Mastering ATR for Smart Stop Loss and Take Profit PlacementUsing the ATR indicator to set Stop Loss and Take Profit levels provides a dynamic and flexible way to manage risk based on the volatility of the market. This method ensures that your SL and TP are always in tune with current market conditions, preventing unnecessary stop-outs while maximizing the potential for profit. The table in the script makes it easy to view your calculated levels directly on the chart, improving your trading efficiency.
If you're looking for a more automated way to manage your trades, integrating ATR-based SL and TP can be a powerful tool in your strategy.
Happy Trading!
Statistics

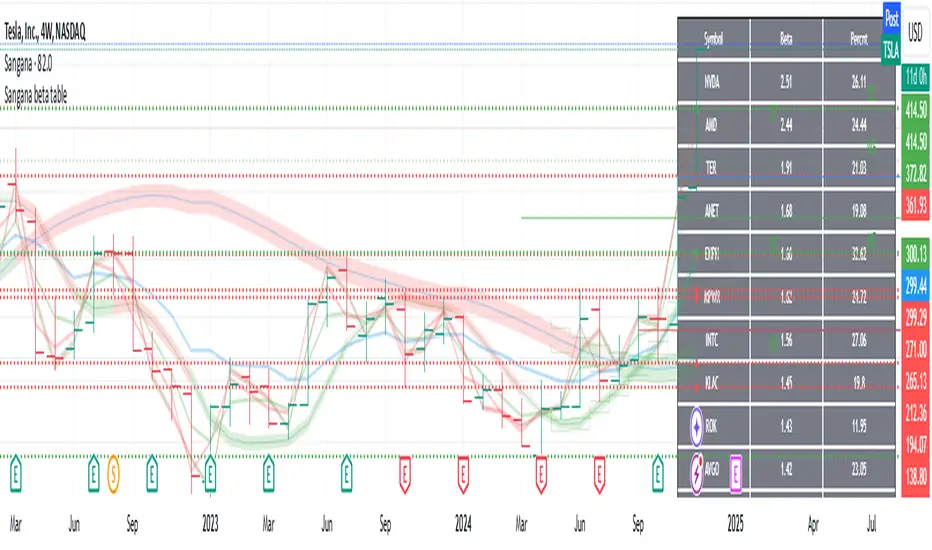
Sangana beta tableIdeal to use this indicator in Monthly timeframe.
This indicator shows three values on a table.
First column is stocks list from a particular sector(sector selection from settings)
Second column is beta of stock. Beta can be used to check how correlated(multiplied by how volatile) the stock is with respect to market S&P500 or Nifty500.
Third column is average percentage of a stock price movement in a month from low price to high price. This is just calculated on the price. If one enters at the low of that monthly candle and exits at the high of that monthly candle, they can expect to gain that much percentage on an average that is shown in this column.
How to use this indicator : Bigger returns on a stock is expected if it swings good amount of percentage from low to high on a regular basis. Either short term or long term, investing in the stocks which high average percentage from low to high, yields better returns. However downside also gives bigger losses if stock is going down. Stay in high volatile stocks, if one is sure of upside movement.
Sorting of beta column or percentage column can be chosen on settings. Sorting is always down high to low.
This indicator is tracks stocks in S&P500 or Nifty500.
Crypto Market Cap Momentum Analyzer (AiBitcoinTrend)The Crypto Market Cap Momentum Analyzer (AiBitcoinTrend) is a robust tool designed to uncover trading opportunities by blending market cap analysis and momentum dynamics. Inspired by research-backed quantitative strategies, this indicator helps traders identify trend-following and mean-reversion setups in the cryptocurrency market by evaluating recent performance and market cap size.
This indicator classifies cryptocurrencies into market cap quintiles and ranks them based on their 2-week momentum. It then suggests potential trades—whether to go long, anticipate reversals, or simply hold—based on the crypto's market cap group and momentum trends.
👽 How the Indicator Works
👾 Market Cap Classification
The indicator categorizes cryptocurrencies into one of five market cap groups based on user-defined inputs:
Large Cap: Highest market cap tier
Upper Mid Cap: Second highest group
Mid Cap: Middle-tier market caps
Lower Mid Cap: Slightly below the mid-tier
Small Cap: Lowest market cap tier
This classification dynamically adjusts based on the provided market cap data, ensuring that you’re always working with a representative market structure.
👾 Momentum Calculation
By default, the indicator uses a 2-week momentum measure (e.g., a 14-day lookback when set to daily). It compares a cryptocurrency’s current price to its price 14 bars ago, thereby quantifying its short-term performance. Users can adjust the momentum period and rebalance period to capture shorter or longer-term trends depending on their trading style.
👾 Dynamic Ranking and Trade Suggestions
After assigning cryptos to size quintiles, the indicator sorts them by their momentum within each quintile. This two-step process results in:
Long Trade: For smaller market cap groups (Small, Lower Mid, Mid Cap) that have low (bottom-quintile) momentum, anticipating a trend continuation or breakout.
Reversal Trade: For the largest market cap group (Large Cap) that shows low momentum, expecting a mean-reversion back to equilibrium.
Hold: In scenarios where the coin’s momentum doesn’t present a strong contrarian or trend-following signal.
👽 Applications
👾 Trend-Following in Smaller Caps: Identify small or mid-cap cryptos with low momentum that might be poised for a breakout or sustained trend.
👾 Mean-Reversion in Large Caps: Pinpoint large-cap cryptocurrencies experiencing a temporary lull in performance, potentially ripe for a rebound.
👽 Why It Works in Crypto
The cryptocurrency market is heavily driven by retail investor sentiment and volatility. Research shows that:
Small-Cap Cryptos: Tend to experience higher volatility and speculative trends, making them ideal for momentum trades.
Large-Cap Cryptos: Exhibit more predictable behavior, making them suitable for mean-reversion strategies when momentum is low.
This indicator captures these dynamics to give traders a strategic edge in identifying both momentum and reversal opportunities.
👽 Indicator Settings
👾 Rebalance Period: The frequency at which momentum and trade suggestions are recalculated (Daily, Weekly, Monthly).
Shorter Periods (Daily): Fast updates, suitable for short-term trades, but more noise.
Longer Periods (Weekly/Monthly): Smoother signals, ideal for swing trading and more stable trends.
👾 Momentum Period: The lookback period for momentum calculation (default is 14 bars).
Shorter Periods: More responsive but prone to noise.
Longer Periods : Reflects broader trends, reducing sensitivity to short-term fluctuations.
Disclaimer: This information is for entertainment purposes only and does not constitute financial advice. Please consult with a qualified financial advisor before making any investment decisions.

Quantum ChronoRenko Dynamics Edge - Traditional### **Quantum ChronoRenko Dynamics Edge - Traditional**
**Description:**
The **Quantum ChronoRenko Dynamics Edge - Traditional** is an advanced Renko-based indicator designed for precision trading. It leverages the power of Renko charts to detect price movements, highlight critical trading signals, and dynamically track profit and risk levels. This indicator is built with modern trading strategies in mind, offering robust tools for all traders, from beginners to professionals.
**Key Features:**
1. **Renko-Based Signal Generation**:
- Detects **Buy Signals** when the price closes above the Renko high level.
- Detects **Sell Signals** when the price closes below the Renko low level.
- Ensures signals are non-repainting and confirmed on bar closures.
2. **Take Profit (TP) and Stop Loss (SL) Tracking**:
- Automatically calculates and plots TP and SL levels for every signal.
- Dynamic levels are displayed directly on the chart for better decision-making.
3. **Advanced Signal Management**:
- Prevents duplicate signals within the same Renko range.
- Resets signal conditions when a new Renko range is formed.
4. **Visual Enhancements**:
- Renko high and low levels are plotted with customizable colors and styles.
- TP and SL levels are marked with distinct cross shapes for clarity.
- Optional fill between Renko levels to highlight price ranges.
5. **Real-Time Alerts**:
- Generates alerts for Buy and Sell signals when a candle closes above or below the Renko levels.
- Alerts are designed to help traders react quickly to opportunities.
6. **Comprehensive Statistics**:
- Tracks the number of Buy/Sell signals.
- Calculates the number of TP and SL hits for each signal type.
- Displays detailed percentages and totals in an easy-to-read table.
**Key Benefits**:
- **Non-Repainting Logic**: Ensures stable and reliable signals based on confirmed price movements.
- **Customizability**: Flexible settings for Renko brick size, TP/SL values, and visual enhancements.
- **Professional-Level Insights**: Provides detailed statistics for tracking strategy performance.
**Use Cases**:
- Perfect for intraday and swing traders who rely on Renko charts for clear trend signals.
- Suitable for identifying key breakout opportunities and managing trades with precise TP/SL levels.
Example Usage:
For daily scalping, set the following parameters:
Brick Size: 3
Time Frame: 10 Minutes
This setup provides clean trend signals and dynamic TP/SL tracking for short-term trades.
**Why "Traditional"?**
This version uses the **Traditional Renko method**, ensuring consistent price-based calculations that align with professional trading strategies.
---
**Disclaimer**:
This indicator is a tool to aid trading decisions but does not guarantee profits. Always use proper risk management.
---
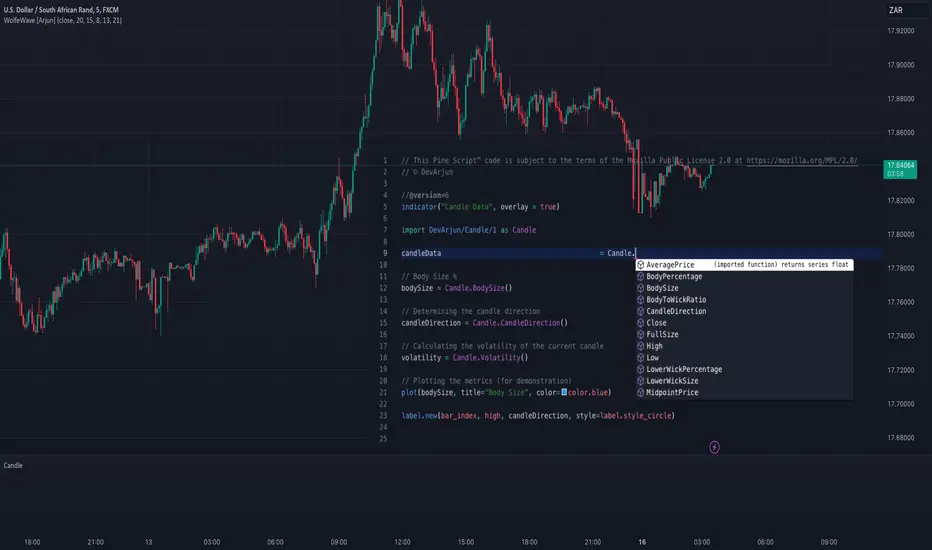
CandleCandle: A Comprehensive Pine Script™ Library for Candlestick Analysis
Overview
The Candle library, developed in Pine Script™, provides traders and developers with a robust toolkit for analyzing candlestick data. By offering easy access to fundamental candlestick components like open, high, low, and close prices, along with advanced derived metrics such as body-to-wick ratios, percentage calculations, and volatility analysis, this library enables detailed insights into market behavior.
