MathSpecialFunctionsDiscreteFourierTransformLibrary "MathSpecialFunctionsDiscreteFourierTransform"
Method for Complex Discrete Fourier Transform (DFT).
dft(inputs, inverse) Complex Discrete Fourier Transform (DFT).
Parameters:
inputs : float array, pseudo complex array of paired values .
inverse : bool, invert the transformation.
Returns: float array, pseudo complex array of paired values .
Arrays

Bursa_SectorLibrary "Bursa_Sector"
: List of stocks classified by sector in Bursa Malaysia (As of Oct 2021)
getSector()
This function will get the sector of current stock that listed in Bursa Malaysia

CreateAndShowZigzagLibrary "CreateAndShowZigzag"
Functions in this library creates/updates zigzag array and shows the zigzag
getZigzag(zigzag, prd, max_array_size) calculates zigzag using period
Parameters:
zigzag : is the float array for the zigzag (should be defined like "var zigzag = array.new_float(0)"). each zigzag points contains 2 element: 1. price level of the zz point 2. bar_index of the zz point
prd : is the length to calculate zigzag waves by highest(prd)/lowest(prd)
max_array_size : is the maximum number of elements in zigzag, keep in mind each zigzag point contains 2 elements, so for example if it's 10 then zigzag has 10/2 => 5 zigzag points
Returns: dir that is the current direction of the zigzag
showZigzag(zigzag, oldzigzag, dir, upcol, dncol) this function shows zigzag
Parameters:
zigzag : is the float array for the zigzag (should be defined like "var zigzag = array.new_float(0)"). each zigzag points contains 2 element: 1. price level of the zz point 2. bar_index of the zz point
oldzigzag : is the float array for the zigzag, you get copy the zigzag array to oldzigzag by "oldzigzag = array.copy(zigzay)" before calling get_zigzag() function
dir : is the direction of the zigzag wave
upcol : is the color of the line if zigzag direction is up
dncol : is the color of the line if zigzag direction is down
Returns: null
MathComplexEvaluateLibrary "MathComplexEvaluate"
TODO: add library description here
is_op(char) Check if char is a operator.
Parameters:
char : string, 1 character string.
Returns: bool.
operator(op, left, right) operation between left and right values.
Parameters:
op : string, operator string character.
left : float, left value of operation.
right : float, right value of operation.
operator_precedence(op) level of precedence of operator.
Parameters:
op : string, operator 1 char string.
Returns: int.
eval() evaluate a string with references to a array of arguments.
| @param tokens string, arithmetic operations with references to indices in arguments, ex:"0+1*0+2*2+3" arguments
| @param arguments float array, arguments.
| @returns float, solution.

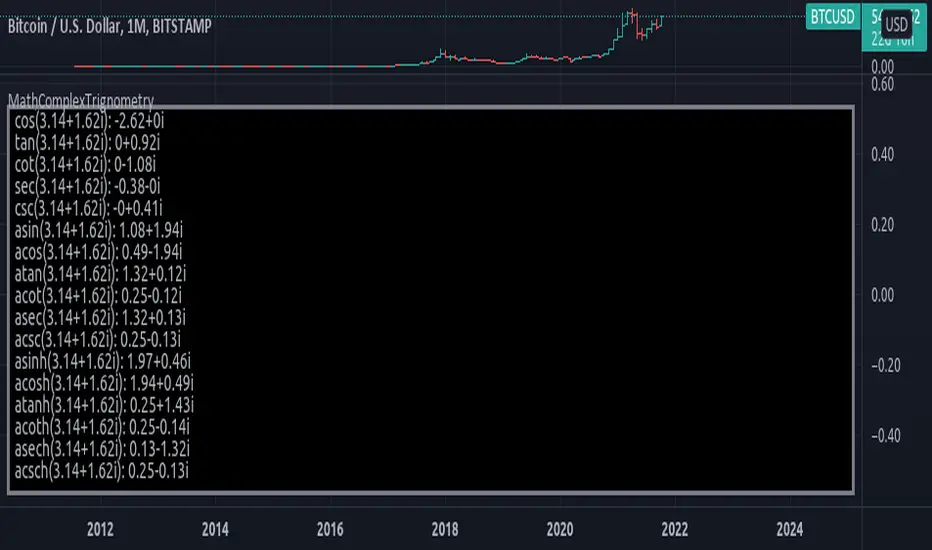
MathComplexTrignometryLibrary "MathComplexTrignometry"
Methods for complex number trignometry operations.
sinh(complex) Hyperbolic Sine of complex number.
Parameters:
complex : float array, complex number.
Returns: float array.
cosh(complex) Hyperbolic cosine of complex number.
Parameters:
complex : float array, complex number.
Returns: float array.
tanh(complex) Hyperbolic tangent of complex number.
Parameters:
complex : float array, complex number.
Returns: float array.
coth(complex) Hyperbolic cotangent of complex number.
Parameters:
complex : float array, complex number.
Returns: float array.
sech(complex) Hyperbolic Secant of complex number.
Parameters:
complex : float array, complex number.
Returns: float array.
csch(complex) Hyperbolic Cosecant of complex number.
Parameters:
complex : float array, complex number.
Returns: float array.
sin(complex) Trigonometric Sine of complex number.
Parameters:
complex : float array, complex number.
Returns: float array.
cos(complex) Trigonometric cosine of complex number.
Parameters:
complex : float array, complex number.
Returns: float array.
tan(complex) Trigonometric tangent of complex number.
Parameters:
complex : float array, complex number.
Returns: float array.
cot(complex) Trigonometric cotangent of complex number.
Parameters:
complex : float array, complex number.
Returns: float array.
sec(complex) Trigonometric Secant of complex number.
Parameters:
complex : float array, complex number.
Returns: float array.
csc(complex) Trigonometric Cosecant of complex number.
Parameters:
complex : float array, complex number.
Returns: float array.
asin(complex) Trigonometric Arc Sine of complex number.
Parameters:
complex : float array, complex number.
Returns: float array.
acos(complex) Trigonometric Arc Cosine of complex number.
Parameters:
complex : float array, complex number.
Returns: float array.
atan(complex) Trigonometric Arc Tangent of complex number.
Parameters:
complex : float array, complex number.
Returns: float array.
acot(complex) Trigonometric Arc Cotangent of complex number.
Parameters:
complex : float array, complex number.
Returns: float array.
asec(complex) Trigonometric Arc Secant of complex number.
Parameters:
complex : float array, complex number.
Returns: float array.
acsc(complex) Trigonometric Arc Cosecant of complex number.
Parameters:
complex : float array, complex number.
Returns: float array.
asinh(complex) Hyperbolic Arc Sine of complex number.
Parameters:
complex : float array, complex number.
Returns: float array.
acosh(complex) Hyperbolic Arc Cosine of complex number.
Parameters:
complex : float array, complex number.
Returns: float array.
atanh(complex) Hyperbolic Arc Tangent of complex number.
