Z-Strike RecoveryThis strategy utilizes the Z-Score of daily changes in the VIX (Volatility Index) to identify moments of extreme market panic and initiate long entries. Scientific research highlights that extreme volatility levels often signal oversold markets, providing opportunities for mean-reversion strategies.
How the Strategy Works
Calculation of Daily VIX Changes:
The difference between today’s and yesterday’s VIX closing prices is calculated.
Z-Score Calculation:
The Z-Score quantifies how far the current change deviates from the mean (average), expressed in standard deviations:
Z-Score=(Daily VIX Change)−MeanStandard Deviation
Z-Score=Standard Deviation(Daily VIX Change)−Mean
The mean and standard deviation are computed over a rolling period of 16 days (default).
Entry Condition:
A long entry is triggered when the Z-Score exceeds a threshold of 1.3 (adjustable).
A high positive Z-Score indicates a strong overreaction in the market (panic).
Exit Condition:
The position is closed after 10 periods (days), regardless of market behavior.
Visualizations:
The Z-Score is plotted to make extreme values visible.
Horizontal threshold lines mark entry signals.
Bars with entry signals are highlighted with a blue background.
This strategy is particularly suitable for mean-reverting markets, such as the S&P 500.
Scientific Background
Volatility and Market Behavior:
Studies like Whaley (2000) demonstrate that the VIX, known as the "fear gauge," is highly correlated with market panic phases. A spike in the VIX is often interpreted as an oversold signal due to excessive hedging by investors.
Source: Whaley, R. E. (2000). The investor fear gauge. Journal of Portfolio Management, 26(3), 12-17.
Z-Score in Financial Strategies:
The Z-Score is a proven method for detecting statistical outliers and is widely used in mean-reversion strategies.
Source: Chan, E. (2009). Quantitative Trading. Wiley Finance.
Mean-Reversion Approach:
The strategy builds on the mean-reversion principle, which assumes that extreme market movements tend to revert to the mean over time.
Source: Jegadeesh, N., & Titman, S. (1993). Returns to Buying Winners and Selling Losers: Implications for Stock Market Efficiency. Journal of Finance, 48(1), 65-91.
Statistics

MA Deviation Suite [InvestorUnknown]This indicator combines advanced moving average techniques with multiple deviation metrics to offer traders a versatile tool for analyzing market trends and volatility.
Moving Average Types :
SMA, EMA, HMA, DEMA, FRAMA, VWMA: Standard moving averages with different characteristics for smoothing price data.
Corrective MA: This method corrects the MA by considering the variance, providing a more responsive average to price changes.
f_cma(float src, simple int length) =>
ma = ta.sma(src, length)
v1 = ta.variance(src, length)
v2 = math.pow(nz(ma , ma) - ma, 2)
v3 = v1 == 0 or v2 == 0 ? 1 : v2 / (v1 + v2)
var tolerance = math.pow(10, -5)
float err = 1
// Gain Factor
float kPrev = 1
float k = 1
for i = 0 to 5000 by 1
if err > tolerance
k := v3 * kPrev * (2 - kPrev)
err := kPrev - k
kPrev := k
kPrev
ma := nz(ma , src) + k * (ma - nz(ma , src))
Fisher Least Squares MA: Aims to reduce lag by using a Fisher Transform on residuals.
f_flsma(float src, simple int len) =>
ma = src
e = ta.sma(math.abs(src - nz(ma )), len)
z = ta.sma(src - nz(ma , src), len) / e
r = (math.exp(2 * z) - 1) / (math.exp(2 * z) + 1)
a = (bar_index - ta.sma(bar_index, len)) / ta.stdev(bar_index, len) * r
ma := ta.sma(src, len) + a * ta.stdev(src, len)
Sine-Weighted MA & Cosine-Weighted MA: These give more weight to middle bars, creating a smoother curve; Cosine weights are shifted for a different focus.
Deviation Metrics :
Average Absolute Deviation (AAD) and Median Absolute Deviation (MAD): AAD calculates the average of absolute deviations from the MA, offering a measure of volatility. MAD uses the median, which can be less sensitive to outliers.
Standard Deviation (StDev): Measures the dispersion of prices from the mean.
Average True Range (ATR): Reflects market volatility by considering the day's range.
Average Deviation (adev): The average of previous deviations.
// Calculate deviations
float aad = f_aad(src, dev_len, ma) * dev_mul
float mad = f_mad(src, dev_len, ma) * dev_mul
float stdev = ta.stdev(src, dev_len) * dev_mul
float atr = ta.atr(dev_len) * dev_mul
float avg_dev = math.avg(aad, mad, stdev, atr)
// Calculated Median with +dev and -dev
float aad_p = ma + aad
float aad_m = ma - aad
float mad_p = ma + mad
float mad_m = ma - mad
float stdev_p = ma + stdev
float stdev_m = ma - stdev
float atr_p = ma + atr
float atr_m = ma - atr
float adev_p = ma + avg_dev
float adev_m = ma - avg_dev
// upper and lower
float upper = f_max4(aad_p, mad_p, stdev_p, atr_p)
float upper2 = f_min4(aad_p, mad_p, stdev_p, atr_p)
float lower = f_min4(aad_m, mad_m, stdev_m, atr_m)
float lower2 = f_max4(aad_m, mad_m, stdev_m, atr_m)
Determining Trend
The indicator generates trend signals by assessing where price stands relative to these deviation-based lines. It assigns a trend score by summing individual signals from each deviation measure. For instance, if price crosses above the MAD-based upper line, it contributes a bullish point; crossing below an ATR-based lower line contributes a bearish point.
When the aggregated trend score crosses above zero, it suggests a shift towards a bullish environment; crossing below zero indicates a bearish bias.
// Define Trend scores
var int aad_t = 0
if ta.crossover(src, aad_p)
aad_t := 1
if ta.crossunder(src, aad_m)
aad_t := -1
var int mad_t = 0
if ta.crossover(src, mad_p)
mad_t := 1
if ta.crossunder(src, mad_m)
mad_t := -1
var int stdev_t = 0
if ta.crossover(src, stdev_p)
stdev_t := 1
if ta.crossunder(src, stdev_m)
stdev_t := -1
var int atr_t = 0
if ta.crossover(src, atr_p)
atr_t := 1
if ta.crossunder(src, atr_m)
atr_t := -1
var int adev_t = 0
if ta.crossover(src, adev_p)
adev_t := 1
if ta.crossunder(src, adev_m)
adev_t := -1
int upper_t = src > upper ? 3 : 0
int lower_t = src < lower ? 0 : -3
int upper2_t = src > upper2 ? 1 : 0
int lower2_t = src < lower2 ? 0 : -1
float trend = aad_t + mad_t + stdev_t + atr_t + adev_t + upper_t + lower_t + upper2_t + lower2_t
var float sig = 0
if ta.crossover(trend, 0)
sig := 1
else if ta.crossunder(trend, 0)
sig := -1
Backtesting and Performance Metrics
The code integrates with a backtesting library that allows traders to:
Evaluate the strategy historically
Compare the indicator’s signals with a simple buy-and-hold approach
Generate performance metrics (e.g., mean returns, Sharpe Ratio, Sortino Ratio) to assess historical effectiveness.
Practical Usage and Calibration
Default settings are not optimized: The given parameters serve as a starting point for demonstration. Users should adjust:
len: Affects how smooth and lagging the moving average is.
dev_len and dev_mul: Influence the sensitivity of the deviation measures. Larger multipliers widen the bands, potentially reducing false signals but introducing more lag. Smaller multipliers tighten the bands, producing quicker signals but potentially more whipsaws.
This flexibility allows the trader to tailor the indicator for various markets (stocks, forex, crypto) and time frames.
Disclaimer
No guaranteed results: Historical performance does not guarantee future outcomes. Market conditions can vary widely.
User responsibility: Traders should combine this indicator with other forms of analysis, appropriate risk management, and careful calibration of parameters.

Ultra Trade JournalThe Ultra Trade Journal is a powerful TradingView indicator designed to help traders meticulously document and analyze their trades. Whether you're a novice or an experienced trader, this tool offers a clear and organized way to visualize your trading strategy, monitor performance, and make informed decisions based on detailed trade metrics.
Detailed Description
The Ultra Trade Journal indicator allows users to input and visualize critical trade information directly on their TradingView charts.
.........
User Inputs
Traders can specify entry and exit prices , stop loss levels, and up to four take profit targets.
.....
Dynamic Plotting
Once the input values are set, the indicator automatically plots horizontal lines for entry, exit, stop loss, and each take profit level on the chart. These lines are visually distinct, using different colors and styles (solid, dashed, dotted) to represent each element clearly.
.....
Live Position Tracking
If enabled, the indicator can adjust the exit price in real-time based on the current market price, allowing traders to monitor live positions effectively.
.....
Tick Calculations
The script calculates the number of ticks between the entry price and each exit point (stop loss and take profits). This helps in understanding the movement required for each target and assessing the potential risk and reward.
.....
Risk-Reward Ratios
For each take profit level, the indicator computes the risk-reward (RR) ratio by comparing the ticks at each target against the stop loss ticks. This provides a quick view of the potential profitability versus the risk taken.
.....
Comprehensive Table Display
A customizable table is displayed on the chart, summarizing all key trade details. This includes the entry and exit prices, stop loss and take profit levels, tick counts, and their respective RR ratios.
Users can adjust the table's Position and text color to suit their preferences.
.....
Visual Enhancements
The indicator uses adjustable background shading between entry and stop loss/take profit lines to visually represent potential trade outcomes. This shading adjusts based on whether the trade is long or short, providing an intuitive understanding of trade performance.
.........
Overall, the Ultra Trade Journal combines visual clarity with detailed analytics, enabling traders to keep a well-organized record of their trades and enhance their trading strategies through insightful data.

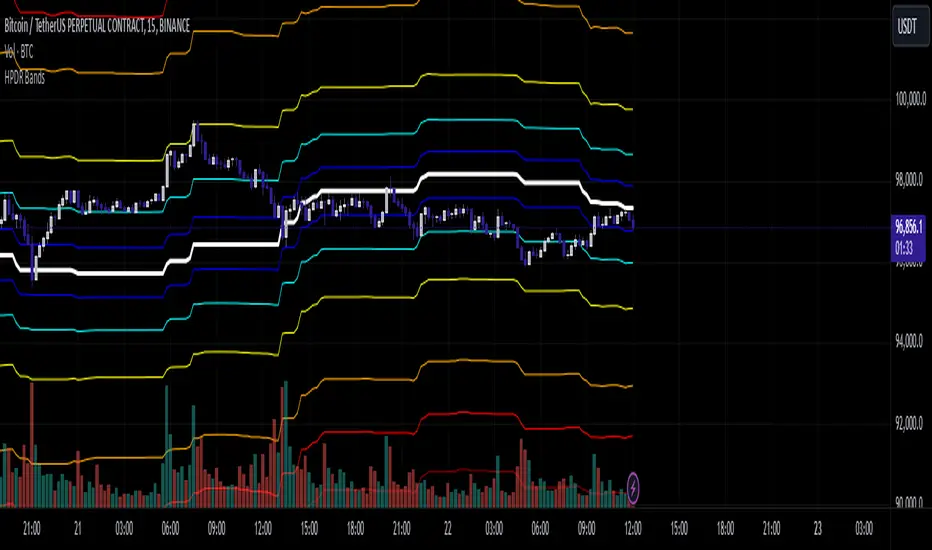
HPDR Bands IndicatorThe HPDR Bands indicator is a customizable tool designed to help traders visualize dynamic price action zones. By combining historical price ranges with adaptive bands, this script provides clear insights into potential support, resistance, and midline levels. The indicator is well-suited for all trading styles, including trend-following and range-bound strategies.
