High/Low Breakout Statistical Analysis StrategyThis Pine Script strategy is designed to assist in the statistical analysis of breakout systems on a monthly, weekly, or daily timeframe. It allows the user to select whether to open a long or short position when the price breaks above or below the respective high or low for the chosen timeframe. The user can also define the holding period for each position in terms of bars.
Core Functionality:
Breakout Logic:
The strategy triggers trades based on price crossing over (for long positions) or crossing under (for short positions) the high or low of the selected period (daily, weekly, or monthly).
Timeframe Selection:
A dropdown menu enables the user to switch between the desired timeframe (monthly, weekly, or daily).
Trade Direction:
Another dropdown allows the user to select the type of trade (long or short) depending on whether the breakout occurs at the high or low of the timeframe.
Holding Period:
Once a trade is opened, it is automatically closed after a user-defined number of bars, making it useful for analyzing how breakout signals perform over short-term periods.
This strategy is intended exclusively for research and statistical purposes rather than real-time trading, helping users to assess the behavior of breakouts over different timeframes.
Relevance of Breakout Systems:
Breakout trading systems, where trades are executed when the price moves beyond a significant price level such as the high or low of a given period, have been extensively studied in financial literature for their potential predictive power.
Momentum and Trend Following:
Breakout strategies are a form of momentum-based trading, exploiting the tendency of prices to continue moving in the direction of a strong initial movement after breaching a critical support or resistance level. According to academic research, momentum strategies, including breakouts, can produce returns above average market returns when applied consistently. For example, Jegadeesh and Titman (1993) demonstrated that stocks that performed well in the past 3-12 months continued to outperform in the subsequent months, suggesting that price continuation patterns, like breakouts, hold value .
Market Efficiency Hypothesis:
While the Efficient Market Hypothesis (EMH) posits that markets are generally efficient, and it is difficult to outperform the market through technical strategies, some studies show that in less liquid markets or during specific times of market stress, breakout systems can capitalize on temporary inefficiencies. Taylor (2005) and other researchers have found instances where breakout systems can outperform the market under certain conditions.
Volatility and Breakouts:
Breakouts are often linked to periods of increased volatility, which can generate trading opportunities. Coval and Shumway (2001) found that periods of heightened volatility can make breakouts more significant, increasing the likelihood that price trends will follow the breakout direction. This correlation between volatility and breakout reliability makes it essential to study breakouts across different timeframes to assess their potential profitability .
In summary, this breakout strategy offers an empirical way to study price behavior around key support and resistance levels. It is useful for researchers and traders aiming to statistically evaluate the effectiveness and consistency of breakout signals across different timeframes, contributing to broader research on momentum and market behavior.
References:
Jegadeesh, N., & Titman, S. (1993). Returns to Buying Winners and Selling Losers: Implications for Stock Market Efficiency. Journal of Finance, 48(1), 65-91.
Fama, E. F., & French, K. R. (1996). Multifactor Explanations of Asset Pricing Anomalies. Journal of Finance, 51(1), 55-84.
Taylor, S. J. (2005). Asset Price Dynamics, Volatility, and Prediction. Princeton University Press.
Coval, J. D., & Shumway, T. (2001). Expected Option Returns. Journal of Finance, 56(3), 983-1009.
Statistics

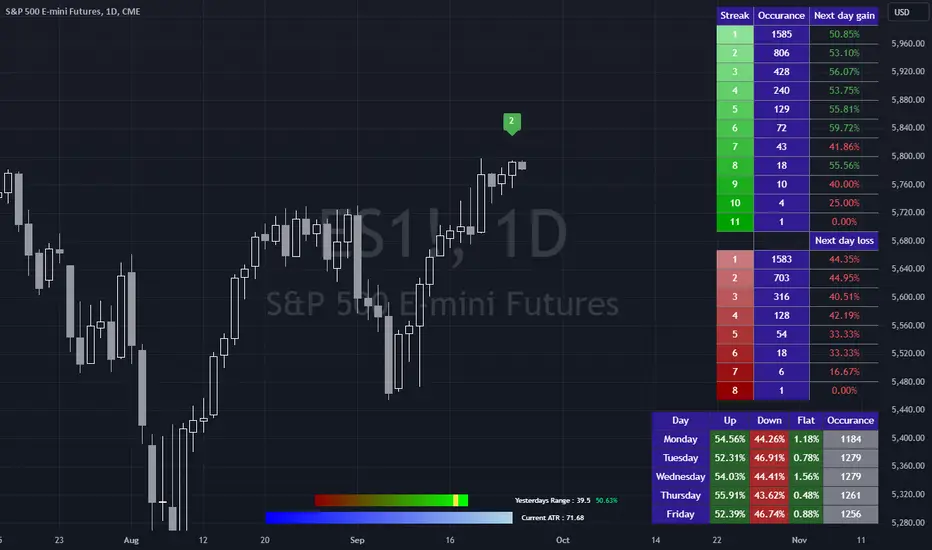
Bias FinderCan we look at what happened yesterday in the market to predict what happens today?
Not really, but we can use simple historical statistics to help form a bias for todays market direction.
This indicator attempts to do just that. It is broken into 3 parts, none of which are related to each other, but taken together can help a trader improve the quality of their daily bias.
The first table simply groups all the daily win and loss streaks together and looks at the change of the next day after each streak.
The second table groups each day of the week then returns what percentage of those days were up, down and flat.
The bottom graphic compares the range of the last session with the current ATR.
The code then groups each session into either being larger or smaller than the current ATR.
Once that is determined, the close is classified into which quartile of the range it closed in. This means there are 8 different groups of closes. Once a close has been grouped, it is compared with all the other closes of the same group to return the historical change of the next day. So for example, a day might have a range inside the current ATR and have closed in the 3rd quartile of the range. From this we can determine the historical percentage of days that were up days after such a close.
The only important thing here is to decide if you want to use a close to close change IE an up day is when the close is higher than the previous close, or an open to close where, as the name suggests, the close is higher than the open for an up day.
The start date and start month can be used to eliminate any bad data and it is advisable to check the start of your dataset to make sure any data included in the statistics is stable and legitimate.
Hope you find this useful!
Stock Info By IT Wala
Purpose of the Indicator
The "Stock Info by IT Wala" indicator was created to display essential stock-related information directly on the chart in a clear and concise manner. This is helpful for traders who want to quickly access details about a stock without having to look them up separately. It is useful for all types of market participants, whether trading stocks, indices, or other financial instruments, and provides an overview of the stock’s attributes such as its country, exchange, industry, and more.
Key Features
Displays a table containing key stock data, such as the stock’s name, country of origin, exchange, industry, sector, and type.
Shows additional details such as stock description, currency, and time zone, all sourced directly from syminfo.
Overlay feature allows the table to appear on the chart itself, making the information easily accessible while analyzing price action.
The table is customizable for style, with a navy blue background, white text, and border customization to match different charting themes.
Inputs (User Parameters)
This indicator doesn't offer customizable user inputs since it automatically pulls stock information from TradingView’s syminfo system. It ensures simplicity in use, allowing traders to focus on the provided data.
Output (How to Read the Indicator)
The output of the "Stock Info by IT Wala" indicator is a table that appears on the chart, showing:
Stock: The stock’s root symbol, such as AAPL for Apple or TSLA for Tesla.
Country: The country where the stock is listed or operates primarily.
Exchange: The prefix of the stock's exchange (e.g., NASDAQ, NYSE).
Industry: The industry to which the stock belongs, such as Technology, Healthcare, or Finance.
Sector: The broader sector, like Consumer Goods or Energy.
Type: Indicates whether the asset is a stock, index, or another type of financial asset.
Description: A brief description of the company or asset.
Currency: The currency in which the stock is traded (e.g., USD, EUR).
Timezone: The timezone of the exchange where the stock is listed.
Best Practices for Usage
Timeframes: This indicator works well across all timeframes, as it only displays stock-related data and is not affected by time-based analysis.
Asset Classes: It’s best suited for use with stocks but can also be applied to other types of assets (such as indices or commodities) where syminfo data is available.
Usage: Use this indicator to quickly review stock information while analyzing price action or planning trades. It is particularly helpful for traders who want quick access to contextual information without switching between different tools.
Limitations and Disclaimers:
The information is sourced directly from TradingView's syminfo and is limited to the data provided by TradingView. If any information is missing or incorrect, it will reflect in the table.
The indicator is purely informational and does not provide any buy or sell signals. Traders should not rely solely on this indicator for decision-making.
Limitations: This indicator does not work for every asset class. For example, it may not display detailed information for cryptocurrencies or certain less common instruments.
Alerts:
This indicator does not include any alert functionality since it is meant to display static stock data, not trigger trading signals.
Customization Options:
Table Styling: While users can't adjust the data displayed, the indicator automatically applies a styled table with a navy blue background and white borders to ensure readability. Users can modify this part of the code if needed for better chart integration.
Backtesting and Performance:
Backtesting is not applicable here as the indicator provides static information about the stock rather than dynamic data or signals. Performance is based on the data retrieval capabilities of TradingView's syminfo feature.
Conclusion:
The "Stock Info by IT Wala" indicator provides traders with instant access to crucial stock-related data, allowing them to review key details about the asset they are analyzing without leaving the chart. By offering details such as stock name, exchange, sector, and more, it makes fundamental information conveniently accessible, enhancing the charting experience.
