Grid Trade Helper📌 Grid Trade Helper – Range-Based Grid Planning Tool
This tool is designed for range-based traders and manual grid strategy operators, providing a framework to balance execution efficiency and risk exposure.
By referencing historical weekly volatility, it helps estimate a reasonable grid width, visualizes key levels, and supports position management with quantitative guidance.
🧭 Design Philosophy:
In multi-entry systems like grid trading, there's always a tradeoff:
"Tighter grids improve opportunity density but increase risk; wider grids reduce risk but lower efficiency."
This tool seeks to provide a dynamic equilibrium between the two, using past volatility to determine practical grid intervals and suggest safe leverage thresholds.
✨ Core Features:
Weekly open level tracking (custom time + time zone support)
Volatility-based suggestions for grid width and safe grid count
Visual range plotting with optional stop-line overlay
Compact live table showing key metrics: average range, grid width, grid count, leverage cap
🔧 Customizable Parameters:
Time zone and custom weekly open hour
Max number of visual elements (lines, boxes)
Color and line style options
📈 Suggested Use Cases:
Planning manual grid structures with volatility-adjusted intervals
Visual support for range-bound or sideways market strategies
Estimating leverage exposure and grid density for better position control
⚠️ This indicator is intended as a strategic support tool and does not constitute financial advice. Use according to your own risk framework and market understanding.
Regressions

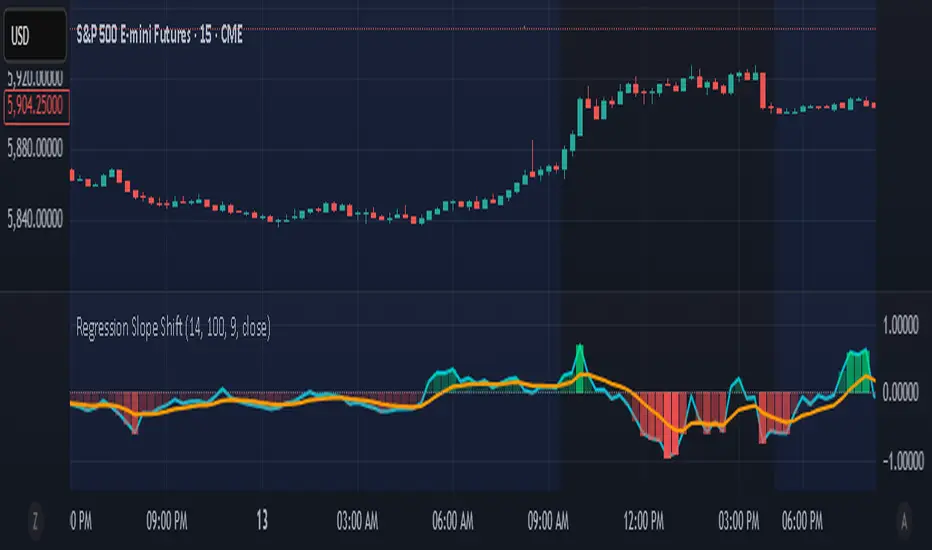
Regression Slope ShiftNormalized Regression Slope Shift + Dynamic Histogram
This indicator detects subtle shifts in price momentum using a rolling linear regression approach. It calculates the slope of a linear regression line for each bar over a specified lookback period, then measures how that slope changes from bar to bar.
Both the slope and its change (delta) are normalized to a -1 to 1 scale for consistent visual interpretation across assets and timeframes. A signal line (EMA) is applied to the slope delta to help identify turning points and crossovers.
Key features:
- Normalized slope and slope change lines
- Dynamic histogram of slope delta with transparency based on magnitude
- Customizable colors for all visual elements
- Signal line for crossover-based momentum shifts
This tool helps traders anticipate trend acceleration or weakening before traditional momentum indicators react, making it useful for early trend detection, divergence spotting, and confirmation signals.
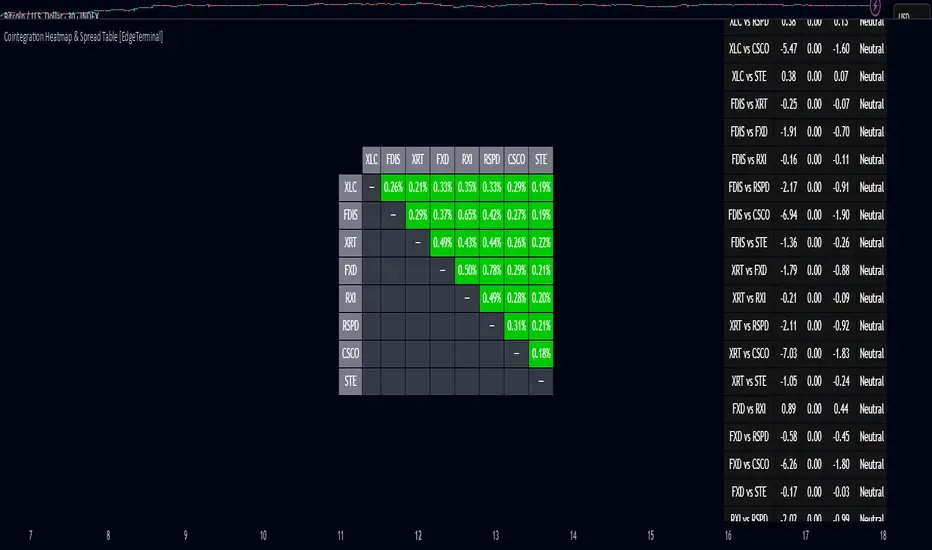
Cointegration Heatmap & Spread Table [EdgeTerminal]The Cointegration Heatmap is a powerful visual and quantitative tool designed to uncover deep, statistically meaningful relationships between assets.
Unlike traditional indicators that react to price movement, this tool analyzes the underlying statistical relationship between two time series and tracks when they diverge from their long-term equilibrium — offering actionable signals for mean-reversion trades .
What Is Cointegration?
Most traders are familiar with correlation, which measures how two assets move together in the short term. But correlation is shallow — it doesn’t imply a stable or predictable relationship over time.
Cointegration, however, is a deeper statistical concept: Two assets are cointegrated if a linear combination of their prices or returns is stationary , even if the individual series themselves are non-stationary.
Cointegration is a foundational concept in time series analysis, widely used by hedge funds, proprietary trading firms, and quantitative researchers. This indicator brings that institutional-grade concept into an easy-to-use and fully visual TradingView indicator.
This tool helps answer key questions like:
“Which stocks tend to move in sync over the long term?”
“When are two assets diverging beyond statistical norms?”
“Is now the right time to short one and long the other?”
Using a combination of regression analysis, residual modeling, and Z-score evaluation, this indicator surfaces opportunities where price relationships are stretched and likely to snap back — making it ideal for building low-risk, high-probability trade setups.
In simple terms:
Cointegrated assets drift apart temporarily, but always come back together over time. This behavior is the foundation of successful pairs trading.
How the Indicator Works
Cointegration Heatmap indicator works across any market supported on TradingView — from stocks and ETFs to cryptocurrencies and forex pairs.
You enter your list of symbols, choose a timeframe, and the indicator updates every bar with live cointegration scores, spread signals, and trade-ready insights.
Indicator Settings:
Symbol list: a customizable list of symbols separated by commas
Returns timeframe: time frame selection for return sampling (Weekly or Monthly)
Max periods: max periods to limit the data to a certain time and to control indicator performance
This indicator accomplishes three major goals in one streamlined package:
Identifies stable long-term relationships (cointegration) between assets, using a heatmap visualization.
Tracks the spread — the difference between actual prices and the predicted linear relationship — between each pair.
Generates trade signals based on Z-score deviations from the mean spread, helping traders know when a pair is statistically overextended and likely to mean revert.
The math:
Returns are calculated using spread tickers to ensure alignment in time and adjust for dividends, splits, and other inconsistencies.
For each unique pair of symbols, we perform a linear regression
Yt=α+βXt+ε
Then we compute the residuals (errors from the regression):
Spreadt=Yt−(α+βXt)
Calculate the standard deviation of the spread over a moving window (default: 100 samples) and finally, define the Cointegration Score:
S=1/Standard Deviation of Residuals
This means, the lower the deviation, the tighter the relationship, so higher scores indicate stronger cointegration.
Always remember that cointegration can break down so monitor the asset over time and over multiple different timeframes before making a decision.
How to use the indicator
The heatmap table:
The indicator displays 2 very important tables, one in the middle and one on the right side. After entering your symbols, the first table to pay attention to is the middle heatmap table.
Any assets with a cointegration value of 25% is something to pay attention to and have a strong and stable relationship. Anything below is weak and not tradable.
Additionally, the 40% level is another important line to cross. Assets that have a cointegration score of over 40% will most likely have an extremely strong relationship.
Think about it this way, the higher the percentage, the tighter and more statistically reliable the relationship is.
The spread table:
After finding a good asset pair using heatmap, locate the same pair in the spread table (right side).
Here’s what you’ll see on the table:
Spread: Current difference between the two symbols based on the regression fit
Mean: Historical average of that spread
Z-score: How far current spread is from the mean in standard deviations
Signal: Trade suggestion: Short, Long, or Neutral
Since you’re expecting mean reversion, the idea is that the spread will return to the average. You want to take a trade when the z-score is either over +2 or below -2 and exit when z-score returns to near 0.
You will usually see the trade suggestion on the spread chart but you can make your own decision based on your risk level.
Keep in mind that the Z-score for each pair refers to how off the first asset is from the mean compared to the second one, so for example if you see STOCKA vs STOCKB with a Z-score of -1.55, we are regressing STOCKB (Y) on STOCKA (X).
In this case, STOCKB is the quoted asset and STOCKA is the base asset.
In this case, this means that STOCKB is much lower than expected relative to STOCKA, so the trade would be a long position on stock B and short position on stock A.
