Statistics
3D Surface Modeling [PhenLabs]📊 3D Surface Modeling
Version: PineScript™ v6
📌 Description
The 3D Surface Modeling indicator revolutionizes technical analysis by generating three-dimensional visualizations of multiple technical indicators across various timeframes. This advanced analytical tool processes and renders complex indicator data through a sophisticated matrix-based calculation system, creating an intuitive 3D surface representation of market dynamics.
The indicator employs array-based computations to simultaneously analyze multiple instances of selected technical indicators, mapping their behavior patterns across different temporal dimensions. This unique approach enables traders to identify complex market patterns and relationships that may be invisible in traditional 2D charts.
🚀 Points of Innovation
Matrix-Based Computation Engine: Processes up to 500 concurrent indicator calculations in real-time
Dynamic 3D Rendering System: Creates depth perception through sophisticated line arrays and color gradients
Multi-Indicator Integration: Seamlessly combines VWAP, Hurst, RSI, Stochastic, CCI, MFI, and Fractal Dimension analyses
Adaptive Scaling Algorithm: Automatically adjusts visualization parameters based on indicator type and market conditions
🔧 Core Components
Indicator Processing Module: Handles real-time calculation of multiple technical indicators using array-based mathematics
3D Visualization Engine: Converts indicator data into three-dimensional surfaces using line arrays and color mapping
Dynamic Scaling System: Implements custom normalization algorithms for different indicator types
Color Gradient Generator: Creates depth perception through programmatic color transitions
🔥 Key Features
Multi-Indicator Support: Comprehensive analysis across seven different technical indicators
Customizable Visualization: User-defined color schemes and line width parameters
Real-time Processing: Continuous calculation and rendering of 3D surfaces
Cross-Timeframe Analysis: Simultaneous visualization of indicator behavior across multiple periods
🎨 Visualization
Surface Plot: Three-dimensional representation using up to 500 lines with dynamic color gradients
Depth Indicators: Color intensity variations showing indicator value magnitude
Pattern Recognition: Visual identification of market structures across multiple timeframes
📖 Usage Guidelines
Indicator Selection
Type: VWAP, Hurst, RSI, Stochastic, CCI, MFI, Fractal Dimension
Default: VWAP
Starting Length: Minimum 5 periods
Default: 10
Step Size: Interval between calculations
Range: 1-10
Visualization Parameters
Color Scheme: Green, Red, Blue options
Line Width: 1-5 pixels
Surface Resolution: Up to 500 lines
✅ Best Use Cases
Multi-timeframe market analysis
Pattern recognition across different technical indicators
Trend strength assessment through 3D visualization
Market behavior study across multiple periods
⚠️ Limitations
High computational resource requirements
Maximum 500 line restriction
Requires substantial historical data
Complex visualization learning curve
🔬 How It Works
1. Data Processing:
Calculates selected indicator values across multiple timeframes
Stores results in multi-dimensional arrays
Applies custom scaling algorithms
2. Visualization Generation:
Creates line arrays for 3D surface representation
Applies color gradients based on value magnitude
Renders real-time updates to surface plot
3. Display Integration:
Synchronizes with chart timeframe
Updates surface plot dynamically
Maintains visual consistency across updates
🌟 Credits:
Inspired by LonesomeTheBlue (modified for multiple indicator types with scaling fixes and additional unique mappings)
💡 Note:
Optimal performance requires sufficient computing resources and historical data. Users should start with default settings and gradually adjust parameters based on their analysis requirements and system capabilities.

Average Daily % Change by Weekday📊 Average Daily % Change by Weekday
This script calculates and displays the average daily percentage change for each weekday (Monday through Sunday) based on historical price data. It helps traders analyze which days tend to be bullish or bearish over a selected backtest date range.
✅ Features:
Customizable date range (From Year/Month/Day to To Year/Month/Day)
Calculates average % change for each weekday (Mon–Sun)
Supports assets that trade 7 days (e.g., crypto)
Color-coded outputs (green = positive, red = negative)
Final results shown as a table in the bottom-right corner
Works only on the 1D timeframe (daily)
🧠 How it works:
For each day within the selected date range:
The script calculates the % change as: (Close - Open) / Open * 100
Then, it groups the data by weekday and averages the values
This gives you insight into how each day of the week behaves historically for the current asset.
⚠️ Notes:
This script only works on daily (1D) timeframes.
For most accurate results, use it on assets with long trading history (e.g., BTCUSD).
Designed for educational and statistical analysis purposes.

Live 30-Point Horizontal Lines with Price LabelsLive 30-Point Horizontal Lines with Price Labels for upper and below current price

Correlation Coefficient with MA & BB中文版介紹
相關係數、移動平均線與布林帶指標 (Correlation Coefficient with MA & BB)
這個 Pine Script 指標是一款強大的工具,旨在幫助交易者和投資者深入分析兩個市場標的之間的關係強度與方向,並結合移動平均線 (MA) 和布林帶 (BB) 來進一步洞察這種關係的趨勢和波動性。
無論您是想尋找配對交易機會、管理投資組合風險,還是僅僅想更好地理解市場動態,這個指標都能提供有價值的見解。
指標特色與功能:
動態相關係數計算:
您可以選擇任何您想比較的股票、商品或加密貨幣代號(例如,預設為 GOOG)。
指標會自動計算當前圖表(主數據源,預設為收盤價)與您指定標的之間的相關係數。
相關係數值介於 -1 (完美負相關) 至 1 (完美正相關) 之間,0 表示無線性關係。
視覺化呈現相關係數線,並標示 1、0、-1 參考水平線,同時填充完美相關區間,讓您一目了然。
特別之處:程式碼中包含了 ticker.modify,確保比較標的數據考慮了股息調整或延長交易時段,使相關性分析更加精準。
相關係數的移動平均線 (MA):
為了平滑相關係數的短期波動,指標提供了多種移動平均線類型供您選擇,包括:SMA、EMA、WMA、SMMA。
您可以設定計算 MA 的週期長度(預設 20 週期)。
這條 MA 線有助於識別相關係數的長期趨勢,判斷兩者關係是趨於增強還是減弱。
相關係數的布林帶 (BB):
將布林帶應用於相關係數,以衡量其波動性和相對高低水平。
中軌與您選擇的移動平均線保持一致。
上軌和下軌則根據相關係數的標準差和您設定的 Z 值(預設 2.0 倍標準差)動態調整。
布林帶可以幫助您識別相關係數何時處於極端水平,可能預示著未來會回歸均值。
如何運用這個指標?
配對交易策略:當兩個通常高度相關的資產,其相關係數短期內顯著偏離平均水平(例如,一個資產價格上漲而另一個原地踏步),您可能可以考慮利用此「失衡」進行配對交易。
投資組合多元化:了解不同資產之間的相關性,有助於構建更穩健的投資組合,避免過度集中於同向變動的資產,有效分散風險。
市場趨勢洞察:透過觀察相關係數的趨勢和波動,您可以更好地理解不同市場板塊或資產類別之間的聯動性,為您的宏觀經濟分析提供數據支持。
請注意,相關性不等於因果性。使用此指標時,請結合您的整體交易策略、宏觀經濟分析以及其他技術指標進行綜合判斷。
English Version Introduction
Correlation Coefficient with Moving Average & Bollinger Bands Indicator (Correlation Coefficient with MA & BB)
This Pine Script indicator is a powerful tool designed to help traders and investors deeply analyze the strength and direction of the relationship between two market instruments. It integrates Moving Averages (MA) and Bollinger Bands (BB) to further insight into the trend and volatility of this relationship.
Whether you're looking for pair trading opportunities, managing portfolio risk, or simply aiming to better understand market dynamics, this indicator can provide valuable insights.
Indicator Features & Functionality:
Dynamic Correlation Coefficient Calculation:
You can select any symbol you wish to compare (e.g., default is GOOG), be it stocks, commodities, or cryptocurrencies.
The indicator automatically calculates the correlation coefficient between the current chart (main data source, default is close price) and your specified symbol.
Correlation values range from -1 (perfect negative correlation) to 1 (perfect positive correlation), with 0 indicating no linear relationship.
It visually plots the correlation line, marks 1, 0, -1 reference levels, and fills the perfect correlation zone for clear visualization.
Special Feature: The code includes ticker.modify, ensuring that the comparative symbol's data accounts for dividend adjustments or extended trading hours, leading to more precise correlation analysis.
Moving Average (MA) for Correlation:
To smooth out short-term fluctuations in the correlation coefficient, the indicator offers multiple MA types for you to choose from: SMA, EMA, WMA, SMMA.
You can set the length of the MA period (default 20 periods).
This MA line helps identify the long-term trend of the correlation coefficient, indicating whether the relationship between the two instruments is strengthening or weakening.
Bollinger Bands (BB) for Correlation:
Bollinger Bands are applied to the correlation coefficient itself to gauge its volatility and relative high/low levels.