This library is ideal for creating custom indicators, trading strategies, and backtesting frameworks, making it a powerful resource for any Pine Script™ developer.
Key Features
1. Core Candlestick Data
• Open : Access the opening price of the current candle.
• High : Retrieve the highest price.
• Low : Retrieve the lowest price.
• Close : Access the closing price.
2. Candle Metrics
• Full Size : Calculates the total range of the candle (high - low).
• Body Size : Computes the size of the candle’s body (open - close).
• Wick Size : Provides the combined size of the upper and lower wicks.
3. Wick and Body Ratios
• Upper Wick Size and Lower Wick Size .
• Body-to-Wick Ratio and Wick-to-Body Ratio .
4. Percentage Calculations
• Upper Wick Percentage : The proportion of the upper wick size relative to the full candle size.
• Lower Wick Percentage : The proportion of the lower wick size relative to the full candle size.
• Body Percentage and Wick Percentage relative to the candle’s range.
5. Candle Direction Analysis
• Determines if a candle is "Bullish" or "Bearish" based on its closing and opening prices.
6. Price Metrics
• Average Price : The mean of the open, high, low, and close prices.
• Midpoint Price : The midpoint between the high and low prices.
7. Volatility Measurement
• Calculates the standard deviation of the OHLC prices, providing a volatility metric for the current candle.
Code Architecture
Example Functionality
The library employs a modular structure, exporting various functions that can be used independently or in combination. For instance:
// This Pine Script™ code is subject to the terms of the Mozilla Public License 2.0 at mozilla.org
// © DevArjun
//@version=6
indicator("Candle Data", overlay = true)
import DevArjun/Candle/1 as Candle
// Body Size %
bodySize = Candle.BodySize()
// Determining the candle direction
candleDirection = Candle.CandleDirection()
// Calculating the volatility of the current candle
volatility = Candle.Volatility()
// Plotting the metrics (for demonstration)
plot(bodySize, title="Body Size", color=color.blue)
label.new(bar_index, high, candleDirection, style=label.style_circle)
Scalability
The modularity of the Candle library allows seamless integration into more extensive trading systems. Functions can be mixed and matched to suit specific analytical or strategic needs.
Use Cases
Trading Strategies
Developers can use the library to create strategies based on candle properties such as:
• Identifying long-bodied candles (momentum signals).
• Detecting wicks as potential reversal zones.
• Filtering trades based on candle ratios.
Visualization
Plotting components like body size, wick size, and directional labels helps visualize market behavior and identify patterns.
Backtesting
By incorporating volatility and ratio metrics, traders can design and test strategies on historical data, ensuring robust performance before live trading.
Education
This library is a great tool for teaching candlestick analysis and how each component contributes to market behavior.
Portfolio Highlights
Project Objective
To create a Pine Script™ library that simplifies candlestick analysis by providing comprehensive metrics and insights, empowering traders and developers with advanced tools for market analysis.
Development Challenges and Solutions
• Challenge : Achieving high precision in calculating ratios and percentages.
• Solution : Implemented robust mathematical operations and safeguarded against division-by-zero errors.
• Challenge : Ensuring modularity and scalability.
• Solution : Designed functions as independent modules, allowing flexible integration.
Impact
• Efficiency : The library reduces the time required to calculate complex candlestick metrics.
• Versatility : Supports various trading styles, from scalping to swing trading.
• Clarity : Clean code and detailed documentation ensure usability for developers of all levels.
Conclusion
The Candle library exemplifies the power of Pine Script™ in simplifying and enhancing candlestick analysis. By including this project in your portfolio, you showcase your expertise in:
• Financial data analysis.
• Pine Script™ development.
• Creating tools that solve real-world trading challenges.
This project demonstrates both technical proficiency and a keen understanding of market analysis, making it an excellent addition to your professional portfolio.
Library "Candle"
A comprehensive library to access and analyze the basic components of a candlestick, including open, high, low, close prices, and various derived metrics such as full size, body size, wick sizes, ratios, percentages, and additional analysis metrics.
Open()
Open
@description Returns the opening price of the current candle.
Returns: float - The opening price of the current candle.
High()
High
@description Returns the highest price of the current candle.
Returns: float - The highest price of the current candle.
Low()
Low
@description Returns the lowest price of the current candle.
Returns: float - The lowest price of the current candle.
Close()
Close
@description Returns the closing price of the current candle.
Returns: float - The closing price of the current candle.
FullSize()
FullSize
@description Returns the full size (range) of the current candle (high - low).
Returns: float - The full size of the current candle.
BodySize()
BodySize
@description Returns the body size of the current candle (open - close).
Returns: float - The body size of the current candle.
WickSize()
WickSize
@description Returns the size of the wicks of the current candle (full size - body size).
Returns: float - The size of the wicks of the current candle.
UpperWickSize()
UpperWickSize
@description Returns the size of the upper wick of the current candle.
Returns: float - The size of the upper wick of the current candle.
LowerWickSize()
LowerWickSize
@description Returns the size of the lower wick of the current candle.
Returns: float - The size of the lower wick of the current candle.
BodyToWickRatio()
BodyToWickRatio
@description Returns the ratio of the body size to the wick size of the current candle.
Returns: float - The body to wick ratio of the current candle.
UpperWickPercentage()
UpperWickPercentage
@description Returns the percentage of the upper wick size relative to the full size of the current candle.
Returns: float - The percentage of the upper wick size relative to the full size of the current candle.
LowerWickPercentage()
LowerWickPercentage
@description Returns the percentage of the lower wick size relative to the full size of the current candle.
Returns: float - The percentage of the lower wick size relative to the full size of the current candle.
WickToBodyRatio()
WickToBodyRatio
@description Returns the ratio of the wick size to the body size of the current candle.
Returns: float - The wick to body ratio of the current candle.
BodyPercentage()
BodyPercentage
@description Returns the percentage of the body size relative to the full size of the current candle.
Returns: float - The percentage of the body size relative to the full size of the current candle.
WickPercentage()
WickPercentage
@description Returns the percentage of the wick size relative to the full size of the current candle.
Returns: float - The percentage of the wick size relative to the full size of the current candle.
CandleDirection()
CandleDirection
@description Returns the direction of the current candle.
Returns: string - "Bullish" if the candle is bullish, "Bearish" if the candle is bearish.
AveragePrice()
AveragePrice
@description Returns the average price of the current candle (mean of open, high, low, and close).
Returns: float - The average price of the current candle.
MidpointPrice()
MidpointPrice
@description Returns the midpoint price of the current candle (mean of high and low).
Returns: float - The midpoint price of the current candle.
Volatility()
Volatility
@description Returns the standard deviation of the OHLC prices of the current candle.
Returns: float - The volatility of the current candle.
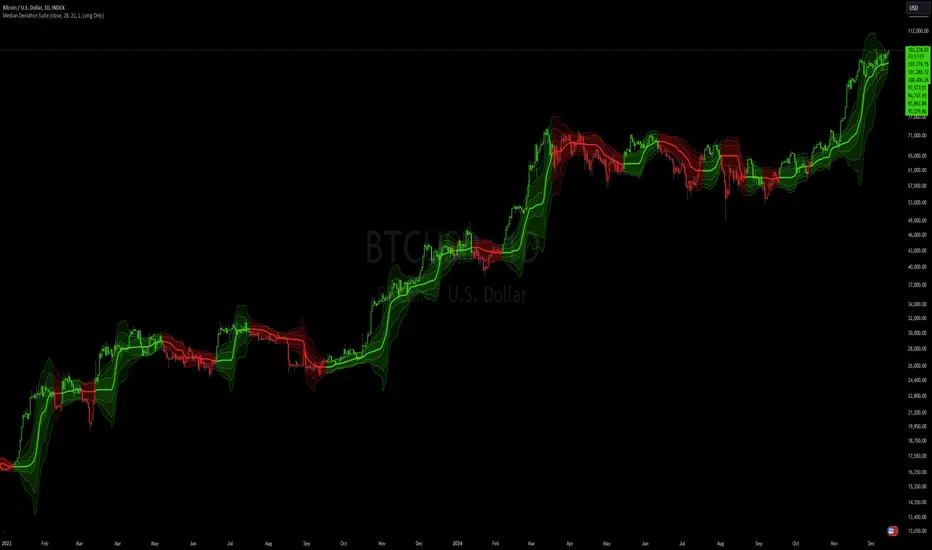
Median Deviation Suite [InvestorUnknown]The Median Deviation Suite uses a median-based baseline derived from a Double Exponential Moving Average (DEMA) and layers multiple deviation measures around it. By comparing price to these deviation-based ranges, it attempts to identify trends and potential turning points in the market. The indicator also incorporates several deviation types—Average Absolute Deviation (AAD), Median Absolute Deviation (MAD), Standard Deviation (STDEV), and Average True Range (ATR)—allowing traders to visualize different forms of volatility and dispersion. Users should calibrate the settings to suit their specific trading approach, as the default values are not optimized.
Core Components
Median of a DEMA:
The foundation of the indicator is a Median applied to the 7-day DEMA (Double Exponential Moving Average). DEMA aims to reduce lag compared to simple or exponential moving averages. By then taking a median over median_len periods of the DEMA values, the indicator creates a robust and stable central tendency line.
float dema = ta.dema(src, 7)
float median = ta.median(dema, median_len)
Multiple Deviation Measures:
Around this median, the indicator calculates several measures of dispersion:
ATR (Average True Range): A popular volatility measure.
STDEV (Standard Deviation): Measures the spread of price data from its mean.
MAD (Median Absolute Deviation): A robust measure of variability less influenced by outliers.
AAD (Average Absolute Deviation): Similar to MAD, but uses the mean absolute deviation instead of median.
Average of Deviations (avg_dev): The average of the above four measures (ATR, STDEV, MAD, AAD), providing a combined sense of volatility.