Index Futures vs Cash ArbitrageThis indicator measures the statistical spread between major stock index futures and their corresponding cash indices (e.g., ES vs SPX, NQ vs NDX) using Z-score normalization. It automatically detects commonly traded index pairs (S&P 500, Nasdaq, Dow Jones, Russell 2000) and calculates a smoothed spread between futures and spot prices. A Z-score is then derived from this spread to highlight potential overpricing or underpricing conditions.
Traders can use customizable thresholds to identify mean-reversion opportunities where the futures contract may be temporarily overvalued or undervalued relative to the index. The histogram highlights the direction of the Z-score (green = futures > index, red = futures < index), while built-in alerts notify users of key threshold breaches or zero-line crosses.
This tool is designed for discretionary traders, pairs traders, or anyone exploring statistical arbitrage strategies between futures and spot markets. It is not a buy/sell signal by itself and should be used with additional confluence or risk management techniques.

Bober XM v2.0# ₿ober XM v2.0 Trading Bot Documentation
**Developer's Note**: While our previous Bot 1.3.1 was removed due to guideline violations, this setback only fueled our determination to create something even better. Rising from this challenge, Bober XM 2.0 emerges not just as an update, but as a complete reimagining with multi-timeframe analysis, enhanced filters, and superior adaptability. This adversity pushed us to innovate further and deliver a strategy that's smarter, more agile, and more powerful than ever before. Challenges create opportunity - welcome to Cryptobeat's finest work yet.
## !!!!You need to tune it for your own pair and timeframe and retune it periodicaly!!!!!
## Overview
The ₿ober XM v2.0 is an advanced dual-channel trading bot with multi-timeframe analysis capabilities. It integrates multiple technical indicators, customizable risk management, and advanced order execution via webhook for automated trading. The bot's distinctive feature is its separate channel systems for long and short positions, allowing for asymmetric trade strategies that adapt to different market conditions across multiple timeframes.
### Key Features
- **Multi-Timeframe Analysis**: Analyze price data across multiple timeframes simultaneously
- **Dual Channel System**: Separate parameter sets for long and short positions
- **Advanced Entry Filters**: RSI, Volatility, Volume, Bollinger Bands, and KEMAD filters
- **Machine Learning Moving Average**: Adaptive prediction-based channels
- **Multiple Entry Strategies**: Breakout, Pullback, and Mean Reversion modes
- **Risk Management**: Customizable stop-loss, take-profit, and trailing stop settings
- **Webhook Integration**: Compatible with external trading bots and platforms
### Strategy Components
| Component | Description |
|---------|-------------|
| **Dual Channel Trading** | Uses either Keltner Channels or Machine Learning Moving Average (MLMA) with separate settings for long and short positions |
| **MLMA Implementation** | Machine learning algorithm that predicts future price movements and creates adaptive bands |
| **Pivot Point SuperTrend** | Trend identification and confirmation system based on pivot points |
| **Three Entry Strategies** | Choose between Breakout, Pullback, or Mean Reversion approaches |
| **Advanced Filter System** | Multiple customizable filters with multi-timeframe support to avoid false signals |
| **Custom Exit Logic** | Exits based on OBV crossover of its moving average combined with pivot trend changes |
### Note for Novice Users
This is a fully featured real trading bot and can be tweaked for any ticker — SOL is just an example. It follows this structure:
1. **Indicator** – gives the initial signal
2. **Entry strategy** – decides when to open a trade
3. **Exit strategy** – defines when to close it
4. **Trend confirmation** – ensures the trade follows the market direction
5. **Filters** – cuts out noise and avoids weak setups
6. **Risk management** – controls losses and protects your capital
To tune it for a different pair, you'll need to start from scratch:
1. Select the timeframe (candle size)
2. Turn off all filters and trend entry/exit confirmations
3. Choose a channel type, channel source and entry strategy
4. Adjust risk parameters
5. Tune long and short settings for the channel
6. Fine-tune the Pivot Point Supertrend and Main Exit condition OBV
This will generate a lot of signals and activity on the chart. Your next task is to find the right combination of filters and settings to reduce noise and tune it for profitability.
### Default Strategy values
Default values are tuned for: Symbol BITGET:SOLUSDT.P 5min candle
Filters are off by default: Try to play with it to understand how it works
## Configuration Guide
### General Settings
| Setting | Description | Default Value |
|---------|-------------|---------------|
| **Long Positions** | Enable or disable long trades | Enabled |
| **Short Positions** | Enable or disable short trades | Enabled |
| **Risk/Reward Area** | Visual display of stop-loss and take-profit zones | Enabled |
| **Long Entry Source** | Price data used for long entry signals | hl2 (High+Low/2) |
| **Short Entry Source** | Price data used for short entry signals | hl2 (High+Low/2) |
The bot allows you to trade long positions, short positions, or both simultaneously. Each direction has its own set of parameters, allowing for fine-tuned strategies that recognize the asymmetric nature of market movements.
### Multi-Timeframe Settings
1. **Enable Multi-Timeframe Analysis**: Toggle 'Enable Multi-Timeframe Analysis' in the Multi-Timeframe Settings section
2. **Configure Timeframes**: Set appropriate higher timeframes based on your trading style:
- Timeframe 1: Default is now 15 minutes (intraday confirmation)
- Timeframe 2: Default is 4 hours (trend direction)
3. **Select Sources per Indicator**: For each indicator (RSI, KEMAD, Volume, etc.), choose:
- The desired timeframe (current, mtf1, or mtf2)
- The appropriate price type (open, high, low, close, hl2, hlc3, ohlc4)
### Entry Strategies
- **Breakout**: Enter when price breaks above/below the channel
- **Pullback**: Enter when price pulls back to the channel
- **Mean Reversion**: Enter when price is extended from the channel
You can enable different strategies for long and short positions.
### Core Components
### Risk Management
- **Position Size**: Control risk with percentage-based position sizing
- **Stop Loss Options**:
- Fixed: Set a specific price or percentage from entry
- ATR-based: Dynamic stop-loss based on market volatility
- Swing: Uses recent swing high/low points
- **Take Profit**: Multiple targets with percentage allocation
- **Trailing Stop**: Dynamic stop that follows price movement
## Advanced Usage Strategies
### Moving Average Type Selection Guide
- **SMA**: More stable in choppy markets, good for higher timeframes
- **EMA/WMA**: More responsive to recent price changes, better for entry signals
- **VWMA**: Adds volume weighting for stronger trends, use with Volume filter
- **HMA**: Balance between responsiveness and noise reduction, good for volatile markets
### Multi-Timeframe Strategy Approaches
- **Trend Confirmation**: Use higher timeframe RSI (mtf2) for overall trend, current timeframe for entries
- **Entry Precision**: Use KEMAD on current timeframe with volume filter on mtf1
- **False Signal Reduction**: Apply RSI filter on mtf1 with strict KEMAD settings
### Market Condition Optimization
| Market Condition | Recommended Settings |
|------------------|----------------------|
| **Trending** | Use Breakout strategy with KEMAD filter on higher timeframe |
| **Ranging** | Use Mean Reversion with strict RSI filter (mtf1) |
| **Volatile** | Increase ATR multipliers, use HMA for moving averages |
| **Low Volatility** | Decrease noise parameters, use pullback strategy |
## Webhook Integration
The strategy features a professional webhook system that allows direct connectivity to your exchange or trading platform of choice through third-party services like 3commas, Alertatron, or Autoview.
The webhook payload includes all necessary parameters for automated execution:
- Entry price and direction
- Stop loss and take profit levels
- Position size
- Custom identifier for webhook routing
## Performance Optimization Tips
1. **Start with Defaults**: Begin with the default settings for your timeframe before customizing
2. **Adjust One Component at a Time**: Make incremental changes and test the impact
3. **Match MA Types to Market Conditions**: Use appropriate moving average types based on the Market Condition Optimization table
4. **Timeframe Synergy**: Create logical relationships between timeframes (e.g., 5min chart with 15min and 4h higher timeframes)
5. **Periodic Retuning**: Markets evolve - regularly review and adjust parameters
## Common Setups
### Crypto Trend-Following
- MLMA with EMA or HMA
- Higher RSI thresholds (75/25)
- KEMAD filter on mtf1
- Breakout entry strategy
### Stock Swing Trading
- MLMA with SMA for stability
- Volume filter with higher threshold
- KEMAD with increased filter order
- Pullback entry strategy
### Forex Scalping
- MLMA with WMA and lower noise parameter
- RSI filter on current timeframe
- Use highest timeframe for trend direction only
- Mean Reversion strategy
## Webhook Configuration
- **Benefits**:
- Automated trade execution without manual intervention
- Immediate response to market conditions
- Consistent execution of your strategy
- **Implementation Notes**:
- Requires proper webhook configuration on your exchange or platform
- Test thoroughly with small position sizes before full deployment
- Consider latency between signal generation and execution
### Backtesting Period
Define a specific historical period to evaluate the bot's performance:
| Setting | Description | Default Value |
|---------|-------------|---------------|
| **Start Date** | Beginning of backtest period | January 1, 2025 |
| **End Date** | End of backtest period | December 31, 2026 |
- **Best Practice**: Test across different market conditions (bull markets, bear markets, sideways markets)
- **Limitation**: Past performance doesn't guarantee future results
## Entry and Exit Strategies
### Dual-Channel System
A key innovation of the Bober XM is its dual-channel approach:
- **Independent Parameters**: Each trade direction has its own channel settings
- **Asymmetric Trading**: Recognizes that markets often behave differently in uptrends versus downtrends
- **Optimized Performance**: Fine-tune settings for both bullish and bearish conditions
This approach allows the bot to adapt to the natural asymmetry of markets, where uptrends often develop gradually while downtrends can be sharp and sudden.