The middle band aligns with your chosen Moving Average.
The upper and lower bands dynamically adjust based on the correlation coefficient's standard deviation and your set Z-score (default 2.0 standard deviations).
Bollinger Bands can help you identify when the correlation coefficient is at extreme levels, potentially signaling a future reversion to the mean.
How to Utilize This Indicator:
Pair Trading Strategies: When two typically highly correlated assets show a significant short-term deviation from their average correlation (e.g., one asset's price rises while the other stagnates), you might consider exploiting this "imbalance" for pair trading.
Portfolio Diversification: Understanding the correlation between different assets helps build a more robust investment portfolio, preventing over-concentration in co-moving assets and effectively diversifying risk.
Market Trend Insight: By observing the trend and volatility of the correlation coefficient, you can better understand the联动 (interconnectedness) between different market sectors or asset classes, providing data support for your macroeconomic analysis.
Please note that correlation does not imply causation. When using this indicator, combine it with your overall trading strategy, macroeconomic analysis, and other technical indicators for comprehensive decision-making.

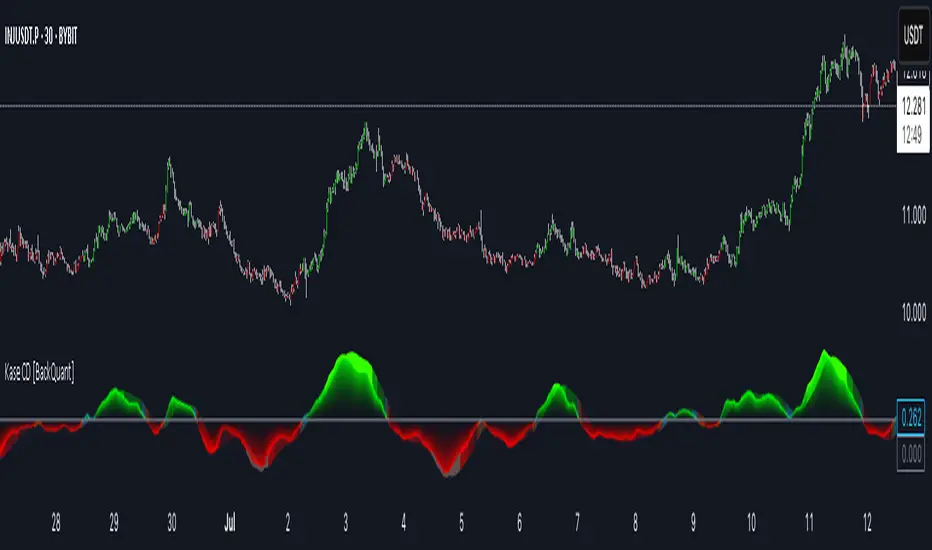
Kase Convergence Divergence [BackQuant]Kase Convergence Divergence
The Kase Convergence Divergence is a sophisticated oscillator designed to measure directional market strength through the lens of volatility-adjusted log return structures. Inspired by Cynthia Kase’s work on statistical momentum and price projection ranges, this unique indicator offers a hybrid framework that merges signal processing, multi-length sweep logic, and adaptive smoothing techniques.
Unlike traditional momentum oscillators like MACD or RSI, which rely on static moving average differences, KCD introduces a dual-process system combining:
Kase-style statistical range projection (via log returns and volatility),
A sweeping loop of lookback lengths for robustness,
First and second derivative modes to capture both velocity and acceleration of price movement.
Core Logic & Computation
The KCD calculation is centered on two volatility-normalized transforms:
KSDI Up: Measures how far the current high has moved relative to a past low, normalized by return volatility.
KSDI Down: Measures how far the current low has moved relative to a past high, also normalized.
For every length in a user-defined sweep range (e.g., 25–35), both KSDI_up and KSDI_dn are computed, and their maximum values across the loop are retained. The difference between these two max values produces the raw signal:
KPO (Kase Projection Oscillator): Measures directional skew.
KCD (Kase Convergence Divergence): Defined as KPO – MA(KPO) — similar in spirit to MACD but structurally different.
Users can choose to visualize either the first derivative (KPO) , or the second derivative (KCD) , depending on market conditions or strategy style.
Key Features
✅ Multi-Length Sweep Logic: Improves signal reliability by aggregating statistical range projections across a set of lookbacks.
✅ Advanced Smoothing Modes: Supports DEMA, HMA, TEMA, LINREG, WMA and more for dynamic adaptation.
✅ Dual Derivative Modes: Choose between speed (first derivative) or smoothness (second derivative) to fit your trading regime.
✅ Color-Encoded Signal Bands: Heatmap-style oscillator coloring enhances visual feedback on trend strength.
✅ Candlestick Painting: Optional bar coloring makes it easy to spot trend shifts on the main chart.
✅ Adaptive Fill Zones: Green and red fills between the oscillator and zero line help distinguish bullish and bearish regimes at a glance.
Practical Applications
📈 Trend Confirmation: Use KCD as a secondary confirmation layer after breakout or pullback entries.
📉 Momentum Shifts: Crossover and crossunder of the zero line highlight potential regime changes.
📊 Strategy Filters: Incorporate into algos to avoid trendless or mean-reverting environments.
🧪 Derivative Switching: Flip between KPO and KCD modes depending on whether you want to measure acceleration or deceleration of price flow.
Alerts & Signals
Two built-in alerts help you catch regime shifts in real time:
Long Signal: Triggered when the selected oscillator crosses above zero.
Short Signal: Triggered when it crosses below zero.
These events can be used to generate entries, exits, or trend validation cues in multi-layer systems.
Conclusion
The Kase Convergence Divergence goes beyond traditional oscillators by offering a volatility-normalized, derivative-aware signal engine with enhanced visual dynamics. Its sweeping architecture and dynamic fill logic make it especially powerful for identifying trending environments, filtering chop, and adding statistical rigor to your trading toolkit.
Whether you’re a discretionary trader seeking precision, or a quant looking to model more robust return structures, KCD offers a creative yet analytically grounded solution.
Capitalife IndexCapitalife Index
Jahres Rendite seit 2008 basierend auf Backtesting & Live Ergebnisse

Digit Sum Mark (3/6/9 + Price ~33 ±15)This indicator highlights the price bars where the digit sum of high or low equals 3, 6, or 9, and the closing price is within a specific range (around ₹33 ±15, i.e., mod 100 ∈ ).
✨ Key Features:
Calculates digit sum of high and low values.
Adds +1 if the decimal portion > 0.50 (smart rounding logic).
Only activates when close price mod 100 is between 18 to 48, a zone inspired by the resonance around 33.
Marks the chart with green downward arrows (for high) and red upward arrows (for low) when digit sum = 3, 6, or 9.
📌 Inspired by Gann numerology and price vibration logic – especially the powerful influence of 3, 6, and 9 as noted by Nikola Tesla.
🚨 Best used on intraday or positional charts where price oscillates frequently around round figures.
🧠 Try pairing this with support/resistance tools for better accuracy!
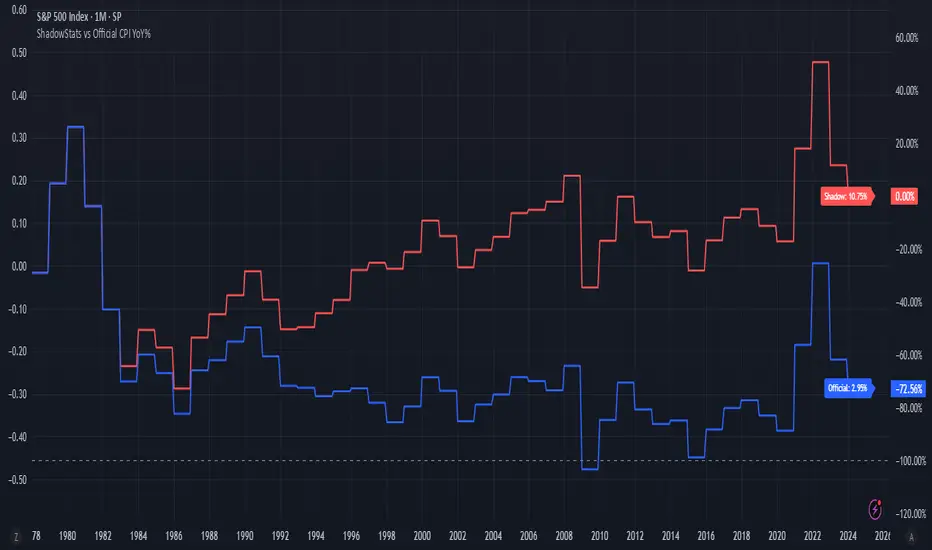
ShadowStats vs Official CPI YoY%This chart visualizes and compares the year-over-year (YoY) percentage change in the Consumer Price Index (CPI) as calculated by the U.S. government versus the alternative methodology used by ShadowStats, which reflects pre-1980 inflation measurement techniques. The red line represents ShadowStats' CPI YoY% estimates, while the blue line shows the official CPI YoY% reported by government sources. This side-by-side view highlights the divergence in reported inflation rates over time, particularly from the 1980s onward, offering a visual representation of how different calculation methods can lead to vastly different interpretations of inflation and purchasing power loss.