Parameters:
complex : float array, complex number.
Returns: float array.
acoth(complex) Hyperbolic Arc Cotangent of complex number.
Parameters:
complex : float array, complex number.
Returns: float array.
asech(complex) Hyperbolic Arc Secant of complex number.
Parameters:
complex : float array, complex number.
Returns: float array.
acsch(complex) Hyperbolic Arc Cosecant of complex number.
Parameters:
complex : float array, complex number.
Returns: float array.
MathComplexExtensionLibrary "MathComplexExtension"
A set of utility functions to handle complex numbers.
get_phase(complex_number, in_radians) The phase value of complex number complex_number.
Parameters:
complex_number : float array, pseudo complex number in the form of a array .
in_radians : boolean, value for the type of angle value, default=true, options=(true: radians, false: degrees)
Returns: float value with phase.
natural_logarithm(complex_number) Natural logarithm of complex number (base E).
Parameters:
complex_number : float array, pseudo complex number in the form of a array .
Returns: float array, complex number.
common_logarithm(complex_number) Common logarithm of complex number (base 10).
Parameters:
complex_number : float array, pseudo complex number in the form of a array .
Returns: float array, complex number.
logarithm(complex_number, base) Common logarithm of complex number (custom base).
Parameters:
complex_number : float array, pseudo complex number in the form of a array .
base : float, base value.
Returns: float array, complex number.
power(complex_number, complex_exponent) Raise complex_number with complex_exponent.
Parameters:
complex_number : float array, pseudo complex number in the form of a array .
complex_exponent : float array, pseudo complex number in the form of a array .
Returns: float array, pseudo complex number in the form of a array
root(complex_number, complex_exponent) Raise complex_number with inverse of complex_exponent.
Parameters:
complex_number : float array, pseudo complex number in the form of a array .
complex_exponent : float array, pseudo complex number in the form of a array .
Returns: float array, pseudo complex number in the form of a array
square(complex_number) Square of complex_number (power 2).
Parameters:
complex_number : float array, pseudo complex number in the form of a array .
Returns: float array, pseudo complex number in the form of a array
square_root(complex_number) Square root of complex_number (power 1/2).
Parameters:
complex_number : float array, pseudo complex number in the form of a array .
Returns: float array, pseudo complex number in the form of a array
square_roots(complex_number) Square root of complex_number (power 1/2).
Parameters:
complex_number : float array, pseudo complex number in the form of a array .
Returns: tuple with 2 complex numbers.
cubic_roots(complex_number) Square root of complex_number (power 1/2).
Parameters:
complex_number : float array, pseudo complex number in the form of a array .
Returns: tuple with 2 complex numbers.
to_polar_form(complex_number, in_radians) The polar form value of complex_number.
Parameters:
complex_number : float array, pseudo complex number in the form of a array .
in_radians : boolean, value for the type of angle value, default=true, options=(true: radians, false: degrees)
Returns: float array, pseudo complex number in the form of a array
** returns a array

MathComplexOperatorLibrary "MathComplexOperator"
A set of utility functions to handle complex numbers.
conjugate(complex_number) Computes the conjugate of complex_number by reversing the sign of the imaginary part.
Parameters:
complex_number : float array, pseudo complex number in the form of a array .
Returns: float array, pseudo complex number in the form of a array
add(complex_number_a, complex_number_b) Adds complex number complex_number_b to complex_number_a, in the form:
.
Parameters:
complex_number_a : pseudo complex number in the form of a array .
complex_number_b : pseudo complex number in the form of a array .
Returns: float array, pseudo complex number in the form of a array
subtract(complex_number_a, complex_number_b) Subtract complex_number_b from complex_number_a, in the form:
.
Parameters:
complex_number_a : float array, pseudo complex number in the form of a array .
complex_number_b : float array, pseudo complex number in the form of a array .
Returns: float array, pseudo complex number in the form of a array
multiply(complex_number_a, complex_number_b) Multiply complex_number_a with complex_number_b, in the form:
Parameters:
complex_number_a : float array, pseudo complex number in the form of a array .
complex_number_b : float array, pseudo complex number in the form of a array .
Returns: float array, pseudo complex number in the form of a array
divide(complex_number_a, complex_number_b) Divide complex_number _a with _b, in the form:
Parameters:
complex_number_a : float array, pseudo complex number in the form of a array .
complex_number_b : float array, pseudo complex number in the form of a array .
Returns: float array, pseudo complex number in the form of a array
reciprocal(complex_number) Computes the reciprocal or inverse of complex_number.
Parameters:
complex_number : float array, pseudo complex number in the form of a array .
Returns: float array, pseudo complex number in the form of a array
negative(complex_number) Negative of complex_number, in the form:
Parameters:
complex_number : float array, pseudo complex number in the form of a array .
Returns: float array, pseudo complex number in the form of a array
inverse(complex_number) Inverse of complex_number, in the form:
Parameters:
complex_number : float array, pseudo complex number in the form of a array .
Returns: float array, pseudo complex number in the form of a array
exponential(complex_number) Exponential of complex_number.
Parameters:
complex_number : pseudo complex number in the form of a array .
Returns: float array, pseudo complex number in the form of a array
ceil(complex_number, digits) Ceils complex_number.
Parameters:
complex_number : float array, pseudo complex number in the form of a array .
digits : int, digits to use as ceiling.
Returns: _complex: pseudo complex number in the form of a array
radius(complex_number) Radius(magnitude) of complex_number, in the form:
This is defined as its distance from the origin (0,0) of the complex plane.
Parameters:
complex_number : float array, pseudo complex number in the form of a array .
Returns: float value with radius.
magnitude(complex_number) magnitude(absolute value) of complex_number, should be the same as the radius.
Parameters:
complex_number : float array, pseudo complex number in the form of a array .
Returns: float.
magnitude_squared(complex_number) magnitude(absolute value) of complex_number, should be the same as the radius.
Parameters:
complex_number : float array, pseudo complex number in the form of a array .
Returns: float.
sign(complex_number) Unity of complex numbers.
Parameters:
complex_number : float array, pseudo complex number in the form of a array .
Returns: float array, complex number.

MathComplexArrayLibrary "MathComplexArray"
Array methods to handle complex number arrays.
new(size, initial_complex) Prototype to initialize a array of complex numbers.
Parameters:
size : size of the array.
initial_complex : Complex number to be used as default value, in the form of array .
Returns: float array, pseudo complex Array in the form of a array
get(id, index) Get the complex number in a array, in the form of a array
Parameters:
id : float array, ID of the array.
index : int, Index of the complex number.
Returns: float array, pseudo complex number in the form of a array
set(id, index, complex_number) Sets the values complex number in a array.
Parameters:
id : float array, ID of the array.
index : int, Index of the complex number.
complex_number : float array, Complex number, in the form: .
Returns: Void, updates array id.
push(id, complex_number) Push the values into a complex number array.
Parameters:
id : float array, ID of the array.
complex_number : float array, Complex number, in the form: .