### Channel Types
#### 1. Keltner Channels
Traditional volatility-based channels using EMA and ATR:
| Setting | Long Default | Short Default |
|---------|--------------|---------------|
| **EMA Length** | 37 | 20 |
| **ATR Length** | 13 | 17 |
| **Multiplier** | 1.4 | 1.9 |
| **Source** | low | high |
- **Strengths**:
- Reliable in trending markets
- Less prone to whipsaws than Bollinger Bands
- Clear visual representation of volatility
- **Weaknesses**:
- Can lag during rapid market changes
- Less effective in choppy, non-trending markets
#### 2. Machine Learning Moving Average (MLMA)
Advanced predictive model using kernel regression (RBF kernel):
| Setting | Description | Options |
|---------|-------------|--------|
| **Source MA** | Price data used for MA calculations | Any price source (low/high/close/etc.) |
| **Moving Average Type** | Type of MA algorithm for calculations | SMA, EMA, WMA, VWMA, RMA, HMA |
| **Trend Source** | Price data used for trend determination | Any price source (close default) |
| **Window Size** | Historical window for MLMA calculations | 5+ (default: 16) |
| **Forecast Length** | Number of bars to forecast ahead | 1+ (default: 3) |
| **Noise Parameter** | Controls smoothness of prediction | 0.01+ (default: ~0.43) |
| **Band Multiplier** | Multiplier for channel width | 0.1+ (default: 0.5-0.6) |
- **Strengths**:
- Predictive rather than reactive
- Adapts quickly to changing market conditions
- Better at identifying trend reversals early
- **Weaknesses**:
- More computationally intensive
- Requires careful parameter tuning
- Can be sensitive to input data quality
### Entry Strategies
| Strategy | Description | Ideal Market Conditions |
|----------|-------------|-------------------------|
| **Breakout** | Enters when price breaks through channel bands, indicating strong momentum | High volatility, emerging trends |
| **Pullback** | Enters when price retraces to the middle band after testing extremes | Established trends with regular pullbacks |
| **Mean Reversion** | Enters at channel extremes, betting on a return to the mean | Range-bound or oscillating markets |
#### Breakout Strategy (Default)
- **Implementation**: Enters long when price crosses above the upper band, short when price crosses below the lower band
- **Strengths**: Captures strong momentum moves, performs well in trending markets
- **Weaknesses**: Can lead to late entries, higher risk of false breakouts
- **Optimization Tips**:
- Increase channel multiplier for fewer but more reliable signals
- Combine with volume confirmation for better accuracy
#### Pullback Strategy
- **Implementation**: Enters long when price pulls back to middle band during uptrend, short during downtrend pullbacks
- **Strengths**: Better entry prices, lower risk, higher probability setups
- **Weaknesses**: Misses some strong moves, requires clear trend identification
- **Optimization Tips**:
- Use with trend filters to confirm overall direction
- Adjust middle band calculation for market volatility
#### Mean Reversion Strategy
- **Implementation**: Enters long at lower band, short at upper band, expecting price to revert to the mean
- **Strengths**: Excellent entry prices, works well in ranging markets
- **Weaknesses**: Dangerous in strong trends, can lead to fighting the trend
- **Optimization Tips**:
- Implement strong trend filters to avoid counter-trend trades
- Use smaller position sizes due to higher risk nature
### Confirmation Indicators
#### Pivot Point SuperTrend
Combines pivot points with ATR-based SuperTrend for trend confirmation:
| Setting | Default Value |
|---------|---------------|
| **Pivot Period** | 25 |
| **ATR Factor** | 2.2 |
| **ATR Period** | 41 |
- **Function**: Identifies significant market turning points and confirms trend direction
- **Implementation**: Requires price to respect the SuperTrend line for trade confirmation
#### Weighted Moving Average (WMA)
Provides additional confirmation layer for entries:
| Setting | Default Value |
|---------|---------------|
| **Period** | 15 |
| **Source** | ohlc4 (average of Open, High, Low, Close) |
- **Function**: Confirms trend direction and filters out low-quality signals
- **Implementation**: Price must be above WMA for longs, below for shorts
### Exit Strategies
#### On-Balance Volume (OBV) Based Exits
Uses volume flow to identify potential reversals:
| Setting | Default Value |
|---------|---------------|
| **Source** | ohlc4 |
| **MA Type** | HMA (Options: SMA, EMA, WMA, RMA, VWMA, HMA) |
| **Period** | 22 |
- **Function**: Identifies divergences between price and volume to exit before reversals
- **Implementation**: Exits when OBV crosses its moving average in the opposite direction
- **Customizable MA Type**: Different MA types provide varying sensitivity to OBV changes:
- **SMA**: Traditional simple average, equal weight to all periods
- **EMA**: More weight to recent data, responds faster to price changes
- **WMA**: Weighted by recency, smoother than EMA
- **RMA**: Similar to EMA but smoother, reduces noise
- **VWMA**: Factors in volume, helpful for OBV confirmation
- **HMA**: Reduces lag while maintaining smoothness (default)
#### ADX Exit Confirmation
Uses Average Directional Index to confirm trend exhaustion:
| Setting | Default Value |
|---------|---------------|
| **ADX Threshold** | 35 |
| **ADX Smoothing** | 60 |
| **DI Length** | 60 |
- **Function**: Confirms trend weakness before exiting positions
- **Implementation**: Requires ADX to drop below threshold or DI lines to cross
## Filter System
### RSI Filter
- **Function**: Controls entries based on momentum conditions
- **Parameters**:
- Period: 15 (default)
- Overbought level: 71
- Oversold level: 23
- Multi-timeframe support: Current, MTF1 (15min), or MTF2 (4h)
- Customizable price source (open, high, low, close, hl2, hlc3, ohlc4)
- **Implementation**: Blocks long entries when RSI > overbought, short entries when RSI < oversold
### Volatility Filter
- **Function**: Prevents trading during excessive market volatility
- **Parameters**:
- Measure: ATR (Average True Range)
- Period: Customizable (default varies by timeframe)
- Threshold: Adjustable multiplier
- Multi-timeframe support
- Customizable price source
- **Implementation**: Blocks trades when current volatility exceeds threshold × average volatility
### Volume Filter
- **Function**: Ensures adequate market liquidity for trades
- **Parameters**:
- Threshold: 0.4× average (default)
- Measurement period: 5 (default)
- Moving average type: Customizable (HMA default)
- Multi-timeframe support
- Customizable price source
- **Implementation**: Requires current volume to exceed threshold × average volume
### Bollinger Bands Filter
- **Function**: Controls entries based on price relative to statistical boundaries
- **Parameters**:
- Period: Customizable
- Standard deviation multiplier: Adjustable
- Moving average type: Customizable
- Multi-timeframe support
- Customizable price source
- **Implementation**: Can require price to be within bands or breaking out of bands depending on strategy
### KEMAD Filter (Kalman EMA Distance)
- **Function**: Advanced trend confirmation using Kalman filter algorithm
- **Parameters**:
- Process Noise: 0.35 (controls smoothness)
- Measurement Noise: 24 (controls reactivity)
- Filter Order: 6 (higher = more smoothing)
- ATR Length: 8 (for bandwidth calculation)
- Upper Multiplier: 2.0 (for long signals)
- Lower Multiplier: 2.7 (for short signals)
- Multi-timeframe support
- Customizable visual indicators
- **Implementation**: Generates signals based on price position relative to Kalman-filtered EMA bands
## Risk Management System
### Position Sizing
Automatically calculates position size based on account equity and risk parameters:
| Setting | Default Value |
|---------|---------------|
| **Risk % of Equity** | 50% |
- **Implementation**:
- Position size = (Account equity × Risk %) ÷ (Entry price × Stop loss distance)
- Adjusts automatically based on volatility and stop placement
- **Best Practices**:
- Start with lower risk percentages (1-2%) until strategy is proven
- Consider reducing risk during high volatility periods
### Stop-Loss Methods
Multiple stop-loss calculation methods with separate configurations for long and short positions:
| Method | Description | Configuration |
|--------|-------------|---------------|
| **ATR-Based** | Dynamic stops based on volatility | ATR Period: 14, Multiplier: 2.0 |
| **Percentage** | Fixed percentage from entry | Long: 1.5%, Short: 1.5% |
| **PIP-Based** | Fixed currency unit distance | 10.0 pips |
- **Implementation Notes**:
- ATR-based stops adapt to changing market volatility
- Percentage stops maintain consistent risk exposure
- PIP-based stops provide precise control in stable markets
### Trailing Stops
Locks in profits by adjusting stop-loss levels as price moves favorably:
| Setting | Default Value |
|---------|---------------|
| **Stop-Loss %** | 1.5% |
| **Activation Threshold** | 2.1% |
| **Trailing Distance** | 1.4% |
- **Implementation**:
- Initial stop remains fixed until profit reaches activation threshold
- Once activated, stop follows price at specified distance
- Locks in profit while allowing room for normal price fluctuations
### Risk-Reward Parameters
Defines the relationship between risk and potential reward:
| Setting | Default Value |
|---------|---------------|
| **Risk-Reward Ratio** | 1.4 |
| **Take Profit %** | 2.4% |
| **Stop-Loss %** | 1.5% |
- **Implementation**:
- Take profit distance = Stop loss distance × Risk-reward ratio
- Higher ratios require fewer winning trades for profitability
- Lower ratios increase win rate but reduce average profit
### Filter Combinations
The strategy allows for simultaneous application of multiple filters:
- **Recommended Combinations**:
- Trending markets: RSI + KEMAD filters
- Ranging markets: Bollinger Bands + Volatility filters
- All markets: Volume filter as minimum requirement
- **Performance Impact**:
- Each additional filter reduces the number of trades
- Quality of remaining trades typically improves
- Optimal combination depends on market conditions and timeframe
### Multi-Timeframe Filter Applications
| Filter Type | Current Timeframe | MTF1 (15min) | MTF2 (4h) |
|-------------|-------------------|-------------|------------|
| RSI | Quick entries/exits | Intraday trend | Overall trend |
| Volume | Immediate liquidity | Sustained support | Market participation |
| Volatility | Entry timing | Short-term risk | Regime changes |
| KEMAD | Precise signals | Trend confirmation | Major reversals |
## Visual Indicators and Chart Analysis
The bot provides comprehensive visual feedback on the chart:
- **Channel Bands**: Keltner or MLMA bands showing potential support/resistance
- **Pivot SuperTrend**: Colored line showing trend direction and potential reversal points
- **Entry/Exit Markers**: Annotations showing actual trade entries and exits
- **Risk/Reward Zones**: Visual representation of stop-loss and take-profit levels
These visual elements allow for:
- Real-time strategy assessment
- Post-trade analysis and optimization
- Educational understanding of the strategy logic
## Implementation Guide
### TradingView Setup
1. Load the script in TradingView Pine Editor
2. Apply to your preferred chart and timeframe
3. Adjust parameters based on your trading preferences
4. Enable alerts for webhook integration
### Webhook Integration
1. Configure webhook URL in TradingView alerts
2. Set up receiving endpoint on your trading platform
3. Define message format matching the bot's output
4. Test with small position sizes before full deployment
### Optimization Process
1. Backtest across different market conditions
2. Identify parameter sensitivity through multiple tests
3. Focus on risk management parameters first
4. Fine-tune entry/exit conditions based on performance metrics
5. Validate with out-of-sample testing
## Performance Considerations
### Strengths
- Adaptability to different market conditions through dual channels
- Multiple layers of confirmation reducing false signals
- Comprehensive risk management protecting capital
- Machine learning integration for predictive edge
### Limitations
- Complex parameter set requiring careful optimization
- Potential over-optimization risk with so many variables
- Computational intensity of MLMA calculations
- Dependency on proper webhook configuration for execution
### Best Practices
- Start with conservative risk settings (1-2% of equity)
- Test thoroughly in demo environment before live trading
- Monitor performance regularly and adjust parameters
- Consider market regime changes when evaluating results
## Conclusion
The ₿ober XM v2.0 represents a significant evolution in trading strategy design, combining traditional technical analysis with machine learning elements and multi-timeframe analysis. The core strength of this system lies in its adaptability and recognition of market asymmetry.
