LEOLA LENS FOOTPRINT Reveal institutional intent with real-time price-based zones.
LEOLALENS™ Footprint tracks liquidity sweeps, high-probability entries, and smart money moves — built for traders who demand accuracy.
🔹 Institutional Sweep Detection
🔹 Non-Lagging Real-Time Zones
🔹 High-Probability Entry/Exit Points
🔹 Orange & Green LCB BOX Zones
🔹 Hidden Support/Resistance Detection
🔹 Psychological Price Levels
🔹 Momentum Shift Awareness Zones
🔹 Compatible across all asset classes: Crypto, Stocks, Forex, Commodities
Note: This is an invite-only script. Access is granted upon approval by the script author.
AI

ML: Lorentzian Classification Premium█ OVERVIEW
Lorentzian Classification Premium represents the culmination of two years of collaborative development with over 1,000 beta testers from the TradingView community. Building upon the foundation of the open-source version, this premium edition introduces powerful enhancements that transform how machine-learning classification can be applied to market analysis.
The premium version maintains the core Lorentzian distance-based classification algorithm while expanding its capabilities through triple the feature dimensionality (up to 15 features), sophisticated mean-reversion detection, first-pullback identification, and a comprehensive signal taxonomy that goes far beyond simple buy/sell signals. Whether you're building automated trading systems, conducting deep market research, or integrating proprietary indicators into ML workflows, this tool provides the advanced edge needed for professional-grade analysis.
█ BACKGROUND
Lorentzian Classification analyzes market structures, especially those exhibiting non-linear distortions under stress, by employing advanced distance metrics like the Lorentzian metric, prominent in fields such as relativity theory. Where traditional indicators assume flat space, we embrace the curve. The heart of this approach is the Lorentzian distance metric—a sophisticated mathematical tool. This framework adeptly navigates the complex curves and distortions of market space, aiming to provide insights that traditional analysis might miss, especially during moments of extreme volatility. It analyzes historical data from a multi-dimensional feature space consisting of various technical indicators of your choosing. Where traditional approaches fail, Lorentzian space reveals the true geometry of market dynamics.
Neighborhoods in Different Geometries: In the above figure, the Lorentzian metric creates distinctive cross-patterns aligned with feature axes (RSI, CCI, ADX), capturing both local similarity and dimensional extremes. This unique geometry allows the algorithm to recognize similar market conditions that Euclidean spheres and Manhattan diamonds would miss entirely. In LC Premium, users can have up to 15 features -- you are not limited to 3-dimensions.
Among the thousands of distance metrics discovered by mathematicians, each perceives data through its own geometric lens. The Lorentzian metric stands apart with its unique ability to capture market behavior during volatile events.
█ COMMUNITY-DRIVEN EVOLUTION
It has been profoundly humbling over the past 2 years to witness this indicator's evolution through the collaborative efforts of our incredible community. This journey has been shaped by thousands of user suggestions and validated through real-world application.
A particularly amazing milestone was the development of a complete community-driven Python port, which meticulously matched even the most minute PineScript quirks. Building on this solid foundation, a new command-line interface (CLI) has opened up exciting possibilities for chart-specific parameter optimization:
Early insights from parameter optimization research: Through grid-search testing across thousands of parameter combinations, the analysis identifies which parameters have the biggest effects on performance and maps regions of stability across different market regimes. This reveals that optimal neighbor counts vary significantly based on market conditions—opening up incredible potential for timeframe-specific optimization.
This is just one of the insights gleaned so far from this ongoing investigation. The potential for chart-specific optimization for any given timeframe could transform how traders approach parameter selection.
Demand from power users for extra capabilities—while keeping the open-source version simple—sparked this Premium release. The open-source branch remains maintained, but the premium tier adds unique features for those who need an analytical edge and to leverage their own custom indicators as feature series for the algorithm.
█ KEY PREMIUM FEATURES
📈 First Pullback Detection System
Automatically identifies high-probability trend-continuation entries after initial momentum moves.
Detects when price retraces to optimal entry zones following breakouts or trend initiations.
Green/red triangle signals often fire before main classification arrows.
Dedicated alerts for both bullish and bearish pullback opportunities.
Based on veryfid's extensive research into pullback mechanics and market structure.
🔄 Dynamic Kernel Regression Envelope
Powerful, zero-setup confluence layer that immediately communicates trend shifts.
Dual-kernel system creates a visual envelope between trend estimates.
Color gradient dynamically represents prediction strength and market conviction.
Crossovers provide additional confirmation without cluttering your chart.
Professional visualization that rivals institutional-grade analysis tools.
✨ Massively Expanded Dimensionality: 10 Custom Sources, 5 Built-In Sources
Transform the indicator from 5 built-in standard to 15 total total features—triple the analytical power.
Integrate ANY TradingView indicator as a machine learning feature.
Built-in normalization ensures all indicators contribute equally regardless of scale.
Create theme-based systems: pure volume analysis, multi-timeframe momentum, or hybrid approaches.
📊 Tiered Mean Reversion Signals with Scalping Alerts
Regular (🔄) and Strong (⬇️/⬆️) mean reversion signals based on statistical extremes.
Opportunities often arise before candle close—perfect for scalping entries.
Visual markers appear at high-probability reversal zones.
Four specialized alert types: upward/downward for both regular and strong reversals.
Pre-optimized probability thresholds, no fine-tuning required.
📅 Daily Kernel Trend Filter
Instantly cleans up noisy intraday charts by aligning with higher timeframe trends.
Swing traders report immediate signal quality improvement.
Automatically deactivates on daily+ timeframes (intelligent context awareness).
Reduces counter-trend signals by up to 60% on lower timeframes.
Simple toggle—no complex multi-timeframe setup required.
📋 Professional Backtesting Stream (-6 to +6)
Multiple distinct signal types (including pullbacks, mean reversions, and kernel deviations) vs. basic binary (buy/sell) output for nuanced analysis.
Enables detailed walk-forward analysis and ML model training.
Compatible with external backtesting frameworks via numeric stream.
Rare precision for TradingView indicators—usually only found in institutional tools.
Perfect for quants building sophisticated strategy layers.
⚡ Performance Optimizations
Faster distance calculations through algorithmic improvements.
Reduced indicator load time (measured via Pine Profiler).
Handles 15 active features without timeouts—critical for multi-chart setups.
Optimized for live auto-trading bots requiring minimal latency.
🎨 Full Visual Customization & Accessibility
Complete color control for all visual elements.
Colorblind-safe default palette with customization options.
Dark mode optimization for extended trading sessions.
Professional appearance matching your trading workspace.
Accessibility features meeting modern UI standards.
🛠️ Advanced Training Modes
Downsampling mode for training on diverse market conditions; Down-sampling and remote-fractals for exotic pattern discovery.
Remote fractals option extends analysis to deep historical patterns.
Reset factor control for fine-tuning neighbor diversity; Reset-factor tuning to control neighbor diversity.
Appeals to systematic traders exploring exotic data approaches.
Prevents temporal clustering bias in model training.
█ HOW TO USE
Understanding the Approach (Core Concept):
Lorentzian Classification uses a k-Nearest Neighbors (k-NN) algorithm. It searches for historical price action "neighborhoods" similar to the current market state. Instead of a simple straight-line (Euclidean) distance, it primarily uses a Lorentzian distance metric, which can account for market "warping" or distortions often seen during high volatility or significant events. Each historical neighbor "votes" on what happened next in its context, and these votes aggregate into a classification score for the current bar.
Interpreting Bar Scores & Signals (Interpreting the Chart):
Bar Prediction Values: Numbers over each candle (e.g., ranging from -8 to +8 if Neighbors Count is 8) represent the aggregated vote from the nearest neighbors. Strong positive scores (e.g., +7, +8) indicate a strong bullish consensus among historical analogs. Strong negative scores (e.g., -7, -8) indicate a strong bearish consensus. Scores near zero suggest neutrality or conflicting signals from neighbors. The intensity of bar colors (if Use Confidence Gradient is on) often reflects these scores.
Main Arrows (Main Buy/Sell Labels): Large ▲/▼ labels are the primary entry signals generated when the overall classification (after filters) is bullish or bearish.
Pullback Triangles: Small green/red ▲/▼ identify potential trend continuation entries. These signals often appear after an initial price move and a subsequent minor retracement, suggesting the trend might resume. This is based on recognizing patterns where a brief counter-movement is followed by a continued advance in the initial trend direction.
Mean-Reversion Symbols: 🔄 (Regular Reversion) appears when price has crossed the average band of the Dynamic Kernel Regression Envelope. ⬇️/⬆️ (Strong Reversion) means price has crossed the far band of the envelope, indicating a more extreme deviation and potentially a stronger reversion opportunity.
Custom Mean Reversion Deviation Markers (Deviation Dots): If Enable Custom Mean Reversion Alerts is on, these dots appear when price deviates from the main kernel regression line by a user-defined ATR multiple, signaling a custom-defined reversion opportunity.
Kernel Regression Lines & Envelope: The Main Kernel Estimate (thicker line) is an adaptive moving average that smooths price and helps identify trend direction. Its color indicates the current trend bias. The Envelope (outer bands and a midline) creates a channel around price, and its interaction with price generates mean reversion signals.
Key Input Groups & Their Purpose:
🔧 GENERAL SETTINGS:
Reduce Price-Time Warping : Toggles the distance metric. When enabled, it reduces the characteristic "warping" effect of the default Lorentzian metric, making the distance calculation more Euclidean in nature. This may be suited for periods exhibiting less pronounced price-time distortions.
Source : Price data for calculations (default: close ).
Neighbors Count : The 'k' in k-NN – number of historical analogs considered.
Max Bars Back : How far back the indicator looks for historical patterns.
Show Exits / Use Dynamic Exits : Controls visibility and logic for exit signals.
Include Full History (Use Remote Fractals) : Allows model to pick "exotic" fractals from deep chart history.
Use Downsampling / Reset Factor : Advanced training parameters affecting neighbor selection.
Show Trade Stats / Use Worst Case Estimates : Displays a real-time performance table (for calibration only).
🎛️ DEFINE CUSTOM SOURCES (OPTIONAL):
Integrate up to 10 external data series (e.g., from other indicators) as features. Each can be optionally normalized. Load the external indicator on your chart first for it to appear in the dropdown.
🧠 FEATURE ENGINEERING:
Configure up to 15 features for the k-NN algorithm. Select type (RSI, WT, CCI, ADX, Custom Sources), parameters, and enable/disable. Start simple (3-5 features) and add complexity gradually. Normalize features with vastly different scales.
🖥️ DISPLAY SETTINGS:
Controls visibility of chart elements: bar colors, prediction values/labels, envelope, etc.
Align Signal with Current Bar : If true, pullback signals appear on the current bar (calculated on closed data). If false (default), they appear on the next bar.
Use ATR Offset : Positions bar prediction values using ATR for visibility.
🧮 FILTERS SETTINGS:
Refine raw classification signals: Volatility, Regime, ADX, EMA/SMA, and Daily Kernel filters.
🌀 KERNEL SETTINGS (Main Kernel):
Adjust parameters for the primary Nadaraya-Watson Kernel Regression line. Lookback Window , Relative Weighting , Regression Level , Lag control sensitivity and smoothness.
✉️ ENVELOPE SETTINGS (for Mean Reversion):
Configure the dynamic Kernel Regression Envelope. ATR Length , Near/Far ATR Factor define band width.
🎨 COLOR SETTINGS (Colors):
Customize colors for all visual elements; override every palette element.
General Approach to Using the Indicator (Suggested Workflow):
Load defaults and observe behavior: Familiarize yourself with the indicator's behavior.
Feature Engineering: Experiment with features, considering momentum, trend, and volatility. Add/replace features gradually.
Apply Filters: Refine signals according to your trading style.
Contextualize: Use kernels and envelope to understand broader trend and potential overbought/oversold areas.
Observe Signals: Pay attention to the interplay of main signals, pullbacks, and mean reversions. Watch interplay of main, pullback & mean-reversion signals.
Calibrate (Not Backtest): Use the "Trade Stats" table for real-time feedback on current settings. This is for calibration, *not a substitute for rigorous backtesting.*
Iterate & refine: Adjust settings, observe outcomes, and refine your approach.
█ ACKNOWLEDGMENTS
This premium version wouldn't exist without the invaluable contributions of:
veryfid for his groundbreaking ideas on unifying pullback detection with Lorentzian Classification, but most of all for always believing in and encouraging me and so many others. For being a mentor and, most importantly, a friend. We all miss you.
RikkiTavi for his help in creating the settings optimization framework and for other invaluable theoretical discussions.
The 1,000+ beta testers worldwide who provided continuous feedback over two years.
The Python porting team who created the foundation for advanced optimization; for the cross-language clone.
The broader TradingView community for making this one of the platform's most popular indicators.
█ FUTURE DEVELOPMENT
The Premium version will continue to evolve based on community feedback. Planned enhancements include:
Specialized exit model trained independently from entry signals (ML-based exit model).
Feature hub with pre-normalized, commonly requested indicators (Pre-normalized feature hub).
Better risk-management options (Enhanced risk-management options).
Fully automated settings optimization (Auto-settings optimization tool).