Disclaimer:
This indicator is for informational purposes only and does not provide trading advice or recommendations. The stock data is sourced from TradingView’s systems and should be cross-verified if used for making trading decisions. Always conduct your own research and consult financial experts before executing any trades.
Importance of Clarity and Transparency:
When publishing a script, especially one like this that provides essential stock information, it's important to clearly explain its purpose, limitations, and intended usage. A transparent description ensures users understand what the indicator does and how to use it effectively in their analysis, preventing confusion or misuse. Clear communication builds trust with your audience and encourages responsible use of the tool.

High Yield Spread Strategy with SMA FilterThis Pine Script strategy is designed for statistical analysis and research purposes only, not for live trading or financial decision-making. The script evaluates the relationship between financial volatility (measured by either the VIX or the High Yield Spread) and market positioning strategies (long or short) based on user-defined conditions. Specifically, it allows users to test the assumption that elevated levels of VIX or the High Yield Spread may justify short positions in the market—a widely held belief in financial circles—but this script demonstrates that shorting is not always the optimal choice, even under these conditions.
Key Components:
1. High Yield Spread and VIX:
• High Yield Spread is the difference between the yields of corporate high-yield (or “junk”) bonds and U.S. Treasury securities. A rising spread often reflects increased market risk perception.
• VIX (Volatility Index) is often referred to as the market’s “fear gauge.” Higher VIX levels usually indicate heightened market uncertainty or expected volatility.
2. Strategy Logic:
• The script allows users to specify a threshold for the VIX or High Yield Spread, and it automatically evaluates if the spread exceeds this level, which traditionally would suggest an environment for higher market risk and thus potentially favoring short trades.
• However, the strategy provides flexibility to enter long or short positions, even in a high-risk environment, emphasizing that a high VIX or High Yield Spread does not always warrant shorting.
3. SMA Filter:
• A Simple Moving Average (SMA) filter can be applied to the price data, where positions are only entered if the price is above or below the SMA (depending on the trade direction). This adds a technical component to the strategy, incorporating price trends into decision-making.
4. Hold Duration:
• The script also allows users to define how long to hold a position after entering, enabling an analysis of different timeframes.
Theoretical Background:
The traditional belief that high VIX or High Yield Spreads favor short positions is not universally supported by research. While a spike in the VIX or credit spreads is often associated with increased market risk, research suggests that excessive volatility does not always lead to negative returns. In fact, high volatility can sometimes signal an approaching market rebound.
For example:
• Studies have shown that long-term investments during periods of heightened volatility can yield favorable returns due to mean reversion. Whaley (2000) notes that VIX spikes are often followed by market recoveries as volatility tends to revert to its mean over time .
• Research by Blitz and Vliet (2007) highlights that low-volatility stocks have historically outperformed high-volatility stocks, suggesting that volatility may not always predict negative returns .
• Furthermore, credit spreads can widen in response to broader market stress, but these may overshoot the actual credit risk, presenting opportunities for long positions when spreads are high and risk premiums are mispriced .
Educational Purpose:
The goal of this script is to challenge assumptions about shorting during volatile periods, showing that long positions can be equally, if not more, effective during market stress. By incorporating an SMA filter and customizable logic for entering trades, users can test different hypotheses regarding the effectiveness of both long and short positions under varying market conditions.
Note: This strategy is not intended for live trading and should be used solely for educational and statistical exploration. Misinterpreting financial indicators can lead to incorrect investment decisions, and it is crucial to conduct comprehensive research before trading.
References:
1. Whaley, R. E. (2000). “The Investor Fear Gauge”. The Journal of Portfolio Management, 26(3), 12-17.
2. Blitz, D., & van Vliet, P. (2007). “The Volatility Effect: Lower Risk Without Lower Return”. Journal of Portfolio Management, 34(1), 102-113.
3. Bhamra, H. S., & Kuehn, L. A. (2010). “The Determinants of Credit Spreads: An Empirical Analysis”. Journal of Finance, 65(3), 1041-1072.
This explanation highlights the academic and research-backed foundation of the strategy and the nuances of volatility, while cautioning against the assumption that high VIX or High Yield Spread always calls for shorting.
Simplified Gap Strategy with SMA FilterThe Simplified Gap Strategy leverages price gaps as a trading signal, focusing on their significance in market behavior. Gaps occur when the opening price of a security differs significantly from the previous closing price, often signaling potential continuation or reversal patterns.
Key Features:
Gap Threshold:
This strategy requires a minimum percentage gap (defined by the user) to qualify for trading signals.
Directional Trading:
Users can select from various gap types, including "Long Up Gap" and "Short Down Gap," allowing for tailored trading approaches.
SMA Filter:
An optional Simple Moving Average (SMA) filter helps refine trade entries based on trend direction, increasing the probability of successful trades.
Hold Duration:
Positions can be held for a user-defined duration, providing flexibility in trade management.
Statistical Significance of Gaps:
Research has shown that gaps can provide insights into future price movements. According to studies such as those by Hutton and Jiang (2008), price gaps are often followed by momentum in the direction of the gap, indicating that they can serve as reliable indicators for traders. The "Gap Theory" suggests that gaps are filled approximately 90% of the time, emphasizing their relevance in market dynamics (Nikkinen, Sahlström, & Kinnunen, 2006).
Important Note:
This strategy is designed solely for statistical analysis and should not be construed as financial advice. Users are encouraged to conduct their own research and analysis before applying this strategy in live trading scenarios.
By understanding the underlying mechanisms of price gaps and their statistical significance, traders can enhance their decision-making processes and potentially improve trading outcomes.
References:
Hutton, A. W., & Jiang, W. (2008). "Price Gaps: A Guide to Trading Gaps."
Nikkinen, J., Sahlström, P., & Kinnunen, J. (2006). "The Gaps in Financial Markets: An Empirical Study."
This description provides an overview of the strategy while emphasizing its analytical purpose and backing it with relevant academic insights.
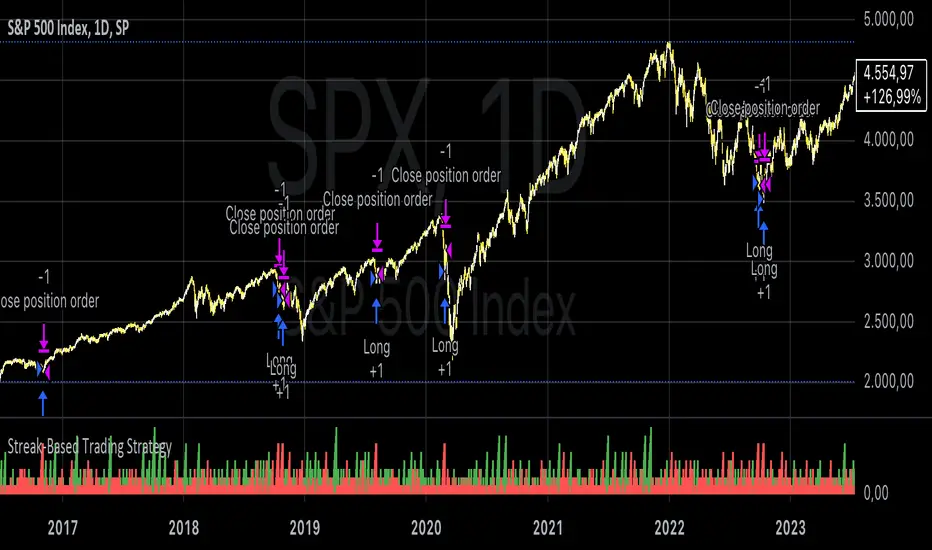
Streak-Based Trading StrategyThe strategy outlined in the provided script is a streak-based trading strategy that focuses on analyzing winning and losing streaks. It’s important to emphasize that this strategy is not intended for actual trading but rather for statistical analysis of streak series.
How the Strategy Works
1. Parameter Definition:
• Trade Direction: Users can choose between “Long” (buy) and “Short” (sell).
• Streak Threshold: Defines how many consecutive wins or losses are needed to trigger a trade.
• Hold Duration: Specifies how many periods the position will be held.
• Doji Threshold: Determines the sensitivity for Doji candles, which indicate market uncertainty.
2. Streak Calculation:
• The script identifies Doji candles and counts winning and losing streaks based on the closing price compared to the previous closing price.
• Streak counting occurs only when no position is currently held.
3. Trade Conditions:
• If the loss streak reaches the defined threshold and the trade direction is “Long,” a buy position is opened.
• If the win streak is met and the trade direction is “Short,” a sell position is opened.
• The position is held for the specified duration.
4. Visualization:
• Winning and losing streaks are plotted as histograms to facilitate analysis.
Scientific Basis
The concept of analyzing streaks in financial markets is well-documented in behavioral economics and finance. Studies have shown that markets often exhibit momentum and trend-following behavior, meaning the likelihood of consecutive winning or losing periods can be higher than what random statistics would suggest (see, for example, “The Behavior of Stock-Market Prices” by Eugene Fama).
Additionally, empirical research indicates that investors often make decisions based on psychological factors influenced by streaks. This can lead to irrational behavior, as they may focus on past wins or losses (see “Behavioral Finance: Psychology, Decision-Making, and Markets” by R. M. F. F. Thaler).
Overall, this strategy serves as a tool for statistical analysis of streak series, providing deeper insights into market behavior and trends rather than being directly used for trading decisions.