### Market Asymmetry and Adaptive Approach
The strategy acknowledges a fundamental truth about markets: bullish and bearish phases behave differently and should be treated as distinct environments. The dual-channel system with separate parameters for long and short positions directly addresses this asymmetry, allowing for optimized performance regardless of market direction.
### Targeted Backtesting Philosophy
It's counterproductive to run backtests over excessively long periods. Markets evolve continuously, and strategies that worked in previous market regimes may be ineffective in current conditions. Instead:
- Test specific market phases separately (bull markets, bear markets, range-bound periods)
- Regularly re-optimize parameters as market conditions change
- Focus on recent performance with higher weight than historical results
- Test across multiple timeframes to ensure robustness
### Multi-Timeframe Analysis as a Game-Changer
The integration of multi-timeframe analysis fundamentally transforms the strategy's effectiveness:
- **Increased Safety**: Higher timeframe confirmations reduce false signals and improve trade quality
- **Context Awareness**: Decisions made with awareness of larger trends reduce adverse entries
- **Adaptable Precision**: Apply strict filters on lower timeframes while maintaining awareness of broader conditions
- **Reduced Noise**: Higher timeframe data naturally filters market noise that can trigger poor entries
The ₿ober XM v2.0 provides traders with a framework that acknowledges market complexity while offering practical tools to navigate it. With proper setup, realistic expectations, and attention to changing market conditions, it delivers a sophisticated approach to systematic trading that can be continuously refined and optimized.
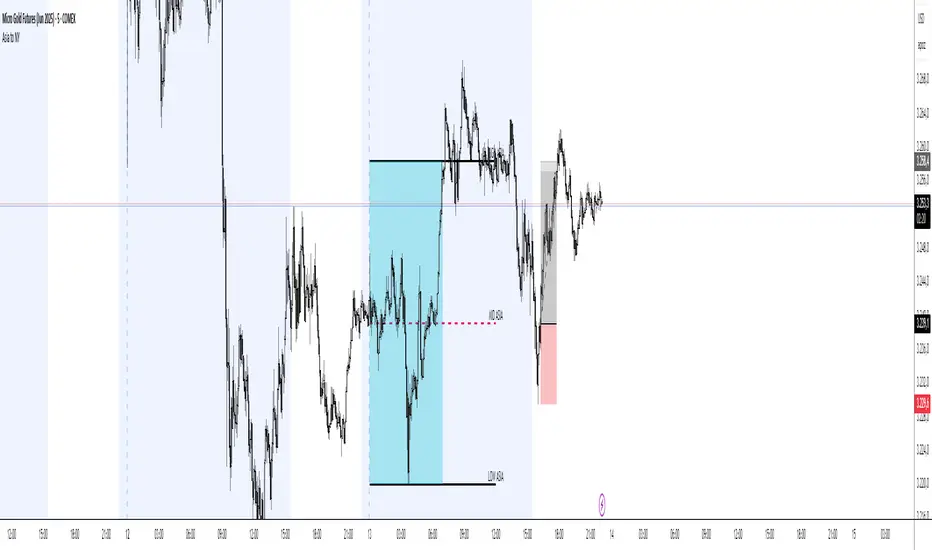
Asia Session Range @mrxautrades🗺️ Asia Session Range by @mrxautrades
🚨 This script is closed-source because it implements a custom logic for session range visualization, deviation projections, and adaptive display based on chart timeframe. No other public script offers this exact functionality.
✅ What does this script do?
This indicator highlights the Asian session range and calculates dynamic extensions during the New York session open. It's designed for traders who rely on price action around key market sessions.
🔧 Unique Features (compared to existing scripts):
Timeframe-aware visibility: The script includes conditional logic to show or hide elements based on the chart timeframe (e.g., only visible on 60-minute or lower charts).
Automatic deviation levels: Calculates and plots extensions above/below the Asian range based on its size, offering projected support/resistance levels in real time.
Adaptive labels: Labels adjust dynamically to chart styling, with options for background, color, and visibility control.
⚙️ Customizable Inputs:
Asian and New York session times
Box, line, and label colors
Number and spacing of deviation levels
Line extension duration (in hours)
Label style: plain text or with background
🧠 Best suited for:
Breakout strategies based on the Asian session range
Using prior session levels as support/resistance
Intraday traders in Forex, indices, or crypto markets
PolyBand Convergence System (PBCS)PolyBand Convergence System (PBCS)
The PolyBand Convergence System (PBCS) is an advanced technical analysis indicator that combines multiple polynomial regressions with statistical bands to identify trend strength and potential reversal zones.
Key Features
Multi-Degree Polynomial Analysis: Combines 1st, 2nd, 3rd, and 4th degree polynomial regressions into a composite regression line
Adaptive Statistical Bands: Uses percentile-based bands enhanced with standard deviation multipliers
Asymmetric Volatility Measurement: Separately calculates upside and downside volatility for more accurate band placement
Smart Trend Detection: Identifies bullish, bearish, or neutral market conditions based on price position relative to bands
How It Works
PBCS creates a composite regression line from multiple polynomial fits to better capture the underlying price structure. This line is then surrounded by adaptive bands that represent statistical thresholds for price movement. When price breaks above the upper band, a bullish trend is signaled; when it breaks below the lower band, a bearish trend is indicated.
Customization Options
Regression Settings: Adjust source data, lookback period, and smoothing parameters
Percentile Controls: Fine-tune the statistical thresholds for upper and lower bands
Volatility Sensitivity: Modify standard deviation multipliers to control band width
Visual Preferences: Choose from multiple color schemes to match your trading platform
Disclaimer
This indicator is provided for educational and informational purposes only and does not constitute investment advice. Trading involves risk and may result in financial loss. Always perform your own research and consult with a qualified financial advisor before making any trading decisions.

Kernel Regression Bands SuiteMulti-Kernel Regression Bands
A versatile indicator that applies kernel regression smoothing to price data, then dynamically calculates upper and lower bands using a wide variety of deviation methods. This tool is designed to help traders identify trend direction, volatility, and potential reversal zones with customizable visual styles.
Key Features
Multiple Kernel Types: Choose from 17+ kernel regression styles (Gaussian, Laplace, Epanechnikov, etc.) for smoothing.
Flexible Band Calculation: Select from 12+ deviation types including Standard Deviation, Mean/Median Absolute Deviation, Exponential, True Range, Hull, Parabolic SAR, Quantile, and more.
Adaptive Bands: Bands are calculated around the kernel regression line, with a user-defined multiplier.
Signal Logic: Trend state is determined by crossovers/crossunders of price and bands, coloring the regression line and band fills accordingly.
Custom Color Modes: Six unique color palettes for visual clarity and personal preference.
Highly Customizable Inputs: Adjust kernel type, lookback, deviation method, band source, and more.
How to Use
Trend Identification: The regression line changes color based on the detected trend (up/down)
Volatility Zones: Bands expand/contract with volatility, helping spot breakouts or mean-reversion opportunities.
Visual Styling: Use color modes to match your chart theme or highlight specific market states.
Credits:
Kernel regression logic adapted from:
ChartPrime | Multi-Kernel-Regression-ChartPrime (Link in the script)
Disclaimer
This script is for educational and informational purposes only. Not financial advice. Use at your own risk.