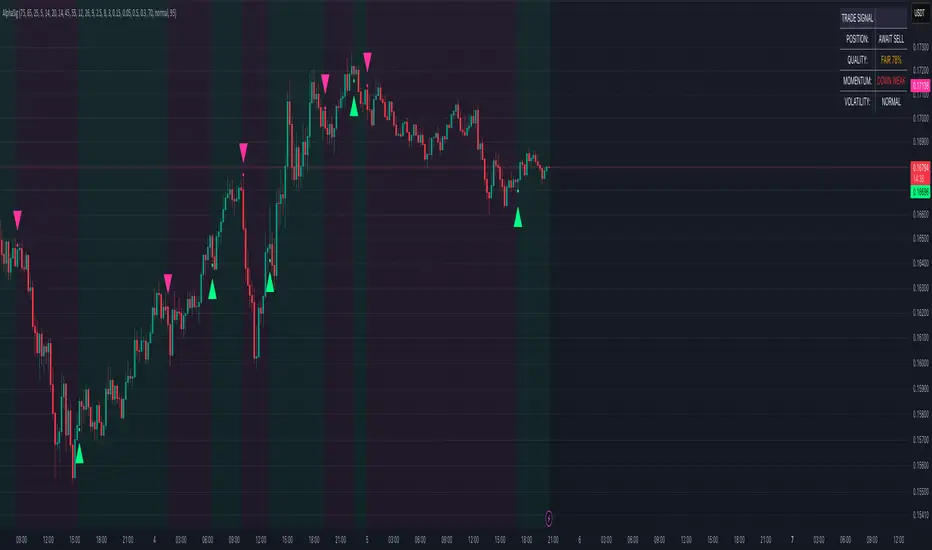
AlphaSignal | MindMarketAlphaSignal — Smart Indicator for Precise Entries
What does AlphaSignal do?
AlphaSignal looks for moments when the price moves too far from its average, volume spikes, and overall market activity increases. When these things line up, it gives you a clean, high-quality trading signal — either to buy or sell.
How it works :
Activity & Volume Detection
It monitors for sudden bursts in trading volume and volatility — clear signs that something important is happening in the market.
Price Deviation with Nadaraya-Watson Envelope
The indicator uses a smooth curve (called the Nadaraya-Watson estimate) to track the average price. When price drifts too far from this curve, it might be ready to snap back. That’s where AlphaSignal starts paying attention.
Signal Rating System
Each potential trade gets a score based on:
Market activity
Volume deviation
How far price is from the NW envelope
(Optionally) Trend strength and momentum via ADX, RSI, MACD
Only if the total score is high enough — a signal is fired.
Advanced Filters (Optional)
Want more confirmation? Turn on ADX, RSI, and MACD checks to avoid weak setups during choppy, low-trend periods.
Cooldown Logic
To avoid overtrading, AlphaSignal waits a set number of bars between signals — you can customize this.
Trading Suggestions (Signal Panel)
AlphaSignal gives you real-time trading guidance with a simple suggestion box:
BUY NOW / SELL NOW
All conditions are met, rating is strong — take action.
PREPARE BUY / PREPARE SELL
No full confirmation yet, but the price is very close to key levels (within 1.5% of the NW envelope). Get ready — a signal might appear soon.
AWAIT BUY / AWAIT SELL
The market is leaning toward a buy or sell, but price isn’t in a good spot yet. Be patient and watch for better positioning.
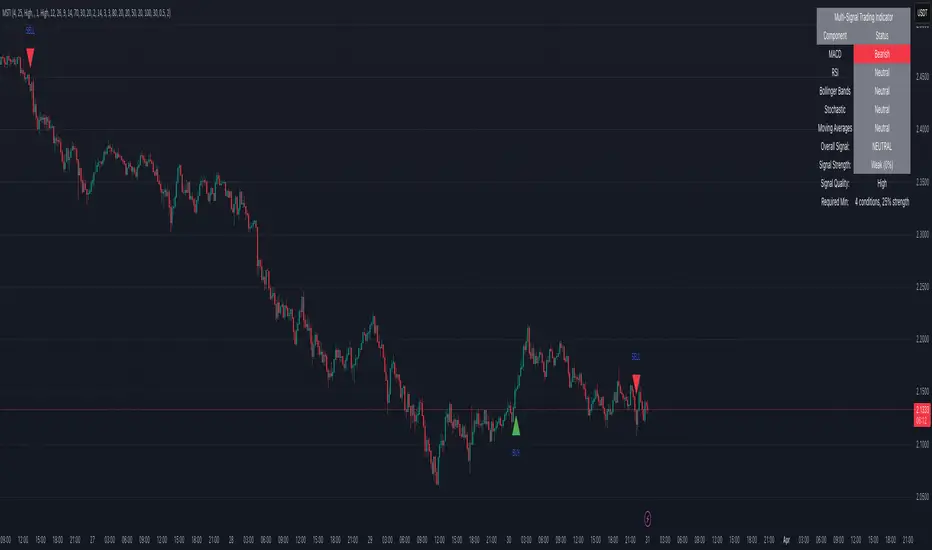
Multi-Signal Trading Indicator (MSTI)Multi-Signal Trading Indicator (MSTI)
Overview
The Multi-Signal Trading Indicator (MSTI) is a comprehensive technical analysis tool that combines eight powerful indicators into a single, unified system. Designed to identify high-probability trading opportunities, MSTI generates precise buy and sell signals by analyzing multiple market factors simultaneously. The indicator excels at detecting potential reversals and trend continuations while filtering out market noise.
Key Features
8 Core Technical Components
MACD: Identifies momentum changes and potential trend reversals
RSI: Detects overbought and oversold conditions
Bollinger Bands: Analyzes price volatility and extreme conditions
Stochastic Oscillator: Identifies potential turning points in price
Moving Averages: Confirms trend direction using dual SMAs
Volume Analysis: Validates price movements with volume confirmation
Fibonacci Levels: Identifies key support/resistance areas
Divergence Detection: Spots divergences between price and momentum
Advanced Predictive Capabilities
Volume Surge Detection: Identifies significant volume increases that often precede major price movements
Enhanced Divergence Analysis: Detects both regular and hidden divergences for early reversal signals
Support/Resistance Tests: Identifies successful tests of key support/resistance zones
Momentum Change Detection: Spots early shifts in price momentum using Rate of Change
Order Flow Analysis: Tracks buying/selling pressure through On-Balance Volume
Signal Quality Management
Adjustable Signal Thresholds: Customize the number of conditions required for signal generation
Multiple Quality Levels: Choose between Normal, High, and Maximum quality settings
Strength Measurement: Displays signal strength as a percentage for better decision-making
Repeat Signal Prevention: Eliminates duplicate signals to reduce noise
Visual Features
Clear Chart Markers: Buy/sell signals displayed directly on price chart
Comprehensive Info Panel: Shows status of all components and overall signal information
Customizable Colors: Adjust visual elements to match your chart theme
Practical Applications
For Day Traders
Identify short-term reversal points with high accuracy
Validate entries with multiple confirmations
Filter out false signals during choppy market conditions
For Swing Traders
Spot early trend changes before they become obvious
Enter positions with higher confidence and precision
Hold positions through noise by following true trend signals
For Position Traders
Identify major trend reversals with multiple confirmations
Filter out minor retracements from significant trend changes
Time entries and exits with greater precision
Customization Options
MSTI is highly customizable with over 30 adjustable parameters allowing you to:
Fine-tune each technical component
Adjust signal quality and filtering
Enable/disable specific components
Customize visual appearance
Usage Tips
Start with the Normal quality setting to understand signal frequency
Progress to High or Maximum settings for fewer but higher quality signals
Adjust minimum conditions based on market volatility
Enable trend filter in trending markets for better signal accuracy
Enable volatility filter to avoid signals during low-volatility periods
ThinkTech AI SignalsThink Tech AI Strategy
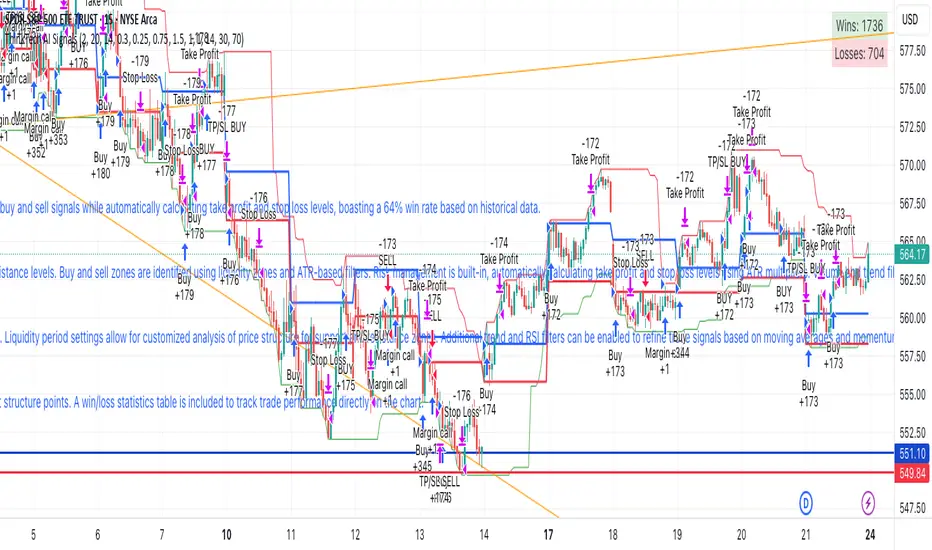
The Think Tech AI Strategy provides a structured approach to trading by integrating liquidity-based entries, ATR volatility thresholds, and dynamic risk management. This strategy generates buy and sell signals while automatically calculating take profit and stop loss levels, boasting a 64% win rate based on historical data.
Usage
The strategy can be used to identify key breakout and retest opportunities. Liquidity-based zones act as potential accumulation and distribution areas and may serve as future support or resistance levels. Buy and sell zones are identified using liquidity zones and ATR-based filters. Risk management is built-in, automatically calculating take profit and stop loss levels using ATR multipliers. Volume and trend filtering options help confirm directional bias using a 50 EMA and RSI filter. The strategy also allows for session-based trading, limiting trades to key market hours for higher probability setups.
Settings
The risk/reward ratio can be adjusted to define the desired stop loss and take profit calculations. The ATR length and threshold determine ATR-based breakout conditions for dynamic entries. Liquidity period settings allow for customized analysis of price structure for support and resistance zones. Additional trend and RSI filters can be enabled to refine trade signals based on moving averages and momentum conditions. A session filter is included to restrict trade signals to specific market hours.
Style
The strategy includes options to display liquidity lines, showing key support and resistance areas. The first 15-minute candle breakout zones can also be visualized to highlight critical market structure points. A win/loss statistics table is included to track trade performance directly on the chart.
This strategy is intended for descriptive analysis and should be used alongside other confluence factors. Optimize your trading process with Think Tech AI today!
Machine Learning Trendlines Cluster [LuxAlgo]The ML Trendlines Cluster indicator allows traders to automatically identify trendlines using a machine learning algorithm based on k-means clustering and linear regression, highlighting trendlines from clustered prices.
For trader's convenience, trendlines can be filtered based on their slope, allowing them to filter out trendlines that are too horizontal, or instead keep them depending on the user-selected settings.
🔶 USAGE
Traders only need to set the number of trendlines (clusters) they want the tool to detect and the algorithm will do the rest.
By default the tool is set to detect 4 clusters over the last 500 bars, in the image above it is set to detect 10 clusters over the same period.
This approach only focuses on drawing trendlines from prices that share a common trading range, offering a unique perspective to traditional trendlines. Trendlines with a significant slope can highlight higher dispersion within its cluster.
🔹 Trendline Slope Filtering
Traders can filter trendlines by their slope to display only steep or flat trendlines relative to a user-defined threshold.
The image above shows the three different configurations of this feature:
Filtering disabled
Filter slopes above threshold
Filter slopes below threshold
🔶 DETAILS
K-means clustering is a popular machine-learning algorithm that finds observations in a data set that are similar to each other and places them in a group.
The process starts by randomly assigning each data point to an initial group and calculating the centroid for each. A centroid is the center of the group. K-means clustering forms the groups in such a way that the variances between the data points and the centroid of the cluster are minimized.
The trendlines are displayed according to the linear regression function calculated for each cluster.