Features:
Dynamic Price Bands: Calculates price zones based on historical highs and lows, blending long-term and short-term price data for responsive adaptation to current market conditions.
Probability Enhancements: Includes a probability plot derived from the relative position of the closing price within the range, adjusted for volatility to highlight potential price movement scenarios.
Fibonacci-Like Levels: Highlights key levels (100%, 95%, 88%, 78%, 61%, 50%, and 38%) for intuitive visualization of price zones, aiding in identifying high-probability trading opportunities.
Midline Visualization: Displays a midline that serves as a reference for price mean reversion or breakout analysis.
How to Use:
Trending Markets: Use the adaptive upper and lower bands to gauge potential breakout or retracement zones.
Range-Bound Markets: Identify support and resistance levels within the defined price range.
Volatility Analysis: Observe the probability plot and its sensitivity to volatility for informed decision-making.
Important Notes:
This script is not intended as investment advice. It is a tool to assist with market analysis and should be used alongside proper risk management and other trading tools.
The script is provided as-is and without warranty. Users are encouraged to backtest and validate its suitability for their specific trading needs.
Happy Trading!
If you find this script helpful, consider sharing your feedback or suggestions for improvement. Collaboration strengthens the TradingView community, and your input is always appreciated!
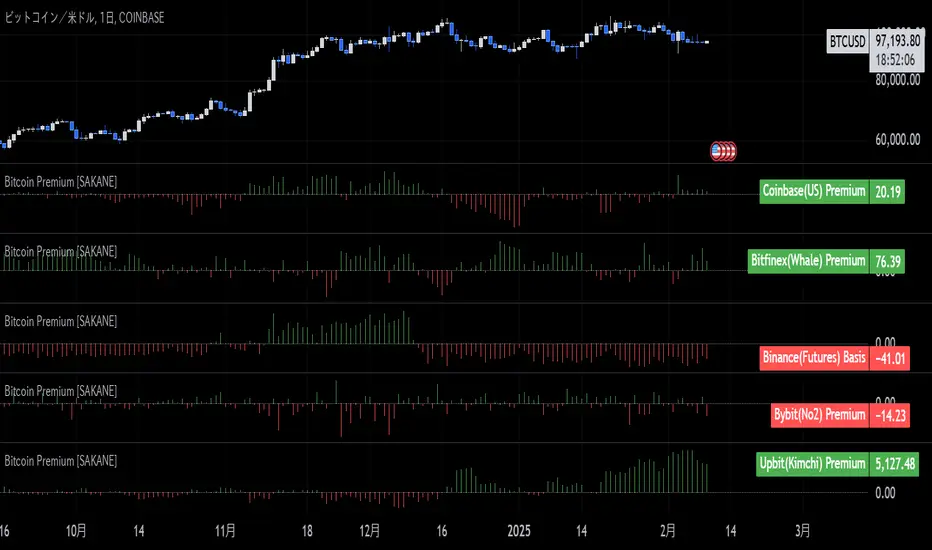
Bitcoin Premium [SAKANE]Overview
"Bitcoin Premium " is an indicator designed to analyze the price differences (premiums) of Bitcoin between major exchanges. By using this tool, you can visualize these differences and trends across exchanges, helping you make more informed trading decisions.
Features
1. Premium Calculation and Display
- Calculates and visualizes the price differences between major exchanges like Coinbase, Bitfinex, Upbit, and Binance.
- Premiums are displayed in a histogram format for intuitive analysis.
2. Forex Rate Adjustment
- Prices quoted in KRW (e.g., from Upbit) are converted to USD using real-time KRW/USD forex rates.
3. Moving Average Option
- Displays moving averages (SMA or EMA) of premiums for a clearer view of long-term trends.
4. Customizable Settings
- Toggle the premium display for each exchange on or off.
- Includes label displays to support visual analysis.
What Can It Do for You?
1. Identify Arbitrage Opportunities
By observing price differences (premiums) between exchanges, you can identify arbitrage opportunities.
Example: If Bitcoin is cheaper on Binance and more expensive on Coinbase, you could buy on Binance and sell on Coinbase to capture the price difference.
2. Understand Regional Supply and Demand Trends
Each exchange's premium reflects the supply and demand dynamics of its respective region.
Example: A high premium on Upbit may indicate excess demand or regulatory impacts in the South Korean market.
3. Analyze Liquidity
Price differences often highlight liquidity disparities between exchanges. Markets with lower trading volumes tend to have larger premiums due to price distortions.
4. Evaluate Macroeconomic Impacts
Premium movements may reflect changes in macroeconomic factors, such as exchange rates, regulations, or financial conditions specific to each region.
5. Analyze Trends and Market Sentiment
By tracking premium trends, you can gauge market sentiment and understand regional or exchange-specific behaviors to inform your investment decisions.
6. Support Strategic Trading
This tool is useful for short-term arbitrage strategies as well as long-term evaluations of market health.
Exchange Characteristics and Premium Implications
The meaning of premiums varies by exchange.
- Coinbase (US Market)
Primarily used by investors buying directly with fiat currency (USD). A higher premium often signals bullish sentiment among institutional and retail investors.
- Bitfinex (Global Market)
A trader-focused exchange with active large-scale and leveraged trading. Premiums may reflect liquidity and risk appetite.
- Upbit (South Korean Market)
Priced in KRW, making it subject to forex rates and local market dynamics. High premiums may indicate strong demand or regulatory influences in South Korea.
- Binance (Global Market)
The largest exchange by trading volume. Premiums here are often a reflection of the overall market balance.
Notes
- This indicator is for reference only and does not guarantee trading decisions.
- Please consider the characteristics and conditions of each exchange when using this tool.
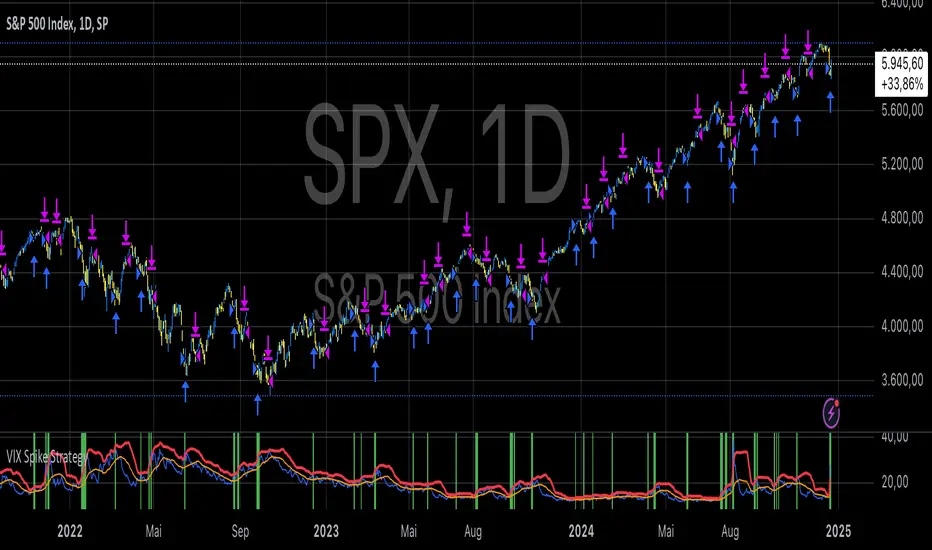
VIX Spike StrategyThis script implements a trading strategy based on the Volatility Index (VIX) and its standard deviation. It aims to enter a long position when the VIX exceeds a certain number of standard deviations above its moving average, which is a signal of a volatility spike. The position is then exited after a set number of periods.
VIX Symbol (vix_symbol): The input allows the user to specify the symbol for the VIX index (typically "CBOE:VIX").
Standard Deviation Length (stddev_length): The number of periods used to calculate the standard deviation of the VIX. This can be adjusted by the user.
Standard Deviation Multiplier (stddev_multiple): This multiplier is used to determine how many standard deviations above the moving average the VIX must exceed to trigger a long entry.
Exit Periods (exit_periods): The user specifies how many periods after entering the position the strategy will exit the trade.
Strategy Logic:
Data Loading: The script loads the VIX data, both for the current timeframe and as a rescaled version for calculation purposes.
Standard Deviation Calculation: It calculates both the moving average (SMA) and the standard deviation of the VIX over the specified period (stddev_length).
Entry Condition: A long position is entered when the VIX exceeds the moving average by a specified multiple of its standard deviation (calculated as vix_mean + stddev_multiple * vix_stddev).
Exit Condition: After the position is entered, it will be closed after the user-defined number of periods (exit_periods).
Visualization:
The VIX is plotted in blue.
The moving average of the VIX is plotted in orange.
The threshold for the VIX, which is the moving average plus the standard deviation multiplier, is plotted in red.
The background turns green when the entry condition is met, providing a visual cue.
Sources:
The VIX is often used as a measure of market volatility, with high values indicating increased uncertainty in the market.
Standard deviation is a statistical measure of the variability or dispersion of a set of data points. In financial markets, it is used to measure the volatility of asset prices.
References:
Bollerslev, T. (1986). "Generalized Autoregressive Conditional Heteroskedasticity." Journal of Econometrics.
Black, F., & Scholes, M. (1973). "The Pricing of Options and Corporate Liabilities." Journal of Political Economy.
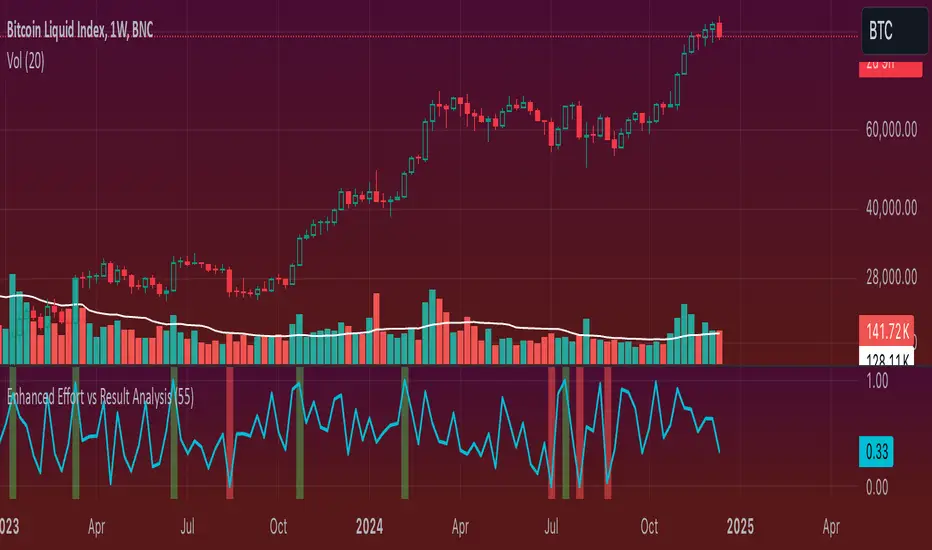
Enhanced Effort vs Result Analysis V.2How to Use in Trading
A. Confirm Breakouts
Check if the Effort-Result Ratio or Z-Score spikes above the Upper Band or Z > +2:
Suggests a strong, efficient price move.
Supports breakout continuation.
B. Identify Reversal or Exhaustion
Look for Effort-Result Ratio or Z-Score dropping below the Lower Band or Z < -2:
Indicates high effort but low price movement (inefficiency).