Trading CalculatorTrading Calculator Indicator
VIBE CODED WITH GROK 3
The Trading Calculator is a Pine Script indicator designed to perform quick and useful trading-related calculations directly on your chart. It allows traders to execute basic arithmetic operations—such as addition, subtraction, multiplication, and division—as well as calculate percent change and average using either numerical values or trading variables (e.g., close, open, high, low, volume). The indicator displays its results in a table that resembles a calculator interface, making it both functional and visually intuitive. Unlike typical indicators, it does not overlay on the price chart but instead appears in a separate pane.
Inputs
Formula (new | old): First value or variable (e.g., 100, close, close ). Example: close uses the current closing price.
Operator: Mathematical operation (e.g., Plus, Minus, Multiply). Example: Plus adds the two inputs.
Second Input: Second value or variable (e.g., 50, open, close ). Example: open uses the current opening price.
Risk Distribution HistogramStatistical risk visualization and analysis tool for any ticker 📊
The Risk Distribution Histogram visualizes the statistical distribution of different risk metrics for any financial instrument. It converts risk data into histograms with quartile-based color coding, so that traders can understand their risk, tail-risks, exposure patterns and make data-driven decisions based on empirical evidence rather than assumptions.
The indicator supports multiple risk calculation methods, each designed for different aspects of market analysis, from general volatility assessment to tail risk analysis.
Risk Measurement Methods
Standard Deviation
Captures raw daily price volatility by measuring the dispersion of price movements. Ideal for understanding overall market conditions and timing volatility-based strategies.
Use case: Options trading and volatility analysis.
Average True Range (ATR)
Measures true range as a percentage of price, accounting for gaps and limit moves. Valuable for position sizing across different price levels.
Use case: Position sizing and stop-loss placement.
The chart above illustrates how ATR statistical distribution can be used by looking at the ATR % of price distribution. For example, 90% of the movements are below 5%.
Downside Deviation
Only considers negative price movements, making it ideal for checking downside risk and capital protection rather than capturing upside volatility.
Use case: Downside protection strategies and stop losses.
Drawdown Analysis
Tracks peak-to-trough declines, providing insight into maximum loss potential during different market conditions.
Use case: Risk management and capital preservation.
The chart above illustrates tale risk for the asset (TQQQ), showing that it is possible to have drawdowns higher than 20%.
Entropy-Based Risk (EVaR)
Uses information theory to quantify market uncertainty. Higher entropy values indicate more unpredictable price action, valuable for detecting regime changes.
Use case: Advanced risk modeling and tail-risk.
VIX Histogram
Incorporates the market's fear index directly into analysis, showing how current volatility expectations compare to historical patterns. The CAPITALCOM:VIX histogram is independent from the ticker on the chart.
Use case: Volatility trading and market timing.
Visual Features
The histogram uses quartile-based color coding that immediately shows where current risk levels stand relative to historical patterns:
Green (Q1): Low Risk (0-25th percentile)
Yellow (Q2): Medium-Low Risk (25-50th percentile)
Orange (Q3): Medium-High Risk (50-75th percentile)
Red (Q4): High Risk (75-100th percentile)
The data table provides detailed statistics, including:
Count Distribution: Historical observations in each bin
PMF: Percentage probability for each risk level
CDF: Cumulative probability up to each level
Current Risk Marker: Shows your current position in the distribution
Trading Applications
When current risk falls into upper quartiles (Q3 or Q4), it signals conditions are riskier than 50-75% of historical observations. This guides position sizing and portfolio adjustments.
Key applications:
Position sizing based on empirical risk distributions
Monitoring risk regime changes over time
Comparing risk patterns across timeframes
Risk distribution analysis improves trade timing by identifying when market conditions favor specific strategies.
Enter positions during low-risk periods (Q1)
Reduce exposure in high-risk periods (Q4)
Use percentile rankings for dynamic stop-loss placement
Time volatility strategies using distribution patterns
Detect regime shifts through distribution changes
Compare current conditions to historical benchmarks
Identify outlier events in tail regions
Validate quantitative models with empirical data
Configuration Options
Data Collection
Lookback Period: Control amount of historical data analyzed
Date Range Filtering: Focus on specific market periods
Sample Size Validation: Automatic reliability warnings
Histogram Customization
Bin Count: 10-50 bins for different detail levels
Auto/Manual Bin Width: Optimize for your data range
Visual Preferences: Custom colors and font sizes
Implementation Guide
Start with Standard Deviation on daily charts for the most intuitive introduction to distribution-based risk analysis.
Method Selection: Begin with Standard Deviation
Setup: Use daily charts with 20-30 bins
Interpretation: Focus on quartile transitions as signals
Monitoring: Track distribution changes for regime detection
The tool provides comprehensive statistics including mean, standard deviation, quartiles, and current position metrics like Z-score and percentile ranking.
Enjoy, and please let me know your feedback! 😊🥂

Alpha - Combined BreakoutThis Pine Script indicator, "Alpha - Combined Breakout," is a combination between Smart Money Breakout Signals and UT Bot Alert, The UT Bot Alert indicator was initially developer by Yo_adriiiiaan
The idea of original code belongs HPotter.
This Indicator helps you identify potential trading opportunities by combining two distinct strategies: Smart Money Breakout and a modified UT Bot (likely a variation of the Ultimate Trend Bot). It provides visual signals, draws lines for potential take profit (TP) and stop loss (SL) levels, and includes a dashboard to track performance metrics.
Tutorial:
Understanding and Using the "Alpha - Combined Breakout" Indicator
This indicator is designed for traders looking for confirmation of market direction and potential entry/exit points by blending structural analysis with a trend-following oscillator.
How it Works (General Concept)
The indicator combines two main components:
Smart Money Breakout: This part identifies significant breaks in market structure, which "smart money" traders often use to gauge shifts in supply and demand. It looks for higher highs/lows or lower highs/lows and flags when these structural points are broken.
UT Bot: This is a trend-following component that generates buy and sell signals based on price action relative to an Average True Range (ATR) based trailing stop.
You can choose to use these signals independently or combined to generate trading alerts and visual cues on your chart. The dashboard provides a quick overview of how well the signals are performing based on your chosen settings and display mode.
Parameters and What They Do
Let's break down each input parameter:
1. Smart Money Inputs
These settings control how the indicator identifies market structure and breakouts.
swingSize (Market Structure Time-Horizon):
What it does: This integer value defines the number of candles used to identify significant "swing" (pivot) points—highs and lows.
Effect: A larger swingSize creates a smoother market structure, focusing on longer-term trends. This means signals might appear less frequently and with some delay but could be more reliable for higher timeframes or broader market movements. A smaller swingSize will pick up more minor market structure changes, leading to more frequent but potentially noisier signals, suitable for lower timeframes or scalping.
Analogy: Think of it like a zoom level on your market structure map. Higher values zoom out, showing only major mountain ranges. Lower values zoom in, showing every hill and bump.
bosConfType (BOS Confirmation Type):
What it does: This string input determines how a Break of Structure (BOS) is confirmed. You have two options:
'Candle Close': A breakout is confirmed only if a candle's closing price surpasses the previous swing high (for bullish) or swing low (for bearish).
'Wicks': A breakout is confirmed if any part of the candle (including its wick) surpasses the previous swing high or low.
Effect: 'Candle Close' provides stronger, more conservative confirmation, as it implies sustained price movement beyond the structure. 'Wicks' provides earlier, more aggressive signals, as it captures momentary breaches of the structure.
Analogy: Imagine a wall. 'Candle Close' means the whole person must get over the wall. 'Wicks' means even a finger touching over the top counts as a breach.
choch (Show CHoCH):
What it does: A boolean (true/false) input to enable or disable the display of "Change of Character" (CHoCH) labels. CHoCH indicates the first structural break against the current dominant trend.
Effect: When true, it helps identify early signs of a potential trend reversal, as it marks where the market's "character" (its tendency to make higher highs/lows or lower lows/highs) first changes.
BULL (Bullish Color) & BEAR (Bearish Color):
What they do: These color inputs allow you to customize the visual appearance of bullish and bearish signals and lines drawn by the Smart Money component.
Effect: Purely cosmetic, helps with visual identification on the chart.
sm_tp_sl_multiplier (SM TP/SL Multiplier (ATR)):
What it does: A float value that acts as a multiplier for the Average True Range (ATR) to calculate the Take Profit (TP) and Stop Loss (SL) levels specifically when you're in "Smart Money Only" mode. It uses the ATR calculated by the UT Bot's nLoss_ut as its base.