Each measure is multiplied by a user-defined multiplier (dev_mul) to scale the width of the bands.
aad = f_aad(src, dev_len, median) * dev_mul
mad = f_mad(src, dev_len, median) * dev_mul
stdev = ta.stdev(src, dev_len) * dev_mul
atr = ta.atr(dev_len) * dev_mul
avg_dev = math.avg(aad, mad, stdev, atr)
Deviation-Based Bands:
The indicator creates multiple upper and lower lines based on each deviation type. For example, using MAD:
float mad_p = median + mad // already multiplied by dev_mul
float mad_m = median - mad
Similar calculations are done for AAD, STDEV, ATR, and the average of these deviations. The indicator then determines the overall upper and lower boundaries by combining these lines:
float upper = f_max4(aad_p, mad_p, stdev_p, atr_p)
float lower = f_min4(aad_m, mad_m, stdev_m, atr_m)
float upper2 = f_min4(aad_p, mad_p, stdev_p, atr_p)
float lower2 = f_max4(aad_m, mad_m, stdev_m, atr_m)
This creates a layered structure of volatility envelopes. Traders can observe which layers price interacts with to gauge trend strength.
Determining Trend
The indicator generates trend signals by assessing where price stands relative to these deviation-based lines. It assigns a trend score by summing individual signals from each deviation measure. For instance, if price crosses above the MAD-based upper line, it contributes a bullish point; crossing below an ATR-based lower line contributes a bearish point.
When the aggregated trend score crosses above zero, it suggests a shift towards a bullish environment; crossing below zero indicates a bearish bias.
// Define Trend scores
var int aad_t = 0
if ta.crossover(src, aad_p)
aad_t := 1
if ta.crossunder(src, aad_m)
aad_t := -1
var int mad_t = 0
if ta.crossover(src, mad_p)
mad_t := 1
if ta.crossunder(src, mad_m)
mad_t := -1
var int stdev_t = 0
if ta.crossover(src, stdev_p)
stdev_t := 1
if ta.crossunder(src, stdev_m)
stdev_t := -1
var int atr_t = 0
if ta.crossover(src, atr_p)
atr_t := 1
if ta.crossunder(src, atr_m)
atr_t := -1
var int adev_t = 0
if ta.crossover(src, adev_p)
adev_t := 1
if ta.crossunder(src, adev_m)
adev_t := -1
int upper_t = src > upper ? 3 : 0
int lower_t = src < lower ? 0 : -3
int upper2_t = src > upper2 ? 1 : 0
int lower2_t = src < lower2 ? 0 : -1
float trend = aad_t + mad_t + stdev_t + atr_t + adev_t + upper_t + lower_t + upper2_t + lower2_t
var float sig = 0
if ta.crossover(trend, 0)
sig := 1
else if ta.crossunder(trend, 0)
sig := -1
Practical Usage and Calibration
Default settings are not optimized: The given parameters serve as a starting point for demonstration. Users should adjust:
median_len: Affects how smooth and lagging the median of the DEMA is.
dev_len and dev_mul: Influence the sensitivity of the deviation measures. Larger multipliers widen the bands, potentially reducing false signals but introducing more lag. Smaller multipliers tighten the bands, producing quicker signals but potentially more whipsaws.
This flexibility allows the trader to tailor the indicator for various markets (stocks, forex, crypto) and time frames.
Backtesting and Performance Metrics
The code integrates with a backtesting library that allows traders to:
Evaluate the strategy historically
Compare the indicator’s signals with a simple buy-and-hold approach
Generate performance metrics (e.g., mean returns, Sharpe Ratio, Sortino Ratio) to assess historical effectiveness.
Disclaimer
No guaranteed results: Historical performance does not guarantee future outcomes. Market conditions can vary widely.
User responsibility: Traders should combine this indicator with other forms of analysis, appropriate risk management, and careful calibration of parameters.
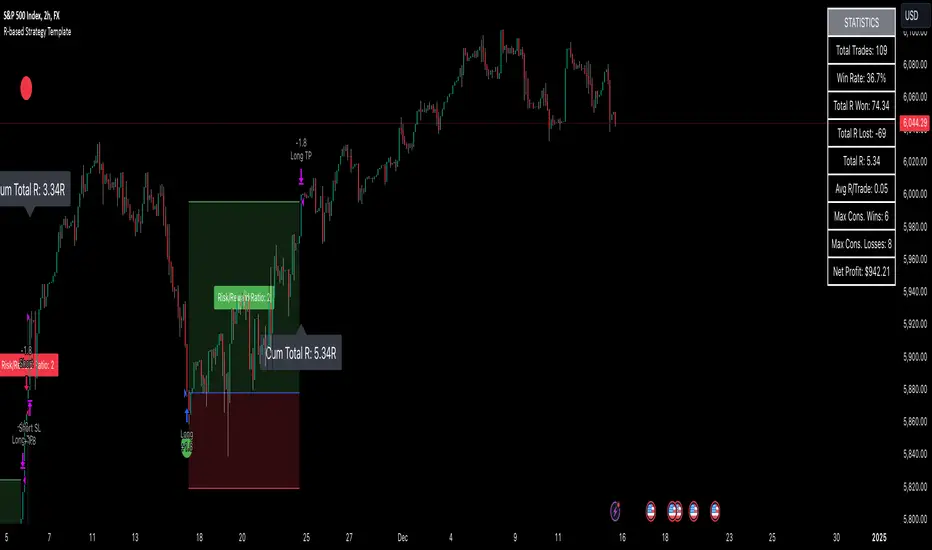
R-based Strategy Template [Daveatt]Have you ever wondered how to properly track your trading performance based on risk rather than just profits?
This template solves that problem by implementing R-multiple tracking directly in TradingView's strategy tester.
This script is a tool that you must update with your own trading entry logic.
Quick notes
Before we dive in, I want to be clear: this is a template focused on R-multiple calculation and visualization.
I'm using a basic RSI strategy with dummy values just to demonstrate how the R tracking works. The actual trading signals aren't important here - you should replace them with your own strategy logic.
R multiple logic
Let's talk about what R-multiple means in practice.
Think of R as your initial risk per trade.
For instance, if you have a $10,000 account and you're risking 1% per trade, your 1R would be $100.
A trade that makes twice your risk would be +2R ($200), while hitting your stop loss would be -1R (-$100).
This way of measuring makes it much easier to evaluate your strategy's performance regardless of account size.
Whenever the SL is hit, we lose -1R
Proof showing the strategy tester whenever the SL is hit: i.imgur.com
The magic happens in how we calculate position sizes.
The script automatically determines the right position size to risk exactly your specified percentage on each trade.
This is done through a simple but powerful calculation:
risk_amount = (strategy.equity * (risk_per_trade_percent / 100))
sl_distance = math.abs(entry_price - sl_price)
position_size = risk_amount / (sl_distance * syminfo.pointvalue)
Limitations with lower timeframe gaps
This ensures that if your stop loss gets hit, you'll lose exactly the amount you intended to risk. No more, no less.
Well, could be more or less actually ... let's assume you're trading futures on a 15-minute chart but in the 1-minute chart there is a gap ... then your 15 minute SL won't get filled and you'll likely to not lose exactly -1R
This is annoying but it can't be fixed - and that's how trading works anyway.
Features
The template gives you flexibility in how you set your stop losses. You can use fixed points, ATR-based stops, percentage-based stops, or even tick-based stops.
Regardless of which method you choose, the position sizing will automatically adjust to maintain your desired risk per trade.
To help you track performance, I've added a comprehensive statistics table in the top right corner of your chart.
It shows you everything you need to know about your strategy's performance in terms of R-multiples: how many R you've won or lost, your win rate, average R per trade, and even your longest winning and losing streaks.
Happy trading!
And remember, measuring your performance in R-multiples is one of the most classical ways to evaluate and improve your trading strategies.
Daveatt
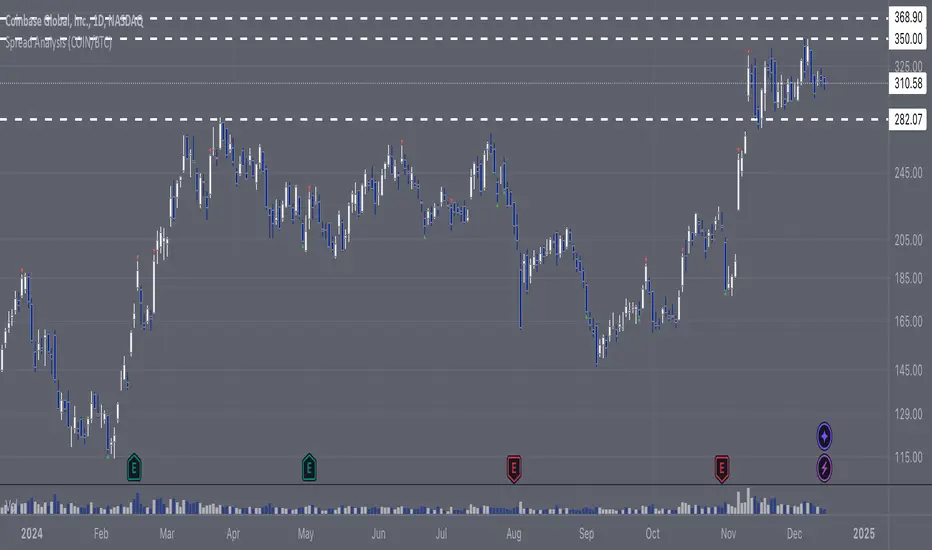
Spread Analysis (COIN/BTC)The Spread Analysis (COIN/BTC) indicator calculates the Z-score of the price ratio between Coinbase stock ( NASDAQ:COIN ) and Bitcoin ( CRYPTOCAP:BTC ). It helps identify overbought or oversold conditions based on deviations from the historical mean of their price relationship.
Key Features:
Z-Score Calculation:
• Tracks the relative price ratio of NASDAQ:COIN to $BTC.
• Compares the current ratio to its historical average, highlighting extreme overvaluation or undervaluation.
• Buy and Sell Signals:
• Buy Signal: Triggered when the Z-score is less than -2, indicating NASDAQ:COIN may be undervalued relative to $BTC.
• Sell Signal: Triggered when the Z-score exceeds 2, suggesting NASDAQ:COIN may be overvalued relative to $BTC.
• Dynamic Z-Score Visualization:
• Blue line plots the Z-score over time.
• Dashed lines at +2 and -2 mark overbought and oversold thresholds.
• Green and red triangles highlight actionable buy and sell signals.