Heatmap Volume ProfileThe Volume Profile with Support/Resistance indicator is a powerful tool designed to help traders visually identify support and resistance zones based on volume analysis at specific price levels. Unlike traditional volume indicators that focus on time-based volume, this indicator analyzes the volume traded at various price levels, offering a clearer view of where the strongest buying and selling forces are concentrated.
Key Features:
Volume Heatmap: The indicator displays a colored heatmap that varies based on the volume traded at different price levels. "Hot zones" (red) indicate areas with high volume, while "cold zones" (blue) represent areas with low volume.
Automatic Detection of Support and Resistance Levels: In addition to the heatmap, the indicator automatically detects price levels where the volume reaches a significant threshold. These levels are marked with white lines on the chart, highlighting potential support and resistance zones.
Adjustable Granularity: The number of price bands can be adjusted, allowing for finer or broader volume analysis. This helps customize the analysis based on the volatility of the asset and the chosen time frame.
Configurable Analysis Period: The number of historical bars used for volume analysis can be defined by the user, enabling the analysis of short-term or long-term volume trends.
Customizable Support/Resistance Threshold: A parameter allows you to define the threshold at which a volume level is considered significant enough to be marked as support or resistance.
Indicator Parameters:
Number of Price Bands (Granularity):
This parameter controls how finely the price is divided into bands. The higher the number of bands, the more precise the volume analysis. The default is set to 50 bands.
Color Transparency:
This parameter adjusts the transparency of the heatmap colors, making it easier to read when overlaid on the price chart.
Number of Bars for Analysis:
Defines the historical period used for volume analysis. The default is 200 bars, but it can be adjusted based on your time frame and the asset being analyzed.
Volume Threshold for Support/Resistance:
This setting allows you to define the intensity of volume (between 0.1 and 1.0) necessary for a price level to be marked as support or resistance. This parameter ensures that only the most relevant levels are displayed.
Practical Use:
Identify Support and Resistance Zones: Traders can use the levels marked by this indicator to identify areas where significant volumes have been traded, signaling potential support or resistance. These zones are often where the market may reverse direction or confirm a trend.
Detect Congestion Zones: The heatmap allows traders to easily spot volume congestion zones, where prices tend to stall due to the high concentration of trading at those levels.
Improve Decision-Making: By combining price-level volume analysis, traders can better understand where the market’s key forces are located, allowing for more informed entry and exit strategies.
Example of Use:
Support: If a support line is detected at a price level with high volume, it may represent an area where buyers are heavily concentrated, making it more difficult for the price to break below that level.
Resistance: Conversely, a resistance line indicates a zone where sellers have a significant presence, suggesting that the price may struggle to move above that level without strong momentum.
Target Audience:
This indicator is ideal for:
Day traders looking to spot short-term reversal points based on volume concentration.
Swing traders identifying key zones to place limit orders or stops.
Long-term traders who want to analyze volume clusters over an extended period to determine critical levels to watch.
Conclusion:
The Volume Profile with Support/Resistance indicator is an essential tool for any trader looking to understand how volume behaves at each price level. With its intuitive visualizations and automatically marked levels, this indicator makes it easy to spot important support and resistance zones, helping traders optimize their strategies and anticipate market movements more effectively.

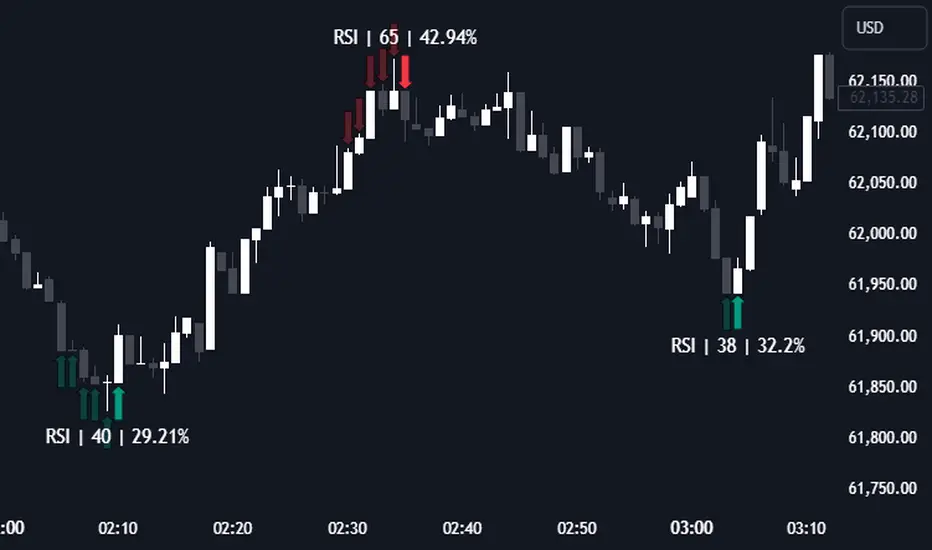
RSI (Kernel Optimized) | Flux Charts💎 GENERAL OVERVIEW
Introducing our new KDE Optimized RSI Indicator! This indicator adds a new aspect to the well-known RSI indicator, with the help of the KDE (Kernel Density Estimation) algorithm, estimates the probability of a candlestick will be a pivot or not. For more information about the process, please check the "HOW DOES IT WORK ?" section.
Features of the new KDE Optimized RSI Indicator :
A New Approach To Pivot Detection
Customizable KDE Algorithm
Realtime RSI & KDE Dashboard
Alerts For Possible Pivots
Customizable Visuals
❓ HOW TO INTERPRET THE KDE %
The KDE % is a critical metric that reflects how closely the current RSI aligns with the KDE (Kernel Density Estimation) array. In simple terms, it represents the likelihood that the current candlestick is forming a pivot point based on historical data patterns. a low percentage suggests a lower probability of the current candlestick being a pivot point. In these cases, price action is less likely to reverse, and existing trends may continue. At moderate levels, the possibility of a pivot increases, indicating potential trend shifts or consolidations.Traders should start monitoring closely for confirmation signals. An even higher KDE % suggests a strong likelihood that the current candlestick could form a pivot point, which could lead to a reversal or significant price movement. These points often align with overbought or oversold conditions in traditional RSI analysis, making them key moments for potential trade entry or exit.
📌 HOW DOES IT WORK ?
The RSI (Relative Strength Index) is a widely used oscillator among traders. It outputs a value between 0 - 100 and gives a glimpse about the current momentum of the price action. This indicator then calculates the RSI for each candlesticks, and saves them into an array if the candlestick is a pivot. The low & high pivot RSIs' are inserted into two different arrays. Then the a KDE array is calculated for both of the low & high pivot RSI arrays. Explaining the KDE might be too much for this write-up, but for a brief explanation, here are the steps :
1. Define the necessary options for the KDE function. These are : Bandwidth & Nº Steps, Array Range (Array Max - Array Min)
2. After that, create a density range array. The array has (steps * 2 - 1) elements and they are calculated by (arrMin + i * stepCount), i being the index.
3. Then, define a kernel function. This indicator has 3 different kernel distribution modes : Uniform, Gaussian and Sigmoid
4. Then, define a temporary value for the current element of KDE array.
5. For each element E in the pivot RSI array, add "kernel(densityRange.get(i) - E, 1.0 / bandwidth)" to the temporary value.
6. Add 1.0 / arrSize * to the KDE array.
Then the prefix sum array of the KDE array is calculated. For each candlestick, the index closest to it's RSI value in the KDE array is found using binary search. Then for the low pivot KDE calculation, the sum of KDE values from found index to max index is calculated. For the high pivot KDE, the sum of 0 to found index is used. Then if high or low KDE value is greater than the activation threshold determined in the settings, a bearish or bullish arrow is plotted after bar confirmation respectively. The arrows are drawn as long as the KDE value of current candlestick is greater than the threshold. When the KDE value is out of the threshold, a less transparent arrow is drawn, indicating a possible pivot point.
🚩 UNIQUENESS
This indicator combines RSI & KDE Algorithm to get a foresight of possible pivot points. Pivot points are important entry, confirmation and exit points for traders. But to their nature, they can be only detected after more candlesticks are rendered after them. The purpose of this indicator is to alert the traders of possible pivot points using KDE algorithm right away when they are confirmed. The indicator also has a dashboard for realtime view of the current RSI & Bullish or Bearish KDE value. You can fully customize the KDE algorithm and set up alerts for pivot detection.
⚙️ SETTINGS
1. RSI Settings
RSI Length -> The amount of bars taken into account for RSI calculation.
Source -> The source value for RSI calculation.
2. Pivots
Pivot Lengths -> Pivot lengths for both high & low pivots. For example, if this value is set to 21; 21 bars before AND 21 bars after a candlestick must be higher for a candlestick to be a low pivot.
3. KDE
Activation Threshold -> This setting determines the amount of arrows shown. Higher options will result in more arrows being rendered.
Kernel -> The kernel function as explained in the upper section.
Bandwidth -> The bandwidth variable as explained in the upper section. The smoothness of the KDE function is tied to this setting.
Nº Bins -> The Nº Steps variable as explained in the upper section. It determines the precision of the KDE algorithm.
QuantBuilder | FractalystWhat's the strategy's purpose and functionality?