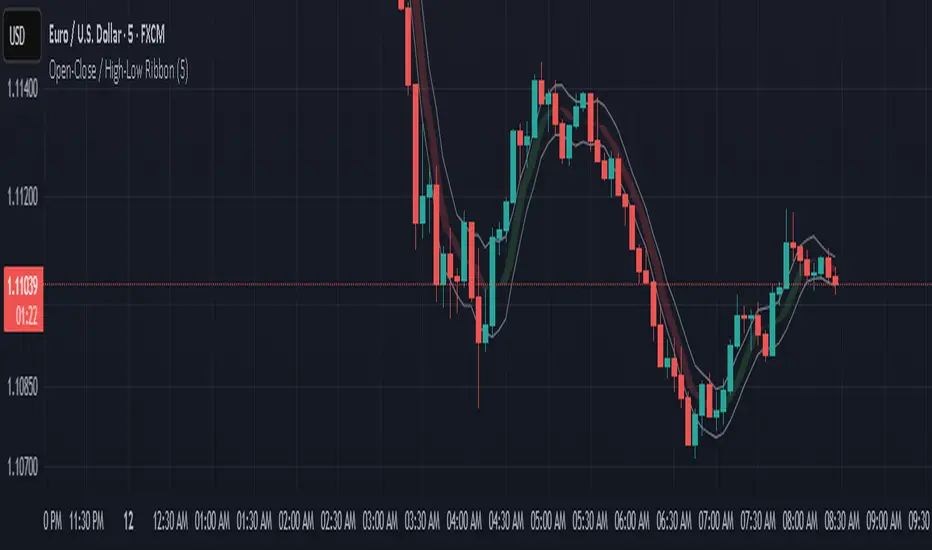
Open-Close / High-Low RibbonThis indicator visualizes smoothed Open, Close, High, and Low price levels as continuous lines, helping users observe underlying price structure with reduced noise. The Open and Close values are shaded to highlight bullish (green) or bearish (red) zones based on their relationship. Smoothing is applied using a simple moving average (SMA) over a user-defined length to make trends easier to interpret. This tool can be useful for identifying directional bias, trend shifts, or areas of support and resistance on any timeframe.
Linear Regression Volume | Lyro RSLinear Regression Volume | Lyro RS
⚠️Disclaimer⚠️
Always combine this indicator with other forms of analysis and risk management. Please do your own research before making any trading decisions.
The LR Volume | 𝓛𝔂𝓻𝓸 𝓡𝓢 indicator blends linear regression with volume-adjusted moving average s to dynamically outline price equilibrium and trend intensity. By integrating volume into its regression model, it highlights meaningful price movement relative to trading activity.
📌 How It Works:
Volume-Weighted Regression Baseline
Price is filtered through one of four volume-adjusted moving averages (SMA, RMA, HMA, ALMA) before being passed through a linear regression model, forming a dynamic fair value line.
Deviation Bands
The indicator plots 1x, 2x, and 3x standard deviation zones above and below the baseline, helping identify potential extremes, volatility spikes, and mean reversion areas.
Slope-Based Color Logic
The baseline and fill areas are dynamically colored:
- 🟢 Green for positive slope (uptrend)
- 🔴 Red for negative slope (downtrend)
- ⚪ Gray for neutral movement
⚙️ Inputs & Options:
Regression Length – Controls how many bars are used in the moving average and regression calculation.
Deviation Multiplier – Adjusts the width of the bands surrounding the regression baseline.
MA Type – Choose from 4 types:
SMA (Simple Moving Average)
RMA (Relative Moving Average)
HMA (Hull Moving Average)
ALMA (Arnaud Legoux Moving Average)
Band Colors – Customizable upper/lower band colors to match your visual style.
🔔 Alerts:
Long Signal – Triggers when the regression slope turns positive.
Short Signal – Triggers when the regression slope turns negative.

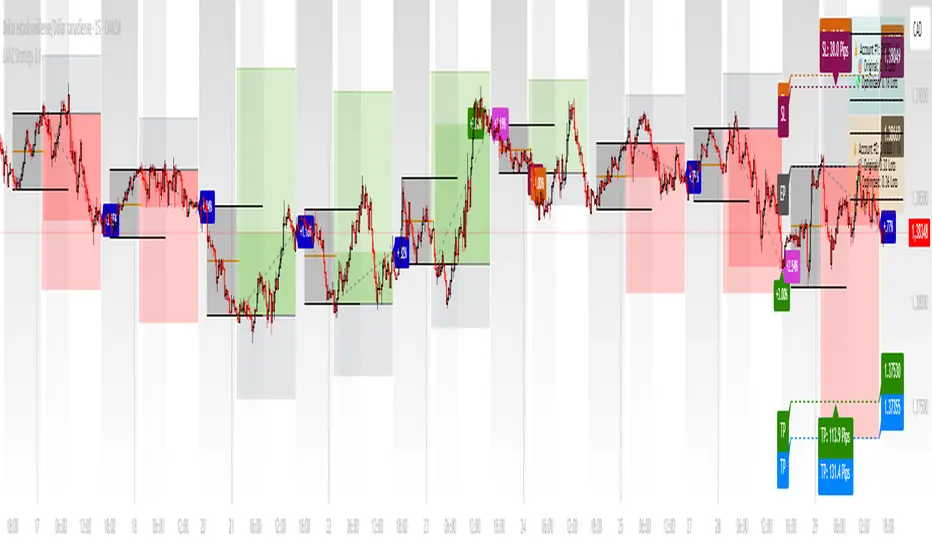
LANZ Strategy 3.0🔷 LANZ Strategy 3.0 — Asian Range Fibonacci Strategy with Execution Window Logic
LANZ Strategy 3.0 is a rule-based trading system that utilizes the Asian session range to project Fibonacci levels and manage entries during a defined execution window. Designed for Forex and index traders, this strategy focuses on structured price behavior around key levels before the New York session.
🧠 Core Components:
Asian Session Range Mapping: Automatically detects the high, low, and midpoint during the Asian session.
Fibonacci Level Projection: Projects configurable Fibonacci retracement and extension levels based on the Asian range.
Execution Window Logic: Uses the 01:15 NY candle as a reference to validate potential reversals or continuation setups.
Conditional Entry System: Includes logic for limit order entries (buy or sell) at specific Fib levels, with reversal logic if price breaks structure before execution.
Risk Management: Entry orders are paired with dynamic SL and TP based on Fibonacci-based distances, maintaining a risk-reward ratio consistent with intraday strategies.
📊 Visual Features:
Asian session high/low/mid lines.
Fibonacci levels: Original (based on raw range) and Optimized (user-adjustable).
Session background coloring for Asia, Execution Window, and NY session.
Labels and lines for entry, SL, and TP targets.
Dynamic deletion of untriggered orders after execution window expires.
⚙️ How It Works:
The script calculates the Asian session range.
Projects Fibonacci levels from the range.
Waits for the 01:15 NY candle to close to validate a signal.
If valid, a limit entry order (BUY or SELL) is plotted at the selected level.
If price structure changes (e.g., breaks the high/low), reversal logic may activate.
If no trade is triggered, orders are cleared before the NY session.
🔔 Alerts:
Alerts trigger when a valid setup appears after 01:15 NY candle.
Optional alerts for order activation, SL/TP hit, or trade cancellation.
📝 Notes:
Intended for semi-automated or discretionary trading.
Best used on highly liquid markets like Forex majors or indices.
Script parameters include session times, Fib ratios, SL/TP settings, and reversal logic toggle.
Credits:
Developed by LANZ, this script merges traditional session-based analysis with Fibonacci tools and structured execution timing, offering a unique framework for morning volatility plays.
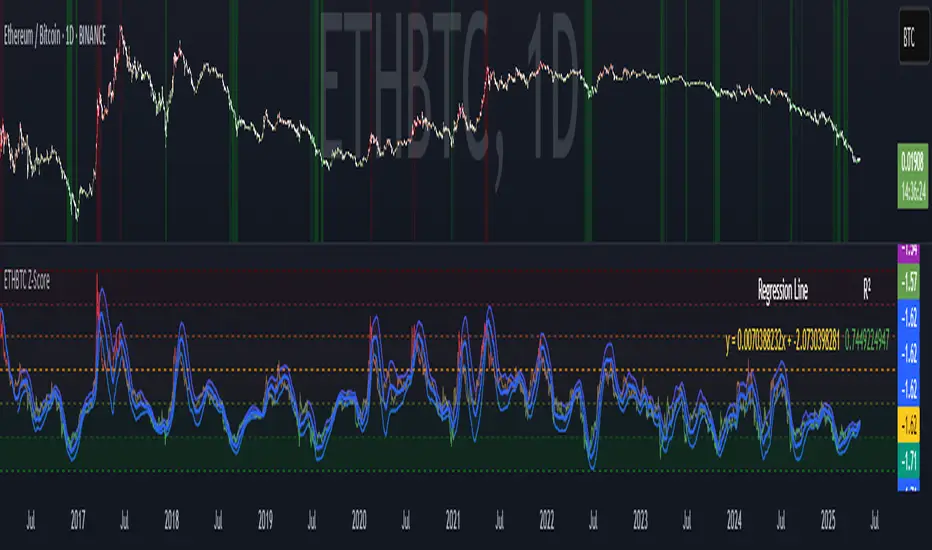
ETHBTC Z-ScoreETHBTC Z-Score Indicator
Key Features
Z-Score Calculation: Measures how far ETHBTC deviates from its mean over a user-defined period.
Linear Regression Line: Tracks the trend of the Z-score using least squares regression.
Standard Deviation Bands: Plots ±N standard deviations around the regression line to show expected Z-score range.
Dynamic Thresholds: Highlights overbought (e.g. Z > 1) and oversold (e.g. Z < -2) zones using color and background fill.
Visual & Table Display: Color-coded bars, horizontal level fills, and optional table showing regression formula and R².
Usage
Spot overbought/oversold extremes when Z-score crosses defined thresholds.
Use the regression line as a dynamic baseline and its bands as range boundaries.
Monitor R² to gauge how well the regression line fits the recent Z-score trend.
Example
Z > 1: ETHBTC may be overbought — potential caution or mean-reversion.
Z < -2: ETHBTC may be oversold — possible buying opportunity.
Z near regression line: Price is in line with recent trend.
Machine Learning: ARIMA + SARIMADescription
The ARIMA (Autoregressive Integrated Moving Average) and SARIMA (Seasonal ARIMA) are advanced statistical models that use machine learning to forecast future price movements. It uses autoregression to find the relationship between observed data and its lagged observations. The data is differenced to make it more predictable. The MA component creates a dependency between observations and residual errors. The parameters are automatically adjusted to market conditions.