Use Case:
This indicator is ideal for identifying relative valuation opportunities between NASDAQ:COIN and $BTC. Use it to exploit divergences in their historical relationship and anticipate potential reversions to the mean.
Limitations:
• Best suited for range-bound markets; may produce false signals in strongly trending conditions.
• Assumes a consistent correlation between NASDAQ:COIN and CRYPTOCAP:BTC , which may break during independent price drivers like news or earnings.
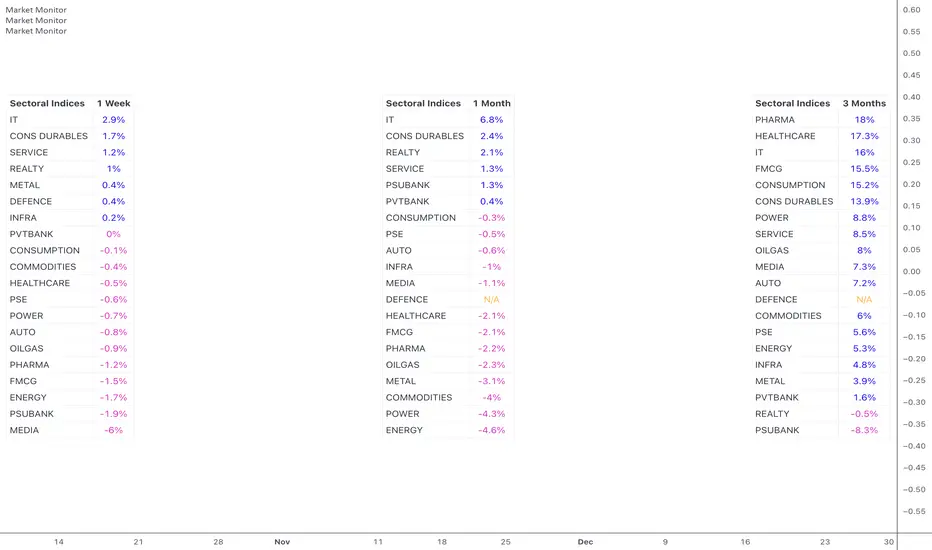
Market MonitorOverview
The Market Monitor Indicator provides a customisable view of dynamic percentage changes across selected indices or sectors, calculated by comparing current and previous closing prices over the chosen timeframe.
Key Features
Choose up to 20 predefined indices or your own selected indices/stocks.
Use checkboxes to show or hide individual entries.
Monitor returns over daily, weekly, monthly, quarterly, half-yearly, or yearly timeframes
Sort by returns (descending) to quickly identify top-performing indices or alphabetically for an organised and systematic review.
Customisation
Switch between Light Mode (Blue or Green themes) and Dark Mode for visual clarity.
Adjust the table’s size, position, and location.
Customise the table title to your own choice e.g. Sectoral, Broad, Portfolio etc.
Use Cases
Use multiple instances of the script with varying timeframes to study sectoral rotation and trends.
Customise the stocks to see your portfolio returns for the day or over the past week, or longer.
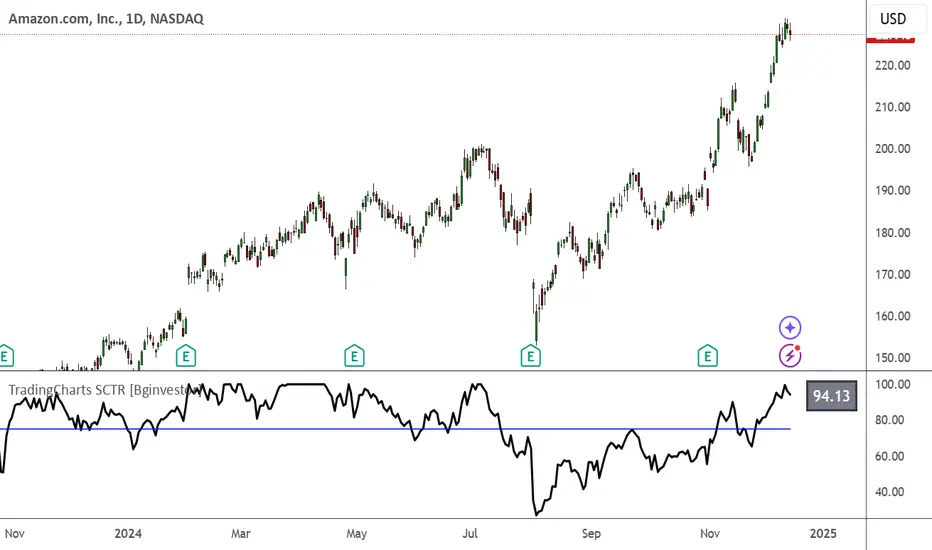
TradingCharts SCTR [Bginvestor]This indicator is replicating Tradingcharts, SCTR plot. If you know, you know.
Brief description: The StockCharts Technical Rank (SCTR), conceived by technical analyst John Murphy, emerges as a pivotal tool in evaluating a stock’s technical prowess. This numerical system, colloquially known as “scooter,” gauges a stock’s strength within various groups, employing six key technical indicators across different time frames.
How to use it:
Long-term indicators (30% weight each)
-Percent above/below the 200-day exponential moving average (EMA)
-125-day rate-of-change (ROC)
Medium-term indicators (15% weight each)
-percent above/below 50-day EMA
-20-day rate-of-change
Short-term indicators (5% weight each)
-Three-day slope of percentage price oscillator histogram divided by three
-Relative strength index
How to use SCTR:
Investors select a specific group for analysis, and the SCTR assigns rankings within that group. A score of 99.99 denotes robust technical performance, while zero signals pronounced underperformance. Traders leverage this data for strategic decision-making, identifying stocks with increasing SCTR for potential buying or spotting weak stocks for potential shorting.
Credit: I've made some modifications, but credit goes to GodziBear for back engineering the averaging / scaling of the equations.
Note: Not a perfect match to TradingCharts, but very, very close.
Sector Relative Strength [Afnan]This indicator calculates and displays the relative strength (RS) of multiple sectors against a chosen benchmark. It allows you to quickly compare the performance of various sectors within any global stock market. While the default settings are configured for the Indian stock market , this tool is not limited to it; you can use it for any market by selecting the appropriate benchmark and sector indices.
📊 Key Features ⚙️
Customizable Benchmark: Select any symbol as your benchmark for relative strength calculation. The default benchmark is set to `NSE:CNX100`. This allows for global market analysis by selecting the appropriate benchmark index of any country.
Multiple Sectors: Analyze up to 23 different sector indices. The default settings include major NSE sector indices. This can be customized to any market by using the relevant sector indices of that country.
Individual Sector Control: Toggle the visibility of each sector's RS on the chart.
Color-Coded Plots: Each sector's RS is plotted with a distinct color for easy identification.
Adjustable Lookback Period: Customize the lookback period for RS calculation.
Interactive Table: A sortable table displays the current RS values for all visible sectors, allowing for quick ranking.
Table Customization: Adjust the table's position, text size, and visibility.
Zero Line: A horizontal line at zero provides a reference point for RS values.
🧭 How to Use 🗺️
Add the indicator to your TradingView chart.
Select your desired benchmark symbol. The default is `NSE:CNX100`. For example, use SPY for the US market, or DAX for the German market.
Adjust the lookback period as needed.
Enable/disable the sector indices you want to analyze. The default includes major NSE sector indices like `NSE:CNXIT`, `NSE:CNXAUTO`, etc.
Customize the table's appearance as needed.
Observe the RS plots and the table to identify sectors with relative strength or weakness.
📝 Note 💡
This indicator is designed for sectorial analysis. You can use it with any market by selecting the appropriate benchmark and sector indices.
The default settings are configured for the Indian stock market with `NSE:CNX100` as the benchmark and major NSE sector indices pre-selected.
The relative strength calculation is based on the price change of the sector index compared to the benchmark over the lookback period.
Positive RS values indicate relative outperformance, while negative values indicate relative underperformance.
👨💻 Developer 🛠️
Afnan Tajuddin

Scatter Plot with Symbol or Data Source InputsDescription of setting items
Use Symbol for X Data?
Type: Checkbox (input.bool)
Explanation: Selects whether the data used for the X axis is obtained from a “symbol” or a “data source”.
If true: data for the X axis will be taken from a symbol (e.g. stock ticker).
If false: X axis data will be taken from the specified data source (e.g., closing price or volume).
Use Symbol for Y Data?
type: checkbox (input.bool)
Explanation: Selects whether the data used for the Y axis is retrieved from a “symbol” or a “data source”.
If true: Y-axis data is obtained from symbols.
If false: Data for the Y axis is obtained from the specified data source.
Select Ticker Symbol for X Data
type: symbol input (input.symbol)
description: selects the symbol to be used for the X axis (default is “AAPL”).
If “Use Symbol for X Data?” is set to true, this symbol will be used as the data for the X axis.
Select Ticker Symbol for Y Data
Type: Symbol input (input.symbol)
description: selects the symbol to be used for the Y axis (default is “GOOG”).
If “Use Symbol for Y Data?” is set to true, this symbol will be used as the data for the Y axis.
X Data Source
type: data source input (input.source)
description: specifies the data source to be used for the X axis.
Default is “close” (closing price).
Other possible values include open, high, low, volume, etc.
Y Data Source
Type: data source input (input.source)
Description: Specifies the data source to be used for the Y axis.
Default is “volume” (volume).
Other possible values include open, high, low, close, etc.
X Offset
type: integer input (input.int)
description: sets the offset value of the X axis.
This shifts the position of the X axis on the grid. The range is from -500 to 500.
Y Offset
Type: Integer input (constant)
description: offset value for y-axis.
Defaults to 0, but can be changed to adjust the Y axis position.
grid_width
type: integer input (input.int)
description: sets the width of the grid.
The default is 200. Increasing the value results in a finer grid.
grid_height
type: integer input (input.int)
description: sets the height of the grid.
Defaults to 200. Increasing the value results in a finer grid.
Frequency of updates
type: integer input (input.int)
description: set frequency of updates.
The higher the frequency of updates, the more bars will be used to calculate minimum and maximum values.
X Tick Interval
type: integer input (input.int)
description: sets the tick interval for the X axis.
The default is 10. To increase the number of ticks, decrease the value.
Y Tick Interval
Box border color
type: select color (input.color)
description: select color for grid box border
Default is blue.
Explanation of usage
To use symbol data: Set Use Symbol for X Data?