🔶 SETTINGS
Window Size: Maximum number of bars to get data from
Clusters: Maximum number of clusters (trendlines) to detect
🔹 Optimization
Maximum Iteration Steps: Maximum loop iterations for cluster computation
🔹 Slope Filter
Threshold Multiplier: Multiplier applied to a volatility measure, higher multiplier equals higher threshold
Filter Slopes: Enable/Disable Trendline Slope Filtering, select to filter trendlines with slopes ABOVE or BELOW the threshold
🔹 Style
Upper Zone: Color to display in the top zone
Lower Zone: Color to display in the bottom zone
Lines: Style for the lines
Size: Line size

AI Adaptive Oscillator [PhenLabs]📊 Algorithmic Adaptive Oscillator
Version: PineScript™ v6
📌 Description
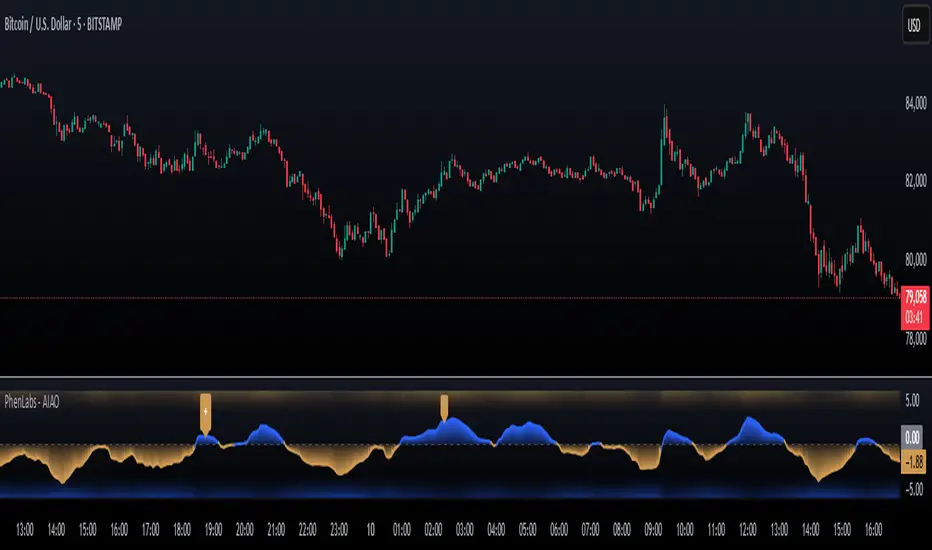
The AI Adaptive Oscillator is a sophisticated technical indicator that employs ensemble learning and adaptive weighting techniques to analyze market conditions. This innovative oscillator combines multiple traditional technical indicators through an AI-driven approach that continuously evaluates and adjusts component weights based on historical performance. By integrating statistical modeling with machine learning principles, the indicator adapts to changing market dynamics, providing traders with a responsive and reliable tool for market analysis.
🚀 Points of Innovation:
Ensemble learning framework with adaptive component weighting
Performance-based scoring system using directional accuracy
Dynamic volatility-adjusted smoothing mechanism
Intelligent signal filtering with cooldown and magnitude requirements
Signal confidence levels based on multi-factor analysis
🔧 Core Components
Ensemble Framework : Combines up to five technical indicators with performance-weighted integration
Adaptive Weighting : Continuous performance evaluation with automated weight adjustment
Volatility-Based Smoothing : Adapts sensitivity based on current market volatility
Pattern Recognition : Identifies potential reversal patterns with signal qualification criteria
Dynamic Visualization : Professional color schemes with gradient intensity representation
Signal Confidence : Three-tiered confidence assessment for trading signals
🔥 Key Features
The indicator provides comprehensive market analysis through:
Multi-Component Ensemble : Integrates RSI, CCI, Stochastic, MACD, and Volume-weighted momentum
Performance Scoring : Evaluates each component based on directional prediction accuracy
Adaptive Smoothing : Automatically adjusts based on market volatility
Pattern Detection : Identifies potential reversal patterns in overbought/oversold conditions
Signal Filtering : Prevents excessive signals through cooldown periods and minimum change requirements
Confidence Assessment : Displays signal strength through intuitive confidence indicators (average, above average, excellent)
🎨 Visualization
Gradient-Filled Oscillator : Color intensity reflects strength of market movement
Clear Signal Markers : Distinct bullish and bearish pattern signals with confidence indicators
Range Visualization : Clean representation of oscillator values from -6 to 6
Zero Line : Clear demarcation between bullish and bearish territory
Customizable Colors : Color schemes that can be adjusted to match your chart style
Confidence Symbols : Intuitive display of signal confidence (no symbol, +, or ++) alongside direction markers
📖 Usage Guidelines
⚙️ Settings Guide
Color Settings
Bullish Color
Default: #2b62fa (Blue)
This setting controls the color representation for bullish movements in the oscillator. The color appears when the oscillator value is positive (above zero), with intensity indicating the strength of the bullish momentum. A brighter shade indicates stronger bullish pressure.
Bearish Color
Default: #ce9851 (Amber)
This setting determines the color representation for bearish movements in the oscillator. The color appears when the oscillator value is negative (below zero), with intensity reflecting the strength of the bearish momentum. A more saturated shade indicates stronger bearish pressure.
Signal Settings
Signal Cooldown (bars)
Default: 10
Range: 1-50
This parameter sets the minimum number of bars that must pass before a new signal of the same type can be generated. Higher values reduce signal frequency and help prevent overtrading during choppy market conditions. Lower values increase signal sensitivity but may generate more false positives.
Min Change For New Signal
Default: 1.5
Range: 0.5-3.0
This setting defines the minimum required change in oscillator value between consecutive signals of the same type. It ensures that new signals represent meaningful changes in market conditions rather than minor fluctuations. Higher values produce fewer but potentially higher-quality signals, while lower values increase signal frequency.
AI Core Settings
Base Length
Default: 14
Minimum: 2
This fundamental setting determines the primary calculation period for all technical components in the ensemble (RSI, CCI, Stochastic, etc.). It represents the lookback window for each component’s base calculation. Shorter periods create a more responsive but potentially noisier oscillator, while longer periods produce smoother signals with potential lag.
Adaptive Speed
Default: 0.1
Range: 0.01-0.3
Controls how quickly the oscillator adapts to new market conditions through its volatility-adjusted smoothing mechanism. Higher values make the oscillator more responsive to recent price action but potentially more erratic. Lower values create smoother transitions but may lag during rapid market changes. This parameter directly influences the indicator’s adaptiveness to market volatility.
Learning Lookback Period
Default: 150
Minimum: 10
Determines the historical data range used to evaluate each ensemble component’s performance and calculate adaptive weights. This setting controls how far back the AI “learns” from past performance to optimize current signals. Longer periods provide more stable weight distribution but may be slower to adapt to regime changes. Shorter periods adapt more quickly but may overreact to recent anomalies.
Ensemble Size
Default: 5
Range: 2-5
Specifies how many technical components to include in the ensemble calculation.
Understanding The Interaction Between Settings
Base Length and Learning Lookback : The base length determines the reactivity of individual components, while the lookback period determines how their weights are adjusted. These should be balanced according to your timeframe - shorter timeframes benefit from shorter base lengths, while the lookback should generally be 10-15 times the base length for optimal learning.
Adaptive Speed and Signal Cooldown : These settings control sensitivity from different angles. Increasing adaptive speed makes the oscillator more responsive, while reducing signal cooldown increases signal frequency. For conservative trading, keep adaptive speed low and cooldown high; for aggressive trading, do the opposite.
Ensemble Size and Min Change : Larger ensembles provide more stable signals, allowing for a lower minimum change threshold. Smaller ensembles might benefit from a higher threshold to filter out noise.
Understanding Signal Confidence Levels
The indicator provides three distinct confidence levels for both bullish and bearish signals:
Average Confidence (▲ or ▼) : Basic signal that meets the minimum pattern and filtering criteria. These signals indicate potential reversals but with moderate confidence in the prediction. Consider using these as initial alerts that may require additional confirmation.
Above Average Confidence (▲+ or ▼+) : Higher reliability signal with stronger underlying metrics. These signals demonstrate greater consensus among the ensemble components and/or stronger historical performance. They offer increased probability of successful reversals and can be traded with less additional confirmation.
Excellent Confidence (▲++ or ▼++) : Highest quality signals with exceptional underlying metrics. These signals show strong agreement across oscillator components, excellent historical performance, and optimal signal strength. These represent the indicator’s highest conviction trade opportunities and can be prioritized in your trading decisions.
Confidence assessment is calculated through a multi-factor analysis including:
Historical performance of ensemble components
Degree of agreement between different oscillator components
Relative strength of the signal compared to historical thresholds
✅ Best Use Cases:
Identify potential market reversals through oscillator extremes
Filter trade signals based on AI-evaluated component weights
Monitor changing market conditions through oscillator direction and intensity
Confirm trade signals from other indicators with adaptive ensemble validation
Detect early momentum shifts through pattern recognition
Prioritize trading opportunities based on signal confidence levels
Adjust position sizing according to signal confidence (larger for ++ signals, smaller for standard signals)
⚠️ Limitations
Requires sufficient historical data for accurate performance scoring
Ensemble weights may lag during dramatic market condition changes
Higher ensemble sizes require more computational resources
Performance evaluation quality depends on the learning lookback period length
Even high confidence signals should be considered within broader market context
💡 What Makes This Unique
Adaptive Intelligence : Continuously adjusts component weights based on actual performance
Ensemble Methodology : Combines strength of multiple indicators while minimizing individual weaknesses
Volatility-Adjusted Smoothing : Provides appropriate sensitivity across different market conditions
Performance-Based Learning : Utilizes historical accuracy to improve future predictions
Intelligent Signal Filtering : Reduces noise and false signals through sophisticated filtering criteria
Multi-Level Confidence Assessment : Delivers nuanced signal quality information for optimized trading decisions
🔬 How It Works
The indicator processes market data through five main components:
Ensemble Component Calculation :
Normalizes traditional indicators to consistent scale
Includes RSI, CCI, Stochastic, MACD, and volume components
Adapts based on the selected ensemble size
Performance Evaluation :
Analyzes directional accuracy of each component
Calculates continuous performance scores
Determines adaptive component weights
Oscillator Integration :
Combines weighted components into unified oscillator
Applies volatility-based adaptive smoothing
Scales final values to -6 to 6 range
Signal Generation :
Detects potential reversal patterns
Applies cooldown and magnitude filters
Generates clear visual markers for qualified signals
Confidence Assessment :
Evaluates component agreement, historical accuracy, and signal strength
Classifies signals into three confidence tiers (average, above average, excellent)
Displays intuitive confidence indicators (no symbol, +, ++) alongside direction markers
💡 Note:
The AI Adaptive Oscillator performs optimally when used with appropriate timeframe selection and complementary indicators. Its adaptive nature makes it particularly valuable during changing market conditions, where traditional fixed-weight indicators often lose effectiveness. The ensemble approach provides a more robust analysis by leveraging the collective intelligence of multiple technical methodologies. Pay special attention to the signal confidence indicators to optimize your trading decisions - excellent (++) signals often represent the most reliable trade opportunities.
Smart Adaptive Signal SystemSmart Adaptive Signal System
Description: The Smart Adaptive Signal System is a sophisticated indicator that generates intelligent buy/sell signals by dynamically adapting to market conditions. It predicts target prices based on momentum and volatility, providing more accurate and reliable trading opportunities.
How It Works:
Dynamic Signal Generation: The system predicts target prices by considering factors such as volatility and momentum. This allows it to react instantly to trend changes and market fluctuations.
Adaptive Thresholds: Buy and sell signals are triggered with adaptive thresholds, adjusting according to market volatility. This ensures flexibility in the face of sudden market changes.
Trend-Based Reset: Users can choose to reset threshold values based on a time interval or trend change. This feature helps the system re-adapt to current market conditions for greater accuracy.
Target Price Prediction: Target prices are calculated using momentum and volatility, helping the system predict future price movements.
How to Use:
Buy/Sell Signals: The indicator generates buy and sell signals based on market conditions. Look for a "down arrow" for a buy signal and an "up arrow" for a sell signal on the chart.
Target Price Lines: Along with buy and sell signals, the system draws target price lines. This helps you visualize potential future price levels.
Flexible Settings: Users can customize analysis periods, minimum change percentages, and other parameters to fit their needs.
Features:
Dynamic buy and sell signals
Target price predictions
Volatility and momentum-based analysis
User-friendly and flexible settings
Trend-based adaptive resetting
Alerts: The Smart Adaptive Signal System responds quickly to sudden market changes, but always use it in conjunction with other indicators like support and resistance levels. Signal accuracy may vary depending on market conditions.
Flux Charts - SFX Automation💎 GENERAL OVERVIEW
The SFX Automation is a powerful and versatile tool designed to help traders rigorously test their trading strategies against historical market data. With various advanced settings, traders can fine-tune their strategies, assess performance, and identify key improvements before deploying in live trading environments. This tool offers a wide range of configurable settings, explained within this write-up.
Features of the new SFX Automation :
Step By Step : Configure your strategy step by step, which will allow you to have OR & AND logic in your strategies.
Highly Configurable : Offers multiple parameters for fine-tuning trade entry and exit conditions.
Multi-Timeframe Analysis : Allows traders to analyze multiple timeframes simultaneously for enhanced accuracy.
Provides advanced stop-loss, take-profit, and break-even settings.
Incorporates Buy & Sell signals, with settings like Signal Sensitivity, Strength, Time Weighting, Dynamic TP & SL Methods and more for refined strategy execution.
🚩 UNIQUENESS
The SFX Automation stands out from conventional backtesting tools due to its unparalleled flexibility, precision, and advanced trading logic integration. Key factors that make it unique include:
✅ Comprehensive Strategy Customization – Unlike traditional backtesters that offer basic entry and exit conditions, SFX Automation provides a highly detailed parameter set, allowing traders to fine-tune their strategies with precision.
✅ Multi-Timeframe Signals – This is the first-ever tool that allows traders to backtest Buy & Sell Signals on multiple timeframes.