Returns: Void, updates array id.
pop(id, complex_number) Pop the values from a complex number array.
Parameters:
id : float array, ID of the array.
complex_number : float array, Complex number, in the form: .
Returns: Void, updates array id.
to_string(id, format) Reads a array of complex numbers into a string, of the form: " [ , ... ]""
Parameters:
id : float array, ID of the array.
format : string, format of the number conversion, default='#.##########'.
Returns: string, translated complex array into string.
MathComplexCoreLibrary "MathComplexCore"
Core functions to handle complex numbers.
set_real(complex_number, real) Set the real part of complex_number.
Parameters:
complex_number : float array, pseudo complex number in the form of a array .
real : float, value to replace real value of complex_number.
Returns: Void, Modifies complex_number.
set_imaginary(complex_number, imaginary) Set the imaginary part of complex_number.
Parameters:
complex_number : float array, pseudo complex number in the form of a array .
imaginary : float, value to replace imaginary value of complex_number.
Returns: Void, Modifies complex_number.
new(real, imaginary) Creates a prototype array to handle complex numbers.
Parameters:
real : float, real value of the complex number. default=0.
imaginary : float, imaginary number of the complex number. default=0.
@return float array, pseudo complex number in the form of a array .
zero() complex number "0+0i".
@return float array, pseudo complex number in the form of a array .
one() complex number "1+0i".
@return float array, pseudo complex number in the form of a array .
imaginary_one() complex number "0+1i".
@return float array, pseudo complex number in the form of a array .
nan() complex number "0+1i".
@return float array, pseudo complex number in the form of a array .
from_polar_coordinates(magnitude, phase) Create a complex number from a point's polar coordinates.
Parameters:
magnitude : float, default=0.0, The magnitude, which is the distance from the origin (the intersection of the x-axis and the y-axis) to the number.
phase : float, default=0.0, The phase, which is the angle from the line to the horizontal axis, measured in radians.
@return float array, pseudo complex number in the form of a array .
get_real(complex_number) Get the real part of complex_number.
Parameters:
complex_number : pseudo complex number in the form of a array .
Returns: float, Real part of the complex_number.
get_imaginary(complex_number) Get the imaginary part of complex_number.
Parameters:
complex_number : pseudo complex number in the form of a array .
Returns: float, Imaginary part of the complex number.
is_complex(complex_number) Checks that its a valid complex_number.
Parameters:
complex_number : pseudo complex number in the form of a array .
Returns: bool.
is_nan(complex_number) Checks that its empty "na" complex_number.
Parameters:
complex_number : pseudo complex number in the form of a array .
Returns: bool.
is_real(complex_number) Checks that the complex_number is real.
Parameters:
complex_number : pseudo complex number in the form of a array .
Returns: bool.
is_real_non_negative(complex_number) Checks that the complex_number is real and not negative.
Parameters:
complex_number : pseudo complex number in the form of a array .
Returns: bool.
is_zero(complex_number) Checks that the complex_number is zero.
Parameters:
complex_number : pseudo complex number in the form of a array .
Returns: bool.
equals(complex_number_a, complex_number_b) Compares two complex numbers:
Parameters:
complex_number_a : float array, pseudo complex number in the form of a array .
complex_number_b : float array, pseudo complex number in the form of a array .
Returns: boolean value representing the equality.
to_string(complex, format) Converts complex_number to a string format, in the form: "a+bi"
Parameters:
complex : pseudo complex number in the form of a array .
format : string, formating to apply.
Returns: a string in "a+bi" format

FunctionBestFitFrequencyLibrary "FunctionBestFitFrequency"
TODO: add library description here
array_moving_average(sample, length, ommit_initial, fillna) Moving Average values for selected data.
Parameters:
sample : float array, sample data values.
length : int, length to smooth the data.
ommit_initial : bool, default=true, ommit values at the start of the data under the length.
fillna : string, default='na', options='na', '0', 'avg'
Returns: float array
errors:
length > sample size "Canot call array methods when id of array is na."
best_fit_frequency(sample, start, end) Search a frequency range for the fairest moving average frequency.
Parameters:
sample : float array, sample data to based the moving averages.
start : int lowest frequency.
end : int highest frequency.
Returns: tuple with (int frequency, float percentage)

ArrayStatisticsLibrary "ArrayStatistics"
Statistic Functions using arrays.
rms(sample) Root Mean Squared
Parameters:
sample : float array, data sample points.
Returns: float
skewness_pearson1(sample) Pearson's 1st Coefficient of Skewness.
Parameters:
sample : float array, data sample.
Returns: float
skewness_pearson2(sample) Pearson's 2nd Coefficient of Skewness.
Parameters:
sample : float array, data sample.
Returns: float
pearsonr(sample_a, sample_b) Pearson correlation coefficient measures the linear relationship between two datasets.
Parameters:
sample_a : float array, sample with data.
sample_b : float array, sample with data.
Returns: float p
kurtosis(sample) Kurtosis of distribution.
Parameters:
sample : float array, data sample.
Returns: float
range_int(sample, percent) Get range around median containing specified percentage of values.
Parameters:
sample : int array, Histogram array.
percent : float, Values percentage around median.
Returns: tuple with , Returns the range which containes specifies percentage of values.

ArrayOperationsIntLibrary "ArrayOperationsInt"
Array Basic Operations for Integers
add(sample_a, sample_b) Adds sample_b to sample_a and returns a new array.
Parameters:
sample_a : values to be added to.
sample_b : values to add.
Returns: int array with added results.
subtract(sample_a, sample_b) subtracts sample_b from sample_a and returns a new array.
Parameters:
sample_a : values to be subtracted from.
sample_b : values to subtract.
Returns: int array with subtracted results.
multiply(sample_a, sample_b) multiply sample_a with sample_b and returns a new array.
Parameters:
sample_a : values to multiply.
sample_b : values to multiply with.
Returns: int array with multiplied results.
divide(sample_a, sample_b) divide sample_a with sample_b and returns a new array.
Parameters:
sample_a : values to divide.
sample_b : values to divide with.
Returns: int array with divided results.
power(sample_a, sample_b) rise sample_a to the power of sample_b and returns a new array.
Parameters:
sample_a : base values to raise.
sample_b : values of exponents.
Returns: int array with raised results.
remainder(sample_a, sample_b) integer remainder of sample_a under the dividend sample_b and returns a new array.
Parameters:
sample_a : values of quotients.
sample_b : values of dividends.
Returns: int array with remainder results.
ArrayOperationsFloatLibrary "ArrayOperationsFloat"
Array Basic Operations for Integers
add(sample_a, sample_b) Adds sample_b to sample_a and returns a new array.
Parameters:
sample_a : values to be added to.
sample_b : values to add.
Returns: float array with added results.
subtract(sample_a, sample_b) subtracts sample_b from sample_a and returns a new array.
Parameters:
sample_a : values to be subtracted from.
sample_b : values to subtract.