When “Use Symbol for X Data?” and “Use Symbol for Y Data?” are set to true, the data of the specified symbol is displayed on each axis. For example, you can use “AAPL” (Apple's stock price data) for the X axis and “GOOG” (Google's stock price data) for the Y axis.
To set the symbol, select the desired ticker in Select Ticker Symbol for X Data and Select Ticker Symbol for Y Data.
To use a data source: select the
You can set Use Symbol for X Data? and Use Symbol for Y Data? to false and use the data source specified in X Data Source or Y Data Source instead (e.g., closing price or volume).
Change Grid Size:.
Set the width and height of the grid with grid_width and grid_height. Larger values allow for more detailed scatter plots.
Set Tick Intervals: Set the X Tick Interval and Y Tick Interval.
Adjust X Tick Interval and Y Tick Interval to change the tick spacing on the X and Y axes.
Data Range Adjustment: Adjust the Frequency of updates to change the frequency of updates.
The Frequency of updates can be changed to control how often the data range is updated. The higher this value, the more historical data is considered and displayed.
Box Color.
Box Border Color allows you to change the color of the box border.
This script is useful for visualizing different symbols and data sources, especially to show the relationship between financial data.
Caution.
Some data may exceed the memory size, but the scale is the same, so you will know most of the locations.
*I made it myself because I could not find anything to draw a scatter plot. You can also compare more than 3 pieces of data by displaying more than one scatter plot. Here is how to do it. Set X or Y as the reference data. Set the data you want to compare to the one that is not the standard. Next, set the same indicator and set the reference to another set of data you wish to compare. Now you can compare the three sets of data. It is effective to change the color of the display box to prevent the user from not knowing which is which. Thus, you should be able to compare more than 3 pieces of data, so give it a try.
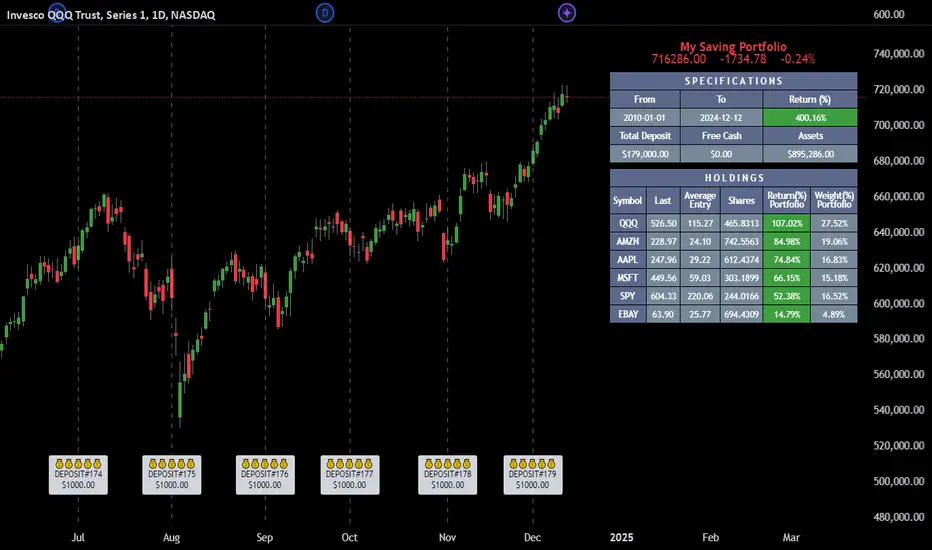
Employee Portfolio Generator [By MUQWISHI]▋ INTRODUCTION :
The “Employee Portfolio Generator” simplifies the process of building a long-term investment portfolio tailored for employees seeking to build wealth through investments rather than traditional bank savings. The tool empowers employees to set up recurring deposits at customizable intervals, enabling to make additional purchases in a list of preferred holdings, with the ability to define the purchasing investment weight for each security. The tool serves as a comprehensive solution for tracking portfolio performance, conducting research, and analyzing specific aspects of portfolio investments. The output includes an index value, a table of holdings, and chart plots, providing a deeper understanding of the portfolio's historical movements.
_______________________
▋ OVERVIEW:
● Scenario (The chart above can be taken as an example) :
Let say, in 2010, a newly employed individual committed to saving $1,000 each month. Rather than relying on a traditional savings account, chose to invest the majority of monthly savings in stable well-established stocks. Allocating 30% of monthly saving to AMEX:SPY and another 30% to NASDAQ:QQQ , recognizing these as reliable options for steady growth. Additionally, there was an admired toward innovative business models of NASDAQ:AAPL , NASDAQ:MSFT , NASDAQ:AMZN , and NASDAQ:EBAY , leading to invest 10% in each of those companies. By the end of 2024, after 15 years, the total monthly deposits amounted to $179,000, which would have been the result of traditional saving alone. However, by sticking into long term invest, the value of the portfolio assets grew, reaching nearly $900,000.
_______________________
▋ OUTPUTS:
The table can be displayed in three formats:
1. Portfolio Index Title: displays the index name at the top, and at the bottom, it shows the index value, along with the chart timeframe, e.g., daily change in points and percentage.
2. Specifications: displays the essential information on portfolio performance, including the investment date range, total deposits, free cash, returns, and assets.
3. Holdings: a list of the holding securities inside a table that contains the ticker, last price, entry price, return percentage of the portfolio's total deposits, and latest weighted percentage of the portfolio. Additionally, a tooltip appears when the user passes the cursor over a ticker's cell, showing brief information about the company, such as the company's name, exchange market, country, sector, and industry.
4. Indication of New Deposit: An indication of a new deposit added to the portfolio for additional purchasing.
5. Chart: The portfolio's historical movements can be visualized in a plot, displayed as a bar chart, candlestick chart, or line chart, depending on the preferred format, as shown below.
_______________________
▋ INDICATOR SETTINGS:
Section(1): Table Settings
(1) Naming the index.
(2) Table location on the chart and cell size.
(3) Sorting Holdings Table. By securities’ {Return(%) Portfolio, Weight(%) Portfolio, or Ticker Alphabetical} order.
(4) Choose the type of index: {Assets, Return, or Return (%)}, and the plot type for the portfolio index: {Candle, Bar, or Line}.
(5) Positive/Negative colors.
(6) Table Colors (Title, Cell, and Text).
(7) To show/hide any of selected indicator’s components.
Section(2): Recurring Deposit Settings
(1) From DateTime of starting the investment.
(2) To DateTime of ending the investment
(3) The amount of recurring deposit into portfolio and currency.
(4) The frequency of recurring deposits into the portfolio {Weekly, 2-Weeks, Monthly, Quarterly, Yearly}
(5) The Depositing Model:
● Fixed: The amount for recurring deposits remains constant throughout the entire investment period.
● Increased %: The recurring deposit amount increases at the selected frequency and percentage throughout the entire investment period.
(5B) If the user selects “ Depositing Model: Increased % ”, specify the growth model (linear or exponential) and define the rate of increase.
Section(3): Portfolio Holdings
(1) Enable a ticker in the investment portfolio.
(2) The selected deposit frequency weight for a ticker. For example, if the monthly deposit is $1,000 and the selected weight for XYZ stock is 30%, $300 will be used to purchase shares of XYZ stock.
(3) Select up to 6 tickers that the investor is interested in for long-term investment.
Please let me know if you have any questions
Calculate Order Entry Units based on set Dollar ValuesFUNCTIONS
- Calculate UNITS quantity based on user's input dollar values.
- Show Units in table
USAGE
- Enter 6 usual order $ values
- Use units value in order entry
Tradingview doesn't have order entry in dollar value for most connections/exchanges so it's really tedious to calculate Units some other way every time.
This gives you the Units based on your most used order value sizes in a quick way.
Possible future updates
- Allow user settings for number of values to display
- Allow user option to set titles for each row
Note:
Tradingview really need to get off their butts and give us a real DOM panel and working dollar value order entry for all exchanges among other order entry panel updates.
I hope everyone is suggesting this to them.

DynamicPeriodPublicDynamic Period Calculation Library
This library provides tools for adaptive period determination, useful for creating indicators or strategies that automatically adjust to market conditions.
Overview
The Dynamic Period Library calculates adaptive periods based on pivot points, enabling the creation of responsive indicators and strategies that adjust to market volatility.
Key Features
Dynamic Periods: Computes periods using distances between pivot highs and lows.
Customizable Parameters: Users can adjust detection settings and period constraints.
Robust Handling: Includes fallback mechanisms for cases with insufficient pivot data.
Use Cases
Adaptive Indicators: Build tools that respond to market volatility by adjusting their periods dynamically.
Dynamic Strategies: Enhance trading strategies by integrating pivot-based period adjustments.
Function: `dynamic_period`
Description
Calculates a dynamic period based on the average distances between pivot highs and lows.
Parameters
`left` (default: 5): Number of left-hand bars for pivot detection.
`right` (default: 5): Number of right-hand bars for pivot detection.
`numPivots` (default: 5): Minimum pivots required for calculation.
`minPeriod` (default: 2): Minimum allowed period.
`maxPeriod` (default: 50): Maximum allowed period.
`defaultPeriod` (default: 14): Fallback period if no pivots are found.
Returns
A dynamic period calculated based on pivot distances, constrained by `minPeriod` and `maxPeriod`.
Example
//@version=6
import CrimsonVault/DynamicPeriodPublic/1
left = input.int(5, "Left bars", minval = 1)
right = input.int(5, "Right bars", minval = 1)
numPivots = input.int(5, "Number of Pivots", minval = 2)
period = DynamicPeriodPublic.dynamic_period(left, right, numPivots)
plot(period, title = "Dynamic Period", color = color.blue)
Implementation Notes
Pivot Detection: Requires sufficient historical data to identify pivots accurately.
Edge Cases: Ensures a default period is applied when pivots are insufficient.
Constraints: Limits period values to a user-defined range for stability.

Market Anomaly Detector (MAD)Market Anomaly Detector (MAD) Indicator - Detailed Description:
The Market Anomaly Detector (MAD) Indicator is a unique tool designed to identify potential market anomalies by combining several price action-based and momentum indicators. This indicator is especially useful for traders who seek to identify significant market shifts and anomalies before they become visible in conventional technical indicators.
Key Features of the MAD Indicator:
1. Z-Score Threshold for Anomaly Detection:
• The Z-Score measures how far a current price is from its average over a defined period, normalized by standard deviation. This allows the MAD indicator to detect outliers or anomalies in price movements.
• By adjusting the Z-Score Threshold, traders can tune the sensitivity of the indicator to capture only the most significant price deviations, filtering out noise and reducing false signals.