QuantBuilder is designed for both traders and investors who want to utilize mathematical techniques to develop profitable strategies through backtesting on historical data.
The primary goal is to develop profitable quantitive strategies that not only outperform the underlying asset in terms of returns but also minimize drawdown.
For instance, consider Bitcoin (BTC), which has experienced significant volatility, averaging an estimated 200% annual return over the past decade, with maximum drawdowns exceeding -80%. By employing this strategy with diverse entry and exit techniques, users can potentially seek to enhance their Compound Annual Growth Rate (CAGR) while managing risk to maintain a lower maximum drawdown.
While this strategy employs quantitative techniques, including mathematical methods such as probabilities and positive expected values, it demonstrates exceptional efficacy across all markets. It particularly excels in futures, indices, stocks, cryptocurrencies, and commodities, leveraging their inherent trending behaviors for optimized performance.
In both trending and consolidating market conditions, QuantBuilder employs a combination of multi-timeframe probabilities, expected values, directional biases, moving averages and diverse entry models to identify and capitalize on bullish market movements.
How does the strategy perform for both investors and traders?
The strategy has two main modes, tailored for different market participants: Traders and Investors.
1. Trading:
- Designed for traders looking to capitalize on bullish markets.
- Utilizes a percentage risk per trade to manage risk and optimize returns.
- Suitable for both swing and intraday trading with a focus on probabilities and risk per trade approach.
2. Investing:
- Geared towards investors who aim to capitalize on bullish trending markets without using leverage while mitigating the asset's maximum drawdown.
- Utilizes pre-define percentage of the equity to buy, hold, and manage the asset.
- Focuses on long-term growth and capital appreciation by fully/partially investing in the asset during bullish conditions.
How does the strategy identify market structure? What are the underlying calculations?
The strategy utilizes an efficient logic with for loops to pinpoint the first swing candle featuring a pivot of 2, establishing the point at which the break of structure begins.
What entry criteria are used in this script? What are the underlying calculations?
The script utilizes two entry models: BreakOut and fractal.
Underlying Calculations:
Breakout: The script assigns the most recent swing high to a variable. When the price closes above this level and all other conditions are met, the script executes a breakout entry (conservative approach).
Fractal: The script identifies a swing low with a period of 2. Once this condition is met, the script executes the trade (aggressive approach).
How does the script calculate probabilities? What are the underlying calculations?
The script calculates probabilities by monitoring price interactions with liquidity levels. Here’s how the underlying calculations work:
Tracking Price Hits: The script counts the number of times the price taps into each liquidity side after the EQM level is activated. This data is stored in an array for further analysis.
Sample Size Consideration: The total number of price interactions serves as the sample size for calculating probabilities.
Probability Calculation: For each liquidity side, the script calculates the probability by taking the average of the recorded hits. This allows for a dynamic assessment of the likelihood that a particular side will be hit next, based on historical performance.
Dynamic Adjustment: As new price data comes in, the probabilities are recalculated, providing real-time aduptive insights into market behavior.
Note: The calculations are performed independently for each directional range. A range is considered bearish if the previous breakout was through a sellside liquidity. Conversely, a range is considered bullish if the most recent breakout was through a buyside liquidity.
How does the script calculate expected values? What are the underlying calculations?
The script calculates expected values by leveraging the probabilities of winning and losing trades, along with their respective returns. The process involves the following steps:
This quantitative methodology provides a robust framework for assessing the expected performance of trading strategies based on historical data and backtesting results.
How is the contextual bias calculated? What are the underlying calculations?
The contextual bias in the QuantBuilder script is calculated through a structured approach that assesses market structure based on swing highs and lows. Here’s how it works:
Identification of Swing Points: The script identifies significant swing points using a defined pivot logic, focusing on the first swing high and swing low. This helps establish critical levels for determining market structure.
Break of Structure (BOS) Assessment:
Bullish BOS: The script recognizes a bullish break of structure when a candle closes above the first swing high, followed by at least one swing low.
Bearish BOS: Conversely, a bearish break of structure is identified when a candle closes below the first swing low, followed by at least one swing high.
Bias Assignment: Based on the identified break of structure, the script assigns directional biases:
A bullish bias is assigned if a bullish BOS is confirmed.
A bearish bias is assigned if a bearish BOS is confirmed.
Quantitative Evaluation: Each identified bias is quantitatively evaluated, allowing the script to assign numerical values representing the strength of each bias. This quantification aids in assessing the reliability of market sentiment across multiple timeframes.
What's the purpose of using moving averages in this strategy? What are the underlying calculations?
Using moving averages is a widely-used technique to trade with the trend.
The main purpose of using moving averages in this strategy is to filter out bearish price action and to only take trades when the price is trading ABOVE specified moving averages.
The script uses different types of moving averages with user-adjustable timeframes and periods/lengths, allowing traders to try out different variations to maximize strategy performance and minimize drawdowns.
By applying these calculations, the strategy effectively identifies bullish trends and avoids market conditions that are not conducive to profitable trades.
The MA filter allows traders to choose whether they want a specific moving average above or below another one as their entry condition.
What type of stop-loss identification method are used in this strategy? What are the underlying calculations?
- Initial Stop-loss:
1. ATR Based:
The Average True Range (ATR) is a method used in technical analysis to measure volatility. It is not used to indicate the direction of price but to measure volatility, especially volatility caused by price gaps or limit moves.
Calculation:
- To calculate the ATR, the True Range (TR) first needs to be identified. The TR takes into account the most current period high/low range as well as the previous period close.
The True Range is the largest of the following:
- Current Period High minus Current Period Low
- Absolute Value of Current Period High minus Previous Period Close
- Absolute Value of Current Period Low minus Previous Period Close
- The ATR is then calculated as the moving average of the TR over a specified period. (The default period is 14)
2. ADR Based:
The Average Day Range (ADR) is an indicator that measures the volatility of an asset by showing the average movement of the price between the high and the low over the last several days.
Calculation:
- To calculate the ADR for a particular day:
- Calculate the average of the high prices over a specified number of days.
- Calculate the average of the low prices over the same number of days.
- Find the difference between these average values.
- The default period for calculating the ADR is 14 days. A shorter period may introduce more noise, while a longer period may be slower to react to new market movements.
3. PL Based:
This method places the stop-loss at the low of the previous candle.
If the current entry is based on the hunt entry strategy, the stop-loss will be placed at the low of the candle that wicks through the lower FRMA band.
Example:
If the previous candle's low is 100, then the stop-loss will be set at 100.
This method ensures the stop-loss is placed just below the most recent significant low, providing a logical and immediate level for risk management.
- Trailing Stop-Loss:
One of the key elements of this strategy is its ability to detect structural liquidity and structural invalidation levels across multiple timeframes to trail the stop-loss once the trade is in running profits.
By utilizing this approach, the strategy allows enough room for price to run.
By using these methods, the strategy dynamically adjusts the initial stop-loss based on market volatility, helping to protect against adverse price movements while allowing for enough room for trades to develop.
Each market behaves differently across various timeframes, and it is essential to test different parameters and optimizations to find out which trailing stop-loss method gives you the desired results and performance.
What type of break-even and take profit identification methods are used in this strategy? What are the underlying calculations?
For Break-Even:
Percentage (%) Based:
Moves the initial stop-loss to the entry price when the price reaches a certain percentage above the entry.
Calculation:
Break-even level = Entry Price * (1 + Percentage / 100)
Example:
If the entry price is $100 and the break-even percentage is 5%, the break-even level is $100 * 1.05 = $105.
Risk-to-Reward (RR) Based:
Moves the initial stop-loss to the entry price when the price reaches a certain RR ratio.
Calculation:
Break-even level = Entry Price + (Initial Risk * RR Ratio)
For TP1 (Take Profit 1):
- You can choose to set a take profit level at which your position gets fully closed or 50% if the TP2 boolean is enabled.
- Similar to break-even, you can select either a percentage (%) or risk-to-reward (RR) based take profit level, allowing you to set your TP1 level as a percentage amount above the entry price or based on RR.
For TP2 (Take Profit 2):
- You can choose to set a take profit level at which your position gets fully closed.
- As with break-even and TP1, you can select either a percentage (%) or risk-to-reward (RR) based take profit level, allowing you to set your TP2 level as a percentage amount above the entry price or based on RR.
What's the day filter Filter, what does it do?
The day filter allows users to customize the session time and choose the specific days they want to include in the strategy session. This helps traders tailor their strategies to particular trading sessions or days of the week when they believe the market conditions are more favorable for their trading style.
Customize Session Time:
Users can define the start and end times for the trading session.
This allows the strategy to only consider trades within the specified time window, focusing on periods of higher market activity or preferred trading hours.
Select Days:
Users can select which days of the week to include in the strategy.
This feature is useful for excluding days with historically lower volatility or unfavorable trading conditions (e.g., Mondays or Fridays).
Benefits:
Focus on Optimal Trading Periods:
By customizing session times and days, traders can focus on periods when the market is more likely to present profitable opportunities.
Avoid Unfavorable Conditions:
Excluding specific days or times can help avoid trading during periods of low liquidity or high unpredictability, such as major news events or holidays.
What tables are available in this script?
- Summary: Provides a general overview, displaying key performance parameters such as Net Profit, Profit Factor, Max Drawdown, Average Trade, Closed Trades and more.
Total Commission: Displays the cumulative commissions incurred from all trades executed within the selected backtesting window. This value is derived by summing the commission fees for each trade on your chart.
