
Option to color bars based on the drawdown heatmap.
Detailed Functionality
Drawdown Calculation:
The DD() function calculates the current drawdown and the maximum historical drawdown based on the high and low values.
The drawdown is calculated as 100 - (lowvalue / ATH * 100), where ATH is the highest value observed so far.
// - - - - - Custom Function - - - - - //{
DD() =>
ATH = highvalue
ATH := na(ATH ) ? highvalue : math.max(highvalue, ATH )
Drawdown = 100 - lowvalue / ATH * 100
MaxDrawdown = Drawdown
MaxDrawdown := na(MaxDrawdown ) ? Drawdown : math.max(Drawdown, MaxDrawdown )
//}
Security Request:
Uses the request.security() function to fetch drawdown data for each specified asset on a daily timeframe.
Computes both current drawdown (TnDD) and maximum drawdown (TnMDD) for each asset.
// - - - - - Create Variables - - - - - //{
= request.security("", "1D", DD()) // Chart
= request.security(t1, "1D", DD())
= request.security(t2, "1D", DD())
= request.security(t3, "1D", DD())
= request.security(t4, "1D", DD())
= request.security(t5, "1D", DD())
= request.security(t6, "1D", DD())
= request.security(t7, "1D", DD())
= request.security(t8, "1D", DD())
= request.security(t9, "1D", DD())
= request.security(t10, "1D", DD())
//}
Plotting:
Plots the drawdown values for each asset on the chart, with the option to enable or disable plotting for individual assets.
Colors the plotted lines and labels based on user-specified preferences.
HeatMap:
Creates a heatmap color gradient based on the drawdown values over the lookback period.
Colors the bars on the chart according to the heatmap to visualize drawdown severity over time.
// - - - - - HeatMap - - - - - //{
heatcol = color.from_gradient(T0DD, ta.lowest(T0DD,lookback), ta.highest(T0DD,lookback), topcol, botcol)
barcolor(colbars ? heatcol : na)
//}
Labels:
Displays labels for each asset's drawdown value at the end of the chart for quick reference.
This indicator is an excellent tool for educational purposes, helping users understand drawdown dynamics and their implications on asset performance. It also provides a visual aid for monitoring and comparing drawdowns across multiple assets, which can be beneficial for making informed trading and investment decisions.

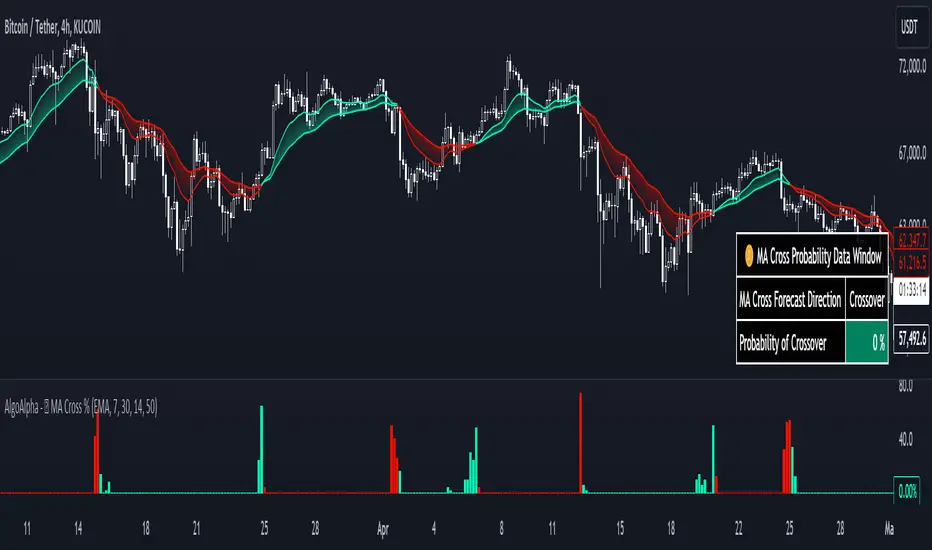
Moving Average Cross Probability [AlgoAlpha]Moving Average Cross Probability 📈✨
The Moving Average Cross Probability by AlgoAlpha calculates the probability of a cross-over or cross-under between the fast and slow values of a user defined Moving Average type before it happens, allowing users to benefit by front running the market.
✨ Key Features:
📊 Probability Histogram: Displays the Probability of MA cross in the form of a histogram.
🔄 Data Table: Displays forecast information for quick analysis.
🎨 Customizable MAs: Choose from various moving averages and customize their length.
🚀 How to Use:
🛠 Add Indicator: Add the indicator to favorites, and customize the settings to suite your trading style.
📊 Analyze Market: Watch the indicator to look for trend shifts early or for trend continuations.
🔔 Set Alerts: Get notified of bullish/bearish points.