Returns: float array with subtracted results.
multiply(sample_a, sample_b) multiply sample_a with sample_b and returns a new array.
Parameters:
sample_a : values to multiply.
sample_b : values to multiply with.
Returns: float array with multiplied results.
divide(sample_a, sample_b) divide sample_a with sample_b and returns a new array.
Parameters:
sample_a : values to divide.
sample_b : values to divide with.
Returns: float array with divided results.
power(sample_a, sample_b) rise sample_a to the power of sample_b and returns a new array.
Parameters:
sample_a : base values to raise.
sample_b : values of exponents.
Returns: float array with raised results.
remainder(sample_a, sample_b) float remainder of sample_a under the dividend sample_b and returns a new array.
Parameters:
sample_a : values of quotients.
sample_b : values of dividends.
Returns: float array with remainder results.
bursamalaysianonshariahLibrary "bursamalaysianonshariah"
List of non-Shariah stock for Bursa Malaysia as of Oct 2021
No parameter required
status() will return 1 if ticker in the list, 0 if ticker not in the list and 2 if ticker not from Bursa Malaysia
Example usage :
//@version=5
indicator("My Script", overlay = true)
import BURSATRENDBANDCHART/bursamalaysianonshariah/1 as b
bgcolor(status() == 1 ? color.new(color.red, 90) : status() == 0 ? color.new(color.green, 90) : color.new(color.blue, 90))
Special thanks to
wmsafwan
RozaniGhani-RG
Vector2OperationsLibrary "Vector2Operations"
functions to handle vector2 operations.
math_fractional(_value) computes the fractional part of the argument value.
Parameters:
_value : float, value to compute.
Returns: float, fractional part.
atan2(_a) Approximation to atan2 calculation, arc tangent of y/ x in the range radians.
Parameters:
_a : vector2 in the form of a array .
Returns: float, value with angle in radians. (negative if quadrante 3 or 4)
set_x(_a, _value) Set the x value of vector _a.
Parameters:
_a : vector2 in the form of a array .
_value : value to replace x value of _a.
Returns: void Modifies vector _a.
set_y(_a, _value) Set the y value of vector _a.
Parameters:
_a : vector in the form of a array .
_value : value to replace y value of _a.
Returns: void Modifies vector _a.
get_x(_a) Get the x value of vector _a.
Parameters:
_a : vector in the form of a array .
Returns: float, x value of the vector _a.
get_y(_a) Get the y value of vector _a.
Parameters:
_a : vector in the form of a array .
Returns: float, y value of the vector _a.
get_xy(_a) Return the tuple of vector _a in the form
Parameters:
_a : vector2 in the form of a array .
Returns:
length_squared(_a) Length of vector _a in the form. , for comparing vectors this is computationaly lighter.
Parameters:
_a : vector in the form of a array .
Returns: float, squared length of vector.
length(_a) Magnitude of vector _a in the form.
Parameters:
_a : vector in the form of a array .
Returns: float, Squared length of vector.
vmin(_a) Lowest element of vector.
Parameters:
_a : vector in the form of a array .
Returns: float
vmax(_a) Highest element of vector.
Parameters:
_a : vector in the form of a array .
Returns: float
from(_value) Assigns value to a new vector x,y elements.
Parameters:
_value : x and y value of the vector. optional.
Returns: float vector.
new(_x, _y) Creates a prototype array to handle vectors.
Parameters:
_x : float, x value of the vector. optional.
_y : float, y number of the vector. optional.
Returns: float vector.
down() Vector in the form . Returns: float vector.
left() Vector in the form . Returns: float vector.
one() Vector in the form . Returns: float vector.
right() Vector in the form . Returns: float vector
up() Vector in the form . Returns: float vector
zero() Vector in the form . Returns: float vector
add(_a, _b) Adds vector _b to _a, in the form
.
Parameters:
_a : vector in the form of a array .
_b : vector in the form of a array .
Returns:
subtract(_a, _b) Subtract vector _b from _a, in the form
.
Parameters:
_a : vector in the form of a array .
_b : vector in the form of a array .
Returns:
multiply(_a, _b) Multiply vector _a with _b, in the form
Parameters:
_a : vector in the form of a array .
_b : vector in the form of a array .
Returns:
divide(_a, _b) Divide vector _a with _b, in the form
Parameters:
_a : vector in the form of a array .
_b : vector in the form of a array .
Returns:
negate(_a) Negative of vector _a, in the form
Parameters:
_a : vector in the form of a array .
Returns:
perp(_a) Perpendicular Vector of _a.
Parameters:
_a : vector in the form of a array .
Returns:
vfloor(_a) Compute the floor of argument vector _a.
Parameters:
_a : vector in the form of a array .
Returns:
fractional(_a) Compute the fractional part of the elements from vector _a.
Parameters:
_a : vector in the form of a array .
Returns:
vsin(_a) Compute the sine of argument vector _a.
Parameters:
_a : vector in the form of a array .
Returns:
equals(_a, _b) Compares two vectors
Parameters:
_a : vector in the form of a array .
_b : vector in the form of a array .
Returns: boolean value representing the equality.
dot(_a, _b) Dot product of 2 vectors, in the form
Parameters:
_a : vector in the form of a array .
_b : vector in the form of a array .
Returns: float
cross_product(_a, _b) cross product of 2 vectors, in the form
Parameters:
_a : vector in the form of a array .
_b : vector in the form of a array .
Returns: float
scale(_a, _scalar) Multiply a vector by a scalar.
Parameters:
_a : vector in the form of a array .
_scalar : value to multiply vector elements by.
Returns: float vector
normalize(_a) Vector _a normalized with a magnitude of 1, in the form.
Parameters:
_a : vector in the form of a array .
Returns: float vector
rescale(_a) Rescale a vector to a new Magnitude.
Parameters:
_a : vector in the form of a array .
Returns:
rotate(_a, _radians) Rotates vector _a by angle value
Parameters:
_a : vector in the form of a array .
_radians : Angle value.
Returns:
rotate_degree(_a, _degree) Rotates vector _a by angle value
Parameters:
_a : vector in the form of a array .
_degree : Angle value.
Returns:
rotate_around(_center, _target, _degree) Rotates vector _target around _origin by angle value
Parameters:
_center : vector in the form of a array .
_target : vector in the form of a array .
_degree : Angle value.
Returns:
vceil(_a, _digits) Ceils vector _a
Parameters:
_a : vector in the form of a array .
_digits : digits to use as ceiling.
Returns:
vpow(_a) Raise both vector elements by a exponent.
Parameters:
_a : vector in the form of a array .
Returns:
distance(_a, _b) vector distance between 2 vectors.
Parameters:
_a : vector in the form of a array .
_b : vector in the form of a array .
Returns: float, distance.
project(_a, _axis) Project a vector onto another.
Parameters:
_a : vector in the form of a array .
_axis : float vector2
Returns: float vector
projectN(_a, _axis) Project a vector onto a vector of unit length.