Average Commission: Represents the average commission per trade, calculated by dividing the Total Commission by the total number of closed trades. This metric is crucial for assessing the impact of trading costs on overall profitability.
Avg Trade: The sum of money gained or lost by the average trade generated by a strategy. Calculated by dividing the Net Profit by the overall number of closed trades. An important value since it must be large enough to cover the commission and slippage costs of trading the strategy and still bring a profit.
MaxDD: Displays the largest drawdown of losses, i.e., the maximum possible loss that the strategy could have incurred among all of the trades it has made. This value is calculated separately for every bar that the strategy spends with an open position.
Profit Factor: The amount of money a trading strategy made for every unit of money it lost (in the selected currency). This value is calculated by dividing gross profits by gross losses.
Avg RR: This is calculated by dividing the average winning trade by the average losing trade. This field is not a very meaningful value by itself because it does not take into account the ratio of the number of winning vs losing trades, and strategies can have different approaches to profitability. A strategy may trade at every possibility in order to capture many small profits, yet have an average losing trade greater than the average winning trade. The higher this value is, the better, but it should be considered together with the percentage of winning trades and the net profit.
Winrate: The percentage of winning trades generated by a strategy. Calculated by dividing the number of winning trades by the total number of closed trades generated by a strategy. Percent profitable is not a very reliable measure by itself. A strategy could have many small winning trades, making the percent profitable high with a small average winning trade, or a few big winning trades accounting for a low percent profitable and a big average winning trade. Most mean-reversion successful strategies have a percent profitability of 40-80% but are profitable due to risk management control.
BE Trades: Number of break-even trades, excluding commission/slippage.
Losing Trades: The total number of losing trades generated by the strategy.
Winning Trades: The total number of winning trades generated by the strategy.
Total Trades: Total number of taken traders visible your charts.
Net Profit: The overall profit or loss (in the selected currency) achieved by the trading strategy in the test period. The value is the sum of all values from the Profit column (on the List of Trades tab), taking into account the sign.
- Monthly: Displays performance data on a month-by-month basis, allowing users to analyze performance trends over each month and year.
- Weekly: Displays performance data on a week-by-week basis, helping users to understand weekly performance variations.
- UI Table: A user-friendly table that allows users to view and save the selected strategy parameters from user inputs. This table enables easy access to key settings and configurations, providing a straightforward solution for saving strategy parameters by simply taking a screenshot with Alt + S or ⌥ + S.
User-input styles and customizations:
To facilitate studying historical data, all conditions and filters can be applied to your charts. By plotting background colors on your charts, you'll be able to identify what worked and what didn't in certain market conditions.
Please note that all background colors in the style are disabled by default to enhance visualization.
How to Use This Quantitive Strategy Builder to Create a Profitable Edge and System?
Choose Your Strategy mode:
- Decide whether you are creating an investing strategy or a trading strategy.
Select a Market:
- Choose a one-sided market such as stocks, indices, or cryptocurrencies.
Historical Data:
- Ensure the historical data covers at least 10 years of price action for robust backtesting.
Timeframe Selection:
- Choose the timeframe you are comfortable trading with. It is strongly recommended to use a timeframe above 15 minutes to minimize the impact of commissions/slippage on your profits.
Set Commission and Slippage:
- Properly set the commission and slippage in the strategy properties according to your broker/prop firm specifications.
Parameter Optimization:
- Use trial and error to test different parameters until you find the performance results you are looking for in the summary table or, preferably, through deep backtesting using the strategy tester.
Trade Count:
- Ensure the number of trades is 200 or more; the higher, the better for statistical significance.
Positive Average Trade:
- Make sure the average trade is above zero.
(An important value since it must be large enough to cover the commission and slippage costs of trading the strategy and still bring a profit.)
Performance Metrics:
- Look for a high profit factor, and net profit with minimum drawdown.
- Ideally, aim for a drawdown under 20-30%, depending on your risk tolerance.
Refinement and Optimization:
- Try out different markets and timeframes.
- Continue working on refining your edge using the available filters and components to further optimize your strategy.
What makes this strategy original?
QuantBuilder stands out due to its unique combination of quantitative techniques and innovative algorithms that leverage historical data for real-time trading decisions. Unlike most algorithmic strategies that work based on predefined rules, this strategy adapts to real-time market probabilities and expected values, enhancing its reliability. Key features include:
Mathematical Framework: The strategy integrates advanced mathematical concepts, such as probabilities and expected values, to assess trade viability and optimize decision-making.
Multi-Timeframe Analysis: By utilizing multi-timeframe probabilities, QuantBuilder provides a comprehensive view of market conditions, enhancing the accuracy of entry and exit points.
Dynamic Market Structure Identification: The script employs a systematic approach to identify market structure changes, utilizing a blend of swing highs and lows to detect contextual/direction bias of the market.
Built-in Trailing Stop Loss: The strategy features a dynamic trailing stop loss based on multi-timeframe analysis of market structure. This allows traders to lock in profits while adapting to changing market conditions, ensuring that exits are executed at optimal levels without prematurely closing positions.
Robust Performance Metrics: With detailed performance tables and visualizations, users can easily evaluate strategy effectiveness and adjust parameters based on historical performance.
Adaptability: The strategy is designed to work across various markets and timeframes, making it versatile for different trading styles and objectives.
Suitability for Investors and Traders: QuantBuilder is ideal for both investors and traders looking to rely on mathematically proven data to create profitable strategies, ensuring that decisions are grounded in quantitative analysis.
These original elements combine to create a powerful tool that can help both traders and investors to build and refine profitable strategies based on algorithmic quantitative analysis.
Terms and Conditions | Disclaimer
Our charting tools are provided for informational and educational purposes only and should not be construed as financial, investment, or trading advice. They are not intended to forecast market movements or offer specific recommendations. Users should understand that past performance does not guarantee future results and should not base financial decisions solely on historical data.
Built-in components, features, and functionalities of our charting tools are the intellectual property of @Fractalyst Unauthorized use, reproduction, or distribution of these proprietary elements is prohibited.
By continuing to use our charting tools, the user acknowledges and accepts the Terms and Conditions outlined in this legal disclaimer and agrees to respect our intellectual property rights and comply with all applicable laws and regulations.

China's stock market Limit up / Limit downThe price limit system in China’s stock market is a regulatory measure implemented by the Chinese securities authorities to curb excessive speculation. It refers to the maximum allowable daily price fluctuation of a stock, which cannot exceed a certain percentage of the previous trading day's closing price. For regular stocks, the daily price movement limit is 10%. For stocks under special treatment (ST stocks), the maximum daily price movement is restricted to 5%. There is no price limit on the listing day of newly issued stocks or stocks undergoing a rights issue. This indicator highlights the K-lines (candlesticks) of stocks that have hit the upper or lower price limits with different background colors and lists the recent number of instances of limit-up and limit-down occurrences in a table format.

Info DisplayThis indicator can display the code, time period and current date of the selected commodity in real time in the upper right corner of the screen.
The display size of the 3 display fonts can be adjusted in the options.

Winning and Losing StreaksThe Pine Script indicator "Winning and Losing Streaks" tracks and visualizes the length of consecutive winning and losing streaks in a financial series, such as stock prices. Here’s a detailed description of the indicator, including the relevance of statistical analysis and streak tracking.
Indicator Description
The "Winning and Losing Streaks" indicator in Pine Script is designed to analyze and display streaks of consecutive winning and losing days in trading data. It helps traders and analysts understand the persistence of trends in price movements.
Here’s how it functions:
Streak Calculation:
Winning Streak: A series of consecutive days where the closing price is higher than the previous day's closing price.
Losing Streak: A series of consecutive days where the closing price is lower than the previous day's closing price.
Doji Candles: The indicator also considers Doji candles, where the difference between the opening and closing prices is minimal relative to the high-low range, and excludes these from being counted as winning or losing days.
Statistical Analysis:
The indicator computes the maximum and average lengths of winning and losing streaks.
It also tracks the current streak lengths and maintains arrays to store the historical streak data.
Visualization:
Histograms: Winning and losing streaks are visualized using histograms, which provide a clear graphical representation of streak lengths over time.
Relevance of Statistical Analysis and Streak Tracking
1. Statistical Significance of Streaks
Tracking winning and losing streaks has significant statistical implications for trading strategies and risk management:
Autocorrelation: Streaks in financial time series can reveal autocorrelation, where past returns influence future returns. Studies have shown that financial time series often exhibit autocorrelation, which can be used to forecast future price movements (Lo, 1991; Jegadeesh & Titman, 1993). Understanding streaks helps in identifying and leveraging these patterns.
Behavioral Finance: Streak analysis aligns with concepts from behavioral finance, such as the "hot-hand fallacy," where investors may perceive trends as more persistent than they are (Gilovich, Vallone, & Tversky, 1985). Statistical streak analysis provides a more objective view of trend persistence, helping to avoid biases.
2. Risk Management and Strategy Development
Risk Assessment: Identifying the length and frequency of losing streaks is crucial for managing risk and adjusting trading strategies. Long losing streaks can indicate potential strategy weaknesses or market regime changes, prompting a reassessment of trading rules and risk management practices (Brock, Lakonishok, & LeBaron, 1992).