Differences
ARIMA - This excels at identifying trends in the form of directions
SARIMA - Incorporates seasonality. It's better at capturing patterns previously seen
How To Use
1. Model: Determine if you want to use ARIMA (better for direction) or SARIMA (better for overall prediction). You can click on the 'Show Historic Prediction' to see the direction of the previous candles. Green = forecast ending up, red = forecast ending down
2. Metrics: The RMSE% and MAPE are 10 day moving averages of the first 10 predictions made at candle close. They're error metrics that compare the observed data with the predicted data. It is better to use them when they're below 8%. Higher timeframes will be higher, as these models are partly mean-reverting and higher TFs tend to trend more. Better to compare RMSE% and MAPE with similar timeframes. They naturally lag as data is being collected
3. Parameter selection: The simpler, the better. Both are used for ARIMA(1,1,1) and SARIMA(1,1,1)(1,1,1)5. Increasing may cause overfitting
4. Training period: Keep at 50. Because of limitations in pine, higher values do not make for more powerful forecasts. They will only criminally lag. So best to keep between 20 and 80

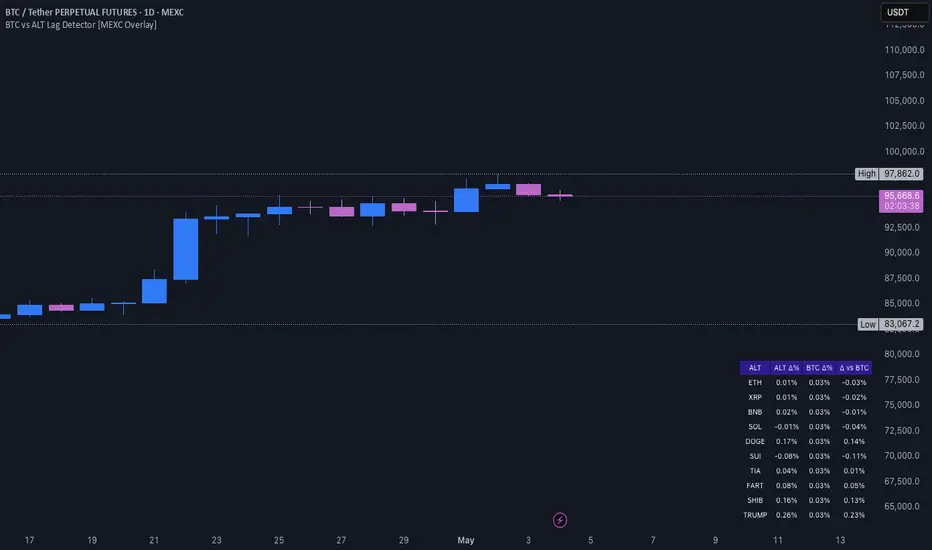
BTC vs ALT Lag Detector [MEXC Overlay]This indicator monitors the price movement of Bitcoin (BTC) and compares it in real time to a customizable list of major altcoins on the MEXC exchange.
It helps you identify lagging altcoins — tokens that are underperforming or overperforming BTC’s price action over a selected timeframe. These temporary deviations can offer profitable entry or rotation opportunities, especially for scalpers, day traders, and arbitrage-style strategies.
Key Features:
- Real-time deviation detection between BTC and altcoins
- Customizable comparison timeframe: 1m, 6m, 12m, 30m, 1h, 4h, or 1d
- Deviation threshold alert: Highlights coins that lag BTC by more than 0.5%, 1%, 2%, or 3%
- Compact stats table embedded in the price chart
- Fully adjustable layout: Table position (Top/Bottom/Center + Left/Right), Font size (Tiny, Small, Medium)
- Built-in alert system when deviation exceeds your chosen threshold
How to Use It:
Set your desired timeframe for comparison (e.g., 1 hour).
Select a deviation threshold (e.g., 1.0%).
The table will show:
Each altcoin’s % change
BTC’s % change
The delta (deviation) vs BTC
Red highlights indicate alts whose deviation exceeded the threshold.
When at least one alt lags beyond your threshold, the indicator can trigger an alert — helping you capitalize on potential catch-up trades.
Please provide any feedback on it.
[Tradevietstock] Fair Value Channel – Premium/Discount ZonesThe Ultimate Tool for Value Traders
Fair Value Channel – Premium/Discount Zones (Polynomial Regression)
Hello again, it’s Tradevietstock ,
This time, we’re introducing a powerful long-term tool for value investors and swing traders — a visual framework that answers one key question:
i. Overview
1. 🧠 Logic Behind the Script
This script creates a Fair Value Channel using polynomial regression to model the upper and lower bounds of a stock's expected price range. The core idea is to estimate "fair value" zones that indicate whether the current price is at a premium (overvalued) or discount (undervalued) relative to its historical range.
The script uses fixed coefficients for third-degree (cubic) polynomial equations to define a top channel and bottom channel, then scales and shifts these curves to match the actual price data. Intermediate levels (25%, 50%, 75%) are calculated using geometric interpolation, offering a graded assessment of price positioning within the channel.
2. The Trading Theory
This indicator is based on the idea that markets move in repeatable cycles of overvaluation and undervaluation. Rather than relying on instinct to judge whether an asset is “cheap” or “expensive,” it uses mathematical modeling — specifically, a fixed third-degree polynomial regression — to identify structured price patterns over time. This regression captures the natural wave-like behavior of prices and defines a fair value channel, with upper and lower bounds representing premium and discount zones.
The lower zone signals undervalued conditions, ideal for accumulating positions, while the upper zone reflects overvalued areas, where it may be time to reduce exposure. These zones are scaled to align with the asset’s real price range, making them practical and adaptive.
Ultimately, the indicator brings logic and discipline to value investing. It helps traders recognize favorable buying opportunities within a cycle — and hold until the next major uptrend, instead of reacting emotionally. The strategy: buy low, hold smart, sell high — driven by data, not guesswork.
ii. How to use
1. Key terms
Lookback_period : Sets the historical period used to calculate the highest and lowest prices. Determines whether the analysis is short-term, mid-term, or long-term.
Timeframe_input : Specifies the timeframe used for polynomial regression calculations. Higher timeframes smooth out noise.
Extrapolation_bars : Defines how many bars into the future the fair value channel should be projected (forecasted). Helps visualize future zones.
Show_forecast : Enables or disables the display of forecasted (future) evaluation zones based on extrapolated regression curves.
🎯 Evaluation Zones Based on Fair Value Range
Each of these zones represents a valuation level relative to a stock's or asset's estimated fair value. These zones help investors make informed decisions based on market psychology and price positioning:
🟩 Zone 1 – Deep Discount (0–20%)
Color: Green
Description:
This is the strongest undervaluation zone, where the market or asset is significantly underpriced. It typically reflects extreme fear and pessimism among investors.
A great opportunity for long-term investors to accumulate high-potential assets at bargain prices.
For example, Tesla (TSLA) stock dropped into the Deep Discount Zone in 2019, offering an exceptional entry point. By 2020, the stock had surged approximately 430%, illustrating how powerful the recovery can be from this zone.
The Deep Discount Zone often appears only during recessionary periods or times of extreme market fear, making it one of the best opportunities to accumulate high-quality stocks.
However, due to the elevated risks and uncertainty in such conditions, it’s crucial to prioritize risk management and approach this zone with a mid- to long-term investment mindset, rather than seeking short-term gains.
🟩 Zone 2 – Undervalued (20–40%)
Color: Lime
Description:
Still considered a strong buying opportunity, this zone offers assets at meaningful discounts. While not as deeply undervalued as Zone 1, it remains attractive for value-seeking investors.
For example, Netflix (NFLX) stock experienced a sharp decline of nearly 80% in 2011, pushing it into the Undervalued Zone. This presented a prime buying opportunity for long-term investors.
After a period of consolidation, NFLX surged over 500% by 2013, demonstrating how deeply discounted zones can signal powerful reversal and growth potential when backed by strong fundamentals.
🟨 Zone 3 – Fair Value (40–60%)
Color: Yellow
Description:
This zone represents the true fair value range. Many high-growth or in-demand assets may only dip this low due to market optimism. Buying in this zone can still be wise—especially for fundamentally strong stocks or tokens—depending on broader conditions and expectations.
For example, Apple stock has historically never fallen below the Fair Value Zone, largely due to the company’s strong core values, resilient business model, and consistent performance. Whether a stock dips further into undervalued zones often depends on its intrinsic fundamentals and long-term growth potential.
Likewise, NVDA stock has only dipped into the Fair Value Zone, but not deeper, due to the company’s strong fundamentals and high growth potential.
🟧 Zone 4 – Overvalued (60–80%)
Color: Orange
Description:
In this range, prices are becoming expensive. This is generally a time to pause further buying and begin looking for potential exit or profit-taking opportunities.
Despite potential continued upside, staying disciplined here is key, as price increases may be driven more by speculation than fundamentals.
🟥 Zone 5 – Extended Premium (80–100%)
Color: Red
Description:
This is the extreme overvaluation zone, often driven by market euphoria, FOMO (Fear of Missing Out), and greed.
Avoid buying in this range. Instead, focus on exiting positions and securing profits. Risk of a reversal is high.
2. How to Use?
This indicator is not designed for short-term trading. Instead, it supports a value investing mindset, applicable across various financial instruments—including stocks, indices, tokens, and CFDs.
Investing based on fair value means focusing on the intrinsic worth of an asset and holding through market cycles—from fear to euphoria.
The goal is to accumulate positions during Deep Discount Zones (often during extreme fear or recession) and hold them patiently until the market reaches the FOMO and Extreme Greed stages.
At that point, those who bought during deep discounts become the true winners, having captured both value and long-term upside.
Trading Tutorial
The strategy is simple: Buy cheap, sell high.
Note:
Discount zones are based on the historical price behavior of each asset.
A strong stock may never drop into the lowest zones, while some tokens/indices/stocks might reach the Deep Discount Zone and still dip further before recovering.
Always analyze the asset’s history—does it usually bounce from the Fair Value Zone, or does it often fall deeper before reversing?
Your strategy should adapt to the specific behavior of the stock, token, or index you're trading.
This indicator works with stocks, crypto, indices, and CFDs.