Effect: A higher multiplier creates wider TP/SL levels, potentially leading to fewer trades but larger wins/losses. A lower multiplier creates tighter TP/SL levels, potentially leading to more frequent but smaller wins/losses.
2. UT Bot Alerts Inputs
These parameters control the behavior and sensitivity of the UT Bot component.
a_ut (UT Key Value (Sensitivity)):
What it does: This integer value adjusts the sensitivity of the UT Bot.
Effect: A higher value makes the UT Bot less sensitive to price fluctuations, resulting in fewer and potentially more reliable signals. A lower value makes it more sensitive, generating more signals, which can include more false signals.
Analogy: Like a noise filter. Higher values filter out more noise, keeping only strong signals.
c_ut (UT ATR Period):
What it does: This integer sets the look-back period for the Average True Range (ATR) calculation used by the UT Bot. ATR measures market volatility.
Effect: This period directly influences the calculation of the nLoss_ut (which is a_ut * xATR_ut), thus defining the distance of the trailing stop loss and take profit levels. A longer period makes the ATR smoother and less reactive to sudden price spikes. A shorter period makes it more responsive.
h_ut (UT Signals from Heikin Ashi Candles):
What it does: A boolean (true/false) input to determine if the UT Bot calculations should use standard candlestick data or Heikin Ashi candlestick data.
Effect: Heikin Ashi candles smooth out price action, often making trends clearer and reducing noise. Using them for UT Bot signals can lead to smoother, potentially delayed signals that stay with a trend longer. Standard candles are more reactive to raw price changes.
3. Line Drawing Control Buttons
These crucial boolean inputs determine which type of signals will trigger the drawing of TP/SL/Entry lines and flags on your chart. They act as a priority system.
drawLinesUtOnly (Draw Lines: UT Only):
What it does: If checked (true), lines and flags will only be drawn when the UT Bot generates a buy/sell signal.
Effect: Isolates UT Bot signals for visual analysis.
drawLinesSmartMoneyOnly (Draw Lines: Smart Money Only):
What it does: If checked (true), lines and flags will only be drawn when the Smart Money Breakout logic generates a bullish/bearish breakout.
Effect: Overrides drawLinesUtOnly if both are checked. Isolates Smart Money signals.
drawLinesCombined (Draw Lines: UT & Smart Money (Combined)):
What it does: If checked (true), lines and flags will only be drawn when both a UT Bot signal AND a Smart Money Breakout signal occur on the same bar.
Effect: Overrides both drawLinesUtOnly and drawLinesSmartMoneyOnly if checked. Provides the strictest entry criteria for line drawing, looking for strong confluence.
Dashboard Metrics Explained
The dashboard provides performance statistics based on the lines drawing control button selected. For example, if "Draw Lines: UT Only" is active, the dashboard will show stats only for UT Bot signals.
Total Signals: The total number of buy or sell signals generated by the selected drawing mode.
TP1 Win Rate: The percentage of signals where the price reached Take Profit 1 (TP1) before hitting the Stop Loss.
TP2 Win Rate: The percentage of signals where the price reached Take Profit 2 (TP2) before hitting the Stop Loss.
TP3 Win Rate: The percentage of signals where the price reached Take Profit 3 (TP3) before hitting the Stop Loss. (Note: TP1, TP2, TP3 are in order of distance from entry, with TP3 being furthest.)
SL before any TP rate: This crucial metric shows the number of times the Stop Loss was hit / the percentage of total signals where the stop loss was triggered before any of the three Take Profit levels were reached. This gives you a clear picture of how often a trade resulted in a loss without ever moving into profit target territory.
Short Tutorial: How to Use the Indicator
Add to Chart: Open your TradingView chart, go to "Indicators," search for "Alpha - Combined Breakout," and add it to your chart.
Access Settings: Once added, click the gear icon next to the indicator name on your chart to open its settings.
Choose Your Signal Mode:
For UT Bot only: Uncheck "Draw Lines: Smart Money Only" and "Draw Lines: UT & Smart Money (Combined)". Ensure "Draw Lines: UT Only" is checked.
For Smart Money only: Uncheck "Draw Lines: UT Only" and "Draw Lines: UT & Smart Money (Combined)". Ensure "Draw Lines: Smart Money Only" is checked.
For Combined Signals: Check "Draw Lines: UT & Smart Money (Combined)". This will override the other two.
Adjust Parameters:
Start with default settings. Observe how the signals appear on your chosen asset and timeframe.
Refine Smart Money: If you see too many "noisy" market structure breaks, increase swingSize. If you want earlier breakouts, try "Wicks" for bosConfType.
Refine UT Bot: Adjust a_ut (Sensitivity) to get more or fewer UT Bot signals. Change c_ut (ATR Period) if you want larger or smaller TP/SL distances. Experiment with h_ut to see if Heikin Ashi smoothing suits your trading style.
Adjust TP/SL Multiplier: If using "Smart Money Only" mode, fine-tune sm_tp_sl_multiplier to set appropriate risk/reward levels.
Interpret Signals & Lines:
Buy/Sell Flags: These indicate the presence of a signal based on your selected drawing mode.
Entry Line (Blue Solid): This is where the signal was generated (usually the close price of the signal candle).
SL Line (Red/Green Solid): Your calculated stop loss level.
TP Lines (Dashed): Your three calculated take profit levels (TP1, TP2, TP3, where TP3 is the furthest target).
Smart Money Lines (BOS/CHoCH): These lines indicate horizontal levels where market structure breaks occurred. CHoCH labels might appear at the first structural break against the prior trend.
Monitor Dashboard: Pay attention to the dashboard in the top right corner. This dynamically updates to show the win rates for each TP and, crucially, the "SL before any TP rate." Use these statistics to evaluate the effectiveness of the indicator's signals under your current settings and chosen mode.
*
Set Alerts (Optional): You can set up alerts for any of the specific signals (UT Bot Long/Short, Smart Money Bullish/Bearish, or the "Line Draw" combined signals) to notify you when they occur, even if you're not actively watching the chart.
By following this tutorial, you'll be able to effectively use and customize the "Alpha - Combined Breakout" indicator to suit your trading strategy.

Floor and Roof Indicator with SignalsFloor and Roof Indicator with Trading Signals
A comprehensive support and resistance indicator that identifies premium and discount zones with automated signal generation.
Key Features:
Dynamic Support/Resistance Zones: Calculates floor (support) and roof (resistance) levels using price action and volatility
Premium/Discount Zone Identification: Highlights areas where price may find resistance or support
Customizable Signal Frequency: Control how often signals are displayed (every Nth occurrence)
Visual Signal Table: Optional table showing the last 5 long and short signal prices
Multiple Timeframe Compatibility: Works across all timeframes
Technical Details:
Uses ATR-based calculations for dynamic zone width adjustment
Combines Bollinger Bands with highest/lowest price analysis
Smoothing options for cleaner signal generation
Fully customizable colors and display options
How to Use:
Floor Zones (Blue): Potential support areas where long positions may be considered
Roof Zones (Pink): Potential resistance areas where short positions may be considered
Signal Crosses: Visual markers when price interacts with key levels
Signal Table: Track recent signal prices for analysis
Settings:
Length: Period for calculations (default: 200)
Smooth: Smoothing factor for cleaner signals
Zone Width: Adjust the thickness of support/resistance zones
Signal Frequency: Control signal display frequency
Visual Options: Customize colors and table position
Alerts Available:
Long signal alerts when price touches discount zones
Short signal alerts when price reaches premium zones
Educational Purpose: This indicator is designed to help traders identify potential support and resistance areas. Always combine with proper risk management and additional analysis.
This description focuses on the technical aspects and educational value while avoiding any language that could be interpreted as financial advice or guaranteed profits.
Jumping watermark# Jumping watermark
## Function description
- Dynamic watermark: Mainly used to add dynamic watermarks to prevent theft and transfer when recording videos.
- Static watermark: Sharing opinions can easily include information such as trading pairs, cycles, current time, and individual signatures.
### Static watermark:
Display the watermark related to the current trading pair in the center of the chart.
- Configuration items:
- You can choose to configure the display content: current trading pair code and name, cycle, date, time, and individual signature content
### Dynamic watermark
Display the configured watermark content in a dynamic random position.
- Configuration items:
- Turn on or off the display of watermark jumping
- Modify the display text content and style by yourself
----- 中文简介-----
# 跳动水印
## 功能描述
- 动态水印: 主要可用于视频录制时添加动态水印防盗、防搬运。
- 静态水印:观点分享是可方便的带上交易对、周期、当前时间、个签等信息。
### 静态水印:
在图表中心位置显示当前交易对相关信息水印。
- 配置项:
- 可选择配置显示内容:当前交易对代码及名称、周期、日期、时间、个签内容
### 动态水印
动态随机位置显示配置水印内容。
- 配置项:
- 开启或关闭显示水印跳动
- 自行修改配置显示文字内容和样式
Kelly Optimal Leverage IndicatorThe Kelly Optimal Leverage Indicator mathematically applies Kelly Criterion to determine optimal position sizing based on market conditions.