Parameters:
_a : vector in the form of a array .
_axis : vector in the form of a array .
Returns: float vector
reflect(_a, _b) Reflect a vector on another.
Parameters:
_a : vector in the form of a array .
_b : vector in the form of a array .
Returns: float vector
reflectN(_a, _b) Reflect a vector to a arbitrary axis.
Parameters:
_a : vector in the form of a array .
_b : vector in the form of a array .
Returns: float vector
angle(_a) Angle in radians of a vector.
Parameters:
_a : vector in the form of a array .
Returns: float
angle_unsigned(_a, _b) unsigned degree angle between 0 and +180 by given two vectors.
Parameters:
_a : vector in the form of a array .
_b : vector in the form of a array .
Returns: float
angle_signed(_a, _b) Signed degree angle between -180 and +180 by given two vectors.
Parameters:
_a : vector in the form of a array .
_b : vector in the form of a array .
Returns: float
angle_360(_a, _b) Degree angle between 0 and 360 by given two vectors
Parameters:
_a : vector in the form of a array .
_b : vector in the form of a array .
Returns: float
clamp(_a, _vmin, _vmax) Restricts a vector between a min and max value.
Parameters:
_a : vector in the form of a array .
_vmin : vector in the form of a array .
_vmax : vector in the form of a array .
Returns: float vector
lerp(_a, _b, _rate_of_move) Linearly interpolates between vectors a and b by _rate_of_move.
Parameters:
_a : vector in the form of a array .
_b : vector in the form of a array .
_rate_of_move : float value between (a:-infinity -> b:1.0), negative values will move away from b.
Returns: vector in the form of a array
herp(_a, _b, _rate_of_move) Hermite curve interpolation between vectors a and b by _rate_of_move.
Parameters:
_a : vector in the form of a array .
_b : vector in the form of a array .
_rate_of_move : float value between (a-infinity -> b1.0), negative values will move away from b.
Returns: vector in the form of a array
area_triangle(_a, _b, _c) Find the area in a triangle of vectors.
Parameters:
_a : vector in the form of a array .
_b : vector in the form of a array .
_c : vector in the form of a array .
Returns: float
to_string(_a) Converts vector _a to a string format, in the form "(x, y)"
Parameters:
_a : vector in the form of a array .
Returns: string in "(x, y)" format
vrandom(_max) 2D random value
Parameters:
_max : float vector, vector upper bound
Returns: vector in the form of a array
noise(_a) 2D Noise based on Morgan McGuire @morgan3d
thebookofshaders.com
www.shadertoy.com
Parameters:
_a : vector in the form of a array .
Returns: vector in the form of a array
array_new(_size, _initial_vector) Prototype to initialize a array of vectors.
Parameters:
_size : size of the array.
_initial_vector : vector to be used as default value, in the form of array .
Returns: _vector_array complex Array in the form of a array
array_size(_id) number of vector elements in array.
Parameters:
_id : ID of the array.
Returns: int
array_get(_id, _index) Get the vector in a array, in the form of a array
Parameters:
_id : ID of the array.
_index : Index of the vector.
Returns: vector in the form of a array
array_set(_id, _index, _a) Sets the values vector in a array.
Parameters:
_id : ID of the array.
_index : Index of the vector.
_a : vector, in the form .
Returns: Void, updates array _id.
array_push(_id, _a) inserts the vector at the end of array.
Parameters:
_id : ID of the array.
_a : vector, in the form .
Returns: Void, updates array _id.
array_unshift(_id, _a) inserts the vector at the begining of array.
Parameters:
_id : ID of the array.
_a : vector, in the form .
Returns: Void, updates array _id.
array_pop(_id, _a) removes the last vector of array and returns it.
Parameters:
_id : ID of the array.
_a : vector, in the form .
Returns: vector2, updates array _id.
array_shift(_id, _a) removes the first vector of array and returns it.
Parameters:
_id : ID of the array.
_a : vector, in the form .
Returns: vector2, updates array _id.
array_sum(_id) Total sum of all vectors.
Parameters:
_id : ID of the array.
Returns: vector in the form of a array
array_center(_id) Finds the vector center of the array.
Parameters:
_id : ID of the array.
Returns: vector in the form of a array
array_rotate_points(_id) Rotate Array vectors around origin vector by a angle.
Parameters:
_id : ID of the array.
Returns: rotated points array.
array_scale_points(_id) Scale Array vectors based on a origin vector perspective.
Parameters:
_id : ID of the array.
Returns: rotated points array.
array_tostring(_id, _separator) Reads a array of vectors into a string, of the form " ""
Parameters:
_id : ID of the array.
_separator : string separator for cell splitting.
Returns: string Translated complex array into string.
line_new(_a, _b) 2 vector line in the form.
Parameters:
_a : vector, in the form .
_b : vector, in the form .
Returns:
line_get_a(_line) Start vector of a line.
Parameters:
_line : vector4, in the form .
Returns: float vector2
line_get_b(_line) End vector of a line.
Parameters:
_line : vector4, in the form .
Returns: float vector2
line_intersect(_line1, _line2) Find the intersection vector of 2 lines.
Parameters:
_line1 : line of 2 vectors in the form of a array .
_line2 : line of 2 vectors in the form of a array .
Returns: vector in the form of a array .
draw_line(_line, _xloc, _extend, _color, _style, _width) Draws a line using line prototype.
Parameters:
_line : vector4, in the form .
_xloc : string
_extend : string
_color : color
_style : string
_width : int
Returns: draw line object
draw_triangle(_v1, _v2, _v3, _xloc, _color, _style, _width) Draws a triangle using line prototype.
Parameters:
_v1 : vector4, in the form .
_v2 : vector4, in the form .
_v3 : vector4, in the form .
_xloc : string
_color : color
_style : string
_width : int
Returns: tuple with 3 line objects.
draw_rect(_v1, _size, _angle, _xloc, _color, _style, _width) Draws a square using vector2 line prototype.
Parameters:
_v1 : vector4, in the form .
_size : float
_angle : float
_xloc : string
_color : color
_style : string
_width : int
Returns: tuple with 3 line objects.

SignalProcessingClusteringKMeansLibrary "SignalProcessingClusteringKMeans"
K-Means Clustering Method.
nearest(point_x, point_y, centers_x, centers_y) finds the nearest center to a point and returns its distance and center index.
Parameters:
point_x : float, x coordinate of point.
point_y : float, y coordinate of point.
centers_x : float array, x coordinates of cluster centers.
centers_y : float array, y coordinates of cluster centers.
@ returns tuple of int, float.
bisection_search(samples, value) Bissection Search
Parameters:
samples : float array, weights to compare.
value : float array, weights to compare.
Returns: int.
label_points(points_x, points_y, centers_x, centers_y) labels each point index with cluster index and distance.
Parameters:
points_x : float array, x coordinates of points.
points_y : float array, y coordinates of points.
centers_x : float array, x coordinates of points.
centers_y : float array, y coordinates of points.