✅ Customizable Take-Profit Conditions – Offers various methods to set take-profit exits, including using core features from SFX Algo, and dynamic exits like signal rating upgrades/downgrades, enabling traders to tailor their exit strategies to specific market behaviors.
✅ Customizable Stop-Loss Conditions – Provides several ways to set up stop losses, including using concepts from SFX Algo and trailing stops or dynamic exits like signal rating upgrades/downgrades, allowing for dynamic risk management tailored to individual strategies.
✅ Integration of External Indicators – Allows the inclusion of other indicators or data sources from TradingView for creating strategy conditions, enabling traders to enhance their strategies with additional insights and data points.
By integrating these advanced features, SFX Automation ensures that traders can rigorously test and optimize their strategies with great accuracy and efficiency.
📌 HOW DOES IT WORK ?
The first setting you will want to set it the pyramiding setting. This setting controls the number of simultaneous trades in the same direction allowed in the strategy. For example, if you set it to 1, only one trade can be active in any time, and the second trade will not be entered unless the first one is exited. If it is set to 2, the script will handle both of them at the same time. Note that you should enter the same value to this pyramiding setting, and the pyramiding setting in the "Properties" tab of the script for this to work.
You can enable and set a backtesting window that will limit the entries to between the start date & end date.
Entry Conditions
From the "Long Conditions" or the "Short Conditions" groups, you can set your position entry conditions. For settings like "initial capital" or "order size", you can open the "Properties" tab, where these are handled.
The SFX Algo can use the following conditions for entry conditions :
1. Buy Signal (Any, or 1-5 ☆)
This condition is triggered when a Buy Signal occurs. Other timeframes are supported with this condition.
2. Buy | TP (1, 2 or 3)
This condition is triggered when a TP signal of any Buy signal occurs.
3. Buy | SL
This condition is triggered when a SL signal of any Buy signal occurs.
4. Buy | Rating Upgrade
This condition is triggered when the rating of a buy signal is increased.
5. Buy | Rating Downgrade
This condition is triggered when the rating of a buy signal is decreased.
6. Sell Signal (Any, or 1-5 ☆)
This condition is triggered when a Sell Signal occurs. Other timeframes are supported with this condition.
7. Sell | TP (1, 2 or 3)
This condition is triggered when a TP signal of any Sell signal occurs.
8. Sell | SL
This condition is triggered when a SL signal of any Sell signal occurs.
9. Sell | Rating Upgrade
This condition is triggered when the rating of a sell signal is increased.
10. Sell | Rating Downgrade
This condition is triggered when the rating of a sell signal is decreased.
11. Retracement Wave Retest (Bullish or Bearish)
A retest on the Retracement Wave occurs when the price temporarily moves against the prevailing trend, touching or entering the wave before continuing in the original trend direction. This retest serves as a confirmation that the wave is acting as dynamic support or resistance.
12. Retracement Wave Retracement (Bullish or Bearish)
A retracement on the Retracement Wave occurs when the price touches the wave, the condition is triggered immediately.
13. Volatility Bands Retest (Bullish or Bearish)
A retest of Volatility Bands occurs when the price initially moves beyond the bands, then pulls back to "retest" the band it just broke through before continuing its move. This can provide traders with confirmation of a breakout or signal a potential reversal.
14. Volatility Bands Retracement (Bullish or Bearish)
A retracement on the Volatility Bands occur when the price touches the band, the condition is triggered immediately.
🕒 TIMEFRAME CONDITIONS
The SFX Automation supports Multi-Timeframe (MTF) features for Buy & Sell signals. When setting an entry condition, you can also choose the timeframe.
External Conditions
Users can use external indicators on the chart to set entry conditions.
The second dropdown in the external condition settings allows you to choose a conditional operator to compare external outputs. Available options include:
Less Than or Equal To: <=
Less Than: <
Equal To: =
Greater Than: >
Greater Than or Equal To: >=
The position entry conditions work like this ;
Each side has 3 SFX Algo conditions and 2 Source conditions. Each condition can be enabled or disabled using the checkbox on the left side of them.
You can select which timeframe this condition should work on for Buy & Sell signals. If you select "Chart", the condition will work for the chart's current timeframe.
Lastly select the step of this condition from 1 to 6.
The Source Condition
The last condition on each side is a source condition that is different from the others. Using this condition, you can create your own logic using other indicators' outputs on your chart. For example, suppose that you have an EMA indicator in your chart. You can have the source condition to something like "EMA > high".
The Step System
Each condition has a step number, and conditions are in topological order based on them.
The conditions are executed step by step. This means the condition with step 2 cannot be executed before the condition with step 1 is executed.
Conditions with the same step numbers have "OR" logic. This means that if you have 2 conditions with step 3, the condition with step 4 can trigger after only one of the step 3 conditions is executed.
➕ OTHER ENTRY FEATURES
The SFX Automation allows traders to choose when to execute trades and when not to execute trades.
1. Only Take Trades
This setting lets users specify the time period when their strategy can open or execute trades.
2. Don't Take Trades
This setting lets users specify time periods when their strategy can't open or execute trades.
↩️ EXIT CONDITIONS
1. Exit on Opposite Signal
When enabled, a long position will close when short entry conditions are met, and a short position will close when long entry conditions are met.
2. Exit on Session End
When enabled, positions will be closed at the end of the trading session.
📈 TAKE PROFIT CONDITIONS
There are several methods available for setting take profit exits and conditions.
1. Entry Condition TP
Users can use entry conditions as triggers for take profit exits. This setting can be found under the long and short exit conditions.
2. Fixed TP
Users can set a fixed TP for exits. This setting can be found under the long and short exit conditions. Users can choose between the following:
Price: This method triggers a TP exit when price reaches a specified level. For example, if you set the Price TP to 10 and buy NASDAQ:TSLA at $190, the trade will automatically exit when the price reaches $200 ($190 + $10).
Ticks: This method triggers a TP exit when price moves a specified number of ticks.
Percentage (%): This method triggers a TP exit when price moves a specified percentage.
ATR: This method triggers a TP exit based on a specified multiple of the Average True Range (ATR).
🧩EXIT PERCENTAGES
For each 3 dynamic take-profit conditions, you can set the amount of the position to exit in terms of percentage. It's important to make sure that the total of the exit percentages are 100%.
📉 STOP LOSS CONDITIONS
There are several methods available for setting stop-loss exits and conditions.
1. Entry Condition SL
Users can use entry conditions as triggers for stop-loss exits. This setting can be found under the long and short exit conditions.
2. Fixed SL
Users can set a fixed SL for exits. This setting can be found under the long and short exit conditions. Users can choose between the following:
Price: This method triggers a SL exit when price reaches a specified level. For example, if you set the Price SL to 10 and buy NASDAQ:TSLA at $200, the trade will automatically exit when the price reaches $190 ($200 - $10).
Ticks: This method triggers a SL exit when price moves a specified number of ticks.
Percentage (%): This method triggers a SL exit when price moves a specified percentage.
ATR: This method triggers a SL exit based on a specified multiple of the Average True Range (ATR).
3. Trailing Stop
An explanation & example for the trailing stop feature is present on the write-up within the next section.
Exit conditions have the same logic of constructing conditions like the entry ones. You can construct a Take-Profit Condition & a Stop-Loss Condition. Note that the Take-Profit condition will only work if the position is in profit, regardless of if it's triggered or not. The same applies for the Stop-Loss condition, meaning that it will only work if the position is in loss.
You can also set a Fixed TP & Fixed SL based on the price movement after the position is entered. You have options like "Price", "Ticks", "%", or "Average True Range". For example, you can set a Fixed TP like "5%", and the position will be entered once it moves 5% up in a long position.
Trailing Stop
For the Fixed SL, you also have a "Trailing" stop option, which you can set it's activation level as well. The Trailing stop activation level and it's value are expressed in ticks. Check this scenerio for an example :
We have a ticker with a tick value of $1. Our Trailing Stop is set to 10 ticks, and the activation level is set to 30 ticks.
We buy 1 contract when the price is $100.
When the price becomes $110, we are in $10 (10 ticks) profit and the trailing stop is now activated.
The current price our stop's on is $110 - $30 (30 ticks), which is the level of $80.
The trailing stop will only move if the price moves up the highest high the price has been after we entered the position.
Let's suppose that price moves up $40 right after our trailing stop is activated. The price will now be $150, and our trailing stop will sit on $150 - $30 (30 ticks) = $120.
If the price is down the $120 level, our stop loss will be triggered.
There is also a "Hard SL" option designed for a backup stop-loss when trailing stops are enabled. You can enable & set this option and if the price goes down before our trailing stop even activates, the position will be exited.
You can also move stop-loss to the break-even (entry price of the position) after a certain profit is achieved using the last setting of the exit conditions. Note that for this to work, you will need to have a Fixed SL setup.
➕ OTHER EXIT FEATURES
1. Move Stop Loss to Breakeven
This setting allows the strategy to automatically move the SL to Breakeven (BE) when the position is in profit by a certain amount. Users can choose between the following:
Price: This method moves the SL to BE when price reaches a specified level.
Ticks: This method moves the SL to BE when price moves a specified number of ticks.
Percentage (%): This method moves the SL to BE when price moves a specified percentage.
ATR: This method moves the SL to BE when price moves a specified multiple of the Average True Range (ATR).
Example Entry Scenario
To give an example , check this scenario; out conditions are :
LONG CONDITIONS
Buy Signal Any☆, Step 1
Bullish R. Wave Retest, Step 2
Bullish V. Bands Retest, Step 2
open > close, Step 3
First, the strategy needs to detect a Buy Signal with any star rating in order to start working.
After it's detected, now it's looking for either a Bullish R. Wave Retest, or a Bullish V. Bands Retest to proceed to the next step, the reason for this is that they both have the same step number.
After one of them is detected, the strategy will consistently check candlesticks for the condition open > close. If a bullish candlestick occurs, a long position will be entered.
⏰ ALERTS
This indicator uses TradingView's strategy alert system. All entries and exits will be sent as an alert if configured. It's possible to further customize these alerts to your liking. For more information, check TradingView's strategy alert customization page: www.tradingview.com
⚙️ SETTINGS
1. Backtesting Settings
Pyramiding: Controls the number of simultaneous trades allowed in the strategy. This setting must have the same value that is entered on the script's properties tab on the settings pane.
Enable Custom Backtesting Period: Restricts backtesting to a specific date range.
Start & End Time Configuration: Define precise start and end dates for historical analysis.
2. Algorithm Settings
Sensitivity: The sensitivity setting is a key parameter that influences the number of signals the SFX Algo generates. By adjusting this parameter, you can control the frequency of signals produced by the algorithm.
Signal Strength: The Signal Strength setting filters signals based on their quality, allowing traders to focus on the most reliable opportunities. This feature helps traders balance the quantity and reliability of the algorithm’s signals to suit their trading strategy.
Time Weighting: The Time Weighting setting determines how the SFX Algo evaluates historical market data to generate signals.
a) Recent Trends
Focuses on the most recent movements for short-term analysis. This setting is good for scalpers and intraday traders who need to react quickly to market changes.
b) Mixed Trends
Balances recent and historical price movements for a comprehensive market view. This setting is well-suited for swing traders and those who want to capture medium-term opportunities by combining the benefits of short-term responsiveness with the reliability of long-term trends.
c) Long-term Trends
Relies on extended historical market data to identify broader market trends, making it an excellent choice for traders focused on long-term strategies.
Minimum Star Rating: The Minimum Star Rating setting allows you to filter signals based on their strength, showing only those that meet or exceed your chosen threshold. For instance, setting the minimum star rating to 3 ensures you only receive signals with a rating of 3 stars or higher.
3. Take Profit / Stop Loss Methods
Key Levels
The Key Levels method uses pivot points to set take profit and stop-loss levels. The TP and SL levels are shown when a new signal is generated.
Volatility Bands
This TP/SL method uses the Volatility Bands overlay to set dynamic TP and SL levels. These levels are not predetermined so they will not be shown in advance when a signal is generated.
Signal Rating
Sets take profit and stop-loss levels based on changes in a signal's rating strength. These levels are not predetermined so they will not be shown in advance when a signal is generated.
Auto Stop-Loss
The auto method can only be applied to the SL. The auto method allows the algorithm to detect SL automatically when a momentum shift is detected. You can adjust the risk tolerance of the Auto SL by adjusting the ‘Auto Risk Tolerance’ setting. You can choose between Low, Medium, and High. A high-risk tolerance will result in stop losses being triggered less often.
4. Entry Conditions for Long & Short Trades
Multiple Conditions (1-6): Configure up to six independent conditions per trade direction.
Timeframe Specification: Choose between timeframes for Buy & Sell signals.
Trade Execution Filters: Restrict trades within specific trading sessions.
5. Exit Conditions for Long & Short Trades
Exit on Opposite Signal: Automatically exit trades upon opposite trade conditions.
Exit on Session End: Closes all positions at the end of the trading session.
Multiple Take-Profit (TP) and Stop-Loss (SL) Configurations:
TP/SL based on % move, ATR, Ticks, or Fixed Price.
Hard SL option for additional risk control.
Move SL to BE (Break Even) after a certain profit threshold.