You can adjust any input settings to match your own strategy and risk tolerance, as long as you understand what you're doing.

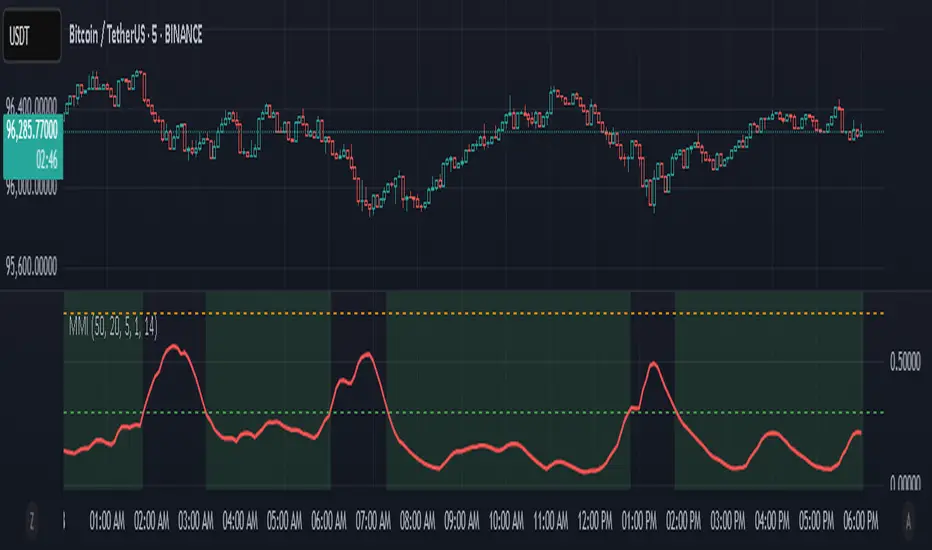
Market Manipulation Index (MMI)The Composite Manipulation Index (CMI) is a structural integrity tool that quantifies how chaotic or orderly current market conditions are, with the aim of detecting potentially manipulated or unstable environments. It blends two distinct mathematical models that assess price behavior in terms of both structural rhythm and predictability.
1. Sine-Fit Deviation Model:
This component assumes that ideal, low-manipulation price behavior resembles a smooth oscillation, such as a sine wave. It generates a synthetic sine wave using a user-defined period and compares it to actual price movement over an adaptive window. The error between the real price and this synthetic wave—normalized by price variance—forms the Sine-Based Manipulation Index. A high error indicates deviation from natural rhythm, suggesting structural disorder.
2. Predictability-Based Model:
The second component estimates how well current price can be predicted using recent price lags. A two-variable rolling linear regression is computed between the current price and two lagged inputs (close and close ). If the predicted price diverges from the actual price, this error—also normalized by price variance—reflects unpredictability. High prediction error implies a more manipulated or erratic environment.
3. Adaptive Mechanism:
Both components are calculated using an adaptive smoothing window based on the Average True Range (ATR). This allows the indicator to respond proportionally to market volatility. During high volatility, the analysis window expands to avoid over-sensitivity; during calm periods, it contracts for better responsiveness.
4. Composite Output:
The two normalized metrics are averaged to form the final CMI value, which is then optionally smoothed further. The output is scaled between 0 and 1:
0 indicates a highly structured, orderly market.
1 indicates complete structural breakdown or randomness.
Suggested Interpretation:
CMI < 0.3: Market is clean and structured. Trend-following or breakout strategies may perform better.
CMI > 0.7: Market is structurally unstable. Choppy price action, fakeouts, or manipulative behavior may dominate.
CMI 0.3–0.7: Transitional zone. Caution or reduced risk may be warranted.
This indicator is designed to serve as a contextual filter, helping traders assess whether current market conditions are conducive to structured strategies, or if discretion and defense are more appropriate.
Future Candle Reversal Projection (Mastersinnifty)Overview
This tool identifies potential future market reversal zones by dynamically projecting pivot-based swing patterns forward in time. Unlike traditional ZigZag indicators that only reflect past movements, this indicator anticipates probable future turning points based on historical swing periodicity.
---
Key Features
- Forward Projections: Calculates and projects future swing zones based on detected pivot distances.
- Customizable Detection: Adjust the ZigZag depth for different trading styles (scalping, swing, position).
- Dynamic Updates: Real-time recalibration as new pivots form.
- Clean Visual Markers: Projects reversal estimates as intuitive labels and dotted lines.
---
How it Works
The indicator identifies significant swing highs and lows using a user-defined ZigZag depth setting. It measures the time (bars) and price characteristics of the latest swing movement. Using this pattern, it projects forward estimated reversal points at consistent intervals. Midpoint price levels between the last high and low are used for each future projection.
---
Who Can Benefit
- Intraday and swing traders seeking advanced planning zones.
- Technical analysts relying on pattern periodicity.
- Traders who wish to combine projected reversal markers with their own risk management strategies.
---
Disclaimer
This tool is an analytical and educational utility. It does not predict markets with certainty. Always combine it with your own analysis and risk management. Past behavior does not guarantee future results.

Liquidity Trap Reversal Pro (Radar v2)Liquidity Trap Reversal Pro (Radar v2) is a non-repainting indicator designed to detect hidden liquidity traps at key swing highs and lows. It combines wick analysis, volume spike detection, and optional trend and exhaustion filters to identify high-probability reversal setups.
🔷 Features:
Non-Repainting: Pivots confirmed after lookback period, no future leaking.
Volume Spike Detection: Filters traps that occur during major liquidity events.
EMA Trend Filter (Optional): Focus on traps aligned with the prevailing trend.
Higher Timeframe Trend Filter (Optional): Confirm traps using a higher timeframe EMA bias.
Exhaustion Guard (Optional): Prevents traps after overextended moves based on ATR stretch.
Clean Visuals: Distinct plots for raw trap points vs confirmed traps.
Alerts Included: Set alerts for confirmed high/low liquidity traps.
📚 How to Use:
Watch for Trap Signals:
A Trap High signal suggests a potential bearish reversal.
A Trap Low signal suggests a potential bullish reversal.
Use Confirmed Signals for Best Entries:
Confirmed traps fire only after price moves opposite to the trap direction, adding reliability.
Use Trend Filters to Improve Accuracy:
In an uptrend (price above EMA), prefer Trap Lows (buy setups).
In a downtrend (price below EMA), prefer Trap Highs (sell setups).
Use the Exhaustion Guard to Avoid Bad Trades:
This filter blocks signals when price has moved too far from trend, helping avoid late entries.
Recommended Settings:
Best used on 15-minute, 1-hour, or 4-hour charts.
Trend filter ON for trending markets.
Exhaustion guard ON for volatile or stretched markets.
📈 Important Notes:
This script does not repaint once a pivot is confirmed.
Alerts trigger only on confirmed trap signals.
Always combine signals with sound risk management and trading strategy.
Disclaimer:
This script is for educational purposes only. It is not investment advice or a guarantee of results. Always do your own research before trading.

Auto Trend Channel + Buy/Sell AlertsThis indicator automatically detects trend channels using a linear regression line, and dynamically plots upper and lower channel boundaries based on standard deviation. It helps traders identify potential Buy and Sell zones with clear visual signals and customizable alerts.
💡 How It Works:
🧠 Regression-Based Channel: Calculates the central trend line using ta.linreg() over a user-defined length.
📏 Dynamic Boundaries: Upper and lower channel lines are offset by a multiplier of the standard deviation for precision volatility tracking.
✅ Buy Signals: Triggered when price crosses above the lower boundary — potential bounce entry.
❌ Sell Signals: Triggered when price crosses below the upper boundary — potential reversal exit.
🔔 Alerts Enabled: Get real-time alerts when price touches the channel lines.

TradeSmart Morning GloryThe Morning Glory Indicator by TradeSmart University is a pre-market volume visualization tool designed to help traders quickly assess the quality of a morning gap. By highlighting volume levels before the market opens, this indicator helps distinguish between a professional gap (likely to continue running) and a retail/news-driven gap (likely to fade or reverse).
💡 What It Does:
This indicator plots color-coded volume bars in the pre-market session and highlights when volume crosses two key thresholds:
Teal Bars – Low institutional interest
Yellow Bars – Medium institutional interest (100K+ volume)
Red Bars – High institutional interest (400K+ volume)
These thresholds are most effective on AMEX:SPY and other high-volume ETFs or stocks, but may be customized to fit your trading style. Consider using a 15-minute chart for the above settings.
🧠 How to Use It:
This indicator works best in conjunction with the Morning Glory Strategy and Qualified Trade Setup . On its own, the indicator gives a real-time read on pre-market strength , helping you:
Confirm gap-and-go setups (gap + high volume = likely continuation)
Fade the gap (gap + low volume = higher likelihood of reversal)
While the indicator focuses exclusively on volume, the full Morning Glory strategy adds an important price gap size filter to create powerful trade signals.
📊 Probabilities of Success (Based on Full Strategy):
When used as part of the Morning Glory Qualified Trade Setup, here are the historical win rates by day of the week:
Monday: 65%
Tuesday: 77%
Wednesday: 79%
Thursday: 82%
Friday: 78%
If used in conjunction with an artificial intelligence like the Deep Sky Trading Assistant™, win-loss ratios improve to 89% or better across all days of the week.
🔔 Note: For best results, activate premium ARCA data on your TradingView account. This ensures the most accurate and complete pre-market volume data.

NexAlgo AI with Dynamic TP/SLThe NexAlgo Indicator combines a Gaussian kernel regression engine with adaptive volatility thresholds to generate clear, data‑driven trade signals and built‑in risk levels. It predicts the next bar’s price relative to a simple moving average, then measures the average deviation between actual and forecasted values to form dynamic bands. Breakouts beyond these bands, aligned with the prediction’s direction, produce buy or sell signals directly on your chart.
How It Works & What You’ll See
Kernel Regression Forecast: A rolling “lookback” window builds a Gaussian similarity matrix of recent prices. This matrix is used to project the next price, smoothing around a moving average.