Often signals potential trend reversal or consolidation.
C. Assess Efficiency of Trends
Use Relative Efficiency Index (REI):
REI near 1 during a trend → Confirms strength (efficient movement).
REI near 0 → Weak or inefficient movement, likely signaling exhaustion.
D. Evaluate Volume-Price Relationship
Monitor the Volume-Price Correlation:
Positive correlation (+1): Confirms price is driven by volume.
Negative correlation (-1): Indicates divergence; price moves independently of volume (potential warning signal).
3. Example Scenarios
Scenario 1: Breakout Confirmation
Effort-Result Ratio spikes above the Upper Band.
Z-Score exceeds +2.
REI approaches 1.
Volume-Price Correlation is positive (near +1).
Action: Strong breakout confirmation → Trend continuation likely.
Scenario 2: Reversal or Exhaustion
Effort-Result Ratio drops below the Lower Band.
Z-Score is below -2.
REI approaches 0.
Volume-Price Correlation weakens or turns negative.
Action: Signals trend exhaustion → Watch for reversal or consolidation.
Scenario 3: Range-Bound Market
Effort-Result Ratio stays within the Bollinger Bands.
Z-Score remains between -1 and +1.
REI fluctuates around 0.5 (neutral efficiency).
Volume-Price Correlation hovers near 0.
Action: Normal conditions → Look for breakout signals before acting.
*IMPORTANT*
There is a problem with the overlay ... How to fix some of it
The Standard Deviation bands dont work while the other variable activated so Id suggest deselecting them. The fix for this is to make sure you have the background selected and by doing this it will highlight on the chart ( you may need to increase the opacity ) when the bands ( Second standard deviation) are touched.
- Also you can use them all at once if you can but you do not need to
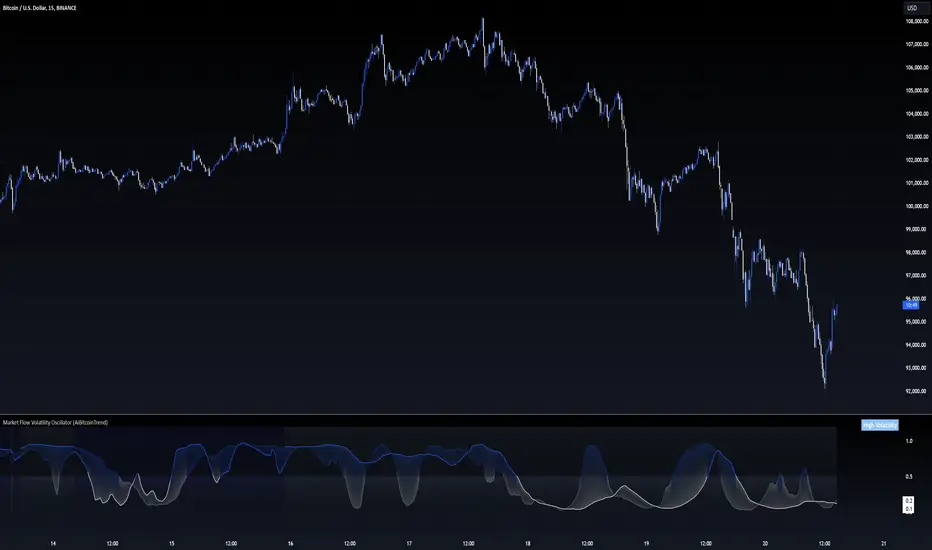
Market Flow Volatility Oscillator (AiBitcoinTrend)The Market Flow Volatility Oscillator (AiBitcoinTrend) is a cutting-edge technical analysis tool designed to evaluate and classify market volatility regimes. By leveraging Gaussian filtering and clustering techniques, this indicator provides traders with clear insights into periods of high and low volatility, helping them adapt their strategies to evolving market conditions. Built for precision and clarity, it combines advanced mathematical models with intuitive visual feedback to identify trends and volatility shifts effectively.
👽 How the Indicator Works
👾 Volatility Classification with Gaussian Filtering
The indicator detects volatility levels by applying Gaussian filters to the price series. Gaussian filters smooth out noise while preserving significant price movements. Traders can adjust the smoothing levels using sigma parameters, enabling greater flexibility:
Low Sigma: Emphasizes short-term volatility.
High Sigma: Captures broader trends with reduced sensitivity to small fluctuations.
👾 Clustering Algorithm for Regime Detection
The core of this indicator is its clustering model, which classifies market conditions into two distinct regimes:
Low Volatility Regime: Calm periods with reduced market activity.
High Volatility Regime: Intense periods with heightened price movements.
The clustering process works as follows:
A rolling window of data is analyzed to calculate the standard deviation of price returns.
Two cluster centers are initialized using the 25th and 75th percentiles of the data distribution.
Each price volatility value is assigned to the nearest cluster based on its distance to the centers.
The cluster centers are refined iteratively, providing an accurate and adaptive classification.
👾 Oscillator Generation with Slope R-Values
The indicator computes Gaussian filter slopes to generate oscillators that visualize trends:
Oscillator Low: Captures low-frequency market behavior.
Oscillator High: Tracks high-frequency, faster-changing trends.
The slope is measured using the R-value of the linear regression fit, scaled and adjusted for easier interpretation.
👽 Applications
👾 Trend Trading
When the oscillator rises above 0.5, it signals potential bullish momentum, while dips below 0.5 suggest bearish sentiment.
👾 Pullback Detection
When the oscillator peaks, especially in overbought or oversold zones, provide early warnings of potential reversals.
👽 Indicator Settings
👾 Oscillator Settings
Sigma Low/High: Controls the smoothness of the oscillators.
Smaller Values: React faster to price changes but introduce more noise.
Larger Values: Provide smoother signals with longer-term insights.
👾 Window Size and Refit Interval
Window Size: Defines the rolling period for cluster and volatility calculations.
Shorter windows: adapt faster to market changes.
Longer windows: produce stable, reliable classifications.
Disclaimer: This information is for entertainment purposes only and does not constitute financial advice. Please consult with a qualified financial advisor before making any investment decisions.
Intrabar DistributionThe Intrabar Distribution publication is an extension of the Intrabar BoxPlot publication. Besides a boxplot, it showcases price and volume distribution using intrabar Lower Timeframe (LTF) values (close) which can be displayed on the chart or in a separate pane.
🔶 USAGE
Intrabar Distribution has several features, users can display:
Recent candle for comparison against the other features
Boxplot of recent candle
Price distribution (optionally displayed as a curve)
Volume distribution
🔹 Recent candle / Boxplot
The middle 50% intrabar close values (Interquartile range, or IQR) are shown as a box, where the upper limit is percentile 75 (p75), and the lower limit is percentile 25 (p25). The dashed lines show the addition/subtraction of 1.5*IQR. All values out of range are considered outliers. They are displayed as white dots within the IQR*1.5 range or white X's when beyond the IQR*3 range (extreme outliers).
By showing the middle 50% intrabar values through a box, we can more easily see where the intrabar activity is mainly situated.
Note in the example above an upward-directed candle with a negative volume delta, displayed as a red box and dot (see further).
As seen in the following example, compared against the recent candle (grey candle at the left), most of the intrabar activity lies just beneath the opening price.
Note that results will be more accurate when more data is available, which can be done by making the difference between the current timeframe and the intrabar timeframe large enough.
🔹 Price / Volume distribution
The price and volume distribution can be helpful for highlighting areas of interest.
Here, we can see two areas where intrabar closing prices are mainly positioned.
The following example shows three successive bars. The recent bar is displayed on the left side, together with the volume distribution. The boxplot and price distribution are displayed on the right.
You can see the difference between volume and price distribution.
At the first bar, most price activity is at the top, while most of the volume was generated at the bottom; in other words, the price got briefly in the bottom region, with high volume before it returned.
At the second bar, price and volume are relatively equally distributed, which fits for indecisiveness.
The third bar shows more volume at a higher region; most intrabar closing prices are above the closing price.
Following example shows the same with 'Curve shaped' enabled (Settings: 'Price Distribution')
When 'Curve shaped' is enabled, lines/labels are shown with the standard deviation distance.
A blue 'guide line' can be enabled for easier interpretation.
🔹 Volume Delta
When there is a discrepancy between the delta volume and direction of the candle, this will be displayed as follows:
Red candle: when the sum of the volume of green intrabars is higher than the sum of the volume of red intrabars, the 'mean dot' will be coloured green.
Green candle: when the sum of the volume of red intrabars is higher than the sum of the volume of green intrabars, the 'mean dot' will be coloured red.
🔶 DETAILS
The intrabar values are sorted and split in parts/sections. The number of values in each section is displayed as a white line
The same principle applies to volume distribution, where the sum of volume per section is displayed as an orange area.
The boxplot displays several price values
Last close price
Highest / lowest intrabar close price
Median
p25 / p75
🔹 LTF settings
When 'Auto' is enabled (Settings, LTF), the LTF will be the nearest possible x times smaller TF than the current TF. When 'Premium' is disabled, the minimum TF will always be 1 minute to ensure TradingView plans lower than Premium don't get an error.
Examples with current Daily TF (when Premium is enabled):
500 : 3 minute LTF
1500 (default): 1 minute LTF
5000: 30 seconds LTF (1 minute if Premium is disabled)
🔶 SETTINGS
Location: Chart / Pane (when pane is opted, move the indicator to a separate pane as well)
Parts: divides the intrabar close values into parts/sections
Offset: offsets every drawing at once
Width: width of drawings, only applicable on "location: chart"
Label size: size of price labels
🔹 LTF
LTF: LTF setting
Auto + multiple: Adjusts the initial set LTF
Premium: Enable when your TradingView plan is Premium or higher
🔹 Current Bar
Display toggle + color setting
Offset: offsets only the 'Current Bar' drawing
🔹 Intrabar Boxplot
Display toggle + Colors, dependable on different circumstances.
Up: Price goes up, with more bullish than bearish intrabar volume.
Up-: Price goes up, with more bearish than bullish intrabar volume.
Down: Price goes down, with more bearish than bullish intrabar volume.
Down+: Price goes down, with more bullish than bearish intrabar volume.
Offset: offsets only the 'Boxplot' drawing
🔹 Price distribution
Display toggle + Color.
Curve Shaped
Guide Lines: Display 2 blue lines
Display Price: Show price of 'x' standard deviation
Offset: offsets only the 'Price distribution' drawing
Label size: size of price labels (standard deviation)
🔹 Volume distribution
Display toggle + Color.
Offset: offsets only the 'Volume distribution' drawing
🔹 Table
Show TF: Show intrabar Timeframe.