2. Volume and Liquidity Filter:
• Volume is a key indicator of market participation and sentiment. The MAD Indicator uses a volume multiplier to assess when price movements are supported by sufficient trading volume.
• A volume spike is identified when the current volume exceeds the average volume by a certain multiplier. This ensures that only high-confidence signals are generated, particularly useful for spotting trend reversals and breakout opportunities.
3. Signal Cooldown Period:
• To prevent overfitting and reduce false signals, a signal cooldown period is implemented. Once a buy or sell signal is triggered, the indicator waits for a specified number of bars (e.g., 5) before triggering another signal, even if the price action meets the criteria for a new signal. This helps maintain a cleaner trading environment and avoids confusion when the market is volatile.
4. Upper and Lower Bands for Trend Confirmation:
• The MAD Indicator uses bands based on the mean price and standard deviation, similar to Bollinger Bands. These upper and lower bands help to define the expected price range for a given period, indicating overbought or oversold conditions.
• The combination of Z-Score, volume, and band analysis helps pinpoint when the price breaks out of expected ranges, providing early warning signs for potential market shifts.
5. Trend Confirmation from Higher Timeframes:
• The MAD Indicator includes a multi-timeframe approach to trend confirmation, using the 50-period EMA on a higher timeframe (e.g., 1-hour chart). This ensures that signals are aligned with the overall market trend, enhancing the reliability of buy and sell signals.
How It Works:
• The MAD Indicator continuously monitors price action, volume, and statistical anomalies, using the Z-Score to determine when the price is significantly deviating from its historical average.
• When the price breaks above the upper band and a bullish anomaly is detected, a buy signal is generated. (Green Background)
• Similarly, when the price breaks below the lower band and a bearish anomaly is detected, a sell signal is triggered. (Red Background
• By filtering signals based on volume and using the cooldown period, the MAD Indicator ensures that only high-quality trades are signaled.
How to Use the MAD Indicator:
• Buy Signal: Occurs when the price breaks above the upper band and there is a significant deviation from the mean (bullish anomaly).
• Sell Signal: Occurs when the price breaks below the lower band and there is a significant deviation from the mean (bearish anomaly).
• Volume Confirmation: Ensure that the buy/sell signals are supported by a volume spike, indicating strong market participation.
• Signal Cooldown Period: After a signal is triggered, the indicator waits for the cooldown period to avoid triggering multiple signals in quick succession.
Why It’s Worth Paying For:
The MAD Indicator combines advanced statistical analysis (Z-Score), price action, and volume analysis to identify market anomalies and breakouts before they are visible on standard indicators. By leveraging the power of mean reversion and statistical anomalies, this tool provides traders with high-confidence signals that can lead to profitable trades, especially in volatile markets. The integration of a multi-timeframe trend filter ensures that signals are aligned with the overall market trend, reducing the likelihood of false breakouts.
This indicator is ideal for trend-following traders looking for high-probability entries and mean-reversion traders aiming to capture price deviations. The signal cooldown period and volume filter provide an additional layer of precision, ensuring that you only act on the strongest market signals.

Salience Theory Crypto Returns (AiBitcoinTrend)The Salience Theory Crypto Returns Indicator is a sophisticated tool rooted in behavioral finance, designed to identify trading opportunities in the cryptocurrency market. Based on research by Bordalo et al. (2012) and extended by Cai and Zhao (2022), it leverages salience theory—the tendency of investors, particularly retail traders, to overemphasize standout returns.
In the crypto market, dominated by sentiment-driven retail investors, salience effects are amplified. Attention disproportionately focused on certain cryptocurrencies often leads to temporary price surges, followed by reversals as the market stabilizes. This indicator quantifies these effects using a relative return salience measure, enabling traders to capitalize on price reversals and trends, offering a clear edge in navigating the volatile crypto landscape.
👽 How the Indicator Works
Salience Measure Calculation :
👾 The indicator calculates how much each cryptocurrency's return deviates from the average return of all cryptos over the selected ranking period (e.g., 21 days).
👾 This deviation is the salience measure.
👾 The more a return stands out (salient outcome), the higher the salience measure.
Ranking:
👾 Cryptos are ranked in ascending order based on their salience measures.
👾 Rank 1 (lowest salience) means the crypto is closer to the average return and is more predictable.
👾 Higher ranks indicate greater deviation and unpredictability.
Color Interpretation:
👾 Green: Low salience (closer to average) – Trending or Predictable.
👾 Red/Orange: High salience (far from average) – Overpriced/Unpredictable.
👾 Text Gradient (Teal to Light Blue): Helps visualize potential opportunities for mean reversion trades (i.e., cryptos that may return to equilibrium).
👽 Core Features
Salience Measure Calculation
The indicator calculates the salience measure for each cryptocurrency by evaluating how much its return deviates from the average market return over a user-defined ranking period. This measure helps identify which assets are trending predictably and which are likely to experience a reversal.
Dynamic Ranking System
Cryptocurrencies are dynamically ranked based on their salience measures. The ranking helps differentiate between:
Low Salience Cryptos (Green): These are trending or predictable assets.
High Salience Cryptos (Red): These are overpriced or deviating significantly from the average, signaling potential reversals.
👽 Deep Dive into the Core Mathematics
Salience Theory in Action
Salience theory explains how investors, particularly in the crypto market, tend to prefer assets with standout returns (salient outcomes). This behavior often leads to overpricing of assets with high positive returns and underpricing of those with standout negative returns. The indicator captures these deviations to anticipate mean reversions or trend continuations.
Salience Measure Calculation
// Calculate the average return
avgReturn = array.avg(returns)
// Calculate salience measure for each symbol
salienceMeasures = array.new_float()
for i = 0 to array.size(returns) - 1
ret = array.get(returns, i)
salienceMeasure = math.abs(ret - avgReturn) / (math.abs(ret) + math.abs(avgReturn) + 0.1)
array.push(salienceMeasures, salienceMeasure)
Dynamic Ranking
Cryptos are ranked in ascending order based on their salience measures:
Low Ranks: Cryptos with low salience (predictable, trending).
High Ranks: Cryptos with high salience (unpredictable, likely to revert).
👽 Applications
👾 Trend Identification
Identify cryptocurrencies that are currently trending with low salience measures (green). These assets are likely to continue their current direction, making them good candidates for trend-following strategies.
👾 Mean Reversion Trading
Cryptos with high salience measures (red to light blue) may be poised for a mean reversion. These assets are likely to correct back towards the market average.
👾 Reversal Signals
Anticipate potential reversals by focusing on high-ranked cryptos (red). These assets exhibit significant deviation and are prone to price corrections.
👽 Why It Works in Crypto
The cryptocurrency market is dominated by retail investors prone to sentiment-driven behavior. This leads to exaggerated price movements, making the salience effect a powerful predictor of reversals.
👽 Indicator Settings
👾 Ranking Period : Number of bars used to calculate the average return and salience measure.
Higher Values: Smooth out short-term volatility.
Lower Values: Make the ranking more sensitive to recent price movements.
👾 Number of Quantiles : Divide ranked assets into quantile groups (e.g., quintiles).
Higher Values: More detailed segmentation (deciles, percentiles).
Lower Values: Broader grouping (quintiles, quartiles).
👾 Portfolio Percentage : Percentage of the portfolio allocated to each selected asset.
Enter a percentage (e.g., 20 for 20%), automatically converted to a decimal (e.g., 0.20).
Disclaimer: This information is for entertainment purposes only and does not constitute financial advice. Please consult with a qualified financial advisor before making any investment decisions.

Valuation MetricValuation Metric Indicator
The Valuation Metric Indicator provides a comprehensive tool for evaluating price dynamics in relation to a moving average and standard deviation. It combines the power of statistical analysis with clear visualizations to help traders assess market valuation levels and potential overbought or oversold conditions.
Key Features:
Z-Score Calculation:
Displays the Z-score of the price relative to the moving average, normalized by standard deviation.
Z-score is clamped within the range of -3 to +3 to focus on significant deviations.
Standard Deviation Bands:
Plots bands at 1x, 2x, and 3x standard deviations above and below the moving average.
Helps identify areas of extreme overvaluation or undervaluation.
Dynamic Valuation Table:
Displays the current Z-score and provides a textual assessment of the market's valuation:
Overvalued
Slightly Overvalued
Neutral
Slightly Undervalued
Undervalued
Background color dynamically changes based on the valuation.
Customizable Background Signals:
Optional background highlighting for "Top Signal" (overvaluation) and "Bottom Signal" (undervaluation).
Configurable Display:
Users can toggle the visibility of standard deviation bands and background signals to fit their preferences.
Color-Coded Visualization:
Uses gradient-based color coding for Z-scores and standard deviation bands, improving readability and decision-making.

Asset Correlation CheckThis indicator evaluates how your current chart symbol interacts with key markets such as stock indices NASDAQ:NDX SP:SPX AMEX:IWM XETR:DAX PEPPERSTONE:CN50 , commodities CAPITALCOM:GOLD CAPITALCOM:SILVER , bonds NASDAQ:TLT NASDAQ:SHY , and cryptocurrencies BINANCE:BTCUSD , and displays the results in a compact, interactive table. It allows you to adjust the analysis period and select one of three correlation calculation methods (Index, Relative, and Beta) to gain different perspectives on the relationships between assets.
Index Correlation
Advantages: Provides a classic statistical correlation value, making it easy to understand overall directional alignment.
Drawbacks: Less reliable for highly volatile or short-term conditions, as temporary spikes can distort the correlation.
When to use: Ideal if you want a clear overview of whether two markets generally move together, for example to assess diversification effects.
Relative Correlation
Advantages: Focuses on percentage changes rather than absolute prices, offering a more dynamic view of short-term shifts.
Drawbacks: More prone to noise due to emphasizing daily or intra-period fluctuations.
When to use: Useful for timing-sensitive strategies, helping you quickly identify if one asset consistently outpaces or lags another in the short run.
Beta Correlation
Advantages: Examines how strongly one asset responds to changes in another, factoring in volatility and sensitivity, helpful for risk profiling.
Drawbacks: More abstract since it does not convey simple directional similarity but how intensely an asset reacts to market movements.
When to use: Ideal if you need to understand how a security may amplify or dampen broader market-level shifts, aiding in portfolio risk management.
Additionally, a Bull-Market Filter narrows the analysis to upward-trending phases, potentially delivering more meaningful insights. The indicator also computes average correlation values over your selected period, so you are not misled by brief fluctuations. It shows the percentage of positive versus negative readings to reveal if markets generally move in tandem or counter to each other.