Adaptive Volatility Bands: The indicator computes the mean absolute error between actual and predicted prices, multiplies it by your chosen volatility factor, and plots upper and lower bands.
Signal Triggers: When price closes above the upper band while the prediction is rising, a green “BUY” label appears; when price closes below the lower band as the forecast falls, a red “SELL” label is shown.
Automatic SL/TP Levels: After each signal, the script scans recent swing highs/lows and applies an ATR buffer. Stop‑loss is set conservatively at the more protective of these levels, while take‑profit is calculated by your reward‑to‑risk ratio and capped near the opposite swing extreme.
Customizable Inputs
Lookback Period & Smoothing: Adjust how many bars the regression and volatility calculations use, and tune the noise regularization to suit fast or slow markets.
Volatility Multiplier: Widen or tighten the adaptive bands to control signal frequency and confidence.
Swing Lookback & ATR Options: Define how far back the indicator searches for swing points, and choose between ATR calculation methods.
Reward‑to‑Risk Ratio: Set your preferred multiple of stop‑loss distance for take‑profit targets.
What Makes NexAlgo Different
Hybrid Statistical Approach: Unlike fixed‑period moving averages or standard regression, the Gaussian kernel adapts locally to evolving price patterns and regimes.
Self‑Adjusting Thresholds: Volatility bands derive from prediction errors—so they expand in choppy markets and contract in trending conditions.
Integrated Risk Controls: Automatically calculated stop‑loss and take‑profit levels remove manual guesswork, yet remain grounded in both ATR and price structure.
Trader‑Driven Flexibility: Every parameter—from lookback length to risk ratio—can be dialed in for scalping, swing trading, or longer‑term strategies.
Getting Started
• Apply NexAlgo to your preferred timeframe (5–15 min for intraday scalps, 1 h–4 h for swings, daily for position plays).
• Begin with default settings and gradually adjust lookback and smoothing to balance responsiveness versus noise.
• Experiment with volatility multipliers: tighten in strong trends, widen when markets churn.
• Backtest different ATR buffers and reward ratios to discover your ideal risk‑reward profile.

TASC 2025.05 Trading The Channel█ OVERVIEW
This script implements channel-based trading strategies based on the concepts explained by Perry J. Kaufman in the article "A Test Of Three Approaches: Trading The Channel" from the May 2025 edition of TASC's Traders' Tips . The script explores three distinct trading methods for equities and futures using information from a linear regression channel. Each rule set corresponds to different market behaviors, offering flexibility for trend-following, breakout, and mean-reversion trading styles.
█ CONCEPTS
Linear regression
Linear regression is a model that estimates the relationship between a dependent variable and one or more independent variables by fitting a straight line to the observed data. In the context of financial time series, traders often use linear regression to estimate trends in price movements over time.
The slope of the linear regression line indicates the strength and direction of the price trend. For example, a larger positive slope indicates a stronger upward trend, and a larger negative slope indicates the opposite. Traders can look for shifts in the direction of a linear regression slope to identify potential trend trading signals, and they can analyze the magnitude of the slope to support trading decisions.
One caveat to linear regression is that most financial time series data does not follow a straight line, meaning a regression line cannot perfectly describe the relationships between values. Prices typically fluctuate around a regression line to some degree. As such, analysts often project ranges above and below regression lines, creating channels to model the expected extent of the data's variability. This strategy constructs a channel based on the method used in Kaufman's article. It measures the maximum distances from points on the linear regression line to historical price values, then adds those distances and the current slope to the regression points.
Depending on the trading style, traders might look for prices to move outside an established channel for breakout signals, or they might look for price action to reach extremes within the channel for potential mean reversion opportunities.
█ STRATEGY CALCULATIONS
Primary trade rules
This strategy implements three distinct sets of rules for trend, breakout, and mean-reversion trades based on the methods Kaufman describes in his article:
Trade the trend (Rule 1) : Open new positions when the sign of the slope changes, indicating a potential trend reversal. Close short trades and enter a long trade when the slope changes from negative to positive, and do the opposite when the slope changes from positive to negative.
Trade channel breakouts (Rule 2) : Open new positions when prices cross outside the linear regression channel for the current sample. Close short trades and enter a long trade when the price moves above the channel, and do the opposite when the price moves below the channel.
Trade within the channel (Rule 3) : Open new positions based on price values within the channel's range. Close short trades and enter a long trade when the price is near the channel's low, within a specified percentage of the channel's range, and do the opposite when the price is near the channel's high. With this rule, users can also filter the trades based on the channel's slope. When the filter is active, long positions are allowed only when the slope is positive, and short positions are allowed only when it is negative.
Position sizing
Kaufman's strategy uses specific trade sizes for equities and futures markets:
For an equities symbol, the number of shares traded is $10,000 divided by the current price.
For a futures symbol, the number of contracts traded is based on a volatility-adjusted formula that divides $25,000 by the product of the 20-bar average true range and the instrument's point value.
By default, this script automatically uses these sizes for its trade simulation on equities and futures symbols and does not simulate trading on other symbols. However, users can control position sizes from the "Settings/Properties" tab and enable trade simulation on other symbol types by selecting the "Manual" option in the script's "Position sizing" input.
Stop-loss
This strategy includes the option to place an accompanying stop-loss order for each trade, which users can enable from the "SL %" input in the "Settings/Inputs" tab. When enabled, the strategy places a stop-loss order at a specified percentage distance from the closing price where the entry order occurs, allowing users to compare how the strategy performs with added loss protection.
█ USAGE
This strategy adapts its display logic for the three trading approaches based on the rule selected in the "Trade rule" input:
For all rules, the script plots the linear regression slope in a separate pane. The plot is color-coded to indicate whether the current slope is positive or negative.
When the selected rule is "Trade the trend", the script plots triangles in the separate pane to indicate when the slope's direction changes from positive to negative or vice versa. Additionally, it plots a color-coded SMA on the main chart pane, allowing visual comparison of the slope to directional changes in a moving average.
When the rule is "Trade channel breakouts" or "Trade within the channel", the script draws the current period's linear regression channel on the main chart pane, and it plots bands representing the history of the channel values from the specified start time onward.
When the rule is "Trade within the channel", the script plots overbought and oversold zones between the bands based on a user-specified percentage of the channel range to indicate the value ranges where new trades are allowed.
Users can customize the strategy's calculations with the following additional inputs in the "Settings/Inputs" tab:
Start date : Sets the date and time when the strategy begins simulating trades. The script marks the specified point on the chart with a gray vertical line. The plots for rules 2 and 3 display the bands and trading zones from this point onward.
Period : Specifies the number of bars in the linear regression channel calculation. The default is 40.
Linreg source : Specifies the source series from which to calculate the linear regression values. The default is "close".
Range source : Specifies whether the script uses the distances from the linear regression line to closing prices or high and low prices to determine the channel's upper and lower ranges for rules 2 and 3. The default is "close".
Zone % : The percentage of the channel's overall range to use for trading zones with rule 3. The default is 20, meaning the width of the upper and lower zones is 20% of the range.
SL% : If the checkbox is selected, the strategy adds a stop-loss to each trade at the specified percentage distance away from the closing price where the entry order occurs. The checkbox is deselected by default, and the default percentage value is 5.
Position sizing : Determines whether the strategy uses Kaufman's predefined trade sizes ("Auto") or allows user-defined sizes from the "Settings/Properties" tab ("Manual"). The default is "Auto".
Long trades only : If selected, the strategy does not allow short positions. It is deselected by default.
Trend filter : If selected, the strategy filters positions for rule 3 based on the linear regression slope, allowing long positions only when the slope is positive and short positions only when the slope is negative. It is deselected by default.
NOTE: Because of this strategy's trading rules, the simulated results for a specific symbol or channel configuration might have significantly fewer than 100 trades. For meaningful results, we recommend adjusting the start date and other parameters to achieve a reasonable number of closed trades for analysis.
Additionally, this strategy does not specify commission and slippage amounts by default, because these values can vary across market types. Therefore, we recommend setting realistic values for these properties in the "Cost simulation" section of the "Settings/Properties" tab.

Pullback SARPullback SAR - Parabolic SAR with Pullback Detection
Description: The "Pullback SAR" is an advanced indicator built on the classic Parabolic SAR but with additional functionality for detecting pullbacks. It helps identify moments when the price pulls back from the main trend, offering potential entry signals. Perfect for traders looking to enter the market after a correction.
Key Features:
SAR (Parabolic SAR): The Parabolic SAR indicator is used to determine potential trend reversal points. It marks levels where the price could reverse its direction.
Pullback Detection: The indicator catches periods when the price moves away from the main trend and then returns, which may suggest a re-entry opportunity.
Long and Short Signals: Once a pullback in the direction of the main trend is identified, the indicator generates signals that could be used to open positions.
Simple and Clear Construction: The indicator is based on the classic SAR, with added pullback detection logic to enhance the accuracy of the signals.
Parameters:
Start (SAR Step): Determines the initial step for the SAR calculation, which controls the rate of change in the indicator at the beginning.
Increment (SAR Increment): Defines the maximum step size for SAR, allowing traders to adjust the indicator’s sensitivity to market volatility.
Max Value (SAR Max): Sets the upper limit for the SAR value, controlling its volatility.
Usage:
Swing Trading: Ideal for swing strategies, aiming to capture larger price moves while maintaining a safe margin.
Scalping: Due to its precise pullback detection, it can also be used in scalping, especially when the price quickly returns to the main trend.
Risk Management: The combination of SAR and pullback detection allows traders to adjust their positions according to changing market conditions.
Special Notes:
Adjusting Parameters: Depending on the market and trading style, users can adjust the SAR parameters (Start, Increment, Max Value) to fit their needs.
Combination with Other Indicators: It's recommended to use the indicator alongside other technical analysis tools (e.g., EMA, RSI) to enhance the accuracy of the signals.
Link to the script: This open-source version of the indicator is available on TradingView, enabling full customization and adjustments to meet your personal trading strategy. Share your experiences and suggestions!