Textcolor
Size Table: Text Size
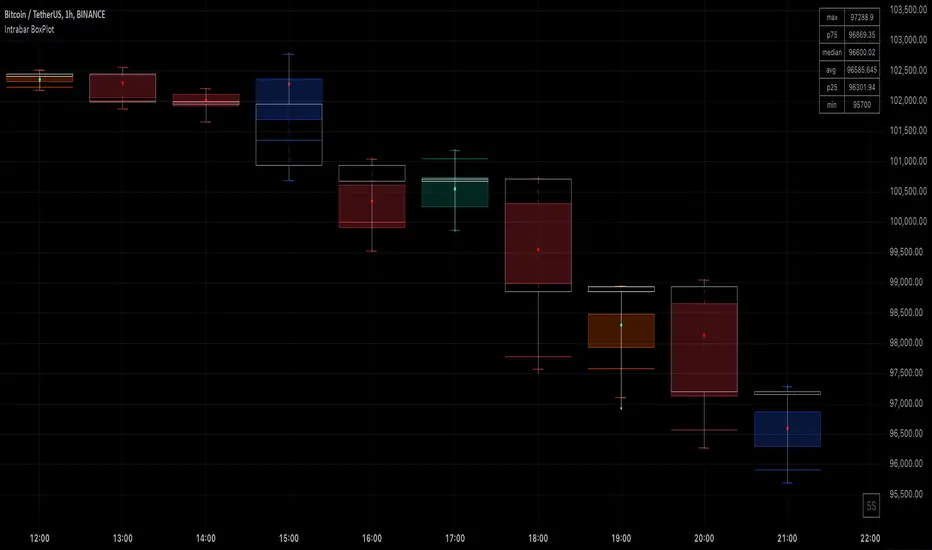
Intrabar BoxPlotThe Intrabar BoxPlot publication highlights an uncommon technique by displaying statistical intrabar Lower Timeframe (LTF) values on the chart.
🔶 USAGE
🔹 Middle 50% Boxes
By showing the middle 50% intrabar values through a box, we can more easily see where the intrabar activity is mainly situated.
The middle 50% intrabar values are referred to from here on as Interquartile range (IQR).
In this example, the successive IQRs form a channel where the price eventually breaks out.
Disproportionately distributed values can give insights which can be used to find potential support/resistance areas.
IQR gaps can give valuable information as well. Potentially, the price can return to these gaps.
Seeing the IQR areas against regular candles gives an alternative image of the underlying price movements.
🔹 Highest volume Price level
The script displays the price level with the highest volume situated, dependable on the user's source setting. Setting the source at 'close' will only display intrabar close values; the same goes for high, low, ...
As seen in the above example, the volume levels can aid in finding support/resistance.
🔹 Median
The location of the median off all intrabar values is displayed as a coloured dot: green when the close price is higher than the opening price and red if otherwise. The median can give valuable insights into price movements.
🔹 Outliers
Medium (white dots) and extreme (white X) outliers, in combination with the IQR box, can help identify potential areas of interest.
🔹 Volume Delta
When there is a discrepancy between the delta volume and direction of the candle, this will be displayed as follows:
Green candle: when the sum of the volume of red intrabars is higher than the sum of the volume of green intrabars, the candle will be coloured orange.
Red candle: when the sum of the volume of green intrabars is higher than the sum of the volume of red intrabars, the candle will be coloured blue.
🔹 Highlight Boxplot only
Probably the easiest way to display boxplot only is by changing the Bar's style to Bars .
🔶 DETAILS
All intrabar values (Lower TimeFrame - LTF) are sorted and evaluated. Values can be close , high , low , ... by selecting this in Settings ( source ).
The middle 50% of all values are displayed as a box; this contains the values between percentile 25 (p25) and percentile 75 (p75). The value of percentile rank 75 means 75% of all values are lower. The value of percentile rank 25 means 25% of all values are lower, or 75% is higher.
The difference between p75 and p25 is also known as Interquartile range (IQR)
IQR is used to check for outliers.
Wiki: Boxplot , Interquartile range
Extreme high: maximum value, higher than p75 + IQR*3
Max outlier high: maximum value, higher than p75 + IQR*1.5 but lower than p75 + IQR*3
Max: maximum value, lower than p75 + IQR*1.5
Min: minimum value, higher than p25 - IQR*1.5
Min outlier low: minimum value, lower than p25 - IQR*1.5 but higher than p25 - IQR*3
Extreme low: minimum value, lower than p25 - IQR*3
Max and min must not be interpreted with the current candle high/low.
🔹 Example: Length of chart-puppets
The following example can make it easier to digest. Forty "chart-puppets" are sorted by their length.
The p25 value is 97
The p50 value is 120
The p75 value is 149
75% of all "chart-puppets" are smaller than p75, and 25% is larger than p75.
50% of all "chart-puppets" are smaller than p50, and 50% is larger than p50 (= median).
25% of all "chart-puppets" are smaller than p25, and 75% is larger than p25.
IQR = 149 - 97 = 52
Extreme outlier limit max: p75 + IQR*3 = 149 + 52*3 = 305
Mild outlier limit max: p75 + IQR*1.5 = 149 + 52*1.5 = 227
Mild outlier limit min: p25 - IQR*1.5 = 97 - 52*1.5 = 19
Extreme outlier limit min: p25 - IQR*3 = 97 - 52*3 = -59
In this example there are no outliers to be found, all values are located between p25 - IQR*1.5 (19) and p75 + IQR*1.5. (227)
🔹 Source settings
Note that results are dependable on the chosen source (settings). When, for example, close is chosen as the source, only intrabar close prices are included. This means a low or high can stretch further then the min or max.
Here we can see different results with different source settings
🔹 LTF settings
When 'Auto' is enabled (Settings, LTF), the LTF will be the nearest possible x times smaller TF than the current TF. When 'Premium' is disabled, the minimum TF will always be 1 minute to ensure TradingView plans lower than Premium don't get an error.
Examples with current Daily TF (when Premium is enabled):
500 : 3 minute LTF
1500 (default): 1 minute LTF
5000: 30 seconds LTF (1 minute if Premium is disabled)
🔶 SETTINGS
Source: Set source at close, high, low,...
🔹 LTF
LTF: LTF setting
Auto + multiple: Adjusts the initial set LTF
Premium: Enable when your TradingView plan is Premium or higher
🔹 Intrabar Delta : Colors, dependable on different circumstances.
Up: Price goes up, with more bullish than bearish intrabar volume.
Up-: Price goes up, with more bearish than bullish intrabar volume.
Down: Price goes down, with more bearish than bullish intrabar volume.
Down+: Price goes down, with more bullish than bearish intrabar volume.
🔹 Table
Show table: Show details at the top right corner
Show TF: Show LTF at the bottom right corner
Text color/table size
See DETAILS for more information
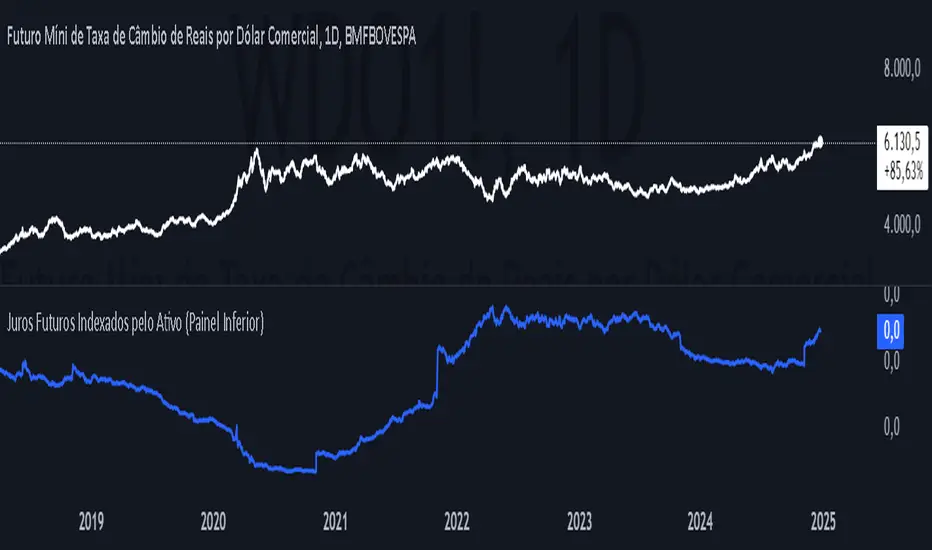
Future Interest Indexed by AssetEste script em Pine Script calcula e exibe o índice dos juros futuros (DI1) em relação ao preço de um ativo, utilizando o preço de fechamento do ativo e a taxa de juros futuros (DI1). O cálculo é realizado dividindo a taxa de juros pelos preços do ativo, resultando no índice indice_juros. Para evitar a divisão por zero, o script verifica se o preço do ativo é válido e não nulo. O índice calculado é então plotado em um painel inferior no gráfico, representado por uma linha azul, permitindo aos usuários observar a relação entre a taxa de juros futuros e o preço do ativo de forma clara e intuitiva.
This Pine Script script calculates and displays the future interest rate (DI1) in relation to the price of an asset, using the asset's closing price and the future interest rate (DI1). The calculation is carried out by dividing the interest rate by the asset prices, resulting in the index_interest index. To avoid division by zero, the script checks that the asset's price is valid and not null. The calculated index is then plotted in a lower panel on the chart, represented by a blue line, allowing users to observe the relationship between the future interest rate and the asset price clearly and intuitively.
Asset Indexed by Future Interest
Este script em Pine Script calcula e exibe o índice de um ativo em relação à taxa de juros futuros (DI1) em um painel inferior. Ele obtém o preço de fechamento do ativo e a taxa de juros futuros DI1!, e em seguida, calcula o índice do ativo dividindo o preço do ativo pela taxa de juros futuros. Para evitar a divisão por zero, o script realiza uma validação para garantir que o valor da taxa de juros não seja nulo ou zero. O índice calculado é então plotado no painel inferior, em uma linha verde, permitindo que os usuários visualizem a relação entre o preço do ativo e os juros futuros de curto prazo. Esse índice pode ser útil para analisar como a taxa de juros influencia o comportamento do ativo.
This script in Pine Script calculates and displays the ratio of an asset to the future interest rate (DI1) in a lower panel. It obtains the asset's closing price and the future interest rate DI1!, and then calculates the asset index by dividing the asset price by the future interest rate. To avoid division by zero, the script performs validation to ensure that the interest rate value is not null or zero. The calculated index is then plotted in the bottom panel, in a green line, allowing users to visualize the relationship between the asset's price and short-term future interest. This index can be useful for analyzing how the interest rate influences the asset's behavior.

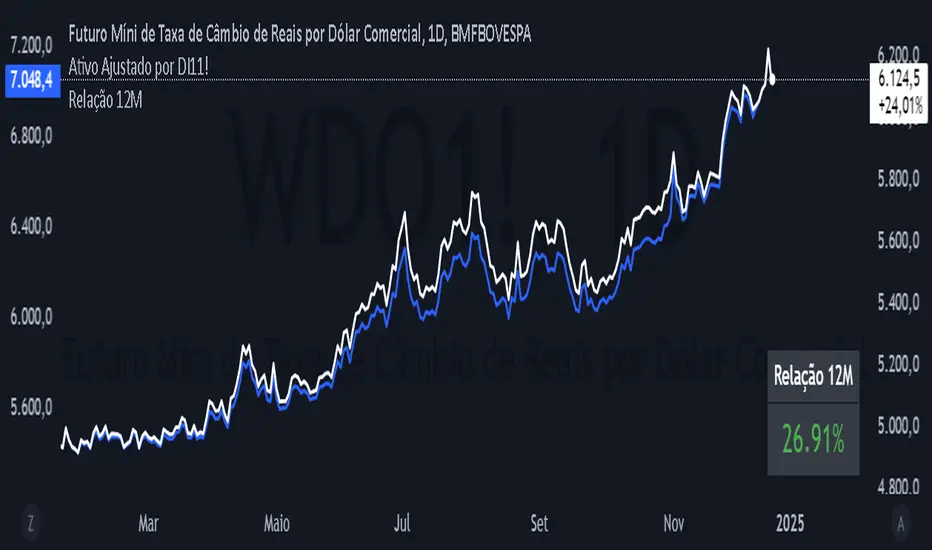
Adjust Asset for Future Interest (Brazil)Este script foi criado para ajustar o preço de um ativo com base na taxa de juros DI11!, que reflete a expectativa do mercado para os juros futuros. O objetivo é mostrar como o valor do ativo seria influenciado se fosse diretamente ajustado pela variação dessa taxa de juros.