Strategy Optimization: Statistical analysis of streaks can aid in optimizing trading strategies. For example, understanding the average length of winning and losing streaks can help in setting more effective stop-loss and take-profit levels, as well as in determining the optimal position sizing (Fama & French, 1993).
Scientific References:
Lo, A. W. (1991). "Long-Term Memory in Stock Market Prices." Econometrica, 59(5), 1279-1313. This paper discusses the presence of long-term memory in stock prices, which is relevant for understanding the persistence of streaks.
Jegadeesh, N., & Titman, S. (1993). "Returns to Buying Winners and Selling Losers: Implications for Stock Market Efficiency." Journal of Finance, 48(1), 65-91. This study explores momentum and reversal strategies, which are related to the concept of streaks.
Gilovich, T., Vallone, R., & Tversky, A. (1985). "The Hot Hand in Basketball: On the Misperception of Random Sequences." Cognitive Psychology, 17(3), 295-314. This paper provides insight into the psychological aspects of streaks and persistence.
Brock, W., Lakonishok, J., & LeBaron, B. (1992). "Simple Technical Trading Rules and the Stochastic Properties of Stock Returns." Journal of Finance, 47(5), 1731-1764. This research examines the effectiveness of technical trading rules, relevant for streak-based strategies.
Fama, E. F., & French, K. R. (1993). "Common Risk Factors in the Returns on Stocks and Bonds." Journal of Financial Economics, 33(1), 3-56. This paper provides a foundation for understanding risk factors and strategy performance.
By analyzing streaks, traders can gain valuable insights into market dynamics and refine their trading strategies based on empirical evidence.

Statistical Anomaly IndicatorThe Statistical Anomaly Indicator is a sophisticated tool designed for traders to detect and highlight candles that significantly deviate from the expected price action based on statistical analysis. By leveraging historical price data, this indicator calculates an anticipated price range using a pricing model rooted in the mean and standard deviation of historical returns. When the actual price moves outside these statistical boundaries, the corresponding candles are marked on the chart, providing traders with unique insights into potential market anomalies.
Purpose and Unique Insights
The primary purpose of the Statistical Anomaly Indicator is to aid traders in identifying periods of abnormal price movements that may signify overbought or oversold conditions, potential reversals, or trend continuations. By highlighting these statistical outliers, the indicator offers:
Early Detection of Market Anomalies: Spot unusual price actions promptly.
Enhanced Decision-Making: Make more informed trading decisions by understanding when prices deviate from historical norms.
Versatility Across Markets: Applicable in various market contexts, whether trending or ranging.
This tool benefits both novice traders, by simplifying complex statistical concepts into visual cues, and experienced traders, by adding a quantitative edge to their analysis.
Methodology
Calculate the return of the period
return(t) = (close - close )/close
Calculate the mean of past returns within a specified window
mean = ta.sma(return , period)
Calculate the standard deviation of past returns within a specified window
stdev = ta.stdev(return , period)
Establish price upper and lower bound using the last close, mean and standard deviation
upper_bound = close * (1 + mean + stdev)
lower_bound = close * (1 + mean - stdev)
Mark the candles where the close price exceeds the established price range
close > upper_bound or close < lower_bound
Visual Presentation on the Chart
Color-Coded Triangles: The indicator places color-coded triangles below the bars of the candles that exceed the expected price range.
Green Triangles: Indicate a close above the upper bound (potential overbought condition).
Red Triangles: Indicate a close below the lower bound (potential oversold condition).
Immediate Recognition: These visual cues enable traders to quickly identify statistical anomalies without sifting through numerical data.
Practical Applications for Traders
Identifying Overbought/Oversold Conditions: Recognize when the asset price may have moved too far in one direction and could be due for a correction.
Spotting Potential Reversals: Use deviations as early signals of possible market reversals.
Confirming Trend Continuations: In strong trends, deviations might indicate momentum is continuing rather than reversing.
Identifying historical trends in the price action.
Combining with Other Tools and Analysis
To maximize the effectiveness of the Statistical Anomaly Indicator:
Pair with the Mean and Standard Deviation Lines Indicator:
Provides additional context by displaying the mean and standard deviation levels directly on the chart.
Use in Conjunction with Fundamental Analysis:
Validate whether statistical anomalies are supported by underlying economic factors or news events.
Integrate with Other Technical Indicators.
Limitations and Caveats
Not a Standalone Tool: Should not be used in isolation; always consider the broader market context.
Statistical Assumptions: Based on historical data; past performance does not guarantee future results.
False Signals: Like all indicators, it may generate false positives, especially in highly volatile or low-volume markets which is why context is needed to interpret the signals.
Parameter Selection: The chosen period for calculating mean and standard deviation can significantly affect the indicator's sensitivity.
Conclusion
The Statistical Anomaly Indicator offers a quantitative approach to identifying unusual price movements in the market. By transforming complex statistical data into simple visual signals, it empowers traders to make more informed decisions. Whether you're a novice trader seeking to understand market dynamics or an experienced trader looking to refine your strategy, this indicator provides practical benefits. Remember to integrate it with fundamental analysis and other technical tools to validate signals and enhance your trading decisions.

FED and ECB Interest RatesFED and ECB Interest Rates Indicator
This indicator provides a clear visual representation of the Federal Reserve (FED) and European Central Bank (ECB) interest rates, offering traders and analysts a quick way to track these crucial economic metrics.
• Displays both FED (red) and ECB (blue) interest rates on a single chart
• Shows rates in basis points in the status line for precise reading
• Uses daily data for up-to-date rate information
• Features robust error handling for consistent performance
How It Works:
• Fetches FED rate from FRED and ECB rate from ECONOMICS database
• Plots rates as percentage values on the chart
• Displays rates in basis points when hovering over the chart
Use Cases:
• Monitor central bank policies and their potential impact on markets
• Compare FED and ECB rate trends over time
• Analyze correlation between interest rates and asset prices
• Assist in fundamental analysis for forex, equities, and fixed income trading
Note:
This indicator is for informational purposes only. Always combine this data with other forms of analysis and stay informed about central bank announcements and economic events.
Enhance your trading strategy with real-time insights into two of the world's most influential interest rates!

[BRAIN] Absolute Volatility of Price
Hello traders!
Today I want to share with you a series of scripts and strategies that I developed a few years ago. This is one of my first works, born from the curiosity of seeing a candlestick representation in a different way, without considering the price movement along the y-axis.
Imagine observing the price movement in dollars and percentages, always starting from the same reference point: the 0 axis. This approach can offer new insights and ideas on how and how much prices move.
To explain it better, the open of each candle does not start from the previous close negotiations but always starts from the 0 axis . In this way, it is possible to clearly compare the bodies of the candles with each other.
Script Visualization Methods and Input
- Study Normal: Simply reports the prices, including the negative ones of the red candles, on the same scale in absolute terms (ABS), as shown in the first indicator above.
- Study Normal Neg: In this version, the red candles vary negatively below zero, instead of in absolute terms above zero, as shown in the second indicator above.
- Study Perc: Similar to "Study Normal" but uses percentage values instead of dollars, useful for very low timeframes and low variations with many decimals, such as 1 minute on EUR/USD.
- Study Perc Neg: Similar to "Study Normal Neg" but uses percentage values.
Additionally, I have added the possibility to display or not, through two buttons, an average of the candle bodies adjustable in length via input and the range of each candle, always correlated in dollars or percentages, as per the main study setting.
I hope this work can be useful to many of you. I invite you to like if you appreciate my scripts and want to see more like these. Do not hesitate to comment or contact me for any doubts or questions.
PS: If you notice that in the script the sum of the percentage values between the shadow and the body of the candle does not correspond to the range, it is only a rounding issue. Change the precision setting to a lower value and you will see that the rounding disappears.
PS: In the script, to better visualize the percentage growth and decline of the instrument on very high timeframes, I decided to represent it as follows:
- If close ≥ open: (high - low) / low * 100
- If close < open: (high - low) / high * 100
The same method is also applied for calculating the percentage variations of the shadows relative to themselves.
I hope you like this version! If you need any further modifications or adjustments, let me know. Good luck with your project!
(In the photos below I show 3 versions of the indicator open on 3 different tickers as an example: from top to bottom in the 3 indicators are set these Study: Study Normal, Study Perc and Study Perc Neg)

Currency Futures StatisticsThe "Currency Futures Statistics" indicator provides comprehensive insights into the performance and characteristics of various currency futures. This indicator is crucial for portfolio management as it combines multiple metrics that are instrumental in evaluating currency futures' risk and return profiles.
Metrics Included:
Historical Volatility:
Definition: Historical volatility measures the standard deviation of returns over a specified period, scaled to an annual basis.
Importance: High volatility indicates greater price fluctuations, which translates to higher risk. Investors and portfolio managers use volatility to gauge the stability of a currency future and to make informed decisions about risk management and position sizing (Hull, J. C. (2017). Options, Futures, and Other Derivatives).
Open Interest:
Definition: Open interest represents the total number of outstanding futures contracts that are held by market participants.
Importance: High open interest often signifies liquidity in the market, meaning that entering and exiting positions is less likely to impact the price significantly. It also reflects market sentiment and the degree of participation in the futures market (Black, F., & Scholes, M. (1973). The Pricing of Options and Corporate Liabilities).
Year-over-Year (YoY) Performance:
Definition: YoY performance calculates the percentage change in the futures contract's price compared to the same week from the previous year.