Returns: tuple with int array, float array.
kpp(points_x, points_y, n_clusters) K-Means++ Clustering adapted from Andy Allinger.
Parameters:
points_x : float array, x coordinates of the points.
points_y : float array, y coordinates of the points.
n_clusters : int, number of clusters.
Returns: tuple with 2 arrays, float array, int array.

AnalysisInterpolationLoessLibrary "AnalysisInterpolationLoess"
LOESS, local weighted Smoothing function.
loess(sample_x, sample_y, point_span) LOESS, local weighted Smoothing function.
Parameters:
sample_x : int array, x values.
sample_y : float array, y values.
point_span : int, local point interval span.
aloess(sample_x, sample_y, point_span) aLOESS, adaptive local weighted Smoothing function.
Parameters:
sample_x : int array, x values.
sample_y : float array, y values.
point_span : int, local point interval span.

ArrayExtensionLibrary "ArrayExtension"
Functions to extend Arrays.
index_2d_to_1d(dimension_x, dimension_y, index_x, index_y) returns the flatened one dimension index of a two dimension array.
Parameters:
dimension_x : int, dimension of X.
dimension_y : int, dimension of Y.
index_x : int, index of X.
index_y : int, index of Y.
Returns: int, index in 1 dimension
index_3d_to_1d(dimension_x, dimension_y, dimension_z, index_x, index_y, index_z) returns the flatened one dimension index of a three dimension array.
Parameters:
dimension_x : int, dimension of X.
dimension_y : int, dimension of Y.
dimension_z : int, dimension of Z.
index_x : int, index of X.
index_y : int, index of Y.
index_z : int, index of Z.
Returns: int, index in 1 dimension
down_sample(sample, new_size) Down samples a array to a specified size.
Parameters:
sample : float array, array with source data.
new_size : new size of down sampled array.
Returns: float array with down sampled data.
sort_indices_float(sample, order) Sorts array and returns a extra array with sorting indices.
Parameters:
sample : float array with values to be sorted.
order : string, default='forward', options='forward', 'backward'.
Returns: _indices int array with indices.
_ordered float array with ordered values.
sort_indices_int(sample, order) Sorts array and returns a extra array with sorting indices.
Parameters:
sample : int array with values to be sorted.
order : string, default='forward', options='forward', 'backward'.
Returns: _indices int array with indices.
_ordered float array with ordered values.
sort_bool_from_indices(indices, sample) Sorts sample array using a array with indices.
Parameters:
indices : int array with positional indices.
sample : bool array with data sample to be sorted.
Returns: bool array
sort_box_from_indices(indices, sample) Sorts sample array using a array with indices.
Parameters:
indices : int array with positional indices.
sample : box array with data sample to be sorted.
Returns: box array
sort_color_from_indices(indices, sample) Sorts sample array using a array with indices.
Parameters:
indices : int array with positional indices.
sample : color array with data sample to be sorted.
Returns: color array
sort_float_from_indices(indices, sample) Sorts sample array using a array with indices.
Parameters:
indices : int array with positional indices.
sample : float array with data sample to be sorted.
Returns: float array
sort_int_from_indices(indices, sample) Sorts sample array using a array with indices.
Parameters:
indices : int array with positional indices.
sample : int array with data sample to be sorted.
Returns: int array
sort_label_from_indices(indices, sample) Sorts sample array using a array with indices.
Parameters:
indices : int array with positional indices.
sample : label array with data sample to be sorted.
Returns: label array
sort_line_from_indices(indices, sample) Sorts sample array using a array with indices.
Parameters:
indices : int array with positional indices.
sample : line array with data sample to be sorted.
Returns: line array
sort_string_from_indices(indices, sample) Sorts sample array using a array with indices.
Parameters:
indices : int array with positional indices.
sample : string array with data sample to be sorted.
Returns: string array
sort_table_from_indices(indices, sample) Sorts sample array using a array with indices.
Parameters:
indices : int array with positional indices.
sample : table array with data sample to be sorted.
Returns: table array
sort_bool_inplace_from_indices(indices, sample) Sorts sample array inplace using a array with indices.
Parameters:
indices : int array with positional indices.
sample : bool array with data sample to be sorted.
Returns: void updates sample array.
sort_box_inplace_from_indices(indices, sample) Sorts sample array inplace using a array with indices.
Parameters:
indices : int array with positional indices.
sample : box array with data sample to be sorted.
Returns: void updates sample
sort_color_inplace_from_indices(indices, sample) Sorts sample array inplace using a array with indices.
Parameters:
indices : int array with positional indices.
sample : color array with data sample to be sorted.
Returns: void updates sample
sort_float_inplace_from_indices(indices, sample) Sorts sample array inplace using a array with indices.
Parameters:
indices : int array with positional indices.
sample : float array with data sample to be sorted.
Returns: void updates sample
sort_int_inplace_from_indices(indices, sample) Sorts sample array inplace using a array with indices.
Parameters:
indices : int array with positional indices.
sample : int array with data sample to be sorted.
Returns: void updates sample
sort_label_inplace_from_indices(indices, sample) Sorts sample array inplace using a array with indices.
Parameters:
indices : int array with positional indices.
sample : label array with data sample to be sorted.
Returns: void updates sample
sort_line_inplace_from_indices(indices, sample) Sorts sample array inplace using a array with indices.
Parameters:
indices : int array with positional indices.
sample : line array with data sample to be sorted.
Returns: void updates sample
sort_string_inplace_from_indices(indices, sample) Sorts sample inplace array using a array with indices.
Parameters:
indices : int array with positional indices.
sample : string array with data sample to be sorted.
Returns: void updates sample
sort_table_inplace_from_indices(indices, sample) Sorts sample array inplace using a array with indices.
Parameters:
indices : int array with positional indices.
sample : table array with data sample to be sorted.
Returns: void updates sample
to_float(sample) Transform a integer array into a float array
Parameters:
sample : int array, sample data to transform.
Returns: float array
to_int(sample, method) Transform a float array into a int array
Parameters:
sample : float array, sample data to transform.
method : string, default="round", options= , aproximation method.
Returns: int array
ArrayGenerateLibrary "ArrayGenerate"
Functions to generate arrays.
sequence_int(start, end, step) returns a sequence of int numbers.
Parameters:
start : int, begining of sequence range.
end : int, end of sequence range.
step : int, step, default=1 .
Returns: int , array.
sequence_float(start, end, step) returns a sequence of float numbers.
Parameters:
start : float, begining of sequence range.
end : float, end of sequence range.
step : float, step, default=1.0 .
Returns: float , array.
sequence_from_series(src, length, shift, direction_forward) Creates a array from a series sample range.
Parameters:
src : series, any kind.
length : int, window period in bars to sample series.
shift : int, window period in bars to shift backwards the data sample, default=0.
direction_forward : bool, sample from start to end or end to start order, default=true.