✨ How It Works:
The Moving Average Cross Probability Indicator by AlgoAlpha determines the probability by looking at a probable range of values that the price can take in the next bar and finds out what percentage of those possibilities result in the user defined moving average crossing each other. This is done by first using the HMA to predict what the next price value will be, a standard deviation based range is then calculated. The range is divided by the user defined resolution and is split into multiple levels, each of these levels represent a possible value for price in the next bar. These possible predicted values are used to calculate the possible MA values for both the fast and slow MAs that may occur in the next bar and are then compared to see how many of those possible MA results end up crossing each other.
Stay ahead of the market with the Moving Average Cross Probability Indicator AlgoAlpha! 📈💡
Exponential Grid [Phi, Pi, Euler]If you disagree with one of the EMH principles that price is too random, then by definition you must agree that historic price has deterministic function to a scenario ahead.
I personally believe that constants like phi, pi and e can mimic exponential growth of the price.
In this script, first grid is based on the Lowest price multiplied with self fraction of the constant.
For example:
If you are familiar with fib ratio 1.272, then you must know that it is 1.618 to the power of 0.5.
With default settings of exponent step 0.25
First grid = Lowest price x phi^0.25
Second grid = Lowest price x phi^0.25x2
Third grid = Lowest price x phi^0.25x3 and so on
The script will automatically find the lowest price and update the grid values.
Or you can set up your custom Lowest price manually if you feel like the All Time Low level loses its relevance value after long period.
There are 64 grids including Lowest price level. And it wasn't by a chance. Pine Script has a limitation of max 64 plots. Number of grids shown in the chart depends on the highest price. Once price breaks above ATH a couple of next grids will be plotted automatically. In most cases if everything is plotted, the chart appears squeezed and you'll need to zoom in to see it. Therefore, I adjusted it relatively to the scale of the chart for the comfort.
In some cases 64 plots aren't enough to cover the whole chart. For example, let's take a look at NVIDIA chart:
Since the price has started with 0.0333, it is way too small to cover all with default settings.
We are left with 2 choices:
Either Enable "Round"
OR increase Exponent Step (from 0.25 to 0.5 in the particular example below)
If you set constant to pi or e which is a bigger number than phi, expect the gaps to be bigger. To reduce it to a more gradual way of expansion you can decrease Exponent Step.

Volume, Volatility, and Momentum Metrics IndicatorVolume, Volatility, and Momentum Metrics Indicator
Welcome to our comprehensive TradingView indicator designed to provide traders with essential volume, volatility, and momentum metrics. This powerful tool is ideal for traders looking to enhance their market analysis by visualizing key indicators in a concise and easy-to-read format.
Key Features
1. Volume Metrics:
• Daily Dollar Volume: Understand the monetary value of the traded volume each day.
• Relative Volume (RVOL) Day: Compare the current volume to the previous day’s volume to gauge trading activity.
• Relative Volume (RVOL) 30D: Assess the average trading volume over the past 30 days.
• Relative Volume (RVOL) 90D: Evaluate the average trading volume over the past 90 days.
2. Volatility and Momentum Metrics:
• Average Daily Range (ADR) %: Measure the average daily price range as a percentage of the current price.
• Average True Range (ATR): Track the volatility by calculating the average true range over a specified period.
• Relative Strength Index (RSI): Determine the momentum by analyzing the speed and change of price movements.
3. Customizable Table Positions:
• Place the volume metrics table and the volatility/momentum metrics table in the bottom-left or bottom-right corners of your chart for optimal visibility and convenience.
Why Use This Indicator?
• Enhanced Market Analysis: Quickly assess volume trends, volatility, and momentum to make informed trading decisions.
• User-Friendly Interface: The clear and concise tables provide at-a-glance information without cluttering your chart.
• Customization Options: Choose where to display the tables to suit your trading style and preferences.
How It Works
This indicator uses advanced calculations to provide real-time data on trading volume, price range, and momentum. By displaying this information in separate, neatly organized tables, traders can easily monitor these critical metrics without diverting their focus from the main chart.
Who Can Benefit?
• Day Traders: Quickly gauge intraday trading activity and volatility.
• Swing Traders: Analyze longer-term volume trends and momentum to identify potential trade setups.
• Technical Analysts: Utilize comprehensive metrics to enhance technical analysis and trading strategies.
Get Started
To add this powerful indicator to your TradingView chart, simply search for “Volume, Volatility, and Momentum Metrics” in the TradingView public library, or use the provided link to add it directly to your chart. Enhance your trading analysis and make more informed decisions with our comprehensive TradingView indicator.
Price & Moving Average + Financial IndicatorThis indicator displays:
Moving Average that can be set into SMA or EMA: Default setting is SMA 50
Label price for today's MA
Basic Financial Data:
Type of Sector
Type of Industry
P/E Ratio
Price to Book Ratio
ROE
Revenue (FQ)
Earnings (FQ)
Once again, I let the script open for you guys to custom it based on your own preferences. Hope you guys enjoy it!