AI Volume Breakout for scalpingPurpose of the Indicator
This script is designed for trading, specifically for scalping, which involves making numerous trades within a very short time frame to take advantage of small price movements. The indicator looks for volume breakouts, which are moments when trading volume significantly increases, potentially signaling the start of a new price movement.
Key Components:
Parameters:
Volume Threshold (volumeThreshold): Determines how much volume must increase from one bar to the next for it to be considered significant. Set at 4.0, meaning volume must quadruplicate for a breakout signal.
Price Change Threshold (priceChangeThreshold): Defines the minimum price change required for a breakout signal. Here, it's 1.5% of the bar's opening price.
SMA Length (smaLength): The period for the Simple Moving Average, which helps confirm the trend direction. Here, it's set to 20.
Cooldown Period (cooldownPeriod): Prevents signals from being too close together, set to 10 bars.
ATR Period (atrPeriod): The period for calculating Average True Range (ATR), used to measure market volatility.
Volatility Threshold (volatilityThreshold): If ATR divided by the close price exceeds this, the market is considered too volatile for trading according to this strategy.
Calculations:
SMA (Simple Moving Average): Used for trend confirmation. A bullish signal is more likely if the price is above this average.
ATR (Average True Range): Measures market volatility. Lower volatility (below the threshold) is preferred for this strategy.
Signal Generation:
The indicator checks if:
Volume has increased significantly (volumeDelta > 0 and volume / volume >= volumeThreshold).
There's enough price change (math.abs(priceDelta / open) >= priceChangeThreshold).
The market isn't too volatile (lowVolatility).
The trend supports the direction of the price change (trendUp for bullish, trendDown for bearish).
If all these conditions are met, it predicts:
1 (Bullish) if conditions suggest buying.
0 (Bearish) if conditions suggest selling.
Cooldown Mechanism:
After a signal, the script waits for a number of bars (cooldownPeriod) before considering another signal to avoid over-trading.
Visual Feedback:
Labels are placed on the chart:
Green label for bullish breakouts below the low price.
Red label for bearish breakouts above the high price.
How to Use:
Entry Points: Look for the labels on your chart to decide when to enter trades.
Risk Management: Since this is for scalping, ensure each trade has tight stop-losses to manage risk due to the quick, small movements.
Market Conditions: This strategy might work best in markets with consistent volume and price changes but not extreme volatility.
Caveats:
This isn't real AI; it's a heuristic based on volume and price. Actual AI would involve machine learning algorithms trained on historical data.
Always backtest any strategy, and consider how it behaves in different market conditions, not just the ones it was designed for.

Trading IQ - Razor IQIntroducing TradingIQ's first dip buying/shorting all-in-one trading system: Razor IQ.
Razor IQ is an exclusive trading algorithm developed by TradingIQ, designed to trade upside/downside price dips of varying significance in trending markets. By integrating artificial intelligence and IQ Technology, Razor IQ analyzes historical and real-time price data to construct a dynamic trading system adaptable to various asset and timeframe combinations.
Philosophy of Razor IQ
Razor IQ operates on a single premise: Trends must retrace, and these retracements offer traders an opportunity to join in the overarching trend. At some point traders will enter against a trend in aggregate and traders in profitable positions entered during the trend will scale out. When occurring simultaneously, a trend will retrace against itself, offering an opportunity for traders not yet in the trend to join in the move and continue the trend.
Razor IQ is designed to work straight out of the box. In fact, its simplicity requires just a few user settings to manage output, making it incredibly straightforward to manage.
Long Limit Order Stop Loss and Minimum ATR TP/SL are the only settings that manage the performance of Razor IQ!
Traders don’t have to spend hours adjusting settings and trying to find what works best - Razor IQ handles this on its own.
Key Features of Razor IQ
Self-Learning Retracement Detection
Employs AI and IQ Technology to identify notable price dips in real-time.
AI-Generated Trading Signals
Provides retracement trading signals derived from self-learning algorithms.
Comprehensive Trading System
Offers clear entry and exit labels.
Performance Tracking
Records and presents trading performance data, easily accessible for user analysis.
Self-Learning Trading Exits
Razor IQ learns where to exit positions.
Long and Short Trading Capabilities
Supports both long and short positions to trade various market conditions.
How It Works
Razor IQ operates on a straightforward heuristic: go long during the retracement of significant upside price moves and go short during the retracement of significant downside price moves.
IQ Technology, TradingIQ's proprietary AI algorithm, defines what constitutes a “trend” and a “retracement” and what’s considered a tradable dip buying/shorting opportunity. For Razor IQ, this algorithm evaluates all historical trends and retracements, how much trends generally retrace and how long trends generally persist. For instance, the "dip" following an uptrend is measured and learned from, including the significance of the identified trend level (how long it has been active, how much price has increased, etc). By analyzing these patterns, Razor IQ adapts to identify and trade similar future retracements and trends.
In simple terms, Razor IQ clusters previous trend and retracement data in an attempt to trade similar price sequences when they repeat in the future. Using this knowledge, it determines the optimal, current price level where joining in the current trend (during a retracement) has a calculated chance of not stopping out before trend continuation.
For long positions, Razor IQ enters using a market order at the AI-identified long entry price point. If price closes beneath this level a market order will be placed and a long position entered. Of course, this is how the algorithm trades, users can elect to use a stop-limit order amongst other order types for position entry. After the position is entered TP1 is placed (identifiable on the price chart). TP1 has a twofold purpose:
Acts as a legitimate profit target to exit 50% of the position.
Once TP1 is achieved, a stop-loss order is immediately placed at breakeven, and a trailing stop loss controls the remainder of the trade. With this, so long as TP1 is achieved, the position will not endure a loss. So long as price continues to uptrend, Razor IQ will remain in the position.
For short positions, Razor IQ provides an AI-identified short entry level. If price closes above this level a market order will be placed and a short position entered. Again, this is how the algorithm trades, users can elect to use a stop-limit order amongst other order types for position entry. Upon entry Razor IQ implements a TP order and SL order (identifiable on the price chart).
Downtrends, in most markets, usually operate differently than uptrends. With uptrends, price usually increases at a modest pace with consistency over an extended period of time. Downtrends behave in an opposite manner - price decreases rapidly for a much shorter duration.
With this observation, the long dip entry heuristic differs slightly from the short dip entry heuristic.
The long dip entry heuristic specializes in identifying larger, long-term uptrends and entering on retracement of the uptrends. With a dedicated trailing stop loss, so long as the uptrend persists, Razor IQ will remain in the position.
The short dip entry heuristic specializes in identifying sharp, significant downside price moves, and entering short on upside volatility during these moves. A fixed stop loss and profit target are implemented for short positions - no trailing stop is used.
As a trading system, Razor IQ exits all TP orders using a limit order, with all stop losses exited as stop market orders.
What Classifies As a Tradable Dip?
For Razor IQ, tradable price dips are not manually set but are instead learned by the system. What qualifies as an exploitable price dip in one market might not hold the same significance in another. Razor IQ continuously analyzes historical and current trends (if one exists), how far price has moved during the trend, the duration of the trend, the raw-dollar price move of price dips during trends, and more, to determine which future price retracements offer a smart chance to join in any current price trend.
The image above illustrates the Razor Line Long Entry point.
The green line represents the Long Retracement Entry Point.
The blue upper line represents the first profit target for the trade.
The blue lower line represents the trailing stop loss start point for the long position.
The position is entered once price closes below the green line.
The green Razor Lazor long entry point will only appear during uptrends.
The image above shows a long position being entered after the Long Razor Lazor was closed beneath.
Green arrows indicate that the strategy entered a long position at the highlighted price level.
Blue arrows indicate that the strategy exited a position, whether at TP1, the initial stop loss, or at the trailing stop.
Blue lines above the entry price indicate the TP1 level for the current long trade. Blue lines below the current price indicate the initial stop loss price.
If price reaches TP1, a stop loss will be immediately placed at breakeven, and the in-built trailing stop will determine the future exit price.
A blue line (similar to the blue line shown for TP1) will trail price and correspond to the trailing stop price of the trade.
If the trailing stop is above the breakeven stop loss, then the trailing stop will be hit before the breakeven stop loss, which means the remainder of the trade will be exited at a profit.
If the breakeven stop loss is above the trailing stop, then the breakeven stop loss will be hit first. In this case, the remainder of the position will be exited at breakeven.
The image above shows the trailing stop price, represented by a blue line, and the breakeven stop loss price, represented by a pink line, used for the long position!
You can also hover over the trade labels to get more information about the trade—such as the entry price and exit price.
The image above exemplifies Razor IQ's output when a downtrend is active.
When a downtrend is active, Razor IQ will switch to "short mode". In short mode, Razor IQ will display a neon red line. This neon red line indicates the Razor Lazor short entry point. When price closes above the red Razor Lazor line a short position is entered.
The image above shows Razor IQ during an active short position.
The image above shows Razor IQ after completing a short trade.
Red arrows indicate that the strategy entered a short position at the highlighted price level.
Blue arrows indicate that the strategy exited a position, whether at the profit target or the fixed stop loss.
Blue lines indicate the profit target level for the current trade when below price. and blue lines above the current price indicate the stop loss level for the short trade.
Short traders do not utilize a trailing stop - only a fixed profit target and fixed stop loss are used.
You can also hover over the trade labels to get more information about the trade—such as the entry price and exit price.
Minimum Profit Target And Stop Loss
The Minimum ATR Profit Target and Minimum ATR Stop Loss setting control the minimum allowed profit target and stop loss distance. On most timeframes users won’t have to alter these settings; however, on very-low timeframes such as the 1-minute chart, users can increase these values so gross profits exceed commission.
After changing either setting, Razor IQ will retrain on historical data - accounting for the newly defined minimum profit target or stop loss.
AI Direction
The AI Direction setting controls the trade direction Razor IQ is allowed to take.
“Trade Longs” allows for long trades.
“Trade Shorts” allows for short trades.
Verifying Razor IQ’s Effectiveness
Razor IQ automatically tracks its performance and displays the profit factor for the long strategy and the short strategy it uses. This information can be found in the table located in the top-right corner of your chart showing.
This table shows the long strategy profit factor and the short strategy profit factor.
The image above shows the long strategy profit factor and the short strategy profit factor for Razor IQ.
A profit factor greater than 1 indicates a strategy profitably traded historical price data.
A profit factor less than 1 indicates a strategy unprofitably traded historical price data.
A profit factor equal to 1 indicates a strategy did not lose or gain money when trading historical price data.
Using Razor IQ
While Razor IQ is a full-fledged trading system with entries and exits - manual traders can certainly make use of its on chart indications and visualizations.
The hallmark feature of Razor IQ is its ability to signal an acceptable dip entry opportunity - for both uptrends and downtrends. Long entries are often signaled near the bottom of a retracement for an uptrend; short entries are often signaled near the top of a retracement for a downtrend.
Razor IQ will always operate on exact price levels; however, users can certainly take advantage of Razor IQ's trend identification mechanism and retracement identification mechanism to use as confluence with their personally crafted trading strategy.
Of course, every trend will reverse at some point, and a good dip buying/shorting strategy will often trade the reversal in expectation of the prior trend continuing (retracement). It's important not to aggressively filter retracement entries in hopes of avoiding an entry when a trend reversal finally occurs, as this will ultimately filter out good dip buying/shorting opportunities. This is a reality of any dip trading strategy - not just Razor IQ.
Of course, you can set alerts for all Razor IQ entry and exit signals, effectively following along its systematic conquest of price movement.

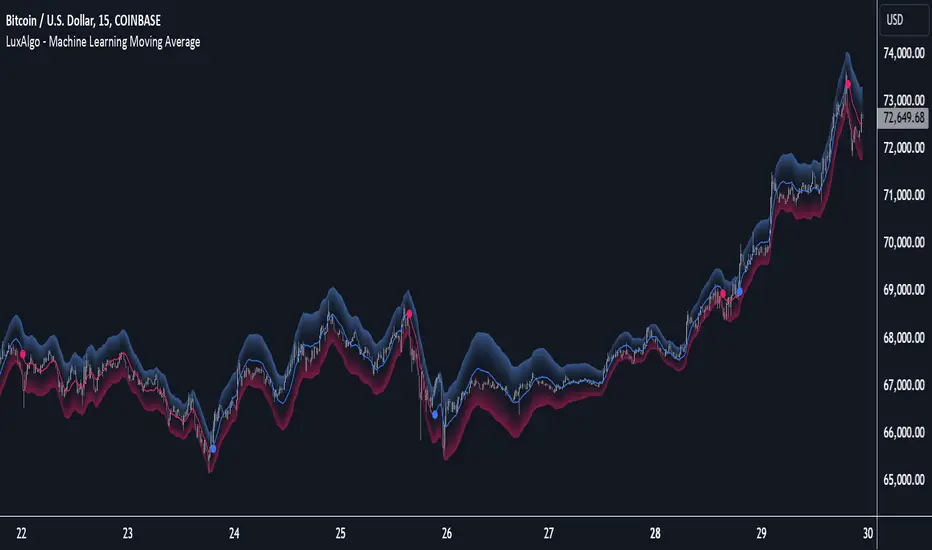
Machine Learning Moving Average [LuxAlgo]The Machine Learning Moving Average (MLMA) is a responsive moving average making use of the weighting function obtained Gaussian Process Regression method. Characteristic such as responsiveness and smoothness can be adjusted by the user from the settings.