Returns: float array
normal_distribution(size, mean, dev) Generate normal distribution random sample.
Parameters:
size : int, size of array
mean : float, mean of the sample, (default=0.0).
dev : float, deviation of the sample from the mean, (default=1.0).
Returns: float array.
log_spaced(length, start_exp, stop_exp) Generate a base 10 logarithmically spaced sample sequence.
Parameters:
length : int, length of the sequence.
start_exp : float, start exponent.
stop_exp : float, stop exponent.
Returns: float array.
linear_range(stop, start) Generate a linearly spaced sample vector within the inclusive interval (start, stop) and step 1.
Parameters:
stop : float, stop value.
start : float, start value, (default=0.0).
Returns: float array.
periodic_wave(length, sampling_rate, frequency, amplitude, phase, delay) Create a periodic wave.
Parameters:
length : int, the number of samples to generate.
sampling_rate : float, samples per time unit (Hz). Must be larger than twice the frequency to satisfy the Nyquist criterion.
frequency : float, frequency in periods per time unit (Hz).
amplitude : float, the length of the period when sampled at one sample per time unit. This is the interval of the periodic domain, a typical value is 1.0, or 2*Pi for angular functions.
phase : float, optional phase offset.
delay : int, optional delay, relative to the phase.
Returns: float array.
sinusoidal(length, sampling_rate, frequency, amplitude, mean, phase, delay) Create a Sine wave.
Parameters:
length : int, The number of samples to generate.
sampling_rate : float, Samples per time unit (Hz). Must be larger than twice the frequency to satisfy the Nyquist criterion.
frequency : float, Frequency in periods per time unit (Hz).
amplitude : float, The maximal reached peak.
mean : float, The mean, or DC part, of the signal.
phase : float, Optional phase offset.
delay : int, Optional delay, relative to the phase.
Returns: float array.
periodic_impulse(length, period, amplitude, delay) Create a periodic Kronecker Delta impulse sample array.
Parameters:
length : int, The number of samples to generate.
period : int, impulse sequence period.
amplitude : float, The maximal reached peak.
delay : int, Offset to the time axis. Zero or positive.
Returns: float array.
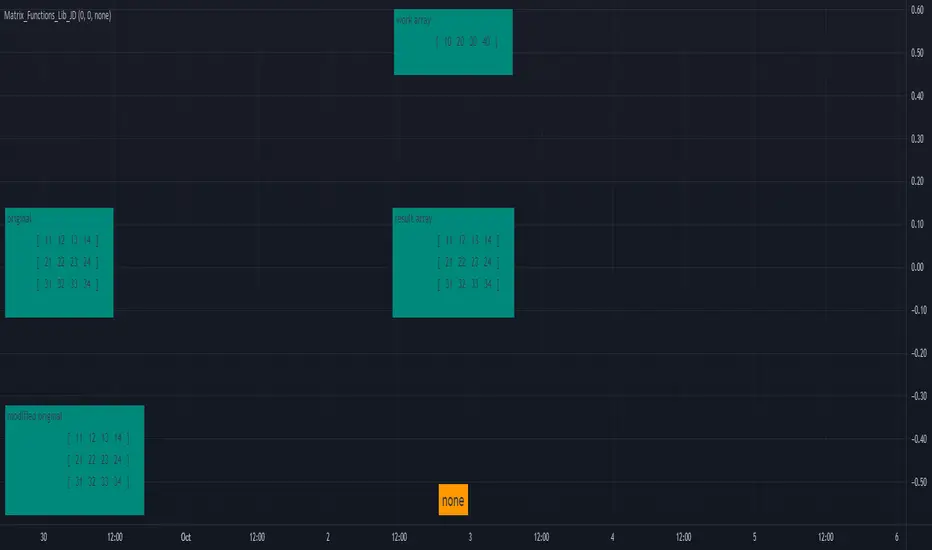
Matrix_Functions_Lib_JDLibrary "Matrix_Functions_Lib_JD"
This is a library to add matrix / 2D array functionality to Pinescript.
once you import the library at the beginning of your script, you can add all the functions described below just by calling them like you do any other built'in function.
Enjoy,
Gr, JD.
PS. if you find functionality or calculation errors in the functions, please let me know, so I can fix them.
There are quite a lot of functions, so little mishaps may have slipped in! ;-)
get_nr_of_rows() Returns the number of rows from a 2D matrix
get_nr_of_columns() Returns the number of columns from a 2D matrix
get_size() Returns a tuple with the total number of rows and columns from a 2D matrix
init() 2D matrix init function, builds a 2D matrix with dimensional metadata in first two values and fills it with a default value, the body of the actual matrix data starts at index 2.
from_list() 2D matrix init function, builds a 2D matrix from an existing array by adding dimensional metadata in first two values, the body of the actual matrix data consists of the data of the source array and starts at index 2.
set() Sets values in 2D matrix with (row index, column index) (index for rows and columns both starts at 0 !!)
fill_val() Fills all elements in a 2D matrix with a value
randomize() Fills a 2D matrix with random values//
get() Gets values from 2D matrix with (row index, column index) (index for rows and columns both starts at 0 !!)
copy_slice_body() Cuts off the metadata header and returns the array body, WITHOUT THE DIMENSIONAL METADATA!!
do_slice This variable should be set as: - 'false' to only make a copy, changes to the new array copy will NOT ALTER the ORIGINAL - 'true' to make a slice, changes to the new array slice WILL(!) ALTER the ORIGINAL
get_record() Gets /retrieve the values from a ROW/RECORD from a certain row/lookback period, the values are returned as an array
get_row_index() Gets the row nr. in a 2D matrix from 1D index (index for rows and columns both starts at 0 !!)
get_column_index() Gets the column nr. in a 2D matrix from 1D index (index for rows and columns both starts at 0 !!)
get_row_column_index() Gets a tuple with the (row, column) coordinates in 2D matrix from 1D index (index starts at 0 and does not include the header!!)
get_array_index() Gets the 1D index from (row, column) coordinates in 2D matrix (index for row and column both starts at 0 !! Index starts at 0 and does not include the header!!)
remove_rows() Removes one or more rows/records from a 2D matrix (if from_row = to_row, only this row is removed)
remove_columns() Remove one or more columns from a 2D matrix (if from_column = to_column, only this column is removed)
insert_array_of_rows() Insert an array of rows/records at a certain row number in a 2D matrix
add_row() ADDS a ROW/RECORD on the TOP of a sheet, shift the whole list one down and gives the option to REMOVE the OLDEST row/record. (2D version of "unshift" + "pop" but with a whole row at once)
insert_array_of_columns() Insert an array of columns at a certain column number in a 2D matrix
append_array_of_rows() Appends/adds an array of rows/records to the bottom of a 2D matrix
append_array_of_columns() Appends/adds an array of columns to the right side of a 2D matrix
pop_row() Removes / pops and returns the last row/record from a 2D matrix.
pop_column() Removes / pops and returns the last (most right) column from a 2D matrix.