Importance: This metric provides insight into the long-term trend and relative performance of a currency future. Positive YoY performance suggests strengthening trends, while negative values indicate weakening trends (Fama, E. F. (1991). Efficient Capital Markets: II).
200-Day Simple Moving Average (SMA) Position:
Definition: This metric indicates whether the current price of the currency future is above or below its 200-day simple moving average.
Importance: The 200-day SMA is a widely used trend indicator. If the price is above the SMA, it suggests a bullish trend, while being below indicates a bearish trend. This information is vital for trend-following strategies and can help in making buy or sell decisions (Bollinger, J. (2001). Bollinger on Bollinger Bands).
Why These Metrics are Important for Portfolio Management:
Risk Assessment: Historical volatility and open interest provide essential information for assessing the risk associated with currency futures. Understanding the volatility helps in estimating potential price swings, which is crucial for managing risk and setting appropriate stop-loss levels.
Liquidity and Market Participation: Open interest is a critical indicator of market liquidity. Higher open interest usually means tighter bid-ask spreads and better liquidity, which facilitates smoother trading and better execution of trades.
Trend Analysis: YoY performance and the SMA position help in analyzing long-term trends. This analysis is crucial for making strategic investment decisions and adjusting the portfolio based on changing market conditions.
Informed Decision-Making: Combining these metrics allows for a holistic view of the currency futures market. This comprehensive view helps in making informed decisions, balancing risks and returns, and optimizing the portfolio to align with investment goals.
In summary, the "Currency Futures Statistics" indicator equips investors and portfolio managers with valuable data points that are essential for effective risk management, liquidity assessment, trend analysis, and overall portfolio optimization.

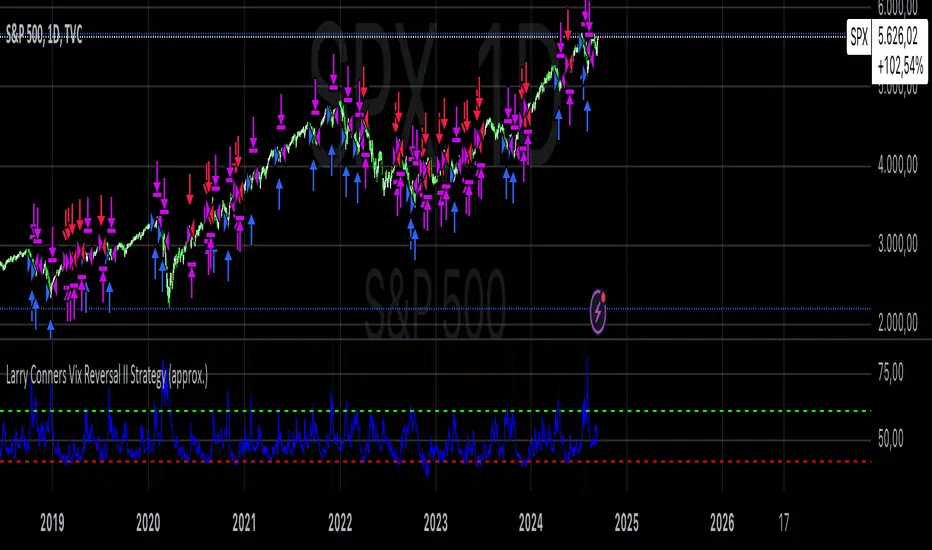
Larry Conners Vix Reversal II Strategy (approx.)This Pine Script™ strategy is a modified version of the original Larry Connors VIX Reversal II Strategy, designed for short-term trading in market indices like the S&P 500. The strategy utilizes the Relative Strength Index (RSI) of the VIX (Volatility Index) to identify potential overbought or oversold market conditions. The logic is based on the assumption that extreme levels of market volatility often precede reversals in price.
How the Strategy Works
The strategy calculates the RSI of the VIX using a 25-period lookback window. The RSI is a momentum oscillator that measures the speed and change of price movements. It ranges from 0 to 100 and is often used to identify overbought and oversold conditions in assets.
Overbought Signal: When the RSI of the VIX rises above 61, it signals a potential overbought condition in the market. The strategy looks for a RSI downtick (i.e., when RSI starts to fall after reaching this level) as a trigger to enter a long position.
Oversold Signal: Conversely, when the RSI of the VIX drops below 42, the market is considered oversold. A RSI uptick (i.e., when RSI starts to rise after hitting this level) serves as a signal to enter a short position.
The strategy holds the position for a minimum of 7 days and a maximum of 12 days, after which it exits automatically.
Larry Connors: Background
Larry Connors is a prominent figure in quantitative trading, specializing in short-term market strategies. He is the co-author of several influential books on trading, such as Street Smarts (1995), co-written with Linda Raschke, and How Markets Really Work. Connors' work focuses on developing rules-based systems using volatility indicators like the VIX and oscillators such as RSI to exploit mean-reversion patterns in financial markets.
Risks of the Strategy
While the Larry Connors VIX Reversal II Strategy can capture reversals in volatile market environments, it also carries significant risks:
Over-Optimization: This modified version adjusts RSI levels and holding periods to fit recent market data. If market conditions change, the strategy might no longer be effective, leading to false signals.
Drawdowns in Trending Markets: This is a mean-reversion strategy, designed to profit when markets return to a previous mean. However, in strongly trending markets, especially during extended bull or bear phases, the strategy might generate losses due to early entries or exits.
Volatility Risk: Since this strategy is linked to the VIX, an instrument that reflects market volatility, large spikes in volatility can lead to unexpected, fast-moving market conditions, potentially leading to larger-than-expected losses.
Scientific Literature and Supporting Research
The use of RSI and VIX in trading strategies has been widely discussed in academic research. RSI is one of the most studied momentum oscillators, and numerous studies show that it can capture mean-reversion effects in various markets, including equities and derivatives.
Wong et al. (2003) investigated the effectiveness of technical trading rules such as RSI, finding that it has predictive power in certain market conditions, particularly in mean-reverting markets .
The VIX, often referred to as the “fear index,” reflects market expectations of volatility and has been a focal point in research exploring volatility-based strategies. Whaley (2000) extensively reviewed the predictive power of VIX, noting that extreme VIX readings often correlate with turning points in the stock market .
Modified Version of Original Strategy
This script is a modified version of Larry Connors' original VIX Reversal II strategy. The key differences include:
Adjusted RSI period to 25 (instead of 2 or 4 commonly used in Connors’ other work).
Overbought and oversold levels modified to 61 and 42, respectively.
Specific holding period (7 to 12 days) is predefined to reduce holding risk.
These modifications aim to adapt the strategy to different market environments, potentially enhancing performance under specific volatility conditions. However, as with any system, constant evaluation and testing in live markets are crucial.
References
Wong, W. K., Manzur, M., & Chew, B. K. (2003). How rewarding is technical analysis? Evidence from Singapore stock market. Applied Financial Economics, 13(7), 543-551.
Whaley, R. E. (2000). The investor fear gauge. Journal of Portfolio Management, 26(3), 12-17.
STRX - Macro TimesSTRX - Macro Times
The STRX - Macro Times is an advanced indicator designed to highlight key moments in financial markets based on specific macroeconomic time frames for Forex, Indices, and Gold. With this tool, you can optimize your trading decisions by monitoring periods of increased volatility and activity in the markets, leveraging the most strategic time windows to operate.
Key Features:
Highlighting Forex, Indices, and Gold Sessions:
The STRX - Macro Times automatically colors the candles on the chart during crucial time intervals for Forex, Indices, and Gold markets, helping you easily spot periods of heightened economic and financial activity. This allows you to focus on times when the market is most liquid and volatile, enhancing your trading performance.
Pre-set Macro Times:
The indicator is programmed to highlight three different key time windows for each market:
Forex: Major sessions from 8:30 to 10:00, 12:00 to 13:00, and 15:00 to 15:30.
Indices: Key times from 9:00 to 10:00, 15:45 to 16:15, and 19:00 to 20:00.
Gold: Strategic moments from 8:30 to 10:00, 14:30 to 16:00, and 20:00 to 21:30.
Total Customization:
You can enable or disable the coloring for different markets (Forex, Indices, Gold) based on your trading preferences. This allows you to focus only on the markets you follow, simplifying chart analysis and optimizing your response time to market changes.
Clear and Intuitive Visual Coloring:
The chart bars are colored in white, creating a clear visual distinction to recognize the most relevant time windows. This makes it easy to identify macroeconomic periods without wasting time manually calculating opportunity windows.
With STRX - Macro Times, you’ll have a strategic advantage in trading by focusing on periods of high volatility and improving the efficiency of your operations in the most active markets. This indicator is perfect for those looking to enhance their strategy and operate in sync with the key moments of the global market.

Global Liquidity Index and DEMA1001. Global Liquidity Index:
The code calculates global liquidity from economic data from multiple countries and regions. Specifically, it aggregates money supply data from major economies such as the United States, Europe, China, and Japan, and sums and adjusts them to get a global liquidity index.
This index is calculated by summing data from different sources and subtracting the impact of some financial instruments (such as reverse repurchase agreements, etc.), and then converting the result into a number in trillions. This can help analyze the liquidity conditions in global money markets.
2. ROC SMA (Simple Moving Average of Rate of Change):
The code calculates the rate of change (ROC) of the global liquidity index, which is a way to measure the speed of change of the index.