For stock pickers, this tool is particularly valuable. It helps determine whether individual equities follow broader market forces, move with specific sectors, or behave independently. With this knowledge, you can refine stock selection, balance sector exposures, and seek opportunities that complement existing positions.
The indicator also facilitates the detection of patterns and anomalies, enabling early recognition of shifts in sentiment or new trend impulses. By visualizing how benchmarks, commodities, bonds, and digital assets relate, you gain deeper insight into key drivers that influence your investments.
Regarding rapid changes in correlation, keep in mind that correlation can frequently flip between positive and negative. Such volatility can create confusion if you rely on single readings. One moment, two assets may seem perfectly aligned; the next, they diverge. This does not necessarily indicate a lack of an underlying pattern; short-term factors can distort the picture. By looking at averages and the frequency of positive and negative occurrences, you confirm whether a correlation trend is genuine or simply a result of temporary noise. In other words, these additional metrics ensure that short-lived swings do not overshadow the true, longer-term relationship between the assets.
In essence, this indicator condenses complex intermarket analysis into a practical resource. By leveraging its insights, you can make data-driven decisions, adapt strategies to evolving market conditions, and lay a stronger foundation for long-term trading success.

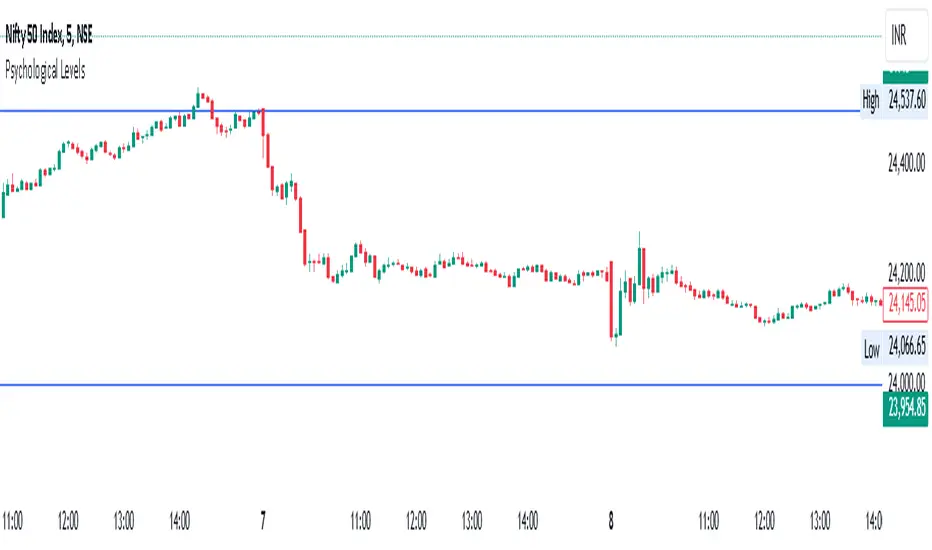
Psychological Levels- Rounding Numbers Psychological Levels Indicator
Overview:
The Psychological Levels Indicator automatically identifies and plots significant price levels based on psychological thresholds, which are key areas where market participants often focus their attention. These levels act as potential support or resistance zones due to human behavioral tendencies to round off numbers. This indicator dynamically adjusts the levels based on the stock's price range and ensures seamless visibility across the chart.
Key Features:
Dynamic Step Sizes:
The indicator adjusts the levels dynamically based on the stock price:
For prices below 500: Levels are spaced at 10.
For prices between 500 and 3000: Levels are spaced at 50, 100, and 1000.
For prices between 3000 and 10,000: Levels are spaced at 100 and 1000.
For prices above 10,000: Levels are spaced at 500 and 1000.
Extended Visibility:
The plotted levels are extended across the entire chart for improved visualization, ensuring traders can easily monitor these critical zones over time.
Customization Options:
Line Color: Choose the color for the levels to suit your charting style.
Line Style: Select from solid, dashed, or dotted lines.
Line Width: Adjust the thickness of the lines for better clarity.
Clean and Efficient Design:
The indicator only plots levels relevant to the visible chart range, avoiding unnecessary clutter and ensuring a clean workspace.
How It Works:
It calculates the relevant step sizes based on the price:
Smaller step sizes for lower-priced stocks.
Larger step sizes for higher-priced stocks.
Primary, secondary, and (if applicable) tertiary levels are plotted dynamically:
Primary Levels: The most granular levels based on the stock price.
Secondary Levels: Higher-order levels for broader significance.
Tertiary Levels: Additional levels for lower-priced stocks to enhance detail.
These levels are plotted across the chart, allowing traders to visualize key psychological areas effortlessly.
Use Cases:
Day Trading: Identify potential intraday support and resistance levels.
Swing Trading: Recognize key price zones where trends may pause or reverse.
Long-Term Investing: Gain insights into significant price zones for entry or exit strategies.
AiTrend Pattern Matrix for kNN Forecasting (AiBitcoinTrend)The AiTrend Pattern Matrix for kNN Forecasting (AiBitcoinTrend) is a cutting-edge indicator that combines advanced mathematical modeling, AI-driven analytics, and segment-based pattern recognition to forecast price movements with precision. This tool is designed to provide traders with deep insights into market dynamics by leveraging multivariate pattern detection and sophisticated predictive algorithms.
👽 Core Features
Segment-Based Pattern Recognition
At its heart, the indicator divides price data into discrete segments, capturing key elements like candle bodies, high-low ranges, and wicks. These segments are normalized using ATR-based volatility adjustments to ensure robustness across varying market conditions.
AI-Powered k-Nearest Neighbors (kNN) Prediction
The predictive engine uses the kNN algorithm to identify the closest historical patterns in a multivariate dictionary. By calculating the distance between current and historical segments, the algorithm determines the most likely outcomes, weighting predictions based on either proximity (distance) or averages.
Dynamic Dictionary of Historical Patterns
The indicator maintains a rolling dictionary of historical patterns, storing multivariate data for:
Candle body ranges, High-low ranges, Wick highs and lows.
This dynamic approach ensures the model adapts continuously to evolving market conditions.
Volatility-Normalized Forecasting
Using ATR bands, the indicator normalizes patterns, reducing noise and enhancing the reliability of predictions in high-volatility environments.
AI-Driven Trend Detection
The indicator not only predicts price levels but also identifies market regimes by comparing current conditions to historically significant highs, lows, and midpoints. This allows for clear visualizations of trend shifts and momentum changes.
👽 Deep Dive into the Core Mathematics
👾 Segment-Based Multivariate Pattern Analysis
The indicator analyzes price data by dividing each bar into distinct segments, isolating key components such as:
Body Ranges: Differences between the open and close prices.
High-Low Ranges: Capturing the full volatility of a bar.
Wick Extremes: Quantifying deviations beyond the body, both above and below.
Each segment contributes uniquely to the predictive model, ensuring a rich, multidimensional understanding of price action. These segments are stored in a rolling dictionary of patterns, enabling the indicator to reference historical behavior dynamically.
👾 Volatility Normalization Using ATR
To ensure robustness across varying market conditions, the indicator normalizes patterns using Average True Range (ATR). This process scales each component to account for the prevailing market volatility, allowing the algorithm to compare patterns on a level playing field regardless of differing price scales or fluctuations.
👾 k-Nearest Neighbors (kNN) Algorithm
The AI core employs the kNN algorithm, a machine-learning technique that evaluates the similarity between the current pattern and a library of historical patterns.
Euclidean Distance Calculation:
The indicator computes the multivariate distance across four distinct dimensions: body range, high-low range, wick low, and wick high. This ensures a comprehensive and precise comparison between patterns.
Weighting Schemes: The contribution of each pattern to the forecast is either weighted by its proximity (distance) or averaged, based on user settings.
👾 Prediction Horizon and Refinement
The indicator forecasts future price movements (Y_hat) by predicting logarithmic changes in the price and projecting them forward using exponential scaling. This forecast is smoothed using a user-defined EMA filter to reduce noise and enhance actionable clarity.
👽 AI-Driven Pattern Recognition
Dynamic Dictionary of Patterns: The indicator maintains a rolling dictionary of N multivariate patterns, continuously updated to reflect the latest market data. This ensures it adapts seamlessly to changing market conditions.
Nearest Neighbor Matching: At each bar, the algorithm identifies the most similar historical pattern. The prediction is based on the aggregated outcomes of the closest neighbors, providing confidence levels and directional bias.
Multivariate Synthesis: By combining multiple dimensions of price action into a unified prediction, the indicator achieves a level of depth and accuracy unattainable by single-variable models.
Visual Outputs
Forecast Line (Y_hat_line):
A smoothed projection of the expected price trend, based on the weighted contribution of similar historical patterns.
Trend Regime Bands:
Dynamic high, low, and midlines highlight the current market regime, providing actionable insights into momentum and range.
Historical Pattern Matching:
The nearest historical pattern is displayed, allowing traders to visualize similarities
👽 Applications
Trend Identification:
Detect and follow emerging trends early using dynamic trend regime analysis.
Reversal Signals:
Anticipate market reversals with high-confidence predictions based on historically similar scenarios.
Range and Momentum Trading:
Leverage multivariate analysis to understand price ranges and momentum, making it suitable for both breakout and mean-reversion strategies.
Disclaimer: This information is for entertainment purposes only and does not constitute financial advice. Please consult with a qualified financial advisor before making any investment decisions.

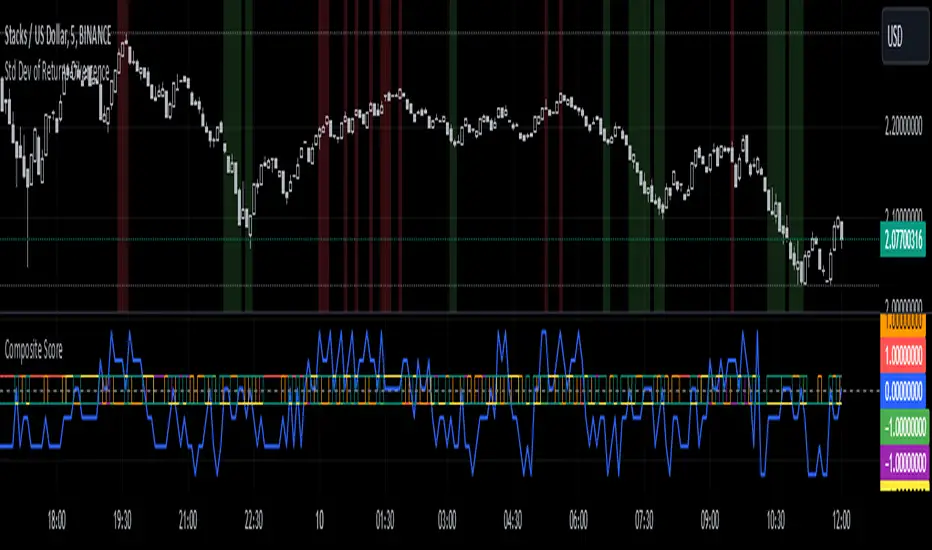
Standard Deviation of Returns: DivergencePurpose:
The "Standard Deviation of Returns: Divergence" indicator is designed to help traders identify potential trend reversals or continuation signals by analyzing divergences between price action and the statistical volatility of returns. Divergences can signal weakening momentum in the prevailing trend, offering insight into potential buying or selling opportunities.