This indicator helps traders answer the critical question: "How much capital should I allocate to this trade?"
Note that "optimal position sizing" does not equal the position sizing that you should have. The Optima position sizing given by the indicator is based on historical data and cannot predict a crash, in which case, high leverage could be devastating.
Originally developed for gambling scenarios with known probabilities, the Kelly formula has been adapted here for financial markets to dynamically calculate the optimal leverage ratio that maximizes long-term capital growth while managing risk.
Key Features
Kelly Position Sizing: Uses historical returns and volatility to calculate mathematically optimal position sizes
Multiple Risk Profiles: Displays Full Kelly (aggressive), 3/4 Kelly (moderate), 1/2 Kelly (conservative), and 1/4 Kelly (very conservative) leverage levels
Volatility Adjustment: Automatically recommends appropriate Kelly fraction based on current market volatility
Return Smoothing: Option to use log returns and smoothed calculations for more stable signals
Comprehensive Table: Displays key metrics including annualized return, volatility, and recommended exposure levels
How to Use
Interpret the Lines: Each colored line represents a different Kelly fraction (risk tolerance level). When above zero, positive exposure is suggested; when below zero, reduce exposure. Note that this is based on historical returns. I personally like to increase my exposure during market downturns, but this is hard to illustrate in the indicator.
Monitor the Table: The information panel provides precise leverage recommendations and exposure guidance based on current market conditions.
Follow Recommended Position: Use the "Recommended Position" guidance in the table to determine appropriate exposure level.
Select Your Risk Profile: Conservative traders should follow the Half Kelly or Quarter Kelly lines, while more aggressive traders might consider the Three-Quarter or Full Kelly lines.
Adjust with Volatility: During high volatility periods, consider using more conservative Kelly fractions as recommended by the indicator.
Mathematical Foundation
The indicator calculates the optimal leverage (f*) using the formula:
f* = μ/σ²
Where:
μ is the annualized expected return
σ² is the annualized variance of returns
This approach balances potential gains against risk of ruin, offering a scientific framework for position sizing that maximizes long-term growth rate.
Notes
The Full Kelly is theoretically optimal for maximizing long-term growth but can experience significant drawdowns. You should almost never use full kelly.
Most practitioners use fractional Kelly strategies (1/2 or 1/4 Kelly) to reduce volatility while capturing most of the growth benefits
This indicator works best on daily timeframes but can be applied to any timeframe
Negative Kelly values suggest reducing or eliminating market exposure
The indicator should be used as part of a complete trading system, not in isolation
Enjoy the indicator! :)
P.S. If you are really geeky about the Kelly Criterion, I recommend the book The Kelly Capital Growth Investment Criterion by Edward O. Thorp and others.

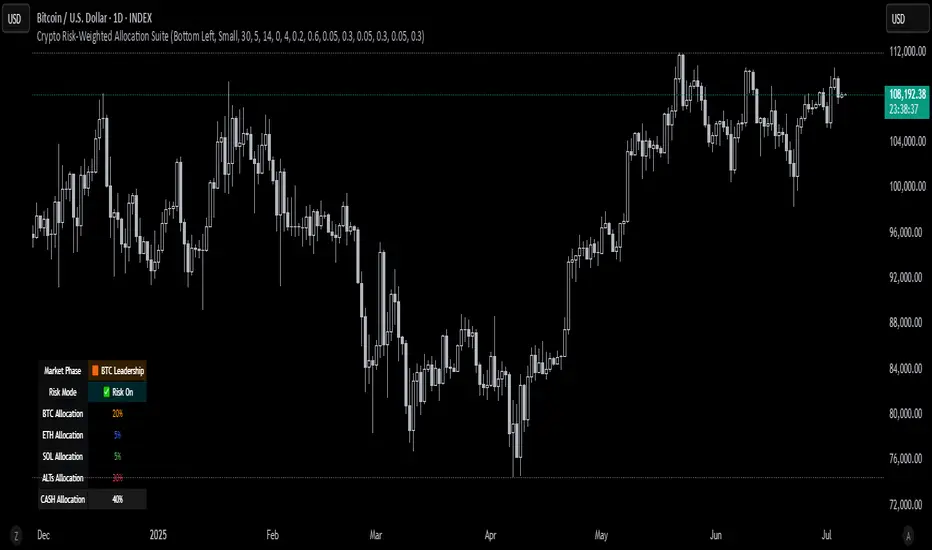
Crypto Risk-Weighted Allocation SuiteCrypto Risk-Weighted Allocation Suite
This indicator is designed to help users explore dynamic portfolio allocation frameworks for the crypto market. It calculates risk-adjusted allocation weights across major crypto sectors and cash based on multi-factor momentum and volatility signals. Best viewed on INDEX:BTCUSD 1D chart. Other charts and timeframes may give mixed signals and incoherent allocations.
🎯 How It Works
This model systematically evaluates the relative strength of:
BTC Dominance (CRYPTOCAP:BTC.D)
Represents Bitcoin’s share of the total crypto market. Rising dominance typically indicates defensive market phases or BTC-led trends.
ETH/BTC Ratio (BINANCE:ETHBTC)
Gauges Ethereum’s relative performance versus Bitcoin. This provides insight into whether ETH is leading risk appetite.
SOL/BTC Ratio (BINANCE:SOLBTC)
Measures Solana’s performance relative to Bitcoin, capturing mid-cap layer-1 strength.
Total Market Cap excluding BTC and ETH (CRYPTOCAP:TOTAL3ES)
Represents Altcoins as a broad category, reflecting appetite for higher-risk assets.
Each of these series is:
✅ Converted to a momentum slope over a configurable lookback period.
✅ Standardized into Z-scores to normalize changes relative to recent behavior.
✅ Smoothed optionally using a Hull Moving Average for cleaner signals.
✅ Divided by ATR-based volatility to create a risk-weighted score.
✅ Scaled to proportionally allocate exposure, applying user-configured minimum and maximum constraints.
🪙 Dynamic Allocation Logic
All signals are normalized to sum to 100% if fully confident.
An overall confidence factor (based on total signal strength) scales the allocation up or down.
Any residual is allocated to cash (unallocated capital) for conservative exposure.
The script automatically avoids “all-in” bias and prevents negative allocations.
📊 Outputs
The indicator displays:
Market Phase Detection (which asset class is currently leading)
Risk Mode (Risk On, Neutral, Risk Off)
Dynamic Allocations for BTC, ETH, SOL, Alts, and Cash
Optional momentum plots for transparency
🧠 Why This Is Unique
Unlike simple dominance indicators or crossovers, this model:
Integrates multiple cross-asset signals (BTC, ETH, SOL, Alts)
Adjusts exposure proportionally to signal strength
Normalizes by volatility, dynamically scaling risk
Includes configurable constraints to reflect your own risk tolerance
Provides a cash fallback allocation when conviction is low
Is entirely non-repainting and based on daily closing data
⚠️ Disclaimer
This script is provided for educational and informational purposes only.
It is not financial advice and should not be relied upon to make investment decisions.
Past performance does not guarantee future results.
Always consult a qualified financial advisor before acting on any information derived from this tool.
🛠 Recommended Use
As a framework to visualize relative momentum and risk-adjusted allocations
For research and backtesting ideas on portfolio allocation across crypto sectors
To help build your own risk management process
This script is not a turnkey strategy and should be customized to fit your goals.
✅ Enjoy exploring dynamic crypto allocations responsibly!
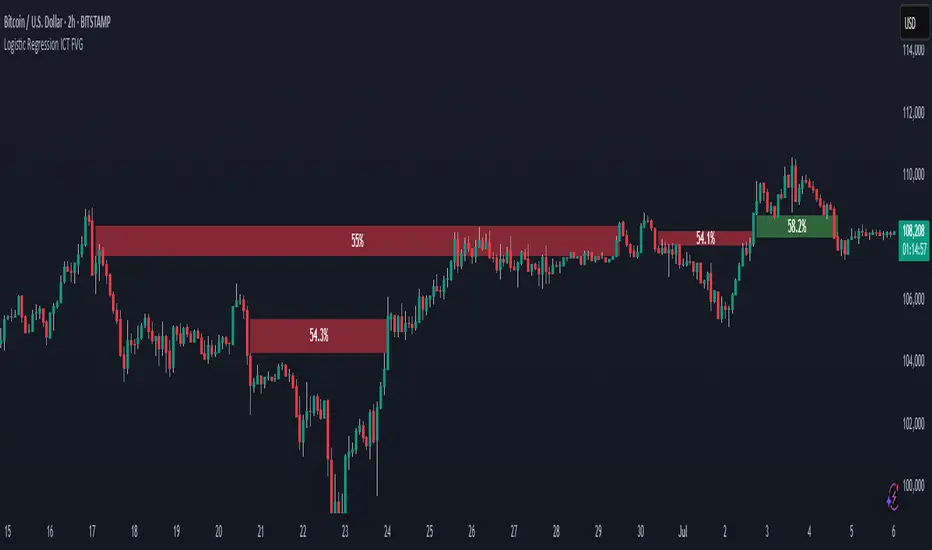
Logistic Regression ICT FVG🚀 OVERVIEW
Welcome to the Logistic Regression Fair Value Gap (FVG) System — a next-gen trading tool that blends precision gap detection with machine learning intelligence.