Como funciona?
Preço do Ativo
O script começa capturando o preço de fechamento do ativo que está sendo visualizado no gráfico. Esse é o ponto de partida para o cálculo.
Taxa de Juros DI11!
Em seguida, ele busca os valores diários da taxa DI11! no mercado. Esta taxa é uma referência de juros de curto prazo, usada para ajustes financeiros e projeções econômicas.
Fator de Ajuste
Com a taxa de juros DI11!, o script calcula um fator de ajuste simples:
Fator de Ajuste
=
1
+
DI11
100
Fator de Ajuste=1+
100
DI11
Esse fator traduz a taxa percentual em um multiplicador aplicado ao preço do ativo.
Cálculo do Ativo Ajustado
Multiplica o preço do ativo pelo fator de ajuste para obter o valor ajustado do ativo. Este cálculo mostra como o preço seria se fosse diretamente influenciado pela variação da taxa DI11!.
Exibição no Gráfico
O script plota o preço ajustado do ativo como uma linha azul no gráfico, com maior espessura para facilitar a visualização. O resultado é uma curva que reflete o impacto teórico da taxa de juros DI11! sobre o ativo.
Utilidade
Este indicador é útil para entender como as taxas de juros podem influenciar ativos financeiros de forma hipotética. Ele é especialmente interessante para analistas que desejam avaliar a relação entre o mercado de renda variável e as condições de juros no curto prazo.
This script was created to adjust the price of an asset based on the DI11! interest rate, which reflects the market's expectation for future interest rates. The goal is to show how the asset's value would be influenced if it were directly adjusted by the variation of this interest rate.
How does it work?
Asset Price
The script starts by capturing the closing price of the asset that is being viewed on the chart. This is the starting point for the calculation.
DI11! Interest Rate
The script then searches for the daily values of the DI11! rate in the market. This rate is a short-term interest reference, used for financial adjustments and economic projections.
Adjustment Factor
With the DI11! interest rate, the script calculates a simple adjustment factor:
Adjustment Factor
=
1
+
DI11
100
Adjustment Factor=1+
100
DI11
This factor translates the percentage rate into a multiplier applied to the asset's price.
Adjusted Asset Calculation
Multiplies the asset price by the adjustment factor to obtain the adjusted asset value. This calculation shows how the price would be if it were directly influenced by the variation of the DI11! rate.
Display on the Chart
The script plots the adjusted asset price as a blue line on the chart, with greater thickness for easier visualization. The result is a curve that reflects the theoretical impact of the DI11! interest rate on the asset.
Usefulness
This indicator is useful for understanding how interest rates can hypothetically influence financial assets. It is especially interesting for analysts who want to assess the relationship between the equity market and short-term interest rate conditions.

12 Month Difference - YoY ComparisonEste script foi desenvolvido para calcular e exibir a variação percentual do preço de um ativo nos últimos 12 meses, de forma simples e visual. Ele utiliza dados históricos de preços e apresenta o resultado diretamente no gráfico, permitindo ao usuário acompanhar a relação entre o valor atual e o valor de 12 meses atrás.
O cálculo é baseado em um período de 12 meses, que equivale a 252 dias úteis no mercado financeiro. O script primeiro identifica o preço atual do ativo e o compara com o preço registrado há exatamente 252 dias úteis. A diferença entre esses dois valores é transformada em uma variação percentual, o que facilita a análise de desempenho do ativo ao longo do período.
Além disso, o script define uma cor para destacar o resultado:
Verde, se a variação percentual for positiva (indicando crescimento).
Vermelho, se a variação for negativa (indicando queda).
O valor calculado é exibido de forma prática no canto inferior direito do gráfico, como uma tabela flutuante. Essa tabela contém o texto "Relação 12M" e o valor percentual correspondente, permitindo uma leitura rápida.
Embora o resultado seja calculado para todos os momentos no gráfico, ele é mostrado apenas como uma tabela no último ponto confirmado da série histórica, ou seja, no momento mais recente com dados disponíveis. Além disso, o script inclui o valor da relação na legenda do gráfico, mas ele está oculto visualmente para evitar sobrecarregar o layout.
Esse indicador é útil para analisar rapidamente o desempenho de um ativo ao longo de um ano, ajudando investidores e analistas a entenderem tendências e mudanças no mercado.
This script was developed to calculate and display the percentage change in the price of an asset over the last 12 months, in a simple and visual way. It uses historical price data and displays the result directly on the chart, allowing the user to monitor the relationship between the current value and the value from 12 months ago.
The calculation is based on a 12-month period, which is equivalent to 252 business days in the financial market. The script first identifies the current price of the asset and compares it with the price recorded exactly 252 business days ago. The difference between these two values is transformed into a percentage change, which makes it easier to analyze the asset's performance over the period.
In addition, the script defines a color to highlight the result:
Green, if the percentage change is positive (indicating growth).
Red, if the change is negative (indicating a decline).
The calculated value is displayed conveniently in the bottom right corner of the chart, as a floating table. This table contains the text "12M Ratio" and the corresponding percentage value, allowing for quick reading.
Although the result is calculated for all points in time on the chart, it is only displayed as a table at the last confirmed point in the historical series, i.e. the most recent point in time with available data. In addition, the script includes the ratio value in the chart legend, but it is visually hidden to avoid cluttering the layout.
This indicator is useful for quickly analyzing the performance of an asset over a year, helping investors and analysts understand trends and changes in the market.
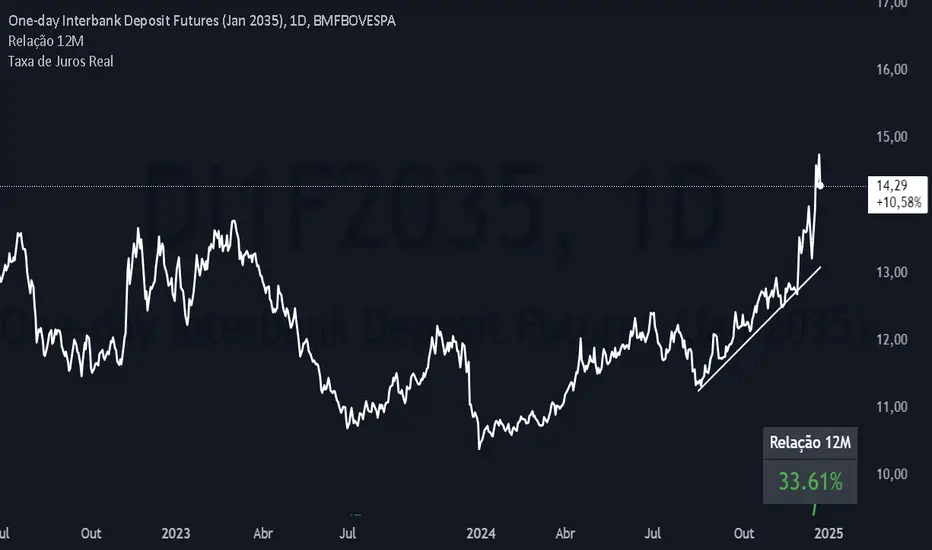
Brazil Real Interest RateEste script foi criado para calcular e exibir a Taxa de Juros Real, permitindo compreender o impacto da inflação sobre os juros nominais do mercado. Ele utiliza dois indicadores principais: a taxa de juros nominal, que reflete os juros antes de considerar a inflação, e a taxa de inflação anual, que mede o aumento dos preços em um ano.
O script funciona da seguinte forma: ele obtém diariamente os dados da taxa de juros nominal (representada pelo contrato futuro DI1) e da inflação anual (indicada pelo BRIRYY). Esses valores são processados para calcular a taxa de juros real, utilizando a fórmula de Fisher, que ajusta os juros nominais ao descontar o efeito da inflação. O resultado é uma medida mais precisa do retorno ou custo real, considerando o poder de compra.
Depois de realizar o cálculo, o script exibe a Taxa de Juros Real diretamente no gráfico, representada por uma linha verde. Isso permite acompanhar, de forma clara e visual, como a inflação e os juros afetam o cenário econômico ao longo do tempo.
This script was created to calculate and display the Real Interest Rate, allowing us to understand the impact of inflation on nominal market interest rates. It uses two main indicators: the nominal interest rate, which reflects interest rates before considering inflation, and the annual inflation rate, which measures the increase in prices over a year.
The script works as follows: it obtains daily data on the nominal interest rate (represented by the DI1 futures contract) and annual inflation (indicated by BRIRYY). These values are processed to calculate the real interest rate, using the Fisher formula, which adjusts nominal interest rates by discounting the effect of inflation. The result is a more accurate measure of real return or cost, considering purchasing power.
After performing the calculation, the script displays the Real Interest Rate directly on the graph, represented by a green line. This allows you to monitor, clearly and visually, how inflation and interest rates affect the economic scenario over time.
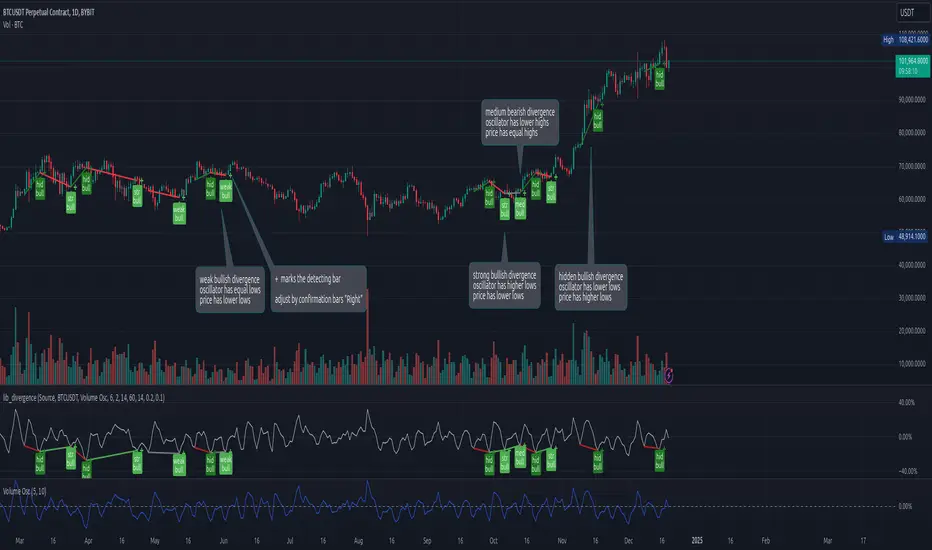
lib_divergenceLibrary "lib_divergence"
offers a commonly usable function to detect divergences. This will take the default RSI or other symbols / indicators / oscillators as source data.
divergence(osc, pivot_left_bars, pivot_right_bars, div_min_range, div_max_range, ref_low, ref_high, min_divergence_offset_fraction, min_divergence_offset_dev_len, min_divergence_offset_atr_mul)
Detects Divergences between Price and Oscillator action. For bullish divergences, look at trend lines between lows. For bearish divergences, look at trend lines between highs. (strong) oscillator trending, price opposing it | (medium) oscillator trending, price trend flat | (weak) price opposite trending, oscillator trend flat | (hidden) price trending, oscillator opposing it. Pivot detection is only properly done in oscillator data, reference price data is only compared at the oscillator pivot (speed optimization)
Parameters:
osc (float) : (series float) oscillator data (can be anything, even another instrument price)
pivot_left_bars (simple int) : (simple int) optional number of bars left of a confirmed pivot point, confirming it is the highest/lowest in the range before and up to the pivot (default: 5)
pivot_right_bars (simple int) : (simple int) optional number of bars right of a confirmed pivot point, confirming it is the highest/lowest in the range from and after the pivot (default: 5)
div_min_range (simple int) : (simple int) optional minimum distance to the pivot point creating a divergence (default: 5)
div_max_range (simple int) : (simple int) optional maximum amount of bars in a divergence (default: 50)
ref_low (float) : (series float) optional reference range to compare the oscillator pivot points to. (default: low)
ref_high (float) : (series float) optional reference range to compare the oscillator pivot points to. (default: high)
min_divergence_offset_fraction (simple float) : (simple float) optional scaling factor for the offset zone (xDeviation) around the last oscillator H/L detecting following equal H/Ls (default: 0.01)
min_divergence_offset_dev_len (simple int) : (simple int) optional lookback distance for the deviation detection for the offset zone around the last oscillator H/L detecting following equal H/Ls. Used as well for the ATR that does the equal H/L detection for the reference price. (default: 14)
min_divergence_offset_atr_mul (simple float) : (simple float) optional scaling factor for the offset zone (xATR) around the last price H/L detecting following equal H/Ls (default: 1)
@return A tuple of deviation flags.