Key Components
1. Returns Calculation:
* The indicator uses logarithmic returns (log(close / close )) to measure relative price changes in a normalized manner.
* Log returns are more effective than simple price differences when analyzing data across varying price levels, as they account for percentage-based changes.
2. Standard Deviation of Returns:
* The script computes the standard deviation of returns over a user-defined lookback period (ta.stdev(returns, lookback)).
* Standard deviation measures the dispersion of returns around their average, effectively quantifying market volatility.
* A higher standard deviation indicates increased volatility, while lower standard deviation reflects a calmer market.
3. Price Action:
* Detects higher highs (new peaks in price) and lower lows (new troughs in price) over the lookback period.
* Price trends are compared to the behavior of the standard deviation.
4. Divergence Detection:
A divergence occurs when price action (higher highs or lower lows) is not confirmed by a corresponding movement in standard deviation:
Bullish Divergence: Price makes a lower low, but the standard deviation does not, signaling potential upward momentum.
Bearish Divergence: Price makes a higher high, but the standard deviation does not, signaling potential downward momentum.
5. Visual Cues:
The script highlights divergence regions directly on the chart:
Green Background: Indicates a bullish divergence (potential buy signal).
Red Background: Indicates a bearish divergence (potential sell signal).
How It Works
Inputs:
* The user specifies the lookback period (lookback) for calculating the standard deviation and detecting divergences.
Calculation:
* Each bar’s returns are computed and used to calculate the standard deviation over the specified lookback period.
* The indicator evaluates price highs/lows and compares these with the highest and lowest values of the standard deviation within the same lookback period.
Highlight of Divergences:
When divergences are detected:
Bullish Divergence: The background of the chart is shaded green.
Bearish Divergence: The background of the chart is shaded red.
Trading Application
Bullish Divergence:
* Occurs when the market is oversold, or downward momentum is weakening.
* Suggests a potential reversal to an uptrend, signaling a buying opportunity.
Bearish Divergence:
* Occurs when the market is overbought, or upward momentum is weakening.
* Suggests a potential reversal to a downtrend, signaling a selling opportunity.
Contextual Use:
* Use this indicator in conjunction with other technical tools like RSI, MACD, or moving averages to confirm signals.
* Effective in volatile or ranging markets to help anticipate shifts in momentum.
Summary
The "Standard Deviation of Returns: Divergence" indicator is a robust tool for spotting divergences that can signal weakening market trends. It combines statistical volatility with price action analysis to highlight key areas of potential reversals. By integrating this tool into your trading strategy, you can gain additional confirmation for entries or exits while keeping a close watch on momentum shifts.
Disclaimer: This is not a financial advise; please consult your financial advisor for personalized advice.
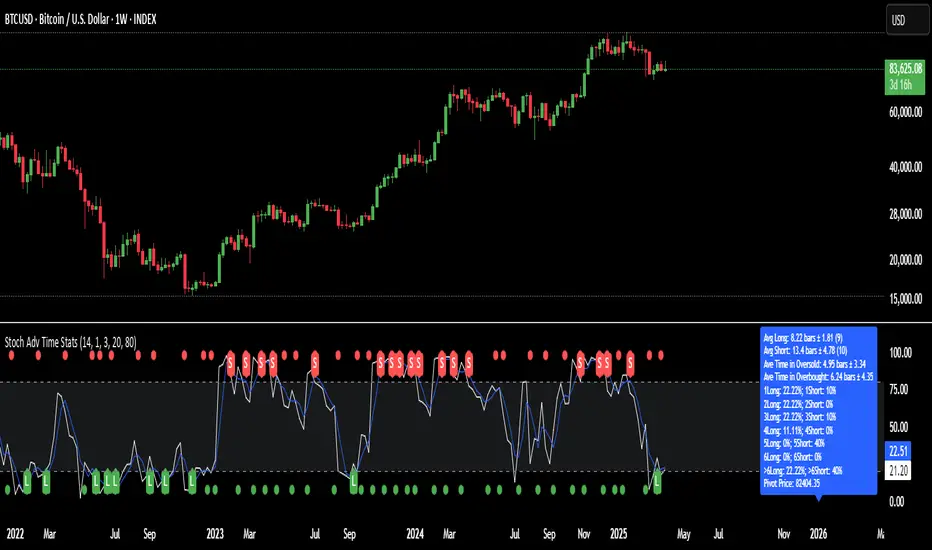
Stochastic Oscillator-Time & Frequency StatsThe Stochastic Oscillator Time & Frequency Statistics indicator is a tool designed to enhance your trading decisions by combining the traditional Stochastic Oscillator with additional metrics and visual aids. Although the Stochastic Oscillator is typically used to indicate trend direction and overbought/oversold conditions, the %K and %D lines can cross over and under multiple times while in the critical zones. The statistics added to this indicator allow traders to assess the probability of multiple crossover signals occurring on an asset or within various time frames. Signal levels and definitions of critical zones can be adjusted while the statistics are automatically updated to the relevant ticker, time frame and thresholds. Visual preferences such as colors and signal shapes can also be customized.
The Stochastic Oscillator is a commonly used momentum indicator developed by George Lane. It measures the position of the current closing price relative to the asset's recent high-low range over a set period. This advanced version calculates various probability and frequency statistics to better understand the oscillator’s behaviour and guide our strategies and risk management. Some key questions that this indicator intends to address are:
How long does the average momentum last in a trend?; How long does the oscillator remain in the critical zones?; How many times could one expect crossovers/unders' to occur in critical zones before momentum changes?; And, at what price does the candle need to close for the k & d lines to cross and signal a momentum shift?
Statistics & Probabilities:
The indicator calculates important time and frequency-based metrics that provide deeper insight into the behavior of the Stochastic Oscillator. These are displayed in a text box on the indicator panel, including:
Avg Long: The average number of bars between the last long signal before exiting the critical oversold zone and the next short signal in the overbought critical zone, including the standard deviation and the sample size within the relevant time frame.
Avg Short: The average number of bars between the last short signal in the overbought critical zone and the next long signal in the oversold critical zone, including the standard deviation and the sample size within the relevant time frame.
Time in Oversold: The average time (in bars/candle sticks) that the Stochastic Oscillator's %K & %D lines both spend in the oversold region (below the buy signal level) after entering and before departing the oversold region, along with the standard deviation.
Time in Overbought: The average time (in bars/candle sticks) that the Stochastic Oscillator's %K & %D lines both spend in the overbought region (above the sell signal level), after entering and before departing the overbought region, along with the standard deviation.
Signal Frequency: It calculates the percentage of long or short signals that occur consecutively within the critical zone before the opposing signal occurs (e.g., 1Long: 40.54%, 2 Long: 28.55%, 3Long: 17.4%, >3 Long: 13.51%, 1Short: 36.15%, 2Short: 30.41%, 3Short: 17.57%, >3Short: 15.88%). This is calculated for 1 through 6 consecutive occurrences and summarised for more than 6 consecutive signals
Key Features:
Oversold: Typically When the Stochastic Oscillator is below 20, it indicates that the asset may be oversold, potentially signalling a buying opportunity. The threshold for "overbought" and "oversold" extreme regions can be adjusted
Overbought: When the Stochastic Oscillator is above 80, it suggests the asset may be overbought, and a downturn might be near.
Stochastic Slope: The slope of the Stochastic Oscillator indicates the prominent trend direction within the selected time period.
Customizable Buy/Sell Signal Levels: The indicator allows customizable levels for detecting oversold (typically below 20-25) and overbought (typically above 75-80) conditions, helping one spot potential reversal zones for initiating long or short trades.
Crossover Alerts: The indicator tracks crossovers between the %K and %D lines, generating:
Long signals: When a crossover occurs below the buy signal level (indicating oversold conditions).
Short signals: when a crossunder occurs above the sell signal level (indicating overbought conditions).
The signals are visualized as labels on the chart:
- **L** for potential long (buy) signals: Marked below the bars when the %K line crosses above the %D line.
- **S** for potential short (sell) signals: Marked above the bars when the %K line crosses below the %D line.
Disclaimers:
No Guarantees: The indicator is provided "as-is" without any warranties or guarantees of accuracy, completeness, or fitness for a particular purpose. The outcomes or performance of trades executed using this indicator are not guaranteed to be successful or profitable.
User Responsibility: You are solely responsible for any trading decisions you make based on the use of this indicator. All trading and investment activities involve risk, and it is essential to conduct your own research, analysis, and due diligence before making any financial decisions.
No Liability: The creator of this indicator is not responsible for any financial losses, direct or indirect, incurred as a result of using this indicator. This includes, but is not limited to, loss of profits, loss of capital, or any other negative financial outcomes.
Market Risks: Markets are volatile, and prices may fluctuate significantly. Trading and investing carry inherent risks, and there is always the potential for loss. You should only trade with capital that you can afford to lose.
Independent Advice: This indicator and the content generated by its creator does not constitute financial advice and is for entertainment purposes only. It is strongly recommended that you seek independent financial advice from a qualified and licensed professional before making any trading or investment decisions based on the use of this indicator.
By using this indicator, you acknowledge that you fully understand and accept the risks involved, and you agree to indemnify and hold harmless the creator of this indicator from any claims, damages, or liabilities arising from its use.
The author of this script has made every effort to ensure that the code is an original interpretation and application of the open-source **Stochastic Oscillator**, as developed by George Lane. The script reflects a unique adaptation aimed at enhancing trading strategies through advanced statistical analysis and trade management features. The author does not claim any proprietary rights over the foundational concepts of the **Stochastic Oscillator** and does not intend to infringe upon any existing copyrights. Should any copyright infringement be identified, the author commits to removing the indicator immediately and forfeits any rights to further or intended financial gain from its use.