Unlike traditional FVG indicators, this one evolves with each bar of price action, scoring and filtering gaps based on real market behavior.
🔧 CORE FEATURES
✨ Smart Gap Detection
Automatically identifies bullish and bearish Fair Value Gaps using volatility-aware candle logic.
📊 Probability-Based Filtering
Uses logistic regression to assign each gap a confidence score (0 to 1), showing only high-probability setups.
🔁 Real-Time Retest Tracking
Continuously watches how price interacts with each gap to determine if it deserves respect.
📈 Multi-Factor Assessment
Evaluates RSI, MACD, and body size at gap formation to build a full context snapshot.
🧠 Self-Learning Engine
The logistic regression model updates on each bar using gradient descent, refining its predictions over time.
📢 Built-In Alerts
Get instant alerts when a gap forms, gets retested, or breaks.
🎨 Custom Display Options
Control the color of bullish/bearish zones, and toggle on/off probability labels for cleaner charts.
🚩 WHAT MAKES IT DIFFERENT
This isn’t just another box-drawing indicator.
While others mark every imbalance, this system thinks before it draws — using statistical modeling to filter out noise and prioritize high-impact zones.
By learning from how price behaves around gaps (not just how they form), it helps you trade only what matters — not what clutters.
⚙️ HOW IT WORKS
1️⃣ Detection
FVGs are identified using ATR-based thresholds and sharp wick imbalances.
2️⃣ Behavior Monitoring
Every gap is tracked — and if respected enough times, it becomes part of the elite training set.
3️⃣ Context Capture
Each new FVG logs RSI, MACD, and body size to provide a feature-rich context for prediction.
4️⃣ Prediction (Logistic Regression)
The model predicts how likely the gap is to be respected and assigns it a probability score.
5️⃣ Classification & Alerts
Gaps above the threshold are plotted with score labels, and alerts trigger for entry/respect/break.
⚙️ CONFIGURATION PANEL
🔧 System Inputs
• Max Retests – How many times a gap must be respected to train the model
• Prediction Threshold – Minimum score to show a gap on the chart
• Learning Rate – Controls how fast the model adapts (default: 0.009)
• Max FVG Lifetime – Expiration duration for unused gaps
• Show Historic Gaps – Show/hide expired or invalidated gaps
🎨 Visual Options
• Bullish/Bearish Colors – Set gap colors to fit your chart style
• Confidence Labels – Show probability scores next to FVGs
• Alert Toggles – Enable alerts for:
– New FVG detected
– FVG respected (entry)
– FVG invalidated (break)
💡 WHY LOGISTIC REGRESSION?
Traditional FVG tools rely on candle shapes.
This system relies on probability — by training on RSI, MACD, and price behavior, it predicts whether a gap will act as a true liquidity zone.
Logistic regression lets the system continuously adapt using new data, making it more accurate the longer it runs.
That means smarter signals, fewer false positives, and a clearer view of where real opportunities lie.
EVaR Indicator and Position SizingThe Problem:
Financial markets consistently show "fat-tailed" distributions where extreme events occur with higher frequency than predicted by normal distributions (Gaussian or even log-normal). These fat tails manifest in sudden price crashes, volatility spikes, and black swan events that traditional risk measures like volatility can underestimate. Standard deviation and conventional VaR calculations assume normally distributed returns, leaving traders vulnerable to severe drawdowns during market stress.
Cryptocurrencies and volatile instruments display particularly pronounced fat-tailed behavior, with extreme moves occurring 5-10 times more frequently than normal distribution models would predict. This reality demands a more sophisticated approach to risk measurement and position sizing.
The Solution: Entropic Value at Risk (EVAR)
EVaR addresses these limitations by incorporating principles from statistical mechanics and information theory through Tsallis entropy. This advanced approach captures the non-linear dependencies and power-law distributions characteristic of real financial markets.
Entropy is more adaptive than standard deviations and volatility measures.
I was inspired to create this indicator after reading the paper " The End of Mean-Variance? Tsallis Entropy Revolutionises Portfolio Optimisation in Cryptocurrencies " by by Sana Gaied Chortane and Kamel Naoui.
Key advantages of EVAR over traditional risk measures:
Superior tail risk capture: More accurately quantifies the probability of extreme market moves
Adaptability to market regimes: Self-calibrates to changing volatility environments
Non-parametric flexibility: Makes less assumptions about the underlying return distribution
Forward-looking risk assessment: Better anticipates potential market changes (just look at the charts :)
Mathematically, EVAR is defined as:
EVAR_α(X) = inf_{z>0} {z * log(1/α * M_X(1/z))}
Where the moment-generating function is calculated using q-exponentials rather than conventional exponentials, allowing precise modeling of fat-tailed behavior.
Technical Implementation
This indicator implements EVAR through a q-exponential approach from Tsallis statistics:
Returns Calculation: Price returns are calculated over the lookback period
Moment Generating Function: Approximated using q-exponentials to account for fat tails
EVAR Computation: Derived from the MGF and confidence parameter
Normalization: Scaled to for intuitive visualization
Position Sizing: Inversely modulated based on normalized EVAR
The q-parameter controls tail sensitivity—higher values (1.5-2.0) increase the weighting of extreme events in the calculation, making the model more conservative during potentially turbulent conditions.
Indicator Components
1. EVAR Risk Visualization
Dynamic EVAR Plot: Color-coded from red to green normalized risk measurement (0-1)
Risk Thresholds: Reference lines at 0.3, 0.5, and 0.7 delineating risk zones
2. Position Sizing Matrix
Risk Assessment: Current risk level and raw EVAR value
Position Recommendations: Percentage allocation, dollar value, and quantity
Stop Parameters: Mathematically derived stop price with percentage distance
Drawdown Projection: Maximum theoretical loss if stop is triggered
Interpretation and Application
The normalized EVAR reading provides a probabilistic risk assessment:
< 0.3: Low risk environment with minimal tail concerns
0.3-0.5: Moderate risk with standard tail behavior
0.5-0.7: Elevated risk with increased probability of significant moves
> 0.7: High risk environment with substantial tail risk present
Position sizing is automatically calculated using an inverse relationship to EVAR, contracting during high-risk periods and expanding during low-risk conditions. This is a counter-cyclical approach that ensures consistent risk exposure across varying market regimes, especially when the market is hyped or overheated.
Parameter Optimization
For optimal risk assessment across market conditions:
Lookback Period: Determines the historical window for risk calculation
Q Parameter: Controls tail sensitivity (higher values increase conservatism)
Confidence Level: Sets the statistical threshold for risk assessment
For cryptocurrencies and highly volatile instruments, a q-parameter between 1.5-2.0 typically provides the most accurate risk assessment because it helps capturing the fat-tailed behavior characteristic of these markets. You can also increase the q-parameter for more conservative approaches.
Practical Applications
Adaptive Risk Management: Quantify and respond to changing tail risk conditions
Volatility-Normalized Positioning: Maintain consistent exposure across market regimes
Black Swan Detection: Early identification of potential extreme market conditions
Portfolio Construction: Apply consistent risk-based sizing across diverse instruments
This indicator is my own approach to entropy-based risk measures as an alterative to volatility and standard deviations and it helps with fat-tailed markets.
Enjoy!

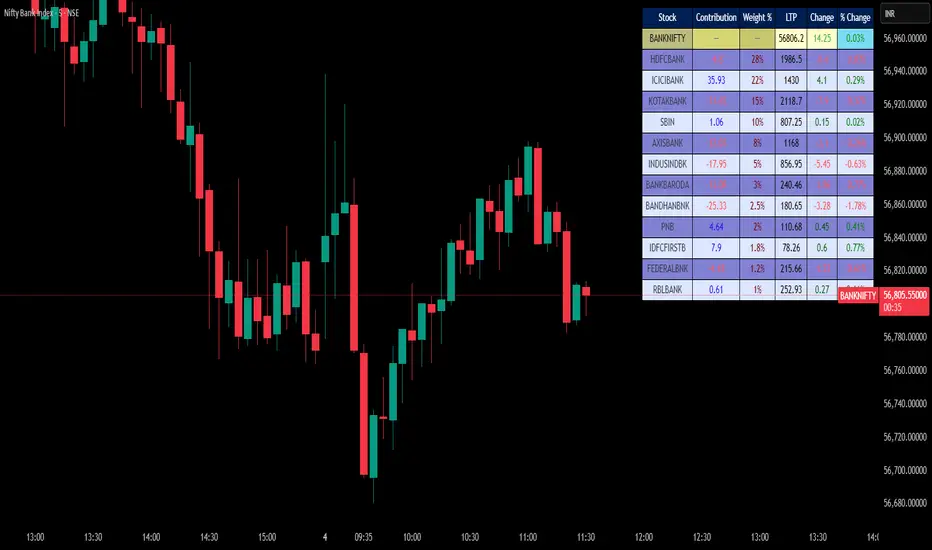
BANKNIFTY Contribution Table [GSK-VIZAG-AP-INDIA]1. Overview
This indicator provides a real-time visual contribution table of the 12 constituent stocks in the BANKNIFTY index. It displays key metrics for each stock that help traders quickly understand how each component is impacting the index at any given moment.