QTALibrary "QTA"
This is simple library for basic Quantitative Technical Analysis for retail investors. One example of it being used can be seen here ().
calculateKellyRatio(returns)
Parameters:
returns (array) : An array of floats representing the returns from bets.
Returns: The calculated Kelly Ratio, which indicates the optimal bet size based on winning and losing probabilities.
calculateAdjustedKellyFraction(kellyRatio, riskTolerance, fedStance)
Parameters:
kellyRatio (float) : The calculated Kelly Ratio.
riskTolerance (float) : A float representing the risk tolerance level.
fedStance (string) : A string indicating the Federal Reserve's stance ("dovish", "hawkish", or neutral).
Returns: The adjusted Kelly Fraction, constrained within the bounds of .
calculateStdDev(returns)
Parameters:
returns (array) : An array of floats representing the returns.
Returns: The standard deviation of the returns, or 0 if insufficient data.
calculateMaxDrawdown(returns)
Parameters:
returns (array) : An array of floats representing the returns.
Returns: The maximum drawdown as a percentage.
calculateEV(avgWinReturn, winProb, avgLossReturn)
Parameters:
avgWinReturn (float) : The average return from winning bets.
winProb (float) : The probability of winning a bet.
avgLossReturn (float) : The average return from losing bets.
Returns: The calculated Expected Value of the bet.
calculateTailRatio(returns)
Parameters:
returns (array) : An array of floats representing the returns.
Returns: The Tail Ratio, or na if the 5th percentile is zero to avoid division by zero.
calculateSharpeRatio(avgReturn, riskFreeRate, stdDev)
Parameters:
avgReturn (float) : The average return of the investment.
riskFreeRate (float) : The risk-free rate of return.
stdDev (float) : The standard deviation of the investment's returns.
Returns: The calculated Sharpe Ratio, or na if standard deviation is zero.
calculateDownsideDeviation(returns)
Parameters:
returns (array) : An array of floats representing the returns.
Returns: The standard deviation of the downside returns, or 0 if no downside returns exist.
calculateSortinoRatio(avgReturn, downsideDeviation)
Parameters:
avgReturn (float) : The average return of the investment.
downsideDeviation (float) : The standard deviation of the downside returns.
Returns: The calculated Sortino Ratio, or na if downside deviation is zero.
calculateVaR(returns, confidenceLevel)
Parameters:
returns (array) : An array of floats representing the returns.
confidenceLevel (float) : A float representing the confidence level (e.g., 0.95 for 95% confidence).
Returns: The Value at Risk at the specified confidence level.
calculateCVaR(returns, varValue)
Parameters:
returns (array) : An array of floats representing the returns.
varValue (float) : The Value at Risk threshold.
Returns: The average Conditional Value at Risk, or na if no returns are below the threshold.
calculateExpectedPriceRange(currentPrice, ev, stdDev, confidenceLevel)
Parameters:
currentPrice (float) : The current price of the asset.
ev (float) : The expected value (in percentage terms).
stdDev (float) : The standard deviation (in percentage terms).
confidenceLevel (float) : The confidence level for the price range (e.g., 1.96 for 95% confidence).
Returns: A tuple containing the minimum and maximum expected prices.
calculateRollingStdDev(returns, window)
Parameters:
returns (array) : An array of floats representing the returns.
window (int) : An integer representing the rolling window size.
Returns: An array of floats representing the rolling standard deviation of returns.
calculateRollingVariance(returns, window)
Parameters:
returns (array) : An array of floats representing the returns.
window (int) : An integer representing the rolling window size.
Returns: An array of floats representing the rolling variance of returns.
calculateRollingMean(returns, window)
Parameters:
returns (array) : An array of floats representing the returns.
window (int) : An integer representing the rolling window size.
Returns: An array of floats representing the rolling mean of returns.
calculateRollingCoefficientOfVariation(returns, window)
Parameters:
returns (array) : An array of floats representing the returns.
window (int) : An integer representing the rolling window size.
Returns: An array of floats representing the rolling coefficient of variation of returns.
calculateRollingSumOfPercentReturns(returns, window)
Parameters:
returns (array) : An array of floats representing the returns.
window (int) : An integer representing the rolling window size.
Returns: An array of floats representing the rolling sum of percent returns.
calculateRollingCumulativeProduct(returns, window)
Parameters:
returns (array) : An array of floats representing the returns.
window (int) : An integer representing the rolling window size.
Returns: An array of floats representing the rolling cumulative product of returns.
calculateRollingCorrelation(priceReturns, volumeReturns, window)
Parameters:
priceReturns (array) : An array of floats representing the price returns.
volumeReturns (array) : An array of floats representing the volume returns.
window (int) : An integer representing the rolling window size.
Returns: An array of floats representing the rolling correlation.
calculateRollingPercentile(returns, window, percentile)
Parameters:
returns (array) : An array of floats representing the returns.
window (int) : An integer representing the rolling window size.
percentile (int) : An integer representing the desired percentile (0-100).
Returns: An array of floats representing the rolling percentile of returns.
calculateRollingMaxMinPercentReturns(returns, window)
Parameters:
returns (array) : An array of floats representing the returns.
window (int) : An integer representing the rolling window size.
Returns: A tuple containing two arrays: rolling max and rolling min percent returns.
calculateRollingPriceToVolumeRatio(price, volData, window)
Parameters:
price (array) : An array of floats representing the price data.
volData (array) : An array of floats representing the volume data.
window (int) : An integer representing the rolling window size.
Returns: An array of floats representing the rolling price-to-volume ratio.
determineMarketRegime(priceChanges)
Parameters:
priceChanges (array) : An array of floats representing the price changes.
Returns: A string indicating the market regime ("Bull", "Bear", or "Neutral").
determineVolatilityRegime(price, window)
Parameters:
price (array) : An array of floats representing the price data.
window (int) : An integer representing the rolling window size.
Returns: An array of floats representing the calculated volatility.
classifyVolatilityRegime(volatility)
Parameters:
volatility (array) : An array of floats representing the calculated volatility.
Returns: A string indicating the volatility regime ("Low" or "High").
method percentPositive(thisArray)
Returns the percentage of positive non-na values in this array.
This method calculates the percentage of positive values in the provided array, ignoring NA values.
Namespace types: array
Parameters:
thisArray (array)
_candleRange()
_PreviousCandleRange(barsback)
Parameters:
barsback (int) : An integer representing how far back you want to get a range
redCandle()
greenCandle()
_WhiteBody()
_BlackBody()
HighOpenDiff()
OpenLowDiff()
_isCloseAbovePreviousOpen(length)
Parameters:
length (int)
_isCloseBelowPrevious()
_isOpenGreaterThanPrevious()
_isOpenLessThanPrevious()
BodyHigh()
BodyLow()
_candleBody()
_BodyAvg(length)
_BodyAvg function.
Parameters:
length (simple int) : Required (recommended is 6).
_SmallBody(length)
Parameters:
length (simple int) : Length of the slow EMA
Returns: a series of bools, after checking if the candle body was less than body average.
_LongBody(length)
Parameters:
length (simple int)
bearWick()
bearWick() function.
Returns: a SERIES of FLOATS, checks if it's a blackBody(open > close), if it is, than check the difference between the high and open, else checks the difference between high and close.
bullWick()
barlength()
sumbarlength()
sumbull()
sumbear()
bull_vol()
bear_vol()
volumeFightMA()
volumeFightDelta()
weightedAVG_BullVolume()
weightedAVG_BearVolume()
VolumeFightDiff()
VolumeFightFlatFilter()
avg_bull_vol(userMA)
avg_bull_vol(int) function.
Parameters:
userMA (int)
avg_bear_vol(userMA)
avg_bear_vol(int) function.
Parameters:
userMA (int)
diff_vol(userMA)
diff_vol(int) function.
Parameters:
userMA (int)
vol_flat(userMA)
vol_flat(int) function.
Parameters:
userMA (int)
_isEngulfingBullish()
_isEngulfingBearish()
dojiup()
dojidown()
EveningStar()
MorningStar()
ShootingStar()
Hammer()
InvertedHammer()
BearishHarami()
BullishHarami()
BullishBelt()
BullishKicker()
BearishKicker()
HangingMan()
DarkCloudCover()
Watermark with dynamic variables [BM]█ OVERVIEW
This indicator allows users to add highly customizable watermark messages to their charts. Perfect for branding, annotation, or displaying dynamic chart information, this script offers advanced customization options including dynamic variables, text formatting, and flexible positioning.
█ CONCEPTS
Watermarks are overlay messages on charts. This script introduces placeholders — special keywords wrapped in % signs — that dynamically replace themselves with chart-related data. These watermarks can enhance charts with context, timestamps, or branding.
█ FEATURES
Dynamic Variables : Replace placeholders with real-time data such as bar index, timestamps, and more.
Advanced Customization : Modify text size, color, background, and alignment.
Multiple Messages : Add up to four independent messages per group, with two groups supported (A and B).
Positioning Options : Place watermarks anywhere on the chart using predefined locations.
Timezone Support : Display timestamps in a preferred timezone with customizable formats.
█ INPUTS
The script offers comprehensive input options for customization. Each Watermark (A and B) contains identical inputs for configuration.
Watermark settings are divided into two levels:
Watermark-Level Settings
These settings apply to the entire watermark group (A/B):
Show Watermark: Toggle the visibility of the watermark group on the chart.
Position: Choose where the watermark group is displayed on the chart.
Reverse Line Order: Enable to reverse the order of the lines displayed in Watermark A.
Message-Level Settings
Each watermark contains up to four configurable messages. These messages can be independently customized with the following options:
Message Content: Enter the custom text to be displayed. You can include placeholders for dynamic data.
Text Size: Select from predefined sizes (Tiny, Small, Normal, Large, Huge) or specify a custom size.
Text Alignment and Colors:
- Adjust the alignment of the text (Left, Center, Right).
- Set text and background colors for better visibility.
Format Time: Enable time formatting for this watermark message and configure the format and timezone. The settings for each message include message content, text size, alignment, and more. Please refer to Formatting dates and times for more details on valid formatting tokens.
█ PLACEHOLDERS
Placeholders are special keywords surrounded by % signs, which the script dynamically replaces with specific chart-related data. These placeholders allow users to insert dynamic content, such as bar information or timestamps, into watermark messages.