The moving average also includes bands, used to highlight possible reversals.
🔶 USAGE
The Machine Learning Moving Average smooths out noisy variations from the price, directly estimating the underlying trend in the price.
A higher "Window" setting will return a longer-term moving average while increasing the "Forecast" setting will affect the responsiveness and smoothness of the moving average, with higher positive values returning a more responsive moving average and negative values returning a smoother but less responsive moving average.
Do note that an excessively high "Forecast" setting will result in overshoots, with the moving average having a poor fit with the price.
The moving average color is determined according to the estimated trend direction based on the bands described below, shifting to blue (default) in an uptrend and fushia (default) in downtrends.
The upper and lower extremities represent the range within which price movements likely fluctuate.
Signals are generated when the price crosses above or below the band extremities, with turning points being highlighted by colored circles on the chart.
🔶 SETTINGS
Window: Calculation period of the moving average. Higher values yield a smoother average, emphasizing long-term trends and filtering out short-term fluctuations.
Forecast: Sets the projection horizon for Gaussian Process Regression. Higher values create a more responsive moving average but will result in more overshoots, potentially worsening the fit with the price. Negative values will result in a smoother moving average.
Sigma: Controls the standard deviation of the Gaussian kernel, influencing weight distribution. Higher Sigma values return a longer-term moving average.
Multiplicative Factor: Adjusts the upper and lower extremity bounds, with higher values widening the bands and lowering the amount of returned turning points.
🔶 RELATED SCRIPTS
Machine-Learning-Gaussian-Process-Regression
SuperTrend-AI-Clustering
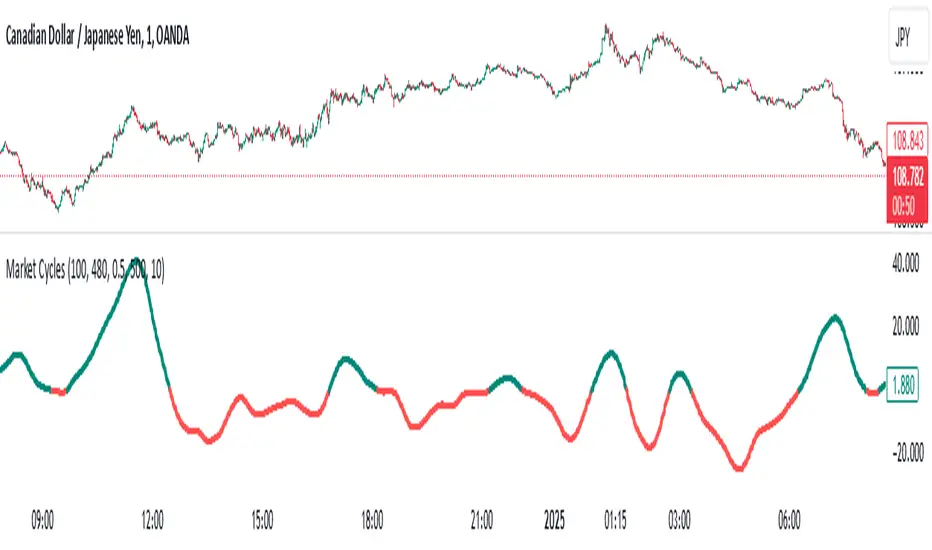
Market Cycles
The Market Cycles indicator transforms market price data into a stochastic wave, offering a unique perspective on market cycles. The wave is bounded between positive and negative values, providing clear visual cues for potential bullish and bearish trends. When the wave turns green, it signals a bullish cycle, while red indicates a bearish cycle.
Designed to show clarity and precision, this tool helps identify market momentum and cyclical behavior in an intuitive way. Ideal for fine-tuning entries or analyzing broader trends, this indicator aims to enhance the decision-making process with simplicity and elegance.
Adaptive AI Predictor (v2) by OberlunarAdaptive AI Predictor by Oberlunar
This script is designed to dynamically adapt to market changes, leveraging a neural network-inspired model to identify reliable trading signals. It analyzes price variations, processes patterns in the market, and provides clear buy and sell signals based on dynamic force calculations.
The script goes beyond simple indicators by incorporating adaptive learning principles. It tracks the success of its signals over time, calculating both the average and median forces behind winning trades. These insights allow the script to continuously refine its performance, ensuring it remains responsive to evolving market conditions.
Clear signals are displayed on the chart, showing the strength of the signal and its median historical success.
Configuration Parameters
Number of Nodes: : This parameter controls the number of nodes through which the data is processed. A higher number of nodes can improve the model’s ability to represent complex dynamics, but may also increase bias and a low capacity of generalization.
Input Scaling: Determines how much the input signal (percentage price change) is amplified before being processed. If the value is too low, the system may not react sufficiently to price changes; if too high, it might become too sensitive to market noise.
Scaling: Controls the strength of interactions between internal nodes. A higher value makes interactions between the neurons (nodes) stronger, but might also lead to instability in the signals.
Leak Rate: This parameter determines how fast information is "forgotten" within the system. A higher value means the model "forgets" previous information more quickly, making it more responsive to recent changes.
Sparsity: Controls the density of connections between internal nodes. A higher value increases the likelihood that a connection between nodes is "active." This affects the system’s ability to model complex dynamics and can also influence computational speed.
Signal Threshold: Sets the limit beyond which the predicted signal is considered significant. A value too low could generate too frequent and noisy signals, while a value too high might reduce useful signals.
History Length: Determines how much historical data is considered for training the system. A higher value uses more historical data but could slow down computations.
Learning Rate: Controls the speed at which the system updates its internal weights. A value too high might cause oscillations in the results, while one too low might slow down the adaptation process.
Exponential Decay Factor: Defines how quickly the weights adapt based on errors. A higher value reduces the impact of older weights, allowing the model to adapt faster to recent changes.
How It Works
Input Signal: The system observes the percentage price change between two consecutive bars (current close vs. previous close).
State Update: The states of the nodes are updated based on the input signal and internal interactions between the neurons. The update is influenced by the leak rate, which determines how fast nodes "forget" previous information.
Weight Training: Weights are trained to minimize the error between the system’s prediction and the observed price change. The system uses exponential regression to update the weights efficiently.
Signal Generation: Buy (BUY) and sell (SELL) signals are generated based on an analysis of the overall values of the nodes' states. If the overall strength (average of the nodes' states) exceeds a certain threshold, a buy signal is generated. If it's lower than a negative threshold, a sell signal is triggered.
Visualization and Signals
Signals on the Chart: Buy and sell signals are displayed on the chart with specific labels, indicating the signal's strength and median successful strength previously adopted . The strength is based on the distance from the threshold. The stronger the signal, the more intense the label color.
Debug Table: A debug table shows details about the input weights, node states, and the success of buy/sell signals, allowing you to monitor the system's behavior in real-time.
Simple Capital Management: The system calculates the position size based on available capital and updates the current capital after each trade. The profit or loss is displayed as a percentage of the initial capital.
How to Use It
Initial Configuration: Customize the configuration parameters based on your trading strategy and style. If you’re a more conservative trader, you might prefer higher thresholds and lower scaling.
Monitor Signals: Follow the buy and sell signals generated on the chart. Each signal is accompanied by its strength (percentage), which will help you decide how aggressively to position.
Very simple Position Management: When a buy signal is emitted, you can open a buy position, and when a sell signal is emitted, you can close the position. The system automatically calculates the profit or loss for each trade.
Adapting to Market Conditions: Adjust the parameters based on market volatility and your risk tolerance. If the market is highly volatile, you might want to increase sensitivity to signals or reduce the number of nodes for faster responsiveness.
With this system, you can leverage dynamic predictive signals based on a combination of historical data and continuous adaptation, improving your trading decisions.
To obtain good results remember to fine-tune by a model reparametrization.

Crypto Index Creator (MEMES & AI Supercycle Dominance, etc)This indicator aims to help to create any INDEX desired including but not limited to its Market Cap and Dominance on the crypto market.
This script was inspired originally by Murad's "Memecoins Dominance" but then I extended it to AI and can be extended to anything in fact, so you can create any index!
I made each token entry editable so that the script can survive the evolution of time as likely projects and INDEXES are going to change a lot, so that you can add/modify your own indices of preference if not listed by default and in order to make it future proof.
You can play with the settings, can compare to BTC, ETC, SOL, etc. for helping in your studies
You also have the option to check the info of each symbol on a table available on the settings, in order to help you figure out if there are any errors and also help you to easily check how the symbols are performing individually
Notes:
- Many projects are not like MEMECOINS that have fixed supply, normally VC projects have a very variable circulating supply, so you might want to update the info of the circulating supply for your projects to make it more accurate if you desire.
- For this script there is a limit of 32 Symbols, due to tradingview own limits, yet you can always "add" multiple projects per line as long as their circulating supply is the same.
- You might want to edit/sort the tickers of the top3, top5 and top10 if they follow bellow those top ranks, but this is not necessary if you don't care about Top 3-10 specific calculations.
- My default "indices" were made of token selections of mine as of November 2024, those defaults indices/tickers I might or might not update them eventually but you are free to adapt/modify the tickers in the settings as history evolves, and you can leave your own indexes on the comment section of this post for others to use
- As you might not be able to create/store multiple different indexes at the same time, you might want to add this indicator multiple times on your screen and then modify the tickers of each instance of this indicator, by that you can have multiple indexes.

TradingIQ - Counter Strike IQIntroducing "Counter Strike IQ" by TradingIQ
Counter Strike IQ is an exclusive trading algorithm developed by TradingIQ, designed to trade upside/downside breakouts of varying significance. By integrating artificial intelligence and IQ Technology, Counter Strike IQ analyzes historical and real-time price data to construct a dynamic trading system adaptable to various asset and timeframe combinations.
Philosophy of Counter Strike IQ
Counter Strike IQ operates on a single premise: Support and resistance levels cannot hold forever. At some point either side must break for the underlying asset to exhibit trends; otherwise, prices would be confined to an infinitely narrowing range.
Counter Strike IQ is designed to work straight out of the box. In fact, its simplicity requires just four user settings to manage output, making it incredibly straightforward to manage.
Minimum ATR Profit, Minimum ATR Stop, EMA Filter and EMA Filter Length are the only settings that manage the performance of Counter Strike IQ!
Traders don’t have to spend hours adjusting settings and trying to find what works best - Counter Strike IQ handles this on its own.
Key Features of Counter Strike IQ
Self-Learning Breakout Detection
Employs AI and IQ Technology to identify notable breakouts in real-time.
AI-Generated Trading Signals
Provides breakout trading signals derived from self-learning algorithms.
Comprehensive Trading System
Offers clear entry and exit labels.
Performance Tracking
Records and presents trading performance data, easily accessible for user analysis.
Self-Learning Trading Exits
Counter Strike IQ learns where to exit positions.
Long and Short Trading Capabilities
Supports both long and short positions to trade various market conditions.
Strike Channel
The Strike Channel represents what Counter Strike IQ considers a tradable long opportunity or a tradable short opportunity. The Strike Channel is dynamic and adjusts from chart to chart.
IQ Graph Gradient
Introduces the IQ Graph Gradient, designed to classify extreme values in price on a grand scale.
How It Works
Counter Strike IQ operates on a straightforward heuristic: go long during significant upside price moves that break established resistance levels and go short during significant downside price moves that break established support levels.
IQ Technology, TradingIQ's proprietary AI algorithm, defines what constitutes a “significant price move” and what’s considered a tradable breakout. For Counter Strike IQ, this algorithm evaluates all historical support/resistance breaks and any subsequent breakouts. For instance, the price move following up to a breakout is measured and learned from, including the significance of the identified support/resistance level (how long it’s been active, how far price moved away from it, etc). By analyzing these patterns, Counter Strike IQ adapts to identify and trade similar future breakout sequences.
In simple terms, Counter Strike IQ learns from violations of historical support/resistance levels to identify potential entry points at currently established support/resistance levels. Using this knowledge, it determines the optimal, current support/resistance price level where a breakout has a higher chance of occurring.
For long positions, Counter Strike IQ places a stop-market order at the AI-identified resistance point. If price violates this level a market order will be placed and a long position entered. Of course, this is how the algorithm trades, users can elect to use a stop-limit order amongst other order types for position entry. After the position is entered TP1 is placed (identifiable on the price chart). TP1 has a twofold purpose:
Acts as a legitimate profit target to exit 50% of the position.
Once TP1 is closed over, the initial stop loss is converted to a trailing stop, and the long position remains active so long as price continues to uptrend.
For short positions, Counter Strike IQ places a stop-market order at the AI-identified support point. If price violates this level a market order will be placed and a short position entered. Again, this is how the algorithm trades, users can elect to use a stop-limit order amongst other order types for position entry. Upon entry TP1 is placed (identifiable on the price chart). TP1 has a twofold purpose:
Acts as a legitimate profit target to exit 50% of the position.
Once TP1 is closed over, the initial stop loss is converted to a trailing stop, and the short position remains active so long as price continues to downtrend.
As a trading system, Counter Strike IQ exits TP1 using a limit order, with all stop losses exited as stop market orders.
What Classifies As a Tradable Upside Breakout or Tradable Downside Breakout?