2. Purpose / Trading Use Case
The tool is designed for intraday and short-term traders who rely on index movement and its internal strength or weakness. By seeing which stocks are contributing positively or negatively, traders can:
Confirm trend strength or divergence within the index.
Identify whether a BANKNIFTY move is broad-based or driven by a few heavyweights.
Detect reversals when individual components decouple from index direction.
3. Key Features and Logic
Live LTP: Current price of each BANKNIFTY stock.
Price Change: Difference between current LTP and previous day’s close.
% Change: Percentage move from previous close.
Weight %: Static weight of each stock within the BANKNIFTY index (user-defined).
This estimates how much each stock contributes to the BANKNIFTY’s point change.
Sorted View: The stocks are sorted by their weight (descending), so high-impact movers are always at the top.
4. User Inputs / Settings
Table Position (tableLocationOpt):
Choose where the table appears on the chart:
top_left, top_right, bottom_left, or bottom_right.
This helps position the table away from your price action or indicators.
5. Visual and Plotting Elements
Table Layout: 6 columns
Stock | Contribution | Weight % | LTP | Change | % Change
Color Coding:
Green/red for positive/negative price changes and contributions.
Alternating background rows for better visibility.
BANKNIFTY row is highlighted separately at the top.
Text & Background Colors are chosen for both readability and direction indication.
6. Tips for Effective Use
Use this table on 1-minute or 5-minute intraday charts to see near real-time market structure.
Watch for:
A few heavyweight stocks pulling the index alone (can signal weak internal breadth).
Broad green/red across all rows (signals strong directional momentum).
Combine this with price action or volume-based strategies for confirmation.
Best used during market hours for live updates.
7. What Makes It Unique
Unlike other contribution tables that show only static data or require paid feeds, this script:
Updates in real time.
Uses dynamic calculated contributions.
Places BANKNIFTY at the top and presents the entire internal structure clearly.
Doesn’t repaint or rely on lagging indicators.
8. Alerts / Additional Features
No alerts are added in this version.
(Optional: Alerts can be added to notify when a certain stock contributes above/below a threshold.)
9. Technical Concepts Used
request.security() to pull both 1-minute and daily close data.
Conditional color formatting based on price change direction.
Dynamic table rendering using table.new() and table.cell().
Static weights assigned manually for BANKNIFTY stocks (can be updated if index weights change).
10. Disclaimer
This script is intended for educational and informational purposes only. It does not constitute financial advice or a buy/sell recommendation.
Users should test and validate the tool on paper or demo accounts before applying it to live trading.
📌 Note: Due to internet connectivity, data delays, or broker feeds, real-time values (LTP, change, contribution, etc.) may slightly differ from other platforms or terminals. Use this indicator as a supportive visual tool, not a sole decision-maker.
Script Title: BANKNIFTY Contribution Table -
Author: GSK-VIZAG-AP-INDIA
Version: Final Public Release
Frahm Factor Position Size CalculatorThe Frahm Factor Position Size Calculator is a powerful evolution of the original Frahm Factor script, leveraging its volatility analysis to dynamically adjust trading risk. This Pine Script for TradingView uses the Frahm Factor’s volatility score (1-10) to set risk percentages (1.75% to 5%) for both Margin-Based and Equity-Based position sizing. A compact table on the main chart displays Risk per Trade, Frahm Factor, and Average Candle Size, making it an essential tool for traders aligning risk with market conditions.
Calculates a volatility score (1-10) using true range percentile rank over a customizable look-back window (default 24 hours).
Dynamically sets risk percentage based on volatility:
Low volatility (score ≤ 3): 5% risk for bolder trades.
High volatility (score ≥ 8): 1.75% risk for caution.
Medium volatility (score 4-7): Smoothly interpolated (e.g., 4 → 4.3%, 5 → 3.6%).
Adjustable sensitivity via Frahm Scale Multiplier (default 9) for tailored volatility response.
Position Sizing:
Margin-Based: Risk as a percentage of total margin (e.g., $175 for 1.75% of $10,000 at high volatility).
Equity-Based: Risk as a percentage of (equity - minimum balance) (e.g., $175 for 1.75% of ($15,000 - $5,000)).
Compact 1-3 row table shows:
Risk per Trade with Frahm score (e.g., “$175.00 (Frahm: 8)”).
Frahm Factor (e.g., “Frahm Factor: 8”).
Average Candle Size (e.g., “Avg Candle: 50 t”).
Toggles to show/hide Frahm Factor and Average Candle Size rows, with no empty backgrounds.
Four sizes: XL (18x7, large text), L (13x6, normal), M (9x5, small, default), S (8x4, tiny).
Repositionable (9 positions, default: top-right).
Customizable cell color, text color, and transparency.
Set Frahm Factor:
Frahm Window (hrs): Pick how far back to measure volatility (e.g., 24 hours). Shorter for fast markets, longer for chill ones.
Frahm Scale Multiplier: Set sensitivity (1-10, default 9). Higher makes the score jumpier; lower smooths it out.
Set Margin-Based:
Total Margin: Enter your account balance (e.g., $10,000). Risk auto-adjusts via Frahm Factor.
Set Equity-Based:
Total Equity: Enter your total account balance (e.g., $15,000).
Minimum Balance: Set to the lowest your account can go before liquidation (e.g., $5,000). Risk is based on the difference, auto-adjusted by Frahm Factor.
Customize Display:
Calculation Method: Pick Margin-Based or Equity-Based.
Table Position: Choose where the table sits (e.g., top_right).
Table Size: Select XL, L, M, or S (default M, small text).
Table Cell Color: Set background color (default blue).
Table Text Color: Set text color (default white).
Table Cell Transparency: Adjust transparency (0 = solid, 100 = invisible, default 80).
Show Frahm Factor & Show Avg Candle Size: Check to show these rows, uncheck to hide (default on).

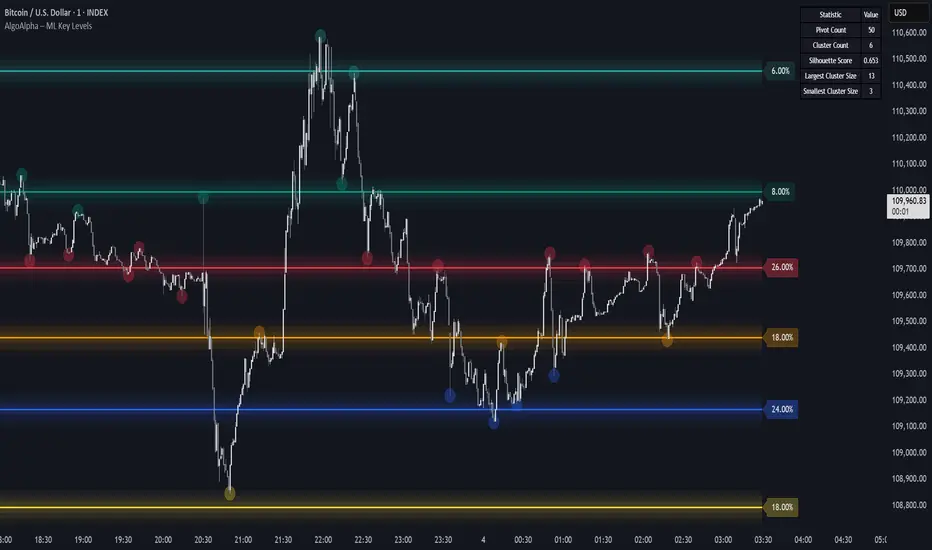
Machine Learning Key Levels [AlgoAlpha]🟠 OVERVIEW
This script plots Machine Learning Key Levels on your chart by detecting historical pivot points and grouping them using agglomerative clustering to highlight price levels with the most past reactions. It combines a pivot detection, hierarchical clustering logic, and an optional silhouette method to automatically select the optimal number of key levels, giving you an adaptive way to visualize price zones where activity concentrated over time.