Below is the complete list of currently available placeholders:
bar_index , barstate.isconfirmed , barstate.isfirst , barstate.ishistory , barstate.islast , barstate.islastconfirmedhistory , barstate.isnew , barstate.isrealtime , chart.is_heikinashi , chart.is_kagi , chart.is_linebreak , chart.is_pnf , chart.is_range , chart.is_renko , chart.is_standard , chart.left_visible_bar_time , chart.right_visible_bar_time , close , dayofmonth , dayofweek , dividends.future_amount , dividends.future_ex_date , dividends.future_pay_date , earnings.future_eps , earnings.future_period_end_time , earnings.future_revenue , earnings.future_time , high , hl2 , hlc3 , hlcc4 , hour , last_bar_index , last_bar_time , low , minute , month , ohlc4 , open , second , session.isfirstbar , session.isfirstbar_regular , session.islastbar , session.islastbar_regular , session.ismarket , session.ispostmarket , session.ispremarket , syminfo.basecurrency , syminfo.country , syminfo.currency , syminfo.description , syminfo.employees , syminfo.expiration_date , syminfo.industry , syminfo.main_tickerid , syminfo.mincontract , syminfo.minmove , syminfo.mintick , syminfo.pointvalue , syminfo.prefix , syminfo.pricescale , syminfo.recommendations_buy , syminfo.recommendations_buy_strong , syminfo.recommendations_date , syminfo.recommendations_hold , syminfo.recommendations_sell , syminfo.recommendations_sell_strong , syminfo.recommendations_total , syminfo.root , syminfo.sector , syminfo.session , syminfo.shareholders , syminfo.shares_outstanding_float , syminfo.shares_outstanding_total , syminfo.target_price_average , syminfo.target_price_date , syminfo.target_price_estimates , syminfo.target_price_high , syminfo.target_price_low , syminfo.target_price_median , syminfo.ticker , syminfo.tickerid , syminfo.timezone , syminfo.type , syminfo.volumetype , ta.accdist , ta.iii , ta.nvi , ta.obv , ta.pvi , ta.pvt , ta.tr , ta.vwap , ta.wad , ta.wvad , time , time_close , time_tradingday , timeframe.isdaily , timeframe.isdwm , timeframe.isintraday , timeframe.isminutes , timeframe.ismonthly , timeframe.isseconds , timeframe.isticks , timeframe.isweekly , timeframe.main_period , timeframe.multiplier , timeframe.period , timenow , volume , weekofyear , year
█ HOW TO USE
1 — Add the Script:
Apply "Watermark with dynamic variables " to your chart from the TradingView platform.
2 — Configure Inputs:
Open the script settings by clicking the gear icon next to the script's name.
Customize visibility, message content, and appearance for Watermark A and Watermark B.
3 — Utilize Placeholders:
Add placeholders like %bar_index% or %timenow% in the "Watermark - Message" fields to display dynamic data.
Empty lines in the message box are reflected on the chart, allowing you to shift text up or down.
Using in the message box translates to a new line on the chart.
4 — Preview Changes:
Adjust settings and view updates in real-time on your chart.
█ EXAMPLES
Branding
DodgyDD's charts
Debugging
█ LIMITATIONS
Only supports variables defined within the script.
Limited to four messages per watermark.
Visual alignment may vary across different chart resolutions or zoom levels.
Placeholder parsing relies on correct input formatting.
█ NOTES
This script is designed for users seeking enhanced chart annotation capabilities. It provides tools for dynamic, customizable watermarks but is not a replacement for chart objects like text labels or drawings. Please ensure placeholders are properly formatted for correct parsing.
Additionally, this script can be a valuable tool for Pine Script developers during debugging . By utilizing dynamic placeholders, developers can display real-time values of variables and chart data directly on their charts, enabling easier troubleshooting and code validation.
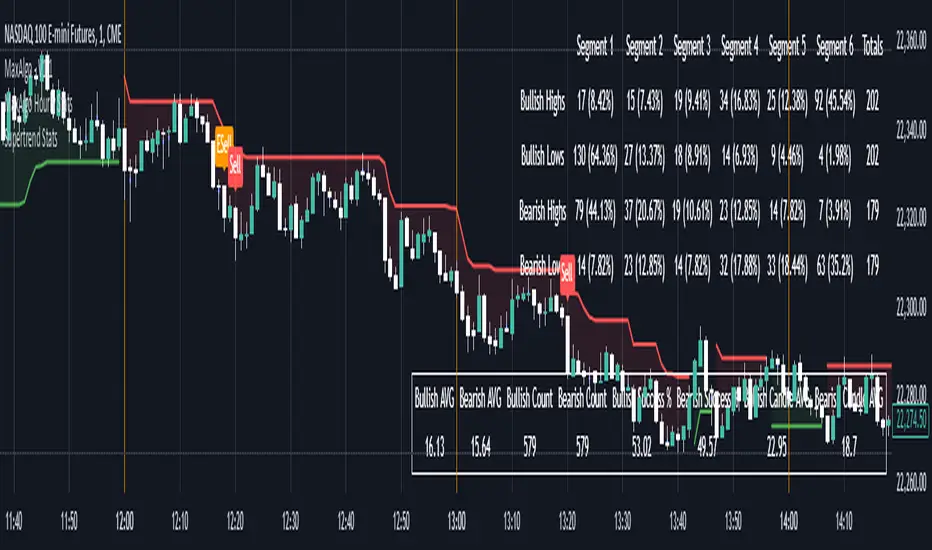
Supertrend StatsSupertrend with Probabilistic Stats and MA Filter
Overview: The Supertrend with Probabilistic Stats and MA Filter is a comprehensive TradingView Pine Script indicator designed to enhance trading strategies by combining the trend-detection capabilities of the Supertrend indicator with the trend-confirmation strength of Moving Averages (MA). Additionally, it offers robust statistical tracking to provide traders with valuable insights into the performance and reliability of their trading signals.
Key Features:
Supertrend Indicator Integration:
Trend Detection: Utilizes the Supertrend algorithm to identify prevailing market trends.
Buy/Sell Signals: Generates clear buy and sell signals based on trend reversals.
Customizable Parameters: Allows adjustment of ATR period and multiplier to suit different trading styles and market conditions.
Visual Aids: Plots Supertrend lines on the chart and highlights trend areas for easy visualization.
Moving Average (MA) Filter:
Trend Confirmation: Filters buy signals to occur only when the open price is above the MA and sell signals only when the open price is below the MA.
Customizable MA Types: Supports various MA types, including SMA, EMA, SMMA (RMA), WMA, and VWMA.
Flexible Configuration: Offers options to enable/disable the MA filter, select MA type, set MA length, and adjust MA source and offset.
Statistical Tracking:
Trimmed Mean Calculation: Computes trimmed means for bullish and bearish movements, removing outliers to provide a more accurate average movement.
Success Rate Metrics: Calculates the success rates (%) for both bullish and bearish signals, indicating the percentage of signals that resulted in favorable price movements.
Candle Count Analysis: Tracks the average number of candles each bullish and bearish move lasts, offering insights into the duration of trends.
Data Visualization: Presents all statistical data in a neatly formatted table on the chart, allowing for quick reference and analysis.
Customizable Statistics Table:
Text Color Customization: Provides an option to change the table text color to match personal preferences or chart aesthetics, enhancing readability.
Comprehensive Metrics: Displays key statistics such as Bullish/Bearish Averages, Counts, Success Rates, and Average Candle Counts.
Optional Pinbar Filtering:
Signal Refinement: Adds an additional layer of signal confirmation by filtering buy and sell signals based on pinbar candlestick patterns.
Adjustable Thresholds: Allows customization of the pinbar wick threshold to fine-tune signal accuracy.
Visual Enhancements:
Markers: Optionally displays markers on the first and last candles of bullish and bearish moves for better trend identification.
Highlighter: Shades the chart background to indicate current trend direction, aiding in visual trend recognition.
How It Works:
Trend Identification with Supertrend:
The indicator calculates the Supertrend based on user-defined ATR periods and multipliers.
It plots the Supertrend lines and generates buy/sell signals when the price crosses these lines, indicating a potential trend reversal.
Filtering Signals with Moving Average:
When the MA filter is enabled, the indicator ensures that buy signals are only considered valid if the candle's open price is above the selected MA, and sell signals only if the open price is below the MA.
This additional confirmation aligns trades with the broader market trend, potentially increasing signal reliability.
Statistical Analysis:
Upon triggering a buy or sell signal, the indicator records the entry price and tracks the subsequent price movements.
It calculates trimmed means to assess average movements while excluding extreme outliers.
Success rates are computed by comparing the closing price against the entry price, indicating how often signals result in favorable outcomes.
The average number of candles per move provides insight into trend duration and volatility.
Visualization and Customization:
All statistical data is presented in a table on the chart, with customizable text colors for enhanced readability.
Optional pinbar filtering and visual markers further refine and illustrate trading signals, aiding in decision-making.
Benefits to Traders:
Enhanced Signal Reliability:
By combining Supertrend with an MA filter, the indicator ensures that only signals aligning with the broader market trend are considered, potentially reducing false signals.
Data-Driven Decision Making:
The comprehensive statistical tracking offers traders insights into the performance of their signals, enabling informed adjustments to their trading strategies based on empirical data.
Trend Confirmation and Alignment:
The MA filter acts as a trend confirmation tool, ensuring that trades are placed in the direction of the prevailing trend, which can enhance the probability of successful trades.
Performance Metrics at a Glance:
The statistics table provides all necessary performance metrics in a single view, allowing traders to quickly assess the effectiveness of their strategy without sifting through extensive data.
Customization and Flexibility:
With options to adjust MA types, lengths, and table text colors, traders can tailor the indicator to fit their specific preferences and trading environments.
Visual Clarity and Aids:
The plotted Supertrend lines, MA line, signal markers, and highlighter enhance visual clarity, making it easier to identify trends and potential trade opportunities on the chart.
Usage Instructions:
Adding the Indicator:
Copy the Script: Select and copy the entire Pine Script provided.
Open TradingView: Navigate to TradingView and open your desired asset's chart.
Access Pine Editor: Click on the Pine Editor tab at the bottom of the TradingView interface.
Paste and Add to Chart: Paste the script into the editor and click "Add to Chart" to apply the indicator.
Configuring Settings:
Supertrend Parameters: Adjust the ATR period and multiplier to suit your trading style and the asset's volatility.
MA Filter Settings:
Enable MA Filter: Toggle "Enable MA Filter?" to ON to activate the filter.
Select MA Type: Choose from SMA, EMA, SMMA (RMA), WMA, or VWMA.
Set MA Length: Define the period for the MA calculation.
MA Source and Offset: Choose the price source (default is close) and set any desired plot offset.
Statistical Tracking:
Trimmed Mean Percentage: Set the percentage to trim outliers in mean calculations.
Show Cross Markers: Toggle to display or hide markers on the first and last candles of bullish and bearish moves.
Table Customization:
Table Text Color: Select your preferred text color for the statistics table to match your chart's theme or enhance readability.
Pinbar Filtering (Optional):
Enable Pinbar Filtering: Toggle to refine signals based on pinbar patterns.
Set Pinbar Wick Threshold: Adjust the threshold to define the characteristics of a valid pinbar.
Interpreting the Indicators:
Buy/Sell Signals: Look for labeled "BUY" and "SELL" signals on the chart that align with Supertrend reversals and MA conditions.