For Counter Strike IQ, tradable price breakouts are not manually set but are instead learned by the system. What qualifies as a significant upside or downside breakout in one market might not hold the same significance in another. Counter Strike IQ continuously analyzes historical and current support/resistance levels, how far price has extended from those levels, the raw-dollar price move leading up to a violation of those levels, their longevity, and more, to determine which future levels have a higher chance of breaking out when retested!
The image above illustrates the Strike Channel and explains the corresponding prices and levels
The green upper line represents the Long Breakout Point.
The pink lower line represents the Short Breakout Point.
Any price between the two deviation points is considered “Acceptable”.
The image above shows a long position being entered after the Upside Breakout Point was reached.
Green arrows indicate that the strategy entered a long position at the highlighted price level.
Blue arrows indicate that the strategy exited a position, whether at TP1, the initial stop loss, or at the trailing stop.
Blue lines indicate the TP1 level for the current trade. Red lines indicate the initial stop loss price.
If price closes above TP1, the initial stop loss will be replaced with a trailing stop. A blue line (similar to the blue line shown for TP1) will trail price and correspond to the trailing stop price of the trade.
The image above shows the trailing stop price, represented by a blue line, used for the long position!
You can also hover over the trade labels to get more information about the trade—such as the entry price and exit price.
The image above shows a short position being entered after the Downside Breakout Point was reached.
Red arrows indicate that the strategy entered a short position at the highlighted price level.
Blue arrows indicate that the strategy exited a position, whether at TP1, the initial stop loss, or at the trailing stop.
Blue lines indicate the TP1 level for the current trade. Red lines indicate the initial stop loss price.
If price closes below TP1, the initial stop loss will be replaced with a trailing stop. A blue line (similar to the blue line shown for TP1) will trail price and correspond to the trailing stop price of the trade.
The image above shows the trailing stop price, represented by a blue line, used for the short position!
You can also hover over the trade labels to get more information about the trade—such as the entry price and exit price.
IQ Gradient Graph
The IQ Gradient Graph provides a macro characterization of extreme prices.
The lower macro extremity of the IQ Gradient Graph is colored green, while the upper macro extremity is colored red.
Minimum Profit Target And Stop Loss
The Minimum ATR Profit Target and Minimum ATR Stop Loss setting control the minimum allowed profit target and stop loss distance. On most timeframes users won’t have to alter these settings; however, on very-low timeframes such as the 1-minute chart, users can increase these values so gross profits exceed commission.
After changing either setting, Counter Strike IQ will retrain on historical data - accounting for the newly defined minimum profit target or stop loss.
AI Direction
The AI Direction setting controls the trade direction Counter Strike IQ is allowed to take.
“Trade Longs” allows for long trades.
“Trade Shorts” allows for short trades.
EMA Filter
The EMA Filter setting controls whether the AI should implement an EMA trading filter. Simply, if the EMA Filter is active, long trades can only initiate if price is trading above the user-defined EMA. Conversely, short trades can only initiate if price is trading below the user-defined EMA.
The image above shows the EMA Filter in action!
Verifying Counter Strike IQ’s Effectiveness
Counter Strike IQ automatically tracks its performance and displays the profit factor for the long strategy and the short strategy it uses. This information can be found in the table located in the top-right corner of your chart showing.
This table shows the long strategy profit factor and the short strategy profit factor.
The image above shows the long strategy profit factor and the short strategy profit factor for Counter Strike IQ.
A profit factor greater than 1 indicates a strategy profitably traded historical price data.
A profit factor less than 1 indicates a strategy unprofitably traded historical price data.
A profit factor equal to 1 indicates a strategy did not lose or gain money when trading historical price data.
Using Counter Strike IQ
While Counter Strike IQ is a full-fledged trading system with entries and exits - manual traders can certainly make use of its on chart indications and visualizations.
The hallmark feature of Counter Strike IQ is its ability to signal a breakout near its origin point. Long entries are often signaled near the start of a large upside price move; short entries are often signaled near the start of a large downside price move.
For live analysis, the Strike Channel serves as a valuable tool for identifying breakout points.
The further price moves toward the Upside Breakout Point (green), the stronger the indication that price might breakout to the upside. Conversely, the deeper price reaches toward the Downside Breakout Point (red), the stronger the indication that price might breakout to the downside.
Of course, should buying or selling pressure stall, price may fail to breakout at the identified breakout level. This is a natural consequence of any breakout trading strategy!
With this information at hand, traders can quickly switch between charts and timeframes to identify optimized areas of interest.
Machine Learning Signal FilterIntroducing the "Machine Learning Signal Filter," an innovative trading indicator designed to leverage the power of machine learning to enhance trading strategies. This tool combines advanced data processing capabilities with user-friendly customization options, offering traders a sophisticated yet accessible means to optimize their market analysis and decision-making processes. Importantly, this indicator does not repaint, ensuring that signals remain consistent and reliable after they are generated.
Machine Learning Integration
The "Machine Learning Signal Filter" employs machine learning algorithms to analyze historical price data and identify patterns that may not be immediately apparent through traditional technical analysis. By utilizing techniques such as regression analysis and neural networks, the indicator continuously learns from new data, refining its predictive capabilities over time. This dynamic adaptability allows the indicator to adjust to changing market conditions, potentially improving the accuracy of trading signals.
Key Features and Benefits
Dynamic Signal Generation: The indicator uses machine learning to generate buy and sell signals based on complex data patterns. This approach enables it to adapt to evolving market trends, offering traders timely and relevant insights. Crucially, the indicator does not repaint, providing reliable signals that traders can trust.
Customizable Parameters: Users can fine-tune the indicator to suit their specific trading styles by adjusting settings such as the temporal synchronization and neural pulse rate. This flexibility ensures that the indicator can be tailored to different market environments.
Visual Clarity and Usability: The indicator provides clear visual cues on the chart, including color-coded signals and optional display of signal curves. Users can also customize the table's position and text size, enhancing readability and ease of use.
Comprehensive Performance Metrics: The indicator includes a detailed metrics table that displays key performance indicators such as return rates, trade counts, and win/loss ratios. This feature helps traders assess the effectiveness of their strategies and make data-driven decisions.
How It Works
The core of the "Machine Learning Signal Filter" is its ability to process and learn from large datasets. By applying machine learning models, the indicator identifies potential trading opportunities based on historical data patterns. It uses regression techniques to predict future price movements and neural networks to enhance pattern recognition. As new data is introduced, the indicator refines its algorithms, improving its accuracy and reliability over time.
Use Cases
Trend Following: Ideal for traders seeking to capitalize on market trends, the indicator helps identify the direction and strength of price movements.
Scalping: With its ability to provide quick signals, the indicator is suitable for scalpers aiming for rapid profits in volatile markets.
Risk Management: By offering insights into trade performance, the indicator aids in managing risk and optimizing trade setups.
In summary, the "Machine Learning Signal Filter" is a powerful tool that combines the analytical strength of machine learning with the practical needs of traders. Its ability to adapt and provide actionable insights makes it an invaluable asset for navigating the complexities of financial markets.
The "Machine Learning Signal Filter" is a tool designed to assist traders by providing insights based on historical data and machine learning techniques. It does not guarantee profitable trades and should be used as part of a comprehensive trading strategy. Users are encouraged to conduct their own research and consider their financial situation before making trading decisions. Trading involves significant risk, and it is possible to lose more than the initial investment. Always trade responsibly and be aware of the risks involved.

Support/Resistance v2 (ML) KmeanKmean with Standard Deviation Channel
1. Description of Kmean
Kmean (or K-means) is a popular clustering algorithm used to divide data into K groups based on their similarity. In the context of financial markets, Kmean can be applied to find the average price values over a specific period, allowing the identification of major trends and levels of support and resistance.
2. Application in Trading
In trading, Kmean is used to smooth out the price series and determine long-term trends. This helps traders make more informed decisions by avoiding noise and short-term fluctuations. Kmean can serve as a baseline around which other analytical tools, such as channels and bands, are constructed.
3. Description of Standard Deviation (stdev)
Standard deviation (stdev) is a statistical measure that indicates how much the values of data deviate from their mean value. In finance, standard deviation is often used to assess price volatility. A high standard deviation indicates strong price fluctuations, while a low standard deviation indicates stable movements.
4. Combining Kmean and Standard Deviation to Predict Short-Term Price Behavior
Combining Kmean and standard deviation creates a powerful tool for analyzing market conditions. Kmean shows the average price trend, while the standard deviation channels demonstrate the boundaries within which the price can fluctuate. This combination helps traders to:
Identify support and resistance levels.
Predict potential price reversals.
Assess risks and set stop-losses and take-profits.
Should you have any questions about code, please reach me at Tradingview directly.
Hope you find this script helpful!
Edge AI Forecast [Edge Terminal]This indicator inputs the previous 150 closing prices in a simple two-layer neural network, normalizes the network inputs using a sigmoid function, uses a feedforward calculation to send it to the second layer, shows the MSE loss curve and uses both automatic and manual backpropagation (user input) to find the most likely forecast values and uses the analog forecasting algorithm to adjust and optimize the data furthermore to display potential prices on the chart.
Here's how it works:
The idea behind this script is to train a simple neural network to predict the future x values based on the sample data. For this, we use 2 types of data, Price and Volume.
The thinking behind this is that price alone can’t be used in this case because it doesn’t provide enough meaningful pattern data for the network but price and volume together can change the game. We’re planning to use more different data sets and expand on this in the future.
To avoid a bad mix of results, we technically have two neural networks, each processing a different data type, one for volume data and one for price data.
The actual prediction is decided by the way price and volume of the closing price relate to each other. Basically, the network passes the price and volume and finds the best relation between the two data set outputs and predicts where the price could be based on the upcoming volume of the latest candle.
The network adjusts the weights and biases using optimization algorithms like gradient descent to minimize the difference between the predicted and actual stock prices, typically measured by a loss function, (in this case, mean squared error) which you can see using the error rate bubble.
This is a good measure to see how well the network is performing and the idea is to adjust the settings inputs such as learning rate, epochs and data source to get the lowest possible error rate. That’s when you’re getting the most accurate prediction results.
For each data set, we use a multi-layer network. In a multi-layer neural network, the outputs of neurons in one layer serve as inputs to neurons in the next layer. Initially, the input layer of the neural network receives the historical data. Each input neuron represents a feature, such as previous stock prices and trading volumes over a specific period.
The hidden layers perform feature extraction and transformation through a series of weighted connections and activation functions. Each neuron in a hidden layer computes a weighted sum of the inputs from the previous layer, applies an activation function to the sum, and passes the result to the next layer using the feedforward (activation) function.
For extraction, we use a normalization function. This function takes a value or data (such as bar price) and divides it up by max scale which is the highest possible value of the bar. The idea is to take a normalized number, which is either below 1 or under 2 for simple use in the neural network layers.
For the activation, after computing the weighted sum, the neuron applies an activation function a(x). To introduce non-linearity into the model to pass it to the next layer. We use sigmoid activation functions in this case. The main reason we use sigmoid function is because the resulting number is between 0 to 1 and is better for models where we have to predict the probability as an output.
The final output of the network is passed as an input to the analog forecasting function. This is an algorithm commonly used in weather prediction systems. In this case, this is used to make predictions by comparing current values and assuming the patterns might repeat in the future.
There are many different ways to build an analog forecasting function but in our case, we’re used similarity measurement model:
X, as the current situation or set of current variables.
Y, as the outcome or variable of interest.
Si as the historical situations or patterns, where i ranges from 1 to n.
Vi as the vector of variables describing historical situation Si.
Oi as the outcome associated with historical situation Si.
First, we define a similarity measure sim(X,Vi) that quantifies the similarity between the current situation X and historical situation Si based on their respective variables Vi.
Then we select the K most similar historical situations (KNN Machine learning) based on the similarity measure sim(X,Vi). We denote the rest of the selected historical situations as {Si1, Si2,...Sik).
Then we examine the outcomes associated with the selected historical situations {Oi1, Oi2,...,Oik}.
Then we use the outcomes of the selected historical situations to forecast the future outcome Y^ using weighted averaging.
Finally, the output value of the analog forecasting is standardized using a standardization function which is the opposite of the normalization function. This function takes a normalized number and turns it back to its original value by multiplying it by the max scale (highest value of the bar). This function is used when the final number is produced by the network output at the end of the analog forecasting to turn the final value back into a price so it can be displayed on the chart with PineScript.
Settings:
Data source: Source of the neural network's input data.
Sample Bars: How many historical bars do you want to input into the neural network
Prediction Bars: How many bars you want the script to forecast
Show Training Rate: This shows the neural network's error rate for the optimization phase
Learning Rate: how many times you want the script to change the model in response to the estimated error (automatic)
Epochs: the network cycle or how many times you want to run the data through the network from the first layer to the last one.
Usage:
The sample bars input determines the number of historical bars to be used as a reference for the network. You need to change the Epochs and Learning Rate inputs for each asset and chart timeframe to get the lowest error rate.
On the surface, the highest possible epoch and learning rate should produce the most effective results but that's not always the case.
If the epochs rate is too high, there is a chance we face overfitting. Essentially, you might be over processing good data which can make it useless.
On the other hand, if the learning rate is too high, the network may overshoot the optimal solution and diverge. This is almost like the same issue I mentioned above with a high epoch rate.