Then, a simple moving average (SMA) is applied to the rate of change, which helps smooth the data and identify trends.
The ROC SMA curve is displayed in yellow to help users observe the trend of liquidity changes.
3. DEMA (Double Exponential Moving Average):
DEMA is a more complex moving average that attempts to reduce the lag of the moving average and provide a more sensitive trend response.
The calculation method is to first calculate a standard exponential moving average (EMA), then calculate the EMA of this EMA, and use these two results to calculate DEMA.
The code allows users to set the period length of DEMA (default is 100), which can adjust the speed of DEMA's response to price changes.
The DEMA curve is displayed in blue, helping users to more accurately capture the trends and changes of global liquidity indicators.

Korean Exchange Relative Volume BarchartKorean Exchange Relative Volume Barchart
The Korean Exchange Relative Volume Barchart indicator compares the trading volume of a cryptocurrency on any symbol with the combined volumes of major Korean exchanges, Upbit and Bithumb. This tool helps traders understand regional trading activities, offering insights into market sentiment influenced by Korean markets.
For example 0.5 would indicate that the Korean exchanges are doing 50% of the volume of the selected symbol.
Features:
Exchange Selection: Include or exclude Upbit and Bithumb in the comparison.
Automatic Symbol Mapping: Automatically maps the current chart's symbol to equivalent symbols on Upbit and Bithumb.
Stacked Bar Chart Visualization: Plots a stacked bar chart showing the relative volume contributions of Binance, Upbit, and Bithumb.
Usage:
Add the Indicator: Apply it to a cryptocurrency chart on TradingView.
Configure Settings: Toggle inclusion of Upbit and Bithumb in the settings.
Interpret the Chart: The stacked bar chart displays the proportion of trading volumes from each exchange.
Notes:
Symbol Compatibility: Ensure the cryptocurrency is listed on the Korean exchanges for accurate comparison.
Data Accuracy: Volumes are compared in the same base currency (e.g., BTC), so no exchange rate conversion is necessary.
Enhance your trading analysis by understanding the influence of Korean exchanges on cryptocurrency volumes with the Korean Exchange Volume Comparison indicator.
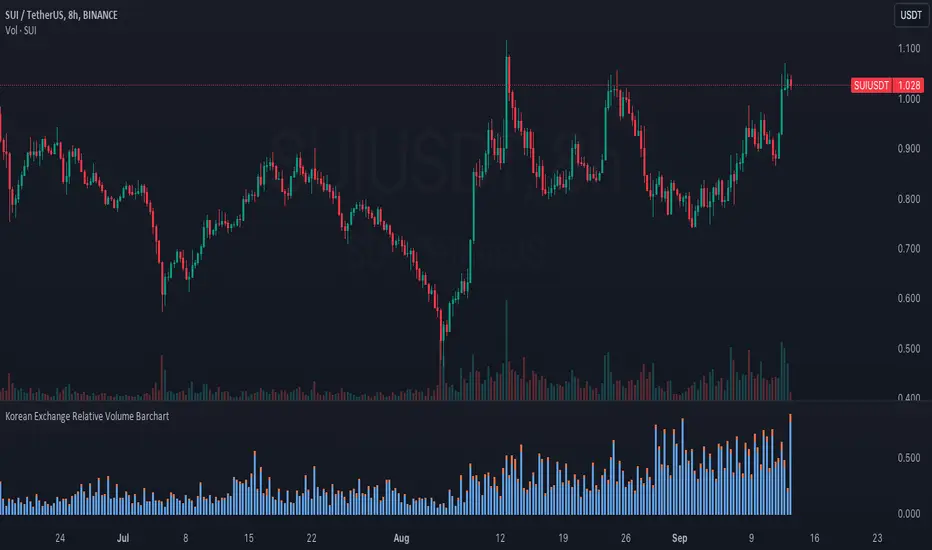
VIX Composite MeterThe VIX Composite Meter is a custom trading indicator designed to help identify potential buy and sell signals based on market volatility, specifically through VIX options. The VIX, also known as the "fear gauge," measures market expectations of future volatility. This meter combines several factors — the VIX-to-SPX ratio, moving average deviation, Z-score, and momentum oscillators — to create a single, easy-to-read score that guides trading decisions.
How It Works
Composite Score: The meter calculates a composite score that ranges from 0 to 1 by weighing four metrics:
VIX/SPX Ratio: Indicates relative volatility compared to the S&P 500.
Moving Average Deviation: Shows how far the VIX is from its typical range.
Z-Score: Measures how extreme the current VIX value is relative to its historical average.
Momentum Oscillator (RSI): Helps identify overbought or oversold conditions in the VIX.
Color-Coded Signals:
Green Background: If the score drops below 0.3, the meter suggests buying VIX calls, indicating a low-volatility environment with potential for increase.
Red Background: If the score rises above 0.7, the meter suggests buying VIX puts, indicating a high-volatility environment likely to decrease.
Use Cases
Buy VIX Calls: When the meter turns green, signaling potential future volatility spikes.
Buy VIX Puts: When the meter turns red, suggesting current high volatility is expected to revert lower.
By using the VIX Composite Meter, traders can better time their entries and exits in VIX options, aligning with market conditions for potential profits in periods of changing volatility.
buysellsignal-yashgode9The "buysellsignal-yashgode9" indicator utilizes a signal library to generate buy and sell signals based on price action, allowing traders to make informed decisions in their trading strategies.
Overview of the Indicator
The "buysellsignal-yashgode9" indicator is a technical analysis tool that identifies potential buying and selling points in the market. It does this by leveraging a signal library imported from `yashgode9/signalLib/2`, which contains predefined algorithms for analyzing market trends based on specified parameters.
Key Features
1.Input Parameters: The indicator allows users to customize several parameters:
- Depth: Determines the number of bars to look back for price analysis (default is 150).
- Deviation: Sets the threshold for price movement (default is 120).
- Backstep: Defines how many bars to step back when evaluating signals (default is 100).
- Label Transparency: Adjusts the transparency of labels displayed on the chart.
- Color Customization: Users can specify colors for buy and sell signals.
2.Signal Generation: The core functionality is driven by the `signalLib.signalLib` function, which analyzes the low and high prices over the specified depth and deviation. It returns a direction indicator along with price points (`zee1` and `zee2`) that are used to determine whether to issue a buy or sell signal.
3. Labeling and Visualization:
- The indicator creates labels on the chart to indicate buy and sell points based on the direction of the signal.
- Labels are color-coded according to user-defined settings, enhancing visual clarity.
- The indicator also manages the deletion of previous labels and lines to avoid clutter on the chart.
4. Repainting Logic: The script includes a repainting option, allowing it to update signals in real-time as new price data comes in. This can be beneficial for traders who want to see the most current signals but may also lead to misleading signals if not used cautiously.
Conclusion:-
The "buysellsignal-yashgode9" indicator is a versatile tool for traders looking to enhance their decision-making process by identifying key market entry and exit points. By allowing customization of parameters and colors, it caters to individual trading preferences while providing clear visual signals based on price action analysis. This indicator is particularly useful for those who rely on technical analysis in their trading strategies, as it combines automated signal generation with user-friendly visual cues.
Benefits and Applications:
1.Intraday Trading: The "buysellsignal-yashgode9" indicator is particularly well-suited for intraday trading, as it provides accurate and timely buy and sell signals based on the current market dynamics.
2.Trend-following Strategies: Traders who employ trend-following strategies can leverage the indicator's ability to identify the overall market direction, allowing them to align their trades with the dominant trend.
3.Swing Trading: The dynamic price tracking and signal generation capabilities of the indicator can be beneficial for swing traders, who aim to capture medium-term price movements.
Security Measures:
1. The code includes a security notice at the beginning, indicating that it is subject to the Mozilla Public License 2.0, which is a reputable open-source license.
2. The code does not appear to contain any obvious security vulnerabilities or malicious content that could compromise user data or accounts.
NOTE:- This indicator is provided under the Mozilla Public License 2.0 and is subject to its terms and conditions.
Disclaimer: The usage of "buysellsignal-yashgode9" indicator might or might not contribute to your trading capital(money) profits and losses and the author is not responsible for the same.
IMPORTANT NOTICE:
While the indicator aims to provide reliable buy and sell signals, it is crucial to understand that the market can be influenced by unpredictable events, such as natural disasters, political unrest, changes in monetary policies, or economic crises. These unforeseen situations may occasionally lead to false signals generated by the "buysellsignal-yashgode9" indicator.
Users should exercise caution and diligence when relying on the indicator's signals, as the market's behavior can be unpredictable, and external factors may impact the accuracy of the signals. It is recommended to thoroughly backtest the indicator's performance in various market conditions and to use it as one of the many tools in a comprehensive trading strategy, rather than solely relying on its output.
Ultimately, the success of the "buysellsignal-yashgode9" indicator will depend on the user's ability to adapt it to their specific trading style, market conditions, and risk management approach. Continuous monitoring, analysis, and adjustment of the indicator's settings may be necessary to maintain its effectiveness in the ever-evolving financial markets.
Author:- yashgode9
PineScript-version:- 5
This indicator aims to enhance trading decision-making by combining DEPTH, DEVIATION, BACKSTEP with custom signal generation, offering a comprehensive tool for traders seeking clear buy and sell signals on the TradingView platform.