Statistics Table: Refer to the table located at the bottom right of the chart to assess:
Bullish/Bearish Averages: Average price movements following signals.
Counts: Total number of bullish and bearish signals.
Success Rates (%): Percentage of signals that resulted in profitable trades.
Candle Averages: Average duration of bullish and bearish moves in terms of candle counts.
Markers and Highlighter: Utilize visual markers and shaded trend areas to better understand market trends and the context of each signal.
Making Informed Decisions:
Assess Signal Performance: Use the success rates and averages to evaluate the effectiveness of your current settings and make necessary adjustments.
Adjust Parameters: Modify Supertrend and MA parameters based on observed performance and changing market conditions to optimize signal accuracy.
Combine with Other Analysis: Integrate insights from this indicator with other technical analysis tools and fundamental factors to form a holistic trading strategy.
Conclusion: The Supertrend with Probabilistic Stats and MA Filter indicator offers a powerful combination of trend detection, signal filtering, and statistical analysis. By providing detailed performance metrics and ensuring that trades align with the broader market trend, this indicator empowers traders to make more informed, data-driven decisions. Whether you're a novice seeking clarity or an experienced trader aiming to refine your strategy, this tool serves as a valuable asset in your trading toolkit.
If you have any further questions or require additional customizations, feel free to reach out!
DCA Fundamentals 1.0DCA Fundamentals 1.0
Description:
DCA Fundamentals 1.0 is an invite-only indicator designed to help traders and investors make informed decisions by analyzing key fundamental metrics of a company. It aggregates essential financial data—such as book value, earnings per share, total equity, total debt, net income, and total revenue—to provide a comprehensive overview of the stock’s intrinsic value and risk profile. By examining factors like the debt-to-equity ratio and dynamically computing Buffet’s Limit, this tool assists in identifying whether a stock may be undervalued, fairly valued, or overvalued.
Key Features:
Intrinsic Value Calculation: Estimates a stock’s intrinsic worth using a weighted combination of book value per share and EPS.
Buffet’s Limit & Margin of Safety: Adjusts intrinsic value based on the company’s debt-to-equity ratio, providing a margin of safety percentage to gauge potential investment risk.
Debt Warning: Highlights when the debt-to-equity ratio exceeds 2, signaling possible financial instability.
Data Visualization: Displays equity, debt, net income, and revenue as area plots or histograms, helping users quickly assess financial health.
Investment Status: Classifies the stock as undervalued, fairly valued, or overvalued based on current price relative to intrinsic value and Buffet’s Limit.
Dividend-to-ROE Ratio: Offers insight into dividend payout sustainability relative to the company’s return on equity.
Instructions
Fallback Data Handling:
If any financial data is unavailable, fallback values are automatically used to ensure that key calculations remain meaningful and uninterrupted.
Intrinsics & Risk Assessment:
Intrinsic Value: Computed using book value and EPS to understand the stock’s core worth.
Buffet’s Limit: Adjusted from the intrinsic value based on the debt-to-equity ratio. The resulting margin of safety helps gauge the current price’s risk level.
Debt Warning:
Debt-to-Equity Ratio > 2: Triggers a red warning, advising caution due to potentially excessive debt.
Visual Indicators:
Intrinsically Undervalued (Green Area): When price is below intrinsic value, a green shaded area suggests the stock may be undervalued, potentially presenting a buying opportunity.
Debt vs. Equity (Area Plots):
Red Area: Represents debt. A larger red area signals relatively high debt levels.
Green Area: Represents equity. A larger green area suggests stronger financial health.
Revenue & Net Income (Histograms):
Green Bars: Positive or improving fundamentals.
Red Bars: Negative or declining performance.
Investment Status:
Undervalued (Green): Price below intrinsic value.
Fairly Valued (Yellow): Price between intrinsic value and Buffet’s Limit.
Overvalued (Red): Price above intrinsic value, implying increased downside risk.
Table Display:
A convenient table summarizes key metrics at a glance, including P/E ratio, Debt-to-Equity ratio, intrinsic value, margin of safety, net income, total revenue, and the Dividend-to-ROE Ratio.
Dividend-to-ROE Ratio:
This metric provides additional context on the company’s dividend policy relative to its return on equity, aiding in evaluating dividend sustainability.
Disclaimer
Important Disclaimer:
The DCA Fundamentals 1.0 indicator is provided solely for educational and informational purposes. It is not investment advice, a recommendation, or an endorsement of any security or strategy. All calculations are based on data provided by third parties, and their accuracy or completeness is not guaranteed.
Investing and trading involve significant risks. You may lose more than your initial investment. Historical performance or indicators cannot guarantee future results. Before making any investment decisions, you should conduct thorough research, consider consulting a qualified financial professional, and implement robust risk management strategies.
By using DCA Fundamentals 1.0, you acknowledge these risks and agree that neither the creator nor any affiliated parties are responsible for any losses incurred. Use this tool at your own discretion and risk.

MOEX Aerospace & Defense IndexMOEX Aerospace & Defense Index is a financial instrument that forms an objective assessment of the capitalization of the entire aerospace and military–industrial complex of Russia, the securities of issuers of which are represented on the public stock market.
The MOEX Aerospace & Defense Index includes shares of 14 issuers of the aerospace and defense industry complex of Russia in fair shares proportional to the occupied shares of the Russian and global arms markets, as well as involvement in the Russian state defense order during wartime. The Index includes issuers from such sectors of the economy as: military aviation industry, rocket and space industry, military automotive industry and wheel products, military electronics and communications, military metallurgy and metal products.
The Index includes:
RUS:AMEZ RUS:CHKZ RUS:CHMF RUS:DZRDP RUS:ELMT RUS:IRKT RUS:KMAZ RUS:NAUK RUS:NSVZ RUS:RKKE RUS:SVAV RUS:UNAC RUS:VSMO RUS:ZVEZ
Based on historical data for the period from 2014 (the year of the beginning of the geopolitical confrontation between Russia and Ukraine), the MOEX Aerospace & Defense Index demonstrates profitability 3-4 times higher than the Russian benchmark of the stock market - the Moscow Stock Exchange Index. It makes the financial instrument the most attractive in times of geopolitical crises or military confrontations.
MOEX Aerospace & Defense Index allows you to:
1. To invest in a balanced manner in the aerospace and defense industrial complex of Russia, which produces advanced military and aerospace weapons for the needs of the Russian army and for export, which occupies 25% of the global arms market. Investing in the aerospace and military-industrial complex of Russia is especially relevant in the context of a special military operation in Ukraine, the growth of geopolitical tensions and the resulting large budget incentives for this industry from the Government of the Russian Federation.
2. To neutralize fluctuations in low-liquid and highly volatile stocks of the aerospace and military-industrial complex of Russia. The aerospace and defense industries are characterized by high volatility in stock prices, which is why the creation of a balanced index can offset price fluctuations for low-liquid shares of companies included in the index and reduce the risk for investors.
3. Politically diversify the investment portfolio. The inclusion of the MOEX Aerospace & Defense Index in the investment portfolio can reduce the risks associated with price fluctuations during geopolitical crises or military confrontations.
----------------------------------------
MOEX Aerospace & Defense Index – финансовый инструмент, формирующий объективную оценку капитализации всего аэрокосмического и оборонно-промышленного комплекса России, ценные бумаги эмитентов которого представлены на публичном рынке акций.
В MOEX Aerospace & Defense Index включены акции 14 эмитентов аэрокосмического и оборонно-промышленного комплекса России в справедливых долях, пропорциональных занимаемым долям российского и мирового рынка вооружений, а также задействования в российском гособоронзаказе в военное время. Индекс включает в себя эмитентов из таких секторов экономики, как: военная авиационная промышленность, ракетно-космическая промышленность, военная автомобильная промышленность и колесные изделия, военная электроника и связь, военная металлургия и изделия из металла.
В Индекс включены:
RUS:AMEZ RUS:CHKZ RUS:CHMF RUS:DZRDP RUS:ELMT RUS:IRKT RUS:KMAZ RUS:NAUK RUS:NSVZ RUS:RKKE RUS:SVAV RUS:UNAC RUS:VSMO RUS:ZVEZ
На исторических данных за период с 2014-го года (года начала геополитической конфронтации России и Украины) MOEX Aerospace & Defense Index демонстрирует доходность в 3-4 раза выше российского бенчмарка рынка акций – Индекса Мосбиржи, что делает финансовый инструмент наиболее привлекательным во времена геополитических кризисов или военных противостояний.
MOEX Aerospace & Defense Index позволяет:
1. Сбалансированно инвестировать в аэрокосмический и оборонно-промышленный комплекс России, производящий передовое военное и аэрокосмическое вооружение для нужд армии России и на экспорт, который занимает 25% мирового рынка вооружений. Инвестирование в аэрокосмический и оборонно-промышленный комплекс России особенно актуально в условиях специальной военной операции на Украине, росте геополитической напряженности и следующих из этого большого бюджетного стимулирования данной отрасли со стороны Правительства Российской Федерации.
2. Нивелировать колебания в низколиквидных и высоко волатильных акциях аэрокосмического и оборонно-промышленного комплекса России. Аэрокосмическая и оборонная отрасли характеризуются высокой волатильностью цен на акции, ввиду чего создание сбалансированного индекса может нивелировать колебания цен на низколиквидные акции компаний, входящих в индекс, и снизить риск для инвесторов.
3. Политически диверсифицировать инвестиционный портфель. Включение MOEX Aerospace & Defense Index в инвестиционный портфель может снизить риски, связанные с колебаниями цен во время геополитических кризисов или военных противостояний.

Up and Downwhat is "Up and Down"?
It is an indicator designed to show you in detail on the chart and warn you when there is an increase or decrease in the market at a level that you consider important.
what it does?
When the price difference between a top and bottom is greater than the level you selected (the default input is 10 percent), it indicates this along with the percentage value on the chart. Then, it indicates the start and end points with lines so that you can see the change from where to where. It shows the price's current percentage distance from the last bottom or top in the upper right corner.
it also colors the candles so you can better understand how fast the price is moving. The greener the candles, the stronger the rise, and conversely, the greater the decline, the redder the candles. Of course, if you set an alarm, it will tell you in which trading pair, in which time period, at what percentage and in which direction there is a movement.
how it does it?
It uses a moving average with a short length to find bottoms and tops. It then measures the distance from the last peak to the bottom and expresses it as a percentage. It uses momentum using the moving average as a source to paint the candles. To compress this momentum between the values 255 and 0, I used a formula that I also used in my limited fisher transform work (because the inputs in the color.rgb function take values between 0 and 255). It was a bit challenging to use the lines correctly, but with the "ta.valuewhen" function and a little experimenting, they were I made sure they were drawn correctly.
how to use it?
It is quite simple to use. First, select the minimum interval you want to receive alarms. If you make this value too high, you will not receive any alarms; if you make it too low, you will receive too many alarms. Choose the range that will benefit you most for the trading pair you are using. Then all you have to do is set an alarm. When you set an alarm, leave the note section blank and the indicator will send you the necessary information.

Mastering ATR for Smart Stop Loss and Take Profit PlacementUsing the ATR indicator to set Stop Loss and Take Profit levels provides a dynamic and flexible way to manage risk based on the volatility of the market. This method ensures that your SL and TP are always in tune with current market conditions, preventing unnecessary stop-outs while maximizing the potential for profit. The table in the script makes it easy to view your calculated levels directly on the chart, improving your trading efficiency.
If you're looking for a more automated way to manage your trades, integrating ATR-based SL and TP can be a powerful tool in your strategy.
Happy Trading!