replace()
abs()
add_value() Returns a new matrix with the same value added to all the elements of the source matrix.
addition() Returns a new matrix with the of the elements of one 2D matrix added to every corresponding element of a source 2D matrix.
subtract_value() Returns a new matrix with the same value subtracted from every element of a 2D matrix
subtraction() Returns a new matrix with the values of the elements of one 2D matrix subtracted from every corresponding element of a source 2D matrix.
scalar_multipy() Returns a new matrix with all the elements of the source matrix scaled/multiplied by a scalar value.
transpose() Returns a new matrix with the elements of the source matrix transposed.
multiply_elem() Performs ELEMENT WISE MULTIPLICATION of 2D matrices, returns a new matrix c.
multiply() Performs DOT PROCUCT MULTIPLICATION of 2D matrices, returns a new matrix c.
determinant_2x2() Calculates the determinant of 2x2 matrices.
determinant_3x3() Calculates the determinant of 3x3 matrices.
determinant_4x4() Calculates the determinant of 4x4 matrices.
print() displays a 2D matrix in a table layout.
Hx MTF Sorted MAs Panel with Freeze WarningThis script displays the close price and 4 sorted moving averages of your choice in a small repositionable panel and, when used on a higher timeframe, warns you when values may be different from actual values in the higher timeframe, inciting you to double check the actual values of the moving averages in the higher timeframe the panel is supposed to reflect.
The 4 moving averages and close are sorted together, providing you with a bird’s-eye view of their relative positions, the same way moving averages and last price values are displayed on the right scale.
The black header reminds of:
(1) the timeframe (resolution) used in the panel
(2) the remaining time before a new bar is created in the panel timeframe. Note that this remaining time is different from the one on the right scale, since it is only updated when a new transaction occurs.
Below, price and moving averages are sorted, color coded and followed by:
(1) a trend indicator ↗ or ↘ meaning that last change is up or down
(2) the number of bars since the moving average is above or below close (0 means current bar). This is obviously not displayed after the close price line (white background color).
Use
This panel was basically developed to display higher timeframe data but it can also be used with the same timeframe as chart for example if you do not want to plot moving averages on your chart but are still interested in their trends and relative positions vs price.
If you see something strange (like header is not black and displays NaN), it just means you requested moving averages that are not available in the panel timeframe. This may happen with newly introduced cryptos and “long” MA timeframes.
Different Timeframe
If you choose to use the panel on a different timeframe than the current one, be aware that you should only use timeframes higher than the current one, as per Tradingview recommendations.
If you select a lower timeframe than the current one, the panel timeframe header cell will turn to the alert color you set (fuchsia by default).
After tinkering for a while with the security function, I noticed that sometimes indicator values “freeze” (i.e. stop udating) and I have found no workaround.
What I mean is that when you look at a sma on a 5 minutes timeframe (the reference) and look at this same sma on a 5 minutes timeframe but from a lower timeframe through the security function set with a timeframe of 5 minutes, values returned by the security function are not always up to date and “freeze”. That’s the bad news.
Freeze warning
The better news is that this unexpected behaviour seems to be predictable, at least on minutes timeframes and I implemented an indicator that endeavors to detecting such situations. When the panel believes data may be frozen, the ‘Remaining Time’ header cell will turn to the alert color.
This feature is only implemented on minutes timeframes and can be switched on or off.
Other points of interest in this script
If you code, this function may also interest you:
sortWithIndexes (arrayToSort) returns a tuple (sortedArray, sortedIndexes) and therefore allows multi-dimensional arrays sorting without actually implementing a sorting algorithm 😉.
Default Settings
The default settings provide an example of commonly used moving averages with associated colors ranked from Hot (more nervous) to Cold (less nervous).
These settings are just an example and are NOT meant to be used as a trading system! DYOR!
Hope it will be useful.
Does the Freeze warning work for you? What do you think of my pseudo sorting algorithm?
Enjoy and please let me know what you think in the comments.

MYX Malaysia Bursa Futures Derivatives Auto DetectThis indicator intended for Malaysia Market only for auto detect Futures Market Derivatives refer to Bursa Malaysia
Indikator ini adalah untuk pasaran Malaysia sahaja untuk automatik mengenalpasti Derivatif Pasaran Hadapan rujuk kepada Bursa Malaysia
Indicator features :
1. Able to detect futures market.
2. List similar symbol or counter including total.
3. Font size small for mobile app and font size normal for desktop.
4. Show date updated by Bursa Malaysia.
Kemampuan indikator :
1. Boleh mengenal pasti pasaran hadapan.
2. Senarai simbol atau kaunter yang terlibat termasuk jumlah.
3. Saiz font kecil untuk mobile app dan saiz size normal untuk desktop.
4. Memaparkan tarikh kemaskini oleh Bursa Malaysia.
FAQ
1. Credits / Kredit
LucF & PineCoders
2. Code Usage / Penggunaan Kod
Free to use for personal usage.
Bebas untuk kegunaan peribadi.
3. Why table overlap with chart ? To avoid this, click indicator > Visual Order > Send to Front.
Kenapa table bertindih dengan carta ? Untuk mengatasi ini, klik indikator > Visual Order > Send to Front.
4. Some symbols not display such as Commodities Derivatives (OCPO and OPOL) and Equity Derivatives (OKLI).
These symbol are offcially displayed at Bursa Malaysia but not available in Trading View under prefix MYX.
And also Futures Market are not available in Trading View.
Beberapa simbol tidak dapat dipaparkan Derivatif Komoditi (OCPO and OPOL) and Derivatif Equiti (OKLI).
Simbol berikut dipaparkan secara rasmi di Bursa Malaysia tetapi tiada di Trading View di bawah prefix MYX.
Dan Pasaran Hadapan juga tiada di Stock Screener.
All Setting enabled.
Semua seting diaktifkan.
Example of recommended usage.
Contoh penggunaan yang disarankan.
Example of other derivatives. Similar derivatives can be shown.
Contoh derivatif lain. Derivatif yang sama boleh dipaparkan

2 Dimensional Array using one floating point entry This is an attempt to create a two dimensional floating point array from the pine single dimension array.
It enables some useful array functions like sorting, when you are trying to keep track of price and location in time or bars and you would like to sort the array.
Other array functions on this array will not work, like average and other statistical functions - they will provide bad results. I would suggest continuing to use a single dimensional array for each element where that kind of array function is required.
I wrote this simply as a mean of using the sort functions when I had to sort price and try to keep the bar location or time in synch.
Other array functions could be written to manipulate this kind of array, leave that to others. The goal here was to avoid using for loops which would be a performance impact on large arrays.
The basic concept is to create one floating point number from two, put that into an array, and then be able to pull the compound value out and parse out the individual components.
I imagine it could also accommodate a 3 or 4 dimensional array with some work, as long as you had some idea of how many digits are consumed by each element. For example you may be interested in storing price, RSI, x_loc values and then be able to sort and parse them out.