🟠 CONCEPTS
Agglomerative clustering is a bottom-up method that starts by treating each pivot as its own cluster, then repeatedly merges the two closest clusters based on the average distance between their members until only the desired number of clusters remain. This process creates a hierarchy of groupings that can flexibly describe patterns in how price reacts around certain levels. This offers an advantage over K-means clustering, since the number of clusters does not need to be predefined. In this script, it uses an average linkage approach, where distance between clusters is computed as the average pairwise distance of all contained points.
The script finds pivot highs and lows over a set lookback period and saves them in a buffer controlled by the Pivot Memory setting. When there are at least two pivots, it groups them using agglomerative clustering: it starts with each pivot as its own group and keeps merging the closest pairs based on their average distance until the desired number of clusters is left. This number can be fixed or chosen automatically with the silhouette method, which checks how well each point fits in its cluster compared to others (higher scores mean cleaner separation). Once clustering finishes, the script takes the average price of each cluster to create key levels, sorts them, and draws horizontal lines with labels and colors showing their strength. A metrics table can also display details about the clusters to help you understand how the levels were calculated.
🟠 FEATURES
Agglomerative clustering engine with average linkage to merge pivots into level groups.
Dynamic lines showing each cluster’s price level for clarity.
Labels indicating level strength either as percent of all pivots or raw counts.
A metrics table displaying pivot count, cluster count, silhouette score, and cluster size data.
Optional silhouette-based auto-selection of cluster count to adaptively find the best fit.
🟠 USAGE
Add the indicator to any chart. Choose how far back to detect pivots using Pivot Length and set Pivot Memory to control how many are kept for clustering (more pivots give smoother levels but can slow performance). If you want the script to pick the number of levels automatically, enable Auto No. Levels ; otherwise, set Number of Levels . The colored horizontal lines represent the calculated key levels, and circles show where pivots occurred colored by which cluster they belong to. The labels beside each level indicate its strength, so you can see which levels are supported by more pivots. If Show Metrics Table is enabled, you will see statistics about the clustering in the corner you selected. Use this tool to spot areas where price often reacts and to plan entries or exits around levels that have been significant over time. Adjust settings to better match volatility and history depth of your instrument.
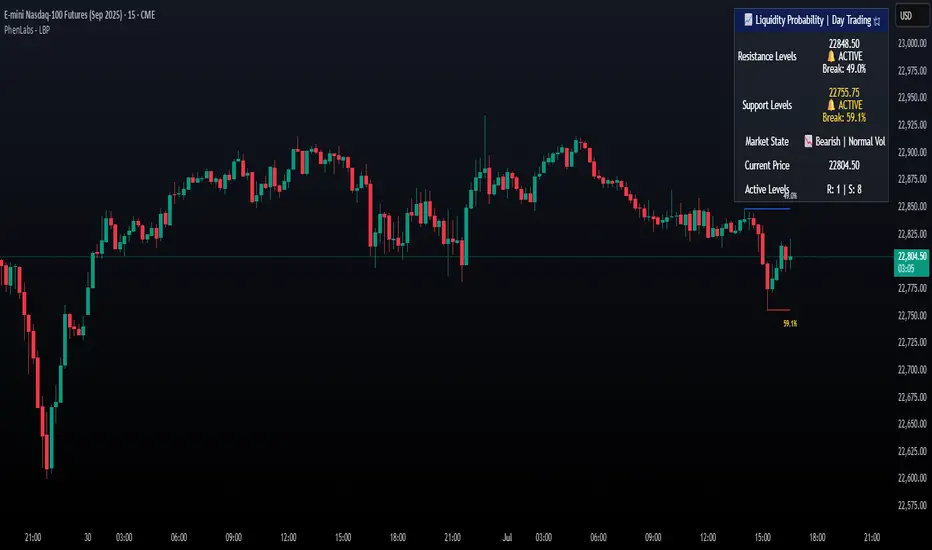
Liquidity Break Probability [PhenLabs]📊 Liquidity Break Probability
Version: PineScript™ v6
The Liquidity Break Probability indicator revolutionizes how traders approach liquidity levels by providing real-time probability calculations for level breaks. This advanced indicator combines sophisticated market analysis with machine learning inspired probability models to predict the likelihood of high/low breaks before they happen.
Unlike traditional liquidity indicators that simply draw lines, LBP analyzes market structure, volume profiles, momentum, volatility, and sentiment to generate dynamic break probabilities ranging from 5% to 95%. This gives traders unprecedented insight into which levels are most likely to hold or break, enabling more confident trading decisions.
🚀 Points of Innovation
Advanced 6-factor probability model weighing market structure, volatility, volume, momentum, patterns, and sentiment
Real-time probability updates that adjust as market conditions change
Intelligent trading style presets (Scalping, Day Trading, Swing Trading) with optimized parameters
Dynamic color-coded probability labels showing break likelihood percentages
Professional tiered input system - from quick setup to expert-level customization
Smart volume filtering that only highlights levels with significant institutional interest
🔧 Core Components
Market Structure Analysis: Evaluates trend alignment, level strength, and momentum buildup using EMA crossovers and price action
Volatility Engine: Incorporates ATR expansion, Bollinger Band positioning, and price distance calculations
Volume Profile System: Analyzes current volume strength, smart money proxies, and level creation volume ratios
Momentum Calculator: Combines RSI positioning, MACD strength, and momentum divergence detection
Pattern Recognition: Identifies reversal patterns (doji, hammer, engulfing) near key levels
Sentiment Analysis: Processes fear/greed indicators and market breadth measurements
🔥 Key Features
Dynamic Probability Labels: Real-time percentage displays showing break probability with color coding (red >70%, orange >50%, white <50%)
Trading Style Optimization: One-click presets automatically configure sensitivity and parameters for your trading timeframe
Professional Dashboard: Live market state monitoring with nearest level tracking and active level counts
Smart Alert System: Customizable proximity alerts and high-probability break notifications
Advanced Level Management: Intelligent line cleanup and historical analysis options
Volume-Validated Levels: Only displays levels backed by significant volume for institutional-grade analysis
🎨 Visualization
Recent Low Lines: Red lines marking validated support levels with probability percentages
Recent High Lines: Blue lines showing resistance zones with break likelihood indicators
Probability Labels: Color-coded percentage labels that update in real-time
Professional Dashboard: Customizable panel showing market state, active levels, and current price
Clean Display Modes: Toggle between active-only view for clean charts or historical view for analysis
📖 Usage Guidelines
Quick Setup
Trading Style Preset
Default: Day Trading
Options: Scalping, Day Trading, Swing Trading, Custom
Description: Automatically optimizes all parameters for your preferred trading timeframe and style
Show Break Probability %
Default: True
Description: Displays percentage labels next to each level showing break probability
Line Display
Default: Active Only
Options: Active Only, All Levels
Description: Choose between clean active-only view or comprehensive historical analysis
Level Detection Settings
Level Sensitivity
Default: 5
Range: 1-20
Description: Lower values show more levels (sensitive), higher values show fewer levels (selective)
Volume Filter Strength
Default: 2.0
Range: 0.5-5.0
Description: Controls minimum volume threshold for level validation
Advanced Probability Model
Market Trend Influence
Default: 25%
Range: 0-50%
Description: Weight given to overall market trend in probability calculations
Volume Influence
Default: 20%
Range: 0-50%
Description: Impact of volume analysis on break probability
✅ Best Use Cases
Identifying high-probability breakout setups before they occur
Determining optimal entry and exit points near key levels
Risk management through probability-based position sizing
Confluence trading when multiple high-probability levels align
Scalping opportunities at levels with low break probability
Swing trading setups using high-probability level breaks
⚠️ Limitations
Probability calculations are estimations based on historical patterns and current market conditions
High-probability setups do not guarantee successful trades - risk management is essential
Performance may vary significantly across different market conditions and asset classes
Requires understanding of support/resistance concepts and probability-based trading
Best used in conjunction with other analysis methods and proper risk management
💡 What Makes This Unique
Probability-Based Approach: First indicator to provide quantitative break probabilities rather than simple S/R lines
Multi-Factor Analysis: Combines 6 different market factors into a comprehensive probability model
Adaptive Intelligence: Probabilities update in real-time as market conditions change
Professional Interface: Tiered input system from beginner-friendly to expert-level customization
Institutional-Grade Filtering: Volume validation ensures only significant levels are displayed
🔬 How It Works
1. Level Detection:
Identifies pivot highs and lows using configurable sensitivity settings
Validates levels with volume analysis to ensure institutional significance
2. Probability Calculation:
Analyzes 6 key market factors: structure, volatility, volume, momentum, patterns, sentiment
Applies weighted scoring system based on user-defined factor importance
Generates probability score from 5% to 95% for each level
3. Real-Time Updates:
Continuously monitors price action and market conditions
Updates probability calculations as new data becomes available
Adjusts for level touches and changing market dynamics
💡 Note: This indicator works best on timeframes from 1-minute to 4-hour charts. For optimal results, combine with proper risk management and consider multiple timeframe analysis. The probability calculations are most accurate in trending markets with normal to high volatility conditions.