Access:
It took over 4 months to develop this script and we’re constantly improving it so it took a lot of manpower to develop this script. Also when it comes to neural networks, Pine Script isn’t the most optimal language to build a neural network in, so we had to resort to a few proprietary mathematical formulas to ensure this runs smoothly without giving out an error for overprocessing, specially when you have multiple neural networks with many layers.
The optimization done to make this script run on Pine Script is basically state of the art and because of this, we would like to keep the code closed source at the moment.
On the other hand we don’t want to publish the code publicly as we want to keep the trading edge this script gives us in a closed loop, for our own small group of members so we have to keep the code closed. We only accept invites from expert traders who understand how this script and algo trading works and the type of edge it provides.
Additionally, at the moment we don’t want to share the code as some of the parts of this network, specifically the way we hand the data from neural network output into the analog method formula are proprietary code and we’d like to keep it that way.
You can contact us for access and if we believe this works for your trading case, we will provide you with access.
MBAND 200 4H BTC/USDT - By MGS-TradingMBAND 200 4H BTC/USDT with RSI and Volume by MGS-Trading: A Neural Network-Inspired Indicator
Introduction:
The MBAND 200 4H BTC/USDT with RSI and Volume represents a groundbreaking achievement in the integration of artificial intelligence (AI) into cryptocurrency market analysis. Developed by MGS-Trading, this indicator is the culmination of extensive research and development efforts aimed at leveraging AI's power to enhance trading strategies. By synthesizing neural network concepts with traditional technical analysis, the MBAND indicator offers a dynamic, multi-dimensional view of the market, providing traders with unparalleled insights and actionable signals.
Innovative Approach:
Our journey to create the MBAND indicator began with a simple question: How can we mimic the decision-making prowess of a neural network in a trading indicator? The answer lay in the weighted aggregation of Exponential Moving Averages (EMAs) from multiple timeframes, each serving as a unique input akin to a neuron in a neural network. These weights are not arbitrary; they were painstakingly optimized through backtesting across various market conditions to ensure they reflect the significance of each timeframe’s contribution to overall market dynamics.
Core Features:
Neural Network-Inspired Weights: The heart of the MBAND indicator lies in its AI-inspired weighting system, which treats each timeframe’s EMA as an input node in a neural network. This allows the indicator to process complex market data in a nuanced and sophisticated manner, leading to more refined and informed trading signals.
Multi-Timeframe EMA Analysis: By analyzing EMAs from 15 minutes to 3 days, the MBAND indicator captures a comprehensive snapshot of market trends, enabling traders to make informed decisions based on a broad spectrum of data.
RSI and Volume Integration: The inclusion of the Relative Strength Index (RSI) and volume data adds layers of confirmation to the signals generated by the EMA bands. This multi-indicator approach helps in identifying high-probability setups, reinforcing the neural network’s concept of leveraging multiple data points for decision-making.
Usage Guidelines:
Signal Interpretation: The MBAND bands provide a visual representation of the market’s momentum and direction. A price moving above the upper band signals strength and potential continuation of an uptrend, while a move below the lower band suggests weakness and a possible downtrend.
Overbought/Oversold Conditions: The RSI component identifies when the asset is potentially overbought (>70) or oversold (<30). Traders should watch for these conditions near the MBAND levels for potential reversal opportunities.
Volume Confirmation: An increase in volume accompanying a price move towards or beyond an MBAND level serves as confirmation of the strength behind the move. This can indicate whether a breakout is likely to sustain or if a reversal has substantial backing.
Strategic Entry and Exit Points: Combine the MBAND readings with RSI and volume indicators to pinpoint strategic entry and exit points. For example, consider entering a long position when the price is near the lower MBAND, RSI indicates oversold conditions, and there is a notable volume increase.
About MGS-Trading:
At MGS-Trading, we are passionate about harnessing the transformative power of AI to revolutionize cryptocurrency trading. Our indicators and tools are designed to provide traders with advanced analytics and insights, drawing on the latest AI techniques and methodologies. The MBAND 200 4H BTC/USDT with RSI and Volume indicator is a prime example of our commitment to innovation, offering traders a sophisticated, AI-enhanced tool for navigating the complexities of the cryptocurrency markets.
Disclaimer:
The MBAND indicator is provided for informational purposes only and does not constitute investment advice. Trading cryptocurrencies involves significant risk and can result in the loss of your investment. We recommend conducting your own research and consulting with a qualified financial advisor before making any trading decisions.

AI Adaptive Money Flow Index (Clustering) [AlgoAlpha]🌟🚀 Dive into the future of trading with our latest innovation: the AI Adaptive Money Flow Index by AlgoAlpha Indicator! 🚀🌟
Developed with the cutting-edge power of Machine Learning, this indicator is designed to revolutionize the way you view market dynamics. 🤖💹 With its unique blend of traditional Money Flow Index (MFI) analysis and advanced k-means clustering, it adapts to market conditions like never before.
Key Features:
📊 Adaptive MFI Analysis: Utilizes the classic MFI formula with a twist, adjusting its parameters based on AI-driven clustering.
🧠 AI-Driven Clustering: Applies k-means clustering to identify and adapt to market states, optimizing the MFI for current conditions.
🎨 Customizable Appearance: Offers adjustable settings for overbought, neutral, and oversold levels, as well as colors for uptrends and downtrends.
🔔 Alerts for Key Market Movements: Set alerts for trend reversals, overbought, and oversold conditions, ensuring you never miss a trading opportunity.
Quick Guide to Using the AI Adaptive MFI (Clustering):
🛠 Customize the Indicator: Customize settings like MFI source, length, and k-means clustering parameters to suit your analysis.
📈 Market Analysis: Monitor the dynamically adjusted overbought, neutral, and oversold levels for insights into market conditions. Watch for classification symbols ("+", "0", "-") for immediate understanding of the current market state. Look out for reversal signals (▲, ▼) to get potential entry points.
🔔 Set Alerts: Utilize the built-in alert conditions for trend changes, overbought, and oversold signals to stay ahead, even when you're not actively monitoring the charts.
How It Works:
The AI Adaptive Money Flow Index employs the k-means clustering machine learning algorithm to refine the traditional Money Flow Index, dynamically adjusting overbought, neutral, and oversold levels based on market conditions. This method analyzes historical MFI values, grouping them into initial clusters using the traditional MFI's overbought, oversold and neutral levels, and then finding the mean of each cluster, which represent the new market states thresholds. This adaptive approach ensures the indicator's sensitivity in real-time, offering a nuanced understanding of market trend and volume analysis.
By recalibrating MFI thresholds for each new data bar, the AI Adaptive MFI intelligently conforms to changing market dynamics. This process, assessing past periods to adjust the indicator's parameters, provides traders with insights finely tuned to recent market behavior. Such innovation enhances decision-making, leveraging the latest data to inform trading strategies. 🌐💥
Machine Learning: Multiple Logistic Regression
Multiple Logistic Regression Indicator
The Logistic Regression Indicator for TradingView is a versatile tool that employs multiple logistic regression based on various technical indicators to generate potential buy and sell signals. By utilizing key indicators such as RSI, CCI, DMI, Aroon, EMA, and SuperTrend, the indicator aims to provide a systematic approach to decision-making in financial markets.
How It Works:
Technical Indicators:
The script uses multiple technical indicators such as RSI, CCI, DMI, Aroon, EMA, and SuperTrend as input variables for the logistic regression model.
These indicators are normalized to create categorical variables, providing a consistent scale for the model.
Logistic Regression:
The logistic regression function is applied to the normalized input variables (x1 to x6) with user-defined coefficients (b0 to b6).
The logistic regression model predicts the probability of a binary outcome, with values closer to 1 indicating a bullish signal and values closer to 0 indicating a bearish signal.
Loss Function (Cross-Entropy Loss):
The cross-entropy loss function is calculated to quantify the difference between the predicted probability and the actual outcome.
The goal is to minimize this loss, which essentially measures the model's accuracy.
// Error Function (cross-entropy loss)
loss(y, p) =>
-y * math.log(p) - (1 - y) * math.log(1 - p)
// y - depended variable
// p - multiple logistic regression
Gradient Descent:
Gradient descent is an optimization algorithm used to minimize the loss function by adjusting the weights of the logistic regression model.
The script iteratively updates the weights (b1 to b6) based on the negative gradient of the loss function with respect to each weight.
// Adjusting model weights using gradient descent
b1 -= lr * (p + loss) * x1
b2 -= lr * (p + loss) * x2
b3 -= lr * (p + loss) * x3
b4 -= lr * (p + loss) * x4
b5 -= lr * (p + loss) * x5
b6 -= lr * (p + loss) * x6
// lr - learning rate or step of learning
// p - multiple logistic regression
// x_n - variables
Learning Rate:
The learning rate (lr) determines the step size in the weight adjustment process. It prevents the algorithm from overshooting the minimum of the loss function.
Users can set the learning rate to control the speed and stability of the optimization process.
Visualization:
The script visualizes the output of the logistic regression model by coloring the SMA.
Arrows are plotted at crossover and crossunder points, indicating potential buy and sell signals.
Lables are showing logistic regression values from 1 to 0 above and below bars
Table Display:
A table is displayed on the chart, providing real-time information about the input variables, their values, and the learned coefficients.
This allows traders to monitor the model's interpretation of the technical indicators and observe how the coefficients change over time.
How to Use:
Parameter Adjustment:
Users can adjust the length of technical indicators (rsi_length, cci_length, etc.) and the Z score length based on their preference and market characteristics.
Set the initial values for the regression coefficients (b0 to b6) and the learning rate (lr) according to your trading strategy.
Signal Interpretation:
Buy signals are indicated by an upward arrow (▲), and sell signals are indicated by a downward arrow (▼).
The color-coded SMA provides a visual representation of the logistic regression output by color.
Table Information:
Monitor the table for real-time information on the input variables, their values, and the learned coefficients.
Keep an eye on the learning rate to ensure a balance between model adjustment speed and stability.
Backtesting and Validation:
Before using the script in live trading, conduct thorough backtesting to evaluate its performance under different market conditions.
Validate the model against historical data to ensure its reliability.
Machine Learning: STDEV Oscillator [YinYangAlgorithms]This Indicator aims to fill a gap within traditional Standard Deviation Analysis. Rather than its usual applications, this Indicator focuses on applying Standard Deviation within an Oscillator and likewise applying a Machine Learning approach to it. By doing so, we may hope to achieve an Adaptive Oscillator which can help display when the price is deviating from its standard movement. This Indicator may help display both when the price is Overbought or Underbought, and likewise, where the price may face Support and Resistance. The reason for this is that rather than simply plotting a Machine Learning Standard Deviation (STDEV), we instead create a High and a Low variant of STDEV, and then use its Highest and Lowest values calculated within another Deviation to create Deviation Zones. These zones may help to display these Support and Resistance locations; and likewise may help to show if the price is Overbought or Oversold based on its placement within these zones. This Oscillator may also help display Momentum when the High and/or Low STDEV crosses the midline (0). Lastly, this Oscillator may also be useful for seeing the spacing between the High and Low of the STDEV; large spacing may represent volatility within the STDEV which may be helpful for seeing when there is Momentum in the form of volatility.
Tutorial:
Above is an example of how this Indicator looks on BTC/USDT 1 Day. As you may see, when the price has parabolic movement, so does the STDEV. This is due to this price movement deviating from the mean of the data. Therefore when these parabolic movements occur, we create the Deviation Zones accordingly, in hopes that it may help to project future Support and Resistance locations as well as helping to display when the price is Overbought and Oversold.
If we zoom in a little bit, you may notice that the Support Zone (Blue) is smaller than the Resistance Zone (Orange). This is simply because during the last Bull Market there was more parabolic price deviation than there was during the Bear Market. You may see this if you refer to their values; the Resistance Zone goes to ~18k whereas the Support Zone is ~10.5k. This is completely normal and the way it is supposed to work. Due to the nature of how STDEV works, this Oscillator doesn’t use a 1:1 ratio and instead can develop and expand as exponential price action occurs.
The Neutral (0) line may also act as a Support and Resistance location. In the example above we can see how when the STDEV is below it, it acts as Resistance; and when it’s above it, it acts as Support.
This Neutral line may also provide us with insight as towards the momentum within the market and when it has shifted. When the STDEV is below the Neutral line, the market may be considered Bearish. When the STDEV is above the Neutral line, the market may be considered Bullish.
The Red Line represents the STDEV’s High and the Green Line represents the STDEV’s Low. When the STDEV’s High and Low get tight and close together, this may represent there is currently Low Volatility in the market. Low Volatility may cause consolidation to occur, however it also leaves room for expansion.
However, when the STDEV’s High and Low are quite spaced apart, this may represent High levels of Volatility in the market. This may mean the market is more prone to parabolic movements and expansion.
We will conclude our Tutorial here. Hopefully this has given you some insight into how applying Machine Learning to a High and Low STDEV then creating Deviation Zones based on it may help project when the Momentum of the Market is Bullish or Bearish; likewise when the price is Overbought or Oversold; and lastly where the price may face Support and Resistance in the form of STDEV.
If you have any questions, comments, ideas or concerns please don't hesitate to contact us.
HAPPY TRADING!